Directorio de artículos
Certificación de cierta equidad distributiva con descomposición de subpoblaciones
Verificar cierta equidad distributiva utilizando la descomposición de subgrupos
Antecedentes : se han realizado grandes esfuerzos para comprender y mejorar la equidad del modelo de aprendizaje automático en función de diferentes métricas de equidad, especialmente en dominios de alto riesgo como seguros de salud, educación, decisiones de contratación, etc.
Problemas y fallas : el rendimiento de los modelos de aprendizaje automático de extremo a extremo carece de imparcialidad verificable .
Método y modelo :
En una distribución de datos dada, la imparcialidad de validación de un modelo ML entrenado se formula como un problema de optimización basado en límites de pérdida de rendimiento del modelo en la distribución de las restricciones de imparcialidad dentro de una distancia de distribución limitada de la distribución de datos de entrenamiento.
Contribuir :
- Se propone un marco de verificación de equidad general y verificación instanciada con compensaciones sensibles y compensaciones generales .
- Descomponga la distribución de datos de origen en distribuciones de subgrupos analizables, resuelva los subproblemas probando su convexidad y, por lo tanto, resuelva el problema de optimización del modelo.
- Los experimentos prueban que la verificabilidad del modelo es estricta en el caso de compensaciones sensibles y es estricta en el caso de compensaciones generales.extraordinariode.
- El marco puede integrar de manera flexiblerestricción imparcial, y el resultado será más estricto.
- Los límites de equidad verificables propuestos se comparan con los existentes.Límites robustos de distribución adaptativaUna comparación muestra que el primero es más estricto.
1. Introducción
Defectos en trabajos anteriores :
-
El trabajo anterior se centra principalmente en el entrenamiento de regularización, desenredo, dualidad, descomposición de matriz de bajo orden, alineación de distribución y otros métodos para mejorar la equidad de ML.
-
Se han realizado algunos trabajos sobre la caracterización de equidad verificable en ML, pero hay un problema: al entrenar un modelo de extremo a extremo en una distribución de datos aleatoria, este modelo carece de equidad verificable en la predicción de resultados.
-
El modelo ML en el que se centra la literatura existente sobre equidad es entrenar el modelo en una distribución de datos (no) balanceada y evaluar el rendimiento del modelo a través del método de evaluación de equidad existente en el dominio objetivo medible, por lo que la equidad La evaluación depende únicamente de la elección del método de evaluación, y no tiene en cuenta la validez del método.
Equidad verificable : en una distribución de prueba restringida por la equidad Q, donde Q está dentro de una distancia limitada de la distribución de entrenamiento P, defina la equidad verificable como el límite superior del peor de los casos en la pérdida de predicción del modelo .
Condiciones de la tarifa basecomo una restricción de equidad en la distribución de prueba Q.
desplazamiento sensible Cambio sensible : La distribución en cascada de etiquetas y atributos sensibles puede cambiar.
cambio general : se puede cambiar todo, incluida la distribución condicional de atributos no sensibles.
Equidad de grupo : medición de la independencia entre las características sensibles y las predicciones del modelo. Separación [separación] indica que dada la etiqueta objetivo, la característica sensible es estadísticamente independiente de la predicción del modelo. Suficiencia [suficiencia] indica que, en una determinada predicción del modelo, las características sensibles son estadísticamente independientes de la etiqueta de destino. Es decir, la equidad de grupo requiere que los atributos sensibles sean independientes de las etiquetas objetivo y las predicciones del modelo.
Equidad individual : características de entrada similares producirán resultados de salida similares.
Este artículo difiere del trabajo anterior :
- La equidad de validación considera el rendimiento de los modelos de ML de extremo a extremo, no el nivel de aprendizaje de representación.
- La equidad se define y verifica en función de una distribución de restricciones de equidad.
- Para cualquier modelo de caja negra entrenado en una distribución de datos aleatoria dada, se puede calcular la equidad verificable.
Pregunta 1: ¿Cómo codifica la restricción condicional de la tasa de interés de referencia la distribución de la restricción de equidad?
