Directorio de artículos
prefacio
- Este artículo se aprende del caballo oscuro, y el contenido importante se resolverá después de la práctica personal del autor.
- Sugerencia: ¡más práctica, más práctica! !
Un documento de consulta de DSL
1.1 Clasificación de consultas DSL
-
Elasticsearch proporciona un DSL ( lenguaje específico de dominio ) basado en JSON para definir consultas. Los tipos de consulta comunes incluyen:
-
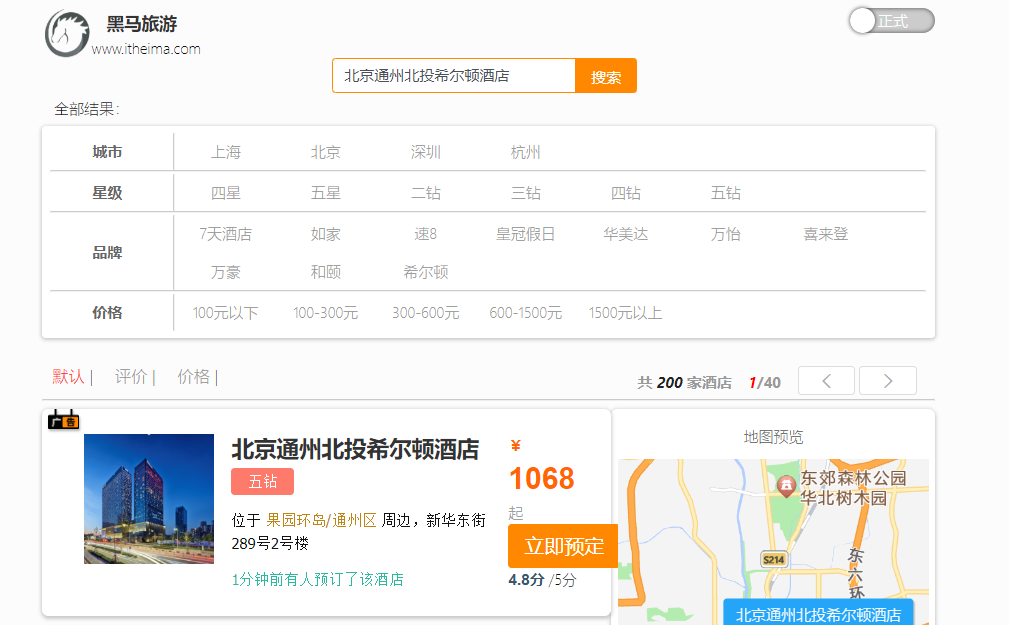
Consultar todo : consulta todos los datos, para pruebas generales. Por ejemplo: match_all
-
Consulta de búsqueda de texto completo (texto completo) : use la palabra segmentador para segmentar el contenido de entrada del usuario y luego conéctelo en la base de datos de índice invertido. Por ejemplo: match_query, multi_match_query
-
Consulta precisa : encuentre datos basados en valores de entrada precisos, generalmente buscando palabras clave, numéricos, de fecha, booleanos y otros tipos de campos. Por ejemplo: ids, range, term
-
Consulta geográfica (geo) : consulta basada en la latitud y la longitud. Por ejemplo: geo_distance, geo_bounding_box
-
Consulta compuesta (compuesto) : la consulta compuesta puede combinar las diversas condiciones de consulta mencionadas anteriormente y fusionar las condiciones de consulta. Por ejemplo: bool, función_puntuación
- La sintaxis de consulta es básicamente la misma:
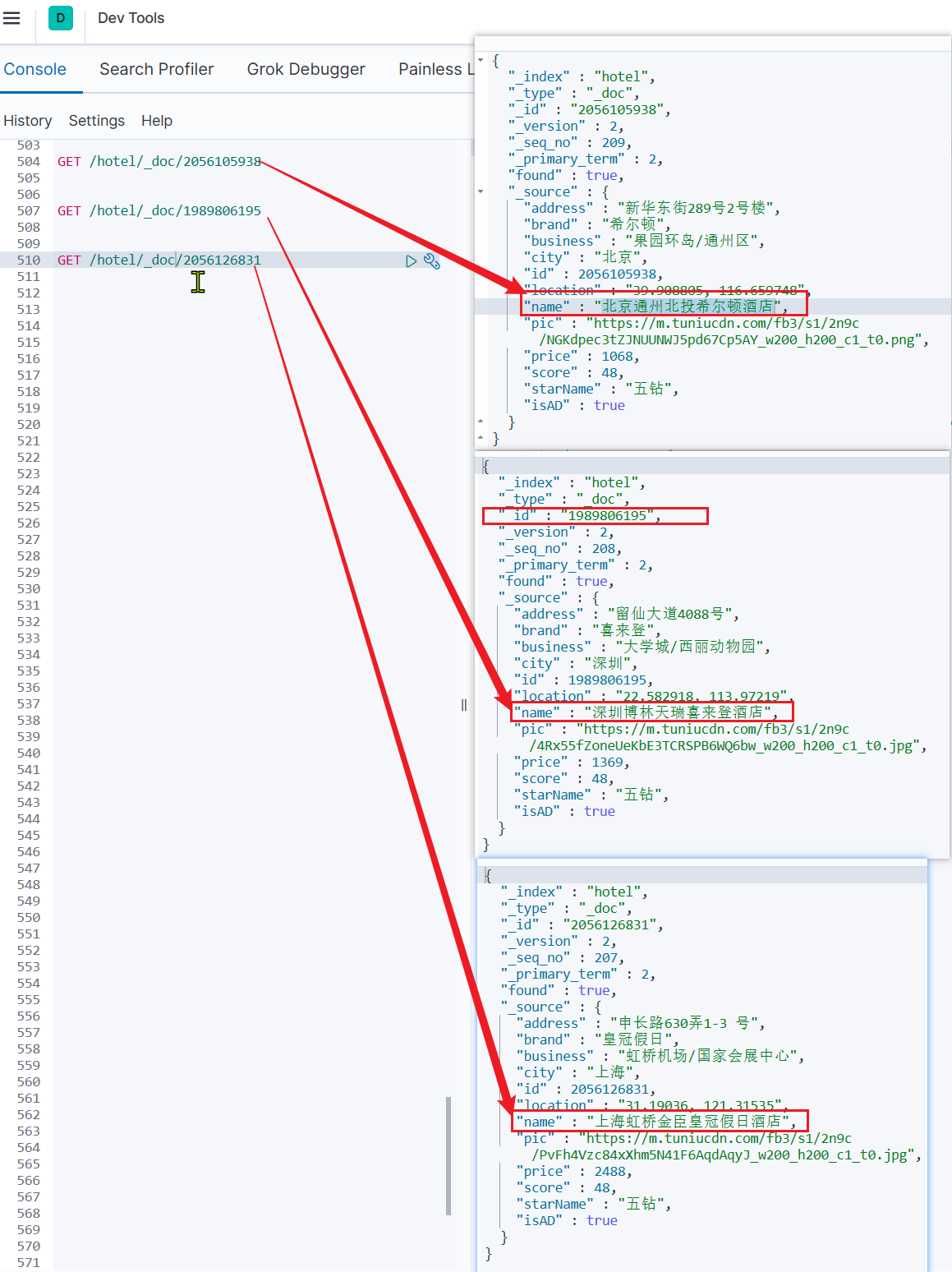
GET /indexName/_search { "query": { "查询类型": { "查询条件": "条件值" } } } - Consultar todo el contenido: el tipo de consulta es match_all && no hay condición de consulta
# 查询所有 GET /indexName/_search { "query": { "match_all": { } } }
1.2 Consulta de búsqueda de texto completo
- El proceso básico de consulta de búsqueda de texto completo:
- Segmente el contenido buscado y obtenga la entrada
- De acuerdo con la entrada que coincida en la biblioteca de índice invertido, obtenga la identificación del documento
- Encuentre el documento de acuerdo con la identificación del documento y devuélvalo al usuario
- Debido a que los términos se utilizan para la coincidencia, los campos que participan en la búsqueda también deben ser campos de tipo texto que se puedan segmentar.
