1. Introducción a Tushare
1. Acerca de Tushare
Tushare es un paquete de interfaz de datos financieros de Python gratuito y de código abierto. El contenido de los datos incluye acciones, índices, fondos, futuros, bonos, divisas, big data de la industria, etc., y también incluye datos de blockchain, como datos del mercado de divisas digitales, proporcionando inversión financiera para varios tipos de Se ha actualizado completamente a Tushare pro, que es muy adecuado para el análisis y la visualización de datos.
Enlace del sitio web oficial: Tushare big data community

2. Instalación e inicialización de Tushare
URL de Github: https://github.com/waditu/Tushare
Instale el paquete tushare usando pip
pip install tushare lxmlimportar tushare
import tushare as tsestablecer token
ts.set_token('your token here')Puede obtener el token registrando una cuenta en el sitio web oficial. Solo es necesario llamar al método anterior por primera vez o después de que caduque el token para completar la configuración de llamar a la credencial de datos de tushare En circunstancias normales, no es necesario repetir la configuración. También puede ignorar este paso y completar la inicialización directamente con pro_api('su token').
Inicializar la interfaz profesional
pro = ts.pro_api()3. Llamada de interfaz Tushare
La interfaz de datos de Tushare se divide en once categorías, que incluyen acciones, índices, fondos, futuros, opciones, bonos, divisas, acciones de Hong Kong, economía industrial, macroeconomía y big data característico de Shanghái y Shenzhen. datos y datos de mercado, datos financieros, datos de referencia del mercado cuatro tipos de interfaz. Tushare también proporciona datos básicos relacionados con blockchain, datos de mercado y anuncios de información, así como macroeconomía, divisas, acciones A, blockchain, etc., acciones de EE. UU., petróleo, oro, divisas de oro, acciones de Hong Kong, materias primas, bonos, empresas, mercados, foco, banco central y otra información financiera.
La interfaz API de Tushare necesita obtener los derechos de acceso correspondientes en función de la cantidad de puntos en la cuenta registrada. Un nivel de puntos insuficiente puede dar lugar a un acceso no autorizado a la interfaz API, y las interfaces relacionadas con la cadena de bloques deben donar para obtener los permisos correspondientes.
Descripción del permiso del sitio web oficial: https://tushare.pro/document/1?doc_id=108
datos de cotizaciones bursátiles
Obtenga datos de información básica de acciones, incluido el código de acciones, apertura alta y cierre inferior, etc.
pro = ts.pro_api()
df = pro.daily(ts_code='000001.SZ', start_date='20180701', end_date='20180718')
#多个股票
df = pro.daily(ts_code='000001.SZ,600000.SH', start_date='20180701', end_date='20180718')muestra de datos
ts_code trade_date open high low close pre_close change pct_chg vol amount
0 000001.SZ 20180718 8.75 8.85 8.69 8.70 8.72 -0.02 -0.23 525152.77 460697.377
1 000001.SZ 20180717 8.74 8.75 8.66 8.72 8.73 -0.01 -0.11 375356.33 326396.994
2 000001.SZ 20180716 8.85 8.90 8.69 8.73 8.88 -0.15 -1.69 689845.58 603427.713
3 000001.SZ 20180713 8.92 8.94 8.82 8.88 8.88 0.00 0.00 603378.21 535401.175
4 000001.SZ 20180712 8.60 8.97 8.58 8.88 8.64 0.24 2.78 1140492.31 1008658.828
5 000001.SZ 20180711 8.76 8.83 8.68 8.78 8.98 -0.20 -2.23 851296.70 744765.824
6 000001.SZ 20180710 9.02 9.02 8.89 8.98 9.03 -0.05 -0.55 896862.02 803038.965
7 000001.SZ 20180709 8.69 9.03 8.68 9.03 8.66 0.37 4.27 1409954.60 1255007.609
8 000001.SZ 20180706 8.61 8.78 8.45 8.66 8.60 0.06 0.70 988282.69 852071.526
9 000001.SZ 20180705 8.62 8.73 8.55 8.60 8.61 -0.01 -0.12 835768.77 722169.579Datos de indicadores financieros
Obtenga varios datos de indicadores financieros de empresas cotizadas, como ROA, ROE, etc.
