개요
이 실습에서는 Enterprise Manager용 Oracle DMS(Data Masking and Subsetting) 팩의 다양한 특징과 기능을 소개합니다. 사용자는 비생산 환경에서 중요한 데이터를 보호하기 위해 이러한 기능을 구성하는 방법을 배울 수 있습니다.
이 실험의 신청 주소는 여기 이며 시간은 60분입니다.
이 실험은 DB Security Advanced 세미나인 Lab 8: Data Masking and Subsetting (DMS)의 8번째 실험이기도 합니다. 이 제품의 중국어 이름은 "Data Masking and Subsetting Package"입니다.
여기에서 실험 도움말을 참조하세요 .
이번 실험에 사용된 제품은 Oracle Enterprise Manager 13.5입니다.
이 실험은 Enterprise Manager와 원본 데이터베이스를 모두 포함하여 하나의 인스턴스만 생성합니다. 내 특정 환경은 다음과 같습니다.
- 158.101.1.3 DBSEC-LAB
OEM(Oracle Enterprise Manager 13c)에 로그인하기 위한 정보는 다음과 같습니다.
- URL: https://<DBSEC-LAB IP 주소>:7803/em (예: https://158.101.1.3:7803/em)
- 사용자 이름: SYSMAN
- 암호: Oracle123
작업 1: 스키마 구조 가져오기
OEM에 로그인합니다.
Enterprise > Quality Management > Application Data Modeling메뉴를 입력합니다 .
보안 테스트 데이터 관리 다이어그램을 간략하게 검토하여 프로세스에 익숙해지십시오.
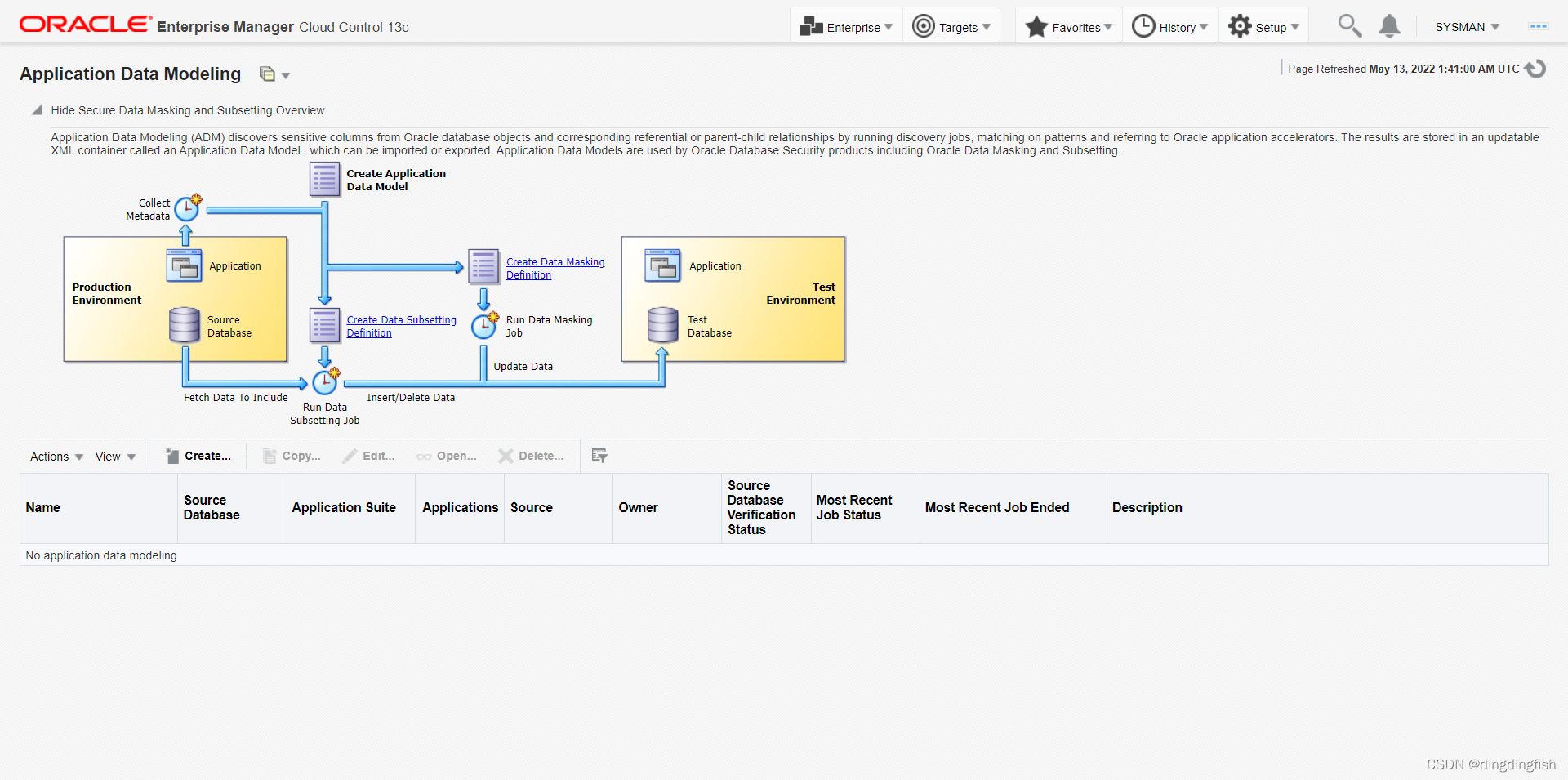
그런 다음 생성을 클릭하여 속성이 다음과 같은 새 ADM(응용 프로그램 데이터 모델)을 추가합니다.
- ADM 이름: Employee_ADM
- 원본 데이터베이스: cdb1_PDB1
- 애플리케이션 제품군 유형:맞춤형 애플리케이션 제품군
- 각 스키마에 대해 하나의 애플리케이션 생성:选中
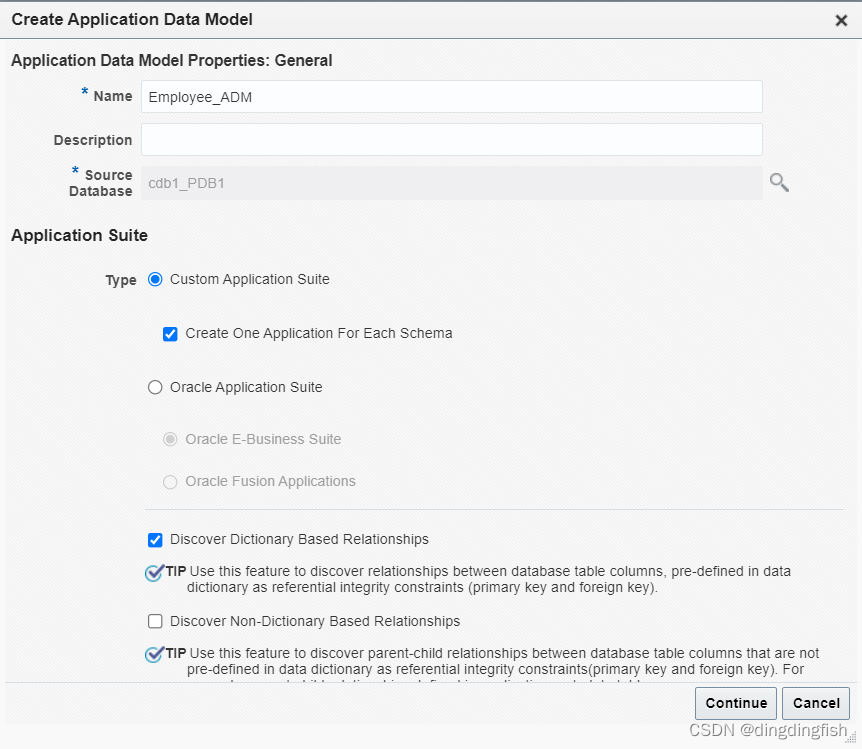
Oracle Enterprise Business Suite(EBS) 및 Fusion Applications 애플리케이션 유형도 지원합니다.
그림과 같이 계속을 클릭하고 미리 정의된 사용자 DMS_ADMIN(암호 Oracle123)을 사용하여 로그인합니다. 참고: SYS 사용자도 사용할 수 있습니다. 프로덕션 환경에서 DMS_ADMIN의 권한을 해당 임무를 수행하는 데 필요한 패키지로만 제한할 수 있습니다.
ADM에 대한 EMPLOYEESEARCH_DEV 스키마를 선택합니다.
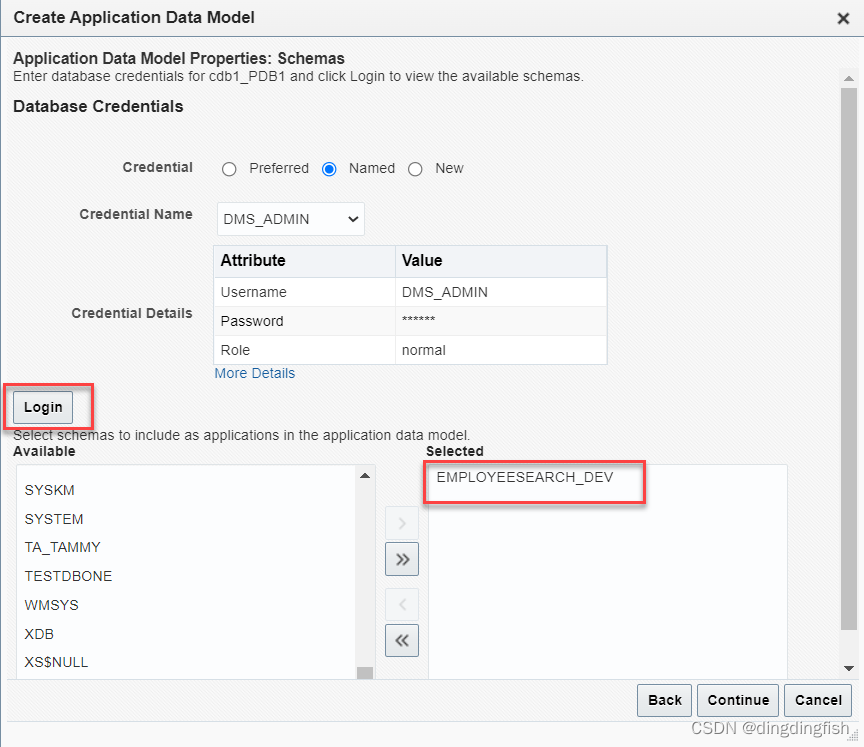
계속을 클릭하고 제출을 클릭하십시오. 작업을 제출합니다(작업 이름 METADATA_COLLECTION_85).
작업의 초기 상태:
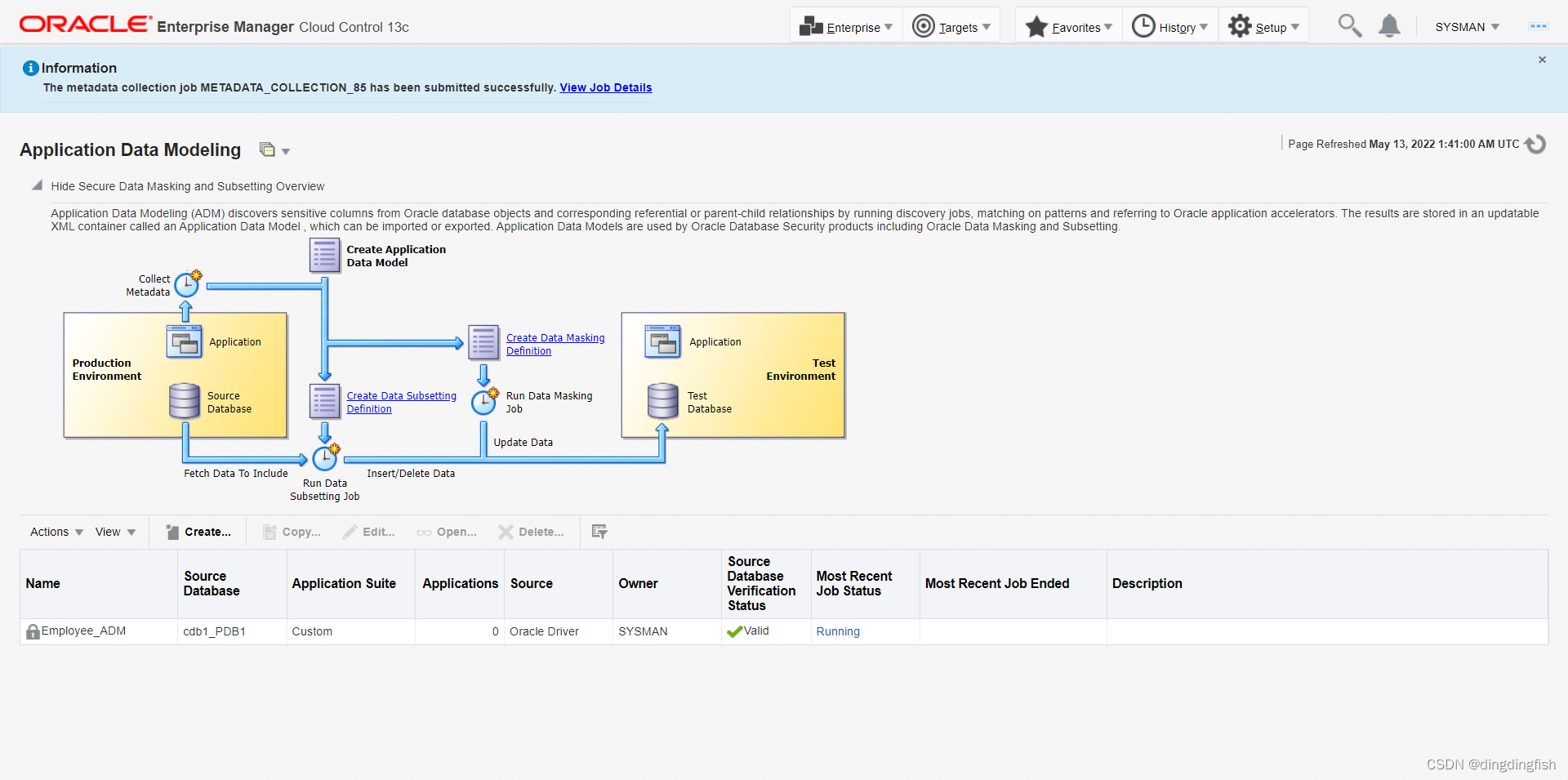
작업이 완료되면 EMPLOYEE_ADM이 더 이상 잠기지 않으며 편집할 수 없습니다. 이 페이지(새로 고침 아이콘)를 새로 고쳐서 상태를 확인하고 Employee_ADM의 최신 작업 상태가 "성공"이면 계속합니다.

