El blogger no ha autorizado a ninguna persona u organización a reimprimir ningún artículo original del blogger, ¡gracias por su apoyo al original!
enlace de blogger
Trabajo para un fabricante de terminales de renombre internacional y soy responsable de la investigación y el desarrollo de chips de módem.
En los primeros días de 5G, fue responsable del desarrollo de la capa de servicio de datos de terminales y la red central. Actualmente, lidera la investigación sobre estándares técnicos para redes de potencia informática 6G.
El contenido del blog gira principalmente en torno a:
Explicación del protocolo 5G/6G
Explicación de la red de potencia informática (computación en la nube, computación de borde, computación final)
Explicación del lenguaje C avanzado Explicación
del lenguaje Rust
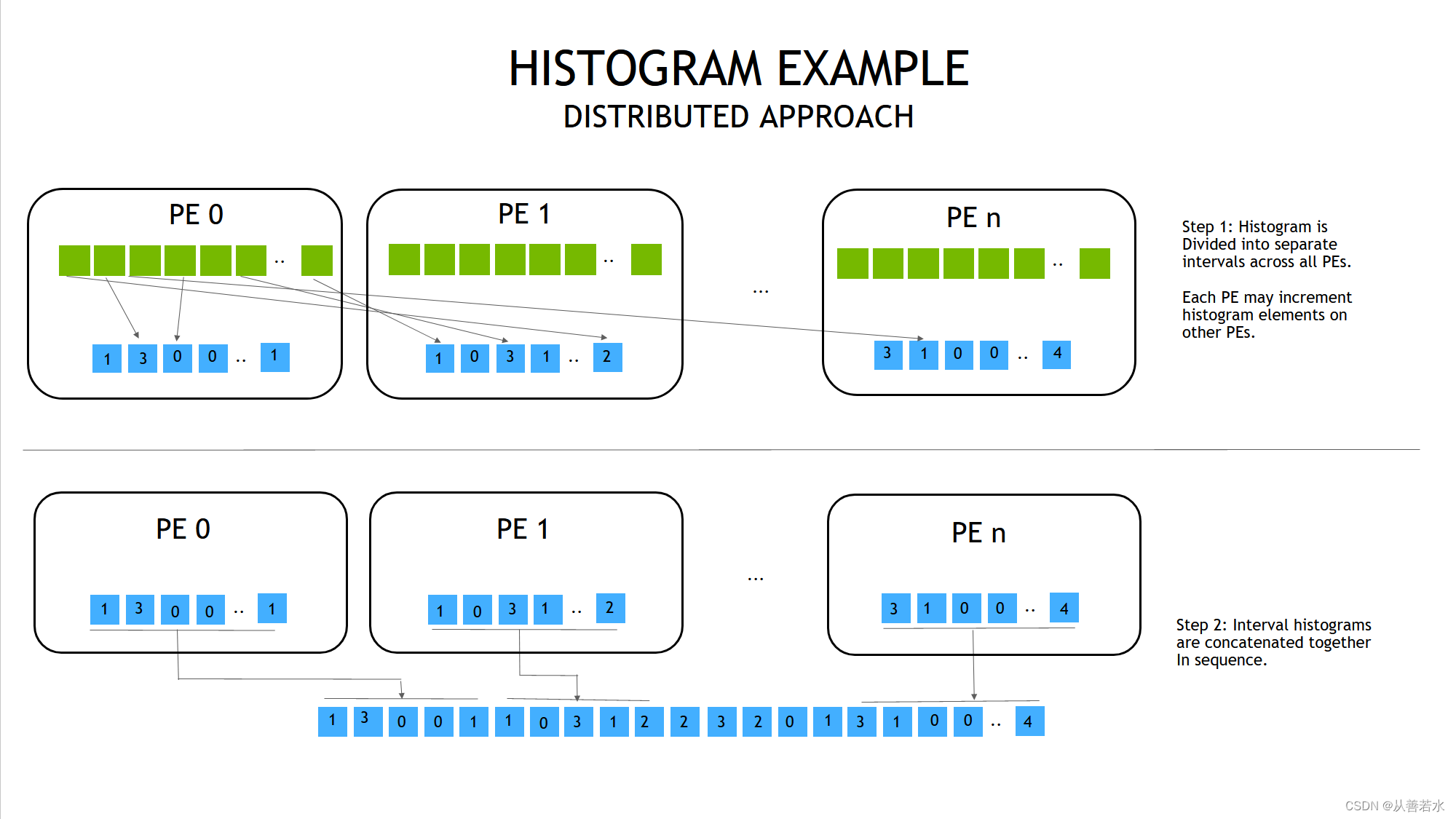
Histograma NVSHMEM: enfoque distribuido

PE: unidad de procesamiento (entidad de proceso)
Veamos otra solución a este problema. Una característica de la solución anterior es que todos los cálculos de histogramas se realizan localmente. Luego sincronice todos los hilos y haga una reducción final en el resultado.
