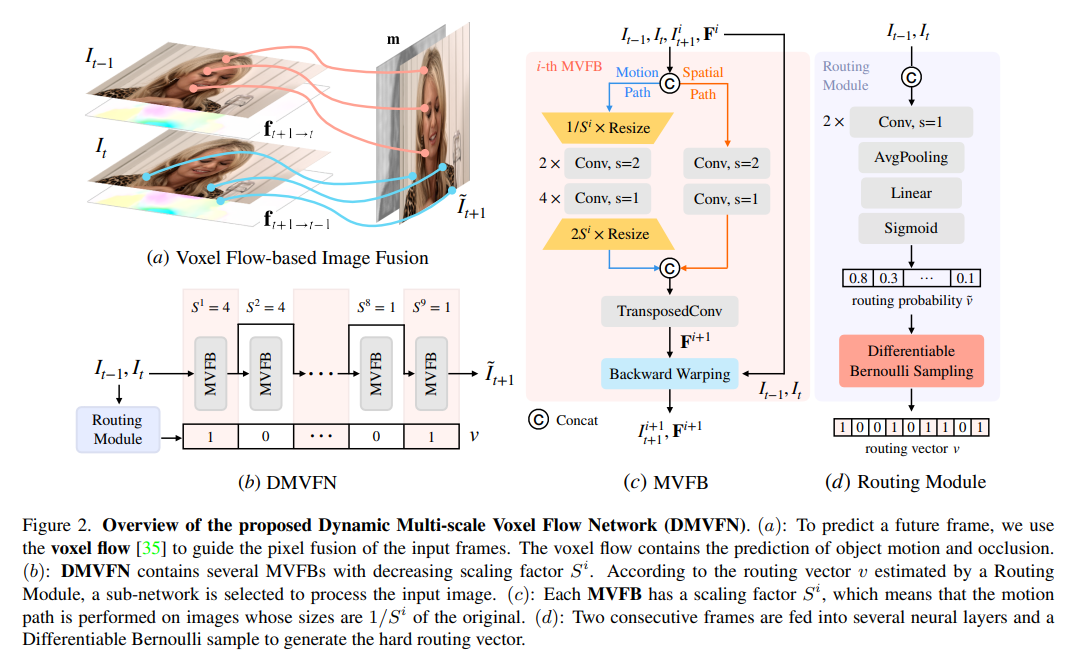
1、비디오 예측을 위한 동적 다중 스케일 복셀 흐름 네트워크
비디오 예측의 성능은 고급 심층 신경망에 의해 크게 향상되었습니다. 그러나 대부분의 최신 방법은 모델 크기가 크고 우수한 성능을 달성하기 위해 추가 입력(예: 시맨틱/깊이 맵)이 필요합니다. 효율성을 위해 본 논문에서는 RGB 영상만을 기반으로 한 동적 다중 스케일 복셀 흐름 네트워크(Dynamic Multi-scale Voxel Flow Network, DMVFN)를 제안한다. 방법은 훨씬 더 빠릅니다.
DMVFN의 핵심은 비디오 프레임의 모션 스케일을 효과적으로 인식할 수 있는 차별화 가능한 라우팅 모듈입니다. 학습이 완료되면 추론 단계에서 다양한 입력에 대해 적응형 하위 네트워크가 선택됩니다. 여러 벤치마크에 대한 실험에 따르면 DMVFN은 Deep Voxel Flow보다 훨씬 빠르며 생성된 이미지 품질 측면에서 최첨단 반복 기반 OPT를 능가합니다.
