Hola a todos, el artículo de hoy fue traducido por mi buena amiga Alpha Rabbit. Ella se quedó hasta tarde en la mañana para estudiar el GPT-4 lanzado por OpenAI. Básicamente leyó todos los puntos clave del contenido publicado y lo compartió con todos. algo de inspiración. .
Autor | OpenAI&TheVerge&Techcrunch
Traducción y análisis |
01
reflejos
* Este artículo tiene unas 6000 palabras
GPT-4 puede aceptar entrada de imagen y texto, mientras que GPT-3.5 solo acepta texto.
GPT-4 logra un rendimiento de "nivel humano" en varios puntos de referencia académicos y profesionales. Por ejemplo, aprobó el examen simulado de la barra con puntajes en el 10% superior de los examinados.
OpenAI tardó 6 meses en ajustar repetidamente GPT-4 utilizando la experiencia obtenida del proyecto de prueba contradictorio y ChatGPT.
En el chat simple, la diferencia entre GPT-3.5 y GPT-4 puede ser insignificante, pero cuando la complejidad de la tarea alcanza un umbral suficiente, la diferencia sale a la luz y GPT-4 es más confiable y creativo que GPT-3.5 Force, capaz de manejar instrucciones más sutiles.
GPT-4 puede ilustrar e interpretar imágenes relativamente complejas, como identificar un adaptador de cable Lightning a partir de una imagen conectada a un iPhone (imagen a continuación).
Las capacidades de comprensión de imágenes aún no están disponibles para todos los clientes de OpenAI, que OpenAI está probando con el socio Be My Eyes.
OpenAI admite que GPT-4 no es perfecto y todavía tiene una sensación de confusión sobre los problemas de verificación de hechos, algunos errores de razonamiento y un exceso de confianza ocasional.
OpenAI Evals de código abierto, para crear y ejecutar puntos de referencia que evalúan modelos como GPT-4 mientras verifican su rendimiento muestra por muestra.
02
Documento oficial
OpenAI ha lanzado oficialmente GPT-4, que es el último hito en la expansión del aprendizaje profundo de OpenAI. GPT-4 es un gran modelo multimodal ( capaz de aceptar entrada de tipo de imagen y texto, dando salida de texto ), aunque GPT-4 no es tan capaz como los humanos en muchos escenarios del mundo real, puede usarse en varios profesionales y académico En los puntos de referencia, exhibe un rendimiento cercano al nivel humano.
Ejemplo: GPT-4 aprobó un examen de barra simulado con puntajes en el 10% superior de todos los examinados. Por el contrario, la puntuación de GPT-3.5 está en el 10 % inferior. Nuestro equipo pasó 6 meses ajustando repetidamente GPT-4 utilizando mi proyecto de prueba contradictorio y la experiencia relacionada basada en ChatGPT. El resultado es que GPT-4 logra los mejores resultados en términos de factualidad, maniobrabilidad y rechazo a salirse de las barreras de seguridad. Todavía no es perfecto)
En los últimos dos años, refactorizamos toda la pila de aprendizaje profundo y nos asociamos con Azure para codiseñar una supercomputadora para la carga de trabajo desde cero. Hace un año, OpenAI entrenó GPT-3.5 como la primera "ejecución de prueba" de todo el sistema, específicamente, encontramos y solucionamos algunos errores y mejoramos la base teórica anterior. Como resultado, nuestro GPT-4 entrena, funciona (con confianza: ¡al menos para nosotros!) con una estabilidad sin precedentes y se convierte en nuestro primer modelo grande cuyo rendimiento de entrenamiento se puede predecir con precisión por adelantado. A medida que continuamos enfocándonos en un escalado confiable, un objetivo intermedio es perfeccionar los métodos para ayudar a OpenAI a continuar prediciendo y preparándose para el futuro, lo que creemos que es fundamental para la seguridad.
