Tabla de contenido
introducción a la colección
¿Por qué usar colecciones?
Cuando queremos guardar un conjunto de datos, los tipos de variables que se pueden usar son colecciones y arreglos. Así que me gustaría decir acerca de las limitaciones de las matrices:
- Una vez que se determina el tipo de matriz, toda la matriz solo puede colocar datos de este tipo, por supuesto, se puede especificar como el tipo Objeto.
- La longitud de la matriz es fija y se producirá un error cuando los datos excedan el tamaño preestablecido. Aunque algunos tipos de colecciones también usan arreglos en la parte inferior, la colección administra automáticamente los arreglos, los expande y copia automáticamente.
- Las matrices son menos selectivas y es imposible elegir la estructura de datos adecuada según el uso de datos. Una matriz es un tipo . La característica de una estructura de datos de matriz es un espacio de direcciones continuo. La dirección de memoria de cada elemento se puede
数组数据结构calcular rápidamente de acuerdo con el número de serie. Puede haber muchos tipos de colecciones, por ejemplo: linkedList es una lista doblemente enlazada. Solo hay un tipo de matriz para la selección, y la colección puede elegir una estructura de tipo de lista enlazada para la eliminación y adición frecuentes de datos.中间插入数据删除数据
Los arreglos son relativamente primitivos, mientras que las funciones de colección son más ricas.Algunas colecciones tienen un arreglo en la capa inferior, que es una mejora de algunas funciones basadas en el arreglo. Las matrices son solo un tipo de datos, y las colecciones pueden usar más tipos de datos, como listas vinculadas, matrices, tablas hash, árboles rojo-negro, etc.
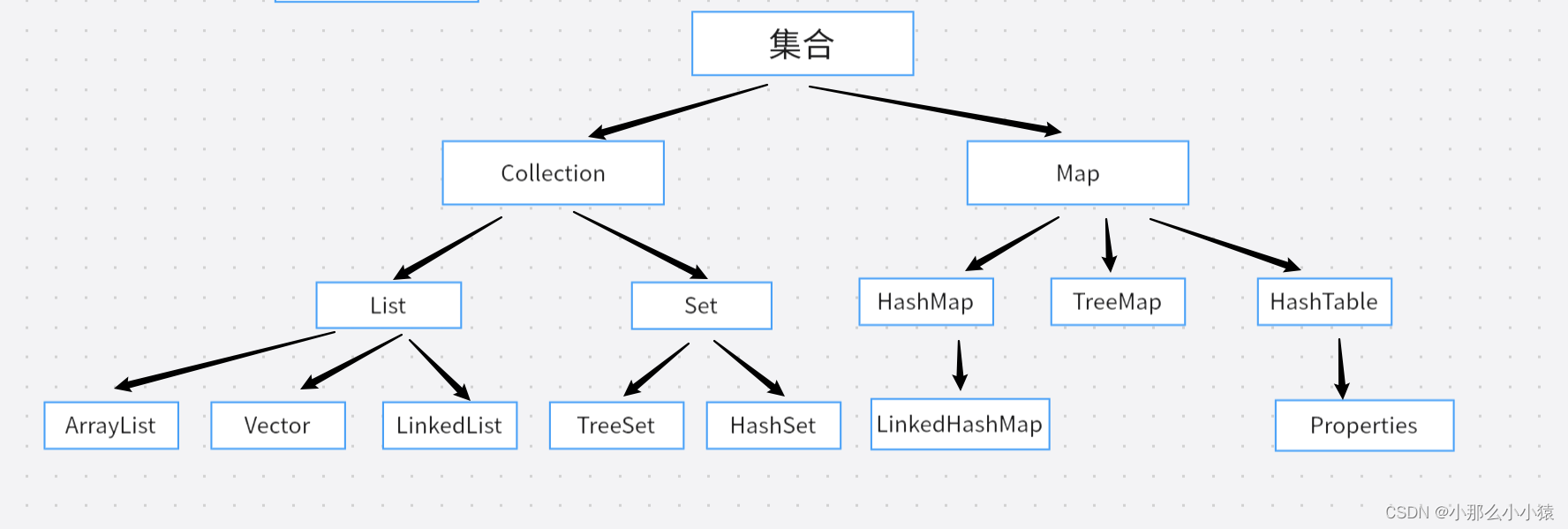
Las colecciones se dividen en colecciones de una sola columna y colecciones de dos columnas. Una colección de valor único es una colección de una sola columna y una colección K_V es una colección de dos columnas.
Las colecciones de una sola columna se dividen en dos categorías, una es Lista, la otra es Conjunto y la colección de doble columna es solo Mapa (modo de par clave-valor k_V, K no se puede repetir). ¿Por qué las funciones de cada colección son diferentes
? ? Porque tienen diferentes estructuras de datos subyacentes, o diferentes mecanismos de expansión, o diferentes mecanismos de seguridad.
Una colección de un tipo se divide en muchos tipos de acuerdo con diferentes requisitos, y aquí solo se presentan algunos tipos de uso común. Tenga en cuenta que la siguiente figura es solo para clasificación en lugar de mostrar la relación padre-hijo entre clases y clases.
Al leer el código fuente, encontré una característica: al código fuente realmente le gusta juzgar y asignar valores cuando se realiza un bucle.
Mapa
mapa hash
El método de construcción de HashMap

al agregar un conjunto de pares clave-valor K_V
En primer lugar, comprenda cómo se almacena la capa subyacente de HashMao.
Al colocar un conjunto de pares clave-valor clave_valor, primero se aplica un hash a la clave y luego se calcula el valor almacenado en Node<k_v> dividiendo el resultado de la operación hash por la longitud de la matriz Node<k_v> subyacente Posición, si ya hay un valor en esta posición, se almacenará al revés, de modo que los nodos en la misma posición en la matriz Node<k_v> formen una única estructura de lista enlazada . Cuando el número de listas vinculadas exceda 8, expanda la matriz Node<k_v> Si la longitud de la matriz expandida ha alcanzado las 64 longitudes, la lista vinculada se convertirá 树化a 红黑树.
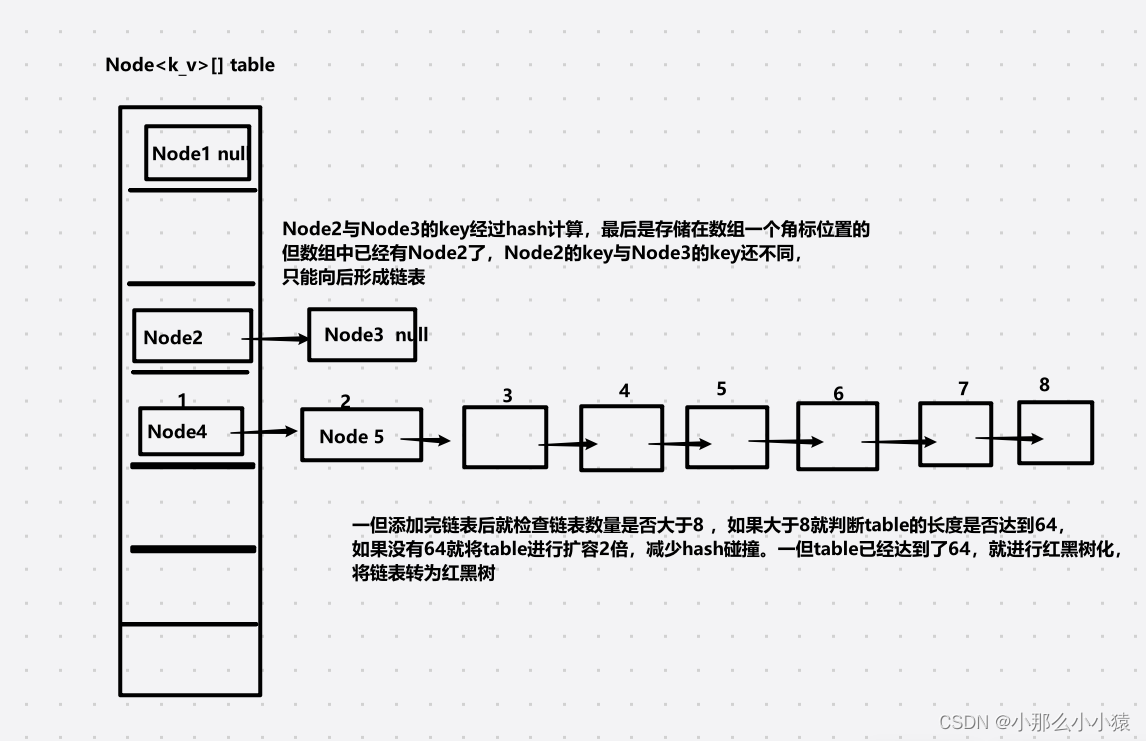
Lo siguiente introducirá este proceso en detalle:
primero juzgue si la clave es nula, si es nula, el valor es 0, si no es nula, obtenga su código hash y muévalo a la derecha 16 bits La capa inferior de