https://huxiaotaostasy.github.io/DMVFN/
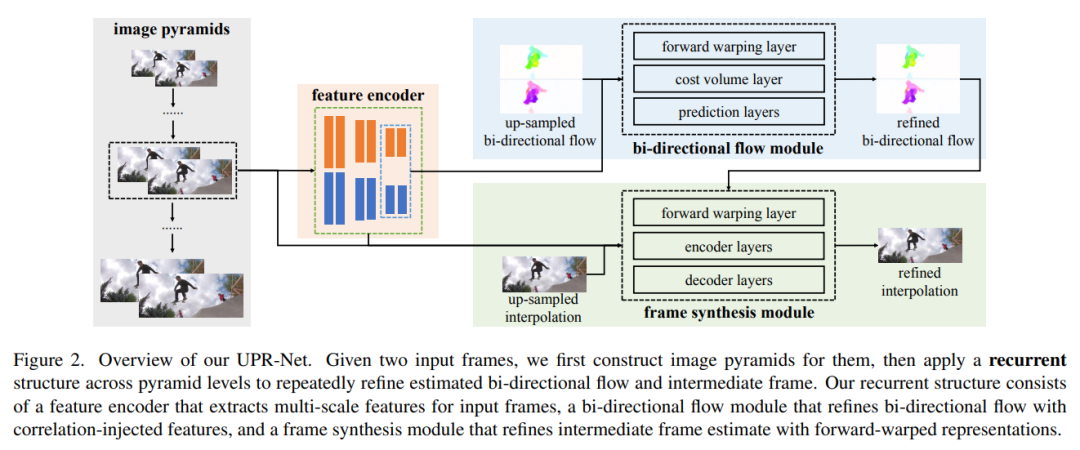
2, 비디오 프레임 보간을 위한 통합 피라미드 순환 네트워크
프레임 보간을 위한 일반적인 프레임워크를 제공하는 흐름 유도 합성. 여기에서 광학 흐름은 두 연속 입력 사이의 중간 프레임 합성을 안내하는 것으로 추정됩니다. 본 논문은 프레임 보간을 위한 새로운 UPR-Net(Unified Pyramid Recurrent Network)을 제안한다. UPR-Net은 양방향 흐름 추정 및 중간 프레임 합성을 위해 경량 반복 모듈이 있는 유연한 피라미드 프레임워크를 활용합니다. 각 피라미드 수준에서 추정된 양방향 흐름을 활용하여 프레임 합성을 위한 정방향 왜곡 표현을 생성하고, 피라미드 수준에서 광학 흐름 및 중간 프레임에 대한 반복 최적화를 가능하게 합니다. 반복 합성 전략은 움직임이 큰 경우 프레임 보간의 견고성을 크게 향상시킬 수 있습니다.
UPR-Net 기반의 기본 버전은 매우 가볍지만(1.7M 매개변수) 많은 벤치마크에서 잘 작동합니다. UPR-Net 시리즈의 코드 및 교육 모델은 https://github.com/srcn-ivl/UPR-Net에 있습니다.
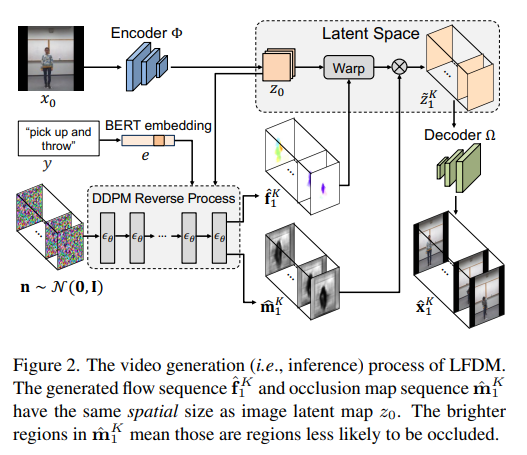
3、Latent Flow 확산 모델을 사용한 조건부 이미지 대 비디오 생성
조건부 이미지 대 비디오(cI2V) 생성은 이미지(예: 얼굴)와 조건(예: 미소와 같은 클래스 레이블)에서 시작하여 그럴듯한 새 비디오를 합성하는 것을 목표로 합니다. cI2V 작업의 핵심 과제는 주어진 이미지와 조건에 해당하는 공간적 외관과 시간적 역학을 동시에 생성하는 것입니다.
