Vivado IP core complex división de punto flotante Punto flotante
Tabla de contenido
1. Ejemplo de división compleja en punto flotante
2. Pasos de configuración del núcleo de IP de punto flotante
prefacio
Con el desarrollo continuo del proceso de fabricación, la matriz de puertas lógicas programables de campo (FPGA) se está integrando cada vez más y su aplicación se está volviendo cada vez más extensa.Entre ellos, se debe usar algún procesamiento matemático IP al procesar señales digitales. nuclear. Recientemente, estoy estudiando la implementación de hardware FPGA de la investigación de la tecnología anti-jamming adaptativa del espacio aéreo, que inevitablemente utiliza algunos núcleos IP.Hoy presentaré cómo usar el núcleo IP de punto flotante en vivo para realizar una división compleja de punto flotante . medida útil.
Consejo: El siguiente es el texto de este artículo, todos los cuales son originales del propio autor. No es fácil escribir un artículo. Espero que adjunte un enlace a este artículo cuando lo vuelva a publicar.
1. Ejemplo de división compleja en punto flotante
Para facilitar el análisis de los resultados en la siguiente simulación, aquí enumeramos el ejemplo de división de números de coma flotante compleja.Durante la simulación, utilice directamente el siguiente ejemplo de simulación para verificar si el resultado de la simulación es correcto.
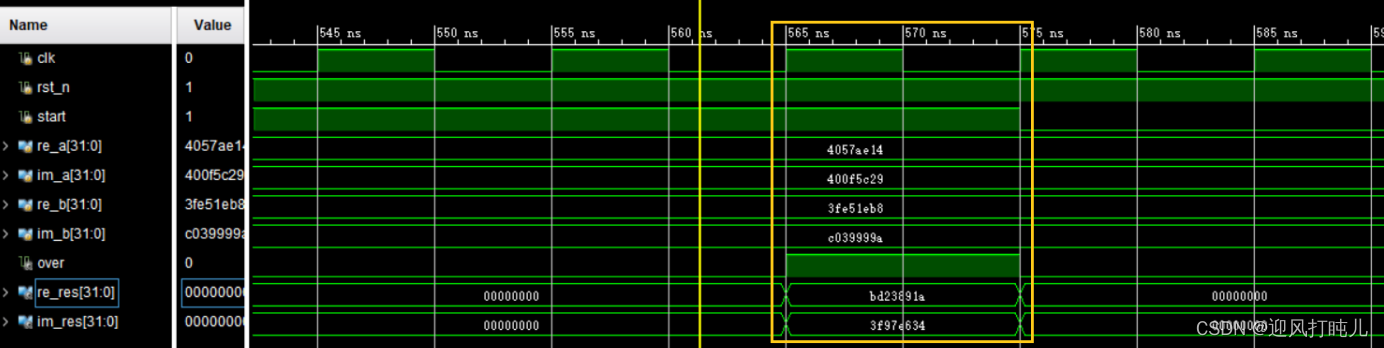
ejemplo : Sea el número de coma flotante a=32'h4057AE14+j32'h400F5C29, es decir, a=3.37+j2.24, el número de coma flotante b=32'h3FE51EB8+j32'hC039999A, es decir, b=1.79-j2 .9, entonces a/b= 32'hBD236E2F+32'h3F97E5C9, es decir, a/b=-0.0399+j1.1867, tenga en cuenta que el resultado solo conserva cuatro lugares decimales.
2. Pasos de configuración del núcleo de IP de punto flotante
En el artículo anterior se ha explicado cómo configurar la suma, resta, multiplicación y división del núcleo IP de coma flotante, los estudiantes que no lo sepan pueden leer mi artículo anterior, por lo que no lo repetiré aquí.
3. Pensamiento general
De acuerdo con la fórmula , primero usamos seis multiplicadores paralelos para calcular los resultados de ac, bd, ad, bc, cc, dd, y luego usamos un restador y dos sumadores para calcular bc-ad y ac+bd, cc+dd en paralelo, y finalmente use dos divisores para calcular la suma
en
paralelo . En mi configuración de IP core, el retraso del multiplicador IP core es de 8 relojes, el retraso del sumador y restador IP core es de 11 relojes, y el retraso del divisor IP core es de 28 relojes. En el código, uno o dos más Los relojes se dan a la señal válida de datos Válido. En todo el código de nivel superior, contar cnt es particularmente importante y los cambios de muchas variables intermedias dependen del valor de cnt. También comenté mucho en el código, y la idea de diseño esta vez no es difícil, creo que todos pueden entenderlo.