pro = ts.pro_api()
df = pro.fina_indicator(ts_code='600000.SH')'20180718')muestra de datos
ts_code ann_date end_date eps dt_eps total_revenue_ps revenue_ps \
0 600000.SH 20180830 20180630 0.95 0.95 2.8024 2.8024
1 600000.SH 20180428 20180331 0.46 0.46 1.3501 1.3501
2 600000.SH 20180428 20171231 1.84 1.84 5.7447 5.7447
3 600000.SH 20180428 20171231 1.84 1.84 5.7447 5.7447
4 600000.SH 20171028 20170930 1.45 1.45 4.2507 4.2507
5 600000.SH 20171028 20170930 1.45 1.45 4.2507 4.2507
6 600000.SH 20170830 20170630 0.97 0.97 2.9659 2.9659
7 600000.SH 20170427 20170331 0.63 0.63 1.9595 1.9595
8 600000.SH 20170427 20170331 0.63 0.63 1.9595 1.9595 2. Robot comercial cuantitativo basado en ElegantRL
1. Descargar datos y preprocesar
Utilice Tushare para descargar 1635 días de datos de acciones A de China, incluidos datos básicos del mercado, varios indicadores técnicos e indicadores financieros.
Datos financieros
Escriba una función para descargarla y procesarla en su propio formato de marco de datos
def get_fund_data(list_ticker):
fund_data = pd.DataFrame()
pro = ts.pro_api()
for i in list_ticker:
data = pro.fina_indicator(ts_code=i, start_date='20150118', end_date='20190731').drop_duplicates(subset='end_date')
fund_data = pd.concat([fund_data,data], axis=0)
date = pd.to_datetime(fund_data['end_date'],format='%Y%m%d').to_frame('date')
tic = fund_data['ts_code'].to_frame('tic')
OPM = fund_data['grossprofit_margin'].to_frame('OPM')
NPM = fund_data['netprofit_margin'].to_frame('NPM')
ROA = fund_data['roa'].to_frame('ROA')
ROE = fund_data['roe'].to_frame('ROE')
EPS = fund_data['eps'].to_frame('EPS')
cur_ratio = fund_data['current_ratio'].to_frame('cur_ratio')
quick_ratio = fund_data['quick_ratio'].to_frame('quick_ratio')
cash_ratio = fund_data['cash_ratio'].to_frame('cash_ratio')
acc_rec_turnover = fund_data['ar_turn'].to_frame('acc_rec_turnover')
debt_ratio = fund_data['debt_to_assets'].to_frame('debt_ratio')
debt_to_equity = fund_data['debt_to_eqt'].to_frame('debt_to_equity')
ratios = pd.concat([date,tic,OPM,NPM,ROA,ROE,EPS,
cur_ratio,quick_ratio,cash_ratio,acc_rec_turnover,
debt_ratio,debt_to_equity], axis=1)
ratios = ratios.sort_values(by=['date','tic']).reset_index(drop=True)
return ratiosLos resultados muestran

Lo mismo ocurre con los datos básicos del mercado y los indicadores técnicos.
Conexión y preprocesamiento de datos
Eliminar datos ilegales
final_ratios = ratios.copy()
final_ratios = final_ratios.fillna(0)
final_ratios = final_ratios.replace(np.inf,0)Usar fecha y tic para conectar datos
import itertools
list_date = list(pd.date_range(df['date'].min(),df['date'].max()))
combination = list(itertools.product(list_date,list_ticker))
# Merge stock price data and ratios into one dataframe
processed_full = pd.DataFrame(combination,columns=["date","tic"]).merge(df,on=["date","tic"],how="left")
processed_full = processed_full.merge(final_ratios,how='left',on=['date','tic'])
processed_full = processed_full.sort_values(['tic','date'])
Rellene los datos de indicadores financieros para garantizar la integridad de los datos
# Backfill the ratio data to make them daily
processed_full = processed_full.bfill(axis='rows')Los resultados muestran

2. Modelo DRL de entrenamiento
El modelo DRL utiliza la biblioteca ElegantRL de código abierto como marco.
