Directorio de artículos
- prefacio
- 1. ¿Qué es una transacción de base de datos?
- 2. Cuatro características de las transacciones
- 3. ¿Cuáles son los niveles de aislamiento de las transacciones? ¿Cuál es el nivel de aislamiento predeterminado para MySQL?
- 4. ¿Por qué Mysql elige RR como nivel de aislamiento predeterminado?
- 5. ¿Por qué muchos de los principales fabricantes eligen el nivel de aislamiento de la base de datos RC?
- 6. En escenarios concurrentes, ¿qué problemas de consistencia tiene la base de datos?
- 7. ¿Qué problemas de concurrencia existirán en los cuatro niveles de aislamiento?
- 8. ¿Cómo se implementa el nivel de aislamiento de MySQL?
- 9. ¿Qué es MVCC y su principio subyacente?
-
- 9.1 ¿Qué es la lectura instantánea y la lectura actual?
- 9.2 Campos implícitos
- 9.3 ¿Qué es el registro de deshacer?
- 9.4 Cadena de versiones de instantáneas
- 9.5 Número de versión de la transacción
- 9.6 Qué es la vista de lectura
- 9.7 ¿Cuál es el proceso de consulta de un registro basado en MVCC?
- 9.8 Basado en MVCC, nivel de aislamiento RC, análisis de problemas de lectura no repetibles
- 10. ¿Cómo lidiar con transacciones grandes y largas? Por favor, da algunas formas de lidiar con eso.
- 11. ¿Cómo optimizar el rendimiento de las transacciones de MySQL? Enumere algunos métodos de optimización.
- 12. El principio básico de la implementación de transacciones de Innodb
- referencia y gracias
prefacio
Próximamente llegarán Oro, Tres, Plata y Cuatro. He preparado 12 preguntas consecutivas sobre asuntos. Creo que será útil que todos las lean.
1. ¿Qué es una transacción de base de datos?
Una transacción consiste en una secuencia limitada de operaciones de base de datos que se ejecutan todas o no se ejecutan en absoluto, y son una unidad de trabajo indivisible.
Si A transfiere 100 yuanes a B, primero descuenta 100 yuanes de la cuenta de A y luego agrega 100 yuanes a la cuenta de B. Si se han deducido los 100 yuanes de A, pero no hay tiempo para agregarlos a B, el sistema bancario es anormal y, finalmente, el saldo de A disminuye, pero el saldo de B no aumenta. Entonces necesita una transacción, revertir el dinero de A, es así de simple.
2. Cuatro características de las transacciones
- Atomicidad: la transacción se ejecuta como un todo, y las operaciones sobre la base de datos que contiene se ejecutan todas o no se ejecuta ninguna.
- Coherencia: significa que los datos no se destruirán antes de que comience la transacción y después de que finalice. Si la cuenta A transfiere 10 yuanes a la cuenta B, la cantidad total de A y B seguirá siendo la misma independientemente del éxito o el fracaso.
- Aislamiento: cuando varias transacciones acceden al mismo tiempo, las transacciones se aíslan entre sí. Una transacción no debe ser interferida por otras transacciones, y las transacciones múltiples concurrentes deben estar aisladas entre sí.
- Persistencia: significa que después de confirmar la transacción, los cambios operativos realizados por la transacción en la base de datos se guardarán de forma persistente en la base de datos.
3. ¿Cuáles son los niveles de aislamiento de las transacciones? ¿Cuál es el nivel de aislamiento predeterminado para MySQL?
Hay cuatro niveles de aislamiento para las transacciones: lectura no confirmada, lectura confirmada, lectura repetible y serializable.
- Nivel de aislamiento de lectura no confirmada: solo dos datos no se pueden modificar al mismo tiempo, pero cuando se modifican los datos, incluso si la transacción no está confirmada, otras transacciones pueden leerla. Este nivel de aislamiento de transacciones incluye lecturas sucias y lecturas repetidas. , El problema de la lectura fantasma;
- Leer el nivel de aislamiento comprometido: la transacción actual solo puede leer los datos enviados por otras transacciones, por lo que el nivel de aislamiento de esta transacción resuelve el problema de las lecturas sucias, pero todavía hay problemas de lecturas repetidas y lecturas fantasma;
- Lectura repetible: el nivel de aislamiento de lectura repetible limita la lectura de datos y no se puede modificar, por lo que resuelve el problema de la lectura repetida, pero cuando se leen datos de rango, se pueden insertar datos, por lo que la lectura fantasma aún existe.
- Serialización: el nivel de aislamiento más alto para transacciones, bajo el cual todas las transacciones se ejecutan en orden serializado. Se pueden evitar todos los problemas simultáneos de lecturas sucias, lecturas no repetibles y lecturas fantasma. Sin embargo, bajo este nivel de aislamiento de transacciones, la ejecución de transacciones consume mucho rendimiento.
El nivel de aislamiento de transacciones predeterminado de Mysql es 可重复读(RR).
4. ¿Por qué Mysql elige RR como nivel de aislamiento predeterminado?
Sabemos que Mysql tiene cuatro niveles de aislamiento de base de datos, a saber 读未提交、读已提交、可重复读、串行化. El nivel de aislamiento de lectura no confirmada es demasiado bajo 会有脏读问题y el nivel de aislamiento de serialización es demasiado alto 会影响并发读. Luego están las lecturas confirmadas (RC) y las lecturas repetibles (RR).
Entonces, ¿ por qué Mysql elige RR como el nivel de aislamiento predeterminado ?
Nuestras bases de datos MySQL generalmente se implementan en clústeres, con bases de datos maestras y esclavas. La biblioteca principal es responsable de la escritura y la biblioteca esclava es responsable de la lectura. Después de escribir la biblioteca maestra, se realizará la replicación maestro-esclavo para sincronizar los datos con la biblioteca esclava.
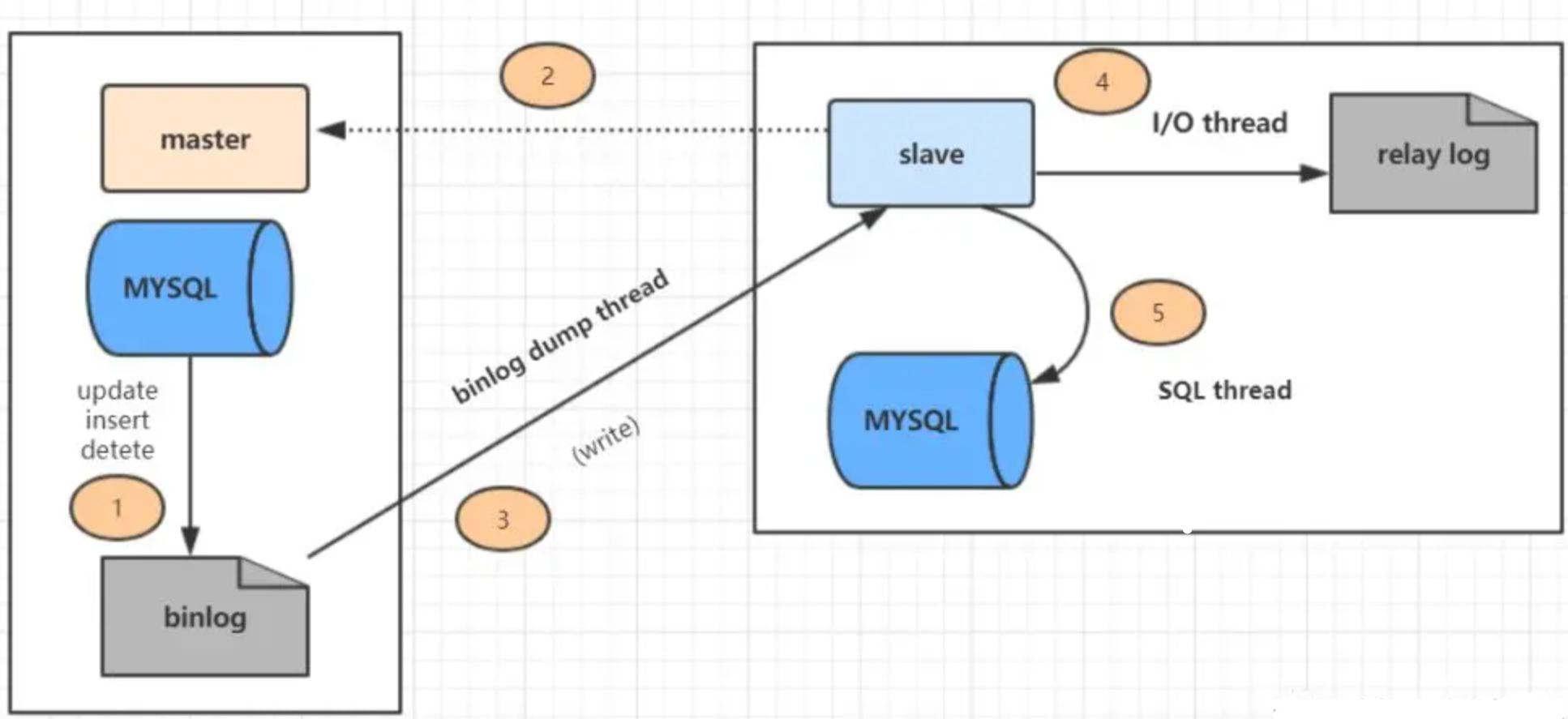
La biblioteca esclava obtiene el registro bin log de la biblioteca principal y ejecuta el bin log para garantizar la coherencia de los datos entre la biblioteca esclava y la biblioteca principal.
En realidad, bin loghay tres formatos, a saber statement, , rowy mixed. Si es statementun formato, bin logse graba SQLel texto original . En los primeros días de Mysql, bin logsolo existía este tipo de formato de registro statementEn el nivel de aislamiento de RC, pueden producirse inconsistencias en los datos.
Este error también está documentado en el sitio web oficial de MySQL.
Podemos reproducir este error, asumiendo que la estructura de la tabla es la siguiente:
CREATE TABLE t (
a int(11) DEFAULT NULL,
b int(11) DEFAULT NULL,
KEY a (a)
) ENGINE=InnoDB DEFAULT CHARSET=latin1;
insert into t values(666,2),(233,1);
Ejecute estas dos transacciones:

Después de la ejecución, debido a que el nivel de aislamiento de la transacción es RC, la transacción A b=2agregará un , por lo que el resultado de la ejecución es (888,2)que la transacción B no se ve afectada por el bloqueo de nivel de fila cuando se ejecuta, y el dos datos se convierten en (888,2),(233,2).
Bajo el nivel de aislamiento RC, veamos bin logel registro nuevamente. Cuando se ejecutan las dos transacciones, bin logel registro de la transacción B se registrará primero, porque se confirma primero, y luego bin logse generará el registro de la transacción A. Cuando bin logel formato de registro es statement, binlogse graba el texto original, es decir, update t set b=2 where b = 1primero se graba el ; y luego se graba update t set a=888 where b=2.
Para Jiangzi, cuando la base de datos maestra sincroniza el binlog con la base de datos esclava y ejecuta la reproducción de SQL, los datos de la base de datos se convierten en (888,2) y (888,2), y los datos en la base de datos maestra y la base de datos esclava son inconsistentes . Bajo RR (nivel de aislamiento de base de datos de lectura repetible), esta situación no ocurrirá debido a la existencia de gap locks, por lo tanto, Mysql elige RR como nivel de aislamiento por defecto.
5. ¿Por qué muchos de los principales fabricantes eligen el nivel de aislamiento de la base de datos RC?
La característica más obvia de las principales empresas de Internet y algunas empresas tradicionales es la alta concurrencia. Entonces las grandes fábricas están más inclinadas a mejorar la lectura concurrente del sistema.
