소개
데이터베이스 윈도우 기능은 SQL에서 사용되는 기능으로, 데이터를 더 잘 분석하고 처리하기 위해 결과 집합의 데이터를 그룹화하고 정렬하는 데 사용할 수 있습니다. 윈도우 함수는 집계 함수와 달리 여러 행의 데이터를 하나의 행으로 집계하지 않고 각 데이터 행을 유지하고 그룹화 및 정렬합니다.
일반적인 윈도우 기능에는 ROW_NUMBER(), RANK(), DENSE_RANK(), NTILE(), LAG(), LEAD() 등이 있습니다. 이러한 기능은 사용자가 데이터를 더 잘 이해하고 분석할 수 있도록 그룹화되고 정렬된 결과 집합을 생성하는 데 도움이 됩니다.
예를 들어 ROW_NUMBER() 함수를 사용하여 하나 이상의 필드를 기반으로 결과 집합을 그룹화하고 각 그룹 내에서 행 번호를 생성하여 사용자가 데이터를 쉽게 추적할 수 있도록 합니다. LAG() 및 LEAD() 함수를 사용하여 결과 집합의 각 행 전후에 데이터를 추출하여 사용자가 현재 행 전후의 데이터를 볼 수 있도록 합니다.
윈도우 기능은 사용자가 데이터를 더 잘 분석하고 처리하기 위해 결과 집합의 데이터를 그룹화하고 정렬하는 데 도움이 되는 SQL의 매우 유용한 도구입니다.
MySQL 공식 문서 : https://dev.mysql.com/doc/refman/8.0/en/window-functions.html
참고 : 창 열기 기능에 대한 공식적인 설명은 MySQL8.0 이후에만 제공됩니다.
1. 창 함수와 집계 함수의 차이점은 무엇입니까?
- 데이터 처리 범위: 집계 함수는 전체 데이터 테이블 또는 데이터 세트에 대해서만 작동할 수 있으며 계산 결과는 단일 값입니다. 창 기능은 각 행에서 작동할 수 있으며 계산 결과는 각 행에 표시됩니다.
- 계산 결과 : 집계 함수의 계산 결과는 1개뿐이며 일반적으로 합산, 평균값, 최대값/최소값 계산 등과 같은 작업을 수행하는 데 사용됩니다. 창 함수는 여러 결과를 가질 수 있지만 쿼리 결과 집합의 각 행에 대해 추가 열을 제공합니다.
- 구문: 집계 함수는 일반적으로 SELECT 절과 SELECT 문의 HAVING 절에서 사용되는 반면, 윈도우 함수는 일반적으로 OVER 키워드 다음에 사용됩니다.
2. 공식적으로 설명된 창 열기 기능

- 번역하다
공식 성명은 매우 공식적이지만 아직 이해하기가 조금 어렵습니다.
3. 윈도우 함수의 분할
3.1, 일련 번호
- ROW_NUMBER() : 이 함수는 결과 집합을 하나 이상의 필드로 그룹화하고 각 그룹 내에서 행 번호를 생성하여 사용자가 데이터를 쉽게 추적할 수 있도록 합니다.
- RANK() : 이 함수는 하나 이상의 필드에 따라 결과 집합을 정렬하고 각 정렬에서 순위를 생성하여 사용자가 데이터의 크기와 순서를 이해할 수 있도록 합니다.
- DENSE_RANK() : 이 함수는 하나 이상의 필드에 따라 결과 집합을 정렬하고 각 정렬에서 순위를 생성할 수 있지만 생략된 위치는 RANK() 함수보다 하나 적습니다.
3.2 배포
- PERCENT RANK() : 이 함수는 데이터 세트에서 각 값의 백분율 순위를 계산하는 데 사용됩니다.
- CUME_DIST() : 데이터셋의 각 값에 대한 누적 밀도 순위를 계산하는 데 사용되는 함수입니다.
3.3 전후
- LAG() : 이 함수는 결과 집합의 각 행 앞의 데이터를 추출하여 사용자가 현재 행 앞의 데이터를 볼 수 있도록 합니다.
