Publicación de blog de referencia: https://blog.csdn.net/qq_37652891/article/details/123932772
Preparación del conjunto de datos
Segmentación semántica multicategoría de imágenes de teledetección, que se dividen en 7 categorías en total (incluido el fondo)
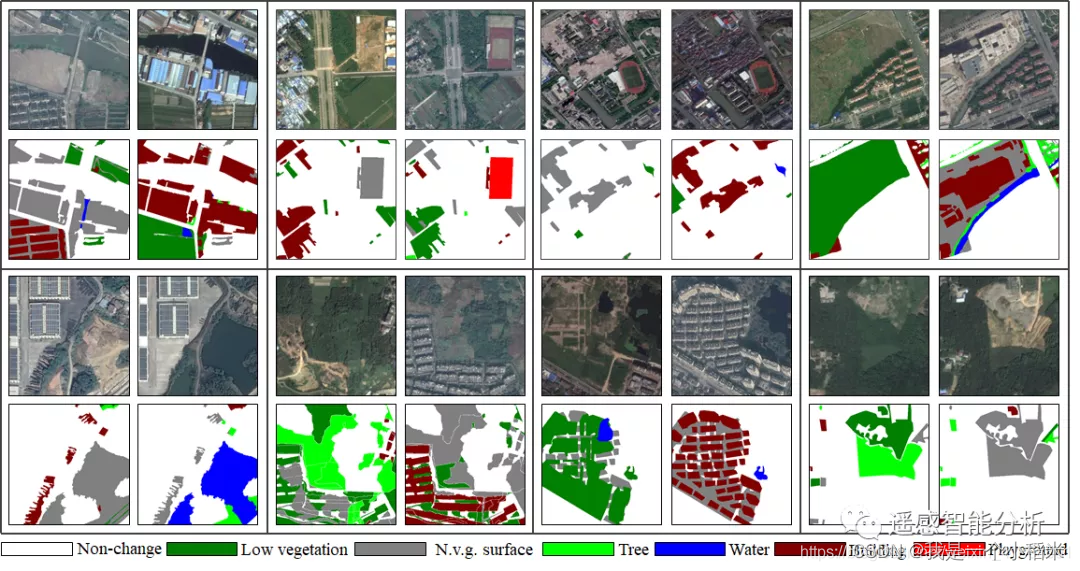
imagen: etiqueta

label_rgb
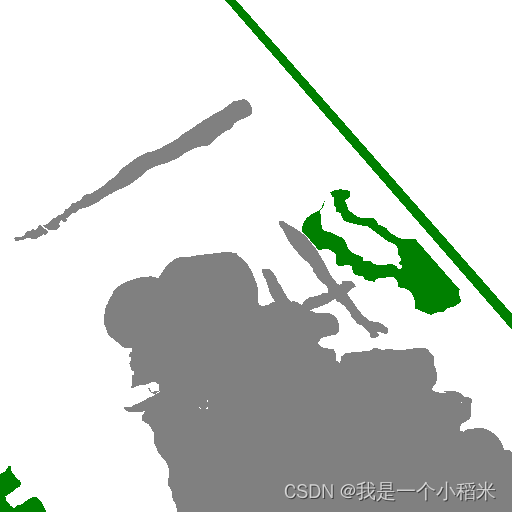
(aquí no todo es negro, el valor de la categoría es 0,1,2,3,4,5,6), y el entrenamiento posterior utiliza dichos datos

Dirección de datos
Baidu cloud: https://pan.baidu.com/s/1zZHnZfBgVWxs6TJW4yjeeQ
Código de extracción: 2022
Dirección del código SwinUNet
Procesamiento de conjuntos de datos
imageLa suma del conjunto de datos label, que debe proporcionar rgbla etiqueta de formato y 0,1,2,3,4,5,6la etiqueta que contiene el valor, utilizando la imagen de etiqueta SwinUNetincluida ;0,1,2,3,4,5,6
1. Conjunto de datos