작업 2: 메타 모델 개선
ADM을 선택 Employee_ADM하고 편집을 클릭합니다.
자격 증명 이름이 DMS_ADMIN을 선택한 후 계속을 클릭합니다.
애플리케이션 데이터 모델 편집 화면에서 EMPLOYEESEARCH_DEV에 대한 애플리케이션이 스키마를 기반으로 생성되었음을 확인합니다.

이제 참조 관계 탭을 클릭하여 ADM에서 캡처된 참조 관계를 봅니다. 이제 OEM은 외래 키에 대해 알고 있으므로 동일한 형식 마스크를 하위 테이블에 자동으로 적용합니다.
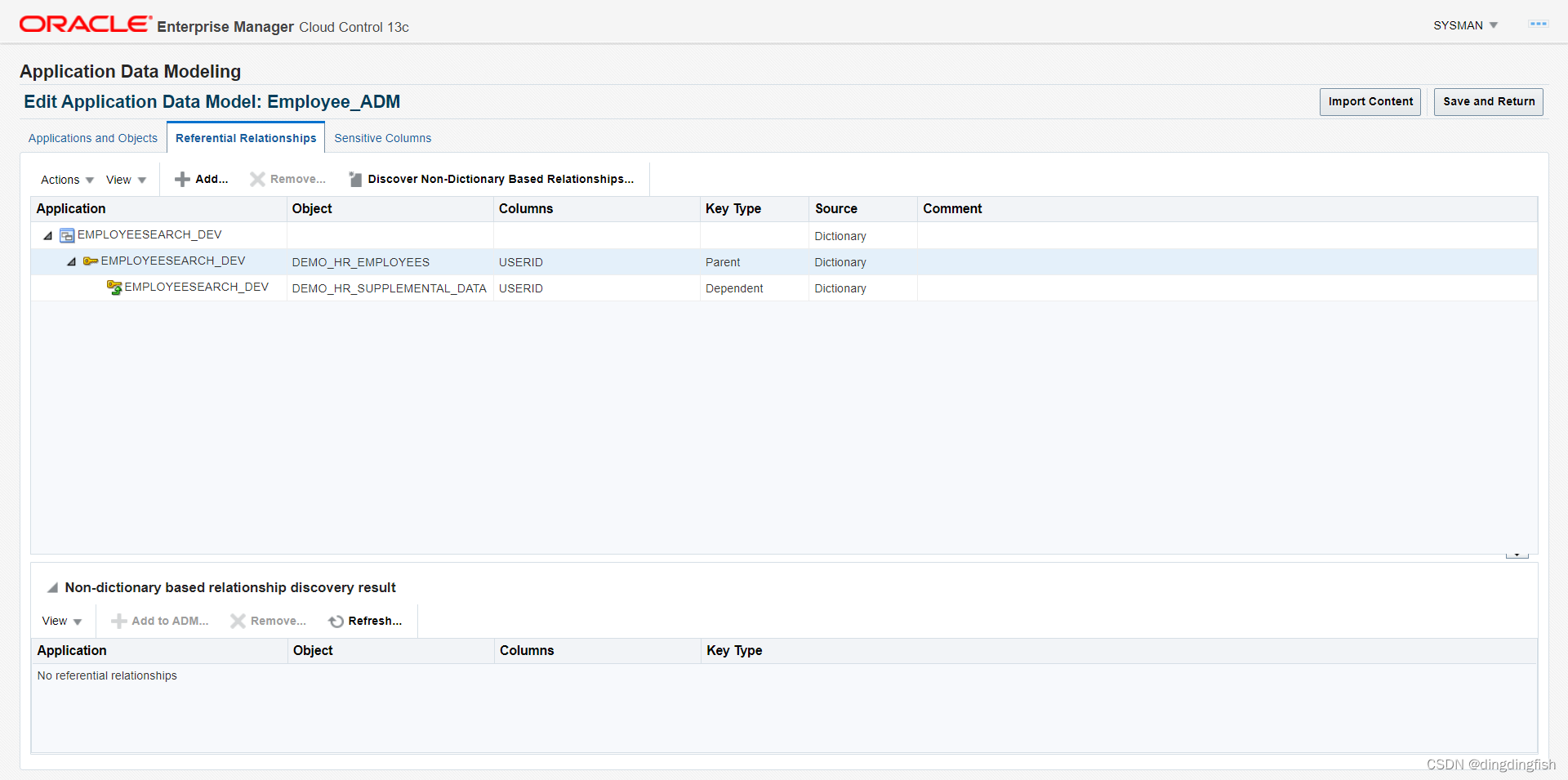
데이터베이스가 참조 관계를 관리하는 경우 ADM은 이를 자동으로 캡처합니다. 애플리케이션에서 관리하는 경우 수동으로 정의해야 합니다. 그러나 여기서는 설명하지 않습니다.
작업 3: 미리 정의된 민감한 열 유형 사용
Enterprise > Quality Management > Application Data Modeling메뉴를 입력합니다 .
작업 메뉴를 확장하고 민감한 열 유형 하위 메뉴 하위 메뉴를 선택합니다.
DMS와 함께 제공되는 기본 민감한 열 검색 템플릿을 확인하십시오.
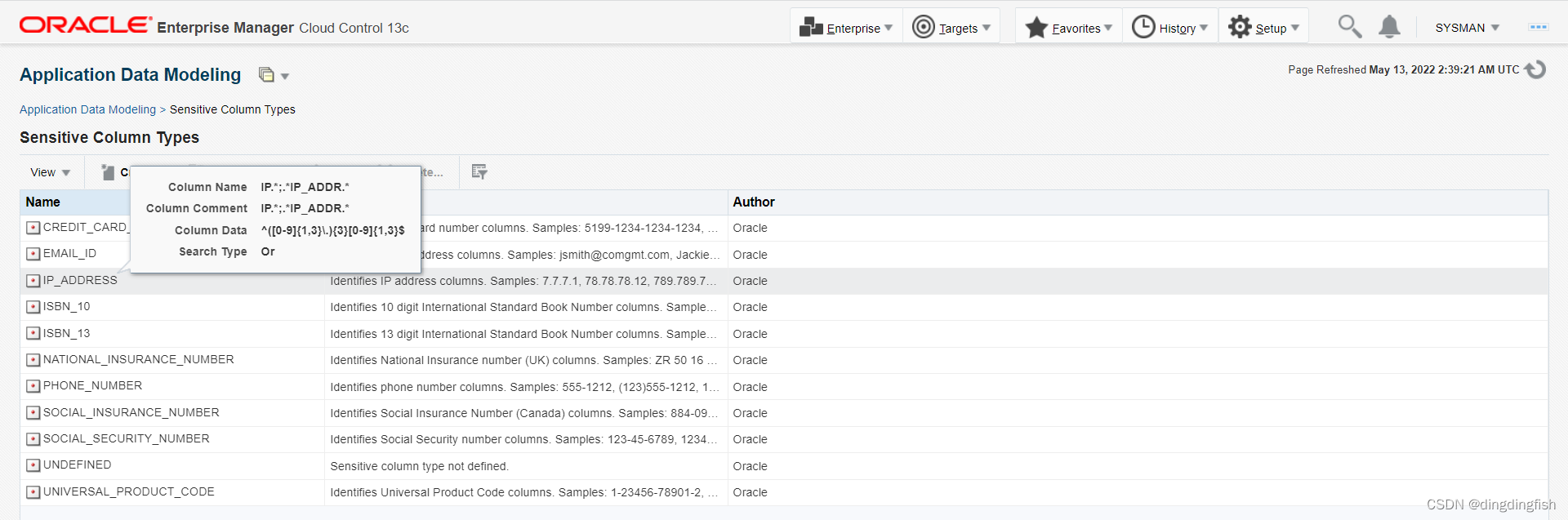
중요한 열의 기본 정의를 보려면 열 위로 마우스를 이동하십시오.
메모:
이 프로시저는 IEEE POSIX(Portable Operating System Interface) 정규식 표준 및 유니코드 컨소시엄 - 유니코드 정규식 지침과 호환되는 Oracle 정규식을 사용합니다. 이 경우 검색 유형이 Or 조건 으로 설정되었으므로 다음과 같은 경우 위의 조건 중 하나라도 일치하면 일치합니다.
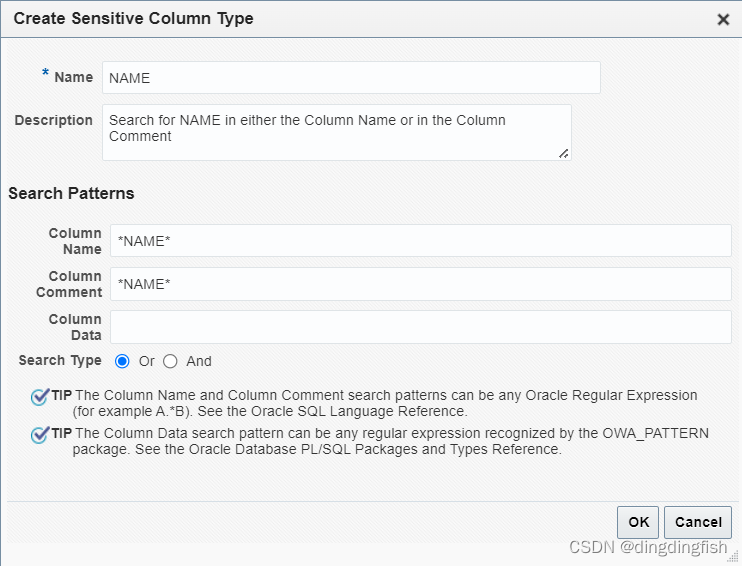
작업 4: 새로운 중요한 열 유형 생성
만들기를 클릭하여 새로운 중요한 열 유형을 만듭니다.
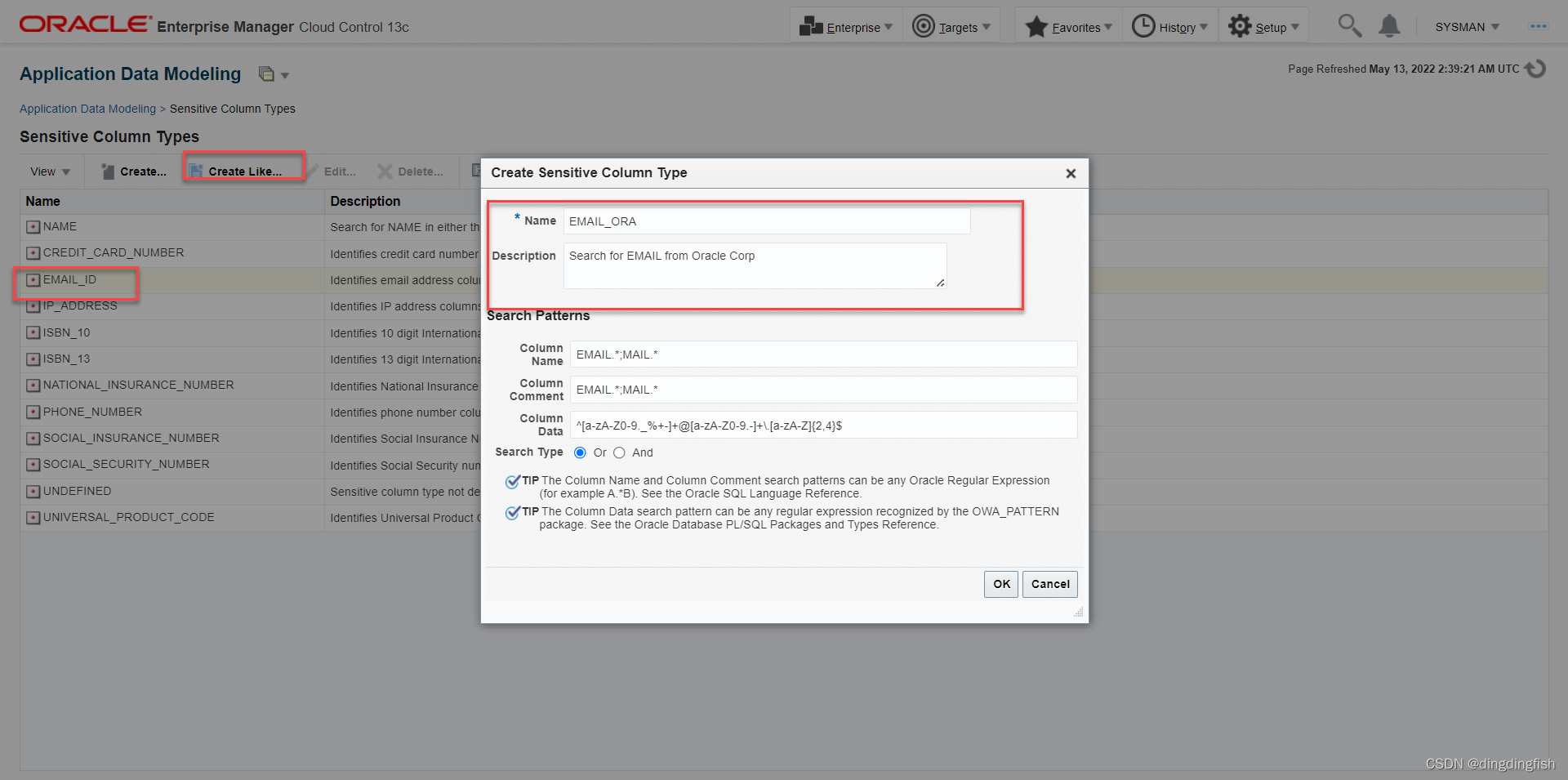
작업 5: 미리 정의된 템플릿을 사용하여 새로운 민감한 열 유형 생성
EMAL_ID를 선택하고 을 선택합니다 Create Like…. 그런 다음 빨간색 상자에 부품을 입력하면 나머지는 자동으로 표시됩니다.
