1. Historia de Linux
1,Unix
La relación entre UNIX y Linux es un tema interesante. Entre los principales sistemas operativos actuales del lado del servidor, UNIX nació a fines de la década de 1960, Windows nació a mediados de la década de 1980 y Linux nació a principios de la década de 1990. Se puede decir que UNIX es el "hermano mayor" en el sistema operativo Tanto Windows como Linux más tarde hicieron referencia a UNIX.
El sistema operativo UNIX fue inventado por Ken Thompson y Dennis Ritchie. Parte de sus orígenes técnicos se remontan al programa de ingeniería Multics iniciado en 1965, iniciado por Bell Labs, el Instituto de Tecnología de Massachusetts y General Electric Company con el objetivo de desarrollar un programa interactivo de programación múltiple. sistema operativo compartido capaz de reemplazar el sistema operativo por lotes que se usaba ampliamente en ese momento.
Descripción: el sistema operativo de tiempo compartido permite que una computadora preste servicios a varios usuarios al mismo tiempo, y los usuarios de la terminal conectados a la computadora emiten comandos de forma interactiva. El tiempo de la CPU se divide en varios segmentos, llamados intervalos de tiempo). El sistema operativo toma intervalos de tiempo como una unidad y sirve a cada usuario final por turno, un intervalo de tiempo a la vez.
Desafortunadamente, el proyecto Multics era tan grande y complejo que sus desarrolladores no tenían idea de cómo sería y terminó en un fracaso.
Los investigadores de Bell Labs encabezados por Ken Thompson aprendieron las lecciones del fracaso del proyecto Multics y realizaron el prototipo de un sistema operativo de tiempo compartido en 1969, que se denominó oficialmente UNIX en 1970.
Curiosamente, la intención original de Ken Thompson para desarrollar UNIX era ejecutar un juego de computadora que escribió, Space Travel, que simula el movimiento de los cuerpos celestes en el sistema solar, con jugadores pilotando naves espaciales, viendo el paisaje e intentando aterrizar en varios planetas y lunas. . Probó sucesivamente en múltiples sistemas, pero los resultados no fueron satisfactorios, por lo que decidió desarrollar su propio sistema operativo, y así nació UNIX.
Desde 1970, el sistema UNIX se ha vuelto gradualmente popular entre los programadores dentro de Bell Labs. En 1971-1972, el colega de Ken Thompson, Dennis Ritchie, inventó el legendario lenguaje C, un lenguaje de alto nivel adecuado para escribir software de sistemas. Su nacimiento fue un hito importante en el desarrollo de los sistemas UNIX. En el desarrollo de los sistemas operativos, el lenguaje ensamblador es ya no es el idioma dominante.
En 1973, la mayor parte del código fuente del sistema UNIX se reescribió en lenguaje C, lo que sentó las bases para mejorar la portabilidad del sistema UNIX (los sistemas operativos anteriores usaban principalmente lenguaje ensamblador, que dependía en gran medida del hardware). condiciones para mejorar la eficiencia de desarrollo del software del sistema. Se puede decir que el sistema UNIX y el lenguaje C son hermanos gemelos y tienen una relación inseparable.
A principios de la década de 1970, hubo otro gran invento en el mundo de la informática: el protocolo TCP/IP, que era un protocolo de red desarrollado después de que el Departamento de Defensa de EE. UU. se hiciera cargo de ARPAnet. El Departamento de Defensa de los EE. UU. empaquetó el protocolo TCP/IP con el sistema UNIX y el lenguaje C, y AT&T emitió una licencia no comercial para varias universidades de los Estados Unidos, lo que dio inicio al desarrollo del sistema UNIX, el C y el protocolo TCP/IP, que han influido en los tres campos de sistema operativo, lenguaje de programación y protocolo de red, respectivamente. Ken Thompson y Dennis Ritchie recibieron el Premio Turing, el premio más importante en informática, en 1983 por sus destacadas contribuciones al campo de la informática.
Posteriormente, aparecieron varias versiones de sistemas UNIX, como Sun Solaris, FreeBSD, IBM AIX, HP-UX, etc.
2. Solaris y FreeBSD
Solaris es una rama importante del sistema UNIX. Solaris puede ejecutarse en plataformas de CPU x86 además de plataformas de CPU SPARC. En el mercado de servidores, la plataforma de hardware de Sun tiene alta disponibilidad y alta confiabilidad, y es el sistema UNIX dominante en el mercado. Solaris x86 es un servidor que se utiliza para aplicaciones de producción reales. Solaris x86 se puede utilizar de forma gratuita para aplicaciones de estudio, investigación o comerciales, sujeto a los términos de licencia pertinentes de Sun.
FreeBSD se originó a partir de la versión UNIX desarrollada por la Universidad de California, Berkeley, es desarrollado y mantenido por voluntarios de todo el mundo, brindando diferentes niveles de soporte para sistemas informáticos con diferentes arquitecturas. FreeBSD se publica bajo el acuerdo de licencia BSD, que permite que cualquier persona lo use y distribuya libremente con la premisa de conservar la información del acuerdo de licencia y los derechos de autor, y no restringe la distribución del código FreeBSD bajo otro acuerdo, por lo que las empresas comerciales pueden integrar libremente el código FreeBSD en en sus productos. OS X de Apple es un sistema operativo basado en FreeBSD.
Una parte considerable de los grupos de usuarios de FreeBSD y Linux se superponen, los entornos de hardware compatibles con los dos también son relativamente consistentes y el software utilizado es relativamente similar. La mayor característica de FreeBSD es la estabilidad y la eficiencia, y es una buena opción como sistema operativo de servidor; sin embargo, su soporte de hardware no es tan completo como el de Linux, por lo que no es adecuado como sistema de escritorio.
3. El nacimiento de Linux
El kernel de Linux fue escrito originalmente por Linus Torvalds como un pasatiempo cuando era estudiante en la Universidad de Helsinki, en ese momento sintió que Minix, una versión mini del sistema operativo UNIX para la enseñanza, era demasiado difícil de usar, por lo que decidió desarrollar su propio sistema operativo. La versión 1 se lanzó en septiembre de 1991 con solo 10 000 líneas de código.
Linus Torvalds no mantuvo los derechos de autor del código fuente de Linux, hizo público el código e invitó a otros a mejorar Linux juntos. A diferencia de Windows y otros sistemas operativos propietarios, Linux es de código abierto y gratuito para que cualquiera lo use.
Se estima que solo el 2 % del código del kernel de Linux ahora está escrito por el propio Linus Torvalds, aunque todavía posee el kernel de Linux (la parte central del sistema operativo) y conserva nuevas formas de seleccionar código nuevo y necesita fusionar el código final. derecho rector. El Linux que todo el mundo usa ahora, prefiero decir que fue desarrollado conjuntamente por Linus Torvalds y muchos expertos en Linux que se incorporaron más tarde.
El software de fuente abierta es un modelo que es diferente del software comercial. Literalmente, significa código de fuente abierta. No tiene que preocuparse por ningún truco, lo que traerá innovación y seguridad al software.
Linux es muy popular entre los entusiastas de la informática por dos razones principales:
- Pertenece al software de código abierto, los usuarios pueden obtenerlo y su código fuente sin pagar una tarifa, y pueden realizar las modificaciones necesarias según sus propias necesidades, usarlo de forma gratuita y continuar difundiéndolo sin restricciones;
- Tiene todas las características de UNIX, y cualquiera que use el sistema operativo UNIX o quiera aprender el sistema operativo UNIX puede beneficiarse de Linux.
Además, el código abierto en realidad no es equivalente a libre, sino un nuevo modelo de ganancias de software. En la actualidad, muchos programas son de código abierto, lo que tiene un profundo impacto en la industria informática e Internet.
2. Introducción al núcleo de Linux
1. La composición del sistema informático.
Un sistema informático es una simbiosis de hardware y software, que son interdependientes e inseparables.
El hardware de la computadora, incluidos los periféricos, los procesadores, la memoria, los discos duros y otros dispositivos electrónicos, constituye el motor de la computadora, pero sin un software que la opere y controle, no puede funcionar por sí misma.
El software que completa este trabajo de control se llama sistema operativo. El sistema operativo es el software del sistema que administra los recursos de hardware y software de la computadora, y también es el núcleo y la piedra angular del sistema informático. El sistema operativo necesita manejar tareas básicas como administrar y configurar la memoria, priorizar el suministro y la demanda de recursos del sistema, controlar los dispositivos de entrada y salida, operar la red y administrar el sistema de archivos. El sistema operativo también proporciona una interfaz para que el usuario interactúe con el sistema.
La composición del sistema operativo:
Bootloader: Es el principal responsable del proceso de arranque del dispositivo.
Shell: Shell es un lenguaje de programación que puede controlar otros archivos, procesos y todos los demás programas.
Kernel: Es el componente principal del sistema operativo, gestiona la memoria, la CPU y otros componentes relacionados.
Entorno de escritorio: este es el entorno con el que los usuarios suelen interactuar.
Servidor gráfico: Es un subsistema del sistema operativo que muestra gráficos en la pantalla
Aplicaciones: Son ensamblajes que realizan diferentes tareas del usuario como word, excel, etc.
· Daemons: proveedores de servicios backend.
2. ¿Qué es el Núcleo?
El núcleo es una parte clave del sistema operativo porque controla todos los programas del sistema. Actúa como un puente entre las aplicaciones y el procesamiento de datos a nivel de hardware con la ayuda de la comunicación entre procesos y las llamadas al sistema.
Cuando el dispositivo arranca, el sistema operativo se carga en la memoria, momento en el que el kernel pasa por un proceso de inicialización que se ocupa de la parte de asignación de memoria y la mantiene allí hasta que el sistema operativo se apaga. Y crea un entorno en el que ejecutar aplicaciones, donde el kernel se encarga de tareas de bajo nivel como la gestión de tareas, la gestión de la memoria, la gestión de riesgos, etc.
El kernel actúa como un proveedor de servicios, por lo que un programa puede pedirle al kernel que realice varias tareas, como solicitar el uso de un disco, una tarjeta de red u otro hardware, y el kernel establece interrupciones para que la CPU permita la multitarea. Protege el entorno informático al evitar que programas erróneos entren en las funciones operativas de otros programas. Bloquea la entrada de programas no autorizados al no permitir espacio de almacenamiento y limita la cantidad de dinero que consumen
tiempo de CPU.
en breve:
1. Desde un punto de vista técnico, el núcleo es una capa intermedia entre el hardware y el software. La función es pasar la solicitud de la capa de aplicación al hardware y actuar como el controlador subyacente para abordar varios dispositivos y componentes en el sistema.
2. Desde el nivel de la aplicación, la aplicación no tiene conexión con el hardware, sino solo con el kernel, que es la capa más baja en la jerarquía que conoce la aplicación. En la práctica, el kernel abstrae los detalles relevantes.
3. El núcleo es un administrador de recursos. Responsable de asignar los recursos compartidos disponibles (tiempo de CPU, espacio en disco, conexión de red, etc.) a varios procesos del sistema.
4. El núcleo es como una biblioteca que proporciona un conjunto de comandos orientados al sistema. Las llamadas al sistema son como llamar funciones ordinarias a una aplicación.
3. Clasificación de los granos
En general, hay tres categorías de núcleos:
1. Kernel monolítico: contiene una serie de controladores de dispositivos que crean una interfaz de comunicación entre el hardware y el software de un dispositivo.
Es el kernel muy utilizado por los sistemas operativos. En una arquitectura monolítica, el kernel consta de varios módulos que pueden cargarse y descargarse dinámicamente. Esta arquitectura extenderá la funcionalidad del sistema operativo y permitirá una fácil extensión del kernel.
Con una arquitectura monolítica, el mantenimiento del núcleo se facilita porque permite cargar y descargar módulos relacionados cuando es necesario corregir un error en un módulo en particular. Por lo tanto, elimina el tedioso trabajo de bajar y volver a compilar todo el kernel para realizar pequeños cambios. En un núcleo monolítico, es más fácil descargar módulos que ya no se utilizan.
2. Micro kernel: solo puede realizar funciones básicas.
Los micronúcleos se han desarrollado como una alternativa a los núcleos monolíticos para abordar el creciente problema del código del núcleo que los núcleos monolíticos no pueden. Esta arquitectura permite que ciertos servicios básicos (como pilas de protocolos, administración de controladores de dispositivos, sistemas de archivos, etc.) se ejecuten en el espacio del usuario. Esto mejora la funcionalidad del sistema operativo con un código mínimo, mejora la seguridad y garantiza la estabilidad.
Limita el daño a las áreas afectadas al permitir que el resto del sistema funcione sin interrupción. En una arquitectura de microkernel, todos los servicios esenciales del sistema operativo están disponibles para los programas a través de la comunicación entre procesos (IPC). Los micronúcleos permiten la interacción directa entre los controladores de dispositivos y el hardware.
3. Núcleo híbrido: combina varios aspectos del núcleo monolítico y el micronúcleo.
Un núcleo híbrido puede decidir qué ejecutar en modo usuario y modo supervisor. Por lo general, en un entorno de kernel mixto, elementos como los controladores de dispositivos y la E/S del sistema de archivos se ejecutarán en modo de usuario, mientras que las llamadas al servidor y el IPC permanecerán en modo de supervisor.
4. Género de diseño del kernel
1. Micronúcleo. Las funciones más básicas son implementadas por un kernel central (microkernel). Windows NT utiliza la arquitectura de micronúcleo. Por las características de la arquitectura del microkernel, la parte central del sistema operativo es un pequeño kernel que implementa algunos servicios básicos, como la creación y eliminación de procesos, la gestión de memoria, la gestión de interrupciones, etc. Las otras partes del sistema de archivos, los protocolos de red, etc., se ejecutan en el espacio del usuario fuera del microkernel. Estas funciones se delegan a unos pocos procesos independientes que se comunican con el kernel central a través de interfaces de comunicación bien definidas.
2. Núcleo macro (único). Todo el código para el núcleo, incluidos los subsistemas (como la gestión de memoria, gestión de archivos, controladores de dispositivos) se empaqueta en un solo archivo. Todas las funciones se realizan juntas, todas en el núcleo, es decir, todo el núcleo es un solo programa muy grande. Cada función en el kernel tiene acceso a todas las demás partes del kernel. En la actualidad, se admite la carga y descarga dinámica (recorte) de módulos, y el kernel de Linux se implementa en función de esta estrategia.
Un sistema operativo que usa un microkernel tiene buena escalabilidad y el kernel es muy pequeño, pero dicho sistema operativo es ineficiente debido al costo del paso de mensajes entre diferentes capas. Para un sistema operativo de arquitectura única, todos los módulos están integrados juntos, la velocidad y el rendimiento del sistema son buenos, pero la escalabilidad y la capacidad de mantenimiento son relativamente deficientes.
Hablando lógicamente, la estructura de microkernel de Linux está implementada, pero no lo está, Linux es una estructura de un solo kernel (monolítica). Esto significa que, si bien Linux se divide en varios subsistemas que controlan varios componentes del sistema (como la gestión de la memoria y la gestión de procesos), todos los subsistemas están estrechamente integrados para formar el kernel completo.
Por el contrario, un sistema operativo de microkernel proporciona un conjunto mínimo de funciones, y todas las demás capas del sistema operativo se ejecutan según el proceso sobre el microkernel. Los sistemas operativos de microkernel son generalmente menos eficientes debido al paso de mensajes entre capas, pero dichos sistemas operativos son muy escalables.
Hablando fundamentalmente, es una de las filosofías de diseño de Linux descomponer una cosa en pequeños problemas, y luego cada pequeño problema es solo responsable de una tarea.El kernel de Linux se puede extender a través de módulos.
Un módulo es un programa que se ejecuta en el espacio del núcleo, que en realidad es una especie de archivo de objeto. No está vinculado y no se puede ejecutar de forma independiente, pero su código se puede vincular al sistema en tiempo de ejecución para que se ejecute como parte del núcleo. o tomado del núcleo, para que pueda extenderse dinámicamente la funcionalidad del núcleo.
Este código objeto generalmente consiste en un conjunto de funciones y estructuras de datos que se utilizan para implementar un sistema de archivos, un controlador u otra funcionalidad del núcleo superior. El nombre completo del mecanismo del módulo debe ser un módulo de kernel cargable dinámicamente (módulo de kernel cargable) o LKM, generalmente denominado módulo. A diferencia de los procesos antes mencionados que se ejecutan en el espacio de usuario externo del sistema operativo del sistema microkernel, el módulo no se ejecuta como un proceso, pero al igual que otras funciones del kernel vinculadas estáticamente, se ejecuta en nombre del proceso actual en modo kernel. Debido a la introducción del mecanismo del módulo, el kernel de Linux se puede minimizar, es decir, algunas funciones básicas se implementan en el kernel, como la interfaz del módulo al kernel, la forma en que el kernel administra todos los módulos, etc. y la escalabilidad del sistema se deja al módulo para completar.
Los módulos tienen características de kernel que brindan los beneficios de un microkernel sin la sobrecarga adicional.
5. Funciones del núcleo
El kernel de Linux implementa muchas propiedades arquitectónicas importantes. En un nivel superior o inferior, el núcleo se divide en subsistemas.
Linux también puede verse como un todo porque integra todos estos servicios básicos en el kernel. Esto es diferente de la arquitectura de microkernel, que proporciona algunos servicios básicos como comunicación, E/S, memoria y administración de procesos, y servicios más específicos se conectan a la capa de microkernel.
Las tareas principales del núcleo son:
· Gestión de procesos para la ejecución de aplicaciones.
· Gestión de memoria y E/S (entrada/salida).
· Control de llamadas al sistema (comportamiento central del núcleo).
· Gestión de dispositivos con controladores de dispositivos.
· Proporcionar un entorno de ejecución para la aplicación.
6. Las funciones principales del núcleo
Las funciones principales del kernel de Linux son: administración de almacenamiento, administración de CPU y procesos , sistema de archivos, administración y controlador de dispositivos, comunicación de red e inicialización del sistema (arranque), llamadas al sistema, etc.

Las funciones principales son las siguientes:
- Gestión de la memoria del sistema
- gestión de programas de software
- gestión de dispositivos de hardware
- gestión del sistema de archivos
1) Gestión de la memoria del sistema
Una de las principales funciones del núcleo del sistema operativo es la gestión de la memoria. El kernel administra no solo la memoria física disponible en el servidor, sino que también crea y administra la memoria virtual (es decir, la memoria que en realidad no existe).
El núcleo implementa la memoria virtual a través del espacio de almacenamiento en el disco duro, que se denomina espacio de intercambio. El núcleo intercambia constantemente el contenido de la memoria virtual entre el espacio de intercambio y la memoria física real. Esto hace que el sistema piense que tiene más memoria disponible que la memoria física.
Una unidad de almacenamiento de memoria se divide en grupos en bloques llamados páginas. El núcleo coloca cada página de memoria en la memoria física o espacio de intercambio. Luego, el kernel mantiene una tabla de páginas de memoria que indica qué páginas están en la memoria física y qué páginas se intercambian en el disco.
2) Gestión de programas de software
El sistema operativo Linux se refiere a ejecutar programas como procesos. Los procesos pueden ejecutarse en primer plano, mostrando la salida en la pantalla, o en segundo plano, escondiéndose detrás de escena. El kernel controla cómo el sistema Linux administra todos los procesos que se ejecutan en el sistema.
El kernel crea el primer proceso (llamado proceso init) para iniciar todos los demás procesos en el sistema. Cuando se inicia el núcleo,
carga el proceso de inicio en la memoria virtual. Cuando el kernel inicia cualquier otro proceso, asigna un área dedicada en la memoria virtual para que el nuevo proceso almacene los datos y el código utilizado por ese proceso.
Algunas distribuciones de Linux usan una tabla para administrar los procesos para que se inicien automáticamente cuando se enciende el sistema. En los sistemas Linux, esta tabla suele estar ubicada en el archivo especial /etc/inittab.
Otros sistemas (como la popular distribución Ubuntu Linux) usan el directorio /etc/init.d, donde
se colocan los scripts que inician o detienen una aplicación en el arranque. Estos scripts se inician a través de entradas en el directorio /etc/rcX.d, donde X representa el nivel de ejecución.
El sistema init del sistema operativo Linux adopta el nivel de ejecución. El nivel de ejecución determina que el proceso de inicio ejecuta ciertos tipos de procesos definidos en el archivo /etc/inittab o el directorio /etc/rcX.d. El sistema operativo Linux tiene 5 niveles de ejecución de arranque.
- En el nivel de ejecución 1, solo se inician los procesos básicos del sistema y un proceso de terminal de consola. Lo llamamos modo de usuario único. El modo de usuario único generalmente se usa para realizar un mantenimiento urgente del sistema de archivos cuando hay un problema con el sistema. Obviamente, en este modo, solo una persona (generalmente el administrador del sistema) puede iniciar sesión en el sistema para manipular datos.
- El nivel de ejecución de inicio estándar es 3. En este nivel de ejecución, se inician la mayoría de las aplicaciones, como los programas de soporte de red. Otro nivel de ejecución común en Linux es 5. En este nivel de ejecución, el sistema inicia el sistema gráfico de ventanas X, lo que permite a los usuarios iniciar sesión en el sistema a través de una ventana de escritorio gráfica.
Puede usar el comando ps para ver los procesos que se ejecutan actualmente en un sistema Linux.
3) Gestión de dispositivos de hardware
Otra responsabilidad del kernel es administrar los dispositivos de hardware. Cualquier dispositivo con el que un sistema Linux necesite comunicarse debe
incluir su código de controlador en el código del kernel. El código del controlador actúa como intermediario entre la aplicación y el dispositivo de hardware, lo que permite el intercambio de datos entre el kernel y el dispositivo. Hay dos métodos para insertar el código del controlador del dispositivo en el kernel de Linux:
- Código de controlador de dispositivo compilado en el kernel
- módulo de controlador de dispositivo conectable al kernel
Anteriormente, la única forma de insertar el código del controlador del dispositivo era volver a compilar el kernel. Cada vez que se agrega un nuevo dispositivo al sistema, se debe volver a compilar el código del núcleo. A medida que el kernel de Linux admite más y más dispositivos de hardware, este proceso se vuelve cada vez más ineficiente. Afortunadamente, los desarrolladores de Linux han ideado una forma mejor de insertar el código del controlador en un kernel en ejecución.
A los desarrolladores se les ocurrió el concepto de módulos del núcleo. Permite que el código del controlador se inserte en un kernel en ejecución sin volver a compilar el
kernel. Al mismo tiempo, los módulos del kernel también se pueden eliminar del kernel cuando el dispositivo ya no está en uso. Este enfoque simplifica y amplía enormemente el uso de dispositivos de hardware en Linux.
El sistema Linux trata los dispositivos de hardware como archivos especiales llamados archivos de dispositivo. Hay 3 categorías de archivos de dispositivo:
- Archivo de dispositivo de caracteres: se refiere a los dispositivos que procesan datos de un carácter a la vez, como la mayoría de los tipos de módems y
terminales. - Archivo de dispositivo de bloque: se refiere a un dispositivo que puede procesar grandes bloques de datos cada vez que procesa datos, como un disco duro.
- Archivo de dispositivo de red: se refiere al dispositivo que utiliza paquetes de datos para enviar y recibir datos, incluidas varias tarjetas de red y un dispositivo de bucle invertido especial.
4) Gestión del sistema de archivos
A diferencia de otros sistemas operativos, el kernel de Linux admite la lectura y escritura de datos del disco duro a través de diferentes tipos de sistemas de archivos. Además
de sus propios sistemas de archivos, Linux también admite
la lectura y escritura de datos de los sistemas de archivos de otros sistemas operativos (como Microsoft Windows). El kernel debe compilarse con soporte para todos los sistemas de archivos posibles. La siguiente tabla enumera los sistemas de archivos estándar que utilizan los sistemas Linux para leer y escribir datos.
Todos los discos duros a los que accede el servidor Linux deben estar formateados con uno de los tipos de sistemas de archivos enumerados en la tabla anterior.
El kernel de Linux es altamente eficiente en el uso de memoria y CPU y es muy estable a lo largo del tiempo. Pero lo más interesante de Linux es la portabilidad de este tamaño y complejidad. Linux está compilado para ejecutarse en una gran cantidad de procesadores y plataformas con diferentes restricciones y requisitos de arquitectura. Un ejemplo es que Linux puede ejecutarse en un procesador con una unidad de gestión de memoria (MMU) o en aquellos procesadores que no proporcionan una MMU. El puerto uClinux del kernel de Linux brinda soporte para no MMU.
En tercer lugar, la arquitectura general del kernel de Linux
1. Arquitectura del núcleo de Linux
El sistema UNIX/Linux se puede resumir aproximadamente en tres niveles, la capa inferior es el kernel del sistema (Kernel); la capa intermedia es la capa Shell, es decir, la capa de interpretación de comandos; la capa superior es la capa de aplicación.
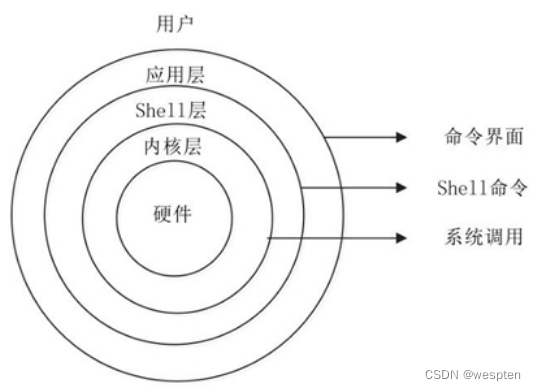
(1) capa del núcleo
La capa del núcleo es el núcleo y la base del sistema UNIX/Linux. Está conectada directamente a la plataforma de hardware, controla y administra varios recursos (recursos de hardware y recursos de software) en el sistema y organiza de manera efectiva la operación del proceso, por lo tanto ampliar las funciones del hardware.Mejorar la eficiencia de utilización de los recursos y proporcionar a los usuarios un entorno de aplicación conveniente, eficiente, seguro y confiable.
(2) Capa de concha
La capa Shell es la interfaz que interactúa directamente con el usuario. El usuario puede ingresar la línea de comando en el indicador, y el Shell lo interpreta y genera los resultados correspondientes o la información relacionada, por lo que también llamamos al Shell un intérprete de comandos, que puede completar muchas tareas de manera rápida y fácil utilizando los comandos enriquecidos proporcionados por el sistema.
(3) capa de aplicación
La capa de aplicación proporciona un entorno gráfico basado en el protocolo X Window. El Protocolo X Window define las funciones que debe tener un sistema.
El kernel de Linux es solo una parte del sistema operativo Linux. A la derecha, administra todos los dispositivos de hardware del sistema; a la derecha, proporciona interfaces para la rutina de la biblioteca (como la biblioteca C) u otras aplicaciones a través de llamadas al sistema.

1) Espacio del núcleo:
El espacio del kernel incluye llamadas al sistema, el kernel y el código relacionado con la arquitectura de la plataforma. El kernel se encuentra en un estado de sistema elevado que incluye un espacio de memoria protegido y acceso completo al hardware del dispositivo. Este estado del sistema y el espacio de la memoria se denominan colectivamente como espacio del kernel. Dentro del espacio del kernel, el acceso principal al hardware y los servicios del sistema se administran y se brindan como servicios al resto del sistema.
2) Espacio de usuario:
El espacio de usuario también contiene, la aplicación del usuario, la biblioteca C. El espacio de usuario o dominio de usuario es el código que se ejecuta fuera del entorno del kernel del sistema operativo, el espacio de usuario se define como las diversas aplicaciones, programas o bibliotecas que utiliza el sistema operativo para interactuar con el kernel.
Las aplicaciones del usuario se ejecutan en el espacio del usuario y pueden acceder a una parte de los recursos disponibles de la computadora a través de llamadas al sistema del kernel. Mediante el uso de los servicios básicos proporcionados por el núcleo, se pueden crear aplicaciones de nivel de usuario, como juegos o software de oficina.
El núcleo proporciona un conjunto de interfaces para que las aplicaciones que se ejecutan en modo de usuario interactúen con el sistema. También conocidas como llamadas al sistema, estas interfaces permiten que las aplicaciones accedan al hardware y otros recursos del núcleo. Las llamadas al sistema no solo proporcionan un nivel de hardware abstracto para las aplicaciones, sino que también garantizan la seguridad y la estabilidad del sistema.
La mayoría de las aplicaciones no usan llamadas al sistema directamente. En su lugar, se utiliza una interfaz de programación de aplicaciones (API) para la programación. Tenga en cuenta que no existe una correlación entre la API y las llamadas al sistema. Las API se proporcionan a las aplicaciones como parte de un archivo de biblioteca y, por lo general, estas API se implementan a través de una o más llamadas al sistema.
2. Arquitectura del kernel de Linux
Para administrar los diversos recursos y dispositivos anteriores, el kernel de Linux propone la siguiente arquitectura:

De acuerdo con las funciones principales del kernel, el kernel de Linux propone 5 subsistemas:

1. Programador de procesos, también conocido como gestión de procesos, programación de procesos. Responsable de administrar los recursos de la CPU para que cada proceso pueda acceder a la CPU de la manera más justa posible.
2. Administrador de memoria, gestión de memoria. Responsable de administrar los recursos de memoria para que los procesos puedan compartir de manera segura los recursos de memoria de la máquina. Además, la gestión de la memoria proporcionará un mecanismo de memoria virtual, que permite que el proceso use más memoria de la que el sistema puede usar. La memoria no utilizada se almacenará en la memoria no volátil externa a través del sistema de archivos, y cuando sea necesario utilizado, se recuperará en la memoria.
3. VFS (Sistema de archivos virtual), sistema de archivos virtual. El kernel de Linux abstrae dispositivos externos con diferentes funciones, como dispositivos de disco (discos duros, discos, NAND Flash, Nor Flash, etc.), dispositivos de entrada y salida, dispositivos de visualización, etc., en una interfaz de operación de archivo unificada (abierta, cerrar, leer, etc.) escribir, etc.) para acceder. Esta es la encarnación de "todo es un archivo" en el sistema Linux (de hecho, Linux no lo hace completamente, porque la CPU, la memoria, la red, etc. aún no son archivos. Si realmente necesita que todo sea un archivo, depende de lo que esté desarrollando Bell Labs. " Plan 9 ").
4. Red, subsistema de red. Responsable de administrar el equipo de red del sistema e implementar una variedad de estándares de red.
5. IPC (Comunicación entre procesos), comunicación entre procesos. IPC no administra ningún hardware, es el principal responsable de la comunicación entre procesos en el sistema Linux.
Programador de procesos
La programación de procesos es el subsistema más importante del kernel de Linux, que proporciona principalmente control de acceso a la CPU. Debido a que en la computadora, los recursos de la CPU son limitados y muchas aplicaciones usan los recursos de la CPU, por lo que se requiere el "subsistema de programación de procesos" para programar y administrar la CPU.
El subsistema de programación de procesos incluye 4 submódulos (ver la figura a continuación), y sus funciones son las siguientes:

- Política de programación, la estrategia para implementar la programación de procesos, que determina qué (o cuáles) procesos tendrán la CPU.
- Los programadores específicos de la arquitectura, la parte relacionada con la arquitectura, se utilizan para abstraer el control de diferentes CPU en una interfaz unificada. Estos controles se utilizan principalmente en procesos de suspensión y reanudación, que implican acceso a registros de CPU, operaciones de instrucciones de ensamblaje, etc.
- Programador independiente de la arquitectura, la parte independiente de la arquitectura. Se comunicará con el "módulo de política de programación" para decidir qué proceso ejecutar a continuación y luego reanudará el proceso especificado a través del "módulo de programadores específicos de la arquitectura".
- Interfaz de llamada del sistema, la interfaz de llamada del sistema. El subsistema de programación de procesos abre la interfaz que debe proporcionarse al espacio de usuario a través de la interfaz de llamada al sistema y, al mismo tiempo, protege los detalles que no necesitan ser afectados por el programa de espacio de usuario.
Administrador de memoria (MM)
La gestión de la memoria es también el subsistema más importante del kernel de Linux, que proporciona principalmente control de acceso a los recursos de la memoria. El sistema Linux establecerá una relación de mapeo entre la memoria física del hardware y la memoria utilizada por el proceso (llamada memoria virtual), este mapeo es en unidades de procesos, por lo que diferentes procesos pueden usar la misma memoria virtual, y estos mismos La memoria virtual se puede mapear a diferentes memorias físicas.
El subsistema de gestión de memoria incluye 3 submódulos (ver la figura a continuación), y sus funciones son las siguientes:

- Administradores específicos de arquitectura, partes relacionadas con la arquitectura. Proporciona una interfaz virtual para acceder a la memoria del hardware.
- Architecture Independent Manager, la parte independiente de la arquitectura. Proporciona todos los mecanismos de administración de memoria, incluidos: asignación de memoria basada en procesos, intercambio de memoria virtual.
- Interfaz de llamada del sistema, la interfaz de llamada del sistema. A través de esta interfaz, las funciones como la asignación de memoria, la liberación y el mapa de archivos se proporcionan a los programas y aplicaciones del espacio del usuario.
Sistema de archivos virtual (VFS)
Un sistema de archivos en el sentido tradicional es un método para almacenar y organizar datos informáticos. Abstrae bloques de datos fríos en discos de computadora, discos duros y otros dispositivos de una manera fácil de entender y humana (estructura de archivos y directorios), lo que facilita su búsqueda y acceso. Por lo tanto, la esencia del sistema de archivos es "el método de almacenamiento y organización de datos", y la manifestación del sistema de archivos es "leer datos de un determinado dispositivo y escribir datos en un determinado dispositivo".
A medida que avanza la tecnología informática, también lo hacen los métodos de almacenamiento y organización de datos, lo que da como resultado varios tipos de sistemas de archivos, como FAT, FAT32, NTFS, EXT2, EXT3 y más. Para que sea compatible, el sistema operativo o kernel debe admitir múltiples tipos de sistemas de archivos en la misma forma, lo que amplía el concepto de sistema de archivos virtual (VFS). La función de VFS es administrar varios sistemas de archivos, proteger sus diferencias y proporcionar a los programas de usuario una interfaz para acceder a los archivos de manera unificada.
Podemos leer o escribir datos de discos, discos duros, NAND Flash y otros dispositivos, por lo que los sistemas de archivos originales se crearon en estos dispositivos. Este concepto también se puede extender a otros dispositivos de hardware, como la memoria, la pantalla (LCD), el teclado, el puerto serie, etc. Nuestro control de acceso a dispositivos de hardware también se puede resumir como lectura o escritura de datos, por lo que se puede acceder a ellos con una interfaz de operación de archivos unificada. El kernel de Linux hace exactamente eso, abstrayendo los sistemas de archivos de los dispositivos, los sistemas de archivos en memoria y más, además de los sistemas de archivos de disco tradicionales. Estas lógicas son implementadas por el subsistema VFS.
El subsistema VFS incluye 6 submódulos (ver la figura a continuación), y sus funciones son las siguientes:

- Los controladores de dispositivos, los controladores de dispositivos, se utilizan para controlar todos los dispositivos y controladores externos. Dado que hay una gran cantidad de dispositivos de hardware (especialmente productos integrados) que no son compatibles entre sí, también hay muchos controladores de dispositivos. Por lo tanto, casi la mitad de los códigos fuente en el kernel de Linux son controladores de dispositivos, y la mayoría de los ingenieros de nivel inferior de Linux (especialmente empresas nacionales) escriben o mantienen controladores de dispositivos y no tienen tiempo para estimar otro contenido (son precisamente los esencia del kernel de Linux). donde).
- Interfaz independiente del dispositivo, este módulo define una forma unificada de describir los dispositivos de hardware (modelo de dispositivo unificado), todos los controladores de dispositivos cumplen con esta definición, lo que puede reducir la dificultad del desarrollo. Al mismo tiempo, la interfaz se puede proporcionar hacia arriba con una situación consistente.
- Sistemas lógicos, cada sistema de archivos corresponde a un Sistema lógico (sistema de archivos lógicos), que implementa una lógica de sistema de archivos específica.
- Interfaz independiente del sistema, este módulo es responsable de representar los dispositivos de hardware y los sistemas de archivos lógicos con una interfaz unificada (dispositivo rápido y dispositivo de caracteres), de modo que el software de la capa superior ya no se preocupe por la forma específica del hardware.
- System Call Interface, la interfaz de llamada del sistema, proporciona al usuario una interfaz unificada para acceder al sistema de archivos y dispositivos de hardware.
Subsistema de red (red)
El subsistema de red en el kernel de Linux es principalmente responsable de administrar varios dispositivos de red, implementar varias pilas de protocolos de red y, finalmente, realizar la función de conectar otros sistemas a través de la red. En el kernel de Linux, el subsistema de red es casi autónomo, incluye 5 submódulos (consulte la figura a continuación) y sus funciones son las siguientes:

- Los controladores de dispositivos de red, los controladores de dispositivos de red, son los mismos que los controladores de dispositivos en el subsistema VFS.
- Interfaz independiente del dispositivo, que es la misma que en el subsistema VFS.
- Protocolos de red, que implementa varios protocolos de transmisión de red, como IP, TCP, UDP, etc.
- Interfaz independiente del protocolo, protege diferentes dispositivos de hardware y protocolos de red, y proporciona interfaces (sockets) en el mismo formato.
- La interfaz de llamada del sistema, la interfaz de llamada del sistema, proporciona espacio de usuario con una interfaz unificada para acceder a dispositivos de red.
subsistema IPC, consulte:
3. Estructura de directorios del código fuente del kernel de Linux
El código fuente del kernel de Linux consta de tres partes principales:
1. Código del núcleo del kernel, incluidos varios subsistemas y submódulos, y otros subsistemas de soporte, como administración de energía, inicialización de Linux, etc.
2. Otros códigos no centrales, como archivos de biblioteca (porque el kernel de Linux es un kernel autónomo, es decir, el kernel no depende de ningún otro software y puede compilarse por sí mismo), colecciones de firmware, KVM (virtual tecnología de máquinas), etc.
3. Scripts de compilación, archivos de configuración, documentos de ayuda, instrucciones de derechos de autor y otros archivos auxiliares
El siguiente directorio del kernel usa el kernel linux-3.14 como explicación:

1. documentación:
Proporcionar asistencia con la documentación. Para obtener información explicativa sobre el núcleo, habrá un manual de ayuda en este directorio.
比如linux-3.14-fs4412/Documentation/devicetree/bindings/interrupt-controller/interrupts.txt
Este archivo explica la descripción detallada de la celda del dispositivo interrumpe la propiedad del nodo del número de dispositivo.
Solo según el nombre de la carpeta, podemos encontrar la documentación que necesitamos.
arco es una abreviatura de arquitectura. Todo el código relacionado con la arquitectura está en este directorio comenzando con
directorios include/asm-*/. Cada arquitectura compatible con Linux tiene un directorio correspondiente en el directorio arch, y más
Los pasos se descomponen en subdirectorios como boot, mm, kernel, etc.:
|--arm brazo y subdirectorios para arquitecturas compatibles
|--boot Bootloader e implementación del administrador de memoria utilizado para iniciar el kernel en esta plataforma de hardware.
|--descompresión del núcleo comprimido
|--programa de herramientas para generar una imagen del núcleo comprimida
| --kernel: contiene implementaciones que admiten características específicas de la arquitectura, como el manejo de semáforos y SMP.
| --lib: contiene implementaciones específicas de la arquitectura de funciones comunes como strlen y memcpy.
| --mm: contiene la implementación del administrador de memoria específico de la arquitectura.
Además de estos tres subdirectorios, la mayoría de las arquitecturas también tienen un subdirectorio de arranque, si es necesario, que contiene la implementación del administrador de memoria utilizado para iniciar el kernel en tales plataformas de hardware.
Código de controlador, un controlador es una pieza de software que controla el hardware. Este directorio es el directorio más grande del kernel, y aquí se pueden encontrar controladores para tarjetas gráficas, tarjetas de red, adaptadores SCSI, buses PCI, buses USB y cualquier otro periférico o bus compatible con Linux.
El código para el sistema de archivos virtual (VFS) y el código para cada uno de los diferentes sistemas de archivos se encuentran en este directorio. Todos los sistemas de archivos compatibles con Linux tienen un subdirectorio correspondiente en el directorio fs. Por ejemplo, el sistema de archivos ext2 corresponde al directorio fs/ext2.
Un sistema de archivos es el medio entre el dispositivo de almacenamiento y los procesos que necesitan acceder al dispositivo de almacenamiento. Los dispositivos de almacenamiento pueden ser localmente accesibles físicamente, como discos duros o unidades de CD-ROM, que utilizan los sistemas de archivos del sistema ext2/ext3 e isofs, respectivamente.
También hay algunos sistemas de archivos virtuales (procs), que son un sistema de archivos estándar presente. Sin embargo, los archivos que contiene solo existen en la memoria y no ocupan espacio en el disco.
Este directorio contiene la mayoría de los archivos de encabezado del núcleo y está agrupado en los siguientes subdirectorios. Para modificar la arquitectura del procesador, simplemente edite el archivo MAKE del kernel y vuelva a ejecutar el programa de configuración del kernel de Linux.
| include/asm-*/ Cada subdirectorio correspondiente a un arco, como include/asm-alpha,
Incluir/asm-brazo, etc. Los archivos en cada subdirectorio definen las funciones de preprocesamiento y en línea necesarias para admitir una arquitectura determinada, la mayoría de las cuales son implementaciones de lenguaje ensamblador completas o parciales.
| include/linux Los archivos de encabezado independientes de la plataforma están todos en este directorio, generalmente está vinculado al directorio
/usr/include/linux (o todos los archivos que contiene se copiarán endirectorio /usrinclude/linux)
Código de inicialización del núcleo. Incluye main.c, código para crear espacio de usuario temprano y otro código de inicialización.
IPC (Comunicación entre Procesos). Contiene memoria compartida, semáforos y otras formas de código IPC.
La parte central del kernel, incluida la programación del proceso (sched.c), así como la creación y cancelación del proceso (fork.c y exit.c), y otra parte del código central relacionado con la plataforma. están en el directorio arch/*/kernel.
Este directorio contiene parte del código de gestión de memoria que es independiente de la arquitectura. El código de gestión de memoria dependiente de la arquitectura se encuentra en arch/*/mm.
El código de red central implementa varios protocolos de red comunes, como TCP/IP, IPX, etc.
Este directorio contiene el código de la biblioteca central. Implementa un subconjunto genérico de la biblioteca C estándar, que incluye funciones para la manipulación de cadenas y memoria (strlen, mmcpy, etc.) y funciones relacionadas con las series sprintf y atoi. A diferencia del código bajo arch/lib, el código de la biblioteca aquí está escrito en C y se puede usar directamente en la nueva versión portada del kernel. El código de la biblioteca relacionado con la arquitectura del procesador se coloca en arch/mm.
Los controladores de dispositivos de bloque incluyen controladores IDE (en ide.c). Un dispositivo de bloque es un dispositivo que recibe y envía datos en bloques. El código de la capa de bloque inicial se encuentra en parte en el directorio de controladores y en parte en el directorio fs. Desde la versión 2.6.15, el código central de la capa de bloques se ha extraído y colocado en el directorio de bloques de nivel superior. Si desea buscar el proceso de inicialización de estos dispositivos que pueden contener sistemas de archivos, debe ser device_setup() en drivers/block/genhd.c. Al instalar un sistema de archivos nfs, no solo se debe inicializar el disco duro sino también la red. Los dispositivos de bloque incluyen dispositivos IDE y SCSI.
Fireware contiene un código que permite a las computadoras leer y comprender las señales enviadas desde los dispositivos. Por ejemplo, una cámara administra su propio hardware, pero la computadora debe comprender las señales que la cámara envía a la computadora. Los sistemas Linux utilizan el firmware vicam para comprender la comunicación de la cámara. De lo contrario, sin el firmware, el sistema Linux no sabría qué hacer con la información de la cámara. Además, el firmware también ayuda a enviar mensajes desde el sistema Linux al dispositivo. De esta forma, el sistema Linux puede decirle a la cámara que se reajuste o apague la cámara.
Implemente cpio, etc. para empaque y compresión. El código de esta carpeta crea estos archivos después de compilar el kernel.
Este directorio contiene código para diferentes modelos de seguridad de Linux. Es importante mantener su computadora a salvo de virus y piratas informáticos. De lo contrario, el sistema Linux puede resultar dañado.
La API de cifrado utilizada por el propio núcleo implementa algoritmos de cifrado y hash de uso común, así como algunos algoritmos de comprobación de compresión y CRC. Ejemplo: "sha1_generic.c" Este archivo contiene el código para el algoritmo de cifrado SHA1.
No hay código del núcleo en este directorio, solo los archivos de secuencias de comandos utilizados para configurar el núcleo. Al ejecutar comandos como make menuconfig o make xconfig para configurar el kernel, el usuario interactúa con los scripts ubicados en este directorio.
Controlador de la tarjeta de sonido y otro código fuente relacionado con el sonido.
Algunos ejemplos de programación del núcleo
Esta carpeta contiene código de virtualización, que permite a los usuarios ejecutar varios sistemas operativos a la vez. Con la virtualización, el sistema operativo invitado se ejecuta como cualquier otra aplicación que se ejecute en el host de Linux.
Esta carpeta contiene herramientas para interactuar con el kernel.
COPIA: Información de licencia y autorización. El kernel de Linux tiene la licencia GPLv2. Esta licencia otorga a cualquier persona el derecho de usar, modificar, distribuir y compartir el código fuente y compilado de forma gratuita. Sin embargo, nadie puede vender el código fuente.
CRÉDITOS: lista de colaboradores
Kbuild: este es un script que establece algunas configuraciones del kernel. Por ejemplo, este script establece una variable ARCH, que es el tipo de procesador que el desarrollador desea generar para que el kernel lo admita.
Kconfig: los desarrolladores utilizarán este script al configurar el kernel
MANTENEDORES: esta es una lista de los mantenedores actuales, sus direcciones de correo electrónico, páginas de inicio y partes o archivos específicos del kernel que son responsables de desarrollar y mantener. Esto es útil cuando un desarrollador encuentra un problema en el kernel y quiere poder informarlo a un mantenedor que pueda solucionarlo.
Makefile: este script es el archivo principal para compilar el kernel. Este archivo pasa los parámetros y archivos de compilación y la información necesaria requerida para la compilación al compilador.
LÉAME: este documento proporciona información para los desarrolladores que desean saber cómo compilar el kernel.
REPORTE DE ERRORES: Este documento proporciona información sobre cómo reportar errores.
El código del núcleo es un archivo con la extensión ".c" o ".h". La extensión ".c" indica que el núcleo está escrito en C, uno de los muchos lenguajes de programación, y los archivos "h" son archivos de encabezado, y también están escritos en C. Los archivos de encabezado contienen una gran cantidad de código que los archivos ".c" deben usar porque pueden importar el código existente en lugar de reescribirlo, lo que ahorra tiempo a los programadores. De lo contrario, existirá un conjunto de código que realiza la misma acción en muchos o en todos los archivos "c". Esto también consume y desperdicia espacio en el disco duro. (Anotación: los archivos de encabezado no solo pueden guardar la codificación repetida, sino que también la reutilización del código reducirá la posibilidad de errores de código)
Resumen de la arquitectura general del kernel de Linux:
Arquitectura del núcleo de Linux:

(1) interfaz de llamada del sistema
La capa SCI proporciona algunos mecanismos para realizar llamadas de función desde el espacio del usuario al kernel. Como se mencionó anteriormente, esta interfaz depende de la arquitectura, incluso dentro de la misma familia de procesadores. SCI es en realidad un servicio de multiplexación y demultiplexación de llamadas de función muy útil. Puede encontrar la implementación de SCI en ./linux/kernel y las partes dependientes de la arquitectura en ./linux/arch.
(2) Gestión de procesos
El enfoque de la gestión de procesos es la ejecución del proceso. En el núcleo, estos procesos se denominan subprocesos y representan una virtualización de procesador separada (código de subproceso, datos, pila y registros de CPU). En el espacio del usuario, el término proceso se usa a menudo, pero la implementación de Linux no distingue entre los dos conceptos (proceso e hilo). El núcleo proporciona una interfaz de programación de aplicaciones (API) a través de SCI para crear un nuevo proceso (fork, exec o funciones de interfaz de sistema operativo portátil [POSIX]), detener procesos (matar, salir) y comunicarse y sincronizarse entre ellos (señalar o mecanismo POSIX).
La gestión de procesos también incluye hacer frente a la necesidad de compartir la CPU entre los procesos activos. El kernel implementa un nuevo tipo de algoritmo de programación que opera en tiempo constante, independientemente de cuántos subprocesos compitan por la CPU. Este algoritmo se denomina programador O(1), y el nombre implica que se necesita la misma cantidad de tiempo para programar varios subprocesos que para programar un subproceso. El programador O(1) también puede soportar múltiples procesadores (llamado multiprocesamiento simétrico o SMP). Puede encontrar el código fuente para la gestión de procesos en ./linux/kernel y la fuente dependiente de la arquitectura en ./linux/arch.
(3) Gestión de la memoria
Otro recurso importante administrado por el núcleo es la memoria. Para mayor eficiencia, si la memoria virtual es administrada por hardware, la memoria se administra en las llamadas páginas de memoria (4 KB para la mayoría de las arquitecturas). Linux incluye formas de administrar la memoria disponible, así como los mecanismos de hardware utilizados para el mapeo físico y virtual. Pero la administración de memoria puede administrar más de 4 KB de búfer. Linux proporciona abstracciones para búferes de 4 KB, como el asignador de bloques. Este modo de administración de memoria utiliza un búfer de 4 KB como base, luego asigna estructuras a partir de él y realiza un seguimiento del uso de la página de memoria, como qué páginas de memoria están llenas, cuáles no están completamente utilizadas y cuáles están vacías. Esto permite que el modo ajuste dinámicamente el uso de la memoria según las necesidades del sistema. Con el fin de permitir que varios usuarios utilicen la memoria, a veces se agota la memoria disponible. Por este motivo, las páginas se pueden sacar de la memoria y colocar en el disco. Este proceso se denomina intercambio porque las páginas se intercambian de la memoria al disco. El código fuente para la gestión de la memoria se puede encontrar en ./linux/mm.
(4) Sistema de archivos virtuales
El sistema de archivos virtual (VFS) es un aspecto muy útil del kernel de Linux porque proporciona una abstracción de interfaz común para el sistema de archivos. VFS proporciona una capa de intercambio entre SCI y los sistemas de archivos compatibles con el kernel.
Jerarquía del sistema de archivos:

Además de VFS, hay una abstracción API genérica para funciones como abrir, cerrar, leer y escribir. Debajo del VFS se encuentra la abstracción del sistema de archivos, que define cómo se implementan las funciones de nivel superior. Son complementos para un sistema de archivos determinado (más de 50). El código fuente del sistema de archivos se puede encontrar en ./linux/fs. Debajo de la capa del sistema de archivos se encuentra la memoria caché del búfer, que proporciona un conjunto general de funciones para la capa del sistema de archivos (independiente del sistema de archivos específico). Esta capa de almacenamiento en caché optimiza el acceso a los dispositivos físicos al retener los datos durante un período de tiempo (o al leerlos por adelantado para que estén disponibles cuando se necesiten). Debajo de la memoria caché del búfer se encuentra el controlador del dispositivo, que implementa una interfaz para un dispositivo físico específico.
(5) Pila de red
La pila de red está diseñada para seguir una arquitectura en capas que imita el propio protocolo. Recuerde que el Protocolo de Internet (IP) es el protocolo de capa de red central subyacente al protocolo de transporte (a menudo llamado Protocolo de control de transmisión o TCP). Por encima de TCP está la capa de socket, que se llama a través de SCI. La capa de socket es la API estándar del subsistema de red, que proporciona una interfaz de usuario para varios protocolos de red. Desde el acceso de marco sin formato a las unidades de datos de protocolo IP (PDU) a TCP y el protocolo de datagramas de usuario (UDP), la capa de socket proporciona una forma estandarizada de administrar conexiones y mover datos entre puntos finales. El código fuente de la red en el núcleo se puede encontrar en ./linux/net.
(6) controlador de dispositivo
Gran parte del código del kernel de Linux se encuentra en los controladores de dispositivos, que pueden ejecutar dispositivos de hardware específicos. El árbol de fuentes de Linux proporciona un subdirectorio de controladores, que se divide en varios dispositivos compatibles, como Bluetooth, I2C, serie, etc. El código de los controladores de dispositivos se puede encontrar en ./linux/drivers.
(7) Código dependiente de la arquitectura
Aunque Linux es en gran medida independiente de la arquitectura en la que se ejecuta, algunos elementos deben tenerse en cuenta en la arquitectura para funcionar correctamente y lograr una mayor eficiencia. El subdirectorio ./linux/arch define la parte del código fuente del kernel que depende de la arquitectura y contiene varios subdirectorios específicos de la arquitectura (que juntos forman el BSP). Para un sistema de escritorio típico, se usa el directorio x86. Cada subdirectorio de arquitectura contiene muchos otros subdirectorios, cada uno de los cuales se centra en un aspecto específico del kernel, como el arranque, el kernel, la gestión de la memoria, etc. Estos códigos dependientes de la arquitectura se pueden encontrar en ./linux/arch.
Si la portabilidad y la eficiencia del kernel de Linux no fueran lo suficientemente buenas, Linux también proporciona algunas otras funciones que no encajan en las categorías anteriores. Como sistema operativo de producción y software de código abierto, Linux es una buena plataforma para probar nuevos protocolos y sus mejoras. Linux admite una serie de protocolos de red, incluido el típico TCP/IP y extensiones para redes de alta velocidad (más de 1 Gigabit Ethernet [GbE] y 10 GbE). Linux también puede admitir protocolos como el Protocolo de transmisión de control de flujo (SCTP), que proporciona muchas funciones más avanzadas que TCP (el sucesor del protocolo de la capa de transporte).
Linux también es un kernel dinámico que admite la adición o eliminación dinámica de componentes de software. Conocidos como módulos del kernel cargables dinámicamente, el usuario puede insertarlos en el momento del arranque según sea necesario (actualmente, el dispositivo en particular requiere este módulo) o en cualquier momento.
Una de las últimas mejoras de Linux es un sistema operativo (llamado hipervisor) que se puede utilizar como sistema operativo para otros sistemas operativos. Más recientemente, ha habido modificaciones en el kernel llamadas Máquinas virtuales basadas en kernel (KVM). Esta modificación habilita una nueva interfaz para el espacio de usuario que permite que otros sistemas operativos se ejecuten sobre el kernel habilitado para KVM. Además de ejecutar otras instancias de Linux, Microsoft Windows también se puede virtualizar. La única limitación es que el procesador subyacente debe admitir las nuevas instrucciones de virtualización.
En cuarto lugar, el diseño de la arquitectura general del núcleo
1. Mecanismo del núcleo
Cada función se convierte en diferentes subsistemas del kernel.Si los subsistemas quieren comunicarse, se debe diseñar un mecanismo que permita que los subsistemas se comuniquen entre sí de una manera segura, confiable y eficiente.
Linux ha absorbido la experiencia de diseño de microkernel en el desarrollo paso a paso.Aunque es un kernel único, tiene las características de microkernel.
Linux utiliza un diseño de kernel modular para tener ambas características de microkernel, pero dicho diseño modular no es un subsistema como un microkernel, sino un kernel compuesto por módulos funcionales centrales y periféricos. Todos los subsistemas del micronúcleo se ejecutan de forma independiente y pueden funcionar sin depender de otras partes. Los módulos de Linux deben depender del núcleo, pero pueden cargarse cuando están en uso y descargarse dinámicamente cuando no están en uso. El módulo en Linux se representa externamente como un archivo de biblioteca del tipo programa, pero el archivo de biblioteca del programa es .so, y el módulo del núcleo es .ko (objeto del núcleo), que es llamado por el núcleo.
Suponiendo que si el kernel proporciona el controlador, imagine compilar un kernel e instalarlo en el host, en caso de que luego se descubra que no puede controlar el nuevo dispositivo de hardware que agregamos más tarde. Dado que todo tipo de hardware está controlado por el kernel, y el kernel no proporciona este programa, es muy problemático para los usuarios y fabricantes recompilar el kernel.
El diseño modular puede evitar esta situación.Cada fabricante desarrolla su propio controlador de forma modular, y solo necesita desarrollar su propio programa de controlador para un dispositivo específico.
Una de las cosas que han hecho los desarrolladores del kernel de Linux es hacer que los módulos del kernel se puedan cargar y descargar durante el tiempo de ejecución, lo que significa que puede agregar o eliminar dinámicamente características del kernel. Esto no solo puede agregar capacidades de hardware al kernel, sino que también puede incluir módulos para ejecutar procesos de servidor, como virtualización de bajo nivel, pero también puede reemplazar todo el kernel sin necesidad de reiniciar la computadora en algunos casos.
Podemos compilar estos módulos cuando sea necesario. Cuando no se necesita una función, se puede desmontar por sí misma sin afectar el funcionamiento del núcleo. Imagínese si pudiera actualizar a un paquete de servicio de Windows sin reiniciar, ese es uno de los beneficios y ventajas de la modularidad.
1) mecanismo de trabajo de la CPU
Modo de trabajo de la CPU
Las CPU modernas generalmente implementan diferentes modos de trabajo. Tome ARM como ejemplo: ARM implementa 7 modos de trabajo. En diferentes modos, las instrucciones que la CPU puede ejecutar o los registros a los que se puede acceder son diferentes:
(1) Modo de usuario usr
(2) Sistema de modo de sistema
(3) Modo de gestión svc
(4) fiq de interrupción rápida
(5) Interrupción externa irq
(6) Terminación de acceso a datos aprox.
(7) Excepción de instrucción indefinida
Tome (2) X86 como ejemplo: X86 implementa 4 niveles diferentes de permisos, Ring0—Ring3; Ring0 puede ejecutar instrucciones privilegiadas y acceder a dispositivos IO; Ring3 tiene muchas restricciones
Por lo tanto, desde la perspectiva de la CPU, para proteger la seguridad del kernel, Linux divide el sistema en espacio de usuario y espacio de kernel.
El espacio de usuario y el espacio del kernel son dos estados diferentes de ejecución del programa. Podemos completar la transferencia del espacio del usuario al espacio del kernel a través de "llamadas al sistema" e "interrupciones de hardware".
Las aplicaciones se ejecutan en el kernel, es solo el caso lógico. Sin embargo, en realidad funciona directamente en el hardware. Todos los datos de la aplicación están en la memoria y el procesamiento de datos es todo CPU, pero no se pueden usar a voluntad y deben ser administrados por el kernel.
Pero solo hay una CPU. Cuando el programa de aplicación está funcionando, el kernel se suspende y el programa de aplicación también está en el espacio de memoria. Una vez que el programa de aplicación quiere acceder a otros recursos de hardware, es decir, cuando quiere ejecutar I /O instrucciones, no se puede ejecutar. Debido a que el programa de aplicación no puede ver el hardware, el programa de aplicación es un programa basado en llamadas al sistema. Cuando el programa de aplicación necesita acceder a recursos de hardware, inicia una solicitud de privilegio a la CPU. Una vez que la CPU recibe la solicitud de privilegio, la CPU despierta el kernel y ejecuta la operación en el kernel.Una pieza de código (no un programa completo del kernel), luego devuelve el resultado a la aplicación, luego el código del kernel sale y el programa del kernel se suspende.
Durante este tiempo, la CPU cambia del modo usuario al modo kernel, que parece ser un modo privilegiado.
Todas las aplicaciones se ejecutan directamente en el hardware, y el kernel solo las administra y monitorea cuando es necesario, por lo que el kernel también es un monitor, un programa de monitoreo y un programa de monitoreo de recursos y procesos.
El kernel no tiene productividad, y la productividad la genera una aplicación llamada, por lo que deberíamos intentar que el sistema se ejecute en modo aplicación, así que cuanto menos tiempo ocupe el kernel, mejor. El núcleo ocupa principalmente tiempo en funciones relacionadas, como el cambio de procesos y el procesamiento de interrupciones. El propósito del cambio de modo es completar la producción, pero el cambio de procesos y la producción no tienen ningún significado. El procesamiento de interrupciones puede considerarse relacionado con la producción en sí, porque la aplicación necesita ejecutar I/O.
El propósito principal del kernel es completar la administración del hardware, y existe la idea en Linux de que cada proceso se deriva de su proceso principal y fork() del proceso principal, luego, quién bifurcará() y administrará estos procesos, por lo que Con el gran programa de ama de llaves init, gestiona todos los procesos en el espacio de usuario como un todo.
El kernel no realizará la administración del espacio de usuario, por lo que después de iniciar el kernel, primero debemos iniciar init si queremos iniciar el espacio de usuario, por lo que el número PID de init siempre es 1. Init también se deriva de su proceso principal fork(), que es un mecanismo en el espacio del kernel para guiar específicamente los procesos del espacio del usuario. init es una aplicación, en /sbin/init, un archivo ejecutable.


tiempo de CPU
Debido a que cada proceso en la memoria monopoliza directamente la CPU, el kernel virtualiza la CPU y se la proporciona al proceso. La CPU se virtualiza a nivel de kernel. Al dividir la CPU en segmentos de tiempo, se completa con el paso del tiempo. En Al asignar la potencia informática entre los procesos, la CPU proporciona su potencia informática en términos de tiempo.
Cuanto mayor sea el poder de cómputo que se puede proporcionar por unidad de tiempo, más rápida debe ser la velocidad, de lo contrario, el tiempo solo se puede extender. Es por eso que necesitamos una CPU más rápida para ahorrar tiempo.
Características computacionales de la CPU
La E/S es el dispositivo más lento. Nuestra CPU pasa mucho tiempo esperando que se complete la E/S. Para evitar esperas inactivas y sin sentido, cuando necesitemos esperar, deje que la CPU ejecute otros procesos o subprocesos.
Deberíamos exprimir al máximo la potencia de cálculo de la CPU, porque la potencia de cálculo de la CPU oscila con el oscilador de la frecuencia del reloj a lo largo del tiempo, y funciona tanto si la usas como si no.
Si deja la CPU inactiva, aún consume energía y, con el tiempo, la potencia informática se pierde, por lo que puede hacer que la CPU funcione al 80-90% de su utilización, lo que significa que su capacidad de producción está en pleno juego. La CPU no está mal, no hay desgaste, es un equipo eléctrico, excepto que la potencia es grande, el calor es grande y la disipación de calor es suficiente.Para el equipo eléctrico, se dañará si no es usó.
9 Mecanismos de Sincronización en el Kernel de Linux
Linux a menudo usa una tabla hash para implementar un caché (Cache), que es información a la que se debe acceder rápidamente.
Después de que el sistema operativo introduce el concepto de proceso, después de que el proceso se convierte en la entidad de programación, el sistema tiene la capacidad de ejecutar múltiples procesos al mismo tiempo, pero también conduce a la competencia de recursos y al intercambio entre los diversos procesos del sistema.
Además, debido a la introducción de interrupciones, mecanismos de excepción y preferencia del estado del núcleo, estas rutas de ejecución del núcleo (procesos) se ejecutan de manera intercalada. Para las rutas del núcleo ejecutadas por estas rutas intercaladas, si no se toman las medidas de sincronización necesarias, se accederá a algunas estructuras de datos clave y se modificarán intercaladas, lo que dará como resultado estados inconsistentes de estas estructuras de datos, lo que a su vez provocará fallas en el sistema. Por lo tanto, para asegurar el funcionamiento eficiente, estable y ordenado del sistema, Linux debe adoptar un mecanismo de sincronización.
En el sistema Linux, llamamos sección crítica al segmento de código que accede a los recursos compartidos. Lo que hace que varios procesos accedan al mismo recurso compartido se denomina fuente concurrente.
Las principales fuentes de concurrencia bajo sistemas Linux son:
Procesamiento de interrupciones: por ejemplo, cuando un proceso se interrumpe mientras se accede a un recurso crítico y luego ingresa al controlador de interrupciones, si está en el controlador de interrupciones, también se accede al recurso crítico. Aunque no es estrictamente concurrencia, también provocará una condición de carrera para el recurso.
Prioridad del estado del kernel: por ejemplo, cuando un proceso accede a un recurso crítico, se produce una prioridad del estado del kernel y luego ingresa a un proceso de alta prioridad.Si el proceso también accede al mismo recurso crítico, causará un conflicto de proceso a proceso. concurrencia
Simultaneidad de múltiples procesadores: existe una estricta concurrencia entre procesos en un sistema multiprocesador.Cada procesador puede programar y ejecutar un proceso de forma independiente, y varios procesos se ejecutan al mismo tiempo.
Como se mencionó anteriormente, se puede ver que el propósito de usar el mecanismo de sincronización es evitar que múltiples procesos accedan simultáneamente al mismo recurso crítico.
9 mecanismos de sincronización:
1) Por variable de CPU
El formulario principal es una matriz de estructuras de datos, un elemento de la matriz para cada CPU del sistema.
Caso de uso: los datos deben ser lógicamente independientes
Pautas de uso: se debe acceder a las variables por CPU con la preferencia deshabilitada en la ruta de control del kernel.
2) Operaciones atómicas
Principio: Se realiza mediante las instrucciones ensambladoras que son atómicas para "leer-modificar-escribir" en instrucciones en lenguaje ensamblador.
3) Barreras de la memoria
Justificación: utilice una primitiva de barrera de memoria para asegurarse de que una operación que precede a la primitiva se haya completado antes de que comience la operación que sigue a la primitiva.
4) bloqueo de giro
Se utiliza principalmente en entornos multiprocesador.
Justificación: si una ruta de control del kernel descubre que el spinlock solicitado ya está "bloqueado" por una ruta de control del kernel que se ejecuta en otra CPU, ejecuta una instrucción de bucle repetidamente hasta que se libera el bloqueo.
Descripción: Los spinlocks se usan generalmente para proteger secciones críticas que el kernel no puede adelantar.
En un solo procesador, los spinlocks solo deshabilitan o habilitan la prioridad del kernel.

