Reimpreso de: https://blog.51cto.com/u_15671528/5604886
solo para registros de aprendizaje
Directorio de artículos
1. Introducción
Como una poderosa herramienta de visualización en Tensorflow, tensorboard ha sido ampliamente utilizado.
Pero para otros marcos, como Pytorch, no ha habido una herramienta de visualización tan buena disponible antes. La herramienta de visualización del marco PyTorch es Visdom, pero los parámetros que deben configurarse en esta API son demasiado complicados y las funciones son no es conveniente ni poderoso, por lo que alguien escribió Una función de biblioteca TensorboardX permite que PyTorch también use tensorboard.
2. Instalación
先安装tensorboard, 再安装tensorboardXDado que tensorboardX encapsula tensorboard y lo abre para su uso , es necesario
(tensorflow puede instalarse o no, pero algunas funciones estarán limitadas y no afectarán el uso de la función principal)
pip install tensorboard
pip install tensorboardX
Tres, usa
1. Visualización escalar
Utilice MNIST como código base y agréguele funciones de visualización.
Importar funciones de biblioteca primero
# 导入可视化模块
from tensorboardX import SummaryWriter
writer = SummaryWriter('../result_tensorboard')
El escritor aquí es una interfaz que queremos grabar y escribir en tensorboard. Este…/result_tensorboard es la ubicación específica donde se guardan los datos.
for batch_idx, (data, target) in enumerate(train_loader):
#...省略一些代码...
if (batch_idx + 1) % 50 == 0:
print('Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}'.format(
epoch, (batch_idx + 1) * len(data), len(train_loader.dataset),
100. * (batch_idx + 1) / len(train_loader), loss.item()))
writer.add_scalar('loss',loss.item(),tensorboard_ind)
tensorboard_ind += 1
La clave es writer.add_scalar(), que tiene tres parámetros clave:
def add_scalar(self, etiqueta, valor_escalar, paso_global):
tagEs solo una cadena En el código anterior, registro el valor de la pérdida cada 50 lotes, por lo que esta etiqueta es 'pérdida':scalar_valueEs el escalar registrado esta vez, que se registra arribaloss.item(). Este cambio de pérdida debería generar un gráfico de líneas, este valor escalar esy轴的值;global_stepDe hecho, es un gráfico de líneasx轴的值, por lo que agrego tensorboard_ind por uno cada vez que registro un punto.
Ejecutar el código anterior generará un archivo de este tipo:

events.out.blah blah Este archivo es el escalar guardado en el código, necesitamos iniciar tensorboard en la consola para visualizar:
tensorboard --logdir==D:\Kaggle\result_tensorboard
若是使用了VPN等网络代理,就是用如下指令:
tensorboard --logdir==D:\Kaggle\result_tensorboard --bind_all
Este –logdir= es seguido por la dirección definida por el escritor anterior, es decir…/result_tensorboard, y luego se ejecuta.
El resultado de la ejecución es:

haga clic en la fuente azul en la imagen de arriba y aparecerá una página web, que es el panel de visualización de tensorboald.
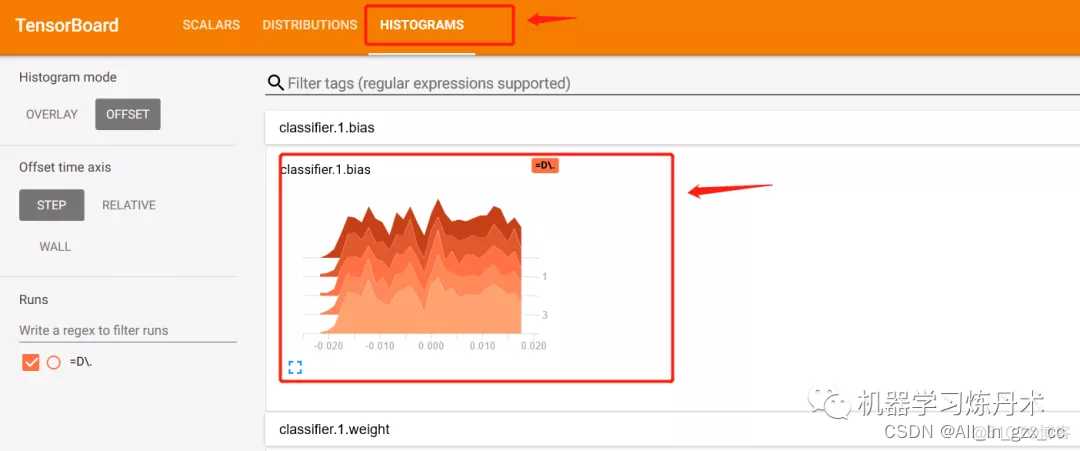
2. Histograma de peso
Agregue parte del código, el propósito es registrar el histograma de parámetros de cada capa del modelo después de que se complete el entrenamiento de cada época.
n_epochs = 5
for epoch in range(n_epochs):
train(epoch,epoch * len(train_loader))
# 每一个epoch之后输出网络中每一层的权重值的直方图
for i, (name, param) in enumerate(model.named_parameters()):
if 'bn' not in name:
writer.add_histogram(name, param, epoch)
Después de ejecutar, sigue siendo un archivo de datos con un nombre largo. Ejecutamos este archivo en tensorboard para mostrar los cambios del histograma. El código anterior registra el histograma de valores de peso de todas las capas en una red. En tareas específicas, puede Solo es necesario generar el histograma de peso de algunas capas.
3. Visualización del mapa de características
En la función de tren en el código, se agrega un fragmento de código de este tipo:
# 第一个batch记录数据
if batch_idx == 0:
out1 = model.features1(data[0:1,:,:,:])
out2 = model.features(out1)
grid1 = make_grid(out1.view(-1,1,out1.shape[2],out1.shape[3]), nrow=8)
grid2 = make_grid(out2.view(-1,1,out1.shape[2],out1.shape[3]), nrow=8)
writer.add_image('features1', grid1, global_step=epoch)
writer.add_image('features', grid2, global_step=epoch)
Es poner la primera muestra del primer lote en el modelo, luego generar el mapa de características de la salida de convolución como out1 y out2, y luego usar la función torchvision.utils.make_grid para convertir el mapa de características en una forma de cuadrícula. Luego escriba en el escritor, las etiquetas son 'features1' y 'features'.
Ejecute el resultado del tensorboard:

en las características 1, puede ver claramente 32 imágenes de '6'. Esta es una visualización de 32 canales del mapa de características de una muestra. Después de verificar el código, aunque la característica anterior se parece a 4 La imagen, pero en realidad son 64 canales, pero cada mapa de funciones es muy pequeño, por lo que se ve borroso y confuso. Esto también se debe a que las imágenes de entrada en el conjunto de datos MNIST tienen un tamaño de 28. Para las imágenes grandes de Imagenet, la entrada de crisálida de gusano de seda es generalmente de 224 o 448 píxeles, lo que será mejor.
En resumen, esta es la visualización del mapa de características.
4. Visualización de gráficos de modelos
Esto es muy simple:
model = Net().to(device)
writer.add_graph(model, torch.rand([1,3,28,28]))
Aquí hay un problema, es decir, no se mostrará la estructura del modelo definida por uno mismo. De momento he buscado en Internet pero no hay mejor solución, por lo que no visualizaré el modelo aquí. Se pueden visualizar algunos modelos proporcionados oficialmente. A continuación se muestra el efecto de visualización oficial:

De hecho, personalmente siento que el resultado de esta visualización de la estructura del modelo no es muy atractivo. Y hay otras formas de visualizar los resultados del modelo, así que no importa si no usas tensorboard. Tensorboard para visualizar pérdidas, mapas de características, etc. también es suficiente.
5. Visualización del kernel de convolución
# 卷积核的可视化
for idx, (name, m) in enumerate(model.named_modules()):
if name == 'features1':
print(m.weight.shape)
in_channels = m.weight.shape[1]
out_channels = m.weight.shape[0]
k_w,k_h = m.weight.shape[3],m.weight.shape[2]
kernel_all = m.weight.view(-1, 1, k_w, k_h) # 每个通道的卷积核
kernel_grid = make_grid(kernel_all, nrow=in_channels)
writer.add_image(f'{
name}_kernel', kernel_grid, global_step=epoch)
Este también es relativamente fácil de entender. Los conocimientos básicos sobre la convolución y el recorrido del modelo se han discutido antes, así que creo que no hay nada difícil de entender para todos aquí.
resultado de la operación:
