1. xxl-job parece ser muy popular?
Lo introduje en la explicación de Quartz que escribí antes. Quartz tiene una historia de casi 20 años. El modelo de programación es muy maduro y es fácil de integrar en Spring. Es una buena opción para realizar tareas comerciales. Sin embargo, cuanto más temprano sea el diseño, más obvios serán los problemas, tales como:
1. La lógica de programación (Scheduler) y la clase de tarea están acopladas en el mismo proyecto A medida que aumenta gradualmente el número de tareas de programación y la lógica de tareas de programación gradualmente aumenta, el sistema de programación general El rendimiento se verá muy afectado
2. Los resultados de la carga entre los nodos del clúster de cuarzo son aleatorios, y quien tome el bloqueo de la fila de la base de datos realizará la tarea, lo que puede provocar la muerte por sequía y la muerte por inundación 3 . Quartz en sí mismo no proporciona
funciones dinámicas de programación e interfaz de administración, y debe desarrollarse de acuerdo con la API
4. Los registros, las estadísticas de datos y el monitoreo de Quartz no son particularmente perfectos,
por lo que xxl-job y Elastic -Job encapsulan Quartz, que es más fácil de usar y más potente.
Los tres objetos más importantes en Quartz: Job (trabajo), Trigger (disparador) y Scheduler (programador). El principio de programación de xxl-job es que el subproceso de programación obtiene continuamente una cierta cantidad de disparadores para activarse en un ciclo while, obtiene el trabajo vinculado y lo empaqueta en un subproceso de trabajo para su ejecución. Por supuesto, no importa en cualquier sistema de programación, la capa inferior es el modelo de subprocesamiento. Si desea escribir un sistema de programación usted mismo, debe tener un estudio más profundo de la concurrencia de subprocesos múltiples, como cómo se inician los subprocesos, cómo esperar, cómo notificar, cómo bloquear, etc.
De hecho, xxl-job fue solo un trabajo amateur de un programador de Dianping al principio, y fue de código abierto en 2015: https://github.com/xuxueli/xxl-job . Como todos sabemos, debido a que Meituan adquirió Dianping, ahora es Meituan Dianping. xxl es la abreviatura del nombre del autor Xu Xueli. Además de xxl-job, el autor también ha abierto muchos otros componentes. Ahora hay 11 proyectos de código abierto en total. Hasta el momento hay cientos de empresas que usan xxl-job, contando aquellas empresas que no están registradas, en realidad debería haber varios miles. En la versión anterior de xxl-job, el modelo de programación de Quartz se usaba directamente y la dependencia de Quartz no se eliminó hasta que se lanzó la versión 7.27 el 7 de julio de 2019. De hecho, incluso si el código de refactorización elimina la dependencia de Quartz, la sombra de Quartz está en todas partes en xxl-job. Por ejemplo, el diseño clásico de las tres dimensiones de tareas, planificadores y disparadores, pero desde la versión 2.2.0, casi no ha habido cambios en las actualizaciones de la versión.
En comparación con el antiguo Quartz, xxl-job tiene funciones más ricas, que generalmente se pueden dividir en tres categorías:
1. Mejora del rendimiento: se pueden programar más tareas
2. Mejora de la confiabilidad: tiempo de espera de la tarea, falla, conmutación por error 3. Operación más conveniente y mantenimiento
: proporciona interfaz de operación, autoridad de usuario, registro detallado, proporciona configuración de notificación y genera informes automáticamente;
2. Inicio rápido
Conozca la estructura del directorio xxl-job
Basado en la versión 2.2.0, introduzca xxl-job: https://github.com/xuxueli/xxl-job/releases/tag/v2.2.0, después de descargar el paquete fuente, abra el proyecto con IDEA, xxl El directorio general La estructura de -job es la siguiente:
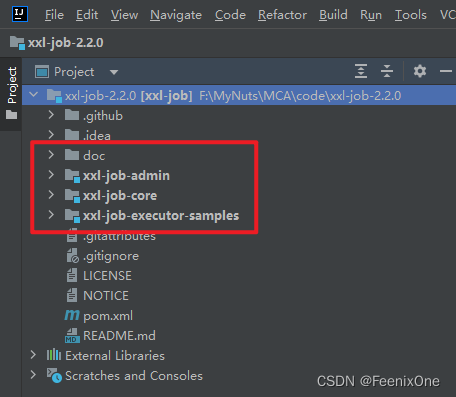
doc : está lleno de documentos relevantes, incluido el lenguaje de secuencias de comandos de la base de datos dependiente. De hecho, no hay nada que decir. Debe leerlo y ejecutarlo;
xxl-job-admin : Equivalente al programador Scheduler en Quartz. Combine el programador y las tareas en Quartz. En xxl-job, el programador se separa como un proyecto independiente y ya no es un subproceso en el proyecto de programación de tareas;
xxl-job-core : De hecho, no hay necesidad de prestar demasiada atención al usarlo.Este es el paquete jar dependiente del núcleo, siempre que importe dependencias a través de coordenadas y las use directamente;
xxl-job-executor-samples : El ejecutor de la tarea puede entenderse como un ejemplo de negocio para demostración. Es decir, cuando necesite usar xxl-job en un proyecto real, puede consultar el diseño y el método de escritura en las muestras, citar lo que cita, cómo lo escribe, simplemente siga el dibujo de la calabaza y listo. re hecho
análisis de la estructura de la tabla xxl-job
La gestión de datos de tareas de xxl-job depende de la base de datos.Muchas personas piensan que xxl-job solo es compatible con la base de datos MySQL, que no es lo suficientemente precisa. Porque xxl-job en sí mismo se conecta a la base de datos basada en JDBC. En otras palabras, siempre que sea una base de datos que admita más que JDBC, xxl-job en realidad se puede usar. Pero si desea utilizar otras bases de datos que no sean MySQL, debe cambiar el código fuente de xxl-job. El xxl-job original en realidad no admite muchas cosas y, para ser honesto, no es tan versátil.
Antes de usar oficialmente xxl-job, debe tener una comprensión simple de la estructura de la tabla de la que depende xxl-job. El script de estructura de la tabla se almacena en: doc/db/tables_xxl_job.sql
xxl_job_group : tabla de información del ejecutor. Mantener la información del ejecutor de tareas;
xxl_job_info : tabla de información de extensión de programación. Se utiliza para guardar la información ampliada de las tareas de programación de trabajos xxl, como la agrupación de tareas, el nombre de la tarea, la dirección de la máquina, el ejecutor, los parámetros de entrada de ejecución y los correos electrónicos de alarma, etc.;
xxl_job_lock : tabla de bloqueo de programación de tareas;
xxl_job_log : tabla de registro de programación. Se utiliza para guardar la información histórica de la programación de tareas de xxl-job, como los resultados de la programación, los resultados de la ejecución, los parámetros de entrada de la programación, las máquinas y ejecutores de programación, etc.;
xxl_job_log_report : informe de registro de programación. El usuario almacena el informe del registro de programación de tareas xxl-job, que se utilizará en la página de función de informe del centro de programación;
xxl_job_logglue : registro de cola de trabajos. Se utiliza para guardar el historial de actualizaciones de Glue y para admitir la función de seguimiento de versiones de Glue; Glue significa que se puede escribir un fragmento de código e incrustarlo directamente en el programa para su ejecución, lo cual es una forma muy peligrosa. Es decir, es posible incrustar una pieza de código en el negocio a través de la programación de tareas de sincronización externa. Este método de operación es muy peligroso. Si tiene la autoridad de la biblioteca de producción, será bastante complicado solucionar el problema. y no sabrás qué está mal con el código. ;
xxl_job_registry : registro de ejecutor. Mantener en línea la información de la dirección de la máquina del centro de despacho y del actuador;
xxl_job_user : tabla de usuarios del sistema. El número de cuenta y la contraseña para iniciar sesión en la gestión en segundo plano, que se pueden configurar en el archivo de configuración;
El programador y la ejecución comercial de xxl-job son independientes. El programador determina la programación de tareas y llama a la interfaz del ejecutor para ejecutar tareas a través de HTTP. Por lo tanto, se necesita al menos un centro de despacho y un ejecutor y, por supuesto, también se puede implementar en clústeres.
Construir centro de despacho
Como se mencionó anteriormente, en el trabajo xxl, el programador se separa en un proyecto independiente: el centro de despacho, lo que significa que el centro de despacho se puede empaquetar en un paquete jar y luego lanzarlo al sistema operativo para comenzar directamente a convertirse en un proceso independiente, las tareas que realmente se realizan y ejecutan no son intrusivas entre sí.
Entonces, si desea empaquetar una aplicación independiente, lo más importante a lo que debe prestar atención es su archivo de configuración:
### web
server.port=7391
server.servlet.context-path=/xxl-job-admin
### actuator
management.server.servlet.context-path=/actuator
management.health.mail.enabled=false
### resources
spring.mvc.servlet.load-on-startup=0
spring.mvc.static-path-pattern=/static/**
spring.resources.static-locations=classpath:/static/
### freemarker
spring.freemarker.templateLoaderPath=classpath:/templates/
spring.freemarker.suffix=.ftl
spring.freemarker.charset=UTF-8
spring.freemarker.request-context-attribute=request
spring.freemarker.settings.number_format=0.##########
### mybatis
mybatis.mapper-locations=classpath:/mybatis-mapper/*Mapper.xml
#mybatis.type-aliases-package=com.xxl.job.admin.core.model
### xxl-job, datasource
spring.datasource.url=jdbc:mysql://127.0.0.1:3306/xxl_job?useUnicode=true&characterEncoding=UTF-8&autoReconnect=true&serverTimezone=Asia/Shanghai
spring.datasource.username=root
spring.datasource.password=Lee@0629
spring.datasource.driver-class-name=com.mysql.cj.jdbc.Driver
### xxl-job-user
xxl.job.login.username=admin
xxl.job.login.password=123456
### datasource-pool
spring.datasource.type=com.zaxxer.hikari.HikariDataSource
spring.datasource.hikari.minimum-idle=10
spring.datasource.hikari.maximum-pool-size=30
spring.datasource.hikari.auto-commit=true
spring.datasource.hikari.idle-timeout=30000
spring.datasource.hikari.pool-name=HikariCP
spring.datasource.hikari.max-lifetime=900000
spring.datasource.hikari.connection-timeout=10000
spring.datasource.hikari.connection-test-query=SELECT 1
### xxl-job, email
spring.mail.host=smtp.qq.com
spring.mail.port=25
[email protected]
spring.mail.password=xxx
spring.mail.properties.mail.smtp.auth=true
spring.mail.properties.mail.smtp.starttls.enable=true
spring.mail.properties.mail.smtp.starttls.required=true
spring.mail.properties.mail.smtp.socketFactory.class=javax.net.ssl.SSLSocketFactory
### xxl-job, access token
xxl.job.accessToken=
### xxl-job, i18n (default is zh_CN, and you can choose "zh_CN", "zh_TC" and "en")
xxl.job.i18n=zh_CN
## xxl-job, triggerpool max size
xxl.job.triggerpool.fast.max=200
xxl.job.triggerpool.slow.max=100
### xxl-job, log retention days
xxl.job.logretentiondays=30
Inesperadamente, xxl-job todavía usa archivos .properties y todavía estoy más acostumbrado a usar archivos .yml. Más cerca de casa, hay algunos puntos en este archivo de configuración que requieren atención adicional:
1. La información de enlace sobre la base de datos debe modificarse en su propia información de enlace de servicio de base de datos;

2. Muestre la información del usuario en el fondo de administración de configuración. La información del usuario debe ser consistente con los datos en la tabla xxl_job_user en la base de datos de la que depende xxl-job. Si la configuración no se muestra, parece que puede haber un probabilidad de que el inicio de sesión no se pueda iniciar sesión;

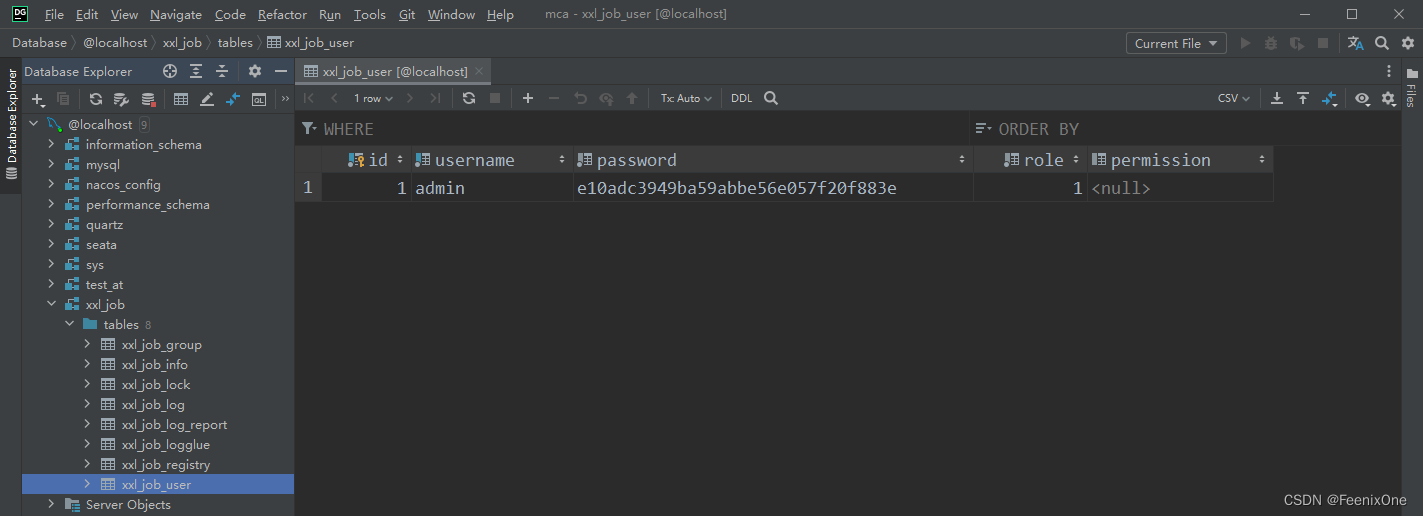
3. xxl.job.accessToken= No es necesario completar este valor temporalmente, pero vale la pena señalar que este token implica una laguna en xxl-job. En el caso de que no se establezca ningún token, el programa se puede cambiar de alguna manera;

Después de modificar alguna información necesaria, inicie el servicio xxl-job-admin, visite: http://localhost:7391/xxl-job-admin/, inicie sesión con su propia cuenta/contraseña [admin/123456]
ejecutor de compilación
El ejecutor es responsable de la ejecución específica de tareas y la asignación de hilos. El ejecutor debe estar registrado en el centro de despacho, para que el programador sepa cómo seleccionar el ejecutor o hacer el enrutamiento. El resultado de la ejecución del ejecutor también debe notificarse al programador a través de una devolución de llamada. xxl-job proporciona demostraciones de 6 ejecutores, y aquí se selecciona el proyecto xxl-job-executor-sample-springboot.
Dado que se utilizará xxl-job, lo primero que debe hacer es introducir las dependencias relacionadas, que se han introducido en la demostración.