- LEAD() : 이 함수는 사용자가 현재 행 이후의 데이터를 볼 수 있도록 결과 집합의 각 행 이후 데이터를 추출할 수 있습니다.
3.4, 시작과 끝
- FIRST_VALUE() : 이 함수는 결과 집합의 정렬된 파티션에서 첫 번째 값을 반환합니다.
- LAST_VALUE() : 이 함수는 결과 집합의 정렬된 파티션에서 마지막 값을 반환합니다.
3.5 기타
- NTILE() : 이 함수는 하나 이상의 필드에 따라 결과 세트를 그룹화하고 각 그룹을 지정된 수의 버킷에 분배하여 사용자가 데이터를 더 잘 분석하고 그룹화할 수 있도록 합니다.
- NTH_VALUE() : 이 함수는 결과 집합의 정렬된 파티션에서 n번째 행의 값을 반환합니다.
넷째, 문법의 사용
4.1 문법 구조
<窗口函数> OVER ([PARTITION BY <分组列>] [ORDER BY <排序列> {ASC|DESC}] [<行窗口>|<范围窗口>] [<开始位置>|<结束位置>|<长度>])- <윈도우 함수>는 SUM, AVG, MAX, MIN, COUNT 등과 같이 실행할 집계 함수를 나타냅니다.
- <그룹화 열>은 그룹화할 열을 나타냅니다.
- <정렬 열>은 정렬할 열을 나타내며 여러 정렬 열을 쉼표로 구분하여 지정할 수 있습니다.
- <행 창> 및 <범위 창>은 각각 행 수준 창과 범위 수준 창을 나타냅니다.
- <시작 위치>, <종료 위치> 및 <길이>는 창의 시작 위치, 종료 위치 및 길이를 나타냅니다.
MySQL 8.0에서 행 창은 연속된 행의 집합으로 전체적으로 간주되며 창 함수 계산에 사용할 수 있습니다.
행 창은 다음 키워드로 지정됩니다.
- ROWS: 행 창을 나타냅니다.
- BETWEEN: 행 창의 시작 및 끝 위치를 지정하는 데 사용됩니다.
- PRECEDING: 행 창의 시작 위치를 나타냅니다.
- FOLLOWING: 행 창의 끝 위치를 나타냅니다.
일반적으로 사용되는 행 창 지정 방법:
- ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW: 결과 집합의 첫 번째 행부터 현재 행을 포함하여 현재 행까지를 나타냅니다.
- ROWS BETWEEN CURRENT ROW AND UNBOUNDED FOLLOWING: 현재 행을 포함하여 결과 집합의 현재 행에서 마지막 행까지를 나타냅니다.
- ROWS BETWEEN 1 PRECEDING AND 1 FOLLOWING: 현재 행을 포함하여 전후의 각 행을 나타냅니다.
설명: 행 창은 각 그룹의 합계, 평균, 개수 및 기타 집계 작업을 계산하는 데 사용할 수 있으며 각 행의 순위, 누적 합계 및 기타 작업을 계산하는 데 사용할 수도 있습니다.
4.2 윈도잉 함수로서의 일반 집계 함수
- 일반 집계 함수는 전체 데이터 테이블 또는 데이터 세트에 대해서만 작동할 수 있으며 계산 결과는 단일 값입니다. 창 기능은 각 행에서 작동할 수 있으며 계산 결과는 각 행에 표시됩니다.
