1. ¿Qué es StarRocks?
- Una nueva generación de base de datos MPP de escena completa ultrarrápida, que puede usar StarRocks para respaldar el análisis ultrarrápido de varios escenarios de análisis de datos;
- Arquitectura simple, que utiliza un motor de vectorización completo y está equipado con un optimizador CBO de nuevo diseño, velocidad de consulta (especialmente consulta de asociación de varias tablas);
- Admite bien el análisis de datos en tiempo real y puede realizar consultas eficientes de datos de actualización en tiempo real, y también admite vistas materializadas modernas para acelerar aún más la consulta;
- Los usuarios pueden construir de manera flexible varios modelos, incluida una mesa grande y ancha, un modelo de estrella, un modelo de copo de nieve;
- Compatible con el protocolo MySQL, admite sintaxis SQL estándar, fácil de usar, sin dependencias externas en todo el sistema, alta disponibilidad, fácil operación y gestión de mantenimiento.
2. Arquitectura del sistema
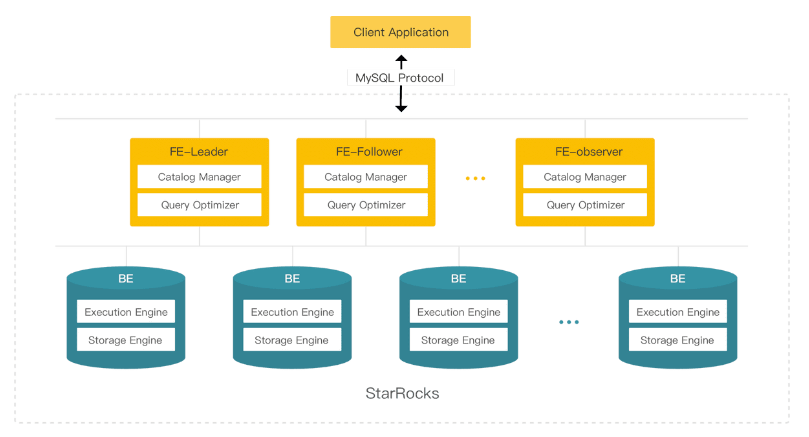
Proceso central: FE (Frontend), BE (Backend).
Nota: Todos los nodos tienen estado.
- FE (Frontend) es responsable de administrar metadatos, administrar conexiones de clientes y realizar la planificación y programación de consultas.
- Seguidor
- Líder: el seguidor seleccionará un líder a través del protocolo BDBJE similar a Paxos, y todos los envíos de transacciones son iniciados y completados por el líder;
- Seguidor: mejore la concurrencia de consultas, participe en la votación y participe en la operación electoral principal.
- Observador: no participa en la operación de selección principal, solo sincroniza de forma asíncrona y reproduce el registro, que se utiliza principalmente para ampliar la capacidad de concurrencia de consultas del clúster.
- BE (Backend) es responsable del almacenamiento de datos y la ejecución de SQL.
3. Arquitectura de almacenamiento
En StarRocks, los datos de una tabla se dividirán en varias tabletas, y cada tableta se almacenará en el nodo BE en forma de copias múltiples, como se muestra en la siguiente figura:
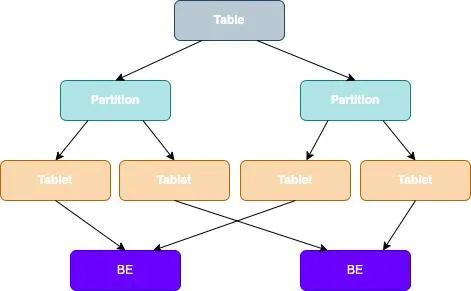
División de datos de tabla + distribución de datos de tres copias de Tablet:
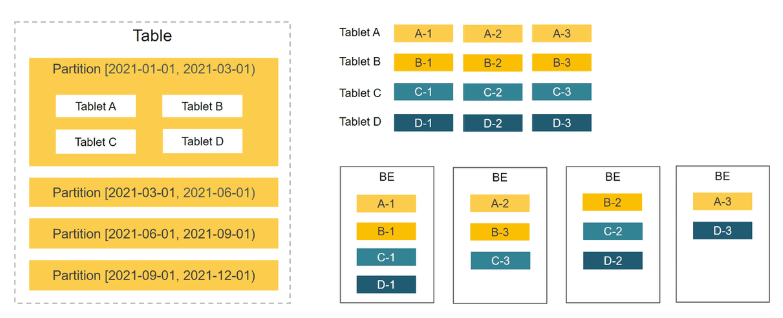
StarRocks es compatible con la distribución Hash y la distribución de datos combinados Range-Hash (recomendado).
