초록: 모델의 일반화 능력을 평가하기 위해, 즉 모델이 좋은지 나쁜지를 판단하기 위해서는 특정 지표를 사용하여 측정해야 합니다. 평가 지표를 통해 장단점을 비교할 수 있습니다. 다른 모델을 사용하고 이 인덱스를 사용하여 모델을 더욱 최적화합니다. .
이 기사는 Huawei 클라우드 커뮤니티 " 표적 감지 모델의 평가 지표 및 코드 구현에 대한 자세한 설명 ", 저자: Embedded Vision에서 공유됩니다.
머리말
모델의 일반화 능력을 이해하기 위해, 즉 모델이 좋은지 나쁜지를 판단하기 위해서는 특정 지표를 사용하여 측정해야 합니다. 평가 지표를 사용하면 서로 다른 모델의 장단점을 비교할 수 있습니다. , 이 인덱스를 사용하여 모델을 더욱 최적화합니다. 분류와 회귀의 두 가지 유형의 감독 모델에 대해 별도의 평가 기준이 있습니다 .
다른 문제와 다른 데이터 세트는 분류 문제와 같은 다른 모델 평가 지표를 가질 것입니다.균형 데이터 세트 범주의 경우 정확도를 평가 지표로 사용할 수 있지만 실제로는 거의 모든 데이터 세트가 불균형 범주이므로 일반적으로 , AP는 분류의 평가 지표로 사용되며 각 카테고리의 AP를 별도로 계산한 다음 mAP를 계산합니다 .
1. 정밀도, 리콜 및 F1
1.1, 정확도
정확도(정밀도) – 전체 샘플에서 예측된 올바른 결과의 백분율인 정확도는 다음과 같이 정의됩니다.
정확도 = ( TP + TN )/( TP + TN + FP + FN )
오류율과 정밀도는 일반적으로 사용되지만 모든 작업 요구 사항을 충족하지는 않습니다. 수박 문제를 예로 들어 보겠습니다. 멜론 농부가 수박 카트를 가져왔다고 가정하면 훈련된 모델을 사용하여 수박을 구별합니다. 이제 정확도는 올바른 범주(두 가지 범주: 좋은 멜론과 나쁜 멜론). 그러나 "수박 중 좋은 수박의 비율" 또는 "모든 좋은 수박의 비율"에 더 관심이 있다면 정확성과 오류율 지표로는 분명히 충분하지 않습니다.
정확도는 전체적인 정확도를 판단할 수 있지만 샘플이 불균형한 경우 결과를 측정하는 좋은 지표로 사용할 수 없습니다. 간단한 예를 들자면, 예를 들어 전체 샘플에서 양성 샘플이 90%, 음성 샘플이 10%를 차지하며 샘플은 심각하게 불균형합니다. 이 경우 90%의 높은 정확도를 얻기 위해 모든 샘플을 양성 샘플로 예측하기만 하면 되지만 실제로는 매우 신중하게 분류하지 않고 그냥 우연히 분류했습니다. 이것은 샘플 불균형 문제로 인해 얻은 높은 정확도의 결과에 많은 양의 물이 포함되어 있음을 보여줍니다. 즉, 샘플의 균형이 맞지 않으면 정확도가 유효하지 않습니다.
1.2, 정밀율, 재현율
정밀도(precision rate) P와 재현율(recall rate) R의 계산에는 혼동행렬의 정의가 포함되며, 혼동행렬표는 다음과 같다.
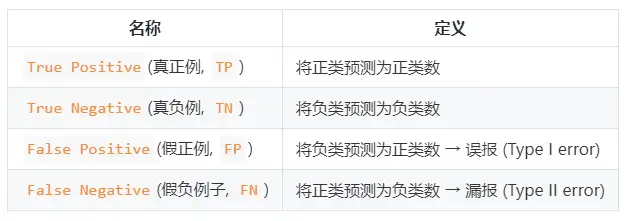
정밀도 및 재현율 공식:
- 정밀율(정밀율) P=TP/(TP+FP) P = TP /( TP + FP )
- 회수율(recall rate) R=TP/(TP+FN) R = TP /( TP + FN )
정밀도 비율과 정확도 비율은 다소 비슷해 보이지만 완전히 다른 개념입니다. 정밀도 비율은 양성 샘플 결과의 예측 정확도를 나타내고 정확도 비율은 양성 샘플과 음성 샘플을 모두 포함하는 전체 예측 정확도를 나타냅니다 .
정밀도 비율은 모델이 얼마나 정확한지 , 즉 예측된 긍정적인 예 중 얼마나 많은 것이 실제 예인지를 설명하고, 재현율은 모델이 얼마나 완전한지 , 즉 모델이 예측한 실제 샘플의 수를 나타냅니다. 긍정적인 예. 정밀도 비율과 재현율의 차이는 다른 분모 에 있습니다 . 한 분모는 양성으로 예측된 샘플 수이고 다른 분모는 원래 샘플의 모든 양성 샘플 수입니다.
1.3, F1 점수
P 와 R 사이의 균형을 찾으려면 F 1 점수라는 새로운 지표가 필요합니다. F 1 점수는 정밀도와 재현율을 모두 고려하여 두 가지가 동시에 최고에 도달할 수 있도록 균형을 유지합니다. F1의 계산 공식은 다음과 같습니다.
여기서 F 1 계산은 이진 분류 모델에 대한 것이므로 다중 분류 작업에 대한 F 1 계산은 다음을 참조하십시오.
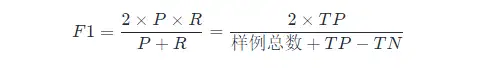
F 1 메트릭의 일반 형식: Fβ 는 정밀도/재현율에 대한 편향을 표현할 수 있게 해줍니다. Fβ 는 다음과 같이 계산됩니다.
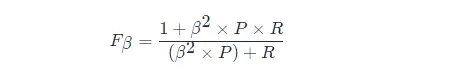
이 중 β > 1일수록 재현율에 더 큰 영향을 미치고, β < 1일수록 정밀도에 더 큰 영향을 미칩니다.
서로 다른 컴퓨터 비전 문제는 두 가지 유형의 오류에 대해 서로 다른 선호도를 가지며 종종 특정 유형의 오류가 특정 임계값을 넘지 않을 때 다른 유형의 오류를 줄이려고 합니다. 대상 감지에서 mAP (평균 평균 정밀도)는 두 오류를 통합 지표로 고려합니다.
혼동 행렬을 얻을 수 있을 때마다 여러 훈련/테스트 또는 알고리즘의 "전역" 성능을 추정하기 위해 여러 데이터 세트에 대한 훈련/테스트와 같은 여러 혼동 행렬이 있을 것입니다. 다중 분류 작업, 두 범주의 각 조합은 혼동 행렬에 해당합니다 ...일반적으로 n n 두 범주 혼동 행렬 에 대한 정밀도와 재현율을 종합적으로 고려하기를 바랍니다.
직접 접근 방식은 먼저 ( P 1 , R 1 ), ( P 2 , R 2 ),...,( Pn , Rn 으로 기록되는 각 혼동 행렬에 대한 정밀도와 재현율을 계산하는 것입니다. ) 그런 다음 평균을 취하여 "Macro Precision(Macro-P)", "Macro Precision(Macro-R)" 및 해당 "Macro F1 F 1(Macro- F1 )"을 얻습니다.
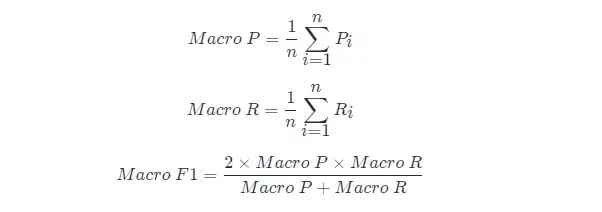
또 다른 방법 은 각 혼동행렬의 해당 요소를 평균하여 TP, FP, TN, FN TP , FP , TN , FN 의 평균값을 구한 후 "미세정밀도"(Micro-P ), "Micro Recall"(Micro-R) 및 "Micro F 1"(Mairo-F1)

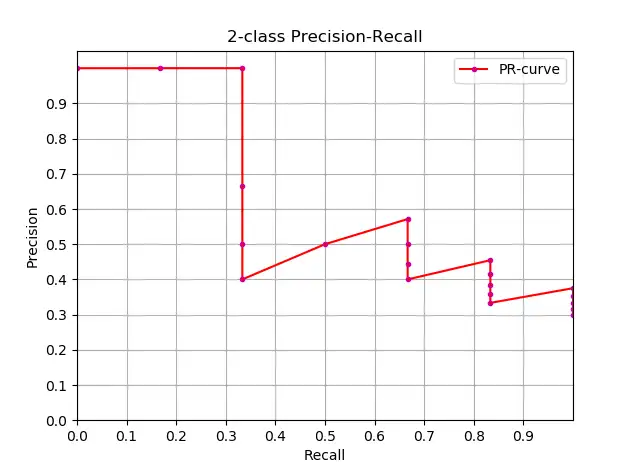
1.4, PR 곡선
정밀율과 재현율의 관계는 PR 그래프로 나타낼 수 있는데 세로축을 정밀율 P, 가로축을 R로 하면 정밀도-재현율 곡선을 얻을 수 있다. PR 곡선 으로 PR 곡선 아래 영역은 AP로 정의됩니다.
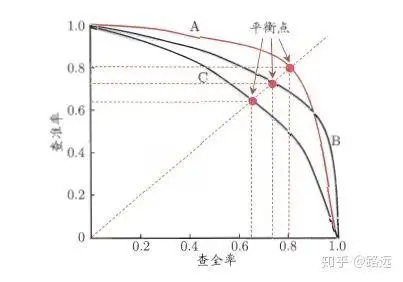
1.4.1, PR 곡선을 이해하는 방법
순위 모델 또는 분류 모델에서 이해할 수 있습니다. 로지스틱 회귀를 예로 들면 로지스틱 회귀의 출력은 0과 1 사이의 확률 숫자입니다. 따라서 이 확률에 따라 사용자가 좋은지 나쁜지를 판단하려면 임계값을 정의해야 합니다. 일반적으로 로지스틱 회귀의 확률이 높을수록 1에 가까우며 이는 불량 사용자일 가능성이 더 높다는 것을 의미합니다. 예를 들어 임계값을 0.5로 정의합니다. 즉 확률이 0.5 미만인 사용자는 모두 좋은 사용자로 간주하고 확률이 0.5보다 큰 사용자는 나쁜 사용자로 간주합니다. 따라서 임계값 0.5에 대해 해당하는 정밀도와 재현율 쌍을 얻을 수 있습니다 .
그러나 문제는 이 임계값이 우리가 임의로 정의한 것이며 이 임계값이 우리의 요구 사항을 충족하는지 알 수 없다는 것입니다. 따라서 요구 사항을 충족하는 가장 적합한 임계값을 찾으려면 0과 1 사이의 모든 임계값을 통과해야 하며 각 임계값은 정밀도와 재현율 쌍에 해당하므로 PR 곡선을 얻습니다.
마지막으로 최상의 임계점을 찾는 방법은 무엇입니까? 우선, 이 두 지표에 대한 요구 사항을 설명해야 합니다. 정확도와 재현율이 동시에 매우 높기를 바랍니다. 그러나 사실 이 두 지표는 한 쌍의 모순이며 이중 고점을 달성하는 것은 불가능합니다. 둘 중 하나가 매우 높으면 다른 하나는 매우 낮음이 그래프에서 명백합니다. 적절한 임계점을 선택하는 것은 실제 필요에 따라 달라집니다.예를 들어 높은 재현율을 원하면 일부 정밀도를 희생합니다.최고의 재현율을 보장하는 경우 정밀도가 그렇게 낮지 않습니다. .
1.5, ROC 곡선 및 AUC 영역
- PR 곡선은 가로축이 Recall이고 세로축이 Precision이며, ROC 곡선은 가로축이 FPR이고 세로축이 TPR입니다**. PR 곡선이 오른쪽 상단에 가까울수록 성능이 좋습니다 . PR 곡선의 두 지표 모두 긍정적인 예에 초점을 맞춥니다.
- PR 곡선은 Precision vs Recall 곡선을 나타내고, ROC 곡선은 FPR(x축: False positive rate) vs TPR(True positive rate, TPR) 곡선을 나타냅니다.
- [ ] ROC 곡선
- [ ] AUC 영역
2. AP와 mAP
2.1, AP 및 mAP 지표의 이해
AP는 각 카테고리에서 학습된 모델의 품질을 측정하고, mAP는 모든 카테고리에서 모델의 품질을 측정합니다.AP를 얻은 후에는 mAP의 계산이 매우 간단해집니다. AP의 계산식은 상대적으로 복잡하므로(별도 장), 자세한 내용은 다음을 참고하시기 바랍니다.
mAP라는 용어는 정의가 다릅니다. 이 메트릭은 일반적으로 정보 검색, 이미지 분류 및 개체 감지 영역에서 사용됩니다. 그러나 두 필드는 mAP를 다르게 계산합니다. 여기서는 객체 감지의 mAP 계산 방법에 대해서만 이야기합니다.
mAP는 대상 감지 알고리즘의 평가 지표로 자주 사용됩니다.구체적으로 각 그림 감지 모델에 대해 여러 예측 프레임(실제 프레임 수를 훨씬 초과함)을 출력하려면 IoU(Intersection Over Union)를 사용하여 예측 상자의 마크 예측이 정확합니다. 마킹이 완료된 후, 예측 프레임이 증가함에 따라 재현율 R은 항상 증가하게 되며, 정확도율 P는 서로 다른 재현율 R 수준에서 평균화되어 AP를 구하고, 마지막으로 모든 카테고리는 그 비율에 따라 평균화됩니다. , 즉, mAP 인덱스를 구합니다.
2.2, 대략적인 AP 계산
AP의 정의를 알면 다음 단계는 AP 계산의 실현을 이해하는 것입니다.이론적으로 AP는 적분으로 계산할 수 있습니다.공식은 다음과 같습니다.
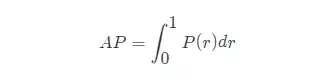
그러나 일반적으로 근사치 또는 보간법을 사용하여 AP를 계산합니다 .
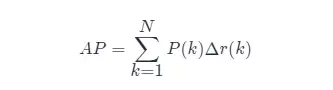
- AP 의 대략적인 계산 (대략적인 평균 정밀도), 이 계산 방법은 대략적인 형식입니다.
- 분명히 수직선에 있는 점은 AP 계산에 기여하지 않습니다 .
- 여기서 N 은 데이터의 총량, k 는 각 샘플 포인트의 인덱스, Δr ( k ) = r ( k )-r ( k - 1)입니다.
AP의 대략적인 계산 과 PR 곡선을 그리는 코드는 다음과 같습니다.
import numpy as np
import matplotlib.pyplot as plt
class_names = ["car", "pedestrians", "bicycle"]
def draw_PR_curve(predict_scores, eval_labels, name, cls_idx=1):
"""calculate AP and draw PR curve, there are 3 types
Parameters:
@all_scores: single test dataset predict scores array, (-1, 3)
@all_labels: single test dataset predict label array, (-1, 3)
@cls_idx: the serial number of the AP to be calculated, example: 0,1,2,3...
"""
# print('sklearn Macro-F1-Score:', f1_score(predict_scores, eval_labels, average='macro'))
global class_names
fig, ax = plt.subplots(nrows=1, ncols=1, figsize=(15, 10))
# Rank the predicted scores from large to small, extract their corresponding index(index number), and generate an array
idx = predict_scores[:, cls_idx].argsort()[::-1]
eval_labels_descend = eval_labels[idx]
pos_gt_num = np.sum(eval_labels == cls_idx) # number of all gt
predict_results = np.ones_like(eval_labels)
tp_arr = np.logical_and(predict_results == cls_idx, eval_labels_descend == cls_idx) # ndarray
fp_arr = np.logical_and(predict_results == cls_idx, eval_labels_descend != cls_idx)
tp_cum = np.cumsum(tp_arr).astype(float) # ndarray, Cumulative sum of array elements.
fp_cum = np.cumsum(fp_arr).astype(float)
precision_arr = tp_cum / (tp_cum + fp_cum) # ndarray
recall_arr = tp_cum / pos_gt_num
ap = 0.0
prev_recall = 0
for p, r in zip(precision_arr, recall_arr):
ap += p * (r - prev_recall)
# pdb.set_trace()
prev_recall = r
print("------%s, ap: %f-----" % (name, ap))
fig_label = '[%s, %s] ap=%f' % (name, class_names[cls_idx], ap)
ax.plot(recall_arr, precision_arr, label=fig_label)
ax.legend(loc="lower left")
ax.set_title("PR curve about class: %s" % (class_names[cls_idx]))
ax.set(xticks=np.arange(0., 1, 0.05), yticks=np.arange(0., 1, 0.05))
ax.set(xlabel="recall", ylabel="precision", xlim=[0, 1], ylim=[0, 1])
fig.savefig("./pr-curve-%s.png" % class_names[cls_idx])
plt.close(fig)2.3, 보간 계산 AP
Interpolated average precision AP AP 공식의 진화 과정은 여기에서 논의 되지 않습니다.자세한 내용은 이 기사를 참조하십시오.여기에 있는 공식과 다이어그램도 이 기사를 참조하십시오. AP 계산을 위한 11점 보간 계산 방법 AP 공식은 다음과 같습니다.
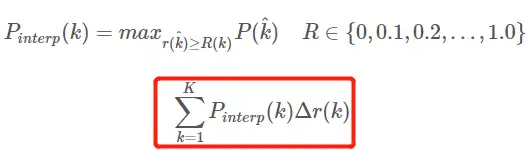
- 이것은 일반적으로 11점의 AP입니다_보간된 형식, 고정된 0,0.1,0.2,…,1.00,0.1,0.2,…,1.0 11 임계값 선택, PASCAL2007에서 사용됨
- 여기서 계산에 포함된 포인트는 11개뿐이므로 K = 11, 11개 포인트_보간이라고 하며 k 는 임계값 인덱스입니다.
- Pinterp ( k )는 여기서 임계값이 0,0.1,0.2,…,1.00,0.1,0.2, … 내부에.
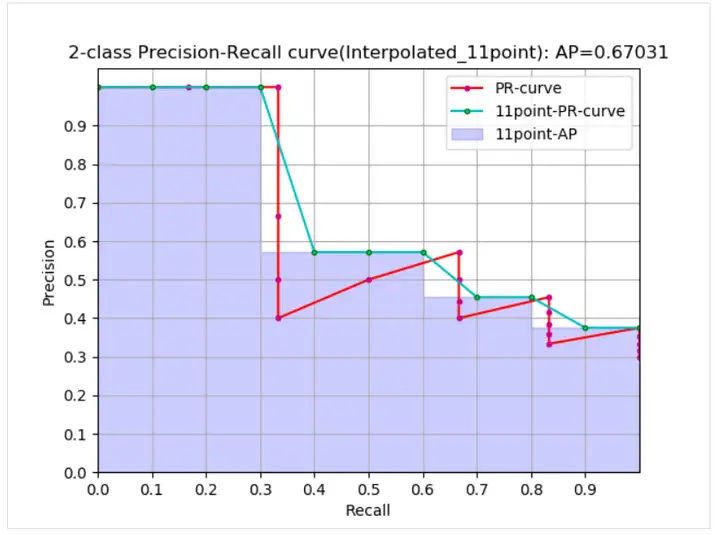
곡선에서 real AP<approximated AP< Interpolated AP, 11-points Interpolated AP는 크거나 작을 수 있으며, 데이터의 양이 많을 경우 Interpolated AP에 가깝습니다. 이전 공식 PR 곡선의 면적 추정치입니다.PASCAL 논문에 제공된 공식은 11개 임계값에서 정밀도의 평균값을 직접 계산하는 더 간단하고 조잡합니다. PASCAL 논문에 제시된 AP 계산을 위한 11점 공식은 다음과 같습니다.
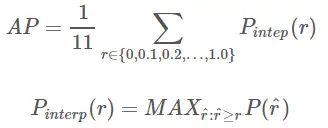
1. 재계산 및 정밀도의 주어진 조건에서 AP를 계산합니다.
def voc_ap(rec, prec, use_07_metric=False):
"""
ap = voc_ap(rec, prec, [use_07_metric])
Compute VOC AP given precision and recall.
If use_07_metric is true, uses the
VOC 07 11 point method (default:False).
"""
if use_07_metric:
# 11 point metric
ap = 0.
for t in np.arange(0., 1.1, 0.1):
if np.sum(rec >= t) == 0:
p = 0
else:
p = np.max(prec[rec >= t])
ap = ap + p / 11.
else:
# correct AP calculation
# first append sentinel values at the end
mrec = np.concatenate(([0.], rec, [1.]))
mpre = np.concatenate(([0.], prec, [0.]))
# compute the precision envelope
for i in range(mpre.size - 1, 0, -1):
mpre[i - 1] = np.maximum(mpre[i - 1], mpre[i])
# to calculate area under PR curve, look for points
# where X axis (recall) changes value
i = np.where(mrec[1:] != mrec[:-1])[0]
# and sum (\Delta recall) * prec
ap = np.sum((mrec[i + 1] - mrec[i]) * mpre[i + 1])
return ap2. 대상 탐지 결과 파일 및 테스트 세트 레이블 파일 xml이 주어진 AP를 계산합니다.
def parse_rec(filename):
""" Parse a PASCAL VOC xml file
Return : list, element is dict.
"""
tree = ET.parse(filename)
objects = []
for obj in tree.findall('object'):
obj_struct = {}
obj_struct['name'] = obj.find('name').text
obj_struct['pose'] = obj.find('pose').text
obj_struct['truncated'] = int(obj.find('truncated').text)
obj_struct['difficult'] = int(obj.find('difficult').text)
bbox = obj.find('bndbox')
obj_struct['bbox'] = [int(bbox.find('xmin').text),
int(bbox.find('ymin').text),
int(bbox.find('xmax').text),
int(bbox.find('ymax').text)]
objects.append(obj_struct)
return objects
def voc_eval(detpath,
annopath,
imagesetfile,
classname,
cachedir,
ovthresh=0.5,
use_07_metric=False):
"""rec, prec, ap = voc_eval(detpath,
annopath,
imagesetfile,
classname,
[ovthresh],
[use_07_metric])
Top level function that does the PASCAL VOC evaluation.
detpath: Path to detections result file
detpath.format(classname) should produce the detection results file.
annopath: Path to annotations file
annopath.format(imagename) should be the xml annotations file.
imagesetfile: Text file containing the list of images, one image per line.
classname: Category name (duh)
cachedir: Directory for caching the annotations
[ovthresh]: Overlap threshold (default = 0.5)
[use_07_metric]: Whether to use VOC07's 11 point AP computation
(default False)
"""
# assumes detections are in detpath.format(classname)
# assumes annotations are in annopath.format(imagename)
# assumes imagesetfile is a text file with each line an image name
# cachedir caches the annotations in a pickle file
# first load gt
if not os.path.isdir(cachedir):
os.mkdir(cachedir)
cachefile = os.path.join(cachedir, '%s_annots.pkl' % imagesetfile)
# read list of images
with open(imagesetfile, 'r') as f:
lines = f.readlines()
imagenames = [x.strip() for x in lines]
if not os.path.isfile(cachefile):
# load annotations
recs = {}
for i, imagename in enumerate(imagenames):
recs[imagename] = parse_rec(annopath.format(imagename))
if i % 100 == 0:
print('Reading annotation for {:d}/{:d}'.format(
i + 1, len(imagenames)))
# save
print('Saving cached annotations to {:s}'.format(cachefile))