Otra forma es dividir el histograma y asignar cada parte a diferentes GPU. Cuando una entrada en los datos de entrada no pertenece a una ubicación de histograma en esa GPU, incrementamos automáticamente la entrada de histograma relevante en el PE remoto . Luego tenemos que unir las partes del histograma al final. Nos referimos a este enfoque como un enfoque "distribuido".
Compensaciones entre enfoques replicados y distribuidos
Reducimos la cantidad de memoria GPU requerida para el histograma en el enfoque distribuido en comparación con el enfoque replicado. También redujimos la presión sobre las operaciones atómicas locales en el histograma. Pero a su vez, esto aumenta la presión del paso de mensajes y la presión de las operaciones atómicas en las GPU remotas.
práctica
Dividimos arbitrariamente el histograma en segmentos iguales a la cantidad de GPU y asignamos estos segmentos secuencialmente a diferentes GPU. También supondremos que la segmentación del histograma está implementada dentro de la función kernel, de modo que podemos calcular matemáticamente a qué PE enviar los datos (aunque es más fácil hacer este paso como el caso general, es decir, la información es no se conoce de antemano y aún debe proporcionarse como datos de entrada a la función del núcleo).
Para actualizar el histograma en el PE remoto, deseamos usar el equivalente de atomicAdd() de CUDA. La función NVSHMEM correspondiente esnvshmem_int_atomic_add()
nvshmem_int_atomic_add(destination, value, target_pe);
en,
- valor: es el valor a aumentar;
- target_pe: es el PE remoto a actualizar;
- el destino debe ser una dirección simétrica (como la dirección asignada por nvshmem_malloc());
En el paso de concatenar el histograma, tenemos una API fácil de usar nvshmem_int_collect()que concatena las matrices en todos los PE, como colocar la matriz de PE0 en la primera parte, la matriz de PE1 en la segunda parte, y así sucesivamente.
nvshmem_int_collect(team, destination, source, nelems);
en,
- destino: almacenar la matriz empalmada (igual en todos los PE);
- fuente: es la matriz fuente con nelems de longitud. Dado que el histograma se distribuye uniformemente entre los PE, la longitud de la matriz de destino debe ser n_pes*nelems, que coincida con la longitud de todo el histograma.
- equipo: Seleccione el grupo PE. Para operaciones colectivas globales, usamos grupos de trabajo
NVSHMEM_TEAM_WORLD, que contienen todos los PE;
El código relevante es el siguiente (nombre de archivo: histogram_step2.cpp)
#include <iostream>
#include <cstdlib>
#include <chrono>
#include <nvshmem.h>
#include <nvshmemx.h>
inline void CUDA_CHECK (cudaError_t err) {
if (err != cudaSuccess) {
fprintf(stderr, "CUDA error: %s\n", cudaGetErrorString(err));
exit(-1);
}
}
#define NUM_BUCKETS 16
#define MAX_VALUE 1048576
#define NUM_INPUTS 65536
__global__ void histogram_kernel(const int* input, int* histogram, int N)
{
int idx = threadIdx.x + blockIdx.x * blockDim.x;
int n_pes = nvshmem_n_pes();
int buckets_per_pe = NUM_BUCKETS / n_pes;
if (idx < N) {
int value = input[idx];
// 计算“全局”直方图索引号
int global_histogram_index = ((size_t) value * NUM_BUCKETS) / MAX_VALUE;
// 找出直方图指数对应的 PE。
// 假设每个 PE 的桶数量相同
// 我们从包含第一个桶的 PE 0 开始
// 直到第一个值为 1 / n_pes 的贮体为止
// 对其他 PE 采用类似方法。我们可在这个阶段采取简单的
// 整数除法。
int target_pe = global_histogram_index / buckets_per_pe;
// 现在求出 PE 的局部直方图索引号。
// 我们只需要用 PE 的起始桶的偏离值即可。
int local_histogram_index = global_histogram_index - target_pe * buckets_per_pe;