Para esperar un mayor rendimiento, se recomienda encarecidamente utilizar la distribución de datos combinados de Range-Hash, es decir, el método de partición y luego la agrupación.
- Las particiones de rango se pueden agregar y eliminar dinámicamente;
- Una vez que se determinan los cubos Hash, no se pueden ajustar. Solo las particiones no creadas pueden establecer una nueva cantidad de cubos.
La elección de la partición y el agrupamiento es crítica. La selección de una buena columna de partición y depósito al crear una tabla puede mejorar de manera efectiva el rendimiento general del clúster.
Las siguientes son algunas sugerencias para la selección de particiones y cubos para escenarios de aplicaciones especiales:
- Sesgo de datos: si el lado comercial determina que los datos están sesgados en gran medida, se recomienda usar una combinación de varias columnas para la agrupación de datos, en lugar de usar solo columnas con una gran asimetría para la agrupación.
- Alta simultaneidad: la partición y el depósito deben cubrir las condiciones de la declaración de consulta tanto como sea posible, lo que puede reducir de manera efectiva el escaneo de datos y mejorar la simultaneidad.
- Alto rendimiento: intente dividir los datos, deje que el clúster escanee los datos con mayor simultaneidad y complete el cálculo correspondiente.
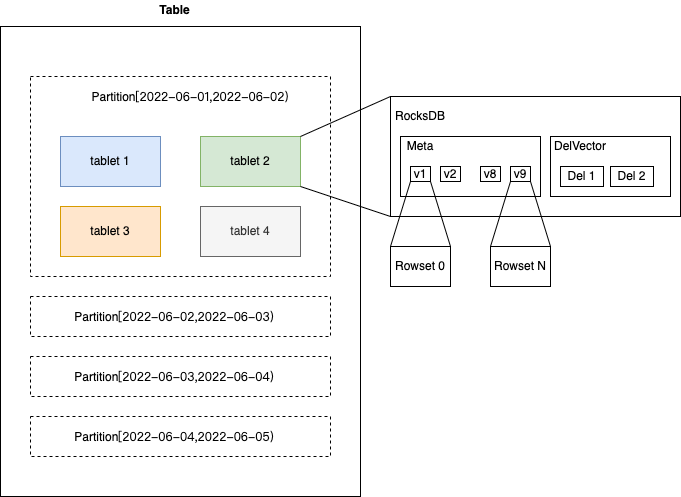
3.1 Almacenamiento de tablas
Al almacenar una tabla, la tabla se dividirá y dividirá en dos capas, y los datos de la tabla se distribuirán a varias máquinas para su almacenamiento y administración.
- Mecanismo de partición: filtrado eficiente para mejorar el rendimiento de las consultas.
El particionamiento es similar al particionamiento de tablas, que consiste en dividir una tabla según la clave de partición, que se puede particionar por tiempo, dividir por día/mes/año según la cantidad de datos, etc. Puede usar la poda de partición para una pequeña cantidad de accesos, o puede dividir los datos en diferentes medios según el grado de frialdad de los datos.
- Mecanismo de uso compartido de cubos: aproveche al máximo el rendimiento del clúster y evite problemas de puntos críticos.
Después de usar la clave Hash de agrupamiento, los datos se distribuyen de manera uniforme a todos los BE y los datos del agrupamiento no deben estar sesgados. El principio de selección de la clave de agrupamiento es combinar columnas de alta cardinalidad o múltiples columnas en una columna de alta cardinalidad. suficientemente los datos.
Nota: El número de cubos debe ser moderado. Si desea aprovechar al máximo el rendimiento, puede configurarlo como: número BE * núcleo de CPU/2. Lo mejor es controlar la tableta con aproximadamente 1 GB. Si hay muy pocas tabletas, el paralelismo puede no ser suficiente. Demasiados datos pueden estar demasiado lejos. Demasiada simultaneidad de escaneo degrada el rendimiento.