4.2.1, 테이블 구조
DROP TABLE IF EXISTS `order_for_goods`;
CREATE TABLE `order_for_goods` (
`order_id` int(0) NOT NULL AUTO_INCREMENT,
`user_id` int(0) NULL DEFAULT NULL,
`money` decimal(10, 2) NULL DEFAULT NULL,
`quantity` int(0) NULL DEFAULT NULL,
`join_time` datetime(0) NULL DEFAULT NULL,
PRIMARY KEY (`order_id`) USING BTREE
) ENGINE = InnoDB AUTO_INCREMENT = 12 CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;4.2.2, 테이블 데이터
INSERT INTO order_for_goods (user_id, money, quantity, join_time )
VALUES
( 1001, 1800.90, 1, '2023-06-07'),
( 1001, 3600.89, 5, '2023-05-02'),
( 1001, 1000.10, 6, '2023-01-08'),
( 1002, 1100.90, 9, '2023-04-07'),
( 1002, 4500.99, 1, '2023-03-14'),
( 1003, 2500.10, 3, '2023-02-14'),
( 1002, 2500.90, 1, '2023-03-14'),
( 1003, 2500.90, 1, '2022-12-12'),
( 1003, 2500.90, 2, '2022-09-08'),
( 1003, 6000.90, 8, '2023-01-10');4.2.3 윈도우 함수로서의 일반 함수
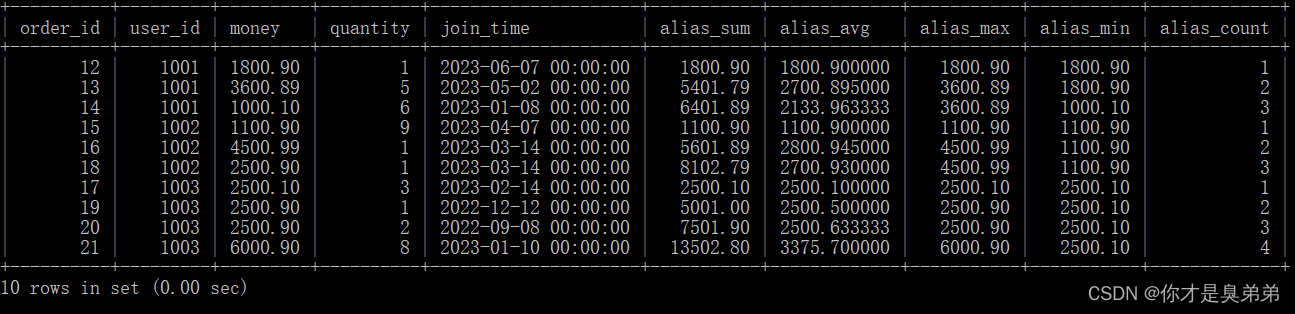
1. 성명은 다음과 같다
select
*,
sum(money) over(partition by user_id order by order_id) as alias_sum,
avg(money) over(partition by user_id order by order_id) as alias_avg,
max(money) over(partition by user_id order by order_id) as alias_max,
min(money) over(partition by user_id order by order_id) as alias_min,
count(money) over(partition by user_id order by order_id) as alias_count
from order_for_goods;- order_for_goods 테이블에서 모든 열을 선택하고 각 사용자에 대한 각 주문의 총 금액, 평균 금액, 최대 금액, 최소 금액 및 횟수를 계산했습니다.
- 이 쿼리는 sum(), avg(), max(), min() 및 count() 함수를 사용하여 각 주문의 합계, 평균, 최대값, 최소값 및 개수를 계산합니다. 이러한 함수 뒤에는 계산 창을 지정하는 over() 절이 옵니다. 이 예에서 창은 user_id로 분할되고 order_id로 정렬됩니다.
2. 쿼리 결과는 다음과 같이 선택한 컬럼과 계산된 별칭 컬럼을 리턴합니다.
4.3, 일련 번호 기능
4.3.1, ROW_NUMBER() 함수
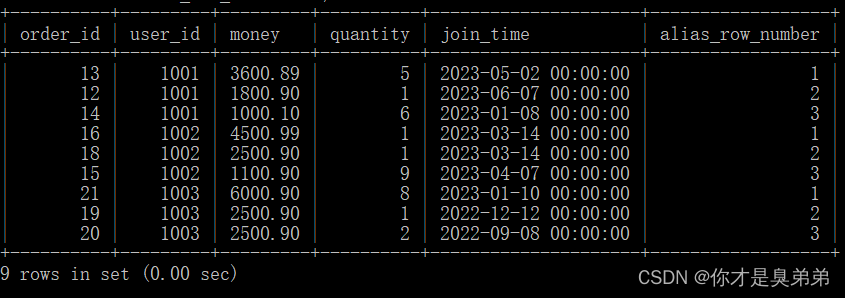
1. 문을 실행
select *
from (
select *,row_number() over(partition by user_id order by money desc) as alias_row_number
from order_for_goods) t
where alias_row_number<=3;- 위의 SQL 문은 윈도우 함수 row_number()를 사용하여 각 파티션의 행에 일련 번호를 할당합니다. 그런 다음 외부 쿼리는 이러한 서수에서 처음 세 개의 가장 높은 행을 선택합니다.