cada El grupo de pares clave-valor k_v se almacena en Node<k_v>, mientras que Node<k_v> hereda
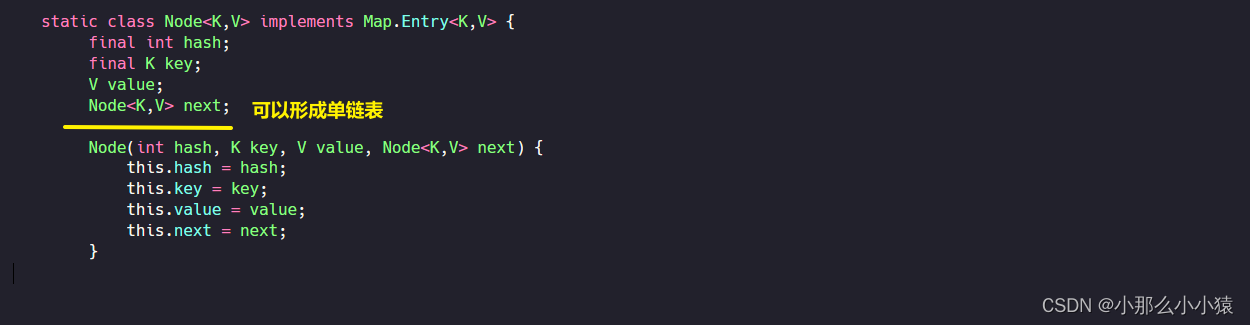
el procedimiento almacenado específico de Map.Entry<k_v>
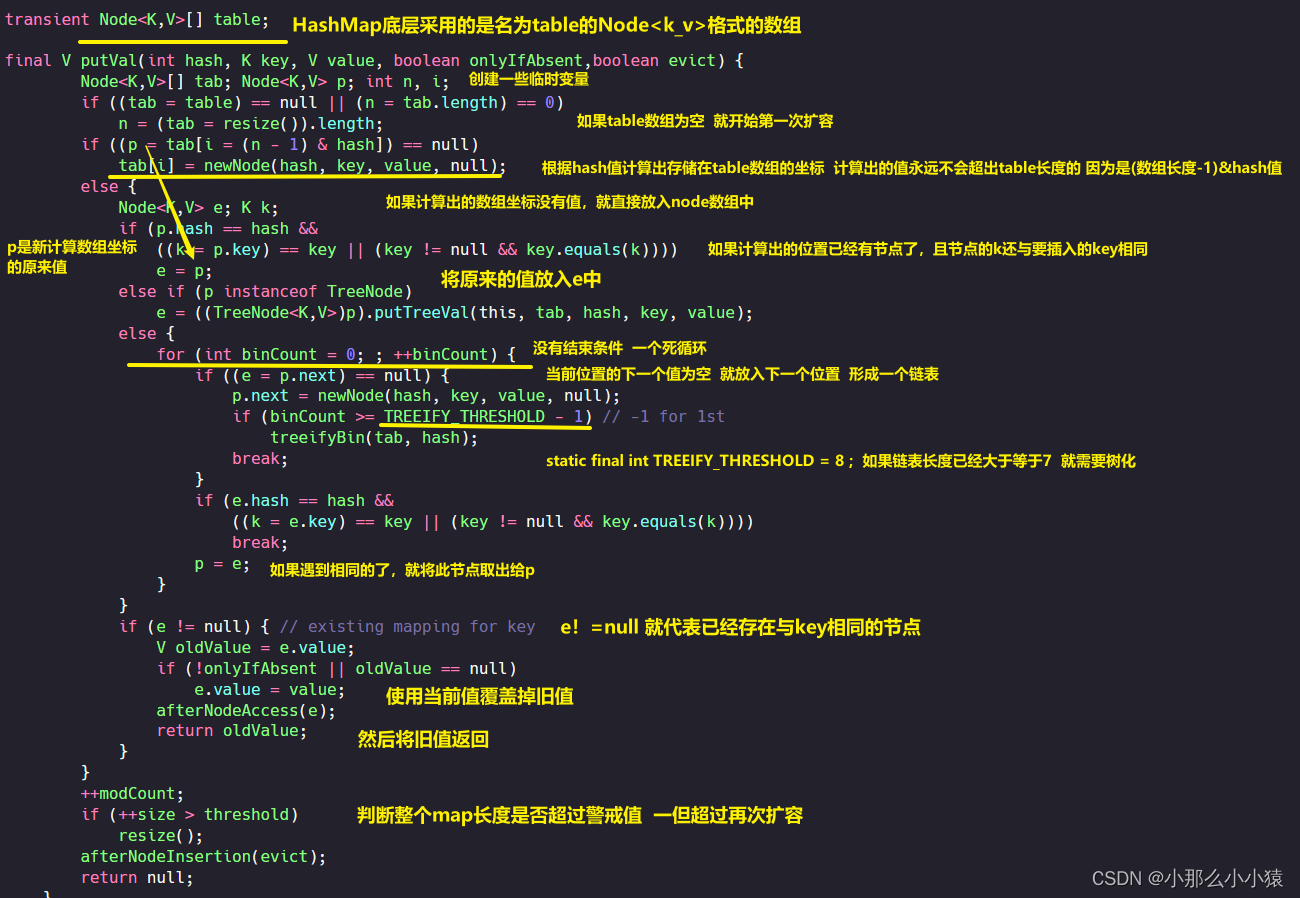
La capa inferior de HashMap es una matriz llamada tabla. Cuando las coordenadas de matriz calculadas ya tienen valores, se almacenarán al revés en forma de una lista vinculada. Si encuentra la misma clave que su propia página de valor hash, elimine el valor anterior y sobrescríbalo con el valor nuevo. Durante este período, hubo dos expansiones, una fue cuando la longitud de la matriz de la tabla era 0 y la otra fue cuando la longitud de la matriz de la tabla (cada tamaño agregado sería ++, por lo que se contó la longitud de la lista vinculada ) alcanzó el valor de advertencia. Entonces, ¿cuál es el proceso de expansión? Esto requiere verificar resize()el método.
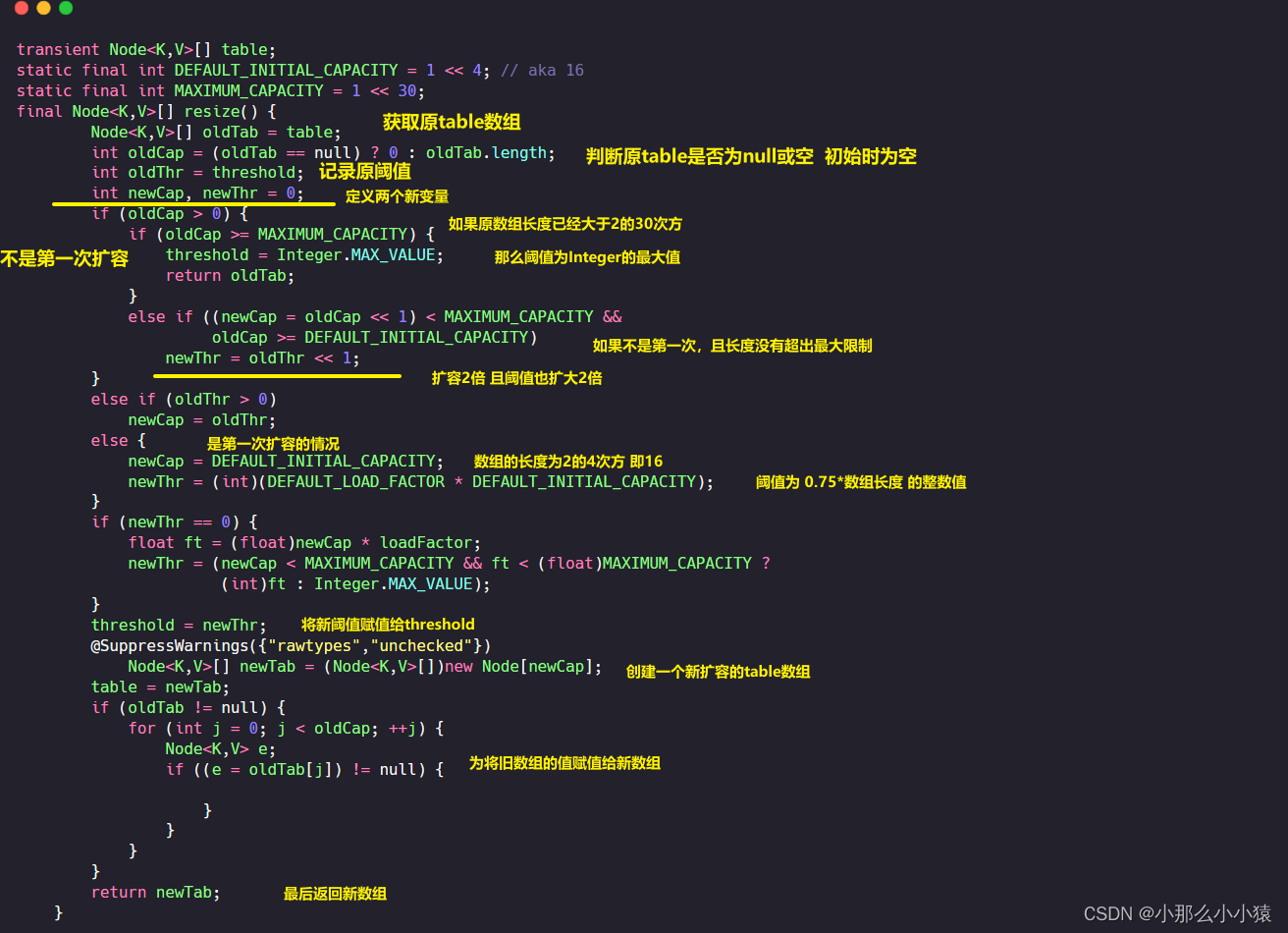
Lo anterior es la expansión de la matriz de tablas cuando el número total de tablas de tablas supera el umbral o cuando se coloca un nuevo valor en una matriz de tablas vacía por primera vez. Cuando el número total de una sola tabla vinculada list excede 8 y el arreglo es menor a 64, también se realizará una expansión tableEntonces ,

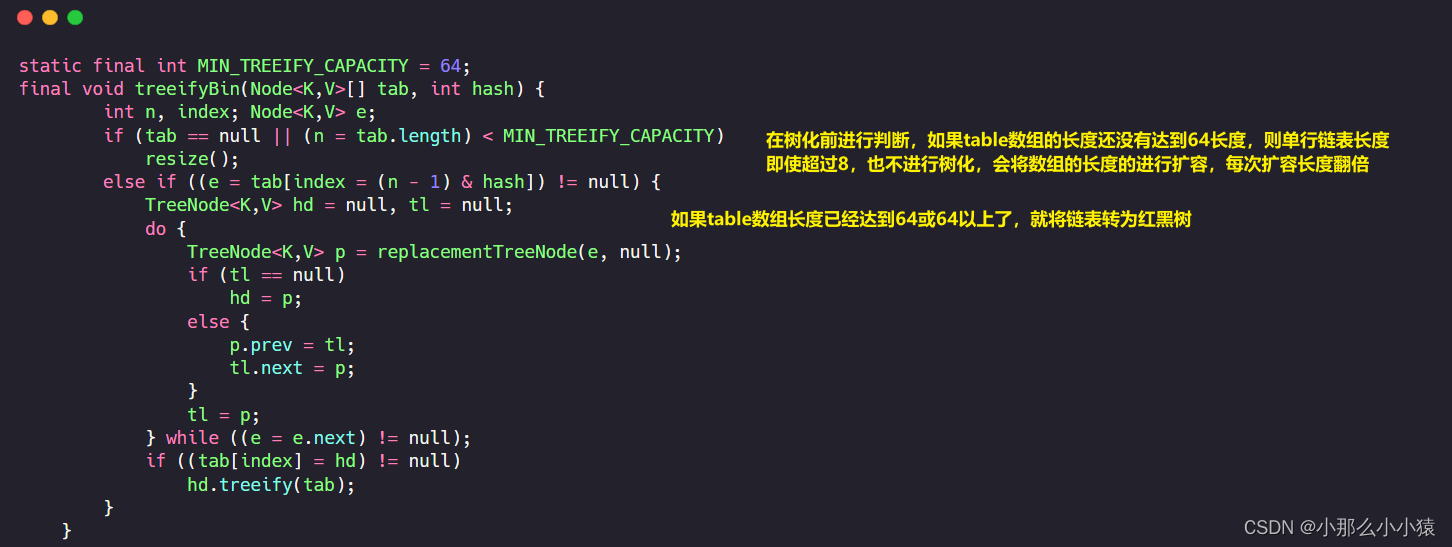
¿por qué HashMap usa el método de almacenamiento de arreglo + lista enlazada + árbol rojo-negro? Las matrices se caracterizan por una búsqueda rápida y una longitud limitada, pero el uso de hash para determinar los subíndices de la matriz es propenso a colisiones de hash, por lo que se deben usar listas enlazadas. Al buscar el valor basado en la clave, el cálculo hash se realiza primero en la clave, de modo que se pueda ubicar rápidamente una determinada posición de la matriz. Sin embargo, puede haber varios nodos en esta ubicación, por lo que las claves deben compararse secuencialmente a lo largo de la lista vinculada. Pero cuando la lista enlazada es demasiado larga, llevará demasiado tiempo buscar en la lista enlazada. Por lo tanto, cuando el número de listas vinculadas llegue a 8, expanda la matriz para reducir la probabilidad de colisiones hash o arboree la lista vinculada para mejorar la eficiencia de la búsqueda de claves.
¿Cómo encuentra hashMap elementos basados en la clave?

Pensando: ¿Qué pasa si juzgas si es el nodo lo que quieres encontrar?
Se ha dado en el código fuente, el valor Hash debe ser el mismo (se ha puesto en el nodo Nodo al agregar el nodo) y la clave debe ser la misma. La clave de HashMap no solo puede usar el tipo String, sino que también puede usar el objeto.
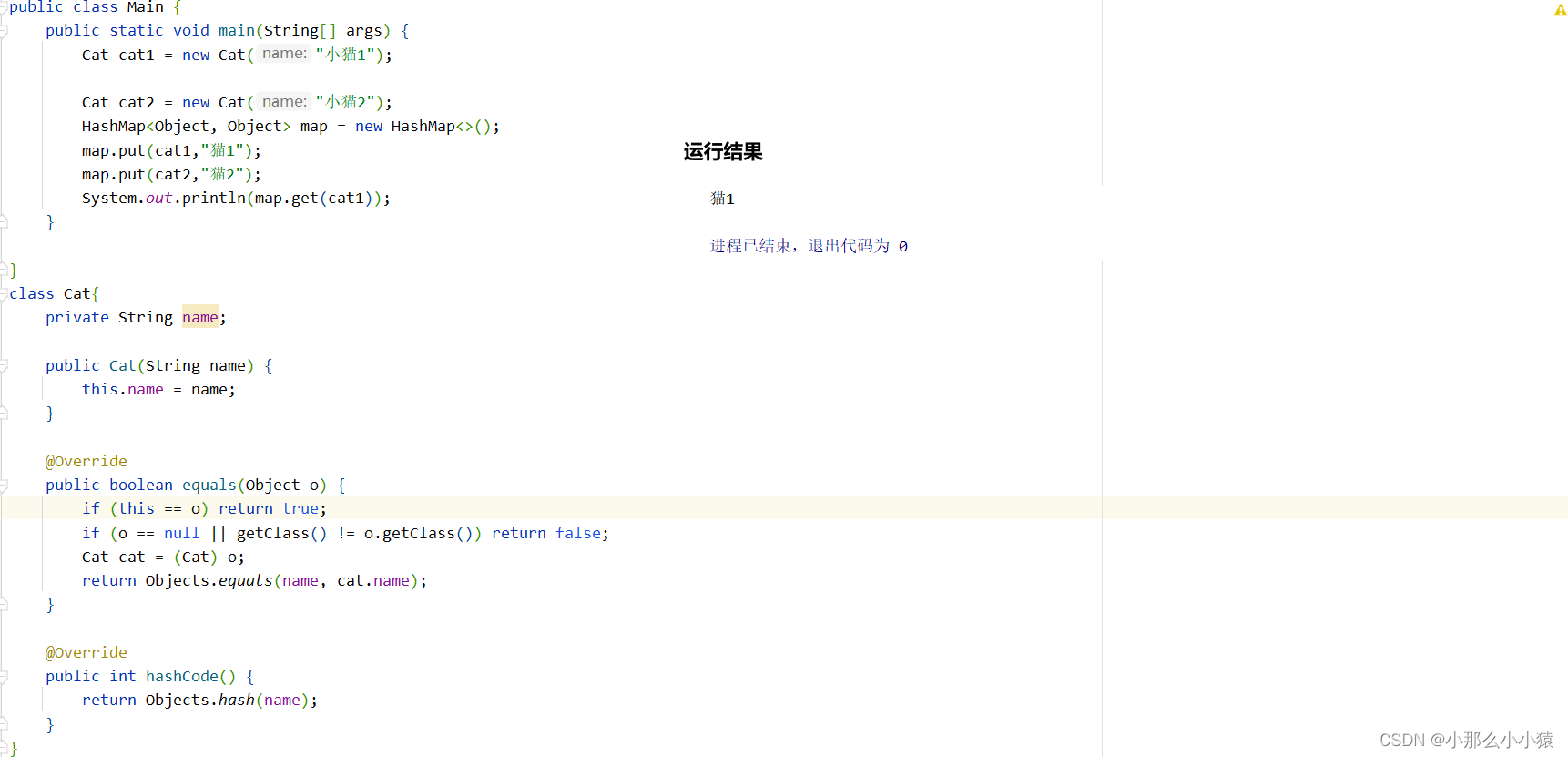
Entonces, ¿cómo hacer que el objeto cat1 cubra al objeto cat2, o solo puede haber un objeto del mismo tipo en la colección de mapas, o solo juzgar si es la misma clave en función de un determinado atributo?
Antes que nada, es necesario entender que es lo mismo que juzgar la clave, se ha introducido antes: el mismo valor hash se usa para comparar si las claves son iguales o iguales. Luego, solo necesita reescribir los métodos HashCode y equals de cada clase, para que pueda juzgar si es la misma clave de acuerdo con nuestras ideas.

Varios métodos de recorrido de HashMap
¿Por qué se dice que la inserción y el recorrido de HashMap están fuera de servicio? Porque cuando se reinserta HashMap, la posición de la matriz que se insertará se obtiene calculando el valor Hash de la clave, en lugar de organizarse en la matriz en secuencia. Al atravesar, el recorrido se realiza en el orden del arreglo, lo que dará como resultado que aunque el orden de inserción sea diferente, estén conectados en el arreglo o en la lista enlazada, haciendo que el orden de los resultados del recorrido sea el mismo.
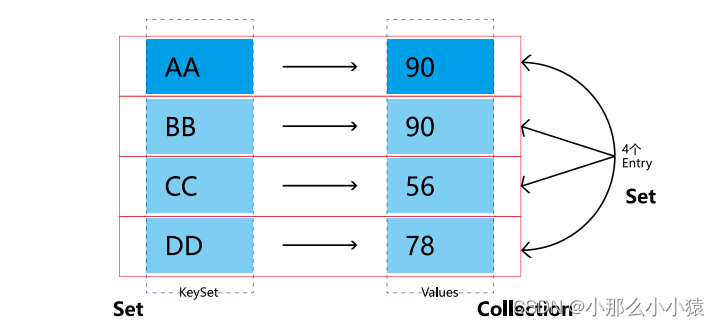
La colección de mapas puede juntar las claves como un conjunto de claves, poner los valores de valor en uno como valores, y cada conjunto de valores_clave es una entrada. Pero tenga en cuenta que cuando se llama al método keySet() o al método Values(), el valor devuelto también se obtiene recorriendo el mapa, en lugar de guardar la clave o el valor por separado.
Por ejemplo: código fuente de keySet
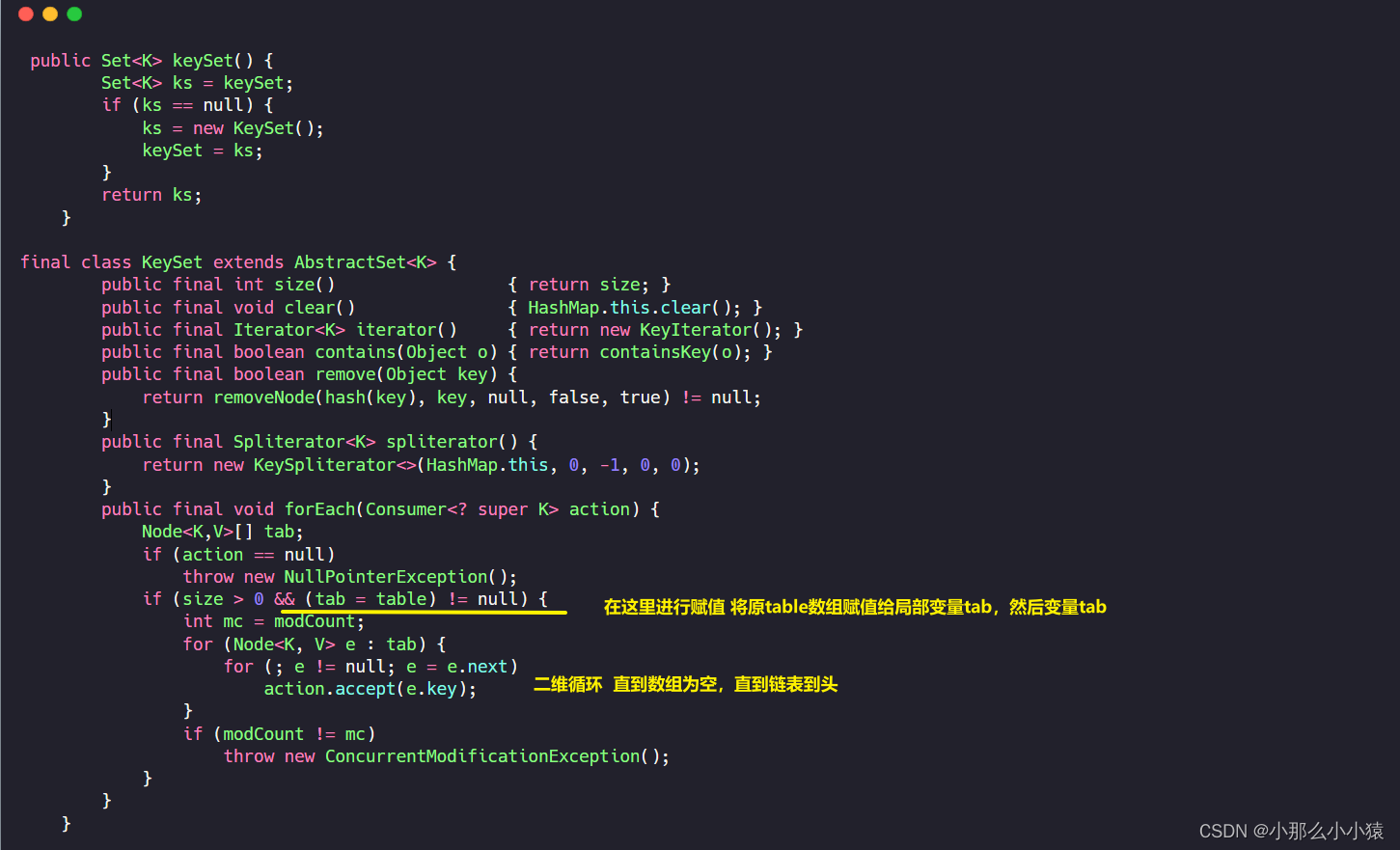
A partir de este código fuente, puede saber que KeySet puede ser una colección Set o un objeto, con métodos size(), Clear(), etc.
Use KeySet () para obtener claves y busque claves a través del mapa para atravesar


Utilice EntrySet() para obtener o establecer el valor k_v



LinkedHashMap
LinkedHashMapheredado HashMap类_ Sobre Node<k_v>la base de esta lista enlazada individualmente, hay más punteros beforeMientras afterque un nodo apunta al siguiente nodo de la lista enlazada individualmente, también apunta a su elemento insertado anterior y al siguiente elemento que se insertará.