- Las consultas comunes de búsqueda de texto completo incluyen:
matchConsulta: consulta de un solo campomulti_matchConsulta: consulta de varios campos, cualquier campo puede cumplir las condiciones
- La sintaxis de consulta de coincidencia es la siguiente:
GET /indexName/_search { "query": { "match": { "FIELD": "TEXT" } } } #match查询示例 GET /hotel/_search { "query": { "match": { "all": "外滩如家" } } } - La sintaxis de mulit_match es la siguiente:
GET /indexName/_search { "query": { "multi_match": { "query": "TEXT", "fields": ["FIELD1", " FIELD12"] } } } #multi_match查询示例 GET /hotel/_search { "query": { "multi_match": { "query": "外滩如家", "fields": ["brand","name","business"] } } }
-
copy_toLos parámetros le permiten copiar los valores de varios campos en un campo de grupo, que luego se puede consultar como un solo campo.PUT /test { "mappings": { "properties": { "first_name": { "type": "text", "copy_to": "full_name" }, "last_name": { "type": "text", "copy_to": "full_name" }, "full_name": { "type": "text" } } } } PUT test/_doc/1 { "first_name": "shanghai", "last_name": "beijing" } GET test/_search { "query": { "match": { "full_name": { "query": "shanghai beijing", "operator": "and" } } } } -
copy_toes un valor de campo, no un término (producido por el proceso de análisis) -
El mismo valor se puede copiar en varios campos usando
"copy_to": [ "field_1", "field_2" ] -
Cuantos más campos de búsqueda, mayor será el impacto en el rendimiento de la consulta, por lo que se recomienda utilizar copy_to y luego la consulta de un solo campo.
1.3 Consulta precisa
- La consulta precisa generalmente busca palabras clave, valores, fechas, booleanos y otros tipos de campos, y no segmentará las condiciones de búsqueda. Los comunes son:
- term: consulta basada en el valor exacto del término
- rango: consulta basada en el rango de valores
- consulta de términos
- Dado que el campo de búsqueda de consulta exacta es un campo sin segmentación por palabra, la condición de consulta también debe ser una entrada sin segmentación por palabra . Al consultar, se considera que el contenido ingresado cumple la condición solo cuando coincide completamente con el valor automático. Si el usuario ingresa demasiado contenido, los datos no se pueden buscar.
- Descripción gramatical:
// term查询 GET /indexName/_search { "query": { "term": { "FIELD": { "value": "VALUE" } } } }
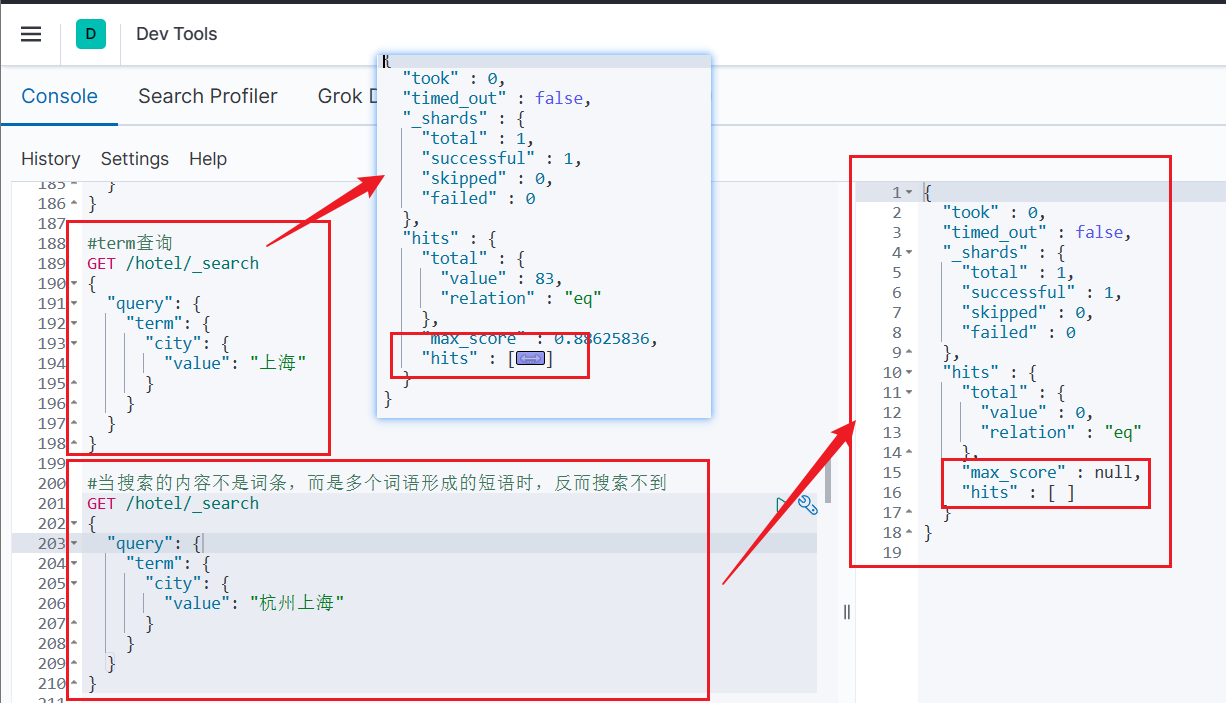
- consulta de rango
- Consulta de rango, generalmente utilizada para el filtrado de rango de tipos numéricos
- Sintaxis básica:
// range查询 GET /indexName/_search { "query": { "range": { "FIELD": { "gte": 10, // 这里的gte代表大于等于,gt则代表大于 "lte": 20 // lte代表小于等于,lt则代表小于 } } } }

1.4 Consulta de coordenadas geográficas
- La consulta de coordenadas geográficas se basa en la consulta de longitud y latitud, documentos oficiales
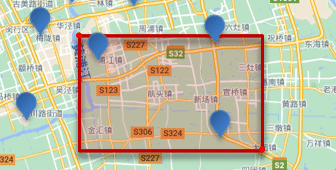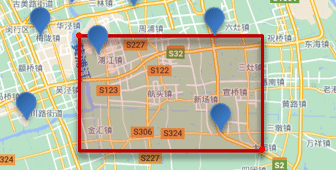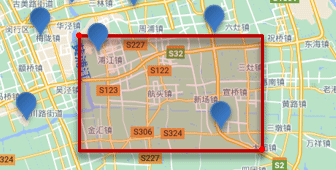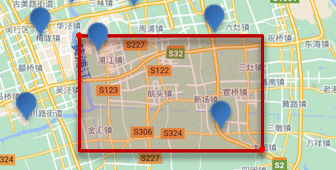