Nivel de aislamiento RC, la concurrencia es mejor que RR, ¿por qué?
Debido al nivel de aislamiento RC, solo es necesario agregar bloqueos de fila a los registros modificados durante el proceso de bloqueo. El nivel de aislamiento de RR también necesita agregar Gap Lock y Next-Key Lock, es decir, bajo el nivel de aislamiento de RR, la probabilidad de interbloqueo es mucho mayor. Además, RC también admite la lectura semiconsistente, lo que puede reducir en gran medida el conflicto de los bloqueos de fila al actualizar las declaraciones; para los registros que no cumplen las condiciones de actualización, los bloqueos se pueden liberar con anticipación para mejorar la concurrencia.
- Lectura consistente: también conocida como lectura instantánea. La instantánea es la versión histórica anterior a los datos de la fila actual. La lectura de instantáneas es el uso de información de instantáneas para mostrar los resultados de la consulta en función de un determinado momento, independientemente de los cambios realizados por otras transacciones que se ejecutan al mismo tiempo.
- Lectura actual: la regla de lectura actual es poder leer los últimos valores de todos los registros enviados.
- Lectura semicoherente: para una declaración de actualización, si el registro coincide con la condición where se ha bloqueado, InnoDB devolverá la versión del registro enviada más recientemente y la capa superior de MySQL juzgará si es necesario bloquearlo.
6. En escenarios concurrentes, ¿qué problemas de consistencia tiene la base de datos?
- Lectura sucia: si una transacción lee datos modificados por otra transacción no confirmada, lo llamamos un fenómeno de lectura sucia.
- Lectura no repetible: en la misma transacción, lea varias veces antes y después, y el contenido de datos leídos es inconsistente
- Lectura fantasma: si una transacción primero consulta algunos registros de acuerdo con ciertas condiciones de búsqueda, y cuando la transacción no está confirmada, otra transacción escribe algunos registros (como insertar, eliminar, actualizar) que cumplen con esas condiciones de búsqueda, lo que significa que la lectura fantasma.
- Actualización perdida: tanto la transacción A como la transacción B modifican los mismos datos, la transacción A modifica primero, la transacción B modifica después y la modificación de la transacción B sobrescribe la modificación de la transacción A.
7. ¿Qué problemas de concurrencia existirán en los cuatro niveles de aislamiento?
| nivel de aislamiento | lectura sucia | lectura no repetible | Lectura fantasma |
|---|---|---|---|
| Lectura no confirmada (RU) | √ | √ | √ |
| Lectura comprometida (RC) | × | √ | √ |
| Lectura repetible (RR) | × | × | √ |
| Serializable | × | × | × |
- En el nivel de aislamiento de RU, pueden ocurrir lecturas sucias, lecturas no repetibles y lecturas fantasma.
- Bajo el nivel de aislamiento RC, pueden ocurrir lecturas no repetibles y lecturas fantasma.
- Bajo el nivel de aislamiento RR, pueden ocurrir lecturas fantasma.
- En el nivel de aislamiento Serializable, las transacciones se ven obligadas a ejecutarse en serie y no habrá lecturas sucias, lecturas no repetibles o lecturas fantasma.
8. ¿Cómo se implementa el nivel de aislamiento de MySQL?
El nivel de aislamiento de MySQL se implementa a través de MVCC y mecanismos de bloqueo.
- El nivel de aislamiento de RU es el más bajo, no hay bloqueo y hay un problema de lectura sucia. La lectura transaccional no bloquea y no bloquea la lectura y escritura de otras transacciones
- Los niveles de aislamiento RC y RR se pueden lograr a través de MVCC.
- La serialización se logra a través de un mecanismo de bloqueo. Lectura más bloqueo compartido, escritura más bloqueo exclusivo, exclusión mutua de lectura y escritura. Si hay transacciones no confirmadas que modifican ciertas filas, todas las declaraciones que seleccionen estas filas se bloquearán.
9. ¿Qué es MVCC y su principio subyacente?
MVCC, es decir Multi-Version Concurrency Control(control de concurrencia multi-versión). Es un método de control de concurrencia, generalmente en el sistema de gestión de bases de datos, para lograr el acceso concurrente a la base de datos.
En términos simples, hay múltiples versiones de datos en la base de datos al mismo tiempo, no múltiples versiones de la base de datos completa, pero existen múltiples versiones de un determinado registro al mismo tiempo. Cuando una transacción opera en él, debe verificar este La identificación de la versión de la transacción de la columna oculta del registro, compare la identificación de la transacción y juzgue qué versión de los datos leer de acuerdo con el nivel de aislamiento de la transacción.
Para comprender los principios subyacentes de MVCC, debe revisar muchos puntos de conocimiento relevantes. Analicémoslo de acuerdo con el siguiente esquema:
- ¿Qué es la lectura instantánea y la lectura actual?
- campo implícito
- ¿Qué es el registro de deshacer?
- ¿Qué es una cadena de versiones de instantáneas?
- número de versión de la transacción
- ¿Qué es la vista de lectura?
- ¿Cuál es el proceso de consulta de un registro basado en MVCC?
- Basado en MVCC, nivel de aislamiento RC, análisis de problemas de lectura no repetibles
9.1 ¿Qué es la lectura instantánea y la lectura actual?
- Lectura de instantánea: lee la versión visible de los datos del registro (hay versiones antiguas). Sin bloqueos, las declaraciones de selección ordinarias son todas lecturas instantáneas.
- Lectura actual: se lee la última versión de los datos registrados y todos los bloqueos explícitos se leen actualmente.
La lectura de instantáneas es la base de la implementación de MVCC.
9.2 Campos implícitos
Para InnoDBel motor de almacenamiento, cada fila tiene dos columnas ocultas trx_id、roll_pointer, y si no hay una clave principal y una clave única que no sea NULL en la tabla, habrá una tercera columna de clave principal oculta row_id.
