A cambio del rendimiento, JVM ha realizado muchas optimizaciones en los bloqueos integrados, y la estrategia de asignación de bloqueos de expansión es una de ellas. Comprender los problemas básicos a resolver de bloqueos sesgados, bloqueos ligeros y bloqueos pesados, así como el proceso de asignación y expansión de varios bloqueos, ayuda a escribir y optimizar programas concurrentes basados en bloqueos.
El proceso de asignación y expansión de las cerraduras integradas es relativamente complicado, limitado por el tiempo y la energía. Esta parte del artículo se basa en la integración de múltiples fuentes en Internet; para facilitar la referencia, también hay una referencia al continuar analice el código fuente de JVM más tarde. Si ya tiene una comprensión básica de los bloqueos en todos los niveles, los lectores pueden omitir este artículo.
1 Problemas fundamentales ocultos bajo cerraduras incorporadas
El bloqueo incorporado es la herramienta de sincronización de subprocesos más conveniente proporcionada por la JVM. Puede usar el bloqueo incorporado agregando la palabra clave sincronizada al bloque de código o declaración de método. El uso de bloqueos integrados puede simplificar el modelo de concurrencia; con la actualización de la JVM, puede disfrutar directamente de los resultados de optimización de la JVM en los bloqueos integrados sin modificar el código. Desde simples bloqueos pesados hasta estrategias de asignación de bloqueos que se expanden gradualmente, se utilizan varios métodos de optimización para resolver los problemas básicos ocultos bajo los bloqueos incorporados.
1.1 Cerradura de peso pesado
Los bloqueos incorporados se abstraen como bloqueos de monitor en Java. Antes de JDK 1.6, se podía considerar que los bloqueos de monitor correspondían directamente a los mutex en el sistema operativo subyacente. El costo de este método de sincronización es muy alto, incluido el cambio entre el modo kernel y el modo de usuario causado por las llamadas al sistema, el cambio de subprocesos causado por el bloqueo de subprocesos, etc. Por lo tanto, este bloqueo se denominó más tarde "bloqueo de peso pesado".
1.1.1 Bloqueos giratorios
En primer lugar, no es fácil optimizar el cambio entre el modo kernel y el modo usuario. Pero a través de bloqueos de giro, se puede reducir el cambio de subprocesos (incluida la suspensión de subprocesos y la reanudación de subprocesos) causado por el bloqueo de subprocesos.
Si la granularidad del bloqueo es pequeña, el tiempo de mantenimiento del bloqueo es relativamente corto (aunque no se puede conocer el tiempo de mantenimiento específico, se puede considerar que, por lo general, algunos bloqueos pueden satisfacer las propiedades anteriores). Entonces, para aquellos que compiten por estos bloqueos, el tiempo de cambio de subprocesos causado por el bloqueo de bloqueos es equivalente al tiempo de retención de bloqueos, reduciendo el cambio de subprocesos causado por el bloqueo de subprocesos puede lograr una gran mejora en el rendimiento. detalles de la siguiente manera:
Cuando el subproceso actual no puede competir por el bloqueo, intenta bloquearse a sí mismo
No te bloquees directamente, pero gira (espera vacía, como un bucle for limitado vacío) por un tiempo
candado recompetidor mientras gira
Si el bloqueo se adquiere antes del final del giro, la adquisición del bloqueo es exitosa; de lo contrario, se bloquea después del final del giro.
Si el propietario anterior libera el bloqueo dentro del tiempo de giro, entonces el subproceso actual no necesita bloquearse (y no necesita recuperarse cuando se libere el bloqueo en el futuro), lo que reduce un cambio de subproceso.