2. Equidad verificable basada en la distribución justa de restricciones
Definición 1 Tipo de interés de referencia : Dada una distribución PP soportada en X*YP , valor de atributo sensiblesss relativo a la etiquetayyLa tasa base de y es:SSS es el atributo sensitivo, [S] es el conjunto de valores que puede tomar el atributo sensitivo,sss es un valor de atributo sensible de un atributo sensible. AAY es el resultado de la predicción del modelo,yyy es la etiqueta de la muestra,XXX es la característica de muestra. La tasa de interés de referencia de una muestra de prueba es [característica de atributo sensibleX s X_sXsel valor es sss , el resultado predicho esyyProbabilidad de y ]:
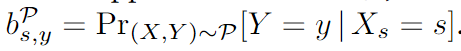
Definición 2. Distribución justa de la tasa de interés de referencia : si y solo si en una distribución generada por la tasa de interés de referencia, para dos muestras cualesquiera iiyo yjjj , ambos tienen la misma etiqueta predichayyy , y ambos tienen el atributo sensibleSSPara un cierto valor de atributo en S , sus tasas de interés de referencia correspondientes son iguales, y esta distribución se denomina distribución de tasa de interés de referencia justa:
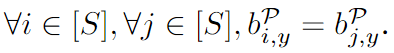
Paridad demográfica : índice de evaluación de equidad grupal
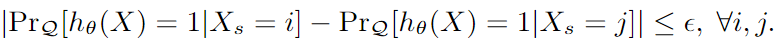
2.1 Equidad verificable
Modelo de generación de datos : X o X_oXoRepresenta características de atributos no confidenciales, X s X_sXsRepresenta características de atributos sensibles, YYY representa la etiqueta de la muestra.
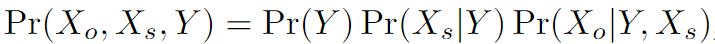
Equidad de verificación con compensación general : P \mathcal PP es la distribución del conjunto de entrenamiento,ρ \rhoρ es la distribución del conjunto de pruebaQ \mathcal QQ yP \mathcal PLa distancia de distribución limitada entre P. Para todas las distribuciones generadas y de conjuntos de entrenamiento a la distancia de distribuciónρ \rhoLa distribución del conjunto de prueba dentro del rango de ρ , el valor de prueba de imparcialidad es: el valor máximo del límite superior del valor de pérdida en todas las distribuciones del conjunto de prueba.
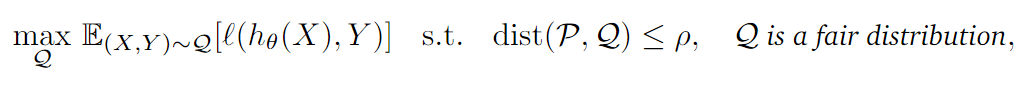
En escenarios reales, el conjunto de entrenamiento del modelo siempre está limitado por la gestión y la recopilación de datos, por lo que siempre hay una injusticia inherente en el modelo entrenado. Suponiendo que el conjunto de prueba que construimos es idealmente justo, esperamos que nuestro modelo no codifique el sesgo generado durante el entrenamiento cuando se prueba, por lo que el rendimiento del modelo en la distribución de restricciones justa indica su injusticia inherente.
Equidad verificable para compensaciones sensibles : para evitar la injusticia inherente del modelo durante el entrenamiento, se agrega una nueva restricción bajo la equidad de verificación de las compensaciones generales. Ps, y P_{s,y}PAGs,yDe Q s , y Q_{s,y}qs,yes PPP yQQEl subgrupo de Q [por el atributo sensitivo sss与 y y y división].
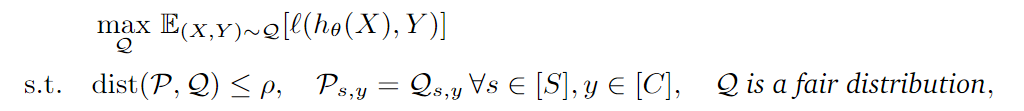
Para restringir la distribución del conjunto de prueba QQQ no está demasiado sesgado hacia los atributos sensiblesX s X_sXs, por lo que se agrega un término de restricción adicional al desplazamiento sensible:
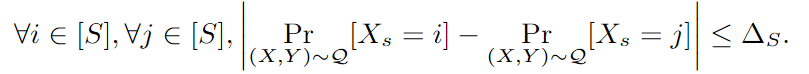
pérdida pérdidapérdida en cada grupo y cada categoría:
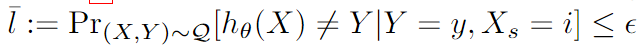
La pérdida anterior se puede transformar en ε-DP y ε-EO :
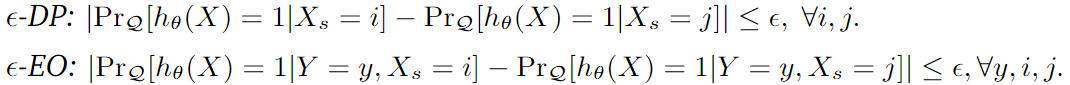
Paridad de grupo (paridad demográfica, DP): La diferencia en la probabilidad predicha de predecir dos grupos diferentes como clases positivas.
