Directorio de artículos
- que es monton
- implementación del montón
-
- definición de estructura de montón
- interfaz de inicialización de montón
- interfaz de destrucción de montón
- interfaz de datos de inserción de montón
- Ajustar la interfaz del montón hacia arriba
- Comprobar si el montón está vacío
- Interfaz de datos de eliminación de montón
- Ajustar la interfaz del montón hacia abajo
- Obtener datos de la parte superior del montón
- Obtener el número de datos válidos en el montón
- Código de implementación completo
- resumen
- ordenar en montón
- Análisis de la complejidad temporal de la construcción del montón y la ordenación del montón
- Introducción a los Problemas TOPK
que es monton
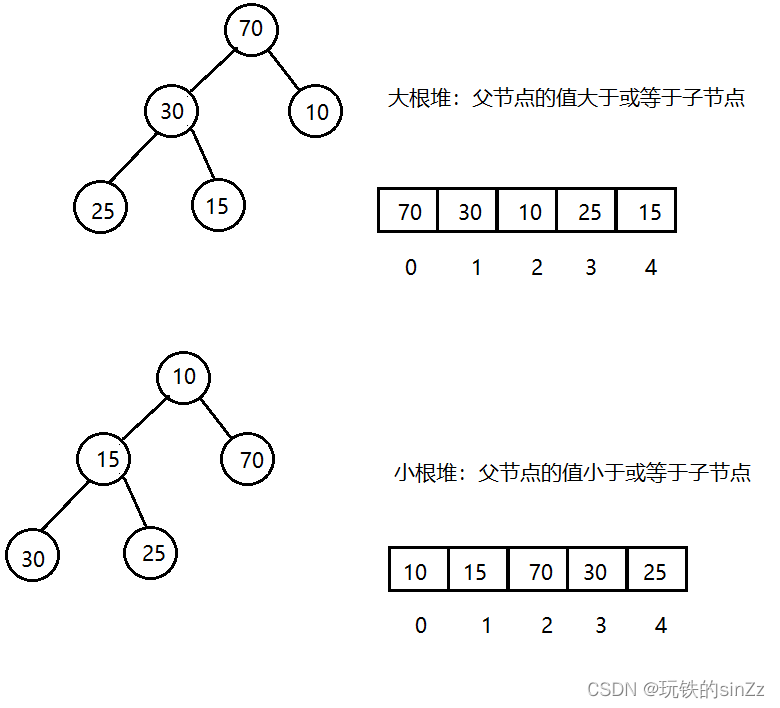
Un montón es una estructura de datos especial, que es un árbol binario completo y cumple la propiedad del montón, es decir, el valor de un nodo principal siempre es mayor o menor que el valor de sus nodos secundarios. Si el valor del nodo principal siempre es mayor que el valor del nodo secundario, entonces lo llamamos montón raíz grande; por el contrario, si el valor del nodo principal es siempre menor que el valor del nodo secundario, lo llamamos es un pequeño montón de raíces. En un montón, el nodo raíz tiene el valor más grande (montón raíz grande) o el valor más pequeño (montón raíz pequeño), por lo que también se denomina la parte superior del montón. Los montones se usan a menudo en escenarios como la clasificación y los problemas topK.
implementación del montón
Este artículo está implementado en lenguaje C y separado de los archivos de encabezado y los archivos fuente. También presentará gradualmente las ideas de implementación de cada interfaz y proporcionará códigos de referencia.
definición de estructura de montón
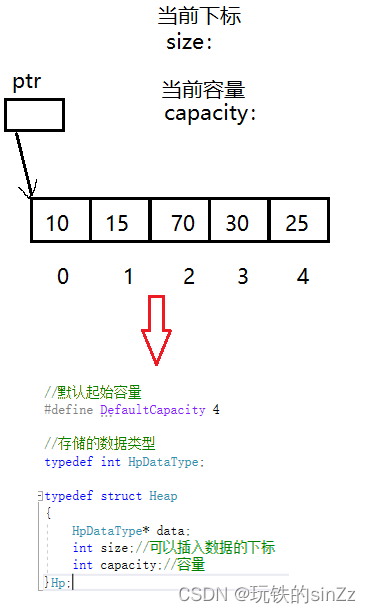
La definición de estructura del montón es en realidad una tabla de secuencia especial, que es similar a la pila. Por lo tanto, es necesario utilizar un puntero para señalar la memoria dinámicamente abierta, una variable que señale la posición actual del subíndice y una capacidad para registrar la memoria dinámica actual.