5) Bloqueo de secuencia
Un bloqueo secuencial es muy similar a un bloqueo giratorio, excepto que el escritor en un bloqueo secuencial tiene una prioridad más alta que el lector, lo que significa que el escritor puede continuar ejecutándose incluso cuando el lector está leyendo.
6)UCR
Se utiliza principalmente para proteger las estructuras de datos que leen varias CPU.
Múltiples lectores y escritores pueden ejecutarse al mismo tiempo, y RCU no tiene bloqueos.
Restricciones de uso:
1) RCU solo protege las estructuras de datos que se asignan y referencian dinámicamente mediante punteros
2) En una sección crítica protegida por RCU, ninguna ruta de control del kernel puede dormir.
principio:
Cuando el escritor quiere actualizar los datos, hace una copia de toda la estructura de datos haciendo referencia al puntero y luego hace modificaciones a esta copia. Después de la modificación, el escritor cambia el puntero a la estructura de datos original para que apunte a la copia modificada (la modificación del puntero es atómica).
7) Semáforo:
Principio: cuando la ruta de control del kernel intenta adquirir el recurso ocupado protegido por el semáforo del kernel, el proceso correspondiente se suspende; solo cuando se libera el recurso, el proceso vuelve a ser ejecutable.
Restricciones de uso: solo las funciones que pueden dormir pueden adquirir semáforos del núcleo;
Ni los manejadores de interrupciones ni las funciones diferibles pueden usar semáforos del núcleo.
8) Inhabilitación de interrupción local
Principio: la prohibición de interrupción local puede garantizar que, incluso si el dispositivo de hardware genera una señal IRQ, la ruta de control del kernel continuará ejecutándose, de modo que la estructura de datos a la que accede la rutina de procesamiento de interrupción esté protegida.
Desventaja: deshabilitar las interrupciones locales no limita el acceso simultáneo a las estructuras de datos compartidas por parte de los controladores de interrupciones que se ejecutan en otra CPU.
Por lo tanto, en un entorno multiprocesador, la desactivación de interrupciones locales debe usarse junto con spinlocks.
9) Prohibición de interrupción suave local
Método 1:
Dado que softirq comienza a ejecutarse al final del controlador de interrupciones de hardware, la forma más fácil es deshabilitar las interrupciones en esa CPU.
Debido a que no se activa ninguna rutina de manejo de interrupciones, softirq no tiene posibilidad de ejecutarse.
Método 2:
Softirq se puede activar o desactivar en la CPU local manipulando el contador softirq almacenado en el campo preempt_count del descriptor thread_info actual. Porque el kernel a veces solo necesita deshabilitar softirq sin deshabilitar las interrupciones.
2) mecanismo de memoria
El mecanismo de memoria de Linux incluye espacio de direcciones, memoria física, asignación de memoria, mecanismo de paginación y mecanismo de conmutación.
espacio de dirección
Una de las ventajas de la memoria virtual es que cada proceso piensa que tiene todo el espacio de direcciones que necesita. El tamaño de la memoria virtual puede ser muchas veces el tamaño de la memoria física del sistema. Cada proceso del sistema tiene su propio espacio de direcciones virtuales, que es completamente independiente entre sí. Un proceso que ejecuta una aplicación no afectará a otros procesos, y las aplicaciones también están protegidas entre sí. El sistema operativo asigna el espacio de direcciones virtuales a la memoria física. Desde el punto de vista de la aplicación, este espacio de direcciones es un espacio de direcciones lineal y plano; sin embargo, el kernel maneja el espacio de direcciones virtuales del usuario de manera muy diferente.
El espacio de direcciones lineal se divide en dos partes: el espacio de direcciones del usuario y el espacio de direcciones del kernel. El espacio de direcciones del usuario no cambia cada vez que ocurre un cambio de contexto, mientras que el espacio de direcciones del kernel siempre permanece igual. La cantidad de espacio asignado para el espacio del usuario y el espacio del kernel depende principalmente de si el sistema tiene una arquitectura de 32 bits o de 64 bits. Por ejemplo, x86 es una arquitectura de 32 bits que admite solo 4 GB de espacio de direcciones, de los cuales 3 GB están reservados para el espacio de usuario y 1 GB se asigna para el espacio de direcciones del kernel. El tamaño de partición específico está determinado por la variable de configuración del kernel PAGE_OFFSET.
memoria física
Para admitir múltiples arquitecturas, Linux usa una forma independiente de la arquitectura para describir la memoria física.
La memoria física se puede organizar en bancos de memoria (bancos), cada uno a una distancia específica del procesador. Este tipo de diseño de memoria se ha vuelto muy común a medida que más y más máquinas adoptan la tecnología Nonuniform Memory Access (NUMA). Las máquinas virtuales Linux representan este arreglo como nodos. Cada nodo se divide en varios bloques de memoria denominados zonas de gestión, que representan un rango de direcciones en la memoria. Hay tres zonas de gestión diferentes: ZONE_DMA, ZONE_NORMAL y ZONE_HIGHMEM. Por ejemplo, x86 tiene las siguientes áreas de administración de memoria:
ZONE_DMA Los primeros 16 MB de la dirección de memoria
ZONE_NORMAL 16 MB~896 MB ZONE_HIGHMEM
896 MB~el final de la dirección de memoria
Cada área de administración tiene su propio propósito. Algunos dispositivos ISA anteriores tenían restricciones sobre qué direcciones podían realizar operaciones de E/S, y ZONE_DMA elimina estas restricciones.
ZONE_NORMAL se utiliza para todas las operaciones y asignaciones del núcleo. Es extremadamente importante para el rendimiento del sistema.
ZONE_HIGHMEM es el resto de la memoria en el sistema. Cabe señalar que ZONE_HIGHMEM no se puede usar para la asignación del kernel y las estructuras de datos, y solo se puede usar para guardar los datos del usuario.
mapa de memoria
Para comprender mejor el mecanismo de mapeo de la memoria del kernel, el siguiente es un ejemplo de x86. Como se mencionó anteriormente, el núcleo solo tiene 1 GB de espacio de direcciones virtuales disponible y los otros 3 GB están reservados para el espacio del usuario. El kernel mapea la memoria física en ZONE_DMA y ZONE_NORMAL directamente en su espacio de direcciones. Esto significa que los primeros 896 MB de memoria física del sistema se asignan al espacio de direcciones virtuales del kernel, lo que deja solo 128 MB de espacio de direcciones virtuales. Estos 128 MB de espacio de direcciones virtuales se utilizan para operaciones como vmalloc y kmap.
Este mecanismo de asignación funciona bien si la capacidad de la memoria física es pequeña (menos de 1 GB). Sin embargo, todos los servidores actuales admiten decenas de gigabytes de memoria. Intel ha introducido un mecanismo de extensión de dirección física (PAE) en su procesador Pentium, que puede admitir hasta 64 GB de memoria física. El mecanismo de mapeo de memoria antes mencionado hace que el manejo de memoria física de hasta decenas de gigabytes sea una fuente importante de problemas para x86 Linux. El kernel de Linux maneja la memoria de gama alta (toda la memoria por encima de 896 MB) de la siguiente manera: cuando el kernel de Linux necesita direccionar una página en la memoria de gama alta, asigna la página a una pequeña ventana de espacio de direcciones virtuales a través de la operación kmap. una operación en la página y, a continuación, desasignar la página. El espacio de direcciones de una arquitectura de 64 bits es enorme, por lo que este tipo de sistema no tiene este problema.
mecanismo de paginación
La memoria virtual se puede implementar de varias maneras, la más eficiente de las cuales es una solución basada en hardware. El espacio de direcciones virtuales se divide en bloques de memoria de tamaño fijo, llamados páginas. Los accesos a la memoria virtual se traducen en direcciones de memoria física a través de tablas de páginas. Para admitir varias arquitecturas y tamaños de página, Linux utiliza un mecanismo de paginación de tres niveles. Proporciona los siguientes tres tipos de tablas de páginas:
La traducción de direcciones de Page Global Directory (PGD)
, Page Middle Directory (PMD) y
Page Table (PTE)
proporciona un método para separar el espacio de direcciones virtuales de un proceso del espacio de direcciones físicas. Cada página de memoria virtual se puede marcar como "presente" o "ausente" en la memoria principal. Si un proceso accede a una dirección de memoria virtual que no existe, el hardware generará un error de página y el kernel lo manejará. La página se coloca en la memoria principal cuando el kernel maneja el error. Durante este proceso, es posible que el sistema deba reemplazar una página existente para hacer espacio para la nueva página.
La estrategia de reemplazo es uno de los aspectos más críticos del sistema de paginación. La versión Linux 2.6 corrige problemas con versiones anteriores de Linux con respecto a varias selecciones y reemplazos de páginas.
mecanismo de intercambio
El intercambio es el proceso de mover un proceso completo dentro o fuera del almacenamiento secundario cuando la memoria principal se está quedando sin capacidad. Debido a la gran sobrecarga del cambio de contexto, muchos sistemas operativos modernos, incluido Linux, no utilizan este enfoque, sino que utilizan un mecanismo de paginación. En Linux, el intercambio se realiza a nivel de página en lugar de a nivel de proceso. La principal ventaja del intercambio es que amplía el espacio de direcciones disponible para un proceso. Cuando el kernel necesita liberar memoria para hacer espacio para nuevas páginas, es posible que deba descartar algunas páginas menos utilizadas o sin usar. Algunas páginas no se liberan fácilmente porque no están respaldadas por disco y deben copiarse en el almacenamiento de respaldo (intercambio) y volver a leerse desde el almacenamiento de respaldo cuando sea necesario. La principal desventaja del mecanismo de intercambio es que es lento. Las lecturas y escrituras de disco suelen ser muy lentas, por lo que el intercambio debe eliminarse tanto como sea posible.
3) Mecanismo de proceso
Procesos, tareas y subprocesos del núcleo
Una tarea es solo una "descripción general del trabajo que debe realizarse", que puede ser un hilo ligero o un proceso completo.
Un subproceso es la instancia de tarea más ligera. El costo de crear un hilo en el kernel puede ser alto o bajo, dependiendo de las características que debe tener el hilo. En el caso más simple, un subproceso comparte todos los recursos con su subproceso principal, incluido el código, los datos y muchas estructuras de datos internas, con solo una pequeña diferencia para distinguir ese subproceso de otros subprocesos.
Un proceso en Linux es una estructura de datos de "peso pesado". Si es necesario, varios subprocesos pueden ejecutarse en un solo proceso (y compartir algunos recursos de ese proceso). En Linux, un proceso es solo un hilo con características de peso completo. El programador programa los subprocesos y los procesos de la misma manera.
Un subproceso del kernel es un subproceso que siempre se ejecuta en modo kernel y no tiene contexto de usuario. Los subprocesos del kernel generalmente existen para una función específica y es fácil manejarlos en el kernel. Los subprocesos del núcleo a menudo tienen la función deseada: poder programarse como cualquier otro proceso; cuando otros procesos necesitan esa funcionalidad para funcionar, proporcione a esos procesos un subproceso de destino que implemente esa funcionalidad (enviando una señal).
Programación y cambio de contexto
La programación de procesos es la ciencia (algunos la llaman el arte) de garantizar que cada proceso obtenga una parte justa de la CPU. Siempre hay desacuerdo sobre la definición de "equidad" porque los programadores a menudo toman decisiones basadas en información que no es obvia ni visible.
Debe tenerse en cuenta que muchos usuarios de Linux creen que un programador que es correcto en su mayor parte todo el tiempo es más importante que un programador que es completamente correcto la mayor parte del tiempo, es decir, un proceso lento es preferible a un programador elegido con demasiado cuidado. proceso que deja de ejecutarse debido a una política o un error. El programa planificador actual de Linux sigue este principio.
Cuando un proceso deja de ejecutarse y es reemplazado por otro proceso, se denomina cambio de contexto. Por lo general, esta operación es costosa y los programadores del kernel y de aplicaciones siempre intentan minimizar la cantidad de cambios de contexto que realiza el sistema. Un proceso puede dejar de ejecutarse activamente porque está esperando algún evento o recurso, o darse por vencido pasivamente porque el sistema decide que la CPU debe asignarse a otro proceso. Para el primer caso, la CPU puede pasar a un estado inactivo si no hay otros procesos esperando para ejecutarse. En el segundo caso, el proceso se reemplaza por otro proceso en espera o se le asigna una nueva porción de tiempo de ejecución o período de tiempo para continuar con la ejecución.
Incluso mientras un proceso se programa y ejecuta de manera ordenada, puede ser interrumpido por otras tareas de mayor prioridad. Por ejemplo, si el disco está listo con datos para una lectura de disco, envía una señal a la CPU y espera que la CPU obtenga los datos del disco. El kernel debe manejar esta situación de manera oportuna, de lo contrario, reducirá la tasa de transferencia del disco. Las señales, las interrupciones y las excepciones son eventos asincrónicos diferentes, pero son similares en muchos aspectos y todos deben manejarse rápidamente, incluso si la CPU ya está ocupada.
Por ejemplo, un disco preparado para datos puede provocar una interrupción. El núcleo llama al controlador de interrupciones para ese dispositivo en particular, interrumpiendo el proceso que se está ejecutando actualmente y utilizando sus muchos recursos. Cuando finaliza la ejecución del controlador de interrupciones, el proceso que se está ejecutando actualmente reanuda la ejecución. Esto efectivamente roba el tiempo de CPU del proceso que se está ejecutando actualmente, porque las versiones actuales del kernel solo miden el tiempo transcurrido desde que el proceso ingresó a la CPU, ignorando el hecho de que las interrupciones consumen un tiempo precioso para el proceso.
Los controladores de interrupciones suelen ser muy rápidos y compactos y, por lo tanto, pueden procesarse y borrarse rápidamente para permitir la entrada de datos posteriores. Pero a veces, una interrupción puede necesitar manejar más trabajo del esperado en el controlador de interrupciones en un corto período de tiempo. Las interrupciones también necesitan un entorno bien definido para hacer su trabajo (recuerde, las interrupciones utilizan los recursos de algún proceso aleatorio). En este caso, recopile suficiente información para retrasar el envío del trabajo al controlador de la mitad inferior para su procesamiento. El controlador de la mitad inferior está programado para ejecutarse de vez en cuando. Aunque el mecanismo de la mitad inferior se usaba comúnmente en versiones anteriores de Linux, se desaconseja su uso en las versiones actuales de Linux.
4) Mecanismo de plataforma impulsado por Linux
Comparado con el mecanismo tradicional de controlador de dispositivo, el mecanismo de controlador de plataforma de Linux tiene una ventaja muy obvia en el sentido de que el mecanismo de plataforma registra sus propios recursos en el núcleo, que es administrado por el núcleo de manera uniforme. Cuando estos recursos se utilizan en el controlador, el estándar Se utiliza la interfaz proporcionada por platform_device Aplicar y usar. Esto mejora la independencia de los conductores y la gestión de recursos, y tiene mejor portabilidad y seguridad. El siguiente es un diagrama esquemático de la jerarquía del controlador SPI. El bus SPI en Linux puede entenderse como el bus derivado del controlador SPI:

Al igual que los controladores tradicionales, el mecanismo de la plataforma también se divide en tres pasos:
1. Etapa de registro de autobuses:
Kernel_init()→do_basic_setup()→driver_init()→platform_bus_init()→bus_register(&platform_bus_type) en el archivo main.c durante la inicialización del inicio del kernel registra un bus de plataforma (bus virtual, platform_bus).
2. Agregar etapa de equipo:
Cuando el dispositivo está registrado, Platform_device_register()→platform_device_add()→ (pdev→dev.bus = &platform_bus_type)→device_add(), simplemente cuelgue el dispositivo en el bus virtual.
3. Etapa de registro de conductores:
Platform_driver_register() →driver_register() →bus_add_driver() →driver_attach()→bus_for_each_dev(), haga __driver_attach()→driver_probe_device() para cada dispositivo colgado en el bus de plataforma virtual, juzgue drv→bus→match() Si la ejecución es correctamente, ejecute platform_match→strncmp(pdev→name , drv→name , BUS_ID_SIZE ) a través del puntero en este momento, si coincide, llame a really_probe (realmente ejecute el controlador de plataforma→probe(platform_device) del dispositivo correspondiente). Inicie la detección real. , si la sonda tiene éxito, el dispositivo está vinculado al controlador.
Como se puede ver en lo anterior, el mecanismo de la plataforma finalmente llama a las tres funciones clave de bus_register(), device_add() y driver_register().
Aquí hay algunas estructuras:
struct platform_device
(/include/linux/Platform_device.h)
{
const char * name;
int id;
struct device dev;
u32 num_resources;
struct resource * resource;
};La estructura Platform_device describe un dispositivo de una estructura de plataforma, que contiene la estructura del dispositivo general struct device dev; la estructura de recursos del dispositivo struct resource * resource; y el nombre del dispositivo const char * name. (Tenga en cuenta que este nombre debe ser el mismo que el nombre de platform_driver.driver más adelante, el motivo se explicará más adelante).
Lo más importante en esta estructura es la estructura de recursos, por lo que se introduce el mecanismo de plataforma.
struct resource
( /include/linux/ioport.h)
{
resource_size_t start;
resource_size_t end;
const char *name;
unsigned long flags;
struct resource *parent, *sibling, *child;
};El bit de bandera indica el tipo de recurso, y el inicio y el final indican la dirección de inicio y la dirección final del recurso respectivamente (/include/linux/Platform_device.h):
struct platform_driver
{
int (*probe)(struct platform_device *);
int (*remove)(struct platform_device *);
void (*shutdown)(struct platform_device *);
int (*suspend)(struct platform_device *, pm_message_t state);
int (*suspend_late)(struct platform_device *, pm_message_t state);
int (*resume_early)(struct platform_device *);
int (*resume)(struct platform_device *);
struct device_driver driver;
};
Platform_driverLa estructura Platform_driver describe el controlador de una estructura de plataforma. Además de algunos punteros de función, también hay una estructura de controlador general device_driver.
Razones para tener el mismo nombre:
El controlador mencionado anteriormente llamará a la función bus_for_each_dev() cuando esté registrado, y hará __driver_attach()→driver_probe_device() para cada dispositivo colgado en el bus de la plataforma virtual, en esta función, dev y drv se emparejarán inicialmente. , lo que llama la función a la que apunta drv->bus->match. En la función platform_driver_register, drv->driver.bus = &platform_bus_type, entonces drv->bus->matc es platform_bus_type→match, que es la función platform_match.La función es la siguiente:
static int platform_match(struct device * dev, struct device_driver * drv)
{
struct platform_device *pdev = container_of(dev, struct platform_device, dev);
return (strncmp(pdev->name, drv->name, BUS_ID_SIZE) == 0);
}Es para comparar los nombres de dev y drv. Si son iguales, ingresarán a la función reality_probe(), para ingresar a la función de sondeo escrita por ellos mismos para una mayor coincidencia. Por lo tanto, dev→name y driver→drv→name deben completarse de la misma manera durante la inicialización.
Los diferentes tipos de controladores tienen diferentes funciones de coincidencia. El controlador de la plataforma compara los nombres de dev y drv. ¿Recuerdas la coincidencia en el controlador usb? Compara la identificación del producto y la identificación del proveedor.
Los beneficios del mecanismo de la Plataforma:
1. Proporcione un bus de tipo platform_bus_type y agregue los dispositivos soc que no sean tipos de bus a este bus virtual. Por lo tanto, el modelo controlado por dispositivo de bus puede popularizarse.
2. Proporcione estructuras de datos del tipo dispositivo_plataforma y controlador_plataforma, incruste estructuras de datos de dispositivos y controladores tradicionales en ellas, y agregue miembros de recursos para facilitar la integración con el nuevo tipo de gestor de arranque y kernel que transfiere dinámicamente recursos de dispositivos como Open Firmware.
2. Escribe tu propio sistema operativo
Como varias aplicaciones, el kernel también es una aplicación, excepto que esta aplicación opera directamente el hardware. El núcleo se enfrenta directamente al hardware, llama a la interfaz de hardware y se desarrolla a través del conjunto de instrucciones proporcionado por un fabricante de hardware y un fabricante de CPU. Es mucho más sencillo desarrollar aplicaciones de cara al kernel, llamadas al sistema o llamadas a bibliotecas.
Para escribir aplicaciones a nivel de kernel, y para evitar un nivel demasiado bajo, hay muchos archivos de biblioteca inherentes que se pueden usar cuando se compila el kernel.
El kernel está directamente orientado al hardware, por lo que los recursos disponibles tienen una gran autoridad, pero el kernel funciona en un espacio de direcciones limitado. En lo que respecta a Linux, en un sistema de 32 bits, en el espacio de direcciones lineal, el kernel solo piensa que tiene 1G, aunque puede Master 4G, pero solo puedes usar 1G para tu propio funcionamiento, y el 3G restante es para otras aplicaciones. ganar es cada 2G. Por lo tanto, el espacio de memoria disponible cuando desarrollamos el kernel es muy limitado, especialmente cuando desarrollamos controladores, debemos entender que nuestro espacio disponible es muy limitado, por lo que debe ser eficiente.
La arquitectura del kernel también es muy clara, desde la capa de hardware, la capa de abstracción de hardware, los módulos básicos del kernel (programación de procesos, administración de memoria, pila de protocolos de red, etc.) hasta la capa de aplicación, que es básicamente el diseño básico del sistema. arquitectura que combina varios software y hardware.Por ejemplo, los sistemas IoT (desde pequeños sistemas integrados como microcomputadoras de un solo chip, MCU, hasta hogares inteligentes, comunidades inteligentes e incluso ciudades inteligentes) pueden referenciarse en los dispositivos finales de acceso.
Linux originalmente se ejecutaba en una PC, y el procesador de arquitectura x86 utilizado era relativamente potente, y todo tipo de instrucciones y modos eran relativamente completos. Por ejemplo, el modo de usuario y el modo kernel que vemos no están disponibles en los procesadores integrados pequeños generales. Su ventaja es proteger el código y los datos en el modo kernel al otorgar diferentes permisos al código y los segmentos de datos (incluidos los recursos de hardware) deben ser se accede a través de una llamada al sistema similar (SysCall) para garantizar la estabilidad del kernel.
El proceso de escribir un sistema operativo:

Imagínese si tuviera que escribir un sistema operativo, ¿qué factores necesitaría considerar?
Gestión de procesos: cómo asignar segmentos de tiempo de CPU de acuerdo con el algoritmo de programación en un sistema multitarea.
Gestión de memoria: cómo asignar memoria virtual y memoria física, asignar y recuperar memoria.
Sistema de archivos: cómo organizar los sectores del disco duro en un sistema de archivos para realizar la operación de lectura y escritura de archivos.
Administración de dispositivos: cómo direccionar, acceder, leer y escribir información y datos de configuración de dispositivos.
Gestión de proceso
Algunos procesos se denominan procesos y otros se denominan tareas en diferentes sistemas operativos. La estructura de datos del proceso en el sistema operativo contiene muchos elementos, a menudo conectados por una lista enlazada.
El contenido relacionado con el proceso incluye principalmente: espacio de direcciones virtuales, prioridad, ciclo de vida (bloqueo, listo, en ejecución, etc.), recursos ocupados (como semáforos, archivos, etc.).
La CPU verifica los procesos en la cola lista (atraviesa la estructura del proceso en la lista enlazada) cuando se genera cada interrupción del sistema. Si hay un nuevo proceso que se ajusta al algoritmo de programación, debe cambiarse y guardar la información. del proceso que se está ejecutando actualmente (incluida la información de la pila, etc.), suspenda el proceso actual y seleccione un nuevo proceso para ejecutar, que es la programación de procesos.
La diferencia en la prioridad de los procesos es la base básica para la programación de la CPU. El objetivo final de la programación es permitir que las actividades de alta prioridad obtengan inmediatamente los recursos informáticos de la CPU (respuesta instantánea) y que las tareas de baja prioridad se asignen de manera justa a los recursos de la CPU. Debido a que es necesario guardar el contexto del proceso, etc., la conmutación del proceso en sí tiene un costo, y el algoritmo de programación también debe considerar la eficiencia de la frecuencia de conmutación del proceso.
En los primeros sistemas operativos Linux, se utiliza principalmente el algoritmo round-robin de intervalo de tiempo (Round-Robin), y el kernel selecciona el proceso de alta prioridad en la cola de procesos listos para ejecutarse, y cada uno se ejecuta durante el mismo tiempo. El algoritmo es simple e intuitivo, pero aún hace que algunos procesos de baja prioridad no estén programados durante mucho tiempo. Para mejorar la equidad de la programación, después de Linux 2.6.23, se introdujo un programador completamente justo llamado CFS (Completely Fair Scheduler).
La CPU solo puede ejecutar un programa en cualquier momento. Cuando el usuario está usando la aplicación Youku para ver videos, está escribiendo y chateando en WeChat al mismo tiempo. Youku y WeChat son dos programas diferentes. ¿Por qué parece que se están ejecutando? ¿al mismo tiempo? El objetivo de CFS es hacer que todos los programas parezcan estar ejecutándose a la misma velocidad en varias CPU paralelas, es decir, nr_running procesos, cada uno ejecutándose simultáneamente a una velocidad de 1/nr_running, por ejemplo, si hay 2 posibles tareas en ejecución, entonces cada se ejecuta simultáneamente al 50% de la potencia física de la CPU.
CFS introduce el concepto de "tiempo de ejecución virtual", que está representado por p->se.vruntime (unidad nanosec), mediante el cual registra y mide el "tiempo de CPU" que debe obtener una tarea. En una situación de programación ideal, todas las tareas deberían tener el mismo valor de p->se.vruntime en todo momento (las mencionadas anteriormente se ejecutan a la misma velocidad). Debido a que cada tarea se ejecuta simultáneamente, ninguna tarea excederá el tiempo de CPU ideal que debería ocupar. La lógica de CFS seleccionando tareas para ejecutar se basa en el valor de p->se.vruntime, que es muy simple: siempre elige la tarea con el valor más pequeño de p->se.vruntime para ejecutar (la tarea menos programada) .
CFS utiliza un árbol rojo-negro basado en el tiempo para programar la ejecución de tareas futuras. Todas las tareas se ordenan por la palabra clave p->se.vruntime. CFS selecciona la tarea más a la izquierda para ejecutar desde el árbol. A medida que se ejecuta el sistema, las tareas ejecutadas se colocan en el lado derecho del árbol, dando progresivamente a cada tarea la oportunidad de ser la tarea más a la izquierda, ganando así recursos de CPU durante un período de tiempo determinable.
Para resumir, CFS primero ejecuta una tarea. Cuando se cambia la tarea (o cuando ocurre la interrupción de Tick), el tiempo de CPU utilizado por la tarea se agregará a p->se.vruntime, cuando el valor de p->se .vruntime gradualmente Cuando otra tarea se convierte en la tarea más a la izquierda del árbol rojo-negro (al mismo tiempo, se agrega una pequeña distancia de granularidad entre la tarea y la tarea más a la izquierda para evitar el cambio excesivo de tareas y afectar el rendimiento), la tarea más a la izquierda es seleccionado para su ejecución, la tarea actual se reemplaza.

árbol rojo-negro CFS
En general, el planificador maneja tareas individuales y trata de dar a cada tarea una cantidad justa de tiempo de CPU. En algún momento, puede ser deseable agrupar tareas y dar a cada grupo una parte justa del tiempo de CPU. Por ejemplo, el sistema puede asignar un tiempo de CPU promedio a cada usuario y luego asignar un tiempo de CPU promedio a cada tarea para cada usuario.
gestión de la memoria
La memoria en sí es un dispositivo de almacenamiento externo, el sistema necesita dirigirse al área de memoria, encontrar la celda de memoria correspondiente y leer y escribir los datos en ella.
El área de memoria se direcciona mediante punteros, y la longitud en bytes de la CPU (máquina de 32 bits, máquina de 64 bits) determina el espacio de direcciones direccionable más grande. El espacio de direccionamiento máximo en una máquina de 32 bits es de 4 GBtyes. En una máquina de 64 bits hay teóricamente 2^64Bytes.
El espacio de direcciones más grande no tiene nada que ver con la cantidad de memoria física que tiene el sistema real, por lo que se denomina espacio de direcciones virtuales. Para todos los procesos en el sistema, parece que cada proceso ocupa este espacio de direcciones de forma independiente y no puede percibir el espacio de memoria de otros procesos. El hecho de que el sistema operativo permita que las aplicaciones no necesiten prestar atención a otras aplicaciones, parece que cada tarea es el único proceso que se ejecuta en esta computadora.
Linux divide el espacio de direcciones virtuales en espacio de kernel y espacio de usuario. El espacio virtual para cada proceso de usuario varía de 0 a TASK_SIZE. El área desde TASK_SIZE hasta 2^32 o 2^64 está reservada para el núcleo y los procesos de usuario no pueden acceder a ella. TASK_SIZE se puede configurar, la configuración predeterminada del sistema Linux es 3: 1, la aplicación usa 3 GB de espacio y el kernel usa 1 GB de espacio. Esta división no depende del tamaño real de RAM. En una máquina de 64 bits, el espacio de direcciones virtuales puede ser muy grande, pero en realidad solo se utilizan 42 o 47 bits (2^42 o 2^47).

espacio de direcciones virtuales
En la gran mayoría de los casos, el espacio de direcciones virtuales es más grande que la memoria física (RAM) disponible para el sistema real, y el kernel y la CPU deben considerar cómo asignar la memoria física disponible real al espacio de direcciones virtuales.
Una forma es asignar direcciones virtuales a direcciones físicas a través de la tabla de páginas. Las direcciones virtuales están relacionadas con las direcciones de usuario y kernel utilizadas por el proceso, y las direcciones físicas se utilizan para abordar la RAM real utilizada.
Como se muestra en la siguiente figura, los espacios de direcciones virtuales de los procesos A y B se dividen en partes del mismo tamaño llamadas páginas. La memoria física también se divide en páginas (marcos de página) de igual tamaño.

Mapeo de espacios de direcciones físicas y virtuales
La primera página de memoria del proceso A se asigna a la cuarta página de la memoria física (RAM); la primera página de memoria del proceso B se asigna a la quinta página de la memoria física. La quinta página de memoria del proceso A y la primera página de memoria del proceso B se asignan a la quinta página de memoria física (el kernel puede decidir qué espacio de memoria comparten los diferentes procesos).
Como se muestra en la figura, no todas las páginas en el espacio de direcciones virtuales están asociadas con un marco de página. Es posible que la página no se use o que los datos no se hayan cargado en la memoria física (no es necesario por el momento), o que se porque la página de la memoria física se reemplaza en el disco duro y luego se reemplaza nuevamente en la memoria cuando realmente se necesita más adelante.
La tabla de páginas asigna el espacio de direcciones virtuales al espacio de direcciones físicas. La forma más fácil de hacer esto es usar una matriz para asignar páginas virtuales a páginas físicas una a una, pero hacerlo puede requerir consumir toda la RAM para mantener esta tabla de páginas, asumiendo que cada página tiene un tamaño de 4 KB y el El espacio de direcciones virtuales tiene un tamaño de 4 GB, necesita una matriz de 1 millón de elementos para contener la tabla de páginas.
Debido a que la mayoría de las áreas del espacio de direcciones virtuales no se usan realmente y estas páginas no están realmente asociadas con el marco de la página, la introducción de la paginación multinivel puede reducir en gran medida la memoria utilizada por la tabla de páginas y mejorar la eficiencia de las consultas. Para obtener una descripción detallada de la mesa de varios niveles, consulte xxx.
El mapeo de memoria es una abstracción importante que se usa en muchos lugares, como el kernel y las aplicaciones de usuario. El mapeo consiste en transferir datos desde una fuente de datos (también puede ser un puerto de E/S de un dispositivo, etc.) al espacio de memoria virtual de un proceso. Las operaciones en el espacio de direcciones mapeado pueden usar el método de tratar con la memoria ordinaria (lectura y escritura directa del contenido de la dirección). Cualquier cambio en la memoria se transferirá automáticamente a la fuente de datos original, como asignar el contenido de un archivo a la memoria, solo necesita leer la memoria para obtener el contenido del archivo y escribir los cambios en la memoria para modificar el contenido del archivo, el kernel asegura que cualquier cambio se refleje automáticamente en el archivo.
Además, en el núcleo, al implementar controladores de dispositivos, las áreas de entrada y salida de los periféricos (dispositivos externos) se pueden asignar a espacios de direcciones virtuales, y el sistema redirigirá la lectura y escritura de estos espacios al dispositivo, de modo que el Se puede operar el dispositivo, implementación del controlador muy simplificada.
El kernel debe realizar un seguimiento de qué páginas físicas se han asignado y cuáles aún están libres para evitar que dos procesos utilicen la misma área de RAM. La asignación y liberación de memoria son tareas muy frecuentes. El kernel debe asegurarse de que la velocidad de finalización sea lo más rápida posible. El kernel solo puede asignar el marco de página completo. Asigna la tarea de dividir la memoria en partes más pequeñas al usuario. space, la biblioteca de programas de espacio de usuario El marco de página recibido del núcleo se puede dividir en regiones más pequeñas y asignarse al proceso.
sistema de archivos virtuales
Los sistemas Unix se basan en algunas ideas perspicaces, una metáfora muy importante es:
Todo es un archivo.
Es decir, casi todos los recursos del sistema pueden considerarse archivos. Para admitir diferentes sistemas de archivos locales, el núcleo incluye una capa de sistema de archivos virtual (Sistema de archivos virtual) entre el proceso de usuario y la implementación del sistema de archivos. Se puede acceder a la mayoría de las funciones proporcionadas por el kernel a través de la interfaz de archivos definida por VFS (Sistema de archivos virtual). Por ejemplo, subsistemas del núcleo: dispositivos de caracteres y bloques, conductos, conectores de red, terminales de entrada y salida interactivos, etc.
Además, los archivos de dispositivo utilizados para operar dispositivos de caracteres y bloques son archivos reales en el directorio /dev Cuando se realizan las operaciones de lectura y escritura, su contenido será creado dinámicamente por el controlador de dispositivo correspondiente.

sistema VFS
En un sistema de archivos virtual, los inodos se utilizan para representar archivos y directorios de archivos (para el sistema, un directorio es un tipo especial de archivo). Los elementos de inode incluyen dos categorías: 1. Los metadatos se utilizan para describir el estado del archivo, como los permisos de lectura y escritura. 2. El segmento de datos utilizado para guardar el contenido del archivo.
Cada inodo tiene un número especial para una identificación única, y la asociación entre el nombre de archivo y el inodo se basa en el número. Tome el núcleo para encontrar /usr/bin/emacs como ejemplo para explicar cómo los inodos forman la estructura de directorios del sistema de archivos. La búsqueda comienza desde el inodo raíz (es decir, el directorio raíz "/"), que está representado por un inodo. El segmento de datos del inodo no tiene datos ordinarios, sino que solo contiene algunos elementos de archivo/directorio almacenados en el directorio raíz. Estos elementos pueden representar archivos u otro directorio, cada elemento contiene dos partes: 1. El número de inodo donde se encuentra el siguiente elemento de datos 2. El nombre del archivo o directorio
Primero escanee el área de datos del inodo raíz hasta encontrar una entrada llamada 'usr', buscando inodos en el subdirectorio usr. Encuentre el inodo asociado por el número de inodo 'usr'. Repita los pasos anteriores para encontrar el elemento de datos llamado 'bin', luego busque el elemento de datos llamado 'emacs' en el inodo correspondiente a 'bin' de su elemento de datos, y el inodo devuelto representa un archivo en lugar de un directorio. El contenido del archivo del último inodo es diferente de los anteriores. Los tres primeros representan cada uno un directorio, que contiene sus subdirectorios y listados de archivos. El inodo asociado con el archivo emacs contiene el contenido real del archivo en su segmento de datos.
Aunque los pasos para encontrar un archivo en VFS son los mismos que los descritos anteriormente, existen algunas diferencias en los detalles. Por ejemplo, debido a que abrir archivos con frecuencia es una operación lenta, la introducción de un caché puede acelerar las búsquedas.
Encuentre un archivo a través del mecanismo de inodo:

controlador de dispositivo
La comunicación con periféricos a menudo se refiere a operaciones de entrada y salida, o E/S para abreviar. Un núcleo de E/S que implementa un periférico debe manejar tres tareas: Primero, el hardware debe abordarse de diferentes maneras para diferentes tipos de dispositivos. En segundo lugar, el núcleo debe proporcionar métodos para que las aplicaciones de usuario y las herramientas del sistema operen diferentes dispositivos, y se necesita un mecanismo uniforme para garantizar el menor esfuerzo de programación posible y para garantizar que las aplicaciones puedan interactuar entre sí incluso con diferentes métodos de hardware. En tercer lugar, el espacio del usuario necesita saber qué dispositivos hay en el núcleo.
La relación jerárquica con los periféricos es la siguiente:

Diagrama de jerarquía de comunicación de dispositivos
La mayoría de los dispositivos externos están conectados a la CPU a través del bus y, a menudo, el sistema tiene más de un bus, pero una colección de buses. Muchos diseños de PC incluyen dos buses PCI conectados por un puente. Algunos buses, como el USB, no se pueden usar como bus principal y necesitan pasar datos al procesador a través de un bus del sistema. El siguiente diagrama muestra cómo se conectan los diferentes buses al sistema.

Topología de bus del sistema
El sistema interactúa con los periféricos principalmente de las siguientes maneras:
Puerto de E/S: en el caso de utilizar la comunicación del puerto de E/S, el kernel envía datos a través de un controlador de E/S, cada dispositivo receptor tiene un número de puerto único y reenvía los datos al hardware conectado al sistema. Hay un espacio de direcciones virtuales separado administrado por el procesador para administrar todas las direcciones de E/S.
El espacio de direcciones de E/S no siempre está asociado con la memoria normal del sistema, lo que a menudo es difícil de entender si se tiene en cuenta que los puertos se pueden asignar a la memoria.
Hay diferentes tipos de puertos. Algunos son de solo lectura, algunos son de solo escritura y, en general, pueden operar en ambas direcciones y los datos se pueden intercambiar en ambas direcciones entre el procesador y los periféricos.
En la arquitectura IA-32, el espacio de direcciones del puerto contiene 2^16 direcciones de 8 bits diferentes, que pueden identificarse de forma única mediante números de 0x0 a 0xFFFFH. Cada puerto tiene asignado un dispositivo, o está inactivo y sin usar, y varios periféricos no pueden compartir un puerto. En muchos casos, el intercambio de datos de 8 bits es insuficiente y, por este motivo, dos puertos de 8 bits consecutivos pueden vincularse en un único puerto de 16 bits. Dos puertos consecutivos de 16 bits se pueden tratar como un puerto de 32 bits y el procesador puede realizar operaciones de entrada y salida ensamblando declaraciones.
Los diferentes tipos de procesadores implementan los puertos de operación de manera diferente, el núcleo debe proporcionar una capa de abstracción adecuada, como outb (escribir un byte), outw (escribir una palabra) e inb (leer un byte). Estos comandos se pueden usar para el puerto de operación.
Asignación de memoria de E/S: muchos dispositivos deben poder direccionarse como memoria RAM. Por lo tanto, el procesador proporciona el puerto de E/S correspondiente al dispositivo periférico que se va a asignar a la memoria, de modo que el dispositivo pueda funcionar como una memoria ordinaria. Por ejemplo, las tarjetas gráficas usan un mecanismo de este tipo, y PCI a menudo se direcciona mediante direcciones de E/S asignadas.
Para implementar la asignación de memoria, los puertos de E/S primero deben asignarse a la memoria normal del sistema (utilizando funciones específicas del procesador). Debido a que las implementaciones varían ampliamente entre plataformas, el kernel proporciona una capa de abstracción para asignar y desasignar regiones de E/S.
Además de cómo acceder al periférico, ¿cuándo sabrá el sistema si el periférico tiene datos para acceder? Hay dos formas principales: sondeo e interrupciones.
El sondeo accede periódicamente al dispositivo de consulta para ver si tiene datos listos y, de ser así, los obtiene. Este método requiere que el procesador acceda continuamente al dispositivo incluso cuando el dispositivo no tiene datos, desperdiciando segmentos de tiempo de CPU.
Otra forma es interrumpir. Su idea es que después de que el periférico haya terminado algo, notificará activamente a la CPU. La interrupción tiene la prioridad más alta e interrumpirá el proceso actual de la CPU. Cada CPU proporciona una línea de interrupción (que puede ser compartida por diferentes dispositivos), cada interrupción se identifica con un número de interrupción único y el núcleo proporciona un método de servicio para cada interrupción utilizada (ISR, Interrupt Service Routine, es decir, después de la interrupción). ocurre, la función de procesamiento llamada por la CPU), la interrupción en sí también puede establecer la prioridad.
Las interrupciones suspenden el funcionamiento normal del sistema. El periférico dispara una interrupción cuando los datos están listos para ser utilizados por el núcleo o indirectamente por una aplicación. El uso de interrupciones garantiza que el sistema solo notifique al procesador cuando un periférico necesite que el procesador intervenga, mejorando efectivamente la eficiencia.
Control de dispositivos a través del bus: no todos los dispositivos se direccionan y operan directamente a través de declaraciones de E/S, sino en muchos casos a través de un sistema de bus.
No todos los tipos de dispositivos se pueden conectar directamente a todos los sistemas de bus, como los discos duros conectados a las interfaces SCSI, pero no las tarjetas gráficas (las tarjetas gráficas se pueden conectar al bus PCI). El disco duro debe estar conectado al bus PCI indirectamente a través de IDE.
Los tipos de bus se pueden dividir en bus de sistema y bus de expansión. Las diferencias de implementación en el hardware no son importantes para el núcleo, solo cómo se abordan el bus y sus periféricos conectados. Para un bus del sistema, como el bus PCI, las declaraciones de E/S y los mapas de memoria se utilizan para comunicarse con el bus, así como con los dispositivos a los que está conectado. El núcleo también proporciona algunos comandos para que los controladores de dispositivos llamen a las funciones del bus, como acceder a la lista de dispositivos disponibles y leer y escribir información de configuración en un formato uniforme.
Buses de expansión como USB, SCSI intercambian datos y comandos con dispositivos conectados a través de un protocolo de bus claramente definido. El kernel se comunica con el bus a través de sentencias de E/S o mapas de memoria, y el bus se comunica con los dispositivos conectados a través de funciones independientes de la plataforma.
La comunicación con un dispositivo conectado al bus no necesariamente debe realizarse a través de un controlador en el espacio del kernel, pero en algunos casos también se puede realizar en el espacio del usuario. Un buen ejemplo es SCSI Writer, dirigido por la herramienta cdrecord. Esta herramienta genera los comandos SCSI requeridos, envía los comandos al dispositivo correspondiente a través del bus SCSI con la ayuda del kernel y procesa y responde a la información generada o devuelta por el dispositivo.
Los dispositivos de bloque (bloque) y los dispositivos de carácter (personaje) difieren significativamente en 3 formas:
Los datos en un dispositivo de bloque se pueden manipular en cualquier punto, mientras que un dispositivo de caracteres no.
Las transferencias de datos de dispositivos en bloque siempre utilizan bloques de tamaño fijo. El controlador del dispositivo siempre obtiene un bloqueo completo del dispositivo, incluso cuando solo se solicita un byte. Por el contrario, los dispositivos de caracteres son capaces de devolver un solo byte.
Leer y escribir en un dispositivo de bloque utiliza la memoria caché. Para las operaciones de lectura, los datos se almacenan en caché en la memoria y se pueden revisar cuando sea necesario. En términos de operaciones de escritura, también se almacenará en caché para retrasar la escritura en el dispositivo. El uso de un caché no es razonable para dispositivos de caracteres (por ejemplo, teclados), cada solicitud de lectura debe interactuar de manera confiable con el dispositivo.
El concepto de bloques y sectores: Un bloque es una secuencia de bytes de un tamaño específico que se utiliza para guardar los datos transferidos entre el núcleo y el dispositivo.El tamaño del bloque se puede configurar. Un sector es un tamaño fijo, la cantidad más pequeña de datos que puede transferir un dispositivo. Un bloque es un segmento contiguo de sectores, y el tamaño del bloque es un múltiplo entero del sector.
la red
El subsistema de red de Linux proporciona una base sólida para el desarrollo de Internet. El modelo de red se basa en el modelo OSI de ISO, como se muestra en la mitad derecha de la figura siguiente. Sin embargo, en aplicaciones específicas, las capas correspondientes a menudo se combinan para simplificar el modelo.La mitad izquierda de la siguiente figura es el modelo de referencia de TCP/IP utilizado por Linux. (Debido a que hay mucha información sobre la parte de la red de Linux, en este artículo solo se brinda una breve introducción al gran nivel y no se brinda ninguna explicación).
La capa Host-to-host (Capa física y capa de enlace de datos, es decir, la capa física y la capa de enlace de datos) es la encargada de transferir datos de una computadora a otra. Esta capa maneja las propiedades eléctricas y de códec del medio de transmisión físico y también divide el flujo de datos en tramas de datos de tamaño fijo para la transmisión. Si varias computadoras comparten una ruta de transmisión, el adaptador de red (tarjeta de red, etc.) debe tener una identificación única (es decir, dirección MAC) para distinguirlo. Desde el punto de vista del kernel, esta capa se implementa a través del controlador de dispositivo de la tarjeta de red.
La capa de red del modelo OSI se denomina capa de red en el modelo TCP/IP La capa de red permite que las computadoras en la red intercambien datos, y estas computadoras no están necesariamente conectadas directamente.
Si no hay conexión directa físicamente, no hay intercambio de datos directo. La tarea de la capa de red es encontrar rutas para la comunicación entre máquinas en la red.
computadora conectada a la red
La capa de red también es responsable de dividir el paquete que se transmitirá en el tamaño especificado, porque el tamaño máximo de paquete admitido por cada computadora en la ruta de transmisión puede ser diferente.Durante la transmisión, el flujo de datos se divide en diferentes paquetes, y luego en el extremo receptor se combinan.
La capa de red asigna direcciones de red únicas a las computadoras en la red para que puedan comunicarse entre sí (a diferencia de las direcciones MAC de hardware, ya que las redes a menudo se componen de subredes). En Internet, la capa de red consta de redes IP y existen versiones V4 y V6.
La tarea de la capa de transporte es regular la transferencia de datos entre aplicaciones que se ejecutan en dos computadoras conectadas. Por ejemplo, los programas de cliente y servidor en dos computadoras, incluidas las conexiones TCP o UDP, identifican las aplicaciones que se comunican por números de puerto. Por ejemplo, el puerto número 80 se utiliza para el servidor web y el cliente del navegador debe enviar solicitudes a este puerto para obtener los datos necesarios. El cliente también debe tener un número de puerto único para que el servidor web pueda enviarle respuestas.
Esta capa también se encarga de proporcionar una conexión fiable (en el caso de TCP) para la transmisión de datos.
La capa de aplicación en el modelo TCP/IP está incluida en el modelo OSI (capa de sesión, capa de presentación, capa de aplicación). Cuando se establece una conexión de comunicación entre dos aplicaciones, esta capa es responsable de la transmisión del contenido real. Por ejemplo, el protocolo y los datos transmitidos entre el servidor web y su cliente son diferentes de los que se transmiten entre el servidor de correo y su cliente.
La mayoría de los protocolos de red se definen en RFC (Solicitud de comentarios).
Modelo en capas de implementación de red: la implementación de la capa de red por parte del kernel es similar al modelo de referencia TCP/IP. Se implementa mediante código C y cada capa solo puede comunicarse con sus capas superior e inferior, la ventaja de esto es que se pueden combinar diferentes protocolos y mecanismos de transmisión. Como se muestra abajo:

4. Explicación detallada de los módulos del kernel de Linux
El kernel no es mágico, pero es esencial para cualquier computadora que funcione. El kernel de Linux se diferencia de OS X y Windows en que contiene controladores a nivel de kernel y hace que muchas cosas funcionen "listas para usar".
¿Qué sucede si Windows ya instaló todos los controladores disponibles y solo necesita abrir el controlador que necesita?Esto es esencialmente lo que hacen los módulos del kernel para Linux. Los módulos del kernel, también conocidos como módulos del kernel cargables (LKM), son esenciales para mantener el kernel funcionando con todo el hardware sin consumir toda la memoria disponible.

Los módulos generalmente agregan funcionalidades como dispositivos, sistemas de archivos y llamadas al sistema al kernel base. La extensión de archivo de lkm es .ko y generalmente se almacena en el directorio /lib/modules. Debido a la naturaleza de los módulos, puede personalizar fácilmente el kernel configurando el módulo para que se cargue o no en el momento del arranque con el comando menuconfig, o editando el archivo /boot/config, o cargando y descargando dinámicamente los módulos con el comando modprobe. .
Los módulos de fuente cerrada y de terceros están disponibles en algunas distribuciones, como Ubuntu, y es posible que no se instalen de forma predeterminada porque el código fuente de estos módulos no está disponible. Los desarrolladores de este software (es decir, nVidia, ATI, etc.) no proporcionan el código fuente, sino que construyen sus propios módulos y compilan los archivos .ko necesarios para su distribución. Si bien estos módulos son gratuitos como la cerveza, no lo son como la libertad de expresión y, por lo tanto, no están incluidos en algunas distribuciones porque los mantenedores creen que "contaminan" el kernel al proporcionar software que no es libre.
Ventajas de usar módulos:
1. Haga que el kernel sea más compacto y flexible
2. Al modificar el kernel, no es necesario volver a compilar todo el kernel, lo que puede ahorrar mucho tiempo y evitar errores manuales. Si necesita usar un nuevo módulo en el sistema, solo necesita compilar el módulo correspondiente y luego insertar el módulo usando un programa de espacio de usuario específico.
3. Es posible que los módulos no dependan de una plataforma de hardware fija.
4. Una vez que el código objeto del módulo está vinculado al núcleo, su función es exactamente la misma que la del código objeto del núcleo vinculado estáticamente. Por lo tanto, no se requiere el paso de mensajes explícitos cuando se llama a una función de un módulo.
Sin embargo, la introducción de los módulos del kernel también trae ciertos problemas:
1. Dado que la memoria ocupada por el kernel no se intercambiará, los módulos vinculados al kernel generarán ciertas pérdidas de rendimiento y utilización de la memoria en todo el sistema.
2. El módulo cargado en el kernel se convierte en parte del kernel y puede modificar otras partes del kernel, por lo tanto, el uso inadecuado del módulo hará que el sistema se bloquee.
3. Para que un módulo del kernel acceda a todos los recursos del kernel, el kernel debe mantener una tabla de símbolos y modificar la tabla de símbolos cuando los módulos se cargan y descargan.
4. Los módulos requerirán el uso de funciones de otros módulos, por lo que el kernel necesita mantener dependencias entre módulos.
Los módulos se ejecutan en el mismo espacio de direcciones que el kernel, y la programación de módulos es, en cierto sentido, programación del kernel. Pero los módulos no están disponibles en todas partes del kernel. Los módulos generalmente se usan en controladores de dispositivos, sistemas de archivos, etc., pero para lugares extremadamente importantes en el kernel de Linux, como la administración de procesos y la administración de memoria, aún es difícil de lograr a través de módulos y, por lo general, el kernel debe modificarse directamente.
En el programa fuente del kernel de Linux, las funciones que a menudo implementan los módulos del kernel incluyen sistemas de archivos, controladores avanzados SCSI, la mayoría de los controladores SCSI, la mayoría de los controladores de CD-ROM, controladores Ethernet, etc.
1. Compilar e instalar el kernel de Linux
Componentes del kernel de Linux:
-
kernel: kernel core, generalmente bzImage, generalmente en el directorio /boot
vmlinuz-VERSION-RELEASE -
objeto kernel: objeto kernel, generalmente colocado en
/lib/modules/VERSION-RELEASE/ -
Archivo auxiliar: ramdisk
initrd-VERSION-RELEASE.img:从CentOS 5 版本以前 initramfs-VERSION-RELEASE.img:从CentOS6 版本以后
Compruebe la versión del núcleo:
uname -r
-r 显示VERSION-RELEASE
-n 打印网络节点主机名
-a 打印所有信息Comandos del módulo del kernel
Las llamadas al sistema son, por supuesto, una forma viable de insertar módulos del kernel en el kernel. Pero es un nivel demasiado bajo. Además, hay dos formas de lograr esto en el entorno Linux. Un método es un poco más automático, que puede cargarse automáticamente cuando sea necesario y descargarse cuando no sea necesario. Este método requiere la ejecución del programa modprobe.
La otra es usar el comando insmod para cargar manualmente el módulo del kernel. En el análisis anterior del ejemplo de helloworld, mencionamos que el rol de insmod es insertar el módulo que debe insertarse en el kernel en forma de código objeto. Tenga en cuenta que solo los superusuarios pueden usar este comando.
La mayoría de las llamadas al sistema proporcionadas por el mecanismo del módulo del kernel de Linux son utilizadas por el programa modutils. Se puede decir que la combinación del mecanismo del módulo del kernel de Linux y modutils proporciona la interfaz de programación del módulo. modutils (modutils-xyztar.gz) se puede obtener dondequiera que se obtenga el código fuente del kernel. Seleccione el nivel de parche más alto xyz igual o menor que la versión actual del kernel. Después de la instalación, habrá insmod, rmmod, ksyms, lsmod en el directorio /sbin, modprobe y otras utilidades. Por supuesto, normalmente cuando cargamos el kernel de Linux, modutils ya se ha cargado.
Comando lsmod:
- mostrar módulos del kernel que han sido cargados por el kernel
- El contenido mostrado proviene de: archivo /proc/modules
De hecho, la función de este programa es leer la información en el archivo /proc/modules en el sistema de archivos /proc. Entonces este comando es equivalente a cat /proc/modules. Su formato es:
[root@centos8 ~]#lsmod
Module Size Used by
uas 28672 0
usb_storage 73728 1 uas
nls_utf8 16384 0
isofs 45056 0 #显示:名称、大小,使用次数,被哪些模块依赖Comando ksyms:
Muestra información sobre los símbolos del núcleo y las tablas de símbolos del módulo, y puede leer el archivo /proc/kallsyms.
comando modinfo:
Función: administrar módulos del kernel
Archivo de configuración:
/etc/modprobe.conf, /etc/modprobe.d/*.conf- Muestra información de descripción detallada del módulo.
modinfo [ -k kernel ] [ modulename|filename... ]Opciones comunes:
-n:只显示模块文件路径
-p:显示模块参数
-a:作者
-d:描述Caso:
lsmod |grep xfs
modinfo xfsComando insmod:
Especifique el archivo del módulo, no resuelva automáticamente los módulos dependientes. Un programa simple para insertar un módulo en el kernel de Linux.
gramática:
insmod [ filename ] [ module options... ]Caso:
insmod
modinfo –n exportfs
lnsmod
modinfo –n xfsinsmod es en realidad una utilidad del módulo modutils, cuando usamos este comando como superusuario, este programa completa la siguiente serie de tareas:
1. Lea el nombre del módulo a vincular desde la línea de comando, generalmente un archivo de objeto con la extensión ".ko" y formato elf.
2. Determine la ubicación del archivo donde se encuentra el código objeto del módulo. Por lo general, este archivo se encuentra en un subdirectorio de lib/modules.
3. Calcule el tamaño de memoria necesario para almacenar el código del módulo, el nombre del módulo y el objeto del módulo.
4. Asigne un área de memoria en el espacio del usuario, copie el objeto del módulo, el nombre del módulo y el código del módulo reubicados para el kernel en ejecución en esta memoria. Entre ellos, el campo init en el objeto del módulo apunta a la dirección reasignada por la función de entrada de este módulo, el campo de salida apunta a la dirección reasignada por la función de salida.
5. Llame a init_module() y pásele la dirección del área de memoria en modo usuario creada anteriormente Hemos analizado el proceso de implementación en detalle.
6. Libere la memoria del modo de usuario y finaliza todo el proceso.
comando modprobe:
- Adición y eliminación de módulos en el kernel de Linux
modprobe [ -C config-file ] [ modulename ] [ module parame-ters... ] modprobe [ -r ] modulename…Opciones comunes:
-C:使用文件
-r:删除模块uso:
装载:modprobe 模块名
卸载: modprobe -r 模块名 # rmmod命令:卸载模块modprobe es un programa proporcionado por modutils que inserta automáticamente módulos en función de las dependencias entre módulos. El método de carga del módulo de carga bajo demanda mencionado anteriormente llamará a este programa para realizar la función de carga bajo demanda. Por ejemplo, si el módulo A depende del módulo B y el módulo B no está cargado en el kernel, cuando el sistema solicite cargar el módulo A, el programa modprobe cargará automáticamente el módulo B en el kernel.
Similar a insmod, el programa modprobe también vincula un módulo especificado en la línea de comando, pero también puede vincular recursivamente otros módulos a los que hace referencia el módulo especificado. En términos de implementación, modprobe solo verifica las dependencias del módulo, e insmod aún implementa el trabajo de carga real. Entonces, ¿cómo sabe las dependencias entre módulos? En pocas palabras, modprobe aprende sobre esta dependencia a través de otro programa modutils, depmod. Y depmod encuentra todos los módulos en el kernel y escribe las dependencias entre ellos en un archivo llamado modules.dep en el directorio /lib/modules/2.6.15-1.2054_FC5.
Comando kmod:
En versiones anteriores del kernel, el mecanismo de carga automática del módulo se implementaba mediante un proceso de usuario kerneld. El kernel se comunicaba con el kernel a través de IPC y enviaba la información del módulo a cargar al kerneld, y luego el kerneld llamaba el programa modprobe para cargar el módulo. Pero en versiones recientes del kernel, se usa otro método kmod para lograr esta función. En comparación con kerneld, la mayor diferencia entre kmod es que es un proceso que se ejecuta en el espacio del kernel.Puede llamar directamente a modprobe en el espacio del kernel, lo que simplifica enormemente todo el proceso.
Comando depmod:
Una herramienta para generar archivos de dependencia del módulo del núcleo y archivos de mapeo de información del sistema, generando módulos .dep y archivos de mapa.
comando rmmod:
Módulo de desinstalación, un programa simple para eliminar un módulo del kernel de Linux.
El programa rmmod eliminará el módulo que se ha insertado en el núcleo del núcleo y rmmod ejecutará automáticamente la función de salida definida por el propio módulo del núcleo. Su formato es:
rmmod xfs
rmmod exportfsPor supuesto, finalmente se implementa a través de la llamada al sistema delete_module().
compilar el núcleo
Compile e instale la preparación del kernel:
(1) preparar el entorno de desarrollo;
(2) Obtener la información relevante del dispositivo de hardware en el host de destino;
(3) Obtener información relevante sobre la función del sistema host de destino, por ejemplo: el sistema de archivos correspondiente debe estar habilitado;
(4) Obtenga el paquete de código fuente del kernel, www.kernel.org;
Compilar preparación
Información sobre el dispositivo de hardware del host de destino
UPC:
cat /proc/cpuinfo
x86info -a
lscpuDispositivos PCI: lspci -v , -vv:
[root@centos8 ~]#lspci
00:00.0 Host bridge: Intel Corporation 440BX/ZX/DX - 82443BX/ZX/DX Host bridge (rev 01)
00:01.0 PCI bridge: Intel Corporation 440BX/ZX/DX - 82443BX/ZX/DX AGP bridge (rev 01)
00:07.0 ISA bridge: Intel Corporation 82371AB/EB/MB PIIX4 ISA (rev 08)
00:07.1 IDE interface: Intel Corporation 82371AB/EB/MB PIIX4 IDE (rev 01)
00:07.3 Bridge: Intel Corporation 82371AB/EB/MB PIIX4 ACPI (rev 08)
00:07.7 System peripheral: VMware Virtual Machine Communication Interface (rev 10)
00:0f.0 VGA compatible controller: VMware SVGA II Adapter
00:10.0 SCSI storage controller: Broadcom / LSI 53c1030 PCI-X Fusion-MPT Dual Ultra320 SCSI (rev 01)
00:11.0 PCI bridge: VMware PCI bridge (rev 02)
00:15.0 PCI bridge: VMware PCI Express Root Port (rev 01)
00:15.1 PCI bridge: VMware PCI Express Root Port (rev 01)Dispositivo USB: lsusb -v, -vv:
[root@centos8 ~]#dnf install usbutils -y
[root@centos8 ~]#lsusb
Bus 001 Device 004: ID 0951:1666 Kingston Technology DataTraveler 100 G3/G4/SE9 G2
Bus 001 Device 001: ID 1d6b:0002 Linux Foundation 2.0 root hub
Bus 002 Device 003: ID 0e0f:0002 VMware, Inc. Virtual USB Hub
Bus 002 Device 002: ID 0e0f:0003 VMware, Inc. Virtual Mouse
Bus 002 Device 001: ID 1d6b:0001 Linux Foundation 1.1 root hub
[root@centos8 ~]#lsmod |grep usb
usb_storage 73728 1 uasdispositivo de bloque lsblk
Toda la información del dispositivo de hardware: hal-device: CentOS 6
Paquetes relacionados con el entorno de desarrollo
gcc make ncurses-devel flex bison openssl-devel elfutils-libelf-devel- Descargar archivos fuente
- Prepare el archivo de configuración de texto /boot/.config
- hacer menuconfig: configurar las opciones del núcleo
- hacer [-j #] o hacerlo en dos pasos:
make -j # bzImage make -j # modules - Instalar módulos: hacer módulos_instalar
- Instalar archivos relacionados con el kernel: hacer instalación
- Instale bzImage como /boot/vmlinuz-VERSION-RELEASE
- Generar archivo initramfs
- Edite el archivo de configuración de grub
Compile e instale el caso de verificación interna:
[root@centos7 ~]#yum -y install gcc gcc-c++ make ncurses-devel flex bison openssl-devel elfutils-libelf-devel
[root@centos7 ~]#tar xvf linux-5.15.51.tar.xz -C /usr/local/src
[root@centos7 ~]#cd /usr/local/src
[root@centos7 src]#ls
linux-5.15.51
[root@centos7 src]#du -sh *
1.2G linux-5.15.51
[root@centos7 src]#cd linux-5.15.51/
[root@centos7 linux-5.15.51]#ls
arch COPYING Documentation include Kbuild lib Makefile README security usr
block CREDITS drivers init Kconfig LICENSES mm samples sound virt
certs crypto fs ipc kernel MAINTAINERS net scripts tools
[root@centos7 linux-5.15.51]#cp /boot/config-3.10.0-1160.el7.x86_64 .config
[root@centos7 linux-5.15.51]#vim .config
#修改下面三行
#CONFIG_MODULE_SIG=y #注释此行
CONFIG_SYSTEM_TRUSTED_KEYRING="" #修改此行
#CONFIG_DEBUG_INFO=y #linux-5.8.5版本后需要注释此行
#升级gcc版本,可以到清华的镜像站上下载相关的依赖包
#https://mirrors.tuna.tsinghua.edu.cn/gnu/gcc/gcc-9.1.0/
#https://mirrors.tuna.tsinghua.edu.cn/gnu/gmp/
#https://mirrors.tuna.tsinghua.edu.cn/gnu/mpc/
#https://mirrors.tuna.tsinghua.edu.cn/gnu/mpfr/
[root@centos7 linux-5.15.51]#cd ..
[root@centos7 src]#tar xvf gcc-9.1.0.tar.gz
[root@centos7 src]#tar xvf gmp-6.1.2.tar.bz2 -C gcc-9.1.0/
[root@centos7 src]#cd gcc-9.1.0/
[root@centos7 gcc-9.1.0]#mv gmp-6.1.2 gmp
[root@centos7 gcc-9.1.0]#cd ..
[root@centos7 src]#tar xvf mpc-1.1.0.tar.gz -C gcc-9.1.0/
[root@centos7 src]#cd gcc-9.1.0/
[root@centos7 gcc-9.1.0]#mv mpc-1.1.0 mpc
[root@centos7 gcc-9.1.0]#cd ..
[root@centos7 src]#tar xvf mpfr-4.0.2.tar.gz -C gcc-9.1.0/
[root@centos7 src]#cd gcc-9.1.0/
[root@centos7 gcc-9.1.0]#mv mpfr-4.0.2 mpfr
#编译安装gcc
[root@centos7 gcc-9.1.0]#./configure --prefix=/usr/local/ --enable-checking=release --disable-multilib --enable-languages=c,c++ --enable-bootstrap
[root@centos7 gcc-9.1.0]#make -j 2 #CPU核数要多加,不然编译会很慢
[root@centos7 gcc-9.1.0]#make install
[root@centos7 gcc-9.1.0]#cd ..
[root@centos7 src]#cd linux-5.15.51/
[root@centos7 linux-5.15.51]#make help
[root@centos7 linux-5.15.51]#make menuconfig
Ingrese [Configuración general] y presione Entrar:

Agregue la versión del kernel y presione Entrar:

Ingrese la versión personalizada del kernel y presione Entrar:

Presione【Tab】, seleccione【Salir】para salir:

Seleccione [Sistema de archivos] y presione Entrar:

Seleccione [Sistema de archivos NT] y presione Entrar:

Seleccione [Sistema de archivos NTFS], presione [Barra espaciadora], M significa modo modular:

Seleccione [Soporte de depuración y escritura], presione [Barra espaciadora] para seleccionar, presione [Tab], seleccione [Salir] y presione Entrar para salir:

Presione [Tab], seleccione [Salir] y presione Entrar para salir:

Presione [Tab], seleccione [Salir] y presione Entrar para salir:

Guarde la configuración y presione Entrar:

[root@centos7 linux-5.15.51]#grep -i ntfs .config
CONFIG_NTFS_FS=m
CONFIG_NTFS_DEBUG=y
CONFIG_NTFS_RW=y
# CONFIG_NTFS3_FS is not set
[root@centos7 linux-5.15.51]#make -j 2 #CPU核数要多加,不然编译会很慢
[root@centos7 linux-5.15.51]#pwd
/usr/local/src/linux-5.15.51
[root@centos7 linux-5.15.51]#du -sh .
3.0G .
[root@centos7 linux-5.15.51]#make modules_install
[root@centos7 linux-5.15.51]#ls /lib/modules
3.10.0-1160.el7.x86_64 5.15.51-150.el7.x86_64
[root@centos7 linux-5.15.51]#du -sh /lib/modules/*
45M /lib/modules/3.10.0-1160.el7.x86_64
224M /lib/modules/5.15.51-150.el7.x86_64
[root@centos7 linux-5.15.51]#make install
[root@centos7 linux-5.15.51]#ls /boot/
config-3.10.0-1160.el7.x86_64 System.map
efi System.map-3.10.0-1160.el7.x86_64
grub System.map-5.15.51-150.el7.x86_64
grub2 vmlinuz
initramfs-0-rescue-afe373e8a26e45c681032325645782c8.img vmlinuz-0-rescue-afe373e8a26e45c681032325645782c8
initramfs-3.10.0-1160.el7.x86_64.img vmlinuz-3.10.0-1160.el7.x86_64
initramfs-5.15.51-150.el7.x86_64.img vmlinuz-5.15.51-150.el7.x86_64
symvers-3.10.0-1160.el7.x86_64.gz
Seleccione el kernel Linux5.15 para comenzar:
[root@centos7 linux-5.15.51]#reboot
[root@centos7 ~]#uname -r
5.15.51-150.el7.x86_64
Instrucciones de compilación del kernel
Configure las opciones del núcleo:
Admite el modo "actualizar" para la configuración, haz ayuda:
(a) make config:基于命令行以遍历的方式配置内核中可配置的每个选项
(b) make menuconfig:基于curses的文本窗口界面
(c) make gconfig:基于GTK (GNOME)环境窗口界面
(d) make xconfig:基于QT(KDE)环境的窗口界面
Admite el modo de "configuración nueva" para la configuración:
(a) make defconfig:基于内核为目标平台提供的“默认”配置进行配置
(b) make allyesconfig: 所有选项均回答为“yes“
(c) make allnoconfig: 所有选项均回答为“no“
compilar el núcleo
- Compilación completa:
make [-j #]- Compilar parte de la función del kernel:
(a) compilar solo el código relevante en un subdirectorio
cd /usr/src/linux
make dir/(b) compilar solo un módulo específico
cd /usr/src/linux
make dir/file.ko
Compile el controlador solo para e1000:
make drivers/net/ethernet/intel/e1000/e1000.kocompilar de forma cruzada el núcleo
La plataforma de destino para la compilación no es la misma que la plataforma actual:
make ARCH=arch_namePara obtener ayuda con el uso de una plataforma de destino específica:
make ARCH=arch_name helpLa recompilación requiere operaciones previas de limpieza:
make clean:清理大多数编译生成的文件,但会保留.config文件等
make mrproper: 清理所有编译生成的文件、config及某些备份文件
make distclean:包含 make mrproper,并清理patches以及编辑器备份文件Desinstalar el núcleo:
1. Elimine el código fuente del núcleo innecesario en el directorio /usr/src/linux/;
2. Elimine los archivos de biblioteca del kernel innecesarios en el directorio /lib/modules/;
3. Elimine el kernel y los archivos de imagen del kernel iniciados en el directorio /boot;
4. Cambie el archivo de configuración de grub y elimine la lista de arranque del kernel innecesaria grub2-mkconfig -o /boot/grub2/grub.cfg
CentOS 8 también necesita eliminar /boot/loader/entries/5b85fc7444b240a992c42ce2a9f65db5-new kernel version.conf;
2. Mecanismo de implementación del módulo kernel de Linux
Antes de sumergirse en los módulos, vale la pena revisar las diferencias entre los módulos del núcleo y nuestras aplicaciones familiares.
El punto principal, debemos ser claros, los módulos del núcleo se ejecutan en el "espacio del núcleo" y las aplicaciones se ejecutan en el "espacio del usuario". El espacio del kernel y el espacio del usuario son los dos conceptos más básicos en los sistemas operativos. Tal vez no sepas la diferencia entre ellos, así que repasémoslos juntos.
Una de las funciones del sistema operativo es proporcionar administración de recursos para las aplicaciones, de modo que todas las aplicaciones puedan usar los recursos de hardware que necesitan. Sin embargo, la norma actual es que los hosts suelen tener solo un conjunto de recursos de hardware; los sistemas operativos modernos pueden aprovechar este conjunto de hardware para admitir sistemas multiusuario. Para garantizar que el programa de aplicación no altere el núcleo, el sistema operativo multiusuario implementa el acceso autorizado a los recursos de hardware, y la realización de este mecanismo de acceso autorizado se beneficia de la realización de diferentes niveles de protección operativa dentro de la CPU. Tomando la CPU de INTEL como ejemplo, siempre se ejecuta en uno de los cuatro niveles de privilegios en cualquier momento.Si necesita acceder al espacio de almacenamiento de alto nivel de privilegios, debe pasar a través de un número limitado de puertas de privilegios. El sistema Linux está diseñado para aprovechar al máximo esta función de hardware y utiliza solo dos niveles de protección (aunque los microprocesadores de la serie i386 proporcionan un modo de cuatro niveles).
En un sistema Linux, el núcleo se ejecuta al más alto nivel. En este nivel, es posible el acceso a cualquier dispositivo. Y las aplicaciones se ejecutan en el nivel más bajo. En este nivel, el procesador prohíbe el acceso directo de los programas al hardware y el acceso no autorizado al espacio del kernel. Por lo tanto, correspondiente al programa del kernel que se ejecuta en el nivel más alto, el espacio de memoria donde se encuentra es el espacio del kernel. Y correspondiente a la aplicación que se ejecuta en el nivel más bajo, el espacio de memoria donde se encuentra es el espacio de usuario. Linux completa la conversión del espacio del usuario al espacio del kernel a través de llamadas al sistema o interrupciones. El código del kernel que ejecuta la llamada del sistema se ejecuta en el contexto del proceso, que completa la operación en el espacio del kernel en nombre del proceso que llama y también puede acceder a los datos en el espacio de direcciones de usuario del proceso. Pero para las interrupciones, no existe en ningún contexto de proceso, sino que lo ejecuta el núcleo.
Bueno, ahora podemos analizar más específicamente las similitudes y diferencias entre los módulos del kernel y las aplicaciones. Veamos la Tabla 6-1.
Una comparación de la forma en que se programan las aplicaciones y los módulos del kernel:

En esta tabla, vemos que el módulo del kernel debe decirle al sistema, "Estoy llegando" a través de la función init_module(); "Me voy" a través de la función cleanup_module(). Esta es la característica más importante de los módulos, que se pueden cargar y descargar dinámicamente. insmod es un comando para cargar módulos en el kernel en el conjunto de herramientas de manipulación de módulos del kernel modutils, que presentaremos en detalle más adelante. Debido al espacio de direcciones, los módulos del kernel no pueden usar libremente las bibliotecas de funciones definidas en el espacio del usuario, como libc, como printf(), como pueden hacerlo las aplicaciones; los módulos solo pueden usar las funciones con recursos limitados definidas en el espacio del kernel, como printk(). . El código fuente de la aplicación puede llamar a funciones que no están definidas por él mismo, y solo necesita resolver esas referencias externas con la biblioteca de funciones correspondiente durante el proceso de conexión. La función a la que se puede llamar desde la aplicación printf() se declara en stdio.h, y hay un código enlazable de destino en libc. Sin embargo, para el módulo del kernel, no puede usar esta función de impresión, solo puede usar la función printk() definida en el espacio del kernel. La función printk() no admite la salida de números de punto flotante y la cantidad de datos de salida está limitada por el espacio de memoria disponible del kernel.
Otra dificultad con los módulos del kernel es que las fallas del kernel a menudo son fatales para todo el sistema o para el proceso actual. Durante el desarrollo de la aplicación, las fallas de segmento no causan ningún daño. Podemos usar depuradores para rastrear fácilmente el lugar equivocado. Por lo tanto, se debe tener especial cuidado en el proceso de programación de los módulos del kernel.
Echemos un vistazo a cómo se implementa en detalle el mecanismo del módulo del núcleo.
tabla de símbolos del kernel
Primero, comprendamos el concepto de la tabla de símbolos del núcleo. La tabla de símbolos del kernel es una tabla especial que se utiliza para almacenar esos símbolos y sus direcciones correspondientes a las que todos los módulos pueden acceder. La vinculación de módulos es el proceso de insertar módulos en el kernel. Cualquier símbolo global declarado por un módulo pasa a formar parte de la tabla de símbolos del kernel. Los módulos del núcleo obtienen las direcciones de los símbolos del espacio del núcleo de acuerdo con la tabla de símbolos del sistema para garantizar un funcionamiento correcto en el espacio del núcleo.
Esta es una tabla de símbolos pública que podemos leer textualmente desde el archivo /proc/kallsyms. El formato para almacenar datos en este archivo es el siguiente:
Dirección de memoria Atributo Símbolo Nombre [Módulo al que pertenece]
En la programación del módulo, puede usar el nombre del símbolo para recuperar la dirección del símbolo en la memoria de este archivo y luego acceder directamente a la memoria para obtener los datos del kernel. Para los símbolos exportados por el módulo del kernel, se incluirá la cuarta columna "perteneciente al módulo", que se utiliza para marcar el nombre del módulo al que pertenece el símbolo; y para los símbolos liberados del kernel, no hay datos en esta columna
La tabla de símbolos del núcleo se encuentra en la parte _ksymtab del segmento de código del núcleo, y su dirección de inicio y dirección final se especifican mediante dos símbolos generados por el compilador de C: __start___ksymtab y __stop___ksymtab.
dependencias del módulo
La tabla de símbolos del núcleo registra los símbolos y las direcciones correspondientes a las que pueden acceder todos los módulos. Después de cargar un módulo del kernel, los símbolos que declara se registrarán en esta tabla y, por supuesto, estos símbolos pueden ser referenciados por otros módulos. Esto lleva al problema de las dependencias de los módulos.
Cuando un módulo A hace referencia a un símbolo exportado por otro módulo B, decimos que el módulo A hace referencia al módulo B, o que el módulo A está cargado encima del módulo B. Si desea vincular el módulo A, primero debe vincular el módulo B. De lo contrario, las referencias a esos símbolos exportados por el módulo B no se pueden vincular al módulo A. Esta interrelación entre módulos se denomina dependencias de módulos.
Análisis de código del núcleo
Implementación del código fuente del mecanismo del módulo del kernel, aportado por Richard Henderson. Después de 2002, reescrito por Rusty Russell. Versiones más nuevas del kernel de Linux, adopte este último.
1) Estructura de datos
La estructura de datos relacionada con el módulo se almacena en include/linux/module.h. Por supuesto, se recomienda el primer módulo de estructura:
include/linux/module.h
232 struct module
233 {
234 enum module_state state;
235
236 /* Member of list of modules */
237 struct list_head list;
238
239 /* Unique handle for this module */
240 char name[MODULE_NAME_LEN];
241
242 /* Sysfs stuff. */
243 struct module_kobject mkobj;
244 struct module_param_attrs *param_attrs;
245 const char *version;
246 const char *srcversion;
247
248 /* Exported symbols */
249 const struct kernel_symbol *syms;
250 unsigned int num_syms;
251 const unsigned long *crcs;
252
253 /* GPL-only exported symbols. */
254 const struct kernel_symbol *gpl_syms;
255 unsigned int num_gpl_syms;
256 const unsigned long *gpl_crcs;
257
258 /* Exception table */
259 unsigned int num_exentries;
260 const struct exception_table_entry *extable;
261
262 /* Startup function. */
263 int (*init)(void);
264
265 /* If this is non-NULL, vfree after init() returns */
266 void *module_init;
267
268 /* Here is the actual code + data, vfree'd on unload. */
269 void *module_core;
270
271 /* Here are the sizes of the init and core sections */
272 unsigned long init_size, core_size;
273
274 /* The size of the executable code in each section. */
275 unsigned long init_text_size, core_text_size;
276
277 /* Arch-specific module values */
278 struct mod_arch_specific arch;
279
280 /* Am I unsafe to unload? */
281 int unsafe;
282
283 /* Am I GPL-compatible */
284 int license_gplok;
285
286 /* Am I gpg signed */
287 int gpgsig_ok;
288
289 #ifdef CONFIG_MODULE_UNLOAD
290 /* Reference counts */
291 struct module_ref ref[NR_CPUS];
292
293 /* What modules depend on me? */
294 struct list_head modules_which_use_me;
295
296 /* Who is waiting for us to be unloaded */
297 struct task_struct *waiter;
298
299 /* Destruction function. */
300 void (*exit)(void);
301 #endif
302
303 #ifdef CONFIG_KALLSYMS
304 /* We keep the symbol and string tables for kallsyms. */
305 Elf_Sym *symtab;
306 unsigned long num_symtab;
307 char *strtab;
308
309 /* Section attributes */
310 struct module_sect_attrs *sect_attrs;
311 #endif
312
313 /* Per-cpu data. */
314 void *percpu;
315
316 /* The command line arguments (may be mangled). People like
317 keeping pointers to this stuff */
318 char *args;
319 };
En el kernel, la información de cada módulo del kernel se describe mediante dicho objeto de módulo. Todos los objetos del módulo están vinculados entre sí por una lista. El primer elemento de la lista enlazada se establece mediante LIST_HEAD(módulos) estáticos, consulte la línea 65 de kernel/module.c. Si lee la definición de macro LIST_HEAD en include/linux/list.h, comprenderá rápidamente que la variable de módulos es una estructura de tipo struct list_head, y el puntero siguiente y el puntero anterior dentro de la estructura apuntan a los módulos mismos cuando se inicializan. Las operaciones en la lista enlazada de módulos están protegidas por module_mutex y modlist_lock.
Aquí hay algunas descripciones de algunos campos importantes en la estructura del módulo:
234 state表示module当前的状态,可使用的宏定义有:
MODULE_STATE_LIVE
MODULE_STATE_COMING
MODULE_STATE_GOING
240 name数组保存module对象的名称。
244 param_attrs指向module可传递的参数名称,及其属性
248-251 module中可供内核或其它模块引用的符号表。num_syms表示该模块定义的内核模块符号的个数,syms就指向符号表。
300 init和exit 是两个函数指针,其中init函数在初始化模块的时候调用;exit是在删除模块的时候调用的。
294 struct list_head modules_which_use_me,指向一个链表,链表中的模块均依靠当前模块。Después de presentar la estructura de datos del módulo{}, es posible que aún sienta que no la comprende, porque hay muchos conceptos y estructuras de datos relacionadas que aún no comprende.
Por ejemplo kernel_symbol{} (ver include/linux/module.h):
struct kernel_symbol
{
unsigned long value;
const char *name;
};Esta estructura se utiliza para contener los símbolos del kernel en el código objeto. Al compilar, el compilador escribe los símbolos del kernel definidos en el módulo en un archivo y lee la información del símbolo contenida en él a través de esta estructura de datos cuando lee el archivo y carga el módulo.
valor define la dirección de entrada del símbolo del kernel;
name apunta al nombre del símbolo del núcleo;
implementar la función
A continuación, tenemos que estudiar varias funciones importantes en el código fuente. Como se mencionó en el párrafo anterior, cuando se inicializa el sistema operativo, LIST_HEAD(módulos) estáticos ha establecido una lista enlazada vacía. Después de eso, cada vez que se carga un módulo del núcleo, se crea una estructura de módulo y se vincula a la lista de módulos.
Sabemos que desde la perspectiva del kernel del sistema operativo, proporciona servicios de usuario a través de la única interfaz denominada llamadas al sistema. Entonces, ¿qué pasa con los servicios relacionados con los módulos del kernel? Consulte arch/i386/kernel/syscall_table.S, la versión 2.6.15 del kernel, cargue el módulo del kernel a través de la llamada al sistema init_module, descargue el módulo del kernel a través de la llamada al sistema delete_module, no hay otra manera. Ahora, la lectura de código se ha vuelto más fácil.
núcleo/módulo.c:
1931 asmlinkage long
1932 sys_init_module(void __user *umod,
1933 unsigned long len,
1934 const char __user *uargs)
1935 {
1936 struct module *mod;
1937 int ret = 0;
1938
1939 /* Must have permission */
1940 if (!capable(CAP_SYS_MODULE))
1941 return -EPERM;
1942
1943 /* Only one module load at a time, please */
1944 if (down_interruptible(&module_mutex) != 0)
1945 return -EINTR;
1946
1947 /* Do all the hard work */
1948 mod = load_module(umod, len, uargs);
1949 if (IS_ERR(mod)) {
1950 up(&module_mutex);
1951 return PTR_ERR(mod);
1952 }
1953
1954 /* Now sew it into the lists. They won't access us, since
1955 strong_try_module_get() will fail. */
1956 stop_machine_run(__link_module, mod, NR_CPUS);
1957
1958 /* Drop lock so they can recurse */
1959 up(&module_mutex);
1960
1961 down(¬ify_mutex);
1962 notifier_call_chain(&module_notify_list, MODULE_STATE_COMING, mod);
1963 up(¬ify_mutex);
1964
1965 /* Start the module */
1966 if (mod->init != NULL)
1967 ret = mod->init();
1968 if (ret < 0) {
1969 /* Init routine failed: abort. Try to protect us from
1970 buggy refcounters. */
1971 mod->state = MODULE_STATE_GOING;
1972 synchronize_sched();
1973 if (mod->unsafe)
1974 printk(KERN_ERR "%s: module is now stuck!\n",
1975 mod->name);
1976 else {
1977 module_put(mod);
1978 down(&module_mutex);
1979 free_module(mod);
1980 up(&module_mutex);
1981 }
1982 return ret;
1983 }
1984
1985 /* Now it's a first class citizen! */
1986 down(&module_mutex);
1987 mod->state = MODULE_STATE_LIVE;
1988 /* Drop initial reference. */
1989 module_put(mod);
1990 module_free(mod, mod->module_init);
1991 mod->module_init = NULL;
1992 mod->init_size = 0;
1993 mod->init_text_size = 0;
1994 up(&module_mutex);
1995
1996 return 0;
1997 }
La función sys_init_module() es la implementación de la llamada al sistema init_module(). El parámetro de entrada umod apunta a la ubicación de la imagen del módulo del núcleo en el espacio del usuario. La imagen se guarda en el formato de archivo ejecutable de ELF. La primera parte de la imagen es la estructura de tipo elf_ehdr, y la longitud se indica mediante len. uargs apunta a argumentos del espacio del usuario. El prototipo de sintaxis de la llamada al sistema init_module() es:
long sys_init_module(void *umod, unsigned long len, const char *uargs);ilustrar:
1940-1941 调用capable( )函数验证是否有权限装入内核模块。
1944-1945 在并发运行环境里,仍然需保证,每次最多只有一个module准备装入。这通过down_interruptible(&module_mutex)实现。
1948-1952 调用load_module()函数,将指定的内核模块读入内核空间。这包括申请内核空间,装配全程量符号表,赋值__ksymtab、__ksymtab_gpl、__param等变量,检验内核模块版本号,复制用户参数,确认modules链表中没有重复的模块,模块状态设置为MODULE_STATE_COMING,设置license信息,等等。
1956 将这个内核模块插入至modules链表的前部,也即将modules指向这个内核模块的module结构。
1966-1983 执行内核模块的初始化函数,也就是表6-1所述的入口函数。
1987 将内核模块的状态设为MODULE_STATE_LIVE。从此,内核模块装入成功。/kernel/module.c:
573 asmlinkage long
574 sys_delete_module(const char __user *name_user, unsigned int flags)
575 {
576 struct module *mod;
577 char name[MODULE_NAME_LEN];
578 int ret, forced = 0;
579
580 if (!capable(CAP_SYS_MODULE))
581 return -EPERM;
582
583 if (strncpy_from_user(name, name_user, MODULE_NAME_LEN-1) < 0)
584 return -EFAULT;
585 name[MODULE_NAME_LEN-1] = '\0';
586
587 if (down_interruptible(&module_mutex) != 0)
588 return -EINTR;
589
590 mod = find_module(name);
591 if (!mod) {
592 ret = -ENOENT;
593 goto out;
594 }
595
596 if (!list_empty(&mod->modules_which_use_me)) {
597 /* Other modules depend on us: get rid of them first. */
598 ret = -EWOULDBLOCK;
599 goto out;
600 }
601
602 /* Doing init or already dying? */
603 if (mod->state != MODULE_STATE_LIVE) {
604 /* FIXME: if (force), slam module count and wake up
605 waiter --RR */
606 DEBUGP("%s already dying\n", mod->name);
607 ret = -EBUSY;
608 goto out;
609 }
610
611 /* If it has an init func, it must have an exit func to unload */
612 if ((mod->init != NULL && mod->exit == NULL)
613 || mod->unsafe) {
614 forced = try_force_unload(flags);
615 if (!forced) {
616 /* This module can't be removed */
617 ret = -EBUSY;
618 goto out;
619 }
620 }
621
622 /* Set this up before setting mod->state */
623 mod->waiter = current;
624
625 /* Stop the machine so refcounts can't move and disable module. */
626 ret = try_stop_module(mod, flags, &forced);
627 if (ret != 0)
628 goto out;
629
630 /* Never wait if forced. */
631 if (!forced && module_refcount(mod) != 0)
632 wait_for_zero_refcount(mod);
633
634 /* Final destruction now noone is using it. */
635 if (mod->exit != NULL) {
636 up(&module_mutex);
637 mod->exit();
638 down(&module_mutex);
639 }
640 free_module(mod);
641
642 out:
643 up(&module_mutex);
644 return ret;
645 }La función sys_delete_module() es la implementación de la llamada al sistema delete_module(). El efecto de llamar a esta función es eliminar un módulo del núcleo que ha sido cargado por el sistema. El parámetro de entrada nombre_usuario es el nombre del módulo a eliminar.
ilustrar:
580-581 调用capable( )函数,验证是否有权限操作内核模块。
583-585 取得该模块的名称
590-594 从modules链表中,找到该模块
597-599 如果存在其它内核模块,它们依赖该模块,那么,不能删除。
635-638 执行内核模块的exit函数,也就是表6-1所述的出口函数。
640 释放module结构占用的内核空间。El contenido del código fuente se puede ver aquí. Hay algunas otras funciones en el archivo kernel/module.c.
Intente analizar, el nombre del proceso que muestra el comando superior contiene el significado de los corchetes "[]"
Al ejecutar el comando top/ , en una columna, encontraremos que se encierran algunos nombres de procesos, por ejemplo:psCOMMAND[]
PID PPID USER STAT VSZ %VSZ %CPU COMMAND
1542 928 root R 1064 2% 5% top
1 0 root S 1348 2% 0% /sbin/procd
928 1 root S 1060 2% 0% /bin/ash --login
115 2 root SW 0 0% 0% [kworker/u4:2]
6 2 root SW 0 0% 0% [kworker/u4:0]
4 2 root SW 0 0% 0% [kworker/0:0]
697 2 root SW 0 0% 0% [kworker/1:3]
703 2 root SW 0 0% 0% [kworker/0:3]
15 2 root SW 0 0% 0% [kworker/1:0]
27 2 root SW 0 0% 0% [kworker/1:1]Análisis de la lógica del código de la aplicación
Después de obtener el código fuente de busybox, intente buscar palabras clave simples y groseras:
[GMPY@12:22 busybox-1.27.2]$grep "COMMAND" -rnw *Resulta que hay demasiados datos coincidentes:
applets/usage_pod.c:79: printf("=head1 COMMAND DESCRIPTIONS\n\n");
archival/cpio.c:100: --rsh-command=COMMAND Use remote COMMAND instead of rsh
docs/BusyBox.html:1655:<p>which [COMMAND]...</p>
docs/BusyBox.html:1657:<p>Locate a COMMAND</p>
docs/BusyBox.txt:93:COMMAND DESCRIPTIONS
docs/BusyBox.txt:112: brctl COMMAND [BRIDGE [INTERFACE]]
docs/BusyBox.txt:612: ip ip [OPTIONS] address|route|link|neigh|rule [COMMAND]
docs/BusyBox.txt:614: OPTIONS := -f[amily] inet|inet6|link | -o[neline] COMMAND := ip addr
docs/BusyBox.txt:1354: which [COMMAND]...
docs/BusyBox.txt:1356: Locate a COMMAND
......En este punto, descubrí que hay muchos archivos que no son fuente en la primera coincidencia, por lo que hay muchos, ¿puedo recuperar solo archivos C?
[GMPY@12:25 busybox-1.27.2]$find -name "*.c" -exec grep -Hn --color=auto "COMMAND" {} \;Esta vez, el resultado es solo 71 líneas. Después de simplemente escanear los archivos coincidentes, hay un descubrimiento interesante:
......
./shell/ash.c:9707: if (cmdentry.u.cmd == COMMANDCMD) {
./editors/vi.c:1109: // get the COMMAND into cmd[]
./procps/lsof.c:31: * COMMAND PID USER FD TYPE DEVICE SIZE NODE NAME
./procps/top.c:626: " COMMAND");
./procps/top.c:701: /* PID PPID USER STAT VSZ %VSZ [%CPU] COMMAND */
./procps/top.c:841: strcpy(line_buf, HDR_STR " COMMAND");
./procps/top.c:854: /* PID VSZ VSZRW RSS (SHR) DIRTY (SHR) COMMAND */
./procps/ps.c:441: { 16 , "comm" ,"COMMAND",func_comm ,PSSCAN_COMM },
......En busybox, cada comando es un archivo separado.Este código tiene una buena estructura lógica.Ingresamos directamente en la línea 626 del archivo procps/top.c.
Función: mostrar_lista_de_procesos
La línea 626 de procps/top.c pertenece a la función display_process_list Solo mire la lógica del código:
static NOINLINE void display_process_list(int lines_rem, int scr_width)
{
......
/* 打印表头 */
printf(OPT_BATCH_MODE ? "%.*s" : "\033[7m%.*s\033[0m", scr_width,
" PID PPID USER STAT VSZ %VSZ"
IF_FEATURE_TOP_SMP_PROCESS(" CPU")
IF_FEATURE_TOP_CPU_USAGE_PERCENTAGE(" %CPU")
" COMMAND");
......
/* 遍历每一个进程对应的描述 */
while (--lines_rem >= 0) {
if (s->vsz >= 100000)
sprintf(vsz_str_buf, "%6ldm", s->vsz/1024);
else
sprintf(vsz_str_buf, "%7lu", s->vsz);
/*打印每一行中除了COMMAND之外的信息,例如PID,USER,STAT等 */
col = snprintf(line_buf, scr_width,
"\n" "%5u%6u %-8.8s %s%s" FMT
IF_FEATURE_TOP_SMP_PROCESS(" %3d")
IF_FEATURE_TOP_CPU_USAGE_PERCENTAGE(FMT)
" ",
s->pid, s->ppid, get_cached_username(s->uid),
s->state, vsz_str_buf,
SHOW_STAT(pmem)
IF_FEATURE_TOP_SMP_PROCESS(, s->last_seen_on_cpu)
IF_FEATURE_TOP_CPU_USAGE_PERCENTAGE(, SHOW_STAT(pcpu))
);
/* 关键在这,读取cmdline */
if ((int)(col + 1) < scr_width)
read_cmdline(line_buf + col, scr_width - col, s->pid, s->comm);
......
}
}Después de eliminar el código irrelevante, la lógica de la función es clara
- Todos los procesos se han recorrido en el código antes de esta función y se ha construido la estructura de descripción.
- Recorra la estructura de descripción en display_process_list e imprima la información en el orden especificado
- Obtenga e imprima el nombre del proceso a través de read_cmdline
Ingresamos a la función read_cmdline
void FAST_FUNC read_cmdline(char *buf, int col, unsigned pid, const char *comm)
{
......
sprintf(filename, "/proc/%u/cmdline", pid);
sz = open_read_close(filename, buf, col - 1);
if (sz > 0) {
......
while (sz >= 0) {
if ((unsigned char)(buf[sz]) < ' ')
buf[sz] = ' ';
sz--;
}
......
if (strncmp(base, comm, comm_len) != 0) {
......
snprintf(buf, col, "{%s}", comm);
......
} else {
snprintf(buf, col, "[%s]", comm ? comm : "?");
}
}Después de eliminar el código extraño, encontré
/proc/<PID>/cmdlineobteniendo el nombre del proceso- Si
/proc/<PID>/cmdlineestá vacío, se usacomm, en este caso está entre[]paréntesis - Si
cmdlineel nombre base escomminconsistente,{}enciérrelo con
Para facilitar la lectura, no hay más análisis cmdliney análisis comm.
Nos centramos en la pregunta, ¿bajo qué circunstancias, /proc/<PID>/cmdlineestá vacío?
Análisis de la lógica del código del kernel
/proc monta proc, un sistema de archivos especial, y cmdline es definitivamente su función única.
Asumiendo que somos nuevos en el kernel, todo lo que podemos hacer en este punto es recuperar la palabra clave cmdline en el código fuente del kernel proc.
[GMPY@09:54 proc]$cd fs/proc && grep "cmdline" -rnw *Se encontraron dos archivos clave coincidentes base.c y cmdline.c
array.c:11: * Pauline Middelink : Made cmdline,envline only break at '\0's, to
base.c:224: /* Check if process spawned far enough to have cmdline. */
base.c:708: * May current process learn task's sched/cmdline info (for hide_pid_min=1)
base.c:2902: REG("cmdline", S_IRUGO, proc_pid_cmdline_ops),
base.c:3294: REG("cmdline", S_IRUGO, proc_pid_cmdline_ops),
cmdline.c:26: proc_create("cmdline", 0, NULL, &cmdline_proc_fops);
Makefile:16:proc-y += cmdline.o
vmcore.c:1158: * If elfcorehdr= has been passed in cmdline or created in 2nd kernel,La lógica del código de cmdline.c es muy simple, es fácil encontrar que es la implementación de /proc/cmdline, no nuestras necesidades.
Centrémonos en base.c, el código relevante
REG("cmdline", S_IRUGO, proc_pid_cmdline_ops),La experiencia me dice la intuición,
- cmdline: es el nombre del archivo
- S_IRUGO: es el permiso del archivo
- proc_pid_cmdline_ops: es la estructura de operación correspondiente al archivo
Efectivamente, entrando proc_pid_cmdline_opsencontramos que se define como:
static const struct file_operations proc_pid_cmdline_ops = {
.read = proc_pid_cmdline_read,
.llseek = generic_file_llseek,
}Función: proc_pid_cmdline_read
static ssize_t proc_pid_cmdline_read(struct file *file, char __user *buf,
size_t _count, loff_t *pos)
{
......
/* 获取进程对应的虚拟地址空间描述符 */
mm = get_task_mm(tsk);
......
/* 获取argv的地址和env的地址 */
arg_start = mm->arg_start;
arg_end = mm->arg_end;
env_start = mm->env_start;
env_end = mm->env_end;
......
while (count > 0 && len > 0) {
......
/* 计算地址偏移 */
p = arg_start + *pos;
while (count > 0 && len > 0) {
......
/* 获取进程地址空间的数据 */
nr_read = access_remote_vm(mm, p, page, _count, FOLL_ANON);
......
}
}
}Xiaobai puede estar confundido en este momento, ¿cómo sabes qué access_remote_vmes?
Muy sencillo, salta a la access_remote_vmfunción, puedes ver que esta función está comentada
/**
* access_remote_vm - access another process' address space
* @mm: the mm_struct of the target address space
* @addr: start address to access
* @buf: source or destination buffer
* @len: number of bytes to transfer
* @gup_flags: flags modifying lookup behaviour
*
* The caller must hold a reference on @mm.
*/
int access_remote_vm(struct mm_struct *mm, unsigned long addr,
void *buf, int len, unsigned int gup_flags)
{
return __access_remote_vm(NULL, mm, addr, buf, len, gup_flags);
}En el código fuente del kernel de Linux, muchas funciones tienen descripciones de funciones, descripciones de parámetros, precauciones, etc. muy estandarizadas. Debemos hacer un uso completo de estos recursos para aprender el código.
Con eso fuera del camino, volvamos al tema.
A partirproc_pid_cmdline_read de esto, descubrimos que leer /proc/<PID>/cmdlinees en realidad leer arg_startlos datos del espacio de direcciones al principio. Por lo tanto, cuando los datos del espacio de direcciones están vacíos, por supuesto, no se pueden leer datos. Entonces, la pregunta es, ¿cuándo están vacíos los datos del espacio de direcciones identificados por arg_start?
Relacionado con el espacio de direcciones, definitivamente no solo proc, tratamos de recuperar palabras clave globalmente en el código fuente del kernel:
[GMPY@09:55 proc]$find -name "*.c" -exec grep --color=auto -Hnw "arg_start" {} \;Hay muchas coincidencias, no quiero mirarlas una por una y no puedo encontrar la dirección del código recuperado:
./mm/util.c:635: unsigned long arg_start, arg_end, env_start, env_end;
......
./kernel/sys.c:1747: offsetof(struct prctl_mm_map, arg_start),
......
./fs/exec.c:709: mm->arg_start = bprm->p - stack_shift;
./fs/exec.c:722: mm->arg_start = bprm->p;
......
./fs/binfmt_elf.c:301: p = current->mm->arg_end = current->mm->arg_start;
./fs/binfmt_elf.c:1495: len = mm->arg_end - mm->arg_start;
./fs/binfmt_elf.c:1499: (const char __user *)mm->arg_start, len))
......
./fs/proc/base.c:246: len1 = arg_end - arg_start;
......Pero el nombre de archivo coincidente me dio inspiración:
/proc/<PID>/cmdline es el atributo de cada proceso. Desde task_struct hasta mm_struct , describen el proceso y los recursos relacionados. ¿Cuándo se modificará a mm_struct donde se encuentra arg_start ? Cuando se inicializa el proceso!
Además, se cree que crear un proceso en el espacio del usuario no es más que dos pasos:
- tenedor
- ejecutivo
Cuando se bifurca, solo se crean nuevos task_struct, y los procesos padre e hijo comparten un recurso compartido mm_struct. Solo execcuando lo son, serán independientes mm_struct, por lo que arg_start debe execmodificarse cuando lo sean. arg_startEn los archivos coincidentes , solo hay exec.c.
Después de verificar la fs/exec.cfunción donde se encuentra la palabra setup_arg_pagesclave, no se encontró el código clave, por lo que continué verificando el nombre del archivo coincidente y se produjeron más asociaciones:
exec ejecuta un nuevo programa, que en realidad carga el archivo bin del nuevo programa, ¡y los archivos que coinciden con la palabra clave están allí binfmt_elf.c!
El problema del posicionamiento no es solo entender el código, Lenovo también es muy efectivo a veces
La función create_elf_tables coincide con la palabra clave arg_start en binfmt_elf.c. La función es bastante larga. Simplifiquémosla:
static int
create_elf_tables(struct linux_binprm *bprm, struct elfhdr *exec,
unsigned long load_addr, unsigned long interp_load_addr)
{
......
/* Populate argv and envp */
p = current->mm->arg_end = current->mm->arg_start;
while (argc-- > 0) {
......
if (__put_user((elf_addr_t)p, argv++))
return -EFAULT;
......
}
......
current->mm->arg_end = current->mm->env_start = p;
while (envc-- > 0) {
......
if (__put_user((elf_addr_t)p, envp++))
return -EFAULT;
......
}
......
}En esta función, argv y envp se almacenan en el espacio de direcciones de arg_start y env_start .
A continuación, intentemos rastrear fuente por fuente y rastrear create_elf_tablesla llamada de la función juntos
En primer lugar, se create_elf_tablesdeclara como estático , lo que significa que su alcance efectivo no puede exceder el archivo donde se encuentra. Recuperando en el archivo, se encuentra que la función superior es:
static int load_elf_binary(struct linux_binprm *bprm)Resultó ser estático , así que continué buscando en este archivo load_elf_binaryy encontré el siguiente código:
static struct linux_binfmt elf_format = {
.module = THIS_MODULE,
.load_binary = load_elf_binary,
.load_shlib = load_elf_library
.core_dump = elf_core_dump,
.min_coredump = ELF_EXEC_PAGESIZE,
};
static int __init init_elf_binfmt(void)
{
register_binfmt(&elf_format);
return 0;
}
core_initcall(init_elf_binfmt);Recuperada aquí, la estructura del código es muy clara, la load_elf_binaryfunción se asigna a struct linux_binfmty se registra en la capa superior a través de ` register_binfmt, proporcionando la devolución de llamada de la capa superior.
¿Por qué bloquear la palabra clave load_binary? Dado .load_binary = load_elf_binary,que , significa que la llamada de la capa superior debe ser XXX->load_binary(...), así que bloquee la palabra clave load_binary para ubicar dónde se llama a esta devolución de llamada.
[GMPY@09:55 proc]$ grep "\->load_binary" -rn *Afortunadamente, esta devolución de llamada solo fs/exec.cllama:
fs/exec.c:78: if (WARN_ON(!fmt->load_binary))
fs/exec.c:1621: retval = fmt->load_binary(bprm);Ingrese la línea 1621 de fs/exex.c , que pertenece a la función search_binary_handler. Desafortunadamente, EXPORT_SYMBOL(search_binary_handler);su existencia significa que es probable que se llame a esta función en varios lugares. Obviamente, es muy difícil continuar con el análisis hacia adelante en este momento. ¿Por qué no intentarlo hacia atrás? análisis?
Cuando el camino falla, mira el problema desde un ángulo diferente y la respuesta está frente a ti.
Dado que no es fácil continuar el análisis desde search_binary_handler, veamos si execvese puede llegar a la llamada del sistema paso a paso search_binary_handler.
En Linux-4.9, la definición de la llamada al sistema es generalmente SYSCALL_DEFILNE<参数数量>(<函数名>..., por lo que buscamos la palabra clave globalmente, primero determinamos dónde se define la llamada al sistema.
[GMPY@09:55 proc]$ grep "SYSCALL_DEFINE.*exec" -rn *Navegar al archivofs/exec.c:
fs/exec.c:1905:SYSCALL_DEFINE3(execve,
fs/exec.c:1913:SYSCALL_DEFINE5(execveat,
fs/exec.c:1927:COMPAT_SYSCALL_DEFINE3(execve, const char __user *, filename,
fs/exec.c:1934:COMPAT_SYSCALL_DEFINE5(execveat, int, fd,
kernel/kexec.c:187:SYSCALL_DEFINE4(kexec_load, unsigned long, entry, unsigned long, nr_segments,
kernel/kexec.c:233:COMPAT_SYSCALL_DEFINE4(kexec_load, compat_ulong_t, entry,
kernel/kexec_file.c:256:SYSCALL_DEFINE5(kexec_file_load, int, kernel_fd, int, initrd_fd,La llamada de la función de seguimiento ya no es engorrosa, y la relación de llamada se resume de la siguiente manera:
execve -> do_execveat -> do_execveat_common -> exec_binprm -> search_binary_handlerDespués de todo, vuelve a search_binary_handler
Después de analizar esto, hemos determinado la lógica de asignación:
-
Cuando
execvese ejecuta un nuevo programa, se inicializamm_struct -
Guarde el
execveargv y el envp pasados a la dirección especificada por arg_start y env_start -
Cuando
cat /proc/<PID>/cmdlinelos datos se obtienen de la dirección virtual de arg_start
Por lo tanto, mientras el proceso creado por el espacio de usuario pase la llamada al sistema execve, habrá /proc/<PID>/cmdline, pero aún no está aclarado, ¿cuándo estará vacío el cmdline?
Sabemos que en Linux, los procesos se pueden dividir en procesos de espacio de usuario y procesos de espacio de kernel.Dado que el proceso de espacio de usuario cmdline no está vacío, echemos un vistazo al proceso de kernel.
En el controlador del kernel, a menudo kthread_runcreamos un proceso del kernel. Usamos esta función como punto de entrada para analizar si se asignará cmdline al crear un proceso del kernel.
Comience directamente desde kthread_run, realice un seguimiento de la relación de llamada y descubra que el trabajo real es la función__kthread_create_on_node:
kthread_run -> kthread_create -> kthread_create_on_node -> __kthread_create_on_nodeElimine el código redundante y concéntrese en lo que hace la función:
static struct task_struct *__kthread_create_on_node(int (*threadfn)(void *data),
void *data, int node, const char namefmt[], va_list args)
{
/* 把新进程相关的属性存于 kthread_create_info 的结构体中 */
struct kthread_create_info *create = kmalloc(sizeof(*create), GFP_KERNEL);
create->threadfn = threadfn;
create->data = data;
create->node = node;
create->done = &done;
/* 把初始化后的create加入到链表,并唤醒kthreadd_task进程来完成创建工作 */
list_add_tail(&create->list, &kthread_create_list);
wake_up_process(kthreadd_task);
/* 等待创建完成 */
wait_for_completion_killable(&done)
......
task = create->result;
if (!IS_ERR(task)) {
......
/* 创建后,设置进程名,此处的进程名属性为comm,不同于cmdline */
vsnprintf(name, sizeof(name), namefmt, args);
set_task_comm(task, name);
......
}
}El método de análisis es similar al anterior y no se repite aquí. En resumen, la función hace dos cosas.
-
Despertar un proceso
kthread_taskpara crear un nuevo proceso -
Establecer las propiedades del proceso, donde las propiedades incluyen comm pero no cmdline
Revise el análisis del código de usuario , si /proc/<PID>/cmdlineestá vacío, use comm y enciérrelo con []**
Por lo tanto, el /proc/<PID>/cmdlinecontenido del proceso del núcleo creado por kthread_run/ktrhread_create está vacío.
En este análisis, se utilizaron principalmente los siguientes métodos de análisis
- Recuperación de palabras clave: desde COMMAND del programa principal hasta arg_start, load_binary, exec del código fuente del kernel
- anotación de función - descripción de la función de la función access_remote_vm
- Asociar: asocie el atributo del proceso al espacio del usuario para crear un proceso y luego ubique la función de procesamiento de la palabra clave arg_start
- Pensamiento inverso: es difícil deducir la relación de llamada de search_binary_handler. ¿Se puede analizar paso a paso la llamada del sistema de execve a search_binary_handler?
En base a este análisis, llegamos a las siguientes conclusiones:
-
Los procesos creados por el espacio del usuario no necesitan [] en la pantalla superior/ps;
-
El proceso creado por el espacio del núcleo tendrá [] en la pantalla superior/ps;
¿Cómo interactúan las unidades del módulo con el kernel del sistema?
El archivo make del módulo kernel:
Primero, echemos un vistazo a cómo se debe escribir el archivo make del programa del módulo. Desde la versión 2.6, las especificaciones de Linux para los módulos del núcleo han cambiado mucho. Por ejemplo, el nombre de la extensión de todos los módulos se cambia de ".o" a ".ko". Para obtener más información, consulte Documentación/kbuild/makefiles.txt. Para editar el Makefile para los módulos del núcleo, consulte Documentación/kbuild/modules.txt.
Cuando practicamos "helloworld.ko", usamos un Makefile simple:
TARGET = helloworld
KDIR = /usr/src/linux
PWD = $(shell pwd)
obj-m += $(TARGET).o
default:
make -C $(KDIR) M=$(PWD) modules$(KDIR) indica la ubicación del directorio de nivel superior del código fuente.
"obj-m += $(TARGET).o" le dice a kbuild que quiere compilar $(TARGET), que es helloworld, en un módulo del kernel.
"M=$(PWD)" significa que los archivos del módulo generado estarán en el directorio actual.
crear un archivo para el módulo kernel multiarchivo
Ahora, ampliemos la pregunta, ¿cómo compilar un módulo kernel de varios archivos? También tomando "Hola, mundo" como ejemplo, debemos hacer lo siguiente:
Entre todos los archivos fuente, solo un archivo agrega la línea #define __NO_VERSION__. Esto se debe a que module.h generalmente incluye la definición de la variable global kernel_version, que contiene la información de la versión del kernel para la que se compiló el módulo. Si necesita version.h, debe incluirlo usted mismo, porque module.h no incluirá version.h después de definir __NO_VERSION__.
A continuación se muestra un ejemplo de un módulo kernel de varios archivos.
Inicio.c:
/* start.c
*
* "Hello, world" –内核模块版本
* 这个文件仅包括启动模块例程
*/
/* 必要的头文件 */
/* 内核模块中的标准 */
#include <linux/kernel.h> /*我们在做内核的工作 */
#include <linux/module.h>
/*初始化模块 */
int init_module()
{
printk("Hello, world!\n");
/* 如果我们返回一个非零值, 那就意味着
* init_module 初始化失败并且内核模块
* 不能加载 */
return 0;
}parada.c:
/* stop.c
*"Hello, world" -内核模块版本
*这个文件仅包括关闭模块例程
*/
/*必要的头文件 */
/*内核模块中的标准 */
#include <linux/kernel.h> /*我们在做内核的工作 */
#define __NO_VERSION__
#include <linux/module.h>
#include <linux/version.h> /* 不被module.h包括,因为__NO_VERSION__ */
/* Cleanup - 撤消 init_module 所做的任何事情*/
void cleanup_module()
{
printk("Bye!\n");
}
/*结束*/Esta vez, el módulo kernel de helloworld contiene dos archivos fuente, "start.c" y "stop.c". Echemos un vistazo a cómo escribir un Makefile para un módulo kernel de varios archivos
Makefile:
TARGET = helloworld
KDIR = /usr/src/linux
PWD = $(shell pwd)
obj-m += $(TARGET).o
$(TARGET)-y := start.o stop.o
default:
make -C $(KDIR) M=$(PWD) modulesEn comparación con el anterior, solo se agrega una línea:
$(TARGET)-y := start.o stop.oEscribir un módulo del núcleo
Intentemos escribir un programa de módulo muy simple, que se pueda implementar en la versión 2.6.15, y puede necesitar algunos ajustes para las versiones del kernel anteriores a la 2.4.
holamundo.c
#include <linux/module.h> /* Needed by all modules */
#include <linux/kernel.h> /* Needed for KERN_INFO */
int init_module(void)
{
printk(KERN_INFO “Hello World!\n”);
return 0;
}
void cleanup_module(void)
{
printk(KERN_INFO “Goodbye!\n”);
}
MODULE_LICENSE(“GPL”);ilustrar:
1. La escritura de cualquier programa de módulo debe incluir el archivo de encabezado linux/module.h, que contiene la definición de estructura del módulo y el control de versión del módulo. Las principales estructuras de datos en el archivo se describirán en detalle más adelante.
2. La función init_module() y la función cleanup_module() son las funciones más básicas y necesarias en la programación de módulos. init_module() registra nuevas funciones proporcionadas por el módulo al kernel; cleanup_module() es responsable de desregistrar todas las funciones registradas por el módulo.
3. Tenga en cuenta que estamos usando la función printk() aquí (no la escriba habitualmente como printf), la función printk() está definida por el kernel de Linux y su función es similar a printf. La cadena KERN_INFO representa la prioridad del mensaje.Una de las características de printk() es que procesa mensajes de diferentes prioridades de manera diferente.
A continuación, necesitamos compilar y cargar este módulo. Una cosa más a tener en cuenta: asegúrese de ser un superusuario ahora. Porque solo el superusuario puede cargar y descargar módulos. Antes de compilar el módulo del kernel, prepare un Makefile:
TARGET = helloworld
KDIR = /usr/src/linux
PWD = $(shell pwd)
obj-m += $(TARGET).o
default:
make -C $(KDIR) M=$(PWD) modulesLuego simplemente ingrese el comando make:
#makeComo resultado, obtenemos el archivo "helloworld.ko". Luego ejecute el comando de carga del módulo del kernel:
#insmod helloworld.ko
Hello World!En este momento, se genera la cadena "¡Hola mundo!", que se define en init_module(). Esto muestra que el módulo helloworld ha sido cargado en el kernel. Podemos usar el comando lsmod para ver. Lo que hace el comando lsmod es brindarnos información sobre todos los módulos que se ejecutan en el kernel, incluido el nombre del módulo, el tamaño de su huella, el recuento de uso y su estado actual y dependencias.
root# lsmod
Module Size Used by
helloworld 464 0 (unused)
…Finalmente, queremos desinstalar este módulo.
# rmmod helloworld
Goodbye!Vio "¡Adiós!" impreso en la pantalla, que se define en cleanup_module(). Esto muestra que el módulo helloworld ha sido eliminado. Si usamos lsmod para verificar nuevamente en este momento, encontraremos que el módulo helloworld ya no está allí.
En cuanto a los dos comandos insmod y rmmod, solo puedo decirte brevemente que son dos utilidades para insertar y quitar módulos del kernel. Las utilidades insmod, rmmod y lsmod utilizadas anteriormente son todas utilidades del módulo modutils.
Hemos implementado con éxito un programa de módulo más simple en la máquina.
3. Gestión de memoria
El subsistema de gestión de memoria es una parte importante del sistema operativo. Desde los primeros días del desarrollo de las computadoras, ha habido una necesidad de memoria que sea más grande que las capacidades físicas del sistema. Para superar esta limitación, se han desarrollado muchas estrategias, la más exitosa de las cuales es la memoria virtual. La memoria virtual hace que el sistema parezca tener más memoria de la que realmente tiene al compartir memoria entre procesos competidores.
La memoria virtual no solo hace que su computadora parezca más memoria, el subsistema de administración de memoria también proporciona:
Grandes espacios de direcciones El sistema operativo hace que parezca que el sistema tiene una mayor cantidad de memoria de la que realmente tiene. La memoria virtual puede ser muchas veces más grande que la memoria física del sistema.
Cada proceso en el sistema de Protección tiene su propio espacio de direcciones virtuales. Estos espacios de direcciones virtuales están completamente separados entre sí, por lo que un proceso que ejecuta una aplicación no afectará a otro proceso. Además, el mecanismo de memoria virtual del hardware permite la protección contra escritura de áreas de memoria. Esto evita que el código y los datos sean sobrescritos por programas maliciosos.
Mapeo de memoria El mapeo de memoria se utiliza para mapear imágenes y datos en el espacio de direcciones de un proceso. Con el mapeo de memoria, el contenido del archivo se vincula directamente al espacio de direcciones virtuales del proceso.
Asignación de memoria física justa El subsistema de administración de memoria permite que cada proceso en ejecución en el sistema comparta la memoria física del sistema de manera justa
Memoria virtual compartida Mientras que la memoria virtual permite que los procesos tengan espacios de direcciones (virtuales) separados, a veces también es necesario compartir la memoria entre procesos. Por ejemplo, puede haber varios procesos en el sistema que ejecutan el intérprete de comandos bash. Si bien es posible tener una copia de bash en el espacio de direcciones virtuales de cada proceso, es mejor tener solo una copia en la memoria física y todos los procesos que ejecutan el código compartido de bash. Las bibliotecas vinculadas dinámicamente son otro ejemplo común de múltiples procesos que comparten código de ejecución. La memoria compartida también se puede utilizar para mecanismos de comunicación entre procesos (IPC), donde dos o más procesos pueden intercambiar información a través de una memoria de propiedad conjunta. El sistema Linux admite el mecanismo IPC de memoria compartida de System V.
3.1 Un modelo abstracto de memoria virtual
Antes de pensar en el enfoque de Linux para soportar la memoria virtual, es mejor pensar en un modelo abstracto para no abarrotarse con demasiados detalles.
Cuando un proceso ejecuta un programa, lee las instrucciones de la memoria y las decodifica. La decodificación de una instrucción puede requerir leer o almacenar el contenido de una ubicación específica en la memoria, y luego el proceso ejecuta la instrucción y pasa a la siguiente instrucción en el programa. Un proceso accede a la memoria ya sea leyendo instrucciones o accediendo a datos.
En un sistema de memoria virtual, todas las direcciones son direcciones virtuales en lugar de direcciones físicas. El procesador traduce direcciones virtuales a direcciones físicas a través de un conjunto de información en poder del sistema operativo.
Para facilitar esta conversión, la memoria virtual y la memoria física se dividen en bloques de tamaño apropiado, llamados páginas. Las páginas son del mismo tamaño. (Por supuesto que puede ser diferente, pero esto hace que la gestión del sistema sea más difícil). Linux usa páginas de 8K bytes en sistemas Alpha AXP y páginas de 4K bytes en sistemas Intel x86. A cada página se le asigna un número único: número de marco de página (número de página PFN). Según este modelo de paginación, una dirección virtual consta de dos partes: el número de página virtual y el desplazamiento dentro de la página. Si el tamaño de la página es 4K, los bits 11 a 0 de la dirección virtual incluyen el desplazamiento dentro de la página, y los bits 12 y superiores son el número de página. Cada vez que el procesador encuentra una dirección virtual, debe extraer el desplazamiento y el número de página virtual. El procesador debe traducir el número de página virtual a la página física y acceder al desplazamiento correcto de la página física. Para ello, el procesador utiliza tablas de páginas.
La Figura 3.1 muestra los espacios de direcciones virtuales de dos procesos, el Proceso X y el Proceso Y, cada uno con su propia tabla de páginas. Estas tablas de páginas asignan las páginas virtuales de cada proceso a páginas físicas de memoria. La figura muestra que la página virtual número 0 del proceso X se asigna a la página física número 1, mientras que la página virtual número 1 del proceso Y se asigna a la página física número 4. En teoría, cada entrada en la tabla de páginas incluye la siguiente información:
Bandera válida Indica si esta entrada en la tabla de páginas es válida
El número de página física descrito por esta entrada de la tabla de páginas
Información de control de acceso Describa cómo se usa esta página: ¿Se puede escribir? ¿Incluye código de ejecución?
Se accede a las tablas de páginas utilizando números de página virtuales como compensaciones. La página virtual número 5 es el sexto elemento de la tabla (0 es el primer elemento)
Para traducir una dirección virtual a una dirección física, el procesador primero encuentra el número de página y el desplazamiento dentro de la página de la dirección virtual. El uso de tamaños de página potencia de 2 se puede manejar simplemente con máscaras o turnos. Mirando nuevamente la Figura 3.1, asumiendo que el tamaño de la página es 0x2000 (8192 decimal) y la dirección en el espacio de direcciones virtuales del proceso Y es 0x2194, el procesador traducirá la dirección para compensar 0x194 dentro de la página virtual número 1.

El procesador utiliza el número de página virtual como índice para encontrar su entrada en la tabla de páginas en la tabla de páginas del proceso. Si la entrada es válida, el procesador obtiene el número de página física de la entrada. Si esta entrada no es válida, el proceso ha accedido a un área de su memoria virtual que no existe. En este caso, el procesador no puede interpretar la dirección y debe pasar el control al sistema operativo para manejarla.
La forma en que el procesador informa específicamente al proceso del sistema operativo que está accediendo a una dirección virtual no válida que no se puede traducir depende del procesador. El procesador comunica esta información (error de página) y se notifica al sistema operativo que la dirección virtual es defectuosa y el motivo del error.
Suponiendo que se trata de una entrada de tabla de páginas válida, el procesador obtiene el número de página física y multiplica el tamaño de página para obtener la dirección base de la página en la memoria física. Finalmente, el procesador agrega el desplazamiento de la instrucción o los datos que necesita.
Usando el ejemplo anterior nuevamente, la página virtual número 1 del proceso Y se asigna a la página física número 4 (comenzando en 0x8000, 4x 0x2000) y se agrega el desplazamiento 0x194 para obtener la dirección física final 0x8194.
Al asignar direcciones virtuales a direcciones físicas de esta manera, la memoria virtual se puede asignar a la memoria física del sistema en cualquier orden. Por ejemplo, en la Figura 3.1, el número de página virtual de la memoria virtual X se asigna a la página física número 1 y la página virtual número 7 se asigna a la página física número 0, aunque es más alta en la memoria virtual que la página virtual 0. Esto también demuestra un subproducto interesante de la memoria virtual: las páginas de la memoria virtual no tienen que asignarse a la memoria física en un orden específico.
3.1.1 Localización por demanda
Debido a que la memoria física es mucho más pequeña que la memoria virtual, el sistema operativo debe evitar el uso ineficiente de la memoria física. Una forma de ahorrar memoria física es cargar solo las páginas virtuales que está usando el ejecutor. Por ejemplo: un programa de base de datos puede estar ejecutando una consulta en la base de datos. En este caso, no todos los datos deben almacenarse en la memoria, sino solo el registro de datos que se examina. Si se trata de una consulta de búsqueda, entonces el código en el cargador para incrementar el registro no tiene mucho sentido. Esta técnica de cargar páginas virtuales solo cuando se accede a ellas se denomina paginación por demanda.
Cuando un proceso intenta acceder a una dirección virtual que no está actualmente en la memoria, el procesador no puede encontrar la entrada de la tabla de páginas para la página virtual a la que se hace referencia. Por ejemplo: el proceso X en la figura 3.1 no tiene una entrada para la página virtual 2 en su tabla de páginas, por lo que si el proceso X intenta leer desde una dirección en la página virtual 2, el procesador no puede traducir la dirección a una dirección física. En este momento, el procesador notifica al sistema operativo de una falla de página.
Si la dirección virtual incorrecta no es válida, significa que el proceso está intentando acceder a una dirección virtual a la que no debería acceder. Tal vez un error de programa, como escribir en una dirección arbitraria en la memoria. En este caso, el sistema operativo lo interrumpirá, protegiendo así otros procesos en el sistema.
Si la dirección virtual defectuosa es válida pero la página en la que se encuentra no está actualmente en la memoria, el sistema operativo debe cargar la página correspondiente en la memoria desde la imagen del disco. Los accesos al disco toman un tiempo relativamente largo, por lo que el proceso debe esperar hasta que la página se obtenga en la memoria. Si hay otros sistemas ejecutándose actualmente, el sistema operativo elegirá uno para ejecutar. La página recuperada se escribe en una página libre y se agrega una entrada de página virtual válida a la tabla de páginas del proceso. Luego, el proceso vuelve a ejecutar las instrucciones de la máquina donde ocurrió el error de memoria. Durante este acceso a la memoria virtual, el procesador puede traducir la dirección virtual a una dirección física, por lo que el proceso puede continuar ejecutándose.
Linux usa tecnología de paginación bajo demanda para cargar la imagen ejecutable en la memoria virtual del proceso. Cuando se ejecuta un comando, el archivo que lo contiene se abre y su contenido se asigna a la memoria virtual del proceso. Este proceso se logra modificando las estructuras de datos que describen el mapeo de memoria del proceso, también conocido como mapeo de memoria. Sin embargo, solo la primera parte de la imagen se coloca realmente en la memoria física. El resto de la imagen permanece en el disco. Cuando la imagen se ejecuta, genera una falla de página y Linux usa la tabla de mapa de memoria del proceso para determinar qué parte de la imagen debe cargarse en la memoria para su ejecución.
3.1.2 Intercambio
Si un proceso necesita colocar una página virtual en la memoria física y no hay páginas físicas libres, el sistema operativo debe descartar otra página en el espacio físico para dejar espacio para esa página.
Si la página en la memoria física que debe descartarse proviene de una imagen o un archivo de datos en el disco y no se ha escrito, por lo que no es necesario almacenarla, la página se descarta. Si el proceso necesita la página nuevamente, se puede cargar nuevamente en la memoria desde el archivo de imagen o datos.
Sin embargo, si la página ha sido cambiada, el sistema operativo debe conservar su contenido para un acceso posterior. Esto también se llama página sucia, y cuando se descarta de la memoria física, se almacena en un archivo especial llamado archivo de intercambio. Debido a que el acceso al archivo de intercambio es lento en comparación con el acceso al procesador y la memoria física, el sistema operativo debe decidir si escribe las páginas de datos en el disco o las guarda en la memoria para el próximo acceso.
Thrashing ocurre si el algoritmo para decidir qué páginas deben descartarse o intercambiarse no es eficiente. En este punto, las páginas se escriben constantemente en el disco y se vuelven a leer, y el sistema operativo está demasiado ocupado para realizar el trabajo real. Por ejemplo, en la Figura 3.1, si se accede con frecuencia a la página física número 1, no la cambie al disco. Lo que utiliza un proceso también se denomina conjunto de trabajo. Un esquema de intercambio eficiente debería garantizar que los conjuntos de trabajo de todos los procesos estén en la memoria física.
Linux utiliza la técnica de página LRU (Usado menos recientemente) para seleccionar de manera justa las páginas que deben descartarse del sistema. Este esquema asigna a cada página del sistema una edad que cambia cuando se accede a la página. Cuantas más páginas visitadas, más jóvenes, menos visitadas, más antiguas, más rancias. Las páginas obsoletas son buenas candidatas para el intercambio.
3.1.3 Memoria virtual compartida
La memoria virtual permite que múltiples procesos compartan memoria fácilmente. Todos los accesos a la memoria son a través de tablas de páginas y cada proceso tiene su propia tabla de páginas. Para que dos procesos compartan una página de memoria física, el número de página física debe aparecer en las tablas de páginas de ambos procesos.
La figura 3.1 muestra dos procesos que comparten la página física número 4. El número de página virtual es 4 para el proceso X y 6 para el proceso Y. Esto también muestra un aspecto interesante de las páginas compartidas: una página física compartida no tiene que existir en el mismo lugar en el espacio de memoria virtual del proceso que la comparte.
3.1.4 Modos de direccionamiento físico y virtual
Para el propio sistema operativo, ejecutar en memoria virtual tiene poco sentido. Esto sería una pesadilla si el sistema operativo tuviera que mantener sus propias tablas de páginas. La mayoría de los procesadores multipropósito admiten los modos de dirección física y virtual. El modo de direccionamiento físico no requiere tablas de páginas y el procesador no necesita realizar ninguna traducción de direcciones en este modo. El kernel de Linux se ejecuta en modo de dirección física.
Los procesadores Alpha AXP no tienen modos de direccionamiento físico especiales. Divide el espacio de la memoria en varias áreas, dos de las cuales se designan como áreas de direcciones asignadas físicas. El espacio de direcciones del núcleo se denomina espacio de direcciones KSEG e incluye todas las direcciones desde 0xfffffc0000000000 en adelante. Para ejecutar el código (código central) adjunto al KSEG o acceder a los datos allí, el código debe ejecutarse en estado central. El kernel de Linux en Alpha se conecta para ejecutar desde la dirección 0xfffffc0000310000.

3.1.5 Control de acceso
Las entradas de la tabla de páginas también incluyen información de control de acceso. Cuando el procesador usa las entradas de la tabla de páginas para asignar la dirección virtual de un proceso a una dirección física, puede usar fácilmente la información de control de acceso para evitar que el proceso acceda a él de una manera no permitida.
Hay muchas razones por las que es posible que desee restringir el acceso a las regiones de memoria. Parte de la memoria, como la que contiene código ejecutable, es esencialmente código de solo lectura, y el sistema operativo debe evitar que un proceso escriba su código ejecutable. A su vez, se pueden escribir páginas que contengan datos, pero los intentos de ejecutar esta memoria deberían fallar. La mayoría de los procesadores tienen dos estados de ejecución: modo kernel y modo usuario. No desea que los usuarios ejecuten directamente código en modo kernel o accedan a estructuras de datos del kernel a menos que el procesador se esté ejecutando en modo kernel.
La información de control de acceso se coloca en el PTE (entrada de la tabla de páginas) y está relacionada con el procesador específico. La Figura 3.2 muestra el PTE de Alpha AXP. El significado de cada bit es el siguiente:
V 有效,这个PTE是否有效
FOE “Fault on Execute” 试图执行本页代码时,处理器是否要报告page fault,并将控制权传递给操作系统。
FOW “Fault on Write” 如上,在试图写本页时产生page fault
FOR “fault on read” 如上,在试图读本页时产生page fault
ASM 地址空间匹配。用于操作系统清除转换缓冲区中的部分条目
KRE 核心态的代码可以读本页
URE 用户态的代码可以读本页
GII 间隔因子,用于将一整块映射到一个转换缓冲条目而非多个。
KWE 核心态的代码可以写本页
UWE 用户态的代码可以写本页
Page frame number 对于V位有效的PTE,包括了本PTE的物理页编号;对于无效的PTE,如果不是0,包括了本页是否在交换文件的信息。Linux define y utiliza los siguientes dos bits:
_PAGE_DIRTY 如果设置,本页需要写到交换文件中
_PAGE_ACCESSED Linux 使用,标志一页已经访问过3.2 Cachés
Si implementa un sistema con el modelo teórico anterior, funcionará, pero no será muy eficiente. Los diseñadores de sistemas operativos y procesadores se esfuerzan por hacer que los sistemas tengan un mayor rendimiento. Además de usar procesadores más rápidos, memoria, etc., el mejor enfoque es mantener un caché de información y datos útiles, lo que hará que algunas operaciones sean más rápidas.
Linux utiliza una serie de técnicas de gestión de memoria relacionadas con la memoria caché:
Caché de búfer: la caché de búfer contiene búferes de datos para controladores de dispositivos de bloque. Estos búferes tienen un tamaño fijo (por ejemplo, 512 bytes) y contienen datos leídos o escritos en un dispositivo de bloque. Un dispositivo de bloque es un dispositivo al que solo se puede acceder leyendo y escribiendo bloques de datos de tamaño fijo. Todos los discos duros son dispositivos de bloque. El dispositivo de bloque utiliza el identificador del dispositivo y el número del bloque de datos al que se accede como un índice para localizar rápidamente el bloque de datos. Solo se puede acceder a los dispositivos de bloque a través de la memoria caché del búfer. Si los datos se pueden encontrar en la memoria caché del búfer, entonces no hay necesidad de leer desde un dispositivo de bloque físico como un disco duro, lo que acelera el acceso.
Ver fs/buffer.c
Page Cache se utiliza para acelerar el acceso a imágenes y datos en el disco. Se utiliza para almacenar en caché el contenido lógico de un archivo, una página a la vez, y se accede a través del archivo y las compensaciones dentro del archivo. Cuando una página de datos se lee del disco a la memoria, se almacena en la memoria caché de la página.
Ver mm/filemap.c
Caché de intercambio Solo existen páginas modificadas (o sucias) en el archivo de intercambio. Siempre que no se modifiquen nuevamente después de escribirlas en el archivo de intercambio, la próxima vez que estas páginas deban intercambiarse, no es necesario escribirlas en el archivo de intercambio, porque la página ya está en el archivo de intercambio. y la página se puede descartar directamente. En un sistema muy intercambiado, esto ahorra muchas operaciones de disco costosas e innecesarias.
Ver mm/swap_state.c mm/swapfile.c

Caché de hardware: una implementación común de caché de hardware se encuentra dentro del procesador: la caché PTE. En este caso, el procesador no siempre necesita leer la tabla de páginas directamente, pero coloca la tabla de traducción de páginas en el caché cuando es necesario. Hay búferes de tablas de traducción (búferes de búsqueda de traducción TLB) en la CPU, que colocan una copia en caché de las entradas de la tabla de páginas de uno o más procesos en el sistema.
Al hacer referencia a una dirección virtual, el área de procesamiento intenta buscar en la TLB. Si la encuentra, traduce directamente la dirección virtual a la dirección física y realiza la operación correcta en los datos. Si no puede encontrarlo, necesita la ayuda del sistema operativo. Señala al sistema operativo que se ha producido una falta de TLB. Un mecanismo dependiente del sistema reenvía la excepción al código correspondiente en el sistema operativo para su procesamiento. El sistema operativo genera nuevas entradas TLB para esta asignación de direcciones. Cuando se borra la excepción, el procesador vuelve a intentar traducir la dirección virtual, pero esta vez tendrá éxito porque hay una entrada válida para esa dirección en la TLB.
Un efecto secundario de los cachés (hardware o de otro tipo) es que Linux tiene que dedicar mucho tiempo y espacio a mantener estos cachés, y si esos cachés fallan, también lo hace el sistema.
3.3 Tablas de páginas de Linux
Linux asume una tabla de páginas de tres niveles. Cada tabla de páginas a la que se accede incluye el número de página de la tabla de páginas del siguiente nivel. La figura 3.3 muestra cómo una dirección virtual se divide en una serie de campos: cada campo proporciona un desplazamiento en una tabla de páginas. Para traducir una dirección virtual a una dirección física, el procesador debe tomar el contenido de cada campo de nivel, traducirlo a un desplazamiento dentro de la página física que incluye esa tabla de páginas y luego leer el número de página de la tabla de páginas del siguiente nivel. Esto se repite tres veces hasta que se encuentra el número de página de la dirección física, incluida la dirección virtual. Luego use el último campo en la dirección virtual: el desplazamiento de bytes para buscar los datos dentro de la página.
Cada plataforma en la que se ejecuta Linux debe proporcionar macros de traducción que permitan que el núcleo maneje las tablas de páginas de un proceso en particular. De esta forma, el kernel no necesita conocer la estructura exacta de las entradas de la tabla de páginas o cómo están organizadas. De esta forma, Linux usa con éxito el mismo controlador de tablas de páginas para los procesadores Alpha e Intel x86, donde Alpha usa tablas de páginas de tres niveles e Intel usa tablas de páginas de dos niveles.
Consulte include/asm/pgtable.h
3.4 Asignación y desasignación de páginas
Hay una gran demanda de páginas físicas en el sistema. Por ejemplo, el sistema operativo necesita asignar páginas cuando se carga una imagen de programa en la memoria. Estas páginas deben liberarse cuando el programa termine de ejecutarse y descargarse. Además, para almacenar estructuras de datos relacionadas con el núcleo, como la propia tabla de páginas, también se requieren páginas físicas. Este mecanismo y estructura de datos para asignar y reclamar páginas es quizás el más importante para mantener la eficiencia del subsistema de memoria virtual.
Todas las páginas físicas del sistema se describen utilizando la estructura de datos mem_map. Esta es una lista enlazada de estructuras mem_map_t, inicializadas al inicio. Cada estructura mem_map_t (confusamente esta estructura también se llama estructura de página) describe una página física en el sistema. Los campos importantes (al menos para la gestión de la memoria) son:
ver incluir/linux/mm.h
contar El número de usuarios en esta página. Si esta página es compartida por varios procesos, el contador es mayor que 1.
Edad Describe la edad de esta página. Se utiliza para decidir si esta página se puede descartar o intercambiar.
El número de página física descrito por Map_nr mem_map_t.
El código de asignación de página utiliza el vector free_area para encontrar páginas gratuitas. Todo el esquema de gestión del búfer está soportado por este mecanismo. Siempre que se utilice este código, el tamaño de la página utilizada por el procesador y el mecanismo de la página física pueden ser irrelevantes.
Cada unidad free_area incluye información de bloque de página. La primera celda de la matriz describe una sola página, la siguiente es un bloque de 2 páginas, la siguiente es un bloque de 4 páginas y así sucesivamente, todos los múltiplos de 2 hacia arriba. Esta celda de lista enlazada se usa como cabeza de la cola, con punteros a las estructuras de datos de las páginas en la matriz mem_map. Los bloques de páginas libres se ponen en cola aquí. Map es un mapa de bits que realiza un seguimiento de los grupos de asignación para páginas de este tamaño. Si el bloque N del bloque de página está libre, se establece el bit N del mapa de bits.
La Figura 3.4 muestra la estructura free_area. La unidad 0 tiene una página libre (página número 0), y la unidad 2 tiene 2 bloques libres de 4 páginas, el primero a partir de la página número 4 y el segundo a partir de la página número 56.
3.4.1 Asignación de página
Ver mm/page_alloc.c get_free_pages()
Linux usa el algoritmo Buddy para asignar y recuperar bloques de página de manera eficiente. El código de asignación de página intenta asignar un bloque de una o más páginas físicas. Las asignaciones de página utilizan bloques de potencia de dos tamaños. Esto significa que se pueden asignar bloques de 1 página, 2 páginas, 4 páginas, etc. Siempre que el sistema tenga suficientes páginas libres para satisfacer las necesidades (nr_free_pages > min_free_pages), el código de asignación buscará en free_area un bloque de páginas del tamaño requerido. Cada celda en Free_area tiene un mapa de bits que describe la ocupación y la vacante de su propio bloque de página de tamaño. Por ejemplo, la celda 2 de la matriz tiene un mapa de asignación que describe los bloques libres y ocupados de 4 páginas de tamaño.
El algoritmo primero encuentra un bloque de páginas de memoria del tamaño que solicita. Realiza un seguimiento de la lista enlazada de páginas gratuitas en la cola de unidades de lista en la estructura de datos free_area. Si un bloque de página del tamaño solicitado no está libre, busque un bloque del siguiente tamaño (2 veces el tamaño solicitado). Continúe este proceso hasta que se atraviesen todas las áreas libres o se encuentre un bloque de página libre. Si el bloque de página encontrado es más grande que el bloque de página solicitado, el bloque se dividirá en bloques de tamaño adecuado. Debido a que todos los bloques se componen de páginas de potencia de 2, el proceso de división es relativamente simple, solo necesita dividirlo en partes iguales. Los bloques libres se colocan en la cola adecuada y los bloques de página asignados se devuelven a la persona que llama.