nvshmem_int_atomic_add(&histogram[local_histogram_index], 1, target_pe);
}
}
int main(int argc, char** argv) {
// 初始化 NVSHMEM
nvshmem_init();
// 获取 NVSHMEM 处理元素 ID 和 PE 数量
int my_pe = nvshmem_my_pe();
int n_pes = nvshmem_n_pes();
// 每个 PE(任意)选择与其 ID 对应的 GPU
int device = my_pe;
CUDA_CHECK(cudaSetDevice(device));
// 每台设备处理 1 / n_pes 的部分工作。
const int N = NUM_INPUTS / n_pes;
// 在主机上构建直方图输入数据
int* input = (int*) malloc(N * sizeof(int));
// 为每个 PE 初始化一个不同的随机数种子。
srand(my_pe);
// 输入数据范围从 0 至 MAX_VALUE - 1 不等
for (int i = 0; i < N; ++i) {
input[i] = rand() % MAX_VALUE;
}
// 复制到设备
int* d_input;
d_input = (int*) nvshmem_malloc(N * sizeof(int));
CUDA_CHECK(cudaMemcpy(d_input, input, N * sizeof(int), cudaMemcpyHostToDevice));
// 分配直方图数组 - 大小等同于主机上的
// 完整直方图,且只分配设备上每个 GPU 的相关部分。
int* histogram = (int*) malloc(NUM_BUCKETS * sizeof(int));
memset(histogram, 0, NUM_BUCKETS * sizeof(int));
int buckets_per_pe = NUM_BUCKETS / n_pes;
int* d_histogram;
d_histogram = (int*) nvshmem_malloc(buckets_per_pe * sizeof(int));
CUDA_CHECK(cudaMemset(d_histogram, 0, buckets_per_pe * sizeof(int)));
// 此外,还要为连接分配完整大小的设备直方图
int* d_concatenated_histogram = (int*) nvshmem_malloc(NUM_BUCKETS * sizeof(int));
CUDA_CHECK(cudaMemset(d_concatenated_histogram, 0, NUM_BUCKETS * sizeof(int)));
// 为合理准确的计时执行一次同步
nvshmem_barrier_all();
using namespace std::chrono;
high_resolution_clock::time_point tabulation_start = high_resolution_clock::now();
// 执行直方图
int threads_per_block = 256;
int blocks = (NUM_INPUTS / n_pes + threads_per_block - 1) / threads_per_block;
histogram_kernel<<<blocks, threads_per_block>>>(d_input, d_histogram, N);
CUDA_CHECK(cudaDeviceSynchronize());
nvshmem_barrier_all();
high_resolution_clock::time_point tabulation_end = high_resolution_clock::now();
// 连接所有 PE
high_resolution_clock::time_point combination_start = high_resolution_clock::now();
nvshmem_int_collect(NVSHMEM_TEAM_WORLD, d_concatenated_histogram, d_histogram, buckets_per_pe);
high_resolution_clock::time_point combination_end = high_resolution_clock::now();
// 打印 PE 0 上的结果
if (my_pe == 0) {
duration<double> tabulation_time = duration_cast<duration<double>>(tabulation_end - tabulation_start);
std::cout << "Tabulation time = " << tabulation_time.count() * 1000 << " ms" << std::endl << std::endl;
duration<double> combination_time = duration_cast<duration<double>>(combination_end - combination_start);
std::cout << "Combination time = " << combination_time.count() * 1000 << " ms" << std::endl << std::endl;
// 将数据复制回主机
CUDA_CHECK(cudaMemcpy(histogram, d_concatenated_histogram, NUM_BUCKETS * sizeof(int), cudaMemcpyDeviceToHost));
std::cout << "Histogram counters:" << std::endl << std::endl;
int num_buckets_to_print = 4;
for (int i = 0; i < NUM_BUCKETS; i += NUM_BUCKETS / num_buckets_to_print) {
std::cout << "Bucket [" << i * (MAX_VALUE / NUM_BUCKETS) << ", " << (i + 1) * (MAX_VALUE / NUM_BUCKETS) - 1 << "]: " << histogram[i];
std::cout << std::endl;
if (i < NUM_BUCKETS - NUM_BUCKETS / num_buckets_to_print - 1) {
std::cout << "..." << std::endl;
}
}
}
free(input);
free(histogram);
nvshmem_free(d_input);
nvshmem_free(d_histogram);
// 最终确定 nvshmem
nvshmem_finalize();
return 0;
}
Compilar y ejecutar comandos:
nvcc -x cu -arch=sm_70 -rdc=true -I $NVSHMEM_HOME/include -L $NVSHMEM_HOME/lib -lnvshmem -lcuda -o histogram_step2 histogram_step2.cpp
nvshmrun -np $NUM_DEVICES ./histogram_step2
El resultado de la operación es el siguiente:
Tabulation time = 0.195561 ms
Combination time = 0.029666 ms
Histogram counters:
Bucket [0, 65535]: 4135
...