9.3 ¿Qué es el registro de deshacer?
registro de deshacer, registro de reversión, utilizado para registrar la información antes de que se modifiquen los datos. Antes de que se modifiquen los registros de la tabla, los datos se copiarán primero en el registro de deshacer. Si se revierte la transacción, los datos se pueden restaurar a través del registro de deshacer.
Se puede considerar que cuando deletehaya registro, se registrará undo logel registro correspondiente en , y cuando haya registro, se registrará el registro opuesto correspondiente.insertupdateupdate
undo log¿Cual es el uso?
- La atomicidad y la consistencia están garantizadas cuando se revierte una transacción.
- Se utiliza para lecturas de instantáneas de MVCC.
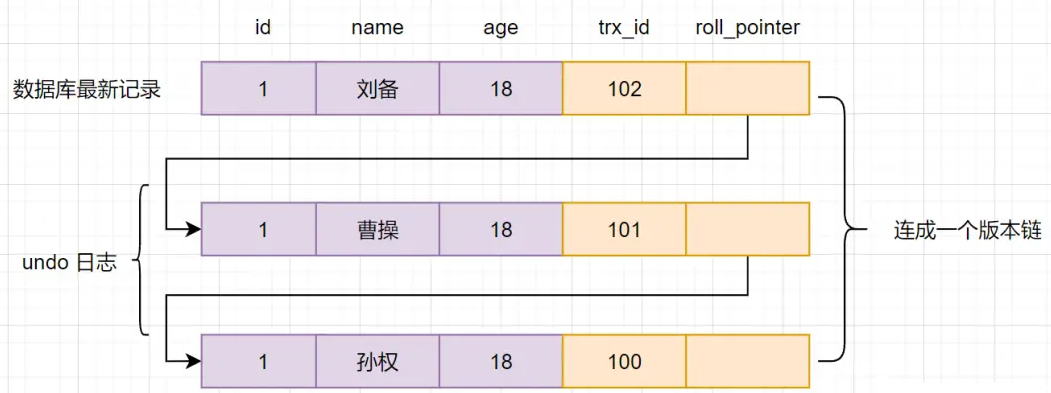
9.4 Cadena de versiones de instantáneas
Cuando múltiples transacciones operan una fila de datos en paralelo, la modificación de la fila de datos por diferentes transacciones generará múltiples versiones, y luego a través del puntero de reversión (roll_pointer), se conectarán en una lista enlazada.Esta lista enlazada se llama una cadena de versión. como sigue:
9.5 Número de versión de la transacción
Antes de que se inicie cada transacción, se obtendrá un ID de transacción de aumento automático de la base de datos, y la secuencia de ejecución de las transacciones se puede juzgar a partir del ID de transacción (trx_id). Este es el número de versión de la transacción.
9.6 Qué es la vista de lectura
¿Qué es la vista de lectura? Es la vista de lectura generada cuando la transacción ejecuta la instrucción SQL. De hecho, en innodb, cada instrucción SQL obtendrá una antes de la ejecución Read View. Se utiliza principalmente para el juicio de visibilidad, es decir, para juzgar qué versión de datos es visible en la transacción actual ~
En Read View, hay varios atributos importantes.
- m_ids: una lista de ID de transacciones de lectura y escritura no confirmadas en el sistema actual.
- min_limit_id: indica el id de transacción más pequeño entre las transacciones activas de lectura y escritura en el sistema actual cuando se genera la vista de lectura, es decir, el valor mínimo en m_ids.
- max_limit_id: indica el valor de id que se debe asignar a la siguiente transacción en el sistema cuando se genera la vista de lectura.
- Creator_trx_id: crea el ID de transacción de la vista de lectura actual
Las reglas de condición de coincidencia de vista de lectura (muy importante) son las siguientes :
- Si se trata de una transacción de datos
ID trx_id < min_limit_id, significa que la transacción que generó esta versión se ha confirmado antes de generar la Vista de lectura (porque se incrementa el ID de la transacción), por lo que la transacción actual puede acceder a esta versión. - Si
trx_id>= max_limit_id, significa que la transacción que genera esta versión se genera después de que se genera la vista de lectura, por lo que la transacción actual no puede acceder a esta versión. - Si es así
min_limit_id =<trx_id< max_limit_id, debe dividirse en 3 situaciones para la discusión.
(1) Si m_ids contiene trx_id, significa que la transacción no se ha enviado en el momento de la
generación de la Vista de lectura, pero si el trx_id de los datos es igual a created_trx_id, indica que los datos se generan por sí mismos, por lo que es visible.
(2) Si m_ids contiene trx_id, y trx_id no es igual a created_trx_id, entonces
cuando se genera la vista de lectura, la transacción no se confirma y no se produce por sí misma, por lo que la transacción actual también es invisible
(3). m_ids no contiene trx_id, significa que su transacción se ha enviado antes de que se genere la vista de lectura, y el resultado de la modificación puede verse en la transacción actual.
9.7 ¿Cuál es el proceso de consulta de un registro basado en MVCC?
- Obtenga el número de versión de la transacción en sí, es decir, el ID de la transacción (trx_id)
- Obtener vista de lectura
- Consulte los datos obtenidos y luego compare el número de versión de la transacción en la Vista de lectura.
- Si no se cumplen las reglas de visibilidad de Vista de lectura, se requiere la instantánea histórica en el registro Deshacer;
- Finalmente, devuelva los datos que cumplan con las reglas.
InnoDB implementa MVCC al Read View+ Undo Logguardar Undo Loginstantáneas históricas y Read Viewlas reglas de visibilidad ayudan a determinar si la versión actual de los datos es visible.
9.8 Basado en MVCC, nivel de aislamiento RC, análisis de problemas de lectura no repetibles
Para profundizar la comprensión de MVCC por parte de todos, analicemos un ejemplo: por ejemplo, nivel de aislamiento RC, hay un problema de lectura no repetible, analicemos este proceso.
