fondo
Hace algún tiempo, nuestro servicio se encontró con un cuello de botella en el rendimiento, debido a la demanda urgente en la etapa inicial, no prestamos atención a la optimización en esta área, cuando llegó el momento de pagar la deuda técnica, fue muy doloroso.
Bajo una presión de QPS muy baja, la carga del servidor puede llegar a 10-20, la tasa de uso de la CPU es superior al 60% y cada vez que el tráfico alcanza su punto máximo, la interfaz informará una gran cantidad de errores.Aunque el marco de fusión de servicios Hystrix es utilizado, el servicio se retrasa después de la fusión No se puede recuperar. Cada vez que se produce un cambio en línea, estoy aún más preocupado, preocupado de que sea la última gota que aplaste el vaso del camello, lo que provocará una avalancha de servicios.
Después de que la demanda finalmente se desaceleró, el líder nos fijó la meta de resolver por completo el problema de rendimiento del servicio en dos semanas. En las últimas dos semanas de investigación y clasificación, se encontraron y resolvieron múltiples cuellos de botella de rendimiento, se modificó el esquema de fusión del sistema y se duplicó el QPS que el servicio puede manejar, lo que permitió servicios bajo una presión de QPS extremadamente alta (3-4 veces) Normal fusión, y puede volver rápidamente a la normalidad después de que se reduce la presión, el siguiente es el proceso de investigación y solución de algunos problemas.
CPU alta del servidor, carga alta
El primer problema que debe resolverse es que el servicio genera una alta carga general del servidor y una CPU alta.
Nuestro servicio en su conjunto se puede resumir en obtener un lote de datos de un determinado almacenamiento o llamada remota, luego realizar varias transformaciones sofisticadas en este lote de datos y finalmente devolverlo. Debido al largo proceso de conversión de datos y muchas operaciones, es normal que la CPU del sistema sea más alta, pero en circunstancias normales, la CPU es más del 50%, lo que todavía es un poco exagerado.
Todos sabemos que puede usar el comando superior para consultar el uso de CPU y memoria de cada proceso en el sistema en el servidor. Pero la JVM es el dominio de las aplicaciones Java. ¿Qué herramienta debo usar para verificar el uso de recursos de cada subproceso en la JVM?
jmc es posible, pero es engorroso de usar y requiere una serie de configuraciones. Tenemos otra opción, que es usar jtop, jtop es solo un paquete jar, su dirección de proyecto está en yujikiriki/jtop, podemos copiarlo fácilmente al servidor, después de obtener el pid de la aplicación java, use java - jar jtop .jar [opciones] puede generar estadísticas internas de JVM.
jtop utilizará el parámetro predeterminado -stack n para imprimir las pilas de 5 subprocesos de la mejor CPU.
Con forma de:
Heap Memory: INIT=134217728 USED=230791968 COMMITED=450363392 MAX=1908932608
NonHeap Memory: INIT=2555904 USED=24834632 COMMITED=26411008 MAX=-1
GC PS Scavenge VALID [PS Eden Space, PS Survivor Space] GC=161 GCT=440
GC PS MarkSweep VALID [PS Eden Space, PS Survivor Space, PS Old Gen] GC=2 GCT=532
ClassLoading LOADED=3118 TOTAL_LOADED=3118 UNLOADED=0
Total threads: 608 CPU=2454 (106.88%) USER=2142 (93.30%)
NEW=0 RUNNABLE=6 BLOCKED=0 WAITING=2 TIMED_WAITING=600 TERMINATED=0
main TID=1 STATE=RUNNABLE CPU_TIME=2039 (88.79%) USER_TIME=1970 (85.79%) Allocted: 640318696
com.google.common.util.concurrent.RateLimiter.tryAcquire(RateLimiter.java:337)
io.zhenbianshu.TestFuturePool.main(TestFuturePool.java:23)
RMI TCP Connection(2)-127.0.0.1 TID=2555 STATE=RUNNABLE CPU_TIME=89 (3.89%) USER_TIME=85 (3.70%) Allocted: 7943616
sun.management.ThreadImpl.dumpThreads0(Native Method)
sun.management.ThreadImpl.dumpAllThreads(ThreadImpl.java:454)
me.hatter.tools.jtop.rmi.RmiServer.listThreadInfos(RmiServer.java:59)
me.hatter.tools.jtop.management.JTopImpl.listThreadInfos(JTopImpl.java:48)
sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
... ...
Al observar la pila de subprocesos, podemos encontrar puntos de código para optimizar.
En nuestro código, encontramos una gran cantidad de serialización y deserialización json y beans para copiar la ubicación de la CPU, y luego, a través de la optimización del código, al mejorar la tasa de reutilización de beans, usar PB en lugar de json, etc., la presión de la CPU se redujo considerablemente. .