Bucket [262144, 327679]: 4028
...
Bucket [524288, 589823]: 4088
...
Bucket [786432, 851967]: 4100
Comparación de métodos replicados y distribuidos en negrita
Hasta ahora, nos hemos centrado en escribir código sintácticamente correcto sin pensar en el rendimiento. Ahora examinemos el rendimiento de los enfoques distribuidos y replicados. En ambos casos, varíe el parámetro NUM_BUCKETS y el parámetro NUM_INPUTS, prestando atención a los tiempos de creación y combinación del histograma. ¿Es un método más rápido que el otro? En caso afirmativo, ¿hay alguna situación en la que se invierta la relación de rendimiento?
Para mayor comodidad, proporcionamos soluciones para ambas implementaciones a continuación.
método de replicación
El código fuente es el siguiente:
#include <iostream>
#include <cstdlib>
#include <chrono>
#include <nvshmem.h>
#include <nvshmemx.h>
inline void CUDA_CHECK (cudaError_t err) {
if (err != cudaSuccess) {
fprintf(stderr, "CUDA error: %s\n", cudaGetErrorString(err));
exit(-1);
}
}
#define NUM_BUCKETS 16
#define MAX_VALUE 1048576
#define NUM_INPUTS 65536
__global__ void histogram_kernel(const int* input, int* histogram, int N)
{
int idx = threadIdx.x + blockIdx.x * blockDim.x;
if (idx < N) {
int value = input[idx];
int histogram_index = ((size_t) value * NUM_BUCKETS) / MAX_VALUE;
atomicAdd(&histogram[histogram_index], 1);
}
}
int main(int argc, char** argv) {
// 初始化 NVSHMEM
nvshmem_init();
// 获取 NVSHMEM 处理元素 ID 和 PE 数量
int my_pe = nvshmem_my_pe();
int n_pes = nvshmem_n_pes();
// 每个 PE(任意)选择与其 ID 对应的 GPU
int device = my_pe;
CUDA_CHECK(cudaSetDevice(device));
// 每台设备处理 1 / n_pes 的部分工作。
const int N = NUM_INPUTS / n_pes;
// 在主机上构建直方图输入数据
int* input = (int*) malloc(N * sizeof(int));
// 为每个 PE 初始化一个不同的随机数种子。
srand(my_pe);
// 输入数据范围从 0 至 MAX_VALUE - 1 不等
for (int i = 0; i < N; ++i) {
input[i] = rand() % MAX_VALUE;
}
// 复制到设备
int* d_input;
d_input = (int*) nvshmem_malloc(N * sizeof(int));
CUDA_CHECK(cudaMemcpy(d_input, input, N * sizeof(int), cudaMemcpyHostToDevice));
// 分配直方图数组
int* histogram = (int*) malloc(NUM_BUCKETS * sizeof(int));
memset(histogram, 0, NUM_BUCKETS * sizeof(int));
int* d_histogram;
d_histogram = (int*) nvshmem_malloc(NUM_BUCKETS * sizeof(int));
CUDA_CHECK(cudaMemset(d_histogram, 0, NUM_BUCKETS * sizeof(int)));
// 为合理准确的计时执行一次同步
nvshmem_barrier_all();
using namespace std::chrono;
high_resolution_clock::time_point tabulation_start = high_resolution_clock::now();
// 执行直方图
int threads_per_block = 256;
int blocks = (NUM_INPUTS / n_pes + threads_per_block - 1) / threads_per_block;
histogram_kernel<<<blocks, threads_per_block>>>(d_input, d_histogram, N);
CUDA_CHECK(cudaDeviceSynchronize());
nvshmem_barrier_all();
high_resolution_clock::time_point tabulation_end = high_resolution_clock::now();
high_resolution_clock::time_point combination_start = high_resolution_clock::now();
// 在所有 PE 上执行归约
nvshmem_int_sum_reduce(NVSHMEM_TEAM_WORLD, d_histogram, d_histogram, NUM_BUCKETS);
high_resolution_clock::time_point combination_end = high_resolution_clock::now();
// 打印 PE 0 上的结果
if (my_pe == 0) {