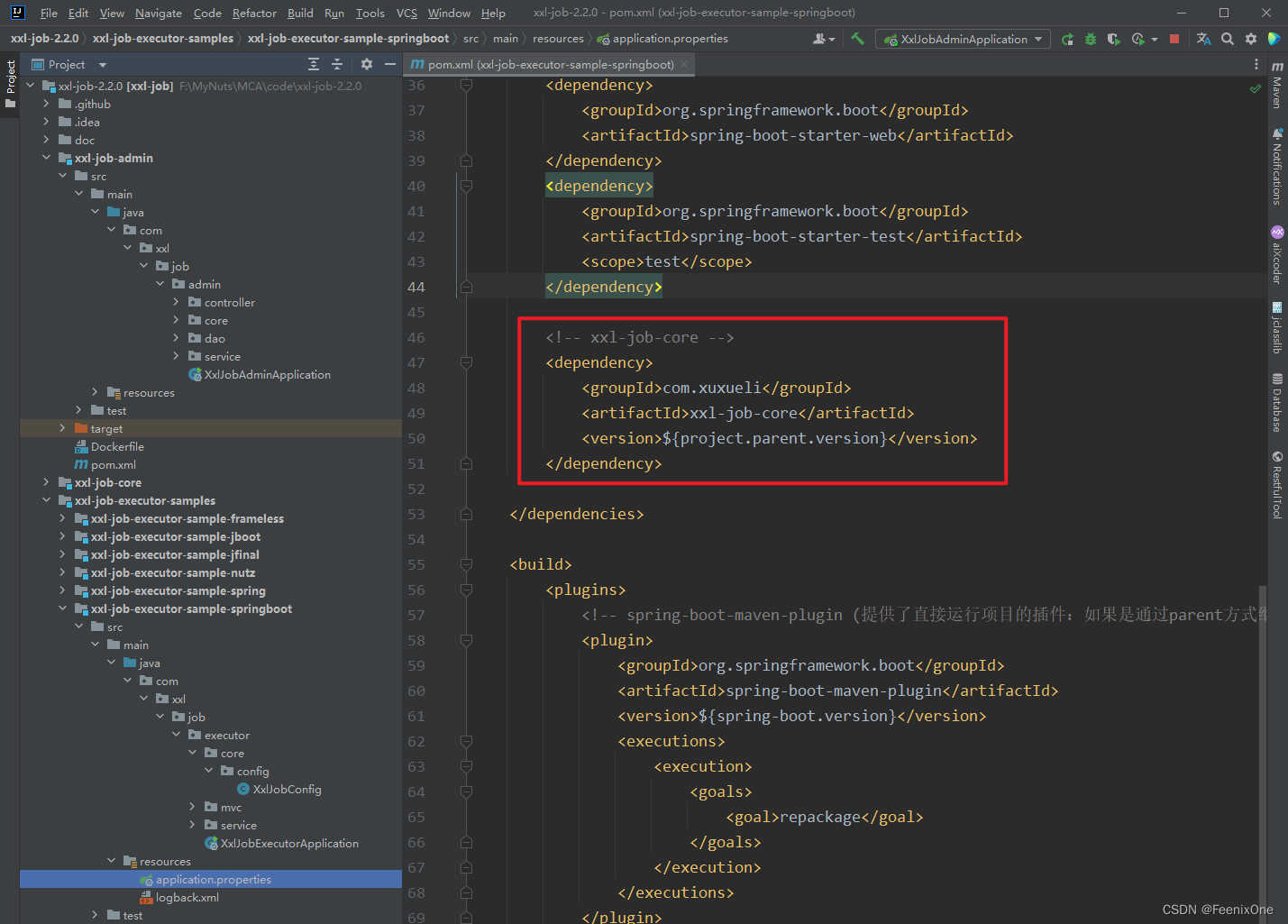
Después de introducir las dependencias relevantes, comience a lanzar el archivo de configuración
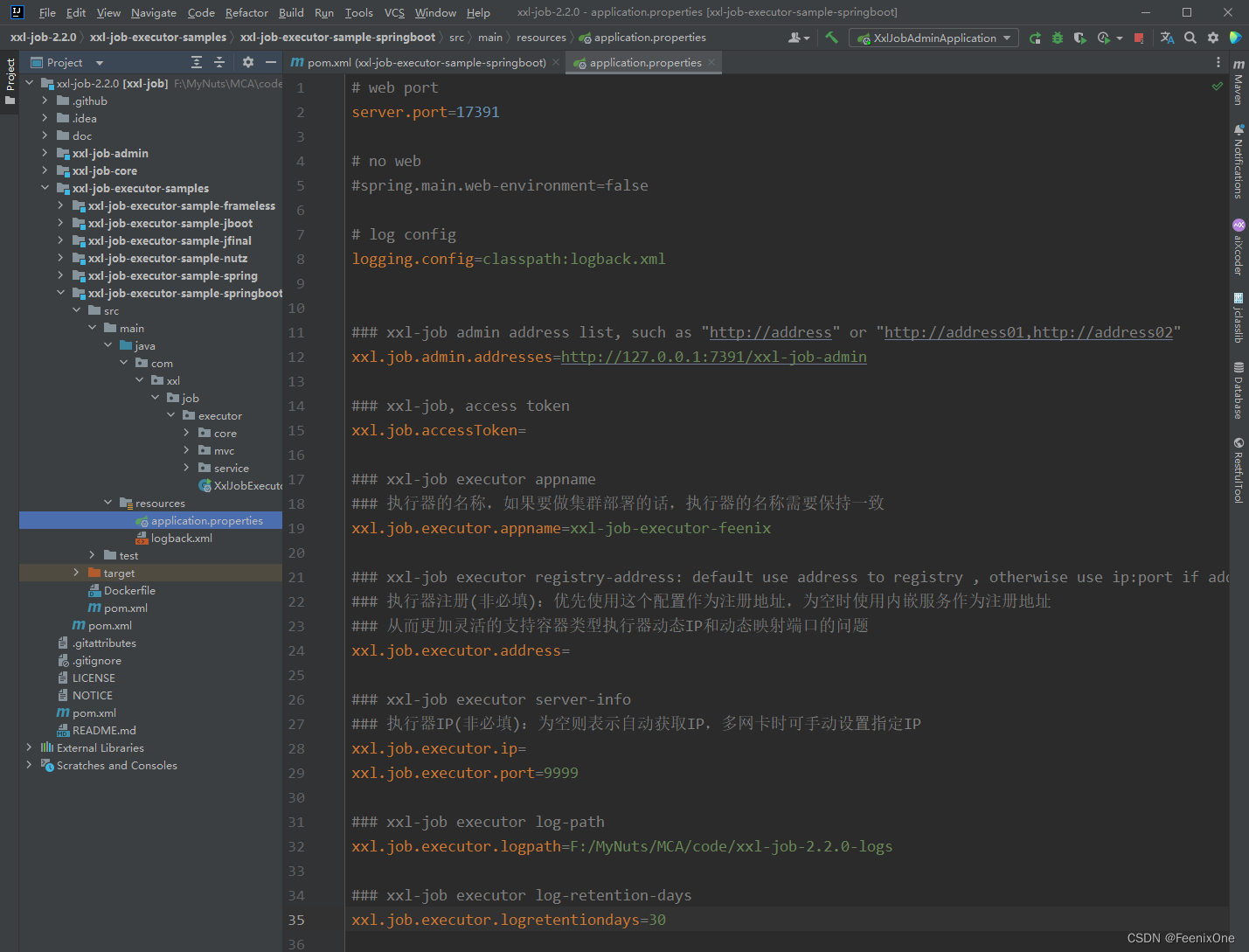
Aquí es el momento de explicar la propiedad xxl.job.accessToken en detalle. xxl-job en sí tiene una cosa muy, muy seria que no admite que se llama laguna. Es incluso más grave que el log4j del año, pero está más o menos manchado de luz doméstica. Después de todo, el software doméstico tiene una tolerancia relativamente alta.
Si suele prestar atención a los productos de código abierto, debe saber que tanto Alibaba Cloud como Tencent Cloud han expuesto una vulnerabilidad de ejecución remota de xxl-job. Si no se completa el xxl.job.accessToken, el acceso del ejecutor y el programador no requiere verificación de identidad, y se puede inyectar manualmente un fragmento de código en la lógica empresarial. Imagínese, suponiendo que es posible cambiar la contraseña de la cuenta del usuario incrustando un código en el momento del pago. Pero la respuesta que da el autor es que es posible porque no hay xxl.job.accessToken, si no se configura xxl.job.accessToken no habrá problema. En otras palabras, es personalizar una cadena y configurar el precio de configuración en ambos lados del planificador y el ejecutor para que sea el mismo texto cifrado. Pero si otros conocen el texto cifrado, aún pueden inyectarlo, por lo que si desea garantizar la seguridad, debe configurar el texto cifrado para que se genere dinámicamente para garantizar que los tokens obtenidos por ambos lados no solo sean consistentes cada vez, sino también cada vez Solo sé diferente. Esto trae dificultad para el desarrollo Creo que la mayoría de los archivos de configuración que usan xxl-job no configuran tokens.
xxl.job.executor.appname=xxl-job-executor-feenix , este atributo también tiene un hoyo. Cuando el ejecutor se inicia por primera vez, el nombre del ejecutor se escribirá en la tabla xxl_job_group. Una vez escrito en la tabla, el nombre del ejecutor no se puede cambiar, incluso si se cambia el nombre en el archivo de configuración, el nombre en la base de datos no se cambiará sincrónicamente. Luego, cuando se ejecuta la tarea, informará un error de que no se puede encontrar el ejecutor, por lo que es mejor no cambiar el nombre una vez que se determina.