- 내부 쿼리는 order_for_goods 테이블에서 모든 열을 선택하고 row_number() 함수를 사용하여 각 파티션 내의 행에 서수를 할당합니다. 이 예에서 하위 쿼리는 데이터를 user_id 열로 분할하고 money 열을 기준으로 내림차순으로 정렬합니다.
- 외부 쿼리는 서수가 3보다 작거나 같은 내부 쿼리의 결과에서 행을 선택합니다. 이 행은 파티션의 상위 3개 행에 해당합니다.
2. 실행 결과
3. 명령문 실행
select *
from (
select *,row_number() over(partition by user_id order by money desc) as alias_row_number
from order_for_goods) t
where alias_row_number<=1;- 위의 쿼리문은 alias_row_number<=3이 alias_row_number<=1로 변경되어 결과가 파티션에서 가장 높은 행만 반환한다는 점을 제외하면 이전 쿼리문과 유사합니다.
4. 실행 결과

요약: 다양하게 생각할 수 있습니다. 예를 들어, 각 상품 분야에서 상위 3개 매출을 세십시오. 창 설정을 사용하면 많은 문제를 해결할 수 있고 유지 관리하기 어렵고 이해할 수 없는 많은 SQL 논리를 피할 수 있습니다.
4.3.2, 랭크() 함수
1. 문을 실행
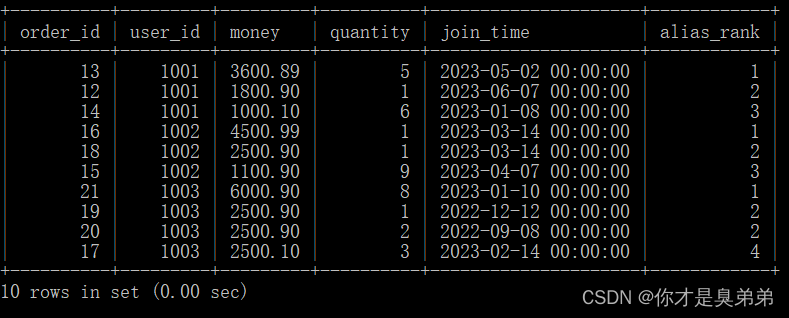
select
*,
rank() over(partition by user_id order by money desc) as alias_rank
from order_for_goods;- 위의 SQL 문은 윈도우 함수 rank()를 사용하여 각 사용자에 대한 별칭 순위(alias_rank)를 계산합니다.
- rank() 함수는 각 파티션 내의 연속 순위에 대한 순위 값을 계산하므로 이 명령문은 각 사용자에 대한 별칭 순위를 계산합니다.
- 문은 조건을 지정하지 않으므로 order_for_goods 테이블의 모든 행과 열을 반환합니다. 특정 행이나 열을 쿼리해야 하는 경우 select 절에 해당 조건이나 열 이름을 지정할 수 있습니다.
2. 실행 결과
4.3.3, DENSE_RANK() 함수
1. 문을 실행
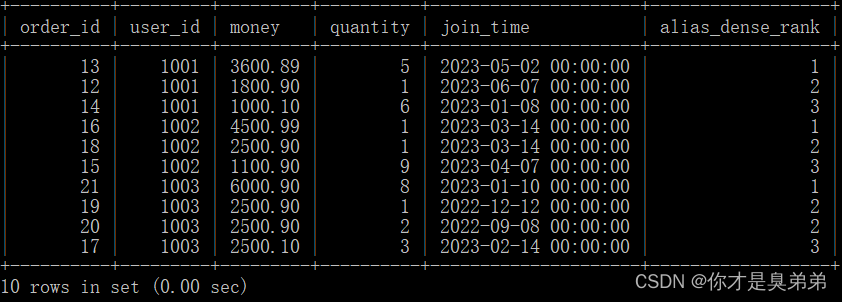
select
*,
dense_rank() over(partition by user_id order by money desc) as alias_dense_rank
from order_for_goods;- 위의 SQL 문은 윈도우 함수 dense_rank()를 사용하여 각 사용자에 대한 별칭 밀집 순위(alias_dense_rank)를 계산합니다.
