この記事は一般的なメモリ機能を共有するものです
上記で共有した関数はすべて文字列に関するものですが、データを操作する場合は文字データだけを操作する必要はありません。
次に、メモリに関連するいくつかの機能を共有します。
目次
memmove関数を実現するための自己定義関数シミュレーション
これらの関数は、コピーする必要があるデータの種類を気にせず、この関数はタスクを完了するのに役立ちます。
1.memcpy

以下の関数関数の説明は、ソース ポインターが指す num バイトのデータを宛先スペースにコピーすることです。
次に、コードに直接移動します
#include<stdio.h>
#include<string.h>
int main()
{
int arr1[] = { 1,2,3,4,5,6,7,8,9,10 };
int arr2[8] = { 0 };
memcpy(arr2, arr1, 20);
return 0;
}上記のコードの意味は、arr1 の 20 バイトのデータを arr2 配列にコピーすることです。
それではデバッグと検証をしてみましょう
これは関数に入る前の arr2 配列の内容です
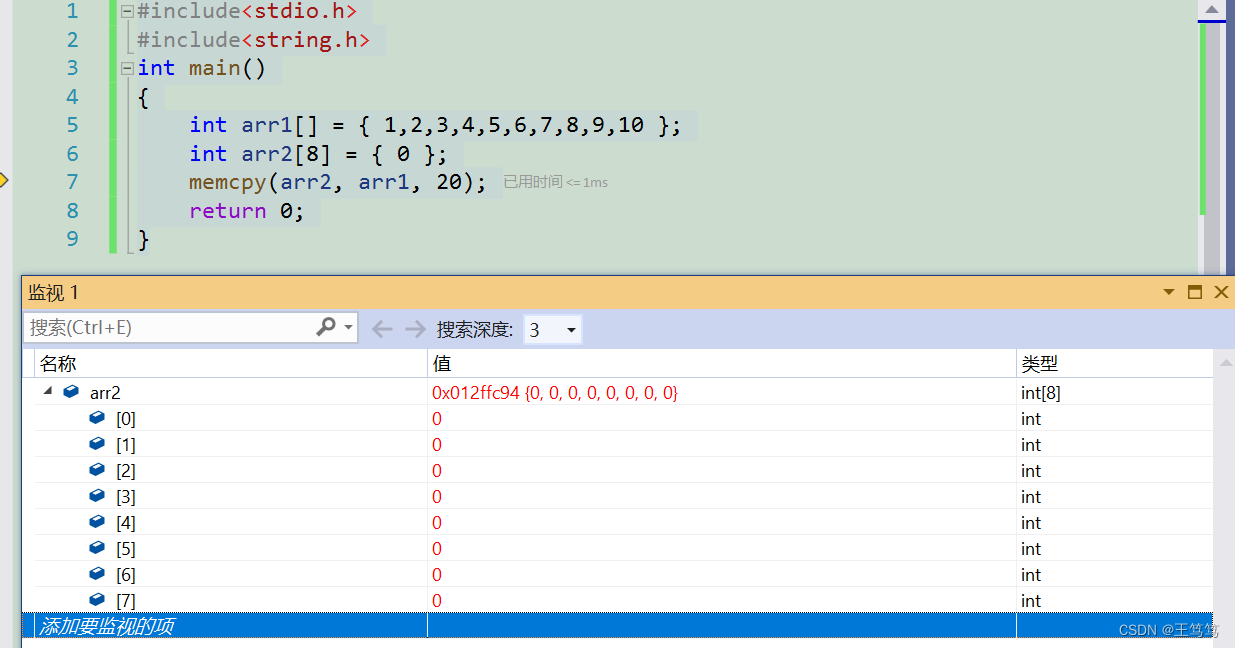
さらに一歩進んでください
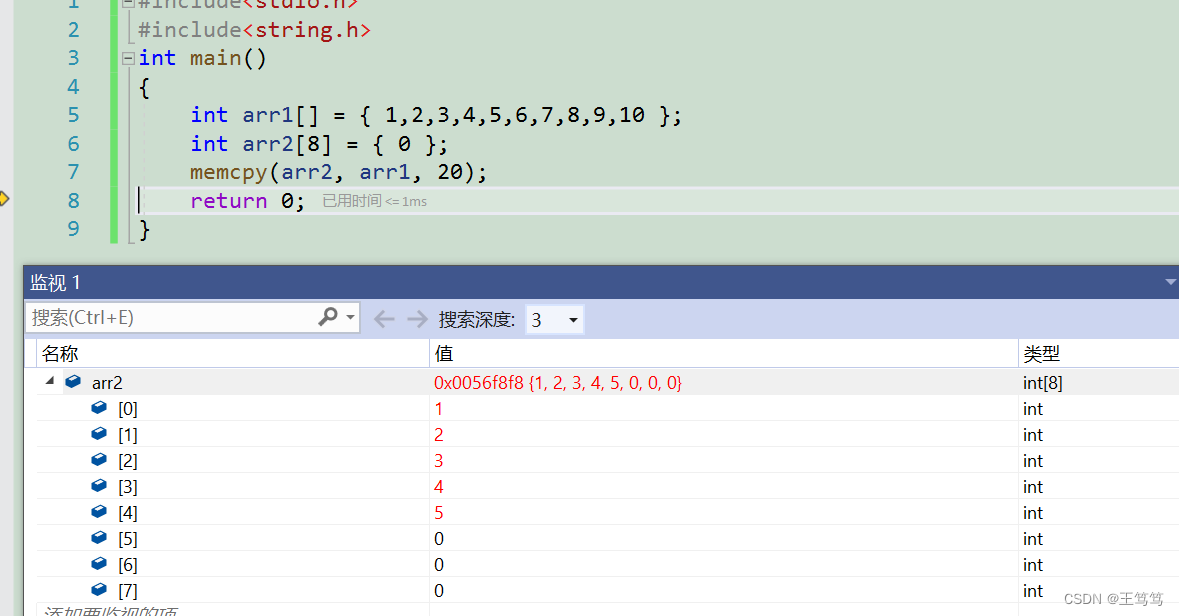
arr2 配列のデータが arr1 の 20 バイトの内容になることがわかります。
これは memcpy 関数の簡単な使用法です
では、この関数を使用して浮動小数点データを処理できるでしょうか?
