Operaciones básicas de Elasticsearch - Operaciones RESTful
- 1. Introducción a RESTful
- 2. Instalación del cliente
- 3. Formato de datos
- 4. Operación HTTP
-
- 4.1 Operación de índice
- 4.2 Operación de documentos
- 4.3 Operación de mapeo
- 4.4 Consulta avanzada
-
- Ver todos los documentos en la biblioteca de índice
- Ver todos los documentos bajo el índice especificado
- consulta de concordancia de condiciones
- consulta de coincidencia de campo
- consulta exacta de palabra clave
- Consulta precisa de varias palabras clave
- especificar campos de consulta
- campo de filtro
- Consulta compuesta
- consulta de rango
- consulta difusa
- Clasificación de un solo campo
- Clasificación de campos múltiples
- resaltar consulta
- consulta completa
- Consulta de paginación
- consulta de agregación
- consulta de agregación de depósito
1. Introducción a RESTful
REST se refiere a un conjunto de restricciones y principios arquitectónicos. Una aplicación o diseño que satisface estas restricciones y principios es RESTful. El principio REST más importante para las aplicaciones web es que la interacción entre el cliente y el servidor no tiene estado entre las solicitudes. Cada solicitud de cliente a servidor debe contener la información necesaria para comprender la solicitud. Si el servidor se reinicia en cualquier momento entre solicitudes, no se notificará al cliente. Además, las solicitudes sin estado pueden ser respondidas por cualquier servidor disponible, lo cual es ideal para entornos como la computación en la nube. Los clientes pueden almacenar datos en caché para mejorar el rendimiento.
En el lado del servidor, el estado y la funcionalidad de la aplicación se pueden agrupar en varios recursos. Un recurso es una entidad conceptual interesante que se expone a los clientes. Ejemplos de recursos son: objetos de aplicación, registros de bases de datos, algoritmos, etc. Cada recurso utiliza URI (Universal Resource Identifier) para obtener una dirección única. Todos los recursos comparten una interfaz uniforme para transferir el estado entre el cliente y el servidor. Se utilizan métodos HTTP estándar, como GET, PUT, POST y DELETE.
En los servicios web RESTful, cada recurso tiene una dirección. Los propios recursos son todos los objetivos de las llamadas a métodos y la lista de métodos es la misma para todos los recursos. Estos métodos son estándar e incluyen HTTP GET, POST, PUT, DELETE y posiblemente HEAD y OPTIONS. El entendimiento simple es que si desea acceder a los recursos en Internet, debe enviar una solicitud al servidor donde se encuentra el recurso, y el cuerpo de la solicitud debe incluir la ruta de red del recurso y las operaciones en el recurso (adición, eliminación, modificación y consulta).
2. Instalación del cliente
Si envía una solicitud al servidor de Elasticsearch directamente a través del navegador, debe incluir el método estándar HTTP en la solicitud enviada, y la mayoría de las funciones de HTTP solo admiten los métodos GET y POST. Por lo tanto, para facilitar el acceso de los clientes, puede usar Postman (no es compatible con chino pero relativamente mucha gente lo usa), Apipost (hecho en chino), Apifox (hecho en chino) y otras herramientas de depuración de api.
Cartero: https://www.postman.com/downloads/
Apipost: https://www.apipost.cn//
Apifox: https://www.apifox.cn/
Postman: una herramienta de depuración de páginas web anticuada y poderosa, con una interfaz simple y clara, operación conveniente y rápida, y un diseño muy fácil de usar. Pero no admite chino, y el paquete de idioma chino para chinos también se detiene en la versión 9.12.2 https://github.com/hlmd/postman-cn
Apipost&Apifox: Es hecho por chinos, soporta chino y la versión personal es gratuita, básicamente tienen lo que tiene Postman, también soportan colaboración, soportan versión web, exportan varios documentos y generan códigos en varios idiomas. La razón principal es que el servidor está en China y su espacio de trabajo se puede sincronizar con el extremo remoto. Sin embargo, el servidor del cartero está en el extranjero y la velocidad de acceso es muy lenta. Trate de no registrarse e iniciar sesión, de lo contrario será muy atascado.
3. Formato de datos
Elasticsearch es una base de datos orientada a documentos, donde un dato es un documento.
Se hace una analogía entre el concepto de almacenamiento de datos de documentos en Elasticsearch y el concepto de almacenamiento de datos en la base de datos relacional MySQL.
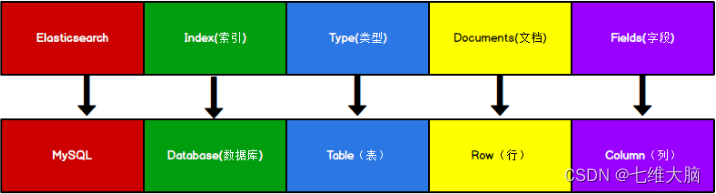
Index en ES se puede considerar como una biblioteca, mientras que Types es equivalente a una tabla y Documents es equivalente a una fila de una mesa. Aquí, el concepto de Tipos se ha debilitado gradualmente. En Elasticsearch 6.X, un índice solo puede contener un tipo. En Elasticsearch 7.X, el concepto de Tipo se ha eliminado.
6 Utilice JSON como formato de serialización de documentos, como una parte de la información del usuario:
{
"name" : "John",
"sex" : "Male",
"age" : 25,
"birthDate": "1990/05/01",
"about" : "I love to go rock climbing",
"interests": [ "sports", "music" ]
}
4. Operación HTTP
4.1 Operación de índice
crear índice