Estamos lanzando capacidades de entrada de texto para GPT-4 a través de ChatGPT y API (puede unirse a WaitList), y estamos trabajando en estrecha colaboración con nuestros socios para tener un buen comienzo y hacer que las capacidades de entrada de imágenes estén más disponibles. Planeamos abrir OpenAI Evals, que también es nuestro marco para evaluar automáticamente el rendimiento de los modelos de IA. Cualquiera puede sugerir deficiencias en nuestro modelo para ayudarlo a mejorar aún más.
03
capacidad
Puede que no sea fácil detectar la diferencia entre GPT-3.5 y GPT-4 en una simple conversación trivial. Sin embargo, cuando la complejidad de la tarea alcanza un umbral suficiente, sus diferencias salen a la luz. Específicamente, GPT-4 es más confiable y creativo que GPT-3.5, capaz de manejar instrucciones más detalladas.
Para comprender las diferencias entre los dos modelos, los probamos en una variedad de puntos de referencia, incluida la simulación de pruebas diseñadas originalmente para humanos. Al usar la última prueba pública (Olympiad, AP, etc.) e incluir la compra de la versión 2022-2023 de la prueba de práctica, no hemos entrenado especialmente al modelo para este tipo de prueba, por supuesto, hay pocos problemas en la prueba está presente durante el proceso de entrenamiento del modelo, pero consideramos que los siguientes resultados son representativos.
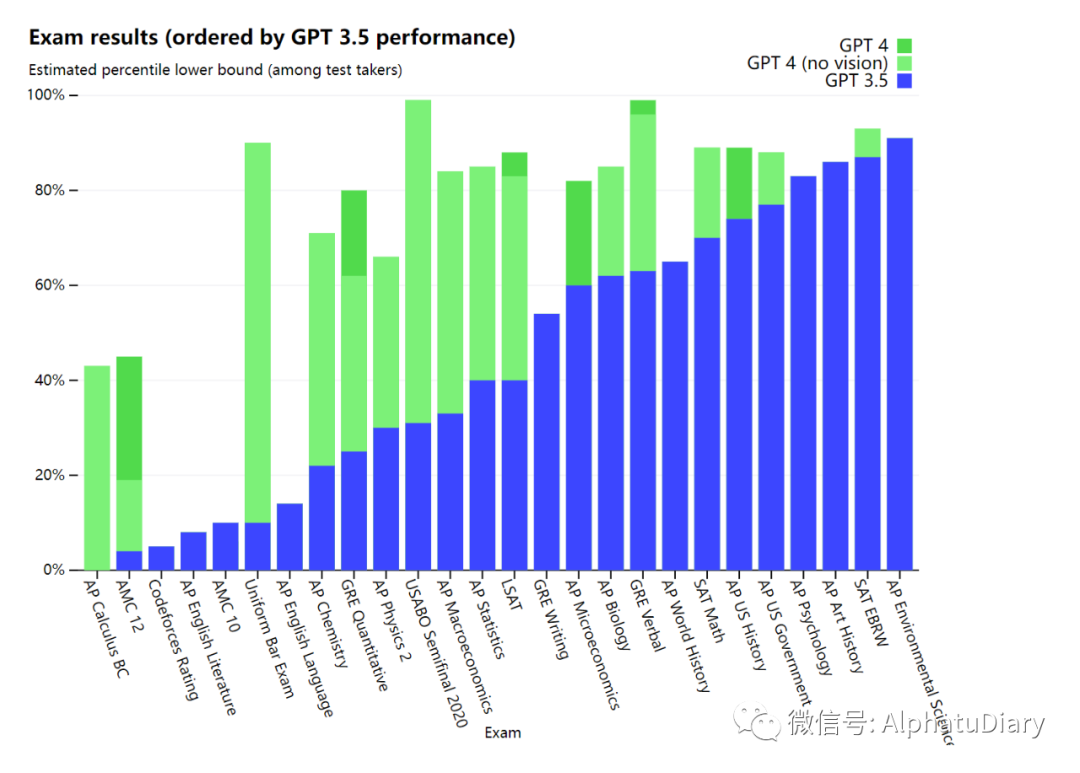
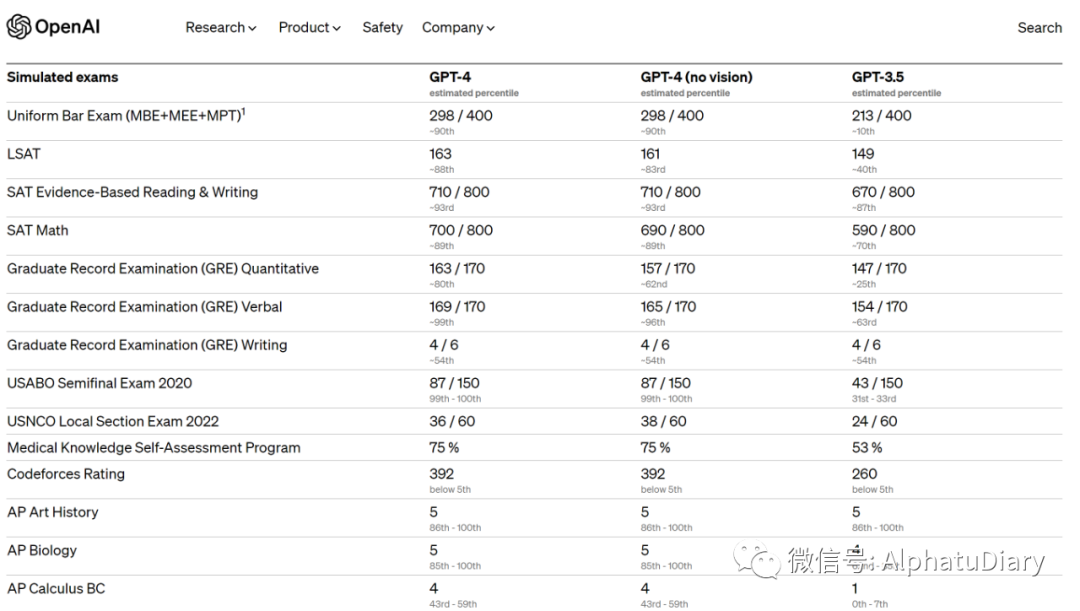
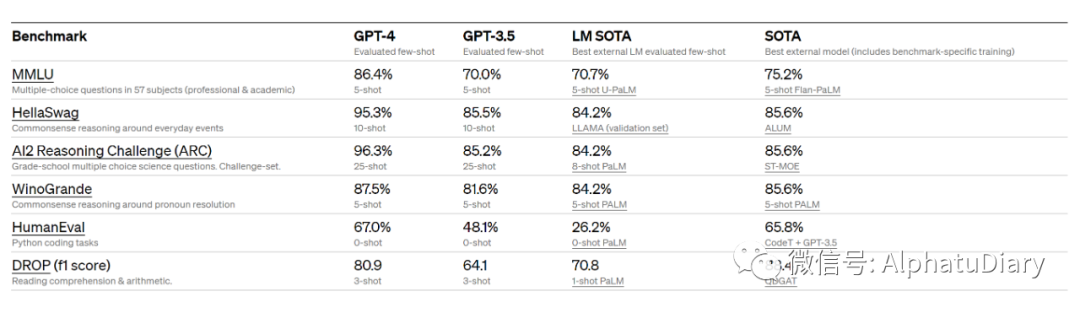
También evaluamos GPT-4 en puntos de referencia tradicionales diseñados para modelos de aprendizaje automático. GPT-4 supera sustancialmente a los modelos de lenguaje grande existentes y está codo a codo con la mayoría de los modelos de última generación (SOTA) que incluyen protocolos de entrenamiento específicos o adicionales.