絶対大丈夫
以下のコードをテストしてください
void test2()
{
float arr1[] = { 1.0,2.0,3.0,4.0,5.0 };
float arr2[8] = { 0 };
memcpy(arr2,arr1,12);
}
int main()
{
test2();
return 0;
}整数型のデータを浮動小数点型のデータに置き換えました
デバッグしてください

arr2 配列が初期化されたことがわかります。
さらに一歩下がってください。
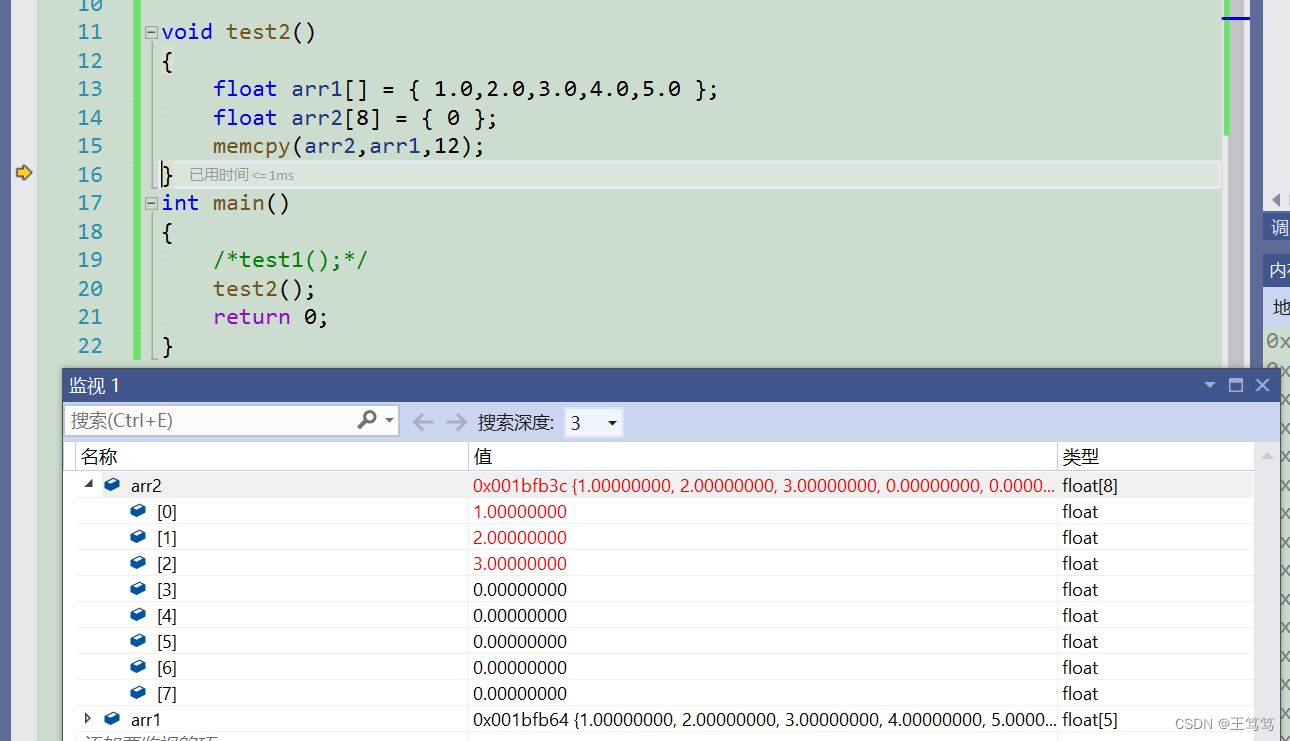
この時点で、arr1 に 12 バイトのデータが表示されます。つまり、最初の 3 つのデータが arr2 配列にコピーされています。
したがって、memcpy 関数はコピーされるデータ型を気にせず、データのバイト数だけをコピーすることがわかります。
次に、関数の引数と戻り値の型を使用する場合の対象空間の開始アドレスを見てみましょう。引数は void* 型のポインタなので、 void* 型のポインタは実際には一般型であることもわかりました。これは、あらゆる種類のデータのアドレスを受け入れることができるため、 memcpy 関数はあらゆる種類のデータをコピーできます。
次に、独自の関数をカスタマイズして memcpy 関数をシミュレートすることもできます。
void* my_memcpy(void* dest,const void* src,size_t num)
{
void test3()
{
int arr1[] = { 1,2,3,4,5,6,7,8,9,10 };
int arr2[8] = { 0 };
my_memcpy(arr2,arr1,20);
}
int main()
{
test3();
return 0;
}したがって、この main 関数は誰にとっても理解するのは難しくありません。
void* 型ポインタ dest は arr2 配列の最初の要素のアドレスを指し、2 番目のパラメータ void* 型ポインタ src は arr1 配列の最初の要素のアドレスを指し、3 番目のパラメータは次のことを意味する整数パラメータです。 20ワードフェスティバルを通過してください。
