コラムディレクトリ: pytorch (画像分割UNet) クイック入門と実戦 - ゼロ、まえがき
pytorch クイック入門と実戦 - 1、知識の準備(要素の紹介)
pytorch クイック入門と実戦 - 2、深層学習の古典的なネットワーク開発
pytorch クイック導入と実際の戦闘 - 3、Unet による
pytorch の迅速な導入と実際の戦闘 - 4、ネットワークのトレーニングとテスト
上記のpytorchクイックスタートと実戦の続き - 2.ディープラーニングクラシックネットワーク開発の8.4章
Unetの実装
1 事前準備
1.1 トーチの取り付け
pytorchのインストールは自動的に解決します
1.2 データセットの準備
私自身のシミュレートされたデータは、すべてのデータが 1600 ペア (入力、ラベル) で、トレーニング セットとテスト セットが 9:1 で抽出されています。
入力サイズは 120*240、ラベル サイズは 256*256 です。
1.3 ネットワークの構造骨格
バックボーンは Unet であり、ニーズに応じて変更できます。独自のネットワークを変更する代わりに、独自の入力と出力に適応する畳み込みを追加します。
まず基本的な Unet 図を示します。これをもとに修正します。

1.4 データ分析とネットワーク改善
[特定のサイズとチャネルは問題ではありません。直接設定できます。設定方法は実装にあり、ここではプロセスについてのみ説明します]
图中input的size是572x572x1,而我的size是120x240x1,我选择在Unet之前加一个卷积层以让我的输入成为方形120x120x1,为了后续计算方便,通过padding(直接padding或者通过卷积都可以)变成128x128x1。接下来就是常规Unet操作,所以我的网络结构图为:

変更プロセス全体を確認できます。変更方法は実装で説明されています(午後中ずっと壊れた写真を見て、罵りながら)
120x240x1--卷积-->120x120x1--卷积-->128x128x1--卷积-->128x128x32
--池化-->64x64x32--卷积-->64x64x64
--池化-->32x32x64--卷积-->32x32x128
--池化-->16x16x128--卷积-->16x16x256
--池化-->8x8x256--卷积-->8x8x512--上采样-->16x16x256
--通道拼接-->16x16x512--反卷积-->16x16x256--上采样-->32x32x128
--通道拼接-->32x32x256--反卷积-->32x32x128--上采样-->64x64x64
--通道拼接-->64x64x128--反卷积-->64x64x64--上采样-->128x128x32
--通道拼接-->128x128x64--反卷积-->128x128x32--上采样-->256x256x16
(注意我左边是128开始的,所以没法拼接了,网络结构并不是严格对称的)
--1x1卷积核代替全连接-->256x256x1
2. ネットワークの実装
2.1 関連知識
- まず最初に、畳み込みの計算式を知る必要があります。
O = (I − K + 2P )/S+1
O (出力) は出力イメージ、I (入力) は元のイメージ、K (カーネル) はコンボリューション カーネル サイズ、P はパディング、S (ストライド) はステップサイズ
- そして、デコンボリューションの計算式は次のとおりです。
Output = (input-1)stride+output_padding -2*padding+kernel_size
O = (I-1)*S + OP - 2P + K
O (出力) は出力イメージ、I (入力) は元のイメージ、K (kernel ) はコンボリューション カーネル サイズ、P はパディング、S (ストライド) はステップ サイズ、OP は Output_padding
- チャンネルチャンネル
私の理解について話しましょう:
実際には、これは特徴です (例として分類を使用します: スイカの根、色、模様など)。
写真では色は特徴ですが、特徴は単なる色ではありません。
たとえば、私のグレースケール画像では、チャネルは 1 です。他のカラー画像 (RGB、BGR、CMY) のチャネルがすべて 3 である場合は、画像のチャネルは 64 です。64 色ですか
? ?
