Tabla de contenido
1. Proceso de solicitud de red
3. Modelo de transmisión de red
2. Conceptos básicos de reptiles
1. Proceso de solicitud de red
1.HTTP
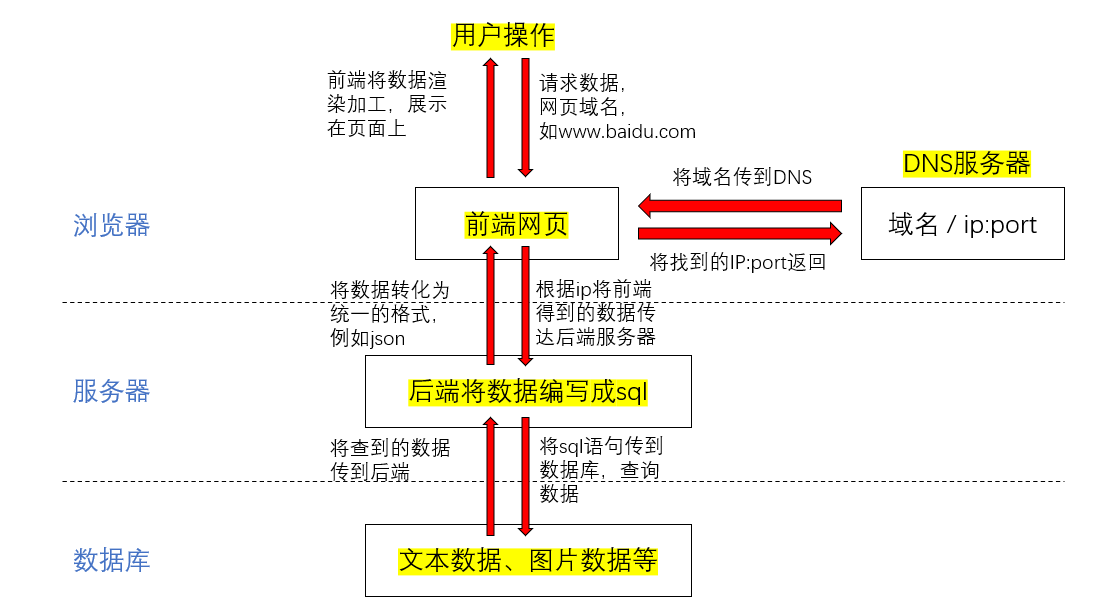
- El usuario ingresa la URL, como www.baidu.com
- El navegador primero solicita el DNS, encuentra la dirección IP y el número de puerto correspondiente al nombre de dominio de la URL y lo envía al front-end
- El navegador solicita acceder al servidor correspondiente a esta dirección IP y luego pasa los parámetros contenidos en el nombre de dominio al backend juntos.
- El backend deletrea los parámetros recibidos en declaraciones sql y consulta los datos de la base de datos a través del lenguaje sql
- La base de datos devuelve el resultado al backend.
- El backend organiza los datos obtenidos en un formato unificado y los devuelve al frontend
- Después de que el front-end obtiene los datos, los representa y los procesa a través del código del front-end y los muestra en la página para los usuarios.
2.URL
Ejemplo de URL:
Las cuatro partes de la URL:
- Protocolo: https://
- Nombre de dominio: www.baidu.com/
- Ruta del recurso: video/BV1dK4y1A7aM/?
- 参数:spm_id_from=333.1007.top_right_bar_window_history.content.click&vd_source=18bd1edf91a238e3df510f2409d7b427
En general, la ruta del recurso y la parte del parámetro están separados por '?', y los parámetros no pueden estar separados por '&'
Al ingresar la URL se debe incluir el protocolo y nombre de dominio, si no se ingresa el protocolo el navegador usará https:// por defecto.
El nombre de dominio incluye la dirección IP y el número de puerto.
3. Modelo de transmisión de red
Protocolo HTTP (HyperText Transfer Prorocol) El protocolo de transferencia de hipertexto es un protocolo para transferir formato de datos entre navegadores y servidores web, basado en el protocolo TCP, es un protocolo de capa de aplicación


Después de asegurarse de que la capa de aplicación, la capa de transporte, la capa de red y la capa de enlace sean consistentes:
- Los datos se pasan primero del cliente a la capa de enlace de la capa de aplicación a la capa de enlace
- Transmisión de datos a través de Ethernet e IP
- A través del token ring (algoritmo de cifrado), los datos se verifican para garantizar que los datos sean auténticos y confiables
- Luego, la capa de enlace pasa los datos a la capa de aplicación, lo que indica que los datos se pueden procesar en el siguiente paso.