次に、コピーしたコンテンツを考えると、次のように直接解凍して適用できます。
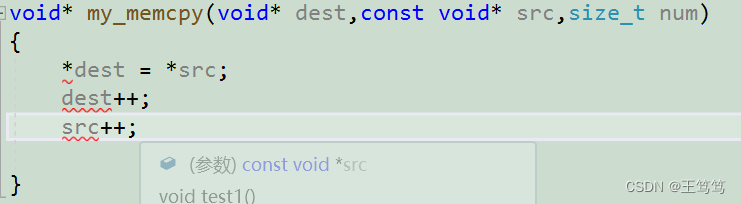
しかし、コンパイラがエラーを報告することがわかります。
ここで説明したいのは、void* 型のポインタは直接分解することはできず、変換したい型に変換する必要があるということです。
ただし、この関数はコピーする際に様々な型を考慮する必要があり、使用時に int 型をコピーしたい場合でも、関数の第 3 引数に 7 を入力すると、int 型のデータを処理するたびに 4 バイト処理することになるため、 2 番目の処理では 7 バイトを超える 8 バイトのデータが処理されるため、これを char* 型のポインターに変換して、一度に 1 ワードのセクション データのみを処理するようにし、その解決策を
コードは次のようになります
しかし、このように書いてもエラーが発生します。
このような強制的な型変換は一時的に型を変更するだけなので、再度関数を呼び出す必要があるときに void* 型ポインタとなりエラーが発生する可能性があるため、最適化します。
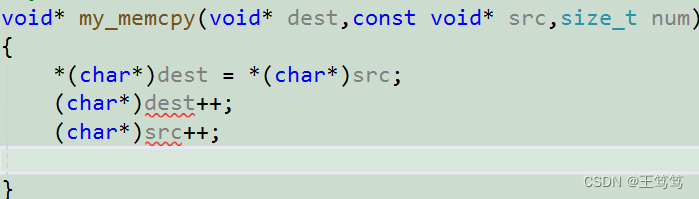
void* my_memcpy(void* dest,const void* src,size_t num)
{
*(char*)dest = *(char*)src;
dest = (char*)dest + 1;
src = (char*)src + 1;
}このように書くことの利点は、強制変換後の型を保存して dest に代入できることです。
この場合、これは 1 回しか処理できません。num バイトのデータを処理する必要があるため、while ループを追加することもできます。
void* my_memcpy(void* dest,const void* src,size_t num)
{
while (num--)
{
*(char*)dest = *(char*)src;