上の文「特徴は色だけではない」を参照してください。他の特徴はわかりません。分布は何ですか。
2.2 コードの実装:
うーん、浅いところから深いところまで説明しましょう。ネットワーク全体のコードは記事の最後にあります。
まず torch パッケージをインポートします。
import torch
import torch.nn as nn
次に、ネットワーク AdUNet を設計し、nn.module を継承するクラスとして作成します。主に初期化__init__ とパラメータ return forward の
2 つのメソッドを書き換えます。
これに先立って、コードの再利用性を向上させるために、二重層畳み込みの繰り返しがコードの再利用性を促進する機能として設計されていました。

def double_conv(in_channels, out_channels): # 双层卷积模型,神经网络最基本的框架
return nn.Sequential(
nn.Conv2d(in_channels, out_channels, 3, padding=1),
nn.BatchNorm2d(out_channels), # 加入Bn层提高网络泛化能力(防止过拟合),加收敛速度
nn.ReLU(inplace=True),
nn.Conv2d(out_channels, out_channels, 3, padding=1), # 3指kernel_size,即卷积核3*3
nn.BatchNorm2d(out_channels),
nn.ReLU(inplace=True)
)
じゃあ始めよう。
2.2.1 初期化メソッド __init__():
- 入力適応層
まず、入力がネットワークに適応できるようにする畳み込み層 Adnet を独立して設計し、それをネットワーク AdUNet クラスに置き、入力 1x120x240 を正方形1x120x120 に畳み込み、pytorch に付属の畳み込みカーネル メソッドConv2d を使用して、成し遂げる:
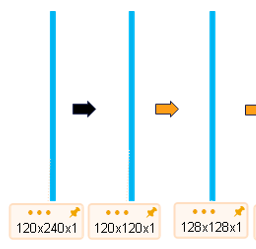
入力チャネル in_channels と出力チャネル out_channels を設定し、2x1 コンボリューション カーネルを選択し、パディングを 0 に設定し、ステップ サイズを (2,1) に設定します。つまり、行方向のステップ サイズは 2 です。列方向のステップ サイズは 1 です。このようにして、ステップ サイズを行方向のサイズの 2 倍に設定できます。。サイズを120x120に調整して
BNレイヤーとReLuレイヤーをバインドします 機能と理由は前回の記事を参照してください。
次に、padding=5 の 3x3 コンボリューション カーネルを使用して、サイズを 120x120 から 128x128 に調整します。
self.adnet = nn.Sequential(
nn.Conv2d(in_channels=1, out_channels=1, kernel_size=(2, 1), padding=0, stride=(2, 1)),
nn.BatchNorm2d(1), # 加入Bn层提高网络泛化能力(防止过拟合),加收敛速度
nn.ReLU(inplace=True),
nn.Conv2d(in_channels=1, out_channels=1, kernel_size=3, padding=5, stride=1),
nn.BatchNorm2d(1), # 加入Bn层提高网络泛化能力(防止过拟合),加收敛速度
nn.ReLU(inplace=True)
)
- ダウンサンプリング中の 4 つの畳み込み層 + 基礎となる 1 つの畳み込み層
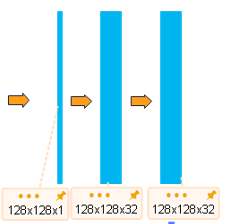
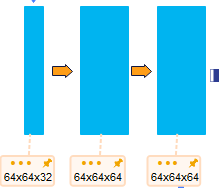