Optimización del marco de fusibles
Para el marco de fusión de servicios, elegimos Hystrix. Aunque ha anunciado que ya no se mantendrá, se recomienda usar resiliencia4j y el centinela de código abierto de Ali. Sin embargo, dado que la pila de tecnología en el departamento es Hystrix, y no tiene deficiencias obvias, continuaremos usándolo.
Permítanme presentarles la situación básica primero. Agregamos anotaciones Hystrix en las llamadas RPC más externas e internas de la interfaz del controlador. El método de aislamiento es el modo de grupo de subprocesos. El período de tiempo de espera en la interfaz se establece en 1000 ms, y el número máximo de subprocesos es 2000. El tiempo de espera se establece en 200 ms y el número máximo de subprocesos es 500.
tiempo de respuesta anormal
El primer problema a resolver es el tiempo de respuesta anormal de la interfaz. Al observar el registro de acceso de la interfaz, se puede encontrar que la interfaz tiene solicitudes que tardan 1200ms, y algunas incluso llegan a más de 2000ms. Debido al modo de grupo de subprocesos, Hystrix utilizará un subproceso asíncrono para ejecutar la lógica comercial real, mientras que el subproceso principal ha estado esperando. Una vez que se agota el tiempo de espera, el subproceso principal puede regresar de inmediato. Por lo tanto, la interfaz toma más tiempo que el tiempo de espera y es probable que el problema ocurra en la capa del marco Hystrix, la capa del marco Spring o la capa del sistema.
En este momento, se puede analizar la pila de subprocesos en tiempo de ejecución. Uso jstack para imprimir la pila de subprocesos y convertir el resultado de la impresión múltiple en un gráfico de llamas para su observación.
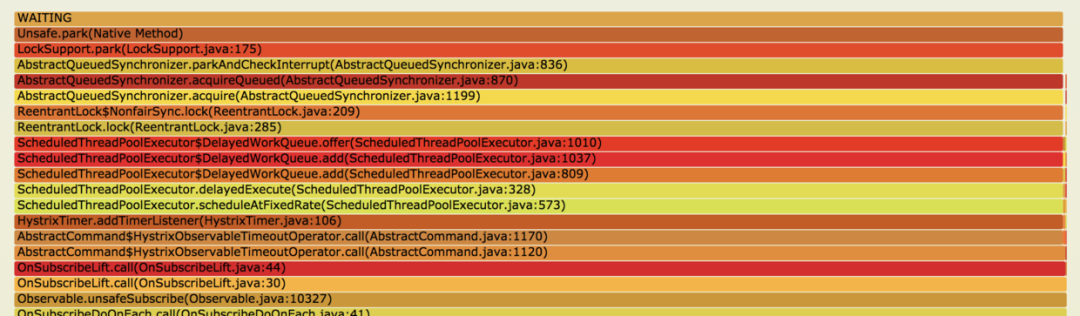
Como se muestra en la figura anterior, puede ver que muchos subprocesos se detienen en LockSupport.park(LockSupport.java:175), y estos subprocesos están todos bloqueados. Mirando hacia abajo en la fuente, es HystrixTimer.addTimerListener(HystrixTimer.java: 106), y luego a Abajo está nuestro código de negocio.
Los comentarios de Hystrix explican que estos TimerListeners son utilizados por HystrixCommand para manejar tiempos de espera de subprocesos asíncronos, se ejecutarán cuando se agote el tiempo de espera de la llamada y se devolverá el resultado del tiempo de espera. Cuando la cantidad de llamadas es grande, la configuración de estos TimerListeners se bloqueará debido a bloqueos, lo que hará que el período de tiempo de espera establecido por la interfaz no tenga efecto.
Luego compruebe por qué hay tantas llamadas a TimerListener.
Dado que el servicio se basa en el mismo valor de retorno de RPC en varios lugares, la respuesta promedio de la interfaz obtendrá el mismo valor de 3 a 5 veces, por lo que la interfaz agrega LocalCache al valor de retorno de RPC. Verifique el código y descubra que HystrixCommand se agrega al método get de LocalCache, de modo que cuando el QPS independiente sea 1000, el método se llamará 3000-5000 veces a través de Hystrix, lo que generará una gran cantidad de Hystrix TimerListeners.