본 논문에서는 새로운 LFDM(Latent Flow Diffusion Models) 기반의 cI2V 방법을 제안한다. 이전의 직접 합성과 비교하여 LFDM은 주어진 이미지의 공간 콘텐츠를 더 잘 활용하여 세부 사항과 움직임을 합성하기 위해 잠재 공간에서 변형을 수행합니다. LFDM 교육은 두 개의 독립적인 단계로 나뉩니다. 시간적 잠재 흐름 생성을 위한 UNet 기반 확산 모델(DM). LFDM은 모션 생성을 위해 저차원 잠재 흐름 공간만 학습하면 되므로 계산 효율이 높습니다.
여러 데이터 세트에 대한 포괄적인 실험은 LFDM이 지속적으로 최신 기술을 능가한다는 것을 보여줍니다. 또한 이미지 디코더를 미세 조정하기만 하면 LFDM을 새로운 도메인에 쉽게 적용할 수 있음을 보여줍니다. 코드는 https://github.com/nihaomiao/CVPR23_LFDM에 있습니다.
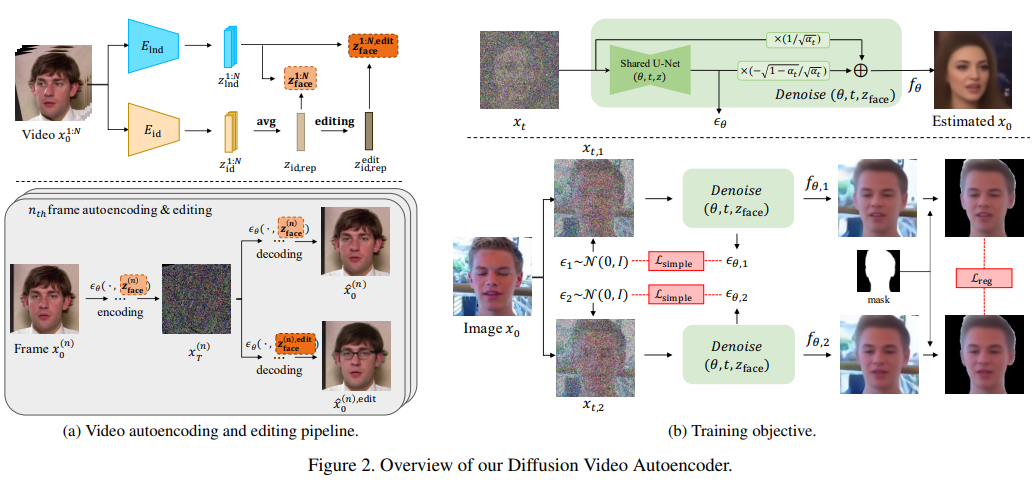
4、Diffusion Video Autoencoders: 분리된 비디오 인코딩을 통해 시간적으로 일관된 얼굴 비디오 편집을 향하여
최근 얼굴 이미지 편집 방법의 우수한 성능에 영감을 받아 자연스럽게 이러한 방법을 비디오 편집 작업으로 확장할 것을 제안하는 여러 연구가 있습니다. 주요 과제 중 하나는 아직 해결되지 않은 편집된 프레임 간의 시간적 일관성입니다.