Por ejemplo, en la Figura 3.4, si se solicita un bloque de datos de 2 páginas, el primer bloque de 4 páginas (que comienza en la página número 4) se dividirá en dos bloques de 2 páginas. El primer bloque de 2 páginas que comienza en la página número 4 se devolverá a la persona que llama, y el segundo bloque de 2 páginas (que comienza en la página número 6) se pondrá en cola en la ubicación 1 en la matriz free_area con 2 páginas libres en la cola de bloques. .
3.4.2 Desasignación de página
En el proceso de asignación de bloques de página, la división de bloques de página grandes en bloques de página pequeños hará que la memoria se fragmente más. El código para la recuperación de páginas une las páginas en bloques grandes siempre que sea posible. De hecho, el tamaño del bloque de página es muy importante (potencia de 2), porque facilita agrupar bloques de página en bloques de página grandes.
Cada vez que se reclama un bloque de página, se comprueba si sus bloques de página adyacentes o juntos del mismo tamaño están libres. Si es así, se combina con el bloque de página recién liberado para formar un nuevo bloque de página libre del siguiente tamaño. Cada vez que dos bloques de páginas de memoria se combinan en un bloque de páginas más grande, el código de recuperación de páginas intenta fusionar los bloques de páginas en un bloque más grande. De esta forma, los bloques de páginas libres serán lo más grandes posible.
Por ejemplo, en la Figura 3.4, si se libera la página número 1, se combina con la página número 0 que ya está libre y se coloca en la cola de bloques de 2 páginas libres en la unidad 1 de free_area.
3.5 Asignación de memoria
Cuando se ejecuta una imagen, el contenido de la imagen en ejecución debe colocarse en el espacio de direcciones virtuales del proceso. Lo mismo se aplica a cualquier biblioteca compartida a la que se conecte la imagen de ejecución. El archivo ejecutable en realidad no se coloca en la memoria física, sino que solo se adjunta a la memoria virtual del proceso. De esta forma, cada vez que un programa en ejecución hace referencia a una parte de la imagen, esa parte de la imagen se carga en la memoria desde el ejecutable. Esta conexión de la imagen al espacio de direcciones virtuales del proceso se denomina mapa de memoria.
La memoria virtual de cada proceso está representada por una estructura de datos mm_struct. Esto incluye información sobre la imagen que se está ejecutando actualmente (por ejemplo, bash) y un puntero a un conjunto de estructuras vm_area_struct. Cada estructura de datos vm_area_struct describe el inicio del área de memoria, los derechos de acceso del proceso al área de memoria y las operaciones en esta memoria. Estas operaciones son un conjunto de rutinas que utiliza Linux para administrar esta memoria virtual. Por ejemplo, una de las operaciones de memoria virtual es la operación correcta que se debe realizar cuando un proceso intenta acceder a esta memoria virtual y descubre (a través de un error de página) que la memoria no está en la memoria física. Esta operación se denomina operación de no página. . La operación nopage se usa cuando Linux solicita que las páginas de la imagen de ejecución se carguen en la memoria.
Cuando se asigna una imagen de ejecución al espacio de direcciones virtuales del proceso, se genera un conjunto de estructuras de datos vm_area_struct. Cada estructura vm_area_struct representa una parte de la imagen de ejecución: código de ejecución, datos inicializados (variables), datos no inicializados, etc. Linux admite un conjunto estándar de operaciones de memoria virtual y se asocia un conjunto correcto de operaciones de memoria virtual cuando se crea la estructura de datos vm_area_struct.
3.6 Localización por demanda
Siempre que la imagen de ejecución esté asignada a la memoria virtual del proceso, puede comenzar a ejecutarse. Porque solo la primera parte de la imagen.
Los puntos se colocan en la memoria física, y luego se accederá al área del espacio virtual que no se ha colocado en la memoria física. Cuando un proceso accede a una dirección virtual que no tiene una entrada válida en la tabla de páginas, el procesador informa una falla de página a Linux. El error de página describe la dirección virtual y el tipo de acceso a la memoria en el que se produce el error de página.
Linux debe encontrar la estructura de datos vm_area_struct (conectada junto con la estructura de árbol Adelson-Velskii y Landis AVL) correspondiente al área de espacio donde ocurrió la falla de página. Si no se encuentra la estructura vm_area_struct correspondiente a esta dirección virtual, significa que el proceso ha accedido a una dirección virtual ilegal. Linux señalará el proceso, enviando una señal SIGSEGV, y si el proceso no maneja la señal, se cerrará.
Ver handle_mm_fault() en mm/memory.c
Luego, Linux verifica el tipo de falla de página y el tipo de acceso permitido para esa área de memoria virtual. También se señala un error de memoria si un proceso accede a la memoria de forma ilegal, como escribir en un área que solo puede leer.
Ahora que Linux determina que la falla de la página es legítima, debe manejarla. Linux debe distinguir entre las páginas del archivo de intercambio y la imagen del disco, que utiliza para determinar la entrada de la tabla de páginas para la dirección virtual donde ocurrió la falla de página.
Ver do_no_page() en mm/memory.c
Si la entrada de la tabla de páginas para la página no es válida pero no está vacía, la página está en el archivo de intercambio. Para las entradas de la tabla de páginas Alpha AXP, se establece el bit válido pero el campo PFN no está vacío. En este caso, el campo PFN mantiene la posición de la página en el archivo de intercambio (y ese archivo de intercambio). La forma en que se manejan las páginas en el archivo de intercambio se analiza más adelante.
No todas las estructuras de datos vm_area_struct tienen un conjunto completo de operaciones de memoria virtual, y es posible que aquellas que tienen operaciones de memoria especiales tampoco tengan operaciones nopang. Porque, de forma predeterminada, para las operaciones sin página, Linux asigna una nueva página física y crea una entrada de tabla de páginas válida. Si esta sección de la memoria virtual tiene una operación especial de no página, Linux llamará a este código especial.
La operación nopage habitual de Linux se usa para mapear en memoria la imagen de ejecución y usar el caché de página para cargar la página de imagen solicitada en la memoria física. Aunque la tabla de páginas del proceso se actualiza después de que la página solicitada se lleva a la memoria física, es posible que se requiera la acción de hardware necesaria para actualizar estas entradas, especialmente si el procesador usa la TLB. Ahora que se solucionó el problema de la página, se puede descartar y reiniciar el proceso en la instrucción que provocó el error de acceso a la memoria virtual.
Ver filemap_nopage() en mm/filemap.c


3.7 La caché de páginas de Linux
La función de la caché de páginas de Linux es acelerar el acceso a los archivos del disco. Un archivo asignado a la memoria se lee una página a la vez y estas páginas se almacenan en la memoria caché de la página. La figura 3.6 muestra la caché de la página, incluido un vector de punteros a la estructura de datos mem_map_t: page_hash_table. Cada archivo en Linux está identificado por una estructura de datos de inodo VFS (descrito en la Sección 9), y cada inodo VFS es único y puede identificar completamente un archivo único. El índice de la tabla de páginas se toma del número de inodo del VFS y el desplazamiento en el archivo.
Ver linux/pagemap.h
Cuando se lee una página de datos de un archivo asignado a la memoria, como cuando la paginación por demanda debe colocarse en la memoria, la página se lee desde la memoria caché de la página. Si la página está en la memoria caché, se devuelve un puntero a la estructura de datos mem_map_t al código de manejo de errores de página. De lo contrario, la página debe cargarse en la memoria desde el sistema de archivos que contiene el archivo. Linux asigna memoria física y lee la página desde un archivo de disco. Si es posible, Linux inicia la lectura de la siguiente página del archivo. Esta búsqueda anticipada de una sola página significa que si el proceso lee datos secuencialmente del archivo, la siguiente página de datos estará esperando en la memoria.
La memoria caché de la página sigue creciendo a medida que se lee y ejecuta la imagen del programa. Si la página ya no es necesaria, se eliminará de la memoria caché. Como una imagen que ya no es utilizada por ningún proceso. Cuando Linux utiliza la memoria, las páginas físicas pueden seguir disminuyendo.En este momento, Linux puede reducir la memoria caché de la página.
3.8 Intercambio y eliminación de páginas
Cuando la memoria física es escasa, el subsistema de administración de memoria de Linux debe intentar liberar páginas físicas. Esta tarea recae en el proceso de intercambio central (kswapd). Un demonio de intercambio de núcleo es un tipo especial de proceso, un subproceso de núcleo. Un subproceso central es un proceso sin memoria virtual y se ejecuta en el espacio de direcciones físicas en estado central. El demonio central de intercambio tiene un nombre ligeramente incorrecto porque hace más que simplemente intercambiar páginas con el archivo de intercambio del sistema. Su trabajo es garantizar que el sistema tenga suficientes páginas libres para que el sistema de administración de memoria funcione de manera eficiente.
El demonio de intercambio del kernel (kswapd) es iniciado por el proceso init del kernel al inicio y espera a que expire el temporizador de intercambio del kernel. Cada vez que el temporizador expira, el proceso de intercambio verifica si hay muy pocas páginas libres en el sistema. Utiliza dos variables: free_pages_high y free_pages_low para decidir si liberar algunas páginas. Mientras el número de páginas libres en el sistema permanezca por encima de free_pages_high, el proceso de intercambio no hace nada. Vuelve a dormir hasta la próxima vez que expire su temporizador. Para hacer esta verificación, el proceso de intercambio tiene en cuenta la cantidad de páginas que se escriben en el archivo de intercambio, contadas por nr_async_pages: incrementa cada vez que una página se pone en cola para escribir en el archivo de intercambio y disminuye cuando finaliza. Free_page_low y free_page_high se establecen en el momento de inicio del sistema y están relacionados con la cantidad de páginas físicas en el sistema. Si la cantidad de páginas libres en el sistema es menor que free_pages_high o menor que free_page_low, el proceso de intercambio del kernel probará tres métodos para reducir la cantidad de páginas físicas utilizadas por el sistema:
Ver kswapd() en mm/vmscan.c
Reducir el tamaño de la memoria caché del búfer y la memoria caché de la página
Intercambiar páginas de memoria compartida de System V
Intercambiar y descartar páginas
Si el número de páginas libres en el sistema cae por debajo de free_pages_low, el proceso de intercambio central intentará liberar 6 páginas antes de la próxima ejecución. De lo contrario, intente liberar 3 páginas. Cada uno de los métodos anteriores se prueba hasta que se liberan suficientes páginas. El proceso de intercambio central registra el último método que utilizó para liberar páginas físicas. Cada vez que se ejecute, primero intentará el último método exitoso para liberar la página.
Después de liberar suficientes páginas, el proceso de intercambio vuelve a suspenderse hasta que su temporizador expire nuevamente. Si la razón por la que el proceso de intercambio del kernel libera páginas es que el número de páginas libres del sistema es menor que free_pages_low, solo duerme la mitad del tiempo que lo haría normalmente. Siempre que el número de páginas libres sea mayor que free_pages_low, el proceso de intercambio reanuda la verificación en el intervalo original.
3.8.1 Reducción del tamaño de las cachés de página y de búfer
Las páginas y las páginas en la memoria caché del búfer son buenas candidatas para el vector de área libre. Page Cache, que contiene páginas de archivos asignados a la memoria, puede tener datos innecesarios que ocupan la memoria del sistema. Del mismo modo, la caché de búfer, que incluye datos leídos o escritos en dispositivos físicos, también puede contener búferes inútiles. Cuando las páginas físicas en el sistema están a punto de agotarse, es relativamente fácil descartar las páginas en estos cachés porque no requiere escribir en el dispositivo físico (a diferencia de intercambiar páginas fuera de la memoria). Abandonar estas páginas no tiene muchos efectos secundarios dañinos, excepto que acceder a dispositivos físicos y archivos mapeados en memoria es un poco más lento. No obstante, si las páginas de estos cachés se descartan de manera justa, todos los procesos se ven afectados por igual.
Cada vez que el proceso de intercambio del kernel desea reducir estos búferes, verifica los bloques de página en el vector de página mem_map para ver si se pueden descartar de la memoria física. Si las páginas libres del sistema son demasiado bajas (peligrosas) y el proceso de intercambio central se intercambia mucho, el tamaño del bloque de página para esta verificación será mayor. El tamaño del bloque de página se comprueba en forma rotativa: cada intento de reducir el mapa de memoria utiliza un tamaño de bloque de página diferente. Esto se llama el algoritmo del reloj, como las manecillas del reloj. Se comprueba todo el vector de la página mem_map, algunas páginas a la vez.
Ver mm/filemap.cshrink_map()
Cada página verificada debe considerarse almacenada en la memoria caché de la página o en la memoria caché del búfer. Tenga en cuenta que el descarte de páginas compartidas no se considera en este momento, y una página no estará en ambos cachés al mismo tiempo. Si la página no está en ningún búfer, se comprueba la página siguiente de la tabla de vectores de páginas mem_map.
Las páginas almacenadas en caché en el caché de búfer ch (o los búferes en las páginas están en caché) hacen que la asignación y desasignación de búfer sean más eficientes. El código que reduce el mapa de memoria intenta liberar el búfer que contiene la página marcada. Si se libera el búfer, también se libera la página que contiene el búfer. Si la página marcada está en la memoria caché de la página de Linux, se eliminará de la memoria caché de la página y se liberará.
ver fs/buffer.c free_buffer()
Si este intento libera suficientes páginas, el proceso de intercambio principal continuará esperando hasta la próxima reactivación periódica. Debido a que las páginas liberadas no pertenecen a la memoria virtual de ningún proceso (solo páginas almacenadas en caché), no es necesario actualizar la tabla de páginas del proceso. Si todavía no hay suficientes páginas de caché descartadas, el proceso de intercambio intentará intercambiar algunas páginas compartidas.
3.8.2 Intercambio de páginas de memoria compartida System V
La memoria compartida en System V es un mecanismo de comunicación entre procesos que intercambia información al compartir memoria virtual entre dos o más procesos. La forma en que se comparte la memoria entre los procesos se analiza en detalle en la Sección 5. Por ahora, es suficiente decir que cada parte de la memoria compartida de System V se describe mediante una estructura de datos shmid_ds. Incluye un puntero a la estructura de datos de lista enlazada vm_area_struct para cada proceso que comparte esta memoria. La estructura de datos Vm_area_struct describe la ubicación de esta memoria compartida en cada proceso. Cada estructura vm_area_struct en esta memoria System V está vinculada con punteros vm_next_shared y vm_prev_shared. Cada estructura de datos shmid_ds tiene una lista enlazada de entradas de tablas de páginas, cada una de las cuales describe la correspondencia entre una página virtual compartida y una página física.
El proceso de intercambio del kernel también usa el algoritmo del reloj cuando intercambia las páginas de memoria compartida de System V. Cada vez que se ejecuta, registra la página de la memoria compartida que se intercambió la última vez. Se registra con dos índices: el primero es el índice en la matriz de estructura de datos shmid_ds y el segundo es el índice en la cadena de tablas de páginas de esta área de memoria compartida. De esta forma, el sacrificio del área de memoria compartida es más justo.
Ver ipc/shm.c shm_swap()
Debido a que el número de página física correspondiente a una página virtual de una memoria compartida System V específica se incluye en la tabla de páginas de cada proceso que comparte la memoria virtual, el proceso de intercambio del kernel debe modificar las tablas de páginas de todos los procesos para reflejar que la página es ya no está disponible en la memoria y en el archivo de intercambio. Para cada página compartida intercambiada, el proceso de intercambio debe encontrar la entrada correspondiente para esta página en la tabla de páginas de cada proceso compartido (buscando cada puntero vm_area_struct) si la entrada para esta página de memoria compartida en la tabla de páginas de un proceso es válida, el el proceso de intercambio lo invalidará, lo marcará como una página de intercambio y disminuirá el número en uso de esta página compartida en 1. El formato de la tabla de páginas compartidas de System V intercambiada consta de un índice en el grupo de estructura de datos shmid_ds y un índice en la entrada de la tabla de páginas en esta área de memoria compartida.
Si se ha modificado toda la memoria compartida y el número de páginas en uso se convierte en 0, la página compartida se puede escribir en el archivo de intercambio. La entrada para esta página en la tabla de páginas a la que apunta la estructura de datos shmid_ds de esta área de memoria compartida de System V se reemplazará con la entrada de la tabla de páginas intercambiadas. La entrada de la tabla de páginas intercambiadas no es válida pero contiene un índice para el archivo de intercambio abierto y el desplazamiento de esta página dentro de este archivo. Esta información se utiliza para recuperar la página en la memoria física.
3.3 Intercambio y eliminación de páginas
El proceso de intercambio se turna para verificar si todos los procesos del sistema están disponibles para el intercambio. Los buenos candidatos son procesos que se pueden intercambiar (algunos no) y tienen una o más páginas que se pueden intercambiar o descartar. Las páginas se intercambian de la memoria física al archivo de intercambio del sistema solo cuando nada más funciona.
Ver mm/vmscan.c swap_out()
La mayor parte del contenido de la imagen de ejecución del archivo de imagen se puede volver a leer desde el archivo. Por ejemplo: las instrucciones de ejecución de una imagen no se cambiarán por sí solas, por lo que no es necesario escribirlas en el archivo de intercambio. Estas páginas simplemente se desechan. Si el proceso vuelve a hacer referencia a él, se puede volver a cargar en la memoria desde la imagen de ejecución.
Una vez que se determina el proceso que se va a intercambiar, el proceso de intercambio analiza todas sus regiones de memoria virtual, buscando regiones que no estén compartidas o bloqueadas. Linux no intercambia todas las páginas del proceso seleccionado que se pueden intercambiar, sino que solo elimina una pequeña cantidad de páginas. Si una página está bloqueada en la memoria, no se puede intercambiar ni descartar.
Consulte mm/vmscan.c swap_out_vme() Rastrea el puntero vm_next vm_nex en la estructura vm_area_struct dispuesta en el proceso mm_struct.
El algoritmo de intercambio de Linux utiliza la antigüedad de la página. Cada página tiene un contador (en la estructura de datos mem_map_t) que le dice al proceso de intercambio del núcleo si vale la pena cambiar la página. Las páginas envejecen cuando no están en uso y se actualizan cuando se accede a ellas. El proceso de intercambio solo intercambia páginas antiguas. De forma predeterminada, a la edad se le asigna el valor 3 cuando se asigna la página por primera vez. Con cada visita, su edad aumenta en 3 hasta llegar a 20. Cada vez que se ejecuta el proceso de intercambio del sistema, se reduce la antigüedad de la página en 1 para hacer que la página sea antigua. Este comportamiento predeterminado se puede cambiar, por lo que esta información (y otra información relacionada) se almacena en la estructura de datos swap_control.
Si la página es demasiado antigua (antigüedad = 0), el proceso de intercambio continúa. Las páginas sucias se pueden intercambiar, y Linux describe dichas páginas con un bit dependiente de la arquitectura en el PTE que describe la página (consulte la Figura 3.2). Sin embargo, no es necesario escribir todas las páginas sucias en el archivo de intercambio. El área de memoria virtual de cada proceso puede tener su propia operación de intercambio (indicado por el puntero vm_ops en vm_area_struct), si es así, el proceso de intercambio lo utilizará de esta manera. De lo contrario, el proceso de intercambio asigna una página del archivo de intercambio y escribe la página en el archivo.
La entrada de la tabla de páginas para esta página se reemplaza con una entrada no válida, pero contiene información sobre la página en el archivo de intercambio: el desplazamiento dentro del archivo donde se encuentra la página y el archivo de intercambio utilizado. Independientemente del intercambio, la página física original se vuelve a colocar en el área libre para volver a publicarla. Las páginas limpias (o no sucias) se pueden descartar y volver a colocar en el área libre para su reutilización.
Si se intercambian o descartan suficientes páginas para el proceso de intercambio, el proceso de intercambio vuelve a suspenderse. La próxima vez que se despierte, considerará el siguiente proceso en el sistema. De esta forma, el proceso de intercambio muerde las páginas físicas de cada proceso hasta que el sistema se reequilibra. Esto es más justo que cambiar todo el proceso.
3.9 La caché de intercambio
Al intercambiar páginas con el archivo de intercambio, Linux evita escribir páginas innecesarias. A veces, una página puede existir tanto en el archivo de intercambio como en la memoria física. Esto sucede cuando una página se extrae de la memoria y luego se vuelve a colocar en la memoria cuando el proceso desea acceder a ella. Mientras no se haya escrito en la página de la memoria, la copia en el archivo de intercambio sigue siendo válida.
Linux usa el caché de intercambio para realizar un seguimiento de estas páginas. La caché de intercambio es una entrada de la tabla de páginas o una lista vinculada de páginas físicas del sistema. Una página de intercambio tiene una entrada en la tabla de páginas que describe el archivo de intercambio utilizado y su ubicación en el archivo de intercambio. Si la entrada de la memoria caché de intercambio no es cero, significa que no se ha cambiado una página en el archivo de intercambio. Si la página se modifica (escribe) más tarde, su entrada se elimina del caché de intercambio)
Cuando Linux necesita intercambiar una página física con el archivo de intercambio, busca en el caché de intercambio y, si hay una entrada válida para la página, no necesita escribir la página en el archivo de intercambio. Porque esta página en la memoria no se ha modificado desde la última vez que se leyó el archivo de intercambio.
Las entradas en el caché de intercambio son entradas de la tabla de páginas que alguna vez se intercambiaron. Están marcados como no válidos, pero contienen información que permite a Linux encontrar el archivo de intercambio correcto y las páginas correctas en el archivo de intercambio.
3.10 Intercambio de página
Es posible que deba acceder nuevamente a las páginas sucias almacenadas en el archivo de intercambio. Por ejemplo: cuando la aplicación quiere escribir datos en la memoria virtual, y la página física correspondiente a esta página se intercambia al archivo de intercambio. Acceder a páginas de memoria virtual que no están en la memoria física provocará un error de página. Una falla de página es una señal del procesador para informar al sistema operativo que no puede convertir la memoria virtual en memoria física. Porque la entrada de la tabla de páginas en la memoria virtual que describe esta página se marca como no válida después del intercambio. El procesador no puede manejar la traducción de direcciones virtuales a físicas, devolviendo el control al sistema operativo, diciéndole la dirección virtual del error y la razón del error. El formato de esta información y cómo el procesador transfiere el control al sistema operativo depende del tipo de procesador. El código de manejo de fallas de página dependiente del procesador debe ubicar la estructura de datos vm_area_struct que describe el área de memoria virtual que contiene la dirección virtual de la falla. Funciona examinando la estructura de datos vm_area_struct del proceso hasta que encuentra la que contiene la dirección virtual errónea. Este es un código muy crítico en el tiempo, por lo que la estructura de datos vm_area_struct de un proceso se organiza de una manera particular para que esta búsqueda tome el menor tiempo posible.
ver arch/i386/mm/fault.c do_page_fault()
Habiendo realizado las acciones apropiadas dependientes del procesador y encontrado una memoria virtual válida que incluye la dirección virtual donde ocurrió (ocurrió) la falla, el proceso de manejo de fallas de página es nuevamente genérico y puede usarse para todos los procesadores en los que se puede ejecutar Linux. El código genérico de manejo de fallas de página busca la entrada de la tabla de páginas para la dirección virtual incorrecta. Si la entrada de la tabla de páginas que encuentra es una página que se intercambió, Linux debe volver a intercambiar la página en la memoria física. El formato de las entradas de la tabla de páginas para las páginas intercambiadas depende del procesador, pero todos los procesadores marcan estas páginas como no válidas y colocan la información necesaria en la entrada de la tabla de páginas para localizar la página en el archivo de intercambio. Linux usa esta información para volver a paginar la página en la memoria física.
Ver mm/memory.c do_no_page()
En este punto, Linux conoce la dirección virtual donde (ocurrió) el error y la entrada de la tabla de páginas sobre dónde se cambia esta página. La estructura de datos Vm_area_struct puede contener un puntero a una rutina para intercambiar páginas en esta memoria virtual de vuelta a la memoria física. Esta es la operación de intercambio. Si hay una operación de intercambio en esta memoria, Linux la usará. De hecho, la razón por la cual la memoria compartida intercambiada de System V necesita un procesamiento especial es porque el formato de las páginas de memoria compartida intercambiadas de System V es diferente al de las páginas de intercambio ordinarias. Si no hay una operación de intercambio, Linux asume que esta es una página normal y no requiere un manejo especial. Asigna una página física libre y lee las páginas intercambiadas del archivo de intercambio. La información sobre dónde (y qué archivo de intercambio) del archivo de intercambio se toma de una entrada de tabla de páginas no válida.
Ver mm/page_alloc.c swap_in()
Si el acceso que causó la falla de la página no fue un acceso de escritura, la página se deja en el caché de intercambio y su entrada en la tabla de páginas se marca como no escribible. Si la página se escribe más tarde, se produce otro error de página, en cuyo momento la página se marca como sucia y su entrada se elimina de la memoria caché de intercambio. Si la página no ha sido modificada y necesita ser intercambiada, Linux puede evitar escribir la página en el archivo de intercambio porque la página ya está en el archivo de intercambio.
Si el acceso para recuperar la página del archivo de intercambio es un acceso de escritura, la página se elimina de la memoria caché de intercambio y la página de entrada de la tabla de páginas para esta página se marca como sucia y se puede escribir.
4. Procesos
Los procesos realizan tareas en el sistema operativo. Un programa es una imagen ejecutable de una serie de instrucciones de código de máquina y datos almacenados en el disco y, por lo tanto, es una entidad pasiva. Un proceso puede considerarse como un programa informático en ejecución. Es una entidad dinámica que cambia constantemente a medida que el procesador ejecuta instrucciones de código de máquina. Al procesar las instrucciones y los datos del programa, el proceso también incluye el contador del programa y otros registros de la CPU, así como la pila, que incluye datos temporales como parámetros de rutina, direcciones de retorno y variables guardadas. El programa o proceso que se está ejecutando actualmente incluye toda la actividad actual en el microprocesador. Linux es un sistema operativo multiproceso. Los procesos son tareas separadas con sus propios derechos y responsabilidades. Si un proceso falla, no debería fallar otro proceso en el sistema. Cada proceso independiente se ejecuta en su propio espacio de direcciones virtuales y no puede afectar a otros procesos excepto a través de un mecanismo administrado por el núcleo seguro.
Durante la vida útil de un proceso, utiliza muchos recursos del sistema. Utiliza la CPU del sistema para ejecutar sus instrucciones y la memoria física del sistema para almacenarla y sus datos. Abre y utiliza archivos en el sistema de archivos y, directa o indirectamente, utiliza los dispositivos físicos del sistema. Linux debe realizar un seguimiento del proceso en sí y de los recursos del sistema que utiliza para administrar de manera justa ese proceso y otros procesos en el sistema. Si un proceso monopoliza la mayor parte de la memoria física y la CPU del sistema, es injusto para otros procesos.
El recurso más preciado del sistema es la CPU. Por lo general, solo hay un sistema. Linux es un sistema operativo multiproceso. Su objetivo es mantener el proceso ejecutándose en cada CPU del sistema, aprovechando al máximo la CPU. Si hay más procesos que la CPU (que suele ser el caso), los procesos restantes deben esperar hasta que la CPU se libere antes de poder ejecutarse. El multiprocesamiento es una idea simple: un proceso continúa ejecutándose hasta que tiene que esperar, generalmente por algún recurso del sistema, antes de que pueda continuar ejecutándose. En un sistema de un solo proceso, como DOS, la CPU simplemente se establece en reposo, por lo que se desperdicia el tiempo de espera. En un sistema multiproceso, muchos procesos están en la memoria al mismo tiempo. Cuando un proceso tiene que esperar, el sistema operativo le quita la CPU al proceso y se la da a otro proceso que la necesita más. es el programador seleccionado
El siguiente proceso más apropiado. Linux utiliza una serie de esquemas de programación para garantizar la equidad.
Linux admite muchos formatos de archivos ejecutables diferentes, ELF es uno de ellos, Java es otro. Linux debe administrar estos archivos de manera transparente porque los procesos usan las bibliotecas compartidas del sistema.
4.1 Procesos Linux
En Linux, cada proceso está representado por una estructura de datos task_struct (interoperabilidad de tareas y procesos en Linux), que se utiliza para administrar los procesos en el sistema. La tabla de vectores de tareas es una matriz de punteros a cada estructura de datos task_struct en el sistema. Esto significa que el número máximo de procesos en el sistema está limitado por la tabla de vectores de tareas, que es 512 por defecto. Cuando se crea un nuevo proceso, se asigna una nueva estructura_tarea desde la memoria del sistema y se agrega a la tabla de vectores de tareas. Para que sea más fácil de encontrar, use el puntero actual para señalar el proceso que se está ejecutando actualmente.
ver include/linux/sched.h
Además de los procesos normales, Linux también admite procesos en tiempo real. Estos procesos deben reaccionar rápidamente a eventos externos (de ahí el nombre de "tiempo real"), y el programador debe tratarse de manera diferente a los procesos de usuario normales. Aunque la estructura de datos task_struct es muy grande y compleja, sus campos se pueden dividir en las siguientes funciones:
Cuando se ejecuta el proceso State, cambia de estado según la situación. Los procesos de Linux usan los siguientes estados: (Aquí se omite SWAPPING porque no parece usarse)
El proceso en ejecución está en ejecución (es el proceso actual del sistema) o está listo para ejecutarse (en espera de ser programado en una CPU del sistema)
Un proceso de espera está esperando un evento o recurso. Linux distingue entre dos tipos de procesos de espera: interrumpibles e ininterrumpibles. Un proceso de espera interrumpible puede ser interrumpido por una señal, mientras que un proceso de espera ininterrumpible espera directamente una condición de hardware y no puede ser interrumpido por ninguna situación.
Detenido Proceso detenido, generalmente al recibir una señal. El proceso que se está depurando puede estar en un estado detenido.
El proceso terminado por Zombie, por alguna razón, tiene una entrada en la estructura de datos task_struct en la tabla de vectores de tareas. Tal como suena, es un proceso muerto.
Información de programación El programador necesita esta información para decidir de manera justa cuál de los procesos del sistema debe ejecutarse.
Cada proceso en el sistema de Identificadores tiene un identificador de proceso. El identificador de proceso no es un índice en la tabla de vectores de tareas, sino solo un número. Cada proceso también tiene identificadores de usuario y grupo. Se utiliza para controlar el acceso de procesos a archivos y dispositivos en el sistema.
Inter-Process Communication Linux admite mecanismos UNIX-IPC tradicionales, a saber, señales, conductos y semáforos, así como los mecanismos IPC de System V, a saber, memoria compartida, semáforos y colas de mensajes. Los mecanismos IPC compatibles con Linux se describen en la Sección 5.
Enlaces En un sistema Linux, ningún proceso es completamente independiente de otros procesos. Cada proceso en el sistema, excepto el proceso inicial, tiene un proceso padre. El nuevo proceso no se crea, sino que se copia o clona a partir del proceso anterior. Cada task_struct de proceso tiene punteros a sus procesos padre y hermano (procesos con el mismo padre) y sus procesos hijo.
En los sistemas Linux, puede ver las relaciones familiares de los procesos en ejecución con el comando pstree:
init(1)-+-crond(98)
|-emacs(387)
|-gpm(146)
|-inetd(110)
|-kerneld(18)
|-kflushd(2)
|-klogd(87)
|-kswapd(3)
|-login(160)---bash(192)---emacs(225)
|-lpd(121)
|-mingetty(161)
|-mingetty(162)
|-mingetty(163)
|-mingetty(164)
|-login(403)---bash(404)---pstree(594)
|-sendmail(134)
|-syslogd(78)
`-update(166)Además, toda la información del proceso en el sistema también se almacena en una lista doblemente enlazada de estructura de datos task_struct, y la raíz es el proceso de inicio. Esta tabla le permite a Linux encontrar todos los procesos en el sistema. Necesita esta tabla para proporcionar soporte para comandos como ps o kill.
Tiempos y temporizadores Durante el ciclo de vida de un proceso, el núcleo realiza un seguimiento de sus otros tiempos además del tiempo de CPU que utiliza. Cada intervalo de tiempo (tick del reloj), el kernel actualiza el tiempo empleado por el proceso actual en santiamén en el modo de sistema y de usuario. Linux también admite contadores para intervalos de tiempo especificados por procesos. Un proceso puede utilizar una llamada al sistema para configurar un temporizador y enviarse una señal a sí mismo cuando expire el temporizador. Este temporizador puede ser de una sola vez o periódico.
El proceso del sistema de archivos puede abrir o cerrar archivos según sea necesario.La estructura task_struct del proceso almacena un puntero a cada descriptor de archivo abierto y un puntero a dos inodos VFS. Cada inodo VFS describe de forma única un archivo o directorio en un sistema de archivos y también proporciona una interfaz común para el sistema de archivos subyacente. La forma en que se admiten los sistemas de archivos en Linux se describe en la Sección 9. El primer inodo es la raíz del proceso (su directorio de inicio) y el segundo es su directorio actual o pwd. Pwd se toma del comando Unix: imprimir el directorio de trabajo. Los dos nodos de VFS tienen campos de conteo que crecen a medida que uno o más procesos los referencian. Es por eso que no puede eliminar un directorio que un proceso ha establecido como su directorio de trabajo.
Memoria virtual La mayoría de los procesos tienen algo de memoria virtual (los subprocesos del kernel y los demonios del kernel no), y el kernel de Linux debe saber cómo se asigna esta memoria virtual a la memoria física del sistema.
El proceso de contexto específico del procesador puede verse como la suma del estado actual del sistema. Mientras el proceso se ejecuta, utiliza los registros del procesador, la pila, etc. Cuando se suspende un proceso, el contexto de estos procesos y el contexto relacionado con la CPU deben guardarse en la estructura task_struct del proceso. Cuando el planificador reinicia el proceso, su contexto se restaura desde aquí.
4.2 Identificadores
Linux, como todos los Unixes, utiliza identificadores de usuarios y grupos para verificar los derechos de acceso a archivos e imágenes en el sistema. Todos los archivos en un sistema Linux tienen propiedad y permisos, y estos permisos describen qué permisos tiene el sistema en ese archivo o directorio. Los permisos básicos son de lectura, escritura y ejecución, y se asignan 3 grupos de usuarios: el propietario del archivo, los procesos pertenecientes a un grupo específico y otros procesos del sistema. Cada grupo de usuarios puede tener diferentes permisos, por ejemplo, un archivo puede ser leído y escrito por su propietario y leído por su grupo, pero otros procesos en el sistema no pueden acceder a él.
Linux usa grupos para otorgar permisos a un grupo de usuarios a un archivo o directorio, en lugar de a un solo usuario o proceso en el sistema. Por ejemplo, puede crear un grupo para todos los usuarios de un proyecto de software, de modo que solo ellos puedan leer y escribir el código fuente del proyecto. Un proceso puede pertenecer a varios grupos (32 por defecto), y estos grupos se colocan en la tabla de vectores de grupos en la estructura task_struct de cada proceso. Siempre que uno de los grupos a los que pertenece un proceso tenga acceso a un archivo, el proceso tiene los permisos de grupo apropiados para el archivo.
Hay 4 pares de identificadores de proceso y grupo en task_struct de un proceso.
Uid, gid el identificador del usuario y el identificador del grupo utilizado por el proceso para ejecutar
uid y gid efectivos Algunos programas cambian el uid y el gid del proceso de ejecución por el suyo propio (en las propiedades de la imagen de ejecución del inodo VFS). Estos programas se denominan programas setuid. Esto es útil porque puede restringir el acceso a los servicios, especialmente aquellos que se ejecutan a la manera de otra persona, como un demonio de red. El uid y el gid efectivos provienen del programa setuid, y el uid y el gid siguen siendo los mismos. El kernel verifica el uid y el gid efectivos al verificar los privilegios.
El uid y el gid del sistema de archivos suelen ser iguales a los uid y gid efectivos, verifique los derechos de acceso al sistema de archivos. Sistema de archivos para montaje a través de NFS. En este momento, el servidor NFS en modo usuario necesita acceder al archivo como un proceso especial. Solo cambian el uid y el gid del sistema de archivos (no el uid y el gid efectivos). Esto evita que los usuarios malintencionados envíen señales Kill a los servidores NFS. Kill se envía al proceso con un uid y un gid efectivos especiales.
Uid y gid guardados Este es un requisito del estándar POSIX, que permite que los programas cambien el uid y el gid de un proceso a través de llamadas al sistema. Se utiliza para almacenar el uid y el gid reales después de que hayan cambiado el uid y el gid originales.
4.3 Programación
Todos los procesos se ejecutan en parte en modo usuario y en parte en modo sistema. La forma en que el hardware subyacente admite estos estados varía, pero generalmente existe un mecanismo de seguridad para pasar del modo de usuario al modo de sistema y viceversa. El modo de usuario tiene permisos mucho más bajos que el modo de sistema. Cada vez que un proceso ejecuta una llamada al sistema, cambia del modo de usuario al modo de sistema y continúa la ejecución. En este punto, deje que el núcleo ejecute el proceso. En Linux, los procesos no compiten entre sí para ser el proceso en ejecución actual, no pueden detener otros procesos en ejecución y ejecutarse ellos mismos. Cada proceso renuncia a la CPU cuando tiene que esperar algún evento del sistema. Por ejemplo, un proceso podría tener que esperar para leer un carácter de un archivo. Esta espera ocurre en una llamada al sistema en modo sistema. El proceso utiliza una función de biblioteca para abrir y leer el archivo, que a su vez ejecuta una llamada al sistema para leer los bytes del archivo abierto. En este punto, el proceso de espera se suspenderá y se seleccionará otro proceso más valioso para su ejecución. Los procesos a menudo llaman llamadas al sistema, por lo que a menudo necesitan esperar. Incluso si el proceso necesita esperar, puede usar eventos de CPU desequilibrados, por lo que Linux usa la programación preventiva. Con este esquema, se permite que cada proceso se ejecute durante un período de tiempo pequeño, milisegundos 200. Cuando transcurre este tiempo, se selecciona otro proceso para ejecutar y el proceso original espera un tiempo hasta que se ejecuta nuevamente. Este período de tiempo se llama segmento de tiempo.
Se requiere que el planificador seleccione el proceso más merecedor de todos los procesos que pueden ejecutarse en el sistema. Un proceso ejecutable es aquel que simplemente espera a la CPU. Linux utiliza un algoritmo de programación basado en prioridades razonable y simple para elegir entre los procesos actuales en el sistema. Cuando selecciona un nuevo proceso para ejecutar, guarda el estado del proceso actual, los registros relacionados con el procesador y otra información contextual que debe guardarse en la estructura de datos task_struct del proceso. Luego restaura el estado del nuevo proceso a ejecutar (nuevamente, asociado con el procesador) y transfiere el control del sistema a este proceso. Para distribuir equitativamente el tiempo de CPU entre todos los procesos ejecutables en el sistema, el programador almacena información en la estructura task_struct de cada proceso:
Véase también kernel/sched.c schedule()
política La política de programación del proceso. Linux tiene dos tipos de procesos: normal y en tiempo real. Los procesos en tiempo real tienen mayor prioridad que todos los demás procesos. Si hay un proceso en vivo listo para ejecutarse, siempre se ejecuta primero. Hay dos estrategias para los procesos en tiempo real: round robin y first in first out. Bajo la estrategia de programación del anillo, cada proceso en tiempo real se ejecuta en secuencia, mientras que bajo la estrategia de primero en entrar, primero en salir, cada proceso ejecutable se ejecuta de acuerdo con su orden en la cola de programación, y este orden no cambiará.
Prioridad La prioridad de programación del proceso. También la cantidad de tiempo (jiffies) que puede usar cuando se le permite ejecutarse. Puede cambiar la prioridad de un proceso mediante llamadas al sistema o el comando renice.
Rt_priority Linux admite procesos en tiempo real. Estos procesos tienen mayor prioridad que otros procesos que no son en tiempo real en el sistema. Este campo permite al planificador asignar una prioridad relativa a cada proceso en tiempo real. La prioridad de un proceso en tiempo real se puede modificar con una llamada al sistema
Contador La cantidad de tiempo (en santiamén) que el proceso puede ejecutarse en este momento. Cuando se inicia el proceso, es igual a la prioridad (prioridad), que se decrementa cada ciclo de reloj.
El programador se ejecuta desde varios lugares en el núcleo. Puede ejecutarse después de que el proceso actual se coloque en la cola de espera, o puede ejecutarse después de la llamada al sistema antes de que el proceso regrese del estado del sistema al estado del proceso. Otra razón para ejecutar el programador es que el reloj del sistema simplemente establece el contador del proceso actual en cero. Cada vez que se ejecuta el programador, hace lo siguiente:
Véase también kernel/sched.c schedule()
El programador de trabajo del kernel ejecuta el controlador de la mitad inferior y maneja la cola de tareas programadas del sistema. Estos hilos de núcleo livianos se describen en detalle en la Sección 11
El proceso actual debe deshacerse del proceso actual antes de seleccionar otro proceso.
Si la política de programación del proceso actual es circular, se coloca al final de la cola de ejecución.
Si la tarea es interrumpible y recibió una señal la última vez que se programó, su estado cambia a EN EJECUCIÓN
Si el proceso actual expira, su estado se convierte en EJECUTANDO
Si el estado del proceso actual es EN EJECUCIÓN, mantenga este estado
Los procesos que no están EN EJECUCIÓN o INTERRUPTIBLES se eliminan de la cola de ejecución. Esto significa que dichos procesos no se tienen en cuenta cuando el programador busca los procesos más valiosos para ejecutar.
El planificador de selección de procesos analiza los procesos en la cola de ejecución para encontrar los procesos más valiosos para ejecutar. Si hay un proceso en tiempo real (con una política de programación en tiempo real), será más pesado que un proceso normal. El peso de un proceso normal es su contador, pero para un proceso en tiempo real es contador más 1000. Esto significa que si hay un proceso ejecutable en tiempo real en el sistema, siempre se ejecutará antes que cualquier proceso ejecutable normal. El proceso actual, debido a que consume algunos intervalos de tiempo (su contador se reduce), estará en desventaja si hay otros procesos de la misma prioridad en el sistema: como debe ser. Si varios procesos tienen la misma prioridad, se selecciona el más cercano al frente de la cola de ejecución. El proceso actual se coloca al final de la cola de ejecución. Si un sistema equilibrado tiene una gran cantidad de procesos de la misma prioridad, ejecute estos procesos en orden. Esto se denomina política de programación de llamadas. Sin embargo, debido a que los procesos necesitan esperar los recursos, el orden en que se ejecutan puede cambiar.
Intercambiar procesos Si el proceso que más vale la pena no es el proceso actual, el proceso actual debe suspenderse y se ejecutará el nuevo proceso. Cuando se ejecuta un proceso, utiliza la CPU, los registros del sistema y la memoria física. Cada vez que llama a una rutina, pasa parámetros a través de registros o pilas, guarda valores como la dirección de retorno de la rutina que llama, etc. Por lo tanto, cuando se ejecuta el programador, se ejecuta en el contexto del proceso actual. Puede estar en modo privilegiado: modo kernel, pero aún es el proceso que se está ejecutando actualmente. Cuando se va a suspender el proceso, todo su estado de máquina, incluido el contador de programa (PC) y todos los registros del procesador, deben almacenarse en la estructura de datos task_struct del proceso. Luego, se debe cargar todo el estado de la máquina del nuevo proceso. Esta operación depende del sistema, no exactamente igual en diferentes CPU, pero a menudo con la ayuda de algún hardware.
El intercambio del contexto del proceso ocurre al final del cronograma. El contexto almacenado por el proceso anterior es una instantánea del contexto de hardware del sistema cuando el proceso está programado para finalizar. Del mismo modo, cuando se carga un nuevo contexto de proceso, todavía hay una instantánea al final de la programación, incluidos los contenidos del contador y los registros del programa del proceso.
Si el proceso anterior o el nuevo proceso actual usa memoria virtual, las tablas de páginas del sistema deben actualizarse. Una vez más, esta acción depende de la arquitectura. Los procesadores Alpha AXP, que usan TLT (Tabla de búsqueda de traducción) o entradas de la tabla de páginas en caché, deben borrar las entradas de la tabla de páginas en caché que pertenecen al proceso anterior.
4.3.1 Planificación en sistemas multiprocesador
En el mundo Linux, hay relativamente pocos sistemas multi-CPU, pero se ha trabajado mucho para hacer de Linux un sistema operativo SMP (multiprocesamiento simétrico). Es decir, la capacidad de equilibrar la carga entre las CPU del sistema. El equilibrio de carga no es más importante que en el programador.
En un sistema multiprocesador, la situación deseada es que todos los procesadores estén ocupados ejecutando procesos. Cada proceso ejecuta el programador de forma independiente hasta que su proceso actual se queda sin intervalo de tiempo o tiene que esperar por los recursos del sistema. Lo primero que debe tener en cuenta en los sistemas SMP es que puede haber más de un proceso inactivo en el sistema. En un sistema de un solo procesador, el proceso inactivo es la primera tarea en la tabla de vectores de tareas.En un sistema SMP, cada CPU tiene un proceso inactivo y es posible que tenga más de una CPU inactiva. Además, cada CPU tiene un proceso actual, por lo que el sistema SMP debe registrar los procesos actuales e inactivos de cada procesador.
En un sistema SMP, task_struct de cada proceso contiene el número de procesador actualmente en ejecución (procesador) y el último número de procesador en ejecución (last_processor). No tiene sentido por qué un proceso no debe ejecutarse en una CPU diferente cada vez que se elige ejecutarlo, pero Linux puede usar la máscara_procesador para restringir un proceso a una o más CPU. Si se establece el bit N, el proceso puede ejecutarse en el procesador N. Cuando el planificador elige un proceso para ejecutar, no considera los procesos cuyos bits correspondientes de procesador_máscara no están establecidos. El programador también aprovecha el último proceso que se ejecuta en el procesador actual, ya que a menudo hay un costo de rendimiento al mover un proceso a otro procesador.

4.4 Archivos
La figura 4.1 muestra las dos estructuras de datos utilizadas para describir la información relacionada con el sistema de archivos en cada proceso del sistema. El primer fs_struct contiene el inodo VFS del proceso y su umask. Umask es el modo predeterminado cuando se crean nuevos archivos y se puede cambiar a través de llamadas al sistema.
ver include/linux/sched.h
La segunda estructura de datos, files_struct, contiene información sobre todos los archivos actualmente en uso por el proceso. Los programas leen desde la entrada estándar, escriben en la salida estándar y envían mensajes de error al error estándar. Estos pueden ser archivos, entrada/salida de terminal o dispositivos del siglo, pero todos son considerados archivos desde el punto de vista de un programa. Cada archivo tiene su descriptor, y files_struct contiene punteros a 256 resultados de datos de archivos, cada uno de los cuales describe un archivo con forma de proceso. El campo F_mode describe el modo en que se creó el archivo: solo lectura, lectura y escritura o solo escritura. F_pos registra la posición de la siguiente operación de lectura y escritura en el archivo. F_inode apunta al inodo que describe el archivo, y f_ops es un puntero a un conjunto de direcciones de rutina, cada una de las cuales es una función para procesar el archivo. Por ejemplo funciones que escriben datos. Esta interfaz abstracta es muy poderosa y permite que Linux admita una gran cantidad de tipos de archivos. Podemos ver que la tubería también se implementa con este mecanismo en Linux.
Cada vez que se abre un archivo, se utiliza un puntero de archivo libre en files_struct para apuntar a la nueva estructura de archivos. Ya hay 3 descriptores de archivos abiertos cuando se inicia el proceso de Linux. Estos son entrada estándar, salida estándar y error estándar, todos heredados del proceso principal que los creó. El acceso a los archivos se realiza a través de llamadas al sistema estándar, que deben pasar o devolver un descriptor de archivo. Estos descriptores son índices en la tabla de vectores fd del proceso, por lo que los descriptores de archivo para la entrada estándar, la salida estándar y el error estándar son 0, 1 y 2, respectivamente. Todo acceso al archivo se logra utilizando las rutinas de operación de archivos en la estructura de datos del archivo junto con su inodo VFS.
4.5 Memoria virtual
La memoria virtual de un proceso incluye la ejecución de código y datos de una variedad de fuentes. La primera es una imagen de programa cargada, como el comando ls. Este comando, como todas las imágenes de ejecución, consta de código de ejecución y datos. El archivo de imagen contiene toda la información necesaria para cargar el código de ejecución y los datos del programa asociado en la memoria virtual del proceso. En segundo lugar, un proceso puede asignar memoria (virtual) durante el procesamiento, como para almacenar el contenido de un archivo que lee. La memoria virtual recién asignada debe conectarse a la memoria virtual existente del proceso antes de que pueda usarse. En el tercero, los procesos de Linux utilizan bibliotecas de código común, como el procesamiento de archivos. No tiene sentido que cada proceso incluya una copia de la biblioteca, Linux usa bibliotecas compartidas, que pueden ser compartidas por varios procesos que se ejecutan simultáneamente. El código y los datos de estas bibliotecas compartidas deben estar vinculados al espacio de direcciones virtuales del proceso y al espacio de direcciones virtuales de otros procesos que comparten la biblioteca.
En un momento dado, un proceso no utiliza todo el código y datos contenidos en su memoria virtual. Puede incluir código destinado a ser utilizado en situaciones específicas, como la inicialización o el manejo de eventos específicos. Puede que solo esté usando algunas de las rutinas en su biblioteca compartida. Sería un desperdicio cargar todo este código en la memoria física y no usarlo. Multiplique este desperdicio por el número de procesos en el sistema, y la eficiencia operativa del sistema será muy baja. En cambio, Linux utiliza la tecnología de paginación por demanda, donde la memoria virtual de un proceso se lleva a la memoria física solo cuando el proceso intenta usarla. Por lo tanto, Linux no carga directamente el código y los datos en la memoria, sino que modifica la tabla de páginas del proceso para marcar estas áreas virtuales como existentes pero no en la memoria. Cuando un proceso intenta acceder a este código o datos, el hardware del sistema generará una falla de página, pasando el control al kernel de Linux para su procesamiento. Por lo tanto, para cada región de memoria virtual del espacio de direcciones del proceso, Linux necesita saber de dónde proviene y cómo colocarlo en la memoria para que pueda manejar estas fallas de página.
El kernel de Linux necesita administrar todas estas áreas de memoria virtual, y el contenido de la memoria virtual de cada proceso se describe mediante una estructura de datos mm_struct mm_struc a la que apunta su task_struct. La estructura de datos mm_struct del proceso también incluye información sobre la imagen de ejecución cargada y un puntero a la tabla de páginas del proceso. Contiene punteros a un conjunto de estructuras de datos vm_area_struct, cada una de las cuales representa un área de memoria virtual en el proceso.
Esta lista enlazada está ordenada en el orden de la memoria virtual. La figura 4.2 muestra la distribución de la memoria virtual de un proceso simple y las estructuras de datos principales que lo gestionan. Debido a que estas áreas de memoria virtual provienen de diferentes fuentes, Linux abstrae la interfaz mediante vm_area_struct que apunta a un conjunto de rutinas de procesamiento de memoria virtual (a través de vm_ops). De esta forma, toda la memoria virtual de un proceso se puede manejar de manera coherente, independientemente del servicio subyacente que administre esta memoria. Por ejemplo, habría una rutina genérica que se llama cuando un proceso intenta acceder a una memoria inexistente, que es como se manejan las fallas de página.
Cuando Linux crea nuevas áreas de memoria virtual para un proceso y maneja las referencias a la memoria virtual que no están en la memoria física del sistema, se hace referencia repetidamente a la lista de estructura de datos vm_area_struct del proceso. Esto significa que el tiempo que lleva encontrar la estructura de datos vm_area_struct correcta es importante para el rendimiento del sistema. Para acelerar el acceso, Linux también coloca la estructura de datos vm_area_struct en un árbol AVL (Adelson-Velskii y Landis). El árbol está dispuesto de modo que cada vm_area_struct (o nodo) tenga un puntero izquierdo y otro derecho a la estructura adyacente vm_area_struct. El puntero izquierdo apunta a un nodo con una dirección virtual inicial más baja y el puntero derecho apunta a un nodo con una dirección virtual inicial más alta. Para encontrar el nodo correcto, Linux comienza en la raíz del árbol y sigue los punteros izquierdo y derecho de cada nodo hasta encontrar la vm_area_struct correcta. Por supuesto, liberar en medio de este árbol no toma tiempo, e insertar un nuevo vm_area_struct toma tiempo de procesamiento adicional.

Cuando un proceso asigna memoria virtual, Linux no reserva memoria física para el proceso. Describe esta memoria virtual a través de una nueva estructura de datos vm_area_struct, que está conectada a la lista de memoria virtual del proceso. Cuando el proceso intenta escribir en esta nueva área de memoria virtual, el sistema fallará en la página. El procesador intenta decodificar esta dirección virtual, pero no hay una entrada en la tabla de páginas para esa memoria, se rendirá y generará una excepción de falla de página, que el kernel de Linux manejará. Linux verifica si la dirección virtual a la que se hace referencia está en el espacio de direcciones virtuales del proceso y, de ser así, crea el PTE apropiado y asigna una página de memoria física para el proceso. Tal vez el código o los datos correspondientes deban cargarse desde el sistema de archivos o el disco de intercambio, y luego el proceso se vuelve a ejecutar desde la instrucción que causó la falla de la página, porque esta vez la memoria realmente existe y puede continuar.
4.6 Creación de un proceso
Cuando el sistema arranca, se ejecuta en el estado del kernel.En este momento, solo hay un proceso: el proceso de inicialización. Como todos los demás procesos, el proceso inicial tiene un conjunto de estados de máquina representados por pilas, registros, etc. Esta información se almacena en la estructura de datos task_struct del proceso inicial cuando se crean y ejecutan otros procesos en el sistema. Al final de la inicialización del sistema, el proceso inicial inicia un subproceso central (llamado init) y ejecuta un bucle inactivo, sin hacer nada. El planificador ejecuta este proceso inactivo cuando no hay nada que hacer. El task_struct de este proceso inactivo es el único que no se asigna dinámicamente sino que se define estáticamente cuando se conecta el núcleo. Para evitar confusiones, se llama init_task.
El subproceso o proceso principal de Init tiene el identificador de proceso 1 y es el primer proceso real del sistema. Realiza alguna configuración inicial del sistema (como encender el sistema para controlarlo, montar el sistema de archivos raíz) y luego ejecuta la rutina de inicialización del sistema. Dependiendo de su sistema, puede ser uno de /etc/init, /bin/init o /sbin/init. El programa Init usa /etc/inittab como un archivo de secuencia de comandos para crear nuevos procesos en el sistema. Estos nuevos procesos pueden por sí mismos crear nuevos procesos. Por ejemplo, el proceso getty puede crear un proceso de inicio de sesión cuando el usuario intenta iniciar sesión. Todos los procesos en el sistema son descendientes del subproceso principal init.
La creación de un nuevo proceso se logra clonando el proceso anterior o clonando el proceso actual. Se crea una nueva tarea a través de una llamada al sistema (bifurcación o clon) y la clonación se produce en el estado del núcleo del núcleo. Al final de la llamada al sistema, se genera un nuevo proceso, en espera de que el planificador elija que se ejecute. Asigne una o más páginas físicas de la memoria física del sistema para la pila del proceso clonado (usuario y núcleo) para la nueva estructura de datos task_struct. Se creará un identificador de proceso que es único dentro del grupo de identificadores de proceso del sistema. Sin embargo, también es posible que el proceso clonado conserve el identificador de proceso de su padre. La nueva estructura_tarea ingresa a la tabla de vectores de tareas y el contenido de la estructura_tarea del proceso anterior (actual) se copia en la estructura_tarea clonada.
Ver kernel/fork.c do_fork()
Al clonar procesos, Linux permite que dos procesos compartan recursos en lugar de tener copias separadas. Incluyendo archivos de proceso, manejo de señales y memoria virtual. Al compartir estos recursos, sus campos de conteo correspondientes aumentan o disminuyen en consecuencia, por lo que Linux no liberará estos recursos hasta que ambos procesos dejen de usarlos. Por ejemplo, si el proceso clonado quiere compartir la memoria virtual, su task_struct incluirá un puntero a mm_struct del proceso original, y el campo de recuento de mm_struct se incrementa para indicar la cantidad de procesos que la comparten actualmente.
La clonación de la memoria virtual de un proceso requiere una habilidad considerable. Se debe generar un conjunto de estructuras de datos vm_area_struct, las estructuras de datos mm_struct correspondientes y la tabla de páginas del proceso clonado sin copiar la memoria virtual del proceso. Esta puede ser una tarea difícil y que requiere mucho tiempo, ya que parte de la memoria virtual puede estar en la memoria física y otra parte puede estar en el archivo de intercambio. En cambio, Linux usa una técnica llamada "copiar al escribir", que copia la memoria virtual solo cuando uno de los dos procesos intenta escribir. Cualquier memoria virtual que no esté escrita, y posiblemente incluso escrita, puede ser compartida entre dos procesos.¿Qué daño haría? La memoria de solo lectura, como el código de ejecución, se puede compartir. Para implementar "copiar al escribir", la entrada de la tabla de páginas de un área de escritura se marca como de solo lectura y la estructura de datos vm_area_struct que la describe se marca como "copiar al escribir". Se produce un error de página cuando un proceso intenta escribir en esta memoria virtual. En este punto, Linux hará una copia de esta memoria y procesará las tablas de páginas y las estructuras de datos de la memoria virtual de los dos procesos.
4.7 Tiempos y Temporizador
El núcleo rastrea el tiempo de CPU del proceso y algún otro tiempo. Cada ciclo de reloj, el kernel actualiza los santiamén del proceso actual para representar la suma del tiempo pasado en modo sistema y modo usuario.
Además de estos temporizadores de contabilidad, Linux también admite temporizadores de intervalos específicos de procesos. Un proceso puede usar estos temporizadores para señalarse a sí mismo cuando expiran estos temporizadores. Se admiten tres tipos de temporizadores de intervalo:
Ver kernel/itimer.c
Real Este temporizador utiliza temporización en tiempo real y, cuando el temporizador expira, se envía una señal SIGALRM al proceso.
Virtual Este temporizador solo cuenta cuando el proceso está en ejecución, cuando caduca, envía una señal SIGVTALARM al proceso.
El perfil es oportuno tanto cuando el proceso se está ejecutando como cuando el sistema se ejecuta en nombre del proceso. Cuando expire, se enviará una señal SIGPROF.
Se pueden ejecutar uno o todos los temporizadores de intervalo, y Linux registra toda la información necesaria en la estructura de datos task_struct del proceso. Estos temporizadores de intervalo se pueden crear, iniciar, detener y leer el valor actual mediante llamadas al sistema. Los temporizadores virtuales y de perfil se manejan de la misma manera: cada ciclo de reloj, el temporizador del proceso actual se reduce y, si caduca, se emite la señal correspondiente.
Ver kernel/sched.c do_it_virtual(), do_it_prof()
Los temporizadores de intervalos en tiempo real son ligeramente diferentes. El mecanismo por el cual Linux usa temporizadores se describe en la Sección 11. Cada proceso tiene su propia estructura de datos timer_list Cuando se utiliza un temporizador en tiempo real, se utiliza la tabla de temporizadores del sistema. Cuando caduca, la segunda mitad del proceso del temporizador lo elimina de la cola y llama al controlador del temporizador de intervalo. Genera la señal SIGALRM y reinicia el temporizador de intervalos, agregándolo nuevamente a la cola del temporizador del sistema.
Ver también: kernel/iterm.c it_real_fn()
4.8 Ejecución de programas
En Linux, como Unix, los programas y comandos se ejecutan generalmente a través de un intérprete de comandos. El intérprete de comandos es un proceso de usuario como cualquier otro proceso, llamado caparazón (imagine una nuez con el núcleo como la parte comestible del medio, y el caparazón lo rodea, proporcionando una interfaz). Hay muchos shells en Linux, los más utilizados son sh, bash y tcsh. Excepto por algunos comandos internos, como cd y pwd, los comandos son binarios ejecutables. Para cada comando ingresado, el shell busca un nombre coincidente en el directorio especificado por la ruta de búsqueda del proceso actual (en la variable de entorno PATH). Si se encuentra el archivo, cárguelo y ejecútelo. El shell se clona a sí mismo utilizando el mecanismo de bifurcación antes mencionado y reemplaza la imagen binaria que está ejecutando (el shell) con el contenido del archivo de imagen de ejecución encontrado en el proceso secundario. Por lo general, el shell espera que finalice el comando o que finalice el subproceso. Puede enviar una señal SIGSTOP al proceso secundario escribiendo control-Z, que detiene el proceso secundario y lo pone en segundo plano, permitiendo que el shell se vuelva a ejecutar. Puede usar el comando de shell bg para que el shell envíe una señal SIGCONT al proceso secundario, coloque el proceso secundario en segundo plano y ejecútelo nuevamente, continuará ejecutándose hasta que finalice o necesite entrada o salida desde la terminal.

El archivo ejecutable puede tener muchos formatos o incluso un archivo de secuencia de comandos. Los archivos de script deben reconocerse y ejecutarse con un intérprete adecuado. Por ejemplo, /bin/sh interpreta scripts de shell. Los archivos de objetos ejecutables contienen código y datos ejecutables y suficiente información adicional para que el sistema operativo pueda cargarlos en la memoria y ejecutarlos. El tipo de archivo de objeto más utilizado en Linux es ELF y, en teoría, Linux es lo suficientemente flexible como para manejar casi cualquier formato de archivo de objeto.
Al igual que los sistemas de archivos, los formatos binarios que admite Linux se integran directamente en el kernel cuando se vincula el kernel o se pueden cargar como módulos. El núcleo mantiene una lista de formatos binarios admitidos (consulte la Figura 4.3), y cuando intenta ejecutar un archivo, se prueba cada formato binario hasta que funcione. En general, los binarios soportados por Linux son a.out y ELF. El ejecutable no necesita leerse completamente en la memoria, sino que utiliza una técnica llamada carga por demanda. Parte de la imagen de ejecución se carga en la memoria cuando el proceso la usa, y las imágenes no utilizadas se pueden descartar de la memoria.
ver fs/exec.c do_execve()

4.9 ELF
Los archivos de objeto ELF (formato ejecutable y enlazable), diseñados por Unix Systems Labs, son ahora el formato más utilizado para Linux. Aunque hay una ligera sobrecarga de rendimiento en comparación con otros formatos de archivo de objetos como ECOFF y a.out, ELF se siente más flexible. Los archivos ejecutables ELF incluyen código ejecutable (a veces llamado texto) y datos. La tabla en la imagen de ejecución describe cómo se debe colocar el programa en la memoria virtual del proceso. Las imágenes enlazadas estáticamente se crean con el enlazador (ld) o el editor de enlaces, y una sola imagen contiene todo el código y los datos necesarios para ejecutar la imagen. Esta imagen también describe el diseño de la imagen en memoria y la dirección en la imagen de la primera parte del código a ejecutar.
La Figura 4.4 muestra el diseño de una imagen ejecutable ELF enlazada estáticamente. Este es un programa simple en C que imprime "hola mundo" y sale. El archivo de encabezado describe que es una imagen ELF, con dos encabezados físicos (e_phnum es 2), a partir del byte 52 al principio del archivo de imagen (e_phoff). El primer encabezado físico describe el código de ejecución en la imagen, en la dirección virtual 0x8048000, con 65532 bytes. Debido a que está vinculado estáticamente, incluye todo el código de la biblioteca que llama a printf() que genera "hola mundo". La entrada de la imagen, es decir, la primera instrucción del programa, no se encuentra al principio de la imagen, sino en la dirección virtual 0x8048090 (e_entry). El código comienza inmediatamente después del segundo encabezado físico. Este encabezado físico describe los datos del programa y se cargará en la memoria virtual en la dirección 0x8059BB8. Este dato se puede leer y escribir. Notará que el tamaño de los datos en el archivo es de 2200 bytes (p_filesz) y el tamaño en la memoria es de 4248 bytes. Porque los primeros 2200 bytes contienen datos preinicializados y los siguientes 2048 bytes contienen datos que serán inicializados por el código de ejecución.
ver include/linux/elf.h
Cuando Linux carga la imagen ejecutable ELF en el espacio de direcciones virtuales del proceso, no es la imagen cargada real. Configura las estructuras de datos de la memoria virtual, el vm_area_struct del proceso y sus tablas de páginas. Cuando el programa ejecuta una falla de página, el código y los datos del programa se colocarán en la memoria física. Las partes del programa no utilizadas no se colocarán en la memoria. Una vez que el cargador de formato binario ELF cumple las condiciones, la imagen es una imagen ejecutable ELF válida, que borra la imagen ejecutable actual del proceso de su memoria virtual. Debido a que este proceso es una imagen clonada (como lo son todos los procesos), la imagen anterior es la imagen del programa ejecutado por el proceso principal (por ejemplo, el intérprete de comandos shell bash). Borrar imágenes ejecutables antiguas descarta estructuras de datos de memoria virtual antiguas y restablece las tablas de páginas del proceso. También borra otros manejadores de señales establecidos, cerrando archivos abiertos. Al final del proceso de limpieza, el proceso está listo para ejecutar la nueva imagen ejecutable. Independientemente del formato de la imagen ejecutable, la misma información se establece en el mm_struct del proceso. Incluye punteros al comienzo del código y datos en la imagen. Estos valores se leen del encabezado físico de la imagen ejecutable ELF y la parte que describen también se asigna al espacio de direcciones virtuales del proceso. Esto también sucede cuando se crea la estructura de datos vm_area_struct del proceso y se modifica la tabla de páginas. La estructura de datos mm_struct también incluye punteros a los parámetros pasados al programa y las variables de entorno del proceso.
Bibliotecas compartidas ELF
Las imágenes vinculadas dinámicamente, a su vez, no contienen todo el código y los datos necesarios para ejecutarse. Algunos de ellos se colocan en bibliotecas compartidas y se vinculan a la imagen en tiempo de ejecución. Cuando la biblioteca dinámica en tiempo de ejecución está vinculada a la imagen, el vinculador dinámico también usa la tabla de biblioteca compartida ELF. Linux usa varios enlazadores dinámicos, ld.so.1, libc.so.1 y ld-linux.so.1, todos en el directorio /lib. Estas bibliotecas incluyen código común, como subrutinas de lenguaje. Sin enlaces dinámicos, todos los programas tendrían que tener copias independientes de estas bibliotecas, lo que requeriría más espacio en disco y memoria virtual. En el caso del enlace dinámico, la tabla de la imagen ELF incluye información sobre todas las rutinas de biblioteca a las que se hace referencia. Esta información le indica al vinculador dinámico cómo ubicar las rutinas de la biblioteca y cómo vincularse al espacio de direcciones del programa.
4.10 Archivos de guiones
Los archivos de script son archivos ejecutables que requieren un intérprete para ejecutarse. Hay una gran cantidad de intérpretes en Linux, como wish, perl e intérpretes de comandos como tcsh. Linux usa la convención estándar de Unix de incluir el nombre del intérprete en la primera línea de un archivo de script. Entonces, un archivo de script típico podría comenzar con:
#!/usr/bin/deseo
El cargador de archivos de secuencias de comandos intenta averiguar qué intérprete está utilizando el archivo. Intenta abrir el ejecutable especificado en la primera línea del archivo de script. Si se puede abrir, obtenga un puntero al inodo VFS del archivo y ejecútelo para interpretar el archivo de script. El nombre del archivo de secuencia de comandos se convierte en el parámetro 0 (el primer parámetro) y todos los demás parámetros se desplazan un lugar hacia arriba (el primer parámetro original se convierte en el segundo parámetro, etc.). Cargar un intérprete es lo mismo que cargar otros programas ejecutables en Linux. Linux prueba varios formatos binarios hasta que funciona. Esto significa que, en teoría, puede apilar varios intérpretes y formatos binarios para que los controladores de formato binario de Linux sean más flexibles.
Ver fs/binfmt_script.c do_load_script()
5. Mecanismos de comunicación entre procesos
Los procesos se comunican entre sí y con el núcleo, coordinando su comportamiento. Linux admite algunos mecanismos para la comunicación entre procesos (IPC). Las señales y las tuberías son dos de ellas, y Linux también es compatible con el mecanismo System V IPC (llamado así por la versión de Unix que apareció por primera vez).
5.1 Señales
Las señales son uno de los métodos más antiguos de comunicación entre procesos utilizados en los sistemas Unix. Señales utilizadas para enviar eventos asíncronos a uno o más procesos. La señal se puede generar utilizando el terminal del teclado o por una condición de error, como un proceso que intenta acceder a una ubicación en su memoria virtual que no existe. El shell también usa señales para enviar señales de control de trabajo a sus procesos secundarios.
Algunas señales son generadas por el núcleo y otras pueden ser generadas por otros procesos privilegiados en el sistema. Puede usar el comando kill (kill -l) para enumerar el conjunto de señales de su sistema, salida en mi sistema Linux Intel:
1) SIGUIR 2) SIGINT 3) SIGQUIT 4) SELLO
5) SIGTRAP 6) SIGIOT 7) SIGBUS 8) SIGFPE
9) SIGKILL 10) SIGUSR1 11) SIGSEGV 12) SIGUSR2
13) SIGPIPE 14) SIGALRM 15) SIGTERM 17) SIGCHLD
18) SIGCONT 19) SIGSTOP 20) SIGTSTP 21) SIGTTIN
22) SIGTTOU 23) SIGURG 24) SIGXCPU 25) SIGXFSZ
26) SIGVTALRM 27) SIGPROF 28) SIGWINCH 29) SIGIO
30) SINGAPUR
Los números son diferentes en los sistemas Alpha AXP Linux. Un proceso puede optar por ignorar la mayoría de las señales que se generan, con dos excepciones: SIGSTOP (para detener la ejecución del proceso) y SIGKILL (para hacer que el proceso finalice) no se pueden ignorar, aunque un proceso puede elegir cómo manejar las señales. Un proceso puede bloquear una señal, y si no bloquea una señal, puede elegir manejarla él mismo o dejar que el núcleo la maneje. Si lo maneja el núcleo, se realizará el comportamiento predeterminado para esta señal. Por ejemplo, la acción predeterminada de un proceso que recibe un SIGFPE (excepción de coma flotante) es generar un núcleo y salir. Las señales no tienen una prioridad inherente, si un proceso genera dos señales al mismo tiempo, aparecerán en el proceso en cualquier orden y se procesarán en cualquier orden. Además, no existe ningún mecanismo para manejar múltiples señales del mismo tipo. No hay forma de que un proceso sepa si recibió 1 o 42 señales SIGCONT.
Linux usa la información almacenada en task_struct del proceso para implementar el mecanismo de señal. Las señales admitidas están limitadas por el tamaño de palabra del procesador. Un procesador de 32 bits de longitud de palabra puede tener 32 señales, mientras que un procesador de 64 bits como Alpha AXP puede tener hasta 64 señales. La señal actualmente pendiente se coloca en el campo de señal y el campo bloqueado se coloca en la máscara de señal para ser bloqueado. Todas las señales se pueden bloquear excepto SIGSTOP y SIGKILL. Si se genera una señal bloqueada, permanece pendiente hasta que se desbloquea. Linux también guarda información sobre cómo cada proceso maneja cada posible señal.Esta información se coloca en una matriz de estructuras de datos sigaction, y el task_struct de cada proceso tiene un puntero a la matriz correspondiente. Esta matriz contiene la dirección de la rutina que maneja la señal, o una bandera que le dice a Linux si el proceso quiere ignorar la señal o dejar que el núcleo la maneje. Los procesos cambian el manejo de señales predeterminado mediante la ejecución de llamadas al sistema que cambian la máscara de bloqueo y la acción de seguimiento de señales adecuadas.
No todos los procesos en el sistema pueden enviar señales a todos los demás procesos, solo el núcleo y el superusuario pueden hacerlo. Los procesos normales solo pueden enviar señales a procesos que tienen el mismo uid y gid o están en el mismo grupo de procesos. Las señales se generan configurando los bits apropiados en la señal de task-struct. Si el proceso no está bloqueando la señal, y está esperando pero puede ser interrumpido (el estado es Interrumpible), entonces su estado cambia a En ejecución y se confirma que está en la cola de ejecución, y de esta manera se despierta. De esta forma, el programador lo tratará como un candidato en ejecución cuando el sistema lo programe la próxima vez. Si se requiere un manejo predeterminado, Linux puede optimizar el manejo de las señales. Por ejemplo, si se produce la señal SIGWINCH (la ventana X cambia el foco) y se usa el controlador predeterminado, no es necesario hacer nada.
Las señales no aparecen en el proceso inmediatamente cuando se generan, deben esperar hasta la próxima vez que se ejecute el proceso. Cada vez que un proceso sale de una llamada al sistema se revisa su señal y campos bloqueados, y si hay alguna señal no bloqueada, se puede enviar. Esto puede parecer muy poco confiable, pero cada proceso en el sistema invoca una llamada al sistema, como en el proceso de escribir un carácter en la terminal. Los procesos pueden optar por esperar una señal si lo desean, y permanecen en el estado Interrumpible hasta que se da una señal. El código de manejo de señales de Linux verifica la estructura sigaction para cada señal actualmente desbloqueada.
Si se establece un controlador de señales como la acción predeterminada, el núcleo lo maneja. El procesamiento predeterminado de la señal SIGSTOP es cambiar el estado del proceso actual a Detenido, luego ejecutar el programador y seleccionar un nuevo proceso para ejecutar. La acción predeterminada de la señal SIGFPE es hacer que el proceso actual genere un núcleo (volcado de núcleo) y lo deje salir. Alternativamente, un proceso puede especificar su propio manejador de señales. Esta es una rutina que se llama cuando se genera la señal y la estructura sigaction contiene la dirección de esta rutina. Linux debe llamar a la rutina de manejo de señales del proceso, y la forma en que eso sucede depende del procesador. Sin embargo, todas las CPU tienen que lidiar con procesos que actualmente se ejecutan en modo kernel y se están preparando para volver al modo de usuario que llama kernel o rutinas del sistema. La solución a este problema es ocuparse de la pila y los registros del proceso. El contador del programa de proceso se establece en la dirección de su controlador de señal y los argumentos de la rutina se agregan a la estructura de la llamada o se pasan a través de los registros. Cuando se reanuda el proceso, parece que el controlador de señal es una llamada normal.
Linux es compatible con POSIX, por lo que un proceso puede especificar una señal para bloquear al llamar a un controlador de señal específico. Esto significa cambiar la máscara bloqueada al llamar al controlador de señales del proceso. Cuando finaliza el controlador de señal, la máscara bloqueada debe restaurarse a su valor original. Por lo tanto, Linux agrega una llamada a una rutina de limpieza a la pila del proceso que recibió la señal, restaurando la máscara bloqueada a su valor original. Linux también optimiza esta situación: si es necesario llamar a varias rutinas de procesamiento de señales al mismo tiempo, se apilan juntas, y cada vez que se sale de un controlador, se llama al siguiente, y la rutina de limpieza no se llama hasta el final.
5.2 Tuberías
Los shells normales de Linux permiten la redirección. P.ej:
$ ls | pr | lpr
Pagine canalizando la salida del comando ls, que enumera los archivos de directorio, a la entrada estándar del comando pr. Finalmente, la salida estándar del comando pr se canaliza a la entrada estándar del comando lpr y el resultado se imprime en la impresora predeterminada. Una canalización es un flujo unidireccional de bytes que conecta la salida estándar de un proceso con la entrada estándar de otro proceso. Ninguno de los procesos es consciente de esta redirección y funciona como de costumbre. Es el caparazón que establece la tubería temporal entre los procesos. En Linux, las tuberías se implementan utilizando dos estructuras de datos de archivos que apuntan al mismo inodo VFS temporal (que a su vez apunta a una página física en la memoria). La figura 5.1 muestra que cada estructura de datos de archivo contiene punteros a una tabla vectorial de diferentes rutinas de manipulación de archivos: una para escribir y otra para leer desde la tubería. Esto enmascara la diferencia con las llamadas habituales del sistema para leer y escribir archivos ordinarios. Cuando el proceso de escritura escribe en la tubería, los bytes se copian en la página de datos compartidos y, cuando se lee desde la tubería, los bytes se copian en la página compartida. Linux debe sincronizar el acceso a las tuberías. Las escrituras y lecturas de canalización deben mantenerse sincronizadas, utilizando bloqueos, colas de espera y señales.
Consulte include/linux/inode_fs.h

Cuando el proceso de escritura escribe en la canalización, utiliza las funciones de biblioteca de escritura estándar. El descriptor de archivo pasado por estas funciones de biblioteca es un índice del grupo de estructuras de datos de archivo del proceso, cada una de las cuales representa un archivo abierto, en este caso, una canalización abierta. La llamada al sistema Linux utiliza la rutina de escritura a la que apunta la estructura de datos del archivo que describe esta canalización. La rutina de escritura utiliza la información almacenada en el inodo VFS que representa la canalización para administrar las solicitudes de escritura. Si hay suficiente espacio para escribir todos los bytes en la tubería, siempre que la tubería no esté bloqueada por el proceso de lectura, Linux bloquea el proceso de escritura y copia los bytes del espacio de direcciones del proceso a la página de datos compartidos. Si la canalización está bloqueada por el proceso de lectura o no hay suficiente espacio, el proceso actual duerme y se coloca en la cola de espera del nodo de canalización I, y llama al planificador para ejecutar otro proceso. Es interrumpible, por lo que puede recibir señales. Cuando hay suficiente espacio en la canalización para escribir datos o se libera el bloqueo, el proceso de lectura activará el proceso de escritura. Una vez que se escriben los datos, se libera el bloqueo del inodo VFS de la canalización y se activan todos los procesos de lectura en la cola de espera del inodo de la canalización.
Ver fs/pipe.c pipe_write()
La lectura de datos de una tubería es muy similar a la escritura de datos. Los procesos pueden realizar lecturas sin bloqueo (según el modo en que abrieron el archivo o la canalización), en cuyo caso se devuelve un error si no hay datos para leer o la canalización está bloqueada. Esto significa que el proceso continuará ejecutándose. Otra forma es esperar en la cola de espera del inodo de la canalización hasta que se complete el proceso de escritura. Si el proceso de la tubería ha completado la operación, el inodo de la tubería y la página de datos compartidos correspondiente se descartan.
Ver fs/pipe.c pipe_read()
Linux también puede admitir canalizaciones con nombre, también llamadas FIFO, porque las canalizaciones funcionan según el principio de "primero en entrar, primero en salir". Los primeros datos escritos en la tubería son los primeros datos que se leerán. No quiero conductos, los FIFO no son objetos temporales, son entidades en el sistema de archivos que se pueden crear con el comando mkfifo. Un proceso puede utilizar una FIFO siempre que tenga los derechos de acceso adecuados. Los FIFO se abren de forma ligeramente diferente a las tuberías. Una tubería (sus dos estructuras de datos de archivos, el inodo VFS y la página de datos compartidos) se crea una vez, mientras que el FIFO ya existe y su usuario puede abrirlo y cerrarlo. Linux tiene que lidiar con procesos que abren FIFO para lectura antes de que el proceso de escritura abra FIFO, y procesos que leen antes de que el proceso de escritura escriba datos. Aparte de eso, los FIFO se manejan casi exactamente como conductos y utilizan las mismas operaciones y estructuras de datos.
5.3 Mecanismos de la IPC del Sistema V
Linux admite tres mecanismos para la comunicación entre procesos que aparecieron por primera vez en Unix System V (1983): colas de mensajes, semáforos y memoria compartida (colas de mensajes, semáforos y memoria compartida). El mecanismo System V IPC comparte un método de autenticación común. Los procesos solo pueden acceder a estos recursos a través de llamadas al sistema, pasando un identificador de referencia único al núcleo. Las comprobaciones de acceso a objetos System V IPC utilizan permisos de acceso de forma muy similar a las comprobaciones de acceso a archivos. El creador del objeto crea el acceso a los objetos System V IPC a través de una llamada al sistema. Cada mecanismo utiliza el identificador de referencia del objeto como un índice en la tabla de recursos. Este no es un índice directo, se requieren algunas operaciones para generar el índice.
Todas las estructuras de datos de Linux en el sistema que representan objetos System V IPC incluyen una estructura de datos ipc_perm, incluidos los identificadores de usuario y grupo del proceso de creación, el modo de acceso (propietario, grupo y otros) para el objeto y la clave del IPC. objeto. . La clave se utiliza como método para localizar el identificador de referencia de un objeto IPC de System V. Se admiten dos tipos de claves: públicas y cuatro. Si la clave es pública, cualquier proceso en el sistema puede encontrar el identificador de referencia del objeto System V IPC correspondiente siempre que pase la verificación de permisos. Los objetos System V IPC no pueden ser referenciados por clave, deben ser referenciados usando su identificador de referencia.
Consulte include/linux/ipc.h
5.4 Colas de mensajes
Una cola de mensajes permite que uno o más procesos escriban mensajes y uno o más procesos lean mensajes. Linux mantiene una tabla de vectores msgque de una serie de colas de mensajes. Cada una de estas unidades apunta a una estructura de datos msqid_ds que describe completamente la cola de mensajes. Al crear una cola de mensajes, asigne una nueva estructura de datos msqid_ds de la memoria del sistema e insértela en la tabla de vectores.
Cada estructura de datos msqid_ds incluye una estructura de datos ipc_perm y punteros a los mensajes que ingresan a la cola. Además, Linux conserva la hora de cambio de la cola, como la hora de la última escritura en la cola, etc. La cola Msqid_ds también incluye dos colas de espera: una para escribir en la cola de mensajes y otra para leer.
Consulte include/linux/msg.h

Cada vez que un proceso intenta escribir un mensaje en la cola de escritura, sus identificadores efectivos de usuario y grupo se comparan con el esquema de la estructura de datos ipc_perm de la cola. Si el proceso puede escribir en esta cola, el mensaje se escribirá desde el espacio de direcciones del proceso en la estructura de datos del mensaje y se colocará al final de la cola de mensajes. Cada mensaje lleva un token de un tipo especificado por la aplicación acordado entre los procesos. Sin embargo, debido a que Linux limita el número y la longitud de los mensajes que se pueden escribir, es posible que no haya espacio para mensajes. En este momento, el proceso se colocará en la cola de espera de escritura de la cola de mensajes y luego se llamará al planificador para seleccionar un nuevo proceso para ejecutar. Despierta cuando se leen uno o más mensajes de esta cola de mensajes.
La lectura de la cola es un proceso similar. Los derechos de acceso del proceso también se comprueban. Un proceso de lectura puede elegir leer el primer mensaje de la cola independientemente del tipo de mensaje o elegir un tipo especial de mensaje. Si no hay un mensaje elegible, el proceso de lectura se agregará al proceso de espera de lectura de la cola de mensajes y luego ejecutará el programador. Cuando se escribe un nuevo mensaje en la cola, el proceso se reactivará y continuará ejecutándose.
5.5 Semáforos
En su forma más simple, un semáforo es una ubicación en la memoria cuyo valor puede ser verificado y establecido por múltiples procesos. La operación de check and set, al menos para cada proceso asociado, es ininterrumpible o atómica: no se puede terminar una vez iniciada. El resultado de la operación de conjunto de suma de verificación es la suma del valor actual y el valor establecido del semáforo, que puede ser positivo o negativo. Dependiendo de los resultados de las operaciones de prueba y establecimiento, un proceso puede tener que dormir hasta que otro proceso cambie el valor del semáforo. Los semáforos se pueden usar para implementar regiones críticas, es decir, áreas de código importantes donde solo se puede ejecutar un proceso a la vez.
Supongamos que tiene muchos procesos cooperativos que leen y escriben registros de un solo archivo de datos. Es posible que desee que el acceso a los archivos esté estrictamente coordinado. Puede usar un semáforo con un valor inicial de 1. En el código para la operación de archivo, agregue dos operaciones de semáforo, la primera para verificar y disminuir el valor del semáforo y la segunda para verificarlo y aumentarlo. El primer proceso que accede al archivo intenta disminuir el valor del semáforo y, si tiene éxito, el valor del semáforo se convierte en 0. El proceso ahora puede continuar ejecutándose y usar el archivo de datos. Sin embargo, si otro proceso necesita usar este archivo y ahora intenta disminuir el valor del semáforo, fallará porque el resultado será -1. El proceso se suspenderá hasta que el primer proceso haya terminado de procesar el archivo de datos. Cuando el primer proceso termina de procesar el archivo de datos, incrementa el semáforo a 1. Ahora el proceso de espera se despertará y su intento de disminuir el semáforo tendrá éxito esta vez.