En comparación con las bases de datos relacionales, crear un índice es equivalente a crear una base de datos
Envíe una solicitud PUT al servidor ES: http://127.0.0.1:9200/shopping
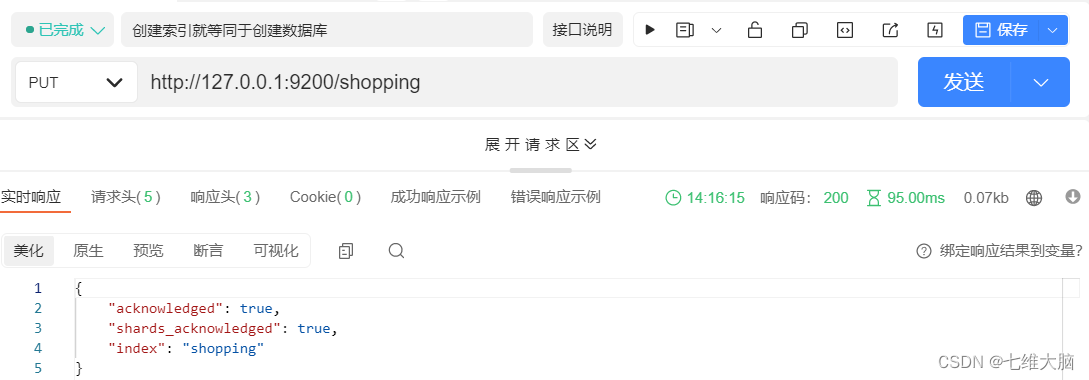
{
"acknowledged"【响应结果】: true, # true 操作成功
"shards_acknowledged"【分片结果】: true, # 分片操作成功
"index"【索引名称】: "shopping"
}
# 注意:创建索引库的分片数默认 1 片,在 7.0.0 之前的 Elasticsearch 版本中,默认 5 片
Si el índice se agrega repetidamente, se devolverá un mensaje de error.

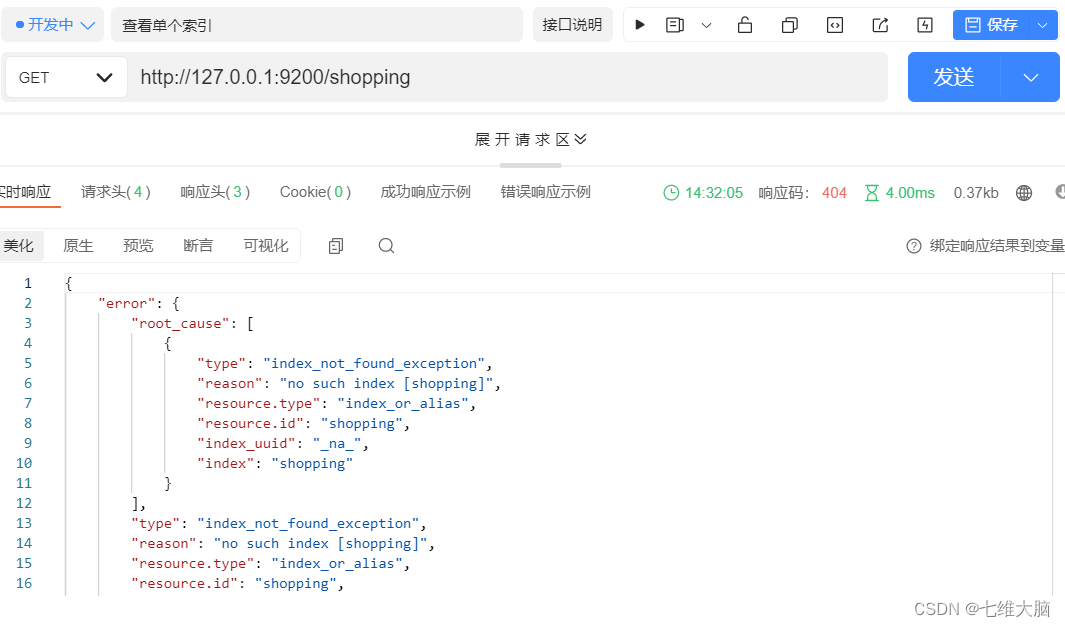
ver un solo índice
Solicitud GET: http://127.0.0.1:9200/shopping
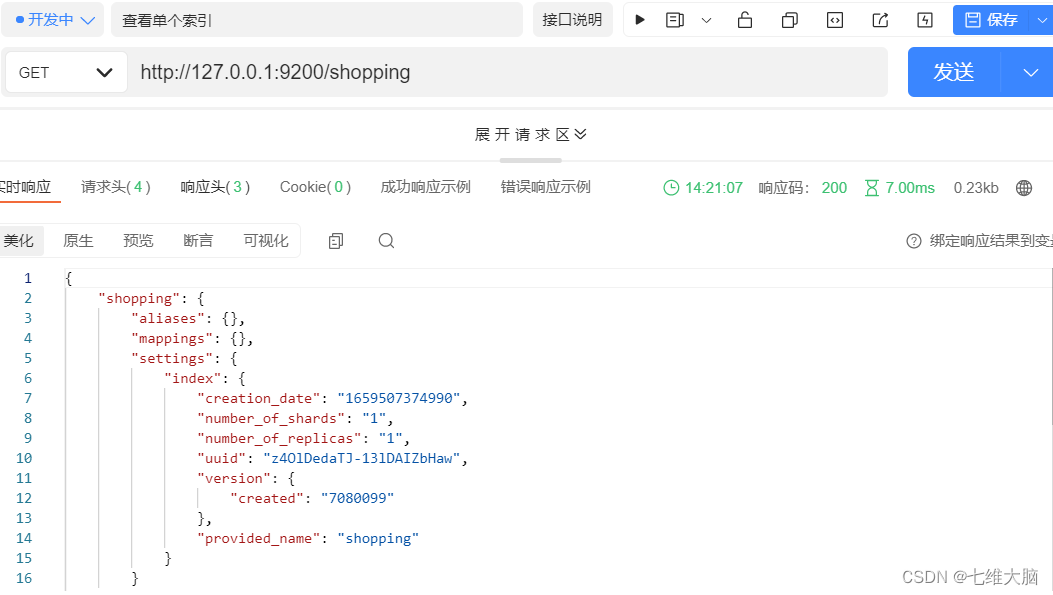
para ver el índice La ruta de la solicitud enviada al servidor ES es coherente con la creación del índice. Pero los métodos HTTP son inconsistentes. Aquí
puede experimentar el significado de RESTful
Después de la solicitud, el servidor responde de la siguiente manera:
{
"shopping"【索引名】: {
"aliases"【别名】: {
},
"mappings"【映射】: {
},
"settings"【设置】: {
"index"【设置 - 索引】: {
"creation_date"【设置 - 索引 - 创建时间】: "1614265373911",
"number_of_shards"【设置 - 索引 - 主分片数量】: "1",
"number_of_replicas"【设置 - 索引 - 副分片数量】: "1",
"uuid"【设置 - 索引 - 唯一标识】:"eI5wemRERTumxGCc1bAk2A",
"version"【设置 - 索引 - 版本】: {
"created": "7080099"
},
"provided_name"【设置 - 索引 - 名称】: "shopping"
}
}
}
}
ver todos los índices
Solicitud GET: http://127.0.0.1:9200/_cat/indices?v
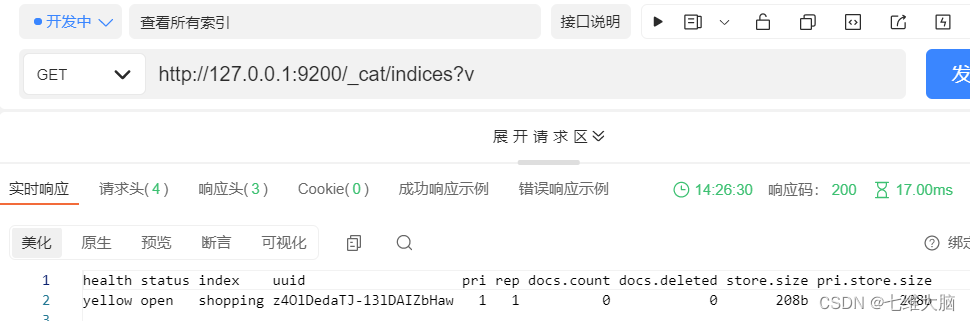
El _cat en la ruta de solicitud aquí significa visualización, e índices significa índice, por lo que el significado general es ver todos los índices en el servidor ES actual, al igual que MySQL La sensación de mostrar tablas en los resultados de respuesta del servidor es la siguiente:
| Encabezamiento | significado |
|---|---|
| salud | Estado de salud actual del servidor: |
| verde (grupo completo) amarillo (punto único normal, grupo incompleto) rojo (punto único anormal) | |
| estado | Índice abierto, estado cerrado |
| índice | nombre de índice |
| uuid | índice de número uniforme |
| en | Número de fragmentos primarios |
| reps | número de copias |
| docs.count | Número de documentos disponibles |
| docs.borrado | Estado de eliminación del documento (tombstone) |
| tienda.tamaño | El tamaño total de los fragmentos primarios y secundarios. |
| pri.store.size | El espacio ocupado por el fragmento principal. |
eliminar índice
Solicitud DELETE: http://127.0.0.1:9200/shopping
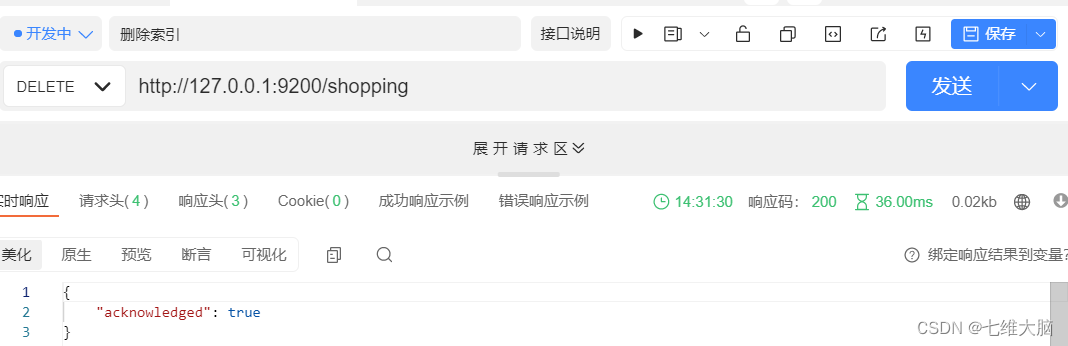
Al volver a visitar el índice, el servidor devuelve una respuesta: El índice no existe
4.2 Operación de documentos
crear documento
Los documentos aquí se pueden comparar con datos de tablas en una base de datos relacional, y el formato de datos agregado está en formato JSON.
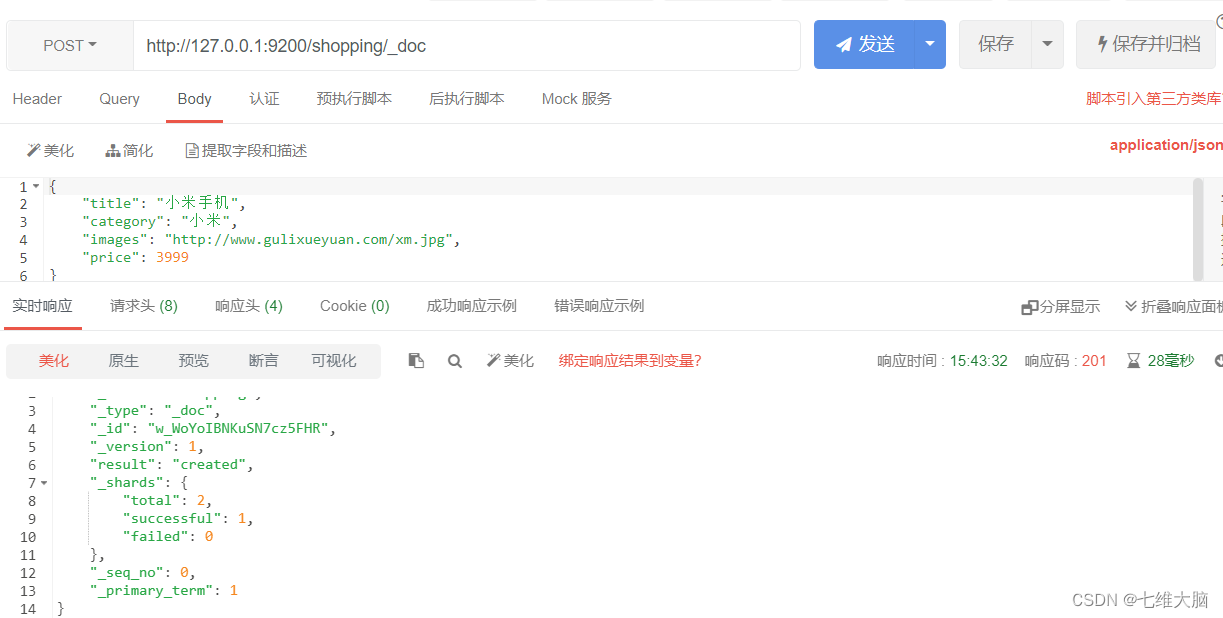
Solicitud POST: http://127.0.0.1:9200/shopping/_doc
El contenido del cuerpo de la solicitud es: (el cuerpo de la solicitud debe existir; de lo contrario, se devolverá un mensaje de error)
{
"title":"小米手机",
"category":"小米",
"images":"http://www.gulixueyuan.com/xm.jpg",
"price":3999.00
}
El método para enviar la solicitud aquí debe ser POST, no PUT, de lo contrario, se producirá un error 405 similar:

Como encontré algunos problemas con la versión Apipost6.x durante mi estudio, cambié a la versión 5.x. La interfaz puede diferir de la captura de pantalla anterior.
La causa del problema es que la versión Apipost6.x redirigirá el código de respuesta 201, haciendo que el servidor ES reciba una solicitud Get. El mensaje de error se muestra arriba. Se ha informado al oficial y se corregirá en versiones posteriores.
La producción nacional todavía necesita seguir trabajando duro.
Los resultados normales de la respuesta del servidor son los siguientes:
{
"_index"【索引】: "shopping",
"_type"【 类型-文档 】: "_doc",
"_id"【唯一标识】: "w_WoYoIBNKuSN7cz5FHR", #可以类比为 MySQL 中的主键,随机生成
"_version"【版本】: 1,
"result"【结果】: "created", #这里的 created 表示创建成功
"_shards"【分片】: {
"total"【分片 - 总数】: 2,
"successful"【分片 - 成功】: 1,
"failed"【分片 - 失败】: 0
},
"_seq_no": 0,
"_primary_term": 1
}
Después de crear los datos anteriores, dado que no se especifica ningún identificador único (ID) de datos, el servidor ES generará uno aleatoriamente de forma predeterminada.
Si desea personalizar el identificador único, debe especificarlo al crear: http://127.0.0.1:9200/shopping/_doc/1 Nota
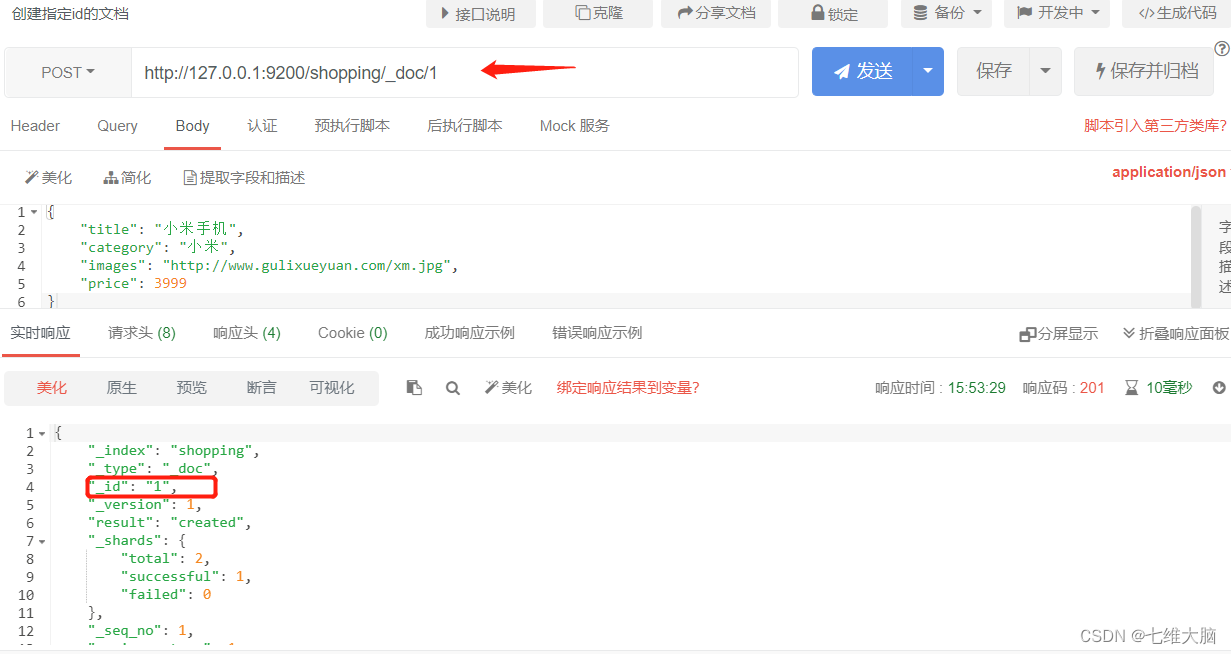
aquí: si especifica la clave principal de datos al agregar datos, entonces el método de solicitud también se puede PONER
ver un solo documento
Al ver un documento, debe especificar el identificador único del documento, similar a la consulta de datos de clave principal en MySQL
OBTENER solicitud: http://127.0.0.1:9200/shopping/_doc/1
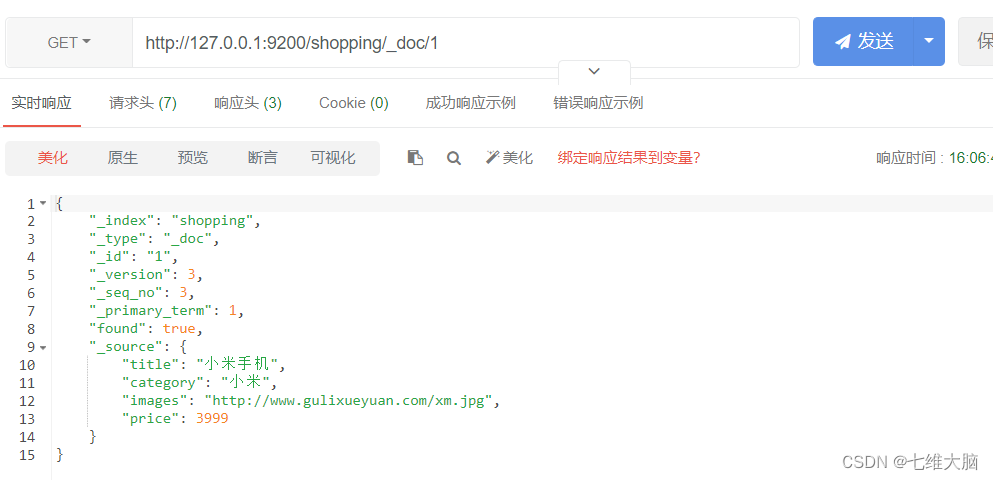
{
"_index"【索引】: "shopping",
"_type"【文档类型】: "_doc",
"_id": "1",
"_version": 2,
"_seq_no": 2,
"_primary_term": 2,
"found"【查询结果】: true, # true 表示查找到,false 表示未查找到
"_source"【文档源信息】: {
"title": "华为手机",
"category": "华为",
"images": "http://www.gulixueyuan.com/hw.jpg",
"price": 4999.00
}
}
Modificar el documento (revisión completa)
Al igual que agregar un nuevo documento, ingrese la misma solicitud de dirección URL, si el cuerpo de la solicitud cambia, el contenido de datos original se sobrescribirá.