- Consulta de rango rectangular
- Consulta de rango rectangular [
geo_bounding_boxconsulta], consulta todos los documentos cuyas coordenadas se encuentran dentro de un cierto rango rectangular - Al consultar, debe especificar las coordenadas de los puntos superior izquierdo e inferior derecho del rectángulo, y luego dibujar un rectángulo, y todos los puntos que se encuentran dentro del rectángulo cumplen las condiciones.
- Gramática Descripción
// geo_bounding_box查询 GET /indexName/_search { "query": { "geo_bounding_box": { "FIELD": { "top_left": { // 左上点“ "lat": 31.1, "lon": 121.5 }, "bottom_right": { // 右下点 "lat": 30.9, "lon": 121.7 } } } } } - Consulta de rango rectangular [
- consulta cercana
- Consulta cercana [consulta de distancia (geo_distance)]: consulta todos los documentos cuyo punto central especificado es menor que un cierto valor de distancia
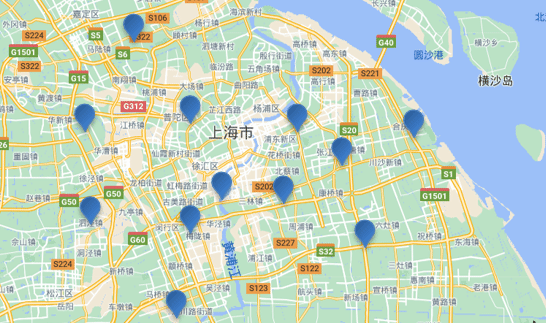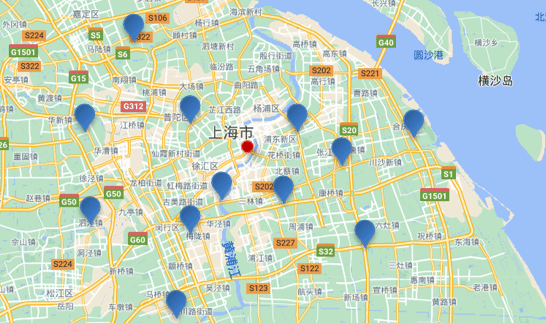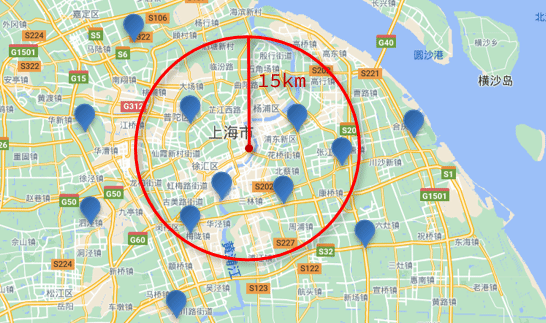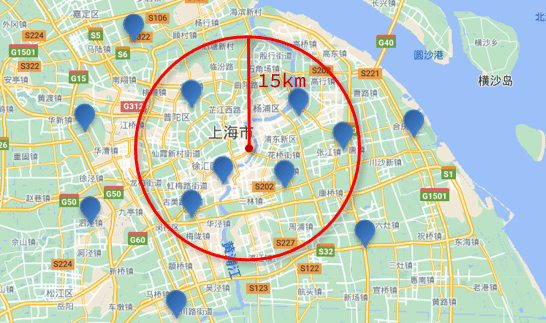
- Descripción gramatical:
// geo_distance 查询 GET /indexName/_search { "query": { "geo_distance": { "distance": "15km", // 半径 "FIELD": "31.21,121.5" // 圆心 } } } - Consulta cercana [consulta de distancia (geo_distance)]: consulta todos los documentos cuyo punto central especificado es menor que un cierto valor de distancia
1.5 Consulta compuesta
- Consulta compuesta: combine otras consultas simples para implementar una lógica de búsqueda más compleja. Hay dos comunes:
fuction score: consulta de función de cálculo, que puede controlar el cálculo de la relevancia del documento y controlar la clasificación de los documentosbool query: consulta booleana, que utiliza relaciones lógicas para combinar varias otras consultas para lograr búsquedas complejas
- Cuando se utiliza una consulta de coincidencia, los resultados del documento se calificarán (_score) de acuerdo con el grado de relevancia para el término de búsqueda y los resultados devueltos se clasificarán en orden descendente de la calificación.
- Algoritmo de puntuación:
- En la búsqueda elástica temprana, el algoritmo de puntuación utilizado fue el algoritmo TF-IDF:

- En la actualización posterior de la versión 5.1, elasticsearch mejoró el algoritmo al algoritmo BM25

- Para aquellos que quieran saber más al respecto, consulte "Explicación detallada y realización de BM25, el blanco más pequeño de la historia"
- En la búsqueda elástica temprana, el algoritmo de puntuación utilizado fue el algoritmo TF-IDF:
- El algoritmo TF-IDF tiene una falla, es decir, cuanto mayor es la frecuencia del término, mayor es la puntuación del documento y un solo término tiene un mayor impacto en el documento. Sin embargo, BM25 tendrá un límite superior para la puntuación de una sola entrada y la curva será más suave:

1.5.1 Consulta de función de cálculo
-
La puntuación basada en la relevancia es un requisito razonable, pero no es necesariamente lo que necesitan los gerentes de producto .