-
Primero cree la tabla core_user e inserte una parte de los datos de inicialización, de la siguiente manera:

-
El nivel de aislamiento se establece en lectura confirmada (RC), y la transacción A y la transacción B realizan operaciones de consulta y modificación en la tabla core_user al mismo tiempo.
事务A: select * fom core_user where id=1
事务B: update core_user set name =”曹操”
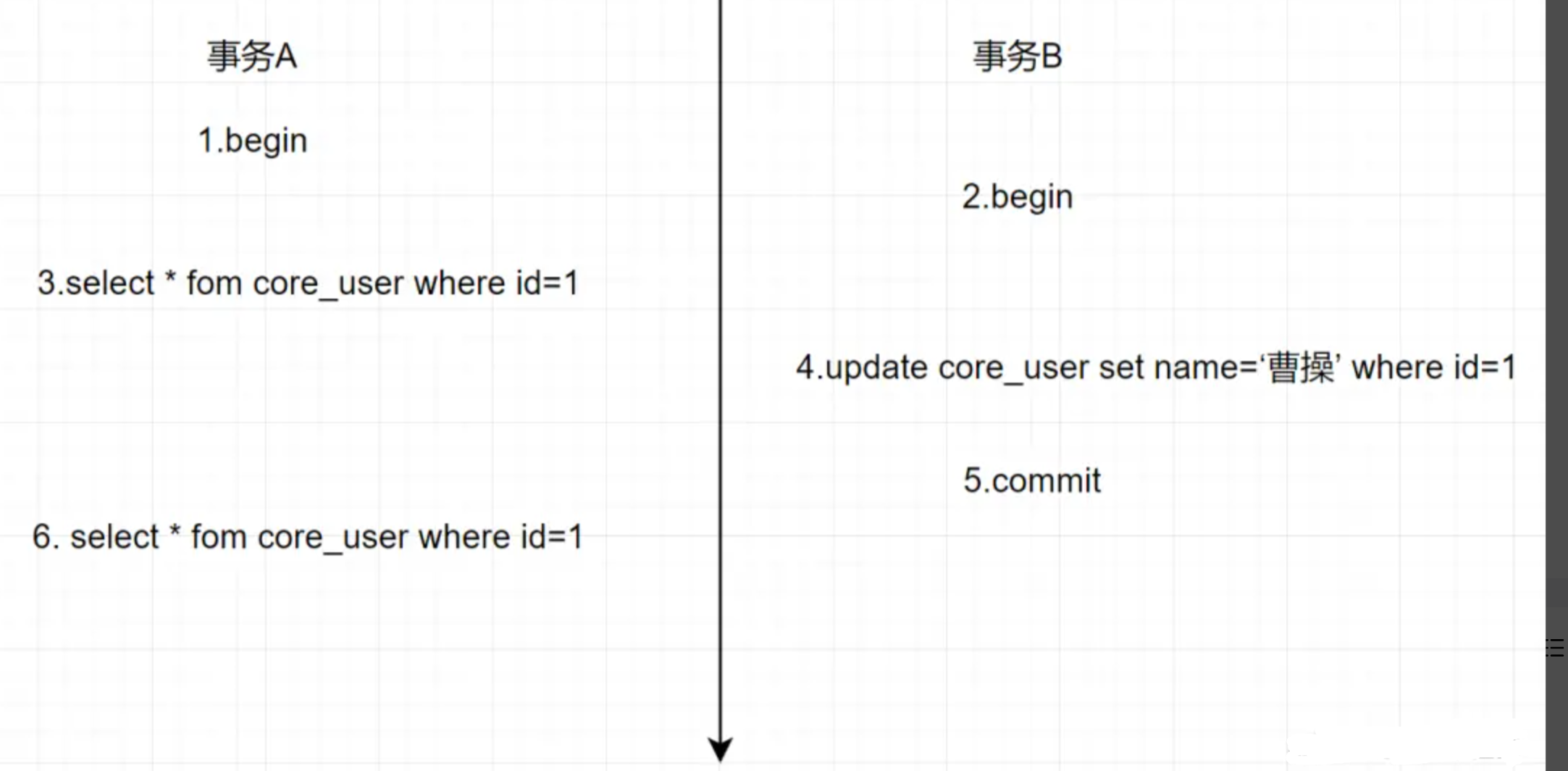
Finalmente, el resultado de la consulta de la transacción A es el registro de nombre = Cao Cao Analicemos el proceso de ejecución basado en MVCC:
(1) A inicia una transacción y primero obtiene una ID de transacción de 100
(2) B inicia una transacción, y obtiene un ID de transacción de 101
(3) La transacción A genera una vista de lectura, y los valores correspondientes a la vista de lectura son los siguientes
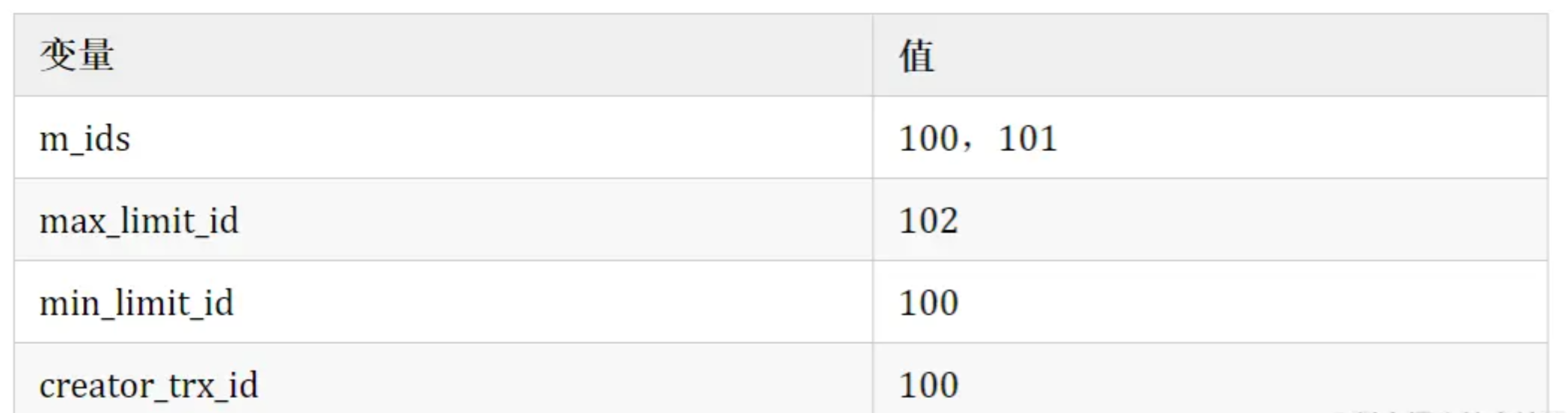
Luego regrese a la cadena de versiones: comience a elegir registros visibles de la cadena de versiones:

En la figura se puede ver que el contenido del nombre de la columna en la última versión es Sun Quan, y el valor de trx_id en esta versión es 100. Juzgando la comprobación de la regla de visibilidad de la vista de lectura:
min_limit_id(100)=<trx_id(100)<102;
creator_trx_id = trx_id =100;
A partir de esto, se puede ver que la transacción actual es visible para el registro de trx_id=100. Entonces se encuentra que el nombre es el registro de Sun Quan.
