Artikelverzeichnis
Vorwort
Das Grundgerüst des cuda-Programms
1. Das Grundgerüst von CUDA
头文件
常量定义(或者宏定义)
C++自定义函数和cuda核函数的声明
int main()
{
a分配主机与设备内存
初始化主机中的数据
将某些数据从主机复制到设备
调用核函数在设备中进行计算
将某些数据从设备复制到主机
释放主机与设备内存
}
c++自定义函数和cuda核函数的实现
Das folgende Beispiel zeigt dieses Framework
Das Programm zum Hinzufügen von Arrays, das direkt in C++ geschrieben wurde
Hier ist ein Array-Additionsprogramm, das direkt in der Gewohnheit geschrieben wurde, Programme in C++ zu schreiben:
#include<stdio.h>
#include<stdlib.h>
#include<math.h>
const double EP = 1.0e-15;
const double a = 1.23;
const double b = 2.34;
const double c = 3.57;
void add(const double *x,const double *y,double *z,const int N);
void check(const double *z,const int N);
int main()
{
const int N = 100000000;
const int M = sizeof(double)*N;
// 分配内存
double *x = (double *)malloc(M);
double *y = (double *)malloc(M);
double *z = (double *)malloc(M);
// double *x = new double[M];
// double *y = new double[M];
// double *z = new double[M];
// 初始化
for(int n=0;n<N;++n)
{
x[n] = a;
y[n] = b;
}
// 数组求和
add(x,y,z,N);
check(z,N);
// 释放内存
free(x);
free(y);
free(z);
// delete []x;
// delete []y;
// delete []z;
return 0;
}
void add(const double *x,const double *y,double *z,const int N)
{
for(int n=0;n<N;++n)
{
z[n] = x[n] + y[n];
}
}
void check(const double *z, const int N)
{
bool has_error = false;
for(int n=0;n<N;++n)
{
if(fabs(z[n]-c)>EP)
{
has_error = true;
}
}
printf("%s\n",has_error?"HAS_ERROR":"NO_ERROR");
}
Programm zum Hinzufügen von Arrays mit Cuda-Kernelfunktionen
// 头文件
#include<stdio.h>
#include<stdlib.h>
#include<math.h>
// 常量定义
const double EP = 1.0e-15;
const double a = 1.23;
const double b = 2.34;
const double c = 3.57;
// c++自定义函数和cuda核函数的声明
__global__ void add(const double *x,const double *y,double *z);
void check(const double *z,const int N);
int main()
{
const int N = 100000000;
const int M = sizeof(double)*N;
// 分配主机内存
double *h_x = (double *)malloc(M);
double *h_y = (double *)malloc(M);
double *h_z = (double *)malloc(M);
// double *h_x = new double[M];
// double *h_y = new double[M];
// double *h_z = new double[M];
// 分配设备内存
double *d_x,*d_y,*d_z;
// printf("%p",d_x);
cudaMalloc((void **)&d_x,M);
cudaMalloc((void **)&d_y,M);
cudaMalloc((void **)&d_z,M);
// 初始化主机上的数据
for(int n=0;n<N;++n)
{
h_x[n] = a;
h_y[n] = b;
}
// 将某些数据从主机复制到设备上
cudaMemcpy(d_x,h_x,M,cudaMemcpyHostToDevice);
cudaMemcpy(d_y,h_y,M,cudaMemcpyHostToDevice);
// 调用核函数在设备中进行计算,数组求和
const int block_size = 128; // 不同型号的GPU有线程限制,开普勒到图灵最大为1024
const int gride_size = N/block_size;
add<<<gride_size,block_size>>>(d_x,d_y,d_z);
// 将某些数据从设备复制到主机上,这个数据传输函数隐式的起到了同步主机与设备的作用,所以后面用不用cudaDeviceSynchronize都可以
cudaMemcpy(h_z,d_z,M,cudaMemcpyDeviceToHost);
check(h_z,N);
// 释放内存
free(h_x);
free(h_y);
free(h_z);
// delete []h_x;
// delete []h_y;
// delete []h_z;
cudaFree(d_x);
cudaFree(d_y);
cudaFree(d_z);
return 0;
}
__global__ void add(const double *x,const double *y,double *z)
{