- dense_rank() 함수는 각 파티션 내 순위에 대한 순위 값을 계산하고 동일한 순위 값을 가진 인접한 행에 대해 순위 값을 연속적으로 할당합니다. 따라서 이 명령문은 각 사용자에 대한 별칭 밀집 순위를 계산합니다.
- 문은 조건을 지정하지 않으므로 order_for_goods 테이블의 모든 행과 열을 반환합니다. 특정 행이나 열을 쿼리해야 하는 경우 select 절에 해당 조건이나 열 이름을 지정할 수 있습니다.
2. 실행 결과
4.3.4 위의 세 가지 일련번호 기능 비교
1. 문을 실행
select
*,
row_number() over(partition by user_id order by money desc) as alias_row_number,
rank() over(partition by user_id order by money desc) as alias_rank,
dense_rank() over(partition by user_id order by money desc) as alias_dense_rank
from order_for_goods;- order_for_goods 테이블에서 모든 열을 선택하고 각 주문에서 각 사용자의 총 금액을 계산하고 각 주문에서 각 사용자의 서수, 순위 및 밀집 순위를 계산했습니다.
- 이 쿼리는 row_number(), rank() 및 dense_rank() 함수를 사용하여 각 파티션 내 행의 서수, 순위 및 밀집 순위를 계산합니다. 이러한 함수 뒤에는 계산 창을 지정하는 over() 절이 옵니다. 이 예에서 창은 user_id로 분할되고 money 열을 기준으로 내림차순으로 정렬됩니다.
2. 실행 결과

4.4 분배 기능
4.4.1, PERCENT RANK() 함수
1. 문을 실행
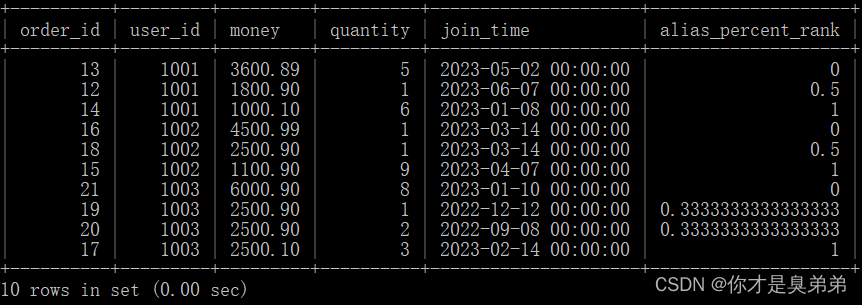
select
*,
percent_rank() over(partition by user_id order by money desc) as alias_percent_rank
from order_for_goods;- order_for_goods 테이블에서 모든 열을 선택하고 각 주문에서 각 사용자의 총 금액을 계산하고 각 주문에서 각 사용자의 백분율 순위를 계산했습니다.
- 이 쿼리는 percent_rank() 함수를 사용하여 각 파티션 내 행의 백분위수 순위를 계산합니다. 이 함수 다음에는 계산 창을 지정하는 over() 절이 옵니다. 이 예에서 창은 user_id로 분할되고 money 열을 기준으로 내림차순으로 정렬됩니다.
2. 실행 결과
4.4.2, CUME_DIST() 함수
1. 문을 실행
select
*,
cume_dist() over(partition by user_id order by money desc) as alias_percent_rank
from order_for_goods;- order_for_goods 테이블에서 모든 열을 선택하고 각 주문에서 각 사용자의 총 금액을 계산하고 각 주문에서 각 사용자의 누적 백분율을 계산했습니다.
- 이 쿼리는 cume_dist() 함수를 사용하여 각 파티션 내 행의 누적 백분율을 계산합니다. 이 함수 다음에는 계산 창을 지정하는 over() 절이 옵니다. 이 예에서 창은 user_id로 분할되고 money 열을 기준으로 내림차순으로 정렬됩니다.
2. 실행 결과

4.5 앞면과 뒷면 기능
4.5.1 LAG() 함수
1. 문법적 설명
- LAG() 함수는 시계열에서 지정된 기간만큼 앞으로 이동하는 데 사용되는 함수입니다.
LAG(expression, offset, default_value)- 표현식: 평가할 열
- 오프셋: 앞으로 처음 몇 행의 값
- default_value: 값이 없을 경우 기본값으로 설정 가능
2. 명령문 실행
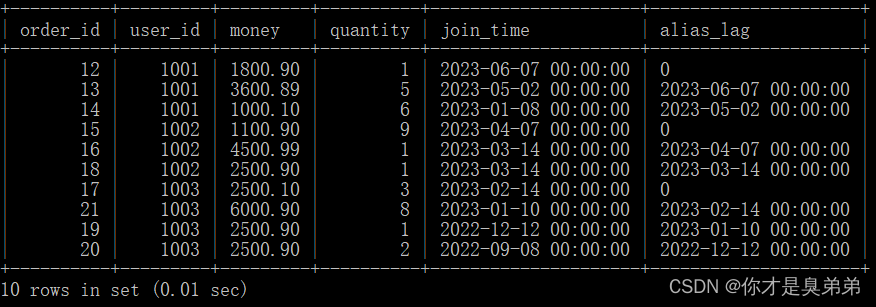
select
*,
lag(join_time, 1, 0) over(partition by user_id order by join_time desc) as alias_lag
from order_for_goods;3. 실행 결과
4.5.2 LEAD() 함수
1. 문법적 설명
- LEAD() 함수는 시계열에서 지정된 기간만큼 뒤로 이동하는 데 사용되는 함수입니다.
LAG(expression, offset, default_value)- 표현식: 평가할 열
- offset: 뒤로 행 수의 값
- default_value: 값이 없을 경우 기본값으로 설정 가능
2. 명령문 실행
select
*,
lead(join_time, 1, 0) over(partition by user_id order by join_time desc) as alias_lead
from order_for_goods;3. 실행 결과
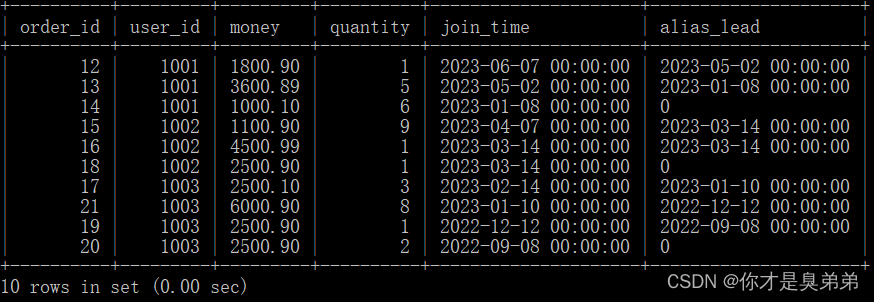
4.6 닫기 기능
4.6.1, FIRST_VALUE() 함수
1. 문법적 설명
- FIRST_VALUE: 창의 첫 번째 행의 값을 가져옵니다.
FIRST_VALUE(expression)- 표현식: 첫 번째 행의 값을 얻기 위해 열 또는 계산 결과를 지정하는 표현식입니다.
2. 실행 구문
select
*,
first_value(money) over(partition by user_id order by join_time desc) as alias_first_value
from order_for_goods;- 사용자가 지정된 시간 범위에 대한 데이터가 없는 경우 LAST_VALUE() 함수는 기본값인 NULL을 반환합니다.