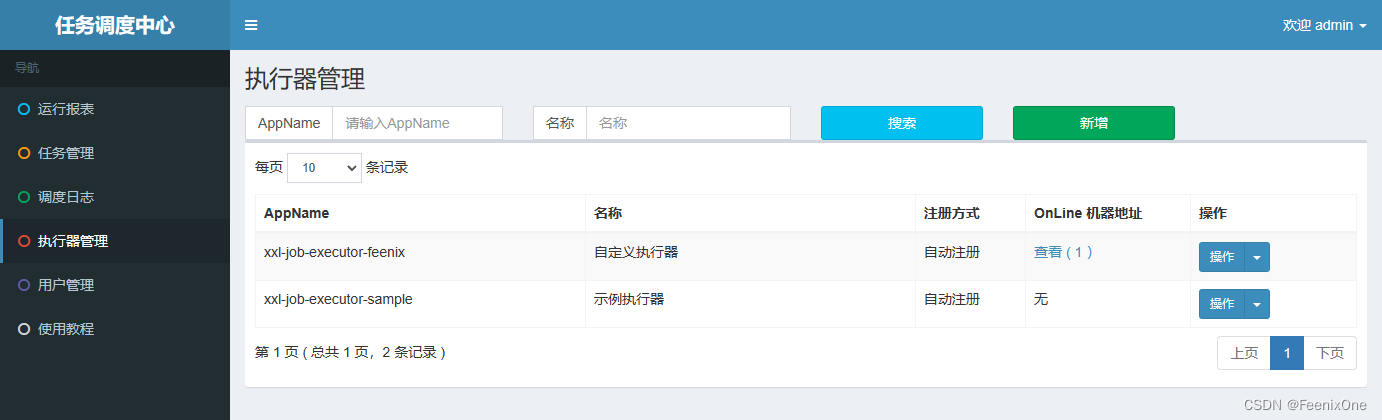
Agregar manualmente un ejecutor
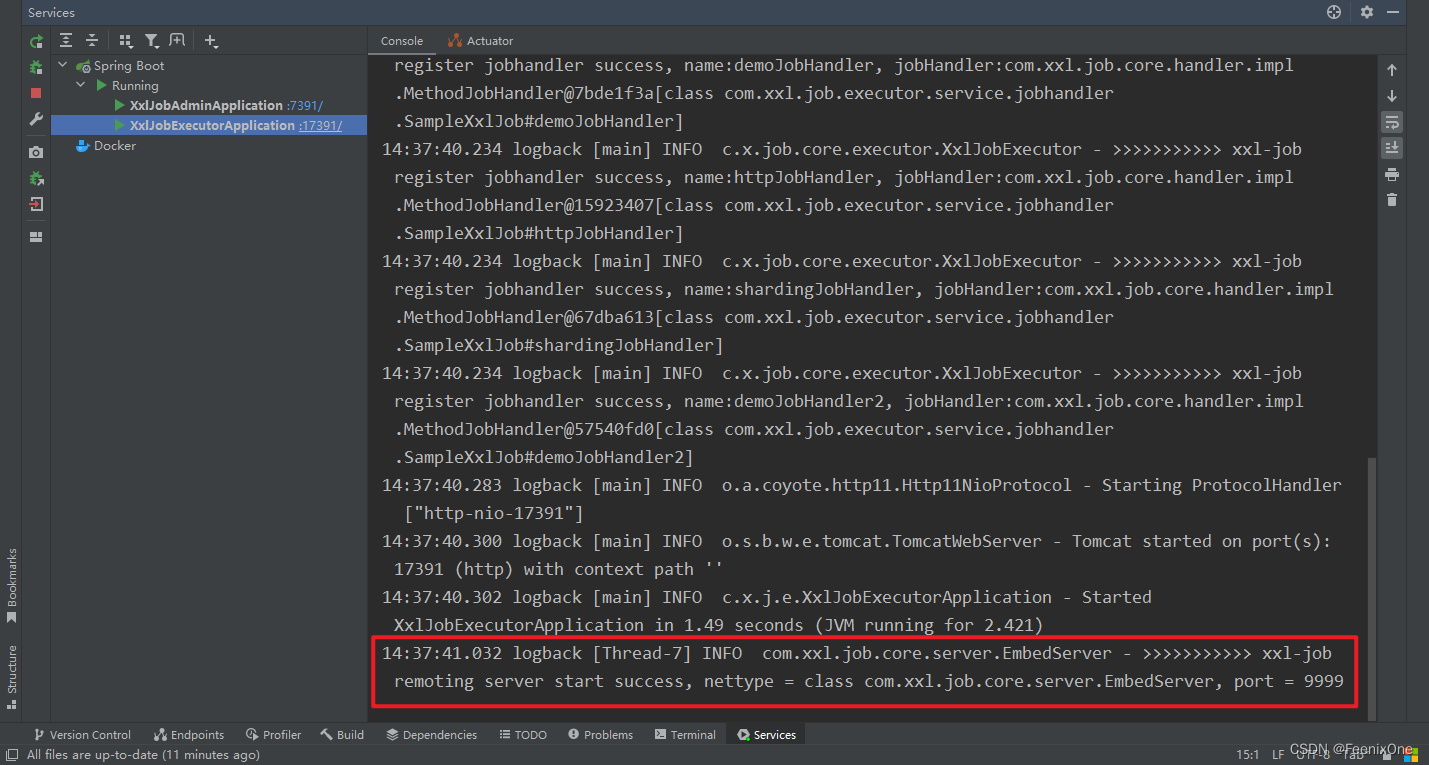
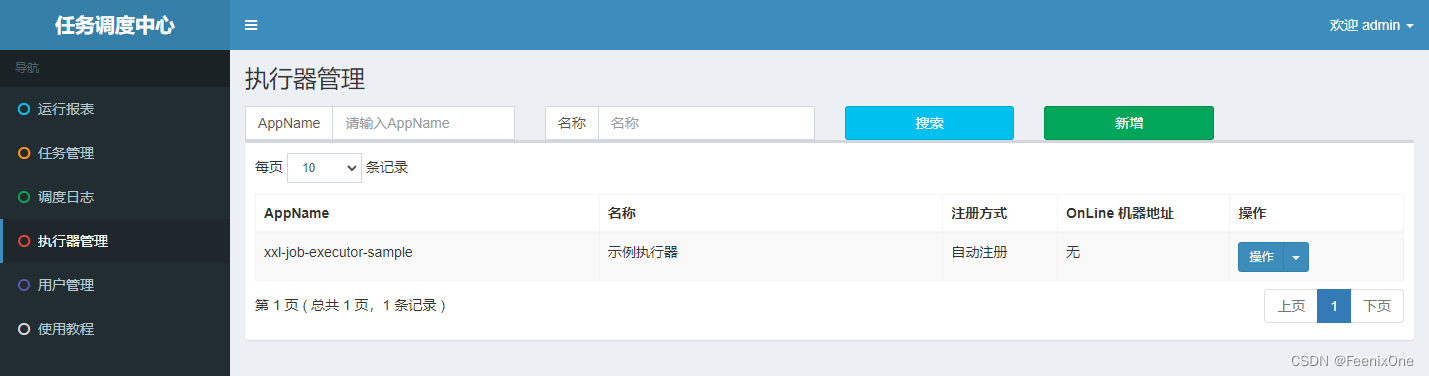
Una vez que se inicia el actuador, se registrará automáticamente con el lado del administrador. Este paso no es un problema. El registro de registro también se ve en la tabla xxl_job_registry.
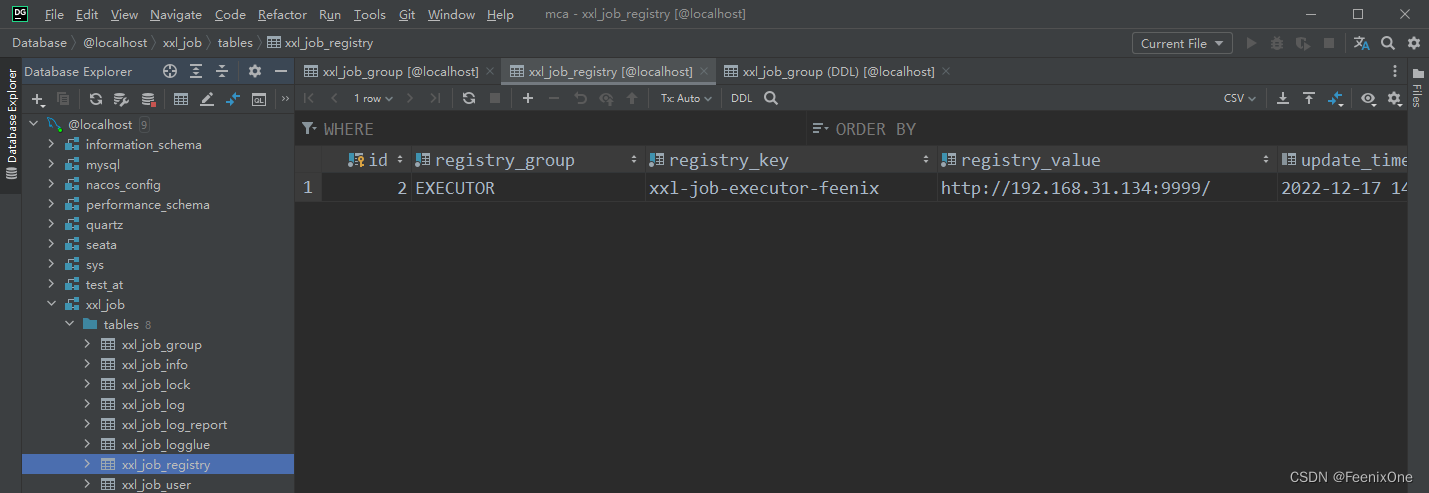
Por lo tanto, aún es necesario agregar un ejecutor en la interfaz de administración de ejecutores, completar la información del ejecutor de acuerdo con la información de su propio proyecto y seleccionar [Registro automático]
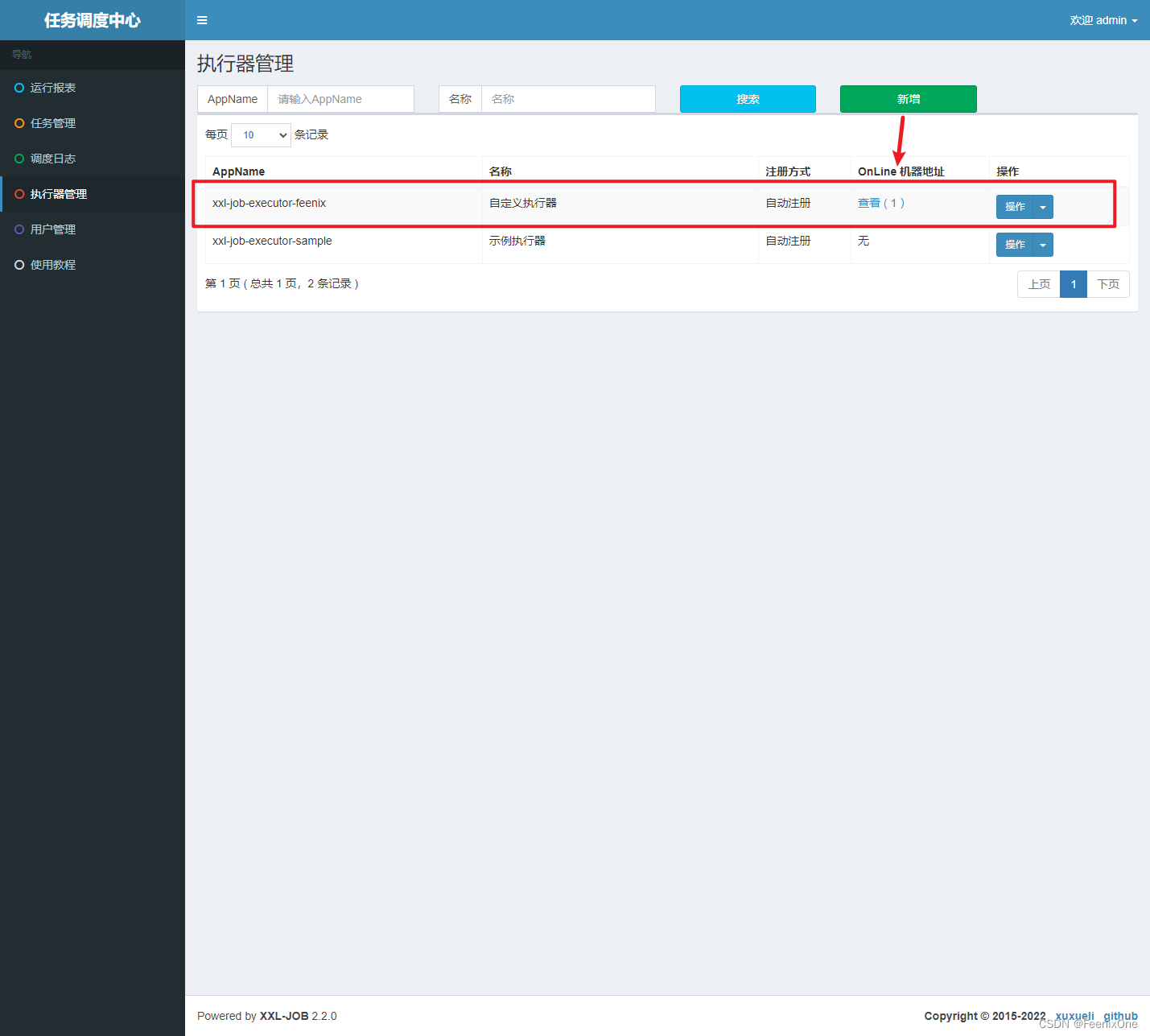
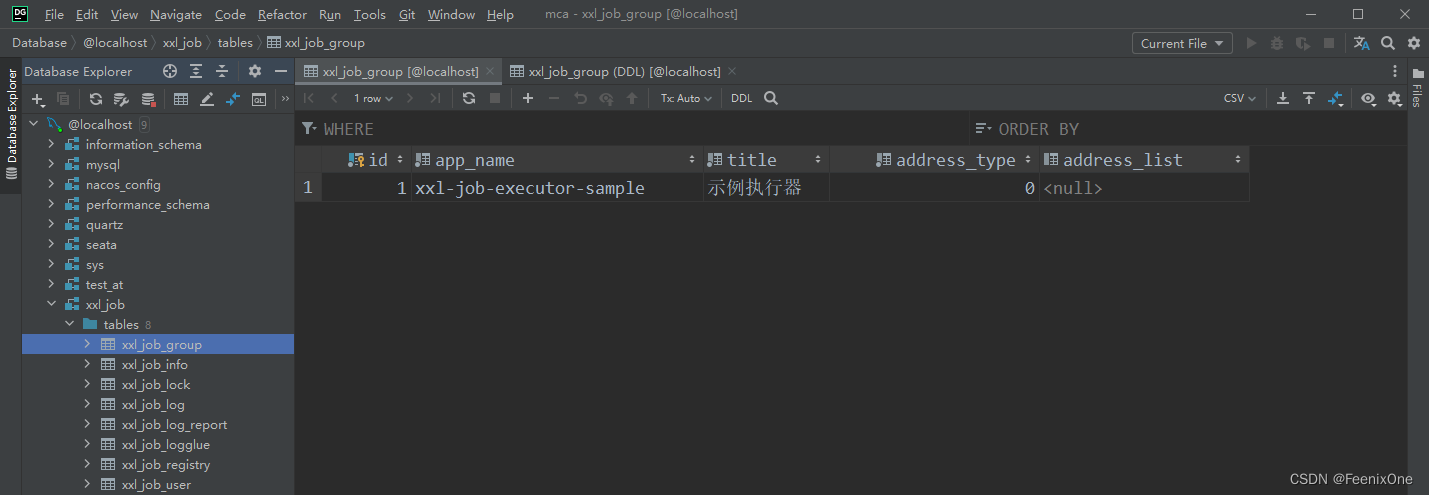
Después de que la adición sea exitosa, podemos ver la información de nuestro actuador en la tabla xxl_job_group. Una cosa a tener en cuenta: después de agregar correctamente xxl_job_group, es posible que el campo address_list no tenga un valor inmediatamente. Esto se debe a que hay un breve retraso en el registro de latidos y puede verlo después de actualizar
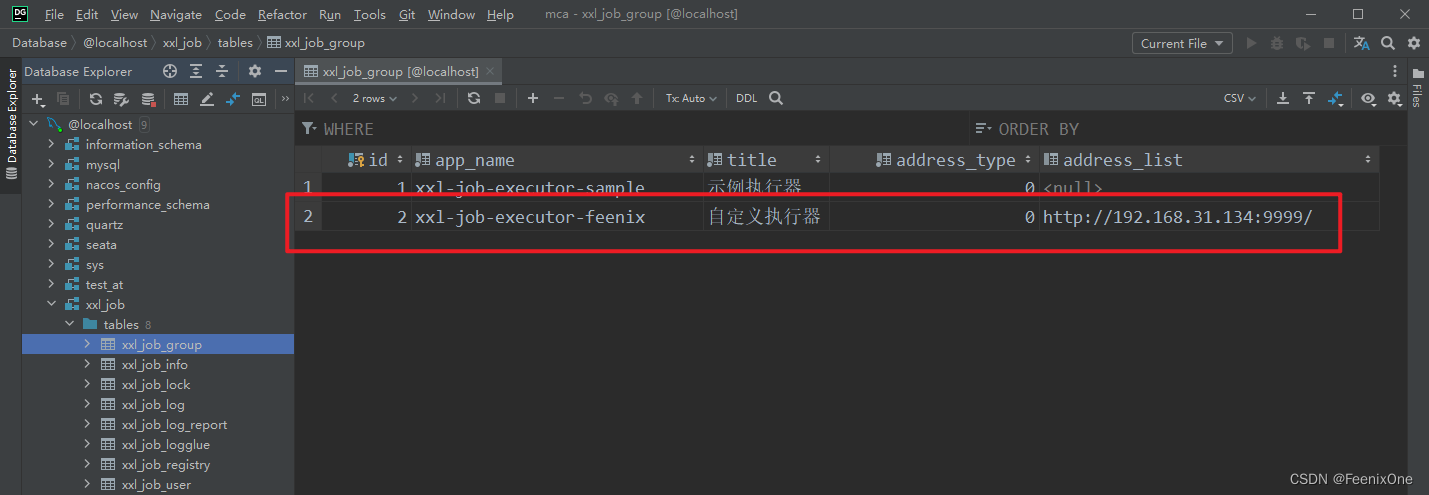
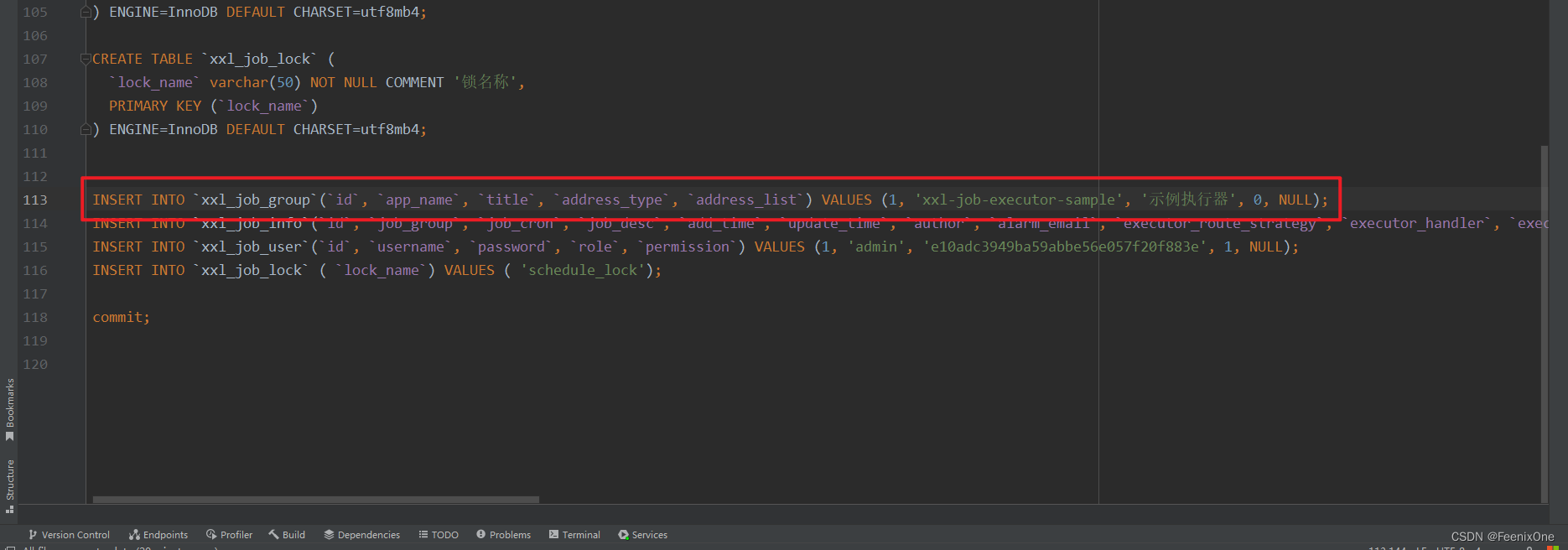
Entonces, ¿por qué el ejecutor de muestra se puede mostrar sin agregarlo manualmente en la interfaz, pero mi propio ejecutor debe agregarse manualmente? De acuerdo con las instrucciones de funcionamiento en el sitio web oficial, el archivo sql tables_xxl_job.sql debe ejecutarse al construir el centro de programación. En el sql, hay el siguiente sql rojo. Es este sql el que inserta manualmente el ejemplo de ejecución en xxl_job_group. Es por eso que el ejemplo de ejecución no necesita ser agregado manualmente en la interfaz.
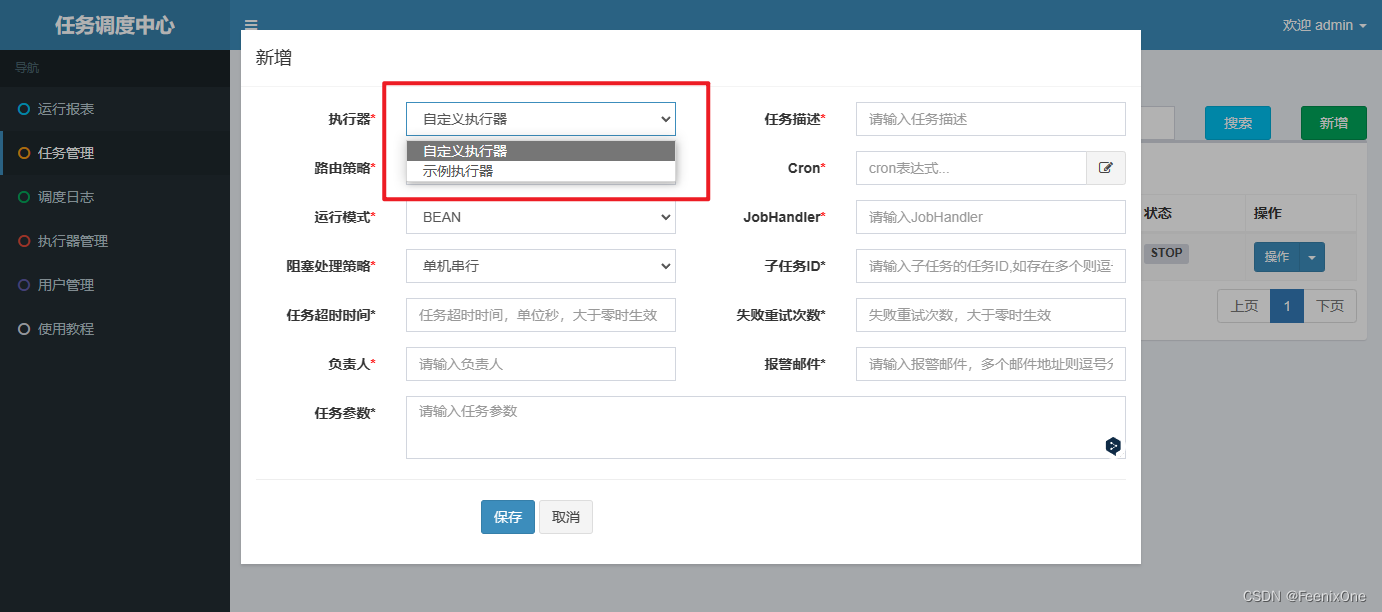
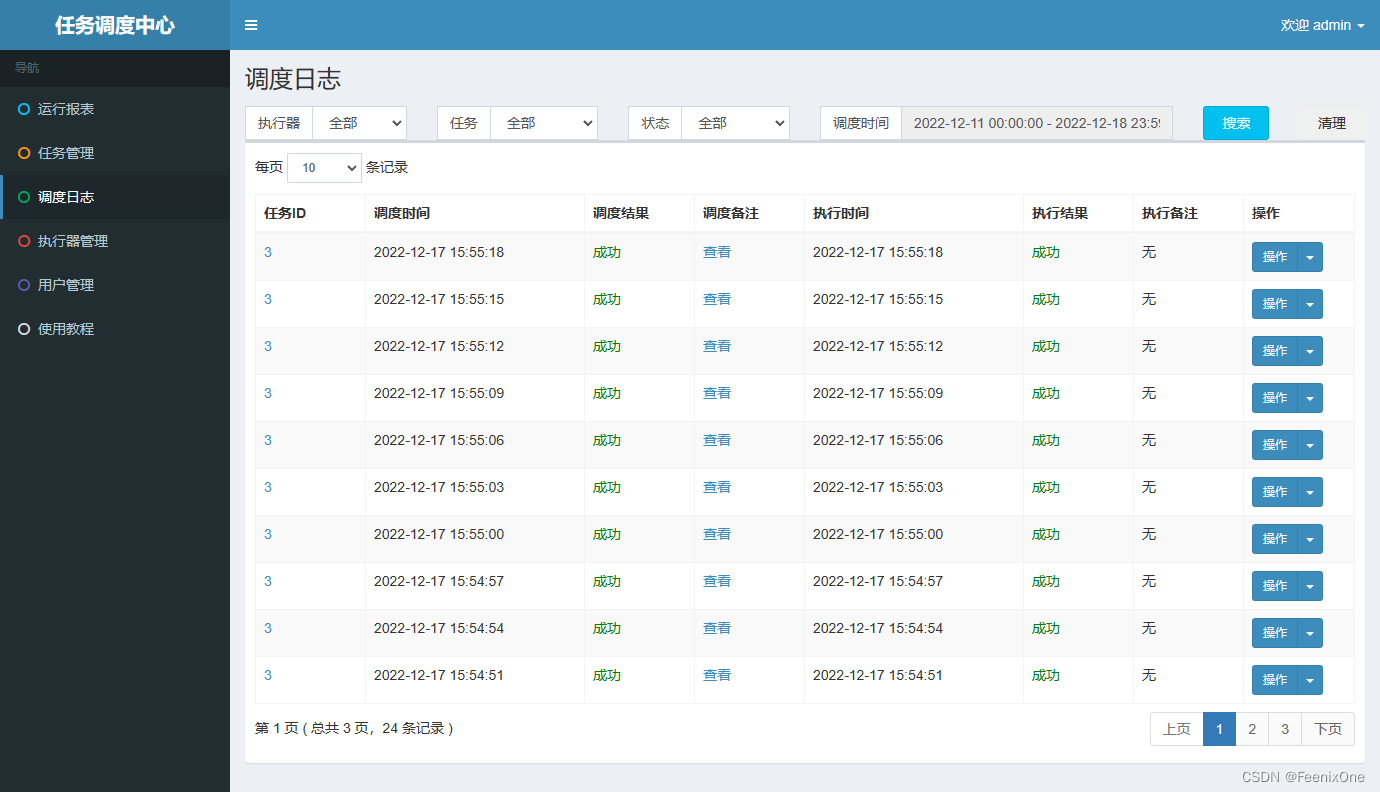
agregar tarea
Ahora que hay un centro de despacho y un ejecutor, puede asignar tareas a los trabajadores, es decir, crear tareas. Inicie sesión en el centro de despacho, abra la interfaz de administración de tareas y agregue tareas
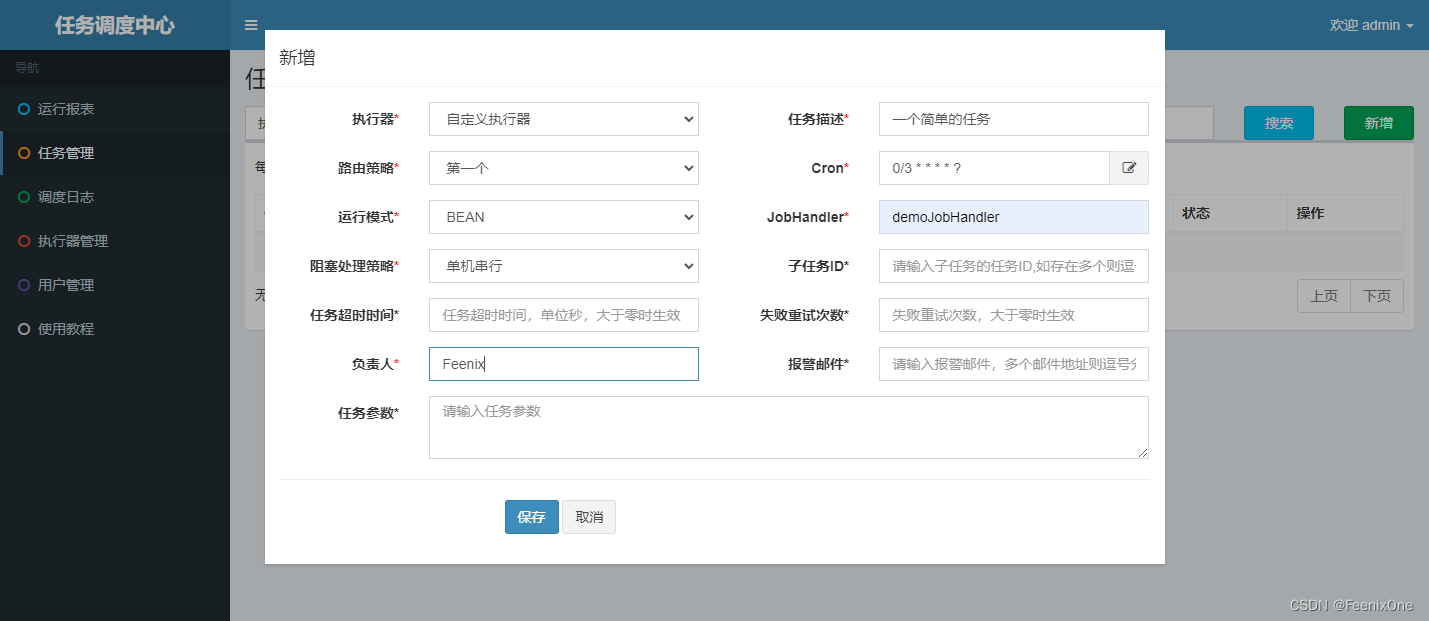
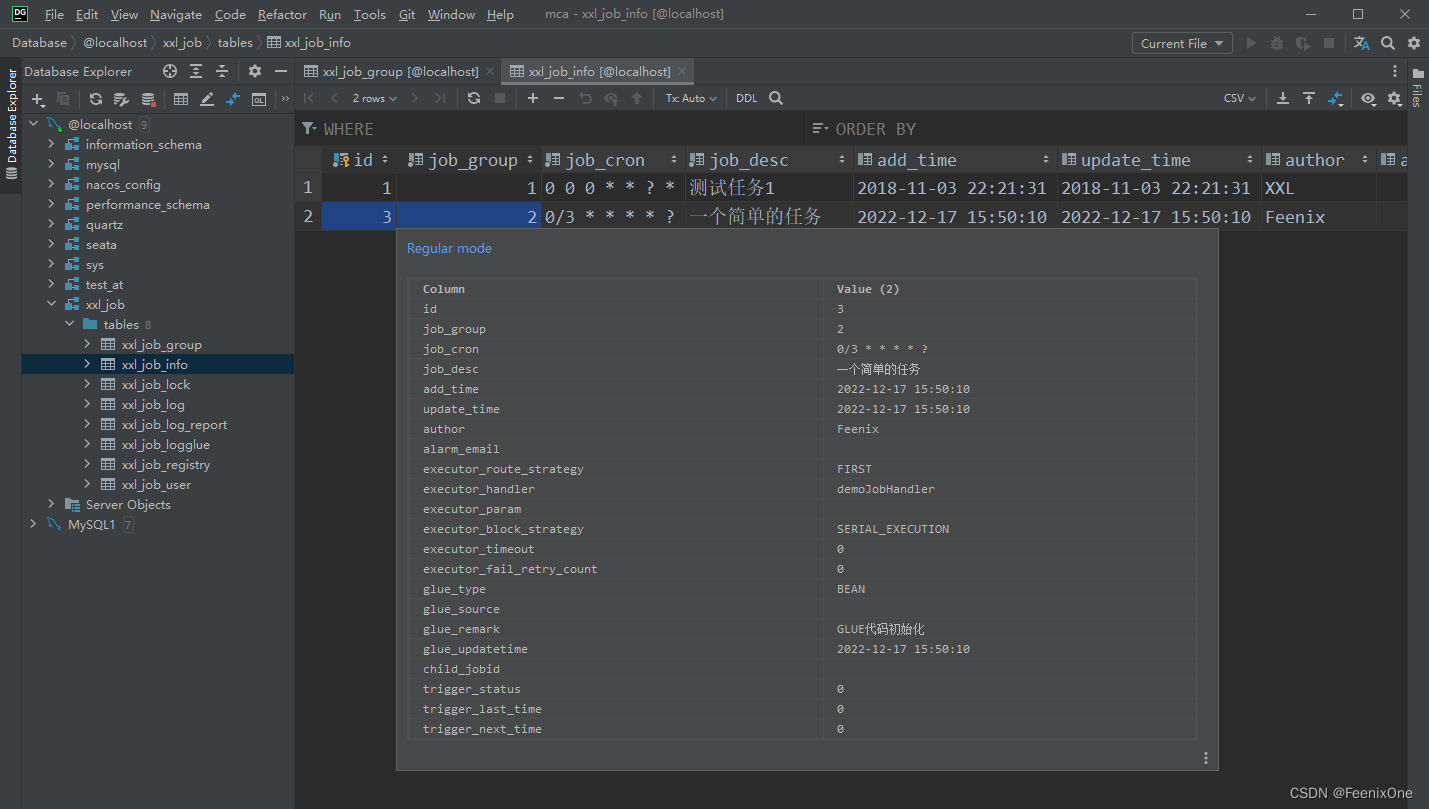
La información relevante de la tarea también se puede ver en la base de datos.
