Проблема небезопасности потока HashMap и ее решение
Проблема небезопасности потока HashMap и ее решение
Мы все знаем
HashMap, что это небезопасно для потоков, и мы должны его использоватьConcurrentHashMap. Но почемуHashMapэто небезопасно для потоков?
Позвольте мне сначала объявить: HashMapнебезопасность потока теперь вызовет такие проблемы, как ** 死循环, 数据丢失, ** . 数据覆盖Среди них бесконечный цикл и потеря данных — это проблемы, которые появились в JDK 1.7 и были решены в JDK 1.8, однако такие проблемы, как перезапись данных, все еще будут в 1.8.
Анализ бесконечного цикла и потери данных, вызванных расширением JDK1.7
Ненадежность потока HashMap в основном возникает в методе расширения, то есть основная причина заключается в методе передачи Метод передачи HashMap в JDK1.7 выглядит следующим образом:
void transfer(Entry[] newTable, boolean rehash) {
int newCapacity = newTable.length;
for (Entry<K,V> e : table) {
while(null != e) {
Entry<K,V> next = e.next;
if (rehash) {
e.hash = null == e.key ? 0 : hash(e.key);
}
int i = indexFor(e.hash, newCapacity);
e.next = newTable[i];
newTable[i] = e;
e = next;
}
}
}
Этот код представляет собой HashMapоперацию расширения, перемещающую нижний индекс каждого сегмента и использующую метод интерполяции головы для переноса элементов в новый массив. Метод вставки заголовка изменит порядок связанного списка, что также является ключевым моментом формирования бесконечного цикла. Поняв метод вставки заголовка, продолжайте смотреть вниз, как вызвать бесконечный цикл и потерю данных.
Предположим, что теперь есть два потока A и B, HashMapодновременно выполняющие операции раскрытия следующего:
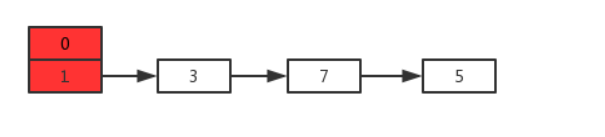
Результат после нормального расширения выглядит следующим образом:
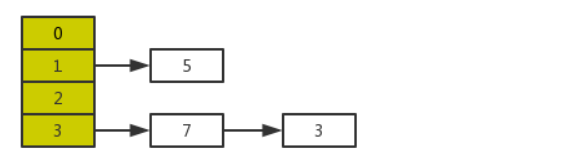
Но когда поток A выполняет transferстроку 11 вышеуказанной функции, квант времени процессора исчерпывается, и поток A приостанавливается. То есть, как показано на рисунке ниже:

В это время в потоке A: e=3, next=7, e.next=null
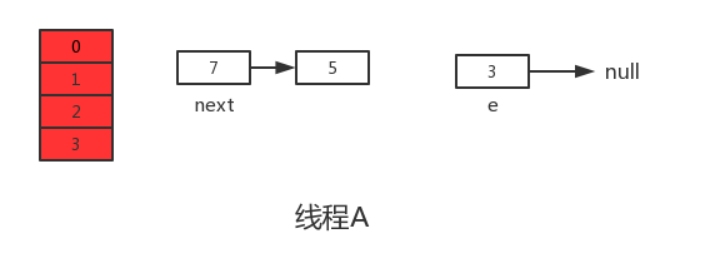
Когда квант времени потока A исчерпан, ЦП начинает выполнять поток B и успешно завершает миграцию данных в потоке B.
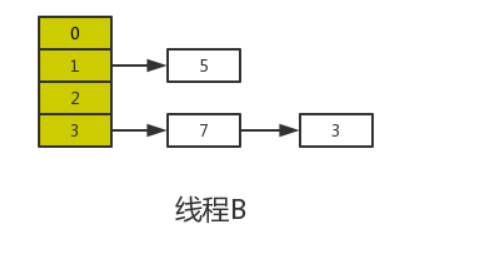
В соответствии с моделью памяти Java после того, как поток B выполнит миграцию данных, newTable и таблица в основной памяти будут самыми последними, то есть: 7.next=3, 3.next=null.
Затем поток A получает квант времени процессора и продолжает выполнять newTable[i] = e, а в позицию, соответствующую новому массиву, помещает 3. После выполнения этого цикла ситуация с потоком A выглядит следующим образом:

Затем продолжаем выполнять следующий цикл, в это время e=7, при чтении e.next из основной памяти обнаруживается, что 7.next=3 в основной памяти, поэтому next=3 , и ставим 7 в путь вставки головы в новый массив и продолжаем выполнять этот цикл, результат такой:
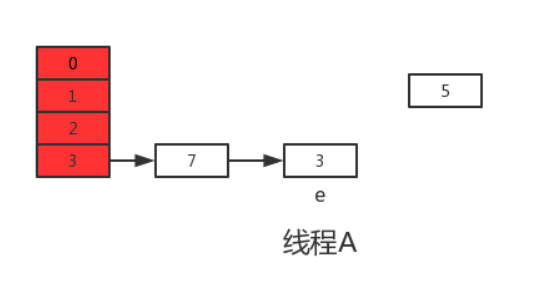
Выполнение следующего цикла может обнаружить, что next=e.next=null, поэтому этот цикл будет последним циклом. Далее, после выполнения e.next=newTable[i], то есть 3.next=7, соединяются между собой 3 и 7. После выполнения newTable[i]=e, 3 повторно вставляется в связанный список, результат выполнения показан на рисунке ниже:
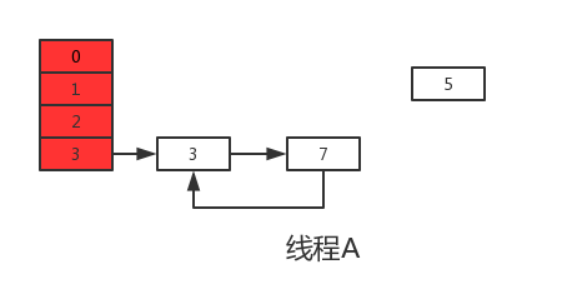
Выше было сказано, что e.next=null в данный момент означает next=null, после выполнения e=null следующий цикл выполняться не будет. На этом завершаются операции раскрытия потоков A и B. Очевидно, что после выполнения потока A в HashMap появляется кольцевая структура, и при дальнейшей эксплуатации HashMap появится бесконечный цикл .
И из рисунка выше мы видим, что элемент 5 был необъяснимо потерян во время расширения, что вызвало проблему потери данных .
Небезопасный поток в JDK1.8
Проблемы в JDK1.8 были решены в JDK1.8.Если вы прочитаете исходный код 1.8, вы обнаружите, что transferфункция не может быть найдена, потому что JDK1.8 непосредственно resizeзавершает миграцию данных в функции. Кроме того, JDK1.8 использует метод вставки хвоста при вставке элементов (порядок не будет нарушен).
Но в JDK1.8 будет перезапись данных
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
if ((p = tab[i = (n - 1) & hash]) == null) // 如果没有hash碰撞则直接插入元素
tab[i] = newNode(hash, key, value, null);
else {
Node<K,V> e; K k;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) {
// existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}
Следующие анализы из двух ситуаций
- Предполагая, что два потока A и B выполняют операции put, а нижний индекс вставки, вычисленный хэш-функцией, одинаков, когда поток A выполняет шестую строку кода метода putVal (для определения наличия коллизии хэшей) , из - за к срезу времени В результате он приостанавливается, и поток B вставляет элемент в индекс после получения среза времени и завершает обычную вставку, а затем поток A получает срез времени. до этого он не будет тогда оценивать, а вставлять напрямую, что приводит к тому, что данные, вставленные потоком B, перезаписываются потоком A, поэтому поток небезопасен.
- Кроме того, параметр размера метода putVal используется для определения количества элементов в HashMap.При многопоточности, когда потоки A и B выполняют операции ввода одновременно, при условии, что текущий размер HashMap равен 10, когда поток A выполняет **size++**, значение размера, полученное из основной памяти, равно 10, и операция +1 готова к выполнению, но из-за исчерпания кванта времени приходится отказаться от ЦП. Поток B благополучно получает ЦП или получает размер из основной памяти. Значение 10 равно +1 операции, операция размещения завершена, и размер = 11 записывается обратно в основную память, а затем поток А снова получает ЦП и продолжает работу. для выполнения (значение размера в это время все еще равно 10), когда операция размещения завершена, по-прежнему записывайте обратно в память размер = 11. В это время оба потока A и B выполнили операцию размещения, но значение размер увеличился только на 1. Говорят, что поток небезопасен из-за перезаписи данных.
Подведем итог
HashMapНенадежность потока в основном отражается в следующих двух аспектах:
1. В JDK1.7, когда операция расширения выполняется одновременно, это вызовет кольцевую цепочку и потерю данных.
2. В JDK1.8 перезапись данных происходит при одновременном выполнении операции put.
Поточно-небезопасное решение
Хэш-таблица (устаревшая)
Для достижения многопоточной безопасности HashTable добавляет синхронизированные блокировки практически ко всем методам (блокировка — это экземпляр класса, то есть вся структура карты). для доступа Синхронные методы будут заблокированы.
Это решение не используется очень часто, поэтому я не буду объяснять его здесь.
Collections.synchronizedMap (обычно не используется)
Collections.synchronizedMap() возвращает новую реализацию Map
Map<String,String> map = Collections.synchronizedMap(new HashMap<>());
Когда мы вызываем вышеуказанный метод, нам нужно передать карту. Как вы можете видеть на рисунке ниже, есть два конструктора. Если вы передаете параметр мьютекса, блокировка исключения объекта назначается переданному объекту.
Если нет, назначьте блокировку исключения объекта этому, то есть объекту, который вызывает synchronizedMap, который является вышеуказанной картой.
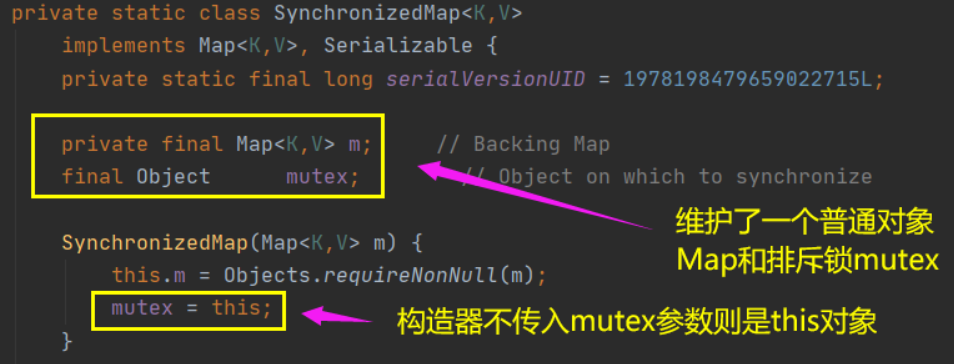
Collections.synchronizedMap() для инкапсуляции всех небезопасных методов HashMap.
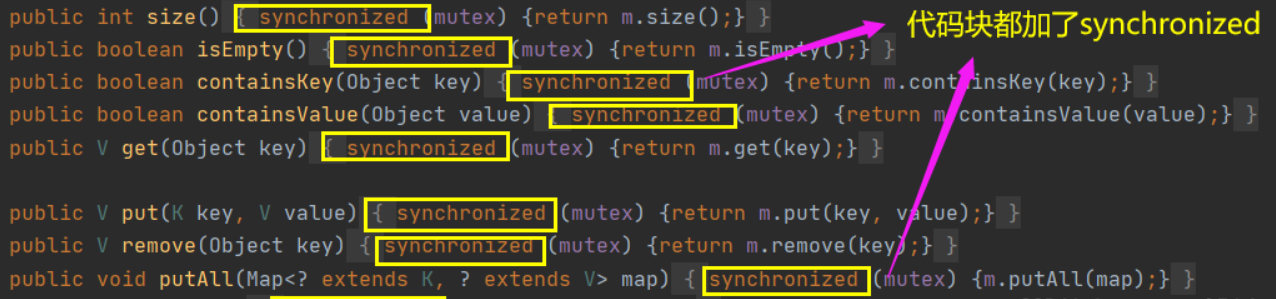
Есть два ключевых момента инкапсуляции
1) использовать классический синхронизированный для взаимного исключения
2) использовать режим прокси для создания нового класса, который также реализует интерфейс карты.На хэшмапе синхронизированный блокирует объект, поэтому первый применить для блокировки другие потоки войдут в блок, ожидая пробуждения
Достоинства: реализация кода очень проста, разобраться можно с первого взгляда
Недостатки: с точки зрения блокировки блокируется максимально возможный блок кода, поэтому производительность будет относительно низкой.
ConcurrentHashMap (обычно используется)
В JDK 1.7 механизм блокировки сегментов используется для реализации параллельных операций обновления.Нижний уровень принимает структуру хранения массив + связанный список, включая два основных статических внутренних класса Segment и HashEntry.
①. Сегмент наследует ReentrantLock (реентерабельная блокировка), чтобы действовать как блокировка. Каждый объект сегмента защищает несколько сегментов каждой таблицы сопоставления хэшей; ②.
HashEntry используется для инкапсуляции пар ключ-значение таблицы сопоставления;
③. Каждый сегмент A связанный список, связанный несколькими объектами HashEntry
Блокировка сегмента : В массиве Segment объект Segment является блокировкой, которая соответствует массиву HashEntry, синхронизация данных в этом массиве зависит от этой же блокировки, и чтение и запись разных массивов HashEntry не мешают друг другу.
В JDK 1.8 от исходной блокировки сегмента отказались, чтобы обеспечить использование Node + CAS + Synchronized для обеспечения безопасности параллелизма. Отмените класс Segment и напрямую используйте массив таблиц для хранения пар ключ-значение; когда длина связанного списка, состоящего из объектов Node, превышает TREEIFY_THRESHOLD, связанный список преобразуется в красно-черное дерево для повышения производительности. Нижний слой изменен на массив + связанный список + красно-черное дерево.
Производительность CAS очень высока, но синхронизация всегда была тяжеловесной блокировкой, в jdk1.8 была введена синхронизация, использующая способ обновления блокировки.
Для синхронизированного способа получения блокировок JVM использует метод оптимизации обновления блокировки, который заключается в использовании предвзятой блокировки, чтобы дать приоритет тому же потоку, а затем снова получить блокировку. lock.Если это не удается, он будет вращаться в течение короткого времени, чтобы предотвратить приостановку потока системой. Наконец, если все вышеперечисленное не помогло, установите более тяжелый замок.
Предвзятая блокировка: чтобы свести к минимуму ненужное упрощенное выполнение блокировки без многопоточной конкуренции, всегда есть только один поток, выполняющий блок синхронизации, и ни один другой поток не выполняет синхронизацию, пока не завершит выполнение снятия блокировки.
Облегченная блокировка: при наличии двух конкурирующих потоков она будет обновлена до облегченной блокировки. Основная цель введения облегченных блокировок — снизить потребление производительности традиционными тяжеловесными блокировками с использованием мьютексов операционной системы без многопоточной конкуренции.
Тяжелая блокировка: в большинстве случаев в один и тот же момент времени за одну и ту же блокировку часто конкурируют несколько потоков.В режиме пессимистической блокировки потоки, которые не могут конкурировать, будут постоянно переключаться между заблокированным и пробужденным состояниями, что относительно дорого.
Из-за ограниченного места анализ исходного кода ConcurrentHashMap не будет здесь показан, а блог с подробным содержанием будет добавлен позже, когда будет время.