De esta manera, la inserción del mapa puede ser en un orden secuencial. Sobre la base de la matriz original y la lista vinculada, el último nodo se puede encontrar a lo largo de la lista vinculada a través del primer nodo insertado. La regla de inserción sigue siendo el método de HashMap, simplemente reemplace el nodo Nodo con
el
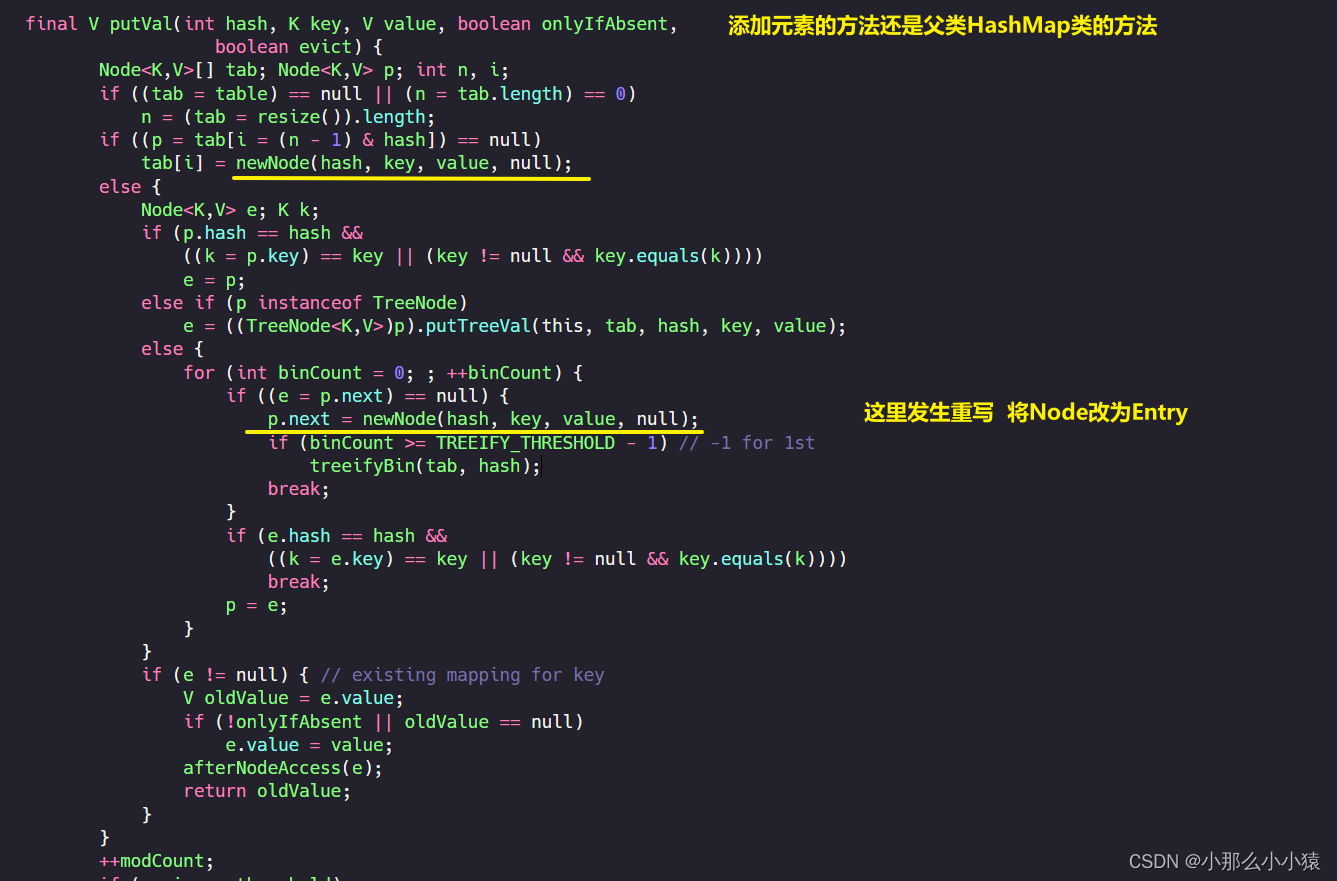
mismo Hashmap mantiene dos estructuras no relacionadas, una es una lista/árbol vinculado para el almacenamiento, y la otra es una lista vinculada para el recorrido, con el primero apuntando a la cabeza y el último apuntando a la cola. Al insertar un nodo, reemplace el último nodo original con un nuevo

nodo El puntero anterior apunta a, y al mismo tiempo asigna su propio nodo como cola, y afterel puntero del último nodo original apunta al último nodo insertado. De esta manera, sobre la base del HashMap original, el orden de inserción forma una lista de un solo enlace, de modo que la inserción está ordenada.
Cuando LinkedHashMap ejecuta keySet() , el HashMap original se atraviesa directamente tabley luego atraviesa el enlace. Luego vea cómo se recorre el LinkedhashMap ordenado.
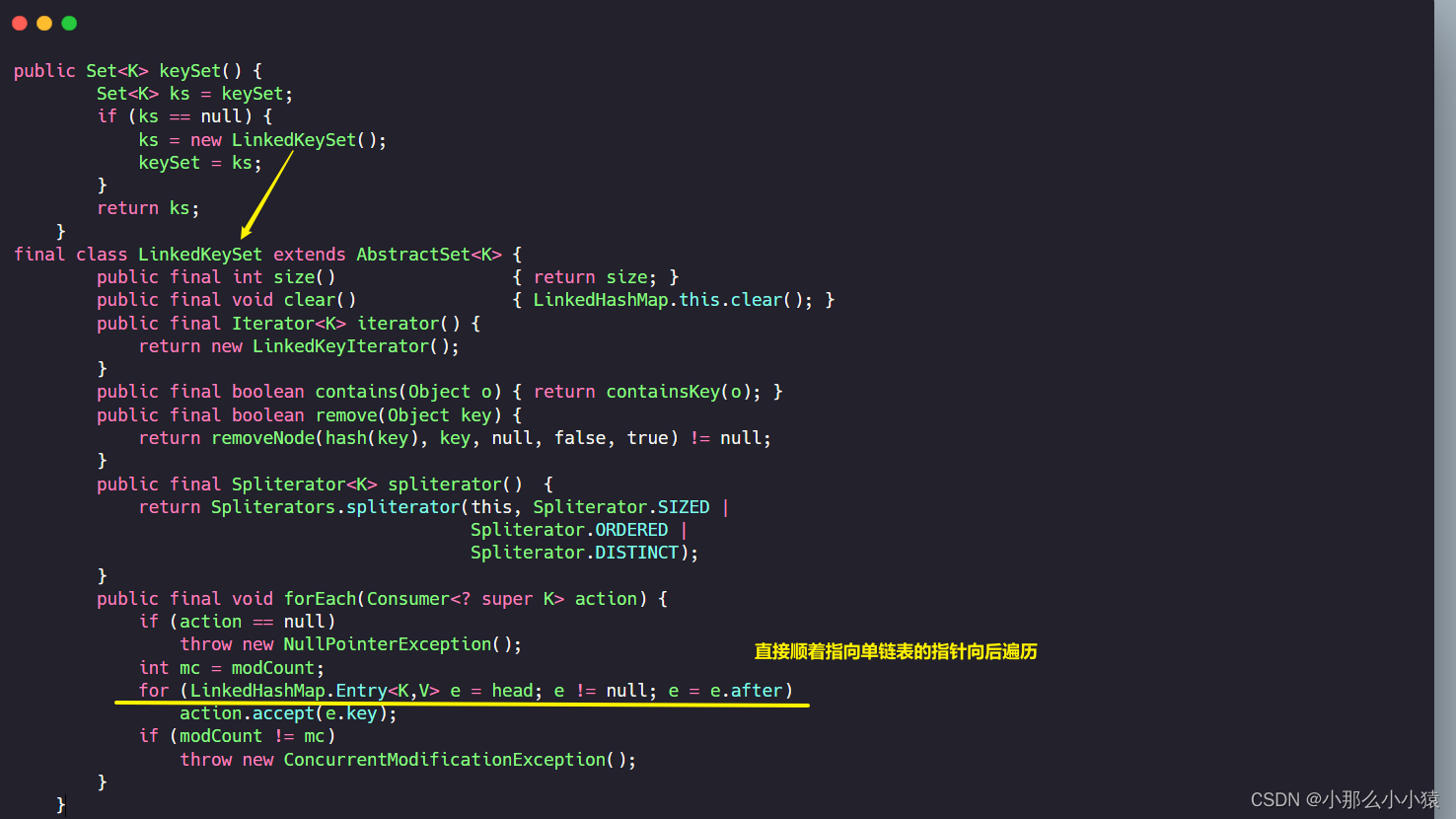
La comparación entre
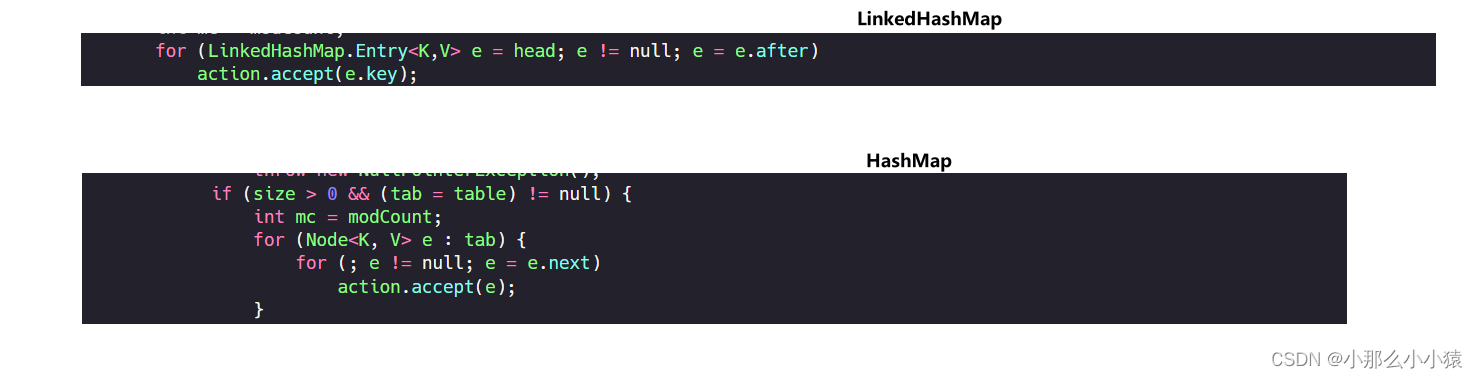
los valores es: LinkedHashMap es muy similar a HashMap. LinedHashMap es solo una pluralidad de listas enlazadas formadas en el orden de inserción. Las dos son casi iguales excepto por el método transversal . Ambas son inseguras.
Tabla de picadillo
La matriz de tablas se inicializó cuando se construyó HashTable.
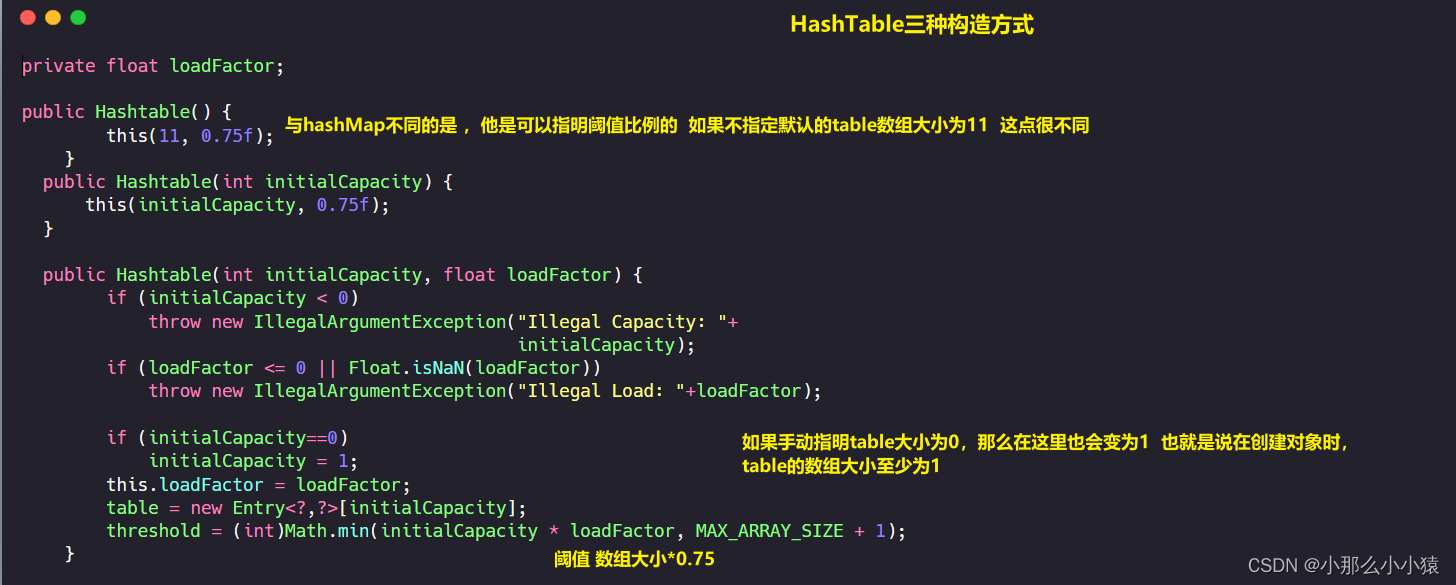
A continuación, echemos un vistazo al método de inserción de HashTable. El mecanismo de expansión y el método de inserción de HashTable son muy especiales.