Modelo MDP de tarea de transacción: Modelamos la tarea de transacción como un proceso de decisión de Markov (MDP) (S, A, P, r, γ) , donde S y A denotan espacio de estado y espacio de acción respectivamente, P(s'| s, A) representa la probabilidad de transición, r(s, a) es la función de recompensa y γ∈(0, 1) es el factor de descuento. Específicamente, el estado representa una observación del entorno del mercado por parte del agente DRL, el espacio de acción consiste en acciones que el agente puede realizar en un determinado estado, y r (s, a, s') motiva al agente a aprender mejores políticas. El propósito de un agente comercial es aprender una política ![]() que maximice el rendimiento esperado
que maximice el rendimiento esperado ![]() .
.
Los códigos relevantes son de FinRL-Meta Demo_China_A_share_market
Ejecutar la configuración de hiperparámetros de la función
def run(gpu_id=0):
env = StockTradingEnv()
env_func = StockTradingEnv
env_args = get_gym_env_args(env=env, if_print=False)
env_args['beg_idx'] = 10 # training set
env_args['end_idx'] = 1296 # training set
args = Arguments(AgentPPO, env_func=env_func, env_args=env_args)
args.target_step = args.max_step * 4
args.reward_scale = 2 ** -7
args.learning_rate = 1.5 ** -14
args.break_step = int(10e5)
args.learner_gpus = gpu_id
args.random_seed += gpu_id + 1943
train_agent(args)Enlace el código de la biblioteca ElegantRL
run()La función utilizará lo siguiente:
# env.py
class StockTradingEnv() # 来自FinRL库的交易仿真环境
def build_env() # 创建训练仿真环境
def get_gym_env_args() # 获得仿真环境的参数
# net.py
class ActorPPO # PPO算法的策略网络
class CriticPPO # PPO算法的价值网络
# agent.py
class AgentPPO # PPO算法的主体
class ReplayBufferList # 经验回放缓存(存放强化学习的训练数据)
# run.py
class Arguments # 强化学习的超参数(可以看这个类的注释了解超参数的作用)
def train_agent() # 训练强化学习智能体的函数Para satisfacer las necesidades de capacitación, es necesario realizar algunas modificaciones en la clase StockTradingEnv.
Entrenar y evaluar el modelo.
Use la función check_env() para probar los datos del conjunto de prueba
- La acción aleatoria indica que la acción de la transacción es aleatoria
action=rd.uniform(-1, 1, action_dim)y que el agente capacitado mediante el aprendizaje por refuerzo no debe tener una puntuación inferior a esta. - comprar todas las acciones significa que la mayor cantidad se ha utilizado para comprar todas las acciones
action=np.ones(action_dim), lo que puede reflejar la tendencia del mercado hasta cierto punto
Para la comodidad de la demostración y el aprendizaje, se seleccionan menos datos para comprimir el tiempo de entrenamiento en 1000 segundos. De hecho, los datos de entrenamiento deben ser un orden de magnitud más.
| StockTradingEnv: close_ary.shape (339, 15)
| StockTradingEnv: tech_ary.shape (339, 120)
| StockTradingEnv: fund_ary.shape (339, 165)
cumulative_returns of random action: 1.21
cumulative_returns of random action: 1.20
cumulative_returns of random action: 1.18
cumulative_returns of random action: 1.43
cumulative_returns of buy all share: 1.36
cumulative_returns of buy all share: 1.36
cumulative_returns of buy all share: 1.36
cumulative_returns of buy all share: 1.36
Usa la función run() para entrenar
| StockTradingEnv: close_ary.shape (1625, 15)
| StockTradingEnv: tech_ary.shape (1625, 120)
| StockTradingEnv: fund_ary.shape (1625, 165)
| Arguments Remove cwd: ./StockTradingEnv-v2_PPO_0