El código es similar a:
@HystrixCommand(
fallbackMethod = "fallBackGetXXXConfig",
commandProperties = {
@HystrixProperty(name = "execution.isolation.thread.timeoutInMilliseconds", value = "200"),
@HystrixProperty(name = "circuitBreaker.errorThresholdPercentage", value = "50")},
threadPoolProperties = {
@HystrixProperty(name = "coreSize", value = "200"),
@HystrixProperty(name = "maximumSize", value = "500"),
@HystrixProperty(name = "allowMaximumSizeToDivergeFromCoreSize", value = "true")})
public XXXConfig getXXXConfig(Long uid) {
try {
return XXXConfigCache.get(uid);
} catch (Exception e) {
return EMPTY_XXX_CONFIG;
}
}
Modifique el código y modifique HystrixCommand al método de carga de localCache para resolver este problema. Además, para reducir aún más el impacto del marco Hystrix en el rendimiento, la estrategia de aislamiento de Hystrix se cambió al modo semáforo y luego se estabilizó el consumo máximo de tiempo de la interfaz. Y debido a que todos los métodos se ejecutan en el subproceso principal, sin el mantenimiento del grupo de subprocesos Hystrix y el cambio de contexto entre el subproceso principal y el subproceso Hystrix, el uso de la CPU del sistema ha disminuido aún más.
Sin embargo, también debe prestar atención a un problema al usar el modo de aislamiento de semáforo: el semáforo solo puede limitar si el método puede entrar en ejecución y luego juzgar si la interfaz se agota después de que el método regresa y maneja el tiempo de espera, pero no puede intervenir en el método que ya se está ejecutando Esto puede causar Cuando una solicitud se agota, un semáforo siempre está ocupado, pero el marco no puede manejarlo.
Aislamiento y degradación del servicio
Otro problema es que el servicio no puede realizar la degradación del servicio y la fusión de la manera esperada, pensamos que cuando el tráfico es muy grande, debe continuar fusionándose, pero Hystrix muestra fusión ocasional.
Al depurar los parámetros del fusible Hystrix al principio, usamos el método de observación de registro. Dado que el registro está configurado en asíncrono, no podemos ver el registro en tiempo real y hay mucha interferencia de información de error, el proceso es ineficiente e inexacto . Después de la introducción de la interfaz visual de Hystrix, se mejoró la eficiencia de depuración.
El modo de visualización de Hystrix se divide en servidor y cliente. El servidor es el servicio que queremos observar. Necesitamos introducir el paquete hystrix-metrics-event-stream en el servicio y agregar una interfaz para generar información de Métricas, luego iniciar hystrix -cliente de tablero y simplemente complete la dirección del servidor.
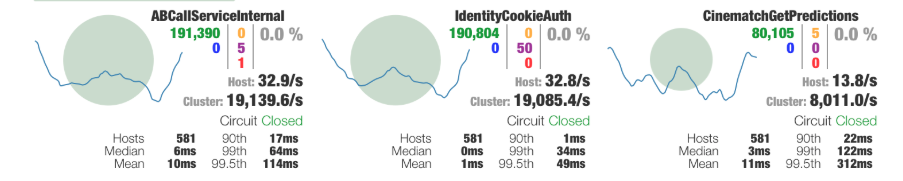
A través de una interfaz visual similar a la figura anterior, el estado general de Hystrix se muestra muy claramente.
Debido a la optimización anterior, el tiempo de respuesta máximo de la interfaz es completamente controlable y la estrategia de fusión de la interfaz se puede modificar limitando estrictamente la concurrencia del método de interfaz. Asumiendo que el tiempo de respuesta promedio de la interfaz máxima que podemos tolerar es de 50ms, y el QPS máximo que el servicio puede aceptar es de 2000, entonces el límite de semáforos apropiado se puede obtener de 2000*50/1000=100. muchos errores rechazados, puede Agregar algo de redundancia.
De esta manera, cuando el tráfico cambia repentinamente, el número total de solicitudes aceptadas por la interfaz se puede controlar rechazando algunas solicitudes, y entre estas solicitudes totales, el tiempo máximo de consumo está estrictamente limitado.Si hay demasiados errores, se también se puede degradar fusionando, se llevan a cabo múltiples estrategias al mismo tiempo y se puede garantizar el tiempo de respuesta promedio de la interfaz.
Irrecuperable debido a la alta carga al fusionar
El siguiente paso es resolver el problema de que cuando se quema la interfaz, la carga del servicio continúa aumentando, pero el servicio no se puede restaurar después de que se reduce la presión del QPS.
Cuando la carga del servidor es particularmente alta, no es confiable usar varias herramientas para observar el estado interno del servicio, porque la observación generalmente adopta el método de recopilación de puntos, y el servicio se ha cambiado mientras se observa el servicio. Por ejemplo, cuando se usa jtop para ver los subprocesos que hacen un uso más intensivo de la CPU bajo una carga alta, los resultados obtenidos siempre son pilas relacionadas con JVM TI.