Cada objeto de semáforo System V IPC describe una matriz de semáforos, que Linux utiliza la estructura de datos semid_ds para representar. Todas las estructuras de datos semids en el sistema son apuntadas por la tabla de vectores de punteros secundarios. Cada matriz de semáforos tiene sem_nsems, que se describen mediante una estructura de datos sem a la que apunta sem_base. Todos los procesos que pueden operar en la matriz de semáforos de un objeto de semáforo System V IPC pueden operar en ellos a través de llamadas al sistema. Una llamada al sistema puede especificar una variedad de operaciones, cada una de las cuales se describe mediante tres entradas adicionales: el índice del semáforo, el valor de la operación y un conjunto de indicadores. El índice de semáforo es el índice de la matriz de semáforos, y el valor de la operación es el valor que se agregará al valor del semáforo actual. Primero, Linux verifica que todas las operaciones hayan sido exitosas. La operación tiene éxito solo si el valor actual del operando más el semáforo es mayor que 0 o tanto el operando como el valor actual del semáforo son 0. Si alguna operación de semáforo falla, Linux suspenderá el proceso siempre que el indicador de operación no requiera que la llamada al sistema no bloquee. Si se va a suspender el proceso, Linux debe guardar el estado de la operación de semáforo que se va a realizar y poner el proceso actual en la cola de espera. Lo hace construyendo una estructura de datos sem_queue en la pila y llenándola. La nueva estructura de datos sem_queue se coloca al final de la cola de espera del objeto semáforo (utilizando los punteros sem_pending y sem_pending_last). El proceso actual se coloca en la cola de espera (durmiente) de esta estructura de datos sem_queue y se llama al planificador para ejecutar otro proceso.
Ver incluir/linux/sem.h
Si todas las operaciones de semáforo tienen éxito, no es necesario suspender el proceso actual. Linux continúa y aplica estas operaciones a los miembros apropiados de la matriz de semáforos. Ahora Linux debe verificar si hay procesos inactivos o colgados, sus acciones ahora pueden ser ejecutables. Linux busca secuencialmente a cada miembro de la cola de espera de operación (sem_pending) para verificar si su operación de semáforo puede tener éxito ahora. Elimina la estructura de datos sem_queue de la lista de espera de operaciones si puede, y aplica la operación de semáforo a la matriz de semáforos. Activa el proceso durmiente para que pueda continuar ejecutándose la próxima vez que se ejecute el programador. Linux comprueba la cola de espera de principio a fin hasta que no se pueden activar más procesos mediante la realización de una operación de semáforo.
Hay un problema en la operación del semáforo: interbloqueo. Esto sucede cuando un proceso cambia el valor de un semáforo en una región crítica pero no abandona la región crítica porque se bloqueó o se eliminó. Linux evita esto manteniendo una tabla de ajuste de la matriz de semáforos. Es decir, si se implementan estos ajustes, el semáforo vuelve al estado de proceso anterior a la operación del semáforo. Estos ajustes se colocan en la estructura de datos sem_undo, se ponen en cola en la estructura de datos sem_ds y se ponen en cola en la estructura de datos task_struct del proceso que utiliza estos semáforos.
Puede ser necesario mantener una acción de ajuste para cada operación de baliza individual. Linux mantiene al menos una estructura de datos sem_undo para cada matriz de semáforos por proceso. Si el proceso solicitado no tiene uno, cree uno para él cuando sea necesario. Esta nueva estructura de datos sem_undo se pone en cola tanto en la estructura de datos task_struct del proceso como en la estructura de datos semid_ds de la cola de semáforos. Al realizar una operación en un semáforo en la cola de semáforos, el valor compensado por el valor de la operación se agrega a la entrada del semáforo en la cola de ajuste de la estructura de datos sem_undo del proceso. Entonces, si el valor de la operación es 2, esto agrega -2 a la entrada de ajuste para este semáforo.
Cuando se elimina un proceso, como al salir, Linux atraviesa su conjunto de estructuras de datos sem_undo e implementa ajustes en la matriz de semáforos. Si se elimina un semáforo, su estructura de datos sem_undo permanece en la cola task_struct del proceso, pero el identificador de la matriz de semáforos correspondiente se marca como no válido. En este caso, el código para borrar el semáforo simplemente descarta la estructura de datos sem_undo.
5.6 Memoria compartida
La memoria compartida permite que uno o más procesos se comuniquen a través de la memoria que está presente simultáneamente en su espacio de direcciones virtuales. Las páginas de esta memoria virtual están referenciadas por entradas de la tabla de páginas en la tabla de páginas de cada proceso compartido. Pero no es necesario tener la misma dirección en la memoria virtual de todos los procesos. Al igual que con todos los objetos IPC de System V, el acceso a las áreas de memoria compartida se controla mediante claves y se verifican los derechos de acceso. Una vez que se comparte la memoria, ya no hay que comprobar cómo el proceso utiliza esta memoria. Deben confiar en otros mecanismos, como los semáforos System V, para sincronizar el acceso a la memoria.
Cada región de memoria recién creada está representada por una estructura de datos shmid_ds. Estas estructuras de datos se mantienen en la tabla de vectores shm_segs. La estructura de datos Shmid_ds describe qué tan grande es este acceso a la memoria compartida, cuántos procesos lo están utilizando y cómo se asigna la memoria compartida a su espacio de direcciones. Depende del creador de la memoria compartida controlar el acceso a esta memoria y si sus claves son públicas o privadas. También puede bloquear la memoria compartida en la memoria física si tiene suficientes privilegios.
Ver incluir/linux/sem.h
Cada proceso que desee compartir esta memoria debe conectarse a la memoria virtual a través de una llamada al sistema. Esto crea una nueva estructura de datos vm_area_struct para el proceso que describe la memoria compartida. Un proceso puede elegir dónde se ubica la memoria compartida en su espacio de direcciones virtuales o Linux puede elegir un área libre suficiente.

Esta nueva estructura vm_area_struct se coloca en la lista vm_area_struct a la que apunta shmid_ds. Vincúlelos a través de vm_next_shared y vm_prev_shared. La memoria virtual en realidad no se crea cuando está pegada, sucede cuando el primer proceso intenta acceder a ella.
Una falla de página ocurre la primera vez que un proceso accede a una de las páginas de la memoria virtual compartida. Cuando Linux maneja esta falla de página, encuentra la estructura de datos vm_area_struct que la describe. Este contiene punteros a tales rutinas de manejo de memoria virtual compartida. El código de manejo de fallas de la página de memoria compartida busca en la lista de entradas de la tabla de páginas shmid_ds para ver si hay una entrada para esta página de memoria virtual compartida. Si no existe, asigna una página física y crea una entrada en la tabla de páginas para ella. Esta entrada no solo se ingresa en la tabla de páginas del proceso actual, sino que también se almacena en este archivo shmid_ds. Esto significa que cuando el siguiente proceso intente acceder a esta memoria y obtenga un error de página, el código de manejo de errores de memoria compartida también permitirá que este proceso use la página física recién creada. Por lo tanto, es el primer proceso para acceder a una página de memoria compartida lo que hace que se cree la página, y otros procesos que acceden a ella posteriormente hacen que la página se agregue a su espacio de direcciones virtuales.
Cuando los procesos ya no necesitan memoria virtual compartida, se desconectan de ella. Esta separación solo afecta al proceso actual siempre que otros procesos sigan utilizando esta memoria. Su vm_area_struct se elimina de la estructura de datos shmid_ds y se libera. La tabla de páginas del proceso actual también se actualiza, invalidando su área de memoria virtual compartida. Cuando se desconecta el último proceso que comparte esta memoria, se liberan las páginas de la memoria compartida actualmente en la memoria física y también se libera la estructura de datos shmid_ds de esta memoria compartida.
Es más complicado si la memoria virtual compartida no está bloqueada en la memoria física. En este caso, las páginas de la memoria compartida pueden intercambiarse en el disco de intercambio del sistema cuando el sistema utiliza mucha memoria. La forma en que la memoria compartida se intercambia hacia y desde la memoria física se describe en la Sección 3.
6, interconexión de componentes periféricos (PCI)
PCI, como su nombre lo indica, es un estándar que describe cómo conectar componentes periféricos en un sistema de manera estructurada y controlada. La especificación de bus local PCI estándar describe cómo se conectan eléctricamente los componentes del sistema y cómo se comportan. Esta sección explora cómo el kernel de Linux inicializa los dispositivos y el bus PCI del sistema.

La Figura 6.1 es un diagrama lógico de un sistema basado en PCI. El bus PCI y el puente PCI-PCI son el pegamento que mantiene unidos los componentes del sistema. Los dispositivos CUP y de video están conectados al bus PCI principal, bus PCI 0. Un dispositivo PCI especial, el puente PCI-PCI, conecta el bus principal al bus PCI secundario, el bus PCI 1. En la terminología de la especificación PCI, el bus PCI 1 se describe como aguas abajo del puente PCI-PCI y el bus PCI 0 está aguas arriba del puente. Conectados al bus PCI secundario están los dispositivos SCSI y Ethernet del sistema. Físicamente, el puente, el bus PCI secundario y ambos dispositivos pueden estar en la misma tarjeta PCI. El puente PCI-ISA del sistema admite dispositivos ISA heredados antiguos. Esta figura muestra un chip controlador de E/S que controla el teclado, el mouse y la unidad de disquete.
6.1 Espacio de direcciones PCI
Los dispositivos CPU y PCI necesitan acceder a la memoria que comparten. Esta memoria permite que los controladores de dispositivos controlen estos dispositivos PCI y pasen información entre ellos. La memoria comúnmente compartida incluye los registros de control y estado del dispositivo. Estos registros se utilizan para controlar el dispositivo y leer su estado. Por ejemplo, un controlador de dispositivo PCI SCSI puede leer el registro de estado del dispositivo SCSI para determinar si puede escribir información en el disco SCSI. O puede escribir en el registro de control para que el dispositivo que apagó comience a funcionar.
La memoria del sistema usada por la CPU se puede usar como tal memoria compartida, pero si es así, cada vez que un dispositivo PCI accede a la memoria, la CPU tiene que detenerse, esperando que el dispositivo PCI se complete. El acceso a la memoria suele estar restringido y solo se permite el acceso a un componente del sistema a la vez. Esto ralentizará el sistema. Tampoco es una buena idea permitir que dispositivos externos al sistema accedan a la memoria principal de manera descontrolada. Esto puede ser muy peligroso: un dispositivo malicioso puede hacer que el sistema sea muy inestable.
Los dispositivos externos tienen su propio espacio de memoria. La CPU puede acceder a estos espacios, pero el acceso del dispositivo a la memoria del sistema está estrictamente controlado y debe pasar por el canal DMA (Direct Memory Access). Los dispositivos ISA pueden acceder a dos espacios de direcciones: ISA I/O (entrada/salida) y memoria ISA. PCI consta de tres partes: E/S PCI, memoria PCI y espacio de configuración PCI. La CPU tiene acceso a todos los espacios de direcciones donde los controladores de dispositivos utilizan los espacios de direcciones de E/S PCI y de memoria PCI y Linux utiliza el espacio de configuración PCI y el código de inicialización PCI en mente.
El procesador Alpha AXP no tiene modos de acceso nativos a los espacios de direcciones que no sean el espacio de direcciones del sistema. Requiere el uso de chips de soporte para acceder a otros espacios de direcciones como el espacio de configuración PCI. Utiliza un esquema de asignación de espacio de direcciones que roba una parte del enorme espacio de direcciones virtuales y lo asigna al espacio de direcciones PCI.
6.2 Encabezados de configuración PCI
Cada dispositivo PCI del sistema, incluido el puente PCI-PCI, consta de una estructura de datos de configuración ubicada en el espacio de direcciones de configuración PCI. El encabezado de configuración PCI permite que el sistema identifique y controle el dispositivo. La ubicación exacta de este encabezado en el espacio de direcciones de configuración PCI depende de la topología PCI utilizada por el dispositivo. Por ejemplo, una tarjeta gráfica PCI que se conecta a una ranura PCI en la placa base de una PC tendrá su encabezado de configuración en una ubicación, mientras que si se inserta en otra ranura PCI, su encabezado aparecerá en otra ubicación en la memoria de configuración PCI. Pero no importa dónde estén ubicados estos puentes y dispositivos PCI, el sistema puede descubrirlos y configurarlos usando los registros de estado y configuración en sus encabezados de configuración.
Por lo general, los sistemas están diseñados para que el encabezado de configuración PCI de cada ranura PCI tenga un desplazamiento relativo a su ranura en la placa. Entonces, por ejemplo, la configuración PCI para la primera ranura en la placa podría estar en el desplazamiento 0 y la segunda ranura en el desplazamiento 256 (todos los encabezados tienen la misma longitud, 256 bytes), y así sucesivamente. Define mecanismos de hardware específicos del sistema para que el código de configuración de PCI pueda intentar verificar todos los encabezados de configuración de PCI posibles en un bus PCI determinado, intente leer un campo en el encabezado (generalmente el campo de identificación del proveedor) y obtenga algunos errores para saber que esos dispositivos existen y esos dispositivos no. La especificación de bus local PCI describe un posible mensaje de error: un intento de leer los campos de identificación de Verdor e identificación de dispositivo de una ranura PCI vacía devuelve 0xFFFFFFFF.

La Figura 6.2 muestra el diseño del encabezado de configuración PCI de 256 bytes. Incluye los siguientes dominios:
ver incluir/linux/pci.h
Identificación del proveedor Un número único que describe al inventor de este dispositivo PCI. La identificación de proveedor PCI de Digital es 0x1011 y la de Intel es 0x8086.
Identificación del dispositivo Un número único que describe el dispositivo en sí. Por ejemplo, el dispositivo Fast Ethernet 21141 de Digital tiene un identificador de dispositivo de 0x0009.
Estado Este campo proporciona el estado del dispositivo, el significado de sus bits está especificado por la especificación de bus local PCI.
El sistema Command controla el dispositivo escribiendo en este campo. Por ejemplo: permitir que el dispositivo acceda a la memoria de E/S PCI.
El código de clase identifica el tipo de dispositivo. Existen clasificaciones estándar para cada tipo de dispositivo: pantalla, SCSI, etc. El código de tipo para SCSI es 0x0100.
Registros de direcciones base Estos registros se utilizan para determinar y asignar el tipo, el tamaño y la ubicación de la E/S PCI y la memoria PCI que puede utilizar un dispositivo.
El pin de interrupción 4 de los pines físicos de la tarjeta PCI se utiliza para enviar interrupciones al bus PCI. Están etiquetados como A, B, C y D en el estándar. El campo Pin de interrupción describe qué pin utiliza este dispositivo PCI. Por lo general, para un dispositivo, esto lo determina el hardware. Es decir, cada vez que se inicia el sistema, el dispositivo utiliza el mismo pin de interrupción. Esta información permite que el subsistema de manejo de interrupciones administre las interrupciones para estos dispositivos.
Línea de interrupción El campo Línea de interrupción en el encabezado de configuración de PCI se utiliza para transferir el control de interrupción entre el código de inicialización de PCI, los controladores de dispositivos y el subsistema de manejo de interrupciones de Linux. El número escrito aquí no tiene sentido para el controlador de dispositivo, pero permite que el controlador de interrupciones envíe correctamente una interrupción desde el dispositivo PCI al código de manejo de interrupciones del controlador de dispositivo correcto en el sistema operativo Linux. Vea la Sección 7 para saber cómo Linux maneja las interrupciones.
6.3 E/S PCI y dirección de memoria PCI
Estos dos espacios de direcciones se utilizan para la comunicación de controladores de dispositivos entre dispositivos y el kernel de Linux que se ejecuta en la CPU. Por ejemplo: el dispositivo Fast Ethernet DECchip 21141 asigna sus registros internos al espacio de E/S PCI. Su controlador de dispositivo Linux luego controla el dispositivo leyendo y escribiendo en estos registros. Los controladores de pantalla suelen utilizar una gran cantidad de espacio de memoria PCI para colocar la información de la pantalla.
Los dispositivos no pueden acceder a estos espacios de direcciones hasta que se establezca el sistema PCI y se habilite el acceso del dispositivo a estos espacios de direcciones mediante el campo Comando en el encabezado de configuración de PCI. Cabe señalar que solo el código de configuración PCI lee y escribe direcciones de configuración PCI, los controladores de dispositivos Linux solo leen y escriben direcciones de memoria PCI y E/S PCI.
6.4 Puentes PCI-ISA
Este puente convierte los accesos de espacio de direcciones de memoria PCI I/O y PCI en accesos de memoria ISA I/O y ISA para admitir dispositivos ISA. La mayoría de los sistemas que se venden hoy en día incluyen varias ranuras de bus ISA y varias ranuras de bus PCI. La necesidad de esta compatibilidad con versiones anteriores seguirá disminuyendo y habrá sistemas solo PCI en el futuro. En los primeros días de la PC basada en Intel 8080, se arregló el espacio de direcciones ISA (E/S y memoria) de los dispositivos ISA en el sistema. Incluso la unidad de disquete ISA de un sistema informático basado en S5000 Alpha AXP tendría las mismas direcciones de E/S ISA que la primera PC de IBM. La especificación PCI reserva las regiones inferiores de los espacios de direcciones de memoria PCI I/O y PCI para periféricos ISA en el sistema y utiliza un puente PCI-ISA para convertir todos los accesos de memoria PCI a estas regiones en accesos ISA.

6.5 Puentes PCI-PCI (PCI-PCI桥)
Los puentes PCI-PCI son dispositivos PCI especiales que unen los buses PCI en el sistema. Solo había un bus PCI en un sistema simple, y en ese momento había un límite eléctrico para la cantidad de dispositivos PCI que podía admitir un solo bus PCI. Agregar más buses PCI mediante un puente PCI-PCI permite que el sistema admita más dispositivos PCI. Esto es especialmente importante para los servidores de alto rendimiento. Por supuesto, Linux es totalmente compatible con el uso de puentes PCI-PCI.
6.5.1 Puentes PCI-PCI: PCI I/O y PCI Memory Windows
El puente PCI-PCI solo pasa aguas abajo un subconjunto de E/S PCI y lecturas y escrituras de memoria PCI. Por ejemplo, en la Figura 6.1, el puente PCI-PCI pasará las direcciones de lectura y escritura del bus PCI 0 al bus 1 solo si las direcciones de lectura y escritura pertenecen a dispositivos SCSI o Ethernet, y el resto se ignora. Este filtrado evita que la información de dirección innecesaria atraviese el sistema. Para lograr esto, los puentes PCI-PCI deben programarse para establecer la base y los límites de los accesos al espacio de direcciones de memoria PCI I/O y PCI que deben pasar del bus primario al bus secundario. Una vez que se configura el puente PCI-PCI en el sistema, el puente PCI-PCI es invisible siempre que el controlador del dispositivo Linux solo acceda a la E/S PCI y al espacio de memoria PCI a través de estas ventanas. Esta es una característica importante que facilita la vida de los autores de controladores de dispositivos PCI para Linux. Pero también hace que el puente PCI-PCI en Linux sea algo complicado de configurar, como veremos en breve.
6.5.2 Puentes PCI-PCI: ciclos de configuración PCI y numeración de bus PCI
Dado que el código de inicialización PCI de la CPU puede ubicar dispositivos que no están en el bus PCI principal, debe haber un mecanismo mediante el cual el puente pueda decidir si pasa ciclos de configuración desde su interfaz principal a la interfaz secundaria. Un ciclo es la dirección que muestra en el bus PCI. La especificación PCI define dos formatos de configuración de direcciones PCI: Tipo 0 y Tipo 1, que se muestran en la Figura 6.3 y la Figura 6.4, respectivamente. Un ciclo de configuración PCI de tipo 0 no contiene un número de bus y es interpretado por todos los dispositivos PCI en este bus PCI para la configuración de direcciones PCI. Los bits 32:11 del ciclo de configuración se consideran el campo de selección de dispositivos. Una forma de diseñar un sistema es hacer que cada bit seleccione un dispositivo diferente. En este caso, 11 puede seleccionar el dispositivo PCI en la ranura 0, el bit 12 puede seleccionar el dispositivo PCI en la ranura 1 y así sucesivamente. Otra forma es escribir el número de ranura del dispositivo directamente en los bits 31:11. El mecanismo que utiliza un sistema depende del controlador de memoria PCI del sistema.
Todos los dispositivos PCI ignoran un ciclo de configuración PCI de tipo 1 que incluye un número de bus PCI, excepto los puentes PCI-PCI. Todos los puentes PCI-PCI que ven un ciclo de configuración PCI Tipo 1 pueden pasarles esta información en sentido descendente. Si un puente PCI-PCI ignora el ciclo de configuración PCI o lo pasa aguas abajo depende de cómo esté configurado el puente. Cada puente PCI-PCI tiene un número de interfaz de bus principal y un número de interfaz de bus secundario. La interfaz de bus principal es la más cercana a la CPU y la interfaz de bus secundaria es la más alejada de la CPU. Cada puente PCI-PCI también tiene un número de bus secundario, que es el número máximo de buses PCI que se pueden puentear fuera de la segunda interfaz de bus. En otras palabras, el número de bus secundario es el número de bus PCI más grande aguas abajo del puente PCI-PCI. Cuando un puente PCI-PCI ve un ciclo de configuración PCI tipo 1, hace lo siguiente:
Si el número de bus especificado no está entre el número de bus menor del puente y el número de bus secundario, se ignora.
Lo convierte en un comando de configuración de tipo 0 si el número de bus especificado coincide con el número de bus menor del puente.
Si el número de bus especificado es mayor que el número de bus secundario y menor o igual que el número de bus subordinado, se pasa a la interfaz de bus secundario sin cambios.
Entonces, si deseamos direccionar el dispositivo 1 en el bus 3 en la topología de la Figura 6.9, debemos generar un comando de configuración de tipo 1 desde la CPU. El puente 1 lo pasa sin cambios al bus 1, el puente 2 lo ignora pero el puente 3 lo convierte en un comando de configuración de tipo 0 y lo envía al bus 3, lo que hace que el dispositivo 1 responda.
Cada sistema operativo individual es responsable de asignar números de bus durante la fase de configuración de PCI, pero independientemente del esquema de codificación utilizado, las siguientes declaraciones deben cumplirse para todos los puentes PCI-PCI del sistema:
Todos los buses PCI ubicados detrás de un puente PCI-PCI deben estar numerados entre (inclusive) el número de bus menor y el número de bus auxiliar
Si se viola esta regla, el puente PCI-PCI no podrá pasar y traducir correctamente el ciclo de configuración PCI tipo 1, y el sistema no podrá encontrar e inicializar correctamente los dispositivos PCI en el sistema. Para completar el esquema de codificación, Linux configura estos dispositivos especiales en un orden específico. Consulte la Sección 6.6.2 para obtener una descripción del esquema de codificación de bus y puente PCI de Linux y un ejemplo de trabajo.

6.6 Inicialización de Linux PCI (proceso de inicialización de Linux PCI)
El código de inicialización de PCI en Linux se divide en tres partes lógicas:
Controlador de dispositivo PCI Este controlador de pseudo dispositivo busca el sistema PCI desde el bus 0 y localiza todos los dispositivos y puentes PCI en el sistema. Construye una lista de estructuras de datos vinculados que describen la topología del sistema. Además, codifica todos los puentes del sistema.
参见drivers/pci/pci.c e include/linux/pci.h
BIOS PCI Esta capa de software proporciona los servicios descritos en la especificación ROM BIOS PCI. Aunque Alpha AXP no tiene servicio de BIOS, hay un código equivalente en el kernel de Linux que proporciona la misma funcionalidad.
Ver arch/*/kernel/bios32.c
Reparación de PCI Código de limpieza relacionado con el sistema para limpiar la pérdida de memoria relacionada con el sistema al final de la inicialización de PCI.
Ver arch/*/kernel/bios32.c
6.6.1 Estructuras de datos PCI del kernel de Linux
Cuando el kernel de Linux inicializa un sistema PCI, crea estructuras de datos que reflejan la topología PCI real del sistema. La Figura 6.5 muestra la relación entre las estructuras de datos utilizadas para describir el sistema PCI ilustrado en la Figura 6.1.
Cada dispositivo PCI (incluidos los puentes PCI-PCI) se describe mediante una estructura de datos pci_dev. Cada bus PCI se describe mediante una estructura de datos pci_bus. El resultado es un árbol de buses PCI, cada uno con dispositivos sub-PCI conectados. Dado que solo se puede acceder a un bus PCI a través de un puente PCI-PCI (excepto el bus PCI principal, bus 0), cada pci_bus incluye un puntero al dispositivo PCI por el que pasa (el puente PCI-PCI). Este dispositivo PCI es un dispositivo secundario del bus principal de este bus PCI.
En la Figura 6.5 no se muestra un puntero a todos los dispositivos PCI del sistema: pci_devices. Las estructuras de datos pci_dev de todos los dispositivos PCI del sistema se ponen en cola en esta cola. El kernel de Linux usa esta cola para encontrar rápidamente todos los dispositivos PCI en el sistema.
6.6.2 El controlador del dispositivo PCI
El controlador de dispositivo PCI no es un controlador de dispositivo real en absoluto, sino una función llamada por el sistema operativo cuando se inicializa el sistema. El código de inicialización de PCI debe escanear todos los buses PCI del sistema para encontrar todos los dispositivos PCI del sistema (incluidos los dispositivos puente PCI-PCI). Utiliza el código PCI BIOS para ver si todas las ranuras posibles en el bus PCI que está escaneando actualmente están ocupadas. Si la ranura PCI está ocupada, crea una estructura de datos pci_dev que describe el dispositivo y lo vincula a la lista de dispositivos PCI conocidos (señalados por pci_deivices).
Ver drivers/pci/pci.c Scan_bus()
El código de inicialización PCI comienza a escanear desde el bus PCI 0. Intenta leer los campos Identificación del proveedor e Identificación del dispositivo de todos los dispositivos PCI posibles en todas las ranuras PCI posibles. Cuando encuentra una ranura ocupada, crea una estructura de datos pci_dev para describirla. Todas las estructuras de datos pci_dev creadas por el código de inicialización PCI (incluidos todos los puentes PCI-PCI) están vinculadas a una tabla vinculada: pci_devices.
Si el dispositivo encontrado es un puente PCI-PCI, cree una estructura de datos pci_bus y vincúlela al árbol de estructuras de datos pci_bus y pci_dev al que apunta pci_root. El código inicial de PCI puede determinar si un dispositivo PCI es un puente PCI-PCI, porque su código de clase es 0x060400. Luego, el kernel de Linux configura el bus PCI (descendente) en el otro extremo del puente PCI-PCI que acaba de encontrar. Si se encuentran más puentes PCI-PCI, todos están configurados de la misma manera. Este proceso se convierte en el algoritmo depthwize: el sistema se desenrolla en profundidad antes de buscar el ancho. Mirando la Figura 6.1, Linux primero configurará el bus PCI 1 y sus dispositivos Ethernet y SCSI, y luego configurará el dispositivo de visualización en el bus PCI 0.
Cuando Linux busca un bus PCI en sentido descendente, debe configurar los números de bus secundario y auxiliar de los puentes PCI-PCI intermedios. Estos se describen en detalle en la Sección 6.6.2 a continuación:
Configuración de puentes PCI-PCI - Asignación de números de bus PCI
Para E/S PCI, memoria PCI o espacio de direcciones de configuración PCI lecturas y escrituras que pasan a través de ellos, el puente PCI-PCI debe tener lo siguiente:
Número de bus primario El número de bus aguas arriba del puente PCI-PCI
Número de bus secundario El número de bus aguas abajo del puente PCI-PCI
Número de autobús subordinado El número de autobús más alto de todos los autobuses a los que se puede llegar desde este puente.
E/S PCI y ventanas de memoria PCI La base y el tamaño del espacio de direcciones de E/S PCI y la ventana de espacio de memoria PCI para todas las direcciones desde este puente PCI-PCI.

El problema es que cuando desea configurar cualquier puente PCI-PCI dado, no sabe la cantidad de buses conectados a ese puente. No sabe si hay otros puentes PCI-PCI aguas abajo. Incluso si lo hace, no sabe qué número se le asignará. La respuesta es usar un algoritmo recursivo profundo. A todos los puentes PCI-PCI se les asignan números a medida que se encuentran en cada bus. Para cada puente PCI-PCI encontrado, asigna un número a su bus secundario, le asigna un número de bus secundario temporal 0xFF y escanea todos los puentes PCI-PCI aguas abajo y asigna números. Esto parece bastante complicado, pero el siguiente ejemplo práctico aclarará el proceso.
Numeración de puentes PCI-PCI: Paso 1 Con referencia a la topología en la Figura 6.6, el primer puente encontrado por el escaneo es Bridge1. El número de bus PCI aguas abajo del puente 1 es 1, y al puente 1 se le asigna un número de bus secundario 1 y un número de bus auxiliar temporal 0xFF. Esto significa que una dirección de configuración PCI de tipo 1 que especifica el bus PCI 1 o superior pasará a través del puente 1 al bus PCI 1. Si su número de bus es 1, se convierten a ciclos de configuración de tipo 0, de lo contrario, no se modifican para otros números de bus. Esto es exactamente lo que debe hacer el código de inicialización PCI de Linux para acceder y escanear el bus PCI 1.

Numeración de puente PCI-PCI: Paso 2 Linux usa un algoritmo profundo, por lo que el código de inicialización comienza a escanear el bus PCI 1. Esto significa que ha encontrado el puente PCI-PCI 2. No hay otro puente PCI-PCI además del puente 2, por lo que su número de bus secundario se convierte en 2, que es el mismo que su interfaz secundaria. La figura 6.7 muestra cómo se codifican el bus y el puente PCI-PCI en este momento.
Numeración de puentes PCI-PCI: Paso 3 El código de inicialización de PCI regresa para escanear el bus PCI 1 y encuentra otro puente PCI-PCI 3. A su interfaz de bus principal se le asigna un valor de 1 y su interfaz de bus secundario es 3, y su número de bus secundario es 0xFF. La figura 6.8 muestra cómo está configurado ahora el sistema. Los ciclos de configuración PCI de tipo 1 con números de bus 1, 2 o 3 ahora se enrutan correctamente al bus PCI apropiado.



6.6.3 Funciones del BIOS PCI
Las funciones PCI BIOS son una serie de rutinas estándar que son comunes en todas las plataformas. Por ejemplo, son los mismos para los sistemas Intel y Alpha AXP. Permiten que la CPU controle el acceso a todos los espacios de direcciones PCI. Solo el kernel de Linux y los controladores de dispositivos necesitan usarlos.
Ver arch/*/kernel/bios32.c
6.6.4 Reparación PCI
El código de intercalación PCI en los sistemas Alpha AXP funciona más que Intel (que básicamente no hace nada). Para los sistemas Intel, el BIOS del sistema que se ejecuta al inicio tiene sistemas PCI completamente configurados. Linux no necesita hacer mucho más que mapear la configuración PCI. Para los sistemas que no son de Intel, es necesario realizar más configuraciones:
Ver arch/kernel/bios32.c
Asignar espacio de memoria PCI I/O y PCI para cada dispositivo
Las ventanas de dirección de memoria PCI y E/S PCI deben configurarse para cada puente PCI-PCI en el sistema
Para que el dispositivo genere un valor de línea de interrupción, estos controlan el procesamiento de interrupción del dispositivo
A continuación se describe cómo funcionan estos códigos.
Averiguar cuánto espacio de memoria PCI y E/S PCI necesita un dispositivo
(Averigüe cuánto espacio de memoria PCI y E/S PCI necesita un dispositivo)
Consulte cada dispositivo PCI encontrado para averiguar cuánto espacio de dirección de memoria y E/S PCI requiere. Para hacer esto, escriba cada registro de dirección base como 1 y léalo. El dispositivo devolverá 1 en los bits de dirección que no le interesan, especificando efectivamente el espacio de direcciones requerido.
Con dos registros básicos de direcciones base (registro de direcciones base), el primero indica el registro del dispositivo y en qué espacio de direcciones deben estar los espacios de E/S PCI y de memoria PCI. Esto está representado por el bit 0 del registro. La figura 6.10 muestra dos formas del registro de dirección base para memoria PCI y E/S PCI.
Para averiguar cuánto espacio de direcciones se requiere para cada registro de dirección base dado, es necesario escribir y leer de todos los registros. El dispositivo establece los bits de dirección que no le interesan en 0, especificando efectivamente el espacio de direcciones que necesita. Este diseño implica que todos los espacios de direcciones utilizados son índices de 2 y están inherentemente alineados.
Por ejemplo, cuando inicializa el dispositivo DECChip 21142 PCI Fast Ethernet, le indica que necesita una dirección de 0x100 bytes en el espacio de memoria PCI I/O o PCI. El código de inicialización le asigna espacio. Después de asignar el espacio, los registros de control y estado del 21142 se pueden ver en estas direcciones.
Asignación de E/S PCI y memoria PCI a dispositivos y puentes PCI-PCI
(Asigna E/S PCI y memoria PCI a puentes y dispositivos PCI-PCI)
Como toda la memoria, el espacio de memoria PCI I/O y PCI es limitado, algunos de los cuales son bastante estrechos. El código de intercalación PCI para sistemas que no son Intel (y el código BIOS para sistemas Intel) debe asignar de manera eficiente a cada dispositivo la cantidad de memoria que necesita. Las asignaciones de memoria PCI I/O y PCI asignadas a un dispositivo deben estar alineadas naturalmente. Por ejemplo, si un dispositivo solicita la dirección de E/S PCI 0xB0, la dirección asignada debe ser un múltiplo de 0xB0. Además, las bases de E/S PCI y las direcciones de memoria PCI asignadas a cualquier puente deben estar alineadas con límites de 4K y 1M, respectivamente. El espacio de direcciones proporcionado por el dispositivo descendente debe estar en el medio del rango de memoria de todos sus puentes PCI-PCI ascendentes. Por lo tanto, la asignación efectiva de espacio de direcciones es un problema más difícil.
El algoritmo utilizado por Linux se basa en cada dispositivo descrito por el árbol de bus/dispositivo establecido por el controlador de dispositivo PCI, que asigna espacio de direcciones en orden creciente de memoria de E/S PCI. De nuevo, se usa un algoritmo recursivo para atravesar las estructuras de datos pci_bus y pci_dev establecidas por el código de inicialización PCI. El código de limpieza del BIOS comienza en la raíz del bus PCI (señalado por pci_root):
Alinee las bases de memoria y E/S PCI globales actuales en límites de 4K y 1M, respectivamente
Para cada dispositivo en el bus actual (en el orden de la memoria de E/S PCI requerida)
- asignar su E/S PCI y/o memoria PCI
- Se movió la E/S PCI global y la base de memoria en la cantidad adecuada
- Permitir que el dispositivo use la E/S PCI y la memoria PCI dadas
Asigne espacio por separado para todos los buses aguas abajo del bus actual, tenga en cuenta que esto cambia la E/S PCI global y la base de memoria.
Alinee las bases de memoria y E/S PCI globales actuales en los límites de 4K y 1M respectivamente, y señale la base y el tamaño de las ventanas de memoria PCI y E/S PCI requeridas por el puente PCI-PCI actual
Para el puente PCI-PCI conectado al bus actual, configure sus direcciones y límites de memoria PCI-PCI I/O y PCI.
Habilita la capacidad de puentear E/S PCI y accesos a memoria PCI en el puente PCI-PCI. Esto significa que cualquier dirección de memoria PCI y E/S PCI que se vea en el bus PCI principal del puente se conectará a su bus secundario si está en su ventana de dirección de memoria PCI y E/S PCI.
Tome el sistema PCI de la Figura 6.1 como un ejemplo de código de intercalación PCI:
Alinee la base PCI (inicial) La E/S PCI es 0x4000, la memoria PCI es 0x100000. Esto permite que el puente PCI-ISA traduzca todas las direcciones debajo de esta a direcciones ISA.
El dispositivo de video solicita una memoria PCI de 0x200000, porque debe alinearse de acuerdo con el tamaño requerido, por lo que comenzamos la asignación desde la memoria PCI 0x200000, la dirección base de la memoria PCI se mueve a 0x400000 y la dirección de E/S PCI sigue siendo 0x4000.
Los puentes PCI-PCI Ahora cruzamos el puente PCI-PCI, donde se asigna la memoria. Tenga en cuenta que no necesitamos sus direcciones base ya que ya están correctamente alineadas.
El dispositivo Ethernet solicita 0xB0 bytes tanto en la E/S PCI como en el espacio de memoria PCI. Se asigna en la dirección de E/S PCI 0x4000, memoria PCI 0x400000. La base de la memoria PCI se movió a 0x4000B0 y la base de E/S PCI se convirtió en 0x40B0.
El dispositivo SCSI solicita memoria PCI en 0x1000, por lo que asigna 0x401000 después de la alineación. La dirección base de E/S PCI sigue siendo 0x40B0 y la base de la memoria PCI se mueve a 0x402000.
Ventanas de memoria y E/S PCI del puente PCI-PCI Ahora volvemos al puente y configuramos su ventana de E/S PCI entre 0x4000 y 0x40B0, y su ventana de memoria PCI entre 0x400000 y 0x402000. Esto significa que el puente PCI-PCI ignorará el acceso a la memoria PCI del dispositivo de visualización, si el acceso al dispositivo Ethernet o SCSI puede pasar.
7. Interrupciones y manejo de interrupciones
Aunque el kernel tiene mecanismos e interfaces generales para manejar interrupciones, la mayoría de los detalles del manejo de interrupciones dependen de la arquitectura.
Linux usa una gran cantidad de hardware diferente para muchas tareas diferentes. Los dispositivos de visualización manejan monitores, los dispositivos IDE manejan discos, etc. Puede controlar estos dispositivos de forma síncrona, es decir, puede emitir una solicitud para realizar alguna operación (como escribir un bloque de memoria en el disco) y esperar a que se complete la operación. Este enfoque, mientras funciona, es muy ineficiente y el sistema operativo pasa mucho tiempo "ocupado sin hacer nada" mientras espera que se complete cada operación. Un enfoque bueno y más eficiente es realizar la solicitud y hacer algo más útil, y luego ser interrumpido por el dispositivo cuando el dispositivo completa la solicitud. Bajo este esquema, puede haber solicitudes de muchos dispositivos en el sistema al mismo tiempo.
Debe haber algún soporte de hardware para que el dispositivo interrumpa el trabajo actual de la CPU. La mayoría de los procesadores de uso general, si no todos, como Alpha AXP, utilizan un enfoque similar. Algunos de los pines físicos de la CPU tienen circuitos que simplemente cambian el voltaje (de +5 V a -5 V, por ejemplo) para que la CPU detenga lo que está haciendo y comience a ejecutar un código especial que maneja las interrupciones: código de manejo de interrupciones. Uno de estos pines puede estar conectado a un medio interno que recibe una interrupción cada milésima de segundo, y el otro puede estar conectado a otros dispositivos en el sistema, como un controlador SCSI.
Los sistemas generalmente usan un controlador de interrupción para agrupar las interrupciones del dispositivo y luego enrutar las señales a un solo pin de interrupción en la CPU. Esto ahorra la gestión de interrupciones de la CPU y aporta flexibilidad al sistema de diseño. El controlador de interrupciones tiene registros de máscara y estado para controlar estas interrupciones. Las interrupciones se pueden habilitar y deshabilitar configurando bits en el registro de máscara, y el registro de estado devuelve las interrupciones actuales en el sistema.
Las interrupciones en algunos sistemas pueden estar cableadas, por ejemplo, el reloj interno del reloj en tiempo real puede estar permanentemente conectado al pin 3 del controlador de interrupciones. Sin embargo, a qué otros pines están conectados puede determinarse qué tarjeta de control está insertada en una ranura ISA o PCI en particular. Por ejemplo, el cuarto pin del controlador de interrupción puede estar conectado a la ranura PCI 0, puede haber una tarjeta Ethernet algún día y luego puede ser una tarjeta controladora SCSI. Cada sistema tiene su propio mecanismo de relé de interrupción y el sistema operativo debe ser lo suficientemente flexible para manejarlo.
La mayoría de los microprocesadores modernos de propósito general manejan las interrupciones de la misma manera. Cuando ocurre una interrupción de hardware, la CPU detiene la instrucción que está ejecutando y salta a una ubicación en la memoria donde contiene un código de manejo de interrupciones o una instrucción que salta al código de manejo de interrupciones. Este código suele funcionar en un modo especial de la CPU: el modo de interrupción, en el que normalmente no se pueden generar otras interrupciones. Aquí hay excepciones: algunas CPU dividen las interrupciones en niveles y pueden ocurrir interrupciones de nivel superior. Esto significa que el primer nivel de los controladores de interrupciones debe escribirse con mucho cuidado. Los controladores de interrupciones generalmente tienen su propia pila, que se utiliza para almacenar el estado de ejecución de la CPU (todos los registros de propósito general y el contexto de la CPU) y manejar las interrupciones. Algunas CPU tienen un conjunto de registros que existen solo en modo de interrupción, que el código de manejo de interrupciones puede usar para almacenar la mayor parte de la información contextual que necesita guardar.

Cuando se procesa la interrupción, se restaura el estado de la CPU y finaliza la interrupción. La CPU continuará haciendo lo que estaba haciendo antes de que ocurriera la interrupción. Importante Los controladores de interrupciones deben ser lo más eficientes posible, por lo general, el sistema operativo no puede bloquear las interrupciones con mucha frecuencia o durante largos períodos de tiempo.
7.1 Controladores de interrupción programables
Los diseñadores de sistemas son libres de usar cualquier arquitectura de interrupción que deseen, pero todas las PC de IBM usan el controlador de interrupción programable Intel 82C59A-2 CMOS o sus derivados. Este controlador se ha utilizado desde el comienzo de la PC. Es programable a través de registros en ubicaciones bien conocidas en el espacio de direcciones ISA. Incluso los conjuntos de chips lógicos muy modernos mantienen registros equivalentes en las mismas ubicaciones en la memoria ISA. Los sistemas que no son de Intel, como Alpha AXP PC, están exentos de estas arquitecturas y, por lo general, utilizan un controlador de interrupción diferente.
La figura 7.1 muestra dos controladores de 8 bits en serie: cada uno tiene una máscara y un registro de estado de interrupción, PIC1 y PIC2. Los registros de máscara están ubicados en las direcciones 0x21 y 0xA1, mientras que los registros de estado están ubicados en 0x20 y 0xA0. Escribir un 1 en un bit especial en el registro de máscara habilita una interrupción y escribir un 0 la deshabilita. Entonces, escribir un 1 en el bit 3 habilita la interrupción 3 y escribir un 0 la deshabilita. Desafortunadamente (y molesto), el registro de máscara de interrupción solo se puede escribir, no puede volver a leer el valor que escribió. Esto significa que Linux debe mantener una copia local del registro de máscara que establece. Modifica estas máscaras guardadas en las rutinas de habilitación y deshabilitación de interrupciones, cada vez que escribe la máscara completa en un registro.
Cuando se genera una señal de interrupción, el manejador de interrupciones lee los dos registros de estado de interrupción (ISR). Considera el ISR de 0x20 como el octavo bit del registro de interrupción de 16 bits y el ISR en 0xA0 como los 8 bits superiores. Por lo tanto, una interrupción que ocurre en el bit 1 del ISR en 0xA0 se considera interrupción 9. El bit 2 de PCI1 no está disponible porque se usa como interrupción para el PIC2 serial, cualquier interrupción de PIC2 establecerá el bit 2 de PIC1.
7.2 Inicialización de las estructuras de datos de manejo de interrupciones
Las estructuras de datos centrales de manejo de interrupciones se crean cuando el controlador de dispositivo requiere el control de las interrupciones del sistema. Para hacer esto, los controladores de dispositivos utilizan una serie de servicios del kernel de Linux para solicitar una interrupción, habilitarla y deshabilitarla. Estos controladores de dispositivos llaman a estas rutinas para registrar las direcciones de sus rutinas de manejo de interrupciones.
参见arch/*/kernel/irq.c request_irq() enable_irq() y disabled_irq()
La arquitectura de la PC corrige algunas interrupciones por conveniencia, por lo que el controlador simplemente solicita sus interrupciones durante la inicialización. Un controlador de dispositivo de disquete es solo eso: siempre solicita la interrupción 6. Pero también es posible que un controlador de dispositivo no sepa qué interrupciones usará el dispositivo. Esto no es un problema para los controladores de dispositivos PCI, ya que siempre conocen su número de interrupción. Desafortunadamente para los dispositivos ISA no existe una manera fácil de encontrar sus números de interrupción, Linux permite que los controladores de dispositivos prueben sus interrupciones para resolver este problema.
Primero, el controlador del dispositivo hace que el dispositivo genere interrupciones y, luego, se habilitan todas las interrupciones no asignadas en el sistema. Esto significa que las interrupciones que esperan ser procesadas por el dispositivo ahora se envían a través del controlador de interrupciones programable. Linux lee el registro de estado de interrupción y devuelve su contenido al controlador del dispositivo. Un resultado distinto de cero indica que se produjeron una o más interrupciones durante el sondeo. El controlador ahora apaga el sondeo y deshabilita las interrupciones para todas las asignaciones de bits. Si el controlador del dispositivo ISA encuentra con éxito su número de IRQ, puede solicitar el control del mismo de forma normal.
ver arch/*/kernel/irq.c irq_probe_*()
Los sistemas PCI son más dinámicos que los sistemas ISA. Las interrupciones del dispositivo ISA generalmente se configuran con puentes en el dispositivo de hardware y se corrigen para el controlador del dispositivo. Por el contrario, las interrupciones para dispositivos PCI son asignadas al inicio del sistema por el BIOS de PCI o el subsistema de PCI durante la inicialización de PCI. Cada dispositivo PCI puede usar uno de los cuatro pines de interrupción: A, B, C o D. En este momento, se determina cuándo se fabrica el dispositivo y la mayoría de los dispositivos usan el pin de interrupción A de forma predeterminada. Las líneas de interrupción PCI A, B, C y D de cada ranura PCI van al controlador de interrupción. Entonces, el pin A de la ranura 4 puede ir al pin 6 del controlador de interrupciones, el pin B de la ranura 4 puede ir al pin 7 del controlador de interrupciones, y así sucesivamente.

La forma en que se reenvían (enrutan) las interrupciones PCI depende completamente del sistema, y debe haber algún código de configuración que comprenda esta topología de enrutamiento de interrupciones PCI. En las PC Intel, esto lo hace el código BIOS del sistema en el momento del arranque. Pero para los sistemas sin BIOS (como los sistemas Alpha AXP), Linux realiza esta configuración. El código de configuración de PCI escribe el número de pin del controlador de interrupciones en el encabezado de configuración de PCI de cada dispositivo. Utiliza la topología de interrupción PCI que conoce y la ranura PCI del dispositivo y el pin de interrupción PCI que está utilizando para determinar el número de pin de interrupción (o IRQ). Los pines de interrupción utilizados por el dispositivo se determinan y colocan en un campo del encabezado de configuración PCI. Escribe esta información en el campo de línea de interrupción (que está reservado para este propósito). Cuando se ejecuta el controlador del dispositivo, lee esta información y la usa para solicitar el control de la interrupción del kernel de Linux.
Consulte arch/alpha/kernel/bios32.c
Muchos recursos de interrupción de PCI se pueden utilizar en el sistema. Por ejemplo, cuando se utiliza un puente PCI-PCI. El número de fuentes de interrupción puede exceder el número de pines del controlador de interrupción programable del sistema. En este caso, los dispositivos PCI pueden compartir interrupciones: un pin en el controlador de interrupciones recibe interrupciones de más de un dispositivo PCI. Linux admite el uso compartido de interrupciones al permitir que la primera fuente que solicita una interrupción declare (declare) si se puede compartir. Los resultados de interrupción compartidos son estructuras de datos donde una entrada en la tabla de vectores irq_action puede apuntar a varias irqactions. Cuando ocurre una interrupción compartida, Linux llama a todos los manejadores de interrupciones para esta fuente. Todos los controladores de dispositivos (que deben ser controladores de dispositivos PCI) que pueden compartir interrupciones deben estar preparados para ser llamados cuando no se atienden interrupciones.
7.3 Manejo de interrupciones
Una de las tareas principales del subsistema de manejo de interrupciones de Linux es enrutar las interrupciones al segmento de código de manejo de interrupciones correcto. Dicho código debe comprender la topología de interrupción del sistema. Por ejemplo, si el controlador de la unidad de disquete interrumpe en el pin 6 del controlador de interrupción, debe poder reconocer que la interrupción proviene de la unidad de disquete y reenviarla al código del controlador de interrupción del controlador del dispositivo de la unidad de disquete. Linux usa una serie de punteros a estructuras de datos que contienen las direcciones de las rutinas que manejan las interrupciones del sistema. Estas rutinas pertenecen a los controladores de dispositivo de los dispositivos en el sistema, y cada controlador de dispositivo debe ser responsable de solicitar las interrupciones que desea cuando se inicializa el controlador. La figura 7.2 muestra que irq_action es una tabla vectorial de punteros a la estructura de datos irqaction. Cada estructura de datos irqaction contiene información sobre el controlador de interrupciones, incluida la dirección del controlador de interrupciones. La cantidad de interrupciones y la forma en que se manejan son diferentes para los diferentes sistemas. Por lo general, entre diferentes sistemas, el código de manejo de interrupciones de Linux depende de la arquitectura. Esto significa que el tamaño de la tabla de vectores irq_action varía según el número de fuentes de interrupción.
Cuando ocurre una interrupción, Linux primero debe determinar su origen leyendo el registro de estado del controlador de interrupción programable del sistema. Luego convierta esta fuente en un desplazamiento en la tabla de vectores irq_action. Por ejemplo, una interrupción en el pin 6 del controlador de interrupciones del controlador de disquete se transferirá al puntero 7 en la tabla de vectores del controlador de interrupciones. Si ocurre una interrupción sin un controlador de interrupción correspondiente, el kernel de Linux registrará un error; de lo contrario, llamará al controlador de interrupción en todas las estructuras de datos irqaction de esta fuente de interrupción.
Cuando el kernel de Linux llama a la rutina de manejo de interrupciones del controlador de dispositivo, debe determinar efectivamente por qué se interrumpió y responder. Para averiguar la causa de la interrupción, el controlador del dispositivo lee el registro de estado del dispositivo de interrupción. El dispositivo puede responder: Se produjo un error o se completó una operación solicitada. Por ejemplo, el controlador de la unidad de disquete podría informar que ha colocado el cabezal de lectura de la unidad de disquete en el sector correcto del disquete. Una vez que se determina la causa de la interrupción, es posible que el controlador del dispositivo deba trabajar más. Si es así, el kernel de Linux tiene mecanismos para permitir que esta operación se retrase por un tiempo. Esto evita que la CPU pase demasiado tiempo en modo de interrupción.
8. Controladores de dispositivos
Uno de los propósitos de un sistema operativo es ocultar al usuario los detalles de los dispositivos de hardware del sistema. Por ejemplo, un sistema de archivos virtual presenta una vista unificada del sistema de archivos montado, independientemente del dispositivo físico subyacente. Esta sección describe cómo el kernel de Linux administra los dispositivos físicos en el sistema.
La CPU no es el único dispositivo inteligente del sistema, cada dispositivo físico está controlado por su propio hardware. El teclado, el mouse y el puerto serie están controlados por el chip SuperIO, el disco IDE está controlado por el controlador IDE, el disco SCSI está controlado por el controlador SCSI, etc. Cada controlador de hardware tiene su propio controlador de control y estado (CSR), que varía de un dispositivo a otro. El CSR de un controlador Adaptec 2940 SCSI es completamente diferente al de un controlador NCR 810 SCSI. El CSR se utiliza para iniciar y detener el dispositivo, inicializar el dispositivo y diagnosticar problemas con él. El código para administrar estos controladores de hardware no se encuentra en todas las aplicaciones, sino en el kernel de Linux. Estos pies de software que manejan o administran los controladores de hardware se denominan controladores de dispositivos. Los controladores de dispositivos en el kernel de Linux son esencialmente una biblioteca compartida de rutinas de control de hardware de bajo nivel privilegiadas y residentes en la memoria. Son las idiosincrasias de los controladores de dispositivos Linux las que se ocupan de los dispositivos que administran.
Una característica fundamental de UN*X es que abstrae el manejo de dispositivos. Todos los dispositivos de hardware se tratan como archivos normales: se pueden abrir, cerrar y leer y escribir utilizando las mismas llamadas al sistema estándar que los archivos. Cada dispositivo en el sistema está representado por un archivo especial de dispositivo. Por ejemplo, el primer disco duro IDE del sistema está representado por /dev/had. Para dispositivos de bloque (disco) y de caracteres, estos archivos especiales de dispositivo se crean con el comando mknod y usan números de dispositivo mayor y menor para describir el dispositivo. Los dispositivos de red también están representados por archivos especiales de dispositivo, pero Linux los crea cuando encuentra e inicializa el controlador de red en el sistema. Todos los dispositivos controlados por el mismo controlador de dispositivo están numerados por un dispositivo principal común. Los números de dispositivo menores se utilizan para distinguir entre diferentes dispositivos y sus controladores. Por ejemplo, las diferentes particiones del disco IDE principal están numeradas por un dispositivo menor diferente. Entonces, /dev/hda2, la segunda partición del disco IDE principal tiene un número mayor de 3 y un número menor de 2. Linux utiliza la tabla de números de dispositivos principales y algunas tablas del sistema (como la tabla de dispositivos de caracteres chrdevs) para asignar archivos especiales de dispositivos pasados en llamadas al sistema (como montar un sistema de archivos en un dispositivo de bloque) al controlador de dispositivo para este dispositivo.
Ver fs/devices.c
Linux admite tres tipos de dispositivos de hardware: carácter, bloque y red. Los dispositivos de caracteres se leen y escriben directamente, sin búfer, como los puertos serie del sistema /dev/cua0 y /dev/cua1. Los dispositivos de bloque solo se pueden leer y escribir en múltiplos de un bloque (generalmente 512 bytes o 1024 bytes). Se accede a los dispositivos de bloque a través de la memoria caché del búfer y se puede acceder de forma aleatoria, es decir, se puede leer o escribir cualquier bloque independientemente de dónde se encuentre en el dispositivo. Se puede acceder a los dispositivos de bloque a través de sus archivos especiales de dispositivo, pero se accede más comúnmente a través del sistema de archivos. Solo un dispositivo de bloque puede admitir un sistema de archivos montado. Se accede a los dispositivos de red a través de la interfaz de socket BSD, y el subsistema de red se describe en la Sección 10.
Linux tiene muchos controladores de dispositivos diferentes (que también es uno de los puntos fuertes de Linux), pero todos tienen algunas propiedades generales:
Código del kernel Los controladores de dispositivos, al igual que otros códigos del kernel, forman parte del kenel y pueden dañar gravemente el sistema si se produce un error. Un controlador mal escrito puede incluso destruir el sistema, posiblemente corrompiendo el sistema de archivos y perdiendo datos.
Interfaces de Kenel Un controlador de dispositivo debe proporcionar una interfaz estándar para el kernel de Linux o el subsistema en el que reside. Por ejemplo, el controlador de terminal proporciona una interfaz de E/S de archivo para el kernel de Linux, y el controlador de dispositivo SCSI proporciona la interfaz de dispositivo SCSI para el subsistema SCSI, que a su vez proporciona al kernel interfaces de E/S de archivo y caché de búfer.
Mecanismos y servicios del núcleo Los controladores de dispositivos utilizan servicios básicos estándar, como la asignación de memoria, el reenvío de interrupciones y las colas de espera para hacer su trabajo.
Linux cargable La mayoría de los controladores de dispositivos pueden cargarse como módulos principales cuando se necesitan y descargarse cuando ya no se necesitan. Esto hace que el núcleo sea muy adaptable y eficiente con respecto a los recursos del sistema.
Los controladores de dispositivos Linux configurables se pueden integrar en el núcleo. Los dispositivos integrados en el núcleo se pueden configurar en el momento de la compilación del núcleo.
Dinámico Al inicio del sistema, busca los dispositivos de hardware que administra cada vez que se inicializa el programa de inicio del dispositivo. No importa si el dispositivo controlado por un controlador de dispositivo no existe. En este punto, el controlador del dispositivo es simplemente redundante y ocupa muy poca memoria del sistema sin causar daños.
8.1 Poling e interrupciones
Cada vez que se da un comando al dispositivo, como "mover la cabeza de lectura al sector 42 del disquete", el controlador del dispositivo puede elegir cómo determina si el comando ha finalizado. Los controladores de dispositivos pueden sondear el dispositivo o usar interrupciones.
Sondear un dispositivo generalmente significa leer constantemente su registro de estado hasta que el estado del dispositivo cambia para indicar que ha completado la solicitud. Debido a que el controlador del dispositivo es parte del núcleo, sería desastroso si el controlador sondeara constantemente y el núcleo no pudiera ejecutar nada más hasta que el dispositivo completara la solicitud. Por lo tanto, el controlador de dispositivo sondeado utiliza un temporizador del sistema para permitir que el sistema llame a una rutina en el controlador de dispositivo en una fecha posterior. Esta rutina del temporizador verifica el estado del comando, que es como funciona el controlador de disquete de Linux. Sondear con un temporizador es el mejor enfoque, y un enfoque más eficiente es usar interrupciones.
Un controlador de dispositivo de interrupción emite una interrupción de hardware cuando el dispositivo de hardware que controla necesita servicio. Por ejemplo, un controlador de dispositivo Ethernet se interrumpirá cuando el dispositivo reciba un paquete Ethernet en la red. El kernel de Linux debe poder reenviar interrupciones desde dispositivos de hardware a los controladores de dispositivo correctos. Esto se logra cuando el controlador del dispositivo registra con el núcleo las interrupciones que utiliza. Registra la dirección de la rutina del manejador de interrupciones y el número de interrupción que desea tener. Puede ver qué interrupciones usa el controlador del dispositivo y cuántas veces se usa cada tipo de interrupción en /proc/interrupts:
0: 727432 timer
1: 20534 keyboard
2: 0 cascade
3: 79691 + serial
4: 28258 + serial
5: 1 sound blaster
11: 20868 + aic7xxx
13: 1 math error
14: 247 + ide0
15: 170 + ide1Las solicitudes de recursos de interrupción se producen en el momento de la inicialización del controlador. Se corrigieron algunas interrupciones en el sistema, un legado de la arquitectura de PC de IBM. Por ejemplo, el controlador de disquete siempre usa la interrupción 6. Otras interrupciones, como las interrupciones de dispositivos PCI, se asignan dinámicamente en el momento del arranque. En este momento, el controlador del dispositivo primero debe averiguar el número de interrupción del dispositivo que controla y luego puede solicitar esta interrupción. Para interrupciones de PCI, Linux admite devoluciones de llamada de BIOS de PCI estándar para determinar información sobre dispositivos en el sistema, incluidas sus IRQ.
La forma en que se reenvía una interrupción a la CPU depende de la arquitectura. Pero en la mayoría de las arquitecturas, las interrupciones se entregan en un modo especial que evita que ocurran otras interrupciones en el sistema. Un controlador de dispositivo debe hacer el menor trabajo posible en su rutina de manejo de interrupciones para que el kernel de Linux pueda finalizar la interrupción y volver a donde se quedó. Los controladores de dispositivos que hacen mucho trabajo después de recibir una interrupción pueden usar el controlador de la mitad inferior del núcleo o una cola de tareas para poner en cola la rutina para una invocación posterior.
8.2 Acceso directo a memoria (DMA)
El uso de un controlador de dispositivo controlado por interrupciones para transferir datos hacia oa través de un dispositivo funciona bastante bien cuando la cantidad de datos es pequeña. Por ejemplo, un módem de 9600 baudios puede transmitir aproximadamente un carácter por milisegundo (1/1000 de segundo). Si la latencia de interrupción, es decir, el tiempo que tarda el dispositivo de hardware en emitir la interrupción hasta el inicio de la llamada al controlador de interrupción en el controlador del dispositivo, es relativamente pequeña (como 2 milisegundos), entonces la imagen de la transferencia de datos en el sistema en su conjunto es muy pequeño. Los datos del módem a una velocidad de transmisión de 9600 solo ocuparán el 0,002 % del tiempo de procesamiento de la CPU. Pero para dispositivos de alta velocidad, como controladores de disco duro o dispositivos Ethernet, la tasa de transferencia de datos es bastante alta. Un dispositivo SCSI puede transmitir hasta 40 Mbytes de información por segundo.
Direct Memory Access, o DMA, se inventó para resolver este problema. Un controlador DMA permite que el dispositivo cree datos en la memoria del sistema sin la intervención del procesador. El controlador ISA DMA de la PC consta de 8 canales DMA, 7 de los cuales están disponibles para los controladores de dispositivos. Cada canal DMA está asociado con un registro de dirección de 16 bits y un registro de conteo de 16 bits. Para iniciar una transferencia de datos, el controlador del dispositivo necesita establecer la dirección y los registros de conteo del canal DMA, además de la dirección de la transferencia de datos, lectura o escritura. Cuando finaliza la transferencia, el dispositivo interrumpe la PC. De esta manera, mientras se realiza la transferencia, la CPU puede hacer otras cosas.
Los controladores de dispositivos deben tener cuidado al usar DMA. Primero, todos los controladores DMA no conocen la memoria virtual, solo pueden acceder a la memoria física en el sistema. Por lo tanto, la memoria que debe transferirse mediante DMA debe ser un bloque contiguo en la memoria física. Esto significa que no puede tener acceso DMA al espacio de direcciones virtuales de un proceso. Pero también puede bloquear físicamente el proceso en la memoria mientras realiza operaciones de DMA. Segundo: el controlador DMA no puede acceder a toda la memoria física. El registro de dirección del canal DMA representa los primeros 16 bits de la dirección DMA y los siguientes 8 bits provienen del registro de página. Esto significa que las solicitudes de DMA están limitadas a los 16 MB inferiores de memoria.
Los canales DMA son recursos escasos, solo 7, y no se pueden compartir entre los controladores de dispositivos. Al igual que las interrupciones, un controlador de dispositivo debe tener la capacidad de descubrir qué canal DMA puede usar. Al igual que las interrupciones, algunos dispositivos tienen canales DMA fijos. Por ejemplo, las unidades de disquete siempre usan el canal DMA 2. A veces, el canal DMA de un dispositivo se puede configurar con puentes: algunos dispositivos Ethernet utilizan esta técnica. Algunos dispositivos más flexibles pueden decirle (a través de su CSR) qué canal DMA usar, momento en el cual el controlador del dispositivo puede simplemente descubrir un canal DMA disponible.
Linux usa una tabla de vectores de estructuras de datos dma_chan (una para cada canal DMA) para rastrear el uso del canal DMA. La estructura de datos Dma_chan tiene solo dos jades: un puntero de carácter que describe al propietario del canal DMA y una bandera que muestra si el canal DMA está asignado. Cuando cat /proc/dma, se muestra la tabla de vectores dma_chan.
8.3 Memoria
Los controladores de dispositivos deben usar la memoria con cuidado. Como son parte del kernel de Linux, no pueden usar memoria virtual. Cada vez que se ejecuta un controlador de dispositivo, puede recibir una interrupción o programar un medio controlador inferior o una cola de tareas, y el proceso actual puede cambiar. Un controlador de dispositivo no puede depender de un proceso especial en ejecución. Al igual que otras partes del núcleo, un controlador de dispositivo utiliza estructuras de datos para realizar un seguimiento de los dispositivos que controla. Estas estructuras de datos podrían asignarse estáticamente en la sección de código del controlador del dispositivo, pero esto haría que el núcleo fuera innecesariamente grande y derrochador. La mayoría de los controladores de dispositivos asignan memoria kernel no paginada para sus datos.
El kernel de Linux proporciona las rutinas de asignación y desasignación de memoria del kernel, que utilizan los controladores de dispositivos. La memoria central se asigna en bloques de potencia de 2. Por ejemplo, 128 o 512 bytes, incluso si el controlador del dispositivo no pide tanto. El número de bytes solicitado por el controlador de dispositivo se redondea al tamaño del siguiente bloque. Esto facilita la recuperación de memoria por parte del núcleo, ya que los bloques libres más pequeños se pueden combinar en bloques más grandes.
Linux también necesita hacer más trabajo adicional al solicitar la memoria del kernel. Si la cantidad total de memoria libre es demasiado baja, las páginas físicas deben descartarse o escribirse para intercambiar. Normalmente, Linux suspenderá al solicitante y pondrá el proceso en una cola de espera hasta que haya suficiente memoria física disponible. No todos los controladores de dispositivos (o en realidad el código del kernel de Linux) quieren que esto suceda, las rutinas de asignación de memoria del kernel pueden solicitar fallar si la memoria no se puede asignar de inmediato. Si el controlador del dispositivo desea asignar memoria para el acceso DMA, también debe indicar que esta memoria es compatible con DMA. Porque es necesario permitir que el kernel de Linux entienda qué memoria en el sistema es contigua para DMA, en lugar de dejar que el controlador del dispositivo decida.
8.4 Interfaz de controladores de dispositivos con el kernel
El kernel de Linux debe poder trabajar con ellos de forma estándar. Cada tipo de controlador de dispositivo: carácter, bloque y red, proporciona una interfaz común para que el núcleo la use cuando necesite solicitar sus servicios. Estas interfaces comunes significan que el núcleo puede mirar dispositivos a menudo muy diferentes y sus controladores de dispositivo exactamente de la misma manera. Por ejemplo, los discos SCSI e IDE se comportan de manera muy diferente, pero el kernel de Linux usa la misma interfaz para ellos.
Linux es muy dinámico y cada vez que se inicia el kernel de Linux, puede encontrar diferentes dispositivos físicos y requerir diferentes controladores de dispositivo. Linux le permite incluir controladores de dispositivos a través de scripts de configuración en el momento de la compilación del kernel. Cuando estos controladores de dispositivos se inicializan al inicio, es posible que no encuentren ningún hardware que puedan controlar. Se pueden cargar otros controladores como módulos principales cuando sea necesario. Para manejar esta naturaleza dinámica de los controladores de dispositivos, los controladores de dispositivos se registran con el kernel cuando se inicializan. Linux mantiene una lista de controladores de dispositivos registrados como parte de la interfaz con ellos. Estas listas incluyen punteros a rutinas e información sobre las interfaces que admiten este tipo de dispositivo.
8.4.1 Dispositivos de caracteres
Se accede a un dispositivo de caracteres, el dispositivo más simple en Linux, como un archivo. Las aplicaciones usan llamadas estándar al sistema para abrir, leer, escribir y cerrar, exactamente como si el dispositivo fuera un archivo ordinario. Incluso el módem utilizado por el demonio PPP que conecta un sistema Linux a Internet es así. Cuando se inicializa un dispositivo de caracteres, su controlador de dispositivo se registra con el kernel de Linux, agregando una entrada de estructura de datos device_struct a la tabla de vectores chrdevs. El identificador de dispositivo principal del dispositivo (p. ej., 4 para dispositivos tty) se utiliza como índice en esta tabla de vectores. El MID de un dispositivo es fijo. Cada entrada en la tabla de vectores Chrdevs, una estructura de datos device_struct, consta de dos elementos: un puntero al nombre del controlador de dispositivo registrado y un puntero a un conjunto de operaciones de archivo. Las operaciones de archivo residen en los controladores de dispositivo de caracteres del dispositivo, cada uno de los cuales maneja operaciones de archivo específicas, como abrir, leer, escribir y cerrar. El contenido de los dispositivos de caracteres en /proc/devices proviene de la tabla de vectores chrdevs
Consulte include/linux/major.h

Cuando se abre un archivo especial de caracteres que representa un dispositivo de caracteres (por ejemplo, /dev/cua0), el núcleo debe hacer algo para deshacerse de las rutinas de manipulación de archivos que usan el controlador de dispositivo de caracteres correcto. Al igual que los archivos o directorios ordinarios, cada archivo específico del dispositivo está representado por un inodo VFS. El inodo VFS para este archivo especial de caracteres (en realidad, todos los archivos especiales de dispositivos) incluye los identificadores principales y secundarios del dispositivo. El inodo VFS es creado por el sistema de archivos subyacente (por ejemplo, EXT2) en función del sistema de archivos real al buscar este archivo específico del dispositivo.
Ver fs/ext2/inode.c ext2_read_inode()
Cada inodo VFS está asociado con un conjunto de operaciones de archivos que varían según el objeto del sistema de archivos representado por el inodo. Cada vez que se crea un inodo VFS que representa un archivo especial de caracteres, su operación de archivo se establece en la operación predeterminada para dispositivos de caracteres. Solo hay una operación de archivo: la operación de apertura. Cuando una aplicación abre este archivo especial de caracteres, la operación genérica de abrir archivo usa el identificador de dispositivo principal del dispositivo como un índice en la tabla de vectores chrdevs para buscar el bloque de operación de archivo para este dispositivo especial. También construye la estructura de datos del archivo que describe el archivo especial de caracteres, haciendo que sus operaciones de archivo apunten a operaciones en el controlador del dispositivo. Luego, todas las operaciones del sistema de archivos de la aplicación se asignan a las operaciones de archivos del dispositivo de caracteres.
Ver fs/devices.c chrdev_open() def_chr_fops
8.4.2 Dispositivos de bloque
Los dispositivos de bloque también admiten el acceso como archivos. El mecanismo para proporcionar el conjunto correcto de operaciones de archivo para archivos especiales de bloque abierto es muy similar al de los dispositivos de caracteres. Linux mantiene archivos de dispositivos de bloque registrados con la tabla de vectores blkdevs. Al igual que la tabla de vectores chrdevs, utiliza el número mayor del dispositivo como índice. Sus entradas también son estructuras de datos device_struct. A diferencia de los dispositivos de caracteres, los dispositivos de bloque están clasificados. SCSI es una categoría e IDE es otra. Las clases se registran con el kernel de Linux y proporcionan operaciones de archivos al kernel. Un controlador de dispositivo para una clase de dispositivo de bloque proporciona interfaces relacionadas con la clase para esta clase. Por ejemplo, un controlador de dispositivo SCSI debe proporcionar una interfaz para el subsistema SCSI que pueda ser utilizada por el subsistema SCSI para proporcionar operaciones de archivos para dichos dispositivos al kernel.
Ver fs/devices.c

Cada controlador de dispositivo de bloque debe proporcionar una interfaz de operación de archivo común y una interfaz para el caché de búfer. Cada controlador de dispositivo de bloque llena su estructura de datos blk_dev_struct en la tabla de vectores blk_dev. El índice de esta tabla de vectores es también el número principal del dispositivo. La estructura de datos blk_dev_struct contiene la dirección de una rutina de solicitud y un puntero a una lista de estructuras de datos de solicitud, cada una de las cuales representa una solicitud para que la caché del búfer lea o escriba un bloque de datos en el dispositivo.
Consulte drivers/block/ll_rw_blk.c include/linux/blkdev.h
Cada vez que la caché del búfer desea leer o escribir un bloque de datos hacia o desde un dispositivo registrado, agrega una estructura de datos de solicitud a su blk_dev_struc. La figura 8.2 muestra que cada solicitud tiene un puntero a una o más estructuras de datos buffer_head, cada una de las cuales es una solicitud para leer o escribir un bloque de datos. La estructura de datos buffer_head está bloqueada (caché de búfer) y puede haber un proceso esperando a que se complete el proceso de bloqueo de este búfer. Cada estructura de solicitud se asigna desde una tabla estática, la tabla all_request. Si la solicitud se agrega a una lista de solicitudes vacía, se llama a la función de solicitud del controlador para procesar la cola de solicitudes. De lo contrario, el controlador simplemente procesa cada solicitud en la cola de solicitudes.
Una vez que el controlador de dispositivo completa una solicitud, debe eliminar cada estructura buffer_head de la estructura de solicitud, marcarlas como actualizadas y desbloquearlas. Desbloquear buffer_head activará cualquier proceso que esté esperando a que se complete esta operación de bloqueo. Ejemplos de esto incluyen el análisis de archivos: debe esperar a que el sistema de archivos EXT2 lea el bloque que contiene la siguiente entrada del directorio EXT2 desde el dispositivo de bloque que contiene el sistema de archivos, el proceso se suspenderá en la cola buff_head que contendrá la entrada del directorio, hasta que el controlador del dispositivo lo despierta Esta estructura de datos de solicitud se marcará como libre y puede ser utilizada por otra solicitud de bloque.
8.5 Discos duros
Los discos duros almacenan datos en platos giratorios, proporcionando una forma más permanente de almacenar datos. Para escribir datos, cabezas diminutas magnetizan un punto diminuto en la superficie del disco. El cabezal magnético puede detectar si la partícula especificada está magnetizada, de modo que se puedan leer los datos.
Una unidad de disco consta de uno o más platos, cada uno de los cuales está hecho de vidrio o cerámica bastante liso y cubierto con una fina capa de óxido de metal. El disco se coloca sobre un eje central y gira a una velocidad constante. La velocidad de rotación varía de 3000 a 1000 RPM (revoluciones por minuto) según el modelo. Los cabezales de lectura/escritura del disco son los encargados de leer y escribir datos, y cada disco tiene un par, uno para cada lado. El cabezal de lectura/escritura y la superficie del plato no están en contacto físico, sino que flotan sobre un colchón de aire delgado (una centésima de pulgada). Los cabezales de lectura y escritura se mueven por la superficie del disco mediante una unidad. Todas las cabezas se pegan y se mueven juntas en la superficie del disco.
La superficie de cada disco está dividida en estrechos anillos concéntricos llamados pistas. La pista 0 es la pista más exterior y la pista con el número más alto es la pista más cercana al eje central. Un cilindro es una combinación de pistas idénticamente numeradas. Entonces, todas las quintas pistas en cada lado de cada disco son el quinto cilindro. Debido a que el número de cilindros es el mismo que el número de pistas, el tamaño de un disco a menudo se describe en cilindros. Cada pista se divide en sectores. Un sector es la unidad de datos más pequeña que se puede leer o escribir desde un disco duro, que es el tamaño de bloque del disco. Por lo general, el tamaño del sector es de 512 bytes, y el tamaño del sector generalmente se establece cuando se formatea el disco durante la fabricación.
Un disco generalmente se describe por su geometría: el número de cilindros, el número de cabezas y el número de sectores. Por ejemplo, Linux describe mi disco IDE así cuando arranca:
hdb: Conner Peripherals 540MB - CFS540A, 516MB w/64kB Cache, CHS=1050/16/63Esto significa que consta de 1050 cilindros (pistas), 16 cabezales (8 discos) y 63 sectores/pista. Para un tamaño de sector o bloque de 512 bytes, la capacidad del disco es de 529200K bytes. Esto es inconsistente con la capacidad de almacenamiento declarada del disco de 516M, porque algunos sectores se usan para almacenar la información de partición del disco. Algunos discos pueden encontrar automáticamente sectores defectuosos y reindexarlos.
Los discos duros se pueden subdividir en particiones. Una partición es un gran grupo de sectores asignados para un propósito específico. Particionar un disco permite que el disco se use para varios sistemas operativos o para múltiples propósitos. La mayoría de los sistemas Linux de disco único constan de 3 particiones: una contiene el sistema de archivos DOS, otra es el sistema de archivos EXT2 y la tercera es la partición de intercambio. La partición del disco duro se describe en la tabla de particiones, y cada entrada describe la posición inicial y final de la partición con el número de cabeza, sector y cilindro. Para discos DOS formateados con fdisk, puede haber 4 particiones de disco primarias. No se deben usar las 4 entradas de la tabla de particiones. Fdisk admite tres tipos de particiones: primaria, extendida y lógica. Una partición extendida no es una partición real, puede incluir cualquier cantidad de particiones lógicas. Las particiones extendidas y las particiones lógicas se inventaron para superar el límite de 4 particiones primarias. Aquí está la salida de fdisk para un disco que incluye 2 particiones primarias:
Disk /dev/sda: 64 heads, 32 sectors, 510 cylinders
Units = cylinders of 2048 * 512 bytes
Device Boot Begin Start End Blocks Id System
/dev/sda1 1 1 478 489456 83 Linux native
/dev/sda2 479 479 510 32768 82 Linux swap
Expert command (m for help): p
Disk /dev/sda: 64 heads, 32 sectors, 510 cylinders
Nr AF Hd Sec Cyl Hd Sec Cyl Start Size ID
1 00 1 1 0 63 32 477 32 978912 83
2 00 0 1 478 63 32 509 978944 65536 82
3 00 0 0 0 0 0 0 0 0 00
4 00 0 0 0 0 0 0 0 0 00Muestra que la primera partición parte del cilindro o pista 0, cabeza 1 y sector 1, hasta el cilindro 477, sector 32 y cabeza 63. Debido a que una pista consta de 32 sectores y 64 cabezas de lectura/escritura, los cilindros de esta partición están completamente incluidos. De forma predeterminada, Fdisk alinea las particiones en los límites del cilindro. Comienza en el cilindro más externo (0) y se expande 478 cilindros hacia adentro hacia el eje central. La segunda partición, la partición de intercambio, comienza en el siguiente cilindro (478) y se extiende hasta el cilindro más interno del disco.