4. Enlace largo/enlace corto
En HTTP/1.0, el servidor usa enlaces cortos de forma predeterminada. El navegador y el servidor establecen una conexión sin realizar una operación HTTP, pero la conexión se interrumpe cuando finaliza la tarea.
Desde HTTP/1.1, los navegadores usan enlaces largos por defecto. El navegador del cliente accede a un HTML u otro tipo de página web que contiene otros recursos web, como archivos js, archivos de imagen, archivos CSS, etc. Cuando el navegador encuentra dicho recurso, establecerá una sesión HTTP.
Conexión: mantener vivo
keep-alive es un acuerdo entre el cliente y el servidor, es decir, un enlace largo, lo que significa que el servidor no cerrará la conexión TCP después de devolver la respuesta, y el cliente no cerrará la conexión TCP después de recibir la respuesta, y lo reutilizará cuando envíe la próxima conexión de solicitud HTTP
- El enlace corto es relativamente simple de implementar para el servidor, y los enlaces existentes son todos conexiones válidas, y no se requieren métodos de control adicionales.
- Después de que el enlace corto se establezca con éxito, la conexión se desconectará después de que se complete una solicitud y una respuesta, y la conexión debe restablecerse cada vez que se envíe una solicitud. A menudo es posible crear una gran cantidad de conexiones en un corto período de tiempo, lo que hace que el servidor responda con demasiada lentitud.
- Los enlaces cortos no consumen demasiados recursos del lado del servidor, pero aumentan el tiempo de espera del usuario y ralentizan la velocidad de acceso.
- Los enlaces largos pueden ahorrar más operaciones de establecimiento y cierre de TCP y mejorar la eficiencia
- Una vez que el enlace largo se establece con éxito, se pueden enviar múltiples solicitudes y respuestas. Cuando las dos partes no se comunican, el servidor desconectará el enlace.
- Los enlaces largos aumentan la sobrecarga de recursos del servidor, lo que puede provocar una carga excesiva en el servidor y, finalmente, hacer que el servicio no esté disponible.
2. Conceptos básicos de reptiles
1. Conceptos básicos

¿Qué son los reptiles? El rastreador es para simular la solicitud de red del usuario y obtener datos del sitio web de destino. En teoría, siempre que sean los datos que se muestran en el navegador, el rastreador puede obtenerlos.
Proceso del rastreador:
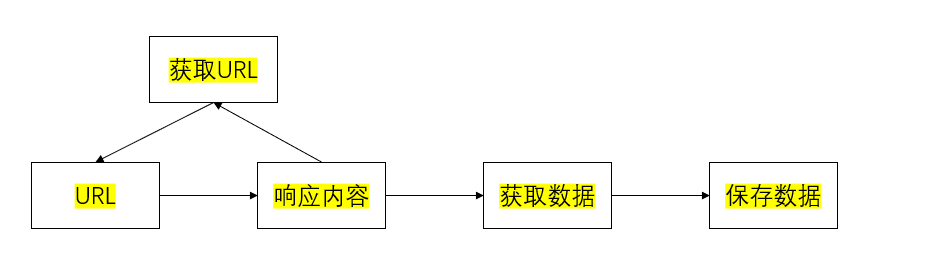
- Envíe una solicitud a url y obtenga una respuesta
- Extrae la respuesta
- Si es necesario extraer la URL, continúe enviando la solicitud para obtener la respuesta.
- extraer datos, guardar datos
HTTP o HTTPS:
- HTTP: Protocolo de transferencia de hipertexto, el número de puerto predeterminado es 80
- HTTPS: HTTP + SSL (Secure Sockets), Protocolo de transferencia de hipertexto con Secure Sockets, número de puerto predeterminado 443
Encabezados de solicitud HTTP comunes:
- Host: host y número de puerto
- Conexión: tipo de conexión
- Upgrade-Insecure-Requests: Actualizar solicitudes HTTPS
- Agente de usuario: nombre del navegador
- Aceptar: tipo de archivo de transferencia
- Referencia: punto de salto de página
- Aceptar codificación: formato de codificación/descodificación de archivos
- Cookie: parámetros
User-Agent y Cookie son los parámetros más importantes, estos dos parámetros indican el origen de la solicitud y son los mejores parámetros para pretender ser solicitudes artificiales.
Código de estado de respuesta (código de estado):
- 200: éxito
- 302: Transferencia temporal a una nueva url
- 307: transferido temporalmente a una nueva URL
- 404: No se puede encontrar la página
- 403: recurso no disponible
- Error interno de servidor 500
- 503: El servidor no está disponible, por lo general es anti-subida
2. Enviar solicitud
solicitudes solicitud: la versión anterior de Python usa urllib para enviar solicitudes, y las solicitudes son una encapsulación adicional de urllib
solicitud de texto
import requests
url = "https://www.baidu.com"
# 向目标url发送get请求
response = requests.get(url)
# 响应内容
print(response.text) # str类型
print(response.content) # bytes类型
print(response.status_code) # 状态码
print(response.request.headers) # 请求头
print(response.headers) # 响应头
print(response.cookies) # 响应的cookie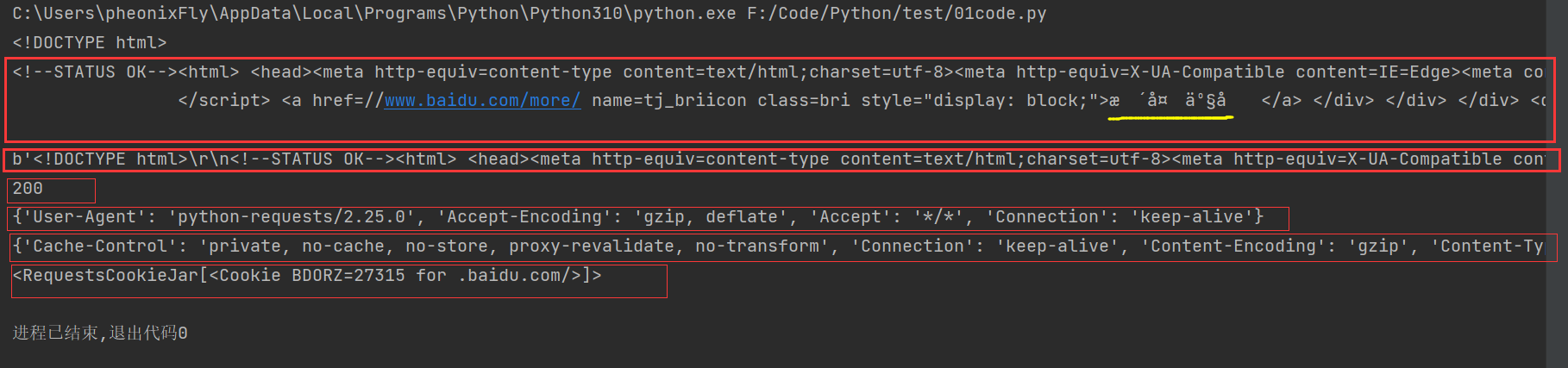
import requests
url = "https://www.baidu.com"
# 向目标url发送get请求
response = requests.get(url)
# 响应内容
print(response.text) # str类型,中文字符为乱码
print(response.content) # bytes类型
print(response.content.decode()) # 正常显示中文字符
print(response.content.decode('utf-8')) # 正常显示中文字符
print(response.content.decode('gbk')) # 报错
solicitud de imagen
import requests
url = "https://hips.hearstapps.com/hmg-prod.s3.amazonaws.com/images/d-1592982809.jpg"
response = requests.get(url)
# 打印图片的字节型内容
print(response.content)
with open("image.jpg", "wb") as f:
# 写入response.content bytes二进制类型
f.write(response.content)
Solicitud de encabezados y parámetros
El encabezado y los parámetros de la solicitud se establecerán de forma predeterminada, pero si queremos personalizar los encabezados y parámetros del encabezado de la solicitud , debemos crear el encabezado de la solicitud y las variables de los parámetros en una estructura de diccionario, y pasar la función de solicitud de obtención o publicación
3. Modo de solicitud
obtener solicitud: una solicitud iniciada directamente en la página web sin ningún parámetro
solicitud posterior: cuando determinamos qué datos necesitamos, debemos traer parámetros cuando iniciamos la solicitud
interino
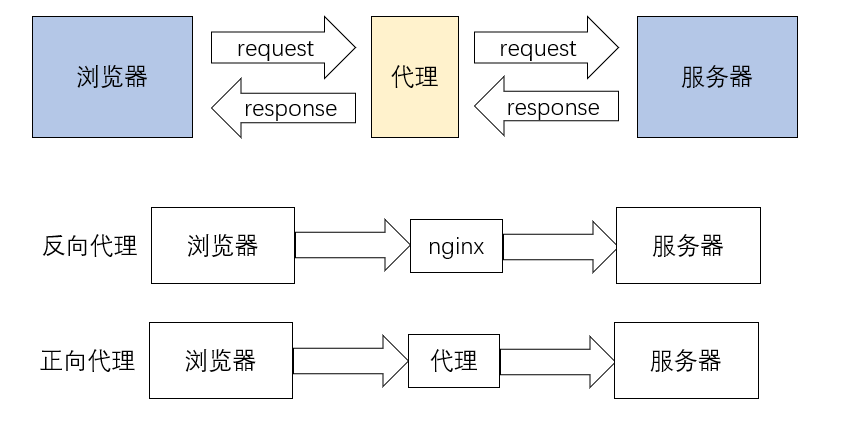
Proxy inverso: el navegador no conoce la dirección real del servidor, como nginx
Reenviar proxy: el navegador conoce la dirección real del servidor, como VPN
El uso de proxies esencialmente oculta la propia dirección IP. Información de inicio de sesión insuficiente, una IP específica está prohibida y la misma IP se visita varias veces en un corto período de tiempo, el servidor las definirá como IP maliciosas y se prohibirá el acceso. Entonces usamos un proxy para reemplazar la ip real y acceder a la información.
import requests
import random as rd
import time
for i in range(1, 100):
# 生成随机代理
proxie_str = f"https://{rd.randint(1, 100)}.{rd.randint(1, 100)}.{rd.randint(1, 100)}." \
f"{rd.randint(1, 100)}:{rd.randint(3000, 9000)}"
print(proxie_str)
# 设置代理
proxie = {
"https": proxie_str
}
url = "http://www.baidu.com"
response = requests.get(url, proxies=proxie)
print(response.content.decode())
time.sleep(0.5)4.cookie
Una cookie es información personal cuando un rastreador visita un sitio web y también es una parte importante del encabezado de la solicitud.
La información en la cookie incluye, pero no se limita a, información del dispositivo, historial y claves de acceso.
Tres formas de usar las solicitudes para manejar las cookies:
1. Coloque la cadena de cookies en el diccionario de encabezado de solicitud de encabezados en formato de par clave-valor
header = {
'Cookie': 'OUTFOX_SEARCH_USER_ID_NCOO=2067300732.9291213;\
OUTFOX_SEARCH_USER_ID="[email protected]"; _ga=GA1.2.831611348.1638177688;\
[email protected]|1647320299|0|youdao_jianwai|00&99|shh&1647226292&mailmas\
ter_ios#shh&null#10#0#0|&0|mailmaster_ios|[email protected]; fanyi-ad-id=305838;\
fanyi-ad-closed=1; ___rl__test__cookies=1653295115820'
}2. Pase el diccionario de cookies al parámetro de cookies del método de solicitud para recibir
cookies = {"cookie的key":"cookie的value"}
requests.get(url,headers=header,cookies=cookie)3. Utilice la plantilla de sesión proporcionada por las solicitudes
header = {
'Cookie': 'OUTFOX_SEARCH_USER_ID_NCOO=2067300732.9291213;\
OUTFOX_SEARCH_USER_ID="[email protected]"; _ga=GA1.2.831611348.1638177688;\
[email protected]|1647320299|0|youdao_jianwai|00&99|shh&1647226292&mailmas\
ter_ios#shh&null#10#0#0|&0|mailmaster_ios|[email protected]; fanyi-ad-id=305838;\
fanyi-ad-closed=1; ___rl__test__cookies=1653295115820'
}
session = requests.session()
response = session.get(url, headers, verify=False)
# 这个写法针对长链接和第三方跳转,保证cookie可以在请求中不被清空5.reintentando
Repetir módulo de solicitud
import requests
from retrying import retry
@retry(stop_max_attempt_number=4)
def get_info(url):
# 超时会报错并重试
# 等待超时时间设为4秒
response = requests.get(url, timeout=4)
# 状态码不是200也会报错重试
assert response.status_code == 200
return response
def parse_info(url):
try:
response = get_info(url)
except:
print(Exception)
response = None
return response
if __name__ == "__main__":
res = parse_info("https://www.baidu.com")
print(res.content.decode())
El reintento aquí tiene la forma de un decorador para monitorear get_info Si el número de reintentos llega a 4 y los datos no se pueden obtener normalmente, se detendrá e informará un error.