Servicio Avalancha Introducción
Si el proveedor de servicios no está disponible, la persona que llama al servicio tampoco estará disponible, y así sucesivamente, todos los microservicios en todo el enlace no estarán disponibles.
Si el proveedor de servicios A falla por algún motivo, el servicio de llamadas del servicio B no puede llamar con éxito a la interfaz proporcionada por el servicio B dependiendo del servicio A. Con el tiempo, más y más solicitudes dependiendo del servicio A provocarán el consumo de recursos de Tomcat del servicio B. Como resultado , el subproceso del servicio B está bloqueado y el servicio B también falla. Entonces, si el servicio C depende del servicio B, el servicio C falla porque el servicio B también falla. Por analogía, todos los microservicios en todo el enlace no están disponibles.
① Entender:

② resolver
Acortar el tiempo de espera (no deseable)
ventaja:
Simple
defecto:
Algunas horas extras de servicio se reservan previamente
En algunos servicios, puede haber una gran cantidad de código o conexión a DB, etc. Si el tiempo de conexión no es suficiente para el tiempo de ejecución del código, entonces no se puede ejecutar un negocio normal.
Establecer interceptor
descripción general
Se puede resolver en microservicios
服务雪崩, llamados熔断器o断路器. Puede evitar que sucedan proyectos distribuidos联动故障(un servicio deja de funcionar, otros servicios no pueden ejecutarse normalmente).Se configura
拦截器un esquema similar en Hystrix: si el servicio al que se debe llamar está inactivo, entonces la máquina no se llamará ni se usará directamente备选方案.
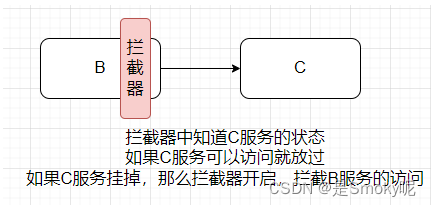
usar
① servicio de alquiler de coches
archivo de configuración
server: port: 8080 spring: application: name: rent-car-service eureka: client: service-url: defaultZone: http://localhost:8761/eureka instance: hostname: localhost instance-id: ${eureka.instance.hostname}:${spring.application.name}:${server.port} lease-renewal-interval-in-seconds: 5API:
@RestController public class CarController { @GetMapping("rent") public String rent(){ return "租车成功"; } }② servicio al consumidor
Hystrix-dependencia
<dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-netflix-hystrix</artifactId> </dependency>archivo de configuración
server: port: 8081 spring: application: name: consumer-service eureka: client: service-url: defaultZone: http://localhost:8761/eureka instance: hostname: localhost instance-id: ${eureka.instance.hostname}:${spring.application.name}:${server.port} lease-renewal-interval-in-seconds: 5interfaz OpenFiign
@FeignClient(value = "rent-car-service",fallback = ConsumerRentCarFeignHystrix.class) // 指定发生服务雪崩时执行哪个类 public interface ConsumerRentCarFeign { @GetMapping("rent") String rent(); }Clase de implementación Hystrix
@Component // 添加到IOC容器中 public class ConsumerRentCarFeignHystrix implements ConsumerRentCarFeign { /** * 备用方案 * 当调用的服务挂掉后执行本方法 * @return */ @Override public String rent() { return "网络异常 稍后重试"; } }API
@RestController public class ConsumerController { @Autowired private ConsumerRentCarFeign consumerRentCarFeign; @GetMapping("consumerToRent") public String consumerToRent(){ System.out.println("有人来租车"); return consumerRentCarFeign.rent(); } }Habilitar Hystrix
feign: hystrix: enabled: true
pensamiento de disyuntor
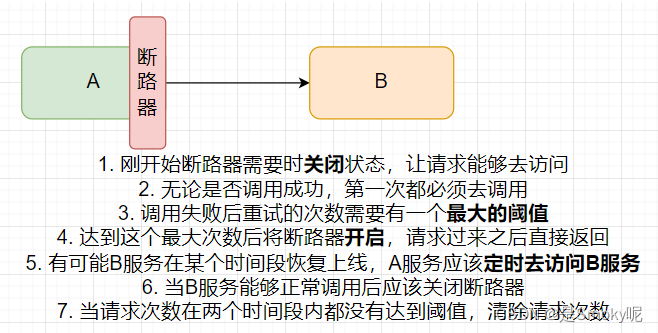
Configuración común
hystrix: #hystrix 的全局控制
command:
default: #default 是全局控制,也可以换成单个方法控制,把 default 换成方法名即可
fallback:
isolation:
semaphore:
maxConcurrentRequests: 1000 #信号量隔离级别最大并发数
circuitBreaker:
enabled: true #开启断路器
requestVolumeThreshold: 3 #失败次数(阀值)
sleepWindowInMilliseconds: 20000 #窗口时间
errorThresholdPercentage: 60 #失败率
execution:
isolation:
Strategy: thread #隔离方式 thread 线程隔离集合和 SEMAPHORE 信号量隔离
thread:
timeoutInMilliseconds: 3000 #调用超时时长Preguntas de entrevista relacionadas
¿Qué es Hystrix?
Herramienta antiavalancha, con funciones como degradación del servicio, fusión del servicio, aislamiento de dependencias, monitorización (Hstrix Dashboard) y otras
¿Qué es un disyuntor de servicio? ¿Cuál es la función del fusible?