이를 위해 Diffusion Autoencoder 기반의 새로운 얼굴 비디오 편집 프레임워크를 제안하며, 이는 시간적으로 안정적인 특징을 간단하게 조작함으로써 비디오 편집이 일관성을 얻을 수 있도록 합니다. 모델의 또 다른 고유한 장점은 확산 기반 모델이 재구성 및 편집 기능을 동시에 충족할 수 있으며 극한 상황 및 자연스러운 장면 얼굴 비디오(예: 폐색 얼굴).
https://diff-video-ae.github.io/
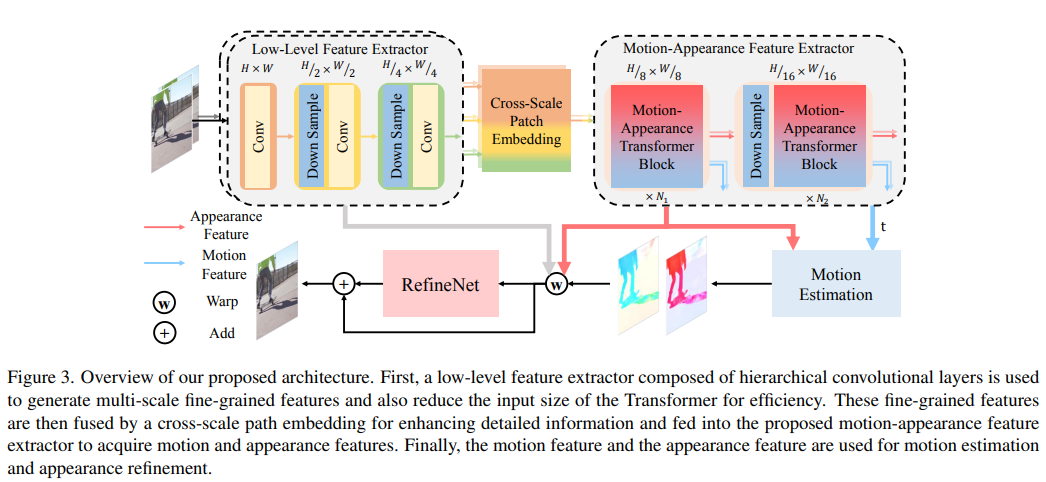
5、효율적인 비디오 프레임 보간을 위한 Inter-Frame Attention을 통한 모션 및 모양 추출
VFI(비디오 프레임 보간)에서는 프레임 간 움직임 및 모양 정보를 효율적으로 추출하는 것이 중요합니다. 과거에는 두 종류의 정보를 혼합하여 추출하거나 각 정보에 대한 완전한 별도의 모듈이 있어 모호하고 비효율적으로 표현되었습니다.
본 논문에서는 통합 연산을 통해 동작 및 외형 정보를 명시적으로 추출하는 새로운 모듈을 제안한다. 구체적으로 프레임 간 어텐션에서의 정보 처리를 재고하고 어텐션 맵을 외형 특징 개선 및 움직임 정보 추출에 재사용한다. 또한 효율적인 VFI를 위해 모듈을 하이브리드 CNN 및 트랜스포머 아키텍처에 원활하게 통합할 수 있습니다. 이 하이브리드 파이프라인은 상세한 저수준 구조 정보를 보존하면서 프레임 간 주의의 계산 복잡성을 완화할 수 있습니다.
실험 결과는 이 방법이 고정 또는 임의 간격의 보간 측면에서 다양한 데이터 세트에서 최첨단 성능을 달성한다는 것을 보여줍니다. 동시에 유사한 성능을 가진 모델에 비해 계산 오버헤드가 적습니다. 소스 코드 및 모델은 https://github.com/MCG-NJU/EMA-VF에 있습니다.
