머리말
이전 기사
[파이썬 학습] 리스트와 튜플
사전 및 컬렉션
딕셔너리는 순서가 없는 일련의 요소들의 조합으로 길이와 크기가 가변적이며 임의로 요소를 삭제하고 변경할 수 있습니다. 그러나 여기서 요소는 키(key)와 값(value)의 쌍입니다.
목록 및 튜플과 비교할 때 사전은 특히 조회, 추가 및 삭제에 대해 더 나은 성능을 가지며 사전은 일정한 시간 복잡성으로 완성될 수 있습니다.
컬렉션과 딕셔너리는 기본적으로 동일하며, 유일한 차이점은 키와 값이 없는 컬렉션의 쌍이 일련의 정렬되지 않은 고유한 요소 조합이라는 것입니다.
d1 = {
'name': 'jason', 'age': 20, 'gender': 'male'}
d2 = dict({
'name': 'jason', 'age': 20, 'gender': 'male'})
d3 = dict([('name', 'jason'), ('age', 20), ('gender', 'male')])
d4 = dict(name='jason', age=20, gender='male')
d1 == d2 == d3 ==d4
True
s1 = {
1, 2, 3}
s2 = Set([1, 2, 3])
s1 == s2
True
컬렉션은 인덱스 작업을 지원하지 않습니다. 컬렉션은 목록과 달리 본질적으로 해시 테이블이기 때문입니다.
s = {
1, 2, 3}
s[0]
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: 'set' object does not support indexing
요소가 사전에 있는지 컬렉션에 있는지 판단하기 위해 dict/set의 값을 사용할 수 있습니다.
s = {
1, 2, 3}
1 in s
True
10 in s
False
d = {
'name': 'Runsen', 'age': 20}
'name' in d
True
'location' in d
False
사전 추가, 삭제 및 수정
In [1]: d = {
'name': 'Runsen', 'age': 20}^M
...:
In [2]: d['gender'] = 'male'
In [3]: d['birthday'] = '1999-10-01'
In [4]: d
Out[4]: {
'name': 'Runsen', 'age': 20, 'gender': 'male', 'birthday': '1999-10-01'}
In [5]: d['birthday'] = '1999/10/01'
In [6]: d.pop('birthday')
Out[6]: '1999/10/01'
In [8]: d
Out[8]: {
'name': 'Runsen', 'age': 20, 'gender': 'male'}
In [9]: s = {
1, 2, 3}^M
...:
In [10]: s.add(4)
In [11]: s
Out[11]: {
1, 2, 3, 4}
In [12]: s.remove(4)
In [13]: s
Out[13]: {
1, 2, 3}****
사전의 오름차순 및 내림차순 정렬
d = {
'b': 1, 'a': 2, 'c': 10}
d_sorted_by_key = sorted(d.items(), key=lambda x: x[0]) # 根据字典键的升序排序
d_sorted_by_value = sorted(d.items(), key=lambda x: x[1]) # 根据字典值的升序排序
d_sorted_by_key
[('a', 2), ('b', 1), ('c', 10)]
d_sorted_by_value
[('b', 1), ('a', 2), ('c', 10)]
추가, 삭제, 검색
사전 및 집합은 특히 조회, 추가 및 삭제 작업에 대해 성능이 매우 최적화된 데이터 구조입니다.
관행 목록
# list version
def find_unique_price_using_list(products):
unique_price_list = []
for _, price in products: # A
if price not in unique_price_list: #B
unique_price_list.append(price)
return len(unique_price_list)
# products id 和 price
products = [
(143121312, 100),
(432314553, 30),
(32421912367, 150),
(937153201, 30)
]
print('number of unique price is: {}'.format(find_unique_price_using_list(products)))
# 输出
number of unique price is: 3
관행 모음
# set version
def find_unique_price_using_set(products):
unique_price_set = set()
for _, price in products:
unique_price_set.add(price)
return len(unique_price_set)
products = [
(143121312, 100),
(432314553, 30),
(32421912367, 150),
(937153201, 30)
]
print('number of unique price is: {}'.format(find_unique_price_using_set(products)))
# 输出
number of unique price is: 3
실행 시간 비교, 일명 성능
import time
id = [x for x in range(0, 100000)]
price = [x for x in range(200000, 300000)]
products = list(zip(id, price))
# 计算列表版本的时间
start_using_list = time.perf_counter()
find_unique_price_using_list(products)
end_using_list = time.perf_counter()
print("time elapse using list: {}".format(end_using_list - start_using_list))
## 输出
time elapse using list: 41.61519479751587
# 计算集合版本的时间
start_using_set = time.perf_counter()
find_unique_price_using_set(products)
end_using_set = time.perf_counter()
print("time elapse using set: {}".format(end_using_set - start_using_set))
# 输出
time elapse using set: 0.008238077163696289
성능 측면에서 앙상블 철저한 목록
사전의 경우 해시 테이블은 세 가지 요소인 해시 값, 키 및 값을 저장합니다.
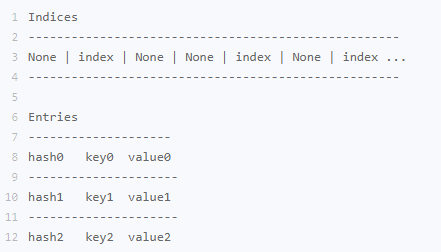
사전과 컬렉션은 모두 정렬되지 않은 데이터 구조이며 내부 해시 테이블 저장 구조는 검색, 삽입 및 삭제 작업의 효율성을 보장합니다. 따라서 사전 및 컬렉션은 일반적으로 요소를 조회하고 중복을 제거하는 데 사용됩니다.
사전을 초기화하는 방법에는 두 가지가 있는데 그 중 하나가 더 효율적이고,
In [20]: timeit a ={
'name':"runsen",'age':20}
127 ns ± 0.8 ns per loop (mean ± std. dev. of 7 runs, 10000000 loops each)
In [21]: timeit b =dict({
'name':"runsen",'age':20})
438 ns ± 3.41 ns per loop (mean ± std. dev. of 7 runs, 1000000 loops each)
첫 번째는 관련 함수를 호출할 필요가 없기 때문입니다.
사전의 키가 목록이 될 수 있습니까? 다음 코드에서 사전의 초기화가 올바릅니까?
In [22]: d = {
'name': 'Runsen', ['education']: [' primary school', 'junior middle school']}^M
...:
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
<ipython-input-22-13cd196aef11> in <module>
----> 1 d = {
'name': 'Runsen', ['education']: [' primary school', 'junior middle school']}
TypeError: unhashable type: 'list'
In [23]: d = {
'name': 'Runsen', ('education'): [' primary school', 'junior middle school']}^M
...:
...:
In [24]: d
Out[24]: {
'name': 'Runsen', 'education': [' primary school', 'junior middle school']}
여기서 목록을 키로 사용하는 것은 허용되지 않습니다. 목록은 동적으로 변경되는 데이터 구조이고 사전의 키는 변경 불가능해야 하기 때문입니다. 그 이유는 잘 알려져 있습니다.
키는 먼저 반복되지 않습니다. 키가 변경될 수 있는 경우 키가 변경됨에 따라 여기에 키가 반복되어 사전의 정의를 위반할 수 있습니다. 여기 목록이 이전 목록으로 대체되면 튜플에 대해 이야기했습니다. 변경할 수 없습니다.
마침내
Python을 처음 접하는 Baozi는 아무것도 이해하지 못하는 경우 비공개 메시지를 보낼 수 있습니다.
무료 비디오 자습서, PDF 전자 책 및 소스 코드도 많이 준비했습니다! 기사 끝에서 명함을 집으십시오!