with open(cachefile, 'wb') as f:
pickle.dump(recs, f)
else:
# load
with open(cachefile, 'rb') as f:
try:
recs = pickle.load(f)
except:
recs = pickle.load(f, encoding='bytes')
# extract gt objects for this class
class_recs = {}
npos = 0
for imagename in imagenames:
R = [obj for obj in recs[imagename] if obj['name'] == classname]
bbox = np.array([x['bbox'] for x in R])
difficult = np.array([x['difficult'] for x in R]).astype(np.bool)
det = [False] * len(R)
npos = npos + sum(~difficult)
class_recs[imagename] = {'bbox': bbox,
'difficult': difficult,
'det': det}
# read dets
detfile = detpath.format(classname)
with open(detfile, 'r') as f:
lines = f.readlines()
splitlines = [x.strip().split(' ') for x in lines]
image_ids = [x[0] for x in splitlines]
confidence = np.array([float(x[1]) for x in splitlines])
BB = np.array([[float(z) for z in x[2:]] for x in splitlines])
nd = len(image_ids)
tp = np.zeros(nd)
fp = np.zeros(nd)
if BB.shape[0] > 0:
# sort by confidence
sorted_ind = np.argsort(-confidence)
sorted_scores = np.sort(-confidence)
BB = BB[sorted_ind, :]
image_ids = [image_ids[x] for x in sorted_ind]
# go down dets and mark TPs and FPs
for d in range(nd):
R = class_recs[image_ids[d]]
bb = BB[d, :].astype(float)
ovmax = -np.inf
BBGT = R['bbox'].astype(float)
if BBGT.size > 0:
# compute overlaps
# intersection
ixmin = np.maximum(BBGT[:, 0], bb[0])
iymin = np.maximum(BBGT[:, 1], bb[1])
ixmax = np.minimum(BBGT[:, 2], bb[2])
iymax = np.minimum(BBGT[:, 3], bb[3])
iw = np.maximum(ixmax - ixmin + 1., 0.)
ih = np.maximum(iymax - iymin + 1., 0.)
inters = iw * ih
# union
uni = ((bb[2] - bb[0] + 1.) * (bb[3] - bb[1] + 1.) +
(BBGT[:, 2] - BBGT[:, 0] + 1.) *
(BBGT[:, 3] - BBGT[:, 1] + 1.) - inters)
overlaps = inters / uni
ovmax = np.max(overlaps)
jmax = np.argmax(overlaps)
if ovmax > ovthresh:
if not R['difficult'][jmax]:
if not R['det'][jmax]:
tp[d] = 1.
R['det'][jmax] = 1
else:
fp[d] = 1.
else:
fp[d] = 1.
# compute precision recall
fp = np.cumsum(fp)
tp = np.cumsum(tp)
rec = tp / float(npos)
# avoid divide by zero in case the first detection matches a difficult
# ground truth
prec = tp / np.maximum(tp + fp, np.finfo(np.float64).eps)
ap = voc_ap(rec, prec, use_07_metric)
return rec, prec, ap2.4, mAP 계산 방법
mAP 값의 계산 은 데이터 셋에 있는 모든 카테고리의 AP 값을 평균하는 것이므로 mAP를 계산하고자 하기 때문에 먼저 특정 카테고리의 AP 값을 찾는 방법을 알아야 합니다. 서로 다른 데이터 세트의 특정 범주에 대한 AP 계산 방법은 유사하며 주로 세 가지 유형으로 나뉩니다.
(1) VOC2007에서는 Recall>=0,0.1,0.2,...,1 Recall >=0,0.1,0.2,...,1, 총 11일 때 Precision의 최대값만 선택하면 됩니다. AP AP는 이 11개의 Precision의 평균이고 mAP mAP는 모든 범주의 모든 AP AP 값 의 평균입니다 . VOC 데이터 세트에서 AP AP를 계산하기 위한 코드 (보간 계산 방법을 사용하여 코드는 py-faster-rcnn 창고 에서 가져옴 )
(2) VOC2010 이상에서는 서로 다른 Recall 값(0과 1 포함) 각각에 대해 이 Recall 값보다 크거나 같을 때 Precision의 최대 값을 선택한 다음 PR 아래 영역을 계산해야 합니다. 곡선을 AP 값으로, mAP mAP는 모두 범주 AP 값 의 평균 입니다 .
(3) COCO 데이터 세트의 경우 여러 IOU 임계값(0.5-0.95, 0.05는 단계 크기)을 설정하고 각 IOU 임계값 아래에 특정 범주의 AP 값이 있으며 다른 IOU 임계값에서 AP 평균을 계산합니다. 즉 카테고리의 원하는 최종 AP 값입니다.