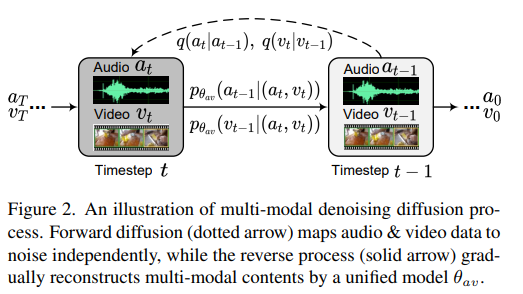
6、MM-Diffusion: 공동 오디오 및 비디오 생성을 위한 다중 모드 확산 모델 학습
우리는 고품질의 사실적인 비디오를 목표로 매력적인 시청 및 청취 경험을 동시에 가져올 수 있는 오디오-비디오 공동 생성을 위한 첫 번째 프레임워크를 제안합니다. 공동 오디오-비디오 쌍을 생성하기 위해 두 개의 결합된 노이즈 제거 자동 인코더를 포함하는 새로운 다중 모드 확산 모델(즉, MM-Diffusion)이 제안됩니다. 기존 단일 모드 확산 모델과 달리 MM-Diffusion은 순차적인 다중 모드 U-Net으로 구성되며 결합 노이즈 제거 프로세스를 위해 설계되었습니다. 오디오 및 비디오에 대한 두 개의 하위 네트워크는 정렬된 오디오-비디오 쌍을 생성하기 위해 가우시안 노이즈에서 점진적으로 학습됩니다.
실험 결과는 무조건적인 오디오-비디오 생성 및 제로 샷 조건부 작업(예: 비디오-오디오)에서 우수한 결과를 보여줍니다. 코드 및 사전 훈련된 모델은 https://github.com/researchmm/MM-Diffusion에 있습니다.
7, MOSO: 비디오 예측을 위한 모션, 장면 및 개체 분해
모션, 장면 및 개체는 비디오의 세 가지 주요 시각적 구성 요소입니다. 특히 개체는 전경을 나타내고 장면은 배경을 나타내며 동작은 역학을 추적합니다. 이러한 이해를 바탕으로 본 논문에서는 MOSO-VQVAE 및 MOSO-Transformer를 포함하여 비디오 예측을 위한 2단계 모션, 장면 및 객체 분해 프레임워크(MOtion, 장면 및 객체 분해, MOSO)를 제안합니다.
첫 번째 단계에서 MOSO-VQVAE는 이전 비디오 클립을 동작, 장면 및 개체 구성 요소로 분해하고 이를 서로 다른 개별 토큰 그룹으로 나타냅니다. 그런 다음 두 번째 단계에서 MOSO-Transformer는 이전 마커를 기반으로 후속 비디오 클립의 개체 및 장면 토큰을 예측하고 생성된 개체 및 장면 토큰 수준에서 동적 모션을 추가합니다.
프레임워크는 무조건적인 비디오 생성 및 비디오 프레임 보간 작업으로 쉽게 확장될 수 있습니다. 실험 결과는 이 방법이 BAIR, RoboNet, KTH, KITTI 및 UCF101과 같은 비디오 예측 및 무조건적 비디오 생성을 위한 5가지 까다로운 벤치마크에서 새로운 최첨단 성능을 달성함을 보여줍니다. 또한 MOSO는 서로 다른 비디오의 개체와 장면을 결합하여 사실적인 비디오를 제작할 수 있습니다.
https://github.com/iva-mzsun/MOSO

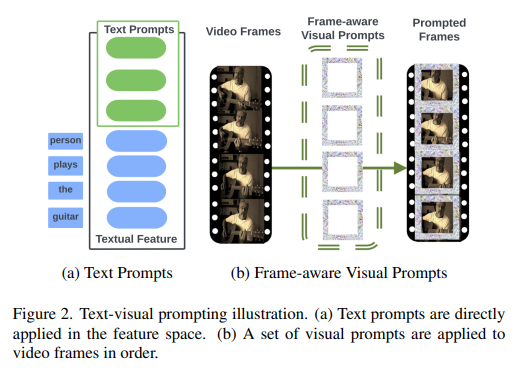
8. 효율적인 2D 임시 비디오 접지를 위한 텍스트-시각적 프롬프트
본 논문은 텍스트 문장으로 설명되는 순간의 영상에서 시작/종료 시점을 예측하는 것을 목표로 하는 시간적 비디오 접지(TVG) 문제를 연구한다. 미세한 3D 시각 기능의 이점으로 인해 TVG는 최근 몇 년 동안 상당한 발전을 이루었습니다. 그러나 3D 컨벌루션 신경망(CNN)의 높은 복잡성은 많은 양의 스토리지 및 컴퓨팅 리소스를 필요로 하는 시간 소모적입니다.
