1. Introducción
Recientemente escribió un procedimiento almacenado simple para datos estadísticos. Tome nota aquí y haga un breve resumen de algunos puntos de conocimiento básicos utilizados en este procedimiento almacenado. (Nota: la base de datos aquí usa postgresql)
2. Fondo
Tabla 1: el servicio de terceros escribe datos en la Tabla 1 cada 10 minutos Cada escritura inserta una nueva pieza de datos en la tabla, por lo que un dispositivo tiene varias piezas de datos en la tabla todos los días.
CREATE TABLE tb_check (
id serial NOT NULL, --自增ID
devicecode text NULL, --设备ID
dateid int4 NULL, --日期,格式: 20220509
num int4 NULL DEFAULT 0, --准确数量
totalnum int4 NULL DEFAULT 0 --检测总数
);
Tabla 2: Realice estadísticas sobre los datos de la Tabla 1 y almacénelas según "dispositivo + fecha" como valor clave, es decir, un dispositivo solo guarda un dato en la tabla al día y calcula la precisión de detección.
create table if not exists tb_check_statistics(
id serial NOT NULL, --自增ID
devicecode text NULL, --设备ID
dateid int4 NULL, --日期,格式: 20220509
num int4 NULL DEFAULT 0, --准确数量
totalnum int4 NULL DEFAULT 0, --检测总数
result text NULL, --准确率(准确数量/检测总数,格式:0.7500)
jczt int4 NULL --1:正常;2:异常(大于等于75%为正常,否则为异常)
);
Gráfico de datos objetivo:

3. Crear el formato básico del procedimiento almacenado
drop function if exists testprocess;
CREATE OR REPLACE FUNCTION testprocess()
RETURNS INTEGER AS
$BODY$
declare
--声明变量
begin
--操作模块
RAISE NOTICE 'this is a test process, date:%', 20220509;
return 0; --这里要和第二行定义的返回值对应,否则会报错
end;
$BODY$
LANGUAGE plpgsql VOLATILE
COST 100;
Ejecución: select * from testprocess();, el resultado de salida es como se muestra en la siguiente figura
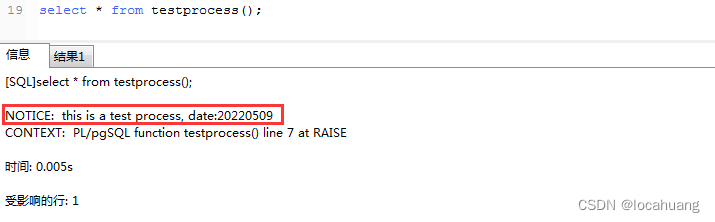
4. Definición de la estructura
La definición de estructura de datos es similar a nuestra programación habitual. A continuación, defino dos estructuras de datos, una para almacenar datos de campo de tabla y otra para almacenar tiempo:
--表字段结构体
CREATE TYPE check_type AS (
devicecode text,
dateid INTEGER,
num INTEGER,
totalnum INTEGER,
result text,
jczt INTEGER
);
--时间结构体
CREATE TYPE time_item AS (
currentdate text, --'2022-04-06 13:37:17'
currentyear text, --'2022'
currentmonth text, --'04'
currentday text, --'06'
timestr text, --'20220406'
timeid INTEGER --20220406
);
5. Declarar variables
Los tipos de variables incluyen: tabla, estructura, matriz, entero, booleano, carácter, etc.
declare
data_list11 tb_check; --为表1声明一个变量,用于读取表数据时提取参数值
timeitem time_item; --时间结构体
ivitem check_type; --表字段结构体
ivitemarray check_type[]; --表字段数组
countid INTEGER := 0;
iindex INTEGER := 0;
isflag boolean := false;
radius NUMERIC := 1.0;
caluresult NUMERIC := 1.0;
datetime NUMERIC := 0;
6. Adquisición de tiempo del sistema y conversión de formato.
1. Obtenga la hora del sistema
Obtenga la hora actual y asígnela a una variable usando select...into...
select floor(extract(epoch from now())) into datetime; --单位:秒
2. Conversión de formato de hora
timeitem time_item; --定义结构体变量
select to_char(to_timestamp(datetime), 'yyyy-mm-dd hh24:mi:ss') into timeitem.currentdate; --'2022-04-06 13:37:17'
timeitem.currentdate = substring(timeitem.currentdate from 1 for 10); --'2022-04-06'
select split_part(timeitem.currentdate ,'-', 1) into timeitem.currentyear; --'2022'
select split_part(timeitem.currentdate ,'-', 2) into timeitem.currentmonth; --'04'
select split_part(timeitem.currentdate ,'-', 3) into timeitem.currentday; --'06'
select timeitem.currentyear || timeitem.currentmonth || timeitem.currentday into timeitem.timestr; -- '20220406'
select timeitem.timestr::INTEGER into timeitem.timeid; --20220406
7. Leer datos de la tabla tb_check
Lea circularmente los datos de la tabla tb_check y guárdelos en la matriz.