En primer lugar, hablemos de lo que es el efecto fan-out y avalancha: al llamar entre múltiples microservicios, asumiendo que los microservicios
El servicio A llama al microservicio B y al microservicio C, y el microservicio B y el microservicio C llaman a otros servicios.
Es el llamado fan-out.Si el tiempo de respuesta de llamada de un microservicio en el enlace de fan-out es demasiado largo, o no es
Disponible, entonces la persona que llama al microservicio bloqueará el subproceso, ocupará más y más recursos del sistema y luego fallará.
De la misma manera, la llamada que afecta a la llamada se derrumbará paso a paso, lo que es el llamado efecto avalancha.
Luego, el mecanismo de fusión de servicios es un mecanismo de protección de enlace de microservicio para hacer frente al efecto de avalancha, y el enlace de abanico
Si un microservicio no está disponible o el tiempo de respuesta es demasiado largo, el servicio se degradará y el microservicio se perderá.
La llamada del microservicio de nodo devuelve rápidamente la información de respuesta incorrecta, cuando se detecta que el microservicio de nodo llama a la respuesta
Cuando sea normal, restaure el enlace. En el marco SpringCloud, el mecanismo de fusión se implementa a través de Hystrix.
Hystrix creará muchos grupos de subprocesos pequeños, como el servicio de inventario de solicitud de servicio de pedidos es un grupo de subprocesos,
El servicio de almacenamiento de solicitudes es un grupo de subprocesos y el servicio de crédito de solicitud es un grupo de subprocesos. Subprocesos en cada grupo de subprocesos
Solo se usa para solicitar ese servicio. Cuando un cierto grupo de subprocesos alcanza el umbral, el fusible del servicio se iniciará y el servicio se degradará.
clase. Si otras solicitudes continúan visitando, el valor predeterminado de respaldo se devolverá directamente.
¿Qué es la degradación del servicio?
Cuando el servicio se interrumpe, realice un proceso fallido antes de regresar, como almacenar la información de la solicitud en los datos
La base de datos se utiliza para la recuperación posterior de datos.Creo que este tipo de procesamiento posterior al fusible se refiere a la degradación del servicio. núcleo de prioridad
Los servicios, los servicios complementarios no están disponibles o están débilmente disponibles.
Caso de degradación del servicio: Double Eleven: "Ay, estoy abrumado..." o aumento de la aplicación: "Deserción de la red
Se ha ido, inténtalo de nuevo más tarde...》
Implemente la lógica de degradación en fallbackMethod (función de respaldo).
Interrupción de circuitos y degradación: Falla rápida después de que falla la llamada a un servicio
Fusible: es para evitar la falta de difusión anormal y garantizar la estabilidad del sistema
Degradación: escriba la lógica de reparación para la falla de la llamada y luego detenga el servicio directamente, de modo que estas interfaces no se puedan llamar normalmente, pero no informará un error directamente, pero el nivel de servicio caerá
Envuelva todos los sistemas externos (o dependencias) a través de HystrixCommand o HystrixObservableCommand, y todo el objeto contenedor se ejecuta en un solo subproceso (este es un modo de comando típico).
Las solicitudes de tiempo de espera deben superar el umbral definido
mantenga un pequeño grupo de subprocesos (o semáforo) para cada dependencia; si se llena, las solicitudes de la dependencia se rechazarán inmediatamente en lugar de ponerse en cola
Cuenta éxitos, fallas (excepciones lanzadas por clientes), tiempos de espera y rechazos de subprocesos
La apertura de un disyuntor detiene todas las solicitudes a un servicio de funciones durante un período de tiempo y cierra manual o automáticamente el disyuntor si el porcentaje de error del servicio supera un umbral.
Cuando se rechaza la solicitud, se agota el tiempo de conexión o se abre el disyuntor, la lógica alternativa se ejecuta directamente.
Supervise las métricas y los cambios de configuración casi en tiempo real.
¿Cómo evita Hystrix el efecto avalancha?
En primer lugar, para evitar la formación del efecto de avalancha se requiere un poderoso mecanismo tolerante a fallas. Hystrix es una biblioteca de herramientas que implementa el mecanismo de tiempo de espera y el modo de disyuntor.
Hystrix implementa principalmente la tolerancia a fallas y demoras a través de los siguientes puntos:
Paquete solicitud: use HystrixCOmmand para empaquetar la lógica de llamada para las dependencias, cada comando se ejecuta en un subproceso independiente. Se usa el mecanismo de activación del "modo de comando" del modo de diseño
: cuando la tasa de error del servicio supera un cierto umbral, Hystrix puede automáticamente o desconectarse manualmente y dejar de solicitar el servicio durante un período de
aislamiento de recursos: Hystrix mantiene un pequeño grupo de subprocesos o semáforos para cada dependencia.Si el subproceso está lleno, la solicitud enviada a la dependencia se rechaza inmediatamente en lugar de esperar en línea, lo que acelera Supervisión: Hystrix puede ser casi en
tiempo real Supervise los indicadores de ejecución y los cambios de configuración, como el éxito, la falla, el tiempo de espera y las solicitudes rechazadas
, etc. Cuando se abre el interruptor automático, se ejecuta la lógica de reversión Reversión La lógica se proporciona por sí misma, incluida la devolución de un valor predeterminado
para la autorreparación: después de que el interruptor automático se abre durante un período de tiempo, automáticamente ingresará en la "media estado abierto", intente solicitar servicios y la solicitud pasará la solicitud de recuperación. Si la solicitud falla, el disyuntor continuará abriéndose