El conjunto de datos se almacena en SwinUNetel directorio raíz, imageel medio es la imagen original labely el medio es la imagen de la etiqueta (un total de 7 categorías, el valor de la etiqueta 0,1,2,3,4,5,6,7);
si usa otros conjuntos de datos, preste atención al valor de la etiqueta Por ejemplo, si es una clasificación binaria. Es decir, la etiqueta 0o 255debe ser reemplazada por 0o1
—SwinUNet
---------configs
---------img_datas
---------------tren
------------ --------imagen
--------------------etiqueta
---------------prueba
---- ----------------imagen
--------------------etiqueta
2. SwinUnetCree npz.pyun archivo en el directorio raíz y ejecute npz.pyel archivo
import glob
import cv2
import numpy as np
import os
def npz(im, la, s):
images_path = im
labels_path = la
path2 = s
images = os.listdir(images_path)
for s in images:
image_path = os.path.join(images_path, s)
label_path = os.path.join(labels_path, s)
image = cv2.imread(image_path)
image = cv2.cvtColor(image,cv2.COLOR_BGR2RGB)
# 标签由三通道转换为单通道
label = cv2.imread(label_path, flags=0)
# 保存npz文件
np.savez(path2+s[:-4]+".npz",image=image,label=label)
npz('./img_datas/train/image/', './img_datas/train/label/', './data/Synapse/train_npz')
npz('./img_datas/test/image/', './img_datas/test/label/', './data/Synapse/test_vol_h5')
3. SwinUnetCree txt.pyun archivo en el directorio raíz y ejecute txt.pyel archivo
El propósito es generar ./list/list_Synapse/train.txty ./list/list_Synapse/test_vol.txtdocumentar
import os
def write_name(np, tx):
#npz文件路径
files = os.listdir(np)
#txt文件路径
f = open(tx, 'w')
for i in files:
#name = i.split('\\')[-1]
name = i[:-4]+'\n'
f.write(name)
write_name('./data/Synapse/train_npz', './lists/lists_Synapse/train.txt')
write_name('./data/Synapse/test_vol_h5', './lists/lists_Synapse/test_vol.txt')
4. Descargue los pesos preentrenados y guárdelos en la carpeta SwinUnetdebajo del directoriopretrained_ckpt
Enlace: https://pan.baidu.com/s/1-hYwJRlr95Fv08e9AEARww
Código de extracción:2022
modificar red
1. Modificar train.pyel archivo
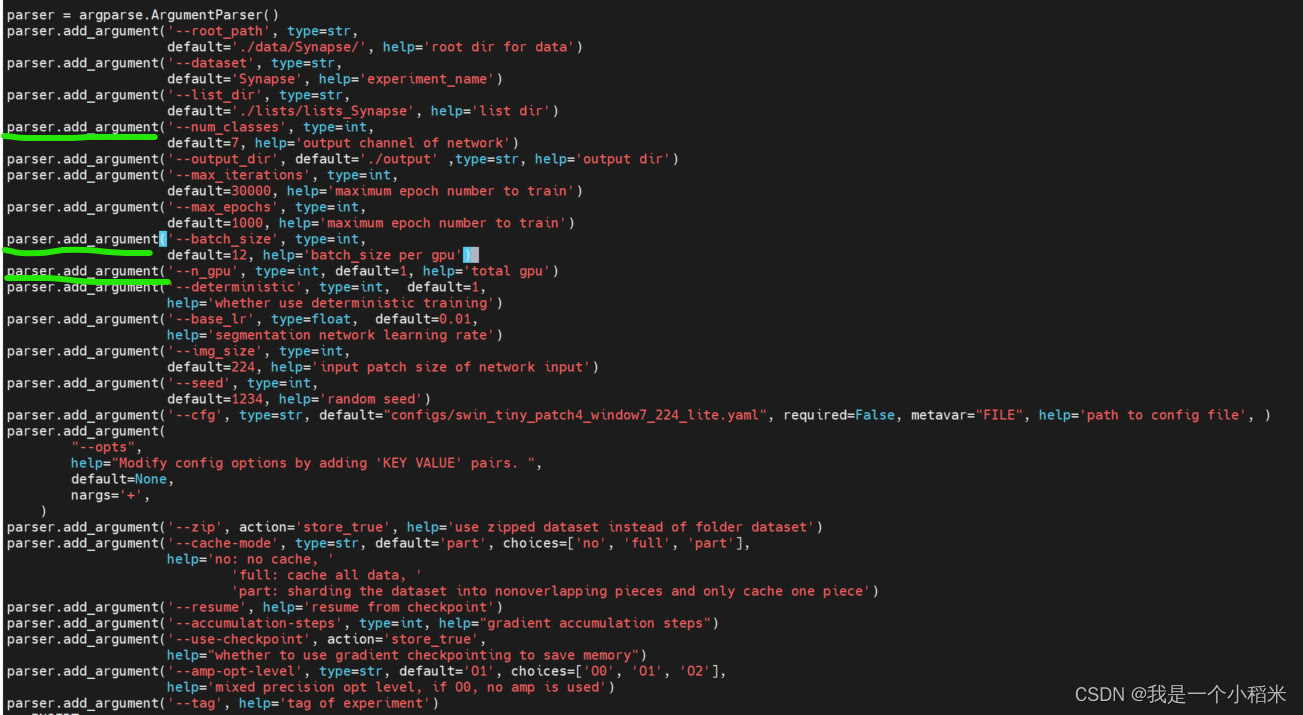
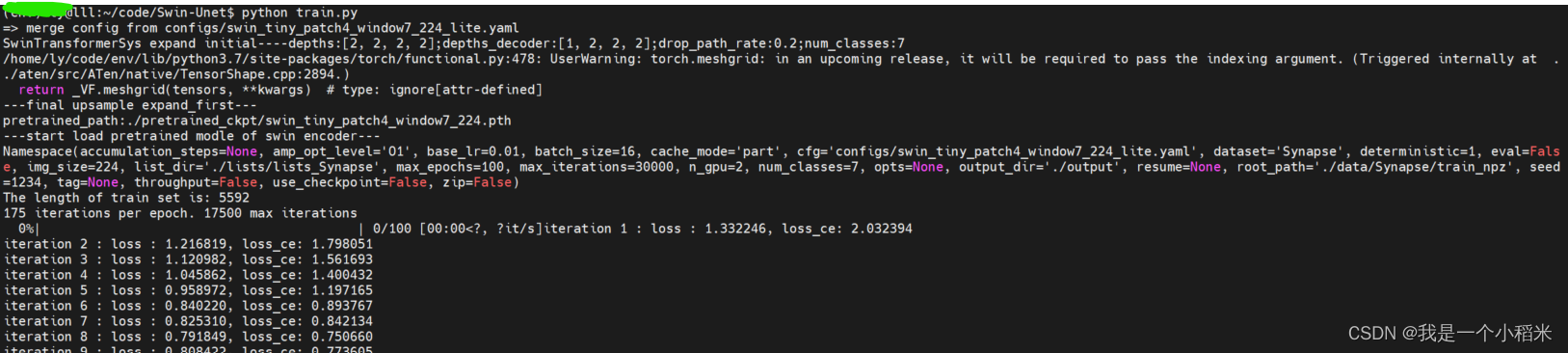
Lo más importante es el número de categorías , otras dependen de la situación.
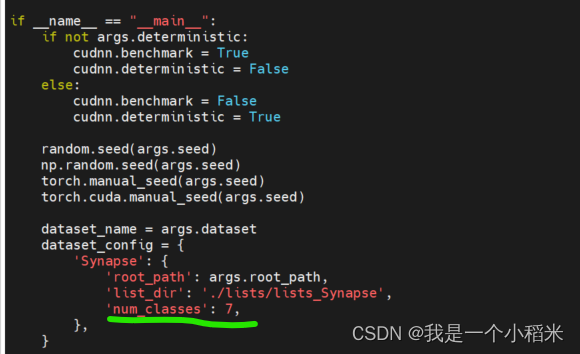
2. Modificar ./datasets/dataset_synapse.pyel archivo
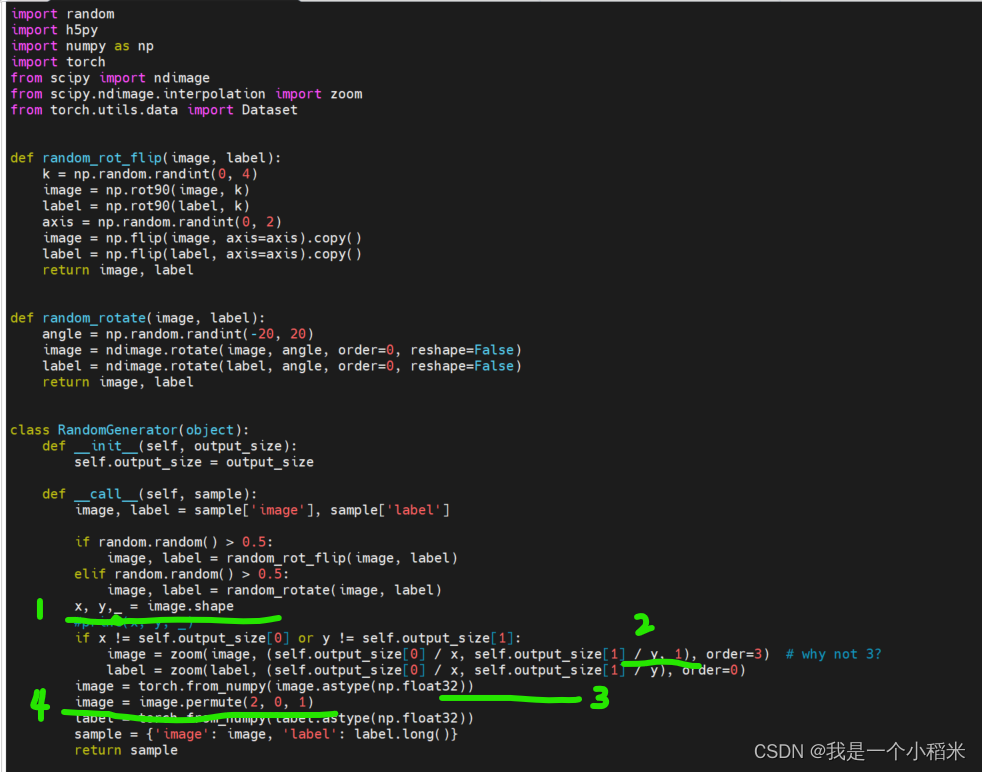
3. Modificar trainer.pyel archivo
no sé por qué aquí
4. Ejecuta el código
Esta información se puede pasar como hiperparámetros. Si no, puede usar default=el método para escribir el valor predeterminado
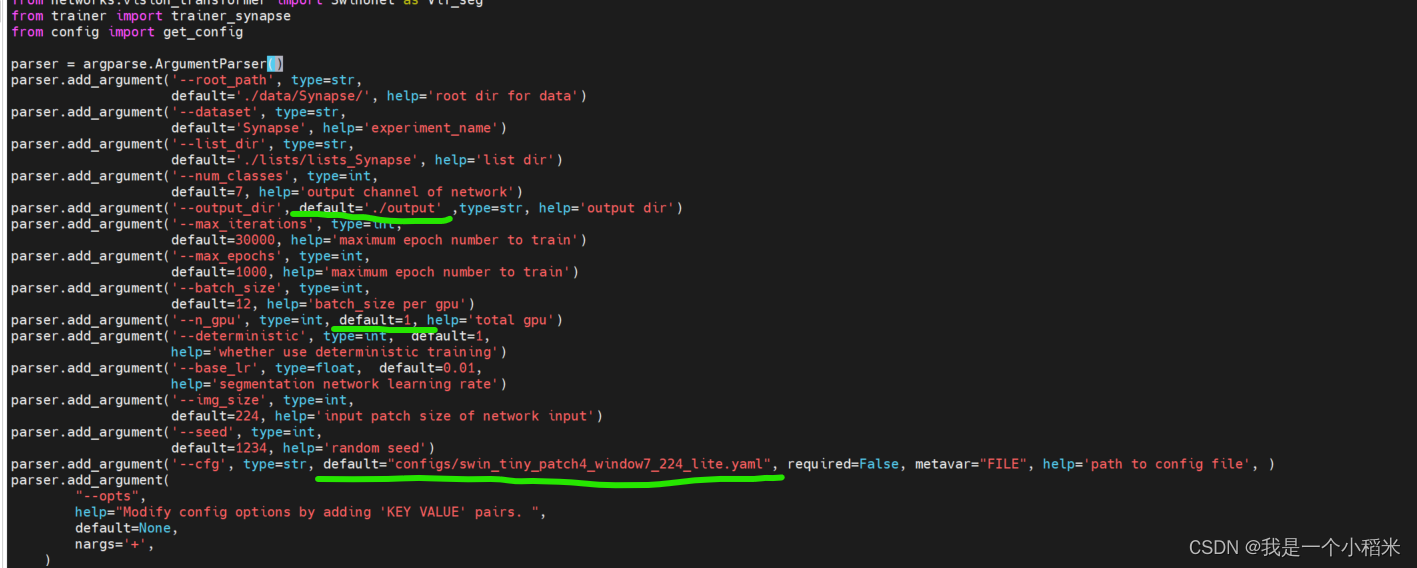
. Si se establece el valor predeterminado, python train.pypuede ejecutarlo.