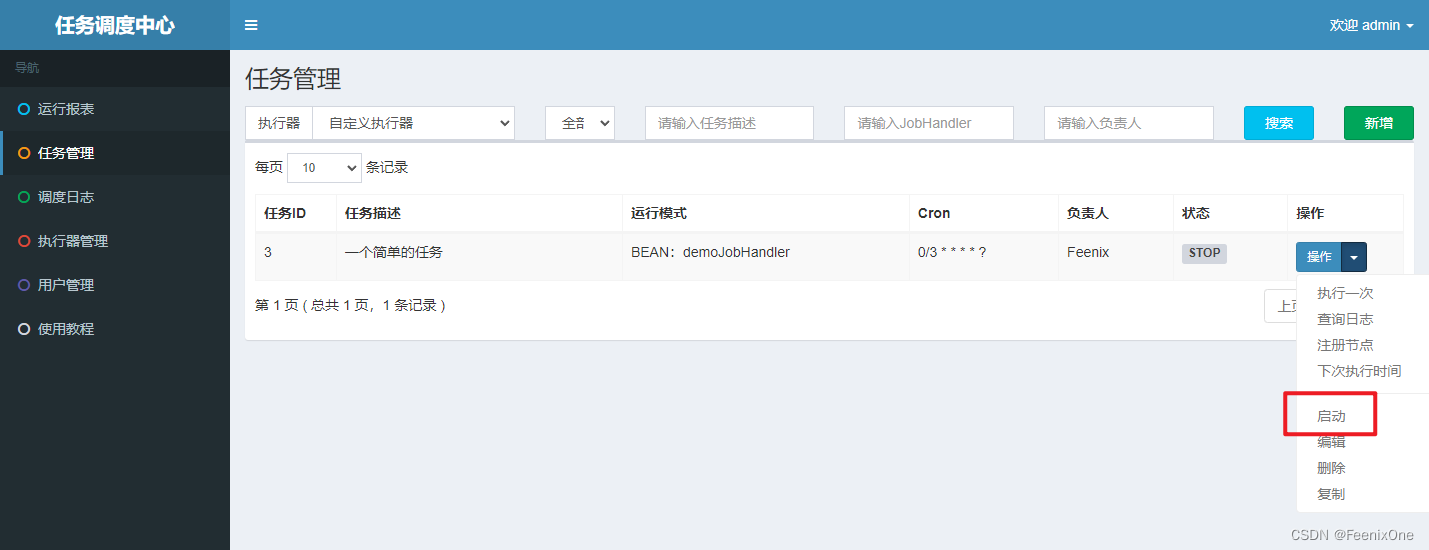
iniciar tarea
El resultado de la ejecución después de que comience la tarea se puede ver en la tabla xxl_job_log
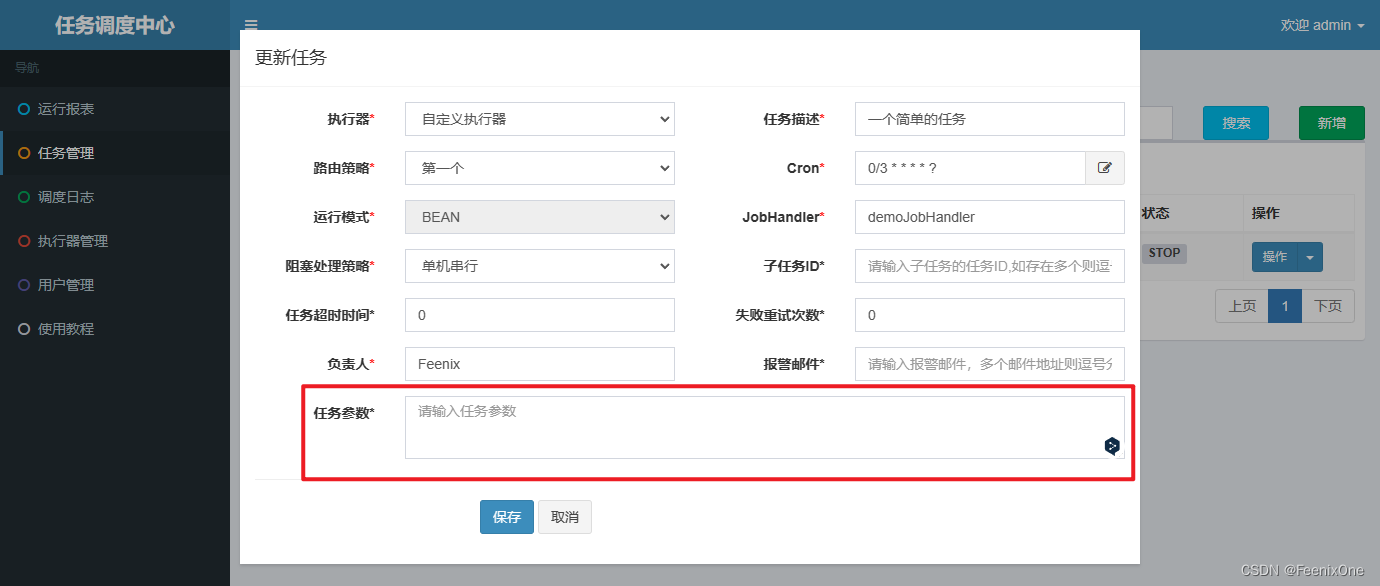
3. Atributos de tareas en xxl-job
Cuando estaba agregando una tarea en este momento, vi un montón de parámetros desordenados para especificar, y mi cabeza se hizo más grande a primera vista. De hecho, los parámetros en xxl-job son relativamente fáciles de entender. A continuación se explican estos parámetros uno por uno en detalle.
Solenoide
No hay nada que decir, esta opción es para enumerar los ejecutores que se han registrado en el centro de despacho y especificar qué ejecutor debe ejecutar la tarea actual. Hay dos actuadores en la lista de actuadores, aquí también hay dos actuadores para elegir.
detalles de la misión
No hay nada que decir al respecto, es una simple explicación del contenido de ejecución o el propósito de la tarea actual, para que otros puedan saber para qué es la tarea.
Este atributo tiene como objetivo principal seleccionar qué ejecutor específico en un clúster de ejecutores para realizar tareas. Simplemente elegí usar [ejecutor personalizado] en el [ejecutor] anterior, pero este [ejecutor personalizado] es esencialmente un grupo compuesto por varias máquinas, por lo que la máquina realizará la tarea específicamente, se especifican reglas de enrutamiento específicas de acuerdo con este enrutamiento política.
Se dijo antes que los resultados de la carga entre los nodos del clúster de cuarzo son aleatorios, y quien tome el bloqueo de la fila de la base de datos realizará la tarea. Esto puede causar la muerte por sequía, anegamiento y el rendimiento de la máquina no se puede ejercer. ., xxl-job proporciona ricas estrategias de enrutamiento:
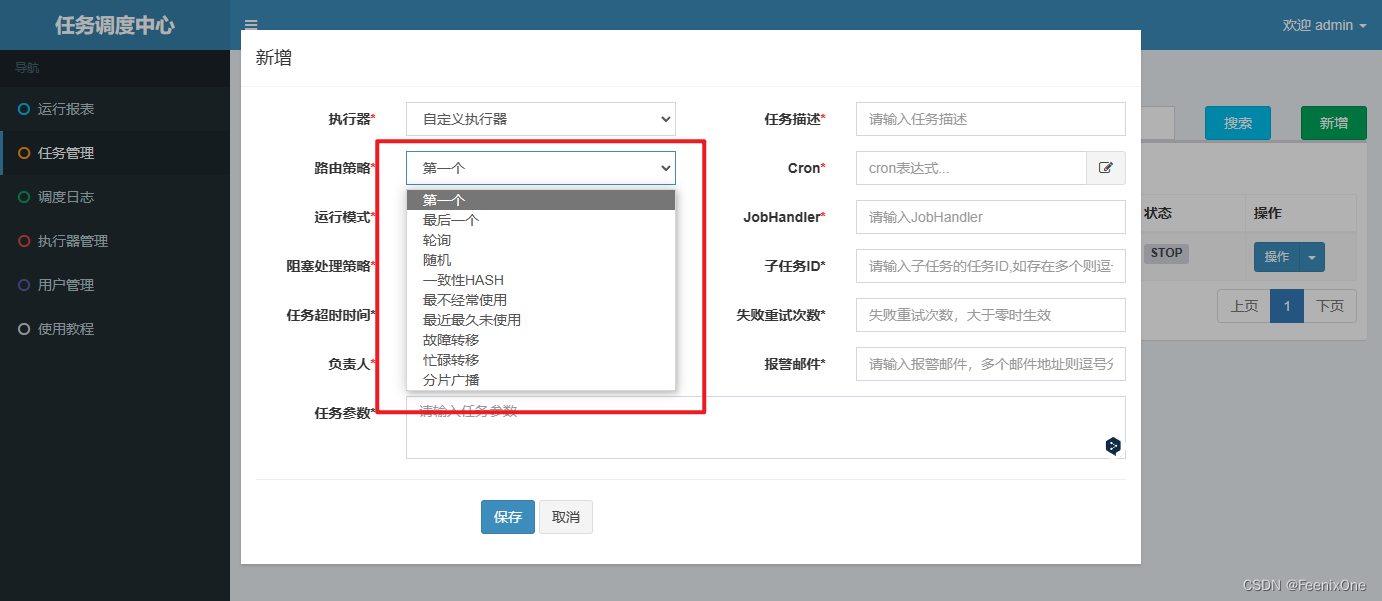
| Estrategia | valor del parámetro | significado detallado |
|---|---|---|
| Primero | PRIMERO | Selección fija de la primera máquina. |
| el último | ÚLTIMO | Selección fija de la última máquina. |
| votación | REDONDO | Seleccione Ejecutar a su vez |
| aleatorio | ALEATORIO | Máquinas en línea seleccionadas al azar |
| HASH consistente | CONSISTENT_HASH | Cada tarea selecciona una determinada máquina de acuerdo con el algoritmo Hash, y todas las tareas se procesan uniformemente en diferentes máquinas |
| usado con menos frecuencia | MENOS_FRECUENTE_USADO | La máquina con menor frecuencia de uso será elegida en primer lugar |
| Más recientemente sin usar | MENOS USADO RECIENTEMENTE | La máquina que no se ha utilizado durante más tiempo se elige primero |
| conmutación por error | CONMUTACIÓN POR ERROR | La detección de latidos se realiza en secuencia, y la primera máquina con detección de latidos exitosa se selecciona como el ejecutor de destino e inicia la programación |
| transferencia ocupada | OCUPADO | Realice la detección de inactividad secuencialmente, y la primera máquina con detección de inactividad exitosa se selecciona como el ejecutor de destino e inicia la programación |
| transmisión de fragmentos | SHARDING_BROADCAST | La transmisión activa todas las máquinas en el clúster correspondiente para ejecutar una tarea, y el sistema transmite automáticamente los parámetros de fragmentación; las tareas de fragmentación se pueden desarrollar de acuerdo con los parámetros de fragmentación |
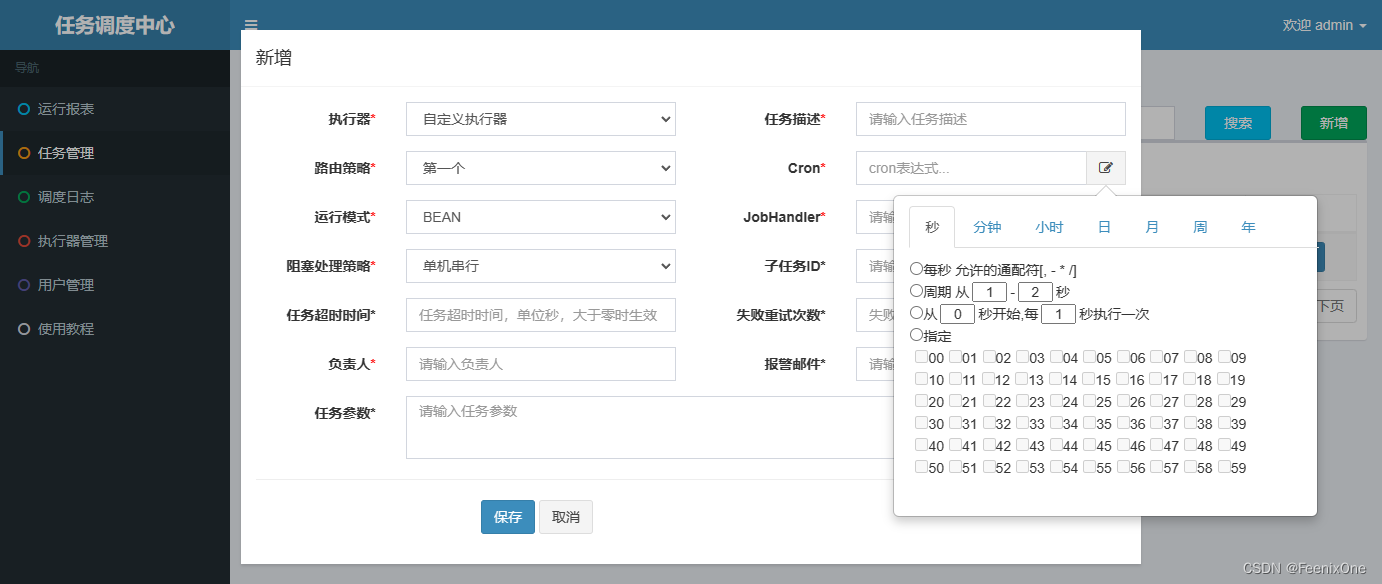
cron
Como se mencionó en el artículo anterior que presenta a Quartz, Quartz admite 4 tipos de disparadores, aunque en comparación con CronTrigger, los otros 3 disparadores básicamente no se usan durante miles de años. Cuando se trata de xxl-job, elimine los otros tres tipos directamente y solo admita la regla de activación del tipo Cron. Pero lo interesante es que no solo completa las expresiones cron. El autor también sabe que pocas personas estudian cómo escribir expresiones cron todos los días en estos días, e integra directamente las herramientas de generación de gráficos de cron:
modo operativo
El modo de operación admitido por xxl-job se divide en dos tipos: modo Bean y modo Glue.
