El blogger no ha autorizado a ninguna persona u organización a reimprimir ningún artículo original del blogger, ¡gracias por su apoyo al original!
enlace de blogger
Trabajo para un fabricante de terminales de renombre internacional y soy responsable de la investigación y el desarrollo de chips de módem.
En los primeros días de 5G, fue responsable del desarrollo de la capa de servicio de datos de terminales y la red central. Actualmente, lidera la investigación sobre estándares técnicos para redes de potencia informática 6G.
El contenido del blog gira principalmente en torno a:
Explicación del protocolo 5G/6G
Explicación de la red de potencia informática (computación en la nube, computación de borde, computación final)
Explicación del lenguaje C avanzado Explicación
del lenguaje Rust
Directorio de artículos
Introducción detallada a las funciones avanzadas de nvidia MIG (2)

1. El mecanismo de concurrencia provisto por CUDA
MIG es básicamente transparente para las aplicaciones CUDA, por lo que el modelo de programación de CUDA puede permanecer sin cambios para reducir el esfuerzo de programación. CUDA ha expuesto varias técnicas para ejecutar trabajos en paralelo en la GPU, y la comparación de estas técnicas con MIG se muestra a continuación. Tenga en cuenta que Streamsy MPSson parte del modelo de programación CUDA y, por lo tanto, están disponibles en las instancias de GPU.
CUDA Streams es una característica del modelo de programación de CUDA en la que se pueden enviar diferentes trabajos a colas separadas en una aplicación de CUDA y ser procesados de forma independiente por la GPU. CUDA Streams solo se puede usar dentro de un solo proceso y no proporciona mucho aislamiento: se comparte el espacio de direcciones, se comparte SM, se comparte el ancho de banda de la memoria de la GPU, la memoria caché y la capacidad de la memoria. Al final, cualquier error afecta a todos los Streams y a toda la ejecución .
MPS (Servicio multiproceso) es un servicio multiproceso de CUDA. Permite que las aplicaciones multiproceso cooperativas compartan recursos informáticos en la GPU . Se usa comúnmente para el trabajo colaborativo de MPI, pero también se usa para aplicaciones no relacionadas para compartir recursos de GPU, al mismo tiempo que acepta los desafíos que plantea esta solución. MPS actualmente no proporciona aislamiento de errores entre clientes , pero es posible limitar la proporción de multiprocesadores de transmisión utilizados por cada cliente MPS entre todos los SM, pero el hardware de programación aún se comparte. El ancho de banda de la memoria, la memoria caché y la capacidad de la memoria se comparten entre los clientes de MPS.
MIG es una nueva forma de simultaneidad que ofrecen las GPU de NVIDIA al mismo tiempo que aborda algunas de las limitaciones de otras tecnologías CUDA cuando se ejecutan trabajos paralelos.
| Corrientes | MPS | A MÍ | |
|---|---|---|---|
| tipo de partición | proceso único | división lógica | División física |
| Número máximo de particiones | ilimitado | 48 | 7 |
| Aislamiento de rendimiento SM | No | Sí (por porcentaje, no partición) | Sí |
| protección de la memoria | No | Sí | Sí |
| QoS de ancho de banda de memoria | No | No | Sí |
| aislamiento de fallos | No | No | Sí |
| Interoperabilidad entre particiones | Siempre | CIP | CIP limitado |
| Cuándo reconfigurar | listo para configurar | inicio del proceso | en estado inactivo |
2. Reglas de nomenclatura de equipos MIG
De forma predeterminada, un dispositivo MIG consta de una "instancia de GPU" y una "instancia de cómputo" . La siguiente tabla destaca una convención de nomenclatura por su instancia de GPUContar el número de rebanadasy esMemoria total en GB(en lugar de solo su número de segmento de memoria) para marcar un dispositivo MIG.

Cuando solo se crea un CI (que consume toda la potencia informática de GI), el tamaño del CI está implícito en el nombre del dispositivo, como se muestra en la figura anterior.
La siguiente tabla describe la descripción del nombre del perfil A100-SXM4-40GB. Para A100-SXM4-80GB, el nombre del perfil cambiará de acuerdo con la relación de memoria, por ejemplo, 1 g, 10 gb, 2 g, 20 gb, 3 g, 40 gb, 4 g, 40 gb, 7 g, 80 gb.
| Memoria | 20 gb | 10 gb | 5 gb |
| Instancia de GPU | 3g | 2g1g | |
| Instancia informática | 3c | 2c | 1c |
| Dispositivo MIG | 3g.20gb | 2g.10gb | 1g.5gb |
| GPCGPCGPC | GPCGPC | GPC |
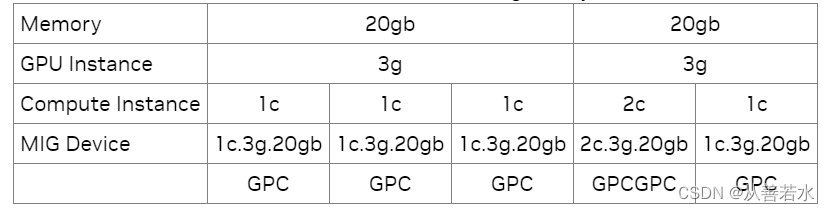
Cada GI se puede subdividir en varios CI según la carga de trabajo del usuario. La siguiente tabla muestra principalmente el nombre del dispositivo MIG en este caso . El ejemplo que se muestra es una subdivisión de un dispositivo de 3 g, 20 gb en un conjunto de subdispositivos con un número variable de segmentos de instancias informáticas.
