Autor: Equipo de operaciones de Internet de Vivo - Duan Chengping
En escenarios de negocios a gran escala, ya no es posible brindar servicios a través de una sola máquina, lo que lleva a la necesidad de equilibrar la carga. Para cumplir con la carga adecuada y confiable, este artículo comenzará con requisitos básicos simples, paso a paso y explicará cómo construir una plataforma de equilibrio de carga.
1. Cómo asegurarse de que su negocio sea confiable
Piense en una pregunta: suponga que tiene 10 servidores que brindan el mismo servicio al mundo exterior, ¿cómo se asegura de que estos 10 servidores puedan manejar solicitudes externas de manera estable?
Puede haber muchas soluciones aquí , pero esencialmente todas se ocupan de los siguientes dos problemas:
① ¿A qué servidor debe asignarse la solicitud del cliente?
② En caso de que algunos de los servidores fallen, ¿cómo aislar los servidores fallidos?
Problema 1. Si el manejo no es bueno, algunos de los 10 servidores pueden estar hambrientos y no se asignan solicitudes de clientes o se asignan muy pocas, mientras que la otra parte ha estado procesando una gran cantidad de solicitudes, lo que resulta en una sobrecarga.
Si el problema ② no se maneja adecuadamente, la disponibilidad (A) en el principio CAP puede no estar garantizada a menos que el sistema no requiera A.
Para resolver los problemas anteriores, debe implementar un conjunto de controladores que puedan programar solicitudes comerciales y administrar servidores comerciales. Desafortunadamente, este controlador suele ser el cuello de botella de todo el sistema en la mayoría de los casos. Porque si el sistema de control no profundiza en el cliente, debe apoyarse en un mecanismo centralizado de toma de decisiones, que debe atender todas las solicitudes del cliente. En este momento, debe considerar la redundancia y el aislamiento de fallas del controlador, que se vuelve interminable.
2. Aislamiento comercial y de control
Entonces, ¿cómo resolver los problemas anteriores?
Es decir, las cosas profesionales se las dejo a las plataformas profesionales, es decir, necesitamos balanceo de carga independiente para dar solución a los dos puntos anteriores.
Para el cliente, cada vez que se solicita un sitio, eventualmente se convertirá en una solicitud de cierta IP. Así que mientras podamos controlar la dirección IP a la que accede el cliente, podemos controlar en qué servidor back-end debe caer la solicitud, para lograr el efecto de programación.Esto es lo que está haciendo DNS. O bien, secuestre todo el tráfico de solicitudes de clientes y redistribuya las solicitudes de tráfico al servidor backend. Este es el método de procesamiento de Nginx, LVS, etc.
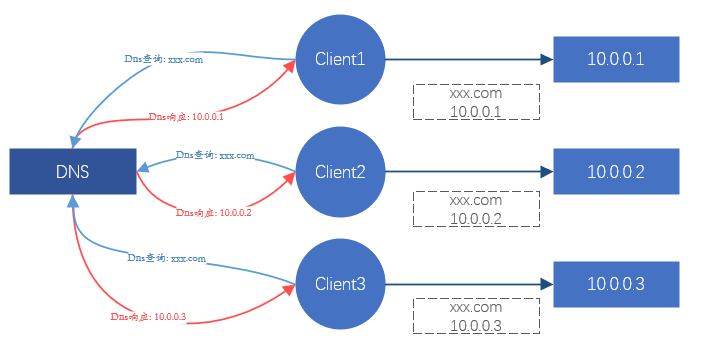
Figura 1. Diagrama esquemático del efecto del equilibrio de carga a través de DNS
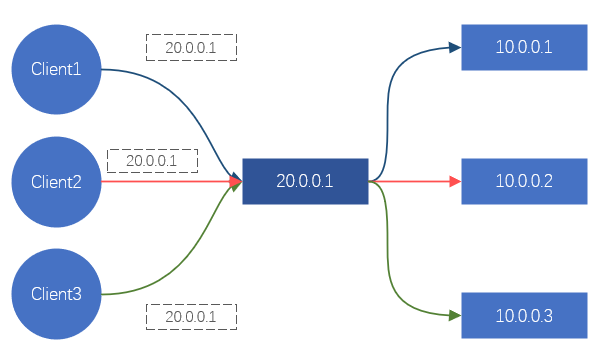
Figura 2. Diagrama esquemático del efecto del equilibrio de carga a través de LVS/Nginx
Estos dos métodos pueden lograr el efecto de equilibrio de carga. Pero aquí hay un problema serio. Los servicios como DNS, Nginx y LVS no pueden proporcionar servicios en una sola máquina en la era de Internet. Todos están agrupados (es decir, compuestos por N servidores), por lo que la confiabilidad y estabilidad de estos clusters ¿Y cómo garantizarlo?
El DNS es el principal responsable de la resolución de nombres de dominio y tiene cierto efecto de equilibrio de carga, pero el efecto de carga suele ser muy pobre, por lo que no es la consideración principal. Nginx proporciona balanceo de carga de capa 7, y se basa principalmente en nombres de dominio para la diferenciación y la carga del negocio. LVS es un equilibrio de carga de capa 4, que se basa principalmente en el protocolo TCP/UDP, la dirección IP y el puerto TCP/UDP para distinguir servicios y cargas.
Para resolver el balanceo de carga y la confiabilidad de los clústeres de balanceador de carga como Nginx y LVS, podemos hacer las siguientes soluciones simples :
-
La carga y confiabilidad del servidor comercial están garantizadas por Nginx;
-
La carga y la confiabilidad de Nginx están garantizadas por LVS.
