Tabla de contenido
3. Obtener comentarios de niños
I. Introducción
No hay una función de búsqueda para los comentarios de Bilibili, así que escribí un rastreador para rastrear los comentarios de Bilibili y almacenarlos en txt local.
Primero, debe instalar la biblioteca de solicitudes de python y la biblioteca beautifulsoup
solicitudes de instalación de pip
pip instalar bs4
Si aparece correctamente, significa que la instalación se ha realizado correctamente.
Aquí están todas las bibliotecas necesarias
import requests
from bs4 import BeautifulSoup
import re
import json
from pprint import pprint
import time2. Analizar páginas web
Ejemplo de página web Lanyin "Explorando la ventana" BV18T411G7xJ
Verificamos el código fuente de la página y encontramos que no hay información sobre los comentarios en el código fuente. Continuamos deslizándonos hacia abajo hasta la posición del comentario, y encontramos que el comentario tardó un poco en cargarse antes de aparecer. En este momento, supuse que necesitábamos capturar el paquete para obtener la información del comentario.
Abra F12, consulte las opciones relacionadas con la respuesta en la red y encuentre la información del comentario.

Extraje la URL y revisé los diversos datos dentro
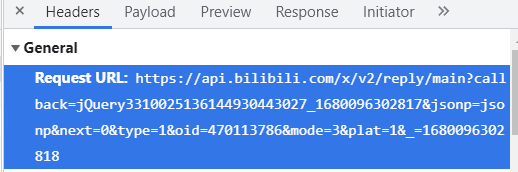
No sé por qué la URL aquí necesita eliminar los datos detrás de la devolución de llamada para verlos normalmente.
Descargue Json Formatter en Edge para una mejor vista.


Encontramos que un paquete no puede mostrar todos los comentarios, continuamos deslizándonos hacia abajo, buscamos datos sobre la respuesta en F12 y extraemos la URL

![]() Se encuentra que solo cambiará el próximo, entonces, ¿qué es el próximo = 1? En la práctica, se encuentra que los datos de next=1 y next=0 son los mismos, por lo que podemos comenzar directamente desde 1 al programar.
Se encuentra que solo cambiará el próximo, entonces, ¿qué es el próximo = 1? En la práctica, se encuentra que los datos de next=1 y next=0 son los mismos, por lo que podemos comenzar directamente desde 1 al programar.
Pero descubrimos que solo hay el comentario raíz y no hay subcomentarios. Sospechamos que los subcomentarios están en otro paquete. Verifique los subcomentarios de uno de los comentarios, y hemos capturado un nuevo paquete en F12.
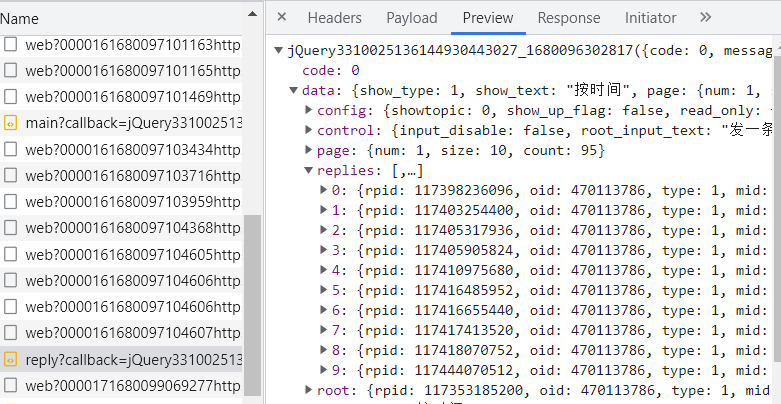
Del mismo modo, extraemos la URL y observamos que las respuestas son los subcomentarios necesarios. Del mismo modo, todas las respuestas no se pueden mostrar en una página.Después de la observación, se encuentra que solo el pn de cada comentario es diferente.

![]()
Entonces, ¿cómo se relacionan los subcomentarios y los comentarios raíz?
Al observar la URL, encontramos que la URL del subcomentario tiene raíz, por lo que estudiamos la consistencia entre la raíz y el subcomentario, y encontramos que el rpid de la raíz es la raíz del subcomentario , por lo que encontró la relación.