Solicitud POST/PUT: http://127.0.0.1:9200/shopping/_doc/1
{
"title":"小米手机",
"category":"小米",
"images":"http://www.gulixueyuan.com/xm.jpg",
"price":2999.00
}
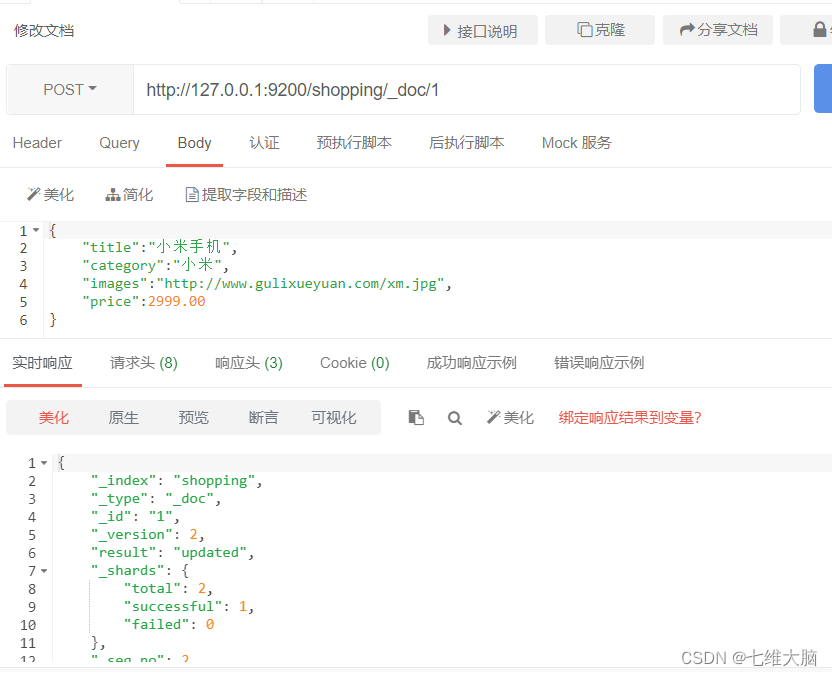
{
"_index": "shopping",
"_type": "_doc",
"_id": "1",
"_version"【版本】: 2,
"result"【结果】: "updated", # updated 表示数据被更新
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"_seq_no": 2,
"_primary_term": 2
}
Modificar campo (modificación local)
Al modificar datos, también puede modificar solo la información parcial de una determinada
solicitud POST de datos: http://127.0.0.1:9200/shopping/_update/1
El contenido del cuerpo de la solicitud es:
{
"doc": {
"price":3000.00
}
}
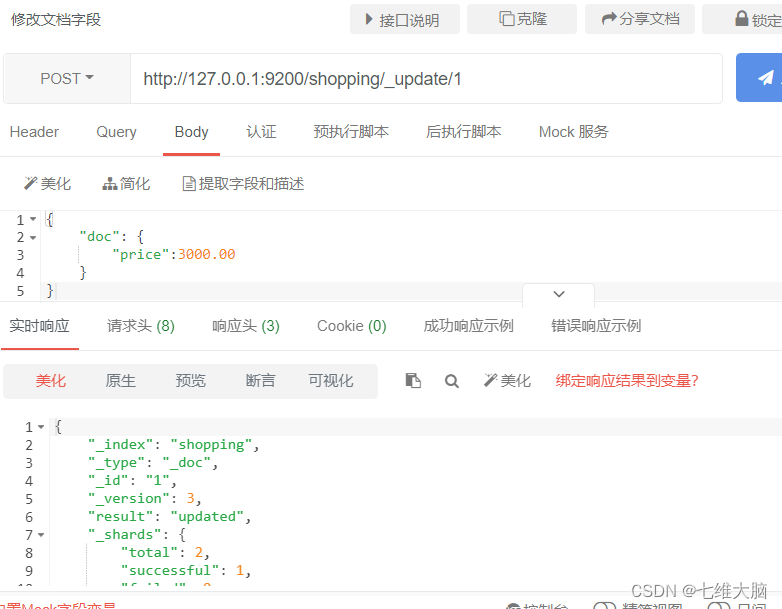
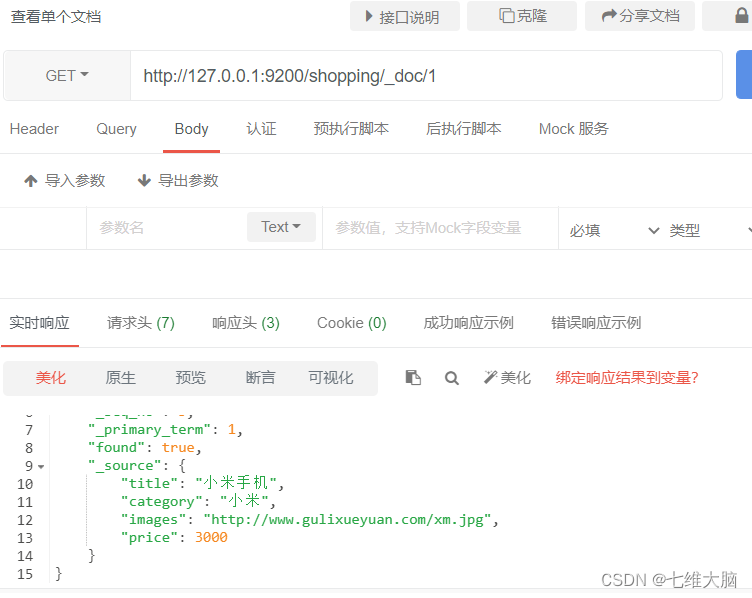
De acuerdo con la identificación única, consulte los datos del documento, los datos del documento se han actualizado
eliminar documento
La eliminación de un documento no se elimina inmediatamente del disco, simplemente se marca como eliminado (tombstone).
ELIMINAR solicitud: http://127.0.0.1:9200/shopping/_doc/1
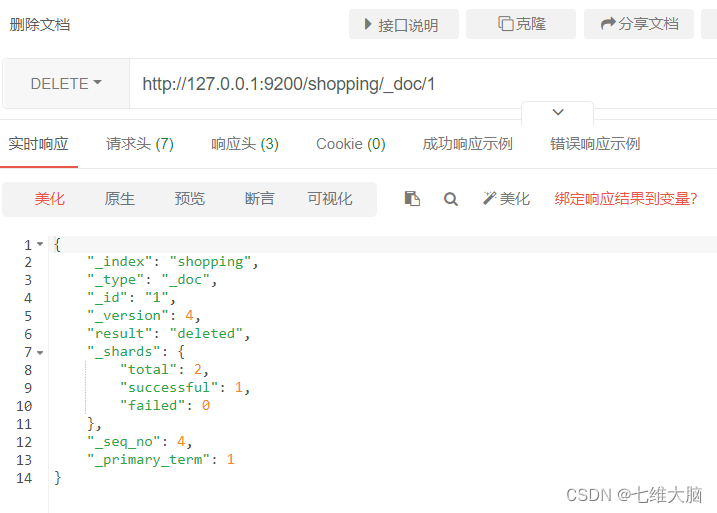
{
"_index": "shopping",
"_type": "_doc",
"_id": "1",
"_version"【版本】: 4, #对数据的操作,都会更新版本
"result"【结果】: "deleted", # deleted 表示数据被标记为删除
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"_seq_no": 4,
"_primary_term": 2
}
Después de eliminar, consulte la información del documento actual
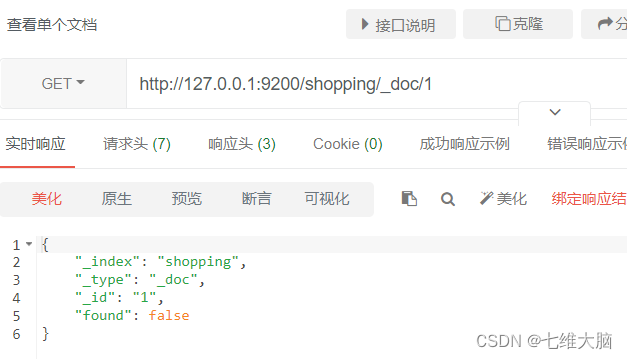
Si elimina un documento que no existe
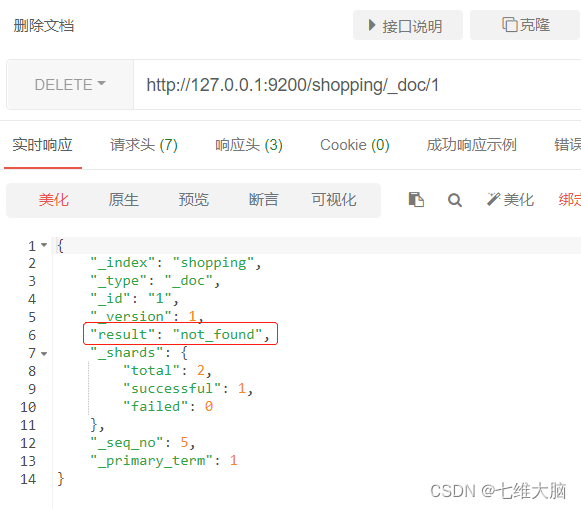
{
"_index": "shopping",
"_type": "_doc",
"_id": "1",
"_version": 1,
"result"【结果】: "not_found", # not_found 表示未查找到
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"_seq_no": 5,
"_primary_term": 2
}
Eliminar documentos condicionalmente
Por lo general, los datos se eliminan de acuerdo con el identificador único del documento. En la operación real, también se pueden eliminar varios datos de acuerdo con las condiciones.
