Directorio de artículos
prefacio
Uso razonable de la memoria global
modo de acceso a la memoria global
Acceso coalescente y no coalescente
El acceso combinado se refiere a una deformación de subprocesos (subprocesos wrapSize adyacentes en el mismo bloque de subprocesos. Ahora, la variable incorporada wrapSize de la GPU es 32) a la solicitud de acceso único global (lectura o escritura) que da como resultado la transmisión del mínimo cantidad de datos
Cuantitativamente, se puede definir un grado de coalescencia igual al número de bytes solicitados por un warp dividido por el número de bytes procesados por todas las transferencias de datos resultantes de esa solicitud. Si los datos procesados en todas las transferencias de datos son requeridos por warp, entonces el grado de consolidación es del 100 %, lo que corresponde al acceso fusionado; de lo contrario, es un acceso no fusionado.
Cabe señalar que para garantizar que la primera dirección del segmento de memoria en una transferencia de datos sea un múltiplo entero de la granularidad mínima (), la primera dirección de memoria asignada por cuda al ejecutar la función cudaMalloc es al menos un múltiplo entero de 256 bytes.
Veamos varios patrones comunes de acceso a la memoria y su grado de coalescencia a través de ejemplos.
(1) Fusión secuencial
__global__ void add(float *x,float *y,float *z)
{
int n = threadIdx.x + blockIdx.x * blockDim.x;
z[n] = x[n] + y[n];
}
add<<<128,32>>>(x,y,z);
Se puede saber por el código anterior que el tamaño del bloque de subprocesos de la función kernel es blockDim.x=32, tipo int, correspondiente a 128 bytes, y cada deformación en el bloque de subprocesos puede acceder a tanta memoria continua. La primera dirección debe ser un entero múltiplo de 256, por lo que según el concepto anterior, en el caso de una consolidación al 100%, un thread warp solicitará 32*4=128 bytes de datos. El acceso solo requiere 128/32=4 transferencias de datos para completarse.
(2) Acceso no coalescente no alineado
__global__ void add_offset(float *x,float *y,float *z)
{
int n = threadIdx.x + blockIdx.x * blockDim.x + 1;
z[n] = x[n] + y[n];
}
add_offset<<<128,32>>>(x,y,z);
El número de subprocesos en el primer bloque de subprocesos accederá a los elementos 1-32 en la matriz x. Suponiendo que la primera dirección de la matriz x es de 256 bytes, esta cantidad de subprocesos accederá a 260-387 bytes de memoria del dispositivo. Se activarán 5 transferencias de datos y las direcciones de memoria correspondientes son 256-287, 288-319, 320-351, 352-383 y 384-415 bytes. Dicho acceso es un acceso no fusionado no alineado, y el grado de fusión es ( 32 ∗ 4 32*432∗4)/(32 ∗ 5 32*532∗5 )=4/5=0.8, que es 80%.
(3) Acceso avanzado sin fusión
__global__ void add_stride(float *x,float *y,float *z)
{
int n = blockIdx.x + threadIdx.x * gridDim.x ;
z[n] = x[n] + y[n];
}
add_offset<<<128,32>>>(x,y,z);
La deformación en el primer bloque de subprocesos del código anterior accederá a los elementos de la matriz x cuyos índices son 0, 128, 256, 384, etc., que no están en un segmento de memoria continuo de 32 bytes, por lo que se realizarán 32 transferencias de datos. activarse, asumiendo que la primera La dirección es de 32 segmentos de bytes discontinuos como 256, 256-287, 384-415, etc. El grado de combinación es ( 32 ∗ 4 32*432∗4)/(32 ∗ 32 32*3232∗32 )=4/32=0.125, que es 12.5%. Tal acceso es un acceso no fusionado con zancadas.