La condición "el bloqueo se mantiene durante un tiempo relativamente corto" se puede relajar. De hecho, siempre que el tiempo de competencia de bloqueo sea relativamente corto (por ejemplo, cuando el subproceso 1 está a punto de liberar el bloqueo, el subproceso 2 competirá por el bloqueo), la probabilidad de obtener el bloqueo por giro puede aumentar. Esto suele ocurrir en escenarios donde los bloqueos se mantienen durante mucho tiempo, pero la competencia no es intensa .
defecto:
En un procesador de un solo núcleo, no hay paralelismo real. Si el subproceso actual no se bloquea a sí mismo, el propietario anterior no puede ejecutar y el bloqueo nunca se liberará. En este momento, no importa cuánto dure el giro, es un desperdicio; además, si hay muchos hilos y pocos procesadores, el giro también causará muchos desperdicios innecesarios.
Los bloqueos giratorios consumen CPU. Si se trata de una tarea computacionalmente intensiva, esta optimización generalmente no vale la pena. Reducir el uso de bloqueos es una mejor opción.
Si el tiempo de competencia de bloqueo es relativamente largo, el giro generalmente no puede obtener el bloqueo y se desperdicia el tiempo de CPU ocupado por el giro. Esto suele ocurrir en escenarios en los que el bloqueo se mantiene durante mucho tiempo y la competencia es feroz En este momento, el bloqueo giratorio debe desactivarse activamente.
Utilice el parámetro -XX:-UseSpinning para desactivar la optimización de spinlock; el parámetro -XX:PreBlockSpin para modificar el número predeterminado de giros.
1.1.2 Giro adaptativo
Adaptativo significa que el tiempo de giro ya no es fijo, sino que está determinado por el tiempo de giro anterior en la misma cerradura y el estado del propietario de la cerradura:
Si en el mismo objeto de bloqueo, la espera de giro acaba de adquirir con éxito el bloqueo, y el subproceso que mantiene el bloqueo se está ejecutando, entonces la máquina virtual pensará que es probable que este giro vuelva a tener éxito y luego permitirá que el giro espere. un período de tiempo relativamente más largo, digamos 100 bucles.
Por el contrario, si para un determinado bloqueo, el giro rara vez se obtiene con éxito, entonces el tiempo de giro puede reducirse o incluso puede omitirse el proceso de giro cuando se adquiera el bloqueo en el futuro, para evitar desperdiciar recursos del procesador. .
El giro adaptativo resuelve el problema del "tiempo de competencia de bloqueo incierto" .
Es difícil para la JVM percibir el tiempo exacto de competencia de bloqueo, y entregarlo al usuario para su análisis viola la intención de diseño original de la JVM. El giro adaptativo supone que diferentes hilos sostienen el mismo objeto de bloqueo durante casi el mismo tiempo y el grado de competencia tiende a ser estable. Por lo tanto, el tiempo del próximo giro se puede ajustar de acuerdo con el tiempo y el resultado del último giro.
defecto:
Sin embargo, el espín adaptativo no puede resolver completamente este problema.Si la configuración predeterminada del número de espín no es razonable (demasiado alta o demasiado baja), será difícil que el proceso adaptativo converja a un valor apropiado.
1.2 Cerraduras ligeras
El objetivo de spinlocks es reducir el costo del cambio de subprocesos. Si la competencia de candados es feroz, tenemos que depender de candados pesados para bloquear los subprocesos que fallan en la competencia; si no hay competencia de candados real, entonces solicitar candados pesados es un desperdicio. El objetivo de los bloqueos ligeros es reducir el consumo de rendimiento causado por el uso de bloqueos pesados sin competencia real, incluido el cambio entre el modo kernel y el modo usuario causado por llamadas al sistema, cambio de subprocesos causado por el bloqueo de subprocesos, etc.