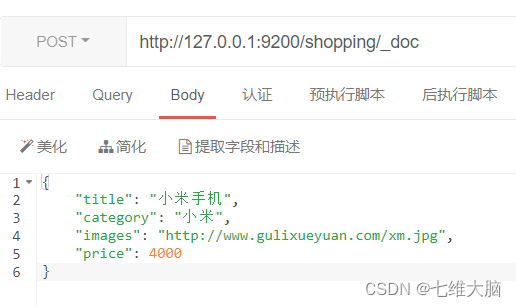
- Primero agregue múltiples piezas de datos respectivamente:
{
"title": "小米手机",
"category": "小米",
"images": "http://www.gulixueyuan.com/xm.jpg",
"price": 4000
}
{
"title":"华为手机",
"category":"华为",
"images":"http://www.gulixueyuan.com/hw.jpg",
"price":4000.00
}
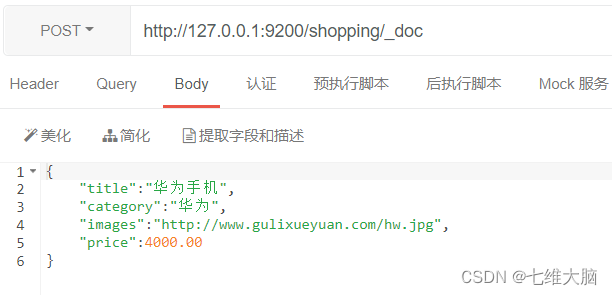
Solicitud POST : http://127.0.0.1:9200/shopping/_delete_by_query
El contenido del cuerpo de la solicitud es:
{
"query":{
"match":{
"price":4000.00
}
}
}
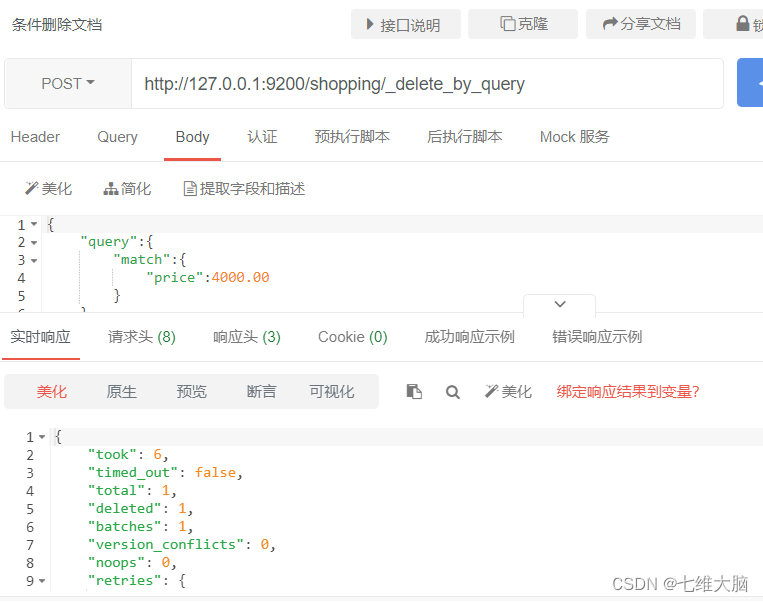
{
"took"【耗时】: 6,
"timed_out"【是否超时】: false,
"total"【总数】: 1,
"deleted"【删除数量】: 1,
"batches": 1,
"version_conflicts": 0,
"noops": 0,
"retries": {
"bulk": 0,
"search": 0
},
"throttled_millis": 0,
"requests_per_second": -1,
"throttled_until_millis": 0,
"failures": []
}
4.3 Operación de mapeo
Con la biblioteca de índices, es equivalente a tener una base de datos en la base de datos.
A continuación, debe crear la asignación en la biblioteca de índices (índice), que es similar a la estructura de la tabla (tabla) en la base de datos (base de datos). Para crear una tabla de base de datos, debe establecer el nombre del campo, el tipo, la longitud, las restricciones, etc.; lo mismo se aplica a la biblioteca de índices, debe saber qué campos están bajo este tipo y qué información de restricción tiene cada campo. Esto se llama mapeo.
crear mapeo
- Cree una
solicitud PUT de índice de estudiante: http://127.0.0.1:9200/student - Cree una
solicitud PUT de mapeo: http://127.0.0.1:9200/student/_mapping
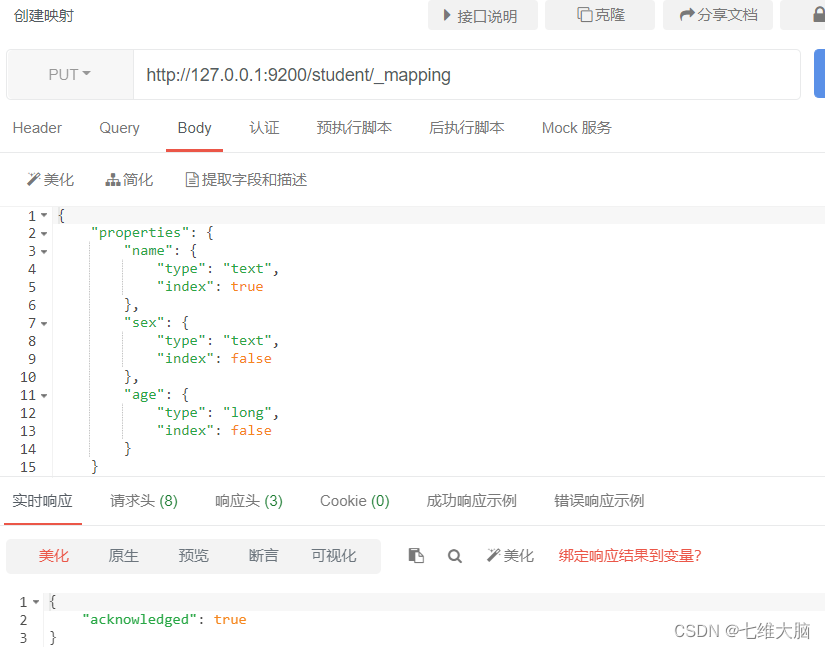
descripción de datos de mapeo: - Nombre del campo: complete libremente, especifique muchos atributos a continuación, por ejemplo: título, subtítulo, imágenes, precio
- tipo: tipo, los tipos de datos admitidos en Elasticsearch son muy ricos, por ejemplo, algunos de los más importantes:
- El tipo String se divide en dos tipos:
- texto: palabras separables
- palabra clave: Indivisible, los datos se compararán como un campo completo
- Numérico: tipo numérico, dividido en dos categorías
- Tipos de datos básicos: long, integer, short, byte, double, float, half_float
- Tipo de alta precisión de números de punto flotante: scaled_float
- Fecha: tipo de fecha
- Matriz: tipo de matriz
- Objeto Objeto
- El tipo String se divide en dos tipos:
- index: Si indexar, el valor predeterminado es verdadero, es decir, todos los campos se indexarán sin ninguna configuración.
- verdadero: el campo se indexará y se puede usar para buscar
- falso: el campo no se indexará y no se podrá utilizar para realizar búsquedas
- almacenar: si se almacenan los datos de forma independiente, el valor predeterminado es falso,
el texto original se almacenará en _source, de manera predeterminada, otros campos extraídos no se almacenan de forma independiente, sino que se extraen de _source. Por supuesto, también puede almacenar un determinado campo de forma independiente, siempre que establezca "almacenar": verdadero. Obtener un campo almacenado de forma independiente es mucho más rápido que analizar desde _source, pero también ocupará más espacio, por lo que debe basarse en la situación real que el negocio necesita establecer. - analizador: separador de palabras, el ik_max_word aquí es para usar el separador de palabras ik, habrá un capítulo especial para aprender más adelante