duration<double> tabulation_time = duration_cast<duration<double>>(tabulation_end - tabulation_start);
std::cout << "Tabulation time = " << tabulation_time.count() * 1000 << " ms" << std::endl << std::endl;
duration<double> combination_time = duration_cast<duration<double>>(combination_end - combination_start);
std::cout << "Combination time = " << combination_time.count() * 1000 << " ms" << std::endl << std::endl;
// 将数据复制回主机
CUDA_CHECK(cudaMemcpy(histogram, d_histogram, NUM_BUCKETS * sizeof(int), cudaMemcpyDeviceToHost));
std::cout << "Histogram counters:" << std::endl << std::endl;
int num_buckets_to_print = 4;
for (int i = 0; i < NUM_BUCKETS; i += NUM_BUCKETS / num_buckets_to_print) {
std::cout << "Bucket [" << i * (MAX_VALUE / NUM_BUCKETS) << ", " << (i + 1) * (MAX_VALUE / NUM_BUCKETS) - 1 << "]: " << histogram[i];
std::cout << std::endl;
if (i < NUM_BUCKETS - NUM_BUCKETS / num_buckets_to_print - 1) {
std::cout << "..." << std::endl;
}
}
}
free(input);
free(histogram);
nvshmem_free(d_input);
nvshmem_free(d_histogram);
// 最终确定 nvshmem
nvshmem_finalize();
return 0;
}
Instrucciones de compilación y ejecución:
nvcc -x cu -arch=sm_70 -rdc=true -I $NVSHMEM_HOME/include -L $NVSHMEM_HOME/lib -lnvshmem -lcuda -o histogram_step1 histogram_step1.cpp
nvshmrun -np $NUM_DEVICES ./histogram_step1
El resultado de la operación es el siguiente:
Tabulation time = 0.035362 ms
Combination time = 0.039909 ms
Histogram counters:
Bucket [0, 65535]: 4135
...
Bucket [262144, 327679]: 4028
...
Bucket [524288, 589823]: 4088
...
Bucket [786432, 851967]: 4100
método distribuido
El código fuente es el siguiente:
#include <iostream>
#include <cstdlib>
#include <chrono>
#include <nvshmem.h>
#include <nvshmemx.h>
inline void CUDA_CHECK (cudaError_t err) {
if (err != cudaSuccess) {
fprintf(stderr, "CUDA error: %s\n", cudaGetErrorString(err));
exit(-1);
}
}
#define NUM_BUCKETS 16
#define MAX_VALUE 1048576
#define NUM_INPUTS 65536
__global__ void histogram_kernel(const int* input, int* histogram, int N)
{
int idx = threadIdx.x + blockIdx.x * blockDim.x;
int n_pes = nvshmem_n_pes();
int buckets_per_pe = NUM_BUCKETS / n_pes;
if (idx < N) {
int value = input[idx];
// 计算“全局”直方图索引号
int global_histogram_index = ((size_t) value * NUM_BUCKETS) / MAX_VALUE;
// 找出直方图指数对应的 PE。
// 假设每个 PE 的桶数量相同
// 我们从包含第一个桶的 PE 0 开始
// 直到第一个值为 1 / n_pes 的贮体为止
// 对其他 PE 采用类似方法。我们可在这个阶段采取简单的
// 整数除法。
int target_pe = global_histogram_index / buckets_per_pe;
// 现在求出 PE 的局部直方图索引号。
// 我们只需要用 PE 的起始桶的偏离值即可。
int local_histogram_index = global_histogram_index - target_pe * buckets_per_pe;
nvshmem_int_atomic_add(&histogram[local_histogram_index], 1, target_pe);
}
}
int main(int argc, char** argv) {
// 初始化 NVSHMEM
nvshmem_init();
// 获取 NVSHMEM 处理元素 ID 和 PE 数量
int my_pe = nvshmem_my_pe();
int n_pes = nvshmem_n_pes();
// 每个 PE(任意)选择与其 ID 对应的 GPU
int device = my_pe;
CUDA_CHECK(cudaSetDevice(device));
// 每台设备处理 1 / n_pes 的部分工作。
const int N = NUM_INPUTS / n_pes;
// 在主机上构建直方图输入数据
int* input = (int*) malloc(N * sizeof(int));
// 为每个 PE 初始化一个不同的随机数种子。
srand(my_pe);
// 输入数据范围从 0 至 MAX_VALUE - 1 不等
for (int i = 0; i < N; ++i) {