작업 6: 새 마스킹 형식 만들기
메뉴를 입력합니다 Enterprise > Quality Management > Data Masking Formats Library. 기본 데이터 마스킹 형식 보기:
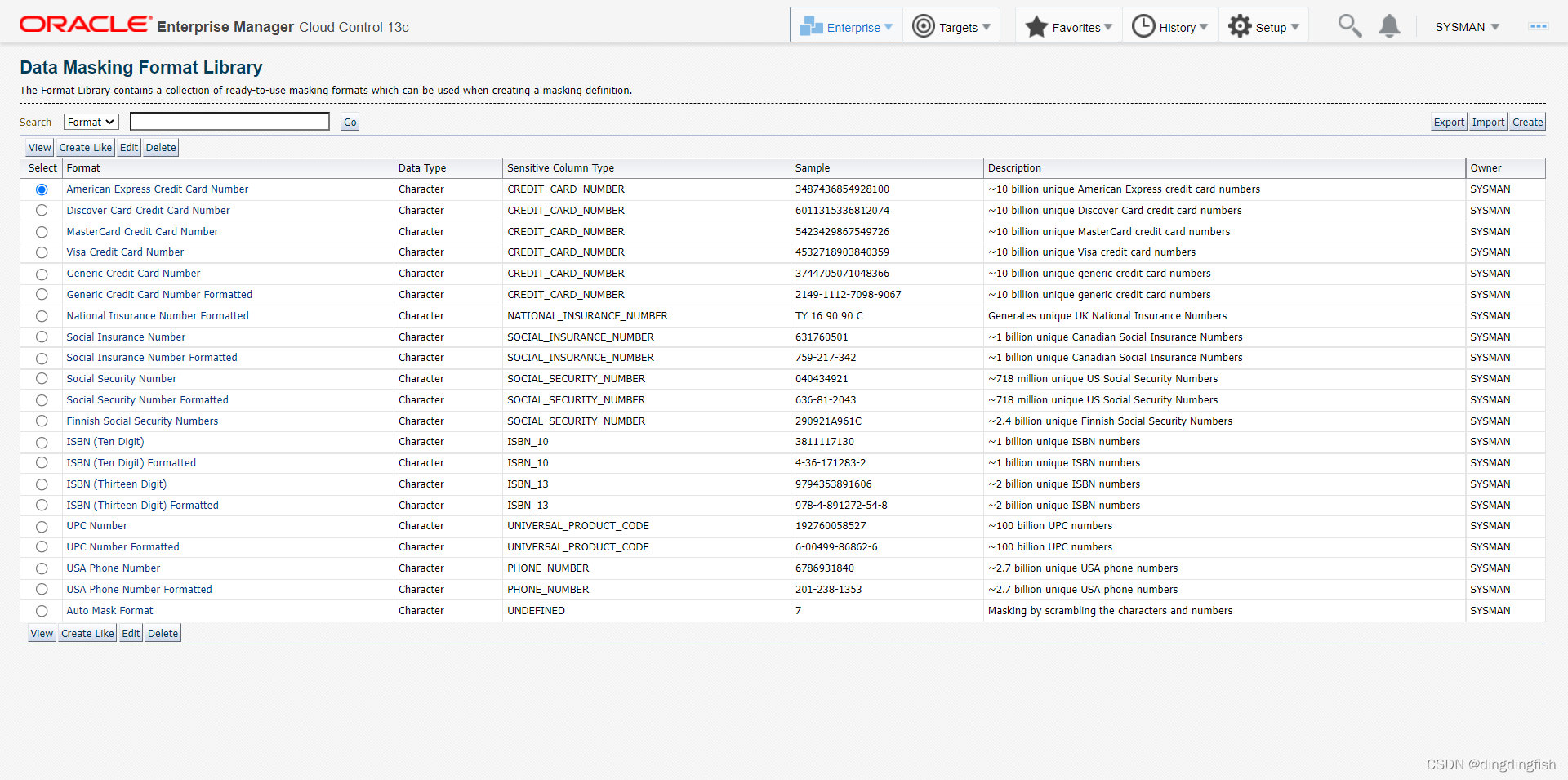
만들기를 클릭하고 아래 그림의 상단 정보를 입력한 다음 오른쪽의 추가 드롭다운 상자를 클릭하여 형식 항목을 추가할 임의 문자열을 선택합니다. 그런 다음 이동을 클릭합니다. 2번 추가 후 최종 결과는 다음과 같습니다.
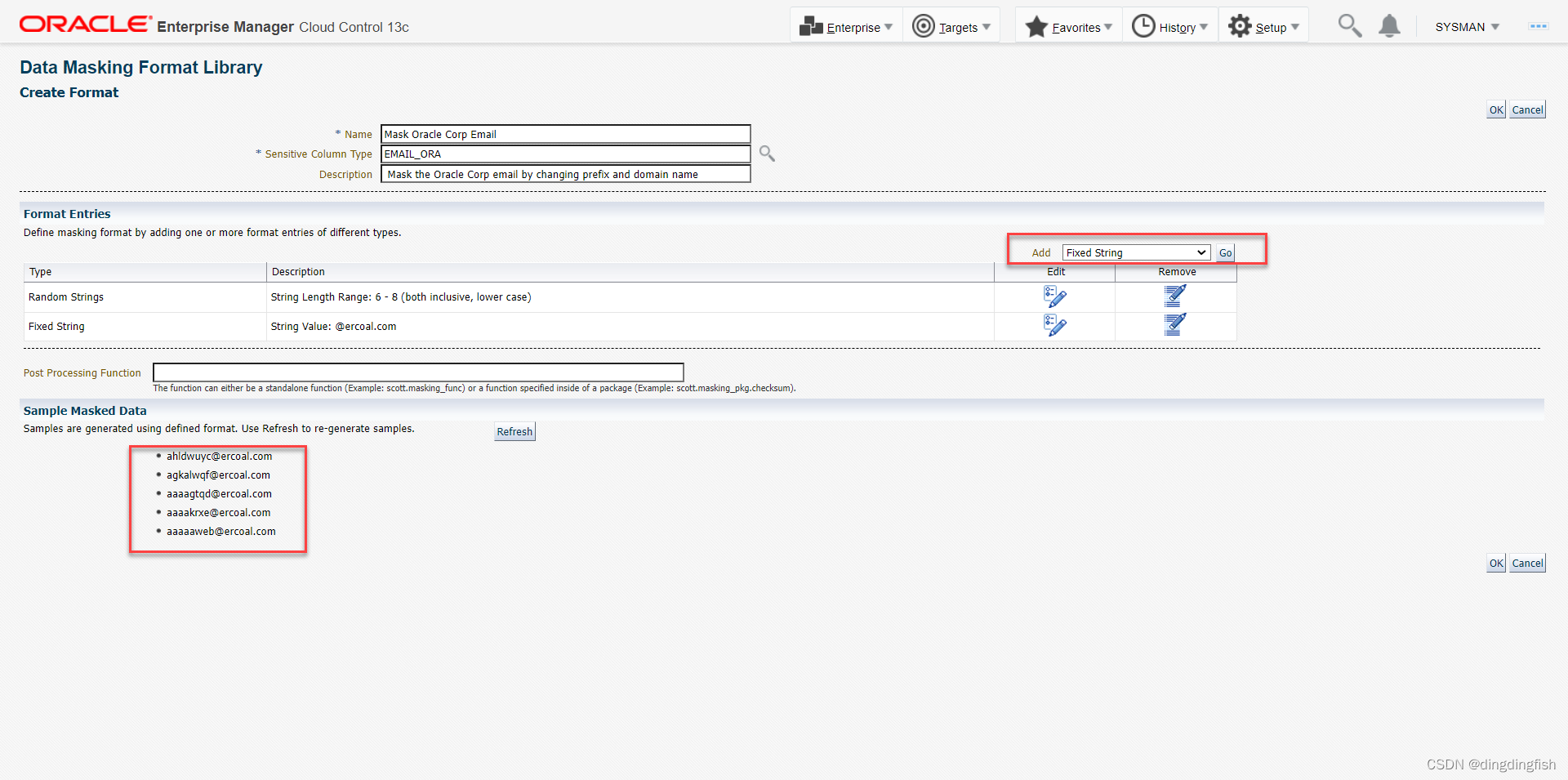
메모:
- EMAIL_ORA는 이전에 생성된 중요한 열 유형입니다.
- 이 마스킹 알고리즘을 사용하면 초기 값을 고정 값 @ercoal과 연결된 시작 부분의 6~8자의 임의 문자열인 새 값으로 바꿉니다.
- 하단에서 사용될 새 값의 예를 볼 수 있습니다.
작업 7: 민감한 열을 수동으로 식별
메뉴를 입력합니다 Enterprise > Quality Management > Application Data Modeling.
ADM을 선택한 상태에서 Employee_ADM를 클릭합니다 Edit.
데이터베이스 키 선택 DMS_ADMIN. 을 클릭하십시오 Continue.
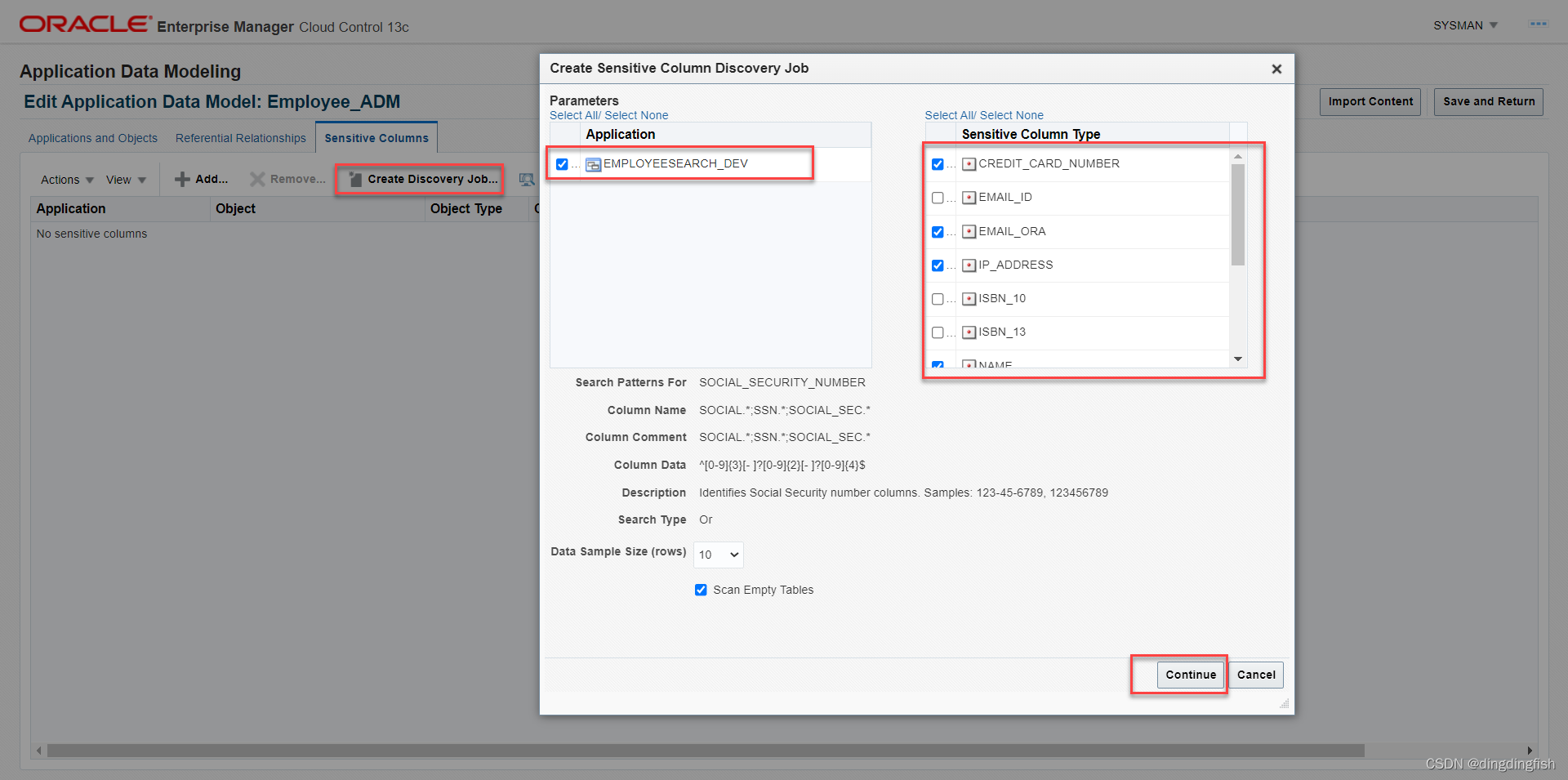
Sensitive Columns탭을 선택합니다 . 현재 중요한 열이 없으므로 검색을 시작해야 합니다. 옵션을 클릭합니다 Create Discovery Job….
EMPLOYEESEARCH_DEV스키마를 선택하면 EMAIL_ID, ISBN_10, ISBN_13, UNIVERSAL_PRODUCT_CODE의 4개 열을 제외합니다. 그런 다음 을 클릭합니다 Continue. 제출을 클릭합니다.
작업이 완료된 후 검색 결과...를 클릭하고 보기를 확장하면(보기->모두 확장) 이러한 열의 현재 중요한 상태가 정의되지 않음임을 알 수 있습니다.