-
Gramática Descripción
-
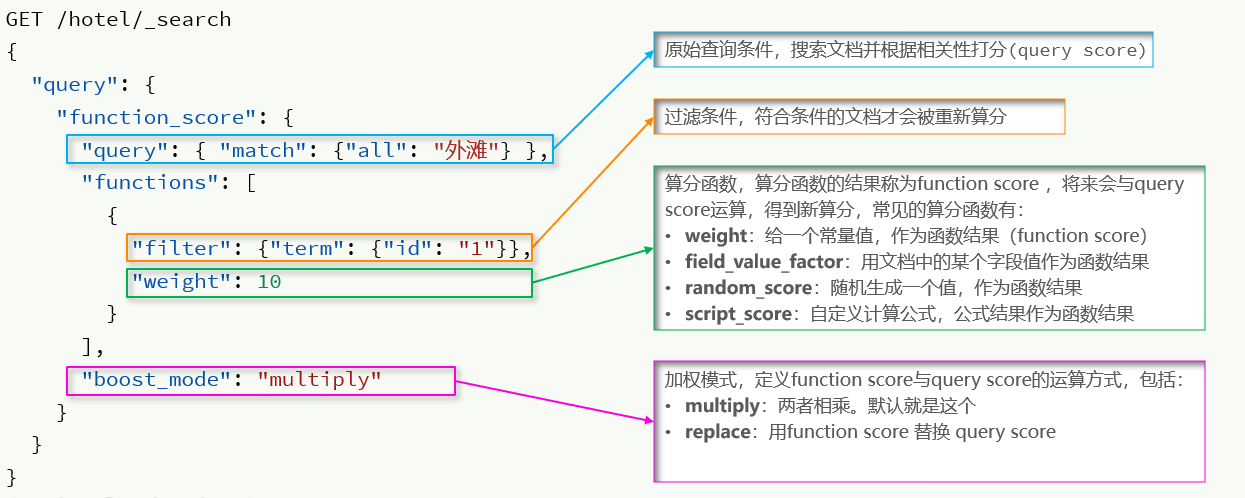
La consulta de puntuación de función consta de cuatro partes:
- Condición de consulta original : parte de consulta, búsqueda de documentos según esta condición y puntuación del documento según el algoritmo BM25, la puntuación original (puntuación de consulta)
- Condición de filtro : la parte del filtro, los documentos que cumplan esta condición serán recalculados
- Función de cálculo : los documentos que cumplen con las condiciones del filtro deben calcularse de acuerdo con esta función, y el puntaje de función obtenido (puntaje de función), hay cuatro funciones
- peso: el resultado de la función es una constante
- field_value_factor: use un valor de campo en el documento como el resultado de la función
- random_score: utiliza números aleatorios como resultado de la función
- script_score: algoritmo de función de puntuación personalizado
- Modo de cálculo : el resultado de la función de cálculo, la puntuación del cálculo de correlación de la consulta original y el método de cálculo entre los dos, incluidos:
- multiplicar: multiplicar
- reemplazar: reemplazar el puntaje de la consulta con el puntaje de la función
- Otros, como: sum, avg, max, min
-
El proceso de operación de la puntuación de función es el siguiente:
- Consulte y busque documentos de acuerdo con las condiciones originales y calcule la puntuación de relevancia, denominada puntuación original (puntuación de consulta)
- Filtrar documentos según criterios de filtrado
- Los documentos que cumplen las condiciones del filtro , según el cálculo de la función de cálculo , obtienen la puntuación de la función (puntuación de la función)
- La puntuación original (puntuación de la consulta) y la puntuación de la función (puntuación de la función) se calculan en función del modo de funcionamiento y el resultado final se obtiene como una puntuación de correlación.
-
punto clave:
- Condiciones de filtro: determine qué documentos tienen sus puntajes modificados
- Función de puntuación: el algoritmo para determinar la puntuación de la función
- Modo de cálculo: determine el resultado final del cálculo
-
manifestación
GET /hotel/_search { "query": { "function_score": { "query": { "match": { "all": "外滩" } }, "functions": [ #算分函数 { "filter": { "term": { "brand": "如家" # 过滤条件 } }, "weight": 10 # 算分权重 } ], "boost_mode": "sum" # 加权模式 } } }
1.5.2 Consultas booleanas
- Una consulta booleana es una combinación de una o más cláusulas de consulta, cada una de las cuales es una subconsulta . Las subconsultas se pueden combinar de las siguientes maneras:
- debe: debe coincidir con cada subconsulta, similar a "y"
- debería: subconsulta de coincidencia selectiva, similar a "o"
- must_not: no debe coincidir, no participa en la puntuación , similar a "no"
- filtro: debe coincidir, no participar en la puntuación
- Nota: Al buscar, cuantos más campos se incluyan en la puntuación, peor será el rendimiento de la consulta . Por lo tanto, al consultar con múltiples condiciones, se recomienda:
- La búsqueda de palabras clave en el cuadro de búsqueda es una consulta de búsqueda de texto completo, el uso debe consultar y participar en la puntuación
- Para otras condiciones de filtro, utilice la consulta de filtro. No participar en la puntuación.
- manifestación
#bool查询 GET /hotel/_search { "query": { "bool": { "must": [ { "term": { "city": "上海"} } ], "should": [ { "term":{ "brand": "皇冠假日" }}, { "term":{ "brand": "华美达"}} ], "must_not": [ { "range": { "price": { "lte": 500 } }} ], "filter": [ { "range": { "score": { "gte": 45 } }} ] } } }
Procesamiento de dos resultados
- Los resultados de la búsqueda se pueden procesar o mostrar de la forma especificada por el usuario.
2.1 Clasificación
2.1.1 Clasificación de campos ordinarios
- Elasticsearch clasifica según la puntuación de correlación (_score) de forma predeterminada, pero también admite formas personalizadas de clasificar los resultados de búsqueda . Los tipos de campo que se pueden ordenar incluyen: tipo de palabra clave, tipo numérico, tipo de coordenadas geográficas, tipo de fecha, etc.