// 单指令-多线程,注意核函数中数据与线程的对应关系
const int n = blockDim.x * blockIdx.x + threadIdx.x;
z[n] = x[n] + y[n];
}
void check(const double *z, const int N)
{
bool has_error = false;
for(int n=0;n<N;++n)
{
if(fabs(z[n]-c)>EP)
{
has_error = true;
}
}
printf("%s\n",has_error?"HAS_ERROR":"NO_ERROR");
}
// 单指令-多线程,注意核函数中数据与线程的对应关系
const int n = blockDim.x * blockIdx.x + threadIdx.x;
blockDim指的是每个线程块的线程总固定大小;
blockIdx指的是线程块的索引;
threadIdx指的是线程的索引;
所以具体的一维线程索引会等于上面代码式子所计算的索引
Wenn die entsprechende Beziehung zwischen Daten und Threads im Kernel funktioniert, beachten Sie, dass die Speichergröße N zum Speichern des entsprechenden Datentyps von selbst definiert ist. Daher gibt es ein Problem, wenn grid_size = N/block_size nicht genau ein ganzzahliges Vielfaches ist kann einen Fehler verursachen (außerhalb der Grenzen). Versuchen Sie daher, die Anzahl der definierten Threads größer als die Anzahl der Elemente zu machen, und verwenden Sie dann bedingte Anweisungen, um unnötige Thread-Operationen zu vermeiden. kann geschrieben werden als
int gride_size = (N%block_size==0?(N/block_size):(N/block_size + 1));
// 简化成
int gride_size = (N-1) / block_size + 1; //or
int gride_size = (N+block_size-1) / block_size;
Verwenden Sie gleichzeitig die bedingte if-Anweisung in der Kernelfunktion, um unnötige Thread-Operationen zu vermeiden:
// 参数传入了 N
void __global__ add(const double *x, const double *y, double *z, const int N)
{
const int n = blockDim.x * blockIdx.x + threadIdx.x;
if (n < N)
{
z[n] = x[n] + y[n];
}
}
Beim Kompilieren wird durch Kompilieren mit nvcc der Gerätecode in PTX-Pseudo-Assembly-Code (Parallel Thread Execution) kompiliert und dann der Pseudo-Assembly-Code in binären Cubin-Code kompiliert. Beim Kompilieren in PTX-Code muss die Rechenleistung der GPU-Architektur angegeben werden. Der Standardwert ist 2.0. Sie können die Rechenleistung Ihrer GPU selbst überprüfen. Fügen Sie beim Kompilieren mit nvcc die Anweisung -arch=sm_XY hinzu. wie:
nvcc -g -arch=sm_75 xxx.cu -o xxx // GeForce RTX2080是7.5的
Vergleichen Sie, indem Sie den obigen grundlegenden Framework-Prozess mit einem C++-Programm kombinieren, das die cuda-Kernel-Funktion nicht verwendet:
- (1) Verwenden Sie für Programme, die cuda-Kernelfunktionen verwenden, cudaMalloc, um Gerätespeicher zuzuweisen und Daten in den Gerätespeicher zu kopieren. Ebenso wie C++ Speicherplatz zuweist, sollten malloc und free übereinstimmen, cudaMalloc und cudaFree sollten übereinstimmen. Eine weitere dynamische Speicherzuordnung new und delete in c++ kann malloc und free ersetzen.
- (2) Die Datenübertragung zwischen dem Host und dem Gerät verwendet cudaMemcpy, um die Daten im Host (oder Gerät) an die Speicheradresse im Gerät (oder Host) zu kopieren.
- (3) Achten Sie auf die entsprechende Beziehung zwischen Daten und Threads in der Kernfunktion, und achten Sie auf die entsprechende Operationsbeziehung für Single-Instruction-Multi-Threaded-Operationen.