input[i] = rand() % MAX_VALUE;
}
// 复制到设备
int* d_input;
d_input = (int*) nvshmem_malloc(N * sizeof(int));
CUDA_CHECK(cudaMemcpy(d_input, input, N * sizeof(int), cudaMemcpyHostToDevice));
// 分配直方图数组 - 大小等同于主机上的
// 完整直方图,且只分配设备上每个 GPU 的相关部分。
int* histogram = (int*) malloc(NUM_BUCKETS * sizeof(int));
memset(histogram, 0, NUM_BUCKETS * sizeof(int));
int buckets_per_pe = NUM_BUCKETS / n_pes;
int* d_histogram;
d_histogram = (int*) nvshmem_malloc(buckets_per_pe * sizeof(int));
CUDA_CHECK(cudaMemset(d_histogram, 0, buckets_per_pe * sizeof(int)));
// 此外,还要为连接分配完整大小的设备直方图
int* d_concatenated_histogram = (int*) nvshmem_malloc(NUM_BUCKETS * sizeof(int));
CUDA_CHECK(cudaMemset(d_concatenated_histogram, 0, NUM_BUCKETS * sizeof(int)));
// 为合理准确的计时执行一次同步
nvshmem_barrier_all();
using namespace std::chrono;
high_resolution_clock::time_point tabulation_start = high_resolution_clock::now();
// 执行直方图
int threads_per_block = 256;
int blocks = (NUM_INPUTS / n_pes + threads_per_block - 1) / threads_per_block;
histogram_kernel<<<blocks, threads_per_block>>>(d_input, d_histogram, N);
CUDA_CHECK(cudaDeviceSynchronize());
nvshmem_barrier_all();
high_resolution_clock::time_point tabulation_end = high_resolution_clock::now();
// 连接所有 PE
high_resolution_clock::time_point combination_start = high_resolution_clock::now();
nvshmem_int_collect(NVSHMEM_TEAM_WORLD, d_concatenated_histogram, d_histogram, buckets_per_pe);
high_resolution_clock::time_point combination_end = high_resolution_clock::now();
// 打印 PE 0 上的结果
if (my_pe == 0) {
duration<double> tabulation_time = duration_cast<duration<double>>(tabulation_end - tabulation_start);
std::cout << "Tabulation time = " << tabulation_time.count() * 1000 << " ms" << std::endl << std::endl;
duration<double> combination_time = duration_cast<duration<double>>(combination_end - combination_start);
std::cout << "Combination time = " << combination_time.count() * 1000 << " ms" << std::endl << std::endl;
// 将数据复制回主机
CUDA_CHECK(cudaMemcpy(histogram, d_concatenated_histogram, NUM_BUCKETS * sizeof(int), cudaMemcpyDeviceToHost));
std::cout << "Histogram counters:" << std::endl << std::endl;
int num_buckets_to_print = 4;
for (int i = 0; i < NUM_BUCKETS; i += NUM_BUCKETS / num_buckets_to_print) {
std::cout << "Bucket [" << i * (MAX_VALUE / NUM_BUCKETS) << ", " << (i + 1) * (MAX_VALUE / NUM_BUCKETS) - 1 << "]: " << histogram[i];
std::cout << std::endl;
if (i < NUM_BUCKETS - NUM_BUCKETS / num_buckets_to_print - 1) {
std::cout << "..." << std::endl;
}
}
}
free(input);
free(histogram);
nvshmem_free(d_input);
nvshmem_free(d_histogram);
// 最终确定 nvshmem
nvshmem_finalize();
return 0;
}
Compilar y ejecutar comandos:
nvcc -x cu -arch=sm_70 -rdc=true -I $NVSHMEM_HOME/include -L $NVSHMEM_HOME/lib -lnvshmem -lcuda -o histogram_step1 histogram_step2.cpp
nvshmrun -np $NUM_DEVICES ./histogram_step2
El resultado de la operación es el siguiente:
Tabulation time = 0.18831 ms
Combination time = 0.028852 ms
Histogram counters:
Bucket [0, 65535]: 4135
...
Bucket [262144, 327679]: 4028
...
Bucket [524288, 589823]: 4088
...
Bucket [786432, 851967]: 4100