효율적인 TVG를 달성하기 위해 최적화된 섭동 패턴("프롬프트"라고 함)을 TVG 모델의 시각적 입력 및 텍스트 기능에 통합하는 새로운 TVP(텍스트-시각적 프롬프트) 프레임워크가 제안됩니다. 3D CNN과 비교하여 TVP는 2D TVG 모델에서 시각적 인코더와 언어 인코더를 효과적으로 공동으로 훈련하고 복잡성이 낮은 희소 2D 시각적 기능을 사용하여 교차 모달 기능 융합의 성능을 향상시킵니다. 또한 TVG의 효율적인 학습을 위해 TDIoU(Temporal Distance IoU) 손실을 제안합니다. Charades-STA 및 ActivityNet Captions 데이터 세트를 기반으로 한 실험은 TVP가 2D TVG의 성능을 크게 향상(예: Charades-STA에서 9.79% 향상, ActivityNet Caption에서 30.77% 향상)하고 TVG를 3D 시각적 기능과 비교하여 추론 가속도는 5배에 이릅니다.
https://github.com/intel
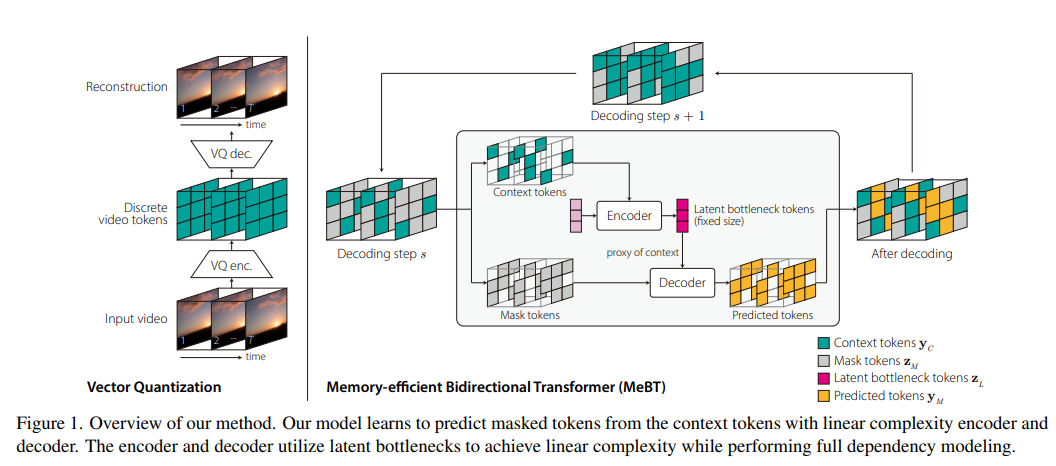
9、메모리 효율적인 양방향 트랜스포머를 사용한 긴 동영상의 종단 간 생성 모델링을 향하여
자동 회귀 변환기는 비디오 생성에 적합합니다. 그러나 self-attention의 2차 복잡성으로 인해 비디오의 장기 종속성은 직접 학습할 수 없으며 자동 회귀 프로세스로 인해 느린 추론 시간 및 오류 전파로 인해 어려움을 겪습니다.
본 논문은 비디오에서 장기 종속성의 end-to-end 학습과 빠른 추론을 위한 메모리 효율적인 Bidirectional Transformer(Memory-efficient Bidirectional Transformer, MeBT)를 제안합니다. 최근의 발전을 기반으로 하는 방법은 부분적으로 관찰된 패치에서 병렬로 비디오의 전체 시공간 볼륨을 디코딩하는 방법을 학습합니다. 관찰 가능한 컨텍스트 토큰을 고정된 수의 잠재 토큰으로 투영하고 교차 주의를 통해 마스크 토큰을 인코딩 및 디코딩하도록 조정함으로써 인코딩 및 디코딩 모두에서 선형 시간 복잡도를 갖습니다.