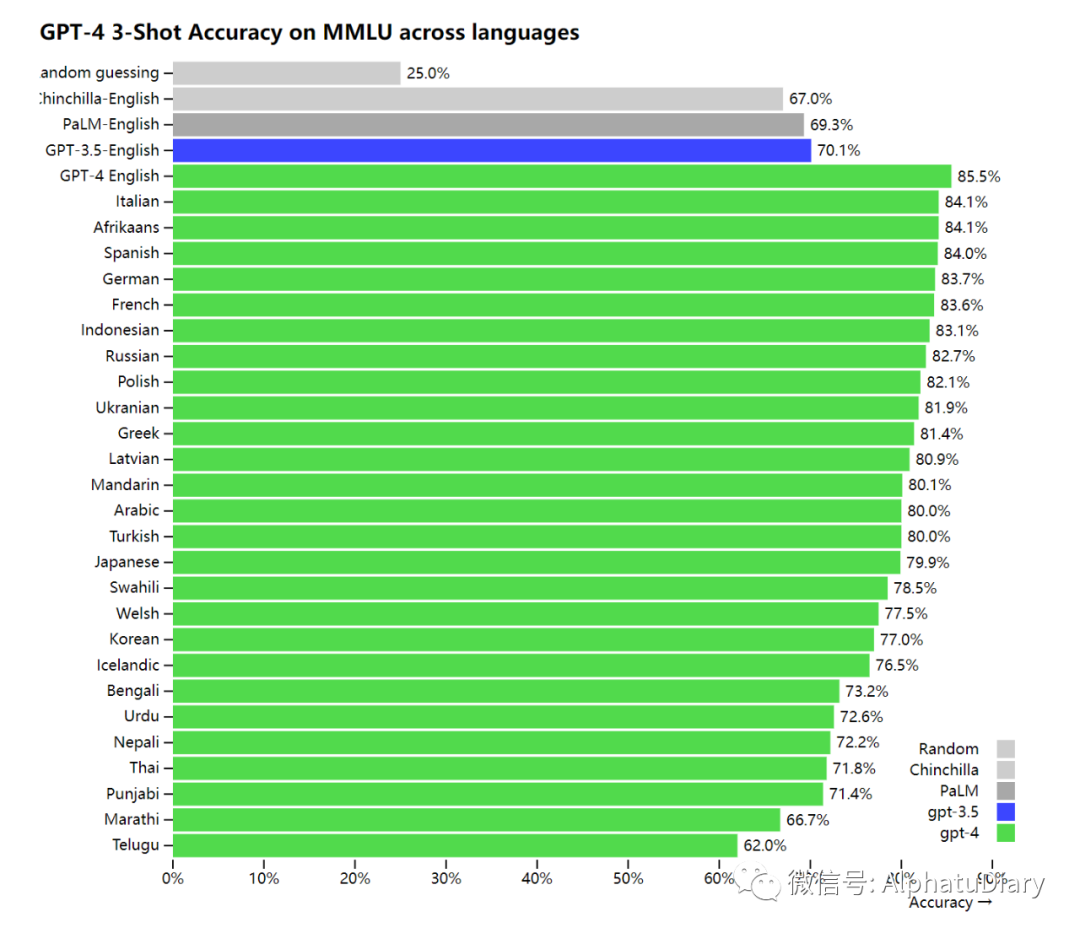
Dado que la mayoría de los puntos de referencia de ML existentes están escritos en inglés, para tener una idea inicial de las capacidades en otros idiomas, usamos Azure Translate para traducir el punto de referencia de MMLU: un conjunto de 14 000 preguntas de opción múltiple que cubren 57 temas, a varios idiomas. En 24 de los 26 idiomas probados, GPT-4 superó a GPT-3.5 y otros modelos grandes (Chinchilla, PaLM) en inglés, y esta excelencia también incluye idiomas como letón, galés y Sri Lanka, Vahili y más.
Hemos estado usando GPT-4 internamente y hemos descubierto que tiene un gran impacto en funciones como soporte, ventas, moderación de contenido y programación. También lo estamos usando para ayudar a los humanos a evaluar el resultado de la IA. Esta es la segunda fase. de nuestra estrategia de ajuste Start.
04
entrada visual
GPT-4 puede aceptar indicaciones de texto e imágenes, lo que es similar a la configuración de solo texto. Por ejemplo, el usuario puede especificar cualquier tarea visual o de lenguaje, puede generar una salida de texto (lenguaje natural, código, etc.), la entrada dada incluye documentos con texto y fotos, diagramas o capturas de pantalla, GPT-4 muestra las mismas capacidades similares para la entrada de texto sin formato. Además, también se puede aplicar a la tecnología de tiempo de prueba desarrollada para el modelo de lenguaje de texto sin formato, incluidas algunas tomas y sugerencias de CoT, pero la entrada de imagen actual sigue siendo una vista previa de investigación y no hay un producto público como el C- lado.