4. Simulación
1. Código de nivel superior
Cree un módulo de nivel superior denominado float_complex_div .
el código se muestra a continuación:
`timescale 1ns / 1ps
//
// Company: cq university
// Engineer: clg
// Create Date: 2022/07/26 12:30:21
// Design Name:
// Module Name: float_complex_div
// Project Name:
// Target Devices:
// Tool Versions: 2017.4
// Description:
// Dependencies:
// Revision:1.0
// Revision 0.01 - File Created
// Additional Comments:
//
//计算公式: (a+bi)/(c+di)=( ac+bd+(bc-ad)i )/(c^2+b^2)
module float_complex_div(
input clk, // 输入时钟信号
input rst_n, //输入复位信号
input start, //输入开始信号
input [31:0] re_a, //输入被除数a的实部
input [31:0] im_a, //输入被除数a的虚部
input [31:0] re_b, //输入除数b的实部
input [31:0] im_b, //输入除数b的虚部
output reg over, //输出计算完成信号
output reg [31:0] re_res, //输出计算结果的实部
output reg [31:0] im_res //输出计算结果的虚部
);
//reg define
reg [5:0] cnt; //过程计数标志
reg valid1; //乘有效信号
reg valid2; //加减有效信号
reg valid3; //除有效信号
//wire define
wire [31:0] result1; //结果1
wire [31:0] result2; //结果2
wire [31:0] result3; //结果3
wire [31:0] result4; //结果4
wire [31:0] result5; //结果5
wire [31:0] result6; //结果6
wire [31:0] result7; //结果7
wire [31:0] result8; //结果8
wire [31:0] result9; //结果9
wire [31:0] result10; //结果10
wire [31:0] result11; //结果11
always @(posedge clk or negedge rst_n)
if(!rst_n)
cnt<=0;
else if(start==1)
begin
if(cnt<6'd56)
cnt<=cnt+1;
else
cnt<=0;
end
else if(start==0)
cnt<=0;
always @(posedge clk or negedge rst_n)
if(!rst_n)
valid1<=0;
else if(6'd0<cnt<=6'd9)
valid1<=1;
else
valid1<=0;
always @(posedge clk or negedge rst_n)
if(!rst_n)
valid2<=0;
else if(6'd12<cnt<=6'd24)
valid2<=1;
else
valid2<=0;
always @(posedge clk or negedge rst_n)
if(!rst_n)
valid3<=0;
else if(6'd24<cnt<=6'd53)
valid3<=1;
else
valid3<=0;
always @(posedge clk or negedge rst_n)
if(!rst_n)
begin over<=0;re_res<=0;im_res<=0; end
else if(cnt==6'd55)
begin over<=1;re_res<=result10;im_res<=result11; end
else
begin over<=0;re_res<=0;im_res<=0; end
float_mul_ip u1_float_mul_ip( //乘法器1 计算ac
.aclk(clk),
.s_axis_a_tvalid(valid1),
.s_axis_a_tdata(re_a),
.s_axis_b_tvalid(valid1),
.s_axis_b_tdata(re_b),
.m_axis_result_tvalid(),
.m_axis_result_tdata(result1)
);
float_mul_ip u2_float_mul_ip( //乘法器2 计算bd
.aclk(clk),
.s_axis_a_tvalid(valid1),
.s_axis_a_tdata(im_a),
.s_axis_b_tvalid(valid1),
.s_axis_b_tdata(im_b),
.m_axis_result_tvalid(),
.m_axis_result_tdata(result2)
);
float_mul_ip u3_float_mul_ip( //乘法器3 计算ad
.aclk(clk),
.s_axis_a_tvalid(valid1),
.s_axis_a_tdata(re_a),
.s_axis_b_tvalid(valid1),
.s_axis_b_tdata(im_b),
.m_axis_result_tvalid(),
.m_axis_result_tdata(result3)
);
float_mul_ip u4_float_mul_ip( //乘法器4 计算bc
.aclk(clk),
.s_axis_a_tvalid(valid1),
.s_axis_a_tdata(im_a),
.s_axis_b_tvalid(valid1),
.s_axis_b_tdata(re_b),
.m_axis_result_tvalid(),
.m_axis_result_tdata(result4)
);
float_mul_ip u5_float_mul_ip( //乘法器5 计算c*c
.aclk(clk),
.s_axis_a_tvalid(valid1),
.s_axis_a_tdata(re_b),
.s_axis_b_tvalid(valid1),
.s_axis_b_tdata(re_b),
.m_axis_result_tvalid(),
.m_axis_result_tdata(result5)
);
float_mul_ip u6_float_mul_ip( //乘法器6 计算d*d
.aclk(clk),