Durante la inicialización, Linux asigna la topología de los discos duros del sistema. Averigua cuántos discos duros hay en el sistema y el tipo de discos duros. Linux también descubre cómo se particiona cada disco. Todas estas son representaciones de lista de un conjunto de estructuras de datos de gendisk a las que apunta una lista de punteros de gendisk_head. Para cada subsistema de disco, como el IDE, la inicialización genera una estructura de datos de gendisk que representa los discos que encuentra. Este proceso ocurre al mismo tiempo que registra sus operaciones de archivo e incrementa su entrada en la estructura de datos blk_dev. Cada estructura de datos de gendisk tiene un número de dispositivo principal único, el mismo que el de un dispositivo específico de bloque. Por ejemplo, el subsistema de disco SCSI crea una entrada gendisk separada ("sd") con el número principal 8 (el número principal para todos los dispositivos de disco SCSI). La Figura 8.3 muestra dos entradas de gendisk, la primera es el subsistema de disco SCSI y la segunda el controlador de disco IDE. Aquí está ide0, el controlador IDE principal.
Aunque el subsistema del disco crea las entradas de gendisk correspondientes durante la inicialización, Linux solo lo usa para verificar la partición. Cada subsistema de disco debe mantener sus propias estructuras de datos que le permitan asignar números mayores y menores de dispositivo a particiones de disco físico. Cada vez que se lee o escribe un dispositivo de bloque, ya sea a través de la memoria caché del búfer o una operación de archivo, el núcleo dirige la operación al dispositivo adecuado en función de los números mayores y menores que encuentra en el archivo de dispositivo especial de bloque (p. ej., /dev/sda2) . . Es cada controlador de dispositivo o subsistema el que asigna el número menor al dispositivo físico real.
8.5.1 Discos IDE
Los discos más utilizados en los sistemas Linux hoy en día son los discos IDE (Discos Electrónicos Integrados). IDE, como SCSI, es una interfaz de disco en lugar de un bus de E/S. Cada controlador IDE puede admitir hasta 2 discos, uno es el maestro y el otro es el esclavo. El maestro y el esclavo generalmente se configuran con puentes en el disco. El primer controlador IDE del sistema se denomina controlador IDE maestro, el siguiente se denomina controlador esclavo, y así sucesivamente. IDE puede transferir 3,3 M/s desde/hacia el disco, y el tamaño máximo del disco IDE es de 538 M bytes. El IDE extendido o EIDE aumenta el tamaño máximo del disco a 8,6 G bytes y la velocidad de transferencia de datos es de hasta 16,6 M/seg. Los discos IDE y EIDE son menos costosos que los discos SCSI, y la mayoría de las PC modernas tienen uno o más controladores IDE en la placa base.
Linux nombra los discos IDE en el orden en que descubre los controladores. El disco primario en el controlador maestro es /dev/had y el disco esclavo es /dev/hdb. /dev/hdc es el disco maestro en el controlador IDE secundario. El subsistema IDE registra controladores IDE con Linux en lugar de discos. El identificador principal del controlador IDE principal es 3 y el identificador del controlador IDE secundario es 22. Esto significa que si un sistema tiene dos controladores IDE, habrá entradas para el subsistema IDE en los índices 3 y 22 en las tablas de vectores blk_dev y blkdevs. Los archivos especiales de bloques para discos IDE reflejan esta numeración: disks /dev/had y /dev/hdb, ambos conectados al controlador IDE principal, ambos tienen el número principal 3. El núcleo utiliza el identificador principal del dispositivo como índice, y todas las operaciones de archivo o caché de búfer realizadas por el subsistema IDE para estos archivos especiales de bloque se dirigen al subsistema IDE correspondiente. Al ejecutar una solicitud, el subsistema IDE es responsable de determinar para qué disco IDE es la solicitud. Para hacer esto, el subsistema IDE usa el número menor en el archivo especial del dispositivo, información que le permite dirigir la solicitud a la partición correcta en el disco correcto. /dev/hdb, el identificador de dispositivo del disco IDE esclavo en el controlador IDE maestro es (3, 64). El identificador de dispositivo de su primera partición (/dev/hdb1) es (3, 65).
8.5.2 Inicialización del subsistema IDE
Los discos IDE han existido durante la mayor parte de la historia de las PC de IBM. Durante este período, las interfaces de estos dispositivos han cambiado. Esto hace que el proceso de inicialización del subsistema IDE sea más complicado que cuando apareció por primera vez.
El número máximo de controladores IDE que puede admitir Linux es 4. Cada controlador está representado por una estructura de datos ide_hwif_t en una tabla de vectores ide_hwifs. Cada estructura de datos ide_hwif_t contiene dos estructuras de datos ide_drive_t, que representan las posibles unidades IDE maestra y esclava admitidas, respectivamente. Durante la inicialización del subsistema IDE, Linux primero mira la información del disco registrada en la memoria CMOS del sistema. Esta memoria respaldada por batería no pierde su contenido cuando se apaga la PC. Esta memoria CMOS se encuentra realmente dentro del dispositivo de reloj en tiempo real del sistema y se ejecuta ya sea que su PC esté encendida o apagada. La BIOS del sistema establece la ubicación de la memoria CMOS y le dice a Linux qué controladores y unidades IDE se encuentran en el sistema. Linux obtiene la geometría del disco encontrado del BIOS y usa esta información para establecer la estructura de datos ide_hwif_t de la unidad. La mayoría de las PC modernas utilizan conjuntos de chips PCI, como el conjunto de chips 82430 VX de Intel, que incluye un controlador PCI EIDE. El subsistema IDE utiliza devoluciones de llamada PCI BIOS para ubicar el controlador PCI(E) IDE en el sistema. A continuación, se llaman las rutinas de consulta para estos conjuntos de chips.
Una vez que se encuentra una interfaz o controlador IDE, su ide_hwif_t se configura para reflejar el controlador y los discos en él. Durante la operación, el controlador IDE escribe comandos en el registro de comandos IDE en el espacio de memoria de E/S. Las direcciones de E/S predeterminadas para los registros de estado y control del controlador IDE principal son 0x1F0-0x1F7. Estas direcciones eran convenciones en las primeras PC de IBM. El controlador IDE registra cada controlador con el caché de búfer de Linux y VFS, y lo agrega a las tablas de vectores blk_dev y blkdevs, respectivamente. El controlador IDE también solicita el control de las interrupciones apropiadas. Nuevamente, estas interrupciones tienen una convención, 14 para el controlador IDE principal y 15 para el controlador IDE secundario. Sin embargo, como todos los detalles del IDE, estos se pueden cambiar con las opciones de línea de comandos principales. El controlador IDE también agrega una entrada de gendisk a la lista de gendisk para cada controlador IDE encontrado al inicio. Esta lista se utiliza posteriormente para ver las tablas de particiones de todos los discos duros encontrados al inicio. El código de verificación de partición entiende que cada controlador IDE puede controlar dos discos IDE.
8.5.3 Discos SCSI
El bus SCSI (Interfaz de sistema de computadora pequeña) es un bus de datos punto a punto efectivo, cada bus admite hasta 8 dispositivos, cada host puede tener uno o más. A cada dispositivo se le debe asignar un identificador único, generalmente establecido por puentes en el disco. Los datos se pueden transferir de forma síncrona o asíncrona entre dos dispositivos en el bus, y se pueden transferir en datos de 32 bits de ancho a velocidades de hasta 40M/seg. El bus SCSI puede transferir datos e información de estado entre dispositivos, y las transacciones entre el iniciador y el destino involucran hasta 8 fases distintas. Puede determinar la etapa actual mediante 5 señales en el bus SCSI. Las 8 etapas son:
AUTOBÚS LIBRE Ningún dispositivo tiene el control del autobús y actualmente no se está realizando ninguna transacción.
ARBITRAJE Un dispositivo SCSI intenta obtener el control del bus SCSI afirmando su identificador SCSI en el pin de dirección. El identificador SCSI con el número más alto tiene éxito.
SELECCIÓN Un dispositivo ha arbitrado con éxito el control del bus SCSI y ahora debe enviar una señal al destino SCSI al que desea enviar comandos. Declara el identificador SCSI del objetivo en los pines de dirección.
RESELECCIÓN El dispositivo SCSI puede desconectarse mientras se procesa la solicitud y el destino volverá a seleccionar al iniciador. No todos los dispositivos SCSI admiten esta etapa.
COMMAND Se pueden enviar comandos de 6, 10 o 12 bytes desde el iniciador al destino.
ENTRADA DE DATOS, SALIDA DE DATOS En esta etapa, los datos se transfieren entre el iniciador y el objetivo.
ESTADO Después de completar todos los comandos, ingrese a esta etapa. Permite que el destino envíe un byte de estado al iniciador indicando éxito o fracaso.
MENSAJE ENTRADA, MENSAJE SALIDA Información adicional pasada entre el iniciador y el destino.
El subsistema Linux SCSI consta de dos elementos básicos, cada uno representado por una estructura de datos:
Host Un host SCSI es una pieza física de hardware, un controlador SCSI. El controlador NCR810 PCI SCSI es un ejemplo de host SCSI. Si un sistema Linux tiene más de un controlador SCSI del mismo tipo, cada instancia está representada por un host SCSI. Esto significa que un controlador de dispositivo SCSI puede controlar más de una instancia del controlador. El host SCSI suele ser siempre el iniciador del comando SCSI.
Dispositivo Los dispositivos SCSI suelen ser discos, pero el estándar SCSI admite varios tipos: cinta, CD-ROM y dispositivos SCSI genéricos. Los dispositivos SCSI suelen ser el destino de los comandos SCSI. Estos dispositivos deben ser tratados de manera diferente. Por ejemplo, medios extraíbles como CD-ROM o cinta, Linux necesita detectar si se extrajo el medio. Los diferentes tipos de discos tienen diferentes números principales, lo que permite que Linux dirija las solicitudes de dispositivos de bloque al tipo de SCSI adecuado.
Inicialización del subsistema SCSI
La inicialización del subsistema SCSI es bastante compleja y refleja la naturaleza dinámica del bus y los dispositivos SCSI. Linux inicializa el subsistema SCSI en el momento del arranque: busca el controlador SCSI (host SCSI) en el sistema y sondea cada bus SCSI, buscando cada dispositivo. Luego, estos dispositivos se inicializan para que el resto del kernel de Linux pueda acceder a ellos a través de operaciones normales de dispositivos de bloque de caché de archivo y búfer. Este proceso de inicialización tiene cuatro etapas:

Primero, Linux descubre qué controlador o adaptador de host SCSI integrado en el núcleo tiene hardware que puede controlar cuando se construye el núcleo. Cada host SCSI integrado tiene una entrada Scsi_Host_Template en la tabla de vectores buildin_scsi_hosts. La estructura de datos Scsi_Host_Template contiene punteros a rutinas que pueden realizar acciones relacionadas con el host SCSI, como detectar qué dispositivos SCSI están conectados al host SCSI. Estas rutinas se llaman durante la configuración del subsistema SCSI y forman parte de los controladores de dispositivos SCSI que admiten este tipo de host. Para cada controlador SCSI descubierto (con un dispositivo SCSI real conectado), su estructura de datos Scsi_Host_Template se agrega a la lista scsi_hosts, lo que representa un host SCSI válido. Cada instancia de cada tipo de host detectado está representada por una estructura de datos Scsi_Host en la lista scsi_hostlist. Por ejemplo, un sistema con dos controladores NCR810 PCI SCSI tendría dos entradas Scsi_Host en esta lista, una para cada controlador. Cada Scsi_Host_Template señalado por Scsi_Host representa su controlador de dispositivo.
Ahora que se encuentra cada host SCSI, el subsistema SCSI debe encontrar todos los dispositivos SCSI en cada bus de host. Los números de dispositivo SCSI van del 0 al 7, y cada número de dispositivo o identificador SCSI es único en el bus SCSI al que está conectado. Los identificadores SCSI generalmente se configuran con puentes en el dispositivo. El código de inicialización SCSI encuentra cada dispositivo SCSI en un bus SCSI enviando el comando TEST_UNIT_READY a cada dispositivo. Cuando un dispositivo responda, envíele un comando de CONSULTA para completar su determinación. Esto le da a Linux el nombre del proveedor y el modelo y número de revisión del dispositivo. Los comandos SCSI están representados por una estructura de datos Scsi_Cmnd y estos comandos se pasan al controlador de dispositivo llamando a las rutinas del controlador de dispositivo en la estructura de datos Scsi_Host_Template de este host SCSI. Cada dispositivo SCSI encontrado está representado por una estructura de datos Scsi_Device, cada uno de los cuales apunta a su principal Scsi_Host. Todas las estructuras de datos Scsi_Device se agregan a la lista scsi_devices. La figura 8.4 muestra la relación entre las principales estructuras de datos y otras estructuras de datos.
Hay cuatro tipos de dispositivos SCSI: disco, cinta, CD y genérico. Cada tipo de SCSI se registra con el núcleo por separado y tiene un tipo de dispositivo de bloque primario diferente. Sin embargo, solo se registran cuando se encuentran uno o más dispositivos de un tipo de dispositivo SCSI determinado. Cada tipo de SCSI, como un disco SCSI, mantiene su propia tabla de dispositivos. Utiliza estas tablas para dirigir las operaciones de bloque central (caché de archivo o búfer) al controlador de dispositivo correcto o al host SCSI. Cada tipo de SCSI está representado por una estructura de datos Scsi_Type_Template. Incluye información sobre este tipo de dispositivo SCSI y direcciones de rutinas que realizan varias tareas. El subsistema SCSI usa estas plantillas para llamar a las rutinas de tipo SCSI para cada tipo de dispositivo SCSI. En otras palabras, si el subsistema SCSI desea conectar un dispositivo de disco SCSI, llama a la rutina de tipo de disco SCSI. Si se detectan uno o más dispositivos SCSI de un determinado tipo, su estructura de datos Scsi_Type_Templates se agrega a la lista scsi_devicelist.
La etapa final de la inicialización del subsistema SCSI es llamar a la función de finalización de cada Scsi_Device_Template registrado. Para los tipos de disco SCSI, haga girar todos los discos SCSI y registre su tamaño de disco. También agrega una lista vinculada de discos que representan todos los discos SCSI a la estructura de datos gendisk, como se muestra en la Figura 8.3.
Entrega de solicitudes de dispositivos de bloques
Una vez que Linux ha inicializado el subsistema SCSI, se pueden usar dispositivos SCSI. Cada tipo de dispositivo SCSI válido se registra en el núcleo, por lo que Linux puede dirigirle solicitudes de dispositivo de bloque. Estas solicitudes pueden ser solicitudes de caché de búfer a través de blk_dev u operaciones de archivo a través de blkdevs. Tome una unidad de disco SCSI que está dividida por uno o más sistemas de archivos EXT2 como ejemplo, ¿cómo se dirigen las solicitudes de búfer del núcleo al disco SCSI correcto cuando se montan sus particiones EXT2?
Cada solicitud para leer/escribir un bloque de datos en/desde una partición de disco SCSI agrega una nueva estructura de datos de solicitud a la lista current_request para ese disco SCSI en la tabla de vectores blk_dev. Si la lista de solicitudes se está procesando, la memoria caché del búfer no hace nada. De lo contrario, debe dejar que el subsistema de disco SCSI maneje su cola de solicitudes. Cada disco SCSI del sistema está representado por una estructura de datos Scsi_Disk. Se almacenan en la tabla de vectores rscsi_disks, indexada por parte del número de dispositivo menor de la partición de disco SCSI. Por ejemplo, /dev/sdb1 tiene un número de dispositivo principal de 8 y un número de dispositivo secundario de 17, por lo que es 1. Cada estructura de datos Scsi_Disk incluye un puntero a la estructura de datos Scsi_Device que representa el dispositivo. Scsi_Device, a su vez, apunta a una estructura de datos Scsi_Host que "lo posee". La estructura de datos de solicitud en la memoria caché del búfer se convierte en una estructura de datos Scsi_Cmd que describe los comandos SCSI que deben enviarse al dispositivo SCSI y se pone en cola en la estructura de datos Scsi_Host que representa este dispositivo. Una vez que se lee/escribe el bloque de datos apropiado, es manejado por el controlador de dispositivo SCSI respectivo.
8.6 Dispositivos de red
Un dispositivo de red, en lo que se refiere al subsistema de red de Linux, es una entidad que envía y recibe paquetes. Por lo general, un dispositivo físico, como una tarjeta Ethernet. Pero algunos dispositivos de red son solo de software, como los dispositivos de bucle invertido, que se envían datos a sí mismos. Cada dispositivo de red está representado por una estructura de datos de dispositivo. Un controlador de dispositivo de red registra los dispositivos que controla con Linux cuando el kernel inicia la inicialización de la red. La estructura de datos del dispositivo contiene información sobre este dispositivo y direcciones de funciones que permiten que varios protocolos de red admitidos utilicen los servicios de este dispositivo. La mayoría de estas funciones están relacionadas con la transferencia de datos utilizando este dispositivo de red. El dispositivo transmite los datos recibidos a la capa de protocolo adecuada utilizando mecanismos de soporte de red estándar. Todos los datos de red (paquetes) transmitidos y recibidos están representados por la estructura de datos sk_buff, que es una estructura de datos flexible que permite que los encabezados de protocolo de red se agreguen y eliminen fácilmente. En la Sección 10 se describe en detalle cómo la capa de protocolo de red usa dispositivos de red y cómo pasan datos de un lado a otro usando la estructura de datos sk_buff. El enfoque aquí está en la estructura de datos del dispositivo y cómo se descubren e inicializan los dispositivos de red.
Consulte include/linux/netdevice.h
La estructura de datos del dispositivo incluye información sobre los dispositivos de red:
Nombre A diferencia de los dispositivos de bloque y de caracteres, cuyos archivos especiales de dispositivo se crean con el comando mknod, los archivos especiales de dispositivo de red aparecen naturalmente cuando se detectan e inicializan los dispositivos de red del sistema. Sus nombres son estándar y cada nombre indica su tipo de dispositivo. Varios dispositivos del mismo tipo se numeran secuencialmente desde 0 en adelante. Por lo tanto, los dispositivos ethernet se numeran /dev/eth0, /dev/eth1, /dev/eth2, etc. Algunos dispositivos de red comunes son:
/dev/ethN 以太网设备
/dev/slN SLIP设备
/dev/pppN PPP设备
/dev/lo loopback 设备Información del bus Esta es la información que el controlador del dispositivo necesita para controlar el dispositivo. Irq es la interrupción utilizada por el dispositivo. La dirección base es la dirección de los registros de control y estado del dispositivo en la memoria de E/S. El canal DMA es el número de canal DMA utilizado por este dispositivo de red. Toda esta información se establece en el momento del arranque cuando se inicializa el dispositivo.
Banderas de interfaz Describen las características y capacidades de este dispositivo de red.
Interfaz IFF_UP en funcionamiento
La dirección de transmisión del dispositivo IFF_BROADCAST es válida
La opción de depuración del dispositivo IFF_DEBUG está activada
IFF_LOOPBACK Este es un dispositivo de bucle invertido
IFF_POINTTOPOINT Esta es una conexión punto a punto (SLIP y PPP)
IFF_NOTRAILERS Sin avances de red
IFF_RUNNING recursos asignados
IFF_NOARP no admite el protocolo ARP
El dispositivo IF_PROMISC está en modo de recepción promiscua, recibirá todos los paquetes independientemente de sus direcciones.
IFF_ALLMULTI recibe todas las tramas IP Multicast
IFF_MULTICAST puede recibir tramas de multidifusión IP
Información de protocolo Cada dispositivo describe cómo puede ser utilizado por la capa de protocolo de red:
La Mtu no incluye el encabezado de la capa de enlace agregado para el paquete de tamaño máximo que la red puede transmitir. Este valor máximo es utilizado por capas de protocolo como IP para seleccionar un tamaño de paquete apropiado para enviar.
Family family muestra la familia de protocolos que el dispositivo puede admitir. La familia admitida por todos los dispositivos de red de Linux es AF_INET, la familia de direcciones de Internet.
Tipo El tipo de interfaz de hardware describe el medio al que está conectado este dispositivo de red. Los dispositivos de red Linux admiten una variedad de tipos de medios. Incluye Ethernet, X.25, Token Ring, Slip, PPP y Apple Localtalk.
La estructura de datos del dispositivo Direcciones contiene algunas direcciones asociadas con este dispositivo de red, incluida la dirección IP
Cola de paquetes Esta es una cola de paquetes sk_buff que espera que los dispositivos de red transmitan
Funciones de soporte Cada dispositivo proporciona un conjunto de rutinas estándar para que la capa de protocolo llame como parte de la interfaz a la capa de enlace del dispositivo. Incluye rutinas de configuración y transferencia de cuadros, así como rutinas para agregar encabezados de cuadros estándar y recopilar estadísticas. Estas estadísticas se pueden ver con ifcnfig
8.6.1 Inicialización de dispositivos de red
Los controladores de dispositivos de red, al igual que otros controladores de dispositivos de Linux, se pueden integrar en el kernel de Linux. Cada dispositivo de red posible está representado por una estructura de datos de dispositivo en la lista de dispositivos de red a los que apunta el puntero de lista dev_base. Si se requieren operaciones relacionadas con el dispositivo, la capa de red llama a una de las rutinas de servicio del dispositivo de red (en la estructura de datos del dispositivo). Sin embargo, inicialmente, la estructura de datos de cada dispositivo solo contiene la dirección de una rutina de inicialización o detección.
Los controladores de red deben abordar dos cuestiones. En primer lugar, no todos los controladores de dispositivos de red integrados en el kernel de Linux tendrán dispositivos controlados; en segundo lugar, los dispositivos Ethernet del sistema siempre se denominan /dev/eth0, /dev/eth1, etc., independientemente del controlador de dispositivo subyacente. El problema de los dispositivos de red "faltantes" es fácil de solucionar. Cuando se llama a la rutina de inicialización de cada dispositivo de red, devuelve un estado que muestra si ha localizado una instancia del controlador que controla. Si el controlador no encuentra ningún dispositivo, se elimina su entrada en la lista de dispositivos a la que apunta dev_base. Si el controlador puede encontrar un dispositivo, completa el resto de la estructura de datos del dispositivo con información sobre el dispositivo y las direcciones de las funciones de soporte en el controlador del dispositivo de red.
El segundo problema, la asignación dinámica de dispositivos ethernet al archivo especial de dispositivo estándar /dev/ethN, se resuelve de una manera más elegante. Hay 8 entradas estándar en la lista de dispositivos: eth0, eth1 a eth7. La rutina de inicialización es la misma para todas las entradas. Intenta crear secuencialmente cada controlador de dispositivo Ethernet en el núcleo hasta que encuentra uno. Cuando el controlador encuentra su dispositivo ethernet, completa la estructura de datos del dispositivo ethN que ahora posee. En este punto, el controlador de red también inicializa el hardware físico que controla y descubre qué IRQ, DMA, etc., utiliza. Un controlador puede encontrar varias instancias del dispositivo de red que controla, en cuyo caso ocupa varias estructuras de datos de dispositivo /dev/ethN. Una vez que se hayan asignado los 8 /dev/ethN estándar, no se probarán más dispositivos Ethernet.
9. El sistema de archivos
Una de las características más importantes de Linux le permite admitir muchos sistemas de archivos diferentes. Esto lo hace muy flexible y puede coexistir con muchos otros sistemas operativos. inux siempre ha soportado 15 sistemas de archivos: ext, ext2, xia, minix, umsdos, msdos, vfat, proc, smb, ncp, iso9660, sysv, hpfs, affs y ufs, y no hay duda de que con el tiempo se irán añadiendo Más sistemas de archivos.
En Linux, como Unix, no se accede a los diferentes sistemas de archivos que el sistema puede usar mediante identificadores de dispositivos (como números de unidades o nombres de dispositivos), sino que están vinculados en una única estructura similar a un árbol, representada por un sistema de archivos de entidad única unificado. Linux lo agrega a este único árbol del sistema de archivos en el momento del montaje del sistema de archivos. Todos los sistemas de archivos, sin importar el tipo, están montados en un directorio, y los archivos del sistema de archivos montado enmascaran el contenido original del directorio. Este directorio se denomina directorio de montaje o punto de montaje. Cuando se desmonta el sistema de archivos, los propios archivos del directorio de instalación pueden volver a aparecer.
Cuando se inicializa un disco (p. ej., con fdisk), se utiliza una estructura de partición para dividir el disco físico en un conjunto de particiones lógicas. Cada partición puede contener un sistema de archivos, como un sistema de archivos EXT2. El sistema de archivos organiza los archivos en una estructura de árbol lógica en bloques de dispositivos físicos a través de directorios, enlaces suaves, etc. Los dispositivos que pueden incluir sistemas de archivos son dispositivos de bloque. La primera partición de la primera unidad de disco IDE del sistema, la partición de disco IDE /dev/hda1, es un dispositivo de bloque. El sistema de archivos de Linux trata estos dispositivos de bloques como simples combinaciones lineales de bloques y no conoce ni se preocupa por el tamaño del disco físico subyacente. Es tarea de cada controlador de dispositivo de bloque mapear una solicitud de lectura para un bloque específico del dispositivo en términos significativos para el dispositivo: la pista, el sector y el cilindro donde se almacena este bloque en el disco duro. Un sistema de archivos debe funcionar de la misma manera y tener el mismo aspecto sin importar en qué dispositivo esté almacenado. Además, con el sistema de archivos de Linux, no importa (al menos para el usuario del sistema) si estos diferentes sistemas de archivos están en diferentes medios físicos bajo el control de diferentes controladores de hardware. Es posible que el sistema de archivos ni siquiera esté en el sistema local, sino que podría montarse de forma remota a través de una conexión de red. Considere el siguiente ejemplo, donde el sistema de archivos raíz de un sistema Linux está en un disco SCSI.
Arranque AE, etc. lib opt tmp usr
CF cdrom fd proc raíz var sbin
D bin dev home mnt perdido+encontrado
Ni el usuario ni el programa que manipula estos archivos necesitan saber que /C es en realidad un sistema de archivos VFAT montado en el primer disco IDE del sistema. En este ejemplo (en realidad, mi sistema Linux en casa), /E es el disco IDE maestro en el controlador IDE secundario. No importa que el primer controlador IDE sea un controlador PCI y el segundo sea un controlador ISA, que también controla el CDROM IDE. Puedo acceder a mi red de trabajo con un módem y un protocolo de red PPP y, en este punto, puedo montar de forma remota el sistema de archivos de mi sistema Alpha AXP Linux en /mnt/remote.
Los archivos en el sistema de archivos contienen colecciones de datos: El archivo que contiene la fuente de esta sección es un archivo ASCII llamado filesystems.tex. Un sistema de archivos contiene no solo los datos de los archivos que contiene, sino también la estructura del sistema de archivos. Contiene toda la información que ven los usuarios y procesos de Linux, como archivos, directorios, enlaces suaves, información de protección de archivos y más. Además, debe almacenar esta información de forma segura y la coherencia básica del sistema operativo depende de su sistema de archivos. Nadie puede usar un sistema operativo que pierde datos y archivos al azar (no sé si lo hay, aunque me ha perjudicado un sistema operativo que tiene más abogados que desarrolladores de Linux).
Minix es el primer sistema de archivos de Linux, que tiene limitaciones considerables y bajo rendimiento. Su nombre de archivo no puede tener más de 14 caracteres (que aún es mejor que 8.3 nombres de archivo), y el tamaño máximo del corpus es de 64M bytes. A primera vista, 64M bytes pueden parecer lo suficientemente grandes, pero configurar una base de datos mediana requiere un tamaño de archivo mayor. El primer sistema de archivos diseñado específicamente para Linux, el Sistema de archivos extendido o EXT (Sistema de archivos extendido), se introdujo en abril de 1992 y resolvió muchos problemas, pero aún se sentía bajo rendimiento. Entonces, en 1993, se agregó la versión 2 del sistema de archivos extendido, o EXT2. Este sistema de archivos se describe en detalle más adelante en esta sección.
Un desarrollo importante tuvo lugar cuando se agregó el sistema de archivos EXT a Linux. El sistema de archivos real está separado del sistema operativo y los servicios del sistema a través de una capa de interfaz denominada sistema de archivos virtual o VFS. VFS permite que Linux admita muchos (a menudo diferentes) sistemas de archivos, cada uno de los cuales presenta una interfaz de software común para VFS. Todos los detalles del sistema de archivos de Linux se traducen por software, por lo que todos los sistemas de archivos aparecen iguales para el resto del kernel de Linux y los programas que se ejecutan en el sistema. La capa del sistema de archivos virtual de Linux le permite montar de forma transparente muchos sistemas de archivos diferentes al mismo tiempo.

La implementación del sistema de archivos virtual de Linux hace que el acceso a sus archivos sea lo más rápido y eficiente posible. También debe asegurarse de que los archivos y los datos del archivo se almacenen correctamente. Estos dos requisitos pueden ser desiguales entre sí. Linux VFS almacena información en caché en la memoria a medida que se monta y utiliza cada sistema de archivos. Estos datos almacenados en caché se modifican a medida que se crean, escriben y eliminan archivos y directorios, y se debe tener mucho cuidado para actualizar correctamente el sistema de archivos. Si puede ver las estructuras de datos del sistema de archivos en el kernel en ejecución, puede ver que el sistema de archivos lee y escribe bloques de datos, las estructuras de datos que describen los archivos y directorios a los que se accede se crean y destruyen, y los controladores de dispositivos no se detienen y ejecutan. , capturar y guardar datos. El más importante de estos cachés es el Buffer Cache, que se incorpora cuando los sistemas de archivos acceden a sus dispositivos de bloque subyacentes. Cuando se accede a los bloques, se colocan en la caché de búfer y se colocan en diferentes colas según su estado. El Buffer Cache no solo almacena en caché los búferes de datos, sino que también ayuda a administrar la interfaz asíncrona del controlador del dispositivo de bloque.
9.1 El segundo sistema de archivos extendido (EXT2)
EXT2 se inventó (Remy Card) como un sistema de archivos escalable y potente para Linux. Es el sistema de archivos de mayor éxito, al menos en la comunidad Linux, y es la base de todas las distribuciones actuales de Linux. El sistema de archivos EXT2, como la mayoría de los sistemas de archivos, se basa en la premisa de que los datos de un archivo se almacenan en bloques de datos. Estos bloques de datos tienen todos la misma longitud, aunque la longitud del bloque de diferentes sistemas de archivos EXT2 puede ser diferente, pero para un sistema de archivos EXT2 específico, su longitud de bloque se determina cuando se crea (usando mke2fs). La longitud de cada archivo se redondea en bloques. Si el tamaño del bloque es de 1024 bytes, un archivo de 1025 bytes ocupará dos bloques de 1024 bytes. Desafortunadamente, esto significa que, en promedio, desperdicia medio bloque por archivo. Por lo general, en informática, cambiará la utilización del disco por el uso de la memoria de la CPU. En este caso, Linux, como la mayoría de los sistemas operativos, utiliza una utilización del disco relativamente ineficiente a cambio de una menor carga de la CPU. No todos los bloques en un sistema de archivos contienen datos, algunos bloques deben usarse para colocar información que describa la estructura del sistema de archivos. EXT2 describe cada archivo en el sistema con una estructura de datos de inodo, que define la topología del sistema. Un inodo describe qué bloques ocupan los datos de un archivo, así como los derechos de acceso del archivo, la hora de modificación del archivo y el tipo de archivo. Cada archivo en el sistema de archivos EXT2 se describe mediante un inodo y cada inodo se identifica mediante un número único. Los inodos del sistema de archivos se mantienen juntos en la tabla de inodos. Los directorios EXT2 son simplemente archivos especiales (también se describen usando inodos) que incluyen punteros a los inodos de sus entradas de directorio.
La figura 9.1 muestra un sistema de archivos EXT2 que ocupa una serie de bloques en un dispositivo con estructura de bloques. Cada vez que se menciona un sistema de archivos, se puede pensar en un dispositivo de bloque como una serie de bloques que se pueden leer y escribir. El sistema de archivos no necesita preocuparse en qué bloque de medios físicos se coloca, ese es el trabajo del controlador del dispositivo. Cuando un sistema de archivos necesita leer información o datos del dispositivo de bloque contenedor, solicita que se lea un número entero de bloques del controlador de dispositivo que admite. El sistema de archivos EXT2 divide las particiones lógicas que ocupa en grupos de bloques. Además de contener archivos y directorios reales como información y bloques de datos, cada grupo replica información que es crítica para la consistencia del sistema de archivos. Esta información replicada es necesaria en caso de desastre y el sistema de archivos debe recuperarse. El contenido de cada grupo de bloques se describe en detalle a continuación.
9.1.1 El inodo EXT2

En el sistema de archivos EXT2, el inodo es la piedra angular de la construcción: cada archivo y directorio en el sistema de archivos se describe mediante un único inodo. Los inodos EXT2 para cada grupo de bloques se colocan en la tabla de inodos, junto con un mapa de bits que permite al sistema realizar un seguimiento de los inodos asignados y no asignados. La Figura 9.2 muestra el formato de un inodo EXT2, entre otra información, incluye algunos campos:
Consulte include/linux/ext2_fs_i.h
El modo contiene dos conjuntos de información: lo que describe el inodo y los derechos del usuario sobre él. Para EXT2, un inodo puede describir un archivo, directorio, enlace simbólico, dispositivo de bloque, dispositivo de caracteres o FIFO.
Información del propietario Identificadores de usuario y grupo para los datos de este archivo o directorio. Esto permite que el sistema de archivos controle adecuadamente los permisos de acceso a los archivos.
Tamaño El tamaño del archivo (bytes)
Marcas de tiempo La hora en que se creó este inodo y la hora en que se modificó por última vez.
Datablocks Puntero a los bloques de datos descritos por este inodo. Los primeros 12 son bloques físicos que apuntan a los datos descritos por este inodo, y los últimos 3 punteros incluyen más niveles de direccionamiento indirecto. Por ejemplo, un puntero de bloque indirecto de dos niveles apunta a un puntero de bloque que apunta a un puntero de bloque de un bloque de datos. Esto significa que los archivos con un tamaño de bloque de datos inferior o igual a 12 son más rápidos de acceder que los archivos más grandes.
Debe tener en cuenta que los inodos EXT2 pueden describir archivos de dispositivos especiales. Estos no son archivos reales que los programas pueden usar para acceder al dispositivo. Todos los archivos de dispositivos en /dev están diseñados para permitir que los programas accedan a dispositivos Linux. Por ejemplo, el programa de montaje toma el archivo del dispositivo que desea montar como argumento.
9.1.2 La Supermanzana EXT2
El superbloque contiene una descripción del tamaño y la forma básicos del sistema de archivos. La información que contiene permite que el administrador del sistema de archivos la use para mantener el sistema de archivos. Por lo general, solo los superbloques en el grupo de bloques 0 se leen cuando se monta el sistema de archivos, pero cada grupo de bloques contiene una copia replicada para usar en caso de un bloqueo del sistema. Además de alguna otra información, incluye:
Consulte include/linux/ext2_fs_sb.h
Magic Number permite que el software de instalación verifique si se trata de un superbloque de un sistema de archivos EXT2. Para la versión actual de EXT2 es 0xEF53.
Nivel de revisión Los niveles de revisión mayor y menor permiten que el código de instalación determine si este sistema de archivos admite funciones que solo están disponibles en esta revisión particular del sistema de archivos. Este es también el campo de compatibilidad de funciones, que ayuda al código de instalación a determinar qué nuevas funciones son seguras para usar en este sistema de archivos.
Número de montajes y Número máximo de montajes Estos juntos permiten que el sistema determine si este sistema de archivos necesita una verificación completa. Cada vez que se monta el sistema de archivos, el recuento de montajes aumenta. Cuando es igual al número máximo de montajes, se muestra el mensaje de advertencia "Se alcanzó el número máximo de montajes, se recomienda ejecutar e2fsck".
Número de grupo de bloques Almacena el número de grupo de bloques de esta copia de superbloque.
Tamaño de bloque El tamaño en bytes de los bloques del sistema de archivos, por ejemplo, 1024 bytes.
Bloques por grupo El número de bloques en el grupo. Al igual que el tamaño del bloque, esto se determina cuando se crea el sistema de archivos.
Bloques libres El número de bloques libres en el sistema de archivos.
Inodos libres Inodos libres en el sistema de archivos.
Primer Inodo Este es el número del primer inodo en el sistema. El primer inodo en un sistema de archivos raíz EXT2 es la entrada de directorio para el directorio '/'.

9.1.3 El descriptor de grupo EXT2
Cada grupo de bloques tiene una descripción de la estructura de datos. Al igual que los superbloques, los descriptores de grupo de todos los grupos ganadores se replican en cada grupo de bloques. Cada descriptor de grupo incluye la siguiente información:
Consulte include/linux/ext2_fs.h ext2_group_desc
Mapa de bits de bloques El número de bloque del mapa de bits de asignación de bloques de este grupo de bloques, utilizado en el proceso de asignación y recuperación de bloques.
Mapa de bits de inodo El número de bloque del mapa de bits de inodo para este grupo de bloques. Se utiliza en la asignación y el reciclaje de inodos.
Tabla de inodos El número de bloque del bloque inicial de la tabla de inodos de este grupo de bloques. El inodo representado por cada estructura de datos de inodo EXT2 se describe a continuación .
Recuento de bloques libres,Recuento de inodos libres,Recuento de directorios usados
Los descriptores de grupo están ordenados en secuencia y juntos forman la tabla de descriptores de grupo. Cada grupo de bloques incluye una copia completa de la tabla de descriptores del grupo de bloques y su superbloque. Solo la primera copia (en el grupo de bloques 0) es realmente utilizada por el sistema de archivos EXT2. Otras copias, como otras copias del superbloque, solo se usan cuando la copia principal está dañada.
9.1.4 Directorios EXT2
En el sistema de archivos EXT2, los directorios son archivos especiales que se utilizan para crear y almacenar rutas de acceso a archivos en el sistema de archivos. La figura 9.3 muestra el diseño de una entrada de directorio en la memoria. Un archivo de directorio es una lista de entradas de directorio, cada entrada de directorio contiene la siguiente información:
Consulte include/linux/ext2_fs.h ext2_dir_entry
inodo El inodo de esta entrada de directorio. Este es un índice en la matriz de inodos ubicada en la tabla de inodos del grupo de bloques. Figura 9.3 El inodo al que hace referencia la entrada de directorio para el archivo llamado archivo es i1.
Longitud del nombre La longitud en bytes de esta entrada de directorio
Nombre El nombre de esta entrada de directorio
Las dos primeras entradas en cada directorio son siempre los estándares "." y "..", que significan "este directorio" y "directorio principal", respectivamente.
9.1.5 Búsqueda de un archivo en un sistema de archivos EXT2
Los nombres de archivo de Linux tienen el mismo formato que todos los nombres de archivo de Unix. Es una serie de nombres de directorio separados por "/" y que terminan con el nombre del archivo. Un ejemplo de nombre de archivo es /home/rusling/.cshrc, donde /home y /rusling son los nombres de directorio y el nombre de archivo es .cshrc. Al igual que otros sistemas Unix, a Linux no le importa el formato del nombre del archivo: puede tener cualquier longitud y consiste en caracteres imprimibles. Para encontrar el inodo que representa este archivo en el sistema de archivos EXT2, el sistema debe analizar los nombres de archivo en el directorio uno por uno hasta encontrar el archivo.
El primer inodo que necesitamos es el inodo de la raíz de este sistema de archivos. Encontramos su número a través del superbloque del sistema de archivos. Para leer un inodo EXT2 debemos buscar en la tabla de inodos en el grupo de bloques apropiado. Por ejemplo, si el número de inodo raíz es 42, entonces necesitamos el inodo 42 en la tabla de inodos en el grupo de bloques 0. El inodo raíz es un directorio EXT2, en otras palabras, el esquema del inodo raíz lo describe como un directorio cuyos bloques de datos incluyen entradas de directorio EXT2.
Home es una de estas entradas de directorio, esta entrada de directorio nos da el número de inodo que describe el directorio /home. Tenemos que leer este directorio (primero leer su inodo, luego leer la entrada del directorio del bloque de datos descrito por este inodo), buscar la entrada de rusling y dar el número de inodo que describe el directorio /home/rusling. Finalmente, leemos la entrada de directorio a la que apunta el inodo que describe el directorio /home/rusling para encontrar el número de inodo del archivo .cshrc, por lo que obtenemos el bloque de datos que contiene la información en el archivo.
9.1.6 Cambiar el tamaño de un archivo en un sistema de archivos EXT2
Un problema común con los sistemas de archivos es que tienden a estar más fragmentados. Los bloques que contienen datos de archivos se distribuyen por todo el sistema de archivos. Cuanto más dispersos estén los bloques de datos, menos eficaz será el acceso secuencial a los bloques de datos de archivos. El sistema de archivos EXT2 intenta superar esta situación asignando nuevos bloques a un archivo que están físicamente cerca o al menos dentro de un grupo de bloques de sus bloques de datos actuales. Solo si esto falla, asigna bloques de datos en otros grupos de bloques.
Cada vez que un proceso intenta escribir datos en un archivo, el sistema de archivos de Linux verifica si los datos excederían el final del último bloque asignado del archivo. Si es así, debe asignar un nuevo bloque de datos para este archivo. Hasta que se complete esta asignación, el proceso no puede ejecutarse, debe esperar a que el sistema de archivos asigne nuevos bloques de datos y escriba los datos restantes antes de que pueda continuar. Lo primero que hace la rutina de asignación de bloques EXT2 es bloquear el superbloque EXT2 para este sistema de archivos. Asignar y liberar bloques requiere cambiar los campos en el superbloque, y el sistema de archivos de Linux no puede permitir que más de un proceso realice cambios al mismo tiempo. Si otro proceso necesita asignar más bloques de datos, debe esperar hasta que finalice este proceso. Un proceso que espera un superbloque se suspende y no puede ejecutarse hasta que su usuario actual libere el control del superbloque. El acceso a la supermanzana se otorga por orden de llegada, una vez que un proceso tiene el control de la supermanzana, mantiene el control hasta que se completa. Después de bloquear el superbloque, el proceso verifica si el sistema de archivos tiene suficientes bloques libres. Si no hay suficientes bloques libres, los intentos de asignar más fallarán y el proceso perderá el control del superbloque del sistema de archivos.
Si hay suficientes bloques libres en el sistema de archivos, el proceso intentará asignar un bloque. Si el sistema de archivos EXT2 ya ha creado bloques de datos preasignados, podemos acceder a ellos. Los bloques preasignados en realidad no existen, son solo bloques reservados en el mapa de bits de los bloques asignados. El inodo VFS usa dos campos específicos de EXT2 para representar el archivo al que estamos tratando de asignar nuevos bloques de datos: prealloc_block y prealloc_count, que son el número del primer bloque en el bloque preasignado y el número de bloques preasignados, respectivamente. Si no hay bloques preasignados o la preasignación está deshabilitada, el sistema de archivos EXT2 debe asignar un nuevo bloque de datos. El sistema de archivos EXT2 primero verifica si el bloque de datos después del último bloque de datos del archivo está libre. Lógicamente, este es el bloque más eficiente que se puede asignar porque los accesos secuenciales se hacen más rápidos. Si el bloque no está libre, continúe buscando el bloque de datos ideal en los siguientes 64 bloques. Este bloque, aunque no es ideal, está al menos bastante cerca del resto del archivo, en un grupo de bloques.
Ver fs/ext2/balloc.c ext2_new_block()
Si ninguno de estos bloques está libre, el proceso comienza a buscar secuencialmente todos los demás grupos de bloques hasta que encuentra un bloque libre. El código de asignación de bloques busca grupos de 8 bloques de datos libres en estos grupos de bloques. Reduce el requisito si no puede encontrar 8 a la vez. Si se desea y se permite la preasignación de bloques, actualiza prealloc_block y prealloc_count en consecuencia.
Siempre que se encuentre un bloque de datos libre, el código de asignación de bloques actualiza el mapa de bits del grupo de bloques y asigna un búfer de datos de la memoria caché del búfer. Este búfer de datos se identifica de forma única mediante el identificador de dispositivo que sustenta el sistema de archivos y el número de bloque del bloque asignado. Los datos del búfer se establecen en 0 y el búfer se marca como "sucio" para indicar que su contenido no se ha escrito en el disco físico. Finalmente, el propio superbloque también marca el bit como "sucio", indicando que ha realizado cambios, y luego se liberan sus bloqueos. Si hay un proceso esperando por el superbloque, se permite que se ejecute el primer proceso en la cola, obtiene el control exclusivo del superbloque y realiza sus operaciones de archivo. Los datos del proceso se escriben en un nuevo bloque de datos.Si el bloque de datos está lleno, todo el proceso se repite y se asignan otros bloques de datos.
9.2 El sistema de archivos virtual (VFS)
La figura 9.4 muestra la relación entre el sistema de archivos virtual del kernel de Linux y su sistema de archivos real. El sistema de archivos virtual debe administrar todos los diferentes sistemas de archivos montados al mismo tiempo. Con este fin, gestiona las estructuras de datos que describen todo el sistema de archivos (virtual) y los sistemas de archivos individuales reales montados.
De manera bastante confusa, VFS también usa los términos superbloque e inodo para describir los archivos del sistema, de la misma manera que el sistema de archivos EXT2 usa superbloques e inodos. Al igual que los inodos EXT2, los inodos VFS describen archivos y directorios en el sistema: el contenido y la topología del sistema de archivos virtual. De ahora en adelante, para evitar confusiones, usaré inodos VFS y superbloques VFS para distinguirlos de los inodos y superbloques EXT2.
ver fs/*
Cuando se inicializa cada sistema de archivos, se registra con el VFS. Esto sucede cuando el sistema arranca el sistema operativo para inicializarse. El propio sistema de archivos está integrado en el kernel o como un módulo cargable. Los módulos del sistema de archivos se cargan cuando el sistema los necesita, por lo que si se implementa un sistema de archivos VFAT como módulo central, solo se carga cuando se instala un sistema de archivos VFAT. Cuando se monta un sistema de archivos de dispositivo de bloque (incluido el sistema de archivos raíz), el VFS debe leer su superbloque. La rutina de lectura de superbloque para cada tipo de sistema de archivos debe averiguar la topología del sistema de archivos y asignar esta información a una estructura de datos de superbloque VFS. Un VFS mantiene una lista de sistemas de archivos montados en el sistema y su lista de superbloques VFS. Cada superbloque VFS contiene información del sistema de archivos y punteros a rutinas que realizan funciones específicas. Por ejemplo, el superbloque que representa un sistema de archivos EXT2 montado contiene un puntero a la rutina de lectura de un inodo relacionado con EXT2. Esta rutina de lectura de inodo EXT2, como todas las rutinas de lectura de inodo relacionadas con el sistema de archivos, llena el campo de inodo VFS. Cada superbloque VFS contiene un puntero a un inodo VFS en el sistema de archivos. Para el sistema de archivos raíz, este es el inodo que representa el directorio "/". Este mapeo de información es bastante eficiente para el sistema de archivos EXT2, pero relativamente ineficiente para otros sistemas de archivos.

Cuando los procesos del sistema acceden a directorios y archivos, llaman a las rutinas del sistema para atravesar los inodos VFS en el sistema. Por ejemplo, ingrese ls o cat un archivo en otro directorio, y deje que VFS encuentre el inodo VFS que representa este sistema de archivos. Cada archivo y directorio en el sistema de mapeo está representado por un inodo VFS, por lo que se accederá a algunos inodos repetidamente. Estos inodos se mantienen en la memoria caché de inodos, lo que hace que acceder a ellos sea más rápido. Si un inodo no está en la memoria caché de inodos, se debe llamar a una rutina relacionada con el sistema de archivos para leer el inodo apropiado. El acto de leer el inodo hace que se coloque en la caché de inodos, y los accesos futuros al inodo hacen que permanezca en la caché. Los inodos VFS menos utilizados se eliminan de esta memoria caché.
ver fs/inode.c
Todos los sistemas de archivos de Linux utilizan un caché de búfer común para almacenar en caché el búfer de datos del dispositivo subyacente, lo que puede acelerar el acceso al dispositivo físico que almacena el sistema de archivos, acelerando así el acceso al sistema de archivos. Este caché de búfer es independiente del sistema de archivos y está integrado en el mecanismo del kernel de Linux para asignar, leer y escribir búferes de datos. Existen beneficios especiales al tener un sistema de archivos de Linux independiente de los medios subyacentes y los controladores de dispositivos compatibles. Todos los dispositivos estructurados en bloques se registran con el kernel de Linux y presentan una interfaz uniforme, basada en bloques y generalmente asíncrona. Esto es cierto incluso para dispositivos de bloque relativamente complejos como los dispositivos SCSI. Cuando el sistema de archivos real lee datos del disco físico subyacente, hace que los controladores de dispositivos de bloque lean bloques físicos del dispositivo que controlan. La memoria caché del búfer está integrada en esta interfaz de dispositivo de bloque. Cuando el sistema de archivos lee bloques, se almacenan en un caché de búfer global compartido por todos los sistemas de archivos y el kernel de Linux. Los búferes están marcados con su número de bloque y un identificador único del dispositivo que se lee. Por lo tanto, si se necesitan los mismos datos con frecuencia, se leerán del caché del búfer en lugar del disco (lo que llevará más tiempo). Algunos dispositivos admiten la lectura anticipada, donde los bloques de datos se leen con anticipación para posibles lecturas posteriores.
Ver fs/buffer.c
El VFS también mantiene un caché de búsqueda de directorio, por lo que el inodo de un directorio de uso frecuente se puede encontrar rápidamente. Como experimento, intente enumerar un directorio que no haya incluido recientemente. La primera vez que haga una lista, notará una breve pausa, y la segunda vez que haga una lista, los resultados aparecerán de inmediato. La caché de directorio en sí no almacena los inodos en el directorio, que es responsabilidad de la caché de inodos.La caché de directorios solo almacena los nombres completos de los elementos del directorio y sus números de inodos.
Ver fs/dcache.c
9.2.1 La Supermanzana VFS
Cada sistema de archivos montado está representado por un superbloque VFS. Entre otra información, la supermanzana VFS incluye:
Consulte include/linux/fs.h
Dispositivo Este es el identificador de dispositivo del dispositivo de bloque que contiene el sistema de archivos. Por ejemplo, /dev/hda1, el primer disco IDE del sistema, tiene un identificador de dispositivo de 0x301
Punteros de inodo El puntero de inodo montado apunta al primer inodo del sistema de archivos. El puntero del inodo cubierto apunta al inodo del directorio en el que está montado el sistema de archivos. Para el sistema de archivos raíz, no hay un puntero cubierto en su superbloque VFS.
Blocksize Tamaño del bloque del sistema de archivos en bytes, por ejemplo, 1024 bytes.
Operaciones de superbloque Puntero a un conjunto de rutinas de superbloque para este sistema de archivos. Entre otros tipos, VFS utiliza estas rutinas para leer y escribir inodos y superbloques.
Tipo de sistema de archivos Un puntero a la estructura de datos file_system_type para este sistema de archivos montado
Sistema de archivos específico un puntero a la información requerida por este sistema de archivos
9.2.2 El inodo VFS
Al igual que el sistema de archivos EXT2, cada archivo, directorio, etc. en el VFS está representado por uno y solo un inodo VFS. La información en cada inodo VFS se recupera del sistema de archivos subyacente mediante rutinas específicas del sistema de archivos. Los inodos de VFS existen solo en la memoria central y se mantienen en la memoria caché de inodos de VFS siempre que sean útiles para el sistema. Entre otra información, el inodo VFS incluye algunos campos:
Consulte include/linux/fs.h
dispositivo El identificador de dispositivo del dispositivo que contiene este archivo (u otra entidad representada por este inodo VFS).
Número de inodo El número de este inodo, único en este sistema de archivos. La combinación de dispositivo y número de inodo es única en todo el sistema de archivos virtual.
Modo Al igual que EXT2, este campo describe lo que representa este inodo VFS y los derechos de acceso al mismo.
Identificador de propietario de ID de usuario
Veces Creado, modificado y escrito
Tamaño de bloque El tamaño en bytes del bloque de este archivo, por ejemplo, 1024 bytes
Operaciones de inodo Puntero a un conjunto de direcciones de rutina. Estas rutinas están relacionadas con el sistema de archivos y realizan operaciones en este inodo, como truncar el archivo representado por este inodo
Recuento El número de componentes del sistema que utilizan actualmente este inodo VFS. Count 0 significa que el inodo está libre y se puede desechar o reutilizar.
Bloquear Este campo se usa para bloquear el inodo VFS. Por ejemplo, al leerlo desde el sistema de archivos.
Dirty muestra si este inodo VFS se ha escrito y, de ser así, el sistema de archivos subyacente debe actualizarse.
Información específica del sistema de archivos
9.2.3 Registro de los sistemas de archivos

Cuando crea el kernel de Linux, se le pregunta si necesita todos los sistemas de archivos compatibles. Cuando se construye el kernel, el código de inicialización del sistema de archivos incluye llamadas a todas las rutinas de inicialización del sistema de archivos integradas. Los sistemas de archivos de Linux también se pueden construir como módulos, en cuyo caso se pueden cargar a pedido o manualmente usando insmod. Cuando home está en un módulo de sistema de archivos, se registra con el kernel y, cuando se descarga, se cancela el registro. La rutina de inicialización de cada sistema de archivos se registra con el sistema de archivos virtual y está representada por una estructura de datos file_system_type, que contiene el nombre del sistema de archivos y un puntero a su rutina de lectura de superbloque VFS. La figura 9.5 muestra que la estructura de datos file_system_type se coloca en una lista a la que apunta el puntero file_systems. Cada estructura de datos file_system_type incluye la siguiente información:
Ver fs/filesystems.c sys_setup()
ver include/linux/fs.h file_system_type
Rutina de lectura de superbloque El VFS llama a esta rutina cuando se monta una instancia de este sistema de archivos
File Systme name El nombre del sistema de archivos, como ext2
Dispositivo necesario ¿Este sistema de archivos necesita un soporte de dispositivo? No todos los sistemas de archivos requieren un dispositivo para almacenarlos. Por ejemplo, el sistema de archivos /proc no requiere un dispositivo de bloque
Puede consultar /proc/filesystems para ver qué sistemas de archivos están registrados, por ejemplo:
ext2
proceso nodev
iso9660
9.2.4 Montaje de un sistema de archivos
Cuando el superusuario intenta montar un sistema de archivos, el kernel de Linux primero debe validar los parámetros pasados en la llamada al sistema. Si bien el montaje puede realizar algunas comprobaciones básicas, no sabe si la compilación principal es un sistema de archivos compatible o si existe el punto de montaje propuesto. Considere el siguiente comando de montaje:
$ montaje –t iso9660 –o ro /dev/cdrom /mnt/cdrom
El comando de montaje pasa tres piezas de información al núcleo: el nombre del sistema de archivos, el dispositivo de bloque físico que contiene el sistema de archivos y en qué parte de la topología del sistema de archivos existente se montará el nuevo sistema de archivos.
Lo primero que hace un sistema de archivos virtual es encontrar el sistema de archivos. Primero mira cada estructura de datos file_system_type en la lista apuntada por file_systems, mirando todos los sistemas de archivos conocidos. Si encuentra un nombre coincidente, continúa hasta que el núcleo admite el tipo de sistema de archivos y obtiene la dirección de las rutinas relacionadas con el sistema de archivos para leer el superbloque del sistema de archivos. Si no puede encontrar un nombre de sistema de archivos que coincida, puede continuar si el núcleo tiene soporte incorporado para la carga a pedido de módulos principales (consulte la Sección 12). En este caso, el núcleo solicitará al demonio del núcleo que cargue el módulo del sistema de archivos apropiado antes de continuar.
ver fs/super.c do_mount()
Ver fs/super.c get_fs_type()

En el segundo paso, si el dispositivo físico pasado por el montaje no se ha montado, se debe encontrar el inodo VFS del directorio que se convertirá en el punto de montaje del nuevo sistema de archivos. El inodo VFS puede estar en la caché de inodos o debe leerse desde el dispositivo de bloque del sistema de archivos que admite este punto de montaje. Una vez que se encuentra el inodo, verifique si es un directorio y no hay ningún otro sistema de archivos montado allí. El mismo directorio no se puede utilizar como punto de montaje para más de un sistema de archivos.
En este punto, el código de montaje VFS debe asignar un superbloque VFS y pasar la información de montaje a la rutina de lectura del superbloque del sistema de archivos. Todos los superbloques VFS en el sistema se almacenan en la tabla vectorial super_blocks que consta de la estructura de datos super_block, y se debe asignar una estructura para esta instalación. La rutina de lectura del superbloque debe llenar los campos del superbloque VFS en función de la información que lee del dispositivo físico. Para el sistema de archivos EXT2, el mapeo o conversión de esta información es bastante fácil, solo necesita leer el superbloque EXT2 y llenarlo en el superbloque VFS. Para otros sistemas de archivos, como el sistema de archivos MS DOS, no es una tarea tan simple. Independientemente del sistema de archivos, llenar el superbloque VFS significa que la información que describe ese sistema de archivos debe leerse desde el dispositivo de bloque que lo admite. El comando de montaje fallará si el dispositivo de bloque no se puede leer o si no contiene este tipo de sistema de archivos.
Cada sistema de archivos montado se describe mediante una estructura de datos vfsmount, consulte la Figura 9.6. Están en cola en una lista a la que apunta vfsmntlist. Otro puntero, vfsmnttail, apunta a la última entrada de la lista, y el puntero mru_vfsmnt apunta al sistema de archivos utilizado más recientemente. Cada estructura vfsmount incluye el número de dispositivo del dispositivo de bloque que almacena el sistema de archivos, el directorio donde se monta el sistema de archivos y un puntero al superbloque VFS asignado cuando se montó el sistema de archivos. El superbloque VFS apunta a la estructura de datos file_system_type de este tipo de sistema de archivos y al inodo raíz de este sistema de archivos. Este inodo reside en la caché de inodos de VFS durante este montaje del sistema de archivos.
Ver fs/super.c add_vfsmnt()
9.2.5 Búsqueda de un archivo en el sistema de archivos virtual
Para encontrar el inodo VFS de un archivo en el sistema de archivos virtual, el VFS debe nombrar secuencialmente, un directorio a la vez, para encontrar el inodo VFS para cada directorio intermedio. Cada búsqueda de directorio llama a la rutina de búsqueda asociada con el sistema de archivos (dirección ubicada en el inodo VFS que representa el directorio principal). Debido a que siempre existe el inodo raíz del sistema de archivos en el superbloque VFS del sistema de archivos, indicado por un puntero en el superbloque, todo el proceso puede continuar. Cada vez que se busca un inodo en el sistema de archivos real, se comprueba la memoria caché del directorio para este directorio. Si la caché del directorio no tiene esta entrada, el sistema de archivos real obtiene el inodo VFS del sistema de archivos subyacente o de la caché de inodos.
9.2.6 Creación de un archivo en el sistema de archivos virtual
9.2.7 Desmontar un sistema de archivos
Mis libros de trabajo generalmente describen el ensamblaje como lo inverso al desensamblado, pero es un poco diferente para desmontar sistemas de archivos. Un sistema de archivos no se puede desmontar si algo en el sistema está usando un archivo en el sistema de archivos. Por ejemplo, si un proceso usa el directorio /mnt/cdrom o sus subdirectorios, no puede desmontar /mnt/cdrom. Si algo está usando el sistema de archivos que se está desmontando, su inodo VFS estará en el caché de inodos VFS. El código de descarga examina toda la lista de inodos en busca de inodos que pertenezcan al dispositivo ocupado por este sistema de archivos. Si el superbloque VFS del sistema de archivos montado está sucio, es decir, se ha modificado, debe volver a escribirse en el sistema de archivos en el disco. Una vez que escribe en el disco, la memoria ocupada por este superbloque VFS se devuelve al grupo de memoria libre del kernel. Finalmente, esta estructura de datos montada de vmsmount también se elimina de vfsmntlist y se libera.
Ver fs/super.c do_umount()
Ver fs/super.c remove_vfsmnt()
9.2.8 La caché de inodos VFS
Al atravesar sistemas de archivos montados, sus inodos VFS se leen constantemente y, a veces, se escriben. El sistema de archivos virtual mantiene un caché de inodos, que se utiliza para acelerar el acceso a todos los sistemas de archivos montados. Cada vez que se lee un inodo VFS desde la caché de inodos, el sistema puede guardar el acceso a los dispositivos físicos.
ver fs/inode.c
La caché de inodos de VFS se implementa en forma de tabla hash y las entradas son punteros a la lista de inodos de VFS con el mismo valor hash. El valor hash de un inodo se calcula a partir de su número de inodo y el número de dispositivo del dispositivo físico subyacente que contiene el sistema de archivos. Cada vez que el sistema de archivos virtual necesita acceder a un inodo, primero busca en la caché de inodos de VFS. Para buscar un inodo en la tabla hash de inodos, el sistema primero calcula su valor hash y luego lo usa como un índice en la tabla hash de inodos. Esto da un puntero a una lista de inodos con el mismo valor hash. Luego lee todos los inodos a la vez hasta que encuentra un inodo con el mismo número de inodo y el mismo identificador de dispositivo que el inodo que estaba buscando.
Si el inodo se puede encontrar en la memoria caché, su recuento se incrementa, lo que indica que tiene otro usuario y continúa el acceso al sistema de archivos. De lo contrario, se debe encontrar un inodo VFS libre para que el sistema de archivos lea el inodo en la memoria. Cómo obtener un inodo gratuito, VFS tiene una variedad de opciones. Si el sistema puede asignar más inodos VFS, lo hace: asigna páginas principales y las divide en nuevos inodos libres, que se colocan en la lista de inodos. Todos los inodos VFS en el sistema también están en una lista a la que apunta first_inode además de la tabla hash de inodos. Si el sistema ya tiene todos los inodos que permite, debe encontrar un inodo que pueda reutilizarse. Los buenos candidatos son los inodos que tienen un recuento de 0: esto significa que el sistema no los está utilizando actualmente. Los inodos VFS realmente importantes, como el inodo raíz del sistema de archivos, ya tienen un uso superior a 0, por lo que nunca se eligen para su reutilización. Una vez que se encuentra un candidato de reutilización, se borra. Este inodo VFS puede estar sucio, en cuyo caso el sistema debe esperar a que se desbloquee antes de continuar. Los candidatos para este inodo VFS deben borrarse antes de volver a utilizarlos.
Mientras se encuentra un nuevo inodo VFS, se debe llamar a una rutina relacionada con el sistema de archivos para llenar el inodo con información del envenenamiento del sistema de archivos real subyacente. Cuando se llena, este nuevo inodo VFS tiene un uso de 1 y está bloqueado, por lo que ningún otro proceso puede acceder a él hasta que se llene con información válida.
Para obtener los inodos VFS que realmente necesita, es posible que el sistema de archivos necesite acceder a otros inodos. Esto sucede cuando lees un directorio: solo se necesita el inodo del directorio final, pero también se debe leer el inodo del directorio intermedio. Cuando el caché de inodos de VFS está en uso y se llena, los inodos menos usados se descartan y los más usados permanecen en el caché.
9.2.9 La caché del directorio
Para acelerar el acceso a directorios de uso frecuente, VFS mantiene un caché de entradas de directorio. Cuando el sistema de archivos real busca directorios, los detalles de esos directorios se agregan a la memoria caché del directorio. La próxima vez que busque el mismo directorio, como listar o abrir un archivo en él, se encontrará en la memoria caché del directorio. Solo se almacenan en caché las entradas de directorio cortas (hasta 15 caracteres), pero esto es razonable ya que los nombres de directorio más cortos son los más utilizados. Por ejemplo: /usr/X11R6/bin se accede con mucha frecuencia cuando se inicia el servidor X.
Ver fs/dcache.c
El caché de directorio contiene una tabla hash, cada entrada apunta a una lista de entradas de caché de directorio con el mismo valor hash. La función Hash utiliza el número de dispositivo y el nombre de directorio del dispositivo que contiene este sistema de archivos para calcular el desplazamiento o índice en la tabla hash. Permite encontrar rápidamente entradas de directorio en caché. Un caché es inútil si se tarda demasiado en buscarlo o si no se encuentra en absoluto.
Para mantener estos cachés válidos y actualizados, el VFS mantiene una lista de entradas de caché de directorio usadas menos recientemente (LRU). Cuando una entrada de directorio se coloca en la memoria caché por primera vez, es decir, cuando se busca por primera vez, se agrega al final de la lista LRU de primer nivel. Para una memoria caché completa, esto elimina las entradas que existen al principio de la lista de LRU. Cuando se vuelve a acceder a la entrada del directorio, se mueve al final de la segunda lista de caché de LRU. Nuevamente, esta vez elimina la entrada del directorio de caché L2 al frente de la lista de caché LRU en el segundo nivel. No hay ningún problema con la eliminación de entradas de directorio de las listas de LRU primarias y secundarias. Estas entradas están al principio de la lista solo porque no se ha accedido a ellas recientemente. Si se accede a ellos, estarán al final de la lista. Las entradas en la lista de caché LRU L2 son más seguras que las entradas en la lista de caché LRU L1. Porque estas entradas no solo se buscan, sino que una vez se hace referencia a ellas repetidamente.