Las siguientes imágenes muestran el embalaje de un adaptador "Lightning Cable" con tres paneles.


Panel 1: un teléfono inteligente con un conector VGA (el gran conector azul de 15 pines que generalmente se usa en los monitores de computadora) conectado a su puerto de carga.
Panel 2: hay una imagen del puerto VGA en el paquete del adaptador "Lightning Cable".
Panel 3: un primer plano del conector VGA, que termina en un pequeño conector Lightning (usado para cargar iPhones y otros dispositivos Apple).
La naturaleza hilarante de esta imagen proviene de enchufar un conector VGA grande y obsoleto en un pequeño y moderno puerto de carga de un teléfono inteligente... luciendo así ridículo
Obtenga una vista previa de GPT-4 evaluando su rendimiento en un conjunto limitado de puntos de referencia de visión académica estándar. Sin embargo, estos números no representan el alcance de sus capacidades, ya que descubrimos que este modelo es capaz de manejar muchas tareas nuevas y emocionantes, y OpenAI planea publicar pronto más números de análisis y evaluación, así como el efecto técnico en la prueba. tiempo Investigue a fondo los resultados.
05
IA controlable
Hemos estado trabajando arduamente para lograr todos los aspectos del plan descrito en el artículo sobre la definición del comportamiento de la IA, incluida la capacidad de control de la IA. En lugar del discurso, el tono y el estilo fijos de las personalidades clásicas de ChatGPT, los desarrolladores (y pronto todos los usuarios de ChatGPT) ahora pueden dictar el estilo y las tareas de su propia IA describiendo estas instrucciones en los mensajes del "sistema". Los mensajes del sistema permiten a los usuarios de API personalizar en gran medida la experiencia del usuario dentro de un cierto rango, y continuaremos mejorando.
06
limitación
A pesar de sus increíbles capacidades, GPT-4 tiene limitaciones similares a los modelos GPT anteriores. Además de eso, todavía no es completamente confiable (digamos, puede "alucinar" hechos y cometer errores de inferencia). Al usar el resultado de un modelo de lenguaje, especialmente en situaciones de alto riesgo, se debe tener mucho cuidado (por ejemplo, se requiere revisión humana, el uso de alto riesgo debe evitarse por completo) y debe adaptarse a las necesidades del uso específico. caso.
Si bien todavía existen todo tipo de cosas, GPT-4 reduce drásticamente las alucinaciones (es decir, ilusiones de red, en este caso tonterías graves) en comparación con los modelos anteriores (que a su vez están mejorando constantemente). En nuestra evaluación fáctica contradictoria interna, GPT-4 obtiene un puntaje 40 % más alto que nuestro GPT-3.5 de última generación.