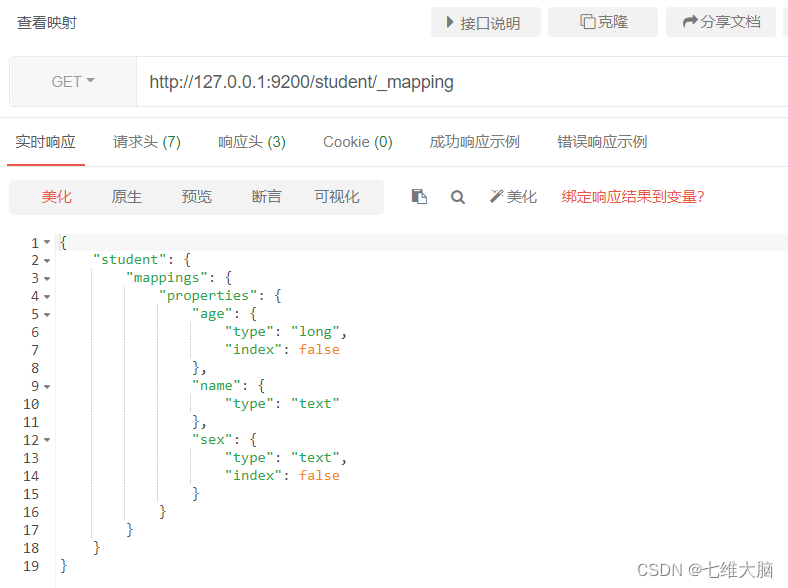
ver el mapa
OBTENER solicitud: http://127.0.0.1:9200/student/_mapping
Asociación de mapa índice
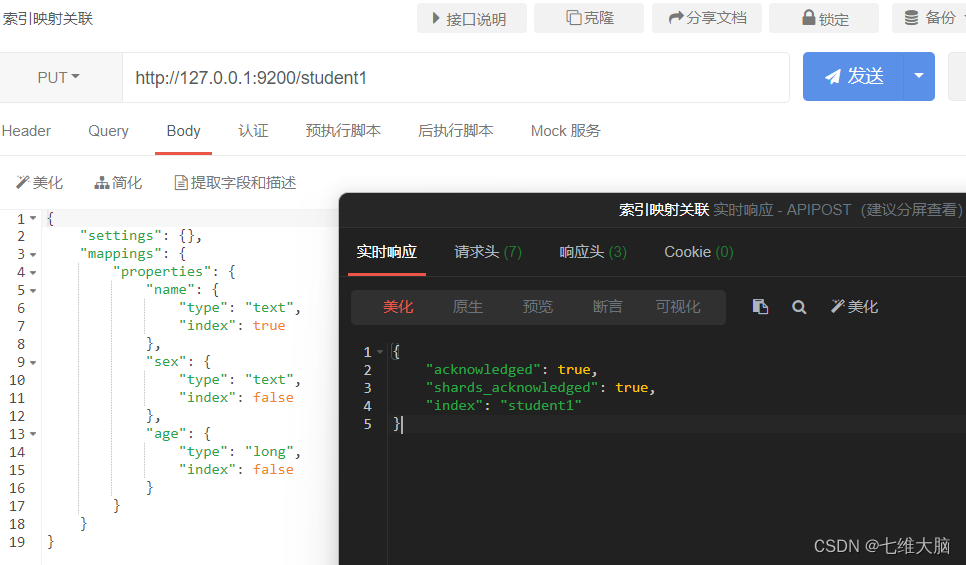
PUT solicitud: http://127.0.0.1:9200/student1
{
"settings": {
},
"mappings": {
"properties": {
"name": {
"type": "text",
"index": true
},
"sex": {
"type": "text",
"index": false
},
"age": {
"type": "long",
"index": false
}
}
}
}
Equivalente a mapeo y asociación al crear un índice
4.4 Consulta avanzada
Elasticsearch proporciona un DSL de consulta completo basado en JSON para definir consultas
y definir datos:
# POST /student/_doc/1001
{
"name":"zhangsan",
"nickname":"zhangsan",
"sex":"男",
"age":30
}
# POST /student/_doc/1002
{
"name":"lisi",
"nickname":"lisi",
"sex":"男",
"age":20
}
# POST /student/_doc/1003
{
"name":"wangwu",
"nickname":"wangwu",
"sex":"女",
"age":40
}
# POST /student/_doc/1004
{
"name":"zhangsan1",
"nickname":"zhangsan1",
"sex":"女",
"age":50
}
# POST /student/_doc/1005
{
"name":"zhangsan2",
"nickname":"zhangsan2",
"sex":"女",
"age":30
}
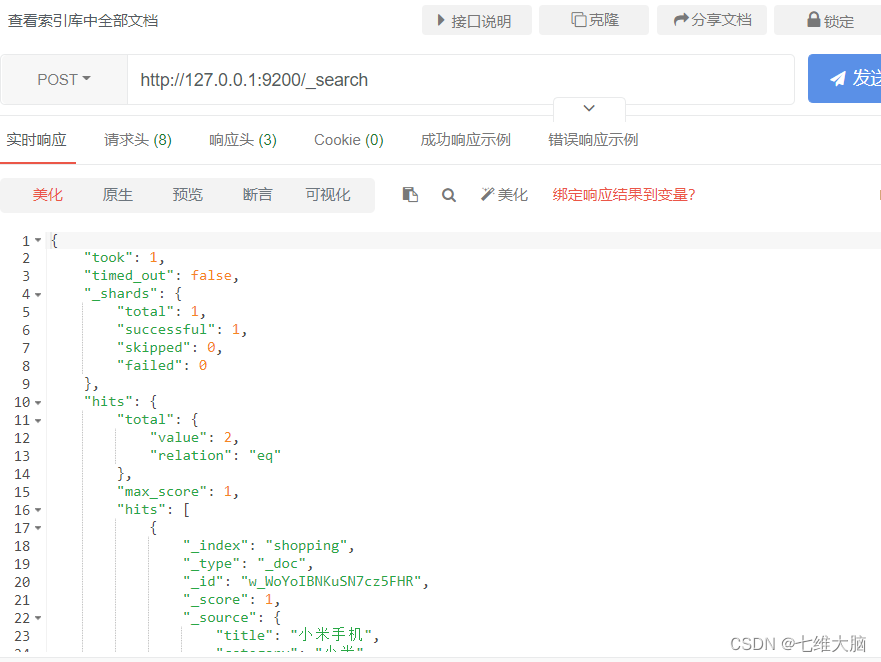
Ver todos los documentos en la biblioteca de índice
Solicitud GET/POST: http://127.0.0.1:9200/_search
Ver todos los documentos bajo el índice especificado
Solicitud GET/POST: http://127.0.0.1:9200/student/_search
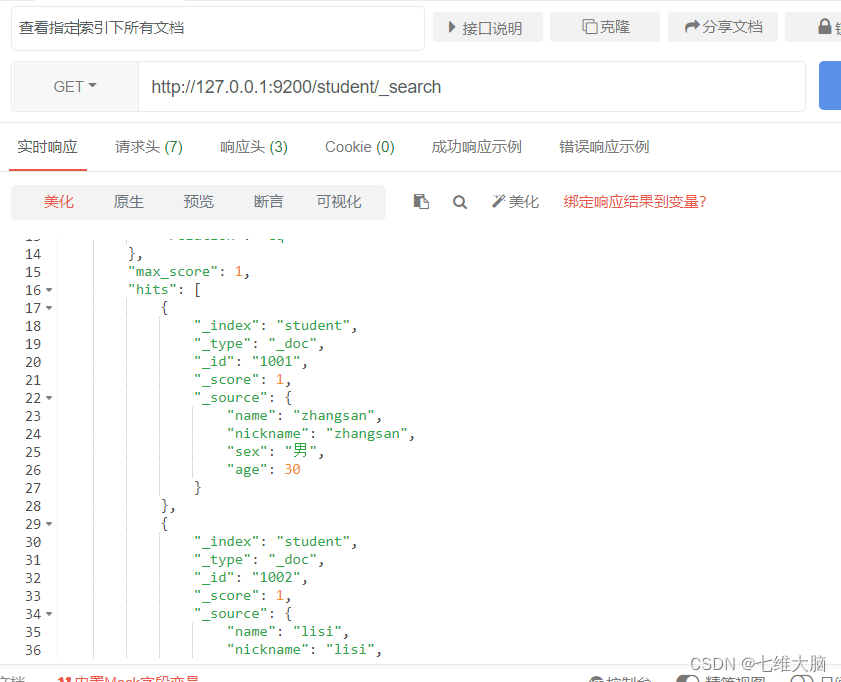
{
"took"【查询花费时间,单位毫秒】: 1,
"timed_out"【是否超时】: false,
"_shards"【分片信息】: {
"total"【总数】: 1,
"successful"【成功】: 1,
"skipped"【忽略】: 0,
"failed"【失败】: 0
},
"hits"【搜索命中结果】: {
"total"【搜索条件匹配的文档总数】: {
"value"【总命中计数的值】: 5,
"relation"【计数规则】: "eq" # eq 表示计数准确, gte 表示计数不准确
},
"max_score"【匹配度分值】: 1,
"hits"【命中结果集合】: [
... ...
]
}
}
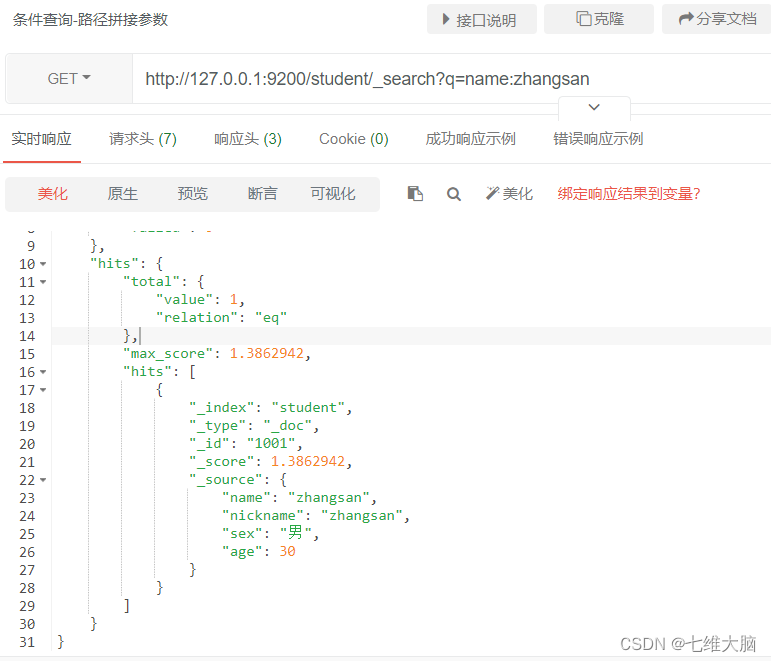
consulta de concordancia de condiciones
- Consulta de parámetros de empalme de ruta (recomendado el segundo)
Solicitud GET/POST: http://127.0.0.1:9200/student/_search?q=name:zhangsan
| parámetro | ilustrar |
|---|---|
| ? | Código para agregar parámetros de consulta |
| q | Indica el significado de la consulta. |
| nombre | nombre del campo de consulta |
- El cuerpo de la solicitud contiene una consulta de parámetros (recomendado)
consulta de tipo de coincidencia de coincidencia, la condición de consulta se dividirá en palabras, y luego se realizará la consulta, y la relación entre múltiples entradas es o
Solicitud GET/POST: http://127.0.0.1:9200/shopping/_search
El contenido del cuerpo de la solicitud es:
{
"query": {
"match":{
"name":"zhangsan"
}
}
}
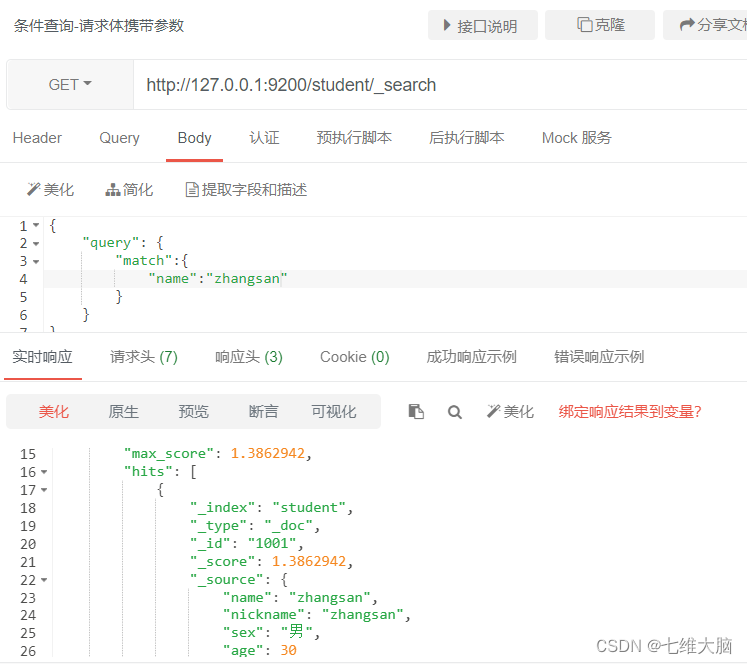
consulta de coincidencia de campo
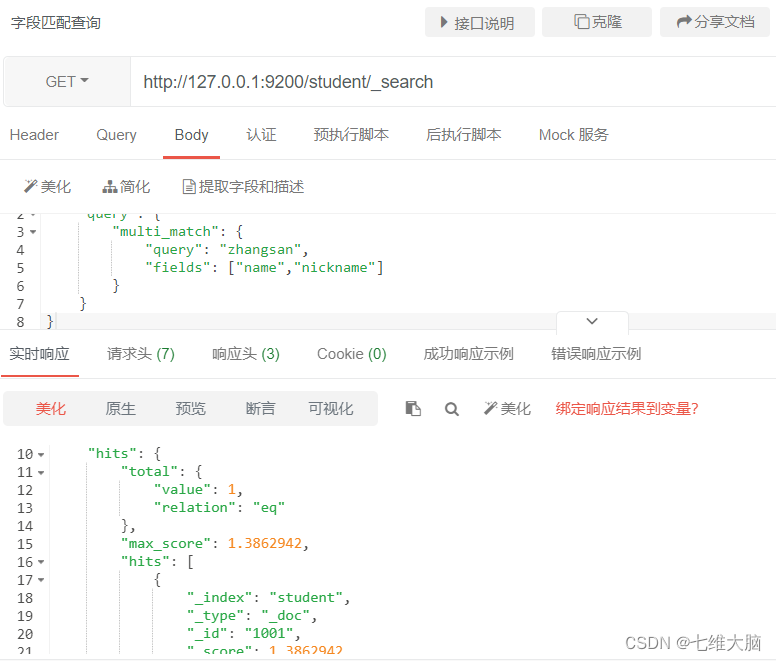
multi_match es similar a match, excepto que se puede consultar en varios campos.
OBTENER solicitud: http://127.0.0.1:9200/student/_search
{
"query": {
"multi_match": {
"query": "zhangsan",
"fields": ["name","nickname"]
}
}
}
consulta exacta de palabra clave
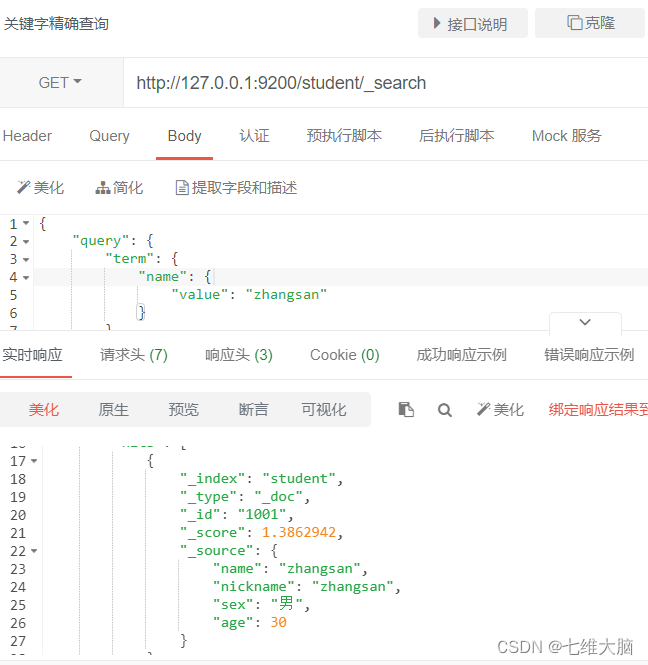
consulta de términos, consulta de concordancia exacta de palabras clave, sin segmentación de palabras para las condiciones de consulta.