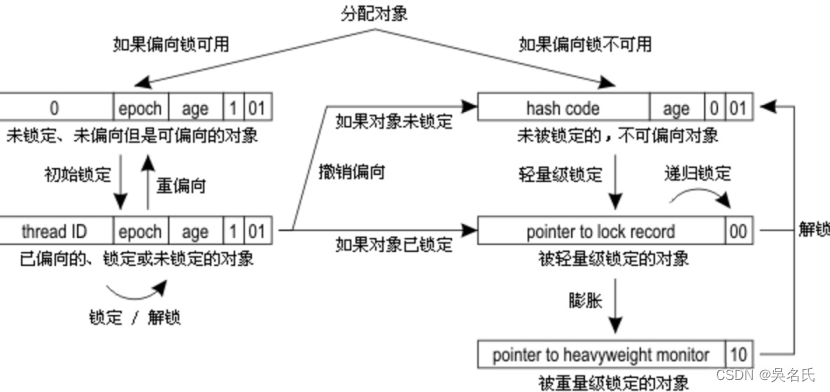
Como su nombre lo indica, las cerraduras livianas son relativas a las cerraduras pesadas. Cuando se utiliza un bloqueo ligero, no hay necesidad de solicitar un mutex, simplemente actualice parte del byte CAS en Mark Word al Registro de bloqueo en la pila de subprocesos, si la actualización es exitosa, el bloqueo ligero se adquiere con éxito_ y registre el estado del bloqueo Es un bloqueo liviano; de lo contrario, significa que un hilo ya adquirió un bloqueo liviano y actualmente hay competencia de bloqueo (no es adecuado continuar usando bloqueos livianos), y luego se expandirá a un bloqueo pesado .
Mark Word es parte del encabezado del objeto; cada subproceso tiene su propia pila de subprocesos (pila de máquina virtual), que registra la información básica de los subprocesos y las llamadas a funciones. Los dos pertenecen al contenido básico de la JVM y no se presentarán aquí.
Por supuesto, dado que los candados livianos están dirigidos naturalmente a escenarios donde no hay competencia de candados, si hay competencia de candados pero no intensa, aún puede usar candados de giro para optimizar y luego expandir a candados de peso pesado después de que falla el giro .
defecto:
Similar a spinlock:
Si la competencia de los candados es feroz , los candados livianos se expandirán rápidamente a candados pesados, y el proceso de mantenimiento de candados livianos se convierte en un desperdicio.
1.3 Bloqueo de polarización
En ausencia de competencia real, puede continuar optimizándose para algunos escenarios. Si no solo no hay competencia real, sino que solo hay un subproceso que usa el bloqueo de principio a fin, entonces mantener bloqueos livianos es un desperdicio. El objetivo de los bloqueos sesgados es reducir el consumo de rendimiento del uso de bloqueos livianos cuando no hay competencia y solo un subproceso usa el bloqueo . Los bloqueos ligeros requieren al menos un CAS cada vez que solicitan y liberan un bloqueo, pero los bloqueos sesgados solo necesitan un CAS cuando se inicializan.
"Sesgo" significa que el bloqueo sesgado asume que solo el primer subproceso que aplica para el bloqueo usará el bloqueo en el futuro (ningún subproceso volverá a aplicar para el bloqueo), por lo que solo es necesario registrar el propietario en CAS en Mark Palabra (esencialmente también actualización, pero el valor inicial está vacío), si el registro es exitoso, el bloqueo sesgado se adquiere con éxito y el estado de bloqueo registrado es un bloqueo sesgado. En el futuro, el subproceso actual es igual al propietario, y el bloqueo se puede obtener directamente a costo cero; de lo contrario, significa que hay otros subprocesos compitiendo, y la expansión es un bloqueo de nivel liviano .
Los bloqueos sesgados no se pueden optimizar utilizando bloqueos giratorios, porque una vez que otros subprocesos solicitan bloqueos, se rompe la suposición de bloqueos sesgados.
defecto:
De manera similar, si obviamente hay otros subprocesos que solicitan bloqueos, el bloqueo sesgado se expandirá rápidamente a un bloqueo ligero.
Sin embargo, este efecto secundario ha sido mucho menor.
Si lo desea, deshabilite la optimización de bloqueo sesgado con el parámetro -XX:-UseBiasedLocking (activado de forma predeterminada).
1.4 Resumen
Consulte a continuación el proceso detallado de bloqueo sesgado, bloqueo ligero, asignación de bloqueo pesado y expansión. Implicará algún conocimiento de Mark Word y CAS.