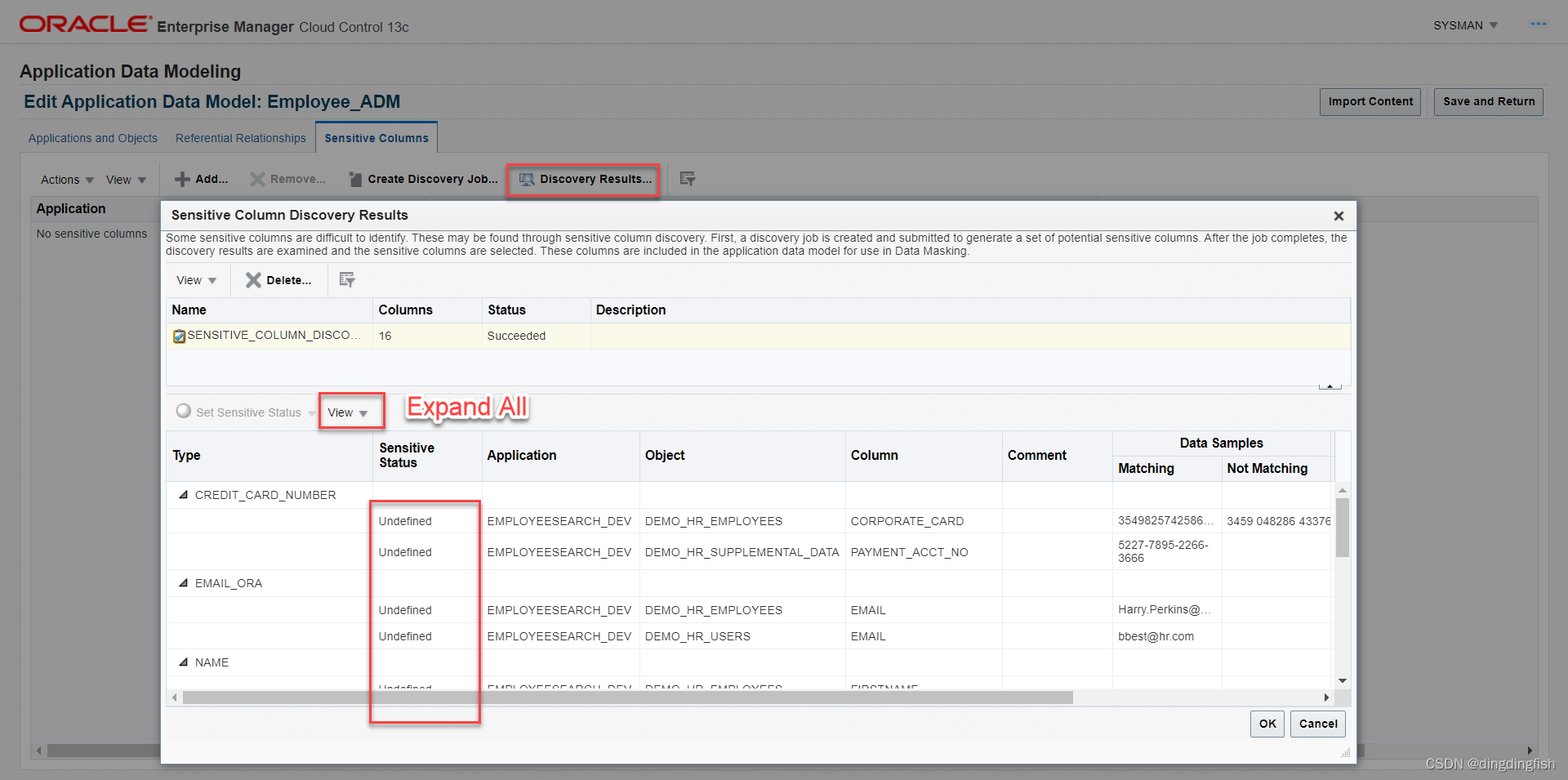
마스킹할 모든 열의 민감도 상태를 민감하게 설정해야 합니다. 다음 열을 확인합니다(tablename.columnname 형식).
- DEMO_HR_SUPPLEMENATL_DATA.PAYMENT_ACCT_NO
- DEMO_HR_EMPLOYEES.EMAIL
- DEMO_HR_USERS.EMAIL
- DEMO_HR_EMPLOYEES.FIRST_NAME
- DEMO_HR_EMPLOYEES.LAST_NAME
- DEMO_HR_SUPPLEMENATL_DATA.ROUTING_NUMBER
민감한 상태 설정을 클릭합니다.
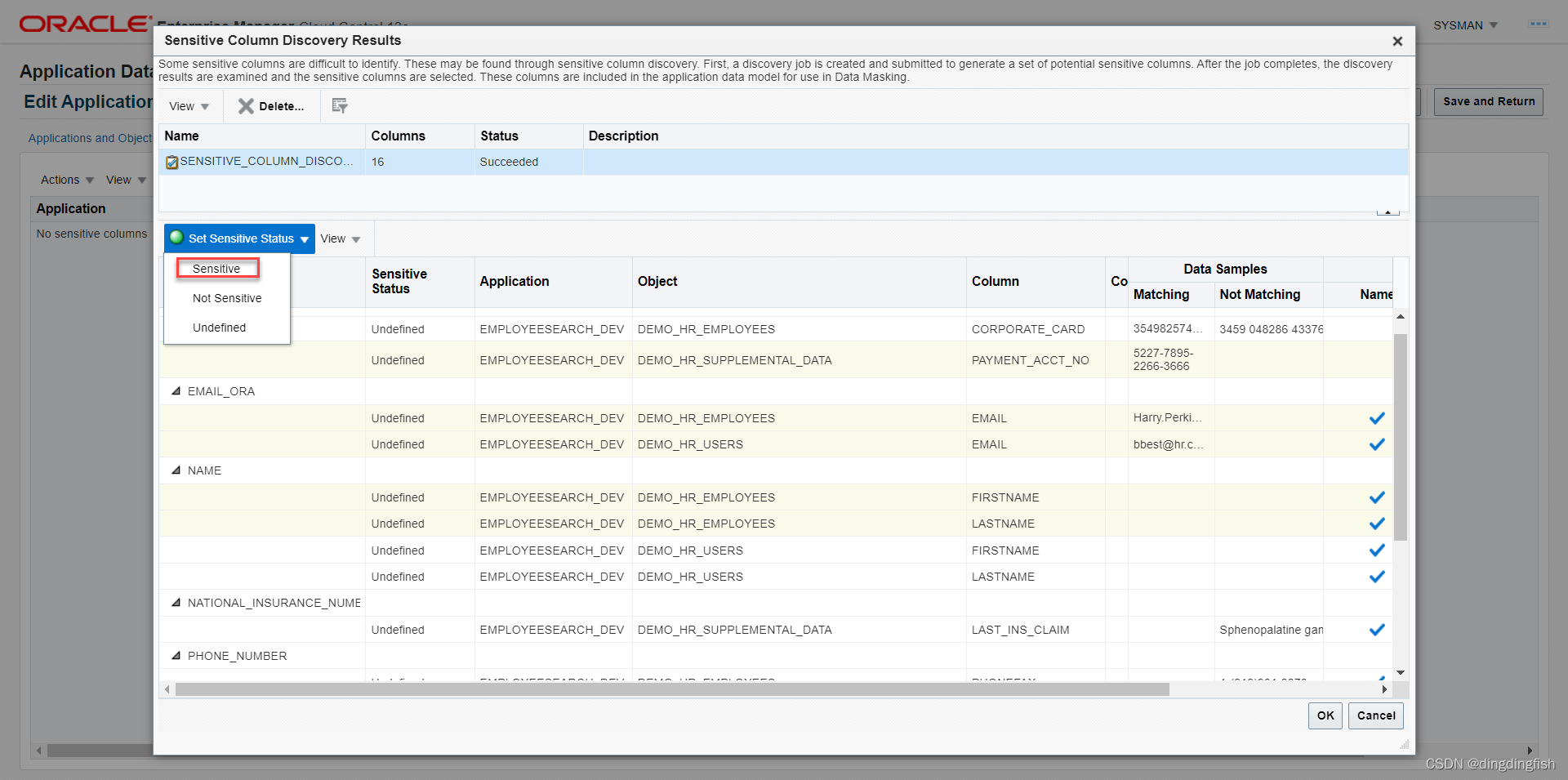
상태가 민감함으로 변경되었음을 확인하십시오.
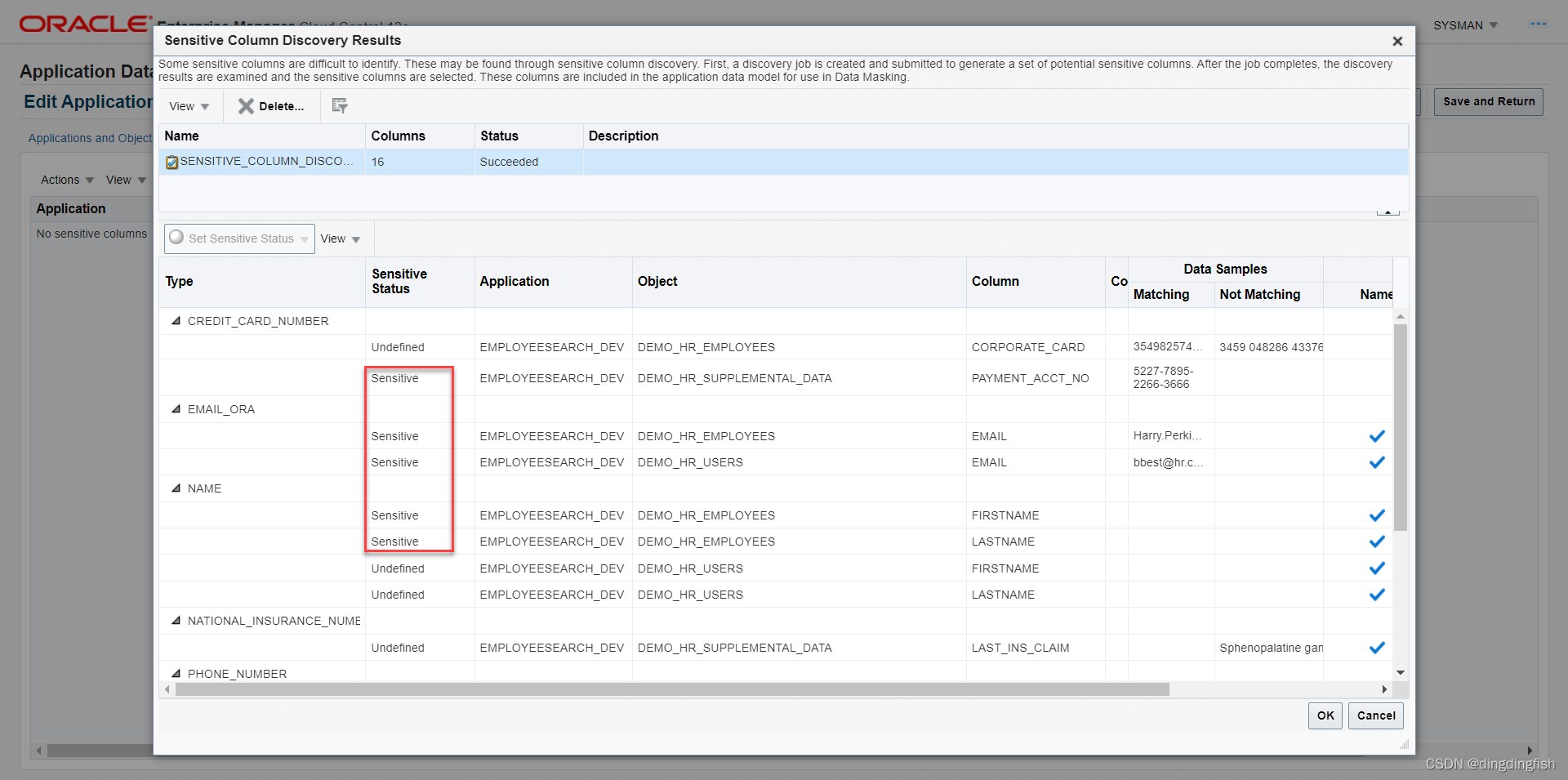
최종 결과는 다음과 같으며 총 6개의 민감한 열이 있습니다.
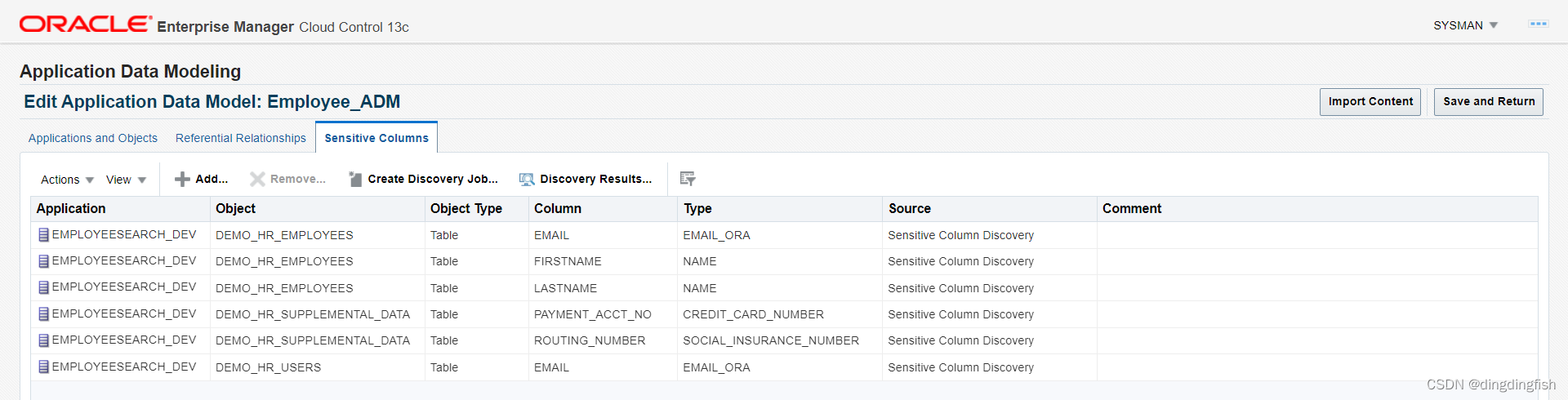
마지막으로 을 클릭합니다 Save and Return.