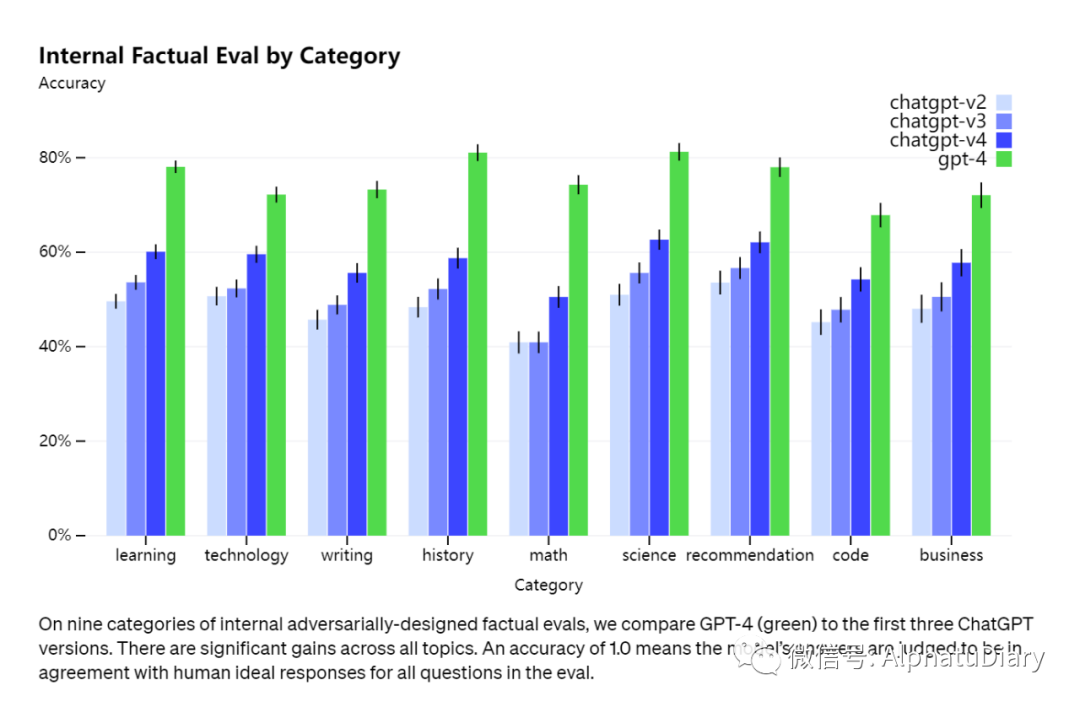
07
IA controlable
El modelo base de GPT-4 solo supera ligeramente a GPT-3.5 en esta tarea; sin embargo, después del entrenamiento posterior con RLHF (aplicando el mismo procedimiento que usamos para GPT-3.5), hay una gran brecha. El modelo tendrá varios sesgos en su salida, y hemos avanzado en estas áreas, pero aún queda trabajo por hacer. Según nuestra reciente publicación de blog, nuestro objetivo es hacer que los sistemas de IA que construimos tengan comportamientos predeterminados sensibles que reflejen una amplia gama de valores de los usuarios, permitan que estos sistemas se personalicen en amplios rangos y obtengan comentarios públicos sobre esos rangos.
GPT-4 generalmente carece de conocimiento de los eventos que ocurrieron después del corte para la gran mayoría de sus datos (septiembre de 2021) y no aprenderá de su experiencia. A veces comete errores de razonamiento simples que no parecen coincidir con las capacidades de tantos dominios, o es demasiado crédulo en las tergiversaciones obvias de los usuarios. A veces también falla en problemas difíciles como los humanos, como la introducción de agujeros de seguridad en el código que produce. GPT-4 también podría errar con confianza en sus predicciones.
08
Riesgos y Mitigaciones
Hemos estado iterando en GPT-4 para hacerlo más seguro y consistente desde el comienzo de la capacitación. Nuestros esfuerzos incluyen la selección y el filtrado de datos previos a la capacitación, la evaluación, la invitación a expertos a participar, la mejora de la seguridad del modelo, el monitoreo y la ejecución.
GPT-4 presenta riesgos similares a los modelos anteriores, como producir consejos dañinos, código incorrecto o información inexacta. Sin embargo, las capacidades adicionales de GPT-4 también conducen a nuevas superficies de riesgo. Para aclarar los detalles de estos riesgos, contratamos a más de 50 expertos en los campos de riesgos de acoplamiento de IA, ciberseguridad, riesgos biológicos, confianza y seguridad, y seguridad internacional para realizar pruebas contradictorias del modelo. Su participación nos permite probar el comportamiento del modelo en dominios de alto riesgo que requieren experiencia para evaluar. Los comentarios y datos de expertos en estos dominios informaron nuestros modelos de mitigación y mejora. Por ejemplo, hemos recopilado datos adicionales para mejorar la capacidad de GPT-4 para rechazar solicitudes sobre cómo sintetizar sustancias químicas peligrosas.
GPT-4 incorpora una señal de recompensa de seguridad adicional en el entrenamiento de RLHF al entrenar el modelo para que rechace las solicitudes de dicho contenido, lo que reduce la producción dañina (según lo definido por nuestras pautas de uso). Las recompensas son proporcionadas por el clasificador de GPT-4, que puede juzgar cómo se realizan los límites de seguridad y las sugerencias relacionadas con la seguridad. Para evitar que los modelos rechacen solicitudes válidas, recopilamos diversos conjuntos de datos de diferentes fuentes (por ejemplo, datos de producción etiquetados, equipos rojos humanos, sugerencias generadas por modelos) y aplicamos recompensas de seguridad en las categorías permitidas y no permitidas Señal (presencia de valor positivo o negativo).
Nuestras mitigaciones mejoran sustancialmente muchas de las propiedades de seguridad de GPT-4 en comparación con GPT-3.5. En comparación con GPT-3.5, redujimos la propensión del modelo a responder a solicitudes de contenido ilegal en un 82 %, mientras que GPT-4 respondió con un 29 % más de frecuencia a solicitudes confidenciales, como consejos médicos y autolesiones, en línea con nuestra póliza %
En general, nuestras intervenciones a nivel de modelo aumentan la dificultad de inducir un comportamiento indeseable, pero todavía hay "jailbreaking" para producir contenido que viola nuestras pautas de uso. A medida que aumentan los riesgos para los sistemas de IA, será fundamental lograr una confiabilidad extrema en estas intervenciones. Lo importante ahora es complementar estas limitaciones con tecnologías de seguridad en el momento de la implementación, como encontrar formas de monitorear.
Es probable que GPT-4 y los modelos posteriores tengan impactos positivos o negativos en la sociedad, y estamos trabajando con investigadores externos para mejorar nuestra comprensión y evaluación de los impactos potenciales, así como para generar conciencia sobre las posibles capacidades peligrosas en los sistemas futuros Evaluar. Compartiremos más de nuestras reflexiones sobre el impacto social y económico potencial de GPT-4 y otros sistemas de IA en breve.
09
proceso de entrenamiento
Al igual que el modelo GPT anterior, el modelo base GPT-4 se entrena para predecir la siguiente palabra en un documento y se entrena utilizando datos disponibles públicamente (como datos de Internet), así como datos que licenciamos. Estos datos se extraen de corpus extremadamente grandes e incluyen soluciones correctas e incorrectas a problemas matemáticos, razonamiento débil y fuerte, declaraciones contradictorias y consistentes, y una amplia variedad de ideologías e ideas.
Por lo tanto, cuando se le solicita una pregunta, el modelo subyacente puede responder en una variedad de formas que pueden estar lejos de lo que pretendía el usuario. Para alinearlo con la intención del usuario, ajustamos el comportamiento del modelo mediante el aprendizaje por refuerzo con retroalimentación humana (RLHF).
Tenga en cuenta que la capacidad del modelo parece provenir principalmente del proceso de preentrenamiento, RLHF no mejora los puntajes de las pruebas (en realidad disminuye los puntajes de las pruebas sin un esfuerzo activo). Pero el arranque para el modelo viene en el proceso posterior al entrenamiento, y el modelo base necesita ingeniería rápida para saber que debe responder la pregunta.
10
expansión predecible
Un gran enfoque del proyecto GPT-4 es construir una pila de aprendizaje profundo que se escale de manera predecible. La razón principal es que para ejecuciones de entrenamiento muy grandes como GPT-4, no es factible realizar muchos ajustes específicos del modelo. Hemos desarrollado y optimizado la infraestructura para que tenga un comportamiento muy predecible a múltiples escalas. Para probar esta escalabilidad, predijimos con precisión por adelantado la pérdida final de GPT-4 en nuestra base de código interna (que no forma parte del conjunto de entrenamiento) al inferir de un modelo entrenado usando el mismo método, pero usando el cálculo. La cantidad es 10000 veces menor .
Creemos que la capacidad del aprendizaje automático para predecir con precisión el futuro es una parte importante de la seguridad que se ha subestimado en relación con su impacto potencial (aunque nos han alentado los esfuerzos de varias instituciones). Estamos ampliando nuestros esfuerzos para desarrollar formas de brindar a la sociedad una mejor orientación sobre qué esperar de los sistemas futuros, y esperamos que esto se convierta en un objetivo común en el campo.
11
Evaluación de IA abierta
Estamos abriendo OpenAI Evals, nuestro marco de software para crear y ejecutar puntos de referencia que evalúan modelos como GPT-4, mientras verifican su rendimiento muestra por muestra. Utilizamos Evals para guiar el desarrollo de nuestros modelos (incluida la identificación de deficiencias y la prevención de regresiones), y nuestros usuarios pueden aplicarlo para realizar un seguimiento del rendimiento de las diferentes versiones del modelo (que ahora se implementarán con regularidad) y la evolución de las integraciones de productos. Por ejemplo, Stripe ya usa Evals para complementar sus evaluaciones humanas para medir la precisión de sus herramientas de documentación con tecnología GPT.
Debido a que el código es de código abierto, Evals admite la escritura de nuevas clases para implementar una lógica de evaluación personalizada. Sin embargo, en nuestra propia experiencia, muchos puntos de referencia siguen una de algunas "plantillas", por lo que también incluimos las plantillas más útiles internamente (incluida una plantilla para "Evaluaciones de calificación de modelos"; descubrimos que GPT-4 tiene un impresionante Sorprendido por el posibilidad de comprobar su propio trabajo). En general, la forma más eficiente de crear una nueva evaluación es instanciar una de estas plantillas y proporcionar los datos. Estamos emocionados de ver lo que otros pueden construir con estas plantillas y Evals en general.
Queremos que Evals sea una herramienta para compartir y hacer crowdsourcing de puntos de referencia que mejor representen una amplia gama de modos de falla y tareas difíciles. Como ejemplo de seguimiento, hemos creado una evaluación de acertijo lógico con diez pistas de que GPT-4 falló. Evals también es compatible con la implementación de puntos de referencia existentes; hemos incluido varios cuadernos que implementan puntos de referencia académicos y algunas variaciones que integran CoQA (un pequeño subconjunto) como ejemplos.
Invitamos a todos a probar nuestros modelos con Evals y enviar sus ejemplos más interesantes. Creemos que Evals será una parte integral del proceso de uso y desarrollo de nuestros modelos, y agradecemos las contribuciones directas, las preguntas y los comentarios.
12
ChatGPT Plus
Los usuarios de ChatGPT Plus obtendrán permisos GPT-4 con límite de uso en chat.openai.com. Ajustaremos el límite de uso exacto en función de la demanda real y el rendimiento del sistema, pero esperamos que la capacidad se vea severamente limitada (aunque ampliaremos y optimizaremos en los próximos meses).
Dependiendo de los patrones de tráfico que veamos, podemos introducir un nuevo nivel de suscripción para un mayor uso de GPT-4, y también esperamos ofrecer una cierta cantidad de consultas gratuitas de GPT-4 en algún momento, para que los usuarios que no tienen una suscripción también puede probar.
API
Para obtener la API de GPT-4 (utilizando la misma API de ChatCompletions que gpt-3.5-turbo), regístrese en la lista de espera oficial de OpenAI.
13
en conclusión
Esperamos que GPT-4 se convierta en una herramienta valiosa que mejore la vida de las personas potenciando muchas aplicaciones. Todavía queda mucho trabajo por hacer, y esperamos construir, explorar y contribuir al modelo a través de los esfuerzos colectivos de la comunidad para mejorar el modelo juntos.
Texto/Republicado de "Notas de investigación de Alpha Rabbit"
referencias:
1.https://openai.com/research/gpt-4
2.https://techcrunch.com/2023/03/14/openai-releases-gpt-4-ai-that-it-claims-is-state-of-the-art/
3.https://www.theverge.com/2023/3/14/23638033/openai-gpt-4-chatgpt-multimodal-deep-learning
Haga clic en la tarjeta de cuenta oficial a continuación para seguirme
En el cuadro de diálogo de la cuenta oficial, responda la palabra clave "1024"
Obtenga un tutorial práctico gratuito sobre cómo ganar dinero con negocios secundarios