- Tableta: La unidad lógica de datos más pequeña, que puede establecer de forma flexible recursos informáticos paralelos.
Una tabla se divide en varias tabletas. Cuando StarRocks ejecuta instrucciones SQL, puede implementar un procesamiento simultáneo para todas las tabletas, a fin de aprovechar al máximo la potencia informática proporcionada por varias computadoras y varios núcleos.
El número de réplicas se puede especificar cuando se crea una tabla, y varias réplicas pueden garantizar una alta confiabilidad del almacenamiento de datos y una alta disponibilidad de los servicios.
- Conjunto de filas: se genera un conjunto de filas para cada cambio de datos.
Son algunos archivos organizados en almacenamiento de columnas grupales. Cada confirmación generará una nueva versión y qué conjuntos de filas se incluyen en cada versión.
Se agrega una versión cada vez que se escribe (ya sea un solo archivo o un archivo con varios gigabytes de carga de flujo).
- Segmento: si la cantidad de datos en un conjunto de filas es relativamente grande, se dividirá en varios segmentos de datos y se cortará el disco.
4. Antecedentes de los requisitos
Caso número uno:
- conocimiento de los negocios
El servicio de fábrica de indicadores es principalmente para el personal comercial. A través de la recopilación y el procesamiento de indicadores comerciales, puede reflejar el estado del producto en tiempo real, proporcionar soporte de datos para las operaciones, detectar vulnerabilidades del producto o anomalías del servicio y proporcionar funciones de alarma de anomalías de indicadores.
- Análisis de Escenarios de Negocios
Hay varias formas de enterrar los indicadores comerciales, y no se limita a una determinada manera. Siempre que los puntos de ocultación estén claramente identificados, los parámetros comerciales sean ricos y los datos cumplan con los requisitos básicos de análisis, se pueden utilizar como Fuentes de datos Se pueden dividir aproximadamente en: SDK, MySQL BinLog, registro comercial, análisis de datos Alibaba Cloud ODPS.
Los desafíos existentes, varios escenarios comerciales son difíciles de ajustar y las características de los datos resumidos son las siguientes:
- Se requieren los detalles completos del registro;
- Los datos deben estar siempre actualizados, es decir, para cumplir con el escenario de actualización en tiempo real;
- Los datos deben agregarse a un nivel, es decir, puede ser mes, semana, día, hora, etc.;
- Necesita poder transportar un volumen de escritura más grande;
- Cada dato comercial debe configurar de manera flexible el tiempo de almacenamiento de datos;
- Hay muchas fuentes de fuentes de datos, y la personalización de los informes es relativamente alta. Hay escenarios en los que varias fuentes de datos se fusionan en una tabla grande y ancha, y también hay requisitos para conexiones de varias tablas;
- Varias gráficas de seguimiento, presentaciones de informes, consultas comerciales en tiempo real, etc., es decir, las más altas no son consultas.
- Presentamos StarRocks
Afortunadamente, StarRocks tiene un modelo de datos relativamente rico, que cubre las necesidades de todos los escenarios comerciales anteriores, a saber: modelo detallado, modelo de actualización, modelo de agregación, modelo de clave principal y elegir un modelo de estrella más flexible en lugar de tablas grandes y anchas. es decir, consulta directamente mediante la asociación de varias tablas.
- Modelo detallado:
- Los datos del punto enterrado se estructuran y almacenan en su totalidad de acuerdo con los detalles;
- Este escenario tiene requisitos más altos en el rendimiento de consultas de la base de datos con un volumen de datos de 100 millones;
- Los datos pueden configurar políticas de caducidad mediante la configuración de particiones dinámicas;
- Cuando se utiliza el escenario, seleccione las dimensiones de campo individuales de los datos estructurados para la consulta de agregación en línea.
- Modelo agregado:
- La cantidad de datos de puntos enterrados es enorme, y los datos detallados no requieren trazabilidad, y los cálculos de agregación se realizan directamente, como escenarios PV y UV;
- Los datos se pueden configurar con políticas de caducidad mediante la configuración de particiones dinámicas.