작업 8: 데이터 마스킹 정의 생성
Enterprise > Quality Management > Data Masking Definitions메뉴를 입력합니다 . 생성을 클릭하여 데이터 마스킹 정의를 생성합니다.
아래 그림과 같이 정보를 입력하고 ADM을 선택합니다 Employee_ADM. 추가를 클릭합니다.
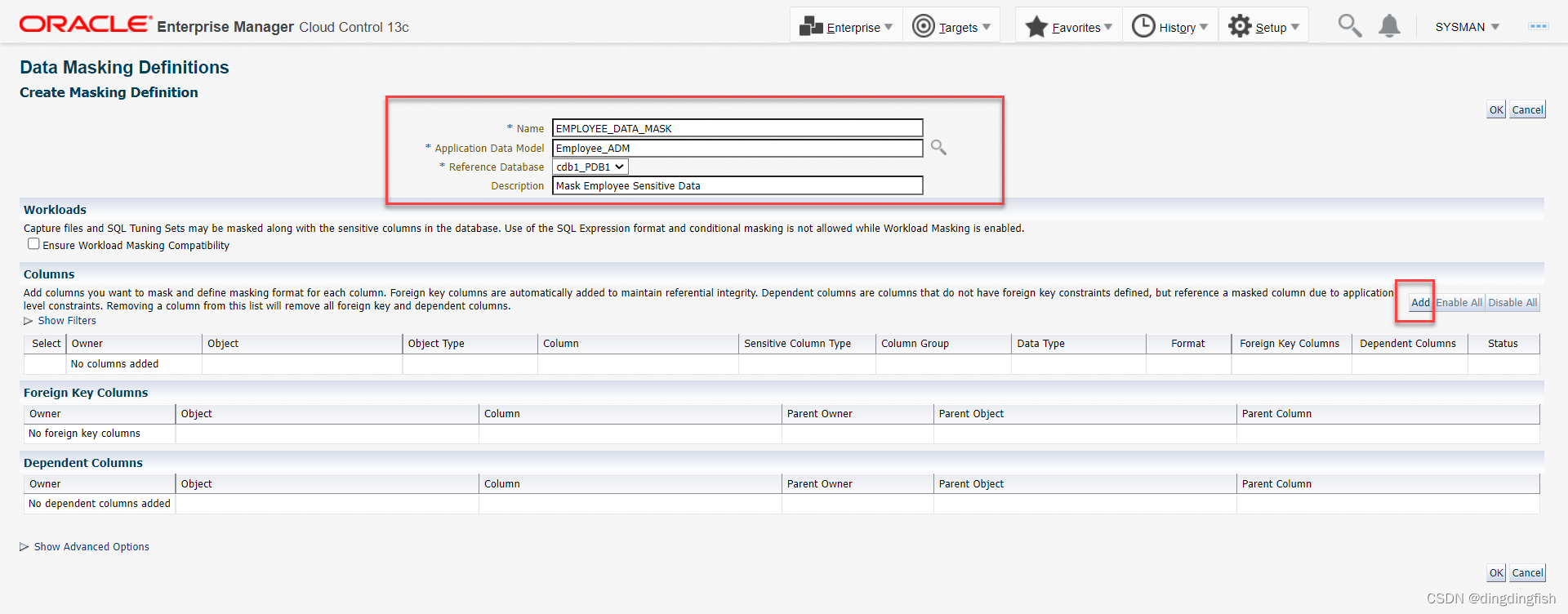
암호가 필요한 경우 명명됨을 선택 DMS_ADMIN하고 로그인을 클릭합니다.
검색을 클릭하면 아래에 이전 기준의 민감 컬럼 6개가 표시되며 모두 선택 후 추가를 클릭합니다.
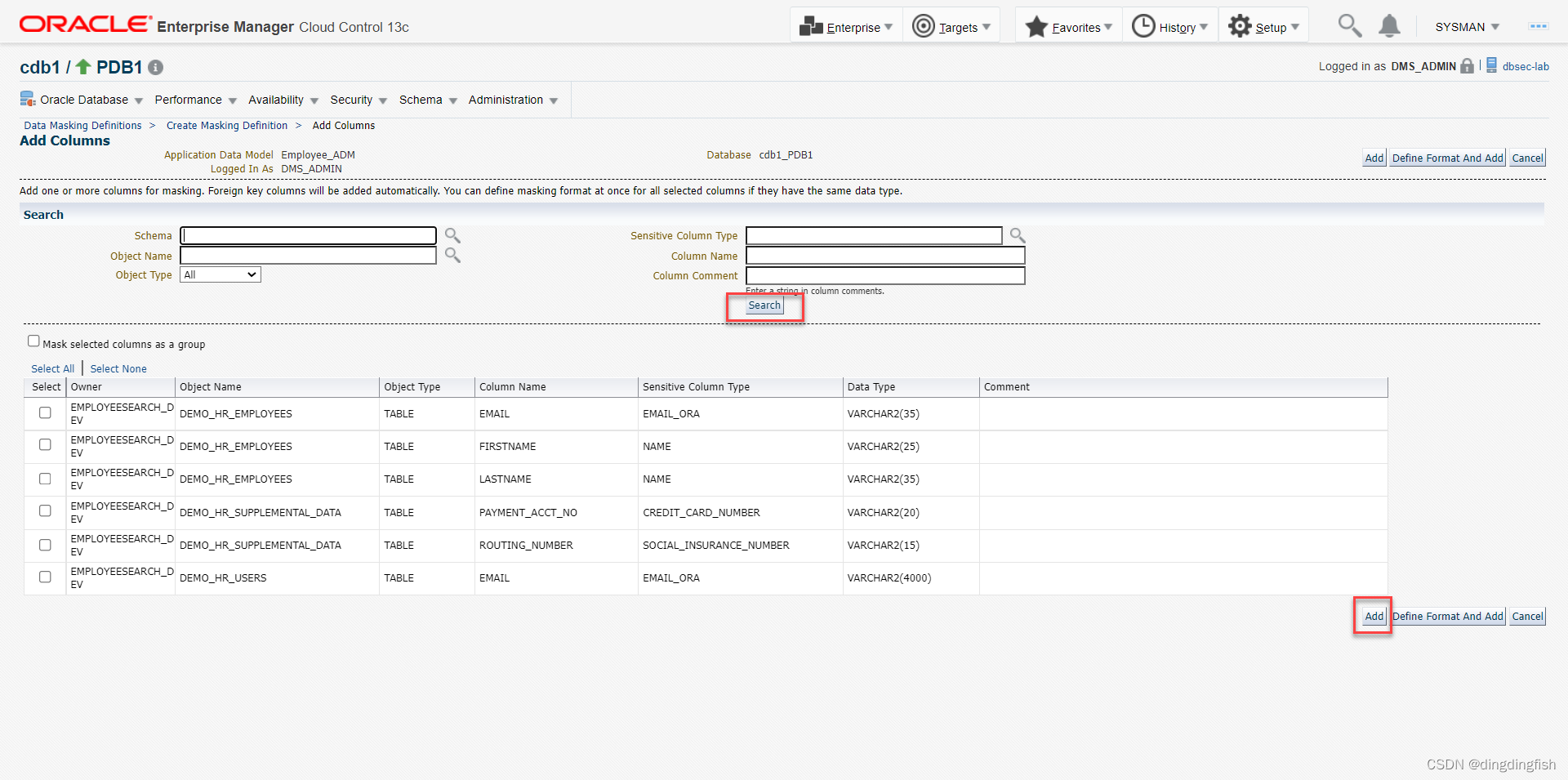
확인을 클릭하여 다음을 저장한 다음 둔감화 형식을 정의합니다.
작업 9: 형식 라이브러리 및 마스킹 프리미티브를 사용하여 열 형식 지정
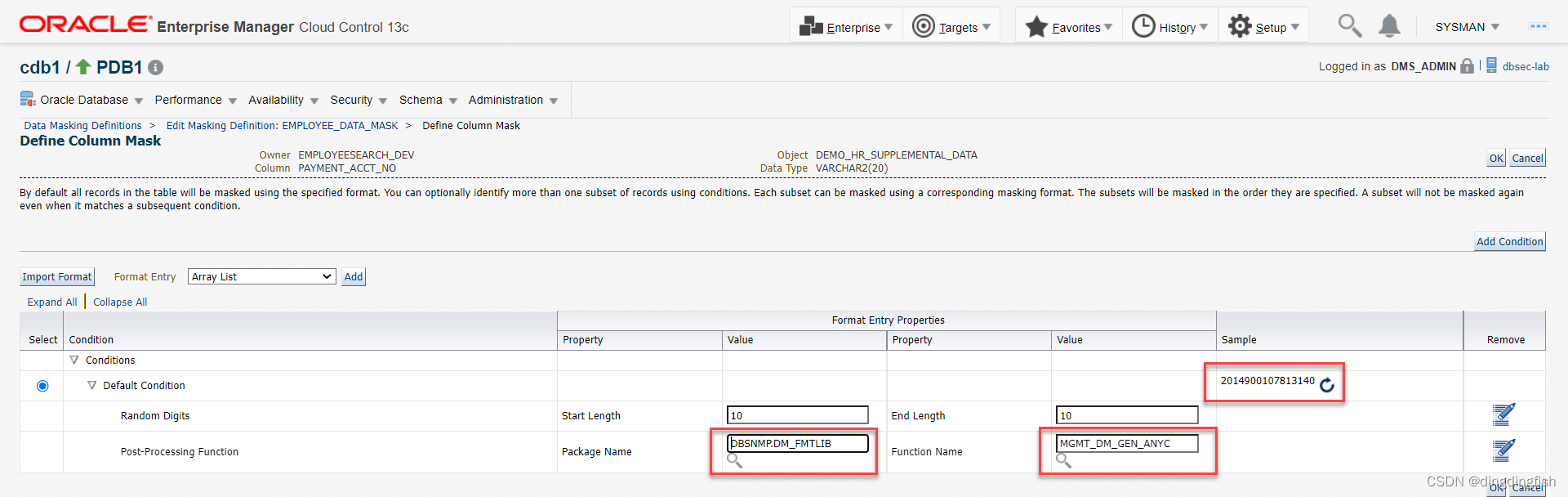
다음 작업을 수행하십시오. 다음으로, 민감 컬럼에 대해 둔감한 형식을 정의합니다.