| StockTradingEnv: close_ary.shape (1286, 15)
| StockTradingEnv: tech_ary.shape (1286, 120)
| StockTradingEnv: fund_ary.shape (1286, 165)
Step:7.71e+03 ExpR: -0.01 Returns: 0.84 ObjC: 0.66 ObjA: -0.02
Step:6.17e+04 ExpR: 0.27 Returns: 3.42 ObjC: 0.49 ObjA: -0.29
Step:1.16e+05 ExpR: 0.23 Returns: 3.18 ObjC: 0.26 ObjA: -0.31
Step:1.70e+05 ExpR: 0.07 Returns: 1.81 ObjC: 0.21 ObjA: -0.23
Step:2.24e+05 ExpR: 0.23 Returns: 3.24 ObjC: 0.17 ObjA: -0.24
Step:2.78e+05 ExpR: 0.00 Returns: 1.15 ObjC: 0.17 ObjA: -0.25
Step:3.32e+05 ExpR: 0.04 Returns: 1.42 ObjC: 0.11 ObjA: -0.25
Step:3.86e+05 ExpR: 0.05 Returns: 1.36 ObjC: 0.07 ObjA: -0.22
Step:4.39e+05 ExpR: 0.05 Returns: 1.51 ObjC: 0.06 ObjA: -0.28
Step:4.93e+05 ExpR: 0.05 Returns: 1.50 ObjC: 0.03 ObjA: -0.24
Step:5.47e+05 ExpR: 0.04 Returns: 1.48 ObjC: 0.15 ObjA: -0.32
Step:6.01e+05 ExpR: 0.05 Returns: 1.54 ObjC: 0.09 ObjA: -0.20
Step:6.55e+05 ExpR: 0.05 Returns: 1.54 ObjC: 0.06 ObjA: -0.25
Step:7.09e+05 ExpR: 0.07 Returns: 1.74 ObjC: 0.06 ObjA: -0.29
Step:7.63e+05 ExpR: 0.05 Returns: 1.40 ObjC: 0.03 ObjA: -0.25
Step:8.17e+05 ExpR: 0.05 Returns: 1.46 ObjC: 0.02 ObjA: -0.36
Step:8.71e+05 ExpR: 0.21 Returns: 2.96 ObjC: 0.25 ObjA: -0.21
Step:9.25e+05 ExpR: 0.21 Returns: 2.86 ObjC: 0.16 ObjA: -0.33
Step:9.79e+05 ExpR: 0.21 Returns: 2.97 ObjC: 0.10 ObjA: -0.29
| UsedTime: 1118 | SavedDir: ./StockTradingEnv-v2_PPO_0Evaluación de modelos usando la función evaluar_modelos_en_directorio()
| StockTradingEnv: close_ary.shape (339, 15)
| StockTradingEnv: tech_ary.shape (339, 120)
| StockTradingEnv: fund_ary.shape (339, 165)
cumulative_returns 1.084 actor_00000000007710_00000011_-0000.01.pth
cumulative_returns 1.411 actor_00000000061680_00000073_00000.27.pth
cumulative_returns 1.381 actor_00000000115650_00000132_00000.23.pth
cumulative_returns 1.167 actor_00000000169620_00000192_00000.07.pth
cumulative_returns 1.445 actor_00000000223590_00000252_00000.23.pth
cumulative_returns 1.210 actor_00000000277560_00000311_00000.00.pth
cumulative_returns 1.126 actor_00000000331530_00000371_00000.04.pth
cumulative_returns 0.965 actor_00000000385500_00000430_00000.05.pth
cumulative_returns 0.965 actor_00000000439470_00000490_00000.05.pth
cumulative_returns 0.965 actor_00000000493440_00000552_00000.05.pth
cumulative_returns 1.025 actor_00000000547410_00000612_00000.04.pth
cumulative_returns 1.339 actor_00000000601380_00000671_00000.05.pth
cumulative_returns 1.265 actor_00000000655350_00000728_00000.05.pth
cumulative_returns 1.258 actor_00000000709320_00000788_00000.07.pth
cumulative_returns 1.258 actor_00000000763290_00000847_00000.05.pth
cumulative_returns 1.258 actor_00000000817260_00000909_00000.05.pth
cumulative_returns 1.421 actor_00000000871230_00000970_00000.21.pth
cumulative_returns 1.421 actor_00000000925200_00001031_00000.21.pth
cumulative_returns 1.421 actor_00000000979170_00001091_00000.21.pthlos rendimientos acumulativos representan las recompensas desde el principio hasta el final de la transacción del agente. Por conveniencia, mostramos directamente el "múltiplo de crecimiento principal".
actor_00000000004998_00000003_00000.08.pthEs el archivo del modelo de red de estrategia guardado durante el entrenamiento actor, lo que significa que muestra 4998 pasos en el entorno, entrena durante 3 segundos y explora el entorno con una puntuación de 0,08. El oro aumentó 1,093 veces.
