Tabla de contenido
3.1 Ver a través del catálogo del sistema
estado de hibernación del disco D
5. Proceso zombie y proceso huérfano
5.1.1 El concepto de proceso zombie
6. Espacio de direcciones del proceso
6.1 Verificación del espacio de direcciones del proceso
6.2 Percepción del espacio de direcciones del proceso
7.2 Por qué existe la prioridad
7.4 Modificar el valor agradable del proceso
8.2 Variables de entorno comunes
8.3 Comandos relacionados con variables de entorno
8.4 Organización de las variables de entorno
8.5 Métodos de obtención de variables de entorno
8.5.1 parámetros de la función principal
8.5.2 Entorno variable de terceros
1. Concepto de proceso
Concepto de libro de texto : una instancia de ejecución de un programa, un programa en ejecución, etc.
Punto de vista del núcleo : una entidad que asigna recursos del sistema (tiempo de CPU, memoria)
Cuando el código se compila y vincula, se generará un programa ejecutable.Este programa ejecutable es esencialmente un archivo y se almacena en el disco. Cuando se ejecuta el programa ejecutable, el programa esencialmente se carga en la memoria, porque solo después de cargarlo en la memoria, la CPU puede ejecutar la declaración línea por línea, y una vez que el programa se carga en la memoria, este programa no debería llamarse programa, debería llamarse proceso en sentido estricto .
Además, los procesos y los programas no necesariamente se corresponden entre sí, un programa puede ejecutarse varias veces al mismo tiempo y existen múltiples procesos.
Competitividad: hay muchos procesos del sistema, pero solo una pequeña cantidad de recursos de CPU, o incluso uno, por lo que los procesos son competitivos. Para completar las tareas de manera eficiente y competir por los recursos relacionados de manera más razonable, tienen prioridades
Independencia: la operación multiproceso requiere el uso exclusivo de varios recursos y no interfiere entre sí durante la operación multiproceso
Paralelismo: Múltiples procesos se ejecutan simultáneamente bajo múltiples CPU, lo que se denomina paralelismo
Simultaneidad: varios procesos utilizan la conmutación de procesos en una CPU para permitir que varios procesos avancen en un período de tiempo, lo que se denomina simultaneidad.
2. Describa el proceso PCB
Hay una gran cantidad de procesos en nuestro ordenador, y se requiere del sistema operativo para gestionarlos. ¿Cómo gestionarlo? Describe primero, organiza después
El sistema operativo describe cada proceso, forma bloques de control de procesos (PCB, esencialmente una estructura) y organiza estos PCB en forma de una lista doblemente enlazada.

PCB es en realidad un término general para los bloques de control de procesos. El bloque de control de procesos en Linux es task_struct, que contiene principalmente la siguiente información:
Identificador : el identificador único que describe este proceso se utiliza para distinguir otros procesos.
Estado : estado de la tarea, código de salida, señal de salida, etc.
Prioridad : Prioridad relativa a otros procesos.
Contador de Programa (pc) : La dirección de la siguiente instrucción a ser ejecutada en el programa.
Punteros de memoria : incluidos punteros al código del programa y datos relacionados con el proceso, así como punteros a bloques de memoria compartidos con otros procesos.
Datos de contexto : Los datos en los registros del procesador cuando se ejecuta el proceso.
Información de estado de E/S : incluidas las solicitudes de E/S mostradas, los dispositivos de E/S asignados al proceso y una lista de archivos utilizados por el proceso.
Información de facturación : puede incluir la suma del tiempo del procesador, la suma de los relojes utilizados, los límites de tiempo, el número de cuenta de facturación, etc.
Información adicional : ...
3. Revisa el proceso
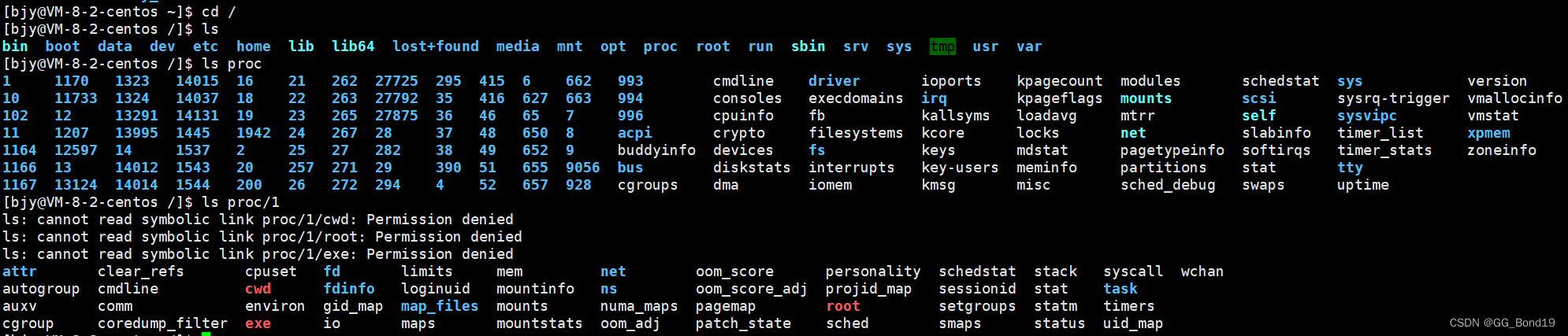
3.1 Ver a través del catálogo del sistema
Hay un directorio del sistema llamado proc debajo del directorio raíz, que contiene mucha información del proceso. Los nombres de directorio de algunos de los subdirectorios son números, estos números son en realidad el PID de un determinado proceso, y la información diversa del proceso correspondiente se registra en la carpeta correspondiente. Si desea ver la información de proceso del proceso con PID 1, puede ver la carpeta denominada 1.
3.2 Ver por comando ps
Para el uso específico del comando ps, puede usar el comando man 1 ps para ver la documentación
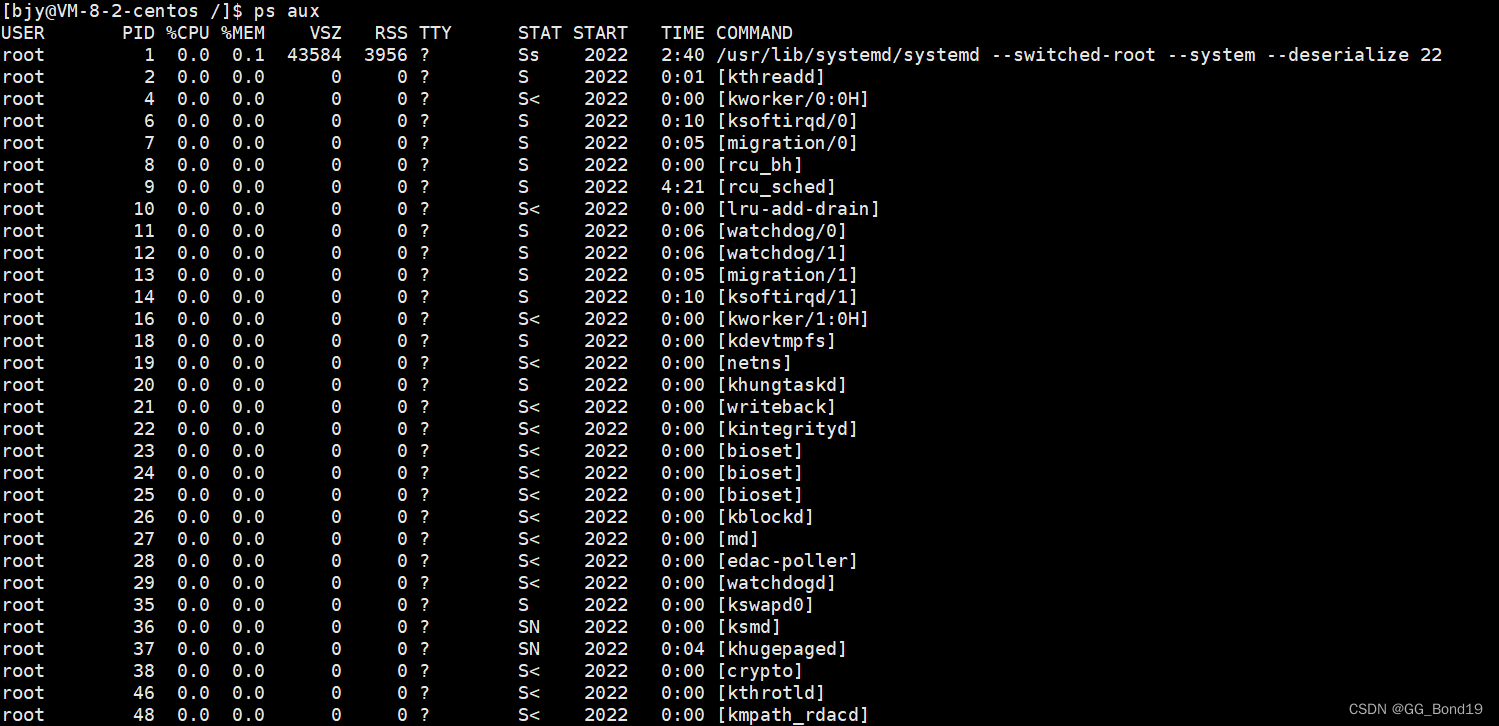

La siguiente situación ocurre cuando se usa el comando ps -l en el sistema operativo Linux.

- UID: representa la identidad del ejecutor.
- PID: representa el nombre en clave de este proceso.
- PPID: representa de qué proceso se deriva este proceso, es decir, el nombre de código del proceso principal.
- PRI: Representa la prioridad con la que se puede ejecutar este proceso, cuanto menor sea el valor, antes se ejecutará.
- NI: representa el buen valor de este proceso.
4. Estado del proceso

El código fuente del sistema operativo Linux tiene la siguiente definición para el estado del proceso:
static const char *task_state_array[] = {
"R (running)", /* 0*/
"S (sleeping)", /* 1*/
"D (disk sleep)", /* 2*/
"T (stopped)", /* 4*/
"T (tracing stop)", /* 8*/
"Z (zombie)", /* 16*/
"X (dead)" /* 32*/
};Estado de funcionamiento R
Todos los procesos en ejecución (es decir, los procesos que se pueden programar) se colocan en la cola de ejecución. Cuando el sistema operativo necesita cambiar el proceso para que se ejecute, selecciona directamente el proceso para que se ejecute en la cola de ejecución. Un proceso está en ejecución (running), no significa que el proceso deba estar en ejecución. El estado de ejecución indica que un proceso se está ejecutando o está en la cola de ejecución. Es decir, pueden existir múltiples procesos en el estado R al mismo tiempo.
estado de sueño
significa que el proceso está esperando que se complete un evento (este estado de suspensión también se puede llamar suspensión interrumpible )
Por ejemplo, cuando el proceso realiza un bucle para mostrar la pantalla, debido a que la velocidad de procesamiento de la CPU es extremadamente rápida, pero la velocidad de la pantalla es relativamente lenta, el proceso debe esperar el recurso de la pantalla (la CPU procesará otros procesos en este momento). En este momento, el proceso cambiará constantemente entre el estado de ejecución y el estado de suspensión, pero debido a la alta velocidad de la CPU, existe una alta probabilidad de que veamos el estado de suspensión al observar
#include <stdio.h>
int main()
{
while(1){
printf("handsome boy!\n");
}
return 0;
} 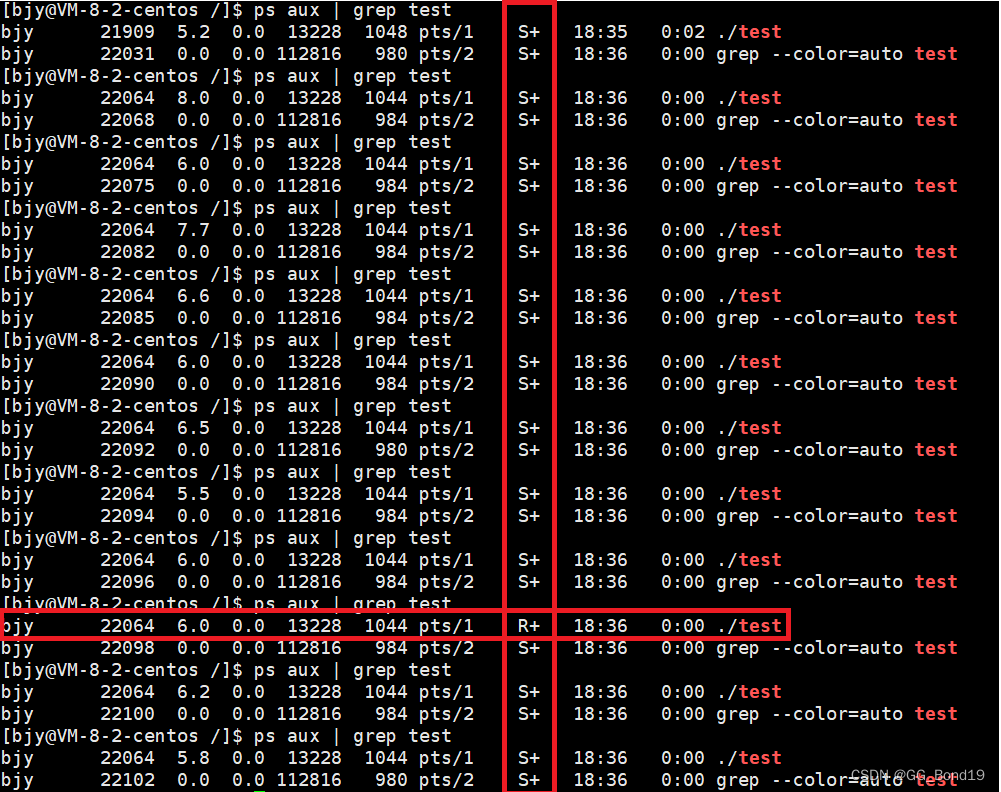
Hay un signo + cuando se muestra el estado, lo que indica que el proceso es un proceso en primer plano y, si no, es un proceso en segundo plano.
El proceso en este estado de suspensión se puede matar, como usar el comando matar para enviar una señal
estado de hibernación del disco D
Un proceso está en el estado de suspensión del disco, lo que significa que el proceso no se eliminará, ni siquiera el sistema operativo, solo el proceso se eliminará cuando se active automáticamente. También se le puede llamar estado de suspensión ininterrumpida (ininterruptible sleep), y el proceso en este estado generalmente espera el final de IO.
Por ejemplo, si un proceso requiere escribir en el disco, el proceso se encuentra en un estado de suspensión profunda durante la escritura en el disco y no se puede eliminar. Porque el proceso necesita esperar la respuesta del disco (si la escritura es exitosa) para dar la respuesta correspondiente.
Use el comando dd para simular la hibernación del disco
Estado en pausa T
En Linux, podemos enviar el proceso al estado suspendido enviando la señal SIGSTOP, y el proceso en estado suspendido puede continuar ejecutándose enviando la señal SIGCONT.

Estado zombi Z
Cuando un proceso está a punto de salir, a nivel del sistema, los recursos que el proceso ha solicitado no se liberan de inmediato, sino que se almacenan temporalmente durante un período de tiempo para que los lea el sistema operativo o su proceso principal. , los datos relevantes no serán liberados.Si un proceso está esperando que se lea su información de salida, llamamos al proceso en un estado zombie. (La información de salida del proceso se almacena en task_struct del proceso)
La existencia del estado zombi es necesaria, porque el propósito del proceso es completar una determinada tarea, luego, cuando se completa la tarea, la persona que llama debe saber la finalización de la tarea, por lo que debe haber un estado zombi, para que el la persona que llama puede conocer el estado de finalización de la tarea, para poder realizar las operaciones de seguimiento correspondientes.
estado de muerteX
El estado de muerte es solo un estado de retorno, cuando se lee la información de salida de un proceso, los recursos solicitados por el proceso se liberarán de inmediato y el proceso ya no existirá, por lo que es casi imposible ver el estado de muerte en el lista de tareas. .
bloqueo (extendido)
Cuando un proceso se está ejecutando, la CPU lo programa. Es decir, el proceso necesita usar recursos de la CPU cuando se programa. Cada CPU tiene una cola de espera en ejecución (cola de ejecución), y la CPU obtiene el proceso de la cola para programar cuando se está ejecutando.

Los procesos en la cola de espera en ejecución están esencialmente esperando recursos de CPU. De hecho, no solo esperan recursos de CPU, sino también otros recursos, como recursos de bloqueo, recursos de disco, recursos de tarjeta de red, etc., tienen sus propios recursos correspondientes. cola de espera de recursos

En correspondencia con el estado en Linux, el bloqueo es el estado de suspensión S y el estado de suspensión del disco D
5. Proceso zombie y proceso huérfano
5.1 Proceso zombi
5.1.1 El concepto de proceso zombie
Si un proceso está esperando que se lea su información de salida, decimos que el proceso está en un estado zombie. Un proceso en estado zombie es un proceso zombie.
En el siguiente código, el proceso secundario creado por la función de bifurcación saldrá después de imprimir información 5 veces, mientras que el proceso principal siempre imprimirá información. Es decir, el proceso secundario sale, el proceso principal todavía se está ejecutando, pero el proceso principal no lee la información de salida del proceso secundario, entonces el proceso secundario entra en estado zombi.
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
int main()
{
pid_t id = fork();
if(id == 0)
{
int count = 5;
while(count){
printf("I am child...PID:%d, PPID:%d, count:%d\n", getpid(), getppid(), count);
sleep(1);
count--;
}
printf("child quit...\n");
exit(1);
}
else if(id > 0)
{
while(1){
printf("I am father...PID:%d, PPID:%d\n", getpid(), getppid());
sleep(1);
}
}
else{
exit(-1);
}
return 0;
}

5.1.2 Daño del Proceso Zombie
- Si el proceso padre nunca lee la información de salida del proceso, el proceso hijo siempre estará en un estado zombie.
- La información de salida del proceso zombi se almacena en task_struct.Si el proceso zombi no sale, la PCB debe mantenerse todo el tiempo.
- Si un proceso principal crea muchos procesos secundarios pero no los recicla, se desperdiciarán recursos.
- Los recursos solicitados por los procesos zombis no se pueden reciclar, por lo que cuantos más procesos zombis haya, menos recursos estarán realmente disponibles y los procesos zombis provocarán fugas de memoria.
5.2 Procesos huérfanos
Si el proceso principal sale primero, cuando el proceso secundario entre en el estado zombie en el futuro, no habrá ningún proceso principal para procesarlo.En este momento, el proceso secundario se denomina proceso huérfano. Si la información de salida del proceso huérfano no se procesa todo el tiempo, el proceso huérfano siempre ocupará recursos, lo que provocará una fuga de memoria. Por lo tanto, cuando ocurre un proceso huérfano, el proceso init n.° 1 adoptará el proceso huérfano y, luego, cuando el proceso huérfano entre en estado zombi, será procesado y reciclado por el proceso int.
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
int main()
{
pid_t id = fork();
if(id == 0){ //child
int count = 5;
while(1){
printf("I am child...PID:%d, PPID:%d\n", getpid(), getppid(), count);
sleep(1);
}
}
else if(id > 0){ //father
int count = 5;
while(count){
printf("I am father...PID:%d, PPID:%d, count:%d\n", getpid(), getppid(), count);
sleep(1);
count--;
}
printf("father quit...\n");
exit(0);
}
else{ //fork error
exit(-1);
}
return 0;
}

Dado que el proceso huérfano será adoptado por el proceso init1, no causará daño.
6. Espacio de direcciones del proceso
6.1 Verificación del espacio de direcciones del proceso
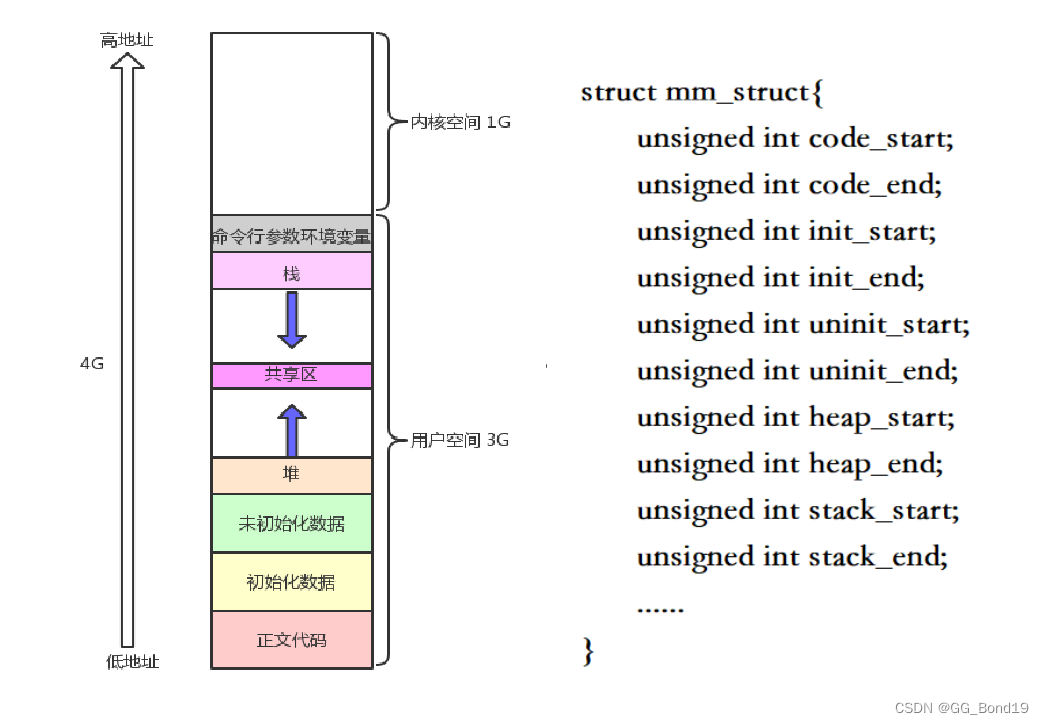
El siguiente código puede verificar que el espacio de direcciones del proceso es consistente con la figura anterior
#include <stdio.h>
#include <stdlib.h>
int un_val;
int init_val = 100;
int main(int argc,char* argv[],char* env[])
{
int i = 0;
int count = 0;
while(env[i] != NULL && count < 5){
printf("环境变量地址: %p\n",env[i]);
++count;
}
for(int i = 0;i < argc; ++i){
printf("命令行参数地址: %p\n",argv[i]);
}
char* p1 = (char*)malloc(10);
char* p2 = (char*)malloc(10);
char* p3 = (char*)malloc(10);
printf("栈区地址: %p\n",&p3);
printf("栈区地址: %p\n",&p2);
printf("栈区地址: %p\n",&p1);
printf("堆区地址: %p\n",p3);
printf("堆区地址: %p\n",p2);
printf("堆区地址: %p\n",p1);
printf("未初始化数据区: %p\n",&un_val);
printf("初始化数据区: %p\n",&init_val);
printf("代码区: %p\n",main);
return 0;
}
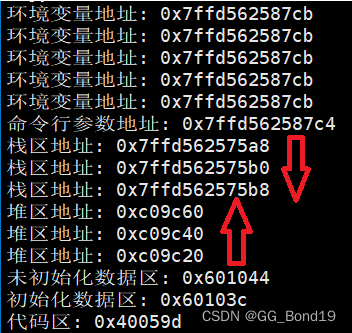
El área de la pila crece hacia las direcciones más bajas y el área del montón crece hacia las direcciones más altas.
6.2 Percepción del espacio de direcciones del proceso
A través del siguiente código podemos encontrar un problema
#include <stdio.h>
#include <unistd.h>
#include <sys/types.h>
#include <stdlib.h>
int val = 100;
int main()
{
pid_t id = fork();
if(id < 0)//err
{
exit(-1);
}
else if(id > 0)//father
{
sleep(3);
printf("PID:%d PPID:%d val:%d &val:%p\n",getpid(),getppid(),val,&val);
}
else//id == 0
{
val = 200;
printf("PID:%d PPID:%d val:%d &val:%p\n",getpid(),getppid(),val,&val);
}
return 0;
}

En el código, se crea un proceso secundario con la función de bifurcación, y se le pide al proceso secundario que cambie la variable global val de 100 a 200 y la imprima, mientras que el proceso principal duerme primero durante 3 segundos y luego imprime el valor de la variable global. Es lógico que el valor de la variable global impresa por el proceso secundario sea 200, y el proceso principal imprima la variable global después de que el proceso secundario cambie la variable global, por lo que también debería ser 200. Pero el resultado no lo es, y la dirección de la variable val en los dos procesos es la misma, pero ¿por qué los resultados impresos son inconsistentes?
Si obtuvimos los datos en la misma dirección física, debe ser el mismo, pero ahora los valores obtenidos en la misma dirección son diferentes, lo que solo demuestra que la dirección que imprimimos definitivamente no es una dirección física .
De hecho, las direcciones que imprimimos a nivel de idioma no son direcciones físicas, sino direcciones virtuales. Los usuarios no pueden ver la dirección física en absoluto y el sistema operativo la administra de manera uniforme. Entonces, incluso si las direcciones (direcciones virtuales) de las variables globales impresas en los procesos padre e hijo son las mismas, los valores de las variables globales en los dos procesos son diferentes.
6.3 Cognición detallada
El tamaño de la dirección del espacio de direcciones del proceso es de 0x00000000 a 0xffffffff, y se divide en varias áreas, como área de código, área de montón, área de pila, etc. En la estructura mm_struct , se registran las direcciones límite de cada área. Dado que la dirección virtual crece linealmente de 0x00000000 a 0xffffffff, la dirección virtual también se denomina dirección lineal .
El crecimiento hacia arriba del montón y el crecimiento hacia abajo de la pila en realidad están cambiando las direcciones de límite del montón y la pila en mm_struct.
El programa ejecutable que generamos en realidad está dividido en varias áreas (como el área de inicialización, el área de no inicialización, etc.) y utiliza el mismo método de direccionamiento que en el kernel de Linux. Cuando el programa ejecutable se está ejecutando, el sistema operativo puede cargar los datos correspondientes en la memoria correspondiente, lo que mejora en gran medida la eficiencia de funcionamiento del sistema operativo. La operación de "partición" del programa ejecutable es en realidad el compilador , por lo que el nivel de optimización del código es en realidad la última palabra del compilador.

Cuando se crea cada proceso, también se crearán su bloque de control de proceso correspondiente (task_struct) y el espacio de direcciones del proceso (mm_struct). El sistema operativo puede encontrar su mm_struct a través de task_struct del proceso, porque hay un puntero de estructura en task_struct que almacena la dirección de mm_struct.

Cuando se acaba de crear el proceso hijo, los datos y el código del proceso hijo y el proceso padre se comparten, es decir, el código y los datos de los procesos padre e hijo se asignan al mismo espacio de memoria física a través de la tabla de páginas. Solo cuando el proceso principal o el proceso secundario necesitan modificar los datos, los datos del proceso principal se copian en la memoria y luego se modifican. Como reflejo de la independencia entre los procesos, esta tecnología de copiar solo cuando se requiere la modificación de datos se denomina tecnología de copia en escritura .
¿Por qué no copiar los datos cuando se crea el proceso secundario?
Existe una alta probabilidad de que el proceso secundario no utilice todos los datos del proceso principal y, si el proceso secundario no escribe datos, no es necesario copiarlos. Reasignar cuando sea necesario modificar los datos (asignación retrasada), para que el espacio de memoria se pueda usar de manera eficiente
¿El código será de copia sobre escritura?
En la mayoría de los casos, no lo es, pero esto no significa que el código no se pueda copiar al escribir, por ejemplo, al realizar el reemplazo del proceso, se requiere copiar al escribir el código.
¿Por qué hay un espacio de direcciones de proceso?
- El espacio de direcciones del proceso y la tabla de páginas son creados y administrados por el sistema operativo. Cualquier acceso o asignación ilegal será terminado por el sistema operativo, que protege todos los datos legales en la memoria física (los datos válidos relevantes de cada proceso y el kernel), y no habrá ningún problema de fuera de los límites a nivel del sistema.
- Con el espacio de direcciones del proceso, cada proceso ve el mismo rango de espacio, incluida la composición del espacio de direcciones del proceso y el orden de división de las áreas internas, etc., de modo que cuando escribimos programas, solo debemos centrarnos en las direcciones virtuales, no sobre dónde se almacenan realmente los datos en la memoria física. Permite que el proceso mire la memoria desde una perspectiva unificada, facilita la compilación y carga de todos los programas ejecutables de forma unificada y simplifica el diseño y la implementación del propio proceso.
- Con el espacio de direcciones del proceso, cada proceso piensa que está monopolizando la memoria, lo que puede completar mejor la independencia del proceso y usar el espacio de memoria de manera razonable (abrir el espacio de memoria cuando realmente se necesita usar), y puede desacoplar el proceso programación desde la gestión de memoria.
¿Cómo se crean los procesos?
La creación de un proceso va acompañada de la creación de su bloque de control de proceso (task_struct), espacio de direcciones de proceso (mm_struct) y tabla de páginas
7. Prioridad del proceso
7.1 Concepto de prioridad
La prioridad es en realidad el orden en que se obtienen ciertos recursos, y la prioridad del proceso es en realidad el orden en que los procesos obtienen la asignación de recursos de la CPU, que se refiere a la prioridad del proceso. Los procesos con alta prioridad tienen prioridad en la ejecución.
7.2 Por qué existe la prioridad
La razón principal de la existencia de la prioridad es que los recursos son limitados, y la razón principal de la existencia de la prioridad del proceso es que los recursos de la CPU son limitados. Una CPU solo puede ejecutar un proceso a la vez y puede haber varios procesos, por lo que hay una necesidad de nivel de prioridad de proceso, para determinar el orden en que los procesos obtienen recursos de CPU.
7.3 PRI y NI
- PRI representa la prioridad del proceso, es decir, el orden en que la CPU ejecuta los procesos, cuanto menor sea el valor, mayor será la prioridad del proceso.
- NI representa el valor agradable, que representa el valor modificado de la prioridad a la que se puede ejecutar el proceso.
- Cuanto menor sea el valor de PRI, más rápido se ejecutará Cuando se agregue el valor agradable, el PRI se convertirá en: PRI (nuevo) = PRI (antiguo) + NI.
- Si el valor de NI es negativo, el PRI del proceso será menor, es decir, su prioridad será mayor.
- Ajustar la prioridad del proceso, bajo Linux, es ajustar el buen valor del proceso.
- El rango de valores de NI es de -20 a 19, un total de 40 niveles.
Nota: En el sistema operativo Linux, PRI (antiguo) por defecto es 80 , es decir, PRI = 80 + NI.
7.4 Modificar el valor agradable del proceso
7.4.1 comando superior
El comando superior es equivalente al administrador de tareas en el sistema operativo Windows, puede monitorear dinámicamente el uso de recursos del proceso en el sistema
Después de usar el comando superior y presionar la tecla "r", se le pedirá que ingrese el PID del proceso cuyo valor de Niza se desea ajustar; después de ingresar el PID del proceso y presionar Enter, se le pedirá que ingrese el Niza ajustado valor. Si desea salir, ingrese q.
7.4.2 comando renice
renice + valor agradable cambiado + PID
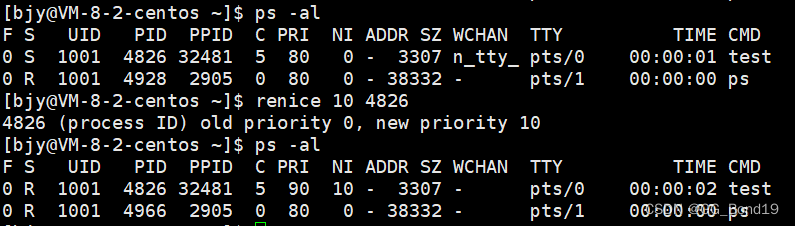
Si desea utilizar el comando renice para ajustar el valor de NI a un valor negativo, necesita privilegios de root
Ocho, variables de entorno
8.1 Concepto
Las variables de entorno (environment variables) generalmente se refieren a algunos parámetros utilizados en el sistema operativo para especificar el entorno operativo del sistema operativo. Por ejemplo, al escribir código C/C++, cuando se vincula cada archivo de objeto, nunca se sabe dónde está la biblioteca estática y dinámica vinculada, pero aún se puede vincular con éxito para generar un programa ejecutable. La razón es que hay un entorno relevante variables para ayudar al compilador a encontrar .
Las variables de entorno suelen tener algún propósito especial y suelen ser globales en el sistema .
8.2 Variables de entorno comunes
- RUTA: especifique la ruta de búsqueda del comando (el comando del sistema es esencialmente un programa ejecutable, pero no necesita especificar la ruta al iniciar)
- INICIO: especifique el directorio de trabajo principal del usuario (es decir, el directorio predeterminado donde el usuario inicia sesión en el sistema Linux)
- SHELL: el Shell actual, su valor suele ser /bin/bash

8.3 Comandos relacionados con variables de entorno
echo : muestra el valor de una variable de entorno
![]()
exportar : establecer una nueva variable de entorno

env : muestra todas las variables de entorno

set : Mostrar variables de entorno y variables de shell definidas localmente
unset : Borrar variables de entorno

8.4 Organización de las variables de entorno
En el sistema Linux, las variables de entorno se organizan de la siguiente manera:
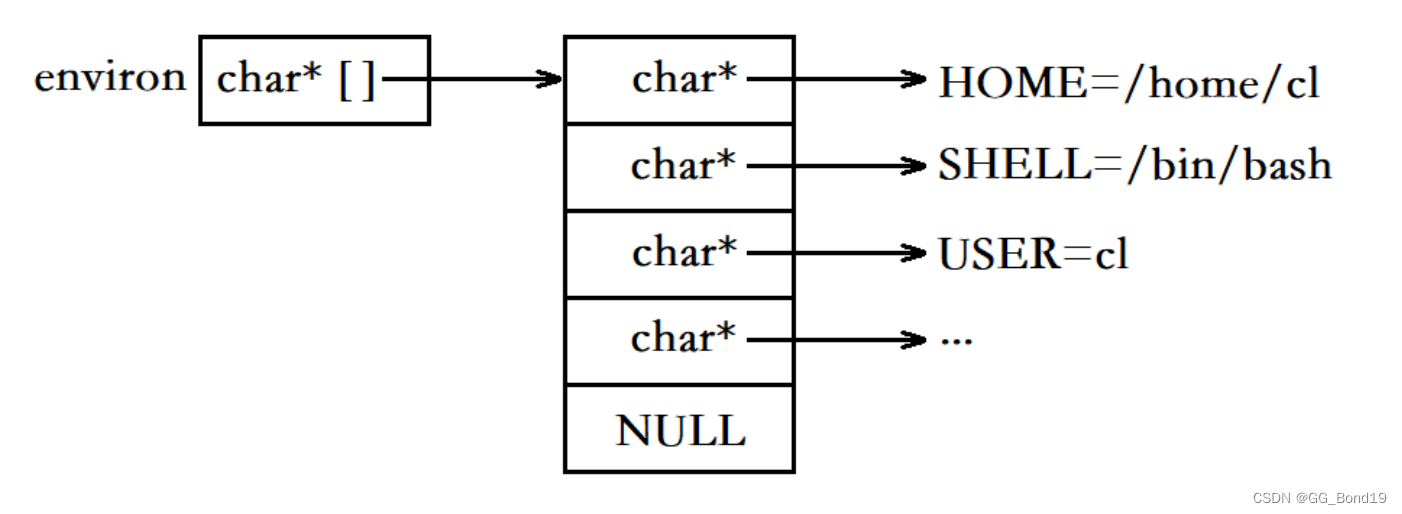
Cada programa recibirá una tabla de variables de entorno, la tabla de entorno es una matriz de punteros de caracteres, cada puntero apunta a una cadena de entorno que termina en '\0' y el último puntero de carácter está vacío.
8.5 Métodos de obtención de variables de entorno
8.5.1 parámetros de la función principal
La función principal en realidad tiene tres parámetros formales, pero no se usan con frecuencia, por lo que no se escriben.
int main(int argc, char* argv[],char* env[])
{ …… }El segundo parámetro de la función principal es una matriz de punteros de caracteres. El primer puntero de caracteres en la matriz almacena la cadena del programa ejecutable, y el resto de los punteros de caracteres almacenan las cadenas de las opciones dadas. El último carácter El puntero es vacío, y el primer parámetro de la función principal representa el número de elementos válidos en la matriz de punteros de caracteres. El tercer parámetro de la función principal en realidad recibe la tabla de variables de entorno, y podemos obtener las variables de entorno del sistema a través del tercer parámetro de la función principal.
#include <stdio.h>
int main(int argc, char* argv[], char* env[])
{
for(int i = 0; env[i] != NULL; ++i){
printf("%s\n",env[i]);
}
return 0;
}
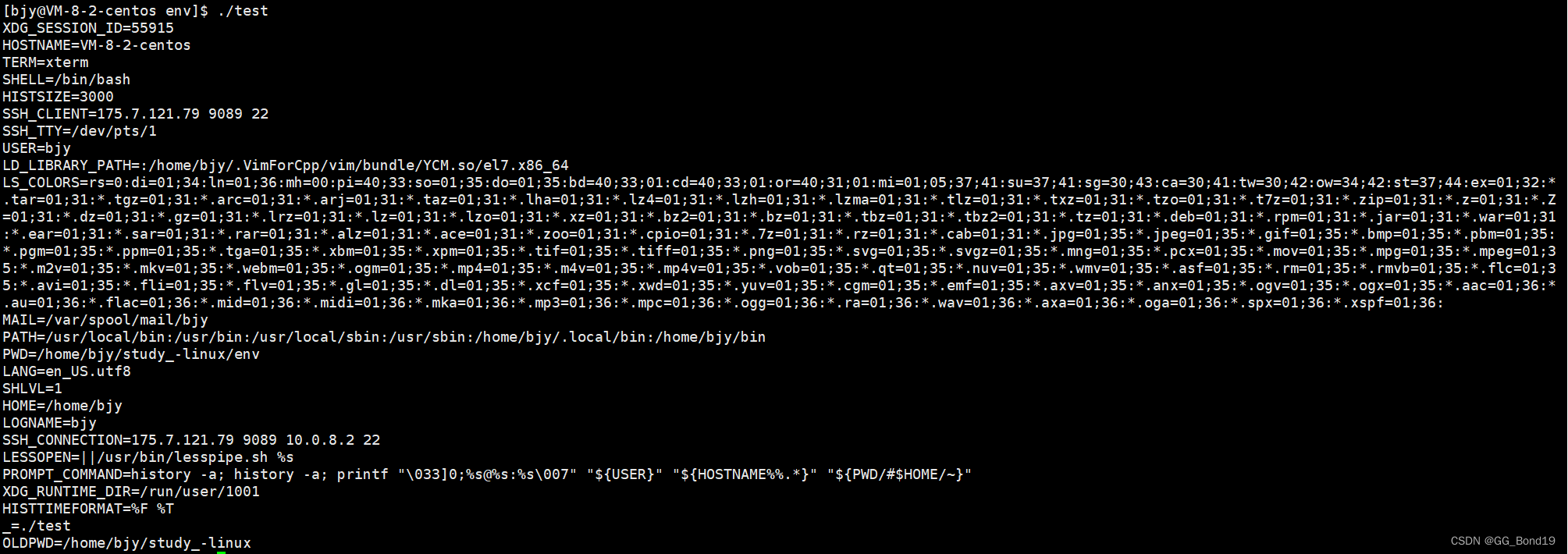
8.5.2 Entorno variable de terceros
El lenguaje c nos proporciona un entorno variable global, que se puede utilizar para acceder a la tabla de entorno.
#include <stdio.h>
int main()
{
extern char** environ;
for(int i = 0;environ[i] != NULL; ++i){
printf("%s\n",environ[i]);
}
return 0;
}
8.5.3 función getenv
Las variables de entorno se pueden obtener llamando a la función getenv del sistema. La función getenv puede buscar en la tabla de variables de entorno de acuerdo con el nombre de la variable de entorno dado y devolver un puntero de cadena que apunta al valor correspondiente.
#include <stdio.h>
#include <stdlib.h>
int main()
{
printf("%s\n",getenv("PATH"));
return 0;
}
![]()