Article directory
Reference article PyTorch implementation of classic convolution architecture: Xception
reference article Convolutional neural network structure brief (2) Inception series network
github project Xception backbone
Depthwise Separable Convolution
In the lightweight network, there will be depthwise separable convolution, which is combined by depthwise and pointwise to extract feature maps.
A convolution kernel of depthwise convolution is only responsible for one channel, the number of input and output channels is the same, the featuremap cannot be expanded, and the feature information of different channels at the same spatial position is not effectively used, so pointwise convolution is required to effectively combine the feature map.
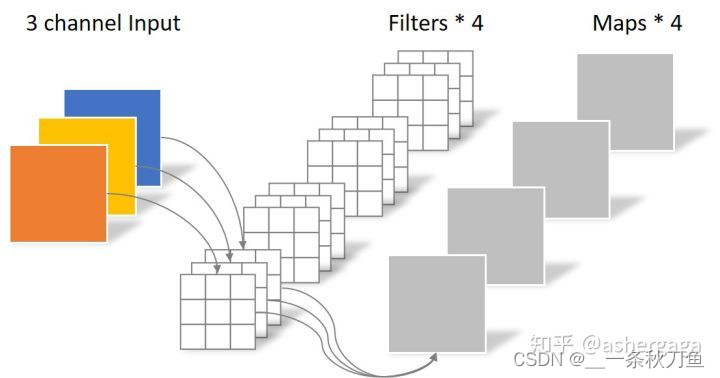
depthwise convolution, N = 3 ∗ 3 ∗ 3 N = 3*3*3N=3∗3∗3
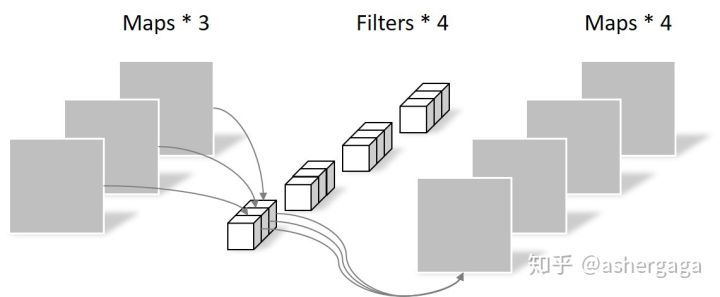
pointwise convolution, N = 1 ∗ 1 ∗ 3 ∗ 4 N = 1*1*3*4 N=1∗1∗3∗4
If it is a conventional convolution operation, you need to use 3 ∗ 3 ∗ 4 3*3*43∗3∗4 parameters, so the use of depth separable convolution can effectively reduce the number of parameters.
class SeparableConv2d(nn.Module):
def __init__(self,in_channels,out_channels,kernel_size=1,stride=1,padding=0,dilation=1,bias=False):
super(SeparableConv2d,self).__init__()
self.conv1 = nn.Conv2d(in_channels,in_channels,kernel_size,stride,padding,dilation,groups=in_channels,bias=bias)
self.pointwise = nn.Conv2d(in_channels,out_channels,1,1,0,1,1,bias=bias)
def forward(self,x):
x = self.conv1(x)
x = self.pointwise(x)
return x
Inception development
GoogleNet
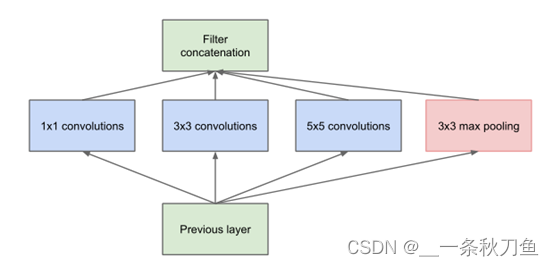
Unlike networks such as VGG, which think that the stacking depth is different, in order to solve the problem of too many parameters and overfitting as the network deepens, GoogleNet first proposed the parallel merger of convolution kernels. Compared with VGG, it has the following improvements:
- Using kernels of different sizes, the network can learn sparse features in each layer ( 3 ∗ 3 3*33∗3, 5 ∗ 5 5*5 5∗5 kernel) and non-sparse features (1 ∗ 1 1*11∗1 kernel)。
- Increase the width of the network and increase the adaptability of the network to the scale.