.s_axis_a_tvalid(valid1),
.s_axis_a_tdata(im_b),
.s_axis_b_tvalid(valid1),
.s_axis_b_tdata(im_b),
.m_axis_result_tvalid(),
.m_axis_result_tdata(result6)
);
float_sub_ip u1_float_sub_ip( //减法器 计算bc-ad
.aclk(clk),
.s_axis_a_tvalid(valid2),
.s_axis_a_tdata(result4),
.s_axis_b_tvalid(valid2),
.s_axis_b_tdata(result3),
.m_axis_result_tvalid(),
.m_axis_result_tdata(result7)
);
float_add_ip u1_float_add_ip( //加法器1 计算ac+bd
.aclk(clk),
.s_axis_a_tvalid(valid2),
.s_axis_a_tdata(result1),
.s_axis_b_tvalid(valid2),
.s_axis_b_tdata(result2),
.m_axis_result_tvalid(),
.m_axis_result_tdata(result8)
);
float_add_ip u2_float_add_ip( //加法器2 计算cc+dd
.aclk(clk),
.s_axis_a_tvalid(valid2),
.s_axis_a_tdata(result5),
.s_axis_b_tvalid(valid2),
.s_axis_b_tdata(result6),
.m_axis_result_tvalid(),
.m_axis_result_tdata(result9)
);
float_div_ip u1_float_div_ip( //除法器1 计算(ac+bd)/(cc+dd)
.aclk(clk),
.s_axis_a_tvalid(valid3),
.s_axis_a_tdata(result8),
.s_axis_b_tvalid(valid3),
.s_axis_b_tdata(result9),
.m_axis_result_tvalid(),
.m_axis_result_tdata(result10)
);
float_div_ip u2_float_div_ip( //除法器2 计算(bc-ad)/(cc+dd)
.aclk(clk),
.s_axis_a_tvalid(valid3),
.s_axis_a_tdata(result7),
.s_axis_b_tvalid(valid3),
.s_axis_b_tdata(result9),
.m_axis_result_tvalid(),
.m_axis_result_tdata(result11)
);
endmodule
2. Código de simulación
Cree un módulo de simulación llamado float_complex_div_tb para simular el módulo de nivel superior.
el código se muestra a continuación:
`timescale 1ns / 1ps
//
// Company: cq university
// Engineer: clg
// Create Date: 2022/07/26 13:32:30
// Design Name:
// Module Name: float_complex_div_tb
// Project Name:
// Target Devices:
// Tool Versions: 2017.4
// Description:
// Dependencies:
// Revision:1.0
// Revision 0.01 - File Created
// Additional Comments:
//
module float_complex_div_tb();
reg clk; // 输入时钟信号
reg rst_n; //输入复位信号
reg start; //输入开始信号
reg [31:0] re_a; //输入因数a的实部
reg [31:0] im_a; //输入因数a的虚部
reg [31:0] re_b; //输入因数b的实部
reg [31:0] im_b; //输入因数b的虚部
wire over; //输出计算完成信号
wire [31:0] re_res; //输出计算结果的实部
wire [31:0] im_res; //输出计算结果的虚部
float_complex_div u1_float_complex_div( //例化顶层模块
.clk(clk),
.rst_n(rst_n),
.start(start),
.re_a(re_a),
.im_a(im_a),
.re_b(re_b),
.im_b(im_b),
.over(over),
.re_res(re_res),
.im_res(im_res)
);
always #5 clk=~clk;
initial begin
clk=1'b0;rst_n=1'b1;start=1'b0;
#5; rst_n=1'b0;
#10; rst_n=1'b1;
start=1'b1;
re_a=32'h4057ae14;
im_a=32'h400f5c29;
re_b=32'h3fe51eb8;
im_b=32'hc039999a;
#560 start=1'b0;
end
endmodule5. Análisis de resultados de simulación
Los resultados de la simulación se muestran en la Figura 1. En comparación con los ejemplos de división de coma flotante compleja mencionados anteriormente, se puede ver que el módulo ha realizado con éxito la división de números de coma flotante complejos. El resultado es 32'hBD23891A+j32'h3F97E634, que es -0,039925672+j1,1867127. Si se mantienen cuatro decimales, es -0,0399+j1,1867, lo cual es coherente con el ejemplo presentado al principio de este artículo.
Resumir
Esta vez presentaremos la división de números complejos de coma flotante.