標準とエコロジーへの焦点、ターゲットの動的検出メカニズムの監視、PromQL など、Prometheus のいくつかの主要な設計。
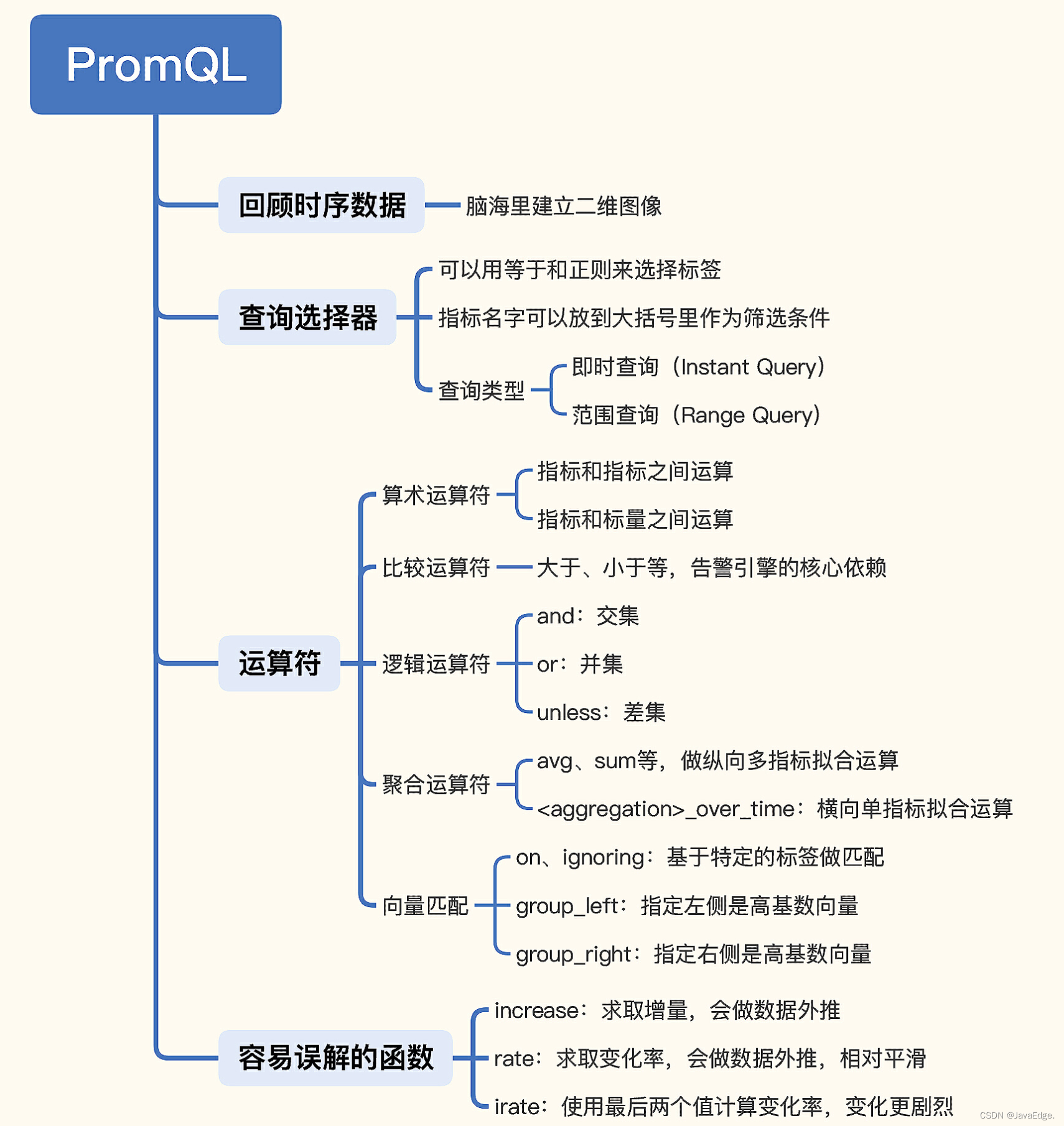
PromQL は Prometheus のクエリ言語であり、柔軟で使いやすいですが、多くの人はそれをより良く活用する方法がわからず、活用できていません。
PromQL は主に、時系列データ クエリと二次コンピューティング シナリオに使用されます。
1 時系列データ
これは時間を軸とした行列として理解できます。次の場合、時間軸上の異なる値に対応する 3 つの時系列があります。
^
│ . . . . . . . . . . node_load1{host="host01",zone="bj"}
│ . . . . . . . . . . node_load1{host="host02",zone="sh"}
│ . . . . . . . . . . node_load1{host="host11",zone="sh"}
v
<------- 时间 ---------->
各点は と呼ばれます
1.1 サンプル(サンプル)
1.1.1 構成
- インジケーター (メトリック): 現在のサンプルの特性を説明するメトリック名とラベルセット
- タイムスタンプ (タイムスタンプ): ミリ秒単位のタイムスタンプ
- value: タイムサンプルの値
PromQL は、このようなサンプル データのバッチをクエリして計算するものです。
2つのアプリケーションシナリオ
時系列データのクエリと二次計算。
PromQL の最初のコアバリュー
2.1 スクリーニング
クエリセレクターによるクエリ
クエリセレクター
各監視チャートのレンダリングや各アラーム ルールの処理は限られた数のデータのみを対象とするため、PromQL の最初の要件はフィルタリングです。
次の 2 つの要件があるとします。
- 上海のすべてのマシンの負荷を 1 分間クエリします
- host0 というプレフィックスが付いたすべてのマシンの負荷を 1 分間クエリします
# = 做 zone 的匹配过滤
node_load1{
zone="sh"}
# =~ 做 host 的正则过滤
node_load1{
host=~"host0.*"}
中括弧内に記述されたフィルタ条件は主にラベル フィルタリング用であり、演算子には等号と通常の一致に加えて、等しくない!=、!~。
メトリック名は中括弧で記述することができます。たとえば、[上海マシンのload1、load5、load15の3つのインジケーターを同時に表示する]とします。メトリック名に対して通常のフィルタリングを実行できます__name__。
{
__name__=~"node_load.*", zone="sh"}
上記の例で指定された 3 つの PromQL 項目はインスタント クエリ (Instant Query) と呼ばれ、返されるコンテンツはインスタント ベクター (Instant Vector) と呼ばれます。
インスタント クエリは最新の現在値を返します。たとえば、クエリが 10:00 に開始された場合、10:00 に対応するデータが返されます。ただし、監視データは定期的に報告されます。データは常に報告されるわけではありません。10:00 にはデータが入ってこない可能性があり、Prometheus は 9:59、9:58、9:57 に期待します。時間を待ちます。データをレポートするポイント。