(4) La transacción B realiza la operación de modificación y cambia el nombre a Cao Cao. Copie los datos originales en el registro de deshacer, luego modifique los datos y marque el ID de la transacción y la dirección de la versión de datos anterior en el registro de deshacer.
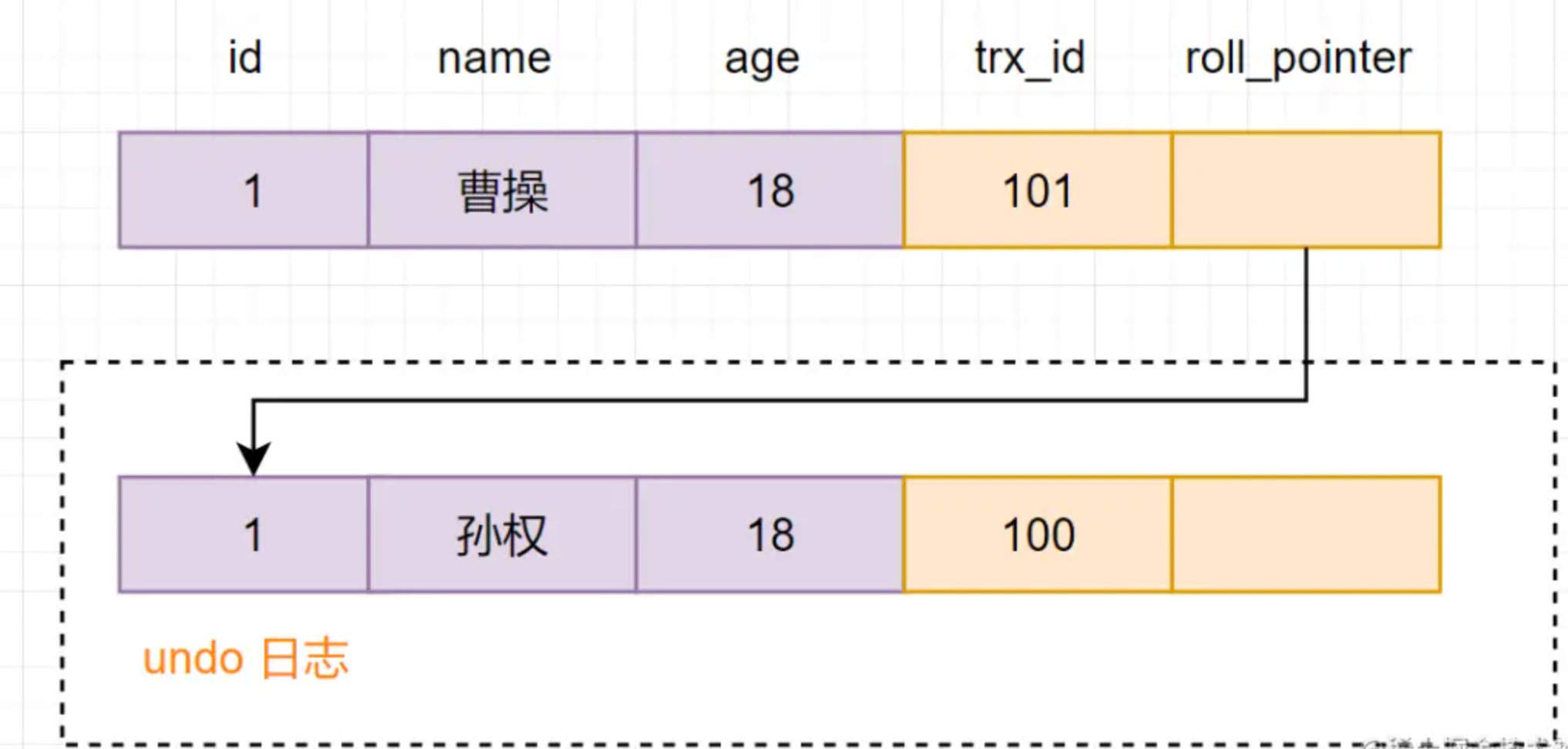
(5) Enviar la transacción
(6) La transacción A ejecuta la operación de consulta nuevamente y genera una nueva vista de lectura, y los valores correspondientes de la vista de lectura son los siguientes

Luego regrese a la cadena de versiones nuevamente: elija los registros visibles de la cadena de versiones:
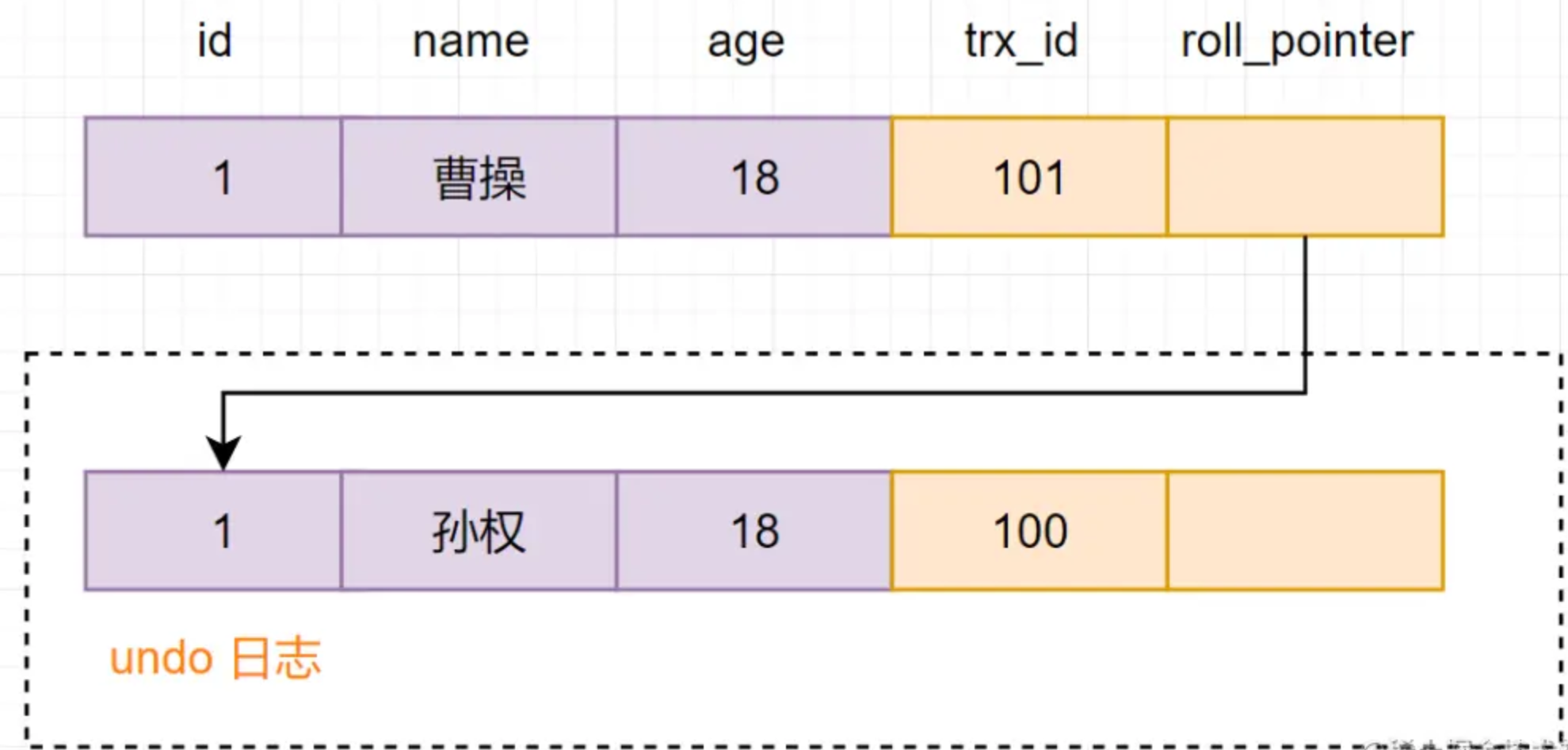
En la figura se puede ver que el contenido del nombre de la columna en la última versión es Cao Cao, y el valor trx_id de esta versión es 101. Evaluación de la comprobación de la regla de visibilidad de la vista de lectura:
min_limit_id(100)=<trx_id(101)<max_limit_id(102);
但是,trx_id=101,不属于m_ids集合
Por lo tanto, el registro trx_id=101 es visible para la transacción actual. Entonces, la consulta SQL es el registro cuyo nombre es Cao Cao.
En resumen, 在读已提交(RC)隔离级别下en la misma transacción, dos consultas idénticas leyeron el mismo registro (id = 1), pero arrojaron datos diferentes (la primera vez se encontró que era Sun Quan y la segunda vez que se descubrió que era Cao Cao Ese registro), por lo que el nivel de aislamiento RC, hay un problema de simultaneidad de lectura no repetible.