Probabilidades igualadas: la diferencia entre las tasas de falsos positivos entre grupos o la diferencia entre las tasas de verdaderos positivos entre grupos. Cuanto menor sea la diferencia, más justo será el modelo.
3. Marco de certificación de equidad
3.1 Descomposición en subgrupos [Básico]
Distancia de Hellinger : Mide la distancia entre dos distribuciones. El rango de valores es [0, 1], cuanto más grande, más relevante
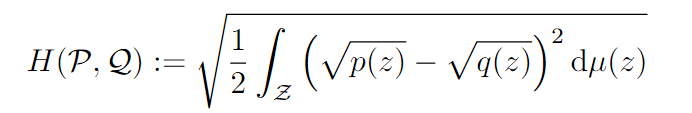
Problema de optimización global :
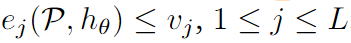
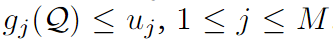
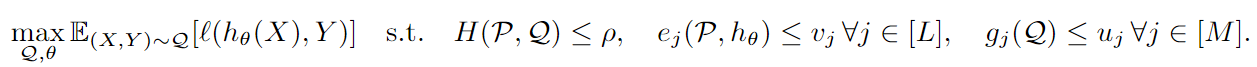
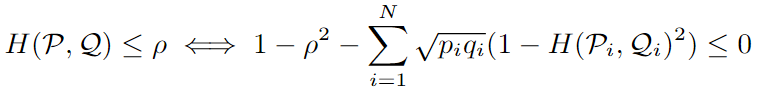
Problema de optimización de subgrupos :
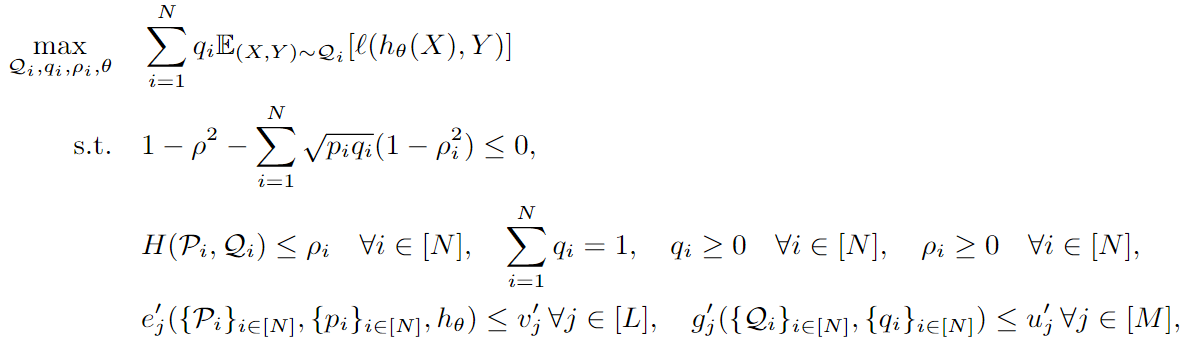
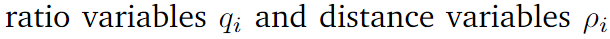
3.2 Imparcialidad verificable con compensación sensible
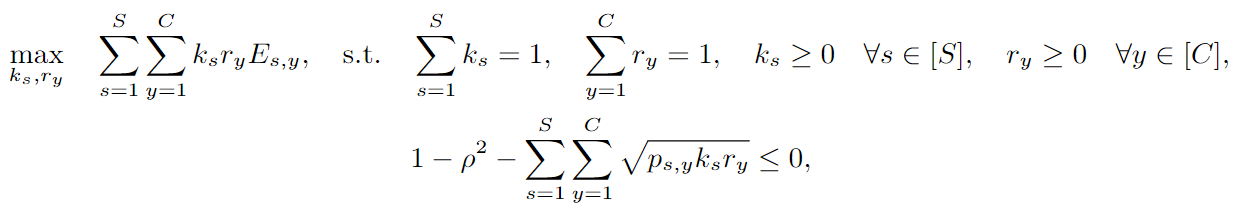
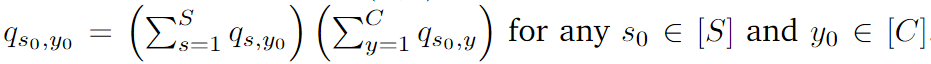
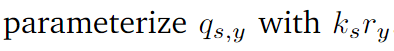

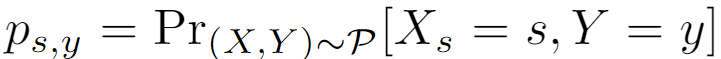
3.3 Imparcialidad verificable con compensación general


Cálculo de pérdidas después de la descomposición en subgrupos :
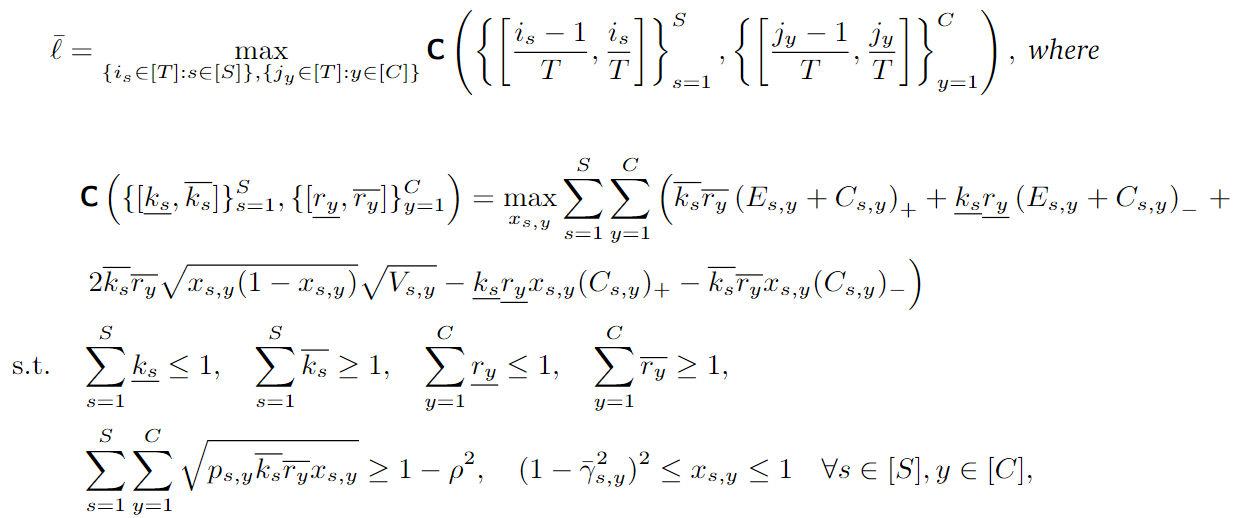
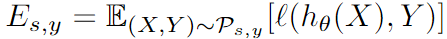
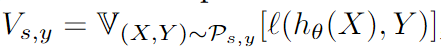
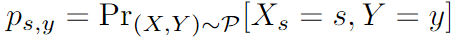
apéndice
Escalar: un escalar es un solo número (entero o real), a diferencia de la mayoría de los otros objetos estudiados en álgebra lineal (generalmente matrices de números). Los escalares generalmente se indican con letras minúsculas en cursiva, por ejemplo: x \mathit xx , un escalar es equivalente al definido en Python
x = 1