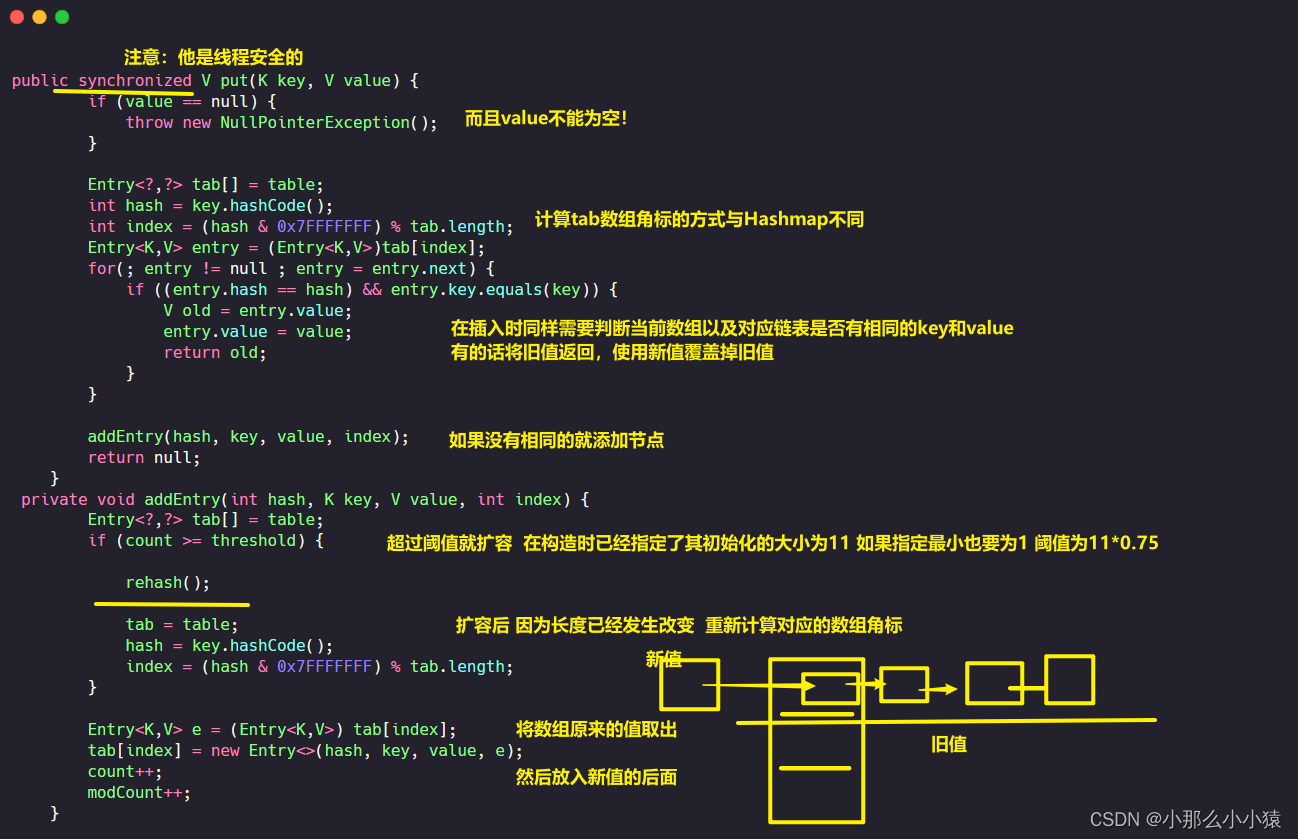
Pensando : ¿ Cuáles son las ventajas Hashtablede simplemente poner datos ?HashMap不同
- HashTable especifica el tamaño inicial de la tabla cuando se construye, el valor predeterminado es 11 y la especificación manual es al menos 1
- HashTable calcula y almacena subíndices de matriz
(hash & 0x7FFFFFFF) % tab.lengthy hashMap lo hace(n - 1) &key.hashCode()) ^ (h >>> 16). - HashTable es seguro para subprocesos, el método put se
synchronizedmodifica y HashMap no es seguro para subprocesos - Cuando HashTable inserta datos, se inserta delante de la lista vinculada, y el valor vacío antes de la matriz, una sola entrada o la lista vinculada de entrada se colocan detrás del nodo insertado
next. - HashTable
Value在插入时不能为空。 - Hashtable usa count para registrar la cantidad de nodos, y HashMap usa size para registrar
- El momento de la expansión de la capacidad varía según las condiciones.

Misma parte :
- La relación de umbral sigue siendo 0,75, pero se puede especificar Hashtable al construir
En el código fuente anterior, count >= thresholdse expandirá rehash(), así que presentemos la
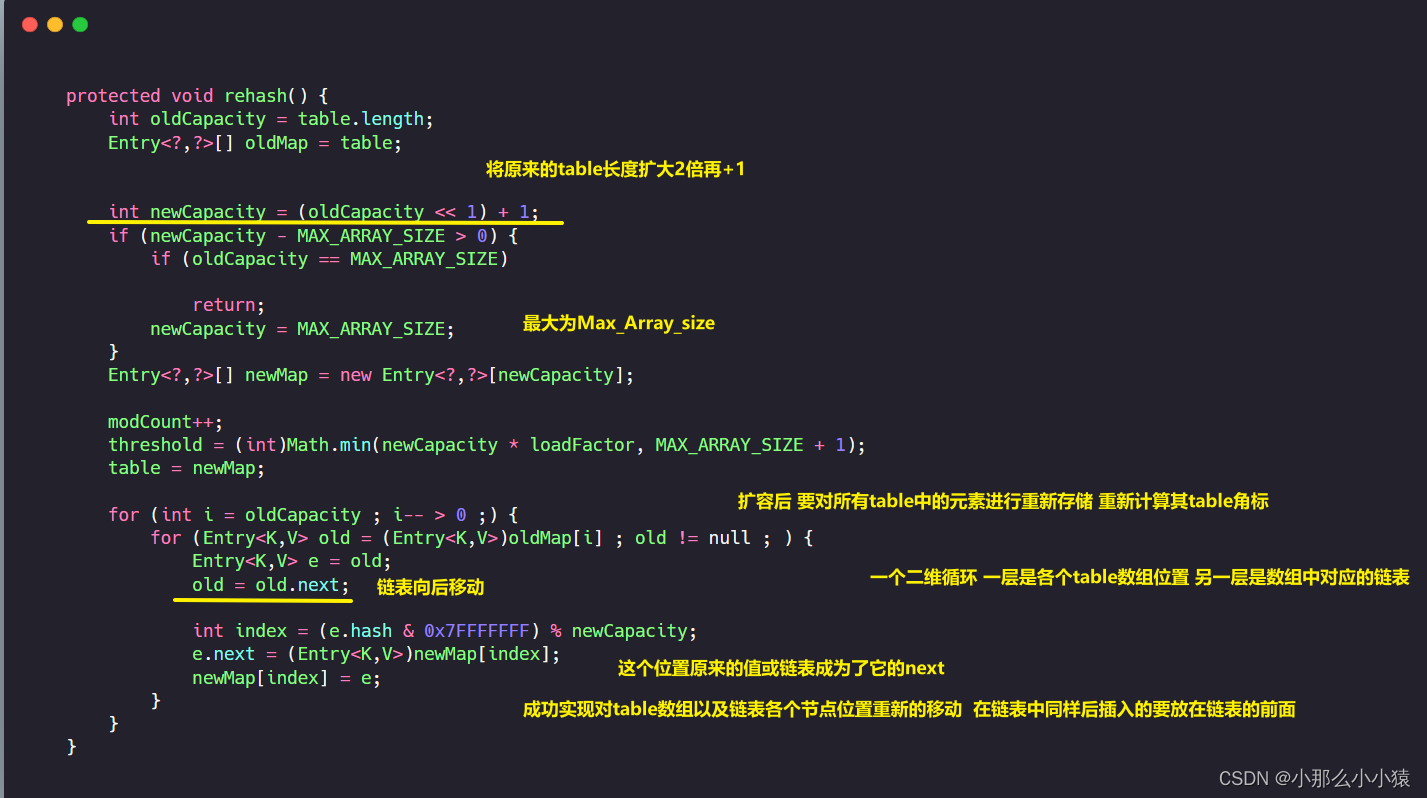
expansión del código fuente de la expansión, que es diferente de HashMap :
- La expansión de la tabla hash necesita reubicar los datos
- HashTable no tiene límite en la longitud de la lista enlazada, no existe
树tal cosa como
Propiedades
Propiedades hereda HashTable, que es muy similar a Hashtable y es más adecuada para leer archivos de configuración y convertirlos a hashTable
Recopilación
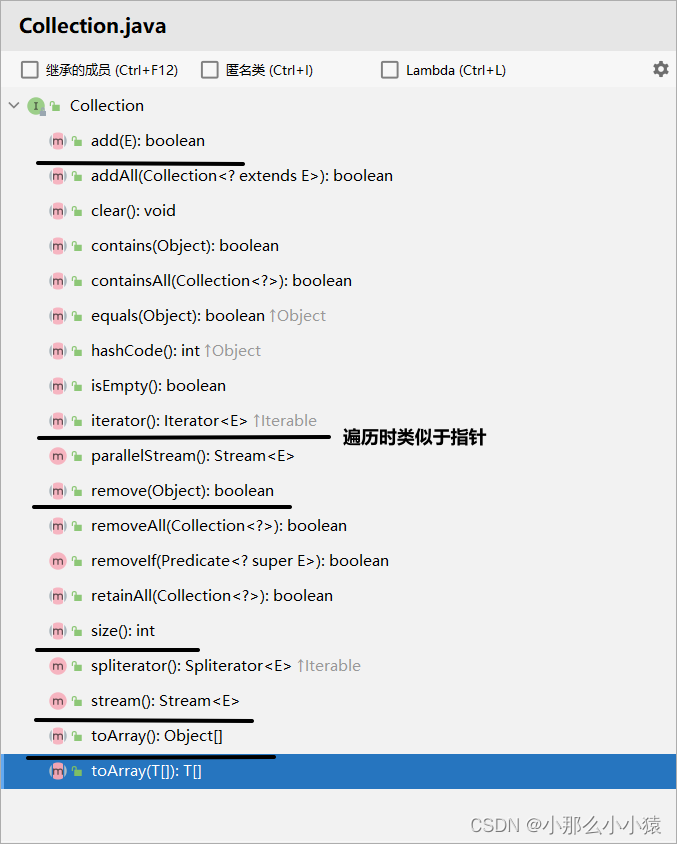
La colección es una interfaz de colección unidireccional y muchos métodos se definen en la interfaz como funciones comunes de todas las colecciones unidireccionales.
Lista
Lista de arreglo
La capa inferior de ArrayList es una elementDatamatriz con nombre. Al crear una colección ArrayList, proporciona una construcción parametrizada y una construcción no paramétrica.
Si se usa directamente new ArrayList(), esta es una construcción no paramétrica. Dentro del constructor, se creará una matriz vacía de tipo Object asignado a la matriz elementData
Construcción sin argumentos para crear un objeto ArrayList

Al construir un ArrayList, pase una colección Collection , y la colección se convertirá y operará sobre la base de esta colección.