最長でどれくらい先を見越すべきでしょうか?
Prometheus 起動パラメータによって--query.lookback-delta制御され、デフォルトは 5 分です。監視の観点から、これを短くして 1 分に変更することをお勧めします--query.lookback-delta=1m。
誰かが HTTP 検出に Telegraf を使用し、アラーム ルールを構成しました。response_code は 3 分後のみアラームを発します (!= 200)。実際、response_code!=200 のデータ ポイントは 1 つだけあり、アラームは 3 分後でも報告されます。
主な理由
- Telegraf の HTTP 検出では、デフォルトでステータス コードがラベルに挿入され、ラベルの構造が不安定になります (この動作は良くありません。そのようなラベルを直接破棄するか、コレクターとして categraf、blackbox_exporter を使用するのが最善です)。通常は code= 200、問題がある場合、code=500 Prometheus エコシステムでは、ラベルが変更されると、新しい時系列になります
query.lookback-deltaに関連しますが、異常点は 1 つだけ、つまり時系列に code=500 の点が 1 つだけありますが、アラーム ルールがクエリを実行するたびに、この異常点が検出され、次のようになります。これを5分間。したがって、ルールの「3分間連続でアラームを発する」という条件は満たされます。このため、--query.lookback-delta長さを短くする
PromQLにはインスタントクエリの他に範囲クエリ(Range Query)があり、返される内容はRange Vectorと呼ばれます。
{
__name__=~"node_load.*", zone="sh"}[1m]
範囲クエリでは、1 分の追加の時間範囲を追加します。即時クエリはメトリクスごとに 1 ポイントを返し、範囲クエリは複数のポイントを返します。データが 10 秒ごとに収集され、1 分間に 6 ポイントがあり、そのすべてが返されるとします。
Prometheus 公式ドキュメント各関数を紹介する際に、Range Vector または Instant Vector を示す関数パラメータについて説明します。
PromQL のもう 1 つの核となる価値
2.2 計算
算術演算子、比較演算子、論理演算子、集計演算子などがあります。
算術演算子
加算、減算、乗除算、剰余などの一般的に使用される記号。
# 计算内存可用率,就是内存可用量除以内存总量,又希望按照百分比呈现,所以最后乘以100
mem_available{
app="clickhouse"} / mem_total{
app="clickhouse"} * 100
# 计算北京区网口出向的速率,原始数据的单位是byte,网络流量单位一般用bit,所以乘以8
irate(net_sent_bytes_total{
zone="beijing"}[1m]) * 8
比較演算子
比較演算子は、「より大きい」、「より小さい」、「等しい」、「等しくない」などで、単純ですが重要です。アラーム ルールのロジックは、比較演算子によってサポートされています。