Transposición de matriz usando memoria global
copia de matriz
Primero considere el problema de replicación de matrices, como B = A
// const real *A, real *B是全局内存,const int N是常量内存
__global__ void copy(const real *A, real *B, const int N)
{
// 二维,TILE_DIM宏定义为32,可以在核函数里直接调用宏定义和const的整型和浮点型变量
const int nx = blockIdx.x * TILE_DIM + threadIdx.x; // 寄存器内存
const int ny = blockIdx.y * TILE_DIM + threadIdx.y;
// 将多维索引转换成一维的索引
const int index = ny * N + nx; // 寄存器内存
if (nx < N && ny < N)
{
B[index] = A[index];
}
}
// 定义网格和线程块大小
const int grid_size_x = (N+TILE_DIM-1)/TILE_DIM;
const int grid_size_y = grid_stride_y;
// 定义多维网格和线程块,第三个维度默认为1
const dim3 block_size(TILE_DIM,TILE_DIM);
const dim3 gride_size(grid_size_x,grid_size_y);
copy<<<gride_size,block_size>>>(d_A,d_B,N);
Transposición de matriz
En la operación de copia anterior, las variables de índice definidas y los códigos de operación de lectura y escritura son:
const int index = ny * N + nx;
if (nx < N && ny < N) B[index] = A[index];
Dos declaraciones escritas como una sola:
if (nx < N && ny < N) B[ny * N + nx] = A[ny * N + nx];
Desde un punto de vista matemático, es equivalente a hacer B ij B_{ij}Byo= Aij A_{ij}Ayo. Así que si quieres transponer, es B ij B_{ij}Byo= A ji A_{ji}Ajioperación.
El código se reemplaza con:
if (nx < N && ny < N) B[nx * N + nx] = A[ny * N + nx];
// or
if (nx < N && ny < N) B[ny * N + nx] = A[nx * N + ny];
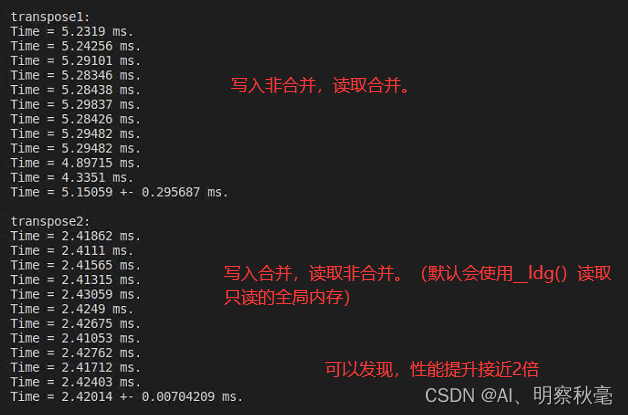
En la primera declaración anterior, las lecturas de la matriz A son secuenciales y las escrituras de la matriz B no son secuenciales. De acuerdo con las reglas de división del modo de acceso de la memoria global, se puede decir que la lectura de la matriz A por la función kernel no se fusiona y la escritura de la matriz B se fusiona. La segunda declaración es todo lo contrario. La lectura de la matriz A no es secuencial y la escritura en la matriz B es secuencial. La lectura de la matriz A por la función kernel se fusiona y la escritura de la matriz B no se fusiona.
Entonces, ¿cuál es la diferencia de rendimiento entre las dos declaraciones que pueden realizar la transposición de matrices correctamente?
A partir de GPU basadas en Pascal, si el compilador puede determinar que una variable de memoria global es de solo lectura dentro del alcance de toda la función del kernel, utilizará automáticamente la función de carga de caché de datos de solo lectura __ldg() mencionada en el artículo anterior. para leerlo Puede mitigar el impacto del acceso no fusionado. Para escribir en la memoria global, no existe una función similar. Por lo tanto, puede haber lecturas combinadas y no combinadas para solo lectura, pero el acceso combinado es mejor para los datos que se pueden escribir.
En 2080Ti, dado N=10000, veamos el impacto del rendimiento a través de ejemplos de código:
Código: https://github.com/brucefan1983/CUDA-Programming/blob/master/src/07-global-memory/matrix.cu
Resumir
La memoria global cuda puede mejorar en gran medida el rendimiento seleccionando el uso razonable del modo de acceso.
Referencia:
si el contenido del blog infringe, ¡póngase en contacto y elimínelo a tiempo!
Programación CUDA: conceptos básicos y práctica
https://docs.nvidia.com/cuda/
https://docs.nvidia.com/cuda/cuda-runtime-api
https://github.com/brucefan1983/CUDA-Programming