Especifique el tamaño inicial de la matriz al crear el objeto ArrayList

Al agregar inicialmente elementos a la matriz, la matriz elementData se expandirá a 10,
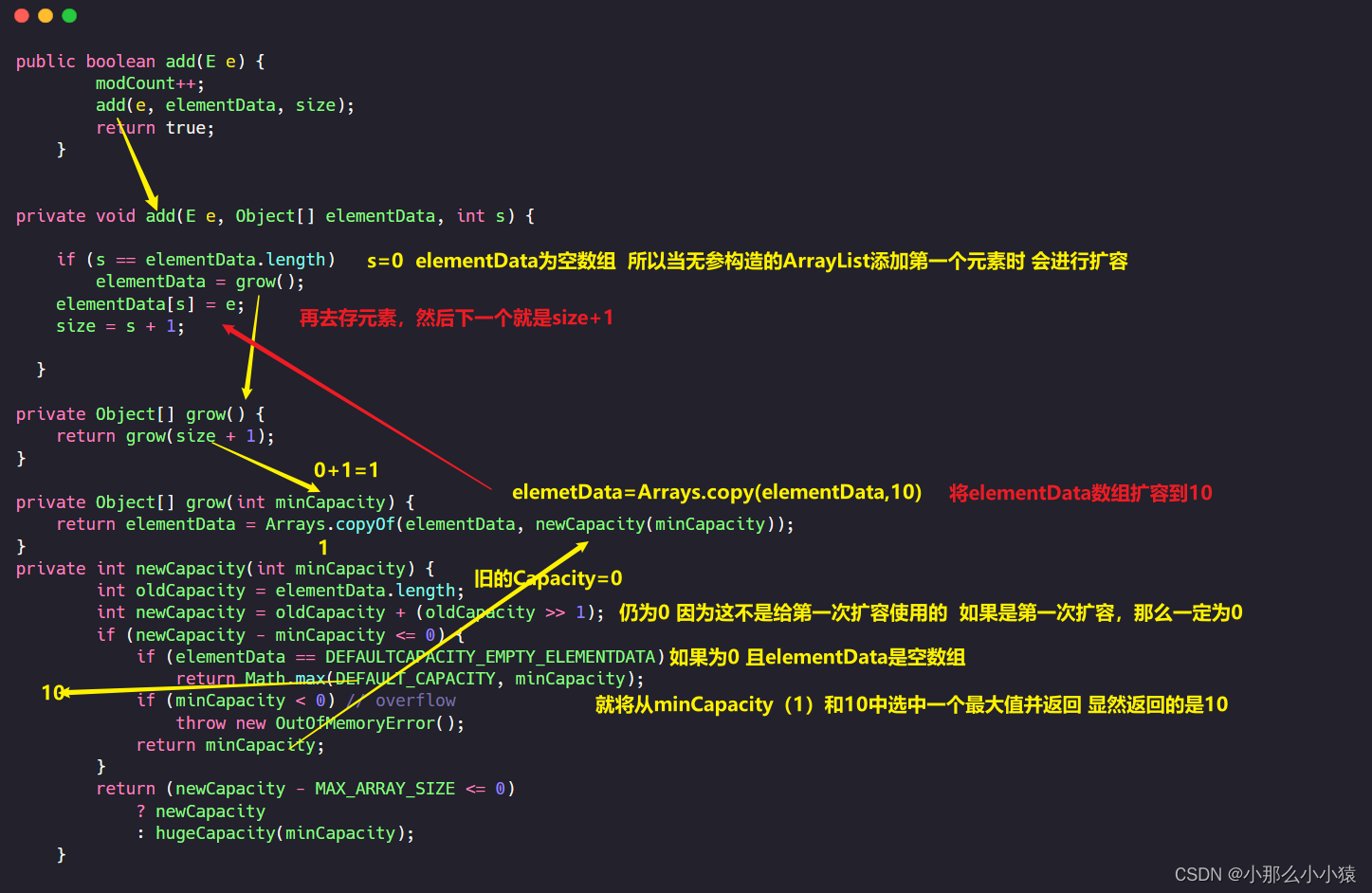
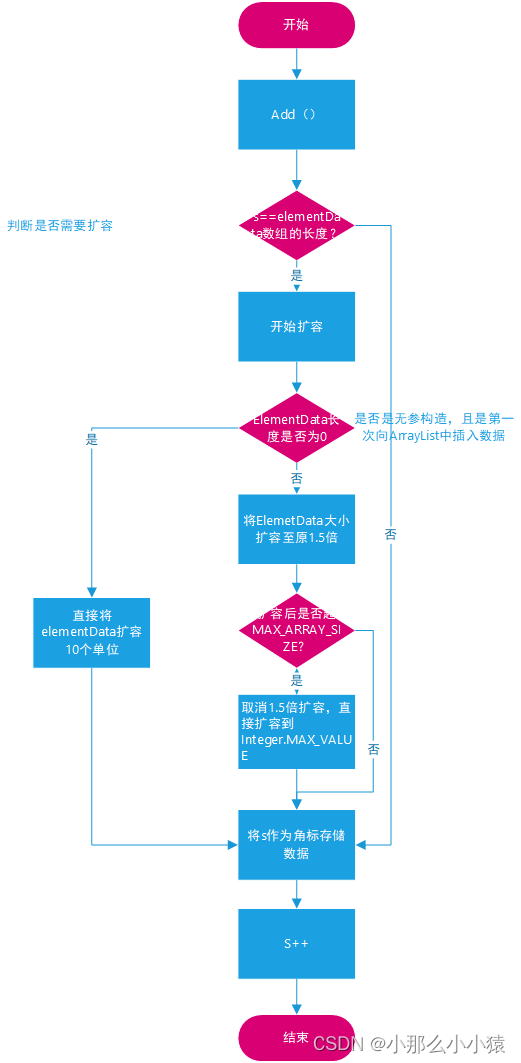
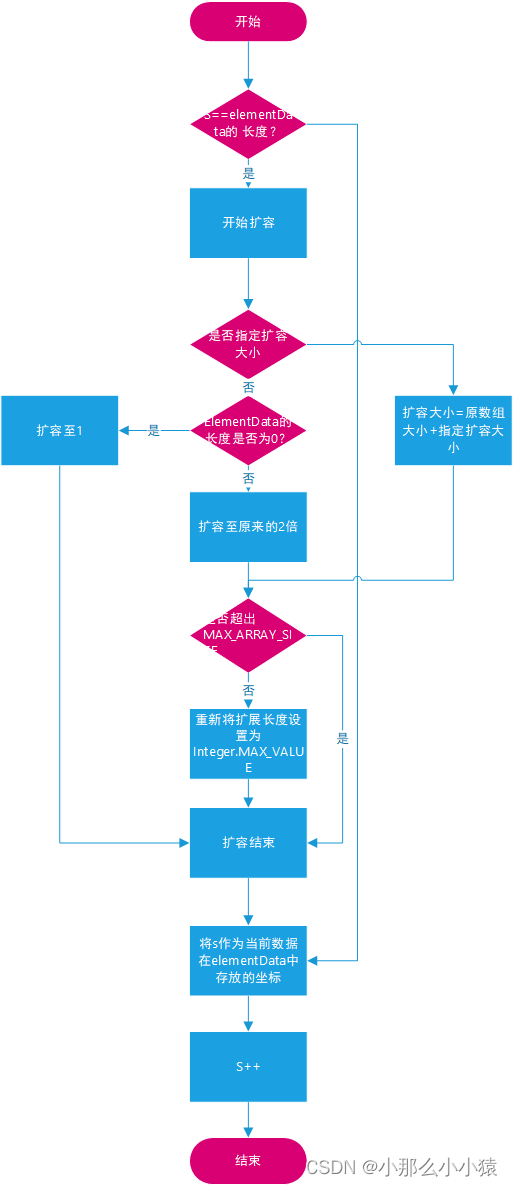
entonces, ¿qué debo hacer cuando se agote la capacidad de la matriz expandida? Si el tamaño ya es MAX_ARRAY_SIZE 1.5倍扩容
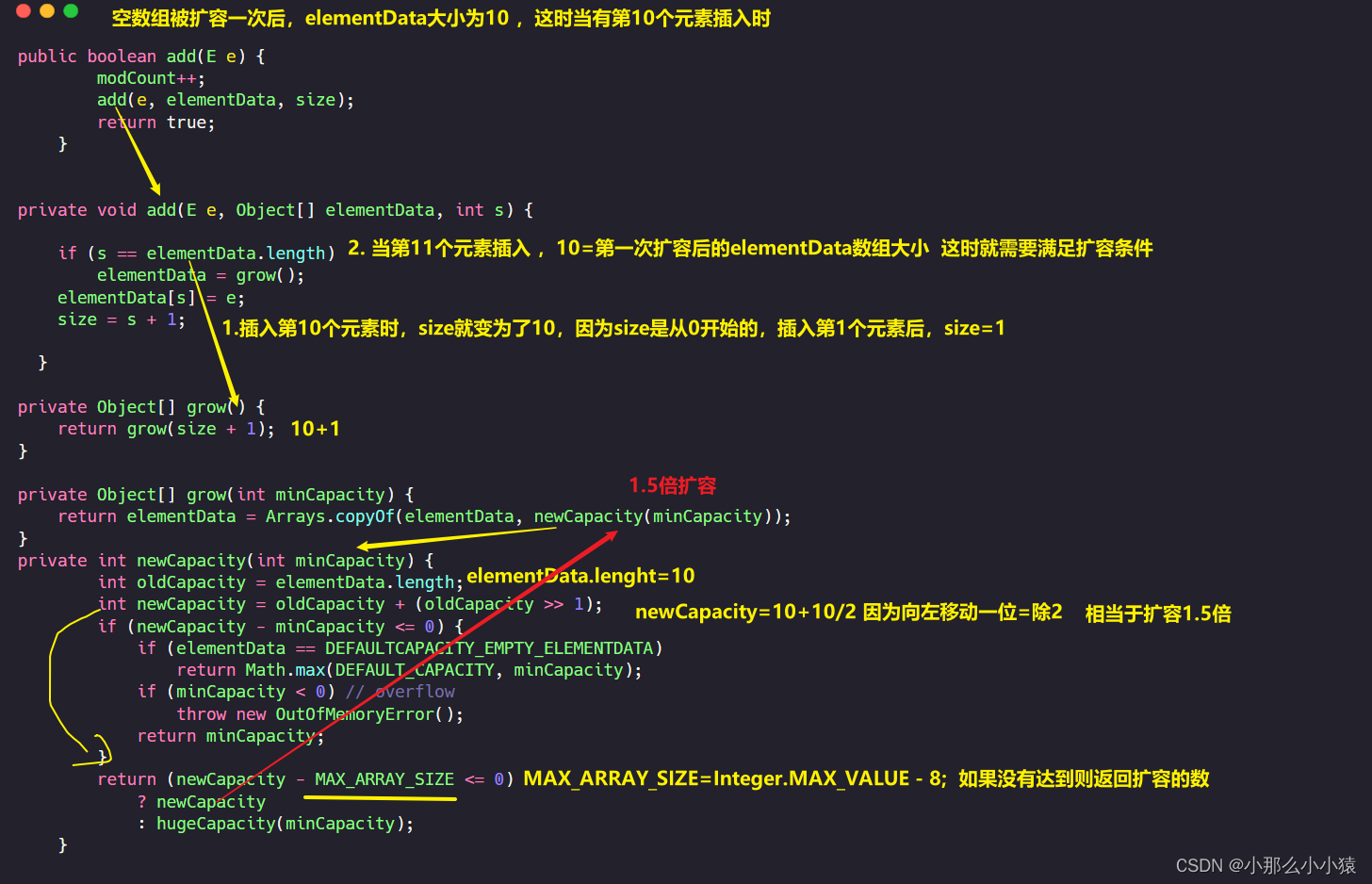
después de la expansión , entonces es el método de expansión, pero vuelve directamente para resumir el método de expansión de ArrayList. s es la coordenada de la matriz cuando se almacenarán los datos. Si s es igual al tamaño de la matriz, significa que no hay lugar para almacenar nuevos datos. , al principio, s = 0, la longitud de elementData es 0, y los datos no se pueden almacenar y deben expandirse. Después de la expansión, elementData [ s]=datos actuales, y luego s++. Cuando el último elemento se agrega a la matriz y s++=10, significa que el siguiente elemento es el dato 11. En este momento, s=elementData.length, la capacidad debe expandirse nuevamente.超出不在采用1.5倍Integer.MAX_VALUE