Los bloqueos sesgados, los bloqueos ligeros y los bloqueos pesados son adecuados para diferentes escenarios de simultaneidad:
Bloqueo sesgado: no hay competencia real, y solo el primer subproceso que solicite un bloqueo utilizará el bloqueo en el futuro.
Bloqueo ligero: sin competencia real, varios subprocesos usan bloqueos alternativamente; se permite la competencia de bloqueo a corto plazo.
Bloqueo de peso pesado: hay competencia real y el tiempo de competencia de bloqueo es largo.
Además, si el tiempo de competencia de bloqueo es corto, los bloqueos giratorios se pueden utilizar para optimizar aún más el rendimiento de los bloqueos livianos y los bloqueos pesados para reducir el cambio de hilo.
Si el grado de competencia de bloqueos aumenta gradualmente (lentamente), la expansión gradual de bloqueos sesgados a bloqueos ponderados puede mejorar el rendimiento general del sistema.
2 Asignación de candados y proceso de expansión
Para reiterar, esta parte se compila principalmente en base a múltiples fuentes en Internet. El núcleo es el diagrama de flujo organizado por este gigante , que es bastante detallado y básicamente lógico.
Anteriormente se han descrito algunos problemas básicos y soluciones en el uso de cerraduras incorporadas, y se han mencionado brevemente los principios de implementación. El proceso detallado de asignación y expansión de bloqueos es el siguiente:
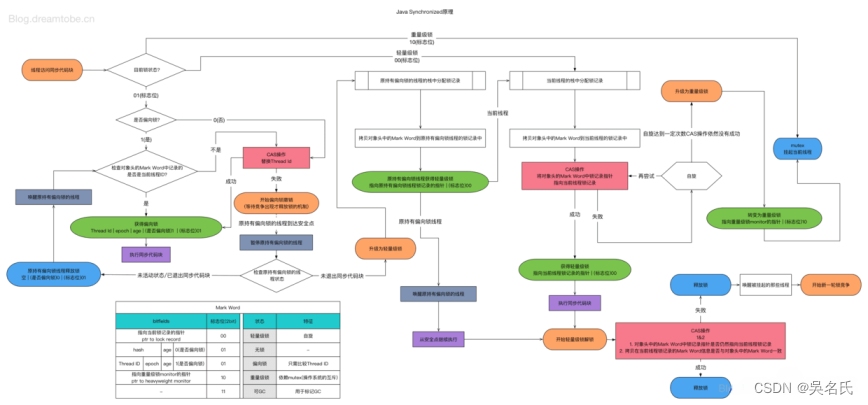
Hay una pregunta en la figura:
según el flujo de la figura, si se encuentra que el candado se ha expandido a un candado pesado, el subproceso actual se bloqueará directamente con el mutex .
Sin embargo, uno de los grandes beneficios de spinlocks es reducir la sobrecarga de la conmutación de subprocesos. No hay necesidad de bloquear directamente el hilo actual aquí, puede ser como un candado liviano, girar por un tiempo y luego bloquear cuando falla.
Dos puntos en particular:
Cuando CAS registra propietario, esperado == nulo y nuevo valor == propietarioThreadId Por lo tanto, solo el primer subproceso que aplica para un bloqueo sesgado puede devolver el éxito, y los subprocesos fallarán inevitablemente (algunos subprocesos detectan sesgo e intentan registrar propietario CAS en el Mismo tiempo).
Los candados incorporados solo pueden expandirse gradualmente en el orden de los candados sesgados, los candados livianos y los candados pesados , y no pueden "reducirse". Esto se basa en otra suposición de la JVM: " Una vez que se rompe la suposición del bloqueo de nivel superior, se considera que la suposición no será cierta en el futuro ".
Además, cuando se libera el bloqueo pesado, es necesario despertar un subproceso bloqueado. Esta parte de la lógica es básicamente la misma que ReentrantLock.
Simplificando el diagrama anterior se muestra: