Ein Index in ES besteht aus einem oder mehreren Shards. Beim Erstellen eines Index können Sie die Anzahl der primären Shards und Replikat-Shards festlegen. Nachdem der primäre Shard bestimmt wurde, kann er nicht mehr geändert werden (da das Routing auf dieser Anzahl basieren muss). Verteilungsanfrage) und die Anzahl der Replikatfragmente kann jederzeit geändert werden
PUT /myIndex
{
"settings" : {
"number_of_shards" : 2, //该索引有2个分片
"number_of_replicas" : 1 //每个分片都有一个副本
}
}Hier gehe ich davon aus, dass zwei Knoten eingerichtet sind, das heißt, zwei ES-Dienste gestartet werden. Shard1 und Shard2 sind die beiden primären Shards, die erstellt werden, und Replikat1 und Replikat2 sind zwei Replikat-Shards. Um eine hohe Verfügbarkeit zu erreichen, wird ES im Allgemeinen der primäre Shards und Replikat-Shards werden in verschiedenen NODE-Knoten gespeichert, und diese Aktion wird automatisch von ES abgeschlossen.

Was sind das für Scherben?
Shard = Lucene-Index
Wir wissen, dass ElasticSearch eine verteilte und skalierbare Echtzeit-Such- und Analysemaschine ist, die eine Suchmaschine ist, die auf der Volltextsuchmaschine Apache Lucene basiert. Dann sind Shards im Wesentlichen einzelne Lucene-Indizes.

Es gibt viele kleine Segmente in Lucene, und jedes Segment enthält viele Datenstrukturen, wie z. B. den oft gehörten invertierten Index (invertierter Index), sortierte Felder, Dokumentwerte ..., von denen das wichtigste invertiert indiziert ist.
Invertierter Index (invertierter Index)
Der invertierte Index besteht hauptsächlich aus zwei Teilen:

Wenn wir suchen, werden wir den Inhalt der Suche in Wörter segmentieren. Suchen Sie dann den entsprechenden Begriff im Wörterbuch, damit Sie den suchbezogenen Dateiinhalt finden können.
-
Wörterbuch der geordneten Daten (einschließlich des Wortbegriffs und seiner Häufigkeit)
-
Postings, die dem Wort entsprechen (d. h. die Datei, in der das Wort vorhanden ist)
Sortierte Felder (Feldsuche)
Diese Struktur wird verwendet, wenn Sie Dokumente finden möchten, die Inhalte mit einer bestimmten Überschrift enthalten. Im Wesentlichen handelt es sich um eine einfache KV-Sammlung, die standardmäßig das gesamte Dokument im Json-Format speichert.
Netzwerkdiagramm:

Dokumentwerte (für Sortierung, Aggregation)
Es wurde geboren, um Sortierung und Aggregation zu lösen. Diese Struktur ist im Wesentlichen ein säulenförmiger Speicher.
Netzwerkdiagramm:

Um die Effizienz zu verbessern, kann ES alle Dokumentwerte unter dem Index für den Betrieb in den Speicher lesen, um die Zugriffsgeschwindigkeit zu verbessern, aber es wird Speicherplatz verbrauchen.
Diese Datenstrukturen, der invertierte Index, die sortierten Felder, die Dokumentwerte und der Cache befinden sich alle innerhalb des Segments.
beim Suchen
Lucene durchsucht alle Segmente und gibt dann die Suchergebnisse für jedes Segment zurück und kehrt dann zum Client zurück.
Zwischenspeicher
Wenn ES nach einem Dokument sucht, erstellt es einen entsprechenden Cache für das Dokument und aktualisiert den Cache jede Sekunde.
Segment zusammenführen
Im Laufe der Zeit wird es immer mehr Segmente geben, es wird diese Segmente zusammenführen und die ursprünglichen nach dem Zusammenführen löschen, so dass es eine Situation geben wird, in der Sie mehr Dokumente hinzufügen und der vom Index belegte Platz möglicherweise kleiner wird und kleiner, weil die Zusammenführung verursacht wird, also gibt es mehr Komprimierung.
Schrittreihenfolge der Dokumentindizierung
Die Abfolge der Schritte, die zum Erstellen eines neuen Einzeldokuments erforderlich sind:
Netzwerkdiagramm:
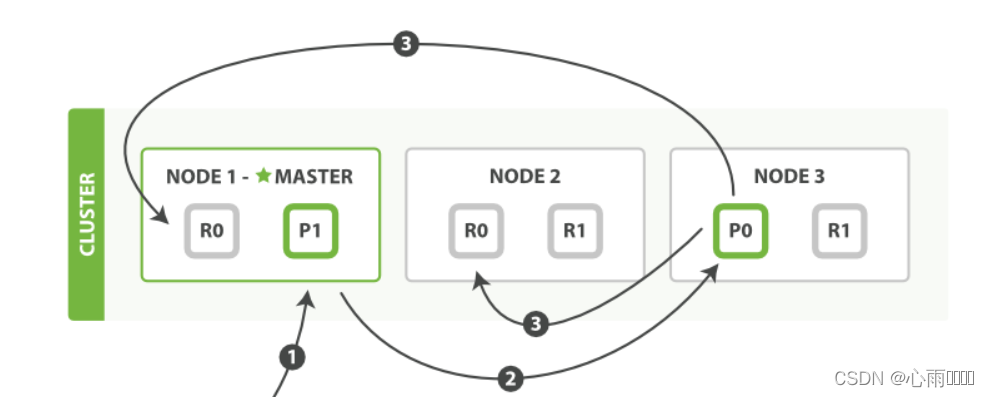
1. Der Client sendet eine neue Index- oder Löschanforderung an Node1.
2. Der Knoten verwendet die _id des Dokuments, um zu bestimmen, zu welchem Shard das Dokument gehört. Die Anfrage wird an den entsprechenden Node weitergeleitet.
3. Führen Sie die Anforderung auf dem Shard aus. Wenn die Ausführung erfolgreich ist, wird die Anfrage an die Replikat-Shards jedes Knotens weitergeleitet, und wenn alle erfolgreich sind, wird eine Erfolgsmeldung an den Client zurückgegeben.
Der Gesamtprozess ist immer noch ein wahnhaftes (Netzwerk-)Diagramm. . .
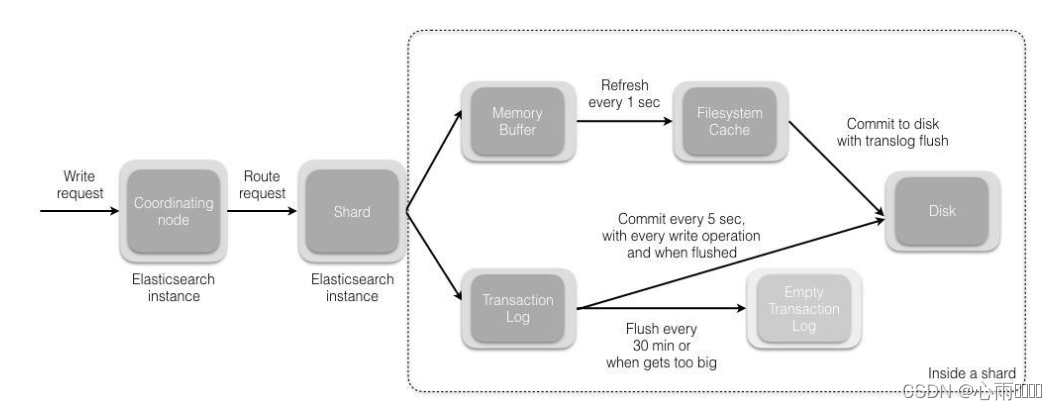
1. Nachdem die Anfrage gesendet wurde, kommt sie zuerst zum koordinierenden Knoten.Standardmäßig wird die ID des Dokuments verwendet, um zu berechnen, welcher Shard die Anfrage verarbeitet.
shard=hash(_id)% Anzahl der Shards
2. Nachdem der Shard die Anfrage erhalten hat, schreibt er die Anfrage zuerst in den Speicherpuffer und dann in regelmäßigen Abständen (standardmäßig 1s) in das Dateisystem. Der Vorgang vom Speicherpuffer zum Dateisystem-Cache wird als Refresh bezeichnet.
3. Das Transaktionsprotokoll wird verwendet, um die Datenzuverlässigkeit sicherzustellen, da Daten im Aktualisierungsprozess verloren gehen können. Nachdem der Shard die Anfrage erhalten hat, schreibt er die Anfrage gleichzeitig in das Translog. Wenn die Daten im Dateisystem-Cache auf die Festplatte geschrieben werden, werden sie gelöscht. Dieser Vorgang wird als Flush bezeichnet.
4. Während des Flush-Vorgangs wird der Cache im Arbeitsspeicher gelöscht, der Inhalt wird in ein neues Segment geschrieben, das fsync des Segments erstellt einen neuen Commit-Punkt, und der Inhalt wird auf die Festplatte und den alten Translog geleert gelöscht werden und ein neues Trabslog starten. Der Flush-Trigger-Mechanismus ist standardmäßig auf 30 Minuten eingestellt oder das Translog ist zu groß.