- Actualizar el modelo:
- El estado de los datos del punto enterrado cambiará y los datos deben actualizarse en tiempo real. El rango de datos actualizado no abarcará varias particiones, como: pedido, estado del cupón, etc.;
- Los datos se pueden configurar con políticas de caducidad mediante la configuración de particiones dinámicas.
Según el análisis de los escenarios comerciales anteriores, estos tres modelos pueden resolver perfectamente el problema de los datos.
Cuando se requiere la escritura de datos en tiempo real, también sigo la solución popular en la industria, es decir, después de recopilar los datos en Kafka, uso Flink para escribir en tiempo real en StarRocks. StarRocks proporciona un complemento de conector Flink muy útil.
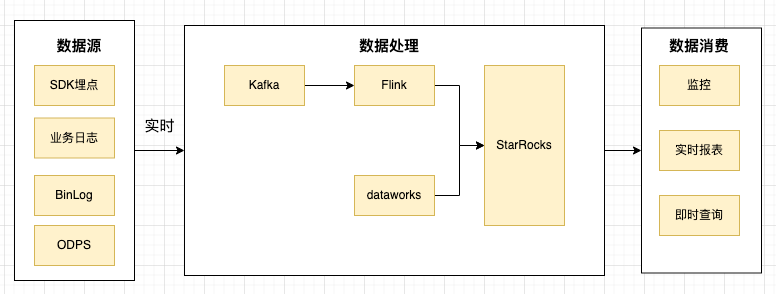
Pequeños consejos:
1. Aunque StarRocks ha optimizado muy bien el rendimiento de escritura, cuando la presión de escritura es alta, aún se producirán rechazos de escritura. Se recomienda aumentar la cantidad de datos importados en una sola vez y reducir la frecuencia, pero también provocará un retraso en el almacenamiento de datos Incremento. Por lo tanto, se deben hacer ciertas compensaciones para maximizar las ganancias.
2. No se recomienda configurar el lado receptor de Flink demasiado grande, lo que provocará demasiadas transacciones simultáneas para informar de errores. Se recomienda que cada origen de tarea de Flink se pueda configurar más, y la cantidad de conexiones receptoras no puede ser demasiado grande. .
- resumen
Tamaño del clúster: 5 FE (8c32GB), 5 BE (32c128GB)
En la actualidad, la solución ha admitido el acceso a cientos de indicadores comerciales, que involucran docenas de indicadores y alarmas a gran escala, terabytes de almacenamiento de datos, crecimiento neto diario de cientos de gigabytes y una operación estable en general.
Caso 2:
- conocimiento de los negocios
El kanban empresarial del sistema interno atiende principalmente a los empleados de toda la empresa y proporciona funciones como el seguimiento de proyectos y tareas.
- Análisis de Escenarios de Negocios
Analizar las características del negocio:
- Los datos cambian con frecuencia (actualizaciones) y el tiempo de cambio es largo
- lapso de tiempo de la consulta
- Los informes deben actualizarse en tiempo real
- Hay muchas consultas de tablas de dimensiones relacionadas, departamento/línea de negocio/dominio de recursos, etc.
- Datos calientes y fríos, las consultas de datos recientes son frecuentes
- Arquitectura histórica y puntos débiles
En la selección inicial de la base de datos, combinada con las características comerciales, los usuarios deben agregar y eliminar sus propias tareas de manera dinámica y flexible. Por lo tanto, se selecciona el modelo JOSN para reducir la impedancia entre el código de la aplicación y la capa de almacenamiento, y se selecciona MongoDB como el almacenamiento de datos.
Con la entrega rápida de la empresa, cuando se requiere la visualización de informes, especialmente cuando el lapso de tiempo es relativamente largo e involucra la visualización de informes multidepartamentales, multidimensionales, detallados y de otro tipo, el tiempo de consulta en MongoDB debe ejecutarse para 10s o incluso más.