- Through the concat of different blocks, non-linear attributes are obtained.
But it also faces the problem of a large amount of calculation as the depth of the network deepens. Therefore, drawing on the idea of Network in network, use 1 ∗ 1 1*11∗The convolution kernel of 1 performs dimensionality reduction operation to reduce the parameter amount of the network, that is, inception V1.
Inception Network
inception V1
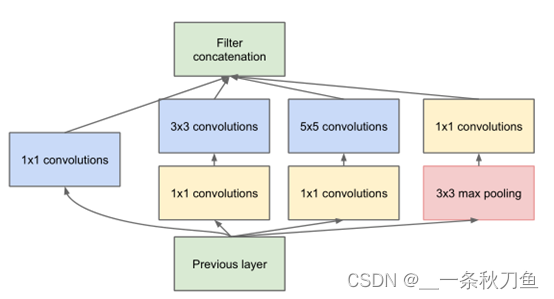
Based on the structure of inception V1, the improvements of inception V2 and V3 follow the following principles:
- The feature map should decrease slowly from input to output
- Adding nonlinearity to convolutional networks can make network training faster
- Dimensionality reduction of the input before large-scale convolution does not affect the expressiveness of the features. That is, aggregation in space can be performed with low-dimensional embeddings.
- Balance the depth and width of your network.
inception V2
Inception V2 uses:
- BN layer
- Use two 3∗3 3*33∗The convolution kernel of 3 replaces5 ∗ 5 5*55∗The convolution kernel of 5 has fewer parameters, which indirectly increases the depth of the network.
Since inception V2 adopts the structure of pooling first and then inception, it will cause the bottleneck problem of expression, that is, the size of the feature map cannot be reduced sharply, and it will drop suddenly after only one layer, and a large amount of information will be lost, which will cause difficulties in model training.
inception V3
Inception V3 adopts a parallel dimensionality reduction structure, that is, after conv and pool and then concat the results.
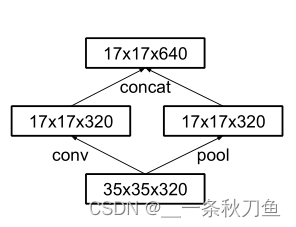
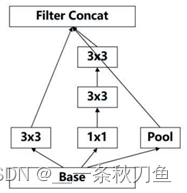
35-17
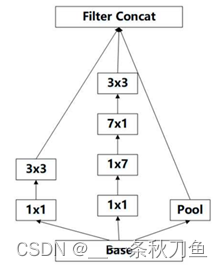
17-8
inception V4
On the basis of inception V3, the convolution and pooling operations of the first few layers of the network are replaced with stem modules to deepen the network structure.
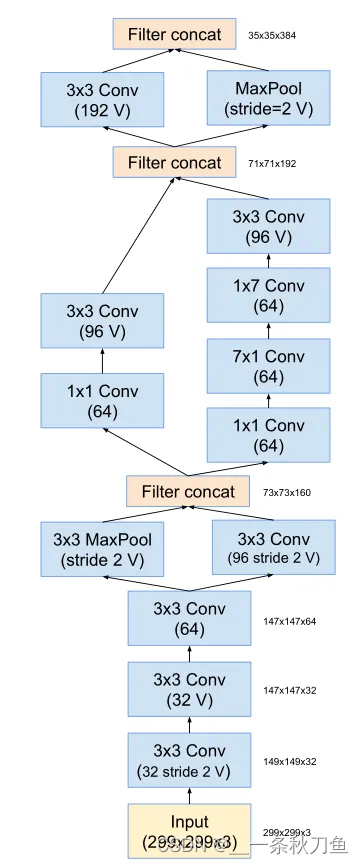
Xception
Xception replaces the inception module in inception with a depthwise separable convolution.
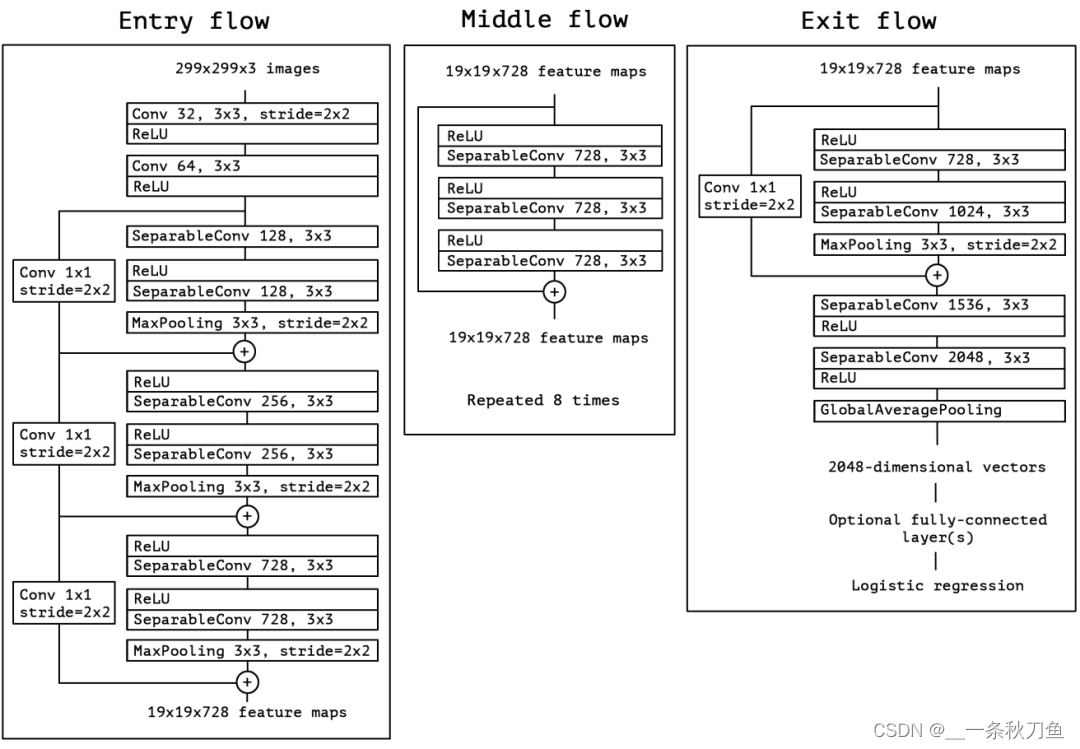
The network introduces the idea of ResNet, introduces skip connection, and performs BN operation after each convolution.
"""
Xception is adapted from https://github.com/Cadene/pretrained-models.pytorch/blob/master/pretrainedmodels/models/xception.py
Ported to pytorch thanks to [tstandley](https://github.com/tstandley/Xception-PyTorch)
@author: tstandley
Adapted by cadene
Creates an Xception Model as defined in:
Francois Chollet
Xception: Deep Learning with Depthwise Separable Convolutions
https://arxiv.org/pdf/1610.02357.pdf
This weights ported from the Keras implementation. Achieves the following performance on the validation set:
Loss:0.9173 Prec@1:78.892 Prec@5:94.292
REMEMBER to set your image size to 3x299x299 for both test and validation
normalize = transforms.Normalize(mean=[0.5, 0.5, 0.5],
std=[0.5, 0.5, 0.5])
The resize parameter of the validation transform should be 333, and make sure to center crop at 299x299
"""
from __future__ import print_function, division, absolute_import
import math
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.utils.model_zoo as model_zoo
from torch.nn import init
__all__ = ['xception']
pretrained_settings = {
'xception': {
'imagenet': {
'url': 'http://data.lip6.fr/cadene/pretrainedmodels/xception-43020ad28.pth',
'input_space': 'RGB',
'input_size': [3, 299, 299],
'input_range': [0, 1],
'mean': [0.5, 0.5, 0.5],
'std': [0.5, 0.5, 0.5],
'num_classes': 1000,
'scale': 0.8975 # The resize parameter of the validation transform should be 333, and make sure to center crop at 299x299
}
}
}
class SeparableConv2d(nn.Module):
def __init__(self,in_channels,out_channels,kernel_size=1,stride=1,padding=0,dilation=1,bias=False):
super(SeparableConv2d,self).__init__()
self.conv1 = nn.Conv2d(in_channels,in_channels,kernel_size,stride,padding,dilation,groups=in_channels,bias=bias)
self.pointwise = nn.Conv2d(in_channels,out_channels,1,1,0,1,1,bias=bias)
def forward(self,x):
x = self.conv1(x)
x = self.pointwise(x)
return x
class Block(nn.Module):
def __init__(self,in_filters,out_filters,reps,strides=1,start_with_relu=True,grow_first=True, dilation=1):
super(Block, self).__init__()
# skip connections
if out_filters != in_filters or strides!=1:
self.skip = nn.Conv2d(in_filters,out_filters,1,stride=strides, bias=False)
self.skipbn = nn.BatchNorm2d(out_filters)
else:
self.skip=None
rep=[]
filters=in_filters
if grow_first:
rep.append(nn.ReLU(inplace=True))
rep.append(SeparableConv2d(in_filters,out_filters,3,stride=1,padding=dilation, dilation=dilation, bias=False))
rep.append(nn.BatchNorm2d(out_filters))
filters = out_filters
for i in range(reps-1):
rep.append(nn.ReLU(inplace=True))