mem_available{
app="clickhouse"} / mem_total{
app="clickhouse"} * 100 < 20
irate(net_sent_bytes_total{
zone="beijing"}[1m]) * 8 / 1024 / 1024 > 700
比較演算子を備えた PromQL は、メモリの可用性に関するアラームなどのアラーム ルールの中核であり、Prometheus で次のように構成されます。
groups:
- name: host
rules:
- alert: MemUtil
# 指定了查询用的 PromQL
expr: mem_available{
app="clickhouse"} / mem_total{
app="clickhouse"} * 100 < 20
# 偶尔一次低于 20% 不是啥大事,只有连续1min每次查询都低于20%才告警,这就是 `for: 1m` 意义
for: 1m
labels:
severity: warn
annotations:
summary: Mem available less than 20%, host:{
{
$labels.ident }}
アラーム エンジンは、ユーザーの設定に従って定期的にクエリを実行します。
- 見つからない場合は、すべてが正常であり、どのマシンのメモリ使用率も 20% 未満であることを意味します。
- 見つかった場合は、アラームがトリガーされたことを意味し、見つかったアラームの数と同じだけ複数のアラームがトリガーされます。
論理演算子
and、or、unless はインスタント ベクトル間の演算に使用されます。And は交差用、または結合用です。ただし、差分用です。
また、使用シナリオでは、ディスク使用量に関しては、16T もの大きなパーティションもあれば、50G もの小さなパーティションもあります。ディスク使用量をアラームとしてのみ使用するのは不合理です。たとえば、ディスク使用量が よりも大きいことdisk_used_percent{app="clickhouse"} > 70を示します 70%。小型株の場合、この戦略は合理的ですが、大型株の場合、70% の稼働率はまだ余裕があることを意味し、これは非合理的です。現時点では、この戦略に制限を追加したいと考えています。200G 未満のハードディスクの使用率が 70% を超えた場合にのみアラームが発行され、次のものが使用できます。
disk_used_percent{
app="clickhouse"} > 70 and disk_total{
app="clickhouse"}/1024/1024/1024 < 200
ベクトルマッチング
ベクトル間の演算では、右ベクトル内の左ベクトルの各エントリに対して一致する要素を見つける必要があり、一致動作は 1 対 1、多対 1、1 対多に分けられます。ここで紹介したディスク使用例は典型的な 1 対 1 タイプで、左側と右側のインジケーターはインジケーター名を除いて同じラベルが付けられているため、対応関係を見つけるのは非常に簡単です。しかし、場合によっては、 と を使用して交点を見つけたいのですが、両側のベクトル ラベルが異なる場合、どうすればよいでしょうか?