interfaz de inicialización de montón
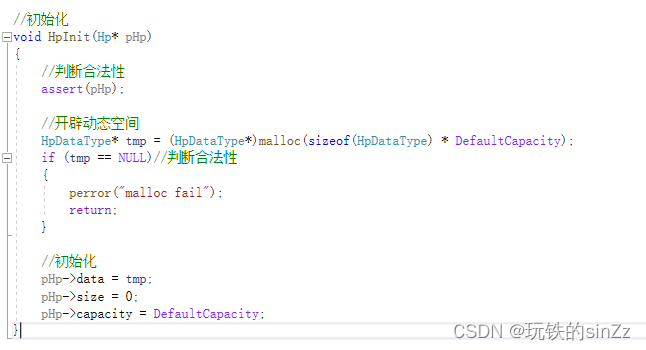
La idea de implementación de la interfaz de inicialización del montón es la siguiente: primero, para cambiar un montón, necesitamos pasar su dirección. Entonces, la parte del parámetro debe escribirse como Hp*. Al comienzo de la interfaz, juzgue la legalidad del puntero. Luego abra la memoria dinámica y juzgue la efectividad de la memoria dinámica. Finalmente, inicialice los miembros de la estructura.
interfaz de destrucción de montón
Deberíamos desarrollar el buen hábito de liberar el espacio para la aplicación dinámica y vaciarlo en el tiempo después de liberarlo. Finalmente, establezca el tamaño y la capacidad en cero.

interfaz de datos de inserción de montón
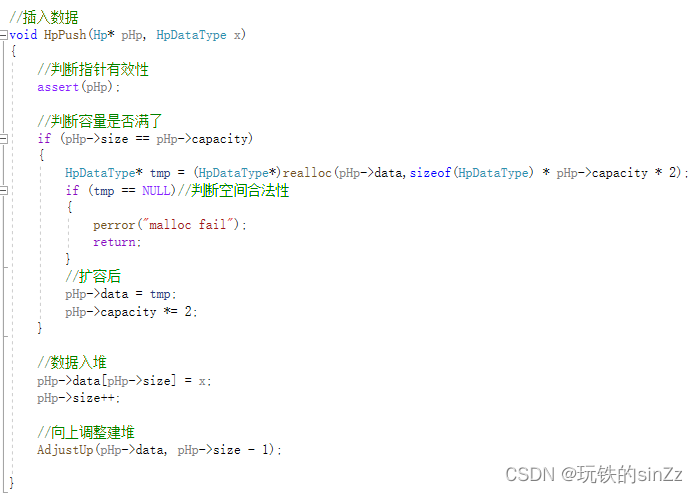
La idea de implementación de la interfaz de inserción de montón es la siguiente. Assert juzga la validez del puntero. Este es un buen hábito de programación. Se recomienda que también desarrolle este hábito en momentos normales. Primero determine si la capacidad está llena y, si lo está, amplíe la capacidad. Entonces, la lógica de insertar datos directamente debajo es similar a una tabla de secuencia. Inserte directamente los datos en la posición del subíndice de tamaño, solo use ++size. Finalmente, llame a la interfaz de creación de montón de ajuste ascendente para mantener la estructura del montón sin cambios.