9.3 El caché de búfer
Cuando se utilizan sistemas de archivos montados, generan una gran cantidad de solicitudes para leer y escribir bloques de datos en dispositivos de bloques. Todas las solicitudes de lectura y escritura de datos de bloque se pasan al controlador de dispositivo en forma de una estructura de datos buffer_head a través de llamadas de rutina de núcleo estándar. Estas estructuras de datos brindan toda la información que necesita un controlador de dispositivo: el identificador de dispositivo identifica de manera única el dispositivo y el número de bloque le dice al controlador qué bloque leer. Todos los dispositivos de bloques se ven como una combinación lineal de bloques del mismo tamaño. Para acelerar el acceso a los dispositivos de bloques físicos, Linux mantiene un caché de búferes de bloques. Todos los búferes de bloque del sistema se almacenan en esta caché de búfer, incluso los búferes nuevos que no se utilizan. Este búfer es compartido por todos los dispositivos de bloques físicos: en cualquier momento hay muchos búferes de bloques en el búfer, que pueden pertenecer a cualquiera de los dispositivos de bloques del sistema, generalmente con diferentes estados. Esto ahorra el acceso del sistema a los dispositivos físicos si hay datos válidos en el caché del búfer. Cualquier búfer de bloque utilizado para leer/escribir datos desde/hacia el dispositivo de bloque va a esta caché de búfer. Con el tiempo, es posible que se elimine de este búfer para dejar espacio para otros búfer que sean más necesarios, o puede permanecer en el búfer si se accede a él con frecuencia.
Los búferes de bloque en este búfer se identifican de forma única por el identificador de dispositivo y el número de bloque al que pertenece este búfer. La memoria caché del búfer consta de dos partes funcionales. La primera parte es una lista de búferes de bloques libres. Una lista para cada búfer del mismo tamaño (que el sistema pueda soportar). Los búferes de bloques libres del sistema se ponen en cola en estas listas cuando se crean o descartan por primera vez. Los tamaños de búfer admitidos actualmente son 512, 1024, 2048, 4096 y 8192 bytes. La segunda parte funcional es el propio caché. Esta es una tabla hash, una tabla vectorial de punteros que se utiliza para vincular búferes con el mismo índice hash. El índice Hash se genera a partir del identificador del dispositivo y el número de bloque al que pertenece el bloque de datos. La figura 9.7 muestra esta tabla hash y algunas entradas. El búfer de bloque está en una de las listas libres o en la memoria caché del búfer. Cuando están en la memoria caché del búfer, también se ponen en cola en la lista LRU. Una lista de LRU por tipo de búfer que el sistema utiliza para realizar operaciones en un tipo de búfer. Por ejemplo, escribir un búfer con nuevos datos en el disco. El tipo de búfer refleja su estado y Linux actualmente admite los siguientes tipos:
clean 未使用,新的缓冲区(buffer)
locked 锁定的缓冲区,等待被写入
dirty 脏的缓冲区。包含新的有效的数据,将被写到磁盘,但是直到现在还没有调度到写
shared 共享的缓冲区
unshared 曾经共享的缓冲区,但是现在没有共享Cada vez que el sistema de archivos necesita leer un búfer de su dispositivo físico subyacente, intenta obtener un bloque del caché del búfer. Si no puede obtener un búfer del caché del búfer, toma un búfer limpio de la lista libre del tamaño adecuado y este nuevo búfer se coloca en el caché del búfer. Si el búfer que necesita ya está en la memoria caché del búfer, puede que esté actualizado o no. Si no está actualizado, o si es un búfer de bloque nuevo, el sistema de archivos debe solicitar al controlador del dispositivo que lea el bloque apropiado del disco.
Como todos los cachés, el caché de búfer debe mantenerse para que funcione de manera eficiente y distribuya las entradas de caché de manera justa entre los dispositivos de bloque que usan el caché de búfer. Linux usa el demonio central bdflush para realizar una gran cantidad de limpieza en este búfer, pero algunas otras cosas se realizan automáticamente en el proceso de uso del búfer.
9.3.1 El bdflush Kernel Daemon (el demonio central bdflsuh)
El demonio central bdflush es un demonio central simple que proporciona respuestas dinámicas para sistemas con muchos búferes sucios (búferes que contienen datos que deben escribirse en el disco simultáneamente). Comienza como un subproceso central cuando se inicia el sistema, lo cual es bastante confuso, y se llama a sí mismo "kflushd", que es el nombre que verá cuando use ps para mostrar los procesos en el sistema. Este proceso duerme la mayor parte del tiempo, esperando que la cantidad de búferes sucios en el sistema crezca hasta que sean demasiado grandes. Cuando se asignan y liberan búferes, verifique la cantidad de búferes sucios en el sistema y active bdflush. El umbral predeterminado es del 60 %, pero bdflush también se reactivará si el sistema necesita muchos búferes. Este valor se puede verificar y configurar con el comando de actualización:
#update –d
bdflush version 1.4
0: 60 Max fraction of LRU list to examine for dirty blocks
1: 500 Max number of dirty blocks to write each time bdflush activated
2: 64 Num of clean buffers to be loaded onto free list by refill_freelist
3: 256 Dirty block threshold for activating bdflush in refill_freelist
4: 15 Percentage of cache to scan for free clusters
5: 3000 Time for data buffers to age before flushing
6: 500 Time for non-data (dir, bitmap, etc) buffers to age before flushing
7: 1884 Time buffer cache load average constant
8: 2 LAV ratio (used to determine threshold for buffer fratricide).Cada vez que se escriben datos y se convierten en un búfer sucio, todos los búferes sucios se vinculan en la lista BUF_DIRTY LRU y bdflush intentará escribir una cantidad razonable de búferes en su disco. Este número también se puede verificar y configurar con el comando de actualización, el valor predeterminado es 500 (consulte el ejemplo anterior).
9.3.2 El proceso de actualización
El comando de actualización no es solo un comando, también es un demonio. Cuando se ejecuta como superusuario (inicialización del sistema), escribe periódicamente todos los búfer sucios antiguos en el disco. Realiza estas tareas llamando a las rutinas de servicio del sistema, más o menos lo mismo que bdflush. Cuando se genera un búfer sucio, se marca con la hora del sistema en la que debe escribirse en su propio disco. Cada vez que se ejecuta la actualización, examina todos los búferes sucios del sistema y busca búferes con tiempos de escritura vencidos. Cada búfer caducado se escribe en el disco.
Ver fs/buffer.c sys_bdflush()
9.3.3 El sistema de archivos /proc
El sistema de archivos /proc realmente incorpora las capacidades del sistema de archivos virtual de Linux. En realidad no existe (otro truco de Linux), tampoco /proc ni sus subdirectorios y los archivos en ellos existen. Pero, ¿por qué puede cat /proc/devices? El sistema de archivos /proc, como un sistema de archivos real, también se registra con el sistema de archivos virtual, pero el sistema de archivos /proc solo usa los inodos en el núcleo cuando se abren sus archivos y directorios y el VFS ejecuta llamadas que solicitan sus inodos. estos archivos y directorios. Por ejemplo, el archivo /proc/devices del kernel se genera a partir de las estructuras de datos del kernel que describen sus dispositivos.
El sistema de archivos /proc representa una ventana legible por el usuario en el espacio de trabajo interno del kernel. Algunos subsistemas de Linux, como los módulos del kernel de Linux descritos en la Sección 12, crean entradas en el sistema de archivos /proc.
9.3.4 Archivos especiales de dispositivos
Linux, como todas las versiones de Unix, representa sus dispositivos de hardware como archivos especiales. Por ejemplo, /dev/null es un dispositivo vacío. Un archivo de dispositivo no ocupa ningún espacio de datos en el sistema de archivos, es solo un punto de acceso para los controladores de dispositivos. Tanto el sistema de archivos EXT2 como el VFS de Linux tratan los archivos de dispositivo como un tipo especial de inodo. Hay dos tipos de archivos de dispositivo: archivos especiales de caracteres y bloques. Dentro del propio núcleo, los controladores de dispositivos implementan las operaciones básicas de los archivos: puede abrirlos, cerrarlos, etc. Los dispositivos de caracteres permiten operaciones de E/S en modo de caracteres, mientras que los dispositivos de bloque requieren que todas las E/S pasen por la memoria caché del búfer. Cuando se realiza una solicitud de E/S en un archivo de dispositivo, se reenvía al controlador de dispositivo apropiado en el sistema. Por lo general, no se trata de un controlador de dispositivo real, sino de un controlador de pseudodispositivo para subsistemas como la capa de controlador de dispositivo SCSI. Los archivos de dispositivos están referenciados por un número de dispositivo principal (que identifica el tipo de dispositivo) y un tipo secundario (que identifica una unidad o instancia de un tipo principal). Por ejemplo, para el disco IDE en el primer controlador IDE del sistema, el número de dispositivo principal es 3 y el número de dispositivo secundario de la primera partición del disco IDE debe ser 1, por lo tanto, ls -l /dev/hda1 produce
$ brw-rw---- 1 disco raíz 3, 1 24 de noviembre 15:09 /dev/hda1
Vea todos los números principales de Linux en /include/linux/major.h
En el núcleo, cada dispositivo se describe de forma única mediante un tipo de datos kdev_t. Este tipo tiene una longitud de dos bytes, el primero contiene el número menor del dispositivo y el segundo contiene el número mayor. El dispositivo IDE anterior se guarda como 0x0301 en el núcleo. Un inodo EXT2 que representa un dispositivo de bloque o carácter coloca los números de dispositivo principal y secundario del dispositivo en su primer puntero de bloque directo. Cuando VFS lo lee, el campo I_rdev de la estructura de datos de inodo de VFS que lo representa se establece en el identificador de dispositivo correcto.
Consulte include/linux/kdev_t.h
10. Redes
Linux y redes son casi sinónimos. De hecho, Linux es un producto de Internet o WWW. Sus desarrolladores y usuarios usan la web para intercambiar información, ideas y códigos, y el mismo Linux se usa a menudo para respaldar las necesidades de red de algunas organizaciones. Esta subsección describe cómo Linux admite los protocolos de red conocidos colectivamente como TCP/IP.
El protocolo TCP/IP fue diseñado para soportar la comunicación entre computadoras conectadas a ARPANET. ARPANET es una red de investigación estadounidense financiada por el gobierno de los Estados Unidos. ARPANET es un precursor de algunos conceptos de red, como el intercambio de mensajes y la estratificación de protocolos, que permiten que un protocolo utilice los servicios proporcionados por otros protocolos. ARPANET salió en 1988, pero sus sucesores (NSF NET e Internet) han crecido aún más. La World Wide Web, como se la conoce ahora, se desarrolló en ARPANET, que a su vez es compatible con el protocolo TCP/IP. Unix se usa mucho en ARPANET, la primera versión de red de Unix lanzada fue 4.3BSD. La implementación de red de Linux se basa en el modelo 4.3BSD, que admite conectores BSD (y algunas extensiones) y la gama completa de funciones de red TCP/IP. Se eligió esta interfaz de programación debido a su popularidad y la capacidad de transferir programas entre Linux y otras plataformas Unix.
10.1 Descripción general de las redes TCP/IP
Esta sección ofrece una descripción general de los principios fundamentales de las redes TCP/IP. Esta no es una descripción exhaustiva. Para una descripción más detallada, lea el Libro de referencia 10 (Apéndice).
En una red IP, a cada máquina se le asigna una dirección IP, que es un número de 32 bits que identifica de manera única a esta máquina. La WWW es una red IP muy grande y en crecimiento, ya cada máquina conectada a ella se le asigna una dirección IP única. Las direcciones IP están representadas por cuatro números separados por puntos, por ejemplo, 16.42.0.9. Una dirección IP en realidad se divide en dos partes: la dirección de red y la dirección de host. Estas direcciones pueden variar en tamaño (dimensiones) (existen varias clases de direcciones IP), en el caso de 16.42.0.9, la dirección de red es 16.42 y la dirección de host es 0.9. Las direcciones de host se pueden dividir en subredes y direcciones de host. Tomando 16.42.0.9 como ejemplo nuevamente, la dirección de subred puede ser 16.42.0 y la dirección de host es 16.42.0.9. Una mayor división de las direcciones IP permite a las organizaciones dividir sus propias redes. Por ejemplo, suponiendo que 16.42 es la dirección de red de ACME Computer Corporation, 16.42.0 podría ser la subred 0 y 16.42.1 podría ser la subred 1. Estas subredes pueden estar en edificios separados, tal vez conectadas por líneas telefónicas dedicadas o incluso por microondas. Los administradores de red asignan las direcciones IP, y el uso de subredes IP es una buena manera de descentralizar las tareas de administración de la red. Los administradores de subredes IP pueden asignar direcciones IP dentro de sus propias subredes.
Sin embargo, normalmente las direcciones IP son difíciles de recordar, mientras que los nombres son más fáciles de recordar. Linux.acme.com se recuerda mejor que 16.42.0.9. Se debe utilizar un mecanismo para convertir nombres de red en direcciones IP. Estos nombres se pueden almacenar estáticamente en el archivo /etc/hosts o haciendo que Linux consulte un servidor de nombres distribuido DNS para resolver los nombres. En este caso, el host local debe conocer las direcciones IP de uno o más servidores DNS, especificados en /etc/resolv.conf.
Siempre que se conecte a otra máquina, como leer una página web, use su dirección IP para intercambiar datos con esa máquina. Estos datos se incluyen en paquetes IP, cada uno de los cuales tiene un encabezado IP (incluidas las direcciones IP de las máquinas de origen y de destino, una suma de verificación y otra información útil. Esta suma de verificación se deriva del paquete IP). los datos del mensaje IP, lo que permite al receptor del mensaje IP determinar si el mensaje IP está dañado durante la transmisión (tal vez una línea telefónica ruidosa). Los datos transmitidos por la aplicación pueden dividirse en partes más pequeñas que son más fáciles de El tamaño de los datagramas IP varía según el medio conectado: los paquetes Ethernet suelen ser más grandes que los paquetes PPP. El host de destino debe volver a ensamblar estos datagramas antes de que puedan entregarse al programa receptor. Si pasa un equivalente Acceda a una página web que incluye una gran cantidad de imágenes gráficas a través de una conexión en serie lenta, y puede ver gráficamente la desagregación y reorganización de los datos.
Los hosts conectados a la misma subred IP pueden enviarse paquetes IP directamente entre sí, mientras que otros paquetes IP deben enviarse a través de un host especial (puerta de enlace). Las puertas de enlace (o enrutadores) están conectadas a más de una subred y reenvían los paquetes IP recibidos en una subred a otra. Por ejemplo, si las subredes 16.42.1.0 y 16.42.0.0 están conectadas a través de una puerta de enlace, todos los paquetes enviados desde la subred 0 a la subred 1 deben enviarse a la puerta de enlace antes de que puedan reenviarse. El host local establece una tabla de enrutamiento para que pueda enviar los paquetes IP para que se reenvíen a la máquina correcta. Para cada destino IP, hay una entrada en la tabla de enrutamiento que le dice a Linux a qué host debe enviar el paquete IP antes de llegar al destino. Estas tablas de enrutamiento son dinámicas y cambian constantemente a medida que las aplicaciones usan la red y cambia la topología de la red.
El protocolo IP es un protocolo de capa de transporte utilizado por otros protocolos para transportar sus datos. El Protocolo de control de transmisión (TCP) es un protocolo confiable de extremo a extremo que utiliza IP para transmitir y recibir sus paquetes. Al igual que los paquetes IP tienen sus propios encabezados, TCP también tiene sus propios encabezados. TCP es un protocolo orientado a la conexión, dos aplicaciones de red están conectadas entre sí mediante una conexión virtual, e incluso puede haber muchas subredes, puertas de enlace y enrutadores entre ellas. TCP transmite y recibe datos de forma fiable entre dos aplicaciones y garantiza que no habrá pérdida ni duplicación de datos. Cuando TCP utiliza IP para transmitir sus mensajes, los datos contenidos en el mensaje IP son el propio mensaje TCP. La capa IP de cada host que se comunica es responsable de transmitir y recibir paquetes IP. El Protocolo de datagramas de usuario (UDP) también usa la capa IP para transmitir sus mensajes, pero a diferencia de TCP, UDP no es un protocolo confiable, solo proporciona servicios de datagramas. Otros protocolos también pueden usar IP, lo que significa que cuando se recibe un paquete IP, la capa IP receptora debe saber a qué protocolo de capa superior pasar los datos contenidos en el paquete IP. Para ello, la cabecera de cada paquete IP tiene un byte que contiene un identificador de protocolo. Cuando TCP solicita a la capa IP que transmita un paquete IP, el encabezado del paquete IP indica que contiene un paquete TCP. La capa IP receptora utiliza este identificador de protocolo para decidir a qué protocolo pasar los datos recibidos, en este caso, la capa TCP. Cuando las aplicaciones se comunican a través de TCP/IP, deben especificar no solo la dirección IP del destino, sino también la dirección del puerto de la aplicación de destino. Una dirección de puerto identifica de forma única una aplicación y las aplicaciones web estándar usan direcciones de puerto estándar: por ejemplo, los servidores web usan el puerto 80. Estas direcciones de puerto registradas se pueden encontrar en /etc/services.
La estratificación de protocolos no se detiene solo en TCP, UDP e IP. El propio protocolo IP utiliza muchos medios físicos diferentes y otros hosts IP para transmitir paquetes IP. Los propios medios también pueden agregar sus propios encabezados de protocolo. Ejemplos de esto son la capa Ethernet, PPP y SLIP. Una Ethernet permite que muchos hosts se conecten simultáneamente en un solo cable físico. Todos los hosts conectados pueden ver cada trama Ethernet transmitida, por lo que cada dispositivo Ethernet tiene una dirección única. Cada trama de Ethernet enviada a esa dirección será recibida por el host en esa dirección e ignorada por otros hosts conectados a la red. Esta dirección única se integra en el dispositivo cuando se fabrica cada dispositivo Ethernet y, por lo general, se almacena en la SROM de la tarjeta Ethernet. Una dirección ether tiene una longitud de 6 bytes, por ejemplo, podría ser 08-00-2b-00-49-4A. Algunas direcciones Ethernet están reservadas para uso de multidifusión, y todos los hosts de la red reciben las tramas Ethernet enviadas con dichas direcciones de destino. Debido a que las tramas de Ethernet pueden transportar muchos protocolos diferentes (como datos), como los paquetes IP, todos contienen un identificador de protocolo en el encabezado. De esta forma, la capa Ethernet puede recibir correctamente los paquetes IP y transmitir los datos a la capa IP.

Para transmitir paquetes IP a través de varios protocolos de conexión, como Ethernet, la capa IP debe averiguar la dirección Ethernet del host IP. Esto se debe a que las direcciones IP son solo un concepto de direccionamiento y los propios dispositivos Ethernet tienen sus propias direcciones físicas. El administrador de la red puede asignar y reasignar las direcciones IP según sea necesario, mientras que el hardware de la red responde solo a las tramas de Ethernet con su propia dirección física o una dirección especial de multidifusión (que todas las máquinas deben recibir). Linux utiliza el Protocolo de resolución de direcciones (ARP) para permitir que las máquinas traduzcan las direcciones IP en direcciones de hardware reales, como direcciones Ethernet. Para obtener la dirección de hardware a la que está asociada una dirección IP, un host envía un paquete de solicitud ARP, que contiene la dirección IP que desea traducir, a una dirección de multidifusión que pueden recibir todos los puntos de la red. El host de destino con esta dirección IP responde con una respuesta ARP, que incluye su dirección de hardware físico. APR no solo se limita a dispositivos Ethernet, sino que también puede resolver direcciones IP de otros medios físicos, como FDDI. Los dispositivos que no pueden ARP están marcados para que Linux no necesite intentar ARP. También existe una función opuesta, ARP inverso o RARP, que traduce las direcciones físicas a direcciones IP. Esto se usa para puertas de enlace, que responden a solicitudes ARP de direcciones IP que representan la red remota.
10.2 Las capas de red TCP/IP de Linux
Al igual que los protocolos de red, la Figura 10.2 muestra la implementación de Linux de la familia de direcciones de protocolos de Internet como una serie de capas de software conectadas. Los sockets BSD son compatibles con el software genérico de administración de sockets que solo está asociado con los sockets BSD. El soporte de estos es la capa de socket INET, que administra los puntos finales de comunicación para los protocolos TCP y UDP basados en IP. UDP es un protocolo sin conexión, mientras que TCP es un protocolo confiable de extremo a extremo. Al enviar paquetes UDP, Linux no sabe y no le importa si llegan a su destino de manera segura. Los paquetes TCP están numerados y cada extremo de una conexión TCP garantiza que los datos transmitidos se reciban correctamente. La capa IP incluye la implementación del código del Protocolo de Internet. Este código agrega un encabezado IP a los datos transmitidos y sabe cómo reenviar los paquetes IP entrantes a la capa TCP o UDP. Debajo de la capa IP, los dispositivos de red como PPP y Ethernet son compatibles con las redes Linux. Los dispositivos de red no siempre se comportan como dispositivos físicos: algunos de ellos, como los dispositivos de bucle invertido, son dispositivos puramente de software. A diferencia de los dispositivos Linux estándar creados con el comando mknod, los dispositivos de red no aparecen hasta que el software subyacente los encuentra y los inicializa. Solo podrá ver el archivo de dispositivo /dev/eth0 después de haber creado un kernel que contenga los controladores de dispositivo ethereum apropiados. El protocolo ARP se encuentra entre la capa IP y los protocolos que admiten ARP.

10.3 La interfaz del zócalo BSD
Esta es una interfaz general que no solo admite varias formas de conexión en red, sino también un mecanismo de comunicación entre procesos. Un socket describe un extremo de una conexión de comunicación, y dos procesos de comunicación tendrán cada uno un socket que describa su propia parte de la conexión de comunicación entre ellos. Los sockets se pueden imaginar como una forma especial de tuberías, pero a diferencia de las tuberías, los sockets no tienen límite en la cantidad de datos que pueden contener. Linux admite varios tipos de sockets, estas clases se denominan familias de direcciones. Esto se debe a que cada clase tiene su propio método de direccionamiento de comunicaciones. Linux admite las siguientes familias o dominios de direcciones de socket:
UNIX Unix domain sockets,
INET The Internet address family supports communications via
TCP/IP protocols
AX25 Amateur radio X25
IPX Novell IPX
APPLETALK Appletalk DDP
X25 X25Hay varios tipos de socket, cada uno de los cuales representa el tipo de servicio admitido en la conexión. No todas las familias de direcciones admiten todos los tipos de servicios. El socket BSD de Linux admite los siguientes tipos de socket.
Flujo Este tipo de conector proporciona un flujo de datos secuencial bidireccional confiable, lo que garantiza que los datos no se pierdan, dañen o dupliquen durante la transmisión. Stream socket es compatible con el protocolo TCP en la familia de direcciones INET
Los sockets de datagramas también proporcionan transferencia de datos bidireccional, pero a diferencia de los sockets de flujo, no garantizan que lleguen los mensajes. Incluso si llega, no hay garantía de que lleguen secuencialmente o sin duplicación o corrupción. Este tipo de socket es compatible con el protocolo UDP en la familia de direcciones de Internet.
RAW Esto permite que el proceso acceda directamente (de ahí el nombre "sin procesar") al protocolo subyacente. Por ejemplo, puede abrir un socket sin procesar a un dispositivo Ethernet y observar el flujo de datos de IP sin procesar.
Mensajes entregados confiables Esto es muy parecido a un datagrama, pero se garantiza que los datos lleguen
Los paquetes secuenciados son como sockets de flujo, pero el tamaño del paquete de datos es fijo
Paquete Este no es un tipo de socket BSD estándar, es una extensión específica de Linux que permite que los procesos accedan a los paquetes directamente en la capa del dispositivo.
Los procesos que se comunican mediante sockets utilizan un modelo cliente-servidor. El servidor proporciona el servicio y el cliente consume el servicio. Un ejemplo de esto es un servidor web que sirve páginas web y un cliente web (o navegador) que lee esas páginas. Un servidor que usa sockets primero crea un socket y luego le asigna un nombre. El formato de este nombre está relacionado con la familia de direcciones del socket, que es la dirección local del servidor. El nombre o la dirección del Socket se especifica utilizando la estructura de datos sockaddr. Un socket INET está vinculado a una dirección de puerto IP. El número de puerto registrado se puede ver en /etc/services: por ejemplo, el puerto para el servidor web es 80. Después de vincular una dirección al socket, el servidor escucha las solicitudes de conexión entrantes a la dirección vinculada. El iniciador de la solicitud, el cliente, crea un socket y ejecuta una solicitud de conexión en él, especificando la dirección de destino del servidor. Para un socket INET, la dirección del servidor es su dirección IP y su dirección de puerto. Estas solicitudes entrantes tienen que pasar por varias capas de protocolo, encontrar su camino y luego esperar en el puerto de escucha del servidor. Una vez que el servidor recibe una solicitud entrante, puede aceptarla o rechazarla. Para aceptar una solicitud entrante, el servidor debe crear un nuevo socket para aceptarla. Una vez que se ha utilizado un socket para escuchar las solicitudes de conexión entrantes, ya no se puede utilizar para admitir una conexión. Una vez que se establece la conexión, ambos extremos pueden enviar y recibir datos. Finalmente, cuando ya no se necesita una conexión, se puede cerrar. Se debe tener cuidado para garantizar el procesamiento correcto de los datagramas que se transmiten.
El significado exacto de las operaciones en un socket BSD depende de su familia de direcciones subyacente. Establecer una conexión TCP/IP es muy diferente a establecer una conexión X.25 de radioaficionado. Al igual que el sistema de archivos virtual, Linux abstrae la interfaz de socket entre los sockets BSD y las aplicaciones en la capa de sockets BSD respaldada por software asociado con familias de direcciones independientes. Cuando se inicializa el kernel, la familia de direcciones integrada en el kernel se registra con la interfaz de socket BSD. Posteriormente, cuando una aplicación crea y utiliza un conector BSD, se establece una asociación entre el conector BSD y su familia de direcciones de soporte. Este vínculo se logra a través de una tabla de estructuras de datos que se cruzan y direcciones de rutinas de apoyo familiar. Por ejemplo, cuando una aplicación crea un nuevo socket, la interfaz de socket BSD usa las rutinas de creación de socket asociadas con la familia de direcciones.
Al configurar el núcleo, se integra un conjunto de familias de direcciones y protocolos en la tabla de vectores de protocolos. Cada uno está representado por su nombre (por ejemplo, "INET") y la dirección de su rutina de inicialización. Cuando se inicia, la interfaz de socket se inicializa y se llama al código de inicialización para cada protocolo. Para las familias de direcciones de socket, se registran en ellas una serie de operaciones de protocolo. Estas son rutinas, cada una de las cuales realiza una operación especial asociada con la familia de direcciones. Las operaciones de protocolo registradas se almacenan en la tabla de vectores pops, que contiene punteros a la estructura de datos proto_ops. La estructura de datos Proto_ops incluye el tipo de familia de protocolos y una colección de punteros a las rutinas de operación de socket asociadas con una familia de direcciones en particular. La tabla de vectores Pops está indexada con un identificador de familia de direcciones, como el identificador de familia de direcciones de Internet (AF_INET es 2).
ver incluir/linux/net.h
10.4 La capa de sockets INET
La capa de socket INET es compatible con la familia de direcciones de Internet, incluido el protocolo TCP/IP. Como se discutió anteriormente, estos protocolos están en capas, cada uno usando los servicios del otro. El código TCP/IP y las estructuras de datos de Linux reflejan esta estratificación. Hace interfaz con la capa de socket BSD a través de las operaciones de socket de la familia de direcciones de Internet que registra con la capa de socket BSD cuando se inicializa la red. Estos se colocan en la tabla de vectores pop junto con otras familias de direcciones registradas. La capa de socket BSD hace su trabajo llamando a las rutinas de soporte de socket de la capa INET en la estructura de datos proto_ops registrada. Por ejemplo, una solicitud de creación de sockets BSD cuya familia de direcciones sea INET utilizará la función de creación de sockets INET subyacente. La estructura de datos de socket que representa el socket BSD se pasa a la capa INET para cada operación de la capa de socket BSD. La capa de socket INET utiliza su propio socket de estructura de datos, que se conecta a la estructura de datos del socket BSD, en lugar de saturar el socket BSD con información relacionada con TCP/IP. Consulte la Figura 10.3 para esta conexión. Utiliza el puntero de datos en el zócalo BSD para vincular la estructura de datos del calcetín a la estructura de datos del zócalo BSD. Esto significa que las llamadas de socket INET posteriores pueden obtener fácilmente esta estructura de datos de sock. En el momento de la creación también se crean punteros de operación de protocolo a la estructura de datos sock, que dependen del protocolo solicitado. Si se solicita TCP, el puntero de operación de protocolo de la estructura de datos sock apuntará a una serie de operaciones de protocolo TCP requeridas por la conexión TCP.
ver include/net/sock.h
10.4.1 Creación de un zócalo BSD
La llamada al sistema que crea un nuevo socket necesita pasar su identificador de familia de direcciones, tipo de socket y protocolo. Primero, busque una familia de direcciones que coincida en la tabla de vectores pop con la familia de direcciones solicitada. Puede ser una familia de direcciones especial implementada usando un módulo kernel, si es así, el proceso central de kerneld debe cargar este módulo antes de que podamos continuar. Luego asigne una nueva estructura de datos de socket para representar este socket BSD. De hecho, la estructura de datos del socket es físicamente parte de la estructura de datos del inodo VFS, y asignar un socket es en realidad asignar un inodo VFS. Esto parece extraño, a menos que considere sockets que pueden manipularse de la misma manera que los archivos normales. Como todos los archivos están representados por una estructura de datos de inodo VFS, para admitir operaciones de archivo, un socket BSD también debe estar representado por una estructura de datos de inodo VFS.
La estructura de datos de socket BSD recién creada contiene un puntero a la rutina de socket asociada con la familia de direcciones, este puntero se establece en la estructura de datos proto_ops tomada de la tabla de vectores pops. Su tipo se establece en el tipo de socket solicitado: uno de SOCK_STREAM, SOCK_DGRAM, etc., y luego se llama a la rutina de creación asociada con la familia de direcciones con la dirección almacenada en la estructura de datos proto_ops.
Luego asigne un descriptor de archivo libre de la tabla de vectores fd del proceso actual, y la estructura de datos del archivo a la que apunta también se inicializa. Esto incluye establecer el puntero de manipulación de archivos en las rutinas de manipulación de archivos de socket BSD compatibles con la interfaz de socket BSD. Todas las operaciones futuras se dirigen a la interfaz de socket, que a su vez se pasa a la familia de direcciones correspondiente llamando a la rutina de operación de la familia de direcciones compatible.

10.4.2 Vinculación de una dirección a un socket INET BSD
Para escuchar las solicitudes de conexión a Internet entrantes, cada servidor debe crear un socket INET BSD y asociarle su propia dirección. La mayoría de las operaciones de Bind son manejadas por la capa de socket INET, y algunas requieren el soporte de las capas de protocolo TCP y UDP subyacentes. Un socket que se ha vinculado a una dirección no se puede utilizar para otras comunicaciones. Esto significa que el estado de este socket debe ser TCP_CLOSE. El sockaddr pasado a la operación de enlace incluye la dirección IP a la que enlazar y un número de puerto (opcional). Por lo general, la dirección vinculada será una de las direcciones asignadas a los dispositivos de red que admiten la familia de direcciones INET, y la interfaz debe estar activa y disponible para su uso. Puede usar el comando ifconfig para ver qué interfaces de red están actualmente activas en el sistema. Una dirección IP también puede ser una dirección de difusión IP (todos 1 o 0). Esta es una dirección especial que significa "enviar a todos". Esta dirección IP también se puede establecer en cualquier dirección IP si la máquina actúa como un proxy transparente o un cortafuegos. Sin embargo, solo los procesos con privilegios de superusuario pueden vincularse a cualquier dirección IP. Esta dirección IP vinculada se almacena en los campos recv_addr y saddr de la estructura de datos sock. Se utilizan para la búsqueda de hash y el envío de direcciones IP, respectivamente. El número de puerto es opcional; si no se establece, se solicitará uno libre a la red de soporte. Por convención, los números de puerto inferiores a 1024 no pueden ser utilizados por procesos sin privilegios de superusuario. Si la red subyacente asigna un número de puerto, siempre asigna un puerto mayor que 1024.
Cuando el dispositivo de red subyacente recibe paquetes, estos paquetes deben reenviarse a los sockets INET y BSD correctos para ser procesados. Con este fin, UDP y TCP mantienen tablas hash, que se utilizan para buscar las direcciones de los mensajes IP entrantes y reenviarlos al par socket/sock correcto. TCP es un protocolo orientado a la conexión, por lo que el procesamiento de paquetes TCP contiene más información que el procesamiento de paquetes UDP.
UDP mantiene una tabla hash de puertos UDP asignados, udp_table. Esto incluye un puntero a la estructura de datos sock, indexada por una función hash basada en el número de puerto. Debido a que la tabla hash UDP es mucho más pequeña que los números de puerto permitidos (udp_hash es solo 128, UDP_HTABLE_SIZE), algunas entradas en la tabla apuntan a una lista vinculada de estructuras de datos sock, unidas entre sí por el siguiente puntero de cada sock.
TCP es más complicado porque mantiene varias tablas hast. Sin embargo, durante la operación de vinculación, TCP en realidad no agrega la estructura de datos sock vinculada a su tabla hash, solo verifica que el puerto solicitado no esté actualmente en uso. La estructura de datos sock se agrega a la tabla hash de TCP durante la operación de escucha.
10.4.3 Realización de una conexión a un zócalo INET BSD
Una vez que se crea un socket, se puede usar para establecer solicitudes de conexión salientes si no está escuchando las solicitudes de conexión entrantes. Para protocolos sin conexión como UDP, esta operación de socket no tiene que hacer mucho, pero para protocolos orientados a conexión como TCP, implica establecer un circuito virtual entre dos aplicaciones.
Una conexión saliente solo se puede realizar en un socket INET BSD que esté en el estado correcto: es decir, no se ha establecido una conexión y no hay escucha de conexiones entrantes. Esto significa que la estructura de datos del socket BSD debe estar en el estado SS_UNCONNECTED. El protocolo UDP no establece una conexión virtual entre dos aplicaciones, todos los mensajes enviados son datagramas, que pueden o no llegar a su destino. Sin embargo, también es compatible con la operación de conexión de conectores BSD. Una operación de conexión en un socket UDP INET BSD simplemente establece la dirección de la aplicación remota: su dirección IP y su número de puerto IP. Además, también configura un búfer de entradas de la tabla de enrutamiento, de modo que los datagramas UDP enviados en este socket BSD no necesitan verificar la base de datos de la tabla de enrutamiento (a menos que la ruta se vuelva inválida). El puntero ip_route_cache en la estructura de datos sock de INET señala esta información de enrutamiento en caché. Si no se proporciona información de dirección, los mensajes enviados por este socket BSD utilizan automáticamente esta información de enrutamiento y dirección IP almacenada en caché. UDP cambia el estado del calcetín a TCP_ESTABLECIDO.
Para una operación de conexión en un socket TCP BSD, TCP debe establecer un mensaje TCP que contenga la información de conexión y enviarlo a la IP de destino dada. Este mensaje TCP incluye información sobre la conexión: un número de secuencia de mensaje inicial único, el tamaño máximo de los mensajes que puede administrar el host de origen, el tamaño de la ventana para enviar y recibir, etc. En TCP, todos los mensajes están numerados y el número de secuencia inicial se usa como el primer número de mensaje. Linux elige un número aleatorio razonable para evitar ataques de protocolos maliciosos. Se reconoce cada mensaje enviado desde un extremo de una conexión TCP y recibido con éxito por el otro extremo, diciéndole que llegó con éxito y sin daños. Los mensajes no reconocidos se reenviarán. El tamaño de la ventana de envío y recepción es el número de mensajes permitidos antes del reconocimiento. Si el tamaño máximo de mensaje admitido por el dispositivo de red del destinatario es más pequeño, la conexión usa el más pequeño de los dos. Una aplicación que realiza una solicitud de conexión TCP saliente ahora debe esperar una respuesta de la aplicación de destino para aceptar o rechazar la solicitud de conexión. Para el sock TCP que espera mensajes entrantes, se agrega a tcp_listening_hash para que los mensajes TCP entrantes puedan dirigirse a esta estructura de datos sock. TCP también inicia temporizadores para que las solicitudes de conexión salientes se agoten si la aplicación de destino no responde a la solicitud.
10.4.4 Escuchar en un socket INET BSD
Una vez que un socket tiene una dirección enlazada, puede escuchar las solicitudes de conexión entrantes especificando la dirección enlazada. Una aplicación de red puede escuchar directamente en un socket sin vincular una dirección, en cuyo caso la capa de socket INET encuentra un número de puerto no utilizado (para este protocolo) y lo vincula automáticamente al socket. La función de escucha del socket pone el socket en el estado TCP_LISTEN y realiza el trabajo requerido relacionado con la red mientras permite las conexiones entrantes.
Para los sockets UDP, cambiar el estado del socket es suficiente, pero TCP lo ha activado ahora para agregar la estructura de datos sock del socket a sus dos tablas hash. Aquí están las tablas tcp_bound_hash y tcp_listening_hash. Ambas tablas están indexadas por una función hash basada en el número de puerto IP.
Cada vez que se recibe una solicitud de conexión TCP entrante a un socket de escucha activa, TCP crea una nueva estructura de datos sock para representarla. La estructura de datos sock se convierte en la mitad inferior de la conexión TCP antes de que finalmente se acepte. También clona el sk_buff entrante que contiene la solicitud de conexión y lo pone en cola en la cola receive_queue de la estructura de datos del sock de escucha. Este sk_buff clonado incluye un puntero a esta estructura de datos sock recién creada.
10.4.5 Aceptar solicitudes de conexión
UDP no admite el concepto de conexión. La aceptación de la solicitud de conexión del socket INET solo se aplica al protocolo TCP. La operación de aceptación en un sock de escucha clonará una nueva estructura de datos de socket del socket de escucha original. Luego, la operación de aceptación se pasa a la capa de protocolo de soporte, en este caso, INET, para aceptar cualquier solicitud de conexión entrante. Si el protocolo subyacente, como UDP, no admite conexiones, la operación de aceptación en la capa del protocolo INET fallará. De lo contrario, la solicitud de conexión se pasa al protocolo real, en este caso, TCP. La operación de aceptación puede ser de bloqueo o de no bloqueo. En el caso de no bloqueo, si no hay conexiones entrantes para aceptar, la operación de aceptación fallará y la estructura de datos del socket recién creada se descartará. En caso de bloqueo, la aplicación de red que realiza la operación de aceptación se agregará a una cola de espera y luego se suspenderá hasta que se reciba una solicitud de conexión TCP. Una vez que se recibe una solicitud de conexión, el sk_buff que contiene la solicitud se descarta y la estructura de datos del sock se devuelve a la capa de socket de INET, donde se conecta a la nueva estructura de datos del socket creada previamente. El descriptor de archivo (fd) del nuevo socket se devuelve a la aplicación de red, y la aplicación puede usar este descriptor de archivo para realizar operaciones de socket en el socket INET BSD recién creado.
10.5 La capa IP
10.5.1 Búferes de socket
Un problema con tales protocolos de red es que cada protocolo necesita agregar encabezados y tráileres de protocolo a los datos cuando se transmite, y cuando se procesan los datos recibidos, se deben dividir en muchas capas. Esto hace que la transferencia de búferes de datos entre protocolos sea bastante difícil, ya que cada capa necesita averiguar dónde están los encabezados y los tráilers de sus protocolos específicos. Una solución es copiar el búfer en cada capa, pero esto es ineficiente. En su lugar, Linux utiliza búferes de socket o sock_buffs para transferir datos entre la capa de protocolo y el controlador del dispositivo de red. Los Sk_buffs incluyen campos de puntero y longitud que permiten que cada capa de protocolo use funciones o métodos estándar para manipular los datos de la aplicación.

La figura 10.4 muestra la estructura de datos de sk_buff: cada sk_buff tiene su dato asociado. Sk_buff tiene cuatro punteros de datos para manipular y administrar datos de búfer de socket.
Consulte include/linux/skbuff.h
head apunta al comienzo del área de datos en la memoria. Determinado cuando se asignan sk_buff y su bloque de datos asociado.
Los datos apuntan al inicio actual de los datos del protocolo hasta el momento. Este puntero varía con la capa de protocolo que posee actualmente el sk_buff.
La cola apunta al final actual de los datos del protocolo. Nuevamente, este indicador varía según la capa de protocolo que tenga.
End apunta al final del área de datos en la memoria. Esto se determina cuando se asigna este sk_buff.
También hay dos campos de longitud, len y truesize, que describen la longitud del mensaje de protocolo actual y la longitud total del búfer de datos, respectivamente. El código de manejo de Sk_buff proporciona mecanismos estándar para agregar y eliminar encabezados y finales de protocolo de los datos de la aplicación. Este código manipula de forma segura los campos de datos, cola y longitud en sk_buff.
Empujar Esto mueve el puntero de datos al comienzo del área de datos e incrementa el campo len. Se utiliza para agregar datos o encabezados de protocolo delante de los datos transmitidos
Ver include/linux/skbuff.h skb_push()
Pull mueve el puntero de datos desde el principio hasta el final del área de datos y reduce el campo len. Se utiliza para eliminar datos o encabezados de protocolo de los datos recibidos.
Ver include/linux/skbuff.h skb_pull()
Put mueve el puntero de cola al final del área de datos y agrega el campo len para agregar datos o información de protocolo al final de los datos transmitidos
Consulte include/linux/skbuff.h skb_put()
trim mueve el puntero de la cola al comienzo del área de datos y reduce el campo len. Se utiliza para eliminar datos o avances de protocolo de los datos recibidos
Ver include/linux/skbuff.h skb_trim()
La estructura de datos sk_buff también incluye algunos punteros.Usando estos punteros, esta estructura de datos se puede almacenar en la lista doblemente enlazada de sk_buff durante el procesamiento. Hay rutinas generales de sk_buff que agregan y eliminan sk_buffs de la cabeza y la cola de estas listas.
10.5.2 Recepción de paquetes IP
La Sección 8 describe cómo se integran y se inicializan los controladores de dispositivos de red de Linux en el núcleo. Esto produce una serie de estructuras de datos de dispositivos, enlazadas entre sí en la lista dev_base. La estructura de datos de cada dispositivo describe su dispositivo y proporciona un conjunto de rutinas de devolución de llamadas a las que la capa de protocolo de red puede llamar cuando el controlador de red necesita funcionar. La mayoría de estas funciones están relacionadas con la transferencia de datos y direcciones de dispositivos de red. Cuando un dispositivo de red recibe un paquete de datos de su red, debe convertir los datos recibidos en la estructura de datos sk_buff. Estos sk_buffs recibidos se agregan a la cola de trabajos pendientes por el controlador de red a medida que se reciben. Si la cola de trabajos pendientes crece demasiado, el sk_buff recibido se descarta. Si hay trabajo por realizar, la mitad del botón de esta red se marca como lista para funcionar.
Ver net/core/dev.c netif_rx()
Cuando el programador llama al manejador de la mitad inferior de la red, primero procesa los paquetes de red que esperan ser entregados y luego procesa la cola de trabajos pendientes de sk_buff para determinar a qué capa de protocolo debe entregarse el paquete recibido. Cuando se inicializa la capa de red de Linux, cada protocolo se registra y agrega una estructura de datos tipo paquete a la lista ptype_all o a la tabla hash ptype_base. La estructura de datos tipo_paquete incluye el tipo de protocolo, un puntero a un dispositivo controlador de red, un puntero a la rutina de procesamiento de recepción de datos del protocolo y un puntero al siguiente tipo de datos tipo_paquete en esta lista o tabla hash. La lista vinculada Ptype_all se utiliza para espiar todos los paquetes de datos recibidos desde cualquier dispositivo de red y, por lo general, no se utiliza. La tabla hash Ptype_base utiliza el hash del identificador de protocolo para determinar qué protocolo debe recibir los paquetes de red entrantes. La mitad inferior de la red coincide con el tipo de protocolo del sk_buff entrante con una o más entradas de tipo de paquete en cualquiera de las tablas. El protocolo puede coincidir con una o más entradas, por ejemplo, al espiar todo el tráfico de la red, en cuyo caso se clonará el sk_buff. Este sk_buff se pasa a la rutina de procesamiento del protocolo de coincidencia.
Ver net/core/dev.c net_bh()
Ver net/ipv4/ip_input.c ip_recv()
10.5.3 Envío de paquetes IP
Los mensajes se transmiten en el proceso de intercambio de datos entre aplicaciones, o también pueden ser generados por protocolos de red para admitir conexiones establecidas o para establecer conexiones. Independientemente de cómo se generen los datos, se crea un sk_buff que contiene los datos y se agregan varios encabezados a medida que pasan por la capa de protocolo.
Este sk_buff debe pasarse al dispositivo de red que está transmitiendo. Pero primero, un protocolo, como IP, debe decidir qué dispositivo de red usar. Esto depende de la mejor ruta para este paquete. Para las computadoras conectadas a una red a través de un módem, como a través del protocolo PPP, este enrutamiento es más fácil. Los paquetes deben pasarse a través del dispositivo de loopback al host local o al gateway en el otro extremo de la conexión del módem PPP. Para las computadoras conectadas a Ethernet, esta elección es difícil porque hay muchas computadoras conectadas a la red.
Para cada paquete IP enviado, IP utiliza la tabla de enrutamiento para resolver la ruta a la dirección IP de destino. Para cada búsqueda de destino IP en la tabla de enrutamiento, el éxito devuelve una estructura de datos rtable que describe la ruta a usar. Esto incluye la dirección IP de origen utilizada, la dirección de la estructura de datos del dispositivo de red y, a veces, un encabezado de hardware prediseñado. Este encabezado de hardware está asociado con dispositivos de red y contiene direcciones físicas de origen y destino y otra información relacionada con los medios. Si el dispositivo de red es un dispositivo Ethernet, el encabezado del hardware se mostrará en la Figura 10.1, donde las direcciones de origen y destino serán direcciones Ethernet físicas. El encabezado de hardware y la ruta se almacenan en caché juntos, porque cada paquete IP transmitido en esta ruta necesita agregar este encabezado, y toma tiempo construir este encabezado. El encabezado del hardware puede contener direcciones físicas que deben resolverse mediante el protocolo ARP. En este momento, los paquetes salientes se suspenderán hasta que la resolución de la dirección sea exitosa. Una vez que se resuelve la dirección de hardware y se establece el encabezado de hardware, el encabezado de hardware se almacena en caché para que los futuros paquetes IP que utilicen esta interfaz no necesiten realizar ARP.
ver include/net/route.h
10.5.4 Fragmentación de datos
Cada dispositivo de red tiene un tamaño de paquete máximo y no puede transmitir ni recibir paquetes de datos más grandes. El protocolo IP permite este tipo de datos, dividiéndolos en unidades más pequeñas de tamaño de paquete que el dispositivo de red puede manejar. El encabezado del protocolo IP contiene un campo de división que contiene un marcador y el desplazamiento de la división.
Cuando se va a transmitir un paquete IP, IP busca el dispositivo de red utilizado para enviar el paquete IP. Encuentre el dispositivo a través de la tabla de enrutamiento IP. Cada dispositivo tiene un campo que describe su unidad máxima de transmisión (bytes), que es el campo mtu. Si la mtu del dispositivo es más pequeña que el tamaño del paquete IP que espera ser transmitido, entonces el paquete IP debe dividirse en fragmentos más pequeños (tamaño mtu). Cada fragmento está representado por un sk_buff: su encabezado IP marca que fue fragmentado y el desplazamiento de este paquete IP en los datos. El último paquete se marca como el último fragmento de IP. Si la IP no puede asignar un sk_buff durante el proceso de fragmentación, la transferencia falla.
Recibir fragmentos de IP es más difícil que enviarlos, porque los fragmentos de IP pueden recibirse en cualquier orden y deben recibirse todos antes de volver a ensamblarlos. Cada vez que se recibe un paquete IP se comprueba si se trata de un fragmento IP. Al recibir el primer fragmento de un mensaje, IP crea una nueva estructura de datos de ipq y se conecta a la lista de ipqueue de fragmentos de IP que esperan ser ensamblados. Cuando se reciben más fragmentos de IP, se encuentra la estructura de datos ipq correcta y se crea una nueva estructura de datos ipfrag para describir el fragmento. Cada estructura de datos de ipq describe de forma única una trama de recepción de IP fragmentada, incluidas sus direcciones IP de origen y destino, el identificador de protocolo de la capa superior y el identificador de la trama de IP. Cuando se reciben todos los fragmentos, se ensamblan en un solo sk_buff y se pasan a la siguiente capa de protocolo para su procesamiento. Cada ipq incluye un temporizador que se reinicia cada vez que se recibe un fragmento válido. Si el temporizador expira, la estructura de datos ipq y su ipfrag se eliminan y se asume que el mensaje se perdió en tránsito. El protocolo de nivel superior es entonces responsable de retransmitir el mensaje.
Ver net/ipv4/ip_input.c ip_rcv()
10.6 Protocolo de resolución de direcciones (ARP)
La tarea del Protocolo de resolución de direcciones es proporcionar la traducción de direcciones IP a direcciones de hardware físico, como direcciones Ethernet. IP solo necesita esta conversión cuando transfiere datos (en forma de sk_buff) al controlador del dispositivo para la transferencia. Realiza algunas comprobaciones para ver si este dispositivo necesita un encabezado de hardware y, de ser así, si es necesario reconstruir el encabezado de hardware para este paquete. Linux almacena en caché los encabezados de hardware para evitar reconstrucciones frecuentes. Si es necesario reconstruir el encabezado de hardware, llama a la rutina de reconstrucción del encabezado de hardware asociada con el dispositivo. Todos los dispositivos usan la misma rutina común de reconstrucción de encabezados y luego usan el servicio ARP para traducir la dirección IP del objetivo a una dirección física.
Ver net/ipv4/ip_output.c ip_build_xmit()
Consulte net/ethernet/eth.c rebuild_header()
El protocolo ARP en sí es muy simple y consta de dos tipos de mensajes: solicitud ARP y respuesta ARP. La solicitud ARP incluye la dirección IP que debe traducirse y la respuesta (con suerte) incluye la dirección IP traducida y la dirección del hardware. Las solicitudes ARP se transmiten a todos los hosts conectados a la red, por lo que para una Ethernet, todas las máquinas conectadas a Ethernet pueden ver la solicitud ARP. La máquina con la dirección IP incluida en la solicitud responderá a la solicitud ARP con una respuesta ARP que contenga su propia dirección física.
La capa del protocolo ARP en Linux se construye alrededor de una tabla de la estructura de datos arp_table. Cada uno describe una correspondencia entre una IP y una dirección física. Estas entradas se crean cuando las direcciones IP deben traducirse y eliminarse cuando se vuelven obsoletas con el tiempo. Cada estructura de datos arp_table contiene los siguientes campos:
Last used 这个ARP条目上一次使用的时间
Last update 这个ARP条目上一次更新的时间
Flags 描述这个条目的状态:它是否完成等等
IP address 这个条目描述的IP地址
Hardware address 转换(翻译)的硬件地址
Hardware header 指向一个缓存的硬件头的指针
Timer 这是一个timer_list的条目,用于让没有回应的ARP请求超时
Retries 这个ARP请求重试的次数
Sk_buff queue 等待解析这个IP地址的sk_buff条目的列表La tabla ARP contiene una tabla de punteros (la tabla vectorial arp_tables) que vincula las entradas de arp_table. Estas entradas se almacenan en caché para acelerar el acceso a ellas. Cada entrada se busca utilizando los dos últimos bytes de su dirección IP como índice en la tabla, y se sigue la cadena de entradas hasta que se encuentra la entrada correcta. Linux también almacena en caché los encabezados de hardware prediseñados de las entradas arp_table, en forma de estructura de datos hh_cache.
Al solicitar una traducción de dirección IP sin una entrada correspondiente en arp_table, ARP DEBE enviar un mensaje de solicitud de ARP. Crea una nueva entrada arp_table en la tabla y coloca el sk_buff, incluidos los paquetes de red que necesitan traducción de direcciones, en la cola sk_buff de esta nueva entrada. Emite una solicitud de ARP y permite que se ejecute el temporizador obsoleto de ARP. Si no hay respuesta, ARP volverá a intentarlo varias veces. Si aún no hay respuesta, ARP eliminará la entrada arp_table. Se notifica cualquier estructura de datos sk_buff en cola para traducción por esta dirección IP, y depende del protocolo de capa superior que los transmite manejar tales fallas. A UDP no le importan los paquetes perdidos, pero TCP intentará reenviarlos en una conexión TCP establecida. Si el propietario de esta dirección IP responde con su dirección de hardware, la entrada arp_table se marca como completa, cualquier sk_buff en cola se elimina de la cola de pares y la transmisión continúa. La dirección de hardware se escribe en el encabezado de hardware de cada sk_buff.
La capa del protocolo ARP también debe responder a las solicitudes ARP especificando su dirección IP. Registra su tipo de protocolo (ETH_P_ARP), produciendo una estructura de datos tipo paquete. Esto significa que todos los paquetes ARP recibidos por un dispositivo de red se le pasarán. Al igual que las respuestas ARP, esto también incluye solicitudes ARP. Genera una respuesta ARP utilizando la dirección de hardware en la estructura de datos del dispositivo del dispositivo receptor.
Las topologías de red cambian constantemente y las direcciones IP pueden reasignarse a diferentes direcciones de hardware. Por ejemplo, algunos servicios de acceso telefónico asignan una dirección IP a cada conexión que realiza. Para mantener la tabla ARP con las entradas más recientes, ARP ejecuta un temporizador periódico que verifica todas las entradas de arp_table para ver cuáles se han agotado. Es muy cuidadoso de no eliminar entradas que contengan encabezados de hardware que contengan uno o más cachés. Eliminar estas entradas es peligroso porque otras estructuras de datos dependen de ellas. Algunas entradas de arp_table son permanentes y están marcadas para que no se liberen. La tabla ARP no puede crecer demasiado: cada entrada de arp_table consume algo de memoria central. Cada vez que se necesita asignar una nueva entrada y la tabla ARP alcanza su tamaño máximo, la tabla se recorta encontrando las entradas más antiguas y eliminándolas.
10.7 Enrutamiento IP
La función de enrutamiento IP determina dónde se deben enviar los paquetes IP destinados a una dirección IP específica. Al transmitir paquetes IP, hay muchas opciones. ¿Es alcanzable el destino? Si es así, ¿qué dispositivo de red debería usarse para enviarlo? ¿Hay más de un dispositivo de red que pueda usarse para llegar al destino y cuál es el mejor? La información mantenida por la base de datos de enrutamiento IP puede responder a estas preguntas. Hay dos bases de datos, la más importante es la base de datos de información de reenvío. Esta base de datos es una lista exhaustiva de destinos IP conocidos y sus mejores rutas. Otra base de datos más pequeña y más rápida, la caché de rutas, se utiliza para encontrar rápidamente rutas a objetivos de IP. Como todos los cachés, debe incluir solo las rutas a las que se accede con más frecuencia y su contenido se deriva de la base de datos de información de reenvío.
Las rutas agregan y eliminan solicitudes IOCTL a través de la interfaz de socket BSD. Estas solicitudes se pasan a protocolos específicos para su procesamiento. La capa del protocolo INET solo permite que los procesos con privilegios de superusuario agreguen y eliminen rutas IP. Estas rutas pueden ser fijas, o dinámicas y en constante cambio. La mayoría de los sistemas usan enrutamiento fijo a menos que ellos mismos sean enrutadores. Los enrutadores ejecutan protocolos de enrutamiento que verifican constantemente las rutas disponibles a todos los destinos IP conocidos. Los sistemas que no son enrutadores se denominan sistemas finales. Los protocolos de enrutamiento se implementan como demonios, como GATED, que también usan el IOCTL de la interfaz de socket BSD para agregar y eliminar rutas.
10.7.1 La caché de rutas
Cada vez que se busca una ruta IP, primero se comprueba la memoria caché de la ruta en busca de una ruta coincidente. Si no hay ninguna ruta coincidente en la caché de rutas, se busca en la base de datos de información de reenvío. Si la ruta no se puede encontrar aquí, la transmisión del paquete IP fallará y se notificará a la aplicación. Si la ruta está en la base de datos de información de reenvío pero no en la caché de rutas, se crea una nueva entrada para la ruta y se agrega a la caché de rutas. La caché de ruta es una tabla (ip_rt_hash_table) que incluye punteros a una cadena de estructuras de datos rtable. El índice de la tabla de enrutamiento se basa en la función hash de los dos bytes mínimos de la dirección IP. Estos dos bytes suelen ser muy diferentes en el destino, lo que permite que el valor hash se distribuya mejor. Cada entrada de rtable incluye información de enrutamiento: la dirección IP de destino, el dispositivo de red (estructura del dispositivo) que se usará para llegar a esta dirección IP, el tamaño máximo de mensaje que se puede usar, etc. También tiene un conteo de referencias, un conteo de uso y la marca de tiempo del último uso (en santiamén). Este contador de referencia se incrementa cada vez que se utiliza la ruta, mostrando el número de conexiones de red que utilizan la ruta, y disminuye cuando la aplicación deja de utilizar la ruta. El contador de uso se incrementa cada vez que se busca una ruta y se utiliza para determinar la antigüedad de las entradas de rtable en esta cadena de entradas hash. La última marca de tiempo utilizada de todas las entradas en el caché de enrutamiento se usa para verificar periódicamente si esta tabla r es demasiado antigua. Si la ruta no se ha utilizado recientemente, se descarta de la tabla de enrutamiento. Si las rutas se almacenan en la memoria caché de rutas, se ordenan de modo que las entradas utilizadas con más frecuencia estén al principio de la cadena hash. Esto significa que será más rápido encontrar estas rutas al buscar rutas.
Ver net/ipv4/route.c check_expire()
10.7.2 La base de datos de información de reenvío

La base de datos de información de reenvío (que se muestra en la Figura 10.5) contiene las rutas disponibles para el sistema desde el punto de vista de IP en ese momento. Es una estructura de datos muy compleja y, si bien está organizada de manera razonablemente eficiente, no es una base de datos rápida para referencia. Especialmente si cada paquete IP transmitido busca el objetivo en esta base de datos, puede ser muy lento. Es por eso que existe un caché de ruta: para acelerar la entrega de paquetes IP que ya conocen la mejor ruta. La caché de ruta se obtiene de esta base de datos de información de reenvío y representa las entradas que se usan con más frecuencia.
Cada subred IP está representada por una estructura de datos fib_zone. Todos son señalados por la tabla hash fib_zones. El índice hash se toma de la máscara de subred IP. Todas las rutas a la misma subred se describen mediante pares de estructuras de datos fib_node y fib_info en cola en la cola fz_list de cada estructura de datos fib_zone. Si la cantidad de rutas en esta subred se vuelve demasiado grande, se genera una tabla hash para facilitar la búsqueda de la estructura de datos fib_node.
Para la misma subred IP, puede haber múltiples rutas que pueden pasar a través de una de las múltiples puertas de enlace. La capa de enrutamiento IP no permite más de una ruta a una subred usando la misma puerta de enlace. En otras palabras, si hay varias rutas para una subred, asegúrese de que cada ruta use una puerta de enlace diferente. Asociada con cada ruta está su métrica, que se utiliza para medir el beneficio de esa ruta. La medida de una ruta es, básicamente, el número de subredes que tiene que saltar antes de llegar a la subred de destino. Cuanto mayor sea esta métrica, peor será el enrutamiento.
11. Mecanismos del núcleo
11.1 Manejo de la mitad inferior
A menudo, en el núcleo hay momentos en los que no desea realizar el trabajo. Un buen ejemplo es durante el manejo de interrupciones. Cuando se genera una interrupción, el procesador detiene lo que está haciendo y el sistema operativo pasa la interrupción al controlador de dispositivo adecuado. Los controladores de dispositivos no deberían dedicar demasiado tiempo a procesar interrupciones, ya que durante este tiempo no se puede ejecutar nada más en el sistema. Por lo general, algo de trabajo se puede hacer en un momento posterior. Linux inventó el medio controlador boffom para que los controladores de dispositivos y otras partes del kernel de Linux pudieran poner en cola el trabajo que podría realizarse más adelante. La figura 11.1 muestra las estructuras de datos centrales asociadas con el procesamiento de la mitad inferior. Hay hasta 32 manejadores de la mitad inferior diferentes: bh_base es una tabla vectorial de punteros a cada manejador de la mitad inferior del núcleo, bh_active y bh_mask configuran sus bits de acuerdo con los manejadores instalados y activados. Si se establece el bit N de bh_mask, el elemento N en bh_base contiene la dirección de una rutina de la mitad inferior. Si se establece el bit N de bh_active, se llamará al controlador de la mitad inferior para el bit N tan pronto como el programador lo considere razonable. Estos índices están definidos estáticamente: el controlador de la mitad inferior del temporizador tiene la prioridad más alta (índice 0), el controlador de la mitad inferior de la consola tiene la siguiente prioridad más alta (índice 1), y así sucesivamente. Por lo general, el controlador de la mitad inferior tendrá una lista de tareas asociada. Por ejemplo, el medio controlador inmediato del botón funciona a través de una cola de tareas inmediatas (tq_immediate) que contiene tareas que deben ejecutarse de inmediato.
Consulte include/linux/interrupt.h


Algunos de los controladores de la mitad inferior del núcleo son específicos del dispositivo, pero otros son más generales:
TIMER Este controlador se marca como activo cada vez que se utiliza la interrupción del reloj de temporización del sistema para controlar el mecanismo de cola del reloj del núcleo.
CONSOLA Este manejador se usa para manejar mensajes de consola
TQUEUE Este manejador se usa para manejar mensajes TTY
NET Este controlador se usa para manejar el procesamiento general de la red
INMEDIATO Controlador genérico, utilizado por algunos controladores de dispositivos para poner en cola el trabajo para más tarde
Cuando un controlador de dispositivo, u otra parte del núcleo, necesita programar el trabajo para que se realice más tarde, agrega el trabajo a la cola del sistema adecuada, como la cola del reloj, y luego envía una señal al núcleo de que parte del procesamiento de la mitad inferior tiene que pasar Lo hace configurando los bits apropiados en bh_active. El bit 8 se establece si el controlador pone en cola algo en la cola inmediata y espera que el controlador de la mitad inferior inmediata lo ejecute y procese. Al final de cada llamada al sistema, se comprueba la máscara de bits bh_active antes de devolver el control al programa que llama. Si se establece alguno de los bits, se llama a la rutina del controlador de la mitad inferior activa correspondiente. Primero se comprueba el bit 0, luego el 1 hasta el bit 31. El bit correspondiente en bh_active se borra cada vez que se llama al controlador de la mitad inferior. Bh_active es volátil: solo tiene sentido entre llamadas al programador y, al configurarlo, no se puede llamar al controlador de la mitad inferior correspondiente cuando no hay trabajo que hacer.
Kernel/softirq.c do_bottom_half()
11.2 Colas de tareas
Las colas de tareas son el método que utiliza el núcleo para diferir el trabajo para un momento posterior. Linux tiene un mecanismo general para poner en cola trabajos y procesarlos en un momento posterior. Las colas de tareas a menudo se usan con controladores de la mitad inferior: la cola de tareas del temporizador se procesa mientras se ejecuta el controlador de la mitad inferior del temporizador. Una cola de tareas es una estructura de datos simple, consulte la Figura 11.2, que consta de una lista enlazada de estructuras de datos tq_struct, cada una de las cuales contiene un puntero a una rutina y un puntero a algunos datos.
Consulte include/linux/tqueue.h Esta rutina se llama cuando se procesa la unidad de la cola de tareas y se le pasa un puntero a los datos.
Cualquier cosa en el núcleo, como los controladores de dispositivos, puede crear y usar colas de tareas, pero hay tres colas de tareas que son creadas y administradas por el núcleo:
temporizador Esta cola se utiliza para poner en cola el trabajo para que se ejecute el mayor tiempo posible después del siguiente reloj del sistema. Cada ciclo de reloj, esta cola se comprueba en busca de una entrada y, de ser así, el controlador de la mitad inferior de la cola de reloj se marca como activo. Este manejador de la mitad inferior de la cola de reloj y otros manejadores de la mitad inferior se procesan cuando el programador se ejecuta en una sola ejecución. No confunda esta cola con un temporizador del sistema, ese es un mecanismo más complicado
inmediata Esta cola también se procesa cuando el planificador procesa el controlador de mitad inferior activo. El controlador de la mitad inferior inmediata no tiene mayor prioridad que el controlador de la mitad inferior de la cola del temporizador, por lo que estas tareas dudarán en ejecutarse.
Programador Esta cola de tareas es manejada directamente por el programador. Se utiliza para admitir otras colas de tareas en el sistema, en cuyo caso la tarea a ejecutar sería una rutina que maneja la cola de tareas (por ejemplo, un controlador de dispositivo).
Al procesar una cola de tareas, un puntero a un elemento de la cola se elimina de la cola y se reemplaza por un puntero nulo. De hecho, esta eliminación es una operación atómica que no se puede interrumpir. A continuación, se llama secuencialmente a su rutina de controlador para cada elemento de la cola. Las celdas de la cola suelen ser datos asignados estáticamente. Pero no existe un mecanismo inherente para descartar la memoria asignada. La rutina de procesamiento de la cola de tareas simplemente se mueve a la siguiente celda de la lista. Es el trabajo de la tarea en sí garantizar que cualquier memoria central asignada se borre correctamente.
11.3 Temporizadores
Un sistema operativo debe poder programar una actividad para un momento en el futuro, lo que requiere un mecanismo que permita programar las actividades para que se ejecuten en un momento relativamente preciso. Cualquier microprocesador que desee soportar un sistema operativo necesita un intervalo moderadamente programable, interrumpiendo el procesador periódicamente. Esta interrupción periódica es el tic del reloj del sistema, que actúa como un metrónomo y dirige la actividad del sistema. Linux mira el tiempo de una manera muy simple: mide el tiempo en ciclos de reloj desde que se inicia el sistema. Cualquier tiempo del sistema se basa en esta medida, llamada jiffers, que tiene el mismo nombre que la variable global.
Linux tiene dos tipos de temporizadores del sistema, cada uno de los cuales organiza rutinas para que se llamen en momentos específicos del sistema, pero difieren ligeramente en la forma en que se implementan. La figura 11.3 muestra dos mecanismos. El primero, el antiguo mecanismo de temporizador, tiene una matriz estática de 32 punteros a la estructura de datos timer_struct y una máscara de relojes activos, timer_active. El lugar donde se coloca el temporizador en esta tabla de temporizador se define estáticamente (a diferencia de bh_base en el controlador de la mitad inferior). Las entradas se agregan a esta tabla durante la inicialización del sistema. El segundo mecanismo utiliza una lista enlazada de estructuras de datos timer_list para organizar los datos por fecha de caducidad.
Consulte include/linux/timer.h
Cada método usa el tiempo en jiffies como el tiempo de caducidad, por lo que un temporizador que desea ejecutarse durante 5 segundos tendrá una unidad de jiffies que se puede convertir a 5 segundos más la hora actual del sistema para obtener la hora del sistema cuando el temporizador expire (en unidades de jiffies). Cada ciclo de reloj del sistema, el controlador de la mitad inferior del temporizador se marca como activo, por lo que la próxima vez que se ejecuta el programador, se procesa la cola del temporizador. El controlador de la mitad inferior del temporizador maneja ambos tipos de temporizadores del sistema. Para los temporizadores del sistema antiguo, verifique que la máscara de bits timer_active esté configurada. Si un temporizador activo caduca (el tiempo de caducidad es menor que los jiffies del sistema actual), se llama a su rutina de cronómetro y se borra su bit activo. Para los nuevos temporizadores del sistema, verifique las entradas en la tabla vinculada de la estructura de datos timer_list. Cada temporizador caducado se elimina de esta lista y se llama a su rutina. La ventaja del nuevo mecanismo del temporizador es que puede pasar parámetros a las rutinas del temporizador.
Ver kernel/sched.c timer_bh() run_old_timers() run_timer_list()
11.4 Colas de espera
Muchas veces un proceso debe esperar por un recurso del sistema. Por ejemplo, un proceso puede necesitar un inodo VFS que describa un directorio en el sistema de archivos, pero este inodo puede no estar en el caché del búfer. En este punto, el sistema debe esperar a que se obtenga el inodo del medio físico que contiene el sistema de archivos antes de continuar.
El kernel de Linux usa una estructura de datos simple, una cola de espera (vea la Figura 11.4), que contiene un puntero a la estructura_tarea del proceso y un puntero al siguiente elemento en la cola de espera.
Consulte include/linux/wait.h