3. 대상 탐지 지표 요약
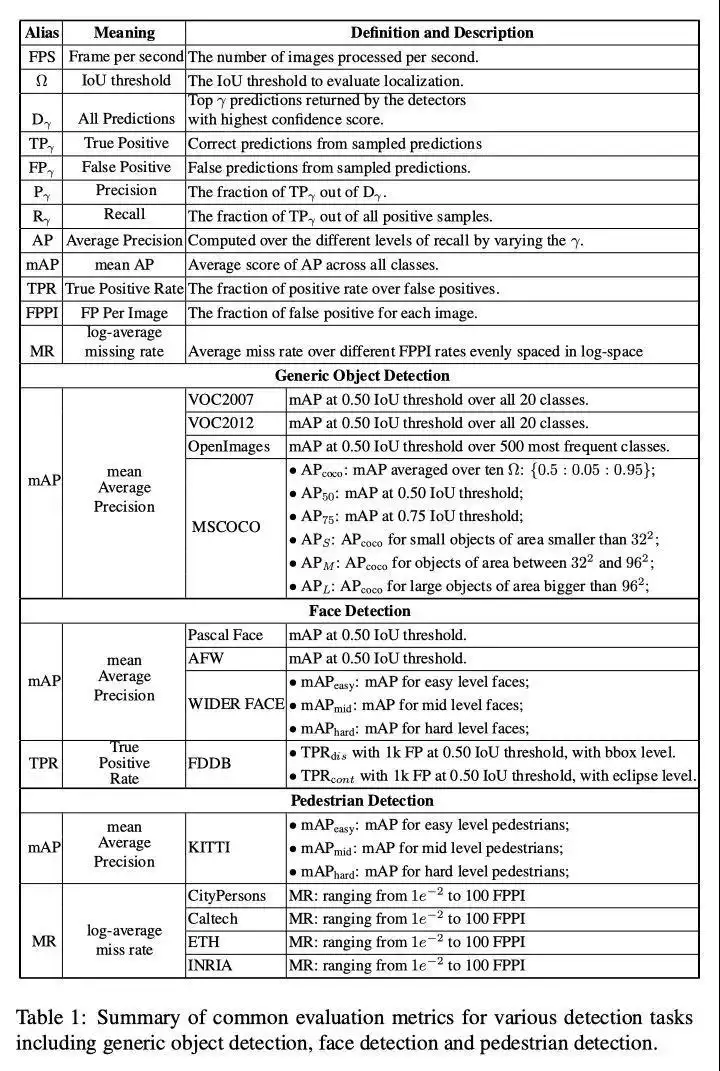
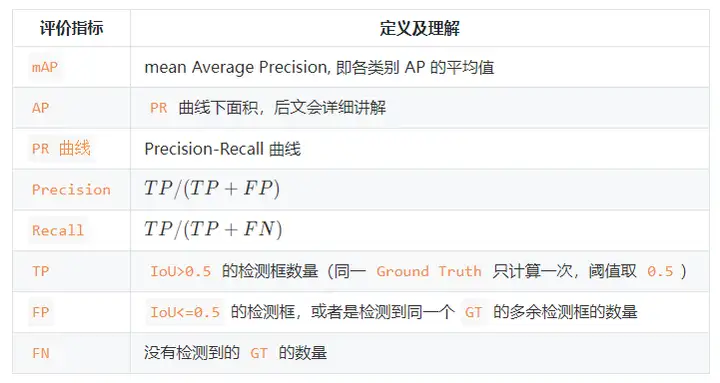
넷째, 참고 자료
- 표적 탐지 평가 표준-AP mAP
- 객체 감지를 위한 성능 평가 지표
- 소프트-NMS
- 객체 감지를 위한 딥 러닝의 최근 발전
- 더 빠른 R-CNN의 간단하고 빠른 구현
- 분류 모델 평가 지표 - 정확도, 정확도, 재현율, F1, ROC 곡선, AUC 곡선
- 이 문서는 정확도, 정밀도, 재현율, 실제 비율, 위양성 비율, ROC/AUC에 대한 철저한 이해를 제공합니다.
처음으로 Huawei Cloud의 새로운 기술에 대해 알아보고 팔로우하려면 클릭하세요~