rep.append(SeparableConv2d(filters,filters,3,stride=1,padding=dilation,dilation=dilation,bias=False))
rep.append(nn.BatchNorm2d(filters))
if not grow_first:
rep.append(nn.ReLU(inplace=True))
rep.append(SeparableConv2d(in_filters,out_filters,3,stride=1,padding=dilation,dilation=dilation,bias=False))
rep.append(nn.BatchNorm2d(out_filters))
if not start_with_relu:
rep = rep[1:]
else:
rep[0] = nn.ReLU(inplace=False)
if strides != 1:
rep.append(nn.MaxPool2d(3,strides,1))
self.rep = nn.Sequential(*rep)
def forward(self,inp):
x = self.rep(inp)
if self.skip is not None:
skip = self.skip(inp)
skip = self.skipbn(skip)
else: # middle flow
skip = inp
x+=skip
return x
class Xception(nn.Module):
"""
Xception optimized for the ImageNet dataset, as specified in
https://arxiv.org/pdf/1610.02357.pdf
"""
def __init__(self, num_classes=1000, replace_stride_with_dilation=None):
""" Constructor
Args:
num_classes: number of classes
"""
super(Xception, self).__init__()
self.num_classes = num_classes
self.dilation = 1
if replace_stride_with_dilation is None:
# each element in the tuple indicates if we should replace
# the 2x2 stride with a dilated convolution instead
replace_stride_with_dilation = [False, False, False, False]
if len(replace_stride_with_dilation) != 4:
raise ValueError("replace_stride_with_dilation should be None "
"or a 4-element tuple, got {}".format(replace_stride_with_dilation))
self.conv1 = nn.Conv2d(3, 32, 3,2, 0, bias=False) # 1 / 2
self.bn1 = nn.BatchNorm2d(32)
self.relu1 = nn.ReLU(inplace=True)
self.conv2 = nn.Conv2d(32,64,3,bias=False)
self.bn2 = nn.BatchNorm2d(64)
self.relu2 = nn.ReLU(inplace=True)
#do relu here
self.block1=self._make_block(64,128,2,2,start_with_relu=False,grow_first=True, dilate=replace_stride_with_dilation[0]) # 1 / 4
self.block2=self._make_block(128,256,2,2,start_with_relu=True,grow_first=True, dilate=replace_stride_with_dilation[1]) # 1 / 8
self.block3=self._make_block(256,728,2,2,start_with_relu=True,grow_first=True, dilate=replace_stride_with_dilation[2]) # 1 / 16
self.block4=self._make_block(728,728,3,1,start_with_relu=True,grow_first=True, dilate=replace_stride_with_dilation[2])
self.block5=self._make_block(728,728,3,1,start_with_relu=True,grow_first=True, dilate=replace_stride_with_dilation[2])
self.block6=self._make_block(728,728,3,1,start_with_relu=True,grow_first=True, dilate=replace_stride_with_dilation[2])
self.block7=self._make_block(728,728,3,1,start_with_relu=True,grow_first=True, dilate=replace_stride_with_dilation[2])
self.block8=self._make_block(728,728,3,1,start_with_relu=True,grow_first=True, dilate=replace_stride_with_dilation[2])