OBTENER solicitud: http://127.0.0.1:9200/student/_search
{
"query": {
"term": {
"name": {
"value": "zhangsan"
}
}
}
}
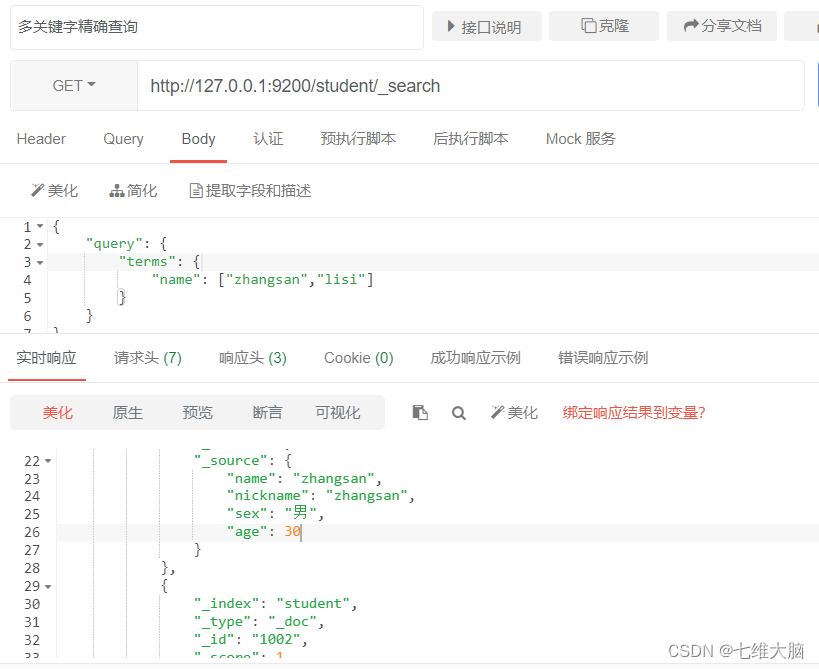
Consulta precisa de varias palabras clave
La consulta de términos es la misma que la consulta de términos, pero le permite especificar varios valores con los que comparar.
Si este campo contiene alguno de los valores especificados, entonces el documento cumple con las condiciones, similar a la de mysql.
OBTENER solicitud: http://127.0.0.1:9200/student/_search
{
"query": {
"terms": {
"name": ["zhangsan","lisi"]
}
}
}
especificar campos de consulta
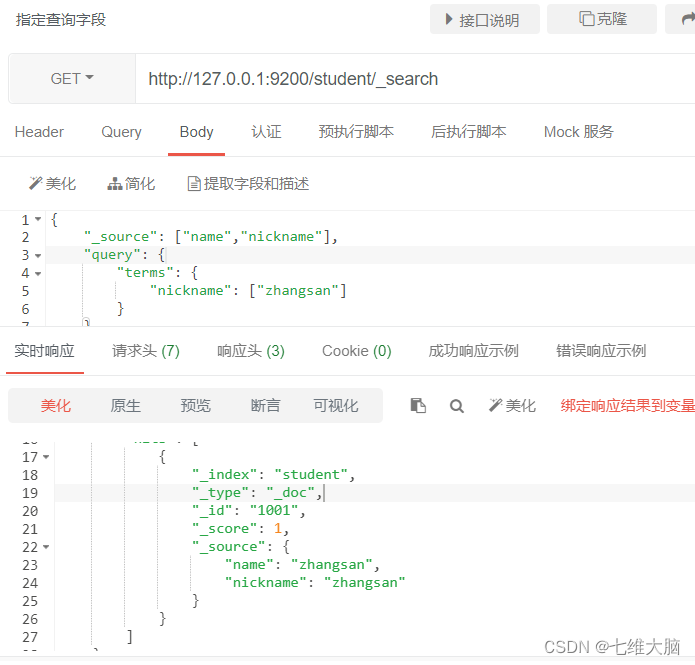
De forma predeterminada, Elasticsearch devolverá todos los campos del documento almacenado en _source en los resultados de búsqueda.
Si solo queremos obtener algunos de los campos, podemos agregar el filtrado _source
OBTENER solicitud: http://127.0.0.1:9200/student/_search
{
"_source": ["name","nickname"],
"query": {
"terms": {
"nickname": ["zhangsan"]
}
}
}
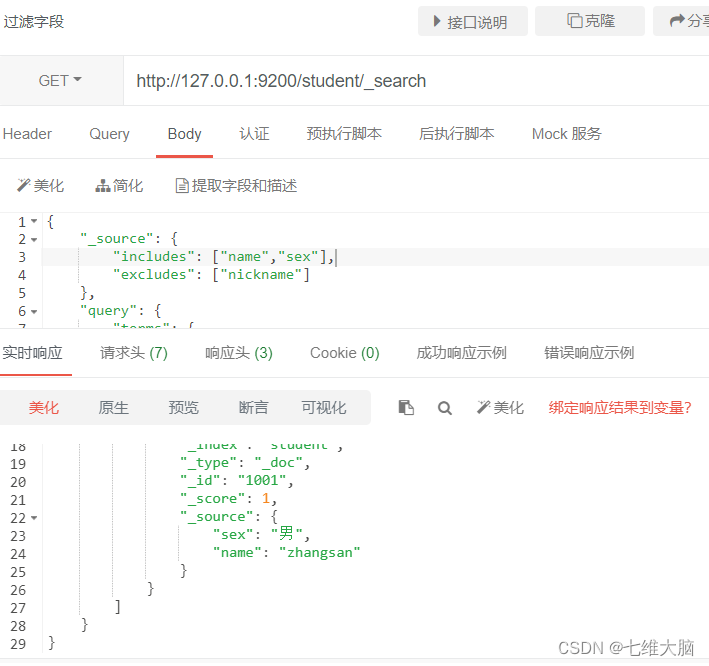
campo de filtro
También podemos pasar:
- incluye: para especificar los campos que desea mostrar
- excluye: para especificar los campos que no se quieren mostrar
OBTENER solicitud: http://127.0.0.1:9200/student/_search
{
"_source": {
"includes": ["name","sex"],
"excludes": ["nickname"]
},
"query": {
"terms": {
"nickname": ["zhangsan"]
}
}
}
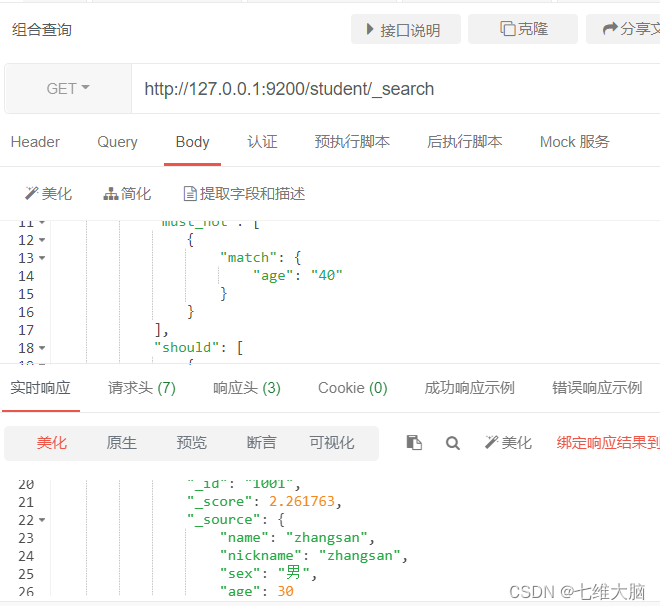
Consulta compuesta
boolCombine varias otras consultas por must(debe), must_not(no debe), should(debería)
OBTENER solicitud: http://127.0.0.1:9200/student/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"name": "zhangsan"
}
}
],
"must_not": [
{
"match": {
"age": "40"
}
}
],
"should": [
{
"match": {
"sex": "男"
}
}
]
}
}
}
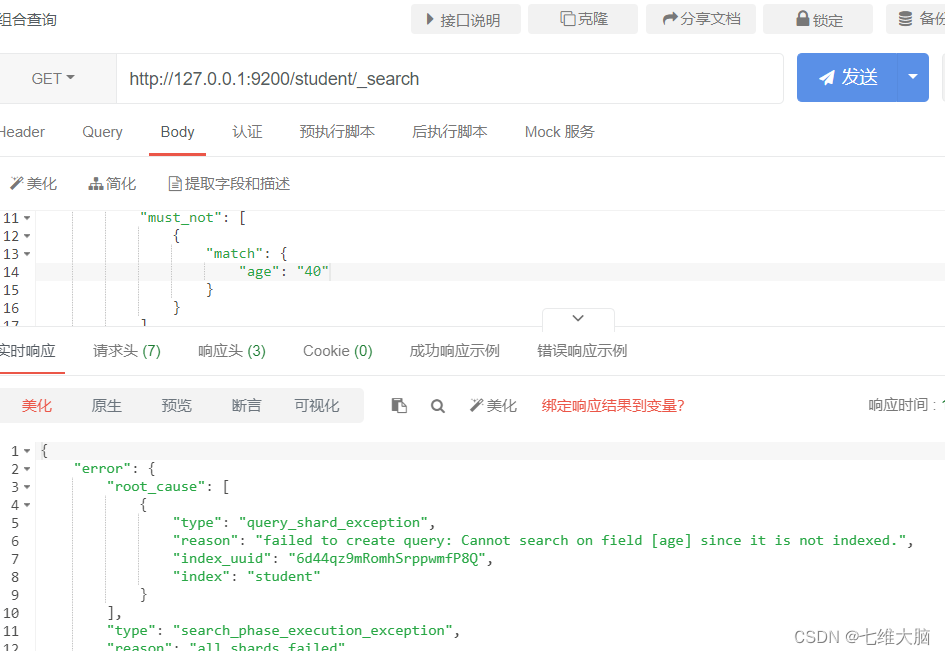
Descripción del error:
la edad no se puede indexar en el mapeo y no se puede ver. (También se encontrarán las siguientes consultas de rango)
Esto se debe a que el índice de edad y sexo se establece en falso al crear el mapeo de índice, la siguiente es la captura de pantalla del error.
Si desea realizar una prueba, se recomienda reconstruir un índice y luego establecer el índice de la edad y el sexo de la asociación de mapeo en verdadero. El
resultado normal de retorno debe ser:
consulta de rango
La consulta de rango encuentra números u horas que se encuentran dentro de un rango específico. las consultas de rango permiten los siguientes caracteres
| operador | ilustrar |
|---|---|
| gt | mayor que> |
| gte | mayor o igual que >= |
| es | menos que< |
| lte | menor o igual que <= |
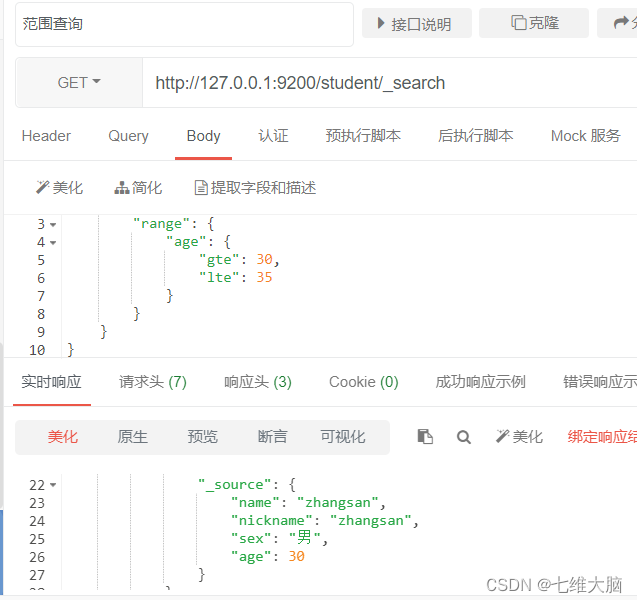
OBTENER solicitud: http://127.0.0.1:9200/student/_search
{
"query": {
"range": {
"age": {
"gte": 30,
"lte": 35
}
}
}
}
consulta difusa
Devuelve documentos que contienen términos similares al término de búsqueda.
