참조 블로그
BatchNormalization、LayerNormalization、InstanceNorm、GroupNorm、SwitchableNorm总结
PyTorch 학습을 위한 정규화 계층(BatchNorm, LayerNorm, InstanceNorm, GroupNorm)
BN, LN, IN, GN은 학문적 관점에서 차이점을 설명합니다.
BatchNorm : 배치 방향을 정규화하고 N H W 의 평균값을 계산하며 작은 배치 크기에는 효과가 좋지 않습니다. BN의 주요 단점은 는 배치 크기의 크기에 민감하며, 배치 단위로 평균과 분산을 계산하므로 배치 크기가 너무 작으면 계산된 평균과 분산이 전체 데이터 분포를 나타내기에 충분하지 않습니다.GroupNorm : 채널 방향을 그룹으로 나눈 후 각 그룹에서 정규화를 수행하여 (C//G) H W 의 평균값을 계산하는데 이는 배치 크기와 무관하며 구속되지 않습니다.
BatchNorm
채널을 따라 각 배치의 평균과 분산을 계산하므로 계산 결과가 배치 크기와 관련됨 ===> 단점: 평균과 분산의 각 계산이 배치에 있기 때문에 배치 크기의 크기에 민감합니다. batchsize가 너무 작고 계산된 평균과 분산이 전체 데이터 분포를 나타내기에 충분하지 않습니다.
# x_shape:[B, C, H, W] x_mean = np.mean(x, axis=(0, 2, 3), keepdims=True) x_var = np.var(x, axis=(0, 2, 3), keepdims=True0)알고리즘 프로세스:
- 채널을 따라 각 배치의 평균 u를 계산합니다.
- 채널을 따라 각 배치의 분산 σ^2를 계산합니다.
- x 정규화, x'=(xu)/제곱근(σ^2+ε)
- 스케일링 및 변환 변수 γ 및 β, 정규화된 값, y=γx'+β를 추가합니다.
스케일링 및 변환 변수를 추가하는 이유는 각 데이터가 정규화된 후에도 원래 학습된 특징이 유지되도록 하고 동시에 완료할 수 있습니다. 정규화 작업을 수행하고 훈련 속도를 높입니다. 이 두 매개변수는 학습 매개변수에 사용됩니다.
구현 공식:
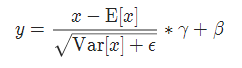
torch.nn.BatchNorm1d( num_features , eps=1e-05 , 모멘텀=0.1 , affine=True , track_running_stats=True )
torch.nn.BatchNorm2d( num_features , eps=1e-05 , 모멘텀=0.1 , affine=True , track_running_stats=True )
torch.nn.BatchNorm3d( num_features , eps=1e-05 , 운동량=0.1 , affine=True , track_running_stats=True )
사용
BN = torch.nn.BatchNorm2d(num_features=3, eps=1e-6, affine=True)
print(x.shape) #torch.Size([6, 3, 2, 2])
print(x)
x = BN(x)
print(x)
print(x.shape) #torch.Size([6, 3, 2, 2])
GroupNorm
GN의 특징은 배치 크기와 무관하며 이에 구속되지 않는다는 것입니다.
주된 이유는 Batch Normalization이 small batch size에는 효과가 좋지 않기 때문인데, GN은 채널 방향을 그룹으로 나눈 다음 각 그룹에서 정규화를 수행하여 (C//G) H W의 평균값을 계산하는데, 이는 배치 크기와 관련이 있으며 이에 구속되지 않습니다.
x_mean = np.mean(x, axis=(2, 3, 4), keepdims=True) x_var = np.var(x, axis=(2, 3, 4), keepdims=True0)
torch.nn.GroupNorm( num_groups , num_channels , eps=1e-05 , affine=True )
매개변수:
num_groups: 나누어야 할 그룹
num_features: 예상되는 입력의 특징 수, 예상되는 입력의 크기는 'batch_size x num_features [x 너비]'
eps: 수치적 안정성 확보를 위해(분모가 접근하거나 취할 수 없음) 0), 분모에 추가된 값을 지정합니다. 기본값은 1e-5입니다.
운동량: 동적 평균 및 동적 분산에 사용되는 운동량. 기본값은 0.1입니다.
affine: 부울 값, true로 설정하면 학습 가능한 아핀 변환 매개변수를 이 레이어에 추가합니다.
공식을 실현하다
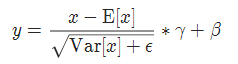
사용
# 随机生成1-10范围内的随机数, 【批处理大小,通道数,宽,高】
x = np.random.randint(1,10, [6,3,2,2])
x = torch.FloatTensor(x)
GN= torch.nn.GroupNorm(num_groups=3, num_channels=3, eps=1e-6, affine=True)
print(x.shape) #torch.Size([6, 3, 2, 2])
print(x)
x = GN(x)
print(x)
print(x.shape) #torch.Size([6, 3, 2, 2])
생성된 데이터, 계산 공식 확인:
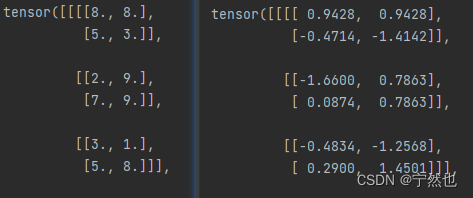

다음 그림 침대