GET /indexName/_search { "query": { "match_all": { } }, "sort": [ { "FIELD": "desc" // 排序字段、排序方式ASC、DESC } ] } - La condición de clasificación es una matriz, es decir, se pueden escribir múltiples condiciones de clasificación. De acuerdo con el orden de declaración, cuando la primera condición es igual, ordene de acuerdo con la segunda condición, y así sucesivamente.
- Demostración: ordene los datos del hotel en orden descendente de las calificaciones de los usuarios (puntuación) y ordene los datos del hotel en orden ascendente del precio (precio) si tienen la misma calificación
#排序 GET /hotel/_search { "query": { "match_all": { } }, "sort": [ { "score": { "order": "desc" }, "price": { "order": "asc" } } ] }
2.1.2 Clasificación por coordenadas geográficas
- Descripción gramatical :
GET /indexName/_search { "query": { "match_all": { } }, "sort": [ { "_geo_distance" : { "FIELD" : "纬度,经度", // 文档中geo_point类型的字段名、目标坐标点 "order" : "asc", // 排序方式 "unit" : "km" // 排序的距离单位 } } ] }- Especifique una coordenada como el punto de destino y calcule la distancia desde la coordenada del campo especificado (debe ser del tipo geo_point) hasta el punto de destino en cada documento y luego ordene según la distancia
2.2 Paginación
- Elasticsearch solo devuelve los datos top10 de forma predeterminada . Y si desea consultar más datos, debe modificar los parámetros de paginación.
- En elasticsearch, los resultados de paginación que se devolverán se controlan modificando los parámetros desde y tamaño: desde: desde qué documento comenzar; tamaño: cuántos documentos consultar en total
2.2.1 Paginación básica
- La sintaxis básica de la paginación es la siguiente:
GET /hotel/_search { "query": { "match_all": { } }, "from": 0, // 分页开始的位置,默认为0 "size": 10, // 期望获取的文档总数 "sort": [ { "price": "asc"} ] }
2.2.2 Problema de paginación profunda
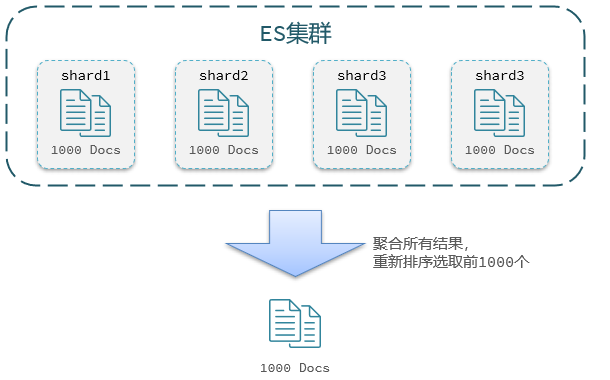
- Si consulta los datos de 990 ~ 1000 ahora, la lógica de consulta debe escribirse de la siguiente manera:
GET /hotel/_search { "query": { "match_all": { } }, "from": 990, // 分页开始的位置,默认为0 "size": 10, // 期望获取的文档总数 "sort": [ { "price": "asc"} ] } - Aquí están los datos a partir de la consulta 990, es decir, 990 → 1000 990\to 1000990a _→El dato número 1000 . Sin embargo, al paginar dentro de elasticsearch, primero debe consultar0 → 1000 0\to10000→1000 piezas, y luego interceptar 990 1000 990 ~ 1000de ellas Estos 10 por 990 1000 :

- ES se distribuye, por lo que enfrentará el problema de la paginación profunda. Por ejemplo, después de ordenar por precio, obtenga los datos de = 990, tamaño = 10:
- Primero ordene y consulte los primeros 1000 documentos en cada fragmento de datos.
- Luego agregue los resultados de todos los nodos y reordene en la memoria para seleccionar los primeros 1000 documentos
- Finalmente, de los 1000 elementos, seleccione 10 documentos a partir de 990
- Si el número de páginas de búsqueda es demasiado profundo o el conjunto de resultados (de + tamaño) es mayor, el consumo de memoria y CPU será mayor. Por lo tanto, ES establece el límite superior de la consulta del conjunto de resultados en 10000
- Para paginación profunda, ES proporciona dos soluciones
- buscar después: se requiere ordenar al paginar, el principio es consultar la siguiente página de datos a partir del último valor de ordenación. [recomendar]
- scroll: el principio es formar una instantánea de los datos ordenados y guardarla en la memoria. [obsoleto]
2.3 Resumen
| Implementaciones comunes de consultas de paginación | ventaja | defecto | Escenas a utilizar |
|---|---|---|---|
from + size |
Admite cambio de página aleatorio | Problema de paginación profunda, el límite superior de consulta predeterminado (desde + tamaño) es 10000 | Búsquedas aleatorias de cambio de página como Baidu, JD.com, Google y Taobao |
after search |
Sin límite superior de consulta (el tamaño de una sola consulta no excede 10000) | Solo puede consultar hacia atrás página por página, no admite el cambio de página aleatorio | Búsquedas sin requisitos de cambio de página aleatorio, como desplazarse hacia abajo y cambiar de página en teléfonos móviles |
scroll |
Sin límite superior de consulta (el tamaño de una sola consulta no excede 10000) | Habrá un consumo de memoria adicional y los resultados de la búsqueda no son en tiempo real | Adquisición y migración de datos masivos. No se recomienda comenzar desde ES7.1 Se recomienda utilizar la solución de búsqueda posterior. |
2.4 Resaltar
- La implementación del resaltado se divide en dos pasos:
- Agregar una etiqueta a todas las palabras clave del documento, como
<em>la etiqueta <em>La página escribe estilos CSS para las etiquetas.
- Agregar una etiqueta a todas las palabras clave del documento, como
- Resaltado de sintaxis :
GET /hotel/_search { "query": { "match": { "FIELD": "TEXT" // 查询条件,高亮一定要使用全文检索查询 } }, "highlight": { "fields": { // 指定要高亮的字段 "FIELD": { "pre_tags": "<em>", // 用来标记高亮字段的前置标签 "post_tags": "</em>" // 用来标记高亮字段的后置标签 } } } } - Aviso:
- El resaltado es para palabras clave, por lo que las condiciones de búsqueda deben contener palabras clave , no consultas de rango.
- De forma predeterminada, el campo resaltado debe ser el mismo que el campo especificado por la búsqueda ; de lo contrario, no se puede resaltar
- Si desea resaltar campos que no son de búsqueda, debe agregar un atributo: required_field_match=false
- manifestación
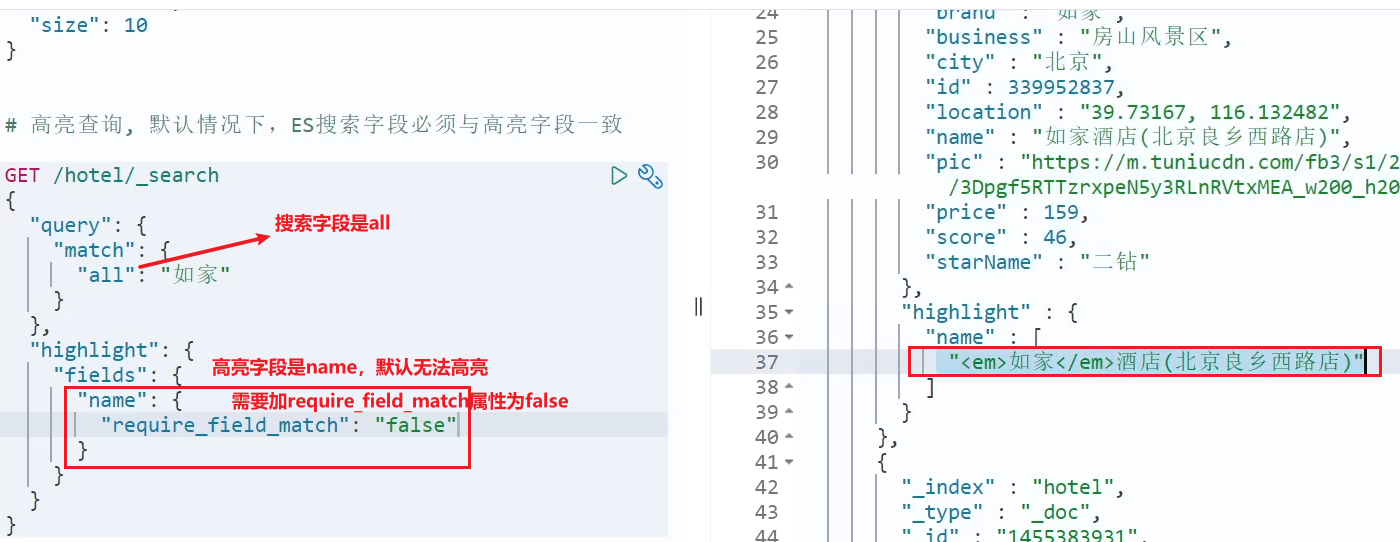
# 实现高亮 GET /hotel/_search { "query": { "match": { "all": "如家" } }, "highlight": { "fields": { "name": { "require_field_match": "false", "pre_tags": "<em>", "post_tags": "</em>" } } } }
Tres documentos de consulta RestClient
3.1 Inicio rápido
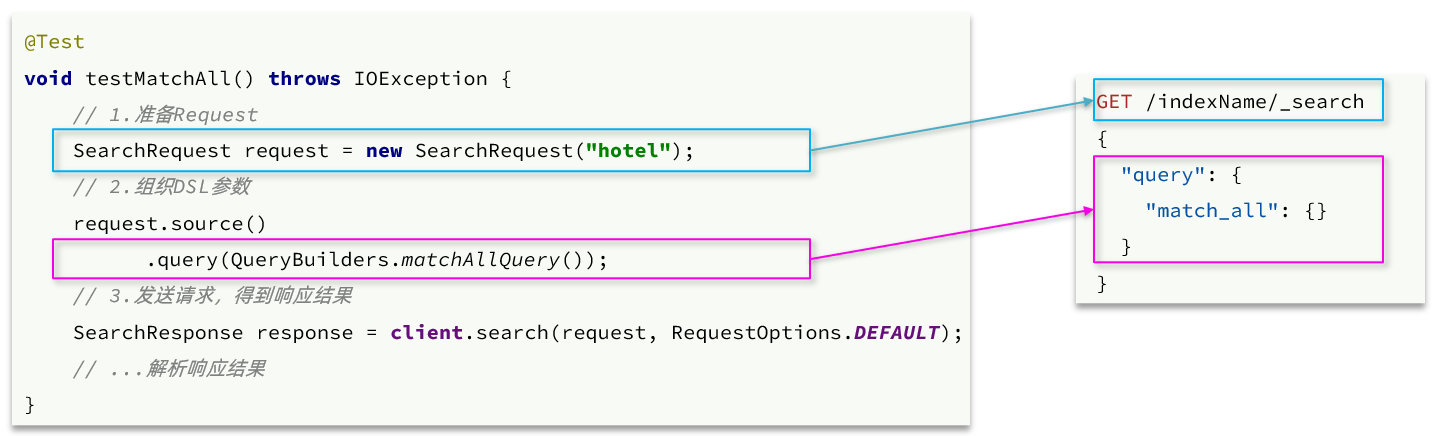
- Interpretación del código:
- El primer paso es crear
SearchRequestun objeto y especificar el nombre de la biblioteca de índice - El segundo paso es utilizar
request.source()la construcción de DSL, que puede incluir consulta, paginación, clasificación, resaltado, etc. query(): representa la condición de la consulta, usandoQueryBuilders.matchAllQuery()el DSL para construir una consulta match_all- El tercer paso es usar client.search() para enviar una solicitud y obtener una respuesta.
- El primer paso es crear
- API clave:
request.source(), que incluye todas las funciones como consulta, clasificación, paginación, resaltado, etc.QueryBuilders, incluidas varias consultas como match, term, function_score, bool, etc.