dest = (char*)dest + 1;
src = (char*)src + 1;
}
}最後に戻り値を追加する必要がありますが、戻り値は void* 型である必要がありますが、この時点では dest は必須型の変換により開始位置からすでに大きく離れているため、別のポインタ変数を関数本体の先頭で開始する場所を保存します
void* my_memcpy(void* dest,const void* src,size_t num)
{
void* p = dest;
while (num--)
{
*(char*)dest = *(char*)src;
dest = (char*)dest + 1;
src = (char*)src + 1;
}
return dest;
}コードをデバッグしてみましょう
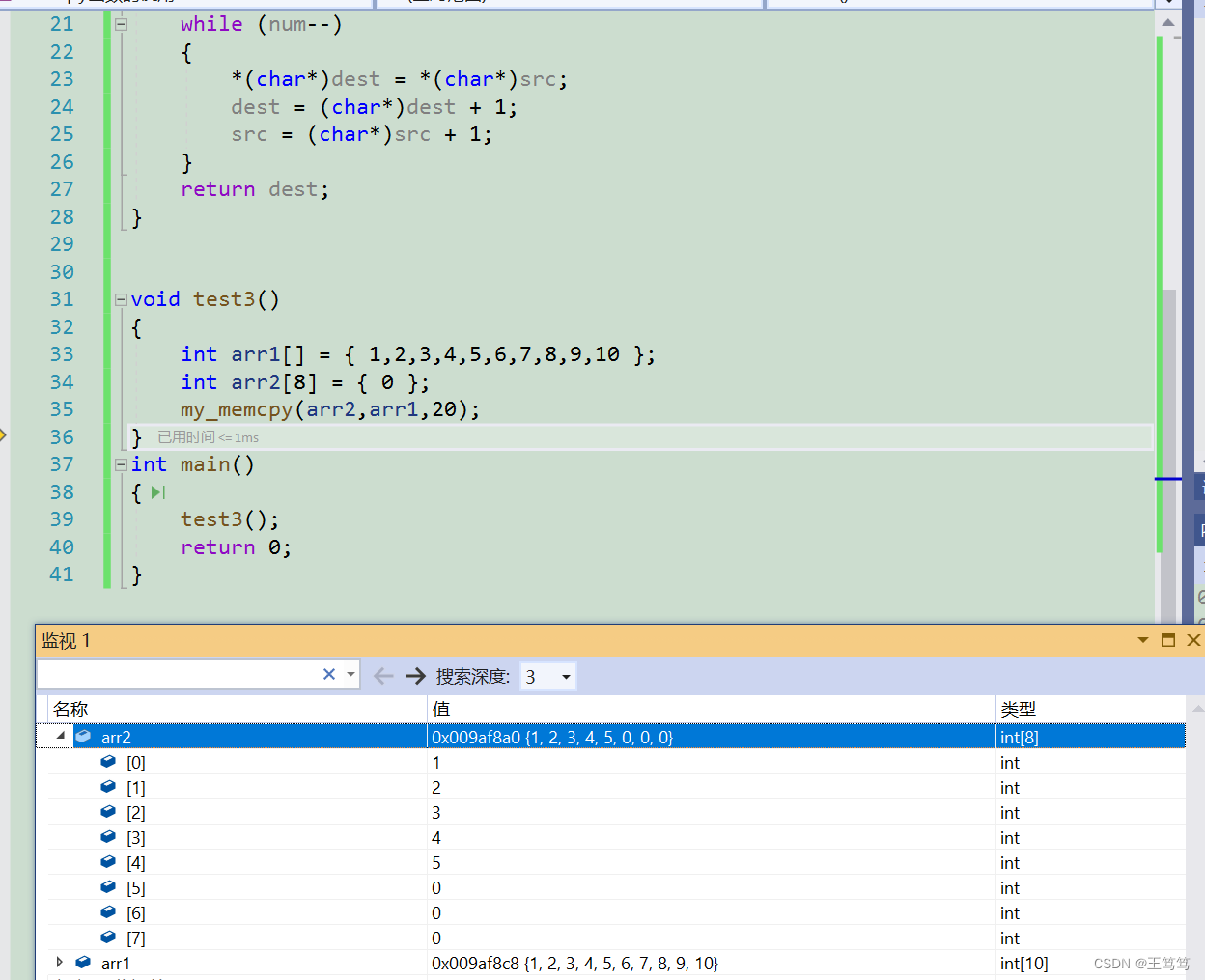
arr2 配列内のデータの最初の 20 バイトが変更されていることがわかります。
その場合、将来コピーしたいコンテンツをコピーするには memcpy を直接使用するのが良い選択になります。
ただし、文字列をコピーしたい場合は strcpy を使用する方が良いです。memcpy 関数には強力な変換の一種である操作があり、大量のデータを処理すると非常に時間がかかります。最も一致する関数を使用してみてください。
memcpy を使用すると、次のようなことが起こります。
void test4()
{
int arr1[] = { 1,2,3,4,5,6,7,8,9,10 };
memcpy(arr1+2,arr1,20);
}
int main()
{
test4();
return 0;
}このコードを書く目的は、memcpy 関数で 3 番目の数値をコピーし、3、4、5、6、7 を 1、2、3、4、5 にすることです。
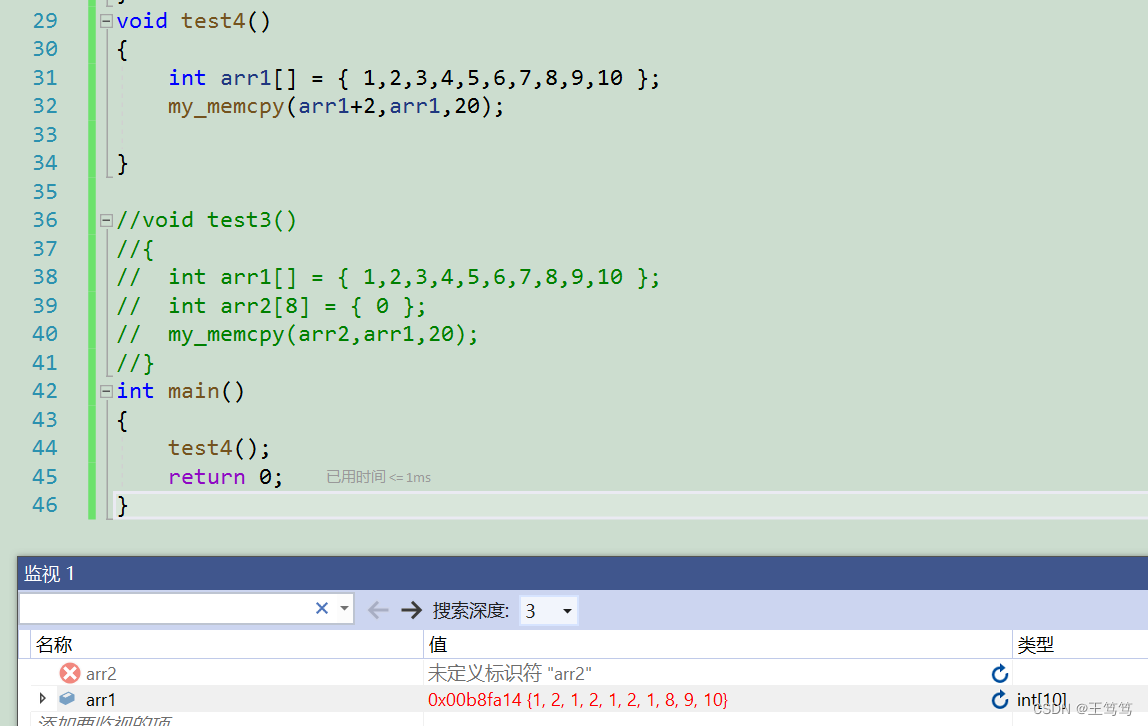
しかし、デバッグしたところ、arr1 配列の要素が想像どおりに変化していないことがわかりました。
では、その原理とは何でしょうか?
内容をコピーすると、同時に arr1 の内容も変更されます。つまり、arr1 配列の内容を変更しながら arr1 配列にコピーするのと同じで、20 バイトの内容だけをコピーすることになります。変更された arr1 内容は 1、2、1、2、3、4、5、6、7、8 です。最初の 20 バイトの内容を arr+2 以降の内容にコピーしたので、次のような配列になりました上の図の内容

そのため、メモリが重複している場合、memcpy を使用すると予期しない結果が生じる可能性があることがわかりました。
メモリが重複する場合は、memmove関数を使用することをお勧めします。
2.メモムーブ
関数名からすると先ほどのmemcpyとは関係ないように感じるかもしれませんが、
ただし、C++公式Webサイトから観察してみましょう

その戻り値の型は、関数パラメータの型 van♂ と完全に一致しています。
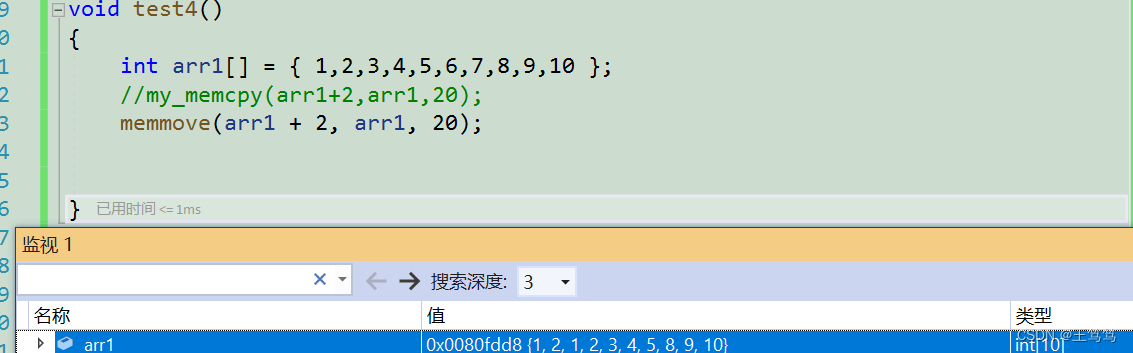
このとき、memmove関数を使用すると、上記の目的が達成できることがわかります。
それなら私たちもそうするかもしれません
memmove関数を実現するための自己定義関数シミュレーション
だから、それはまだ同じです、ステップバイステップで行きましょう、
まず関数の戻り値の型と戻り値のパラメータを記述します。
void* my_memmove(void* dest, void* src, size_t num)
{
}もう一度分析する
arr1 配列の 3 から開始して 20 バイトの要素をカウントし、それらを arr1 の元の配列の要素で上書きしたいとします。
memcpy でコピーすると前のデータの一部が上書きされるので、他のデータを最初に後ろからコピーしてから前のデータをコピーすることもできます。
しかし、私たちは状況について話し合わなければなりません
上記の配列の例に引き続き、arr1 配列の 3、4、5、6、7 を最初の 5 つの要素の位置にコピーしたい場合はどうすればよいでしょうか。つまり、前から後ろにコピーすることになります。
したがって、ケースバイケースで議論する必要があります
2 つの状況を区別するにはどうすればよいでしょうか? 誰でも簡単に絵を描こう
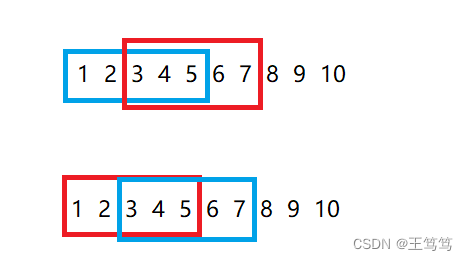
最初のケースは、青いボックス内のデータを赤いボックスに入れることです。これには、データを後ろから前にコピーする必要があります。