Finalmente, al escribir el código, encontré un problema, es decir, algunos comentarios raíz no necesitan expandirse, por lo que el elemento de respuestas en el paquete de subcomentarios está vacío, y la información de estos comentarios existe en el paquete de comentarios raíz. , solo necesitamos simplemente simplemente juzgarlo.
Una vez que comprende la estructura, la programación es mucho más simple.
3. Código
1. cabeza
#网页头
headers = {
"User-Agent" : "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/106.0.0.0 Safari/537.36",
"referer" : "https://www.bilibili.com/"
}2. Obtener comentario raíz
def get_rootReply(headers):
num = 1
replay_index = 1
while True:
URL = (f"https://api.bilibili.com/x/v2/reply/main?&jsonp=jsonp&next={num}&type=1&oid=470113786&mode=3&plat=1&_=1680096302818") #获得网页源码
respond = requests.get(URL , headers = headers) # 获得源代码 抓包
# print(respond.status_code)
reply_num = 0
if(respond.status_code == 200): # 如果响应为200就继续,否则退出
respond.encoding = "UTF-8"
html = respond.text
json_html = json.loads(html) # 把格式转化为json格式 一个是好让pprint打印,一个是好寻找关键代码
if json_html['data']['replies'] is None or len(json_html['data']['replies']) == 0 :
break
for i in range(0,len(json_html['data']['replies'])): #一页只能读取20条评论
reply = json_html['data']['replies'][reply_num]['content']['message']
root = json_html['data']['replies'][reply_num]['rpid']
reply = reply.replace('\n',',')
# print(reply)
file.write(str(replay_index) + '.' + reply + '\n')
if json_html['data']['replies'][reply_num]['replies'] is not None:
if(get_SecondReply(headers,root) == 0):
for i in range(0,len(json_html['data']['replies'][reply_num]['replies'])):
reply = json_html['data']['replies'][reply_num]['replies'][i]['content']['message']
reply = reply.replace('\n',',')
file.write(" " + reply + '\n')
reply_num += 1
replay_index += 1
num += 1
time.sleep(0.5)
else :
print("respond error!")
break
file.close()3. Obtener comentarios de niños
def get_SecondReply(headers,root):
pn = 1
while True:
URL = (f"https://api.bilibili.com/x/v2/reply/reply?jsonp=jsonp&pn={pn}&type=1&oid=824175427&ps=10&root={root}&_=1679992607971")
respond = requests.get(URL , headers = headers) # 获得源代码 抓包
reply_num = 0
if(respond.status_code == 200):
respond.encoding = "UTF-8"
html = respond.text
json_html = json.loads(html)
if json_html['data']['replies'] is None:
if(pn == 1):
return 0
else :
return 1
for i in range(0,len(json_html['data']['replies'])):
if json_html['data']['replies'] is None:
break
reply = json_html['data']['replies'][reply_num]['content']['message']
reply = reply.replace('\n',',')
# print(reply)
reply_num += 1
file.write(" " + reply + '\n')
pn += 1
time.sleep(0.5)
else:
print("Sreply error!")
exit(-1)De esta manera, todos los módulos se ensamblan
Cuatro, el código total
import requests
from bs4 import BeautifulSoup
import re
import json
from pprint import pprint
import time
#网页头
headers = {
"User-Agent" : "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/106.0.0.0 Safari/537.36",
"referer" : "https://www.bilibili.com/"
}
file = open('lanyin.txt', 'w',encoding='utf-8')
def get_SecondReply(headers,root):
pn = 1
while True:
URL = (f"https://api.bilibili.com/x/v2/reply/reply?jsonp=jsonp&pn={pn}&type=1&oid=824175427&ps=10&root={root}&_=1679992607971")
respond = requests.get(URL , headers = headers) # 获得源代码 抓包
reply_num = 0
if(respond.status_code == 200):
respond.encoding = "UTF-8"
html = respond.text
json_html = json.loads(html)
if json_html['data']['replies'] is None:
if(pn == 1):
return 0
else :
return 1
for i in range(0,len(json_html['data']['replies'])):
if json_html['data']['replies'] is None:
break
reply = json_html['data']['replies'][reply_num]['content']['message']
reply = reply.replace('\n',',')
# print(reply)
reply_num += 1
file.write(" " + reply + '\n')
pn += 1
time.sleep(0.5)
else:
print("Sreply error!")
exit(-1)
def get_rootReply(headers):
num = 1
replay_index = 1
while True:
URL = (f"https://api.bilibili.com/x/v2/reply/main?&jsonp=jsonp&next={num}&type=1&oid=470113786&mode=3&plat=1&_=1680096302818") #获得网页源码
respond = requests.get(URL , headers = headers) # 获得源代码 抓包
# print(respond.status_code)
reply_num = 0
if(respond.status_code == 200): # 如果响应为200就继续,否则退出
respond.encoding = "UTF-8"
html = respond.text
json_html = json.loads(html) # 把格式转化为json格式 一个是好让pprint打印,一个是好寻找关键代码
if json_html['data']['replies'] is None or len(json_html['data']['replies']) == 0 :
break
for i in range(0,len(json_html['data']['replies'])): #一页只能读取20条评论
reply = json_html['data']['replies'][reply_num]['content']['message']
root = json_html['data']['replies'][reply_num]['rpid']
reply = reply.replace('\n',',')
# print(reply)
file.write(str(replay_index) + '.' + reply + '\n')
if json_html['data']['replies'][reply_num]['replies'] is not None:
if(get_SecondReply(headers,root) == 0):
for i in range(0,len(json_html['data']['replies'][reply_num]['replies'])):
reply = json_html['data']['replies'][reply_num]['replies'][i]['content']['message']
reply = reply.replace('\n',',')
file.write(" " + reply + '\n')
reply_num += 1
replay_index += 1
num += 1
time.sleep(0.5)
else :
print("respond error!")
break
file.close()
if __name__ == '__main__':
get_rootReply(headers)
print("sucessful")V. Resumen
El código que escribí por mí mismo es basura, bienvenido a corregirme.