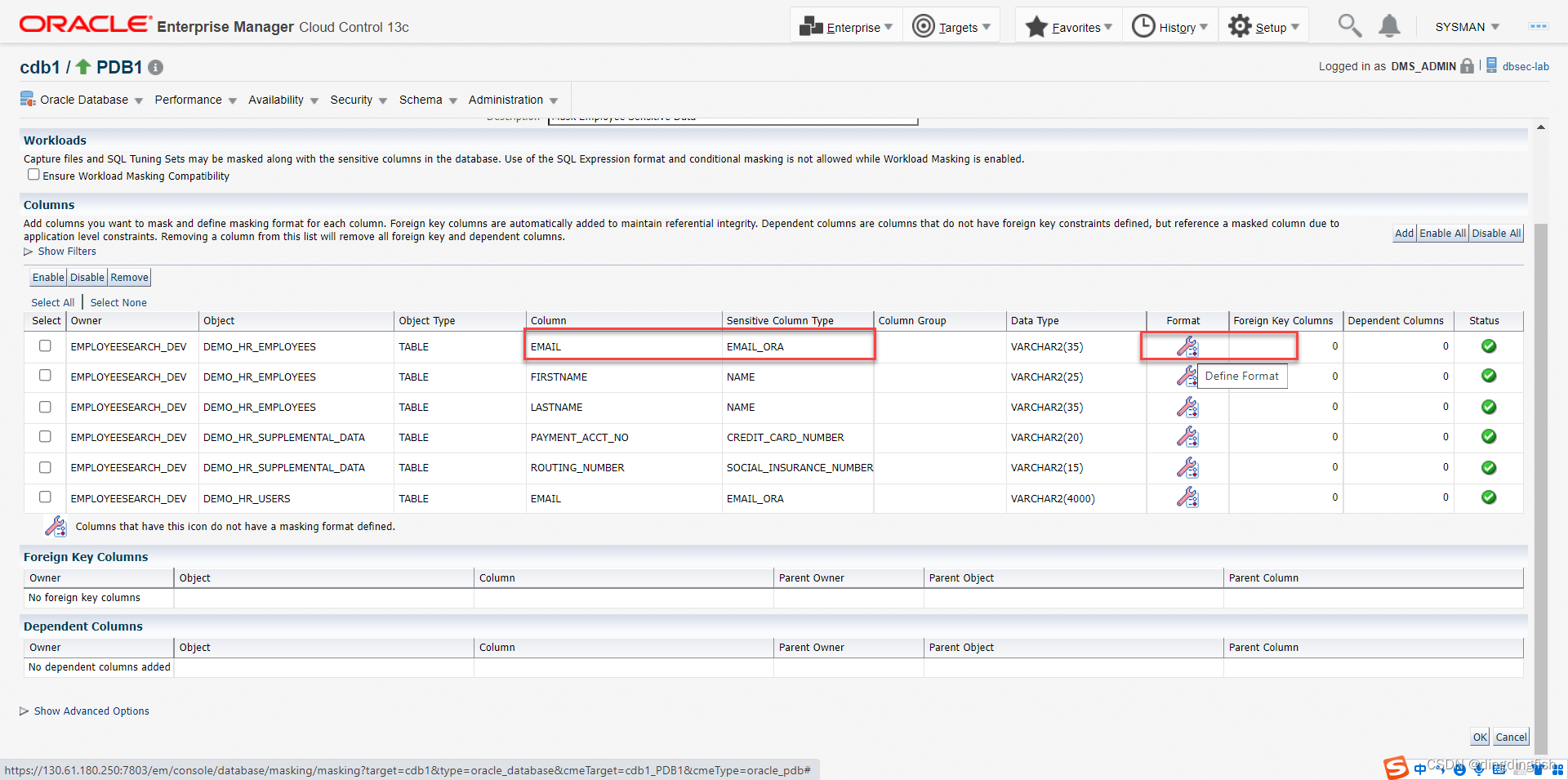
형식 라이브러리에 있는 기존 형식을 사용하려면 [형식 가져오기] 버튼을 클릭한 후 이전에 정의한 형식을 선택합니다. Mask Oracle Corp Email샘플
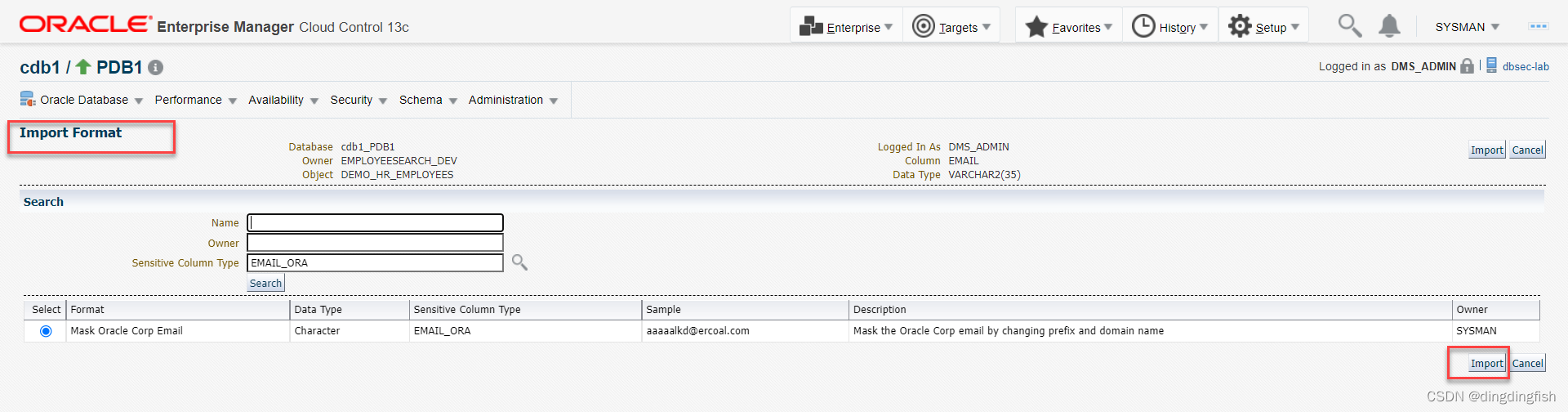
아래의 아이콘을 클릭하여 샘플 데이터를 생성합니다:
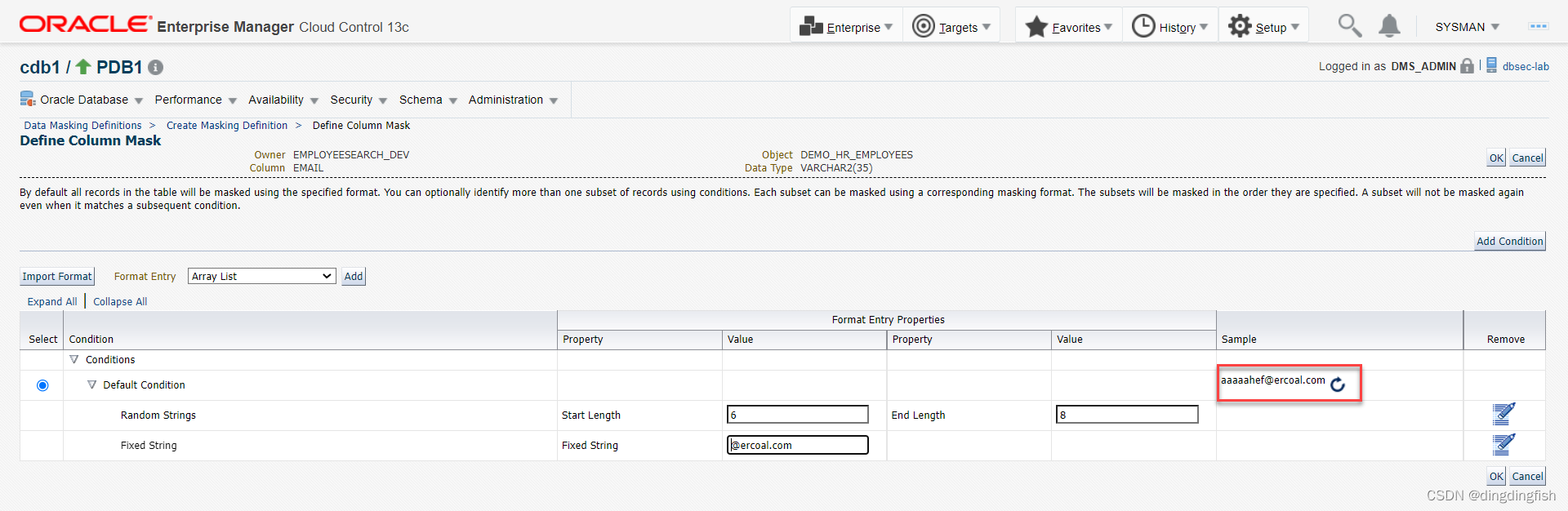
확인을 클릭합니다.
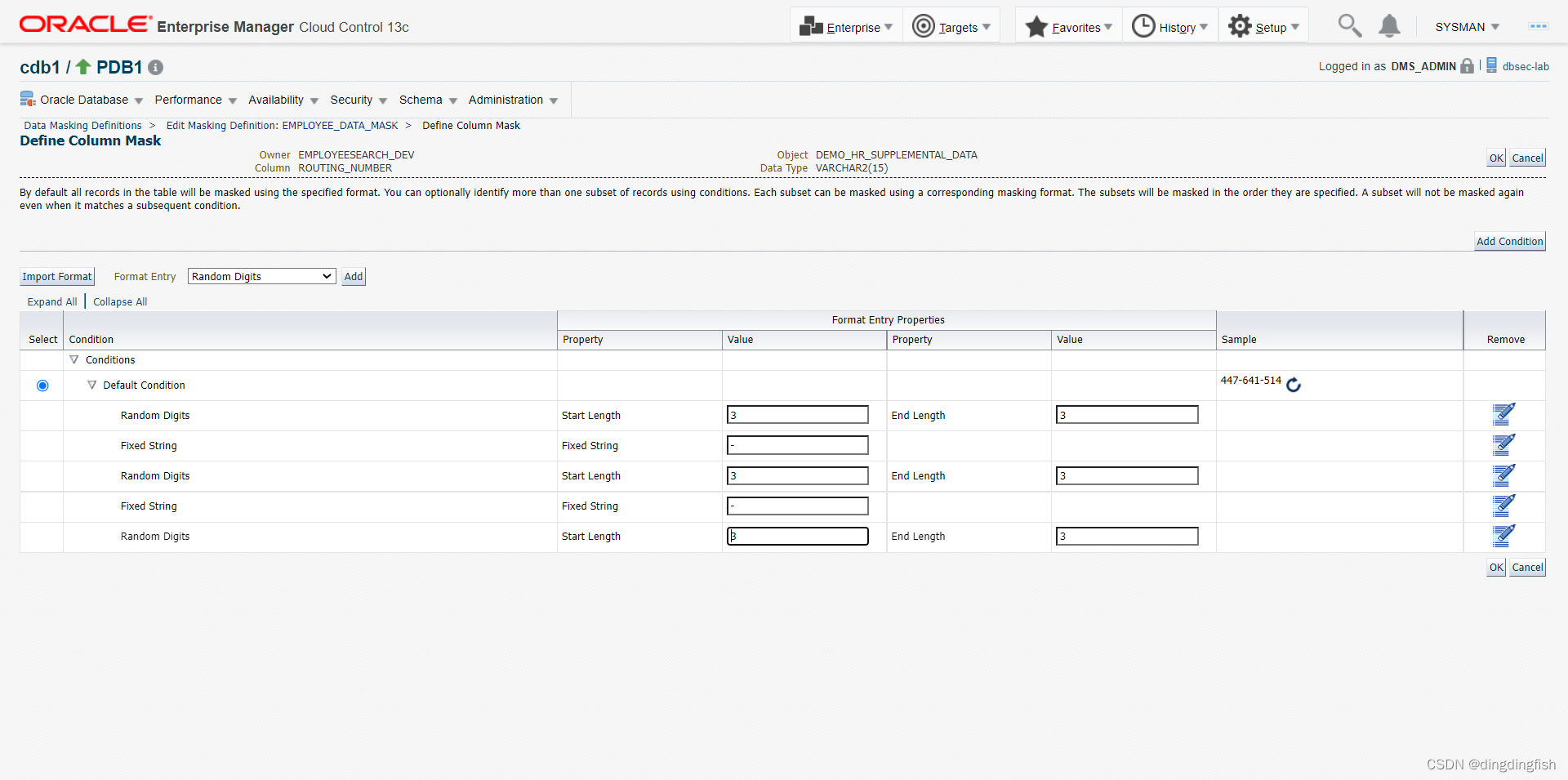
다음으로 두 번째 열을 다른 방식으로 동작시키면 첫 번째 열이 정의된 후 아이콘도 변경되는 것을 확인할 수 있습니다.
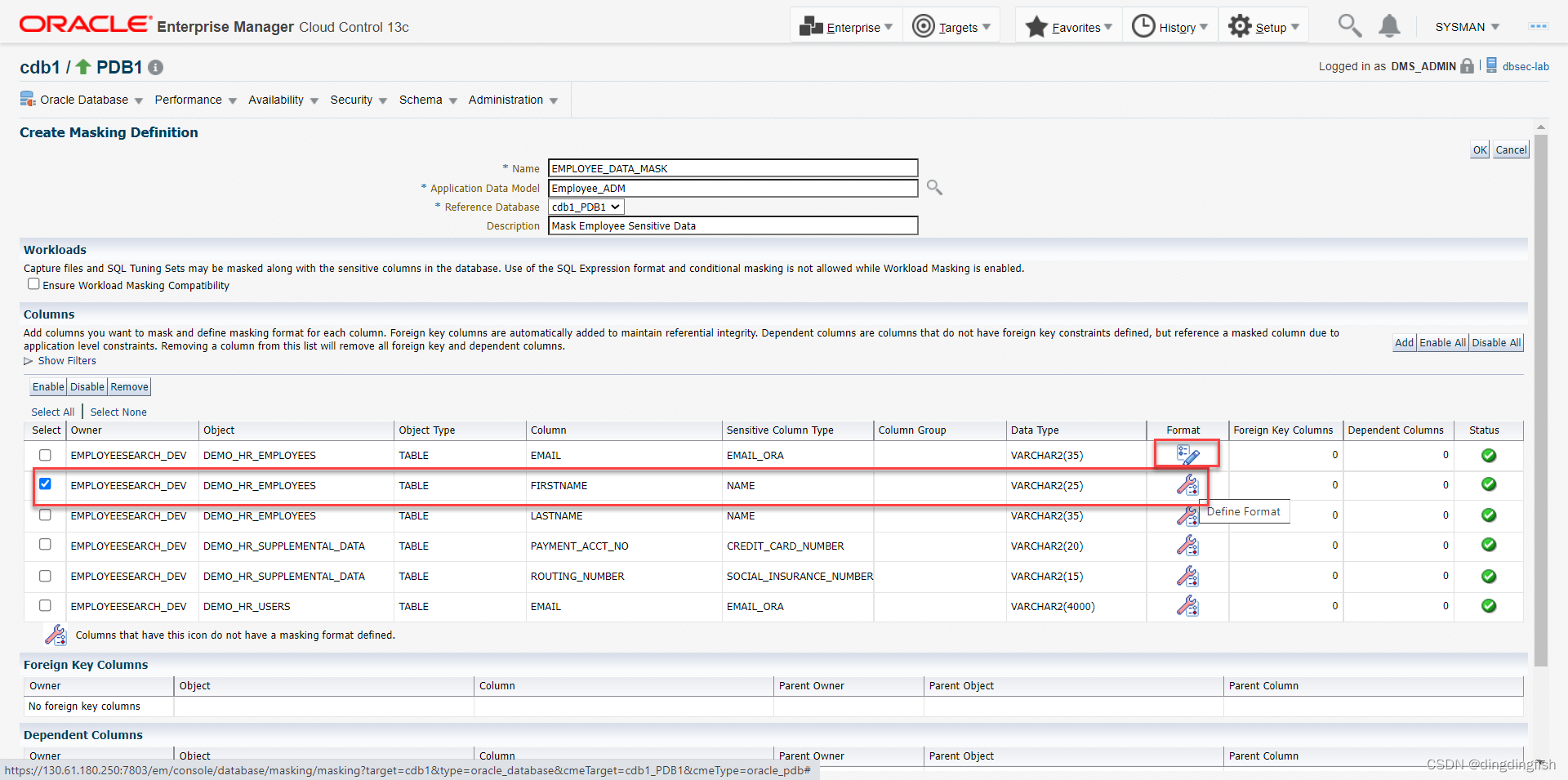
아래 그림과 같이 온라인에서 마스킹 형식을 정의하는 새로운 방법을 사용합니다.