선형 복잡성과 양방향 모델링으로 인해 이 방법은 중간 길이의 비디오의 자동 회귀 생성에 비해 품질과 속도에서 상당한 개선을 보여줍니다. https://sites.google.com/view/mebt-cvpr2023의 비디오 및 코드
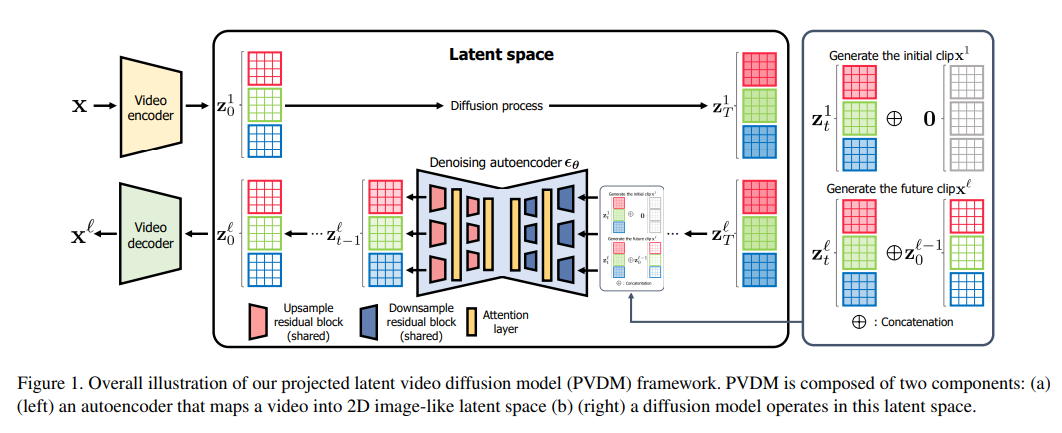
10、Projected Latent Space의 비디오 확률적 확산 모델
심층 생성 모델의 놀라운 발전에도 불구하고 고해상도 및 시간적으로 일관된 비디오를 합성하는 것은 고차원성과 큰 공간 변화가 있는 복잡한 시공간 역학으로 인해 여전히 어려운 과제입니다. 확산 모델에 대한 최근 연구는 이 문제를 해결할 수 있는 가능성을 보여주었지만 계산 및 메모리 효율성 문제에 직면해 있습니다.
이 문제를 해결하기 위해 본 논문에서는 비디오 생성을 위한 새로운 생성 모델인 PVDM(Projective Latent Video Diffusion Model)을 제안합니다. 해상도 비디오. 특히 PVDM은 (a) 주어진 비디오를 비디오 픽셀의 복잡한 입방체 구조를 분해하는 2D 모양의 잠재 벡터로 투영하는 자동 인코더 및 (b) 잠재의 새로운 분해를 위해 특별히 설계된 확산 모델 아키텍처의 두 가지 구성 요소로 구성됩니다. 공간 및 교육/샘플링 절차, 단일 모델을 사용하여 임의 길이의 비디오 합성. 인기 있는 비디오 생성 데이터 세트에 대한 실험은 이전 비디오 합성 방법보다 PVDM의 우수성을 보여줍니다. art 1773.4로 개선된 우수한 방법.
