Dieses Papier stellt kurz einige grundlegende Aufgaben des Deep Learning in Anwendungen natürlicher Sprache, Wortdarstellung, Textübersetzung und maschineller Übersetzung vor.
1. Typische Aufgaben
- Part-of-Speech-Tagging und Syntaxanalyse
- Fragebeantwortungs- und Dialogsysteme
- Text-/Dokumentklassifizierung
- Sentimentanalyse und Opinion Mining
- Maschinenübersetzung
- Textgenerierung
- …
1.1 Part-of-Speech-Tagging und syntaktische Analyse
Part of Speech (POS)-Tagging besteht darin, jedem Wort im Satz seine Wortart wie Substantiv, Verb usw. zuzuweisen:

Die syntaktische Analyse besteht darin, Subjekt, Prädikat, Objekt und andere Strukturen zu analysieren:

1.2 Fragebeantwortungs- und Dialogsystem
Der Benutzer stellt eine Frage und das Dialogsystem kann sie beantworten, was die Hauptaufgabe des Systems ist.

Links ist ein einfaches Frage-Antwort-Format, während letzteres ein Dialog mit Hin- und Her-Echos ist.
1.3 Text-/Dokumentklassifizierung
Zum Beispiel emotionale Einstufung, positiv, negativ, neutral:

Das Objekt der Dokumentenklassifizierungsverarbeitung wird länger sein, nicht ein paar einfache Sätze, sondern ein ganzer Artikel oder ein paar Seiten:

1.4 Maschinelle Übersetzung
Maschinelle Übersetzung ist, wie der Name schon sagt, die Übersetzung einer Sprache in eine andere.

1.5 Sonstiges
Es gibt viele Anwendungen von NLP, wie Couplets und die Generierung alter Gedichte~


Neun Lieder - System zum Schreiben von Gedichten mit künstlicher Intelligenz (thunlp.org)
2. Wortdarstellung
2.1 Wortdarstellung
Das grundlegendste Objekt der Verarbeitung natürlicher Sprache sind Wörter , Wörter bilden Sätze, Sätze bilden Absätze und Absätze bilden Artikel.
Wie stellen wir also ein Wort dar? Das erste, woran Sie denken können, ist in Form von One-Hot , wie zum Beispiel:

Aber dann könnte die Dimension, die Größe des Vokabulars |V| Millionen betragen. Und wenn die Bedeutung zwischen Wörtern ähnlich ist oder die Bedeutung nichts damit zu tun hat, kann sie nicht ausgedrückt werden: dist("Kind", "Kind"), dist("Blume", "Auto")
- Maß zu hoch
- keine Beziehung zwischen Wörtern
Motivation: Verwenden Sie die Nachbarn eines Wortes , um das Wort „Sie sollen ein Wort anhand der Gesellschaft kennen, die es hält“ darzustellen.

Wir können sehen, dass die beiden obigen Sätze mit dem Wort „ Banking “ verwandt sind, also können wir die Wörter drumherum verwenden, d. h. die Wörter in dieser Passage, um die Bedeutung von „ Banking “ auszudrücken.
Wie soll man es ausdrücken?
Vor dem Aufkommen von Deep Learning war es eine typische Vorstellung von Menschen, eine Co-Occurrence-Matrix zu verwenden, um es darzustellen.
2.1.1 Fensterbasierte Co-Occurrence-Matrix
Nehmen Sie den folgenden Beispielkorpus als Beispiel

- Wir wählen ein Fenster aus, und der Einfachheit halber wählen wir eine Fensterlänge von 1 (normalerweise 5-10).
- Die Funktion dieses Fensters besteht darin, die Häufigkeit des Auftretens eines Wortes links und eines Wortes rechts von einem ausgewählten Wort auszuwählen.