この時点で、キーワード on とignore を使用して、一致に使用されるタグのセットを制限できます。
mysql_slave_status_slave_sql_running == 0
and ON (instance)
mysql_slave_status_master_server_id > 0
この PromQL が表現したいのは、MySQL インスタンスがスレーブ (master_server_id>0) の場合、slave_sql_running の値を確認するということです。slave_sql_running==0 の場合、スレーブ SQL スレッドが実行されていないことを意味します。
ただし、2 つのメトリクスのラベル、mysql_slave_status_slave_sql_running と mysql_slave_status_master_server_id は完全に一致していない可能性があります。幸いなことに、どちらにもインスタンス タグがあり、同じインスタンス タグのデータは意味論的な観点からインスタンスの複数のインデックス データを表すため、キーワード on を使用して、インスタンス タグのみが一致に使用されることを指定できます。 、他のラベルを無視します。
on の反対はキーワード無視です。名前が示すように、無視は特定のタグを無視し、残りのタグを照合に使用することです。Prometheus のドキュメントから例を見てみましょう。
## example series
method_code:http_errors:rate5m{method="get", code="500"} 24
method_code:http_errors:rate5m{method="get", code="404"} 30
method_code:http_errors:rate5m{method="put", code="501"} 3
method_code:http_errors:rate5m{method="post", code="500"} 6
method_code:http_errors:rate5m{method="post", code="404"} 21
method:http_requests:rate5m{method="get"} 600
method:http_requests:rate5m{method="del"} 34
method:http_requests:rate5m{method="post"} 120
## promql
method_code:http_errors:rate5m{code="500"}
/ ignoring(code)
method:http_requests:rate5m
## result
{method="get"} 0.04 // 24 / 600
{method="post"} 0.05 // 6 / 120
例題はすべて1対1対応なのでわかりやすいです。理解しにくいのは、1 対多と多対 1 です。この場合、インデックス計算を行うときにキーワードgroup_left と group_rightを使用する必要があります。left、right カーディナリティが高い側を指すベクトル。上記の 2 つのインジケーター、method_code:http_errors:rate5m と method:http_requests:rate5m を例として引き続き使用します。PromQL を確認し、group_left を使用して結果を出力できます。
## promql
method_code:http_errors:rate5m
/ ignoring(code) group_left
method:http_requests:rate5m
## result
{method="get", code="500"} 0.04 // 24 / 600
{method="get", code="404"} 0.05 // 30 / 600
{method="post", code="500"} 0.05 // 6 / 120
{method="post", code="404"} 0.175 // 21 / 120
たとえば、 のエントリmethod="get"の、右ベクトルにはレコードが 1 つしかありませんが、左ベクトルには 2 つのレコードがあるため、カーディナリティが高い側が左側になるため、group_left が使用されます。
ここで、group_left と group_right の一般的な使用法を説明するために、別の例を示します。たとえば、kube-state-metrics を使用して、Kubernetes の各オブジェクトのインジケーター データを収集します。その中には、kube_pod_labels と呼ばれるポッド用のインジケーターがあります。このインジケーターは、ポッドに関する情報をラベルに入れます。インジケーターの値は次のとおりです。 1はメタ情報に相当する。
kube_pod_labels{
[...]
label_name="frontdoor",
label_version="1.0.1",
label_team="blue"
namespace="default",
pod="frontdoor-xxxxxxxxx-xxxxxx",
} = 1
ポッドがアクセス層にあり、HTTP リクエストに関連する多くの指標を収集していると仮定し、5xx リクエストの数をカウントし、ポッドのバージョンに応じて円グラフを描画したいと考えています。ここには問題があります: アクセス層のリクエスト インジケーターにはバージョン ラベルがなく、バージョン情報は kube_pod_labels にのみ表示されます。この 2 つをリンクするにはどうすればよいでしょうか?
sum(
rate(http_request_count{
code=~"^(?:5..)$"}[5m])) by (pod)
*
on (pod) group_left(label_version) kube_pod_labels
この PromQL をいくつかの部分に分割しましょう。乗算記号の前の部分は、1 秒あたり 5xx の数をカウントし、ポッドのディメンションに従って統計をグループ化するための一般的な構文です。
次に、kube_pod_labels を乗算すると、この値は 1 になります。1 を乗算した値はすべて元の値であるため、全体の値には影響しません。また、kube_pod_labels には複数のラベルがあり、sum ステートメントの結果ベクトルのラベルと矛盾するため、on(pod) 構文は次のようになります。ポッドラベルに従ってのみ指定するために使用されます。 対応関係を作成します。
最後に、group_left(label_version) を使用して、label_version を結果ベクトルに追加しますが、カーディナリティの高い部分は明らかに sum の部分なので、group_right の代わりに group_left を使用します。
集計演算
単一のインジケーターの複数のシリーズの場合、集計要件もあります。たとえば、100 台のマシンの平均メモリ可用性または並べ替えを表示するには、値が最も小さい 10 台のマシンを選択します。
この要件では、PromQL 組み込み集計関数を使用します。
# 求取 clickhouse 的机器的平均内存可用率
avg(mem_available_percent{app="clickhouse"})
# 把 clickhouse 的机器的内存可用率排个序,取最小的两条记录
bottomk(2, mem_available_percent{app="clickhouse"})
グループ統計
クリックハウスとカナルのマシン メモリの可用性をそれぞれカウントし、by を使用してグループ統計の次元を指定します (by の反対である without )。
avg(mem_available_percent{app=~"clickhouse|canal"}) by (app)
これらの集計操作は、縦方向の。100 台のマシンのメモリ使用率は折れ線グラフ上に 100 本ありますが、この 100 本を直線に当てはめる場合、各瞬間の 100 点を 1 点に当てはめることと同じになります。100点を1点にするにはどうすればいいですか?平均や最大など、これらの集計演算子があります。
水平フィット
つまり、<aggregation>_over_timeなどの。これらの関数は範囲ベクトルを受け取ります。範囲ベクトルは期間内に複数の値を持ち、<aggregation>これらの複数の値を操作するためです。
# [2m]:获取这个指标最近 2 分钟的所有数据点。若15秒采集一个点,2min就是8个点
# max_over_time:对这8个点求最大值,相当于对各个时间序列做横向拟合
max_over_time(target_up[2m])
3 誤解されている機能
機能を高める
文字通り、増分を求め、範囲ベクトルを受け取ります。範囲ベクトルは明らかに複数の値とタイムスタンプの組み合わせを返します。直感的に理解すると、時間範囲内の最後の値から最初の値を直接減算すると増分が得られるということになります。いいえ!
[外部リンク画像の転送に失敗しました。ソース サイトにはリーチ防止メカニズムがある可能性があります。画像を保存して直接アップロードすることをお勧めします (img-14wDpCXz-1682918864743)(images/623851/5fe64d3408bba9b26b88f556865b2983.png)]
promql: net_bytes_recv{
interface="eth0"}[1m] @ 1661570908
965304237246 @1661570850
965307953982 @1661570860
965311949925 @1661570870
965315732812 @1661570880
965319998347 @1661570890
965323899880 @1661570900
promql: increase(net_bytes_recv{
interface="eth0"}[1m]) @1661570909
23595160.8
監視データは 10 秒ごとにレポートされるため、2 つの PromQL クエリ時間は異なります。
- 1回 1661570908
- 1 回は 1661570909 ですが、クエリの元のデータ内容は同じです。つまり、1661570850 から 1661570900 までの複数の時点に対応するデータです。
直感的には、これらの時点に対応するデータの増加を計算することは、最後の値から最初の値を減算すること、つまり 965323899880-965304237246=19662634 に他なりません。しかし実際は23595160.8、その差は大きい。
実際、PromQL リクエストの増加時刻は 1661570909 で、時間範囲は [1m] です。これは、1661570909-60 (1661570909-60 から派生) ~ 1661570909 の間の増加値をクエリしたいことを Prometheus に伝えるのと同じです。しかし、元の監視データには 1661570849 と 1661570909 の 2 つの瞬間の値がありません。どうすればよいでしょうか? Prometheus は既存のデータに基づいて外挿することしかできません。つまり、最後のポイント値と最初のポイント値の結果を使用し、時間差で割って 60 を掛けます。
( 965323899880.0 − 965304237246.0 ) div ( 1661570900.0 − 1661570850.0 ) 掛ける 60 = 23595160.8 (965323899880.0-965304237246.0)\\div(16) 61570900.0-1661570850.0)\\times60=23595160.8( 965323899880.0−965304237246.0 )d i v ( 1661570900.0−1661570850.0 )60時間_ _=23595160.8
このようにして最終的に1分の増加値が得られますが、これは小数になります。
レート関数
増加は計算された期間の増分であり、データの外挿が存在します。
rate 関数は 1 秒あたりの変化率を計算し、データ外挿も行っており、増加結果を範囲ベクトルの期間サイズで除算 = レート値とします。
rate(net_bytes_recv{
interface="eth0"}[1m])
== bool
increase(net_bytes_recv{
interface="eth0"}[1m])/60.0
== の後に bool が続き、bool 値が返されることが期待されていることを示します。True の場合は 1 を返し、False の場合は 0 を返します。結果を観察したところ、この式は常に 1 を返すことがわかりました。つまり、等号の前後の 2 つの PromQL は意味的に同じです。
レート関数によって計算される変化率は比較的滑らかです。時間範囲内の最後の値と最初の値がデータの外挿に使用されるため、一部の不具合は平滑化されます。より機密性の高いデータを取得したい場合は、 irate 関数を使用できます。irate は時間範囲内の最後の 2 つの値を使用して計算され、変化はより大きくなります。比較としてネットワーク カードの受信トラフィックの指標を使用してみましょう。
[外部リンク画像の転送に失敗しました。ソース サイトにはリーチ防止メカニズムがある可能性があります。画像を保存して直接アップロードすることをお勧めします (img-jjA7oHHy-1682918864746)(images/623851/68ac7b49091b60970b9a8f8a106500c3.png)]
より急激な変化を伴う青い線は irate 関数によって計算され、紫色の比較的滑らかな線は rate 関数によって計算されますが、コントラストは依然として非常に強いです。
4 まとめ
PromQL のコア値:
-
フィルター
クエリセレクターに応じて、クエリは即時クエリと範囲クエリに分かれます
-
計算する
算術演算子、比較演算子、論理演算子、集計演算子、およびベクトル マッチング ロジックがあります。
5 よくある質問
Prometheusには欠落データを警告するabsentという機能があり、これも広く使われていますが、落とし穴はかなり大きいです。ここで質問が残っています。100 台のマシンの node_load1 にデータが欠落していることを警告したい場合、どのように設定すればよいでしょうか? この要件を解決するために、欠席を使用するのは適切ですか? 欠勤の最適な使用例を教えてください。
100 台のマシンという node_load1 データ欠落アラーム要件の場合、次の理由から、不在関数の使用は適切ではありません。
-
Absent 関数は、インジケーター データが欠落しているかどうかではなく、インジケーターが消える (つまり、存在しない) かどうかを監視するために使用されます。特定のノードだけが一定期間欠落している場合、Absent はそのノードが存在しないと誤って報告します。
-
複数のノードが関与している場合、各ノードはさまざまな理由により監視データを Prometheus に送信できず、誤ったアラームがトリガーされる可能性があります。したがって、各ノードに個別にアラームを設定する必要があります。つまり、各ノードのデータを要求するクエリ文を設定し、同時にクエリ結果が正常であることを確認し、各ノードのアラーム状態を区別する必要があります。 。
Absent 関数の最適な使用シナリオでは、無効なアラームをフィルタリングして除外できます。たとえば、まれなイベントや異常なデータ ポイントの場合、これらのイベントやデータが表示されたときにアラームが必要ですが、数が少ないと混乱が生じます。大量の「誤った」陽性警告。このとき、不在機能が役に立ちます。これにより、これらの稀なデータを排除し、アラームの誤判断を回避し、アラームの信頼性と精度を向上させることができます。