Ajustar la interfaz del montón hacia arriba
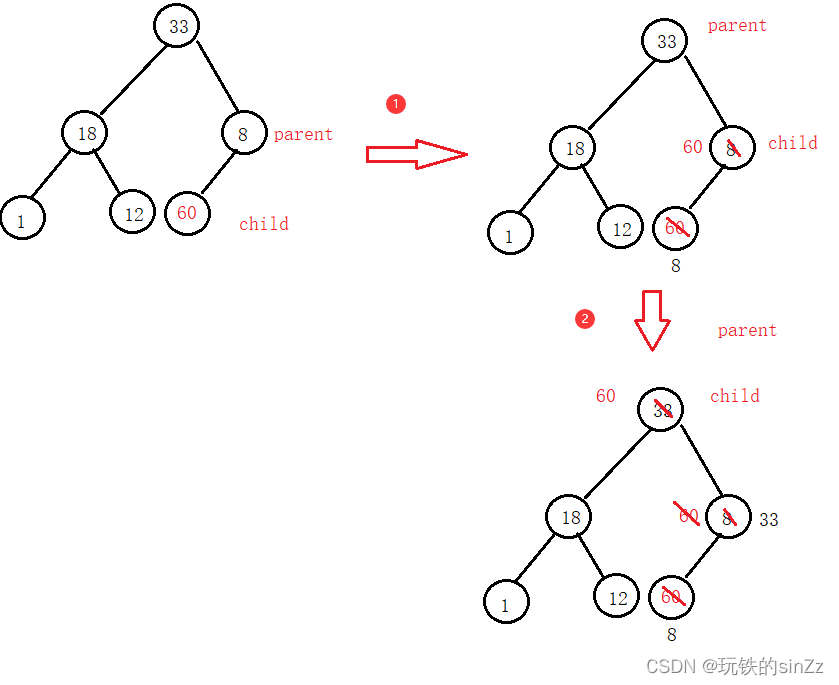
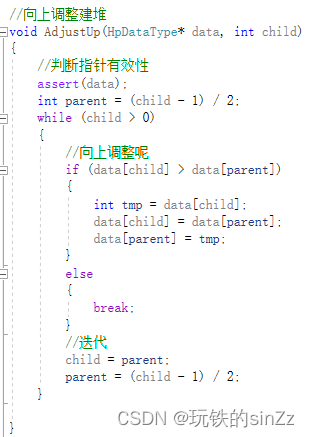
Primero, la posición del subíndice del nodo principal debe deducirse en función de la posición del subíndice del nodo secundario. Luego comience a ajustar hacia arriba. El proceso de ajuste hacia arriba es un proceso cíclico. La condición de iteración del bucle es que cuando el hijo es mayor que el subíndice del nodo raíz, el bucle seguirá siendo compatible. El bucle termina cuando el nodo secundario es más pequeño que el nodo principal. Si el nodo principal es más pequeño que el nodo secundario, realice el intercambio de datos del subíndice correspondiente y luego itere el subíndice del nodo secundario y el subíndice del nodo principal.
Comprobar si el montón está vacío
La idea de juzgar si el montón está vacío es relativamente simple, similar a la idea de juzgar el vacío de la tabla de secuencias.Cuando el siguiente subíndice que se puede insertar en los datos es 0, significa que hay un montón vacío.

Interfaz de datos de eliminación de montón
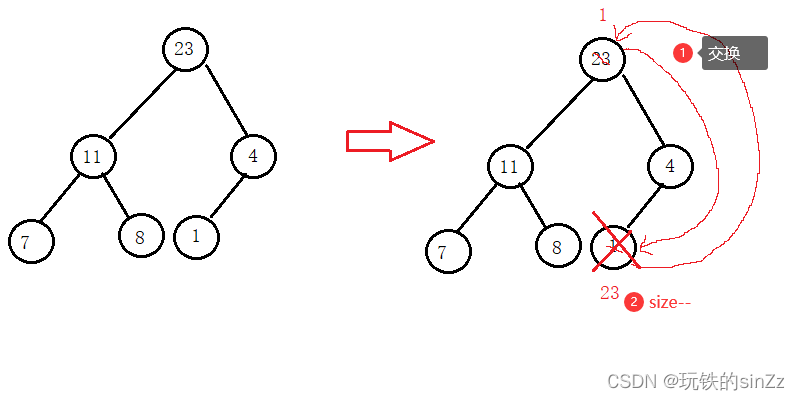
Para eliminar los datos en el montón, ¿debe eliminar los datos en la parte superior del montón o los datos en la parte inferior del montón? La respuesta es eliminar los datos en la parte superior del montón, porque eliminar los datos en la parte inferior del montón tiene poco valor. Y eliminar la parte superior del montón puede generar algún valor, como clasificar o recopilar algunos datos K principales. Por ejemplo, cuando queremos elegir una computadora en la aplicación de compras, podemos ordenarla por volumen de ventas, que también es un escenario para las aplicaciones de montones. Volviendo al tema, la idea de implementación de eliminar la parte superior del montón es la siguiente: intercambiamos los datos en la parte superior del montón con los últimos datos y luego usamos size– para lograr el efecto de eliminar los datos en la parte superior del montón, y mejorar en gran medida la eficiencia. Finalmente, ajuste el montón hacia abajo.

