Autor: JD Retail Zhang Luyao
1. Escenarios de aplicación
En la actualidad, hay muchas funciones en el sistema que requieren un procesamiento retrasado: cancelación del tiempo de espera de pago, tiempo de espera de espera, envío retrasado de SMS, WeChat y otros recordatorios, actualización de token, vencimiento de la tarjeta de membresía, etc. A través del procesamiento retrasado, los recursos del sistema se ahorran en gran medida y no hay necesidad de sondear la base de datos para tareas de procesamiento.
En la actualidad, la mayoría de las funciones se completan con tareas de temporización. Hay dos tipos de tareas de temporización: cuarzo y xxljob. El tiempo de sondeo es corto y se ejecuta una vez por segundo, lo que ejerce cierta presión sobre la base de datos y tiene una duración de 1 segundo. error. El tiempo de sondeo es largo, por ejemplo, una vez cada 30 minutos, se inserta un dato a las 03:01, y el vencimiento normalmente se ejecuta a las 3:31, pero cuando el sondeo se realiza a las 3:30, los datos de 3:00-3:30 se escanea, pero el escaneo es menor que 3: ¡Los datos de 31 solo se pueden escanear a las 4:00, lo que equivale a un retraso de 29 minutos!
2. Investigación sobre métodos de procesamiento de demoras
1.DelayQueue
1. Método de implementación:
La cola de bloqueo de retraso proporcionada por jvm clasifica las tareas con diferentes tiempos de retraso a través de la cola de prioridad, bloquea la condición y adquiere las tareas retrasadas durante el tiempo de retraso de suspensión.
Cuando se agrega una nueva tarea, juzgará si la nueva tarea es la primera tarea que se ejecutará. Si es así, se liberará la suspensión de la cola para evitar que los elementos recién agregados deban ejecutarse y no puedan obtenerse normalmente mediante la ejecución. hilo.
2. Problemas existentes:
1. Operación independiente, después de que el sistema está inactivo, no se puede realizar un reintento efectivo
2. No realizar el registro y la copia de seguridad
3. Sin mecanismo de reintento
4. Cuando el sistema se reinicie, ¡la tarea se borrará!
5. No se permite el consumo de fragmentos
3. Ventajas: implementación simple, bloqueo cuando no hay tarea, ahorro de recursos y tiempo de ejecución preciso
2. Cola de retraso mq
Método de implementación: confíe en mq y logre la función de consumo retrasado configurando el tiempo de consumo retrasado. Al igual que rabbitMq y jmq, puede configurar el tiempo de consumo retrasado. RabbitMq se implementa estableciendo el tiempo de caducidad del mensaje y colocándolo en la cola de mensajes fallidos para su consumo.
Problemas existentes:
1. La configuración de tiempo no es flexible. Cada cola tiene un tiempo de caducidad fijo. Cada vez que se crea una cola de retraso, se debe crear una nueva cola de mensajes.
Ventajas: Confiando en jmq, puede monitorear, consumir registros y reintentar de manera efectiva, tiene la capacidad de consumir varias máquinas al mismo tiempo y no teme el tiempo de inactividad
3. Tareas programadas
Sondeo de datos calificados a través de tareas programadas
defecto:
1. Es necesario leer la base de datos comercial, lo que ejerce cierta presión sobre la base de datos.
2. Hay un retraso
3. Cuando la cantidad de datos escaneados es demasiado grande, consume demasiados recursos del sistema.
4. La fragmentación no se puede consumir
ventaja:
1. Después de que falla el consumo, puede continuar consumiendo la próxima vez y tener la capacidad de volver a intentarlo.
2. Poder adquisitivo estable
4.redis
Las tareas se almacenan en redis, y la cola zset de redis se utiliza para ordenar según la puntuación.El programa obtiene continuamente el consumo de datos de la cola a través del hilo para realizar la cola de retraso
ventaja:
1. Consultar redis es más rápido que la base de datos, y la longitud de la cola establecida es demasiado grande, y la consulta se realizará de acuerdo con la estructura de la tabla de salto, que es altamente eficiente
2. Redis se puede ordenar según la marca de tiempo, solo necesita consultar la tarea de la puntuación en la marca de tiempo actual
3. Sin miedo a reiniciar la máquina
4. Consumo distribuido
defecto:
1. Limitado por el rendimiento de redis, 10 W concurrentes
2. Múltiples comandos no pueden garantizar la atomicidad. El uso de secuencias de comandos lua requerirá que todos los datos estén en un fragmento redis.