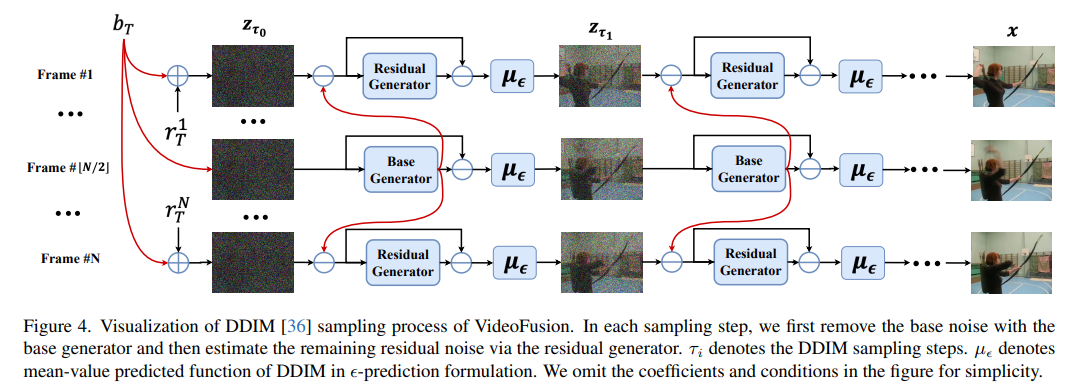
11、VideoFusion: 고품질 비디오 생성을 위한 분해 확산 모델
DPM(확산 확률 모델)은 데이터에 노이즈를 점진적으로 추가하여 순방향 확산 프로세스를 구성하고 새로운 샘플을 생성하는 역 노이즈 제거 프로세스를 학습하여 복잡한 데이터 분포를 처리하는 것으로 나타났습니다. 이미지 생성에서의 성공에도 불구하고 비디오 생성에 DPM을 적용하는 것은 고차원 데이터 공간에 직면하기 때문에 여전히 어려운 일입니다. 이전 방법은 일반적으로 동일한 비디오의 프레임이 독립적인 노이즈로 손상되어 콘텐츠 중복성과 시간적 상관 관계를 무시하는 표준 확산 프로세스를 사용합니다.
본 논문에서는 프레임별 노이즈를 모든 프레임에 공유되는 베이스 노이즈와 시간축에 따라 달라지는 잔여 노이즈로 분해하여 분해 확산 과정을 제안한다. 잡음 제거 파이프라인은 그에 따라 잡음 분해를 일치시키기 위해 공동으로 학습된 두 개의 네트워크를 사용합니다. 다양한 데이터 세트에 대한 실험을 통해 VideoFusion이라고 하는 방법이 고품질 비디오 생성에서 GAN 기반 및 확산 기반 대안을 능가하는 것으로 확인되었습니다.
공식 계정 [머신 러닝 및 AI 생성 생성]에 주목하세요. 더 흥미로운 내용이 여러분을 기다리고 있습니다.
안정적인 확산에 대한 간단한 설명: AI 페인팅 기술 이면의 잠재적 확산 모델 해석
제어 가능한 AIGC 페인팅 생성 알고리즘인 ControlNet에 대한 심층 설명!
클래식 GAN은 다음을 읽어야 합니다. StyleGAN

최신의 가장 완벽한 100개 요약! 확산 모델 생성 확산 모델
ECCV2022 | 대결 네트워크 GAN 생성에 대한 일부 논문 요약
CVPR 2022 | 25개 이상의 지침, 최신 50개의 GAN 논문
ICCV 2021 | 35개 주제에 대한 GAN 논문 요약
110개 이상의 기사! CVPR 2021 가장 완벽한 GAN 종이 빗질
100개 이상의 기사! CVPR 2020 가장 완벽한 GAN 종이 빗질
StarGAN 버전 2: 다중 도메인 다양성 이미지 생성
첨부파일 | "Explainable Machine Learning" 중국어 버전
첨부파일 | "TensorFlow 2.0 Deep Learning Algorithms in Practice"
첨부파일 다운로드 | "컴퓨터 비전의 수학적 방법" 공유
"예기·설지"에는 "친구 없이 혼자 배우는 것은 외롭고 무지하다"는 말이 있다.
밀크티 한 잔을 클릭 하고 AIGC+CV 비전의 개척자가 되어보세요! , AI 생성 및 컴퓨터 비전 지식의 행성에 합류하십시오!