La distancia de edición es el número de cambios de un carácter necesarios para convertir un término en otro. Estos cambios pueden incluir:
- cambiar de personaje (caja → zorro)
- borrar carácter (negro → falta)
- insertar carácter (sic → enfermo)
- transponer dos personajes adyacentes (act → cat)
Para encontrar términos similares, una consulta aproximada crea un conjunto de todas las variaciones o expansiones posibles de un término de búsqueda dentro de una distancia de edición especificada. Luego, la consulta devuelve una coincidencia exacta para cada extensión.
Modificar la distancia de edición por borrosidad. Generalmente se usa el valor predeterminado de AUTO, y la distancia de edición se genera de acuerdo con la duración del término.
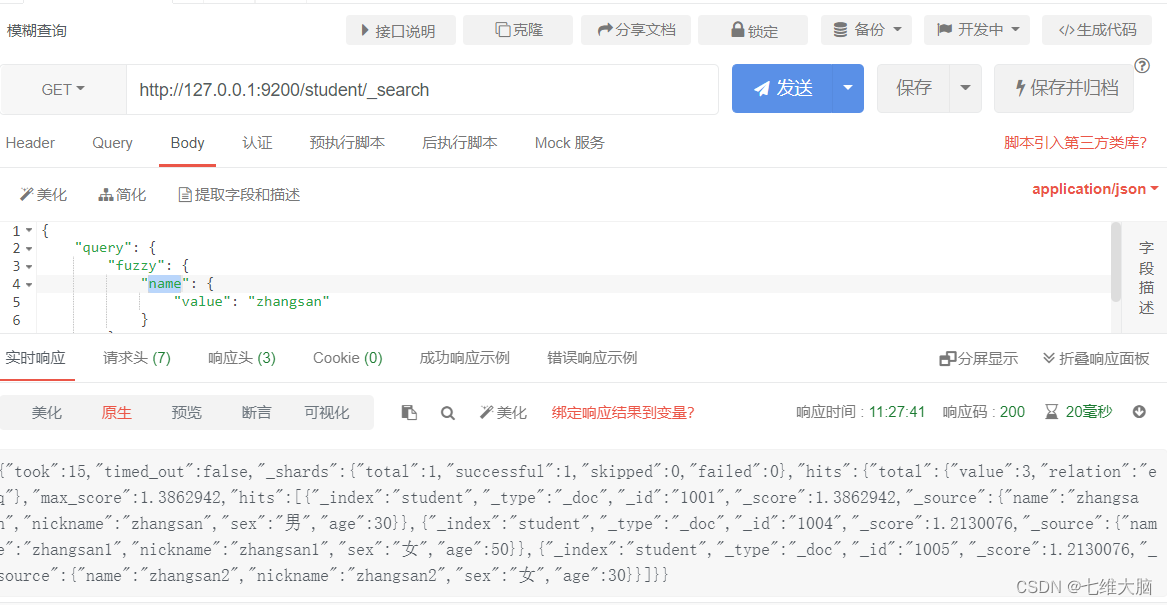
OBTENER solicitud: http://127.0.0.1:9200/student/_search
{
"query": {
"fuzzy": {
"name": {
"value": "zhangsan"
}
}
}
}
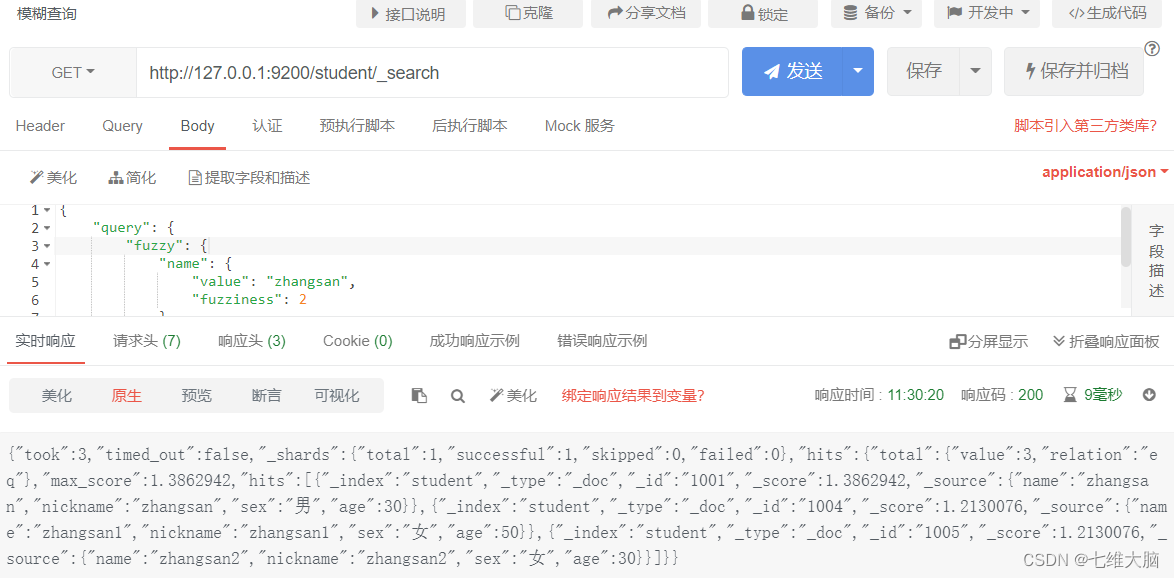
OBTENER solicitud: http://127.0.0.1:9200/student/_search
{
"query": {
"fuzzy": {
"name": {
"value": "zhangsan",
"fuzziness": 2
}
}
}
}
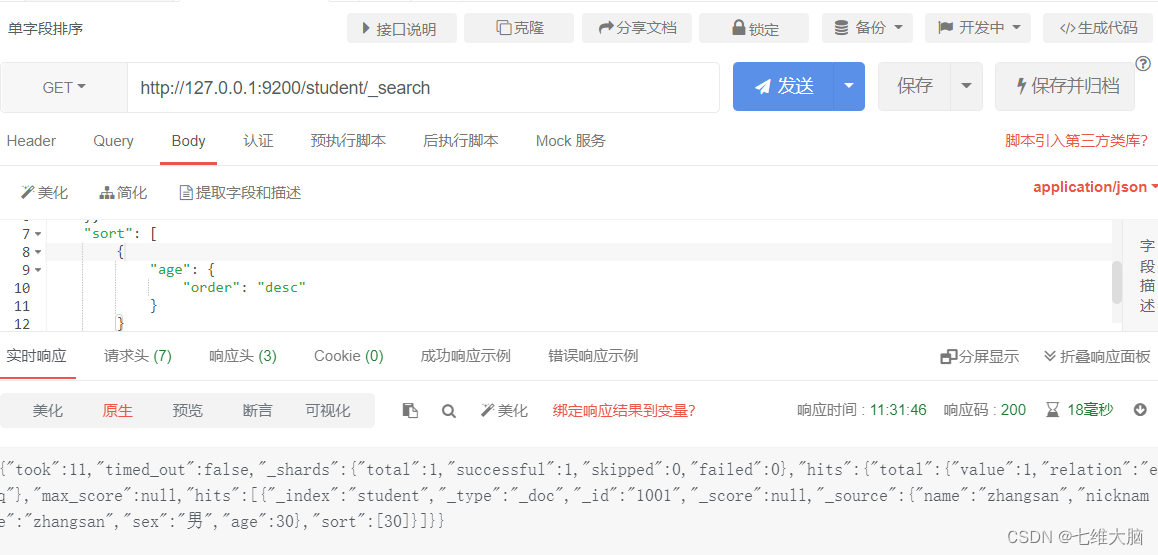
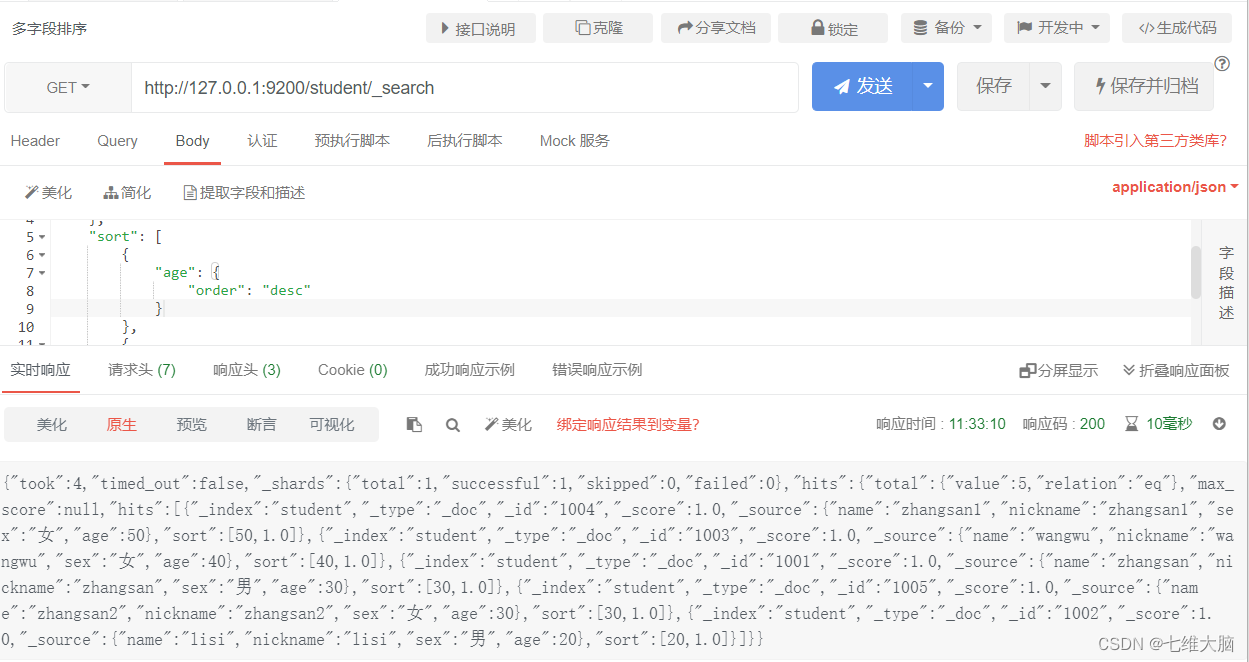
Clasificación de un solo campo
sort nos permite ordenar por diferentes campos y especificar el método de clasificación a través de order. desc orden descendente, asc orden ascendente.
OBTENER solicitud: http://127.0.0.1:9200/student/_search
{
"query": {
"match": {
"name": "zhangsan"
}
},
"sort": [
{
"age": {
"order": "desc"
}
}
]
}
Clasificación de campos múltiples
Supongamos que queremos consultar con edad y _puntuación juntas, y las coincidencias se ordenan primero por edad y luego por puntuación de relevancia.