Tres, enumeración de dispositivos CUDA
Las aplicaciones CUDA permiten programas en dispositivos MIG específicos mediante el uso del identificador de dispositivo MIG. CUDA 11/R450 y CUDA 12/R525 solo admiten la enumeración de una única instancia de MIG. En otras palabras, no importa cuántos dispositivos MIG se creen (o se pongan a disposición del contenedor), un solo proceso CUDA solo puede enumerar un dispositivo MIG .
Una aplicación CUDA ve un CI y su GI principal como un dispositivo CUDA. CUDA solo puede usar un solo CI, si hay varios CI visibles, se elegirá el primer CI disponible. En resumen, hay dos restricciones:
- CUDA solo puede enumerar una única instancia informática;
- CUDA no enumerará GPU que no sean MIG si se enumeran instancias informáticas en cualquier otra GPU;
Soporte extendido CUDA_VISIBLE_DEVICES para MIG. Según la versión del controlador utilizada, se admiten los siguientes dos formatos:
- En controladores >= R470(470.42.01+), a cada dispositivo MIG se le asigna un UUID de GPU en el siguiente formato: MIG-<UUID>;
- controladores > R470 (como R450 y R460), enumera cada dispositivo MIG especificando un CI y el GI principal correspondiente. El formato sigue la siguiente convención: MIG-<GPU-UUID>/<ID de instancia de GPU>/<ID de instancia de cómputo>;
$ nvidia-smi -L
GPU 0: A100-SXM4-40GB (UUID: GPU-5d5ba0d6-d33d-2b2c-524d-9e3d8d2b8a77)
