Definición de clúster: varios servidores brindan el mismo servicio juntos, como (clúster web), etc.
Clasificación de clusters comunes:
LB (clúster de equilibrio de carga): los servidores comparten y procesan de manera conjunta y uniforme múltiples solicitudes de conexión de los clientes. HA (Clúster de alta disponibilidad): modo activo-en espera, el servidor en espera asumirá automáticamente el trabajo después de que el principal se apague.
Software de servicio de clúster común: LB: LVS, Nginx, haproxy, etc. HA: Keepalive, latido del corazón,
1.1 Introducción del software
MHA (maestro de alta disponibilidad)
Desarrollado por la empresa japonesa DeNA youshimaton a través del lenguaje de scripting perl.
Es una excelente solución para lograr una alta disponibilidad de MySQL.
La operación automática de conmutación por error de la base de datos se puede completar en 0~30 segundos.
MHA puede garantizar la máxima consistencia de datos durante la conmutación por error para lograr una verdadera alta disponibilidad.
1.2 Composición de MHA
Maestro MHA (nodo de gestión)
Administrar todos los servidores de bases de datos
Se puede implementar por separado en una máquina independiente
También se puede implementar en un servidor de base de datos.
Nodo MHA (nodo de datos)
Servidor MySQL para almacenar datos
ejecutar en cada servidor MySQL
1.3 Proceso de trabajo de la MHA
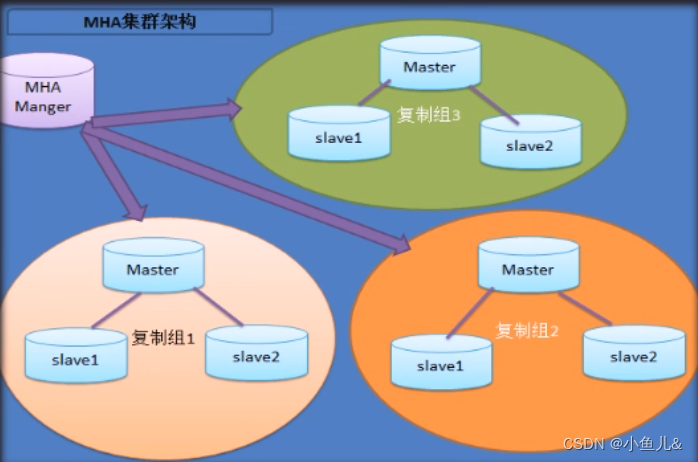
Diagrama de arquitectura de clúster de MHA:
Proceso de trabajo de MHA:
El administrador detecta regularmente el nodo maestro en el clúster
Cuando el maestro falla, el administrador promoverá automáticamente el esclavo con los datos más recientes al nuevo maestro, y el otro host esclavo se convertirá automáticamente en la biblioteca esclava del nuevo maestro, por lo que los hosts en el grupo de clústeres deben tener un maestro. y estructura de múltiples esclavos.
2.2.4 Creación de scripts de conmutación por error
[root@mha20 mha]# cp -r /usr/local/mha4mysql-manager-0.58/samples/scripts/master_ip_failover /etc/mha/##给脚本添加执行权限[root@mha20 mha]# chmod +x /etc/mha/master_ip_failover##下面是完整的脚本文件,需要修改VIP地址和网卡名称。[root@mha20 mha]# vim /etc/mha/master_ip_failover#!/usr/bin/env perl
use strict;
use warnings FATAL =>'all';
use Getopt::Long;
my ($command, $ssh_user, $orig_master_host, $orig_master_ip,
$orig_master_port, $new_master_host, $new_master_ip, $new_master_port);
my $vip='192.168.2.100/24';#指定VIP地址
my $key='1';
my $ssh_start_vip="/sbin/ifconfig ens33:$key$vip";#这里需要注意的就是网卡名称,没人的主机网卡名不一样需要注意。
my $ssh_stop_vip="/sbin/ifconfig ens33:$key down";
GetOptions('command=s'=>\$command,
'ssh_user=s'=>\$ssh_user,
'orig_master_host=s'=>\$orig_master_host,
'orig_master_ip=s'=>\$orig_master_ip,
'orig_master_port=i'=>\$orig_master_port,
'new_master_host=s'=>\$new_master_host,
'new_master_ip=s'=>\$new_master_ip,
'new_master_port=i'=>\$new_master_port,
);exit&main();
sub main {
print "\n\nIN SCRIPT TEST====$ssh_stop_vip==$ssh_start_vip===\n\n";if($command eq "stop"||$command eq "stopssh"){
my $exit_code=1;eval{
print "Disabling the VIP on old master: $orig_master_host\n";&stop_vip();$exit_code=0;};if($@){
warn "Got Error: $@\n";exit$exit_code;}exit$exit_code;}
elsif ($command eq "start"){
my $exit_code=10;eval{
print "Enabling the VIP - $vip on the new master - $new_master_host\n";&start_vip();$exit_code=0;};if($@){
warn $@;exit$exit_code;}exit$exit_code;}
elsif ($command eq "status"){
print "Checking the Status of the script.. OK \n";exit0;}else{
&usage();exit1;}}
sub start_vip(){
`ssh $ssh_user\@$new_master_host \" $ssh_start_vip \"`;}
sub stop_vip(){
return0 unless ($ssh_user);`ssh $ssh_user\@$orig_master_host \" $ssh_stop_vip \"`;}
sub usage {
print
"Usage: master_ip_failover --command=start|stop|stopssh|status --orig_master_host=host --orig_master_ip=ip --orig_master_port=port --new_master_host=host --new_master_ip=ip --new_master_port=port\n";}
2.2.5 Crear una dirección VIP en la base de datos principal (mysql30)
##监控用户是在管理服务器配置文件上指定的:user=xxx,password=xxxx##在主库上执行,从库自然同步过去。
mysql> grant all on *.* to 'mysqldb'@'%' identified by '1234';
Query OK, 0 rows affected, 1 warning (0.00 sec)
[root@mha20 ~]# masterha_check_repl --conf=/etc/mha/app1.cnf...