2 番目のケースは、青いボックスを赤いボックスに入れることです。この場合、データを前から後ろにコピーする必要があります。
最初のタイプでは、関数パラメーターを比較します。データは src ポインターから取得され、宛先は dest です。
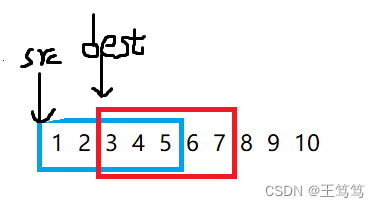
2番目のケースは次のとおりです
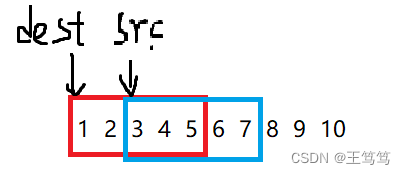
したがって、if ステートメントを使用して判断できます
if(dest<src)
从前向后
else
从后向前では、集団はどのようにして
実際、注意深く観察すると、front-to-back メソッドは memcpy と何ら変わりがなく、直接カットできることがわかります。
void* my_memmove(void* dest, void* src, size_t num)
{
if(dest<src)
{
while (num--)
{
*(char*)dest = *(char*)src;
dest = (char*)dest + 1;
src = (char*)src + 1;
}
}
else
从后向前
}後ろから前へのループはまだしばらく続きます(num--)
後ろから前にコピーしているので、最後の数値のアドレスにアクセスする必要があり、その後、最初の要素のアドレスに num を追加することもできます。num は 20 から始まり、ループに入ります。num-- になります。 19、dest これは開始アドレス 0 で、プラス num は 19 に等しく、これは配列の 20 番目の要素で最後の要素です。この方法で最後の要素のアドレスにアクセスしました。
*((char*)dest + num) = *((char*)src + num);このアドレスを適用して、src へのポインタ、つまり元の配列へのポインタをターゲット空間に割り当てて、ソース空間の値をターゲット アドレスに割り当てる操作が完了するようにすることもできます。 while ループは依然として必要です
もちろん、関数の戻り値は配列の最初の要素を指すポインター型であるため、最初のアドレスを格納するポインター変数を再定義し、関数の最後でそれを返す必要があります。
最終的なコードは次のとおりです