Connect Tensorboard visualización y ajuste de parámetros
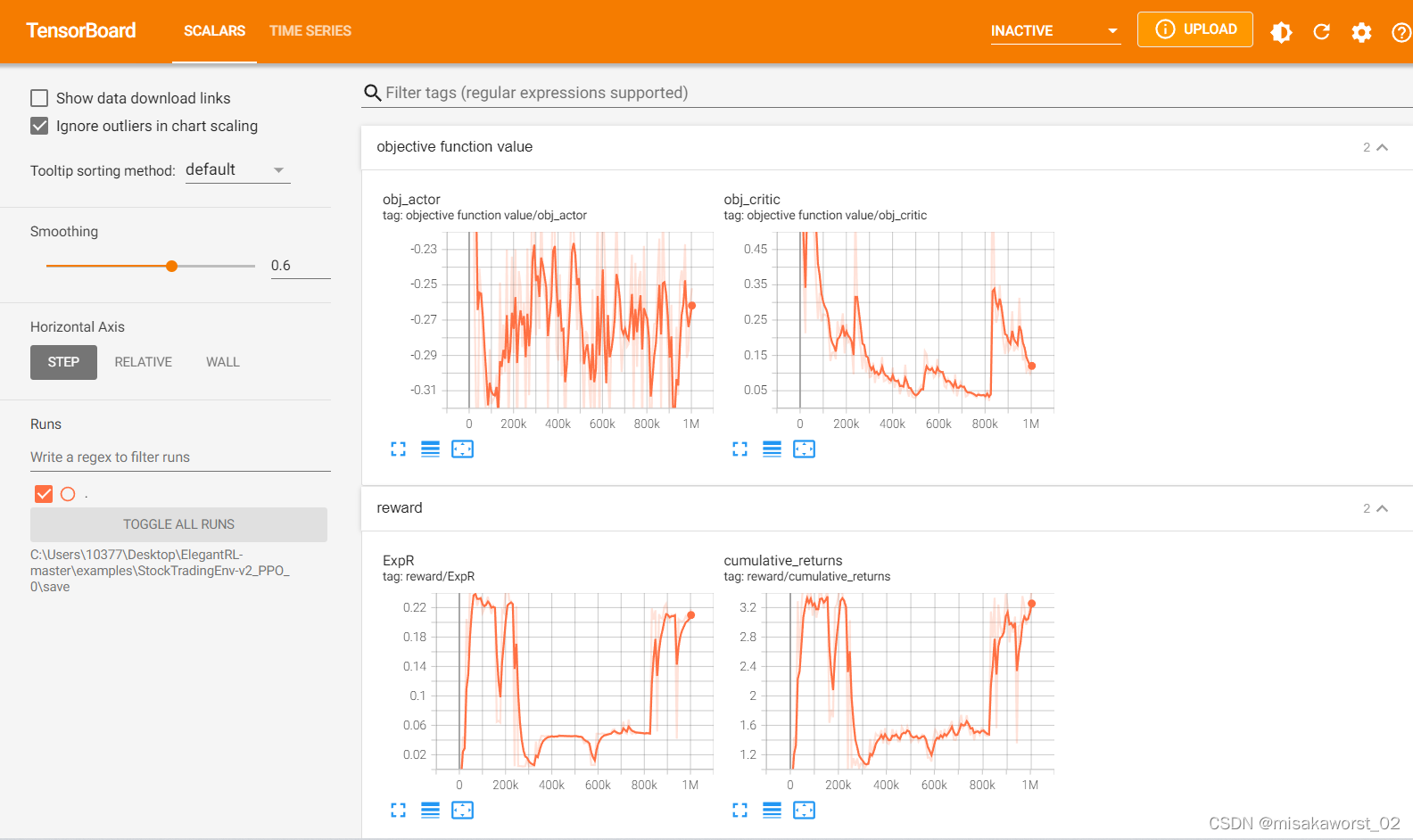
Solo guárdelo como un recuerdo para usted, indíquelo si tiene alguna pregunta.