Vector
Cree un objeto Vector sin parámetros
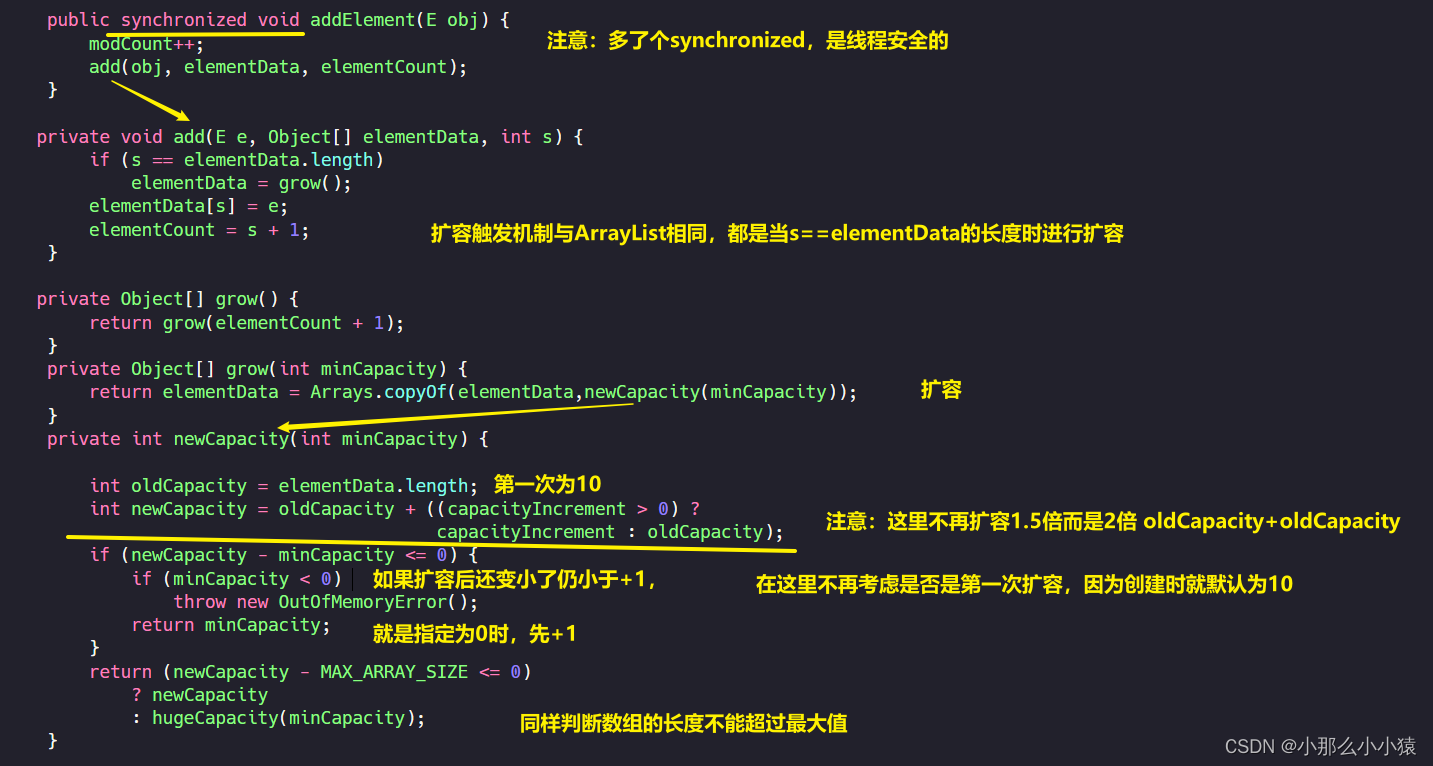
. También se usa la capa inferior de Vector 名为elementData的数组. El tamaño inicial de la matriz no es como el de ArrayList: juzgue al agregar elementos para determinar si es una expansión de matriz vacía. Si es así, expanda la capacidad por 10 unidades Si Vector no es una construcción de parámetros, en la construcción sin argumentos, llame a la construcción de parámetros, establezca el parámetro en 10. Al
 crear el objeto, se creó una matriz de datos de elemento de tipo Objeto de la longitud especificada, que es muy diferente de la ArrayList anterior.En
crear el objeto, se creó una matriz de datos de elemento de tipo Objeto de la longitud especificada, que es muy diferente de la ArrayList anterior.En
la matriz Cuando se agregan elementos inicialmente , a diferencia de ArrayList, es seguro para subprocesos.
Al crear un vector, puede especificar el tamaño de cada expansión. Si no se especifica, el valor predeterminado es agregar el mismo tamaño al tamaño original de la matriz. ¿Qué pasa si la
matriz subyacente está llena? 2倍扩容
Entonces, ¿qué pasa si el tamaño de elementData se especifica manualmente como 0 al construir Veactor?
Si cree que no es apropiado especificar 10 tamaños y longitudes de forma predeterminada al crear un vector, puede especificar manualmente una longitud de 0 al crear un objeto, de modo que la longitud de elementData sea 0. Expanda a medida que agrega elementos

La diferencia entre Vector y ArrayList
- Vector es seguro para subprocesos y se agrega antes del método add()
synchronized, mientras que ArrayList no lo hace. - Vector abre el tamaño de la matriz elementData al crear un objeto sin construcción de parámetros, y el tamaño de la matriz elementData está vacío cuando ArrayList crea un objeto sin construcción de parámetros, y solo se inicializará al agregar elementos
- Vector puede especificar el tamaño de cada expansión. El primer parámetro de la estructura de parámetros especifica el tamaño de elementData, y el segundo parámetro es el tamaño de cada expansión. ArrayList no se puede especificar y el tamaño se fija cada vez.
- Si Vector no especifica el tamaño de cada expansión, la expansión
新数组长度=原数组长度+原数组长度equivale a 2 veces, mientras que ArrayList新数组长度=原数组长度+0.5原数组长度equivale a 1,5 veces - Cuando se construye ArrayList, se le puede asignar una colección de datos
Similitudes entre Vector y ArrayList
- La capa inferior toma
elementDatauna matriz llamada - El mecanismo de expansión del activador es el mismo y se llama al método de expansión cuando s==elementData.length. Después de la expansión, use s como el subíndice de la nueva matriz de datos, y luego s++

Vector es adecuado para escenarios :
si se requiere seguridad de subprocesos, use Vector, y si desea especificar manualmente el tamaño de cada expansión, use Vector.
Resumen :
Lista enlazada
La capa inferior de LinkdList es que 双向链表las dos anteriores son matrices. La diferencia entre una lista enlazada y una matriz es que la lista enlazada es muy flexible. Para agregar un elemento, solo necesita crear un solo nodo y luego señalarlo con el puntero, mientras que la matriz necesita abrir un espacio por adelantado. , lo que hace que el método de construcción de LinkedList sea diferente al de ArrayList y Vector. , no necesita abrir espacio.
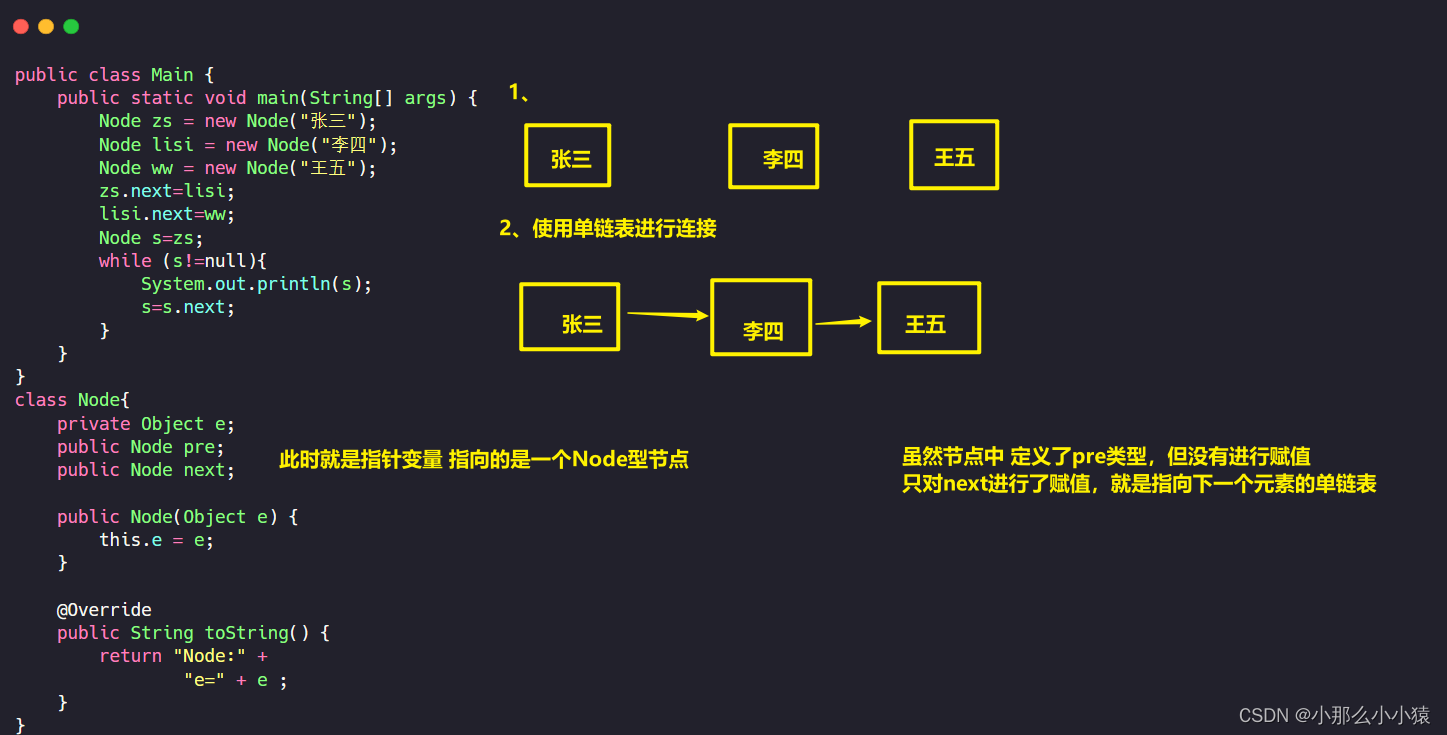
El valor de la atención es: aunque no existe un concepto de punteros en Java, los punteros son reales. Por ejemplo: String a=new String("test"), a apunta a la dirección del objeto String en el espacio de almacenamiento dinámico.
Aquí use Java para escribir una lista enlazada unidireccional simple
El método de construcción de LinkedList