void* my_memmove(void* dest, void* src, size_t num)
{
void* ret = dest;
if (dest < src)//从前往后
{
while (num--)
{
*(char*)dest = *(char*)src;
dest = (char*)dest + 1;
src = (char*)src + 1;
}
}
else//从后往前
while (num--)
{
*((char*)dest + num) = *((char*)src + num);
}
return ret;
}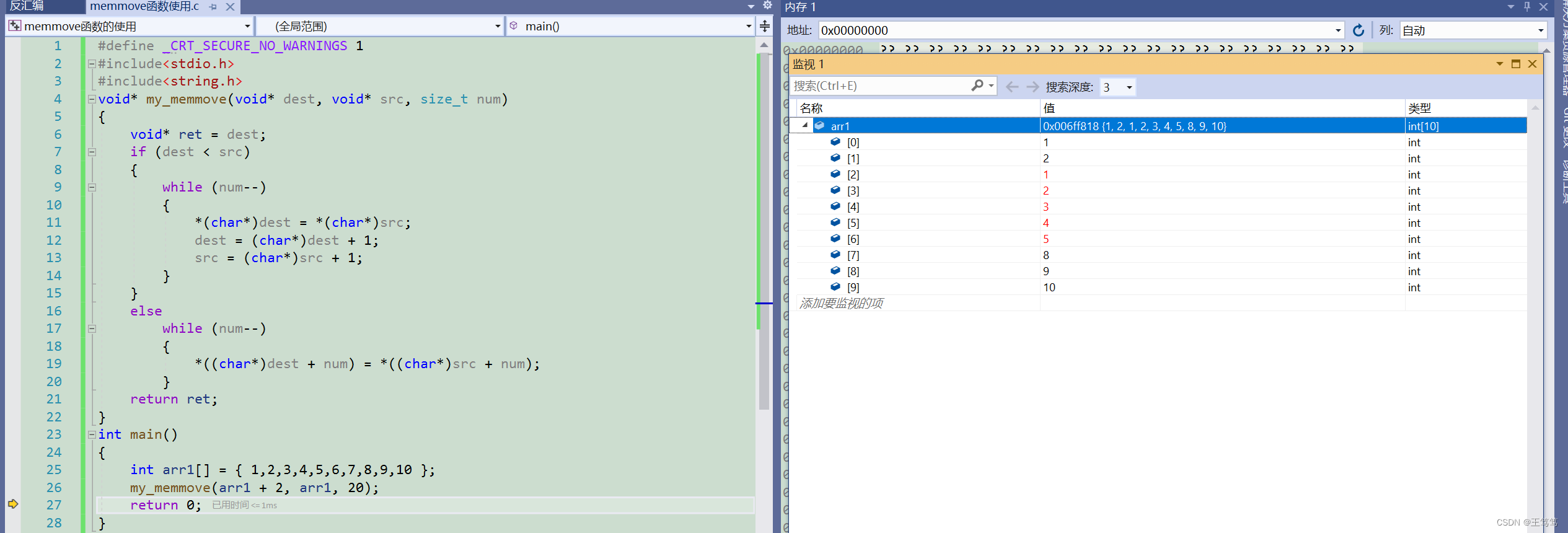
最終的なデバッグ結果が出ると、1 2 3 4 5 が 3 4 5 6 7 の位置に正常に配置されたこともわかります。
関数の実パラメータ内容の位置を変更してみましょう

監視対象のコンテンツも取得できたので、後者のコンテンツを先頭にコピーしました
memcpyとmemmoveの違いがわかりやすい
memcpy は重複しないメモリをコピーします
memmove は重複するメモリをコピーできます
もちろん、memmove の使用範囲が memcpy の使用範囲より大きいことも大まかに理解できます。
3.memcmp
この関数は誰もが推測するかもしれませんが、2 つのメモリを比較することです。

戻り値の型は int 型の整数で、パラメータは任意の型の 2 つのポインタ (比較するメモリの型がわからないため) と size_t (符号なし整数) 型のバイトです。
比較は、ptr1 および ptr2 ポインターから始まる num バイトです。
これは、次の表のような strcmp 関数にも似ています。
ptr1 ポインタが指すメモリは、ptr2 ポインタが指すメモリ内のデータよりも小さく、ゼロ未満の値を返します。
それ以外の場合は 0 より大きい値を返し、等しい場合は 0 を返します。

コードの使い方は簡単です
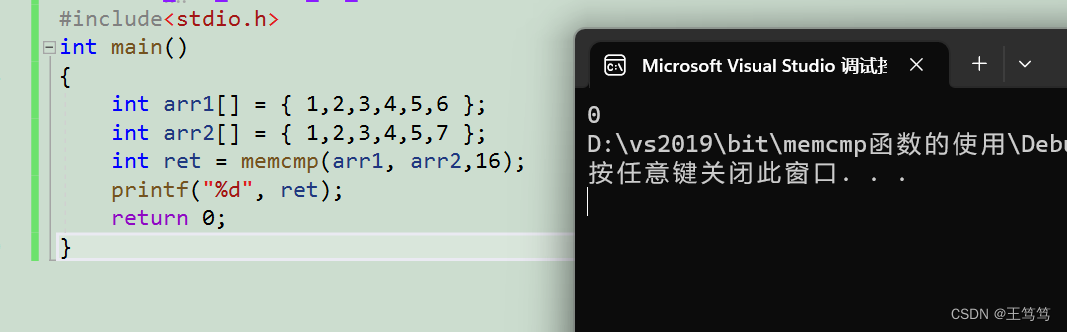
このとき、最初の 16 バイトのデータが比較され、1 2 3 4 が上下に等しいため 0 が返されます。
比較対象を変更する
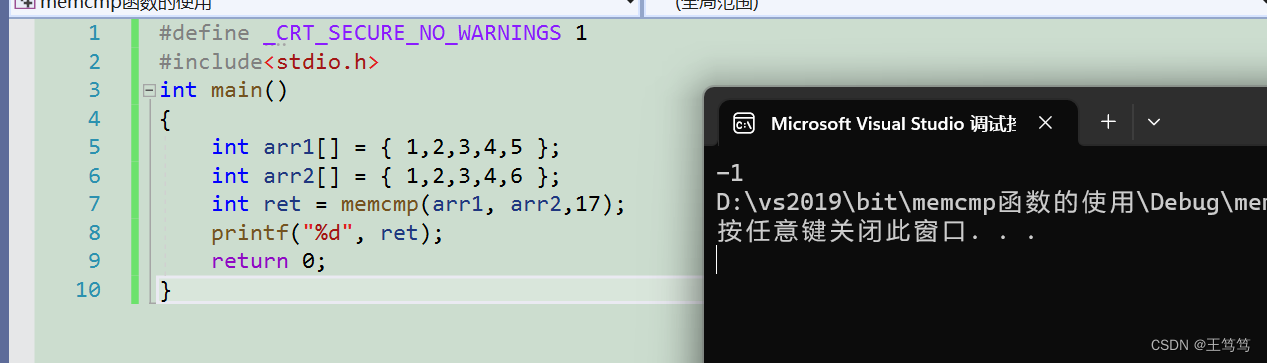
このとき17バイトのデータを比較することになりますが、あと1バイト追加して比較するにはどうすればよいでしょうか?