La solución anterior sigue la lógica del negocio <-- carga de capa 7 <-- carga de capa 4 , y en realidad implementa carga de dos niveles en la capa de aplicación <-- capa de transporte en el modelo de capas de red . Se puede ver que esta solución en realidad usa otra capa de equilibrio de carga para resolver los problemas de carga y confiabilidad de la capa actual. Sin embargo, todavía hay problemas con esta solución.La carga y la confiabilidad de la capa empresarial y el clúster Nginx están garantizadas, pero ¿qué pasa con la confiabilidad de la capa del clúster LVS?
Dado que tenemos dos niveles de carga en la capa de aplicación <-- capa de transporte en el modelo de capas de red , ¿es posible lograr una carga de tres niveles de la capa de aplicación <-- capa de transporte <-- la capa de red ? Afortunadamente, en función del enrutamiento IP, los dispositivos de red (conmutadores, enrutadores) naturalmente tienen la función de equilibrio de carga de la capa de red.
En este punto, podemos implementar toda la cadena de equilibrio de carga: negocio <-- carga de capa 7 (Nginx) <-- carga de capa 4 (LVS) <-- carga de capa 3 (NetworkDevices) ;
Se puede ver a partir de esto que para garantizar que todo el sistema de balanceo de carga sea efectivo y confiable, debe construirse desde la capa de red. Los servicios de alto nivel pueden proporcionar cargas para los servicios de bajo nivel. En comparación con el negocio de bajo nivel, el negocio de alto nivel puede considerarse como el plano de control del negocio de bajo nivel, que puede ser implementado y administrado por un equipo profesional.El lado comercial de bajo nivel solo necesita centrarse en el realización del negocio en sí.
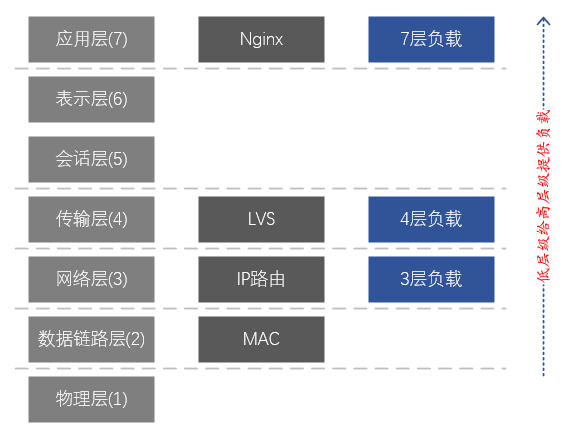
Figura 3. Correspondencia entre el modelo de red de 7 capas y LVS y Nginx
Descripción del modelo de capas de 7 capas de la red:
7. Capa de aplicación: admite aplicaciones de red. Los protocolos de aplicación son solo una parte de las aplicaciones de red. Los procesos que se ejecutan en diferentes hosts usan protocolos de capa de aplicación para comunicarse. Los principales protocolos son: HTTP, FTP, Telnet, SMTP, POP3, etc.
6. Capa de presentación: representación, seguridad y compresión de datos. (En la práctica, esta capa se fusionó con la capa de aplicación)
5. Capa de sesión: establecer, administrar y finalizar sesiones. (En la práctica, esta capa se fusionó con la capa de aplicación)
4. Capa de Transporte: Encargada de brindar servicios de transmisión de datos entre programas de aplicación para origen y destino, esta capa define principalmente dos protocolos de transporte, el Protocolo de Control de Transmisión (TCP) y el Protocolo de Datagramas de Usuario (UDP).
3. Capa de red: Encargada de enviar datagramas de forma independiente desde el origen hasta el destino, resolviendo principalmente problemas como enrutamiento, control de congestión e interconexión de redes.
2. Capa de enlace de datos: responsable de encapsular datagramas IP en formatos de trama adecuados para la transmisión en la red física y transmitirlos, o desencapsular tramas recibidas de la red física, extraer datagramas IP y entregarlos a la capa de red.
1. Capa física: Encargada de transmitir el flujo de bits entre nodos, es decir, responsable de la transmisión física. El protocolo en esta capa está relacionado tanto con el enlace como con el medio de transmisión.
3. Cómo implementar el balanceo de carga de Capa 4
Como se mencionó anteriormente, la carga de la Capa 3 la proporciona naturalmente el equipo de la red, pero en el uso real está estrechamente acoplada con la carga de la Capa 4 y, por lo general, no proporciona servicios de forma independiente. La carga de la capa 4 puede proporcionar directamente servicios para la capa empresarial sin depender de la carga de la capa 7 (la carga de la capa 7 es principalmente para servicios como HTTP/HTTPS), por lo que aquí nos centramos principalmente en la carga de la capa 4 .
3.1 Cómo reenviar tráfico
Para lograr el equilibrio de carga, la implicación es realizar la redirección del tráfico, por lo que el primer problema que debe resolverse es cómo reenviar el tráfico.
4 problemas a resolver:
① ¿Cómo atraer tráfico de clientes al balanceador de carga?
② ¿Cómo selecciona el equilibrador de carga un servidor backend adecuado?
③ ¿Cómo envía el balanceador de carga los datos de la solicitud al servidor backend?
④ ¿Cómo responde el servidor backend a los datos solicitados?
para ①,
La solución es muy simple, proporcionar un lote de servidores back-end con una dirección IP independiente, a la que llamamos IP virtual (también conocida como VIP). Todos los clientes no necesitan acceder directamente a la dirección IP de back-end, sino acceder al VIP. Para el cliente, es equivalente a bloquear el backend.
para ②,
Teniendo en cuenta la versatilidad del equilibrio de carga de bajo nivel, las estrategias de carga complejas generalmente no se implementan. Soluciones como RR (round robin) y WRR (round robin con peso) son más adecuadas y pueden cumplir con los requisitos de la mayoría de los escenarios.
Para ③,
La elección aquí a menudo afectará la elección de ④. Idealmente, esperamos que los datos de la solicitud del cliente se envíen intactos al backend, para evitar que se modifique el paquete de datos. En el modelo de capas de red de siete capas antes mencionado, el reenvío de la capa de enlace de datos se puede lograr sin afectar el contenido de los paquetes de datos de la capa superior, por lo que se puede reenviar sin modificar los datos solicitados por el cliente. Esto es lo que la red suele llamar reenvío de capa 2 (capa de enlace de datos, la segunda capa en el modelo de red de siete capas), que se basa en el direccionamiento de la dirección MAC de la tarjeta de red para reenviar datos.
Entonces, ¿es factible suponer que el paquete de datos de la solicitud del cliente se empaqueta como una pieza de datos de la aplicación y se envía al servidor de back-end? Este método es equivalente a establecer un túnel entre el balanceador de carga y el backend, y transmitir los datos de solicitud del cliente en el medio del túnel, para que también pueda satisfacer la demanda.
Entre las dos soluciones anteriores, la solución que se basa en el reenvío de la capa de enlace de datos se denomina Ruta directa (Direct Route) , es decir, modo DR ; la otra solución que requiere un túnel se denomina modo Túnel . El modo DR tiene una desventaja, porque al confiar en el reenvío de direcciones MAC, el servidor backend y el balanceador de carga deben estar en la misma subred (no se puede considerar estrictamente como el mismo segmento de red), lo que lleva al hecho de que solo el mismo subred como balanceador de carga Se puede acceder a los servidores en la red, y no hay oportunidad de usar el balanceo de carga si no están en la misma subred Esto es obviamente imposible de cumplir con el negocio actual a gran escala. El modo Túnel también tiene desventajas: dado que el reenvío de datos depende del túnel, se debe establecer un túnel entre el servidor backend y el balanceador de carga. Es muy difícil garantizar que el personal comercial diferente pueda configurar correctamente el túnel en el servidor y monitorear el funcionamiento normal del túnel.Se requiere una plataforma de administración completa, lo que significa que el costo de administración es demasiado alto.
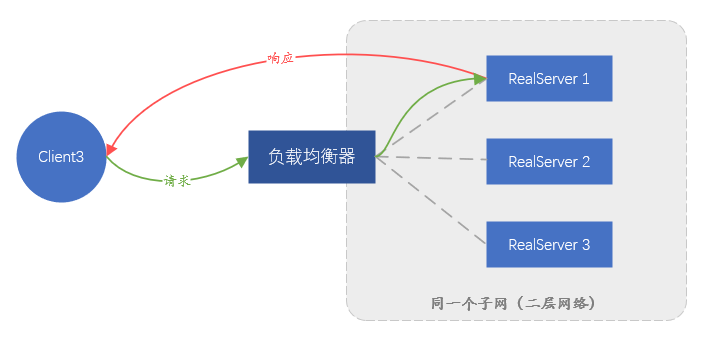
Figura 4. Diagrama esquemático del reenvío en modo DR, el tráfico de respuesta no pasará por el balanceador de carga
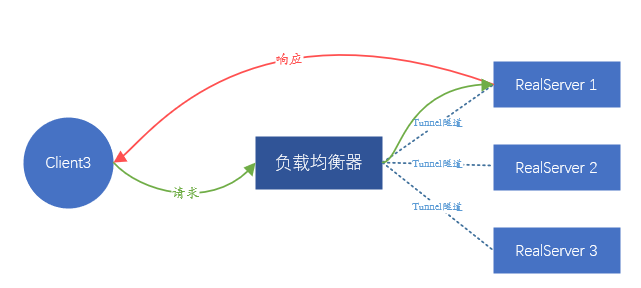
Figura 5. Diagrama esquemático del reenvío en modo túnel Al igual que DR, el tráfico de respuesta no pasará por el balanceador de carga
Dado que ninguno de ellos es ideal, ¿hay alguna otra solución?
Lo que esperamos es que el servidor back-end no perciba la existencia de equilibrio de carga en el front-end, y el servicio se puede colocar en cualquier lugar sin una configuración excesiva. Dado que es imposible transmitir el paquete de datos del cliente intacto, envíe la solicitud del cliente por proxy. Es decir, la traducción de direcciones IP se realiza en la IP de origen y la IP de destino de los paquetes de datos enviados por el cliente.
En detalle, después de recibir la solicitud del cliente A, el balanceador de carga inicia la misma solicitud al servidor backend en el rol del cliente. La carga útil de la solicitud proviene de la carga útil de la solicitud del cliente A, lo que garantiza que los datos de la solicitud sean consistente
En este punto, el balanceador de carga es equivalente a iniciar una nueva conexión (diferente de la conexión iniciada por el cliente A), y la nueva conexión usará la dirección IP del balanceador de carga (llamada LocalIP) como la dirección de origen para contactar directamente con el comunicación IP del servidor back-end.
Cuando el backend devuelve datos al equilibrador de carga, los datos se devuelven al cliente A a través de la conexión del cliente A. Todo el proceso implica dos conexiones, correspondientes a dos traducciones de direcciones IP,
-
Tiempo de solicitud: CIP→VIP, convertido a LocalIP→IP del servidor backend,
-
Tiempo de devolución de datos: IP del servidor backend → IP local, convertido a VIP → CIP.
El proceso de reenvío de datos del cliente se basa completamente en la dirección IP en lugar de la dirección MAC. Siempre que se pueda acceder a la red, los datos se pueden transmitir sin problemas entre el cliente y el backend.
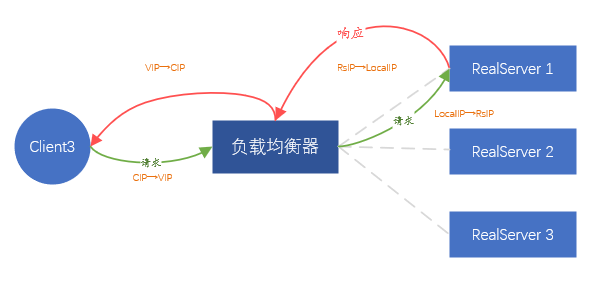
Figura 6. Modo de reenvío FULLNAT
La solución anterior se denomina modo de reenvío FULLNAT , es decir, se realizan dos traducciones de direcciones. Obviamente, este método es bastante simple, no requiere ningún ajuste en el servidor backend y no limita dónde se implementa el backend. Pero también hay un problema obvio, es decir, todas las solicitudes que ve el backend provienen del balanceador de carga y la información de la IP del cliente real es completamente invisible, lo que equivale a bloquear al cliente real. Afortunadamente, la gran mayoría de las aplicaciones en el centro de datos no necesitan conocer la información de la dirección IP del cliente real, incluso si se requiere la información de la IP del cliente real, el balanceador de carga puede cargar esta parte de la información en el TCP/UDP. datos de protocolo, a través de Instale ciertos complementos según sea necesario.
Según las soluciones anteriores, el modo FULLNAT es el mejor para nuestro escenario empresarial (entorno no virtualizado).
Dado que tenemos la intención de utilizar el modo FULLNAT , no hay dificultad para resolver ④, porque el balanceador de carga actúa indirectamente como el cliente, y todos los datos de back-end deben reenviarse al balanceador de carga y luego enviarse al cliente real por el final del equilibrador de carga.
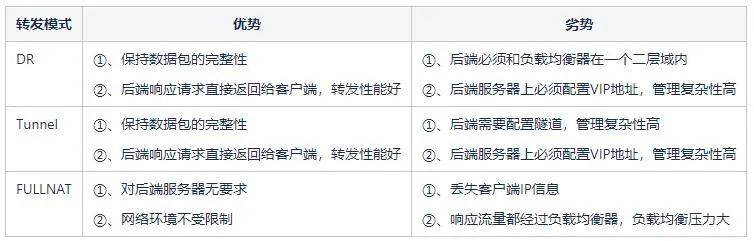
Tabla 1: Análisis de ventajas y desventajas entre varios modos
3.2 Cómo eliminar servidores back-end anómalos
El equilibrio de carga generalmente proporciona un mecanismo de detección de verificación de estado para el backend, de modo que las direcciones IP anómalas del backend se pueden eliminar rápidamente. Idealmente, la detección basada en la semántica es la mejor y puede detectar de manera más efectiva si el backend es anormal. Pero este método traerá mucho consumo de recursos, especialmente cuando el backend es enorme, esto no es particularmente grave, lo más grave es que el backend puede ejecutar muchos tipos de HTTP, DNS, Mysql, Redis, etc. las configuraciones son muy diversas y demasiado complejas. La combinación de los dos problemas hace que el control de salud sea demasiado engorroso, lo que ocupará una gran cantidad de recursos utilizados originalmente para el envío de datos, y el costo de gestión es demasiado alto. Por lo tanto, es necesario un método simple y efectivo, ya que es una carga de Capa 4, no identificamos cuál es el negocio ascendente, sino que solo prestamos atención a si el puerto TCP o UDP es accesible. El trabajo de identificar el negocio de la capa superior se entrega a la carga de 7 capas del tipo Nginx.
Por lo tanto, siempre que verifique regularmente si todos los puertos TCP/UDP de back-end están abiertos, el servicio de back-end se considera normal si está abierto y el servicio se considera anormal si no está abierto.
Entonces, ¿cómo detectarlo? Como solo es para juzgar si el puerto TCP está normalmente abierto, solo necesitamos intentar establecer una conexión TCP, si el establecimiento es exitoso, indica que el puerto está normalmente abierto. Pero para UDP, debido a que UDP no tiene conexión, no existe la creación de una nueva conexión, pero también puede lograr el propósito de detección enviando datos directamente. Es decir, enviar un dato directamente, asumiendo que el puerto UDP normalmente está abierto, por lo que el backend no suele responder. Si el puerto no está abierto, el sistema operativo devolverá un estado de puerto icmp inalcanzable, que se puede usar para determinar que el puerto es inalcanzable. Pero hay un problema: si el paquete de detección de UDP contiene una carga útil, puede hacer que el backend piense que se trata de datos comerciales y reciba datos irrelevantes.
3.3 Cómo implementar el aislamiento de fallas del equilibrador de carga
Como dijimos anteriormente, el balanceo de carga de la capa 4 se basa en el balanceo de la capa de red para garantizar que la carga entre los balanceadores de carga de la capa 4 esté balanceada, por lo que el aislamiento de fallas de los balanceadores de carga depende de la capa de red.
¿Cómo hacerlo?
De hecho, confiamos en el enrutamiento para el equilibrio de carga en la capa de Red. Cada servidor en el clúster de equilibrio de carga notifica la misma dirección VIP al dispositivo de red (conmutador o enrutador) a través del protocolo de enrutamiento BGP, y el dispositivo de red recibe el mismo VIP Si un VIP proviene de diferentes servidores, se formará una ruta de igual costo (ECMP), y la implicación es formar equilibrio de carga. Entonces, si queremos aislar un determinado balanceador de carga, solo necesitamos revocar el VIP emitido por el protocolo de enrutamiento BGP en el servidor, de modo que el interruptor ascendente piense que el servidor ha sido aislado y ya no reenviará datos al correspondiente. servidor en el dispositivo.
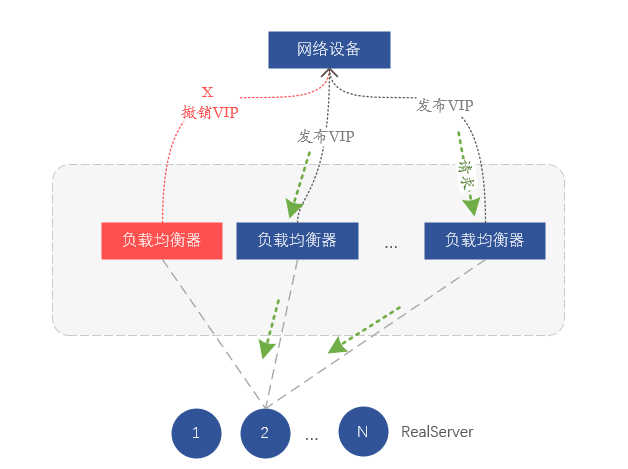
Figura 7. Aislamiento de fallas al retirar rutas VIP
Hasta ahora, hemos implementado un modelo de arquitectura de equilibrio de carga basado en FULLNAT, que se basa principalmente en puertos de protocolo de capa 3 para controles de estado y realiza transceptores VIP a través de BGP y acoplamiento de dispositivos de red.
4. Implementación de VGW
Sobre la base de la arquitectura de carga de 4 capas mencionada anteriormente, creamos VGW (puerta de enlace vivo), que proporciona principalmente servicios de balanceo de carga de 4 capas para servicios de intranet y extranet. A continuación, explicaremos la arquitectura lógica, la arquitectura física, la garantía de redundancia y cómo mejorar el rendimiento del reenvío de gestión.
4.1 Componentes VGW
La función principal de VGW es el equilibrio complejo, y también tiene funciones como verificación de estado y drenaje comercial. Por lo tanto, los componentes que componen VGW son principalmente el módulo de reenvío de equilibrio de carga central, el módulo de verificación de estado y el módulo de control de enrutamiento.
-
Módulo de reenvío de equilibrio de carga: principalmente responsable del cálculo de carga y el reenvío de datos;
-
Módulo de verificación de estado: principalmente responsable de detectar el estado disponible del backend (RealServer) y borrar el backend no disponible a tiempo, o restaurar el backend disponible;
-
Módulo de control de enrutamiento: realiza principalmente liberación y drenaje de VIP y aísla servidores VGW anormales.
4.2 Esquema de arquitectura lógica
Para facilitar la comprensión, llamamos al enlace del cliente a la VGW la red externa (Externa), y el enlace de la VGW al backend (RealServer) es más complejo que la red interna (Interna). En términos de arquitectura lógica, la función de VGW es muy simple, que consiste en distribuir uniformemente las solicitudes comerciales externas al RealServer interno.
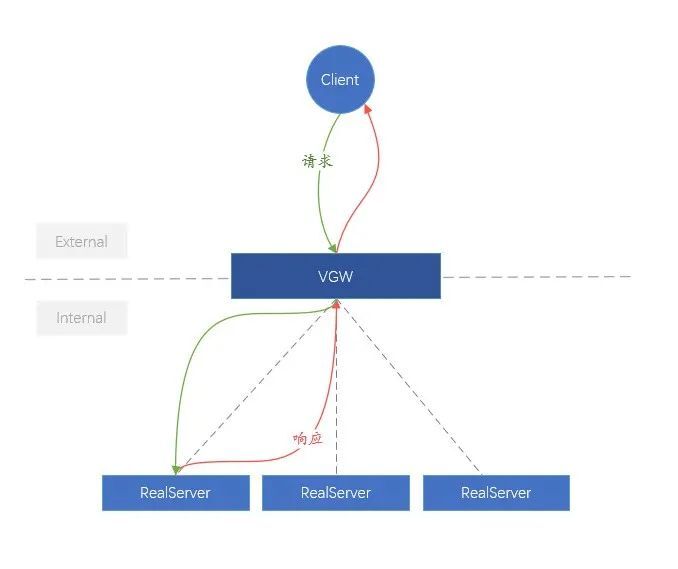
Figura 8. Diagrama lógico de VGW
4.3 Esquema de arquitectura física
En cuanto a la arquitectura física, existen ciertas diferencias entre el VGW que proporciona la red interna y el VGW que proporciona la red externa.
El clúster VGW de la red externa utiliza al menos dos tarjetas de red, que están conectadas respectivamente a los dispositivos de red en el lado de la red externa y a los dispositivos de red en el lado de la red interna. Para el servidor VGW, dos puertos de red extienden dos enlaces, similar a un par de brazos humanos, por lo que este modo se denomina modo de brazo dual , y un paquete de datos solo pasa a través de una única tarjeta de red del servidor VGW una vez.
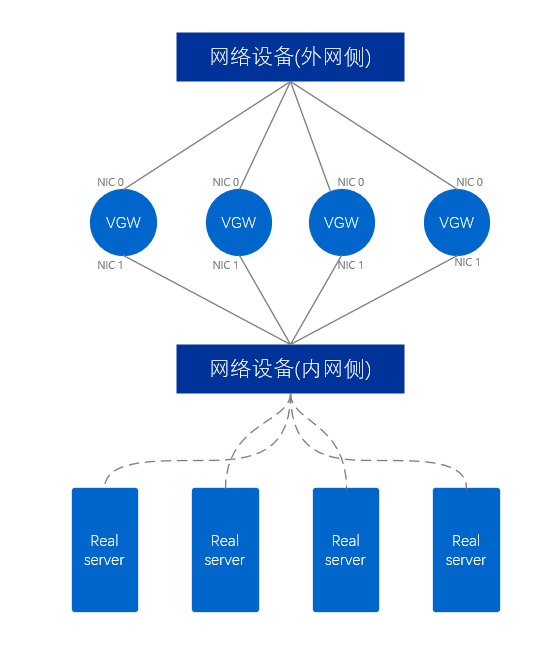
Figura 9. Diagrama físico de la red externa VGW
La red interna VGW es diferente de la red externa, y la red interna VGW solo usa una tarjeta de red para conectarse directamente al equipo de red en el lado de la red interna. En consecuencia, este método se denomina modo de brazo único.Un paquete de datos debe ingresar primero desde una sola tarjeta de red, luego salir de la tarjeta de red y finalmente reenviarlo al exterior, pasando a través de la tarjeta de red dos veces en total.
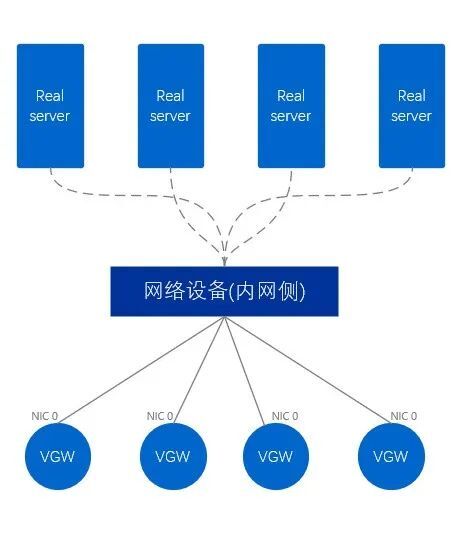
Figura 10. Diagrama físico de intranet VGW
4.4 Modelo comercial existente de VGW
Como dijimos anteriormente, el balanceo de carga puede proporcionar un mayor nivel de balanceo de carga para las cargas de Capa 7.
-
En la actualidad, el mayor tráfico comercial de VGW proviene del tráfico de la plataforma de acceso de 7 capas (es decir, Nginx), y Nginx básicamente lleva la mayor parte del negocio principal de la empresa.
-
Por supuesto, Nginx no admite todos los tipos de servicios. Nginx de capa 7 no admite el tipo de tráfico que no es HTTP creado directamente sobre TCP y UDP. Dichos servicios son reenviados directamente al servidor de servicios por VGW, sin otros enlaces. en el medio. , como Kafka, Mysql, etc.
-
Otra parte del negocio es que los usuarios han creado varias plataformas de proxy, similares a Nginx, etc., pero VGW también les proporciona balanceo de carga de Capa 4.
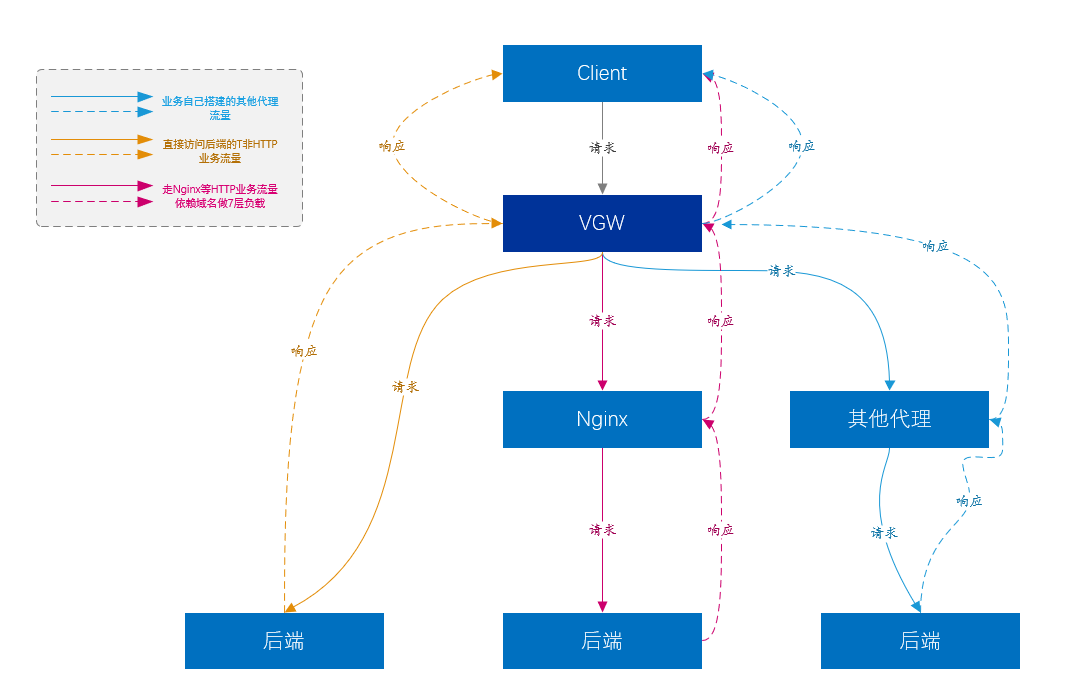
Figura 11. Diagrama del modelo de negocio de VGW
4.5 Garantía de redundancia VGW
Para mejorar la usabilidad, ¿qué riesgos se deben considerar? Todos, naturalmente, consideran escenarios como la falla del servidor y la falla del proceso. Sin embargo, se debe considerar más en el escenario de VGW, porque todo el sistema de VGW incluye enlaces, dispositivos de red, servidores, procesos, etc. Y no podemos simplemente considerar el escenario simple del tiempo de inactividad del dispositivo. De hecho, la situación más problemática es que cualquiera de los dispositivos mencionados anteriormente no se apaga sino que avanza de manera anormal.
Por lo tanto, monitorear si el reenvío del servicio VGW es normal es el primer paso. Regularmente establecemos conexiones con VIP a través de nodos de detección implementados en diferentes salas de computadoras y regiones, y usamos la tasa de fallas de conexión como estándar para medir si el VGW es normal. De hecho, este monitoreo es equivalente a detectar si los enlaces y el reenvío de todos los enlaces que involucran a la VGW son buenos.
El monitoreo anterior cubre la detección a nivel de clúster. Por supuesto, también hemos establecido otro monitoreo más detallado para encontrar problemas específicos.
Después de monitorear los datos de primera mano, podemos proporcionar capacidades de manejo de fallas a nivel de servidor y de manejo de fallas a nivel de clúster.
-
VGW aísla automáticamente el tiempo de inactividad directo de todos los niveles del equipo;
-
Todas las anomalías a nivel de enlace, algunas de las cuales pueden aislarse automáticamente;
-
Todas las excepciones a nivel de proceso se pueden aislar automáticamente;
-
Para otras anormalidades que no son fallas completas, se requiere intervención manual para aislarlas.
El aislamiento de fallas a nivel de servidor significa que algunos servidores VGW cancelarán la liberación de VIP a través del ajuste de ruta, para lograr el propósito del aislamiento;
El aislamiento de fallas a nivel de clúster consiste en anular la publicación de la VIP de todo el clúster de VGW, de modo que el clúster en espera extraiga automáticamente el tráfico y este se haga cargo de todo el tráfico empresarial.
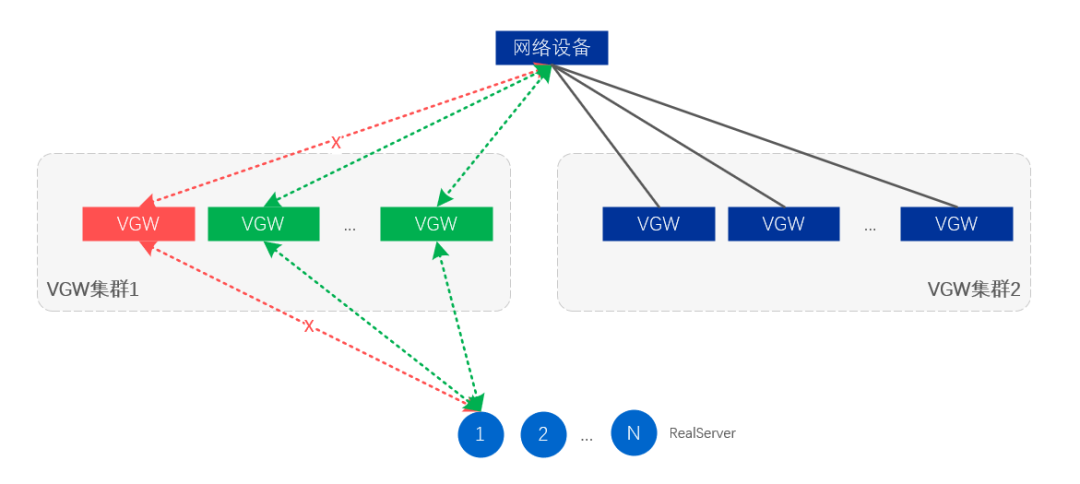
Figura 12. Aislamiento de fallas a nivel de enlace y servidor
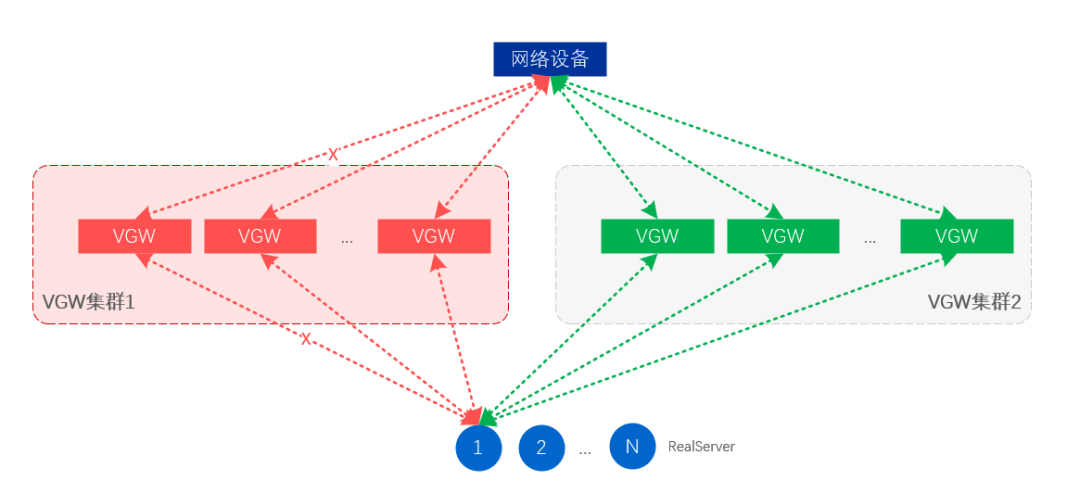
Figura 13. Aislamiento de fallas a nivel de clúster
4.6 Cómo mejorar el rendimiento de VGW
A medida que el volumen de negocios crece cada vez más, una sola VGW necesita recibir casi un millón de solicitudes QPS y, al mismo tiempo, lograr una capacidad de procesamiento de paquetes de más de 500 W/s. Obviamente, los servidores generales no pueden lograr una cantidad tan grande de solicitudes y velocidades de procesamiento de paquetes, la razón principal es el mecanismo de procesamiento de red de Linux. Todos los paquetes de datos de red deben pasar a través del kernel de Linux.Después de que la tarjeta de red reciba los paquetes de datos, debe enviar una interrupción a la CPU, que será procesada por la CPU en el kernel, y luego se copiará una copia a la aplicación. programa. El kernel también debe procesar el envío de datos. Las interrupciones frecuentes y la copia constante de datos entre el espacio del usuario y el espacio del núcleo conducen a un consumo importante de tiempo de CPU en el procesamiento de datos de la red. Cuanto mayor sea la tasa de paquetes, peor será el rendimiento. Por supuesto, hay otros problemas, como Cache Miss, consumo de copia de datos entre CPU, etc.
Es fácil pensar aquí, ¿puede el trabajo sucio realizado por la CPU anterior enviarse a la tarjeta de red para hacerlo, y la CPU solo puede procesar datos comerciales? En la actualidad, muchas soluciones se basan en esta idea. La solución de hardware incluye tarjetas de red inteligentes, y la solución de software puro actualmente utiliza DPDK (Intel Data Plane Development Kit). Obviamente, el costo de la tarjeta de red inteligente será alto, y aún se encuentra en la etapa de desarrollo, y la aplicación tiene un costo determinado. El software puro DPDK es mucho mejor en términos de costo y capacidad de control.Elegimos DPDK como el componente subyacente de reenvío de paquetes (en realidad, un desarrollo secundario basado en el DPVS de código abierto de iQIYI).
DPDK intercepta principalmente el proceso de procesamiento de paquetes del núcleo y envía directamente los paquetes de datos del usuario al programa de aplicación en lugar de ser procesados por el núcleo. Al mismo tiempo, se descarta el comportamiento de depender de la interrupción de la tarjeta de red para procesar los datos y se utiliza el método de sondeo para leer datos de la tarjeta de red, a fin de lograr el propósito de reducir la interrupción de la CPU. Por supuesto, también se utiliza la afinidad de la CPU y se utiliza una CPU fija para procesar los datos de la tarjeta de red, lo que reduce el consumo de conmutación de procesos. Además, existen muchas tecnologías de optimización sobre caché y memoria. En general, la velocidad de procesamiento de paquetes de la tarjeta de red del servidor puede alcanzar decenas de millones de PPS, lo que mejora en gran medida la capacidad de procesamiento de paquetes de la tarjeta de red y luego puede aumentar el CPS (número de conexiones nuevas por segundo) del servidor. En la actualidad, podemos lograr una capacidad de procesamiento comercial de 100w+ CPS y 1200w+PPS con la tarjeta de red de 100G (resultados de prueba en condiciones limitadas, no valores teóricos).
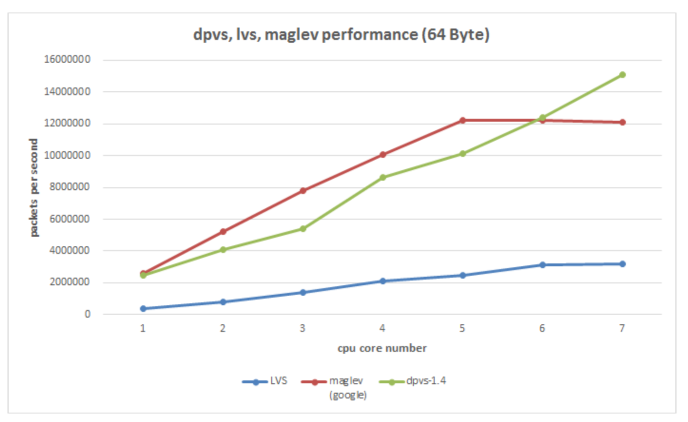
Figura 14. La herramienta subyacente DPVS (DPDK+LVS) utilizada por VGW compara el rendimiento de varias soluciones de equilibrio de carga existentes
V. Resumen
A través de las explicaciones anteriores, deducimos gradualmente un conjunto de soluciones factibles de equilibrio de carga a partir de un requisito de confiabilidad comercial y, combinado con las necesidades reales de vivo, implementamos nuestra plataforma de acceso de equilibrio de carga VGW. Por supuesto, el esquema de equilibrio de carga actual es el resultado de muchas concesiones y es imposible que sea perfecto. Al mismo tiempo, también enfrentaremos el problema del soporte de nuevos protocolos comerciales en el futuro, así como el conflicto entre el modelo comercial descentralizado del centro de datos y el control centralizado del equilibrio de carga. Pero la tecnología ha ido avanzando, ¡pero siempre habrá una solución adecuada!