OBTENER solicitud: http://127.0.0.1:9200/student/_search
{
"query": {
"match_all": {
}
},
"sort": [
{
"age": {
"order": "desc"
}
},
{
"_score": {
"order": "desc"
}
}
]
}
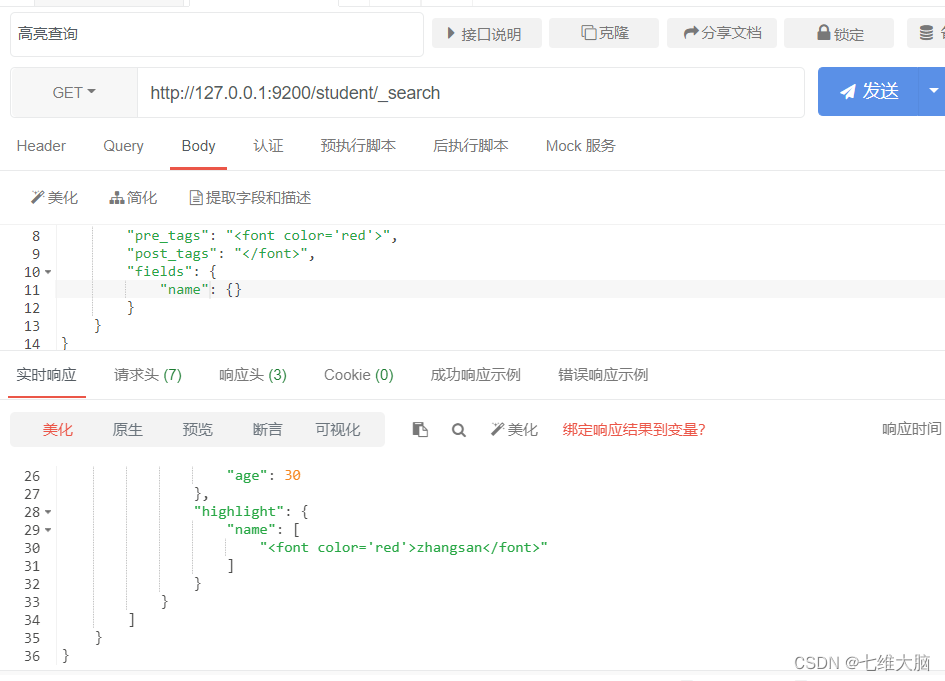
resaltar consulta
Al realizar una búsqueda de palabras clave, las palabras clave en el contenido buscado se mostrarán en diferentes colores, lo que se denomina resaltado.
Elasticsearch puede establecer la etiqueta y el estilo (resaltado) de la parte de la palabra clave en el contenido de la consulta.
Mientras usa la consulta de coincidencia, agregue un atributo destacado:
- pre_tags: pre-etiqueta
- post_tags: etiquetas de publicación
- campos: campos que necesitan ser resaltados
- título: aquí se declara que el campo de título debe resaltarse, y luego puede establecer una configuración única para este campo, o puede estar vacío
OBTENER solicitud: http://127.0.0.1:9200/student/_search
{
"query": {
"match_all": {
}
},
"from": 0,
"size": 2
}
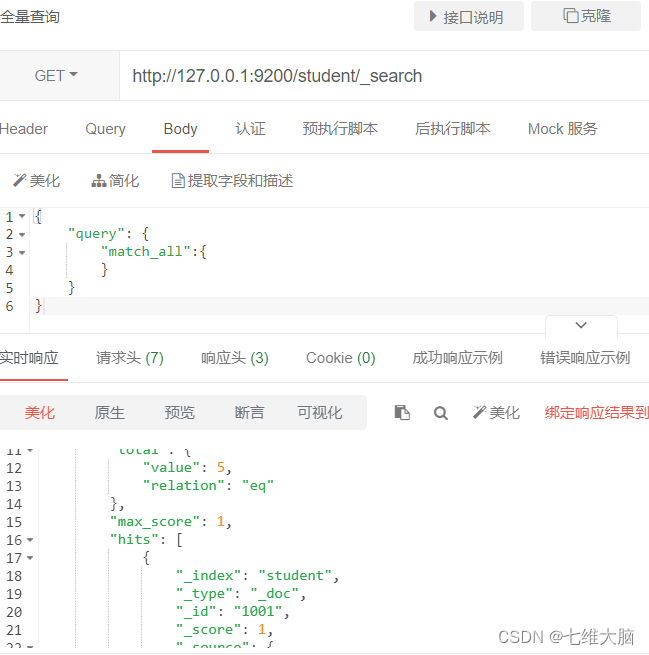
consulta completa
(Usualmente se usa junto con paginación, porque cuando la cantidad de datos es grande...)
Solicitud GET/POST: http://127.0.0.1:9200/student/_search
El contenido del cuerpo de la solicitud es:
{
"query": {
"match_all":{
}
}
}
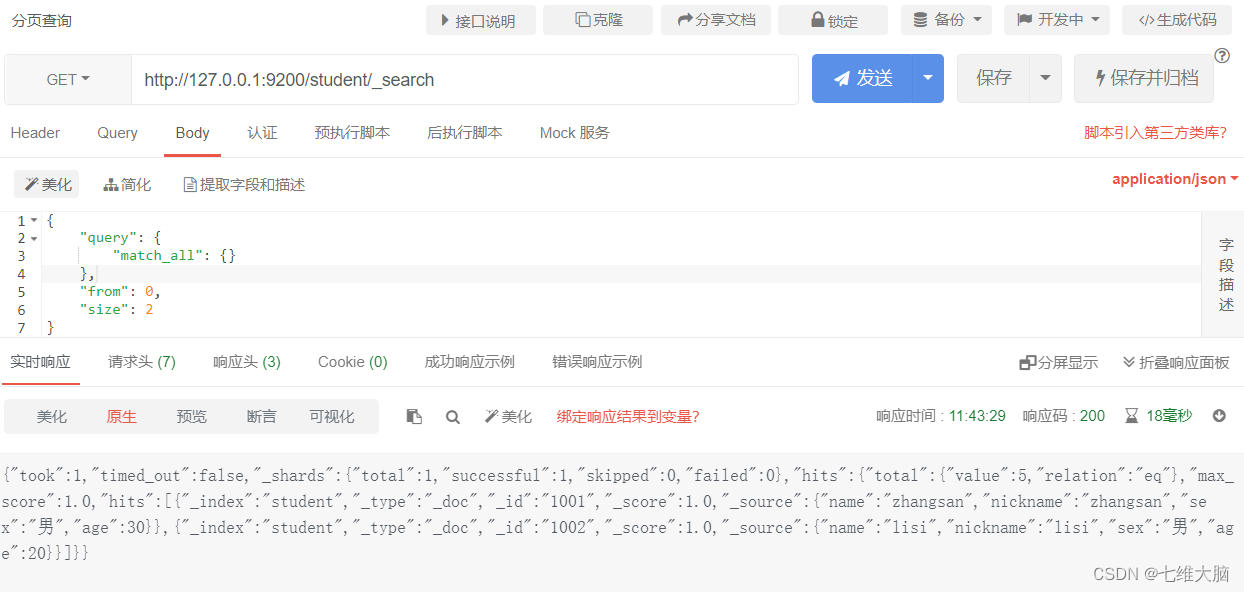
Consulta de paginación
from: el índice de inicio de la página actual, comenzando desde 0 de forma predeterminada. from = (pageNum - 1) * tamaño
tamaño: cuántos elementos se muestran en cada página,
Solicitud GET/POST: http://127.0.0.1:9200/student/_search
El contenido del cuerpo de la solicitud es:
{
"query": {
"match_all": {
}
},
"from": 0,
"size": 2
}
consulta de agregación
La agregación permite a los usuarios realizar análisis estadísticos en documentos es, similar a agrupar por en bases de datos relacionales y, por supuesto, hay muchas otras agregaciones, como tomar el valor máximo, el valor promedio, etc.
- Tome el valor máximo de una
solicitud GET máxima de campo: http://127.0.0.1:9200/student/_search
{
"aggs": {
"max_age": {
"max": {
"field": "age"
}
}
},
"size": 0
}
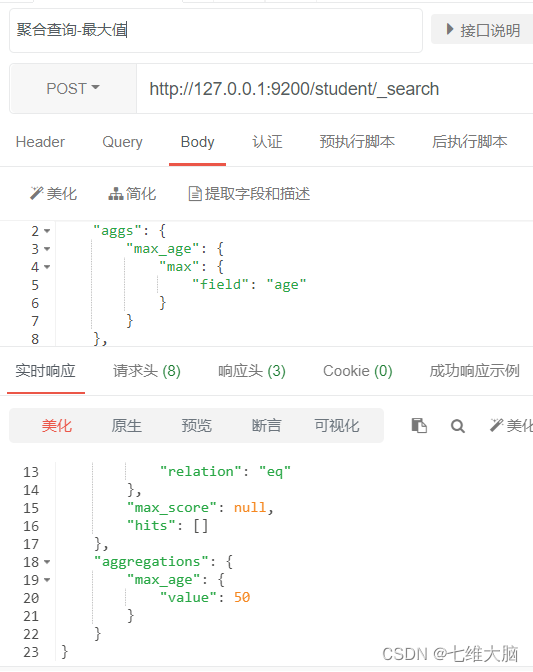
- Tome el valor mínimo min para un campo
{
"aggs": {
"min_age": {
"min": {
"field": "age"
}
}
},
"size": 0
}
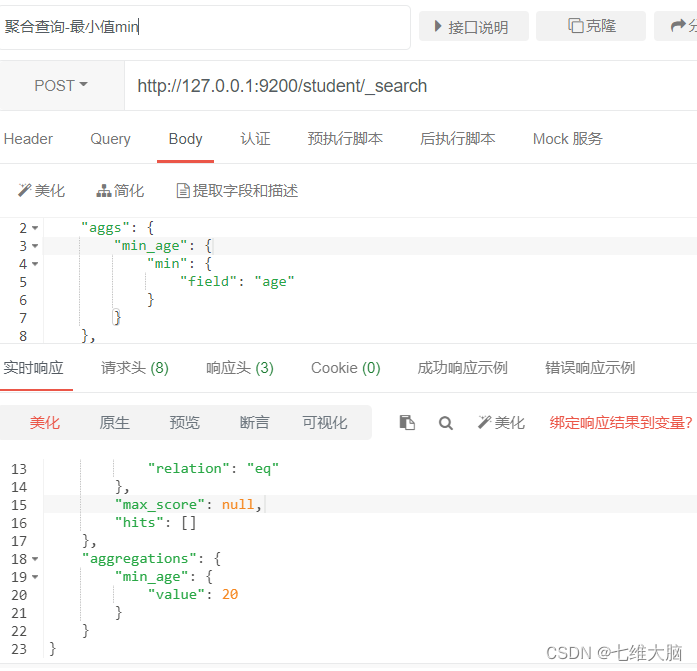
- sumar un campo
{
"aggs": {
"sum_age": {
"sum": {
"field": "age"
}
}
},
"size": 0
}
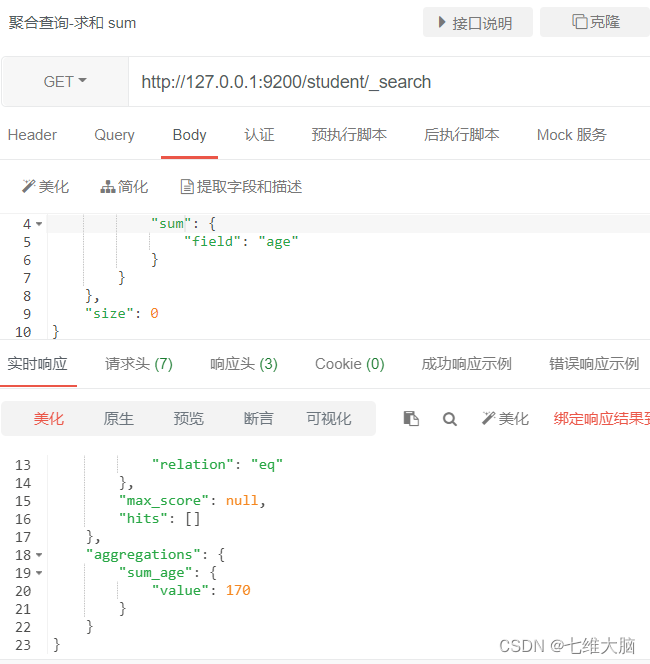
-
Tome el promedio promedio de un campo
-
Deduplicar el valor de un campo y luego tomar el total
-
Agregación estatal