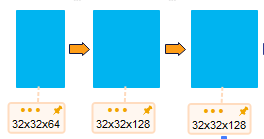
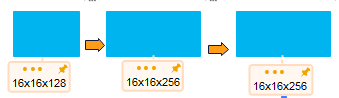

self.dconv_down0 = double_conv(1, 32)
self.dconv_down1 = double_conv(32, 64)
self.dconv_down2 = double_conv(64, 128)
self.dconv_down3 = double_conv(128, 256)
self.dconv_down4 = double_conv(256, 512)
- 最大プーリング層

self.maxpool = nn.MaxPool2d(2)
- アップサンプリング時の 4 つの畳み込み層
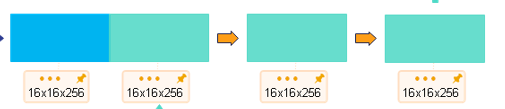
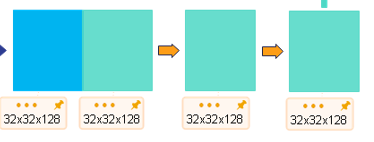
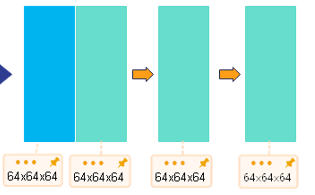
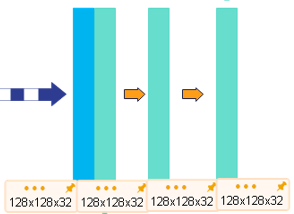
self.dconv_up3 = double_conv(256 + 256, 256)
self.dconv_up2 = double_conv(128 + 128, 128)
self.dconv_up1 = double_conv(64 + 64, 64)
self.dconv_up0 = double_conv(64, 32)
- 5 アップサンプリング
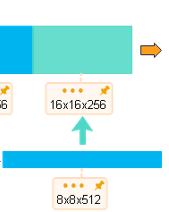
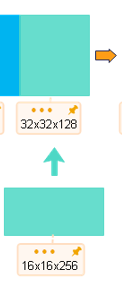
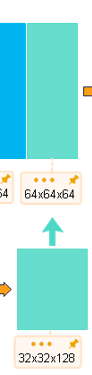
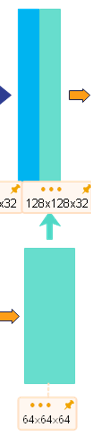

self.upsample4 = nn.ConvTranspose2d(512, 256, 3, stride=2, padding=1, output_padding=1)
self.upsample3 = nn.ConvTranspose2d(256, 128, 3, stride=2, padding=1, output_padding=1)
self.upsample2 = nn.ConvTranspose2d(128, 64, 3, stride=2, padding=1, output_padding=1)
self.upsample1 = nn.ConvTranspose2d(64, 32, 3, stride=2, padding=1, output_padding=1)
self.upsample0 = nn.ConvTranspose2d(32, 16, 3, stride=2, padding=1, output_padding=1)
- 全結合層の代わりに 1x1 畳み込み層
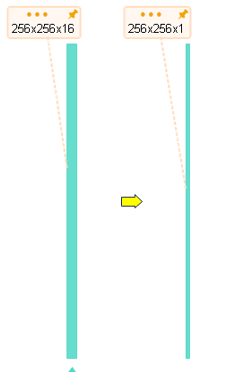
self.conv_last = nn.Conv2d(16, 1, 1)
2.2.2 パラメータの戻りメソッド forward():
上の写真のネットワーク構造に従ってそれらをつなぎ合わせます。大丈夫です!
そうそう、concat を忘れないでください。
ダウンサンプリングとアップサンプリングの繰り返しモジュールを一緒に書いてみませんか? これはダウンサンプリング時にアップサンプリング時にconcat用のプールの前に値を確保しておく必要があるためパラメータを渡したくなかったので別途書きました。concat 操作もシンプルで、コードを見るだけで理解できるため、難しいことはありません。
def forward(self, x):
# reshape
x = self.adnet(x) # 1x128x128
# encode
conv0 = self.dconv_down0(x) # 32x128x128
x = self.maxpool(conv0) # 32x64x64
conv1 = self.dconv_down1(x) # 64x64x64
x = self.maxpool(conv1) # 64x32x32
conv2 = self.dconv_down2(x) # 128x32x32
x = self.maxpool(conv2) # 128x16x16
conv3 = self.dconv_down3(x) # 256x16x16
x = self.maxpool(conv3) # 256x8x8
x = self.dconv_down4(x) # 512x8x8
# decode
x = self.upsample4(x) # 256x16x16
# 因为使用了3*3卷积核和 padding=1 的组合,所以卷积过程图像尺寸不发生改变,所以省去了crop操作!
x = torch.cat([x, conv3], dim=1) # 512x16x16
x = self.dconv_up3(x) # 256x16x16
x = self.upsample3(x) # 128x32x32
x = torch.cat([x, conv2], dim=1) # 256x32x32
x = self.dconv_up2(x) # 128x32x32
x = self.upsample2(x) # 64x64x64
x = torch.cat([x, conv1], dim=1) # 128x64x64
x = self.dconv_up1(x) # 64x64x64
x = self.upsample1(x) # 32x128x128
x = torch.cat([x, conv0], dim=1) # 64x128x128
x = self.dconv_up0(x) # 32x128x128
x = self.upsample0(x) # 16x256x256
out = self.conv_last(x) # 1x256x256
return out
2.2.3 セマンティック セグメンテーションの実装プロセス
ネットワークの構造は実現されたものの、目標に到達するまでにはまだ道が残っていると言うのは残念ですが、幸いなことに、このネットワークは実際に使用可能であり、データがロードされトレーニングされている限り、結果は次のとおりです。一部の行列はトレーニング用の画像として使用されます。
ここではプロセスについて簡単に説明しますが、多くの詳細があり、詳細については次のパートで説明します: pytorch の簡単な導入と実際の戦闘 - 4. ネットワークのトレーニングとテスト
トレーニング:
バッチ サイズに従って、データセット内のトレーニング サンプルとラベルが畳み込みニューラル ネットワークに読み込まれます。実際のニーズに応じて、最初にトレーニング画像とラベルをトリミングやデータ拡張などの前処理する必要があります。これは、深いネットワークのトレーニングに役立ち、収束プロセスを高速化し、過剰適合の問題を回避し、モデルの汎化能力を強化します。
確認:
エポックのトレーニング後、データセット内の検証サンプルとラベルを畳み込みニューラル ネットワークに読み取り、トレーニングの重みを読み込みます。書かれたセマンティック セグメンテーション インデックスに従って検証し、現在のトレーニング プロセスでインデックス スコアを取得し、対応する重みを保存します。一度トレーニングして検証する方法は、モデルのパフォーマンスをより適切に監視するためによく使用されます。
テスト:
すべてのトレーニングが終了したら、データセット内のテスト サンプルとラベルを畳み込みニューラル ネットワークに読み取り、保存されている最適な重み値をテスト用のモデルに読み込みます。テスト結果は、共通の指標スコアに基づいてネットワークのパフォーマンスを測定するものと、ネットワークの予測結果を画像として保存し、セグメンテーションの精度を直感的に感じるものの2種類に分かれています。
2.2.4 統合! (ネットワーク完全コード)
import torch
import torch.nn as nn
def double_conv(in_channels, out_channels): # 双层卷积模型,神经网络最基本的框架
return nn.Sequential(
nn.Conv2d(in_channels, out_channels, 3, padding=1),
nn.BatchNorm2d(out_channels), # 加入Bn层提高网络泛化能力(防止过拟合),加收敛速度
nn.ReLU(inplace=True),
nn.Conv2d(out_channels, out_channels, 3, padding=1), # 3指kernel_size,即卷积核3*3
nn.BatchNorm2d(out_channels),
nn.ReLU(inplace=True)
)
# class UpSample(nn.Module):
# def __init__(self, in_channels, out_channels, kernel_size, stride, padding, output_padding):
# super(UpSample, self).__init__()
# self.up = nn.ConvTranspose2d(in_channels, out_channels, kernel_size=kernel_size, stride=2, padding=1)
# self.conv_relu = nn.Sequential(
# nn.Conv2d(in_channels, out_channels, kernel_size=kernel_size, stride=stride, padding=padding),
# nn.BatchNorm2d(num_features=out_channels),
# nn.ReLU(),
# nn.Conv2d(out_channels, out_channels, kernel_size=kernel_size, stride=stride, padding=padding),
# nn.BatchNorm2d(num_features=out_channels),
# nn.ReLU(),
# )
#
# def forward(self, x, y):
# x = self.up(x)
# x1 = torch.cat((x, y), dim=0)
# x1 = self.conv_relu(x1)
# return x1 + x
class AdUNet(nn.Module):