Ajustar la interfaz del montón hacia abajo
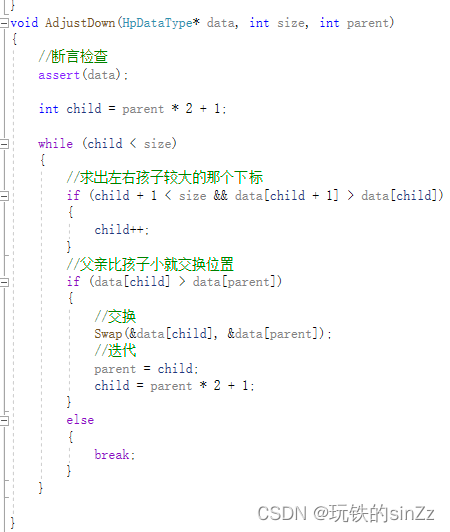
La idea de implementación de la creación de montones de ajuste a la baja es la siguiente: primero, el proceso de ajuste a la baja es un ciclo y su condición de terminación es padre > tamaño. Dentro del cuerpo del bucle está la idea central del ajuste hacia abajo. El padre es más grande (más pequeño) que los hijos izquierdo y derecho. Este artículo toma como ejemplo la realización de una gran pila. Aquí se introduce un concepto más importante: dado que la capa inferior del montón utiliza el almacenamiento de tabla secuencial, los hijos izquierdo y derecho del mismo padre se almacenan de forma adyacente. Es decir, el subíndice del hijo izquierdo + 1 es el subíndice del hijo derecho. Deje que el padre se compare con el más grande de los hijos izquierdo y derecho, y si el padre es más pequeño que el hijo, cambie la posición y luego itere. Nota: La condición para el ajuste a la baja es que los subárboles izquierdo y derecho deben ser montones.
Obtener datos de la parte superior del montón
De hecho, es el primer elemento de la tabla de secuencias de acceso. Sin embargo, proporcionar una interfaz de esta manera es muy coherente con la interfaz y mejora en gran medida la legibilidad del código.

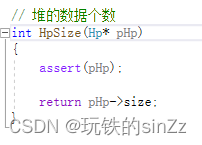
Obtener el número de datos válidos en el montón
Dado que nuestro tamaño comienza desde 0, simplemente devuelva el tamaño directamente.
Código de implementación completo
//Heap.h文件
#include<stdio.h>
#include<stdlib.h>
#include<assert.h>
#include<stdbool.h>
//默认起始容量
#define DefaultCapacity 4
//存储的数据类型
typedef int HpDataType;
typedef struct Heap
{
HpDataType* data;
int size;//可以插入数据的下标
int capacity;//容量
}Hp;
//初始化
void HpInit(Hp* pHp);
//堆的销毁
void HpDestroy(Hp* pHp);
//插入数据
void HpPush(Hp* pHp, HpDataType x);
//向上调整建堆
void AdjustUp(HpDataType* data, int child);
//判断是否为空
bool HpEmpty(Hp* pHp);
//删除数据
void HpPop(Hp* pHp);
//向下调整建堆
void AdjustDown(HpDataType* data,int size, int parent);
// 取堆顶的数据
HpDataType HpTop(Hp* pHp);
// 堆的数据个数
int HpSize(Hp* pHp);
// Heap.c文件
#include"Heap.h"
//初始化
void HpInit(Hp* pHp)
{
//判断合法性
assert(pHp);
//开辟动态空间
HpDataType* tmp = (HpDataType*)malloc(sizeof(HpDataType) * DefaultCapacity);
if (tmp == NULL)//判断合法性
{
perror("malloc fail");
return;
}
//初始化
pHp->data = tmp;
pHp->size = 0;
pHp->capacity = DefaultCapacity;
}
//堆的销毁
void HpDestroy(Hp* pHp)
{
//判断合法性
assert(pHp);
//释放内存和清理
free(pHp->data);
pHp->data = NULL;
pHp->size = pHp->capacity = 0;
}
void Swap(HpDataType* p1, HpDataType* p2)
{
HpDataType tmp = *p1;
*p1 = *p2;
*p2 = tmp;
}
//向上调整建堆
void AdjustUp(HpDataType* data, int child)
{
//判断指针有效性
assert(data);
int parent = (child - 1) / 2;
while (child > 0)
{
//向上调整呢
if (data[child] > data[parent])
{
Swap(&data[child], &data[parent]);
}
else
{
break;
}
//迭代
child = parent;
parent = (child - 1) / 2;
}