Sin embargo, al observar el exterior del servicio, podemos encontrar que habrá una gran cantidad de resultados de registro de errores en este momento, a menudo después de que el servicio haya estado estable durante mucho tiempo, todavía se están imprimiendo registros de errores anteriores y el la unidad de retraso incluso se mide en minutos. Una gran cantidad de registros de errores no solo causan presión de E/S, sino que también la adquisición de pilas de subprocesos y la asignación de memoria de registro aumentarán la presión en el servidor. Además, el servidor ha cambiado a registro asíncrono debido a la gran cantidad de registros, lo que hace que desaparezca la barrera de bloqueo de hilos a través de E/S.
Luego, modifique el punto de registro del registro en el servicio, ya no imprima la pila de excepciones al imprimir el registro y luego vuelva a escribir el ExceptionHandler del marco Spring para reducir completamente la salida del volumen del registro. Los resultados están en línea con las expectativas Cuando la cantidad de errores es extremadamente grande, la salida del registro también se controla dentro del rango normal, de modo que después del fusible, el registro ya no aumentará la presión sobre el servicio. cae, el interruptor de fusible se apaga y el servicio pronto estará disponible. Vuelta a la normalidad.
Excepción de enlace de datos de Spring
Además, al mirar la salida de la pila de subprocesos por jstack, también me topé con una pila extraña.
at java.lang.Throwable.fillInStackTrace(Native Method)
at java.lang.Throwable.fillInStackTrace(Throwable.java:783)
- locked <0x00000006a697a0b8> (a org.springframework.beans.NotWritablePropertyException)
...
org.springframework.beans.AbstractNestablePropertyAccessor.processLocalProperty(AbstractNestablePropertyAccessor.java:426)
at org.springframework.beans.AbstractNestablePropertyAccessor.setPropertyValue(AbstractNestablePropertyAccessor.java:278)
...
at org.springframework.validation.DataBinder.doBind(DataBinder.java:735)
at org.springframework.web.bind.WebDataBinder.doBind(WebDataBinder.java:197)
at org.springframework.web.bind.ServletRequestDataBinder.bind(ServletRequestDataBinder.java:107)
at org.springframework.web.method.support.InvocableHandlerMethod.getMethodArgumentValues(InvocableHandlerMethod.java:161)
...
at org.springframework.web.servlet.DispatcherServlet.doDispatch(DispatcherServlet.java:991)
En una salida de jstack, puede ver que la parte superior de la pila de múltiples subprocesos permanece en el manejo de excepciones de Spring, pero en este momento no hay salida de registro y no hay ninguna excepción en el negocio.Después de ver el código , Spring capturó inesperadamente la excepción en secreto y no hizo nada.
List<PropertyAccessException> propertyAccessExceptions = null;
List<PropertyValue> propertyValues = (pvs instanceof MutablePropertyValues ?
((MutablePropertyValues) pvs).getPropertyValueList() : Arrays.asList(pvs.getPropertyValues()));
for (PropertyValue pv : propertyValues) {
try {
// This method may throw any BeansException, which won't be caught
// here, if there is a critical failure such as no matching field.
// We can attempt to deal only with less serious exceptions.
setPropertyValue(pv);
}
catch (NotWritablePropertyException ex) {
if (!ignoreUnknown) {
throw ex;
}
// Otherwise, just ignore it and continue...
}
... ...
}
Combinado con el contexto del código, resulta que Spring está procesando el enlace de datos de nuestro controlador, y los datos a procesar son uno de nuestra clase de parámetros ApiContext.
El código del controlador es algo así como:
@RequestMapping("test.json")
public Map testApi(@RequestParam(name = "id") String id, ApiContext apiContext) {
}
De acuerdo con la rutina normal, debemos agregar un solucionador de parámetros (HandlerMethodArgumentResolver) a esta clase ApiContext, de modo que Spring llamará a este solucionador de parámetros para generar un tipo de parámetro correspondiente para el método al analizar este parámetro. Pero si no existe tal analizador de parámetros, ¿cómo lo manejará Spring?
La respuesta es usar el código "extraño" anterior, primero cree una clase ApiContext vacía e intente configurar todos los parámetros entrantes en esta clase a su vez, si el conjunto falla, capture la excepción y continúe con la ejecución, y el conjunto tiene éxito Después que, se completa el enlace de parámetros de una propiedad en la clase ApiContext.
Desafortunadamente, la capa superior de nuestra interfaz pasará de manera uniforme treinta o cuarenta parámetros por nosotros, por lo que se realizará una gran cantidad de "intentos de vinculación" cada vez, y las excepciones resultantes y el manejo de excepciones conducirán a una gran pérdida de rendimiento. Después de que el analizador de parámetros resuelve este problema, el rendimiento de la interfaz ha mejorado casi una décima parte.
resumen
La optimización del rendimiento no ocurre de la noche a la mañana, y nunca es una buena opción acumular deuda técnica hasta la última pieza para resolverlo. Por lo general, preste más atención a la escritura de algunos códigos. Cuando use tecnología negra, preste atención a si hay pozos ocultos.