3. 실행 결과
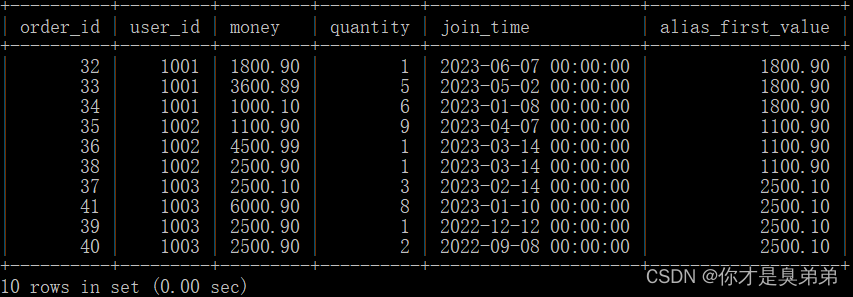
4.6.2, LAST_VALUE() 함수
1. 문법적 설명
- LAST_VALUE: 창의 마지막 행 값을 가져옵니다.
LAST_VALUE(expression)- 표현식: 마지막 행의 값을 얻기 위해 열 또는 계산 결과를 지정하는 표현식입니다.
2. 실행 구문
select
*,
last_value(money) over(partition by user_id order by join_time) as alias_last_value
from order_for_goods;- 사용자가 지정된 시간 범위에 대한 데이터가 없는 경우 LAST_VALUE() 함수는 기본값인 NULL을 반환합니다.
2. 실행 결과

3. 설명
- LAST_VALUE()가 창의 마지막 값을 취하지 않는다는 것을 알 수 있습니다. 창은 user_id로 분할되고 join_time 열로 정렬됩니다. 1001 분할의 돈을 1800.90으로 반환하는 것이 합리적입니다. 이유는 무엇입니까?
- 그 이유는 LAST_VALUE()의 기본 통계 범위가 무제한 이전 행과 현재 행 사이의 행이기 때문입니다.

3. 검증
select
*,
last_value(money) over(partition by user_id order by join_time) as alias_last_value1,
last_value(money) over(partition by user_id order by join_time rows between unbounded preceding and current row) as alias_last_value2,
last_value(money) over(partition by user_id order by join_time rows between unbounded preceding and unbounded following) as alias_last_value3
from order_for_goods;- 별칭 alias_last_value2는 LAST_VALUE()의 기본 통계 범위가 무제한 이전 행과 현재 행 사이의 행임을 확인했음을 알 수 있습니다. 현재 행이 계산되기 전에.)
- 별칭 alias_last_value3은 무한 선행과 무한 후행 사이의 행(경계 없이 현재 행에서 앞뒤로 계산이 수행됨을 나타냄, 즉 전체 파티션을 계산한 결과)을 모두에서 얻을 수 있음을 알 수 있습니다. statistics, user_id 파티션, join_time 컬럼이 정렬되고 1001 파티션에서 money 필드의 마지막 거래 금액이 1800.90으로 리턴됩니다.
+----------+---------+---------+----------+---------------------+------------------+------------------+------------------+
| order_id | user_id | money | quantity | join_time | alias_last_value | alias_last_value | alias_last_value |
+----------+---------+---------+----------+---------------------+------------------+------------------+------------------+
| 34 | 1001 | 1000.10 | 6 | 2023-01-08 00:00:00 | 1000.10 | 1000.10 | 1800.90 |
| 33 | 1001 | 3600.89 | 5 | 2023-05-02 00:00:00 | 3600.89 | 3600.89 | 1800.90 |
| 32 | 1001 | 1800.90 | 1 | 2023-06-07 00:00:00 | 1800.90 | 1800.90 | 1800.90 |
| 36 | 1002 | 4500.99 | 1 | 2023-03-14 00:00:00 | 2500.90 | 4500.99 | 1100.90 |
| 38 | 1002 | 2500.90 | 1 | 2023-03-14 00:00:00 | 2500.90 | 2500.90 | 1100.90 |
| 35 | 1002 | 1100.90 | 9 | 2023-04-07 00:00:00 | 1100.90 | 1100.90 | 1100.90 |
| 40 | 1003 | 2500.90 | 2 | 2022-09-08 00:00:00 | 2500.90 | 2500.90 | 2500.10 |
| 39 | 1003 | 2500.90 | 1 | 2022-12-12 00:00:00 | 2500.90 | 2500.90 | 2500.10 |
| 41 | 1003 | 6000.90 | 8 | 2023-01-10 00:00:00 | 6000.90 | 6000.90 | 2500.10 |
| 37 | 1003 | 2500.10 | 3 | 2023-02-14 00:00:00 | 2500.10 | 2500.10 | 2500.10 |
+----------+---------+---------+----------+---------------------+------------------+------------------+------------------+
10 rows in set (0.00 sec)4.7 기타 기능
4.7.1, NTILE() 함수
1. 문법적 설명
- NTILE()은 쿼리 결과 집합을 지정된 수의 버킷으로 나누고 버킷의 크기에 따라 각 버킷에 데이터를 분배하는 데 사용됩니다.
