Registre y analice los problemas encontrados en el desarrollo de chispas
1 ver registros
| fuente de registro | método de obtención | características |
|---|---|---|
| sistema de programación | Ver directamente el registro de programación | Localice rápidamente problemas simples, el registro es el más conciso y no se puede analizar en profundidad |
| Interfaz de usuario de Spark | Ver por ID de aplicación en la interfaz de usuario de Spark | Visualización gráfica, fácil de analizar problemas y proceso de ejecución, registros más completos |
| registro de hilo | registros de hilo -applicationId app_ld > res.log | Texto de registro, pero el registro es el análisis más detallado y profundo de los problemas |
registro perdido
1. Registros perdidos
1) El nodo donde se encuentra el controlador se pierde, se encoge o se recicla puntualmente.
2 Recursos insuficientes
Tanto el controlador como el ejecutor pueden tener memoria insuficiente;
1. Código de error -134
La función agregada provoca un desbordamiento de memoria
1. Descripción del error
El contenedor salió con un código de salida distinto de cero 134. Archivo de error: prelaunch.err.
Últimos 4096 bytes de prelaunch.err
2. Funciones
recopilar_conjunto, recopilar_lista
3. Motivo
Cierto valor clave (nulo, desconocido, cadena vacía) es demasiado, y el valor del valor agregado es demasiado, lo que hace que el rango (matriz fuera de rango) exceda el límite;
4. Soluciones
1) aumentar la memoria
2) Descubra el valor clave que excede el límite y fíltrelo;
2. Código de error -104
La unión de difusión provoca un desbordamiento de memoria
diagnósticos: la aplicación application_id falló 2 veces debido a que AM Container for appattempt_id salió con exitCode: -104
El contenedor se está ejecutando más allá de los límites de memoria física. Uso actual: 2,4 GB de 2,4 GB de memoria física utilizada; Se utilizan 4,4 GB de 11,9 GB de memoria virtual. Contenedor de matanza.
3. Código de error -137
Contenedor sin memoria
1. Descripción del error
Trabajo cancelado debido a una falla de etapa: la tarea 2 en la etapa 26.0 falló 4 veces, la falla más reciente: se perdió la tarea 2.3 en la etapa 26.0 (TID 3253, ip-10-20-68-111.eu-west-1.compute.internal, ejecutor 43): ExecutorLostFailure (el ejecutor 43 salió debido a una de las tareas en ejecución) Motivo: Contenedor de un nodo incorrecto: container_e03_1634810603944_186010_01_000121 en el host: ip-10-20-68-111.eu-west-1.compute.internal. Estado de salida: 137. Diagnóstico: [2022-05-27 01:49:51.535] Contenedor eliminado a pedido. El código de salida es 137
2. Soluciones
Resolver "Contenedor eliminado a pedido. El código de salida es 137" en Spark en Amazon EMR
El contenedor de la tarea Spark eliminó el error del código de salida 137 en AWS EMR
4. Código de error - OutOfMemoryError
1 desbordamiento de memoria del controlador
1) Mensaje de error
java.lang.OutOfMemoryError: GC overhead limit exceeded
-XX:OnOutOfMemoryError="kill -9 %p"
Executing /bin/sh -c "kill -9 29082"...java.lang.OutOfMemoryError: Java heap space
-XX:OnOutOfMemoryError="kill -9 %p
Executing /bin/sh -c "kill -9 234632) Posibles razones
| causas del problema | solución |
|---|---|
| transmitir la mesa más grande | a.Aumentar la memoria; b. Cancelar la mesa para retransmitir |
| Demasiadas particiones de origen de datos | a. Aumentar la memoria b. Reducir la partición aguas arriba |
| Hay demasiados datos recopilados para el controlador. | a. Aumentar la memoria b. Reducir el conjunto de resultados |
| El servidor donde se encuentra el controlador no tiene recursos suficientes | A. Reducir adecuadamente el controlador pero la memoria b. Cambiar a un servidor con suficientes recursos |
-
3. Invalidación de caché
问题描述:spark3当cache表 where 后有 in 过滤时 不会走cache ,而再去读源数据
-- 不走cache写法:
cache table test_tamp1 as(
select
id
from
table_name_01
where
dt = '20230326'
and pkg in (select pkg from table_name_02)
group by
id
);
解决方法
-- join替代in操作
cache table test_tamp1 as(
select
id
from
table_name_01 aa
left semi join
table_name_02 bb
on aa.pkg = bb.pkg
where
dt = '20230326'
group by
id
);
-- 设置参数
set spark.sql.legacy.storeAnalyzedPlanForView=true;4 datos sesgados
Posibles Causas:
1) Aparece una tecla de acceso rápido (valor nulo, valor anormal) durante la asociación;
2) coalesce reduce la partición, lo que resulta en datos sesgados;
1 Ver el registro de operaciones
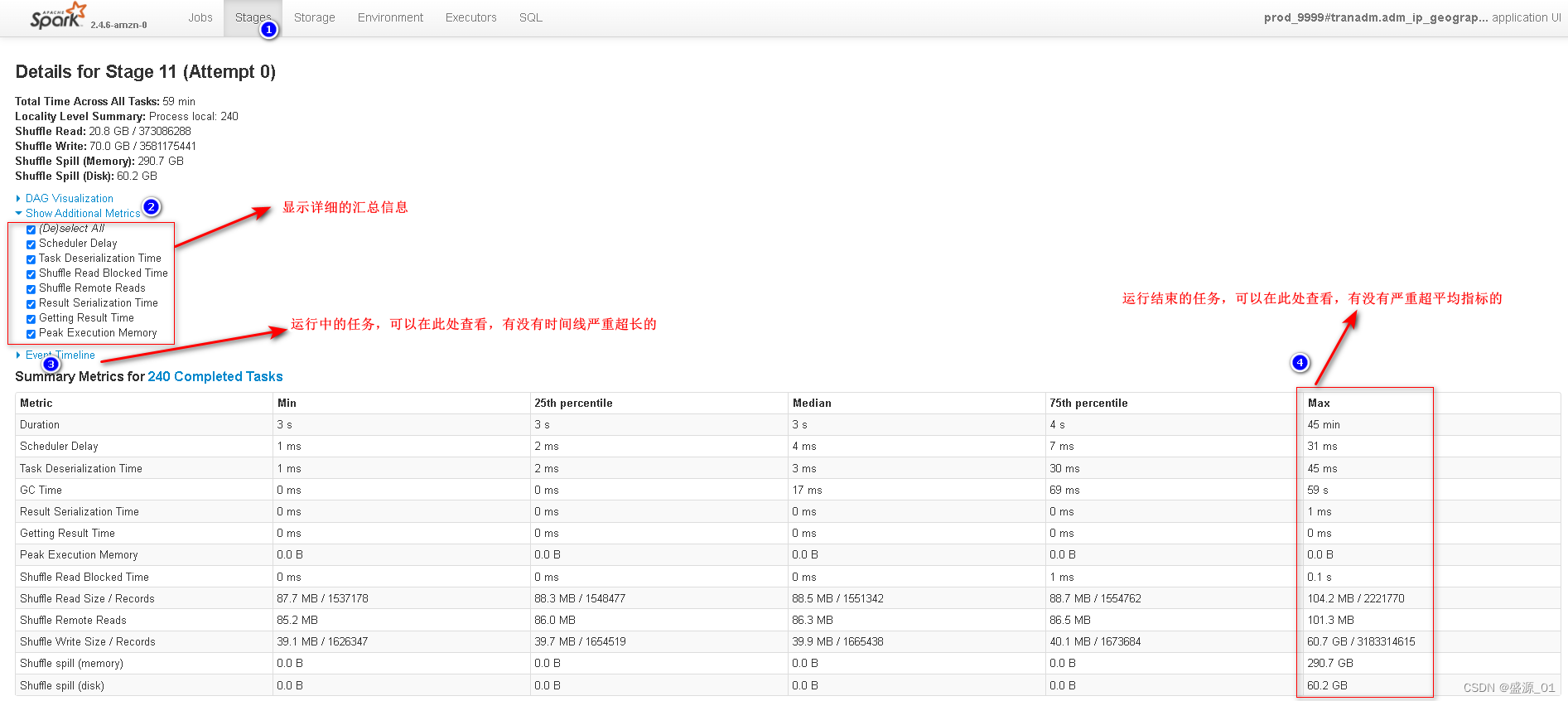
2 Encuentra claves primarias sesgadas
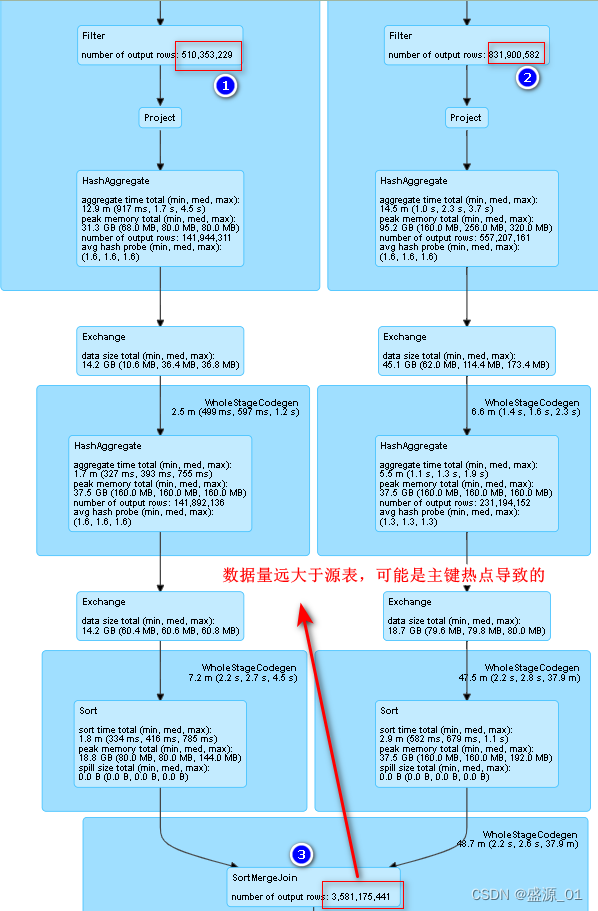
1 Distribución de clave principal de la tabla de origen
Analice la tabla de origen directamente, los datos no explotarán y la consulta es rápida
2. La distribución de la clave principal de las estadísticas de asociación
ha sido sesgada y la velocidad de consulta es lenta
3 medidas de optimización
1 Filtrar claves primarias no válidas y anormales
1) id = 'clave primaria anormal'
2) id es nulo
3) id = ''
5. Error en fase de escritura
1) Aumentar el paralelismo
2) aumentar la memoria
3) Derrame a disco
6. Error de desbordamiento de pila
java.lang.StackOverflowError
`java.lang.StackOverflowError` generalmente es causado por llamadas recursivas demasiado profundas. En Spark, esto puede suceder especialmente cuando realiza uniones complejas o anida varias operaciones de procesamiento de datos.
Escenarios que causan este problema:
unir demasiadas tablas