私たちが学んだビッグエンディアン記憶方法とスモールエンディアン記憶方法について言及する必要があります。
vs環境ではリトルエンディアン(下位バイトのデータを上位アドレスに、上位バイトのデータを下位アドレスに格納)の格納方式となっており、
コンテンツ配列の内容を表示します

次に、17 番目のビットが 05 および 06 と比較され、戻り値は 0 より小さい数値になります。
4.memset
以前に memset に連絡しました

この関数の戻り値の型とパラメーターについて学びます。
戻りパラメータが void* 型であり、最初のパラメータが void* 型のポインタであり、2 番目のパラメータが int 型で、3 番目のパラメータが符号なし整数であることを理解するのは難しくありません。
その機能は、num バイトの内容を、最初のパラメーターが指す配列内の値に変更することです。
簡単な使用コードは次のとおりです
#include<stdio.h>
int main()
{
char arr[] = "hello world";
memset(arr, 'x', 5);
printf("%s\n",arr);
return 0;
}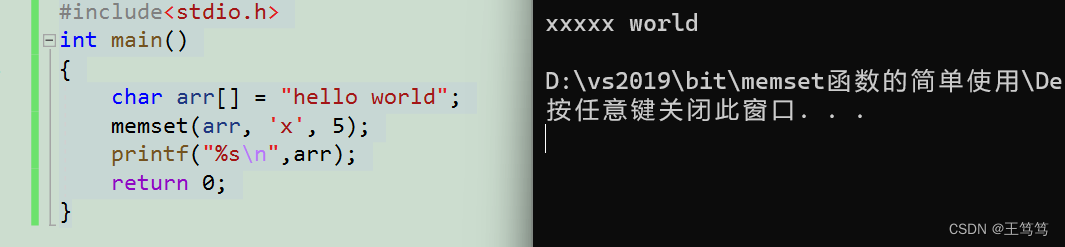
「hello world」が「xxxxx world」になっていることがわかります。
この文字列の役割は、arr 配列の最初の 5 要素を x に変更することですが、これはコードを簡単に使用することで理解するのが難しくありません。
この関数に関して注意すべき唯一の点は、最後のパラメータがバイト単位で設定されることです。
では、配列を変更して、配列のすべての要素を 1 に変更したい場合はどうすればよいでしょうか?
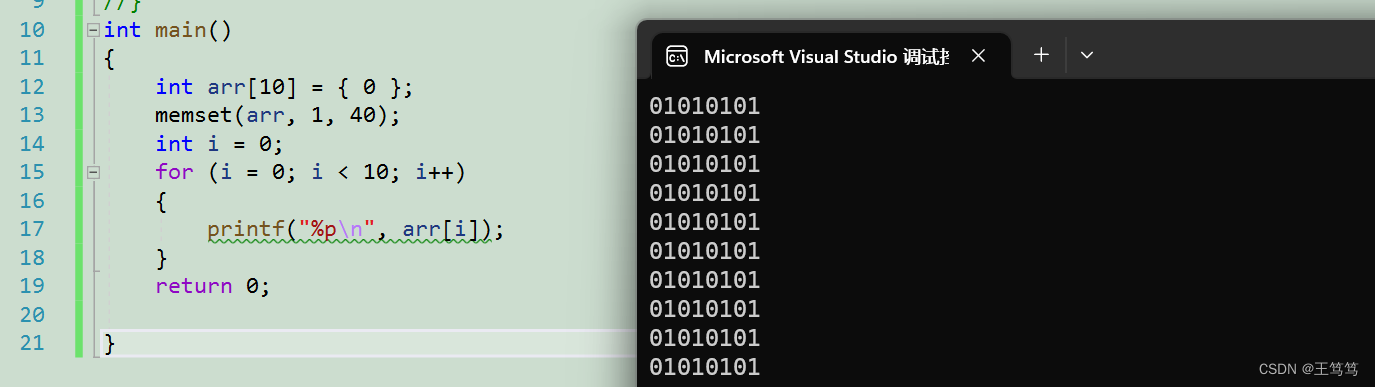
配列内の要素を 1 に変更できないのは残念です。memset はバイト単位で動作するため、コンパイラは 01 01 01 01 を整数とみなし、10 進数で出力します。
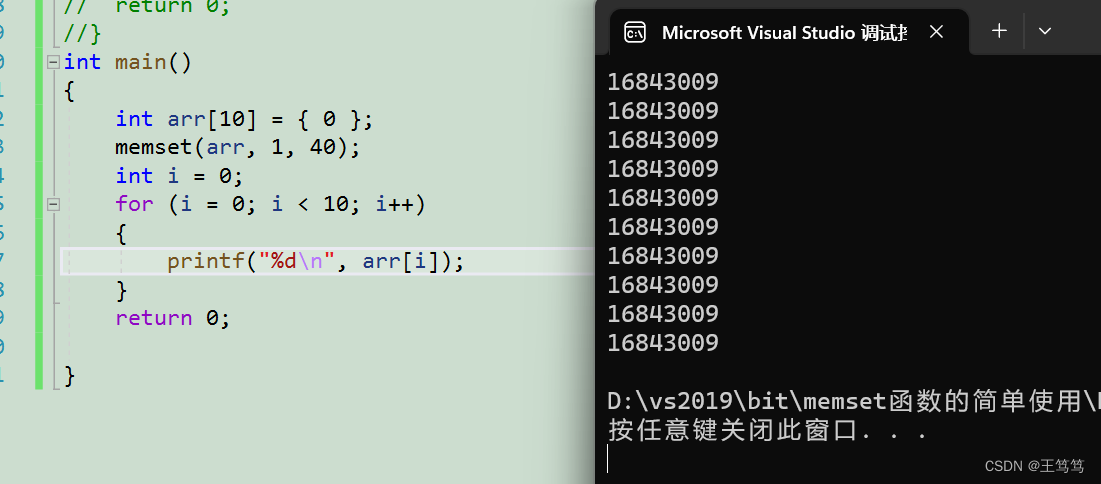
これは非常に大きな数値であることがわかります。そのため、memset を使用して整数配列の内容を設定することはできません。
以上がメモリ機能の共有内容となりますので、ご参考になれば幸いです