En el nivel de aislamiento de RR, en una transacción, cada consulta solo obtendrá una vista de lectura, que es compartida por la copia, para garantizar que los datos de cada consulta sean los mismos **, por lo que resuelve el problema de no lectura repetible Ha** de problemas de concurrencia.
10. ¿Cómo lidiar con transacciones grandes y largas? Por favor, da algunas formas de lidiar con eso.
Lidiar con transacciones grandes y largas es una parte muy importante del diseño y la optimización de la base de datos. Aquí hay algunos métodos de procesamiento comúnmente utilizados:
- Divida una transacción grande en transacciones pequeñas: divida una transacción grande en múltiples transacciones pequeñas, reduzca la cantidad de datos operados por cada transacción, reduzca el riesgo de competencia de bloqueo y punto muerto, y mejore el rendimiento de la concurrencia.
- Optimice las declaraciones de consulta: para las operaciones de consulta en transacciones largas, el rendimiento de la consulta se puede mejorar optimizando las declaraciones de consulta, como agregar índices y optimizar estructuras SQL.
- Evite ocupar bloqueos durante mucho tiempo: las transacciones largas ocuparán recursos de bloqueo, lo que provocará que otras transacciones no puedan acceder a los datos correspondientes. Por lo tanto, es necesario acortar el tiempo de ejecución de las transacciones tanto como sea posible para evitar ocupar bloqueos durante mucho tiempo. .