Vector (vector): Un vector representa un conjunto de números ordenados. Podemos encontrar cada número individual a través del índice en el orden. Los vectores generalmente se representan con letras minúsculas en negrita, por ejemplo: x \bf xx , cada elemento en el vector es un escalar, el i-ésimo elemento en el vector está representado por $x_i$, y el vector es equivalente a una matriz unidimensional en Python
import numpy as np
#行向量
a = np.array([1,2,3,4])
Matriz (matriz): una matriz es una matriz bidimensional, cada elemento del cual está determinado por dos índices ( A i , j A_{i,j}Ayo , j), la matriz suele representarse con letras mayúsculas en negrita y cursiva, por ejemplo: $\boldsymbol X$. Podemos pensar en la matriz como una tabla de datos bidimensional, cada fila de la matriz representa un objeto y cada columna representa una característica. Definido en Python como
import numpy as np
#矩阵
a = np.array([[1,2,3],[4,5,6],[7,8,9]])
Tensor: Una matriz de más de dos dimensiones.En términos generales, los elementos de una matriz se distribuyen en una cuadrícula regular de coordenadas de varias dimensiones, que se denomina tensor. Si un tensor es una matriz tridimensional, entonces necesitamos tres índices para determinar la posición de los elementos ( A i , j , k A_{i,j,k}Ayo , j , k), los tensores generalmente se representan con letras mayúsculas en negrita, por ejemplo: X \bf XX
mport numpy as np
#张量
a = np.array([[[1,2],[3,4]],[[5,6],[7,8]]])
restricción de límite para encontrar el rango
límite del peor de los casos
Cómo calcular el r de cada muestra de prueba, cuando se certifica r<bound
Dentro del rango acotado, el resultado de la predicción debe ser mayor o igual al peor de los casos, por lo que tiene carácter de verificación
Propiedades verificables: en los resultados de la predicción, cuántas muestras están en línea con la predicción limitada R especificada por el usuario.
distribución de datos