self.block9=self._make_block(728,728,3,1,start_with_relu=True,grow_first=True, dilate=replace_stride_with_dilation[2])
self.block10=self._make_block(728,728,3,1,start_with_relu=True,grow_first=True, dilate=replace_stride_with_dilation[2])
self.block11=self._make_block(728,728,3,1,start_with_relu=True,grow_first=True, dilate=replace_stride_with_dilation[2])
self.block12=self._make_block(728,1024,2,2,start_with_relu=True,grow_first=False, dilate=replace_stride_with_dilation[3]) # 1 / 32
self.conv3 = SeparableConv2d(1024,1536,3,1,1, dilation=self.dilation)
self.bn3 = nn.BatchNorm2d(1536)
self.relu3 = nn.ReLU(inplace=True)
#do relu here
self.conv4 = SeparableConv2d(1536,2048,3,1,1, dilation=self.dilation)
self.bn4 = nn.BatchNorm2d(2048)
self.fc = nn.Linear(2048, num_classes)
# #------- init weights --------
# for m in self.modules():
# if isinstance(m, nn.Conv2d):
# n = m.kernel_size[0] * m.kernel_size[1] * m.out_channels
# m.weight.data.normal_(0, math.sqrt(2. / n))
# elif isinstance(m, nn.BatchNorm2d):
# m.weight.data.fill_(1)
# m.bias.data.zero_()
# #-----------------------------
def _make_block(self, in_filters,out_filters,reps,strides=1,start_with_relu=True,grow_first=True, dilate=False):
if dilate:
self.dilation *= strides
strides = 1
return Block(in_filters,out_filters,reps,strides,start_with_relu=start_with_relu,grow_first=grow_first, dilation=self.dilation)
def features(self, input):
x = self.conv1(input)
x = self.bn1(x)
x = self.relu1(x)
x = self.conv2(x)
x = self.bn2(x)
x = self.relu2(x)
x = self.block1(x)
x = self.block2(x)
x = self.block3(x)
x = self.block4(x)
x = self.block5(x)
x = self.block6(x)
x = self.block7(x)
x = self.block8(x)
x = self.block9(x)
x = self.block10(x)
x = self.block11(x)
x = self.block12(x)
x = self.conv3(x)
x = self.bn3(x)
x = self.relu3(x)
x = self.conv4(x)
x = self.bn4(x)
return x
def logits(self, features):
x = nn.ReLU(inplace=True)(features)
x = F.adaptive_avg_pool2d(x, (1, 1))
x = x.view(x.size(0), -1)
x = self.last_linear(x)
return x
def forward(self, input):
x = self.features(input)
x = self.logits(x)
return x
def xception(num_classes=1000, pretrained='imagenet', replace_stride_with_dilation=None):
model = Xception(num_classes=num_classes, replace_stride_with_dilation=replace_stride_with_dilation)
if pretrained:
settings = pretrained_settings['xception'][pretrained]
assert num_classes == settings['num_classes'], \
"num_classes should be {}, but is {}".format(settings['num_classes'], num_classes)
model = Xception(num_classes=num_classes, replace_stride_with_dilation=replace_stride_with_dilation)
model.load_state_dict(model_zoo.load_url(settings['url']))
# TODO: ugly
model.last_linear = model.fc
del model.fc
return model