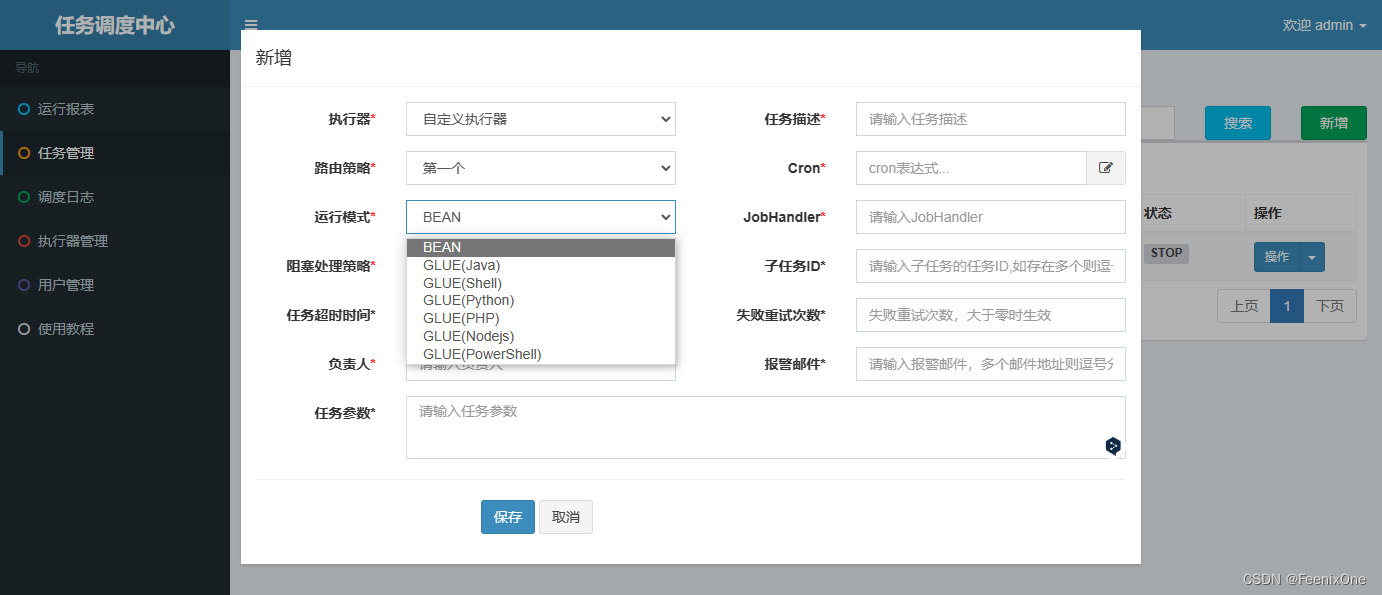
El modo Bean consiste en preescribir el código de la tarea que debe ejecutarse en el ejecutor y luego entregar la tarea como un Bean a Spring para su administración. Las reglas de escritura de Bean se explican con gran detalle en los ejemplos oficiales:
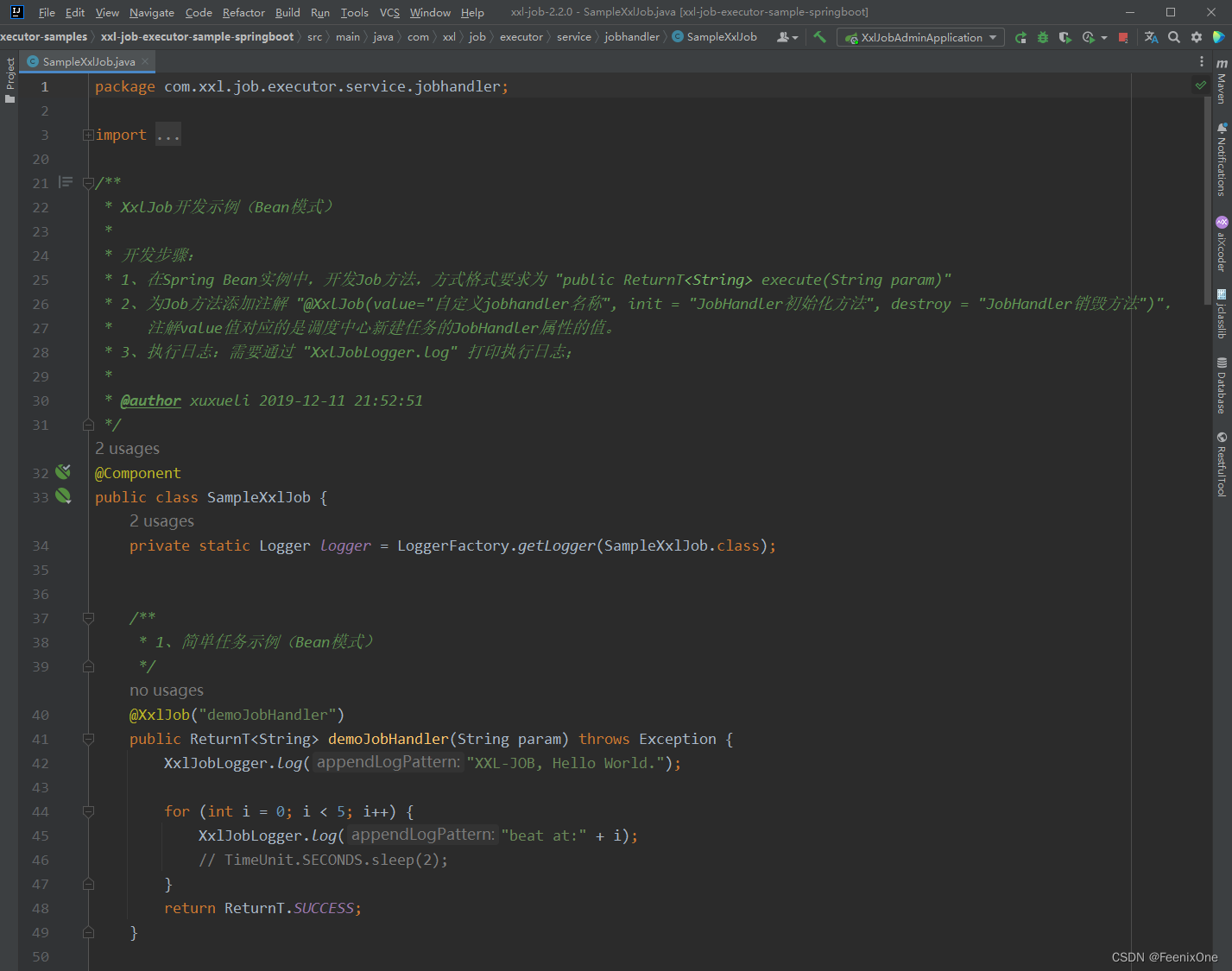
A través del modo Bean, los desarrolladores pueden comenzar rápidamente y concentrarse en la lógica comercial en sí, similar al método ejecutor implementado después de implementar la interfaz Job en Quartz, y este modo se usa básicamente en el desarrollo real.
Pegamento significa pegamento, cuando necesitas usar pegamento, cuando necesitas unir dos objetos, necesitas usar pegamento. En otras palabras, el modo Glue consiste en realidad en insertar una pieza de código en medio de una pieza de código bien escrita, como si fuera un pegamento que une las piezas superior e inferior del código. un palo de pura mierda. En el entorno de producción, el uso del modo Glue está absolutamente estrictamente prohibido. Puede ingresar un fragmento de código a voluntad en la página web e incrustarlo en el entorno de producción. ¿No es algo aterrador en lo que pensar? Aunque el autor salió y dijo que no importa mientras esté equipado con un token, si la persona que usa esta función es un desarrollador, si está de mal humor ese día, bloqueará directamente el código para que elimine la base de datos y elimine la tabla.
controlador de trabajo
Este atributo se usa junto con el modo Bean. Cuando elige usar el modo Bean, debe completar el nombre del controlador de trabajo personalizado aquí, que es el valor en el maestro @XxlJob en el método de tarea personalizado en el ejecutor. .
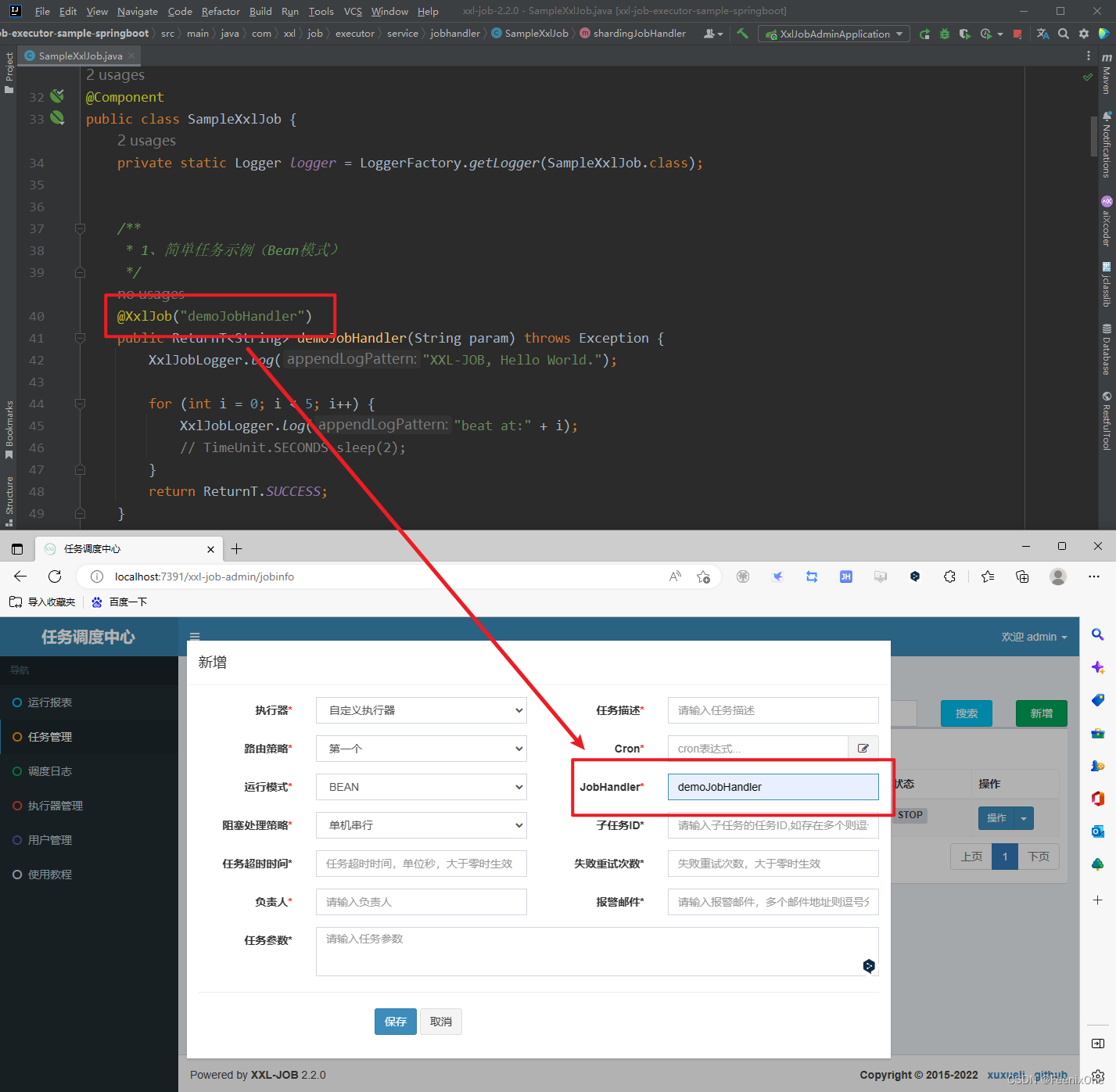
El ejecutor encuentra la tarea correspondiente a través de este JobHandler y la ejecuta.
estrategia de manejo de bloqueo
Se refiere a cómo lidiar con el próximo horario de programación cuando la tarea no ha terminado de ejecutarse una vez. xxl-job proporciona tres estrategias diferentes:
| Estrategia | valor del parámetro | significado detallado |
|---|---|---|
| serie independiente (predeterminado) | SERIAL_EJECUCIÓN | No haga nada en el subproceso actual y agregue una tarea de ejecución a la cola del subproceso actual, y solo ejecute una tarea a la vez. Después de que la solicitud de programación ingresa al ejecutor independiente, la solicitud de programación ingresa a la cola FIFO y se ejecuta en serie. |
| Descartar envío posterior | DESCARTAR_LATER | Si el hilo actual está bloqueado, las tareas posteriores no se ejecutarán y la falla se devolverá directamente y el bloqueo ya no se ejecutará. Después de que la solicitud de programación ingresa al ejecutor independiente, se encuentra que el ejecutor tiene una tarea de programación en ejecución, y la solicitud se descartará y se marcará como fallida. |
| enviar antes de anular | COVER_EARLY | Cree un motivo de eliminación, cree un nuevo hilo para realizar tareas posteriores y elimine el hilo actual. Después de que la solicitud de programación ingrese al ejecutor independiente, si hay una tarea de programación en ejecución en el ejecutor, finalizará la tarea de programación en ejecución y borrará la cola, y luego ejecutará la tarea de programación local. |
ID de subtarea
Si es necesario activar otra tarea cuando la ejecución de esta tarea se complete y se ejecute con éxito, entonces se puede ejecutar otra tarea como una subtarea de esta tarea. Debido a que cada tarea tiene una identificación de tarea única, la identificación de la tarea se puede obtener de la lista de tareas
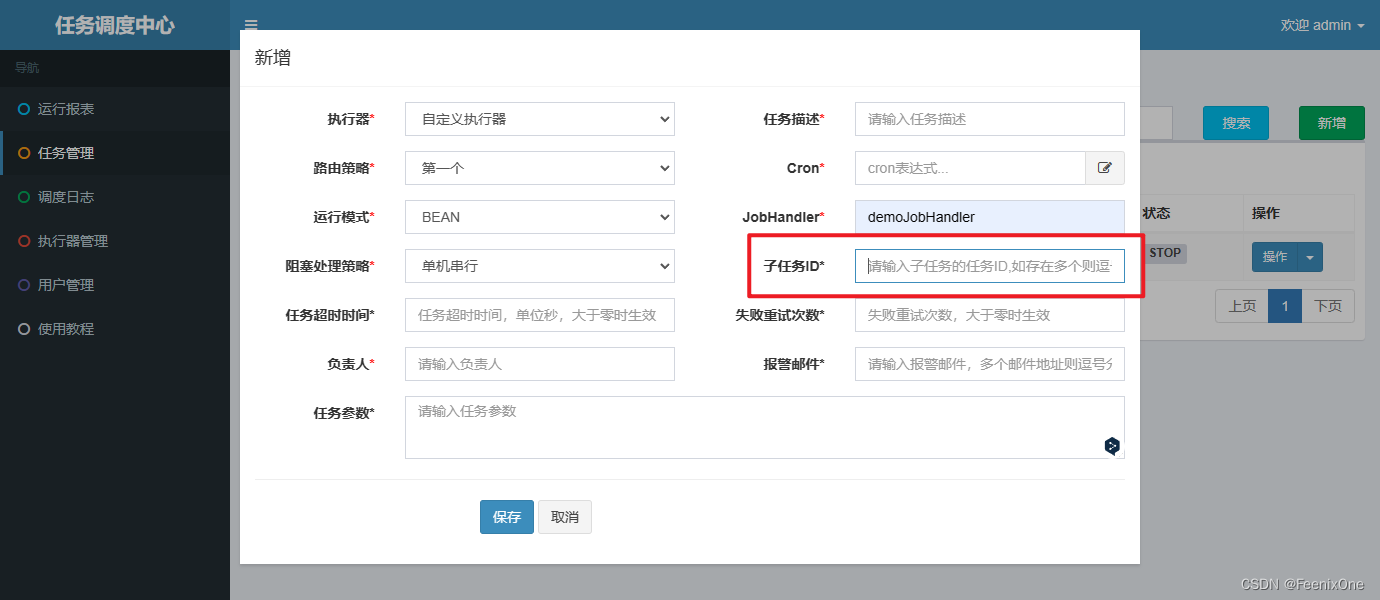
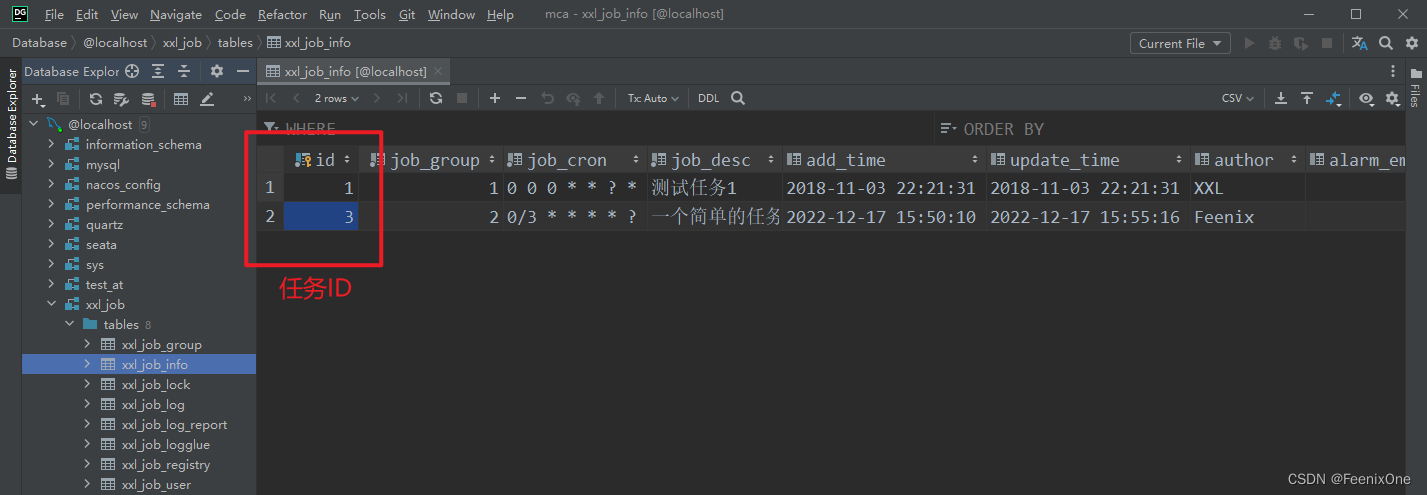
Solo necesita completar el Id. de trabajo. Por ejemplo, después de que la tarea de descargar el archivo de reconciliación sea exitosa, comience a analizar el archivo y almacenarlo en el almacén. Una vez que el almacenamiento es exitoso, se inicia la conciliación de la cuenta, de modo que se pueden programar varias tareas en serie.
Tiempo de espera de la tarea y reintentos fallidos
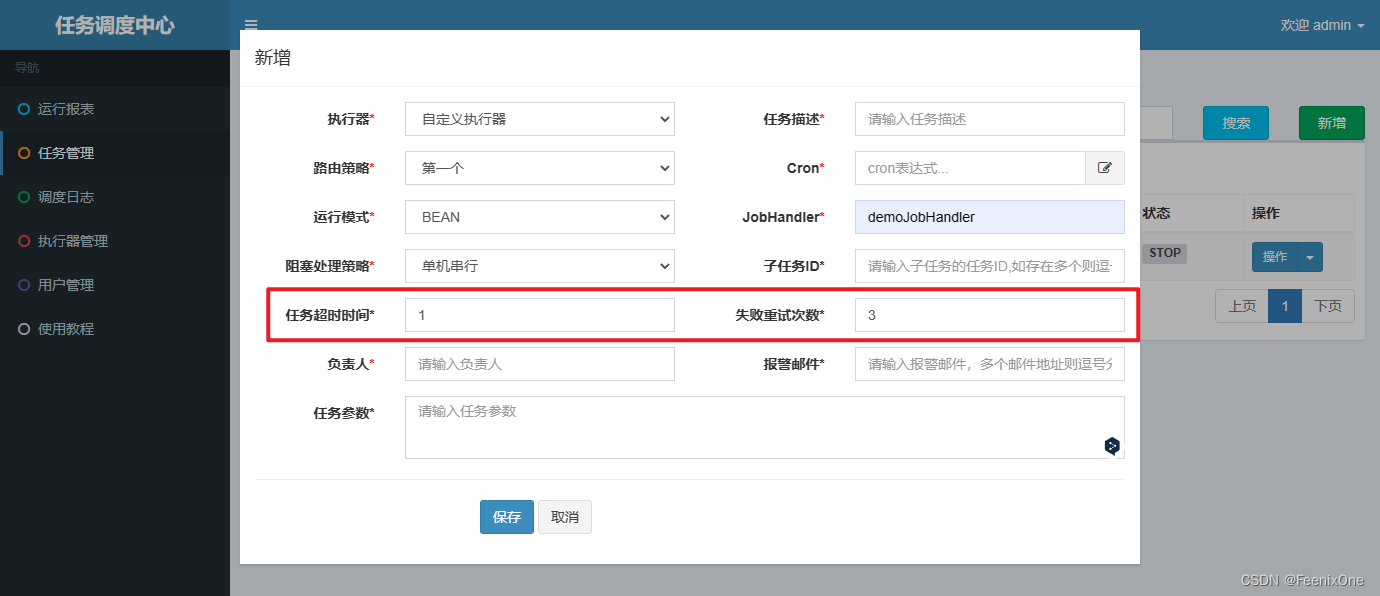
El período de tiempo de espera es realmente controlable.Aunque estas tareas se programan de forma asincrónica, estos subprocesos deben esperar a que se complete su ejecución antes de informar los resultados de la ejecución al programador. Si el período de tiempo de espera se establece en 1 s aquí, luego de 1 s, no importa si el subproceso se ejecuta o no, no le importa, simplemente elimine el subproceso directamente e intente ejecutar la tarea nuevamente de acuerdo con la cantidad de reintentos fallidos. .
principal
Si hay un problema con la tarea, busque a alguien a quien culpar.