NTILE(bucket_size)- bucket_size: 결과 집합을 나눌 버킷 수를 나타내는 정수 매개 변수입니다.
2. 명령문 실행
select
*,
ntile(1) over(partition by user_id order by join_time desc) as alias_ntile1,
ntile(2) over(partition by user_id order by join_time desc) as alias_ntile2,
ntile(3) over(partition by user_id order by join_time desc) as alias_ntile3
from order_for_goods;- 쿼리는 데이터 세트를 지정된 수의 버킷에 균등하게 분배하고 각 행이 속한 버킷 번호를 반환할 수 있는 윈도우 함수 NTILE()를 사용합니다.
- 별칭 "alias_ntile3"을 예로 들어 보겠습니다. 이 쿼리에서 ntile(3)은 각 사용자를 3개의 그룹으로 나누는 것을 의미하고, partition by user_id는 user_id로 그룹화하는 것을 의미하고, order by join_time desc는 join_time을 내림차순으로 정렬하는 것을 의미합니다.
- ntile(2)이면 두 그룹으로 나눈다는 의미이고, ntile(1)은 한 그룹으로 나눈다는 뜻이다.
3. 실행 결과

설명: NTILE() 함수는 정렬된 데이터 세트를 지정된 수의 버킷에 균등하게 분배하고 각 행에 버킷 번호를 할당할 수 있습니다. 고르게 분배할 수 없는 경우 버킷 번호가 작은 버킷이 추가 행을 할당하며 각 버킷에 배치할 수 있는 행의 수는 최대 1개까지 다릅니다.
4.7.2, NTH_VALUE() 함수
1. 문법적 설명
- NTH_VALUE() 함수는 정렬된 데이터 세트에서 지정된 위치의 값을 계산하기 위해 SQL에서 사용되는 창 함수입니다.
NTH_VALUE(expression, nth_parameter)- 표현식: 단일 값으로 평가되는 평가할 표현식입니다.
- nth_parameter: 계산할 값의 시퀀스 번호를 나타내는 정수 매개변수입니다.
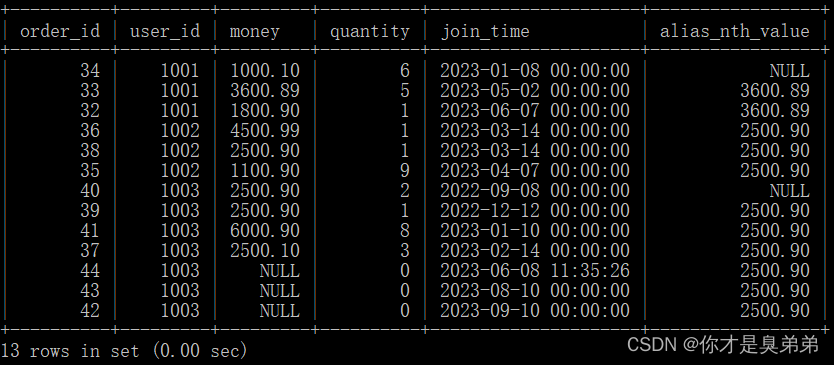
2. 명령문 실행
select
*,
nth_value(money, 2) over(partition by user_id order by join_time ) as alias_nth_value
from order_for_goods;- 사용자가 지정된 시간 범위 내에 데이터가 없는 경우 NTH_VALUE() 함수는 기본값 NULL을 반환합니다.
3. 실행 결과