Para evitar esta situación, puede probar las siguientes soluciones
1. Aumente el tamaño de la pila de la JVM: establecer el parámetro `-Xss` al iniciar la aplicación puede aumentar el tamaño de la pila de la JVM. Por ejemplo, `spark-submit --conf spark.driver.extraJavaOptions=-Xss4m yourApp.jar`, establece el tamaño de la pila en 4 MB. Sin embargo, este enfoque puede hacer que la JVM use más memoria, por lo que debe usarse con precaución.
2. Use el método `repartición`: El método `repartición` puede volver a particionar los datos, reduciendo así la carga al unir. Por ejemplo, si tiene 100 particiones en su conjunto de datos, puede usar `df.repartition(10)` para dividirlo en 10 particiones para reducir la carga.
3. Use la variable `broadcast`: La variable `broadcast` puede transmitir la variable a todos los nodos de trabajo. Este enfoque generalmente es adecuado para conjuntos de datos pequeños y puede reducir la carga en cada nodo trabajador. Por ejemplo, si necesita unir un conjunto de datos muy grande con un conjunto de datos muy pequeño, puede transmitir el conjunto de datos pequeño a todos los nodos trabajadores para reducir la carga.
10 Otro Resumen
| descripción china | código de error | Solución |
|---|---|---|
| no puedo leer el medidor | Error en la consulta: java.lang.IllegalArgumentException: no se puede crear una ruta a partir de una cadena vacía; |
1 recrear vista en colmena |
| no se puede leer el archivo directamente | Catalyst.analysis.UnresolvedException: Llamada no válida a tipo de datos en objeto no resuelto, árbol | 1 Se leyó una columna que no existe |
| Eliminar otros datos de partición | Problema de sobrescritura de partición dinámica | Problema de sobreescritura de la partición dinámica de Apache Spark: memoria anterior |
| no se puede leer y escribir la misma tabla | Error en la consulta: no se puede sobrescribir una ruta que también se está leyendo. |
-- No use metadatos de colmena establecer chispa.sql.hive.convertMetastoreParquet=falso; establecer chispa.sql.hive.convertMetastoreOrc=false; |
| El parámetro de configuración no tiene efecto. | 1. Confirme en el entorno de chispa 2. ¿Se sobrescribe nuevamente (causado por componentes intermedios, como kyuubi tiene sus propios parámetros predeterminados)? |
-
20 problemas abiertos
| número de serie | Descripción del problema |
|---|---|
| 1 | select * from table_name where dt = '20220423' Después de filtrar los datos y escribirlos en la tabla, cómo controlar el paralelismo de escritura y aumentar el paralelismo de procesamiento |
| 2 | Cómo manejar excepciones en spark-sql |
| 3 | Cómo cargar en serie cada tabla cuando se asocian varias tablas |