Resumen: Merge sort y quick sort son dos algoritmos de clasificación un poco complicados. Ambos usan la idea de divide y vencerás. Los códigos se implementan a través de la recursión, y el proceso es muy similar. La clave para comprender la ordenación por fusión es comprender la fórmula de recurrencia y la función de fusión merge().
Este artículo se comparte desde Huawei Cloud Community " Ocho algoritmos de clasificación de manera simple ", autor: Embedded Vision.
Merge sort y quick sort son dos algoritmos de clasificación ligeramente complicados. Ambos usan la idea de divide y vencerás, y el código se implementa a través de la recursividad. El proceso es muy similar. La clave para comprender la ordenación por fusión es comprender la fórmula de recurrencia y la función de fusión merge().
Uno, clasificación de burbujas (clasificación de burbujas)
El algoritmo de clasificación es un tipo de algoritmo que los programadores deben comprender y conocer. Hay muchos tipos de algoritmos de clasificación, como: burbujeo, inserción, selección, rápido, fusión, conteo, cardinalidad y clasificación de cubos.
La clasificación de burbujas solo funcionará en dos datos adyacentes. Cada operación de burbujeo comparará dos elementos adyacentes para ver si cumplen con los requisitos de relación de tamaño y, de no ser así, permitirá que se intercambien. Un burbujeo moverá al menos un elemento a donde debería estar y se repetirá n veces para completar la clasificación de n datos.
Resumen: si la matriz tiene n elementos, en el peor de los casos, se requieren n operaciones de burbujeo.
El código C++ del algoritmo básico de clasificación de burbujas es el siguiente:
// 将数据从小到大排序
void bubbleSort(int array[], int n){
if (n<=1) return;
for(int i=0; i<n; i++){
for(int j=0; j<n-i; j++){
if (temp > a[j+1]){
temp = array[j]
a[j] = a[j+1];
a[j+1] = temp;
}
}
}
}De hecho, el algoritmo de clasificación de burbujas anterior también se puede optimizar. Cuando una determinada operación de burbujeo ya no realiza el intercambio de datos, significa que la matriz ya está en orden y no hay necesidad de continuar realizando operaciones de burbujeo posteriores. El código optimizado es el siguiente:
// 将数据从小到大排序
void bubbleSort(int array[], int n){
if (n<=1) return;
for(int i=0; i<n; i++){
// 提前退出冒泡循环发标志位
bool flag = False;
for(int j=0; j<n-i; j++){
if (temp > a[j+1]){
temp = array[j]
a[j] = a[j+1];
a[j+1] = temp;
flag = True; // 表示本次冒泡操作存在数据交换
}
}
if(!flag) break; // 没有数据交换,提交退出
}
}Características de Bubble Sort :
- El proceso de burbujeo solo implica el intercambio de elementos adyacentes y solo requiere un nivel constante de espacio temporal, por lo que la complejidad del espacio es O(1) O (1), que es un algoritmo de clasificación en el lugar .
- Cuando hay dos elementos adyacentes del mismo tamaño, no intercambiamos, y los datos del mismo tamaño no cambiarán el orden antes y después de la clasificación, por lo que es un algoritmo de clasificación estable .
- El peor de los casos y la complejidad de tiempo promedio son O(n2) O ( n 2 ), y la mejor complejidad de tiempo es O(n) O ( n ).
En segundo lugar, ordenación por inserción (Ordenación por inserción)
- El algoritmo de ordenación por inserción divide los datos de la matriz en dos intervalos: el intervalo ordenado y el intervalo no ordenado. El rango ordenado inicial tiene solo un elemento, que es el primer elemento de la matriz.
- La idea central del algoritmo de ordenación por inserción es tomar un elemento del rango sin ordenar, encontrar una posición adecuada para insertarlo en el rango ordenado y asegurarse de que los datos en el rango ordenado estén siempre en orden.
- Repita este proceso hasta que los elementos de intervalo no ordenados estén vacíos, luego finaliza el algoritmo.
La ordenación por inserción, como la ordenación por burbujas, también incluye dos operaciones, una es la comparación de elementos y la otra es el movimiento de elementos .
Cuando necesitamos insertar un dato a en el rango ordenado, necesitamos comparar el tamaño de a con los elementos del rango ordenado para encontrar una posición de inserción adecuada. Después de encontrar el punto de inserción, también debemos mover el orden de los elementos después del punto de inserción un poco hacia atrás, para dejar espacio para que se inserte el elemento a.
La implementación del código C++ del ordenamiento por inserción es la siguiente:
void InsertSort(int a[], int n){
if (n <= 1) return;
for (int i = 1; i < n; i++) // 未排序区间范围
{
key = a[i]; // 待排序第一个元素
int j = i - 1; // 已排序区间末尾元素
// 从尾到头查找插入点方法
while(key < a[j] && j >= 0){ // 元素比较
a[j+1] = a[j]; // 数据向后移动一位
j--;
}
a[j+1] = key; // 插入数据
}
}Funciones de clasificación por inserción:
- La clasificación por inserción no requiere espacio de almacenamiento adicional y la complejidad del espacio es O(1) O (1), por lo que la clasificación por inserción también es un algoritmo de clasificación en el lugar.
- En la ordenación por inserción, para elementos con el mismo valor, podemos optar por insertar los elementos que aparecen más tarde en la parte posterior de los elementos que aparecen antes, de modo que el orden frontal y posterior original se pueda mantener sin cambios, por lo que la ordenación por inserción es estable. algoritmo de clasificación.
- El peor de los casos y la complejidad de tiempo promedio son O(n2) O ( n 2 ), y la mejor complejidad de tiempo es O(n) O ( n ).
Tres, clasificación por selección (clasificación por selección)
La idea de implementación del algoritmo de ordenación por selección es algo similar a la ordenación por inserción, y también se divide en intervalos ordenados e intervalos no ordenados. Pero la ordenación por selección encontrará el elemento más pequeño del intervalo sin ordenar cada vez y lo colocará al final del intervalo ordenado.
La complejidad temporal del mejor de los casos, el peor de los casos y el caso promedio de clasificación por selección es O(n2) O ( n 2), que es un algoritmo de clasificación en el lugar y un algoritmo de clasificación inestable .
El código C++ para la ordenación por selección se implementa de la siguiente manera:
void SelectSort(int a[], int n){
for(int i=0; i<n; i++){
int minIndex = i;
for(int j = i;j<n;j++){
if (a[j] < a[minIndex]) minIndex = j;
}
if (minIndex != i){
temp = a[i];
a[i] = a[minIndex];
a[minIndex] = temp;
}
}
}Resumen de clasificación de selección de inserción de burbuja
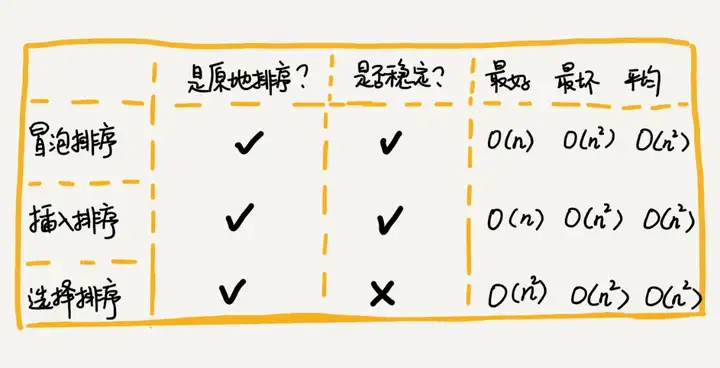
Los códigos de implementación de estos tres algoritmos de clasificación son muy simples y son muy eficientes para clasificar datos a pequeña escala. Sin embargo, cuando se clasifican datos a gran escala, la complejidad temporal sigue siendo un poco alta, por lo que se tiende más a utilizar un algoritmo de clasificación con una complejidad temporal de O(nlogn) O ( nlogn ).
Ciertos algoritmos dependen de ciertas estructuras de datos. Los tres algoritmos de clasificación anteriores se implementan en base a matrices.
Cuarto, ordenar por fusión (Merge Sort)
La idea central de la ordenación por fusión es relativamente simple. Si queremos ordenar una matriz, primero dividimos la matriz en partes delantera y trasera desde el medio, luego ordenamos las partes delantera y trasera por separado, y luego fusionamos las dos partes ordenadas , de modo que la matriz completa esté en orden.
Merge sort utiliza la idea de divide y vencerás. Divide y vencerás, como su nombre indica, es dividir y vencer, descomponiendo un gran problema en pequeños subproblemas a resolver. Cuando se resuelven los pequeños subproblemas, también se resuelve el gran problema.
La idea de divide y vencerás es algo similar a la idea recursiva, y el algoritmo de divide y vencerás generalmente se implementa con recursividad. Divide y vencerás es una idea de procesamiento para resolver problemas, y la recursividad es una técnica de programación, y las dos no entran en conflicto.
Sabiendo que la ordenación por combinación utiliza el pensamiento de divide y vencerás, y que el pensamiento de divide y vencerás generalmente se implementa mediante recursividad, el siguiente enfoque es cómo usar la recursividad para implementar la ordenación por combinación . La habilidad de escribir código recursivo es analizar el problema para obtener la fórmula recursiva, luego encontrar la condición de terminación y finalmente traducir la fórmula recursiva en código recursivo. Por lo tanto, si desea escribir el código para la ordenación por fusión, primero debe escribir la fórmula recursiva para la ordenación por fusión .
递推公式:
merge_sort(p…r) = merge(merge_sort(p…q), merge_sort(q+1…r))
终止条件:
p >= r 不用再继续分解,即区间数组元素为 1 El pseudocódigo para la ordenación por fusión es el siguiente:
merge_sort(A, n){
merge_sort_c(A, 0, n-1)
}
merge_sort_c(A, p, r){
// 递归终止条件
if (p>=r) then return
// 取 p、r 中间的位置为 q
q = (p+r)/2
// 分治递归
merge_sort_c(A[p, q], p, q)
merge_sort_c(A[q+1, r], q+1, r)
// 将A[p...q]和A[q+1...r]合并为A[p...r]
merge(A[p...r], A[p...q], A[q+1...r])
}4.1, análisis de rendimiento de ordenación por fusión
1. Merge sort es un algoritmo de clasificación estable . Análisis: La función merge_sort_c() en el pseudocódigo solo descompone el problema y no implica mover elementos ni comparar tamaños. La comparación de elementos reales y el movimiento de datos están en la parte de la función merge(). En el proceso de fusión, se garantiza que el orden de los elementos con el mismo valor permanecerá sin cambios antes y después de la fusión. La clasificación por fusión es un algoritmo de clasificación estable.
2. La eficiencia de ejecución de merge sort no tiene nada que ver con el grado de orden de la matriz original que se ordenará, por lo que su complejidad temporal es muy estable. Ya sea en el mejor de los casos, en el peor de los casos o en el caso promedio, la la complejidad del tiempo es O ( nlogn ) O ( nlogn ). Análisis: el problema de solución recursiva no solo se puede escribir como una fórmula recursiva, sino que la complejidad temporal del código recursivo también se puede escribir como una fórmula recursiva:

3. La complejidad del espacio es O(n) . Análisis: La complejidad del espacio del código recursivo no se suma como la complejidad del tiempo. Aunque cada operación de fusión del algoritmo necesita solicitar espacio de memoria adicional, una vez que se completa la fusión, se libera el espacio de memoria abierto temporalmente. En cualquier momento, la CPU solo tendrá una función en ejecución y, por lo tanto, solo un espacio de memoria temporal en uso. El espacio de memoria temporal máximo no excederá el tamaño de n datos, por lo que la complejidad del espacio es O(n) O ( n ).
Cinco, clasificación rápida (Quicksort)
La idea de la ordenación rápida es esta: si queremos ordenar un conjunto de datos con subíndices de p a r en la matriz, elegimos cualquier dato entre p y r como pivote (punto de partición ) . Atravesamos los datos entre p y r, colocamos los datos más pequeños que el pivote a la izquierda, colocamos los datos más grandes que el pivote a la derecha y colocamos el pivote en el medio. Después de este paso, los datos entre la matriz p y r se dividen en tres partes. Los datos entre p y q-1 en el frente son más pequeños que el pivote, el medio es el pivote y los datos entre q+1 y r es mayor que el pivote.
De acuerdo con la idea de divide y vencerás y la recursividad, podemos ordenar recursivamente los datos con subíndices de p a q-1 y los datos con subíndices de q+1 a r hasta que el intervalo se reduce a 1, lo que significa que todos Los datos están todos en orden.
La fórmula de recurrencia es la siguiente:
递推公式:
quick_sort(p,r) = quick_sort(p, q-1) + quick_sort(q, r)
终止条件:
p >= rCombinación de ordenación y resumen de ordenación rápida
Merge sort y quick sort son dos algoritmos de clasificación ligeramente complicados. Ambos usan la idea de divide y vencerás, y el código se implementa a través de la recursividad. El proceso es muy similar. La clave para comprender la ordenación por fusión es comprender la fórmula de recurrencia y la función de fusión merge(). De la misma manera, la clave para comprender el ordenamiento rápido es comprender la fórmula recursiva, así como la función de partición partición().
Además de los 5 algoritmos de clasificación anteriores, existen 3 algoritmos de clasificación lineal cuya complejidad temporal es O(n) O ( n ) : clasificación de cubos, clasificación de conteo y clasificación de base. El rendimiento de estos ocho algoritmos de clasificación se resume en la siguiente figura:
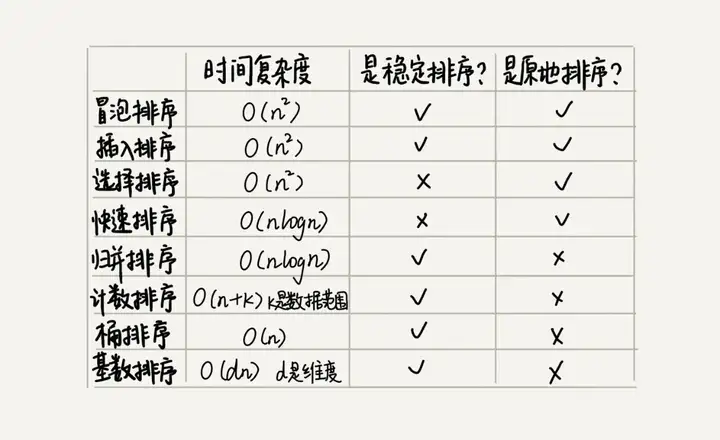
Referencias
- Clasificación (Parte 1): ¿Por qué la clasificación por inserción es más popular que la clasificación por burbuja?
- Clasificación (abajo): ¿Cómo encontrar el K-ésimo elemento más grande en O(n) con la idea de clasificación rápida?
Haga clic para seguir y conocer las nuevas tecnologías de Huawei Cloud por primera vez~