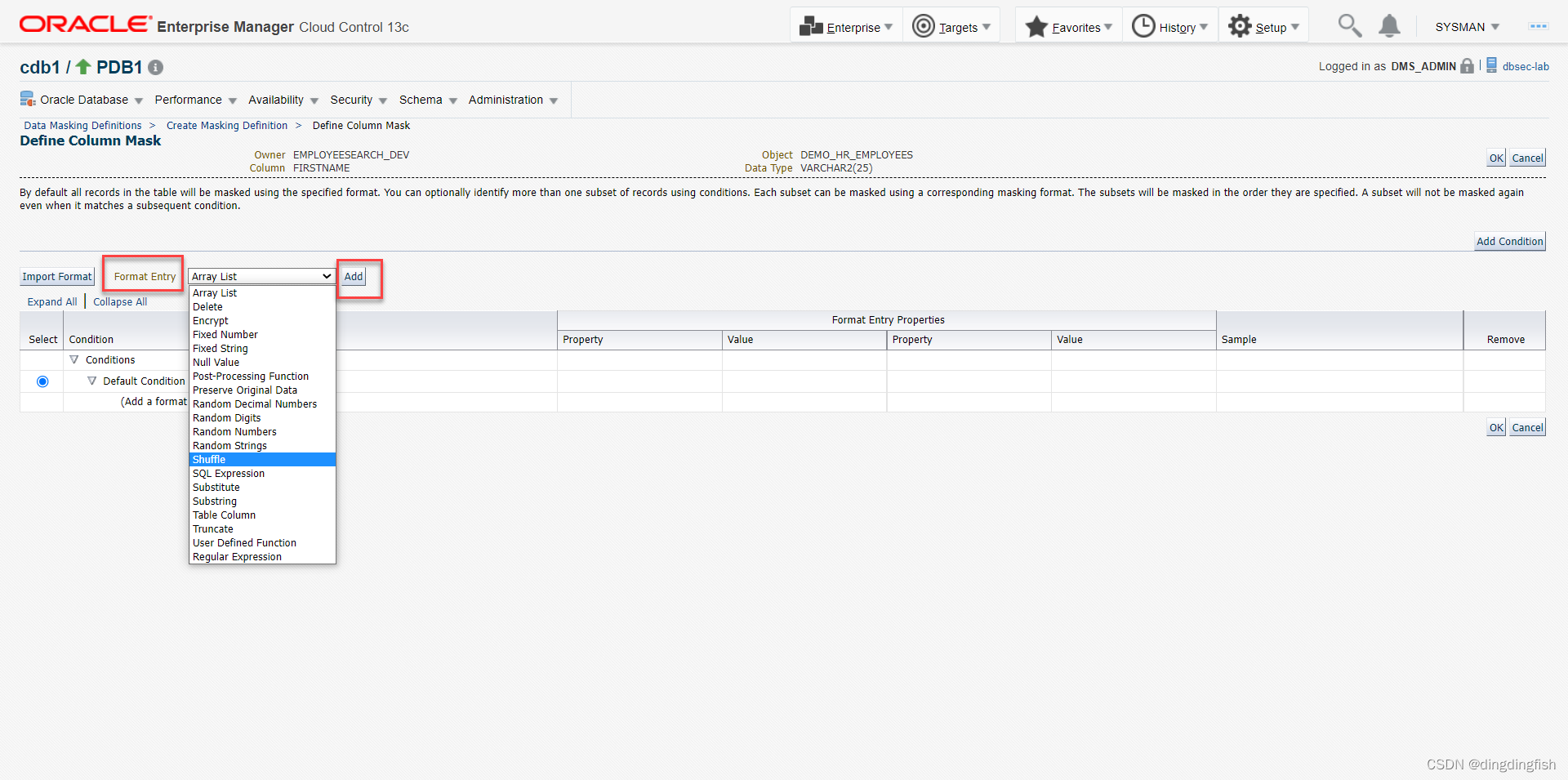
Shuffle을 선택하고 Add를 클릭한 다음 OK를 클릭합니다.
열 3 DEMO_HR_EMPLOYEES.LASTNAME도 셔플을 선택합니다.
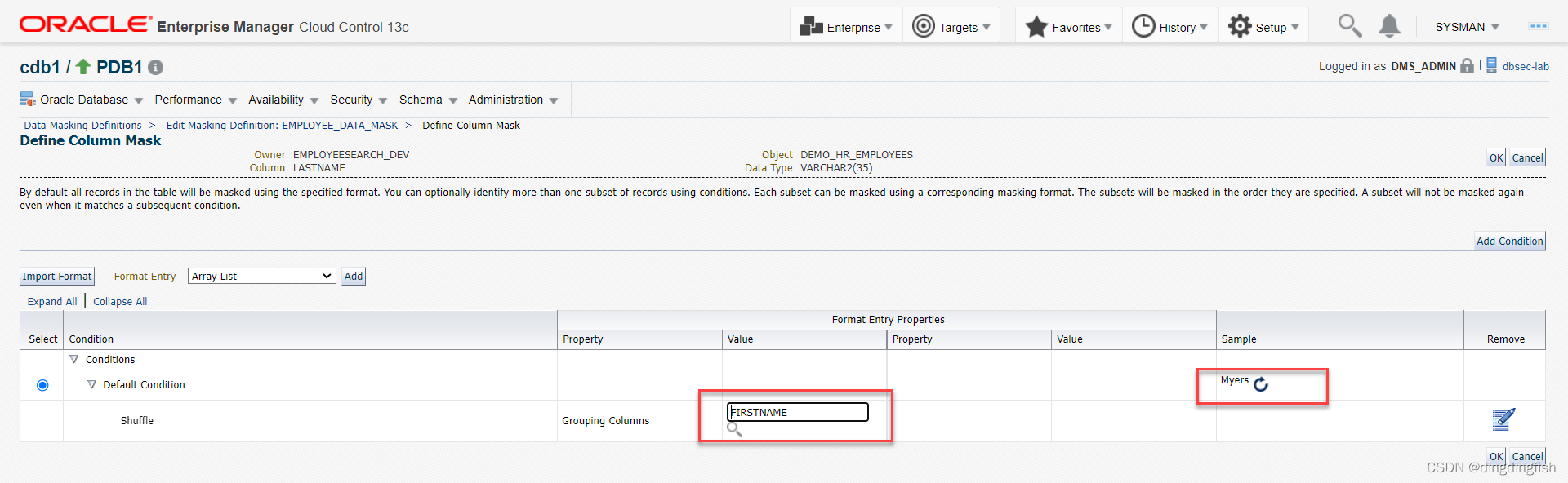
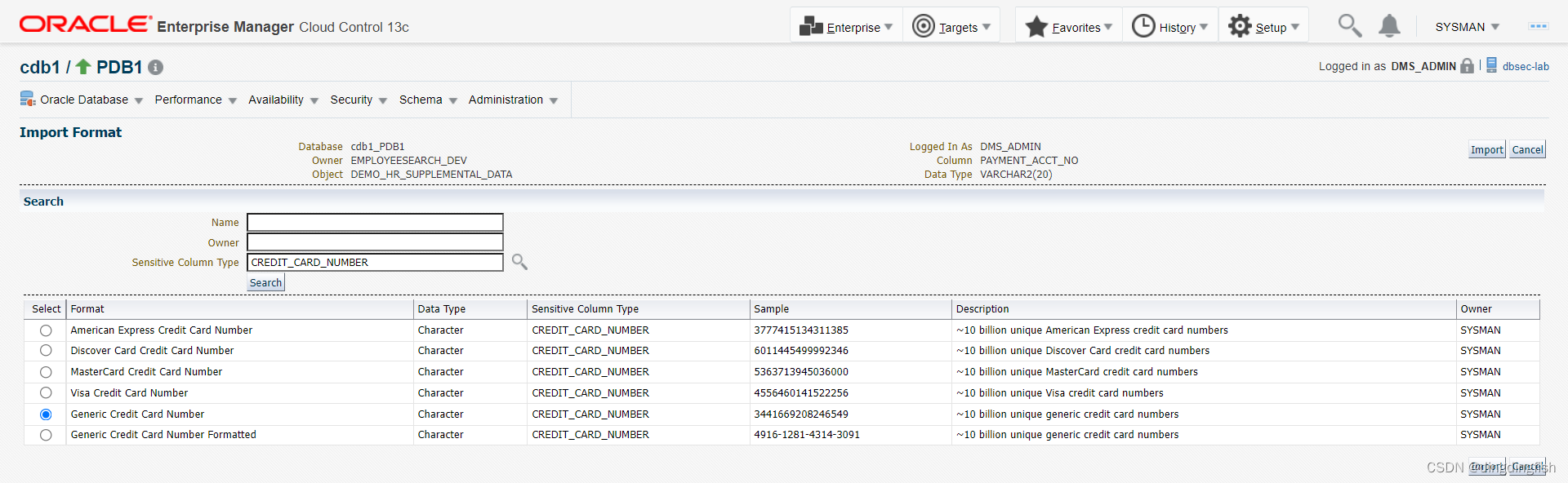
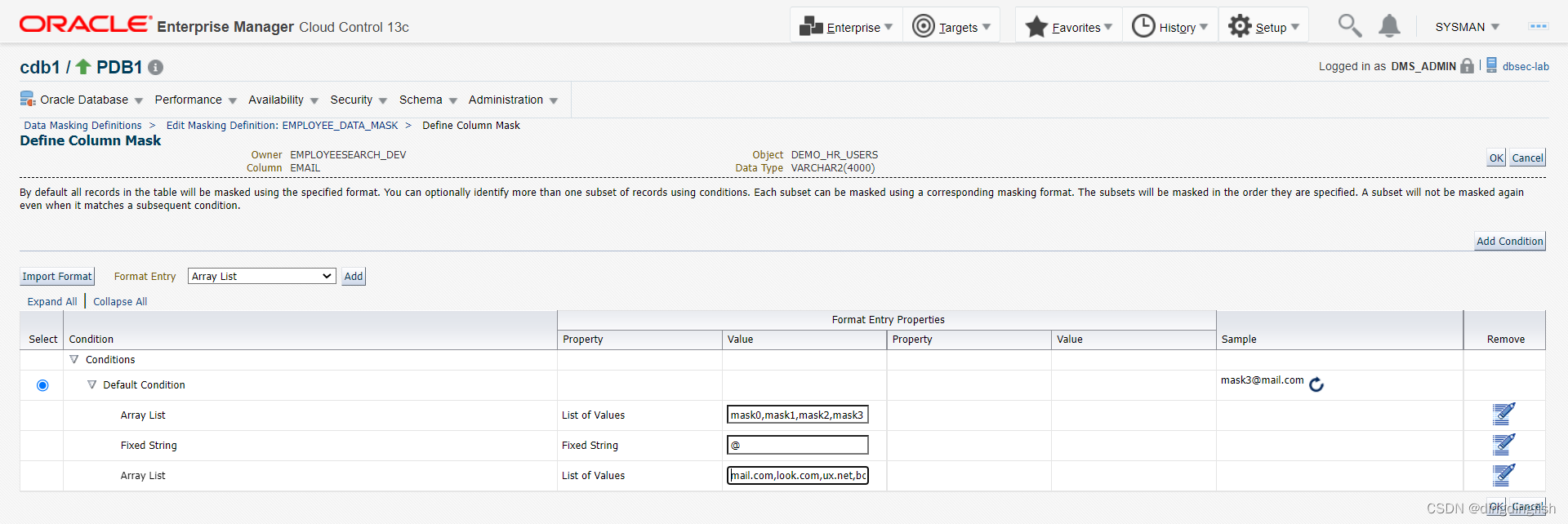
마지막으로 확인을 클릭하여 저장합니다.
작업 10: 데이터 마스킹 스크립트 생성
9단계에서 모든 데이터 마스크 형식을 정의한 후 마스크 정의의 상태는 스크립트가 생성되지 않음입니다.
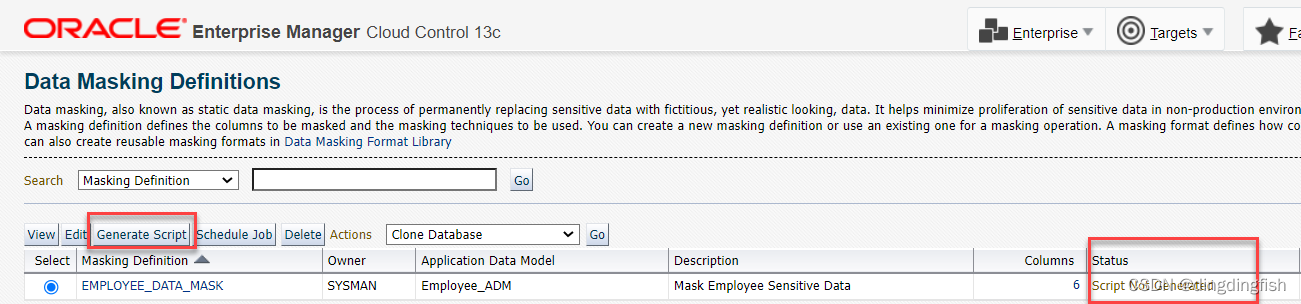
스크립트 생성을 클릭하여 스크립트를 생성합니다. 비밀 키는 여전히 DMS_ADMIN을 선택합니다.
Script Generation Options 섹션에서 Mask In-Database를 선택합니다. 즉, 데이터베이스의 중요한 데이터를 마스킹된 데이터로 대체하여 지정된 데이터베이스(일반적으로 프로덕션에서 복사됨)를 마스킹합니다.
또 다른 옵션인 Mask In-Export는 Oracle Data Pump를 사용하여 지정된 소스 데이터베이스(일반적으로 프로덕션)에서 마스킹된 데이터를 내보내는 것을 의미합니다.
마지막으로 제출을 클릭합니다.
스크립트 생성 중. 상태가 스크립트 생성 작업 예약됨에서 스크립트 생성 중으로 변경되고 마지막으로 스크립트 생성됨으로 변경됩니다.
다음과 같이 스크립트 보기 :
설명:
- Oracle Data Masking Pack은 일련의 유효성 검사 단계를 수행하여 데이터 마스킹 프로세스가 성공적이고 오류가 없는지 확인합니다. 수행하는 한 가지 검사는 마스킹된 형식의 유효성을 검사하는 것입니다. 선택한 마스킹 형식이 데이터베이스 및 애플리케이션 무결성 요구 사항을 충족하는지 확인하기 위해 데이터 마스킹 프로세스에서 필요한 단계입니다.
- 이러한 요구 사항에는 고유성 제약 조건으로 인해 마스킹된 열에 대해 고유한 값을 생성하거나 열 길이 또는 유형 요구 사항을 충족하는 값을 생성하는 것이 포함될 수 있습니다.
- 유효성 검사가 성공적으로 완료되면 Oracle Data Masking Pack은 실행을 위해 대상 데이터베이스로 전송되는 PL/SQL 기반 마스킹 스크립트를 생성합니다.
- Oracle Data Masking Pack은 효율적이고 강력한 메커니즘을 사용하여 마스킹된 데이터를 생성합니다.
- Oracle Data Masking Pack은 대량 작업을 수행하여 원래 데이터베이스 제약 조건, 참조 무결성 및 관련 액세스 구조(예: INDEX 및 PARTITION) 및 액세스 권한(예: GRANT)을 유지하면서 중요한 데이터가 포함된 테이블을 마스킹된 데이터가 포함된 동일한 테이블로 신속하게 교체합니다.