pero al agregar datos a LinkedList
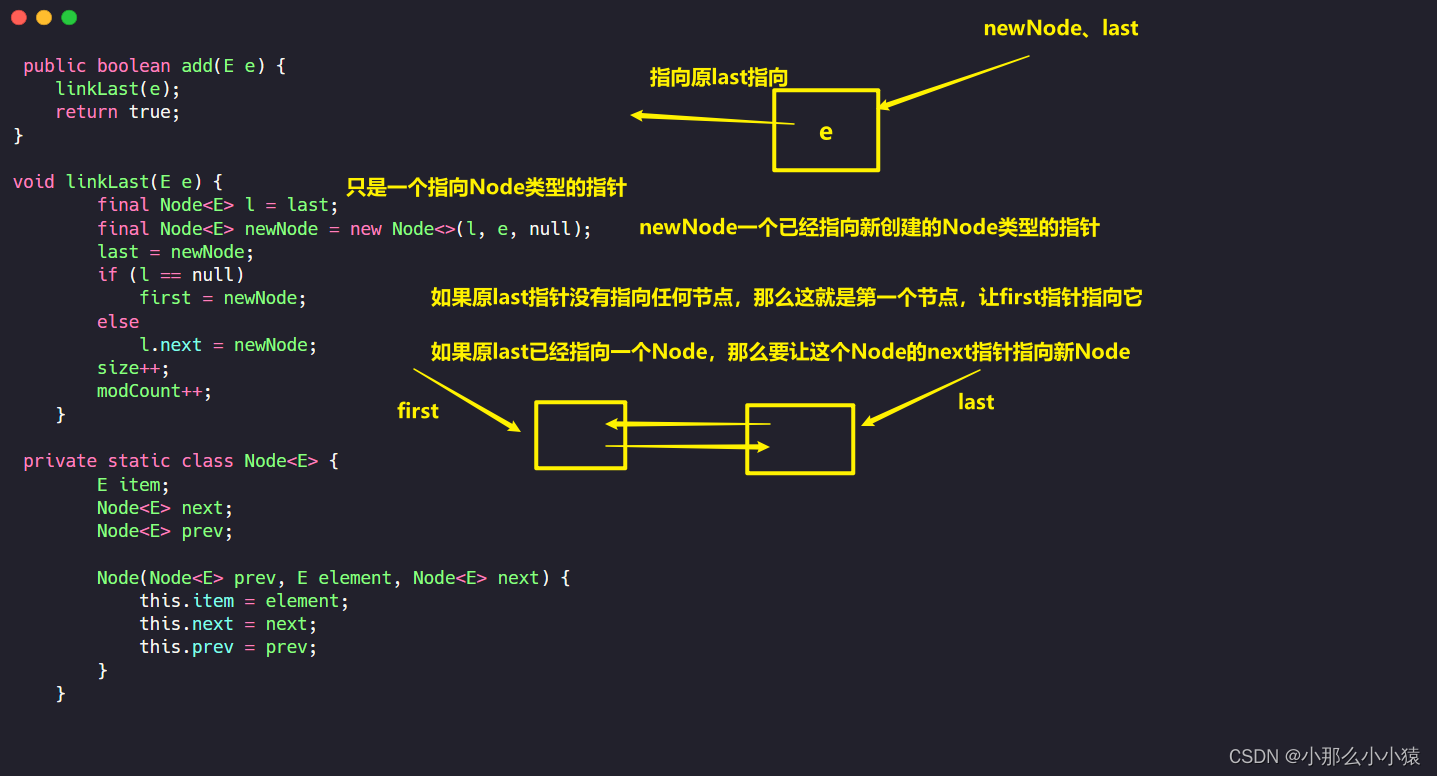
Registre el nodo al que se dirigió el último y, a continuación, apunte al nodo recién agregado. Juzgar si este nodo es el primer nodo depende de si el último nodo señalador original está vacío, si el último nodo señalador original está vacío, entonces este nodo es el primer nodo, y el primer nodo se ejecutará para ejecutarlo. Si el nodo apuntado por el last original no está vacío, significa que hay nodos antes del nodo recién agregado, porque al crear un nuevo nodo, el puntero pred del nuevo nodo ha apuntado a la posición apuntada por last, pero para el nodo anterior, no hay ninguna voluntad nextque apunte al nodo recién agregado.
Entonces, ¿cómo funciona la lista doblemente enlazada al eliminar elementos?
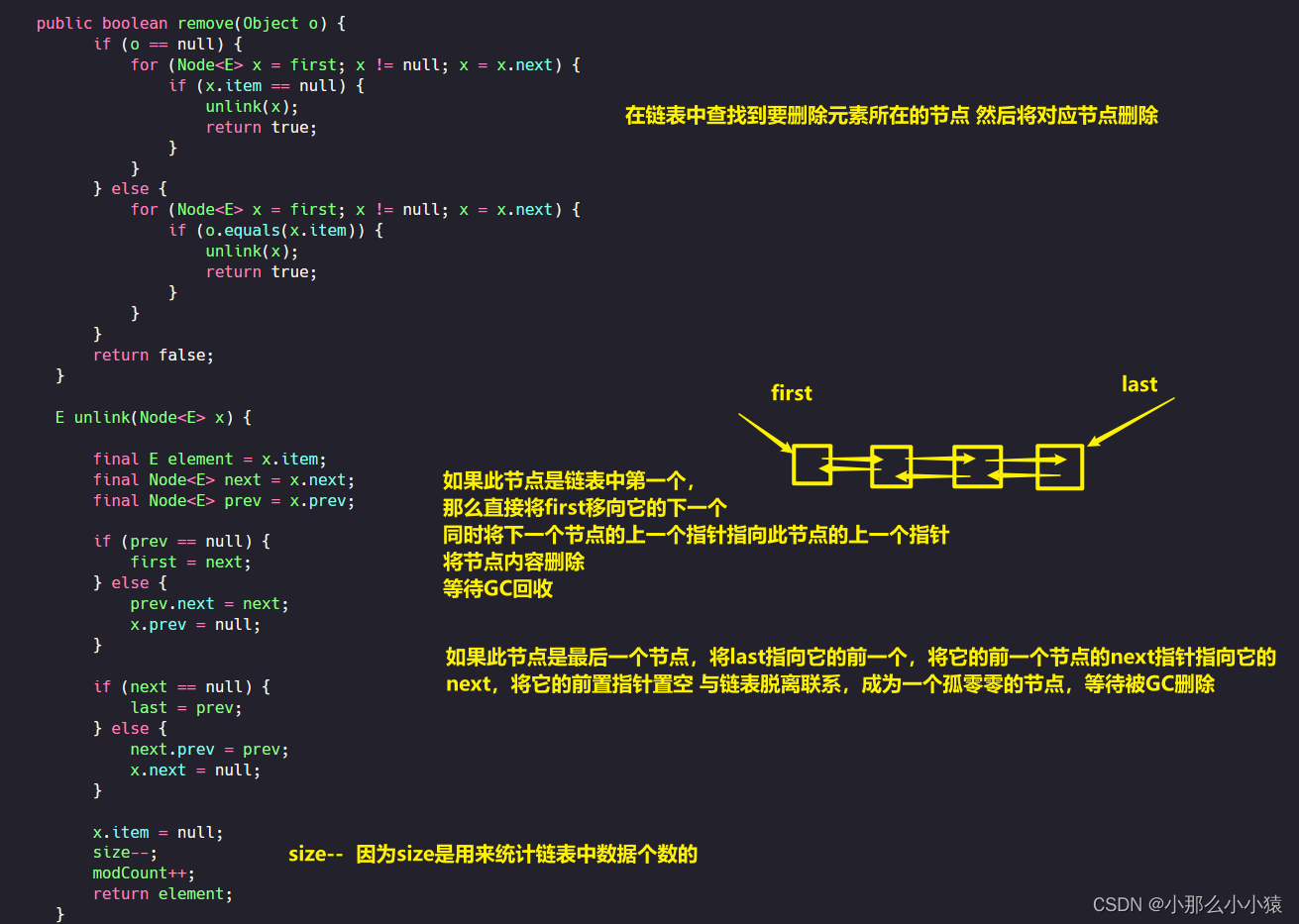
Colocar
HashSet
La esencia de HashSet es un HashMap. Cada valor en HashSet corresponde a la clave de HashMap, y su valor se establece en un objeto vacío.
Esto también explica las dos características de HashSet:
- Sin repetición: porque la clave de HashMap no permite la repetición
- Desordenado: Se dice que está desordenado, y no está en el orden de inserción, porque la capa inferior de HashMap calcula la posición de los datos en el arreglo de la tabla (tipo Nodo) según el valor Hash, no en el orden de inserción .
A continuación, presentaré el código fuente de HashSet, pero debido a que HashMap se introdujo antes, no se repetirá la misma parte aquí . , o el tamaño inicial de la tabla

al agregar datos add()

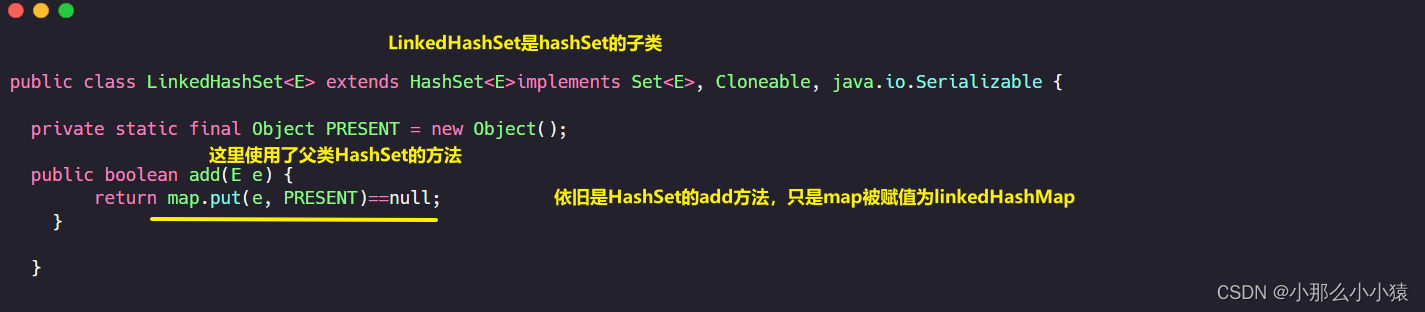
LinkedHashSet
La capa inferior de LinkedHashSet también es LinkedHashMap, entonces, ¿cuáles son las características de LinkedhashMap en comparación con HashMap? La característica más importante es mantener una lista vinculada por separado para que el HashMap se pueda generar en el orden de inserción. Entonces, la mayor diferencia entre LinkedhashSet y HashSet es que LinkedHashMap está ordenado, pero Key aún no se puede repetir

al agregar un elemento.
ÁrbolConjunto
La capa inferior de TreeSet usa TreeMap. La característica más importante de TreeMap es que la capa inferior es un árbol rojo-negro, que puede ordenar las claves insertadas. Por supuesto, si desea personalizar, puede pasar el método que también usa TreeSet Comparator.

el valor como la clave de TreeMap, y puede establecer el valor en Establecer orden.