MySQL Replication Health is OK. ---出现这个说明MySQL复制运行状况正常
3.3 Iniciar el servicio de gestión
Inicie el servicio de administración con el comando masterha_manager
—— --remove_dead_master_conf significa que cuando la biblioteca principal está inactiva, la configuración de la biblioteca principal inactiva se eliminará, de lo contrario, el servicio no se iniciará después de que la biblioteca principal esté inactiva --ignore_last_failover significa ignorar el archivo xxx.health, que significa que cuando la biblioteca principal está inactiva después del host, el servicio se conectará a los servidores esclavos restantes dentro del tiempo especificado para elegir la biblioteca maestra. Si no agrega esta opción al iniciar el servicio, no cambiará a la biblioteca principal si no se ha conectado dentro del tiempo especificado. Después de agregar esta opción, no podrá conectarse a los esclavos restantes dentro del tiempo especificado. El servidor continuará intentando conectarse después, hasta que se elija cambiar la biblioteca principal.
4.1 Simular la falla del servidor de la base de datos principal
Métodos para simular fallas:
detener el servicio mysqld
cerrar
Proceso de conmutación por error: cuando el host de administración no puede conectarse al servidor maestro mysql, se considera que el servidor maestro mysql está inactivo, y luego el servicio del host de administración se detiene automáticamente, y luego se llama al script de conmutación por error para eliminar el contenido sobre el servidor maestro mysql en el host de administración (/etc/mha/app1.cnf) Luego, el script creará una dirección VIP en el servidor maestro elegido.
##在mysql30主服务关闭mysql服务[root@mysql30 ~]# systemctl stop mysqld.service##检查管理主机的配置文件是否删除mysql30的信息。[root@mha20 ~]# grep "192.168.2.30" /etc/mha/app1.cnf --执行这条命令可以看的出来,已经没有mysql30的信息了。##在管理主机上查看日志文件master现在是哪台?[root@mha20 ~]# grep "new master" /etc/mha/manager.log
Fri Feb 2414:58:16 2023 - [info] Searching new master from slaves..192.168.2.40(192.168.2.40:3306)(new master)
Fri Feb 2414:58:16 2023 - [info] Getting new master's binlog name and position..
Enabling the VIP - 192.168.2.100/24 on the new master - 192.168.2.40
Fri Feb 2414:58:17 2023 - [info] Resetting slave 192.168.2.50(192.168.2.50:3306) and starting replication from the new master 192.168.2.40(192.168.2.40:3306)..
Fri Feb 2414:58:18 2023 - [info] Resetting slave info on the new master..
Selected 192.168.2.40(192.168.2.40:3306) as a new master.
##可以看的出来mysql40被选举出来作为master##在mysql40上查看VIP地址是否在[root@mysql40 ~]# ifconfig ens33:1
ens33:1: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 192.168.2.100 netmask 255.255.255.0 broadcast 192.168.2.255
ether 00:0c:29:83:e3:d4 txqueuelen 1000(Ethernet)##查看mysql50的slave状态[root@mysql50 ~]# mysql -uroot -p1234 -e "show slave status \G;"|head -13|tail -11
mysql: [Warning] Using a password on the command line interface can be insecure.
Master_Host: 192.168.2.40 ---可以看的出来mysql40已经是masterl
Master_User: master
Master_Port: 3306
Connect_Retry: 60
Master_Log_File: master40.000001
Read_Master_Log_Pos: 154
Relay_Log_File: mysql50-relay-bin.000002
Relay_Log_Pos: 319
Relay_Master_Log_File: master40.000001
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
##启动管理主机的mha服务[root@mha20 ~]# nohup masterha_manager --conf=/etc/mha/app1.cnf --remove_dead_master_conf --ignore_last_failover &##查看mha状态[root@mha20 ~]# masterha_check_status --conf=/etc/mha/app1.cnf
app1 (pid:57758) is running(0:PING_OK), master:192.168.2.40
4.2 Reparación de un servidor de base de datos fallido