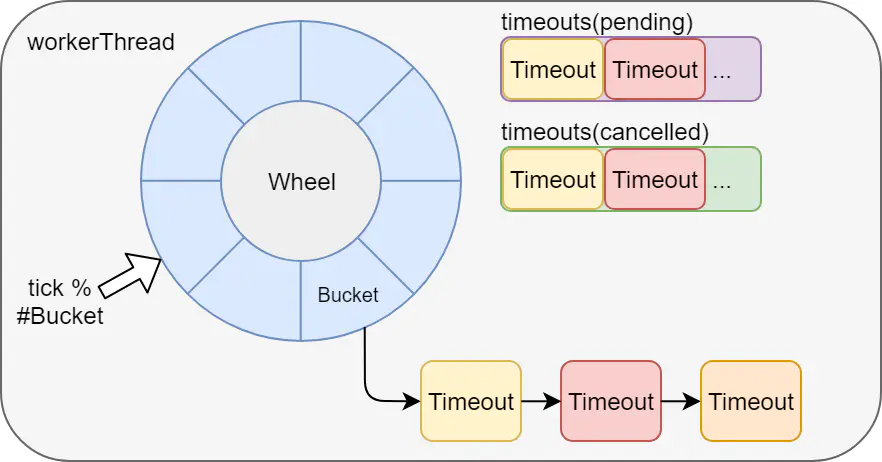
5. Rueda del tiempo
La ejecución de tareas retrasadas a través de la rueda de tiempo también se basa en la operación independiente de jvm. Por ejemplo, kafka y netty implementan ruedas de tiempo, y el perro guardián de redisson también se realiza a través de la rueda de tiempo de netty.
Desventajas: no es adecuado para el uso de servicios distribuidos y las tareas se perderán después del tiempo de inactividad.
3. Lograr metas
Compatible con los componentes de eventos asincrónicos actualmente en uso, y proporciona componentes de retardo de alto rendimiento, más confiables, reintentables, grabados y de monitoreo de alarmas.
• Confiabilidad de transmisión de mensajes: después de que un mensaje ingresa a la cola de espera, se garantiza que se consumirá al menos una vez.
• Soporte de cliente enriquecido: admite varios idiomas.
• Alta disponibilidad: admite la implementación de instancias múltiples. Después de que se suspende una instancia, hay una instancia de respaldo que continúa brindando servicios.
•Tiempo real: se permite cierto error de tiempo.
• Eliminación de mensajes de soporte: los usuarios comerciales pueden eliminar mensajes específicos en cualquier momento.
• Consulta de consumo de soporte
• Reintento manual de soporte
• Aumentar el seguimiento de la ejecución del evento asíncrono actual
4. Diseño de arquitectura
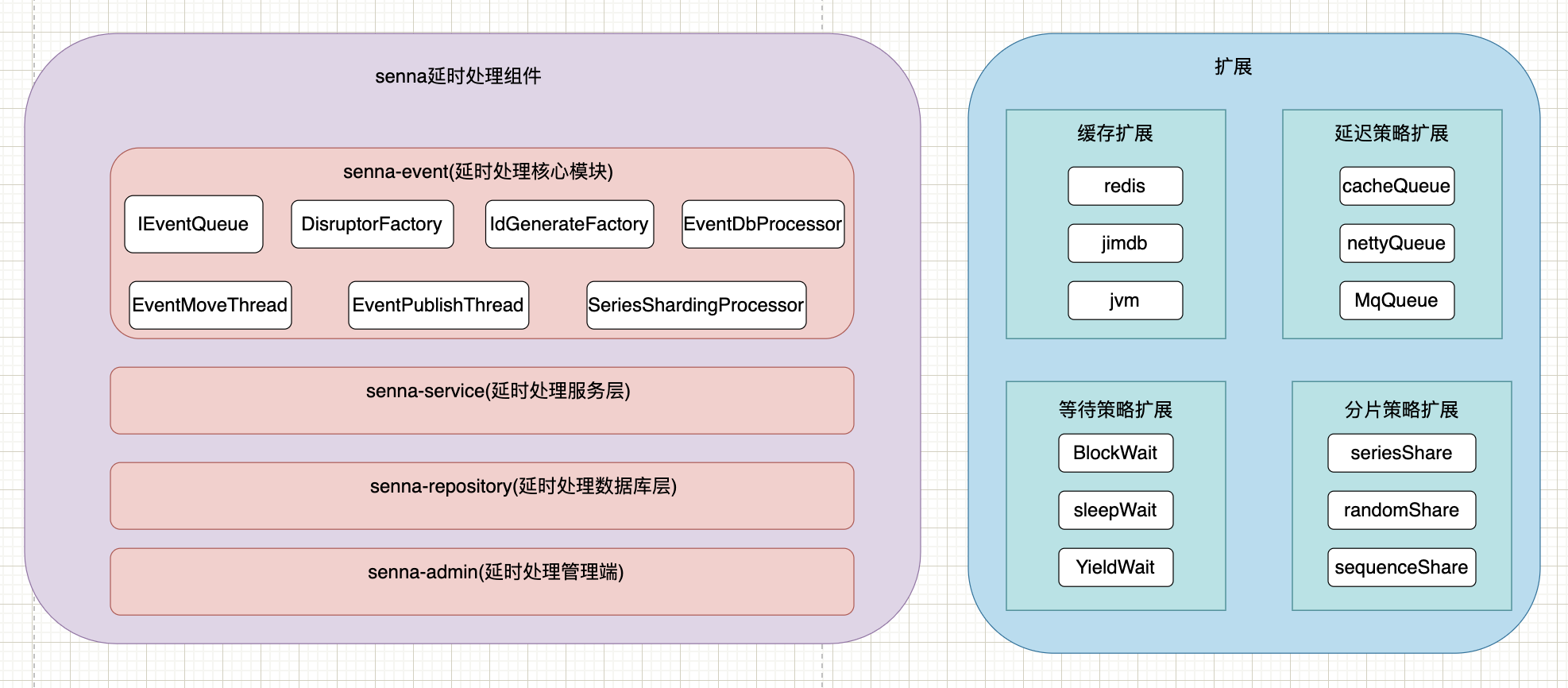
5. Implementación del componente de retraso
1. Principio de implementación
En la actualidad, elegimos usar jimdb para implementar la función de retraso a través de zset, y almacenar la identificación de la tarea y el tiempo de ejecución correspondiente como puntaje en la cola de zset. De manera predeterminada, se ordenarán por puntaje, y cada vez que tomemos la identificación de la tarea de 0-puntuación dentro del tiempo actual,
Al enviar una tarea retrasada, se generará una identificación única de acuerdo con la marca de tiempo + ip de la máquina + nombre de cola + secuencia, y el cuerpo del mensaje se construirá, cifrará y colocará en la cola zset.