Correo electrónico de alarma
Si la dirección de correo electrónico configurada en el archivo de configuración del centro de despacho no está preconfigurada, el correo electrónico no se puede enviar correctamente
Tarea simple
En primer lugar, debe quedar claro que todas las tareas en xxl-job tienen el mismo proceso de desarrollo:
1. En la instancia de Spring Bean, desarrolle el método Job y se requiere que el formato del método sea "public ReturnT<String> execute(String param) {.....El contenido de la tarea específica que se ejecutará...}" ;
El tipo de retorno no se puede modificar, porque el código de retorno correspondiente se ha definido en el tipo de retorno, y a través de estos códigos de retorno, la página puede conocer el resultado específico de la ejecución.
El nombre del método es aleatorio, lo que puede dar a los desarrolladores la mayor libertad. Los parámetros del método no se pueden cambiar, y el tipo debe ser Cadena. De hecho, este parámetro es el valor de [Parámetro de tarea] al agregar una tarea. Cualquier cosa que se complete en la página, puede obtenerla aquí.
2. Agregue la anotación "@XxlJob(value="nombre personalizado del controlador de trabajos", init = "Método de inicialización del controlador de trabajos", destroy = "método de destrucción del controlador de trabajos")" al método de trabajo y el valor de la anotación corresponde al controlador de trabajos. de la tarea recién creada en el centro de programación el valor del atributo;
valor Este valor se rellena en [JobHandler], y el centro de programación ejecuta la tarea correspondiente de acuerdo con este nombre. Además, hay otros dos parámetros init y destroy, similares al oyente en Quartz. Después de definir el nombre del método, se puede ejecutar antes de que se ejecute el método y después de que finalice el método.
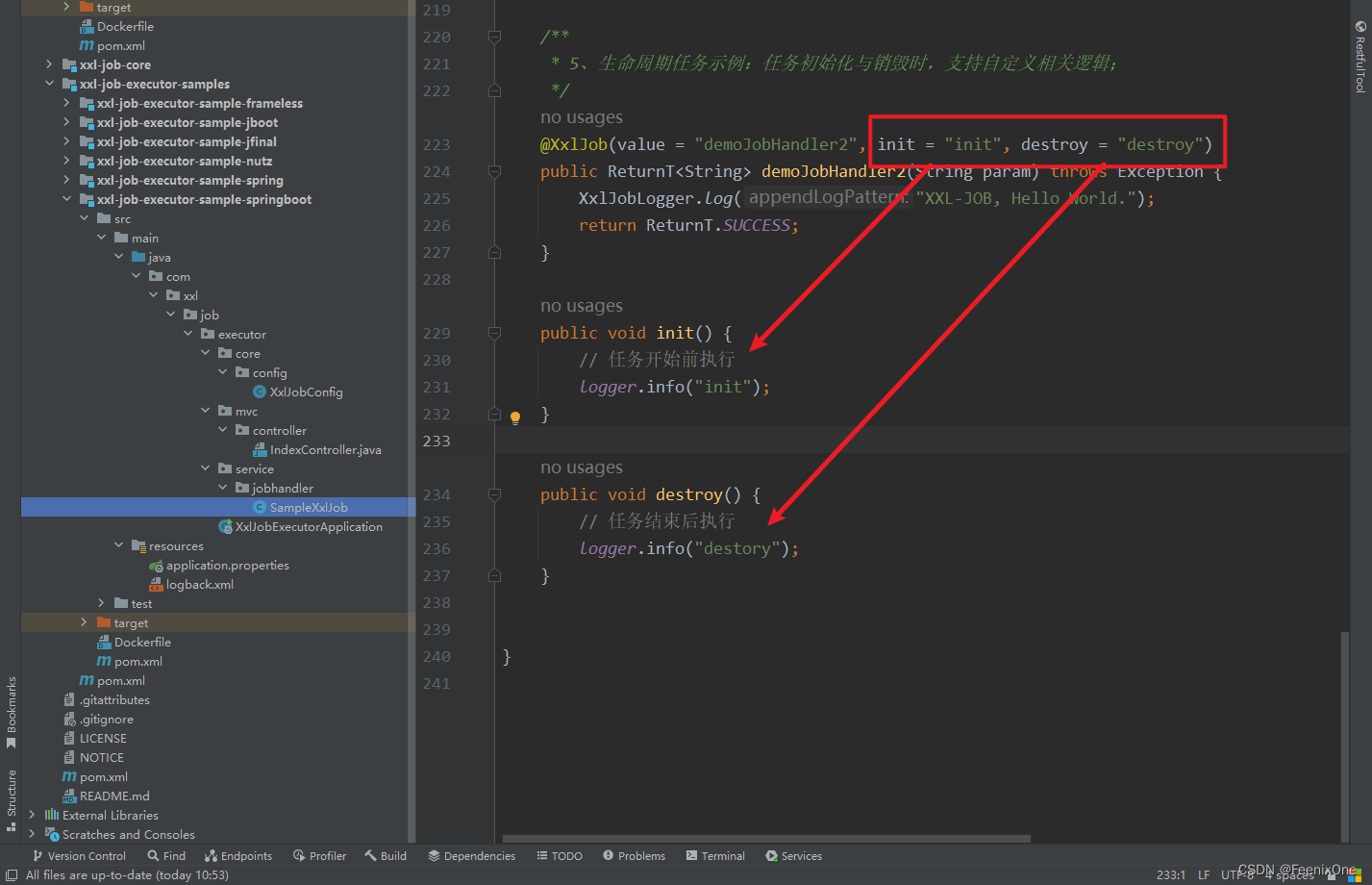
3. Registro de ejecución: debe imprimir el registro de ejecución a través de "XxlJobLogger.log", solo el registro impreso de esta manera se registrará en la base de datos de xxl-job.
Lo anterior es para crear una tarea, que es muy simple. Los llamados cinco tipos diferentes de tareas en xxl-job se basan en tareas simples, y procesar diferentes contenidos de tareas es una tarea inaceptable. Por ejemplo, una tarea de ciclo de vida se denomina tarea de ciclo de vida después de que la tarea simple reduce los parámetros init y destroy. Además, los otros 4 tipos de tareas son:
Tarea de fragmento
Primero, al crear una tarea, seleccione [Difusión de fragmentación] en [Política de enrutamiento]
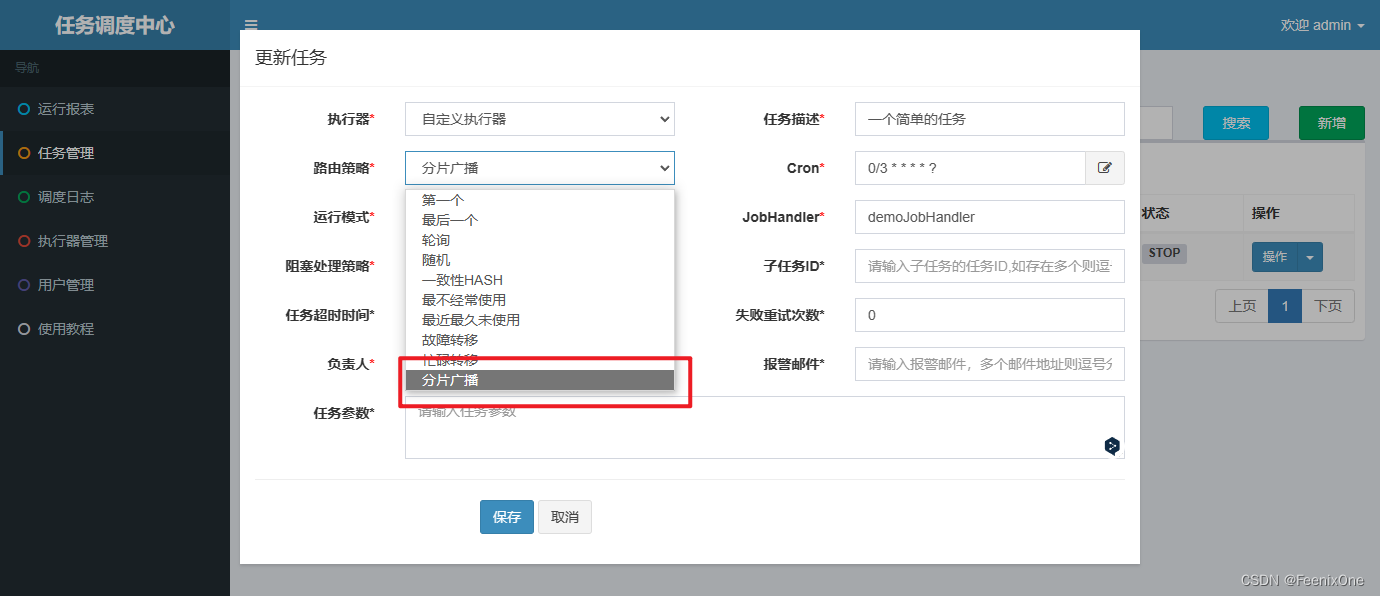
xxl-job proporciona una herramienta para obtener parámetros de fragmentación y solo necesita ejecutar la lógica comercial correspondiente de acuerdo con los números de fragmentación obtenidos
/**
* 2、分片广播任务
*/
@XxlJob("shardingJobHandler")
public ReturnT<String> shardingJobHandler(String param) throws Exception {
// 分片参数
ShardingUtil.ShardingVO shardingVO = ShardingUtil.getShardingVo();
XxlJobLogger.log("分片参数:当前分片序号 = {}, 总分片数 = {}",
shardingVO.getIndex(), shardingVO.getTotal());
// 业务逻辑
for (int i = 0; i < shardingVO.getTotal(); i++) {
// 获取当前的分片号
if (i == shardingVO.getIndex()) {
// 根据不同的分片号,处理不同的逻辑业务
XxlJobLogger.log("第 {} 片, 命中分片开始处理", i);
} else {
XxlJobLogger.log("第 {} 片, 忽略", i);
}
}
return ReturnT.SUCCESS;
}tarea de línea de comandos
De hecho, nunca he entendido del todo por qué ejecuto la línea de comandos en código Java. Pero a veces, cuando lo piensa, parece bueno usar esta cosa para la conveniencia del personal de operación y mantenimiento.Por ejemplo, en un momento determinado todos los días, necesita hacer una copia de seguridad de los archivos de la base de datos en un directorio específico. Este comando de copia de seguridad puede utilizar esta tarea de línea de comandos para ejecutarse regularmente todos los días, sin necesidad de que el personal de operación y mantenimiento realice una copia de seguridad manual todos los días. Pero similar a este tipo de demanda, deje que la operación y el mantenimiento escriban un script de temporización y lo ejecuten en el servidor...
Este tipo de tarea también se basa en tareas simples.Al crear una tarea, se pasa el comando a ejecutar al método a través de [parámetros de la tarea], y después de obtener este parámetro, se llama a Runtime.getRuntime().exec(command) ; Simplemente ejecute el comando.
/**
* 3、命令行任务
*/
@XxlJob("commandJobHandler")
public ReturnT<String> commandJobHandler(String param) throws Exception {
String command = param;
int exitValue = -1;
BufferedReader bufferedReader = null;
try {
// command process
Process process = Runtime.getRuntime().exec(command);
BufferedInputStream bufferedInputStream = new BufferedInputStream(process.getInputStream());
bufferedReader = new BufferedReader(new InputStreamReader(bufferedInputStream));
// command log
String line;
while ((line = bufferedReader.readLine()) != null) {
XxlJobLogger.log(line);
}
// command exit
process.waitFor();
exitValue = process.exitValue();
} catch (Exception e) {
XxlJobLogger.log(e);
} finally {
if (bufferedReader != null) {
bufferedReader.close();
}
}
if (exitValue == 0) {
return IJobHandler.SUCCESS;
} else {
return new ReturnT<String>(IJobHandler.FAIL.getCode(), "command exit value(" + exitValue + ") is failed");
}
}tarea HTTP
xxl-job define reglas de solicitud http específicas. Al crear una tarea, los parámetros de solicitud http escritos de acuerdo con las reglas se pasan al método a través de [parámetros de la tarea]. El método analiza y verifica los parámetros de la solicitud y luego verifica la dirección de destino. preguntar
/**
* 4、跨平台Http任务
* 参数示例:
* "url: http://www.baidu.com\n" +
* "method: get\n" +
* "data: content\n";
*/
@XxlJob("httpJobHandler")
public ReturnT<String> httpJobHandler(String param) throws Exception {
// param parse
if (param == null || param.trim().length() == 0) {
XxlJobLogger.log("param[" + param + "] invalid.");
return ReturnT.FAIL;
}
String[] httpParams = param.split("\n");
String url = null;
String method = null;
String data = null;
for (String httpParam : httpParams) {
if (httpParam.startsWith("url:")) {
url = httpParam.substring(httpParam.indexOf("url:") + 4).trim();
}
if (httpParam.startsWith("method:")) {
method = httpParam.substring(httpParam.indexOf("method:") + 7).trim().toUpperCase();
}
if (httpParam.startsWith("data:")) {
data = httpParam.substring(httpParam.indexOf("data:") + 5).trim();
}
}
// param valid
if (url == null || url.trim().length() == 0) {
XxlJobLogger.log("url[" + url + "] invalid.");
return ReturnT.FAIL;
}
if (method == null || !Arrays.asList("GET", "POST").contains(method)) {
XxlJobLogger.log("method[" + method + "] invalid.");
return ReturnT.FAIL;
}
// request
HttpURLConnection connection = null;
BufferedReader bufferedReader = null;
try {
// connection
URL realUrl = new URL(url);
connection = (HttpURLConnection) realUrl.openConnection();
// connection setting
connection.setRequestMethod(method);
connection.setDoOutput(true);
connection.setDoInput(true);
connection.setUseCaches(false);
connection.setReadTimeout(5 * 1000);
connection.setConnectTimeout(3 * 1000);
connection.setRequestProperty("connection", "Keep-Alive");
connection.setRequestProperty("Content-Type", "application/json;charset=UTF-8");
connection.setRequestProperty("Accept-Charset", "application/json;charset=UTF-8");
// do connection
connection.connect();
// data
if (data != null && data.trim().length() > 0) {
DataOutputStream dataOutputStream = new DataOutputStream(connection.getOutputStream());
dataOutputStream.write(data.getBytes("UTF-8"));
dataOutputStream.flush();
dataOutputStream.close();
}
// valid StatusCode
int statusCode = connection.getResponseCode();
if (statusCode != 200) {
throw new RuntimeException("Http Request StatusCode(" + statusCode + ") Invalid.");
}
// result
bufferedReader = new BufferedReader(new InputStreamReader(connection.getInputStream(), "UTF-8"));
StringBuilder result = new StringBuilder();
String line;
while ((line = bufferedReader.readLine()) != null) {
result.append(line);
}
String responseMsg = result.toString();
XxlJobLogger.log(responseMsg);
return ReturnT.SUCCESS;
} catch (Exception e) {
XxlJobLogger.log(e);
return ReturnT.FAIL;
} finally {
try {
if (bufferedReader != null) {
bufferedReader.close();
}
if (connection != null) {
connection.disconnect();
}
} catch (Exception e2) {
XxlJobLogger.log(e2);
}
}
}Es solo un enlace compuesto por una simple solicitud http, por lo que, aparte de las tareas simples y las tareas de fragmentación, estas otras tareas sofisticadas no se sienten muy significativas, y muchas personas piensan que estas tareas no son muy prácticas.
5. Diseño de arquitectura xxl-job
Programación y desacoplamiento de tareas
En Quartz, la lógica de programación y el código de tareas están acoplados. Y xxl-job abstrae y separa las acciones de programación, formando una plataforma pública de "centro de programación". El centro de despacho solo es responsable de iniciar las solicitudes de despacho, y la plataforma en sí no lleva a cabo la lógica comercial. Las tareas se abstraen en JobHandlers dispersos, que son administrados por el "ejecutor", y el "ejecutor" es responsable de recibir solicitudes de programación y ejecutar la lógica comercial en el JobHandler correspondiente. Por lo tanto, las dos partes de "programación" y "tarea" se pueden desacoplar entre sí para mejorar la estabilidad y escalabilidad general del sistema.
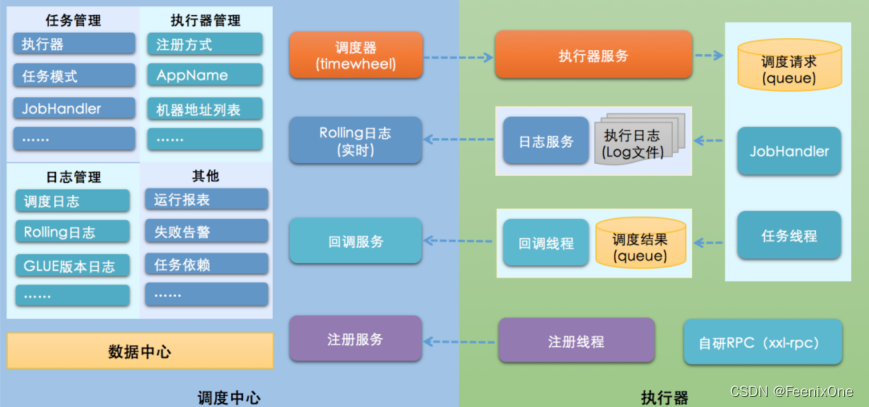
Hay un pequeño problema con este diagrama de arquitectura, esta es la arquitectura de la versión 2.1.0, el ejecutor usa xxl-rpc para informar al centro de despacho del estado de ejecución de la tarea, pero ahora ha sido reemplazado por la notificación http, pero el sitio web oficial no proporciona el diagrama de arquitectura más reciente, confórmate con eso.
