JD Logística: Kang Rui, Yao Zaiyi, Li Zhen, Liu Bin, Wang Beiyong
Nota: Todo lo siguiente se basa en la versión 8.1 de ElasticSearch
1. Recuperación entre clústeres - ccr
Dirección del documento del sitio web oficial:
https://www.elastic.co/guide/en/elasticsearch/reference/8.1/modules-cross-cluster-search.html
Antecedentes e implicaciones de la recuperación entre clústeres
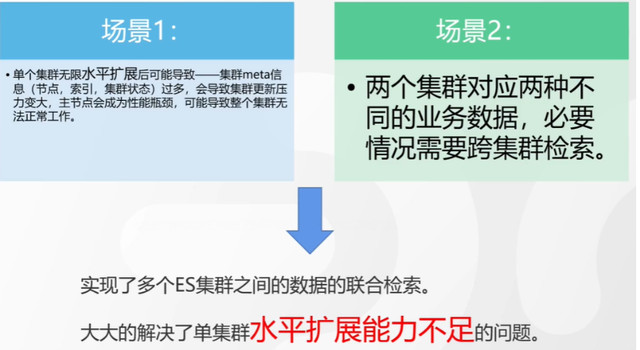
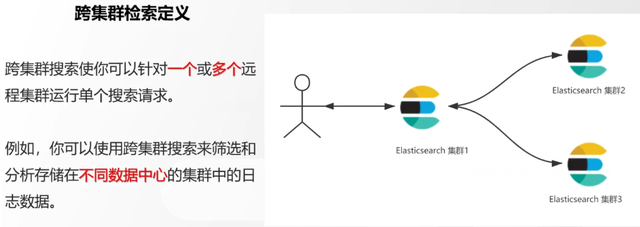
Recuperación de definiciones entre clústeres
Creación de un entorno de recuperación entre clústeres
Dirección del documento del sitio web oficial:
https://www.elastic.co/guide/en/elasticsearch/reference/8.1/modules-cross-cluster-search.html
Paso 1: cree dos clústeres locales de un solo nodo y la configuración de seguridad se puede cancelar para los ejercicios locales
Paso 2: Ejecute el siguiente comando para cada clúster
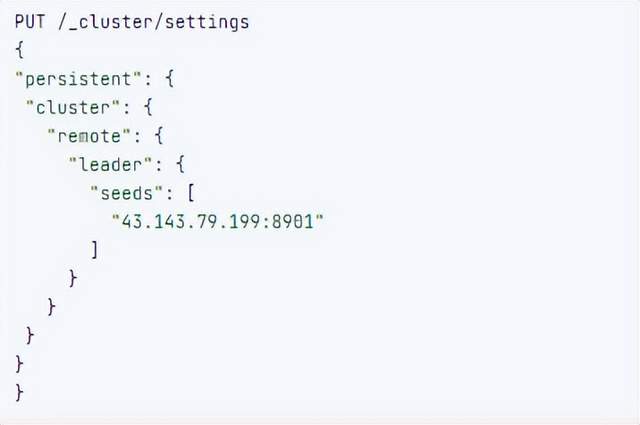
PUT _cluster/settings { "persistente": { "cluster": { "remoto": { "cluster_one": { "semillas": [ "172.21.0.14:9301" ] },"cluster_two": { "semillas": [ "172.21.0.14:9302" ] } } } } }
Paso 3: verificar si los clústeres se comunican entre sí
Solución 1: Inspección visual de Kibana: Gestión de pilas -> Clústeres remotos -> ¡El estado debe estar conectado! Y debe estar marcado con una marca de verificación verde.
Solución 2: OBTENER _remote/info
Ejercicio de consulta entre clústeres
# 步骤1 在集群 1 中添加数据如下
PUT test01/_bulk
{"index":{"_id":1}}
{"title":"this is from cluster01..."}
# 步骤2 在集群 2 中添加数据如下:
PUT test01/_bulk
{"index":{"_id":1}}
{"title":"this is from cluster02..."}
# 步骤 3:执行跨集群检索如下: 语法:POST 集群名称1:索引名称,集群名称2:索引名称/_search
POST cluster_one:test01,cluster_two:test01/_search
{
"took" : 7,
"timed_out" : false,
"num_reduce_phases" : 3,
"_shards" : {
"total" : 2,
"successful" : 2,
"skipped" : 0,
"failed" : 0
},
"_clusters" : {
"total" : 2,
"successful" : 2,
"skipped" : 0
},
"hits" : {
"total" : {
"value" : 2,
"relation" : "eq"
},
"max_score" : 1.0,
"hits" : [
{
"_index" : "cluster_two:test01",
"_id" : "1",
"_score" : 1.0,
"_source" : {
"title" : "this is from cluster02..."
}
},
{
"_index" : "cluster_one:test01",
"_id" : "1",
"_score" : 1.0,
"_source" : {
"title" : "this is from cluster01..."
}
}
]
}
}
2. Replicación entre clústeres - ccs - esta función requiere pago
Dirección del documento del sitio web oficial:
https://www.elastic.co/guide/en/elasticsearch/reference/current/xpack-ccr.html
Cómo garantizar la alta disponibilidad del clúster
- mecanismo de copia
- instantánea y recuperación
- Replicación entre clústeres (similar a la sincronización maestro-esclavo mysql)
Descripción general de la replicación entre clústeres

Copiar configuración entre clústeres
- Preparar dos clústeres para la comunicación de red
- Abre la licencia y úsala, puedes probarla durante 30 días
- Ubicación abierta: Gestión de pilas -> Gestión de licencias.
3. Defina quién es el grupo de clientes potenciales y quién es el grupo de seguidores
4. Configurar el clúster líder en el clúster seguidor
5. Configure las reglas de sincronización de índice del clúster líder en el clúster seguidor (configuración de la página kibana)
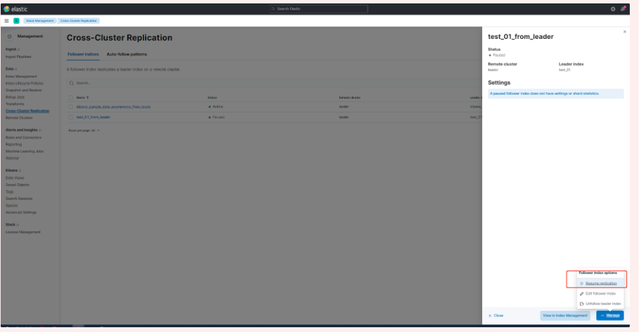
a. Stack Management -> Cross Cluster Replication -> crear un índice de seguidores.
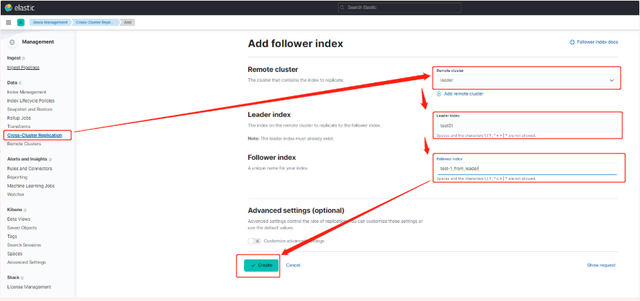
6. Habilitar la configuración del paso 5
Plantilla de tres índices
Dirección del documento del sitio web oficial:
https://www.elastic.co/guide/en/elasticsearch/reference/8.1/index-templates.html
Plantilla de componente 8.X
1. Cree una configuración de índice de plantilla de componente relacionada
# 组件模板 - 索引setting相关
PUT _component_template/template_sttting_part
{
"template": {
"settings": {
"number_of_shards": 3,
"number_of_replicas": 0
}
}
}
2. Cree una plantilla de componentes relacionada con el mapeo de índices
# 组件模板 - 索引mapping相关
PUT _component_template/template_mapping_part
{
"template": {
"mappings": {
"properties": {
"hosr_name":{
"type": "keyword"
},
"cratet_at":{
"type": "date",
"format": "EEE MMM dd HH:mm:ss Z yyyy"
}
}
}
}
}
3. Cree una plantilla de componente: configure la asociación entre la plantilla y el índice
// **注意:composed_of 如果多个组件模板中的配置项有重复,后面的会覆盖前面的,和配置的顺序有关**
# 基于组件模板,配置模板和索引之间的关联
# 也就是所有 tem_* 该表达式相关的索引创建时,都会使用到以下规则
PUT _index_template/template_1
{
"index_patterns": [
"tem_*"
],
"composed_of": [
"template_sttting_part",
"template_mapping_part"
]
}
4. prueba
# 创建测试
PUT tem_001
Operaciones básicas de las plantillas de índice

Ejercicio práctico
Requisito 1: de forma predeterminada, si la asignación no se especifica explícitamente, el tipo de valor se asignará dinámicamente al tipo largo, pero, de hecho, los valores comerciales son relativamente pequeños y habrá desperdicio de almacenamiento. Necesidad de especificar el valor predeterminado como Integer
Plantilla de índice, dirección del documento del sitio web oficial:
https://www.elastic.co/guide/en/elasticsearch/reference/8.1/index-templates.html
plantilla dinámica de mapeo, dirección del documento del sitio web oficial:
https://www.elastic.co/guide/en/elasticsearch/reference/8.1/dynamic-templates.html
# 结合mapping 动态模板 和 索引模板
# 1.创建组件模板之 - mapping模板
PUT _component_template/template_mapping_part_01
{
"template": {
"mappings": {
"dynamic_templates": [
{
"integers": {
"match_mapping_type": "long",
"mapping": {
"type": "integer"
}
}
}
]
}
}
}
# 2. 创建组件模板与索引关联配置
PUT _index_template/template_2
{
"index_patterns": ["tem1_*"],
"composed_of": ["template_mapping_part_01"]
}
# 3.创建测试数据
POST tem1_001/_doc/1
{
"age":18
}
# 4.查看mapping结构验证
get tem1_001/_mapping
Requisito 2: los campos que comienzan con date_* se comparan uniformemente como tipos de fecha.
Plantilla de índice, dirección del documento del sitio web oficial:
https://www.elastic.co/guide/en/elasticsearch/reference/8.1/index-templates.html
plantilla dinámica de mapeo, dirección del documento del sitio web oficial:
https://www.elastic.co/guide/en/elasticsearch/reference/8.1/dynamic-templates.html
# 结合mapping 动态模板 和 索引模板
# 1.创建组件模板之 - mapping模板
PUT _component_template/template_mapping_part_01
{
"template": {
"mappings": {
"dynamic_templates": [
{
"integers": {
"match_mapping_type": "long",
"mapping": {
"type": "integer"
}
}
},
{
"date_type_process": {
"match": "date_*",
"mapping": {
"type": "date",
"format":"yyyy-MM-dd HH:mm:ss"
}
}
}
]
}
}
}
# 2. 创建组件模板与索引关联配置
PUT _index_template/template_2
{
"index_patterns": ["tem1_*"],
"composed_of": ["template_mapping_part_01"]
}
# 3.创建测试数据
POST tem1_001/_doc/2
{
"age":19,
"date_aoe":"2022-01-01 18:18:00"
}
# 4.查看mapping结构验证
get tem1_001/_mapping
4. Gestión del ciclo de vida del índice LIM
Dirección del documento del sitio web oficial:
https://www.elastic.co/guide/en/elasticsearch/reference/8.1/index-lifecycle-management.html
¿Qué es el ciclo de vida del índice?
Vida indexada -> viejo -> enfermo -> muerto
¿Alguna vez te has planteado que si se crea un índice, ya no se gestionará? ¿lo que pasa?
¿Qué es la gestión del ciclo de vida del índice?
¿Qué sucede si el índice es demasiado grande?
El tiempo de recuperación de un índice grande es mucho más lento que la recuperación de un índice pequeño. Después de que el índice múltiple sea grande, la recuperación será muy lenta y la escritura y la actualización también se verán afectadas en diversos grados. Cuando el índice es grande en cierta medida, cuando el índice tiene problemas de salud, hará que el negocio principal de todo el clúster no esté disponible
Mejores prácticas
El límite superior de la cantidad máxima de documentos en un solo fragmento de un clúster: 2 elevado a la 32 menos 1, es decir, alrededor de 2 mil millones Recomendaciones oficiales: el tamaño de un fragmento debe controlarse en 30 GB-50 GB. de datos de índice aumenta infinitamente, definitivamente superará este valor
Los usuarios no prestan atención a la cantidad total
En algunos escenarios comerciales, la empresa presta más atención a los datos recientes. Por ejemplo, el índice grande de los últimos 3 días o los últimos 7 días reunirá todos los datos históricos, lo que no es propicio para la consulta en este escenario.
La evolución histórica de la gestión del ciclo de vida de los índices

LIM Prelude - índice de desplazamiento de rollover
Dirección del documento del sitio web oficial:
https://www.elastic.co/guide/en/elasticsearch/reference/8.1/index-rollover.html
# 0.自测前提,lim生命周期rollover频率。默认10分钟
PUT _cluster/settings
{
"persistent": {
"indices.lifecycle.poll_interval": "1s"
}
}
# 1. 创建索引,并指定别名
PUT test_index-0001
{
"aliases": {
"my-test-index-alias": {
"is_write_index": true
}
}
}
# 2.批量导入数据
PUT my-test-index-alias/_bulk
{"index":{"_id":1}}
{"title":"testing 01"}
{"index":{"_id":2}}
{"title":"testing 02"}
{"index":{"_id":3}}
{"title":"testing 03"}
{"index":{"_id":4}}
{"title":"testing 04"}
{"index":{"_id":5}}
{"title":"testing 05"}
# 3.rollover 滚动规则配置
POST my-test-index-alias/_rollover
{
"conditions": {
"max_age": "7d",
"max_docs": 5,
"max_primary_shard_size": "50gb"
}
}
# 4.在满足条件的前提下创建滚动索引
PUT my-test-index-alias/_bulk
{"index":{"_id":7}}
{"title":"testing 07"}
# 5.查询验证滚动是否成功
POST my-test-index-alias/_search
Preludio de LIM: compresión del índice de contracción
Dirección del documento del sitio web oficial:
https://www.elastic.co/guide/en/elasticsearch/reference/8.1/ilm-shrink.htmlPasos básicos:
1. Migrar todos los datos a un nodo independiente
2. El índice prohíbe escribir
3. Antes de comprimir
# 1.准备测试数据
DELETE kibana_sample_data_logs_ext
PUT kibana_sample_data_logs_ext
{
"settings": {
"number_of_shards": 5,
"number_of_replicas": 0
}
}
POST _reindex
{
"source": {
"index": "kibana_sample_data_logs"
},
"dest": {
"index": "kibana_sample_data_logs_ext"
}
}
# 2.压缩前必要的条件设置
# number_of_replicas :压缩后副本为0
# index.routing.allocation.include._tier_preference 数据分片全部路由到hot节点
# "index.blocks.write 压缩后索引不再允许数据写入
PUT kibana_sample_data_logs_ext/_settings
{
"settings": {
"index.number_of_replicas": 0,
"index.routing.allocation.include._tier_preference": "data_hot",
"index.blocks.write": true
}
}
# 3.实施压缩
POST kibana_sample_data_logs_ext/_shrink/kibana_sample_data_logs_ext_shrink
{
"settings":{
"index.number_of_replicas": 0,
"index.number_of_shards": 1,
"index.codec":"best_compression"
},
"aliases":{
"kibana_sample_data_logs_alias":{}
}
}
combate LIM
Establecimiento de la cognición global - cuatro etapas
Dirección del documento del sitio web oficial:
https://www.elastic.co/guide/en/elasticsearch/reference/8.1/overview-index-lifecycle-management.html
Fase de gestión del ciclo de vida (Política):
https://www.elastic.co/guide/en/elasticsearch/reference/8.1/ilm-index-lifecycle.html
Etapa caliente (crudo)
Fijar prioridad
Dejar de seguir
Dese la vuelta
Solo lectura
Encogerse
Fusión forzada
Instantánea de búsqueda
Fase cálida (antigua)
Fijar prioridad
Dejar de seguir
Solo lectura
Asignar
emigrar
Shirink
Fusión forzada
Etapa fría (enfermedad)
Instantánea de búsqueda
Eliminar etapa (muerta)
Eliminar
perforar
1. Crear una política
-
Configuración de etapa activa, rollover: max_age :3d, max_docs:5, max_size:50gb, prioridad: 100
-
Configuración de escenario tibio: min_age: 15 s, fusión de segmento forzado, nodo caliente migrado a nodo tibio, número de copias establecido en 0, prioridad: 50
-
Configuración de etapa fría: min_age 30s, cálido migra a etapa fría
-
Eliminar configuración de etapa: min_age 45s, realizar operación de eliminación
PUT _ilm/policy/kr_20221114_policy
{
"policy": {
"phases": {
"hot": {
"min_age": "0ms",
"actions": {
"set_priority": {
"priority": 100
},
"rollover": {
"max_size": "50gb",
"max_primary_shard_size": "50gb",
"max_age": "3d",
"max_docs": 5
}
}
},
"warm": {
"min_age": "15s",
"actions": {
"forcemerge": {
"max_num_segments": 1
},
"set_priority": {
"priority": 50
},
"allocate": {
"number_of_replicas": 0
}
}
},
"cold": {
"min_age": "30s",
"actions": {
"set_priority": {
"priority": 0
}
}
},
"delete": {
"min_age": "45s",
"actions": {
"delete": {
"delete_searchable_snapshot": true
}
}
}
}
}
}

2. Crear plantilla de índice
PUT _index_template/kr_20221114_template
{
"index_patterns": ["kr_index-**"],
"template": {
"settings": {
"index": {
"lifecycle": {
"name": "kr_20221114_policy",
"rollover_alias": "kr-index-alias"
},
"routing": {
"allocation": {
"include": {
"_tier_preference": "data-hot"
}
}
},
"number_of_shards": "3",
"number_of_replicas": "1"
}
},
"aliases": {},
"mappings": {}
}
}
3. La prueba necesita modificar la frecuencia de actualización del cambio de límite
PUT _cluster/settings
{
"persistent": {
"indices.lifecycle.poll_interval": "1s"
}
}
4. Ejecute la prueba
# 创建索引,并制定可写别名
PUT kr_index-0001
{
"aliases": {
"kr-index-alias": {
"is_write_index": true
}
}
}
# 通过别名新增数据
PUT kr-index-alias/_bulk
{"index":{"_id":1}}
{"title":"testing 01"}
{"index":{"_id":2}}
{"title":"testing 02"}
{"index":{"_id":3}}
{"title":"testing 03"}
{"index":{"_id":4}}
{"title":"testing 04"}
{"index":{"_id":5}}
{"title":"testing 05"}
# 通过别名新增数据,触发rollover
PUT kr-index-alias/_bulk
{"index":{"_id":6}}
{"title":"testing 06"}
# 查看索引情况
GET kr_index-0001
get _cat/indices?v
resumen del proceso
Paso 1: configurar la policía lim
-
Horizontal: Etapa de frase (Caliente, Tibio, Frío, Borrar) Nacimiento, vejez, enfermedad y muerte
-
Vertical: operación de acción (cambiar, fusionar forzadamente, solo lectura, eliminar)
Paso 2: Cree una política de enlace de plantilla y especifique un alias
Paso 3: crea un índice inicial
Paso 4: el índice se desplaza según la política especificada en el primer paso
5. Flujo de datos
Dirección del documento del sitio web oficial:
https://www.elastic.co/guide/en/elasticsearch/reference/8.1/ilm-actions.html
Análisis de características
Data Stream nos permite almacenar datos de series temporales en múltiples índices y, al mismo tiempo, proporciona una interfaz externa única (nombre de flujo de datos)
-
Las solicitudes de escritura y recuperación se envían al flujo de datos
-
El flujo de datos enruta estas solicitudes al índice de respaldo (índice de fondo)

Índices de respaldo
Cada flujo de datos consta de múltiples índices de fondo ocultos
-
creado automáticamente
-
Índice de plantillas de solicitud
El mecanismo de índice móvil de rollover se utiliza para generar automáticamente índices de fondo
- Se convertirá en el nuevo índice de escritura del flujo de datos
Escenario de aplicación
- Registros, eventos, métricas y otros datos comerciales que se crean continuamente (menos actualizados)
- Dos características principales
- datos de series de tiempo
- Los datos rara vez o nunca se actualizan
Pasos principales para crear un flujo de datos

Dirección del documento del sitio web oficial:
https://www.elastic.co/guide/en/elasticsearch/reference/8.1/set-up-a-data-stream.html
Configurar un flujo de datos
Para configurar un flujo de datos, siga estos pasos:
- Crear una política de ciclo de vida de índice
- Crear plantillas de componentes
- Crear una plantilla de índice
- Crear el flujo de datos
- Asegure el flujo de datos
perforar
1. Cree un flujo de datos llamado my-data-stream
2. El nombre de index_template es my-index-template
3. Todos los índices que cumplan con el formato de índice ["my-data-stream*"] deben aplicarse a
4. Cuando se insertan datos, en el nodo data_hot
5. Pase al nodo data_warm después de 3 minutos
6. Vaya al nodo data_cold en otros 5 minutos
# 步骤1 。创建 lim policy
PUT _ilm/policy/my-lifecycle-policy
{
"policy": {
"phases": {
"hot": {
"actions": {
"rollover": {
"max_size": "50gb",
"max_age": "3m",
"max_docs": 5
},
"set_priority": {
"priority": 100
}
}
},
"warm": {
"min_age": "5m",
"actions": {
"allocate": {
"number_of_replicas": 0
},
"forcemerge": {
"max_num_segments": 1
},
"set_priority": {
"priority": 50
}
}
},
"cold": {
"min_age": "6m",
"actions": {
"freeze":{}
}
},
"delete": {
"min_age": "45s",
"actions": {
"delete": {}
}
}
}
}
}
# 步骤2 创建组件模板 - mapping
PUT _component_template/my-mappings
{
"template": {
"mappings": {
"properties": {
"@timestamp": {
"type": "date",
"format": "date_optional_time||epoch_millis"
},
"message": {
"type": "wildcard"
}
}
}
},
"_meta": {
"description": "Mappings for @timestamp and message fields",
"my-custom-meta-field": "More arbitrary metadata"
}
}
# 步骤3 创建组件模板 - setting
PUT _component_template/my-settings
{
"template": {
"settings": {
"index.lifecycle.name": "my-lifecycle-policy",
"index.routing.allocation.include._tier_preference":"data_hot"
}
},
"_meta": {
"description": "Settings for ILM",
"my-custom-meta-field": "More arbitrary metadata"
}
}
# 步骤4 创建索引模板
PUT _index_template/my-index-template
{
"index_patterns": ["my-data-stream*"],
"data_stream": { },
"composed_of": [ "my-mappings", "my-settings" ],
"priority": 500,
"_meta": {
"description": "Template for my time series data",
"my-custom-meta-field": "More arbitrary metadata"
}
}
# 步骤5 创建 data stream 并 写入数据测试
PUT my-data-stream/_bulk
{ "create":{ } }
{ "@timestamp": "2099-05-06T16:21:15.000Z", "message": "192.0.2.42 - - [06/May/2099:16:21:15 +0000] \"GET /images/bg.jpg HTTP/1.0\" 200 24736" }
{ "create":{ } }
{ "@timestamp": "2099-05-06T16:25:42.000Z", "message": "192.0.2.255 - - [06/May/2099:16:25:42 +0000] \"GET /favicon.ico HTTP/1.0\" 200 3638" }
POST my-data-stream/_doc
{
"@timestamp": "2099-05-06T16:21:15.000Z",
"message": "192.0.2.42 - - [06/May/2099:16:21:15 +0000] \"GET /images/bg.jpg HTTP/1.0\" 200 24736"
}
# 步骤6 查看data stream 后台索引信息
GET /_resolve/index/my-data-stream*