Es gibt 7 Wörter im obigen Korpus, also ist die Matrix 7*7.
Am Beispiel des Like-Verhaltens sehen Sie, dass das Wort I zweimal im Fenster mit einem linken und rechten Abstand von 1 erscheint, einmal tief, einmal in NLP und 0 in den anderen.
Allerdings ist die Darstellung dieser Co-Occurrence-Matrix immer noch, wie viele Wörter es gibt, und die Länge des Vektors ist immer noch nicht so "sparsam", aber im Vergleich zur One-Hot-Codierung ist es nicht so spärlich (aber immer noch relativ spärlich).
- Maß zu hoch
- Repräsentationsspärlichkeit macht das Modell weniger robust
- Das Hinzufügen eines Wortes zum Vokabular erfordert die Neuberechnung aller Wortdarstellungen
2.1.2 Darstellung von Wörtern mit niedrigdimensionalen Vektoren
Ziel: "wichtigste" Informationen in festen, niedrigdimensionalen Vektoren ( dense vectors ) speichern:
- Normalerweise etwa 25-1000 Dimensionen
- Basierend auf dieser Darstellung lassen sich Aufgaben (Klassifizierung, Generierung etc.)
Methode:
- Neuronale probabilistische Sprachmodelle
- Bengio et al., Ein neuronales probabilistisches Sprachmodell. Zeitschrift für maschinelle Lernforschung, 2003.
- Unlängst einfacheres und schnelleres Modell: word2vec (geerbt von Neural Probabilistic Language Model)
- Mikolov et al., Verteilte Darstellungen von Wörtern und Phrasen und ihre Zusammensetzung, NeurIPS 2013
Der Einfluss neuronaler probabilistischer Sprachmodelle

2.2 Die Grundidee von word2vec
2.2.1 Einführung in Ideen
Kernidee: Anstatt die Anzahl der gemeinsamen Vorkommen von Wörtern zu zählen, sollen die Wörter um jedes Wort herum vorhergesagt werden.

Geben Sie, wie in der Abbildung gezeigt, ein Wort ein ( One-Hot- Codierung) und erstellen Sie eine verborgene Schicht des neuronalen Netzwerks in der Mitte. Diese verborgene Schicht ist sehr einfach und weist keine Nichtlinearität auf (keine Aktivierungsfunktion, dh lineare Abbildung). . Machen Sie schließlich eine Ausgabe (jede Ausgabe ist auch One-Hot) und sagen Sie die Wörter bei t-2, t-1, t+1, t+2 voraus (in Bezug auf die Fenstergröße).
- |V| ungefähr 10.000-millionendimensional
- d reicht von 50 bis 1000, d. h. hochdimensionales Mapping auf niedrigdimensionales und dann zurück Mapping auf hochdimensionales.

Der erste Schritt: Multiplizieren Sie das Wort wt mit dem Gewicht C, um vwt zu erhalten, was eigentlich die Spalte von C ist.

Im zweiten Schritt wird vwt mit K multipliziert und man erhält einen V-dimensionalen Vektor.Jede Zeile dieses einspaltigen Vektors stellt die Ähnlichkeit (Score) mit der Zeile von K (dieses Wort) in diesem Moment dar (zum Beispiel) . Nach einem Softmax wird das Ergebnis zwischen 0-1 gedrückt und je nach Größe des Ergebnisses als Wort an Position t-2 projiziert.
- Jede Spalte von C entspricht einem Wort: "Eingabevektor"
- Jede Reihe von K entspricht einem Wort: "Ausgangsvektor"
Notiz:
- Die Entsprechung zwischen den Spalten von C und den Wörtern im Korpus muss vordefiniert werden
- Die Zeilen in der gleichen Reihenfolge müssen in K verwendet werden.
Nach dem Lernen können die i-te Spalte von C und die i-te Zeile von K gemittelt werden, um das i-te Wort darzustellen.
Das Diagramm ist wie folgt:
Nehmen Sie das aktuelle Wort Frankreich als Beispiel:

Nach der Projektion erhalten wir den Eingabevektor „Frankreich“ des Wortes France, multiplizieren ihn mit K, um einen hochdimensionalen reellen Zahlenvektor zu erhalten, und erhalten den Ausgabevektor zu einem bestimmten Zeitpunkt zwischen 0-1 bis Softmax.
Zum Zeitpunkt t-2 haben wir auch eine One-Hot-Codierung, die der Standardantwort "Kapital" entspricht, was auch zeigt, dass die letzte Zeile von K Kapital darstellt.
In ähnlicher Weise sollten andere Wörter wie von zum Zeitpunkt t-1 sein, dann sollte die Zeile von K, die von entspricht ( entsprechender Ausgangsvektor ), zu diesem Zeitpunkt ebenfalls dem Eingangsvektor Frankreich ähnlich sein, um von zu erhalten .
2.3 Trainingsmethoden
Ziel: Bei gegebenem Eingabewort die Wahrscheinlichkeit umgebender Wörter maximieren
2.3.1 Skip-Gramm-Modell
Skip-Gram-Modell : Verwenden Sie das aktuelle Wort, um die Wahrscheinlichkeit umgebender Wörter vorherzusagen

Nehmen Sie das Wort zum Zeitpunkt t-1 als Beispiel, um die Wahrscheinlichkeit dieses Wortes zu maximieren.
Die Wahrscheinlichkeit eines Wortes an Position t+j ( j = -2,-1,1,2 ) ist:

Während des Trainingsprozesses beträgt der Kreuzentropieverlust des gewünschten Ausgabeworts:
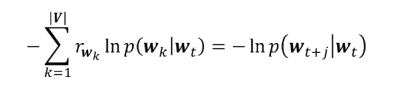
2.3.2 Zielfunktion
- Wir haben die gleiche Anforderung an anderer Stelle im Fenster . Summieren Sie die Verluste über alle Positionen

wobei c die Fenstergröße ist, die alle Parameter darstellt
Durchschnitt über alle gegebenen Eingaben

- Entspricht der Maximierung der mittleren Log-Wahrscheinlichkeit
- Trainieren Sie das Modell mit dem Backpropagation-Algorithmus und SGD
2.3.3 Alternativen zu softmax
An jeder Position des Fensters steht die Ausgabe von softmax

in
Das Problem bei diesem Verfahren besteht darin, dass die Berechnung des Normalisierungsterms lange dauert.
Alternative Methode:
- Hierarchischer Softmax
- Negativprobenahme
2.4 Ergebnisse
Einige interessante Phänomene sind unten zu sehen:

Die Länder sind alle auf der linken Seite und die Hauptstädte auf der rechten Seite, und die Beispiele sind ähnlich und im Grunde parallel.

Der Vektor German und der Vektor Fluggesellschaften werden addiert, und das Ergebnis ist ihrem Airline-Busunternehmen sehr ähnlich ...
Wie stellt man einen Satz oder Absatz dar?
3. Neuronales Netz zur Textklassifikation
Wie kann man einen Satz oder Absatz darstellen, nachdem wir Wortvektoren für jedes Wort erhalten haben?
3.1 CNN für die Textklassifizierung
Antwort: Wir fügen diese Wortvektoren in einer bestimmten Reihenfolge zusammen, um eine zweidimensionale Matrix zu erhalten , die eine neue Darstellung eines Satzes/Absatzes sein kann. Danach ist das Klassifizieren von Sätzen/Absätzen eigentlich das Klassifizieren von zweidimensionalen Matrizen. An diesem Punkt können wir diese zweidimensionalen Matrizen mit den vorherigen Methoden der Bildverarbeitung verarbeiten.

Die Breite des Faltungskerns und die Breite des Wortvektors sind beide K, sodass nach der Faltung ein Vektor anstelle einer Matrix erhalten wird.
Führen Sie dann MaxPooling für jeden Satz durch, jedes Mal, wenn MaxPooling eine Zahl erhält, und es gibt mehrere Elemente, wenn es mehrere Kernel gibt.
Schließlich kann ein vollständig verbundenes Netzwerk für die Satzklassifikation erstellt werden.
3.1.1 Was ist falsch an diesem Modell?
nicht tief genug
- Eine Faltungsschicht und eine Pooling-Schicht
Die Merkmale sind nicht vielfältig genug
- Jeder Faltungskern erzeugt eine 1-dimensionale Merkmalskarte, d. h. einen Merkmalsvektor
- Das Anwenden von globalem Max-Pooling auf einen Merkmalsvektor, d. h. Max-Pooling für alle Zeiten, ergibt einen Skalar.
3.1.2 Ein tieferes Modell

- Bestimmen Sie, wie lang der Satz ist, und verwenden Sie dynamisches K-Maxpooling, damit die erhaltenen Ergebnisse gleich lang sind.
3.2 RNN für die Textklassifikation
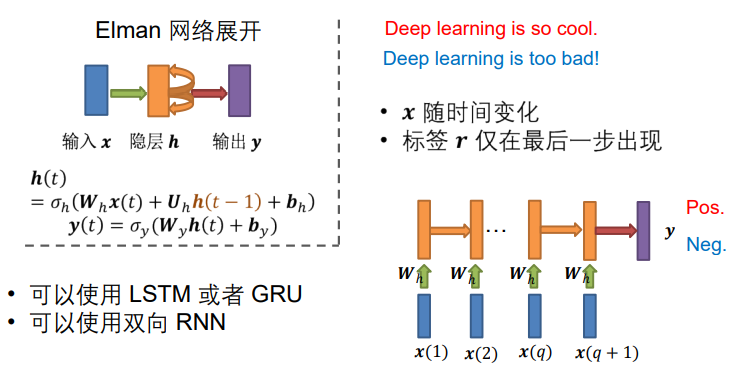
Wir haben oben erwähnt, dass CNN die Textklassifizierung durchführt und RNN im Allgemeinen verwendet wird, um kontinuierliche Informationen zu verarbeiten.Tatsächlich ist es für uns natürlicher, RNN für die Textklassifizierung zu verwenden, und es ist jetzt auch die allgemeine Wahl.
Nehmen Sie das Elman-Netzwerk als Beispiel, wo x die Eingabe in jedem Moment ist (Wörter in jedem Moment), r erscheint im letzten Moment und wir erweitern die verborgene Schicht ...
- Kann LSTM oder GRU verwenden
- Bidirektionale RNNs können verwendet werden
4. Neuronales Netzwerk für maschinelle Übersetzung
Stellen Sie ein sehr typisches Modell vor, das Sequenz-zu-Sequenz-Lernmodell.

Normalerweise sind zwei RNNs beteiligt : Encoder und Decoder
Viele NLP-Aufgaben können als Sequenz-zu-Sequenz formuliert werden:
- Maschinelle Übersetzung (Französisch → Englisch)
- Zusammenfassung (Langtext → Kurztext)
- Dialog (vorherige Äußerung → nächste Äußerung)
- Codegenerierung (natürliche Sprache → Python-Code)
- Melodieerzeugung (eine Phrase → nächste Phrase)
- Spracherkennung (Ton → Text)
4.1 Maschinelle Übersetzung (NMT)
Wie folgt: Französisch-Englisch

- Auf der linken Seite erzeugt der Encoder RNN eine Codierung eines Quellsatzes
- Rechts erzeugt der Decoder RNN den Zielsatz bedingt durch die Codierung
Für Encoder und Decoder
- Für den Encoder können Sie vortrainierte Wortvektoren wie word2vec oder One-Hot-Form-Wortvektoren verwenden
- Verwenden Sie für den Decoder die One-Hot-Form, um die Ausgabe darzustellen
Wörterbuch der Encoder und Decoder
- Für einige Aufgaben, z.B. maschinelle Übersetzung, sind sie unterschiedlich
- Für andere Aufgaben, z. B. Zusammenfassungs- und Dialogaufgaben, sind sie gleich
Das Codieren von RNNs und das Decodieren von RNNs sind normalerweise unterschiedlich , und es können auch tiefe RNNs verwendet werden .
4.2 Training des NMT-Systems

Zunächst einmal brauchen wir viel Korpus, Französisch -> Englisch, Französisch -> Englisch, Französisch -> Englisch, ..., Französisch -> Englisch
Geben Sie Französisch in Encoder RNN und Englisch in Decoder RNN ein
Es wird jedes Mal ein Wort ausgegeben, berechnet unter Verwendung der Cross-Entropie-Funktion, wobei die Ergebnisse der Cross-Entropie-Berechnung zu jedem Zeitpunkt addiert werden, ein Durchschnitt genommen wird, um J zu erhalten, dieses J minimiert wird und Backpropagation erfolgt (mehrere Wörter haben mehrere Verluste). Passen Sie die Parameter in Encoder RNN und Decoder RNN an.
Modellproblem

Die im obigen Bild eingekreiste Stelle stellt den einzigen Eingang des Decoders dar. Wir erwarten, dass der Zustand des Encoders zu diesem Zeitpunkt alle Informationen des vorherigen ursprünglichen Satzes enthält. Aber nur diesen einen Vektor zu verwenden, um alle Informationen dieses Satzes darzustellen, ist die Anforderung dafür nicht etwas hoch?
Die Lösung : der Aufmerksamkeitsmechanismus
Der Aufmerksamkeitsmechanismus bietet eine Lösung für das Flaschenhalsproblem
4.3 Aufmerksamkeitsmechanismus (Attention)
Kernidee: Konzentrieren Sie sich in jedem Schritt des Decoders auf einen bestimmten Teil der Quellsequenz.
Das heißt, wenn ich ein bestimmtes Wort ausgeben möchte, gehen wir zur ursprünglichen Sequenz und konzentrieren uns darauf, herauszufinden, welche Wörter die stärkste Beziehung dazu haben.
Aufmerksamkeitsmechanismen gibt es in vielen Formen, ein Beispiel ist unten gezeigt:
4.3.1 Seq2seq mit Achtung

Wir beginnen vom ersten Moment an, um die Ausgabe im ersten Moment vorherzusagen, Punktprodukt des Vektors der verborgenen Schicht im Decoder und des Vektors der verborgenen Schicht des Encoders, und erhalten einen Skalar an jeder Stelle, der Skalar sein kann groß oder klein, und einige können mehr als 1 sein, einige können negativ sein:

Führen Sie zu diesem Zeitpunkt eine Softmax-Konvertierung auf 0-1 durch, die den Abstand/die Ähnlichkeit zwischen jedem Vektor im Encoder und dem aktuellen Vektor des Decoders angibt.
Es ist ersichtlich, dass das erste Wort im Decoder dem ersten Wort im Encoder sehr ähnlich ist.
Wir multiplizieren diese Ergebnisse (äquivalent zu Gewichten) nach Softmax mit dem Vektor im Encoder, um eine gewichtete Summierung durchzuführen:

In dem gewichteten Summenergebnis ist die Komponente/der Anteil des ersten Vektors am größten.
Kombinieren Sie das Ergebnis Attention nach der gewichteten Summierung mit dem Hidden-Layer-Zustand des Decoders im aktuellen Moment und verwenden Sie einen Softmax, um vorherzusagen, was im aktuellen Moment ausgegeben werden soll:

Ebenso für den nächsten Moment:
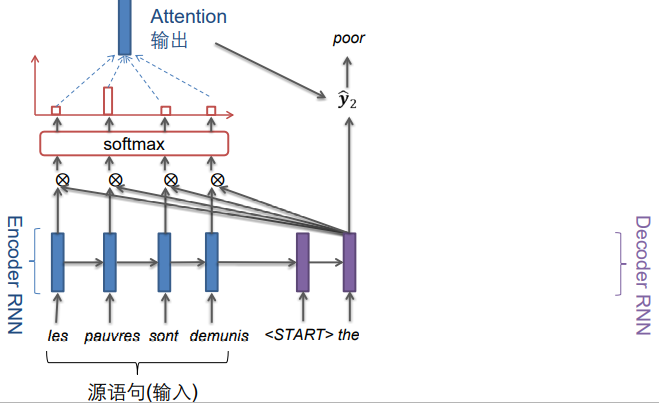
Entsprechende Formel:

5. Hauptreferenzen und weiterführende Literatur
- Kim (2014) Faltungsneuronale Netze für die Satzklassifikation arXiv Preprint arXiv:1408.5882
- Bengio, Ducharme, Vincent, Jauvin (2003) Ein neuronales probabilistisches Sprachmodell Journal of Machine Learning Research
- Mikolov, et al. (2013) Verteilte Darstellungen von Wörtern und Phrasen und ihre Kompositionalität NeurIPS
- Sutskever, Vinyals, Le (2014) Sequenz-zu-Sequenz-Lernen mit neuronalen Netzwerken NeurIPS
- Vaswani, Shazeer, Parmar, et al. (2017) Aufmerksamkeit ist alles, was Sie brauchen NeurIPS
- Devlin, Chang, Lee, Toutanova (2019) BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding NAACL