}
//插入数据
void HpPush(Hp* pHp, HpDataType x)
{
//判断指针有效性
assert(pHp);
//判断容量是否满了
if (pHp->size == pHp->capacity)
{
HpDataType* tmp = (HpDataType*)realloc(pHp->data,sizeof(HpDataType) * pHp->capacity * 2);
if (tmp == NULL)//判断空间合法性
{
perror("malloc fail");
return;
}
//扩容后
pHp->data = tmp;
pHp->capacity *= 2;
}
//数据入堆
pHp->data[pHp->size] = x;
pHp->size++;
//向上调整建堆
AdjustUp(pHp->data, pHp->size - 1);
}
void AdjustDown(HpDataType* data, int size, int parent)
{
//断言检查
assert(data);
int child = parent * 2 + 1;
while (child < size)
{
//求出左右孩子较大的那个下标
if (child + 1 < size && data[child + 1] > data[child])
{
child++;
}
//父亲比孩子小就交换位置
if (data[child] > data[parent])
{
//交换
Swap(&data[child], &data[parent]);
//迭代
parent = child;
child = parent * 2 + 1;
}
else
{
break;
}
}
}
void HpPop(Hp* pHp)
{
//断言检查
assert(pHp);
//删除数据
Swap(&pHp->data[0], &pHp->data[pHp->size-1]);
pHp->size--;
//向下调整建堆
AdjustDown(pHp->data,pHp->size-1,0);
}
//判断是否为空
bool HpEmpty(Hp* pHp)
{
assert(pHp);
return pHp->size == 0;
}
// 取堆顶的数据
HpDataType HpTop(Hp* pHp)
{
assert(pHp);
return pHp->data[0];
}
// 堆的数据个数
int HpSize(Hp* pHp)
{
assert(pHp);
return pHp->size;
}
resumen
Operar la estructura de datos del montón es como comer pasteles de esposa. Usted come pasteles dulces, pero no está seguro de si su esposa los hizo. Sin embargo, cuando lo comes, te imaginas que el pastel hecho por tu esposa tiene un sabor especial. En la estructura lógica del montón, lo que opera es un árbol y en el almacenamiento subyacente es una tabla de secuencia. Este es un lugar relativamente abstracto, que necesita poner a prueba nuestra capacidad para dibujar imágenes y leer el código de depuración.
ordenar en montón
La clasificación de montones es en realidad un uso común de la estructura de datos de montones. La idea central de la clasificación de montones es utilizar la idea de eliminación de montones para realizar operaciones de clasificación. Heap sort es una clasificación inestable con complejidad de tiempo O(N*logN). En cuanto a la explicación de la estabilidad de la clasificación, se la presentaré en el siguiente blog.
Implementación de clasificación de montón
La idea de implementación de la clasificación de pilas es la siguiente: primero, determine el orden de clasificación y cree los datos en pilas, cree pilas grandes en orden ascendente y cree pilas pequeñas en orden descendente. Se recomienda usar el ajuste hacia abajo para construir un montón. Debido a que la complejidad de tiempo es O(logN), si usa un ajuste ascendente para construir el montón, entonces la complejidad de tiempo es O(N*logN). Este tipo de complejidad de tiempo es demasiado costoso para encontrar los datos superiores del montón, por lo que es mejor recorrerlo directamente (complejidad de tiempo).

Luego use la idea de la eliminación del montón para ordenar. El siguiente es un ejemplo de clasificación en orden ascendente.
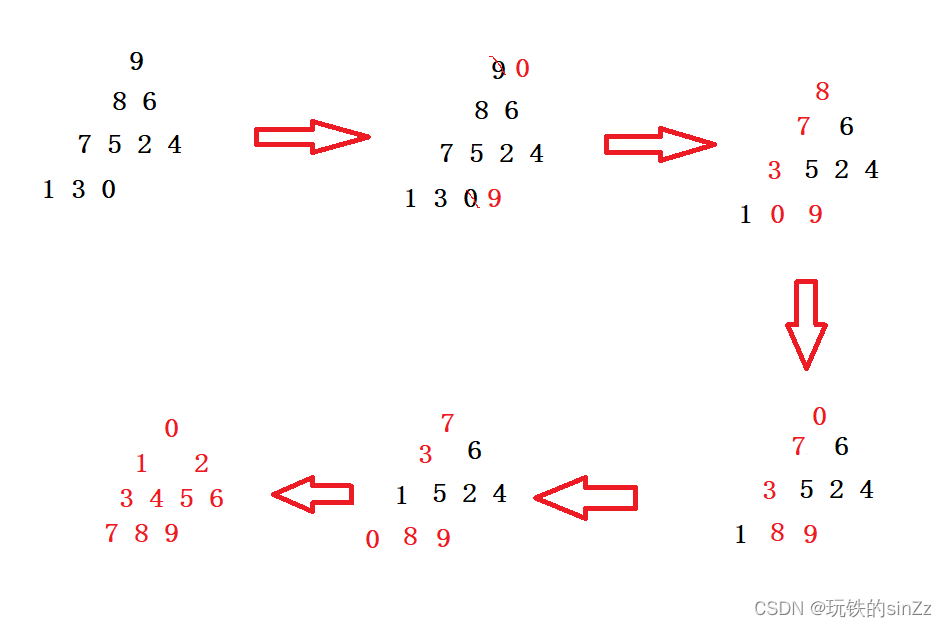
//堆排序--排升序建大堆
void HeapSort(int* arr, int n)
{
//向下建堆,效率更高
for (int i = (n - 1 - 1) / 2; i >= 0; --i)
{
AdjustDown(arr,n-1,i);
}
//排序
//利用堆删除的思想进行排序
int end = n - 1;
while (end > 0)
{
//交换
int tmp = arr[0];
arr[0] = arr[end];
arr[end] = tmp;
//调整堆
AdjustDown(arr, end-1, 0);
end--;
}
}
Análisis de la complejidad temporal de la construcción del montón y la ordenación del montón
ajustar la construcción hacia abajo
En la implementación anterior de la clasificación del montón, se menciona que el ajuste hacia abajo del montón es más eficiente, porque la complejidad temporal del ajuste hacia abajo del montón es O(N). A continuación, lo llevaré a analizar brevemente la complejidad temporal de ajustar el montón hacia abajo.
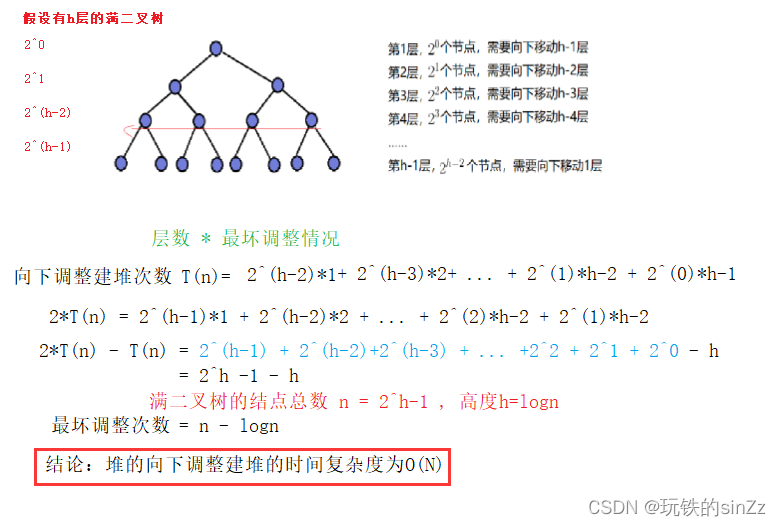
Ajustar acumulación
La complejidad temporal de la construcción del almacenamiento dinámico de ajuste ascendente es O(N*logN). Veamos el problema de la complejidad temporal del ajuste al alza.
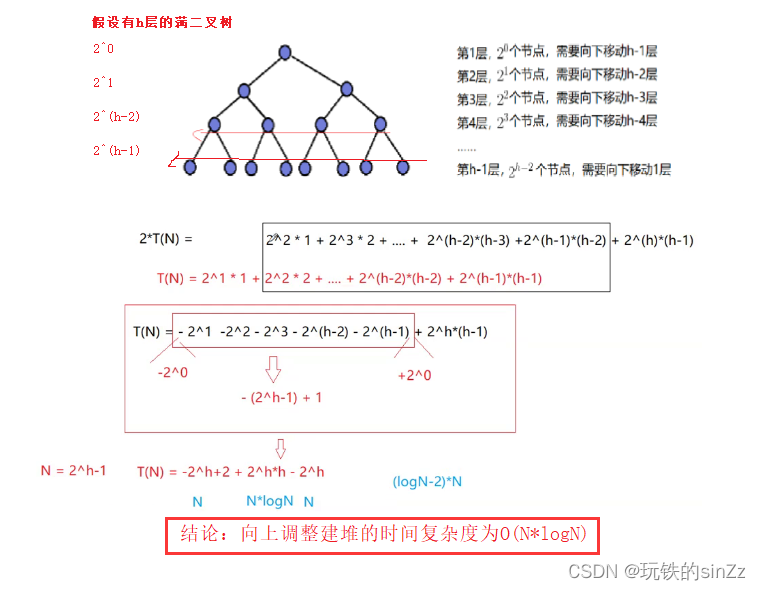
ordenar en montón
La complejidad temporal de la ordenación del montón es O(N logN). La complejidad de ajustar el montón hacia abajo es O(N), que se ha analizado anteriormente. La parte de clasificación es O(N logN) combinada con el ajuste del montón hacia abajo desde el primer nodo que no es hoja .

resumen
Para la complejidad temporal de la construcción de un montón y la complejidad de la clasificación del montón descrita anteriormente, en realidad es suficiente para escribir una conclusión. Por supuesto, desde la perspectiva de la implementación, no es difícil analizar la brecha de eficiencia aproximada entre el ajuste al alza y el ajuste a la baja de la construcción de pilotes. Debido a que el ajuste hacia abajo comienza desde el primer nodo que no es hoja, el peor de los casos es ajustar la mitad de los nodos menos que el ajuste hacia arriba. Esto ya ha ganado mucho en términos de eficiencia.
Introducción a los Problemas TOPK
El problema TOPK se refiere al problema de encontrar los datos más grandes o más pequeños de K en un conjunto de datos. Las soluciones comunes incluyen clasificación de pilas, clasificación rápida, clasificación de combinación, etc. Este problema surge a menudo en campos como el análisis de datos y el aprendizaje automático. Por supuesto, hay un escenario especial en el que es maravilloso usar el montón para la detección de TOK. Suponiendo que ahora hay 10 000 millones de números enteros y que se requieren los primeros 50 números, podemos construir un montón pequeño y, siempre que los datos recorridos sean más grandes que los datos superiores del montón, reemplazarlos en el montón (ajustar hacia abajo) , y finalmente obtenga el mayor número de los 50 principales. Tomemos un ejemplo simple para sentirlo.
void AdjustDownSH(HpDataType* data, int size, int parent)
{
//断言检查
assert(data);
int child = parent * 2 + 1;
while (child < size)
{
//求出左右孩子较大的那个下标
if (child + 1 < size && data[child + 1] < data[child])
{
child++;
}
//父亲比孩子小就交换位置
if (data[child] < data[parent])
{
//交换
Swap(&data[child], &data[parent]);
//迭代
parent = child;
child = parent * 2 + 1;
}
else
{
break;
}
}
}
void PrintTopK(const char* file, int k)
{
// 1. 建堆--用a中前k个元素建小堆
int* topk = (int*)malloc(sizeof(int) * k);
assert(topk);
FILE* fout = fopen(file, "r");
if (fout == NULL)
{
perror("fopen error");
return;
}
// 读出前k个数据建小堆
for (int i = 0; i < k; ++i)
{
fscanf(fout, "%d", &topk[i]);
}
for (int i = (k - 2) / 2; i >= 0; --i)
{
AdjustDownSH(topk, k, i);
}
// 2. 将剩余n-k个元素依次与堆顶元素交换,不满则则替换
int val = 0;
int ret = fscanf(fout, "%d", &val);
while (ret != EOF)
{
if (val > topk[0])
{
topk[0] = val;
AdjustDownSH(topk, k, 0);
}
ret = fscanf(fout, "%d", &val);
}
for (int i = 0; i < k; i++)
{
printf("%d ", topk[i]);
}
printf("\n");
free(topk);
fclose(fout);
}
void CreateNDate()
{
// 造数据
int n = 10000;
srand(time(0));
const char* file = "data.txt";
FILE* fin = fopen(file, "w");
if (fin == NULL)
{
perror("fopen error");
return;
}
for (size_t i = 0; i < n; ++i)
{
int x = rand() % 10000;
fprintf(fin, "%d\n", x);
}
fclose(fin);
}
int main()
{
CreateNDate();
PrintTopK("data.txt", 10);
return 0;
}