- 테이블 업데이트 수행으로 인해 속도가 느린 기존 마스킹 프로세스와 달리 Oracle Data Masking Pack은 데이터베이스에 내장된 최적화를 활용하여 데이터베이스 로깅을 비활성화 하고 병렬로 실행하여 원래 테이블의 마스킹된 교체를 신속하게 생성합니다.
- 민감한 데이터가 포함된 원본 테이블이 데이터베이스에서 완전히 제거되어 더 이상 액세스할 수 없습니다.
팁:
- 스크립트는 정확히 동일한 스키마를 가진 다른 대상에서 실행될 수 있습니다.
- [스크립트 저장]을 클릭하여 로컬에 스크립트를 저장할 수 있습니다.
작업 11: 데이터 마스킹 스크립트 실행
Data Masking 스크립트를 실행하려면 SSH 키 쌍이 필요하며 퍼티 키 쌍을 사용하지 말고 아래 지침에 따라 RSA 키 쌍을 생성하십시오.
cd ~
ssh-keygen -b 2048 -t rsa
cd .ssh
cat id_rsa >/tmp/rsa_priv
cat id_rsa.pub >>authorized_keys
새 SSH 키로 명명된 자격 증명을 업데이트합니다.
Enterprise > Quality Management > Data Masking Definitions메뉴를 입력합니다 . EMPLOYEE_DATA_MASK를 클릭하고 편집을 선택하여 업데이트합니다.
이 전략은 실제로 oracle 사용자가 개인 키를 통해 로그인하도록 설정하는 것입니다.
Enterprise > Quality Management > Data Masking Definitions메뉴를 입력합니다 . EMPLOYEE_DATA_MASK를 선택하고 작업 예약을 클릭합니다.
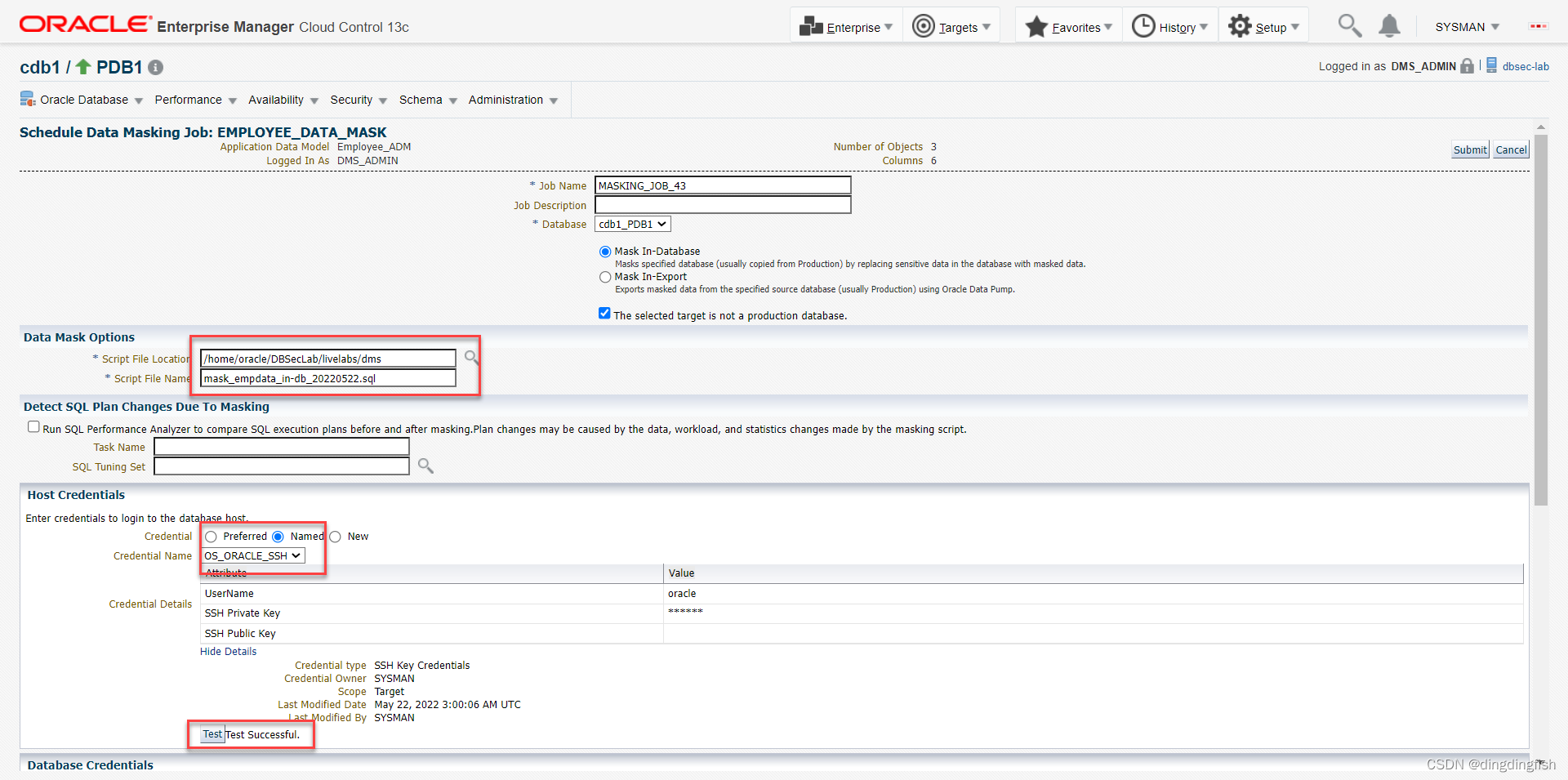
Mask In-Databas를 확인하십시오. 그리고 선택한 대상이 프로덕션 데이터베이스가 아닙니다..를 확인합니다.
스크립트 디렉토리 및 스크립트 이름은 다음과 같이 설정됩니다.
- /홈/오라클/DBSecLab/livelabs/dms
- mask_empdata_in-db_20220522.sql
Host Credentials 섹션에서 Named 및 이전에 설정한 OS_ORACLE_SSH를 선택합니다.
데이터베이스 키는 여전히 DMS_ADMIN을 선택합니다.
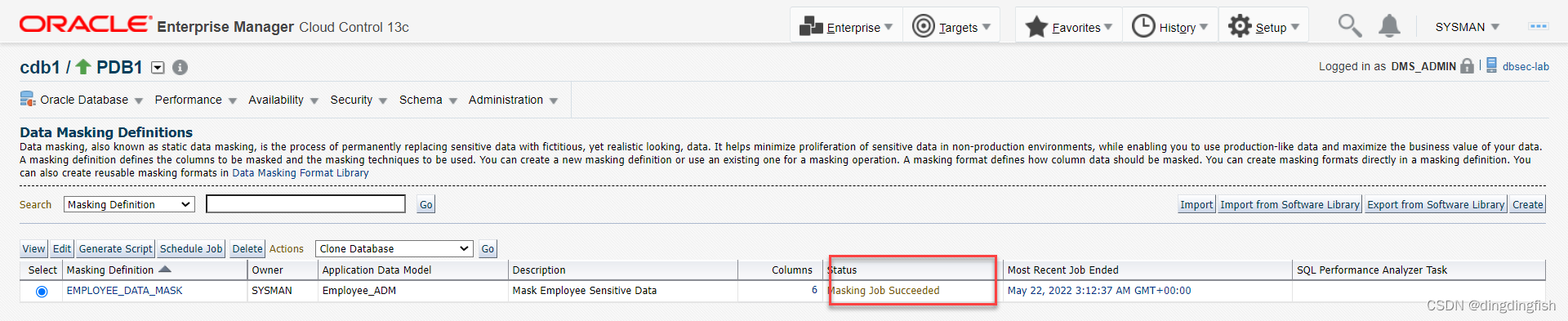
제출을 클릭하여 아래 그림과 같이 작업이 성공했음을 확인합니다.
작업 12: 사전 마스킹된 데이터와 사후 마스킹된 데이터 비교
작업이 성공적으로 완료된 후 이전과 이후 비교를 위해 개발 및 프로덕션 환경에서 민감하지 않은 데이터를 쿼리합니다.
작업 13: 데이터 부분 집합화 정의 만들기
작업 14: 데이터 부분 집합화 스크립트 실행
작업 15: 하위 집합 이전 데이터와 하위 집합 이후 데이터 비교
작업 16: (선택 사항) 랩 환경 재설정
부록: 제품 정보
개요
오라클의 포괄적인 데이터베이스 보안 솔루션 포트폴리오의 일부인 Oracle Data Masking Pack for Enterprise Manager는 조직이 Sarbanes-Oxley(SOX), PCI(Payment Card Industry) DSS(Data Security Standard), HIPAA(Health Insurance Portability and Accountability Act), 유럽 연합의 일반 데이터 보호 규정(GDPR) 및 다가오는 캘리포니아 소비자 개인정보 보호법(CCPA) 등 실제 고객 데이터 의 사용을 제한하는 많은 법률이 있습니다.
Oracle Data Masking을 사용하면 신용 카드나 주민등록번호와 같은 민감한 정보를 실제 값으로 대체할 수 있으므로 프로덕션 데이터를 개발, 테스트에 안전하게 사용하거나 다른 비프로덕션 목적을 위해 아웃소싱 또는 해외 파트너와 공유할 수 있습니다 . Oracle Data Masking은 템플릿 라이브러리와 서식 지정 규칙을 사용하여 데이터를 일관되게 변환함으로써 애플리케이션에 대한 참조 무결성을 유지합니다 .
데이터 마스킹(데이터 스크램블링 및 데이터 익명화라고도 함) 은 프로덕션 데이터베이스에서 테스트 또는 비프로덕션 데이터베이스로 복사된 민감한 정보를 마스킹 규칙을 기반으로 실제 데이터로 대체하는 프로세스 입니다. 데이터 마스킹은 기밀 또는 규제 데이터를 다른 비생산 사용자와 공유해야 하는 거의 모든 상황 에 적용됩니다 . 이러한 비생산 사용자는 일부 원시 데이터에 액세스해야 하지만 특히 정보가 정부 규정에 의해 보호되는 경우 모든 테이블의 모든 열을 볼 필요는 없습니다.
데이터 마스킹을 통해 조직은 원래 데이터와 유사한 특성을 가진 신뢰할 수 있고 완벽하게 작동하는 데이터를 생성하여 민감하거나 기밀 정보를 대체할 수 있습니다. 이는 단순히 데이터를 숨기고 적절한 액세스 권한이나 키를 사용하여 원본 데이터를 검색할 수 있는 암호화 또는 가상 사설 데이터베이스와 대조됩니다. 데이터 마스킹을 사용하면 민감한 원시 데이터를 검색하거나 액세스할 수 없습니다. 이름, 주소, 전화번호 및 신용카드 정보는 부적절한 가시성으로부터 보호해야 하는 데이터의 예입니다. 라이브 프로덕션 데이터베이스 환경에는 귀중한 기밀 데이터가 포함되어 있습니다. 이 정보에 대한 액세스는 엄격하게 통제됩니다. 그러나 **모든 프로덕션 시스템에는 일반적으로 중복 개발 사본이 있으며 이러한 테스트 환경은 덜 엄격하게 제어됩니다. 이는 데이터가 부적절하게 사용될 수 있는 위험을 크게 증가시킵니다. **데이터 마스킹은 기밀 또는 개인 식별 정보를 포함하지 않고 사용 가능한 상태로 유지되도록 민감한 데이터베이스 레코드를 수정합니다. 그러나 마스킹된 테스트 데이터는 응용 프로그램의 무결성을 보장하기 위해 원본 데이터와 시각적으로 유사합니다.

데이터 마스킹이 필요한 이유는 무엇입니까?
다음과 같은 문제에 따라 여러 가지 이유로 필요합니다.
- 개인 식별이 가능하고 민감한 데이터는 업무적으로 알 필요가 없는 개발 및 테스트 그룹의 당사자들과 공유되고 있습니다.
- 테스트 목적으로 개인 정보 또는 기타 민감한 정보가 포함된 운영 데이터베이스를 사용합니다. 식별된 모든 민감한 세부 정보 및 콘텐츠는 사용하기 전에 인식할 수 없을 정도로 제거하거나 수정해야 합니다.
- 개발 및 QA 환경에 배포하기 전에 민감한 프로덕션 데이터의 둔감화 및 삭제를 위한 데이터 삭제 표준의 확립되고 문서화된 절차 및 시행이 없습니다.
- 적절하게 삭제된 데이터로 개발 및 QA 환경을 제공하는 데 필요한 단계와 프로세스는 시간이 많이 걸리고 수동적이며 일관성이 없습니다.
DMS 사용의 이점 실현
- 민감한 정보를 차폐하여 데이터의 상업적 가치 극대화
- 민감한 생산 정보를 확산하지 않음으로써 규정 준수 경계 최소화
- 데이터를 부분 집합화하여 테스트 및 개발 환경의 스토리지 비용 절감
- 민감한 데이터 및 부모-자식 관계를 자동으로 검색
- 포괄적인 마스크 형식, 마스크 변환, 부분 집합화 기술 및 응용 프로그램 템플릿 선택 제공
- 데이터베이스 또는 파일에서 데이터 마스킹 및 부분 집합화 수행(소스 데이터베이스에서 데이터 추출)
- Oracle 및 비 Oracle 데이터베이스에 대한 마스킹 및 데이터 하위 집합 지원
- Oracle Cloud에서 호스팅되는 Oracle 데이터베이스 마스크 및 하위 집합
- 마스킹 및 하위 설정 중에 데이터 무결성을 유지하고 더 고유한 기능을 제공합니다.
- 선택된 Oracle 테스트, 보안 및 통합 제품과 통합합니다.
더 알아보고 싶으신가요?
문서: Oracle Data Masking & Subsetting Pack 12.2
설명: Oracle Data Masking & Subsetting - Advanced Use Cases(2019년 6월)
감사의 말
데이터베이스 보안 PM인 Hakim Loumi가 작성했습니다. 기여자는 Rene Fontcha입니다.