--以天为条件循环读取一天的数据, 提取数据并存储到数组中
for data_list11 in select * from tb_check where dateid=timeitem.timeid loop
--1)循环遍历数组ivitemarray,以devicecode为唯一标识,查看数组中是否已经存在该设备的值,如果存在则更新;
isflag := false;
if countid > 0 then
FOR n IN 1..countid LOOP --循环数组
if ivitemarray[n].devicecode = data_list11.devicecode then --数组中可以查到,则更新数据
ivitem.devicecode = data_list11.devicecode;
ivitem.dateid = data_list11.dateid;
ivitem.num = ivitemarray[n].num+data_list11.num;
ivitem.totalnum = ivitemarray[n].totalnum+data_list11.totalnum;
ivitemarray[n] = ivitem; --覆盖原值
isflag := true;
EXIT; --找到则退出循环
end if;
END LOOP;
end if;
--2)若不存在则添加到数组
if isflag = false then --数组中查询不到,则添加到数组
ivitem.devicecode = data_list11.devicecode;
ivitem.dateid = data_list11.dateid;
ivitem.num = data_list11.num;
ivitem.totalnum = data_list11.totalnum;
countid := countid+1;
ivitemarray[countid] = ivitem;
end if;
end loop;
8. Los datos se insertan en la tabla tb_check_statistics
Recorra la matriz e inserte los datos en la tabla tb_check_statistics.
if countid > 0 then
FOR n IN 1..countid LOOP
--准确率计算
--这里省略,不做说明........
--插入表中
insert into tb_check_statistics
(
devicecode, dateid, num, totalnum, result, jczt
)values
(
ivitemarray[n].devicecode, ivitemarray[n].dateid, ivitemarray[n].num,
ivitemarray[n].totalnum, ivitemarray[n].result, ivitemarray[n].jczt
);
END LOOP;
end if;
9. Insertar datos: actualice si existe, de lo contrario inserte
Requerimientos fuera de tema: Hay una tabla que requiere insertar datos, si ya existe se actualizará, si no existe se insertará.
Mysql y postgresql son diferentes en la implementación, aquí hay una breve introducción al ON CONFLICTuso .
1. El uso ON CONFLICTtiene requisitos especiales para la tabla, es decir, la tabla debe especificar el ' identificador único de restricción '
create table if not exists tb_check_ex(
id serial NOT NULL,
devicecode text NULL,
dateid int4 NULL,
t11 int4 NULL DEFAULT 0,
t12 int4 NULL DEFAULT 0,
t13 text NULL,
t14 int4 NULL,
t21 int4 NULL DEFAULT 0,
t22 int4 NULL DEFAULT 0,
t23 text NULL,
t24 int4 NULL,
unique(dateid,devicecode) --需要特别指定 约束唯一标识
);
El identificador único de la restricción puede ser un solo campo o una combinación de varios campos. Aquí, los dos campos 'dateid y devicecode' se utilizan como identificador único de la restricción.
2. Insertar/actualizar declaración
--insert t11, t12, t13, t14
insert into tb_check_ex
(
devicecode, dateid, t11, t12, t13, t14
)values
(
ivitemarray[n].devicecode, ivitemarray[n].dateid, ivitemarray[n].num,
ivitemarray[n].totalnum, ivitemarray[n].result, ivitemarray[n].jczt
)ON CONFLICT (devicecode,dateid)
DO UPDATE SET t11=ivitemarray[n].num,t12=ivitemarray[n].totalnum,t13=ivitemarray[n].result,t14=ivitemarray[n].jczt;
--insert t21, t22, t23, t24
insert into tb_check_ex
(
devicecode, dateid, t21, t22, t23, t24
)values
(
ivitemarray[n].devicecode, ivitemarray[n].dateid, ivitemarray[n].num,
ivitemarray[n].totalnum, ivitemarray[n].result, ivitemarray[n].jczt
)ON CONFLICT (devicecode,dateid)
DO UPDATE SET t21=ivitemarray[n].num,t22=ivitemarray[n].totalnum,t23=ivitemarray[n].result,t24=ivitemarray[n].jczt;
De esta forma, en el caso del mismo código de dispositivo e ID de fecha, solo se guarda un dato en la tabla después de ejecutar las dos declaraciones de inserción anteriores.