- Presentamos StarRocks
He investigado StarRocks y ClickHouse, que son excelentes bases de datos analíticas. Al seleccionar modelos, analizamos escenarios de aplicaciones comerciales, centrándonos principalmente en consultas de agregación de una sola tabla, consultas de asociación de varias tablas y consultas de lectura y escritura de actualización en tiempo real. La tabla de dimensiones se actualiza con frecuencia, es decir, se almacena en MySQL. StarRocks admite mejor las consultas relacionadas con la apariencia externa, lo que reduce en gran medida la dificultad del desarrollo. Al final, se decidió utilizar StarRocks como motor de almacenamiento.
En la etapa de transformación, una colección en el MongoDB original se divide en tres tablas. Utilice el modelo detallado para registrar la información de tareas del personal correspondiente todos los días y divídalo por día, desde el registro anterior de un registro por persona por día hasta la unidad de evento, y cada persona puede tener múltiples registros por día.
Para implementar tablas de dimensiones actualizadas con frecuencia, elija usar tablas externas para reducir la complejidad de sincronizar datos de dimensiones con StarRocks. \
- resumen
Antes de la transformación, la consulta de MongoDB era complicada y se consultaba varias veces.
db.time_note_new.aggregate(
[
{'$unwind': '$depart'},
{'$match': {
'depart': {'$in': ['部门id']},
'workday': {'$gte': 1609430400, '$lt': 1646064000},
'content.id': {'$in': ['事项id']},
'vacate_state': {'$in': [0, 1]}}
},
{'$group': {
'_id': '$depart',
'write_hour': {'$sum': '$write_hour'},
'code_count': {'$sum': '$code_count'},
'all_hour': {'$sum': '$all_hour'},
'count_day_user': {'$sum': {'$cond': [{'$eq': ['$vacate_state', 0]}, 1, 0]}},
'vacate_hour': {'$sum': {'$cond': [{'$eq': ['$vacate_state', 0]}, '$all_hour', 0]}},
'vacate_write_hour': {'$sum': {'$cond': [{'$eq': ['$vacate_state', 0]}, '$write_hour', 0]}}}
-- ... more field
},
{'$project': {
'_id': 1,
'write_hour': {'$cond': [{'$eq': ['$count_day_user', 0]}, 0, {'$divide': ['$vacate_write_hour', '$count_day_user']}]},
'count_day_user': 1,
'vacate_hour': 1,
'vacate_write_hour': 1,
'code_count': {'$cond': [{'$eq': ['$count_day_user', 0]}, 0, {'$divide': ['$code_count', '$count_day_user']}]},
'all_hour': {'$cond': [{'$eq': ['$count_day_user', 0]}, 0, {'$divide': ['$vacate_hour', '$count_day_user']}]}}
-- ... more field
}
]
)Después de la transformación, es directamente compatible con SQL y se puede agregar en una sola vez.
WITH cont_time as (
SELECT b.depart_id, a.user_id, a.workday, a.content_id, a.vacate_state
min(a.content_second)/3600 AS content_hour,
min(a.write_second)/3600 AS write_hour,
min(a.all_second)/3600 AS all_hour
FROM time_note_report AS a
JOIN user_department AS b ON a.user_id = b.user_id
-- 更多维表关联
WHERE b.depart_id IN (?) AND a.content_id IN (?)
AND a.workday >= '2021-01-01' AND a.workday < '2022-03-31'
AND a.vacate_state IN (0, 1)
GROUP BY b.depart_id, a.user_id, a.workday, a.content_id,a.vacate_state
)
SELECT M.*, N.*
FROM (
SELECT t.depart_id,
SUM(IF(t.content_id = 14, t.content_hour, 0)) AS content_hour_14,
SUM(IF(t.content_id = 46, t.content_hour, 0)) AS content_hour_46,
-- ...more
FROM cont_time t
GROUP BY t.depart_id
) M
JOIN (
SELECT depart_id AS join_depart_id,
SUM(write_hour) AS write_hour,
SUM(all_hour) AS all_hour
-- 更多指标
FROM cont_time
GROUP BY depart_id
) N ON M.depart_id = N.join_depart_id
ORDER BY depart_id ASCPara comparar los datos entre el 01/01/2021 y el 01/03/2022 en el informe de consulta:
- StarRocks: 1 agregación de consultas, que se puede calcular completamente a través de funciones complejas de agregación de SQL, lo que lleva 295 ms
- Mongodb: debe dividirse en 2 consultas + cálculo, lo que toma 3 s + 9 s = 12 s en total
5. Compartir experiencias
Algunos errores y soluciones encontrados al usar StarRocks (información de error con menos información en línea):
a. Error de carga de flujo de importación de datos: "txns en ejecución actual en db 13003 es 100, mayor que el límite 100"
Causa: se superó el número máximo de trabajos de importación en ejecución por base de datos, el valor predeterminado es 100. La cantidad de trabajos por importación se puede aumentar ajustando el parámetro max_running_txn_num_per_db, preferiblemente ajustando el lote de envío de trabajos. Eso es para guardar lotes y reducir la concurrencia.