- Evite largas esperas de transacciones: Las transacciones largas pueden hacer que otras transacciones esperen demasiado, lo que afecta el rendimiento y la disponibilidad del sistema. Por lo tanto, es necesario acortar el tiempo de ejecución de las transacciones tanto como sea posible para evitar largas esperas de transacciones.
- Optimice los registros de transacciones: las transacciones largas ocuparán una gran cantidad de registros de transacciones, lo que resultará en una disminución del rendimiento de la base de datos. Por lo tanto, es necesario optimizar las estrategias de escritura y vaciado de los registros de transacciones para mejorar el rendimiento.
- Use tareas programadas: las transacciones de ejecución prolongada se pueden ejecutar regularmente a través de tareas programadas para evitar la ocupación de recursos a largo plazo.
- Aumente adecuadamente los recursos de hardware: si los métodos anteriores no pueden resolver el problema, puede aumentar adecuadamente los recursos de hardware, como aumentar la memoria, la CPU, el almacenamiento, etc., para mejorar el rendimiento del sistema.
11. ¿Cómo optimizar el rendimiento de las transacciones de MySQL? Enumere algunos métodos de optimización.
La optimización del rendimiento de transacciones de MySQL es una de las claves para mejorar el rendimiento de la base de datos. A continuación se enumeran algunos métodos de optimización de uso común:
- Elija el motor de almacenamiento adecuado: los diferentes motores de almacenamiento tienen diferentes características y rendimiento, por lo que debe elegir el motor de almacenamiento adecuado según las necesidades comerciales específicas, como MyISAM, InnoDB, Memory, etc.
- Use índices apropiados: los índices apropiados pueden mejorar la eficiencia de las operaciones de consulta y actualización, por lo que debe agregar índices apropiados en función de las condiciones comerciales reales para evitar exploraciones de tablas completas.
- Evite el bloqueo innecesario: el bloqueo innecesario reducirá el rendimiento de la concurrencia, por lo que se debe evitar el bloqueo innecesario, como optimizar las declaraciones de consulta, usar el bloqueo optimista, etc.
- Seleccione un nivel de aislamiento de transacciones adecuado: los diferentes niveles de aislamiento de transacciones tienen diferentes características e impactos en el rendimiento, por lo que debe seleccionar un nivel de aislamiento de transacciones adecuado en función de las condiciones comerciales reales.
- Reduzca el alcance de las transacciones: minimice el alcance de las transacciones tanto como sea posible y divida las transacciones grandes en múltiples transacciones pequeñas, lo que puede reducir el riesgo de competencia de bloqueo y punto muerto, y mejorar el rendimiento de la concurrencia.
- Use un método de compromiso de transacción adecuado: para las transacciones que no necesitan revertirse, puede usar el método de compromiso automático para reducir la cantidad de operaciones de compromiso y mejorar el rendimiento.
- Evite las transacciones largas: las transacciones de larga duración consumirán muchos recursos y afectarán el rendimiento de la concurrencia, por lo tanto, es necesario acortar el tiempo de ejecución de las transacciones tanto como sea posible para evitar la espera de transacciones a largo plazo.
- Optimización del hardware y la configuración del servidor de la base de datos: la optimización del hardware y la configuración del servidor de la base de datos puede mejorar el rendimiento de la base de datos, como aumentar la memoria, optimizar el rendimiento del disco y ajustar el tamaño de la memoria caché, etc.
- Use una base de datos distribuida: para escenarios de alta simultaneidad, puede usar una arquitectura de base de datos distribuida para distribuir datos a varios nodos de base de datos para mejorar el rendimiento de la simultaneidad.
Por supuesto, estos métodos pueden no ser aplicables a todos los escenarios comerciales y deben seleccionarse y ajustarse de acuerdo con situaciones específicas.
12. El principio básico de la implementación de transacciones de Innodb
InnoDB es un motor de almacenamiento de uso común en MySQL que admite funciones avanzadas como transacciones y bloqueos de nivel de fila. Los siguientes son los principios básicos de la implementación de transacciones de InnoDB:
- En InnoDB, cada transacción tiene una ID de transacción única (ID de transacción), que se utiliza para distinguir diferentes transacciones.
- InnoDB utiliza MVCC (control de concurrencia de múltiples versiones) para lograr el aislamiento de transacciones. Cada modificación generará una nueva versión. Al consultar, solo puede ver la versión que se envió antes de que comience la consulta, para evitar leer datos sucios.
- Al realizar una operación de actualización en una transacción, InnoDB bloqueará las filas de datos relevantes según sea necesario para garantizar la atomicidad y la coherencia de la transacción. Los bloqueos de nivel de fila en InnoDB se implementan mediante el bloqueo de nodos de índice, por lo que para la misma fila de datos, diferentes transacciones pueden acceder y modificar datos a través de diferentes índices.
- Las transacciones en InnoDB admiten propiedades ACID, a saber, atomicidad, consistencia, aislamiento y durabilidad. InnoDB garantiza la atomicidad y la durabilidad de las transacciones mediante el registro de rehacer y el registro de deshacer. El registro de rehacer registra las operaciones de modificación de transacciones, mientras que el registro de deshacer registra las operaciones de reversión de transacciones. Cuando el sistema falla u ocurren otras fallas, InnoDB puede restaurar los datos al estado anterior a la confirmación de la transacción mediante el registro de rehacer y el registro de deshacer para garantizar la coherencia y la durabilidad de los datos.
- Los niveles de aislamiento de transacciones en InnoDB incluyen lectura no confirmada, lectura confirmada, lectura repetible y serializable. El nivel de aislamiento predeterminado es Lectura repetible, que se implementa mediante bloqueos y mecanismos MVCC. En el caso de alta simultaneidad, si la granularidad de bloqueo es demasiado grande o la competencia de bloqueo es demasiado intensa, puede causar cuellos de botella en el rendimiento o problemas de punto muerto, por lo que debe optimizarse para escenarios específicos.