def __init__(self):
super().__init__()
self.adnet = nn.Sequential(
nn.Conv2d(in_channels=1, out_channels=1, kernel_size=(2, 1), padding=0, stride=(2, 1)),
nn.BatchNorm2d(1), # 加入Bn层提高网络泛化能力(防止过拟合),加收敛速度
nn.ReLU(inplace=True),
nn.Conv2d(1, 1, kernel_size=3, padding=5, stride=1),
nn.BatchNorm2d(1), # 加入Bn层提高网络泛化能力(防止过拟合),加收敛速度
nn.ReLU(inplace=True)
)
self.dconv_down0 = double_conv(1, 32)
self.dconv_down1 = double_conv(32, 64)
self.dconv_down2 = double_conv(64, 128)
self.dconv_down3 = double_conv(128, 256)
self.dconv_down4 = double_conv(256, 512)
self.maxpool = nn.MaxPool2d(2)
# self.upsample = nn.Upsample(scale_factor=2, mode='bilinear', align_corners=True)
self.upsample4 = nn.ConvTranspose2d(512, 256, 3, stride=2, padding=1, output_padding=1)
self.upsample3 = nn.ConvTranspose2d(256, 128, 3, stride=2, padding=1, output_padding=1)
self.upsample2 = nn.ConvTranspose2d(128, 64, 3, stride=2, padding=1, output_padding=1)
self.upsample1 = nn.ConvTranspose2d(64, 32, 3, stride=2, padding=1, output_padding=1)
self.upsample0 = nn.ConvTranspose2d(32, 16, 3, stride=2, padding=1, output_padding=1)
self.dconv_up3 = double_conv(256 + 256, 256)
self.dconv_up2 = double_conv(128 + 128, 128)
self.dconv_up1 = double_conv(64 + 64, 64)
self.dconv_up0 = double_conv(64, 32)
self.conv_last = nn.Conv2d(16, 1, 1)
def forward(self, x):
# reshape
x = self.adnet(x) # 1x128x128
# encode
conv0 = self.dconv_down0(x) # 32x128x128
x = self.maxpool(conv0) # 32x64x64
conv1 = self.dconv_down1(x) # 64x64x64
x = self.maxpool(conv1) # 64x32x32
conv2 = self.dconv_down2(x) # 128x32x32
x = self.maxpool(conv2) # 128x16x16
conv3 = self.dconv_down3(x) # 256x16x16
x = self.maxpool(conv3) # 256x8x8
x = self.dconv_down4(x) # 512x8x8
# decode
x = self.upsample4(x) # 256x16x16
# 因为使用了3*3卷积核和 padding=1 的组合,所以卷积过程图像尺寸不发生改变,所以省去了crop操作!
x = torch.cat([x, conv3], dim=1) # 512x16x16
x = self.dconv_up3(x) # 256x16x16
x = self.upsample3(x) # 128x32x32
x = torch.cat([x, conv2], dim=1) # 256x32x32
x = self.dconv_up2(x) # 128x32x32
x = self.upsample2(x) # 64x64x64
x = torch.cat([x, conv1], dim=1) # 128x64x64
x = self.dconv_up1(x) # 64x64x64
x = self.upsample1(x) # 32x128x128
x = torch.cat([x, conv0], dim=1) # 64x128x128
x = self.dconv_up0(x) # 32x128x128
x = self.upsample0(x) # 16x256x256
out = self.conv_last(x) # 1x256x256
return out