MIG 1g.5gb Device 0: (UUID: MIG-c6d4f1ef-42e4-5de3-91c7-45d71c87eb3f)
MIG 1g.5gb Device 1: (UUID: MIG-cba663e8-9bed-5b25-b243-5985ef7c9beb)
MIG 1g.5gb Device 2: (UUID: MIG-1e099852-3624-56c0-8064-c5db1211e44f)
MIG 1g.5gb Device 3: (UUID: MIG-8243111b-d4c4-587a-a96d-da04583b36e2)
MIG 1g.5gb Device 4: (UUID: MIG-169f1837-b996-59aa-9ed5-b0a3f99e88a6)
MIG 1g.5gb Device 5: (UUID: MIG-d5d0152c-e3f0-552c-abee-ebc0195e9f1d)
MIG 1g.5gb Device 6: (UUID: MIG-7df6b45c-a92d-5e09-8540-a6b389968c31)
GPU 1: A100-SXM4-40GB (UUID: GPU-0aa11ebd-627f-af3f-1a0d-4e1fd92fd7b0)
MIG 2g.10gb Device 0: (UUID: MIG-0c757cd7-e942-5726-a0b8-0e8fb7067135)
MIG 2g.10gb Device 1: (UUID: MIG-703fb6ed-3fa0-5e48-8e65-1c5bdcfe2202)
MIG 2g.10gb Device 2: (UUID: MIG-532453fc-0faa-5c3c-9709-a3fc2e76083d)
4. Archivos de configuración MIG que se pueden utilizar
No podemos configurar MIG casualmente, NVIDIA tiene algunos archivos de configuración para que MIG use
Debido a que estoy usando el A100, aquí se usa el archivo de configuración MIG del A100, de la siguiente manera:
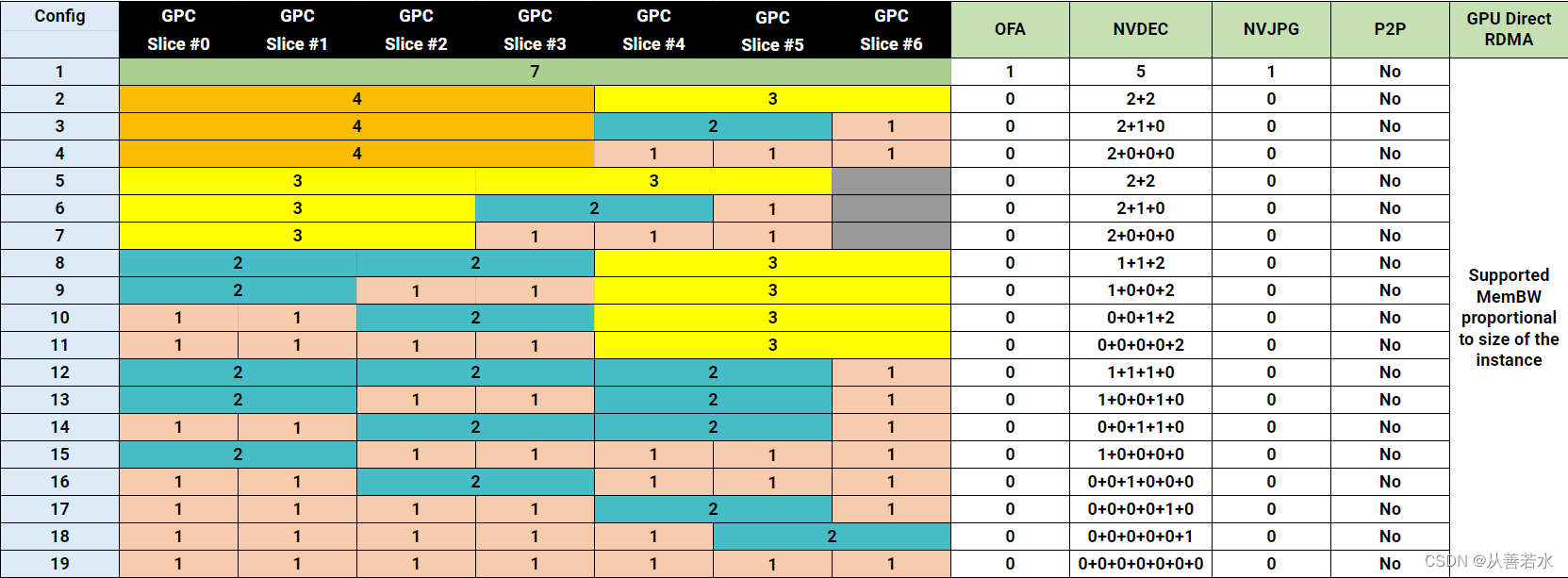
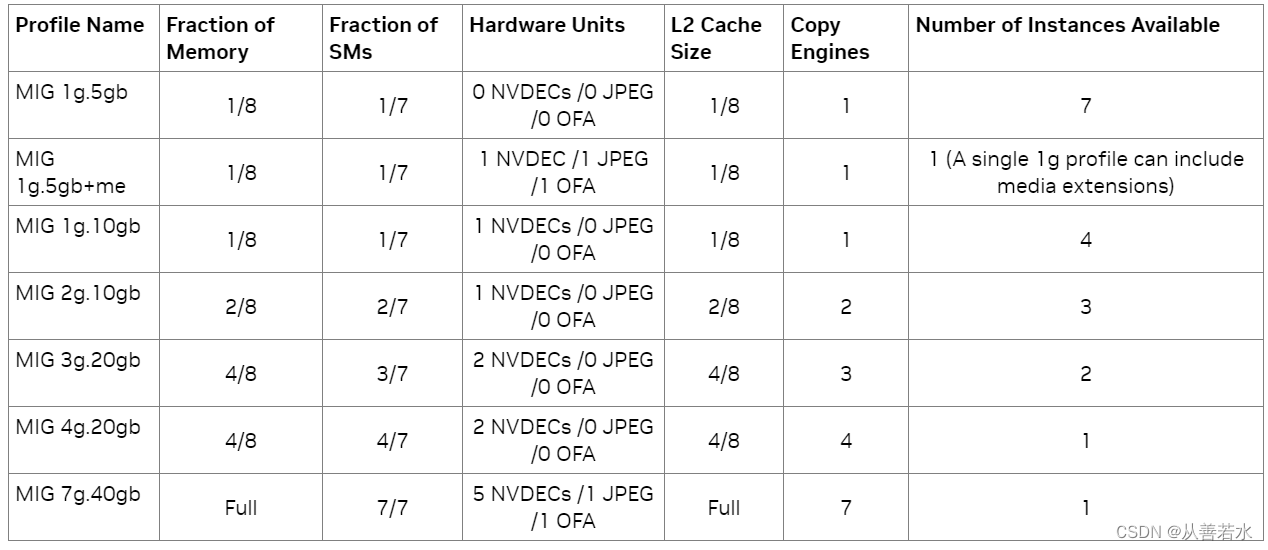
Los archivos de configuración compatibles con A100-SXM4-40GB se muestran en la siguiente tabla. Para A100-SXM4-80GB, el nombre del perfil variará según la relación de memoria, por ejemplo, 1g.10gb, 1g.10gb+me, 1g.20gb, 2g.20gb, 3g.40gb, 4g.40gb y 7g.80gb.
¡Gracias por leer, aquí está el blog de Congshanruoshui!