3.2 Análisis de la respuesta
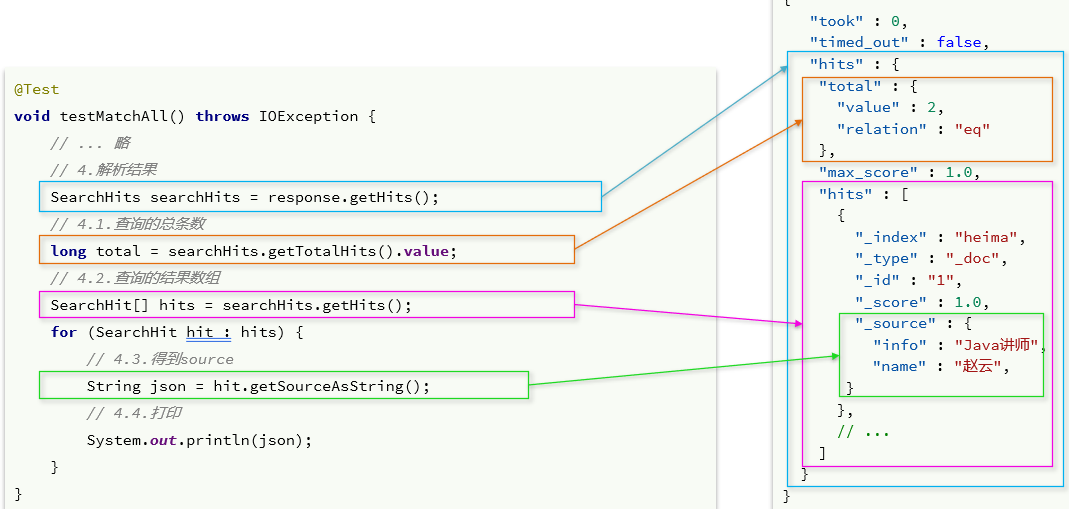
El resultado devuelto por elasticsearch es una cadena JSON, la estructura contiene:
hits: el resultado del golpetotal: El número total de entradas, donde value es el valor de entrada total específicomax_score: la puntuación de relevancia del documento con la puntuación más alta en todos los resultadoshits: una matriz de documentos para resultados de búsqueda, cada uno de los cuales es un objeto json_source: los datos originales en el documento, también un objeto json
Para analizar la cadena JSON capa por capa, el proceso es el siguiente:
SearchHits: Obtenido a través de response.getHits(), que son los hits más externos en JSON, que representan el resultado del hitSearchHits#getTotalHits().value: Obtener el número total de informaciónSearchHits#getHits(): obtenga la matriz SearchHit, que es la matriz de documentosSearchHit#getSourceAsString(): obtenga el _source en el resultado del documento, que son los datos del documento json original
- código completo
@Test void testMatchAll() throws IOException { // 1.准备Request SearchRequest request = new SearchRequest("hotel"); // 2.准备DSL request.source() .query(QueryBuilders.matchAllQuery()); // 3.发送请求 SearchResponse response = client.search(request, RequestOptions.DEFAULT); // 4.解析响应 handleResponse(response); } private void handleResponse(SearchResponse response) { // 4.解析响应 SearchHits searchHits = response.getHits(); // 4.1.获取总条数 long total = searchHits.getTotalHits().value; System.out.println("共搜索到" + total + "条数据"); // 4.2.文档数组 SearchHit[] hits = searchHits.getHits(); // 4.3.遍历 for (SearchHit hit : hits) { // 获取文档source String json = hit.getSourceAsString(); // 反序列化 HotelDoc hotelDoc = JSON.parseObject(json, HotelDoc.class); System.out.println("hotelDoc = " + hotelDoc); } }
3.3 Consulta de búsqueda de texto completo
- Las consultas de coincidencia y coincidencia múltiple de la búsqueda de texto completo son básicamente las mismas que la API de match_all. La diferencia es la condición de consulta, que es la parte de la consulta. Utilice también los métodos proporcionados por QueryBuilders:
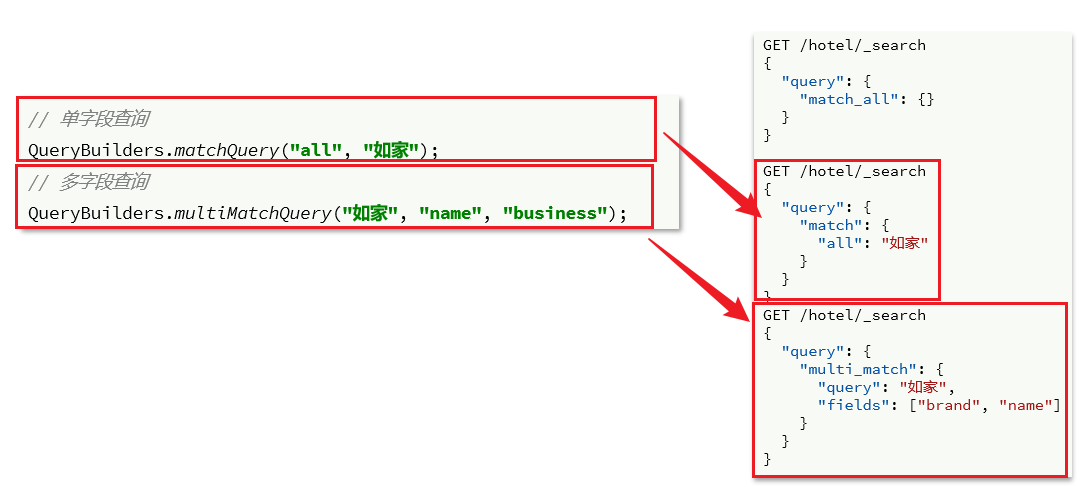
@Test
void testMatch() throws IOException {
// 1.准备Request
SearchRequest request = new SearchRequest("hotel");
// 2.准备DSL
request.source()
.query(QueryBuilders.matchQuery("all", "如家"));
// 3.发送请求
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
// 4.解析响应
handleResponse(response);
}
3.4 Consulta exacta

@Test
void testTerm() throws IOException {
// 1.准备Request
SearchRequest request = new SearchRequest("hotel");
// 2.准备DSL
//request.source().query(QueryBuilders.termQuery("city", "杭州"));
request.source().query(QueryBuilders.rangeQuery("price").gte(100).lte(150));
// 3.发送请求
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
// 4.解析响应
handleResponse(response);
}
3.5 consultas booleanas
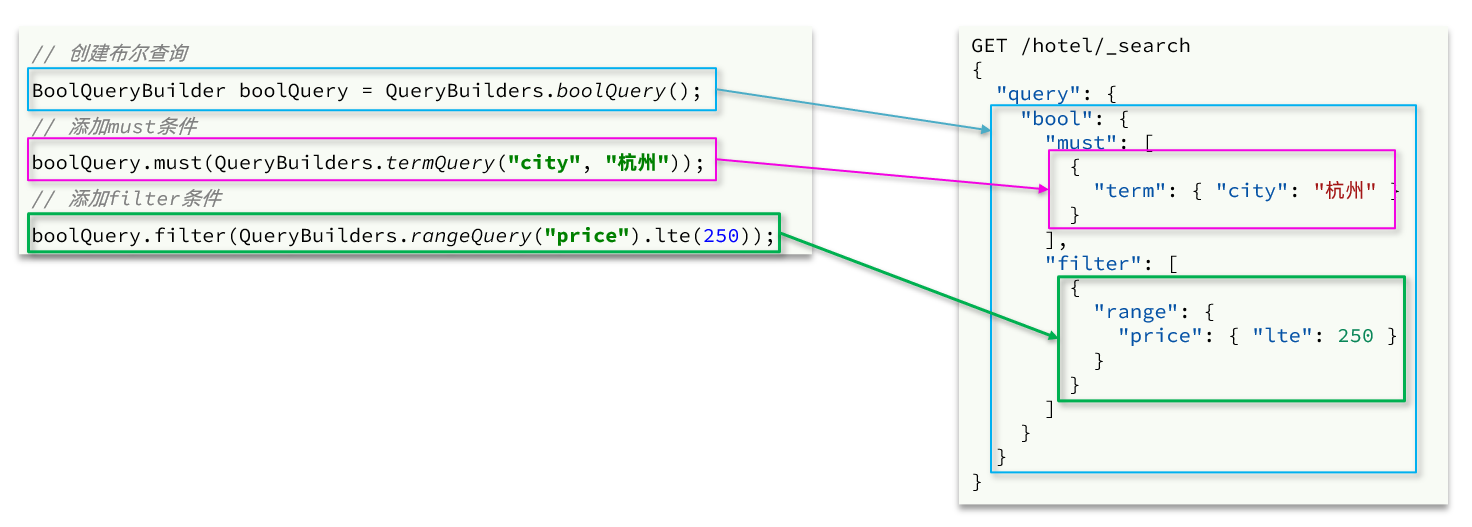
- La consulta booleana es combinar otras consultas con must, must_not, filter, etc.