Die oben von cuda ausgeführte API kann in der offiziellen Dokumentation eingesehen werden:
https://docs.nvidia.com/cuda/cuda-runtime-api
wie cudaMalloc, suchen Sie direkt im Suchfeld und klicken Sie dann hinein, um die Anweisungen anzuzeigen :
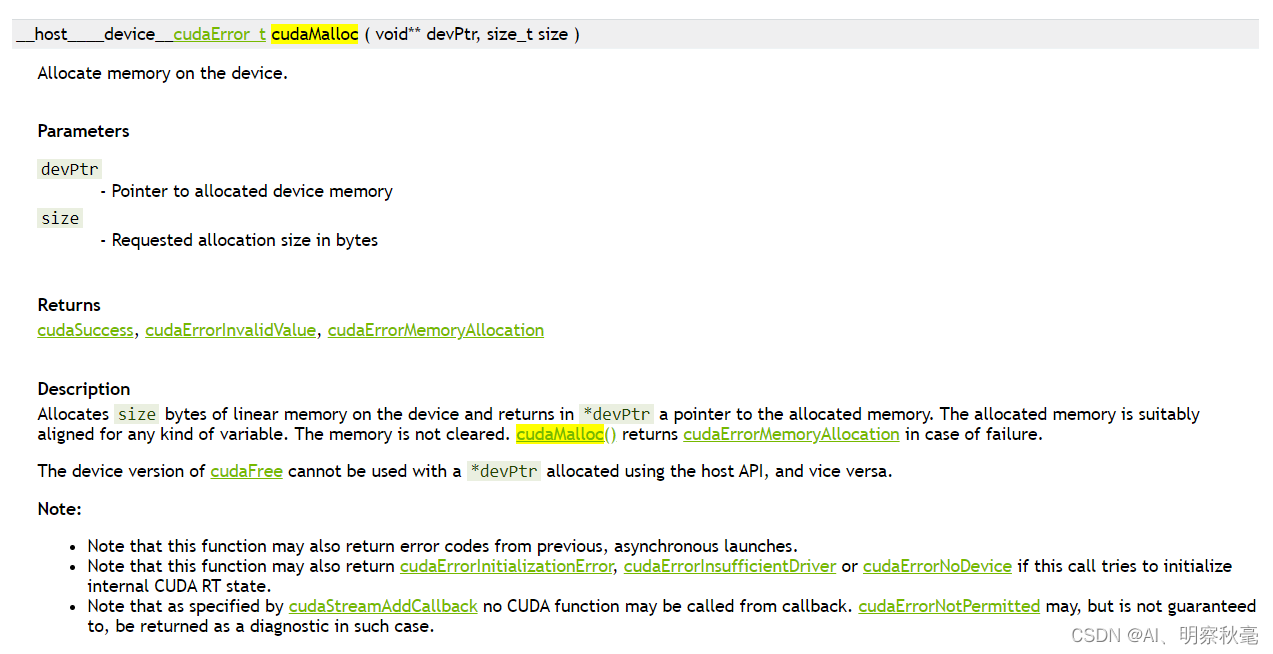
hier aufpassen Rückgabewert und Eingabeparameter: Der Rückgabewert ist eine Information vom Typ cudaError_t, die angibt, ob die api erfolgreich ausgeführt wurde, was für spätere Programmüberprüfungen nützlich ist verwendet, also verwendet der Eingabeparameter einen doppelten Zeiger, der Zeiger auf den Zeiger, um auf die ursprüngliche Adresse der Daten zu zeigen.
Kennung des Funktionsausführungsraums
In einem cuda-Programm können Bezeichner verwendet werden, um zu bestimmen, wo eine Funktion aufgerufen und ausgeführt wird.
(1) Eine mit __global__ modifizierte Funktion wird als Kernfunktion bezeichnet. In der Regel vom Host aufgerufen und im Gerät ausgeführt. Während der dynamischen Parallelität können sich Kernel-Funktionen auch gegenseitig aufrufen.
(2) Mit __device__ modifizierte Funktionen werden Gerätefunktionen genannt, die nur von Kernelfunktionen oder anderen Gerätefunktionen aufgerufen und im Gerät ausgeführt werden können.
(3) Die mit __host__ modifizierte Funktion ist eine übliche C++-Funktion auf der Host-Seite, die im Host aufgerufen und ausgeführt wird. Er kann auch weggelassen werden Der Grund, warum dieser Modifikator bereitgestellt wird, ist, dass manchmal __host__ und __device__ verwendet werden können, um eine Funktion gleichzeitig zu modifizieren, wodurch Code-Redundanz vermieden werden kann.
(4) Sie können den Modifikator __noinline__ oder __forceinline__ verwenden, um vorzuschlagen, dass eine Gerätefunktion eine Nicht-Inline-Funktion oder eine Inline-Funktion ist.
Hinweis:
1. Sie können __global__ und __device__ nicht verwenden, um dieselbe Funktion gleichzeitig zu ändern.
2. Sie können __global__ und __host__ nicht verwenden, um dieselbe Funktion gleichzeitig zu ändern.
Zusammenfassen
Vertraut mit dem Grundgerüst des cuda-Programms.
Referenz:
Sollte der Inhalt des Blogs rechtsverletzend sein, setzen Sie sich bitte rechtzeitig mit uns in Verbindung, um ihn zu löschen!
CUDA-Programmierung: Grundlagen und Praxis
https://docs.nvidia.com/cuda/
https://docs.nvidia.com/cuda/cuda-runtime-api
https://github.com/brucefan1983/CUDA-Programming