El centro de despacho es responsable de administrar la información de despacho, enviar solicitudes de despacho de acuerdo con la configuración de despacho y no asume el código comercial en sí. El sistema de programación está desacoplado de las tareas, lo que mejora la disponibilidad y la estabilidad del sistema y, al mismo tiempo, el rendimiento del sistema de programación ya no está limitado por los módulos de tareas;
El centro de programación admite la gestión visual, simple y dinámica de la información de programación, incluida la creación, actualización, eliminación de tareas, desarrollo de Glue y alarmas de tareas. Todas las operaciones anteriores tendrán efecto en tiempo real. También admite la supervisión de los resultados y la ejecución de la programación. logs y admite la conmutación por error del ejecutor.
Los ejecutores son responsables de recibir solicitudes de programación y ejecutar la lógica de tareas. El módulo de tareas se enfoca en operaciones como la ejecución de tareas, haciendo que el desarrollo y el mantenimiento sean más fáciles y eficientes; recibe solicitudes de ejecución, solicitudes de finalización y solicitudes de registro del "centro de programación". En general, la arquitectura xxl-job es menos dependiente, poderosa, simple pero no simple, fácil de implementar y fácil de usar.
Diseño totalmente asíncrono
La lógica empresarial en el sistema xxl-job se ejecuta en el ejecutor remoto y el proceso de activación está diseñado de forma completamente asíncrona. En comparación con la ejecución directa de la lógica empresarial en el centro de programación, reduce en gran medida el tiempo ocupado por la programación de subprocesos;
Programación asíncrona : el centro de programación solo envía una solicitud de programación una vez cada vez que se activa una tarea. La solicitud de programación se envía primero a la "cola de programación asíncrona" y luego se envía al ejecutor remoto de forma asíncrona.
Ejecución asíncrona : el ejecutor almacenará la solicitud en la "cola de ejecución asíncrona" e inmediatamente responderá al centro de despacho para que se ejecute de forma asíncrona.
Diseño liviano : la lógica de cada trabajo en el centro de programación de trabajos xxl es muy "liviana". Sobre la base de la asincronización completa, el tiempo promedio de ejecución de un solo trabajo es básicamente de "10 ms", que es básicamente la sobrecarga de red de una solicitud Por lo tanto, se garantiza el uso de subprocesos limitados para admitir una gran cantidad de trabajos que se ejecutan simultáneamente;
Gracias a los tres puntos de optimización anteriores, en teoría, el centro de despacho con la configuración predeterminada puede admitir 5000 tareas que se ejecutan de manera simultánea y estable en una sola máquina; los diferentes grados de intensidad de programación harán que el límite superior del volumen de tareas fluctúe hacia arriba y hacia abajo . Si necesita admitir más tareas, puede optimizarlo aumentando la cantidad de subprocesos de programación, reduciendo la demora de ping entre el centro de programación y el ejecutor, y mejorando la configuración de la máquina.
programación equilibrada
Cuando el centro de despacho se implementa en el clúster, distribuirá automáticamente las tareas de manera uniforme, activando los componentes para obtener tareas relacionadas con la cantidad de grupos de subprocesos cada vez (el centro de despacho admite el tamaño personalizado del grupo de subprocesos de despacho), para evitar la concentración de una gran cantidad de tareas en un solo nodo de clúster de centro de despacho. En pocas palabras, en realidad son las opciones en [Estrategia de enrutamiento]: sondeo, aleatorio, hash consistente, LSU, LRU, fragmentación... Esta es la razón por la cual la nueva versión de xxl-job reemplaza la eliminación original de Quartz Dependency, re- escribir un modelo de programación, está fuera de estas consideraciones de diseño de programación más diversas y más flexibles.
6. Análisis en profundidad de xxl-job
Puesta en marcha y registro del actuador
Cuando se implementa un clúster de ejecutores, el programador debe seleccionar ejecutores para la ejecución de tareas. Por lo tanto, cuando el ejecutor inicia, primero debe registrarse en el centro de despacho y luego guardarlo en la base de datos. Hay dos formas de registrarse y descubrir al ejecutor:
1. Cuando se inicia el ejecutor, se registra activamente en el centro de despacho y envía latidos regularmente para mantener el contrato. Cuando el actuador se apaga normalmente, también informa activamente al centro de despacho para que cierre la sesión. Este enfoque se denomina registro activo. Si el ejecutor está caído o hay un problema con la red, el centro de despacho no sabrá la situación del ejecutor. Si la tarea se enruta a un ejecutor no disponible para su ejecución, la ejecución de la tarea fallará; 2. El centro de despacho en sí también necesita
sondear constantemente el actuador. El centro de despacho iniciará un subproceso especial en segundo plano, llamará a la interfaz del ejecutor regularmente y se desconectará si se encuentra alguna anomalía;
Puede verificarlo desde el código fuente del actuador: Primero, ¿dónde comienza un proyecto Spring Boot? A partir de la clase de configuración XxlJobConfig, aquí se utilizan parámetros de configuración. La clase de configuración define un XxlJobSpringExecutor, que creará un ejecutor cuando se inicie la clase de configuración de exploración. XxlJobSpringExecutor hereda XxlJobExecutor. La clase principal implementa la interfaz SmartInitializingSingleton y se llama al método afterSingletonsInstantiated() cuando se inicializa el objeto. El método start() de la clase principal hace varias cosas:
// Inicializar la ruta de registro
XxlJobFileAppender.initLogPath(logPath);
// Crear el cliente del programador
initAdminBizList(adminAddresses, accessToken);
// Inicializar el subproceso de limpieza de registros
JobLogFileCleanThread.getInstance().start(logRetentionDays);
// Inicializar el subproceso de devolución de llamada Trigger
TriggerCallbackThread.getInstance().start();
// Inicializar el servidor ejecutor
initEmbedServer(address, ip, port, appname, accessToken);
initAdminBizList crea el cliente del programador, que utiliza el ejecutor para conectarse al programador. El subproceso Trigger callback se usa para manejar la devolución de llamada después de que se ejecuta la tarea. Esto es lo último que hay que decir, ¿por qué es necesaria la devolución de llamada? Ingrese la creación del ejecutor desde el método initEmbedServer, a embedServer.start. Se llama embedServer porque Spring Boot se inicia con el Tomcat integrado.
EmbedServer = nuevo EmbedServer();
embedServer.start(dirección, puerto, nombre de la aplicación, token de acceso);
En este método de inicio, finalmente hay un hilo.start(), que llama al método de ejecución del hilo. El hilo es nuevo desde arriba. En el método de ejecución, se crea un ThreadPoolExecutor denominado bizThreadPool, que es el grupo de subprocesos de subprocesos comerciales.
ThreadPoolExecutor bizThreadPool = nuevo ThreadPoolExecutor()
Luego inició un paquete Netty de ServerBootstrap e inició el servidor.
ServerBootstrap bootstrap = nuevo ServerBootstrap();
Aquí, el albacea debe estar registrado en el centro de despacho:
startRegistry(nombre de la aplicación, dirección);
Cuando se trata de ExecutorRegistryThread, el subproceso finalmente se inicia en el método de inicio:
ExecutorRegistryThread.getInstance().start(nombre de aplicación, dirección);
subproceso de registro.start();
Es decir, se ejecuta el método de ejecución del hilo creado. Primero obtenga la lista de planificadores, que puede implementar el clúster.
para (AdminBiz adminBiz: XxlJobExecutor.getAdminBizList()) {.....}
Luego regístrese uno por uno, llamando al método de registro de AdminBizClient (esta clase está en el paquete principal):
registro público ReturnT<String> (RegistryParam RegistryParam) { return XxlJobRemotingUtil.postBody(addressUrl + "api/registry", accessToken, timeout, RegistryParam, String.class); }
Se llama a la interfaz HTTP, la dirección real es: http://127.0.0.1:7391/xxl-job-admin/api/registry
En la versión anterior, se usaba XXL-RPC y luego se cambió a Restful API. La solicitud es el método api de com.xxl.job.admin.controller.JobApiController, aquí hay una rama:
if ("registro".equals(uri)) { RegistryParam RegistryParam = GsonTool.fromJson(data, RegistryParam.class); volver adminBiz.registry(registryParam); }
En este momento, se llamará al método RegistryUpdate de AdminBizImpl:
xxlJobRegistryDao.registrySave(registryParam.getRegistryGroup(), RegistryParam.getRegistryKey(), RegistryParam.getRegistryValue(), new Date());
No existe una clase de implementación para este método de interfaz; de hecho, es el Mapeador de MyBatis, que guarda el ejecutor en la base de datos.
XxlJobRegistryMapper.xml
<insertar id="registrySave" >
INSERTAR EN xxl_job_registry( `registry_group` , `registry_key` , `registry_value`, `update_time`) VALORES( #{registryGroup} , #{registryKey} , #{registryValue}, #{updateTime})
</insertar>
El subproceso de fondo explora esta parte, en el código del programador, y luego lo analiza más tarde:
JobRegistryMonitorHelper.getInstance().start();
Inicio del programador y ejecución de tareas
Después de activar el actuador, los trabajadores están listos para trabajar. A continuación, echemos un vistazo a cómo el comandante dirige a los trabajadores después de que asumen sus funciones. De hecho, primero se inicia el programador y luego se inicia el ejecutor, pero debido a que el proceso de programación involucra al ejecutor, primero se analiza el ejecutor. Echemos un vistazo a cómo se inicia el programador y cómo se ejecutan las tareas.
El proyecto SpringBoot también comienza con la clase de configuración XxlJobAdminConfig. Implementa la interfaz InitializingBean y llama al método afterPropertiesSet durante la inicialización:
public void afterPropertiesSet() arroja una excepción { adminConfig = this; xxlJobScheduler = new XxlJobScheduler(); xxlJobScheduler.init(); }
El método init hace algunas cosas:
// Monitor de registro de tareas
JobRegistryMonitorHelper.getInstance().start();
// Supervisar fallas en la programación de tareas, reintentar en caso de fallas, enviar correo electrónico de fallas
JobFailMonitorHelper.getInstance().start();
// Resultado de la tarea perdido procesando
JobLosedMonitorHelper.getInstance().start();
// inicia el conjunto de desencadenadores
JobTriggerPoolHelper.toStart();
// inicia el informe de registro
JobLogReportHelper.getInstance().start();
// programa de inicio
JobScheduleHelper.getInstance().start();
Lo que hace JobRegistryMonitorHelper es seguir actualizando el registro y eliminar los ejecutores con tiempo extra. Ejecutar cada 30 segundos: TimeUnit.SECONDS.sleep(RegistryConfig.BEAT_TIMEOUT);
JobTriggerPoolHelper crea dos grupos de subprocesos, un grupo de subprocesos rápidos y un grupo de subprocesos lentos. La principal preocupación aquí es cómo se inicia el programador (comandante), ingrese el método de inicio de JobScheduleHelper, este método generalmente se ve así:
public void start() { // programar subproceso programarSubproceso = nuevo Subproceso(…...); programarSubproceso.setDaemon(verdadero); ScheduleThread.setName("xxl-job, admin JobScheduleHelper#scheduleThread"); programarSubproceso.start();
// subproceso de anillo
subproceso de anillo = nuevo subproceso (…...);
hilo de anillo.setDaemon(verdadero);
ringThread.setName("xxl-job, admin JobScheduleHelper#ringThread");
hilo de anillo.start();
}
Es decir, se crean y se inician dos subprocesos de fondo, uno es el subproceso de programación y el otro es el subproceso de rueda de tiempo. Comencemos con el primer hilo.
subproceso del programador
Aquí se crea un subproceso ScheduleThread, y el método de inicio se llama más tarde, es decir, ingresará al método de ejecución. En el método de ejecución de ScheduleThread, duerma durante 4-5 segundos aleatoriamente primero, ¿por qué? Para evitar una competencia excesiva de recursos en el inicio centralizado de los ejecutores: TimeUnit.MILLISECONDS.sleep(5000 - System.currentTimeMillis()%1000 );
Luego calcule el número de tareas de lectura previa, aquí el valor predeterminado es 6000.
int preReadCount = (XxlJobAdminConfig.getAdminConfig().getTriggerPoolFastMax() + XxlJobAdminConfig.getAdminConfig().getTriggerPoolSlowMax()) * 20;
Detrás hay un ciclo while, que es lo que el programador está haciendo repetidamente.
Obtener un bloqueo de tareas
El primer paso es obtener un bloqueo exclusivo en la base de datos, porque todos los nodos están conectados a la misma instancia de la base de datos, por lo que aquí hay un bloqueo en un entorno distribuido. Es decir, los siguientes procesos son mutuamente excluyentes.Si hay varios servicios de programador, solo un programador puede obtener información de la tarea a la vez:
PrepareStatement = conn.prepareStatement( "select * from xxl_job_lock where lock_name = 'schedule_lock' for update" );
Lo que se adquiere es el bloqueo de fila de la fila de datos lock_name=schedule_lock en la tabla job_lock. Si el bloqueo no tiene éxito, significa que otros centros de programación están cargando tareas y solo pueden adquirir el bloqueo después de que otros nodos envíen o reviertan la transacción y liberen el bloqueo. Tarea de consulta después de adquirir el bloqueo con éxito:
<select id="scheduleJobQuery" parámetroType="java.util.HashMap" resultMap="XxlJobInfo">
SELECCIONE <include refid="Base_Column_List" />
DESDE xxl_job_info COMO t DONDE
t.trigger_status = 1
y t.trigger_next_time <![CDATA [ <= ]]> #{maxNextTime}
ORDENAR POR id ASC
LIMIT #{pagesize}
</select>
Este SQL consulta las tareas cuyo estado es 1 de la tabla de tareas y cuyo próximo tiempo de activación es menor que {maxNextTime}; {maxNextTime}=nowTime (hora actual) + PRE_READ_MS (5 segundos), es decir, la consulta debe ser activado dentro de la tarea de 5 segundos.
Programación de tareas
Aquí, se divide en tres situaciones según la hora de activación de la tarea.Suponga que la próxima hora de activación de la tarea (TriggerNextTime) es a las 9:00:30, que se activa cada 2 segundos.
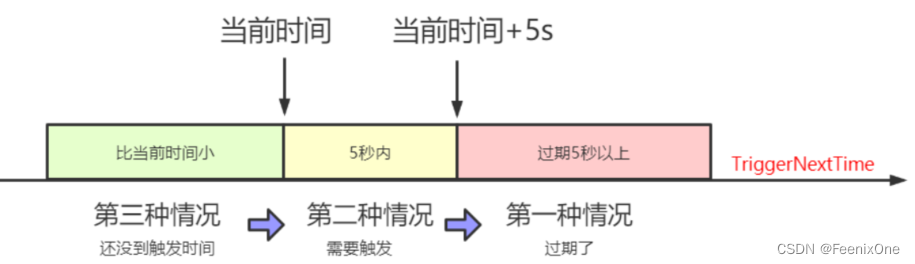
La primera situación es que la hora actual ya es posterior a las 9:00: 35. Si nowTime > jobInfo.getTriggerNextTime() + PRE_READ_MS, es decir, el tiempo de activación ha expirado por más de 5 segundos, no se puede programar (fallo), para que se ejecute hasta la próxima hora de activación, aquí solo necesita actualizar la próxima hora de activación. ¿Cuándo terminará? Por ejemplo, su consulta es muy lenta, o después de consultar la tarea que espera ser activada, la depuración se detiene durante mucho tiempo antes de llegar al juicio de tiempo.
La segunda situación (situación normal): nowTime > jobInfo.getTriggerNextTime(), el tiempo de activación ha pasado, pero no más de 5 segundos, y el tiempo es entre las 9:00:30 y las 9:00:35. Hay cuatro pasos que hacer aquí: 1. Activar la tarea, 2. Actualizar la siguiente hora de activación, 3. Ingresarla a la rueda del tiempo, 4. Una vez completada la activación, actualizar la hora a la siguiente hora de actualización, hay dos puntos clave, el disparado Qué hizo en ese momento, qué hizo cuando fue arrojado a la rueda del tiempo.
La tercera situación: aún no son las 9:00:30. Primero tírelo a la rueda de tiempo y luego actualice la siguiente hora de activación, porque aún no se ha activado y la hora real no ha cambiado. Por lo tanto, aquí debemos centrarnos en cómo se activa la tarea cuando se activa. Lanzarlo a la rueda del tiempo es otra operación.
disparador de tareas
Ingrese desde el método de activación de JobTriggerPoolHelper y luego vaya al método addTrigger de JobTriggerPoolHelper. Se diseñaron dos grupos de subprocesos: fastTriggerPool y slowTriggerPool. Si caduca 10 veces en 1 minuto, use el grupo de subprocesos lentos:
ThreadPoolExecutor triggerPool_ = fastTriggerPool;
AtomicInteger jobTimeoutCount = jobTimeoutCountMap.get(jobId);
if (jobTimeoutCount!=null && jobTimeoutCount.get() > 10) { // trabajo-tiempo de espera 10 veces en 1 min
triggerPool_ = slowTriggerPool;
}
Es equivalente a un aislamiento de grupo de subprocesos Incluso si hay muchas tareas lentas, el grupo de subprocesos de tareas lentas solo se puede agotar. ¿Qué tipo de tareas se realizarán con el grupo de subprocesos lentos? Al final de addTrigger en JobTriggerPoolHelper: si esta ejecución supera los 500ms, márquelo, si supera las 10 veces, se arrojará a la clase inferior.
if (coste > 500) { // umbral de tiempo de espera ob 500 ms
AtomicInteger timeoutCount = jobTimeoutCountMap.putIfAbsent(jobId, new AtomicInteger(1));
if (timeoutCount != null) { timeoutCount.incrementAndGet(); } }
Después de seleccionar el grupo de subprocesos, ejecútelo, es decir, asigne subprocesos para ejecutar la tarea desencadenante. Introduzca el método de activación de XxlJobTrigger:
XxlJobTrigger.trigger(jobId, triggerType, failRetryCount, executorShardingParam, executorParam, addressList);
En el método de activación de XxlJobTrigger, primero obtenga la información de la tarea, si el parámetro del método failRetryCount>0, use el valor del parámetro; de lo contrario, use el failRetryCount definido por Job. Lo que se pasa aquí es -1.
XxlJobInfo jobInfo = XxlJobAdminConfig.getAdminConfig().getXxlJobInfoDao().loadById(jobId);
Obtenga el número y el grupo de reintentos fallidos:
int finalFailRetryCount = failRetryCount>=0?failRetryCount:jobInfo.getExecutorFailRetryCount();
Grupo XxlJobGroup = XxlJobAdminConfig.getAdminConfig().getXxlJobGroupDao().load(jobInfo.getJobGroup());
Independientemente de la situación de fragmentación de la emisión, el principio de fragmentación se analizará más adelante. Vaya directamente al else al final, processTrigger:
processTrigger(grupo, jobInfo, finalFailRetryCount, triggerType, shardingParam[0], shardingParam[1]);
El frente es para obtener algunos parámetros, luego registrar el registro e inicializar los parámetros del disparador. Luego obtenga la ruta y coloque el resultado en routeAddressResult. Si se trata de sharding de difusión, todos los nodos deben participar en la carga, de lo contrario, se debe obtener la dirección del ejecutor de acuerdo con la política. Diferentes estrategias de enrutamiento tienen diferentes formas de obtener rutas.Aquí hay un patrón de estrategia típico:
routeAddressResult = executorRouteStrategyEnum.getRouter().route(triggerParam, group.getRegistryList());
| parámetros de enrutamiento | traducir | significado detallado |
|---|---|---|
| PRIMERO | Primero | Selección fija de la primera máquina. |
| ÚLTIMO | el último | Selección fija de la última máquina. |
| REDONDO | votación | Seleccione Ejecutar a su vez |
| ALEATORIO | aleatorio | Máquinas en línea seleccionadas al azar |
| CONSISTENT_HASH | HASH consistente | Cada tarea selecciona una determinada máquina de acuerdo con el algoritmo Hash, y todas las tareas se procesan uniformemente en diferentes máquinas |
| MENOS_FRECUENTE_USADO | LRU de uso menos frecuente | La máquina con menor frecuencia de uso será elegida en primer lugar |
| MENOS USADO RECIENTEMENTE | LRU no se ha utilizado durante mucho tiempo | La máquina que no se ha utilizado durante más tiempo se elige primero |
| CONMUTACIÓN POR ERROR | conmutación por error | La detección de latidos se realiza en secuencia, y la primera máquina con detección de latidos exitosa se selecciona como el ejecutor de destino e inicia la programación |
| OCUPADO | transferencia ocupada | Realice la detección de inactividad secuencialmente, y la primera máquina con detección de inactividad exitosa se selecciona como el ejecutor de destino e inicia la programación |
| SHARDING_BROADCAST | transmisión de fragmentos | La transmisión activa todas las máquinas en el clúster correspondiente para ejecutar una tarea, y el sistema transmite automáticamente los parámetros de fragmentación; las tareas de fragmentación se pueden desarrollar de acuerdo con los parámetros de fragmentación |
Si el ejecutor no se inicia, no se puede obtener la dirección del ejecutor. Después de obtener la dirección del ejecutor, runExecutor activa el ejecutor remoto: triggerResult = runExecutor(triggerParam, address);
El método de ejecución de ExecutorBizClient se llama aquí:
public ReturnT<String> run(TriggerParam triggerParam) { return XxlJobRemotingUtil.postBody(addressUrl + "run", accessToken, timeout, triggerParam, String.class); }
Aquí, se llama a la interfaz remota del ejecutor ( http://192.168.44.1:9999/run ) Más adelante se explicará cómo el ejecutor recibe la solicitud de llamada.
Para recapitular, lo anterior decía el segundo caso:
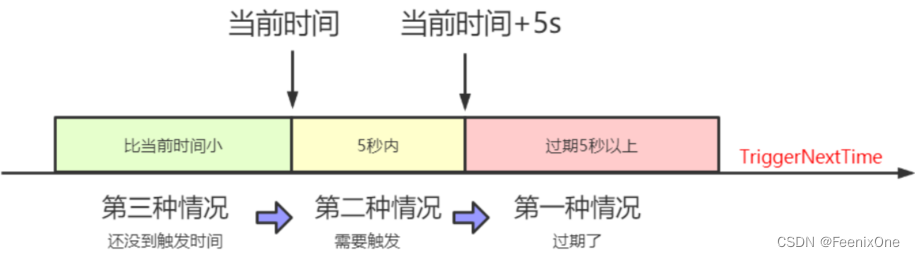
Hay cuatro pasos en total, y el primer paso ha terminado:
1. Activar la tarea,
2. Actualizar el siguiente tiempo de activación,
3. Tíralo a la rueda del tiempo,
4. Después de que finalice el activador, actualiza el tiempo al siguiente tiempo de actualización;
Pasos 2 y 4 El primer paso es muy simple, es operar la base de datos. Paso 3, tíralo a la rueda del tiempo, ¿qué es la rueda del tiempo? ¿Por qué tirarlo a la rueda del tiempo?
rueda del tiempo
Para responder a esta pregunta, comencemos con el método más primitivo de programación de tareas en Java. Dado un lote de tareas (suponiendo que hay 1000 tareas), todas se ejecutan en momentos diferentes y el tiempo es preciso al segundo. ¿Cómo implementa la programación de todas las tareas? La primera idea es iniciar un hilo, recorrer todas las tareas cada segundo, averiguar el tiempo de ejecución que coincide con el tiempo actual y ejecutarlo. Si el número de tareas es demasiado grande, llevará mucho tiempo recorrer y comparar todas las tareas.
La segunda idea es clasificar estas tareas y poner primero las que tienen el tiempo de ejecución más corto (activadas primero). El paquete JDK viene con una clase de herramienta Timer (bajo el paquete java.util), que puede implementar tareas retrasadas (como la activación después de 30 minutos) o tareas periódicas (como la activación una vez cada hora). Su esencia es una cola de prioridad (TaskQueue) y un hilo (TimerThread) para ejecutar tareas.
Temporizador de clase pública { cola de TaskQueue final privada = new TaskQueue(); subproceso final de TimerThread privado = nuevo TimerThread(cola); public Timer(String name, boolean isDaemon) { thread.setName(name); hilo.setDaemon(esDaemon); hilo.start(); } }
En esta cola de prioridad, la tarea que debe ejecutarse primero se clasifica en primer lugar en la cola de prioridad. Luego, TimerThread compara constantemente el tiempo de ejecución de la primera tarea con el tiempo actual. Si se acabó el tiempo, primero verifique si la tarea es una tarea periódica. Si es así, modifique el tiempo actual de la tarea al siguiente tiempo de ejecución. Si no es una tarea periódica, elimine la tarea de la cola de prioridad. Finalmente realiza la tarea. Sin embargo, Timer es de subproceso único y no puede cumplir con los requisitos comerciales en muchos escenarios. Después de JDK1.5, se introdujo una herramienta de programación de tareas que admite subprocesos múltiples, ScheduledThreadPoolExecutor, para reemplazar a Timer, que es uno de varios grupos de subprocesos de uso común. Mire el constructor, que es una cola retrasada DelayedWorkQueue, que también es una cola prioritaria.
public ScheduledThreadPoolExecutor(int corePoolSize) { super(corePoolSize, Integer.MAX_VALUE, 0, NANOSECONDS,new DelayedWorkQueue()); }
La complejidad del tiempo de inserción y eliminación de la cola de prioridad es O (logn).Cuando la cantidad de datos es grande, el rendimiento de la entrada y salida frecuentes del montón no es muy bueno. Aquí consideramos agrupar todas las tareas y juntar tareas al mismo tiempo de ejecución. Por ejemplo, aquí, un subíndice en la matriz representa 1 segundo. Se convertirá en una estructura de datos de una matriz más una lista vinculada. Después de agrupar, se reducirá el tiempo de recorrido y comparación. Pero todavía hay un problema, si el número de tareas es muy grande y el tiempo es diferente, o hay tareas con tiempos de ejecución muy distantes, ¿la longitud de este arreglo debería ser muy larga? Por ejemplo, hay una tarea que se ejecutará después de 2 meses, y su subíndice es 5253120 a partir de ahora. Entonces la longitud no debe ser infinita, solo puede ser una longitud fija. Por ejemplo, la longitud fija es 60, una cuadrícula representa 1 segundo (ahora se denomina ranura de cubeta) y un círculo puede representar 60 segundos. Los hilos que atraviesan solo necesitan adquirir tareas cuadrícula por cuadrícula y ejecutarlas. ¿Cómo se puede usar una matriz de longitud fija para representar el tiempo más allá de la longitud máxima? Se puede utilizar una matriz circular. Por ejemplo, una matriz de bucles con una longitud de 60 puede representar 60 segundos. ¿Cómo poner la tarea ejecutada después de 60 segundos? Simplemente divide por 60, usa el resto y colócalo en la cuadrícula correspondiente. Por ejemplo, 90%60=30, se coloca en la cuadrícula 30. Aquí existe el concepto de rondas, y la tarea en el segundo 90 solo se ejecuta en la segunda ronda.
En este momento, ha surgido el concepto de rueda del tiempo. Si hay demasiadas tareas y se ejecutan muchas tareas al mismo tiempo, la lista enlazada será muy larga. Aquí podemos transformar aún más esta rueda del tiempo y hacer una rueda del tiempo de varias capas. Por ejemplo: 60 cuadrículas en la capa más interna, 1 segundo por cada cuadrícula; 60 cuadrículas en la capa externa, 1 punto por cada cuadrícula; 24 cuadrículas en la capa externa, 1 hora por cada cuadrícula. La capa más interna camina un círculo y la capa externa camina un cuadrado. En este momento, la rueda del tiempo se parece más a un reloj. A medida que pasa el tiempo, las tareas se degradarán y las tareas de la capa externa se trasladarán lentamente a la capa interna. La complejidad temporal de la inserción y eliminación de tareas de rueda de tiempo es O (1). Tiene una amplia gama de aplicaciones y es más adecuado para escenarios de retraso con una gran cantidad de tareas. Se implementa en Dubbo, Netty y Kafka.
¿Cómo se implementa la rueda del tiempo en xxl-job? Volvamos al método de inicio de JobScheduleHelper:
int ringSecond = (int)((jobInfo.getTriggerNextTime()/1000)%60);
pushTimeRing(ringSecond, jobInfo.getId());
ringSecond es el segundo valor de 0 a 59 (millionSeconds es el número de milisegundos). Piense en ello como el índice de segundos en un dial. Pon este fragmento de código en la rueda del tiempo:
// insertar anillo asíncrono
List<Integer> ringItemData = ringData.get(ringSecond);
if (ringItemData == null) { ringItemData = new ArrayList<Integer>(); ringData.put(ringSecond, ringItemData); } ringItemData.add(jobId);
Este ringData es un ConcurrentHashMap, la clave es Integer y se coloca el ringSecond (0-59). El valor es List<Integer>, que contiene jobId. Hasta ahora, se ha analizado la primera mitad del método de inicio de JobScheduleHelper. El siguiente es el hilo ringThread para ver cómo se ejecutan las tareas de la rueda del tiempo.
Anillo de hilo de rueda de tiempoHilo
Alinee los segundos en el momento de la inicialización: los segundos actuales de hibernación son módulos con un resto de 1000, lo que significa que se ejecutará el siguiente segundo positivo.
UnidadDeTiempo.MILLISECONDS.sleep(1000 - System.currentTimeMillis()%1000 );
Luego ingrese un ciclo while. Obtenga el número actual de segundos, evite procesar demasiado tiempo, cruce la escala y verifique una escala hacia adelante.
// Obtener la tarea de la rueda de tiempo según la escala de segundos actual y la escala anterior
int nowSecond = Calendar.getInstance().get(Calendar.SECOND);
for (int i = 0; i < 2; i++) { List<Integer> tmpData = ringData.remove( (nowSecond+60-i)%60 ); if (tmpData != null) { ringItemData.addAll(tmpData); } }
(nowSecond+60-k)%60 es exactamente igual que el resultado de nowSecond-k, es decir, el segundo actual y el segundo anterior. Por ejemplo, si el segundo actual es 40, obtenga las tareas de 40 y 39. Sáquelo de ringData y colóquelo en ringItemData, que almacena los ID de trabajo de todas las tareas que deben activarse en estos dos segundos.
Lo siguiente es activar la tarea:
JobTriggerPoolHelper.trigger(jobId, TriggerTypeEnum.CRON, -1, null, null, null);
Se llama de nuevo al addTrigger de JobTriggerPoolHelper. En el método de activación de XxlJobTrigger, se llama a processTrigger y se llama a runExecutor:
ejecutarResultado = executorBiz.run(triggerParam);
La clase de implementación aquí es ExecutorBizClient, que inicia una solicitud HTTP.
public ReturnT<String> run(TriggerParam triggerParam) { return XxlJobRemotingUtil.postBody(addressUrl + "run", accessToken, timeout, triggerParam, String.class); }
La dirección URL final es el puerto del ejecutor 9999: http://192.168.44.1:9999/run, igual que arriba. Es decir, las tareas que se colocan en la rueda del tiempo y esperan a ser activadas también serán solicitadas por el ejecutor para ejecutar la tarea de forma remota.
El actuador maneja llamadas remotas, devoluciones de llamada
En el lado de la instancia empresarial, cuando el ejecutor comienza a escuchar en el puerto 9999, se crea un grupo de subprocesos bizThreadPool en el método channelRead0 de EmbedHttpServerHandler, y el método de proceso maneja el acceso URI.
if ("/run".equals(uri)) { TriggerParam triggerParam = GsonTool.fromJson(requestData, TriggerParam.class); return executorBiz.run(triggerParam); }
En este momento, se llama al método de ejecución de ExecutorBizImpl en el paquete principal. El primer paso es obtener el JobThread de la tarea (indicando si hay un hilo ejecutando la tarea de este JobId):
JobThread jobThread = XxlJobExecutor.loadJobThread(triggerParam.getJobId());
IJobHandler jobHandler = jobThread!=null?jobThread.getHandler():null;
Si hay un subproceso, obtenga jobHandler. ¿Qué es un controlador de trabajo? En el proyecto SpringBoot, jobHandler es un método de tarea anotado con @XxlJob (un método por tarea). Para usar en los otros cuatro marcos, debe escribir su propio controlador (clase de tarea) para heredar IJobHandler. El significado de esta interfaz IjobHandler es el mismo que el de la interfaz Job en Quartz, que debe anular el método de ejecución de la clase principal.
En el medio está el juicio de jobThread y jobHandler. Para bean, GROOVY y otras tareas de tipo script, el procesamiento es diferente. El principio básico es que debe haber un Manejador, y debe ser el mismo que el Manejador anterior. Si la tarea actual se está ejecutando (el JobThread se puede encontrar según el JobId), se deben tomar diferentes medidas según la estrategia configurada, como:
1. DISCARD_LATER (descartar la programación posterior): si el subproceso actual está bloqueado, las tareas posteriores no se ejecutarán y la falla se devolverá directamente (bloqueado y ya no ejecutado).
if (jobThread.isRunningOrHasQueue()) { return new ReturnT<String>(ReturnT.FAIL_CODE, "efecto de estrategia de bloque:"+ExecutorBlockStrategyEnum.DISCARD_LATER.getTitle()); }
2. COVER_EARLY (programación antes de la cobertura): cree un motivo para la eliminación y cree un nuevo hilo para realizar tareas posteriores (matar el hilo actual).
if (jobThread.isRunningOrHasQueue()) { removeOldReason = "bloquear el efecto de la estrategia:" + ExecutorBlockStrategyEnum.COVER_EARLY.getTitle(); trabajoSubproceso = nulo; }
3. SERIAL_EXECUTION (serie independiente, predeterminado): no realice ningún procesamiento en el subproceso actual y agregue una tarea de ejecución a la cola del subproceso actual (solo se ejecuta una tarea a la vez). Finalmente, llame al método pushTriggerQueue de JobThread para poner el disparador en la cola.
ReturnT<String> pushResult = jobThread.pushTriggerQueue(triggerParam);
¿Qué es esta cola? ¿Qué es TriggerQueue? LinkedBlockingQueue. Un subproceso de procesamiento de una sola tarea en un ejecutor solo puede ejecutar una tarea a la vez. JobThread se iniciará cuando se cree, entrará en el bucle infinito del método de ejecución y obtendrá tareas de la cola continuamente: triggerParam = triggerQueue.poll(3L, TimeUnit.SECONDS);
Finalmente llame al método de ejecución de Handler (clase de tarea): return handler.execute(triggerParamTmp.getExecutorParams());
El método de devolución de llamada se llama en el método finalmente para informar al planificador del resultado de la ejecución:
if(triggerParam != null) { // información del controlador de devolución de llamada if (!toStop) { // commonm TriggerCallbackThread.pushCallBack(new HandleCallbackParam(triggerParam.getLogId(), triggerParam.getLogDateTime(), executeResult)); } else { // se cancela ReturnT<String> stopResult = new ReturnT<String>(ReturnT.FAIL_CODE, stopReason + " [trabajo en ejecución, cancelado]"); TriggerCallbackThread.pushCallBack(nuevo HandleCallbackParam(triggerParam.getLogId(), triggerParam.getLogDateTime(), stopResult)); } }
en una cola. En el método de ejecución del subproceso de fondo de TriggerCallbackThread, llame al método doCallback, conéctese al programador y escriba el resultado de la programación.
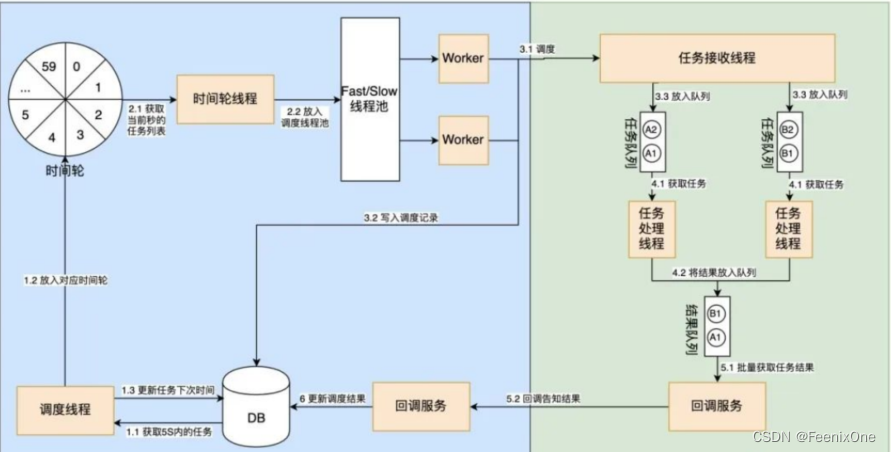
Para resumir el proceso general de programación:
1. El centro de programación obtiene el bloqueo de la tarea, consulta la tarea y la activa o la pone en la rueda del tiempo según la situación;
2. Para activar una tarea, primero debe obtener la dirección de enrutamiento y luego llamar a la interfaz del ejecutor;
3. El ejecutor recibe la solicitud de llamada, ejecuta la tarea a través de JobThread y devuelve la llamada (devolución de llamada) a la interfaz del programador;
Principio de fragmentación de tareas
Obtenga el parámetro de fragmentación: parámetro de fragmentación. ¿Recuerdas qué es este parámetro de fragmentación? Lo mejor es diseñar un campo de fragmentación que no tenga nada que ver con el negocio y agregar la información de fragmentación que utiliza el índice para obtener los datos para la segmentación. Si solo hay dos, y ambos son números, conviértalos en enteros; si es una tarea de transmisión, procese Trigger en todos los nodos.
Activar manualmente la ejecución de una tarea
@RequestMapping("/trigger")
@ResponseBody
//@PermissionLimit(limit = false)
public ReturnT<String> triggerJob(int id, String executorParam, String addressList) { // forzar el trabajo de cobertura param if (executorParam == null) { ejecutorParam = ""; }
JobTriggerPoolHelper.trigger(id, TriggerTypeEnum.MANUAL, -1, null, executorParam, addressList);
return RetornoT.ÉXITO;
}
Después de eso, es lo mismo que el proceso del programador que activa automáticamente la tarea.