Al mover el hilo, la tarea que ha llegado al tiempo de ejecución se mueve a la cola de liberación, esperando que el consumidor la obtenga.
La fiesta de seguimiento integra ump
Los registros de consumo se completan a través de redis backup + persistencia de la base de datos.
El método implementado por el almacenamiento en caché es solo un tipo de implementación, cuyo método de implementación se puede controlar a través de parámetros y se puede expandir libremente a través de spi.
2. Estructura del mensaje
Cada trabajo debe contener los siguientes atributos:
•Tema: tipo de trabajo, es decir, QueueName
•Id: el identificador único del Trabajo. Se utiliza para recuperar y eliminar la información del trabajo especificado.
•Retraso: El trabajo necesita retrasar el tiempo. Unidad: segundos. (El servidor lo convertirá a tiempo absoluto)
•Cuerpo: el contenido del trabajo, que se almacena en formato json para que los consumidores realicen un procesamiento comercial específico.
•traceId: el traceId del subproceso de envío, después de que el pfinder posterior admita la configuración de traceId, puede compartir el mismo traceid con el subproceso de envío, lo cual es conveniente para el seguimiento de registros
La estructura específica se muestra en la siguiente figura:

TTR está diseñado para garantizar la fiabilidad de la transmisión de mensajes.
3. Flujo de datos y diagrama de flujo

Publique y consuma según el método redis-disruptor, que se puede usar como un mensaje. Los consumidores usan la cola sin bloqueo del disruptor de eventos asincrónico original para el consumo, y no hay bloqueo entre diferentes aplicaciones y diferentes colas.
1. Admite la aplicación solo para publicar, no consumir y lograr la función de cola de mensajes.
2: soporte de depósito.Para el problema de las claves grandes, si hay muchos eventos, puede establecer la cantidad de colas de retraso y depósitos de colas de tareas para reducir el problema de bloqueo de redis causado por las claves grandes.
3: A través de la configuración del ducc se amplía el rendimiento, actualmente solo se habilita el consumo y se deshabilita el consumo.