b. FE informa un error: "java.io.FileNotFoundException: /proc/net/snmp (demasiados archivos abiertos)"
Motivo: identificador de archivo insuficiente Cabe señalar aquí que si el supervisor administra el proceso, la configuración del identificador de archivo debe agregarse a la secuencia de comandos de inicio de fe.
if [[ $(ulimit -n) -lt 60000 ]]; then
ulimit -n 65535
fi
c. StarRocks admite el uso del lenguaje Java para escribir UDF de funciones definidas por el usuario, y se informa un error en la función de ejecución: "rpc falló, host: xxxx", y se informa un error en el registro be.out:
start time: Tue Aug 9 19:05:14 CST 2022
Error occurred during initialization of VM
java/lang/NoClassDefFoundError: java/lang/ObjectMotivo: cuando utilice el supervisor para administrar el proceso, debe prestar atención al aumento de la variable de entorno JAVA_HOME. Incluso el nodo BE necesita llamar a algunas funciones de Java, y puede agregar directamente la configuración de la variable de entorno JAVA_HOME al script de inicio BE .
D. Se informa el siguiente error cuando se ejecuta la operación Eliminar:
SQL > delete from tableName partition (p20220809,p20220810) where `c_time` > '2022-08-09 15:20:00' and `c_time` < '2022-08-10 15:20:00';
ERROR 1064 (HY000): Where clause only supports compound predicate, binary predicate, is_null predicate and in predicateMotivo: actualmente, la condición where después de eliminar no admite la operación between and, actualmente solo admite =, >, >=, <, <=, !=, IN, NOT IN
e. Cuando se utiliza la carga de rutina para consumir datos de kakfa, se genera una gran cantidad de identificadores de grupo aleatorios.
Sugerencia: especifique el nombre del grupo al crear una carga de rutina.
F. Se agotó el tiempo de espera de la conexión de StarRocks y la declaración de consulta informó un error: "ERROR 1064 (HY000): no hay backend de scanNode". Después de reiniciar el nodo BE, se recuperó brevemente. El error de registro es el siguiente:
kafka log-4-FAIL, event: [thrd:x.x.x.x:9092/bootstrap]: x.x.x.x:9092/1: ApiVersionRequest failed: Local: Timed out: probably due to broker version < 0.10 (see api.version.request configuration) (after 10009ms in state APIVERSION_QUERY)Motivo: cuando hay un problema con la carga de rutina que se conecta a kafka, hará que se agote el subproceso BrpcWorker, lo que afectará el acceso normal a StarRocks. Una solución temporal es encontrar la tarea problemática, suspenderla y reanudarla.
6. Planificación futura
A continuación, conectaremos más servicios a StarRocks para reemplazar el motor de consulta OLAP original; usaremos más escenarios comerciales para acumular experiencia y mejorar la estabilidad del clúster. En el futuro, espero que StarRocks optimice y aumente el uso de memoria del modelo de clave principal, admita una forma más flexible de actualizar algunas columnas, siga optimizando y mejorando el rendimiento de las consultas de mapa de bits y optimice el aislamiento de recursos multiinquilino. En el futuro, continuaremos participando activamente en las discusiones de la comunidad de StarRocks y brindando comentarios sobre los escenarios comerciales.
*Texto /Shen Rui
Preste atención a la tecnología Dewu y actualice los productos secos técnicos a las 18:30 todos los lunes, miércoles y viernes por la noche.
Si cree que el artículo es útil para usted, comente, reenvíe y haga clic en Me gusta ~