@Test
void testBool() throws IOException {
// 1.准备Request
SearchRequest request = new SearchRequest("hotel");
// 2.准备DSL
// 2.1.准备BooleanQuery
BoolQueryBuilder boolQuery = QueryBuilders.boolQuery();
// 2.2.添加term
boolQuery.must(QueryBuilders.termQuery("city", "上海"));
// 2.3.添加range
boolQuery.filter(QueryBuilders.rangeQuery("price").lte(250));
request.source().query(boolQuery);
// 3.发送请求
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
// 4.解析响应
handleResponse(response);
}
3.6 Clasificación y paginación

@Test
void testPageAndSort() throws IOException {
// 页码,每页大小
int page = 1, size = 3;
// 1.准备Request
SearchRequest request = new SearchRequest("hotel");
// 2.准备DSL
// 2.1.query
request.source().query(QueryBuilders.matchAllQuery());
// 2.2.排序 sort
request.source().sort("price", SortOrder.ASC);
// 2.3.分页 from、size
request.source().from((page - 1) * size).size(size);
// 3.发送请求
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
// 4.解析响应
handleResponse(response);
}
3.7 Resaltar
- La API destacada incluye dos partes: solicitud de construcción de DSL y análisis de resultados. Primero veamos la construcción DSL de la solicitud:

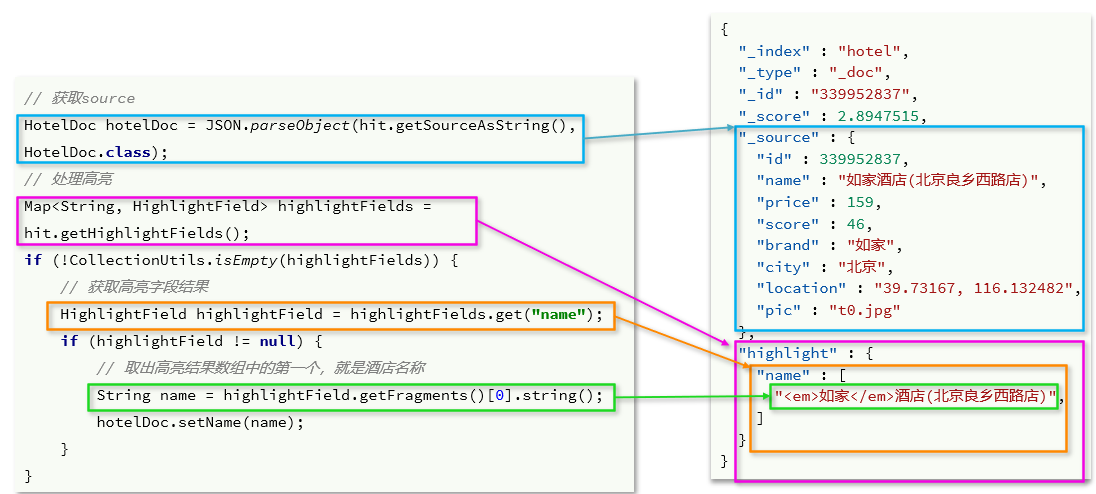
- El procesamiento de resultados resaltado es relativamente engorroso:
@Test
void testHighlight() throws IOException {
// 1.准备Request
SearchRequest request = new SearchRequest("hotel");
// 2.准备DSL
// 2.1.query
request.source().query(QueryBuilders.matchQuery("all", "如家"));
// 2.2.高亮
request.source().highlighter(new HighlightBuilder().field("name").requireFieldMatch(false));
// 3.发送请求
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
// 4.解析响应
//高亮的结果与查询的文档结果默认是分离的,并不在一起。
highlightResponse(response);
}
private static void highlightResponse(SearchResponse response) {
SearchHits searchHits = response.getHits();
//查询的总条数
long total = searchHits.getTotalHits().value;
System.out.println("共搜索到" + total + "条数据");
//查询的结果数组 文档数组
SearchHit[] hits = searchHits.getHits();
for(SearchHit hit:hits) {
//获取文档source
String json = hit.getSourceAsString();
//反序列化
HotelDoc hotelDoc = JSON.parseObject(json, HotelDoc.class);
//获取高亮结果
Map<String, HighlightField> highlightFields = hit.getHighlightFields();
if (!CollectionUtils.isEmpty(new Map[]{
highlightFields})) {
// 根据字段名获取高亮结果
HighlightField highlightField = highlightFields.get("name");
if (highlightField != null) {
// 获取高亮值
String name = highlightField.getFragments()[0].string();
// 覆盖非高亮结果
hotelDoc.setName(name);
}
}
System.out.println("hotelDoc="+hotelDoc);
}
}
Conclusión: Sugerencias sobre el turismo de caballos oscuros
-
Si utiliza el navegador perimetral y visita la página del caso de Dark Horse, se recomienda desactivar la protección de seguimiento del sitio web.

-
En la parte de agregar la marca publicitaria: al verificar el resultado, primero puede consultar la información del hotel con la marca publicitaria agregada e ir directamente a la página para buscar el hotel.