4: admite la configuración de tiempo de espera para evitar que los subprocesos de los consumidores se ejecuten durante demasiado tiempo
Cuello de botella: la velocidad de consumo es lenta y la velocidad de producción es demasiado rápida, lo que hará que la cola del búfer circular se llene. Cuando la aplicación actual es tanto un productor como un consumidor, el productor dormirá y el rendimiento dependerá de la velocidad de consumo. La máquina se puede expandir horizontalmente para mejorar directamente el rendimiento. Supervise la longitud de la cola Redis. Si continúa creciendo, considere agregar consumidores para mejorar directamente el rendimiento.
Situación posible: debido a que una aplicación comparte un disruptor y tiene 64 subprocesos de consumo, si el consumo de un determinado evento es demasiado lento, los 64 subprocesos consumen este evento, lo que hará que otros eventos no sean consumidos por ningún subproceso de consumidor y el productor el subproceso también consumirá está bloqueado, lo que hace que se bloquee el consumo de todos los eventos.
Para observar si existe un cuello de botella de rendimiento de este tipo más adelante, puede asignar a cada cola un grupo de subprocesos de consumidores.
6. ejemplo de demostración
Agregar archivo de configuración
Determinar si habilitar jd.event.enable:true
<dependency> <groupId>com.jd.car</groupId>
<artifactId>senna-event</artifactId>
<version>1.0-SNAPSHOT</version> </dependency>
configuración
jd:
senna:
event:
enable: true
queue:
retryEventQueue:
bucketNum: 1
handleBean: retryHandle
Código de consumo:
package com.jd.car.senna.admin.event;
import com.jd.car.senna.event.EventHandler;
import com.jd.car.senna.event.annotation.SennaEvent;
import lombok.extern.slf4j.Slf4j;
import org.springframework.stereotype.Component;
/**
* @author zhangluyao
* @description
* @create 2022-02-21-9:54 下午
*/
@Slf4j
@Component("retryHandle")
public class RetryQueueEvent extends EventHandler {
@Override
protected void onHandle(String key, String eventType) {
log.info("Handler开始消费:{}", key);
}
@Override
protected void onDelayHandle(String key, String eventType) {
log.info("delayHandler开始消费:{}", key);
}
}
Formulario de anotación:
package com.jd.car.senna.admin.event;
import com.jd.car.senna.event.EventHandler;
import com.jd.car.senna.event.annotation.SennaEvent;
import lombok.extern.slf4j.Slf4j;
/**
* @author zhangluyao
* @description
* @create 2022-02-21-9:54 下午
*/
@Slf4j
@SennaEvent(queueName = "testQueue", bucketNum = 5,delayBucketNum = 5,delayEnable = true)
public class TestQueueEvent extends EventHandler {
@Override
protected void onHandle(String key, String eventType) {
log.info("Handler开始消费:{}", key);
}
@Override
protected void onDelayHandle(String key, String eventType) {
log.info("delayHandler开始消费:{}", key);
}
}
enviar código
package com.jd.car.senna.admin.controller;
import com.jd.car.senna.event.queue.IEventQueue;
import lombok.extern.slf4j.Slf4j;
import org.springframework.context.annotation.Lazy;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.ResponseBody;
import org.springframework.web.bind.annotation.RestController;
import javax.annotation.Resource;
import java.util.concurrent.CompletableFuture;
/**
* @author zly
*/
@RestController
@Slf4j
public class DemoController {
@Lazy
@Resource(name = "testQueue")
private IEventQueue eventQueue;
@ResponseBody
@GetMapping("/api/v1/demo")
public String demo() {
log.info("发送无延迟消息");
eventQueue.push("no delay 5000 millseconds message 3");
return "ok";
}
@ResponseBody
@GetMapping("/api/v1/demo1")
public String demo1() {
log.info("发送延迟5秒消息");
eventQueue.push(" delay 5000 millseconds message,name",1000*5L);
return "ok";
}
@ResponseBody
@GetMapping("/api/v1/demo2")
public String demo2() {
log.info("发送延迟到2022-04-02 00:00:00执行的消息");
eventQueue.push(" delay message,name to 2022-04-02 00:00:00", new Date(1648828800000));
return "ok";
}
}
Consulte el diseño de Youzan: https://tech.youzan.com/queuing_delay/
7. Solicitud actual:
1. Yunxiu cancelará automáticamente después de 24 horas en línea en la tienda
2. Meituan solicita la actualización del token con regularidad.
3. La tarjeta de garantía se generará dentro de las 24 horas.
5. Aplazamiento de la generación de declaraciones
6. Envío de SMS retrasado