Cuando los procesos se agregan al final de una cola de espera, pueden o no ser interrumpibles. Los procesos interrumpibles pueden ser interrumpidos por eventos mientras esperan en la cola de espera, como un temporizador expirado o una señal enviada. Se reflejará el estado del proceso de espera, que puede ser INTERRUPTIBLE o ININTERRUMPIBLE. Dado que el proceso no puede continuar ejecutándose ahora, el planificador comienza a ejecutarse y, cuando elige un nuevo proceso para ejecutar, el proceso de espera se suspende.
Al procesar la cola de espera, el estado de cada proceso en la cola de espera se establece en EN EJECUCIÓN. Si el proceso se elimina de la cola de ejecución, se vuelve a colocar en la cola de ejecución. La próxima vez que se ejecute el programador, los procesos que estaban en la cola de espera ahora son candidatos para ejecutarse porque ya no están esperando. Cuando se programa un proceso que espera en una cola, lo primero que debe hacer es eliminarse de la cola de espera. Las colas de espera se pueden usar para sincronizar el acceso a los recursos del sistema y Linux implementa sus semáforos de esta manera.
11.5 Bloqueos de zumbido
A menudo llamados bloqueos giratorios, este es un método primitivo para proteger una estructura de datos o un segmento de código. Permiten que solo un proceso a la vez esté en un área importante del código. Linux los usa para restringir el acceso a los campos en las estructuras de datos, usando un campo entero como candado. Cada proceso que desee ingresar a esta área intenta cambiar el valor inicial del bloqueo de 0 a 1. Si la corriente provoca 1, el proceso vuelve a intentarlo, girando en un bucle de código apretado. El acceso a la ubicación de memoria que contiene este bloqueo debe ser atómico, lea su valor, verifique que sea 0 y luego cámbielo a 1, esta acción no debe ser interrumpida por ningún otro proceso. La mayoría de las arquitecturas de CPU admiten esto con instrucciones especiales, pero también puede implementar este bloqueo de zumbido utilizando la memoria principal no almacenada en caché.
Cuando el proceso propietario abandona esta importante área de código, reduce el bloqueo de zumbido y devuelve su valor a 0. Cualquier proceso que se repita en este bloqueo ahora leerá 0, y el primer proceso que lo haga lo incrementará a 1 e ingresará a esta importante región.
11.6 Semáforos
Los semáforos se utilizan para proteger regiones de código importantes o estructuras de datos. Recuerde que cada acceso a estructuras de datos importantes, como un inodo VFS que describe un directorio, lo realiza el kernel para el proceso. Es muy peligroso permitir que un proceso cambie estructuras de datos importantes utilizadas por otro proceso. Una forma de hacer esto es usar un bloqueo de zumbido en la parte importante del código al que se accede, aunque esta es la forma más fácil pero no tendrá un rendimiento muy bueno del sistema. Linux utiliza una implementación de semáforo para permitir que solo un proceso acceda a código importante y áreas de datos a la vez: todos los demás procesos que deseen acceder a este recurso se ven obligados a esperar hasta que el semáforo esté libre. El proceso de espera se raspa y otros procesos en el sistema se ejecutan normalmente como de costumbre.
Una estructura de datos de semáforo de Linux incluye la siguiente información:
Consulte include/asm/semaphore.h
count Este campo registra el número de procesos que desean utilizar este recurso. Un número positivo indica que el recurso está disponible. Un valor negativo o 0 indica que hay un proceso en espera. Un valor inicial de 1 significa que uno y solo un proceso puede usar el recurso a la vez. Cuando los procesos desean usar el recurso, decrementan el conteo y cuando terminan de usar el recurso, incrementan el conteo.
despertar La cantidad de procesos que esperan este recurso, que también es la cantidad de procesos que esperan ser activados cuando el recurso esté libre.
Cola de espera Cuando los procesos están esperando este recurso, se colocan en esta cola de espera.
Bloqueo Bloqueo de Buzz utilizado al acceder al dominio activo
Suponiendo que el semáforo comienza con un valor de 1, el primer proceso que llegue verá que el conteo es positivo y lo decrementará de 1 a 0. El proceso ahora "posee" la pieza importante de código o recurso protegido por el semáforo. Incrementa el conteo de semáforos cuando el proceso deja esta importante área. Idealmente, ningún otro proceso compite por la propiedad de esta importante área. La implementación de semáforos en Linux funciona muy eficientemente en este caso común.
También disminuye este conteo si otro proceso desea ingresar a esta área importante mientras ya es propiedad de un proceso. Debido a que el conteo ahora es -1, el proceso no puede ingresar a esta importante región. Debe esperar hasta que finalice el proceso de propiedad. Linux pone el proceso de espera en suspensión hasta que el proceso propietario sale de esta área importante para despertarlo. El proceso de espera se agrega a la cola de espera del semáforo y realiza un bucle para verificar el valor del campo de activación, llamando al planificador hasta que la activación sea distinta de cero.
El dueño de esta importante área aumenta el conteo del semáforo, si es menor o igual a 0, entonces todavía hay procesos durmiendo esperando este recurso. Idealmente, la cuenta del semáforo volvería a su valor inicial de 1, de modo que no se requiera ningún trabajo. El proceso propietario incrementa el contador de activación y activa los procesos durmientes en la cola de espera del semáforo. Cuando se activa el proceso de espera, el contador de activación ahora es 1 y sabe que ahora puede ingresar a esta área importante. Decrementa el contador de activación, lo devuelve a 0 y continúa. Todo acceso al campo de vigilia de este semáforo está protegido por el bloqueo de zumbido del bloqueo del semáforo.
12, módulos
¿Cómo carga dinámicamente el kernel de Linux funciones solo cuando es necesario, por ejemplo, el sistema de archivos?
Linux es un núcleo completo, es decir, es un único programa enorme, y los componentes funcionales del núcleo tienen acceso a todas sus estructuras de datos y rutinas internas. Otro método es utilizar una estructura de microkernel, donde las piezas funcionales del núcleo se dividen en unidades independientes que tienen mecanismos estrictos de comunicación entre sí. De esta forma, no lleva mucho tiempo agregar nuevos componentes al núcleo a través del proceso de configuración. Por ejemplo, si desea agregar un controlador SCSI para una tarjeta SCSI NCR 810, no necesita conectarlo al núcleo. De lo contrario, debe configurar y construir un nuevo núcleo para usar este NCR 810. Como solución alternativa, Linux permite que los componentes del sistema operativo se carguen y descarguen dinámicamente a medida que los necesite. Un módulo de Linux es un bloque de código que se puede vincular dinámicamente al núcleo en cualquier momento después de que se inicie el sistema. Se pueden quitar del núcleo y desinstalar cuando no se necesiten. La mayoría de los módulos del kernel de Linux son controladores de dispositivos, controladores de pseudodispositivos, como controladores de red o sistemas de archivos.
Puede cargar y descargar módulos del kernel de Linux explícitamente usando los comandos insmod y rmmod, o el propio kernel puede pedirle al demonio del kernel (kerneld) que cargue y descargue estos módulos cuando sean necesarios. Cargar código dinámicamente cuando es necesario es bastante atractivo porque mantiene el núcleo mínimo y el núcleo es muy flexible. Mi núcleo Intel actual hace un uso intensivo de los módulos y solo tiene un tamaño de 406K. Por lo general, solo uso el sistema de archivos VFAT, por lo que construyo mi kernel de Linux para montar automáticamente el sistema de archivos VFAT cuando monto una partición VFAT. Cuando desmonté el sistema de archivos VFAT, el sistema detectó que ya no necesitaba el módulo del sistema de archivos VFAT y lo eliminó del sistema. Los módulos también se pueden usar para probar un nuevo código central sin crear y reiniciar el núcleo cada vez. Sin embargo, no hay cosas tan buenas, y el uso de módulos centrales generalmente conlleva una ligera sobrecarga de rendimiento y memoria. Un módulo cargable debe proporcionar más código, y este código y las estructuras de datos adicionales ocupan un poco más de memoria. Además, debido al acceso indirecto a los recursos básicos, la eficiencia del módulo se reduce ligeramente.
Una vez que se carga el kernel de Linux, se convierte en parte del kernel como el código del kernel normal. Tiene los mismos derechos y obligaciones que cualquier código del kernel: en otras palabras, es tan probable que un módulo del kernel de Linux bloquee el kernel como cualquier código del kernel o controlador de dispositivo.
Dado que los módulos pueden usar recursos básicos cuando los necesitan, deben poder encontrarlos. Por ejemplo, un módulo necesita llamar a kmalloc(), la rutina de asignación de memoria del núcleo. Cuando se construye, el módulo no sabe dónde está kmalloc() en la memoria, por lo que cuando se carga el módulo, el núcleo debe ordenar todas las referencias a kmalloc() por el módulo antes de que el módulo pueda funcionar. El núcleo mantiene una lista de todos los recursos del núcleo en la tabla de símbolos del núcleo, por lo que cuando se carga el módulo, puede resolver las referencias a esos recursos en el módulo. Linux permite el apilamiento (stacking) de módulos, donde un módulo necesita los servicios de otro módulo. Por ejemplo, el módulo del sistema de archivos VFAT necesita los servicios del módulo del sistema de archivos FAT porque el sistema de archivos VFAT es más o menos una extensión del sistema de archivos FAT. La situación en la que un módulo necesita los servicios o recursos de otro módulo es muy similar a la situación en la que un módulo necesita sus propios servicios y recursos, excepto que el servicio solicitado está en otro módulo previamente cargado. A medida que se carga cada módulo, el núcleo modifica su tabla de símbolos, agregando todos los recursos o símbolos exportados del módulo recién cargado a la tabla de símbolos del núcleo. Esto significa que cuando se carga el siguiente módulo, puede acceder a los servicios del módulo ya cargado.
Cuando el gráfico está descargando un módulo, el núcleo necesita saber que el módulo ya no está en uso y también necesita alguna forma de notificarle que el módulo está listo para descargar. De esta forma, un módulo puede liberar cualquier recurso del sistema que ocupe, como la memoria del kernel o las interrupciones, antes de que se elimine del kernel. Cuando se descarga un módulo, el kernel elimina todos los símbolos que el módulo exporta a la tabla de símbolos principal.
Además de la posibilidad de corromper el sistema operativo por módulos cargables mal escritos, existe otro peligro. ¿Qué sucede si carga un módulo creado para un núcleo anterior o posterior al que está ejecutando actualmente? Pueden surgir problemas si el módulo ejecuta una rutina central con los argumentos incorrectos. El núcleo puede optar por evitar esto haciendo una verificación estricta de la versión cuando se carga el módulo.
12.1 Cargando un Módulo
Un módulo central se puede cargar de dos maneras. El primero es insertarlo manualmente en el núcleo usando el comando insmod. Una segunda forma más inteligente es cargar el módulo cuando sea necesario: esto se denomina carga por demanda. Cuando el núcleo encuentra que se necesita un módulo, como cuando el usuario monta un sistema de archivos que no está en el núcleo, el núcleo le pide al demonio del núcleo (kerneld) que intente cargar el módulo apropiado.
Kerneld e insmod, lsmod y rmmod están todos en el paquete de módulos.
El demonio central suele ser un proceso de usuario normal con privilegios de superusuario. Cuando se inicia (generalmente al arrancar el sistema), abre un canal IPC al kernel. El kernel usa esta conexión para enviar mensajes a kerneld pidiéndole que realice una serie de tareas. La función principal de Kerneld es cargar y descargar módulos principales, pero también puede realizar otras tareas, como iniciar una conexión PPP en una línea serie cuando sea necesario y cerrarla cuando no sea necesario. Kerneld en sí mismo no realiza estas tareas, ejecuta los programas necesarios, como insmod, para realizar el trabajo. Kerneld es solo un proxy para el núcleo, programando su trabajo.
Consulte include/linux/kerneld.h
El comando insmod debe encontrar el módulo principal solicitado para que se cargue. Los módulos principales cargados por Xu generalmente se colocan en el directorio /lib/mmodules/kernel-version. Los módulos del kernel son archivos de objeto de programa vinculados como otros programas en el sistema, pero están vinculados a una imagen reubicable. Es una imagen que no está conectada a una dirección específica para ejecutarse. Pueden ser archivos de objetos en formato a.out o elf. Insmod apunta a una llamada de sistema privilegiada para averiguar los símbolos de salida del sistema. Se almacenan en pares en forma de un nombre simbólico y un valor como su dirección. La tabla de símbolos de salida del núcleo se coloca en la estructura de datos del primer módulo en la lista de módulos mantenida por el núcleo, a la que apunta el puntero module_list. Solo los símbolos especialmente designados se agregan a esta tabla cuando el núcleo se compila y vincula, no todos los símbolos en el núcleo exportan su módulo. Por ejemplo, el símbolo "request_irq" es una rutina del sistema que debe llamarse cuando un controlador desea controlar una interrupción del sistema en particular. En mi núcleo actual, su valor es 0x0010cd30. Puede inspeccionar el archivo /proc/ksyms o usar la herramienta ksyms para ver simplemente la salida de los símbolos principales y sus valores. La herramienta Ksyms puede mostrarle todos los símbolos principales exportados o solo los exportados por módulos cargados. Insmod lee el módulo en su memoria virtual y utiliza los símbolos de exportación del núcleo para clasificar las referencias no resueltas del módulo a las rutinas y recursos del núcleo. Este proceso de limpieza se realiza parcheando la imagen del módulo en la memoria, insmod escribe físicamente la dirección del símbolo en la ubicación adecuada del módulo.
Ver kernel/module.c kernel_syms() include/linux/module.h

Cuando insmod termina de ordenar la referencia del módulo a los símbolos del núcleo exportados, solicita suficiente espacio del núcleo para colocar el nuevo núcleo, nuevamente a través de una llamada al sistema privilegiada. El núcleo asigna una nueva estructura de datos del módulo y suficiente memoria del núcleo para contener el nuevo módulo y lo coloca al final de la lista de módulos del núcleo. Este nuevo módulo está marcado SIN INICIALIZAR. La figura 12.1 muestra que los dos últimos módulos de la lista de módulos principales: FAT y VFAT se cargan en la memoria. No se muestra en la figura el primer módulo de la lista: este es un pseudomódulo donde se coloca la tabla de símbolos de salida del núcleo. Puede usar el comando lsmod para enumerar todos los módulos centrales cargados y sus dependencias. Lsmod simplemente reorganiza /proc/modules extraídos de la lista de estructuras de datos de módulos principales. La memoria asignada por el kernel para el módulo se asigna al espacio de direcciones del proceso insmod, para que pueda acceder a él. Insmod copia el módulo en el espacio asignado y lo reubica para que pueda ejecutarse desde la dirección principal asignada. Las reubicaciones son necesarias porque no se puede esperar que un módulo se cargue en la misma dirección dos veces o que se cargue en la misma dirección en dos sistemas Linux diferentes. Esta vez, la reubicación consiste en parchear la imagen del módulo con la dirección adecuada.
Ver kernel/module.c create_module()
Los nuevos módulos también exportan símbolos al kernel e Insmod crea un mapa de exportación. Cada módulo del kernel debe contener el proceso de inicialización y limpieza del módulo. Estos símbolos deben ser privados y no exportarse, pero insmod debe conocer sus direcciones y poder pasarlas al kernel. Después de hacer todo esto, Insmod ahora está listo para inicializar el módulo, que ejecuta una llamada de sistema privilegiada pasando la dirección de las rutinas de inicialización y limpieza del módulo al kernel.
Ver kernel/module.c sys_init_module()
Cuando se agrega un nuevo módulo al núcleo, debe actualizar la tabla de símbolos del núcleo y cambiar los módulos utilizados por el nuevo módulo. Los módulos de los que dependen otros módulos deben mantener una lista de referencias después de su tabla de símbolos, señalada por la estructura de datos de su módulo. La figura 12.1 muestra que el módulo del sistema de archivos VFAT depende del módulo del sistema de archivos FAT. Entonces, el módulo FAT contiene una referencia al módulo VFAT: esta referencia se incrementa cuando se carga el módulo VFAT. El núcleo llama a la rutina de inicialización del módulo y, si tiene éxito, comienza a instalar el módulo. La dirección de la rutina de limpieza del módulo se almacena en su estructura de datos del módulo y el núcleo la llama cuando se descarga el módulo. Finalmente, el estado del módulo se establece en EN EJECUCIÓN.
12.2 Descarga de un módulo
Los módulos se pueden eliminar con el comando rmmod, pero kerneld puede eliminar todos los módulos no utilizados cargados a pedido del sistema. Cada vez que su temporizador de inactividad caduca, kerneld ejecuta una llamada al sistema solicitando que se eliminen del sistema todos los módulos bajo demanda innecesarios. El valor de este temporizador se establece cuando inicia kerneld: my kerneld verifica cada 180 segundos. Si instala un CD ROM iso9660 y su sistema de archivos iso9660 es un módulo cargable, el módulo iso9660 se eliminará del núcleo poco después de que se desmonte el CD ROM.
Si otros componentes del núcleo dependen de un módulo, no se puede eliminar. Por ejemplo, si tiene uno o más sistemas de archivos VFAT instalados, no puede desinstalar el módulo VFAT. Si marca la salida de ls, verá un contador asociado a cada módulo. P.ej:
Module: #pages: Used by:
msdos 5 1
vfat 4 1 (autoclean)
fat 6 [vfat msdos] 2 (autoclean)El conteo (count) es el número de entidades centrales que dependen de este módulo. En el ejemplo anterior, tanto vfat como msdos dependen del módulo fat, por lo que el contador del módulo fat es 2. Tanto el módulo Vfat como el msdos tienen un recuento de dependencias de 1 porque ambos tienen un sistema de archivos montado. Si cargo otro sistema de archivos VFAT, el contador del módulo vfat se convierte en 2. El contador de un módulo se coloca en la primera palabra larga de su imagen.
Debido a que también coloca las banderas AUTOCLEAN y VISITED, este campo tiene una ligera sobrecarga. Ambos indicadores se utilizan para cargar módulos bajo demanda. Estos módulos están marcados AUTOCLEAN para que el sistema pueda identificar cuáles puede descargar automáticamente. El indicador VISITED indica que este módulo es utilizado por uno o más componentes del sistema: este indicador se activa cada vez que otro componente lo utiliza. Cada vez que kerneld solicita al sistema que elimine un módulo bajo demanda no utilizado, examina todos los módulos del sistema y encuentra un candidato adecuado. Solo mira los módulos marcados AUTOCLEAN y cuyo estado es EN EJECUCIÓN. Si se borra el indicador de VISITADO candidato, entonces elimina el módulo; de lo contrario, borra el indicador de VISITADO y pasa al siguiente módulo en el sistema.
Suponiendo que se puede descargar un módulo, se llama a su rutina de limpieza para liberar los recursos centrales que asignó. La estructura de datos del módulo se marca como DELTED y se elimina de la lista de módulos principales. Las listas de referencias de cualquier otro módulo del que depende se modifican para que ya no lo consideren un dependiente. Se libera toda la memoria central que necesita este módulo.
Ver kernel/module.c delete_module()
13. Las fuentes del kernel de Linux
¿Dónde comienza el programa fuente central de Linux para buscar funciones centrales específicas?
Practique viendo el código fuente central para obtener una comprensión profunda del sistema operativo Linux. Esta sección brinda una descripción general de los programas fuente principales: cómo están organizados y dónde debe comenzar a buscar un código específico.
Dónde obtener las fuentes del kernel de Linux
Todas las principales distribuciones de Linux (Craftworks, Debian, Slackware, RedHat, etc.) tienen fuentes centrales en el medio. Por lo general, el kernel de Linux instalado en su sistema Linux está construido con estos programas fuente. De hecho, estas fuentes parecen estar algo desactualizadas, por lo que es posible que desee obtener la fuente más reciente de los sitios web mencionados en el Apéndice C. Se colocan en ftp://ftp.cs.helsinki.fi y en todos los demás sitios web duplicados. El sitio web de Helsinki está actualizado, pero otros sitios como MIT y Sunsite no se quedan atrás.
Si no tiene acceso a Internet, hay muchos fabricantes de CDROM que ofrecen bloques de los principales sitios web del mundo a precios muy razonables. Algunos incluso ofrecen servicios de suscripción, con actualizaciones trimestrales o mensuales. Su grupo local de usuarios de Linux también es una buena fuente de código fuente.
Los programas fuente principales de Linux tienen un sistema de numeración muy simple. Cualquier núcleo con número par (p. ej., 2.0.30) es un núcleo publicado estable, y cualquier núcleo con número impar (p. ej., 2.1.42) es un núcleo en desarrollo. Este libro se basa en el código fuente estable 2.0.30. Los núcleos de desarrollo tienen todas las características más recientes y son compatibles con todos los dispositivos más recientes, pero es posible que no sean estables y que no sean lo que desea, pero es importante que la comunidad de Linux pruebe los núcleos más recientes. Esto permite que toda la comunidad sea probada. Recuerde, incluso si está probando núcleos que no son de producción, es una buena idea hacer una copia de seguridad de su sistema.
Los cambios en el programa fuente central se distribuyen como archivos de parche. El parche de herramientas puede aplicar una serie de modificaciones a una serie de archivos fuente. Por ejemplo, si tiene un árbol de código fuente 2.0.29 y quiere pasar a 2.0.30, puede tomar los archivos de parche 2.0.30 y aplicar esos parches (ediciones) al árbol de código fuente:
$ cd /usr/src/linux
$ patch -p1 < patch-2.0.30Esto le evita tener que copiar todo el árbol fuente, especialmente para conexiones seriales lentas. Una buena fuente de parches básicos (oficiales e informales) es http://www.linuxhq.com
Cómo se organizan las fuentes del kernel
En la parte superior del árbol de fuentes verá algunos directorios:
arch El subdirectorio arch contiene todo el código central relacionado con la arquitectura. También tiene subdirectorios más profundos, cada uno de los cuales representa una arquitectura compatible, como i386 y alpha.
El subdirectorio de inclusión incluye la mayoría de los archivos de inclusión necesarios para compilar el núcleo. También tiene subdirectorios más profundos, uno para cada arquitectura admitida. Incluir/asm es un enlace flexible al directorio de inclusión real requerido por esta arquitectura, por ejemplo, incluir/asm-i386. Para cambiar la arquitectura, debe editar el archivo make del núcleo y volver a ejecutar el configurador del núcleo de Linux.
Init Este directorio contiene el código de inicialización del núcleo y es un buen punto de partida para estudiar cómo funciona el núcleo.
Mm Este directorio contiene todo el código de administración de memoria. El código de administración de memoria relacionado con la arquitectura se encuentra en arch/*/mm/, como arch/i386/mm/fault.c
Controladores Todos los controladores de dispositivos del sistema se encuentran en este directorio. Se dividen en clases de controladores de dispositivos, como bloque.
Ipc Este directorio contiene el código principal de comunicación entre procesos.
Módulos Este es solo un directorio para almacenar módulos establecidos
Fs Todo el código del sistema de archivos. se divide en subdirectorios, uno para cada sistema de archivos compatible, como vfat y ext2
El código central principal de Kernel. De manera similar, el código central relacionado con el sistema se coloca en arch/*/kernel
Código de red de núcleo de red
Lib Este directorio alberga el código de la biblioteca principal. El código de la biblioteca relacionado con la arquitectura está en arch/*/lib/
Scripts Este directorio contiene scripts (como awk y tk scripts) que configuran el núcleo
Dónde empezar a buscar
Es bastante difícil mirar un programa tan grande y complejo como el kernel de Linux. Es como una bola gigante de hilo que no muestra fin. Mirar una parte del código principal generalmente lleva a mirar varios otros archivos relacionados; de lo contrario, olvidará lo que miró. La siguiente sección le da una pista sobre dónde es mejor buscar en el árbol de fuentes para un tema determinado.
Arranque e inicialización del sistema
En un sistema Intel, el kernel se inicia cuando loadlin.exe o LILO carga el kernel en la memoria y le pasa el control. Ver arch/i386/kernel/head.S para esta parte. head.S realiza algunos trabajos de configuración dependientes de la arquitectura y salta a la rutina main() en init/main.c.
Gestión de la memoria
La mayor parte del código está en mm, pero el código relacionado con la arquitectura está en arch/*/mm. El código de manejo de fallas de página está en mm/memory.c, y el mapa de memoria y el código de caché de página están en mm/filemap.c. La caché de búfer se implementa en mm/buffer.c, y la caché de intercambio está en mm/swap_state.c y mm/swapfile.c.
Núcleo
La mayor parte del código relativamente general está en el kernel y el código relacionado con la arquitectura está en arch/*/kernel. El planificador está en kernel/sched.c y el código de la bifurcación está en kernel/fork.c. El código de procesamiento de la mitad inferior está en include/linux/interrupt.h. La estructura de datos task_struct se puede encontrar en include/linux/sched.h
ordenador personal
El pseudo controlador PCI está en drivers/pci/pci.c, y la definición de todo el sistema está en include/linux/pci.h. Cada arquitectura tiene un código PCI BIOS especial, el Alpha AXP se encuentra en arch/alpha/kernel/bios32.c
Comunicación entre procesos
Todo en el directorio ipc. Todos los objetos System V IPC incluyen la estructura de datos ipc_perm, que se puede encontrar en include/linux/ipc.h. Los mensajes de System V se implementan en ipc/msg.c, la memoria compartida está en ipc/shm.c y los semáforos están en ipc/sem.c. Las tuberías se implementan en ipc/pipe.c.
Manejo de interrupciones
El código central de manejo de interrupciones casi siempre es específico del microprocesador (y generalmente de la plataforma). El código de manejo de interrupciones de Intel está en arch/i386/kernel/irq.c y su definición está en inude/asm-i386/irq.h.
Controladores de dispositivo
La mayoría de las líneas de código fuente del núcleo de Linux se encuentran en sus controladores de dispositivo. Todo el código fuente del controlador de dispositivo para Linux está en los controladores, pero se clasifican en otras categorías:
/bloquear controladores de dispositivos como ide (ide.c). Si desea ver cómo se inicializan todos los dispositivos que pueden contener sistemas de archivos, puede consultar device_setup() en drivers/block/genhd.c. No solo inicializa el disco duro, sino que también inicializa la red, porque necesita la red cuando monta el sistema de archivos nfs. Los dispositivos de bloque incluyen dispositivos SCSI y basados en IDE.
/char Aquí puede ver dispositivos basados en caracteres como tty, puerto serie, etc.
/cdrom Todo el código del CDROM para Linux. Los dispositivos de CD-ROM especiales (p. ej., CD-ROM de Soundblaster) se pueden encontrar aquí. Tenga en cuenta que el controlador de CD ide es ide-cd.c en drivers/block y el controlador de CD SCSI está en drivers/scsi/scsi.c
/pci Seudocontrolador PCI. Este es un buen lugar para observar cómo se mapea e inicializa el subsistema PCI. También vale la pena mirar el código de recopilación Alpha AXP PCI en arch/alpha/kernel/bios32.c
/scsi Aquí puede encontrar no solo controladores para todos los dispositivos scsi compatibles con Linux, sino también todos los códigos SCSI
/net Aquí puede encontrar controladores de dispositivos de red como el controlador DEC Chip 21040 PCI Ethernet en tulip.c
/sonido la ubicación de todos los controladores de la tarjeta de sonido
Sistemas de archivos
Los programas fuente del sistema de archivos EXT2 se encuentran en el subdirectorio fs/ext2/ y las estructuras de datos se definen en include/linux/ext2_fs.h, ext2_fs_i.h y ext2_fs_sb.h. La estructura de datos del sistema de archivos virtual se describe en include/linux/fs.h, el código es fs/*. La caché de búfer y los demonios centrales de actualización se implementan con fs/buffer.c
La red
El código de red se coloca en el subdirectorio net y la mayoría de los archivos de inclusión están en include/net. El código de socket BSD está en net/socket.c, y el código de socket Ipv4 INET está en net/ipv4/af_inet.c. El código de soporte para los protocolos comunes (incluidas las rutinas de manejo de sk_buff) está en net/core y el código de red TCP/IP está en net/ipv4. Los controladores de dispositivos de red están en drivers/net
Módulos
El código del módulo central está en parte en el núcleo y en parte en el paquete de módulos. El código central está todo en kernel/modules.c, el resultado de los datos y el mensaje del demonio central kerneld están en include/linux/module.h e include/linux/kerneld.h respectivamente. También puede querer ver la estructura de un archivo de objeto ELF en include/linux/elf.h.
Apéndice A
Estructuras de datos de Linux
Este apéndice enumera las principales estructuras de datos utilizadas por Linux como se describe en este libro. Se han editado ligeramente para facilitar la accesibilidad en la página.
Block_dev_struct
La estructura de datos block_dev_struct se usa para registrar los dispositivos de bloque disponibles para el uso de la memoria caché del búfer. Se colocan en la tabla de vectores blk_dev.
ver include/linux/blkdev.h
struct blk_dev_struct {
void (*request_fn)(void);
struct request * current_request;
struct request plug;
struct tq_struct plug_tq;
};
buffer_head
La estructura de datos buffer_head almacena información sobre un búfer de bloque en la memoria caché del búfer.
Consulte include/linux/fs.h
dispositivo
Cada dispositivo de red en el sistema está representado por una estructura de datos de dispositivo.
Consulte include/linux/netdevice.h
estructura_de_dispositivo
La estructura de datos device_struct se usa para registrar caracteres y bloquear dispositivos (conteniendo el nombre del dispositivo y posibles operaciones de archivo). Cada miembro válido de las tablas de vectores Chrdevs y blkdevs representa un carácter o dispositivo de bloque, respectivamente.
Ver fs/devices.c
struct device_struct {
const char * name;
struct file_operations * fops;
};expediente
Cada archivo abierto, socket, etc. está representado por una estructura de datos de archivo.
Consulte include/linux/fs.h
estructura_archivo
La estructura de datos file_struct describe los archivos abiertos por un proceso.
ver include/linux/sched.h
gendisk
La estructura de datos gendisk almacena información sobre el disco duro. Se utiliza en el proceso de inicialización para encontrar el disco, al detectar particiones.
Consulte include/linux/genhd.h
inodo
La estructura de datos del inodo VFS almacena información sobre un archivo o directorio en el disco.
Consulte include/linux/fs.h
ipc_perm
La estructura de datos ipc_perm describe los permisos de acceso para un objeto System V IPC.
Consulte include/linux/ipc.h
irqaccion
La estructura de datos irqaction describe los controladores de interrupción del sistema.
Consulte include/linux/interrupt.h
linux_binfmt
Cada formato de archivo binario entendido por Linux está representado por una estructura de datos linux_binfmt.
Consulte include/linux/binfmt.h
mem_map_t
La estructura de datos mem_map_t (también llamada página) se utiliza para almacenar información sobre cada página de memoria física.
ver incluir/linux/mm.h
mm estructura
La estructura de datos mm_struct se utiliza para describir la memoria virtual de una tarea o proceso.
ver include/linux/sched.h
pci_bus
Cada bus PCI del sistema está representado por una estructura de datos pci_bus.
ver incluir/linux/pci.h
pci_dev
Cada dispositivo PCI del sistema, incluidos los dispositivos puente PCI-PCI y PCI-ISA, está representado por una estructura de datos pci_dev.
ver incluir/linux/pci.h
solicitud
request se utiliza para realizar una solicitud a un dispositivo de bloque en el sistema. Las solicitudes son para leer/escribir bloques de datos desde/hacia la memoria caché del búfer.
ver include/linux/blkdev.h
mesa
Cada estructura de datos rtable almacena información sobre la ruta para enviar paquetes a un host IP. La estructura de datos Rtable se utiliza en la caché de ruta IP.
ver include/net/route.h
semáforo
Los semáforos se utilizan para proteger estructuras de datos importantes y áreas de código.
Consulte include/asm/semaphore.h
sk_buff
La estructura de datos sk_buff describe los datos de la red a medida que se mueven entre las capas del protocolo.
Consulte include/linux/sk_buff.h
calcetín
Cada estructura de datos sock almacena información relacionada con el protocolo en un socket BSD. Por ejemplo, para un socket INET, esta estructura de datos contendrá toda la información relacionada con TCP/IP y UDP/IP.
ver incluir/linux/net.h
enchufe
Cada estructura de datos de socket almacena información sobre un socket BSD. No se sostiene por sí solo y en realidad es parte de la estructura de datos del inodo VFS.
ver incluir/linux/net.h
estructura_tarea
Cada task_struct describe una tarea o proceso en el sistema.
ver include/linux/sched.h
timer_list
La estructura de datos timer_list se utiliza para implementar el temporizador en tiempo real del proceso.
Consulte include/linux/timer.h
tq_struct
Cada estructura de datos de la cola de tareas (tq_struct) contiene información sobre el trabajo en cola. Por lo general, es una tarea que necesita un controlador de dispositivo, pero que no debe realizarse de inmediato.
Consulte include/linux/tqueue.h
vm_area_struct
Cada estructura de datos vm_area_struct describe un área de memoria virtual de un proceso.
ver incluir/linux/mm.h
Suplementos adicionales:
1. Hardware básico (aspectos básicos del hardware)
1)CPU
La CPU, o microprocesador, es el corazón de cualquier sistema informático. El microprocesador realiza operaciones matemáticas, operaciones lógicas y lee y ejecuta instrucciones de la memoria, controlando así el flujo de datos. En los primeros días del desarrollo de las computadoras, los diversos módulos funcionales de los microprocesadores estaban compuestos por unidades separadas (y de gran tamaño). Este es también el origen del término "unidad central de procesamiento". Los microprocesadores modernos combinan estos bloques funcionales en un circuito integrado hecho de una oblea de silicio muy pequeña. En este libro, los términos CPU, microprocesador y procesador se usan indistintamente.
Los microprocesadores manejan datos binarios: estos datos consisten en 1 y 0. Estos 1 y 0 corresponden al encendido o apagado del interruptor eléctrico. Así como 42 representa 4 unidades de 10 y 2, un número binario consta de una serie de números que representan potencias de 2. Aquí, potencia significa el número de veces que un número se multiplica por sí mismo. La primera potencia de 10 es 10, la segunda potencia de 10 es 10x10, la tercera potencia de 10 es 10x10x10 y así sucesivamente. El 0001 binario es el 1 decimal, el 0010 binario es el 2 decimal, el 0011 binario es el 3 decimal, el 0100 binario es el 4 decimal, y así sucesivamente. Entonces, 42 en decimal es 101010 en binario o (2+8+32 o 21+23+25). Además de usar binario para representar números en programas de computadora, a menudo se usa otra base, hexadecimal. En esta base, cada dígito representa una potencia de 16. Debido a que los números decimales solo van del 0 al 9, del 10 al 15 en hexadecimal se representan con las letras A, B, C, D, E, F respectivamente. Por ejemplo, E en hexadecimal es 14 en decimal y 2A en hexadecimal es 42 en decimal (2 16+10). En la notación C (usada a lo largo de este libro), los números hexadecimales tienen el prefijo "0x": 2A en hexadecimal se escribe como 0x2A.

El microprocesador puede realizar operaciones aritméticas como suma, multiplicación y división, así como operaciones lógicas como "es X mayor que Y".
La ejecución del procesador está controlada por un reloj externo. Este reloj, el reloj del sistema, genera pulsos de reloj constantes para el procesador, y en cada pulso de reloj, el procesador realiza algún trabajo. Por ejemplo, un procesador puede ejecutar una instrucción por pulso de reloj. La velocidad del procesador está descrita por la frecuencia del reloj del sistema. Un procesador de 100Mhz recibe 100.000.000 pulsos de reloj por segundo. Es un malentendido describir las capacidades de una CPU en términos de frecuencia de reloj, porque diferentes procesadores realizan diferentes cantidades de trabajo en cada pulso de reloj. No obstante, en igualdad de condiciones, una frecuencia de reloj más rápida significa un procesador más capaz. Las instrucciones ejecutadas por el procesador son muy simples, por ejemplo: "Lea el contenido de la ubicación de memoria X en el registro Y". Los registros son el espacio de almacenamiento interno de los microprocesadores, que se utilizan para almacenar datos y realizar operaciones. La operación realizada puede hacer que el procesador detenga la operación actual y, en su lugar, ejecute instrucciones en otra parte de la memoria. Son estas pequeñas colecciones de instrucciones las que le dan al microprocesador moderno capacidades casi ilimitadas, ya que puede ejecutar millones o incluso miles de millones de instrucciones por segundo.
Las instrucciones deben recuperarse de la memoria cuando se ejecutan, y las propias instrucciones pueden hacer referencia a datos en la memoria, que también deben recuperarse en la memoria y guardarse en la memoria cuando sea necesario.
El tamaño, número y tipo de los registros internos de un microprocesador están completamente determinados por su tipo. Un procesador Intel 80486 y un procesador Alpha AXP tienen conjuntos de registros completamente diferentes. Además, Intel tiene 32 bits de ancho y Alpha AXP tiene 64 bits de ancho. Sin embargo, en general, todos los procesadores específicos tendrán algunos registros de propósito general y algunos registros de propósito especial. La mayoría de los procesadores tienen registros dedicados para los siguientes propósitos especiales:
Contador de programa (PC) contador de programa
Este registro registra la dirección de la siguiente instrucción a ejecutar. El contenido de la PC se incrementa automáticamente cada vez que se obtiene una instrucción.
Puntero de pila (SP) puntero de pila
El procesador debe tener acceso a una gran cantidad de memoria de acceso aleatorio (RAM) externa de lectura y escritura utilizada para almacenar datos temporalmente. La pila es un método para almacenar y restaurar datos temporales en la memoria externa. Por lo general, los procesadores brindan instrucciones especiales para insertar datos en la pila y recuperarlos más tarde, según sea necesario. La pila utiliza el método LIFO (último en entrar, primero en salir). En otras palabras, si coloca dos valores x e y en la pila y luego extrae un valor de la pila, obtiene el valor de y.
Algunos procesadores tienen pilas que crecen hacia la parte superior de la memoria, mientras que otros crecen hacia la parte inferior de la memoria. También hay algunos procesadores que pueden soportar ambas formas, por ejemplo: ARM.
Estado del procesador (PS)
Las instrucciones pueden producir resultados. Por ejemplo: "¿Es el contenido del registro X mayor que el contenido del registro Y?" puede arrojar un resultado verdadero o falso. El registro PS contiene estos resultados y otra información sobre el estado actual del procesador. La mayoría de los procesadores tienen al menos dos modos: kernel (modo kernel) y usuario (modo usuario), y el registro PS registrará la información que puede determinar el modo actual.
2) Memoria
Todos los sistemas tienen una estructura de memoria jerárquica que consta de memoria a diferentes niveles de velocidad y capacidad.
La memoria más rápida es la memoria caché, como su nombre lo indica, utilizada para almacenar temporalmente o almacenar en caché el contenido de la memoria principal. Este tipo de memoria es muy rápida pero relativamente costosa, por lo que la mayoría de los chips de procesador tienen una pequeña cantidad de memoria caché incorporada y la mayor parte de la memoria caché está en la placa base del sistema. Algunos procesadores usan una memoria caché para guardar tanto las instrucciones como los datos, mientras que otros tienen dos cachés: una para las instrucciones y otra para los datos. El procesador Alpha AXP tiene dos almacenes de caché incorporados en la memoria: uno para datos (D-Cache) y otro para instrucciones (I-Cache). Su caché externo (o B-Cache) mezcla los dos.
El último tipo de memoria es la memoria principal. Muy lenta en relación con la memoria caché externa, la memoria principal es literalmente un rastreo para la memoria caché integrada en la CPU.
La memoria caché y la memoria principal deben estar sincronizadas (coherentes). En otras palabras, si una palabra en la memoria principal se mantiene en una o más ubicaciones en la memoria caché, el sistema debe asegurarse de que el contenido de la memoria caché y la memoria principal sea el mismo. Parte del trabajo de sincronización de cachés lo realiza el hardware y la otra parte lo realiza el sistema operativo. Para algunas otras tareas importantes del sistema, el hardware y el software también deben trabajar en estrecha colaboración.
3) Autobuses
Los diversos componentes de la placa del sistema están interconectados por un sistema de conexiones denominado bus. El bus del sistema se divide en tres funciones lógicas: bus de direcciones, bus de datos y bus de control. El bus de direcciones especifica la ubicación de la memoria (dirección) de la transferencia de datos, y el bus de datos contiene los datos transferidos. El bus de datos es bidireccional, permite que la CPU lea y también permite que la CPU escriba. El bus de control contiene varias líneas de señal que se utilizan para enviar señales de reloj y de control en el sistema. Hay muchos tipos de bus diferentes, los buses ISA y PCI son las formas comunes que usan los sistemas para conectar periféricos.
4) Controladores y Periféricos
Los periféricos se refieren a dispositivos físicos como tarjetas gráficas o discos controlados por un chip de control en la placa del sistema o tarjetas complementarias de la placa del sistema. El chip controlador IDE controla los discos IDE, mientras que el chip controlador SCSI controla los discos SCSI. Estos controladores están conectados a la CPU y entre sí a través de diferentes buses. La mayoría de los sistemas fabricados en la actualidad utilizan el bus PCI o ISA para conectar entre sí los principales componentes del sistema. El controlador en sí también es un procesador como la CPU, puede considerarse como el asistente inteligente de la CPU, y la CPU tiene el control más alto del sistema.
Todos los controladores son diferentes, pero generalmente tienen registros que se utilizan para controlarlos. El software que se ejecuta en la CPU debe poder leer y escribir estos registros de control. Un registro puede contener un código de estado que describe el error, y otro registro puede usarse con fines de control, cambiando el modo del controlador. Cada controlador en un bus puede ser direccionado individualmente por la CPU, de modo que los controladores de dispositivos de software puedan leer y escribir sus registros para controlarlo. Un cable IDE es un buen ejemplo, le brinda la capacidad de acceder a cada unidad en el bus individualmente. Otro buen ejemplo es el bus PCI, que permite acceder a cada dispositivo (como una tarjeta gráfica) de forma independiente.
5) Espacios de direcciones
El bus del sistema que conecta la CPU y la memoria principal y el bus que conecta la CPU y los periféricos de hardware del sistema están separados. El espacio de memoria propiedad de los periféricos de hardware se denomina espacio de E/S. El espacio de E/S en sí se puede dividir aún más, pero no lo discutiremos por ahora. La CPU puede acceder al espacio de memoria del sistema y al espacio de E/S, mientras que el controlador solo puede acceder a la memoria del sistema indirectamente a través de la CPU. Desde la perspectiva de un dispositivo, como un controlador de unidad de disquete, solo ve el espacio de direcciones (ISA) donde residen sus registros de control, no la memoria del sistema. Una CPU usa diferentes instrucciones para acceder a la memoria y al espacio de E/S. Por ejemplo, puede haber una instrucción que diga "leer un byte de la dirección de E/S 0x3f0 en el registro X". Este es también el método por el cual la CPU controla los periféricos leyendo y escribiendo los registros de los periféricos de hardware del sistema en el espacio de direcciones de E/S. En el espacio de direcciones, los registros de periféricos comunes (como controladores IDE, puertos serie, controladores de disquete, etc.) se han convertido en la norma en el desarrollo de periféricos de PC a lo largo de los años. La dirección 0x3f0 del espacio de E/S es la dirección del registro de control del puerto serie (COM1).
A veces, el controlador necesita leer grandes cantidades de memoria directamente desde la memoria del sistema o escribir grandes cantidades de datos directamente en la memoria del sistema. Por ejemplo, escribir datos de usuario en el disco duro. En este caso, se utiliza un controlador de acceso directo a la memoria (DMA), que permite que los dispositivos de hardware accedan directamente a la memoria del sistema, pero, por supuesto, este acceso debe realizarse bajo el estricto control y supervisión de la CPU.
6) Temporizador (reloj)
Todos los sistemas operativos necesitan saber la hora, y las PC modernas incluyen un periférico especial llamado reloj en tiempo real (RTC). Proporciona dos cosas: fechas confiables e intervalos de tiempo precisos. El RTC tiene su propia batería, por lo que incluso si la PC no está encendida, sigue funcionando. Esta es también la razón por la cual la PC siempre "sabe" la fecha y la hora correctas. La sincronización de intervalos permite que el sistema operativo programe con precisión el trabajo esencial.
La arquitectura Alpha AXP es una arquitectura RISC de carga/almacenamiento de 64 bits diseñada para la velocidad. Todos los registros tienen una longitud de 64 bits: 32 registros de enteros y 32 registros de punto flotante. El 31º registro de enteros y el 31º registro de coma flotante se utilizan para operaciones nulas: leerlos da 0, escribir en ellos no da nada. Todas las instrucciones y operaciones de memoria (ya sea de lectura o escritura) son de 32 bits. Se permiten diferentes implementaciones siempre que la implementación concreta siga esta arquitectura.
No hay instrucciones para manipular valores directamente en la memoria: todas las operaciones de datos se realizan entre registros. Entonces, si desea incrementar un contador en la memoria, primero debe leerlo en una tienda, modificarlo y luego volver a escribirlo. La interacción entre instrucciones solo es posible si una instrucción escribe en un registro o ubicación de memoria y otra lee ese registro o ubicación de memoria. Una característica interesante de Alpha AXP es que tiene instrucciones que pueden generar bits de bandera, como probar si dos números enteros son iguales, esta estructura no se almacena en uno de los registros de estado del procesador, sino en un tercer registro. Puede parecer extraño al principio, pero no confiar en el registro de estado significa que es más fácil hacer que la CPU ejecute varias instrucciones por ciclo. Las instrucciones que usan registros no relacionados durante la ejecución no necesitan esperarse entre sí y deben esperar si solo hay un registro de estado. No hay manipulación directa de la memoria y la gran cantidad de registros también es útil para múltiples instrucciones al mismo tiempo.
La arquitectura Alpha AXP utiliza una serie de subrutinas llamadas código de biblioteca de arquitectura privilegiada PALcode. La implementación específica de PALcode y el sistema operativo y la CPU del sistema Alpha AXP está relacionada con el hardware del sistema. Estas subrutinas brindan al sistema operativo soporte básico para cambios de contexto, interrupciones, excepciones y administración de memoria. Estas subrutinas pueden ser llamadas por hardware o por la instrucción CALL_PAL. PALcode está escrito en el ensamblador Alpha AXP estándar, con la implementación de algunas extensiones especiales para brindar acceso directo a hardware de bajo nivel, como los registros internos del procesador. PALcode se ejecuta en modo PAL, un modo privilegiado que detiene el envío de algunos eventos del sistema y permite que PALcode tome el control total del hardware físico del sistema.
2. Software Básico
Un programa es una combinación de instrucciones de computadora para realizar una tarea específica. Los programas se pueden escribir en lenguaje ensamblador, un lenguaje informático de muy bajo nivel, o en lenguajes de alto nivel independientes de la máquina, como C. Un sistema operativo es un programa especial que permite a los usuarios ejecutar aplicaciones a través de él, como hojas de cálculo y procesadores de texto.
2.1 Lenguajes informáticos
2.1.1 Lenguaje ensamblador
Las instrucciones que la CPU lee y ejecuta desde la memoria son incomprensibles para los humanos. Son códigos de máquina que le dicen a la computadora exactamente qué hacer. Por ejemplo, el número hexadecimal 0x89E5 es una instrucción Intel 80486 para copiar el contenido del registro ESP al registro EBP. Una de las primeras herramientas de software en las primeras computadoras fue el ensamblador, que tomaba archivos fuente legibles por humanos y los ensamblaba en código de máquina. El lenguaje ensamblador maneja explícitamente las operaciones en los registros y en los datos que son específicos de un microprocesador en particular. El lenguaje ensamblador del microprocesador Intel X86 es completamente diferente del lenguaje ensamblador del microprocesador Alpha AXP. El siguiente código ensamblador Alpha AXP demuestra los tipos de operaciones que puede realizar un programa:
Ldr r16, (r15) ; 第一行
Ldr r17, 4(r15) ; 第二行
Beq r16,r17,100; 第三行
Str r17, (r15); 第四行
100: ; 第五行La primera instrucción (línea 1) carga el contenido de la dirección especificada por el registro 15 en el registro 16. La segunda instrucción carga el contenido de la siguiente memoria en el registro 17. La tercera línea compara el registro 16 y el registro 17, si son iguales, ramifica a la etiqueta 100, de lo contrario, continúa ejecutando la cuarta línea y almacena el contenido del registro 17 en la memoria. Si los datos en la memoria son los mismos, no hay necesidad de almacenar los datos. Escribir programas a nivel de ensamblador es complicado, tedioso y propenso a errores. Pocas partes del núcleo del sistema Linux están escritas en lenguaje ensamblador, y la razón por la que estas partes usan lenguaje ensamblador es solo para mejorar la eficiencia y está relacionada con microprocesadores específicos.
2.1.2 El lenguaje de programación C y el compilador
Escribir programas grandes en lenguaje ensamblador es difícil, lleva mucho tiempo, es propenso a errores y los programas resultantes no son portátiles y están vinculados a una familia de procesadores en particular. Una mejor opción es usar un lenguaje independiente de la máquina como C. C le permite describir programas y datos para ser procesados en algoritmos lógicos. Un programa especial llamado compilador lee un programa C y lo convierte en lenguaje ensamblador, que a su vez produce código dependiente de la máquina. Un buen compilador puede generar instrucciones ensambladoras que están cerca de la eficiencia de un programa escrito por un buen programador ensamblador. La mayor parte del kernel de Linux está escrito en lenguaje C. El siguiente fragmento de C:
if (x != y)
x = y;Realiza exactamente la misma operación que el código ensamblador del ejemplo anterior. Si el contenido de la variable x no es el mismo que el contenido de la variable y, el contenido de la variable y se copia en la variable x. El código C se compone de rutinas, cada una de las cuales realiza una tarea. Las rutinas pueden devolver cualquier número o tipo de datos compatible con C. Los programas grandes, como el kernel de Linux, se componen de muchos módulos de lenguaje C, cada uno con sus propias rutinas y estructuras de datos. Estos módulos de código fuente C constituyen colectivamente el código de procesamiento para funciones lógicas como el sistema de archivos.
C admite muchos tipos de variables. Una variable es una ubicación específica en la memoria a la que se puede hacer referencia mediante un nombre simbólico. En el fragmento de C anterior, x e y se refieren a ubicaciones en la memoria. El programador no necesita preocuparse por la ubicación exacta de la variable en la memoria, esto es lo que debe manejar el enlazador (descrito a continuación). Algunas variables contienen varios datos, como números enteros, números de punto flotante, etc. y otras contienen punteros.
Un puntero es una variable que contiene la dirección de otros datos en la memoria. Suponiendo una variable x, ubicada en la dirección de memoria 0x80010000, es posible que tenga un puntero px que apunte a x. Px puede estar en la dirección 0x80010030. El valor de Px es la dirección de la variable x, 0x80010000.
C le permite agrupar variables relacionadas en estructuras. P.ej:
Struct {
Int I;
Char b;
} my_struct;es una estructura de datos llamada my_struct, que consta de dos elementos: un número entero (32 bits) I y un carácter (datos de 8 bits) b.
2.1.3 Enlazadores
El enlazador vincula varios módulos de objetos y archivos de biblioteca en un solo programa completo. Un módulo de objeto es la salida de código de máquina de un ensamblador o compilador, que incluye código de máquina, datos e información del enlazador para uso del enlazador. Por ejemplo, un módulo de objeto puede incluir todas las funciones de base de datos del programa, mientras que otro módulo de objeto incluye funciones que manejan argumentos de línea de comandos. El enlazador determina la relación de referencia entre los módulos de destino, es decir, determina la ubicación real de las rutinas y los datos a los que hace referencia un módulo en otro módulo. El núcleo de Linux es un gran programa independiente conectado por múltiples módulos de objetos.
2.2 ¿Qué es un Sistema Operativo?
Sin software, una computadora es solo un montón de componentes electrónicos calientes. Si el hardware es el corazón de una computadora, el software es su alma. Un sistema operativo es un conjunto de programas del sistema que permite a los usuarios ejecutar aplicaciones. El sistema operativo abstrae el hardware del sistema y presenta una máquina virtual frente a usuarios y aplicaciones. Es el software que caracteriza a un sistema informático. La mayoría de las PC pueden ejecutar uno o más sistemas operativos, cada uno de los cuales se ve y se siente muy diferente. Linux se compone de partes con diferentes funciones, y la combinación general de estas partes constituye el sistema operativo Linux. La parte más obvia de Linux es el propio Kernel, pero es inútil sin un shell o bibliotecas.
Para comprender qué es un sistema operativo, observe lo que sucede cuando escribe el comando más simple:
$ls
Mail c images perl
Docs tcl
$El $ aquí es el mensaje de salida del shell conectado (bash en este caso): significa que el shell está esperando que usted (el usuario) ingrese un comando. Al ingresar ls, el controlador del teclado reconoce los caracteres ingresados y el controlador del teclado pasa los caracteres reconocidos al shell para su procesamiento. El shell primero busca una imagen ejecutable del mismo nombre, encuentra /bin/ls y luego llama al servicio central para cargar el ejecutor ls en la memoria virtual y comenzar a ejecutar. El ejecutor ls encuentra archivos mediante la ejecución de llamadas al sistema del subsistema de archivos del núcleo. El sistema de archivos puede usar la información del sistema de archivos en caché o leer la información del archivo del disco a través del controlador del dispositivo de disco, o puede leer la información detallada del archivo remoto al que accede el sistema intercambiando información con el host remoto a través del dispositivo de red. controlador (los sistemas de archivos se pueden montar de forma remota a través de sistemas de archivos de red NFS). Independientemente de cómo se obtenga la información del archivo, ls genera la información y la muestra en la pantalla a través del controlador de pantalla.
El proceso anterior parece bastante complicado, pero muestra que incluso los comandos más simples son el resultado de la cooperación entre varios módulos funcionales del sistema operativo, y solo de esta manera puede brindarle a usted (el usuario) una vista completa del sistema.
2.2.1 Gestión de la memoria
Con recursos ilimitados, como la memoria, mucho de lo que tiene que hacer el sistema operativo puede ser redundante. Un truco fundamental de todos los sistemas operativos es hacer que una pequeña cantidad de memoria física funcione como si hubiera una cantidad considerable de memoria. Esta memoria superficialmente grande se llama memoria virtual, y cuando el software se está ejecutando, hace creer que tiene mucha memoria. El sistema divide la memoria en páginas manejables y cambia estas páginas al disco duro mientras el sistema está funcionando. El software de la aplicación no lo sabe, porque el sistema operativo también utiliza otra tecnología: el multiprocesamiento.
2.2.2 Procesos
Un proceso puede verse como un programa en ejecución, y cada proceso es una entidad independiente de un programa específico que se está ejecutando. Si observa su sistema Linux, verá que hay muchos procesos en ejecución. Por ejemplo: escribir ps en mi sistema muestra los siguientes procesos:
$ ps
PID TTY STAT TIME COMMAND
158 pRe 1 0:00 -bash
174 pRe 1 0:00 sh /usr/X11R6/bin/startx
175 pRe 1 0:00 xinit /usr/X11R6/lib/X11/xinit/xinitrc --
178 pRe 1 N 0:00 bowman
182 pRe 1 N 0:01 rxvt -geometry 120x35 -fg white -bg black
184 pRe 1 < 0:00 xclock -bg grey -geometry -1500-1500 -padding 0
185 pRe 1 < 0:00 xload -bg grey -geometry -0-0 -label xload
187 pp6 1 9:26 /bin/bash
202 pRe 1 N 0:00 rxvt -geometry 120x35 -fg white -bg black
203 ppc 2 0:00 /bin/bash
1796 pRe 1 N 0:00 rxvt -geometry 120x35 -fg white -bg black
1797 v06 1 0:00 /bin/bash
3056 pp6 3 < 0:02 emacs intro/introduction.tex
3270 pp6 3 0:00 ps
$Si mi sistema tiene varias CPU, cada proceso podría (al menos en teoría) ejecutarse en una CPU diferente. Desafortunadamente, solo hay uno, por lo que el sistema operativo nuevamente usa trucos para ejecutar cada proceso por turno durante un corto período de tiempo. Este período de tiempo se llama segmento de tiempo. Este truco se llama multiprocesamiento o programación, y engaña a cada proceso para que parezca que es el único. Los procesos están protegidos entre sí, por lo que si un proceso falla o no funciona, no afectará a otros procesos. El sistema operativo implementa la protección dando a cada proceso un espacio de direcciones separado, y un proceso solo puede acceder a su propio espacio de direcciones.
2.2.3 Controladores de dispositivos
Los controladores de dispositivos forman la parte principal del kernel de Linux. Al igual que otras partes del sistema operativo, funcionan en un entorno de alta prioridad y, si algo sale mal, pueden causar problemas graves. Los controladores de dispositivos controlan la interacción entre el sistema operativo y los dispositivos de hardware que controla. Por ejemplo, el sistema de archivos escribe bloques de datos en discos IDE utilizando la interfaz de dispositivo de bloque genérico. El conductor controla los detalles y maneja las partes específicas del dispositivo. Un controlador de dispositivo está relacionado con el chip controlador específico que maneja, por lo que si su sistema tiene un controlador SCSI NCR810, entonces necesita el controlador NCR810.
2.2.4 Los sistemas de archivos
Al igual que Unix, en Linux, el sistema no utiliza identificadores de dispositivos (como números de unidades o nombres de unidades) para acceder a sistemas de archivos individuales, sino que está vinculado a una estructura de árbol. Cuando Linux instala un nuevo sistema de archivos, lo instala en un directorio de instalación específico, como /mnt/cdrom, fusionándose así en este único árbol de sistema de archivos. Una característica importante de Linux es que admite muchos sistemas de archivos diferentes. Esto lo hace muy flexible y puede coexistir bien con otros sistemas operativos. El sistema de archivos más utilizado para Linux es EXT2, que es compatible con la mayoría de las distribuciones de Linux.
El sistema de archivos proporciona al usuario los archivos y directorios almacenados en el disco duro del sistema en una forma comprensible y unificada, de modo que el usuario no tiene que considerar el tipo de sistema de archivos o las características del dispositivo físico subyacente. Linux admite de forma transparente varios sistemas de archivos (como MS-DOS y EXT2) e integra todos los archivos y sistemas de archivos instalados en un sistema de archivos virtual. Por lo tanto, los usuarios y los procesos generalmente no necesitan saber exactamente en qué tipo de sistema de archivos se encuentran los archivos que usan, simplemente utilícelos.
Los controladores de dispositivos de bloque enmascaran la distinción entre los tipos de dispositivos de bloque físicos (por ejemplo, IDE y SCSI). Para un sistema de archivos, un dispositivo físico es una colección lineal de bloques de datos. El tamaño de bloque de los distintos dispositivos puede ser diferente. Por ejemplo, las unidades de disquete suelen tener 512 bytes, mientras que los dispositivos IDE suelen tener 1024 bytes. Una vez más, estas diferencias están enmascaradas para los usuarios del sistema. El sistema de archivos EXT2 se ve igual sin importar qué dispositivo use.
2.3 Estructuras de datos de Kernet
El sistema operativo debe registrar mucha información sobre el estado actual del sistema. Si algo sucede en el sistema, estas estructuras de datos deben cambiar en consecuencia para reflejar la realidad actual. Por ejemplo, cuando un usuario inicia sesión en el sistema, se debe crear un nuevo proceso. En consecuencia, el núcleo debe crear las estructuras de datos que representan este nuevo proceso, vinculadas a las estructuras de datos que representan otros procesos en el sistema.
Dichas estructuras de datos se encuentran principalmente en la memoria física y solo el núcleo y sus subsistemas pueden acceder a ellas. Las estructuras de datos incluyen datos y punteros (direcciones de otras estructuras de datos o rutinas). A primera vista, las estructuras de datos utilizadas por el kernel de Linux pueden resultar bastante confusas. De hecho, cada estructura de datos tiene un propósito y, aunque algunas estructuras de datos se utilizan en múltiples subsistemas, en realidad son mucho más simples que cuando las ve por primera vez.
La clave para comprender el kernel de Linux es comprender sus estructuras de datos y la gran cantidad de funciones que utiliza el kernel para procesar esas estructuras de datos. Este libro describe el kernel de Linux en términos de estructuras de datos. Analiza los algoritmos de cada subsistema central, la forma en que se procesan y su uso de estructuras de datos centrales.
2.3.1 Listas enlazadas
Linux utiliza una técnica de ingeniería de software para unir sus estructuras de datos. La mayoría de las veces utiliza una estructura de datos de lista enlazada. Si cada estructura de datos describe una sola instancia de un objeto o evento, como un proceso o un dispositivo de red, el kernel debe poder encontrar todas las instancias. En una lista enlazada, el puntero raíz contiene la dirección de la primera unidad o estructura de datos, y cada estructura de datos de la lista contiene un puntero al siguiente elemento de la lista. El siguiente puntero al último elemento puede ser 0 o NULL, lo que indica que este es el final de la lista. En una estructura de lista doblemente enlazada, cada elemento incluye no solo un puntero al siguiente elemento de la lista, sino también un puntero al elemento anterior de la lista. El uso de una lista doblemente enlazada facilita agregar o eliminar elementos del medio de la lista, pero requiere más acceso a la memoria. Este es un dilema típico del sistema operativo: la cantidad de accesos a la memoria o la cantidad de ciclos de CPU.
2.3.2 Tablas hash
Las listas vinculadas son una estructura de datos común, pero atravesar listas vinculadas puede no ser eficiente. Si está buscando un elemento específico, es posible que deba buscar en toda la tabla para encontrarlo. Linux usa otra técnica: Hashing para abordar esta limitación. La tabla hash es una matriz o tabla vectorial de punteros. Las matrices o tablas vectoriales son objetos que se colocan secuencialmente en la memoria. Se puede decir que una estantería es un conjunto de libros. Se accede a las matrices mediante índices, que son compensaciones dentro de la matriz. Volviendo al ejemplo de la estantería, puede usar la posición en la estantería para describir cada libro: digamos el libro 5.
Una tabla hash es una matriz de punteros a estructuras de datos cuyos índices se derivan de la información de las estructuras de datos. Si usa una estructura de datos para describir la población de un pueblo, puede usar la edad como índice. Para averiguar los datos de una persona determinada, puede usar su edad como índice para buscar en la tabla hash de población y encontrar la estructura de datos, incluida la información detallada por puntero. Desafortunadamente, puede haber muchas personas en un pueblo de la misma edad, por lo que el puntero de la tabla hash apunta a otra estructura de datos de lista enlazada, cada elemento describe a un compañero. Incluso entonces, buscar estas listas enlazadas más pequeñas es aún más rápido que buscar todas las estructuras de datos.
Las tablas hash se pueden usar para acelerar el acceso a las estructuras de datos de uso común, y las tablas hash se usan comúnmente en Linux para implementar el almacenamiento en búfer. El almacenamiento en búfer es información a la que se debe acceder rápidamente y es un subconjunto de la información total disponible. Las estructuras de datos se colocan en búferes y se mantienen allí porque el núcleo accede con frecuencia a estas estructuras. El uso de búferes también tiene efectos secundarios, ya que es más complicado de usar que una simple lista enlazada o una tabla hash. Si la estructura de datos se puede encontrar en el búfer (esto se llama un golpe de búfer), entonces todo es perfecto. Pero si la estructura de datos no está en el búfer, entonces se debe buscar la estructura de datos relevante utilizada y, si se encuentra, se agrega al búfer. Agregar nuevas estructuras de datos al búfer puede requerir descartar una entrada de búfer anterior. Linux tiene que decidir qué estructura de datos desaprobar, a riesgo de desaprobar a qué estructura de datos accederá Linux a continuación.
2.3.3 Interfaces abstractas
El kernel de Linux a menudo abstrae sus interfaces. Una interfaz es una serie de rutinas y estructuras de datos que funcionan de una manera específica. Por ejemplo: todos los controladores de dispositivos de red deben proporcionar rutinas específicas para manejar estructuras de datos específicas. A modo de interfaz abstracta, la capa de código general puede utilizar los servicios (interfaces) proporcionados por el código especial subyacente. Por ejemplo, la capa de red es genérica, mientras que está respaldada por un código subyacente específico del dispositivo que se ajusta a una interfaz estándar.
Por lo general, estas capas inferiores se registran con las capas superiores al inicio. Este proceso de registro generalmente se implementa agregando una estructura de datos a la lista vinculada. Por ejemplo, cada sistema de archivos vinculado al kernel se registra cuando se inicia el kernel (o si usa módulos, la primera vez que se usa el sistema de archivos). Puede ver el archivo /proc/filesystems para verificar qué sistemas de archivos están registrados. Las estructuras de datos utilizadas para el registro suelen incluir punteros a funciones. Esta es la dirección de una función de software que realiza una tarea específica. Usando nuevamente el ejemplo de registro del sistema de archivos, cada estructura de datos que se pasa al kernel de Linux durante el registro del sistema de archivos incluye la dirección de una rutina asociada con un sistema de archivos específico, que debe llamarse cuando se monta el sistema de archivos.
5. Gestión del núcleo de Linux
1. Carpeta virtual
1. Introducción a las carpetas virtuales
Carpetas virtuales, porque su contenido de datos se almacena en la memoria, no en el disco duro, /proc y /sys son carpetas virtuales. Algunos de estos archivos devolverán mucha información cuando se visualicen con el comando de visualización, pero el tamaño del archivo en sí se mostrará como 0 bytes. Además, los atributos de fecha y hora de la mayoría de estos archivos especiales suelen ser la fecha y hora actual del sistema, ya que se actualizan (almacenan en RAM) en cualquier momento.
Vista de rendimiento externo del sistema de archivos /proc y proporciona a los usuarios una vista de las estructuras de datos internas del kernel. Se puede usar para ver y modificar ciertas estructuras de datos internas del núcleo, cambiando así el comportamiento del núcleo.
El sistema de archivos /proc proporciona una forma sencilla de mejorar el rendimiento de la aplicación y del sistema en general mediante el ajuste fino de los recursos del sistema.El sistema de archivos /proc es un sistema de archivos virtual creado dinámicamente por el kernel para generar datos. Está organizado en directorios, cada uno de los cuales corresponde a opciones ajustables para un subsistema en particular.
El directorio /proc contiene muchos subdirectorios nombrados con números, y estos números representan el número de proceso del proceso actualmente en ejecución en el sistema, que contiene varios archivos de información relacionados con el proceso correspondiente.
[root@rhel5 ~]# ll /proc
total 0
dr-xr-xr-x 5 root root 0 Feb 8 17:08 1
dr-xr-xr-x 5 root root 0 Feb 8 17:08 10
dr-xr-xr-x 5 root root 0 Feb 8 17:08 11
dr-xr-xr-x 5 root root 0 Feb 8 17:08 1156
dr-xr-xr-x 5 root root 0 Feb 8 17:08 139
dr-xr-xr-x 5 root root 0 Feb 8 17:08 140
dr-xr-xr-x 5 root root 0 Feb 8 17:08 141
dr-xr-xr-x 5 root root 0 Feb 8 17:09 1417
dr-xr-xr-x 5 root root 0 Feb 8 17:09 1418
En la lista anterior hay algunos directorios relacionados con procesos en el directorio /proc, y cada directorio es un archivo con información sobre el proceso en sí. Los siguientes son archivos relacionados de un proceso saslauthd con PID 2674 ejecutándose en el sistema del autor (RHEL5.3), algunos de los cuales son archivos que tendrá cada proceso.
[root@rhel5 ~]# ll /proc/2674
total 0
dr-xr-xr-x 2 root root 0 Feb 8 17:15 attr
-r-------- 1 root root 0 Feb 8 17:14 auxv
-r--r--r-- 1 root root 0 Feb 8 17:09 cmdline
-rw-r--r-- 1 root root 0 Feb 8 17:14 coredump_filter
-r--r--r-- 1 root root 0 Feb 8 17:14 cpuset
lrwxrwxrwx 1 root root 0 Feb 8 17:14 cwd -> /var/run/saslauthd
-r-------- 1 root root 0 Feb 8 17:14 environ
lrwxrwxrwx 1 root root 0 Feb 8 17:09 exe -> /usr/sbin/saslauthd
dr-x------ 2 root root 0 Feb 8 17:15 fd
-r-------- 1 root root 0 Feb 8 17:14 limits
-rw-r--r-- 1 root root 0 Feb 8 17:14 loginuid
-r--r--r-- 1 root root 0 Feb 8 17:14 maps
-rw------- 1 root root 0 Feb 8 17:14 mem
-r--r--r-- 1 root root 0 Feb 8 17:14 mounts
-r-------- 1 root root 0 Feb 8 17:14 mountstats
-rw-r--r-- 1 root root 0 Feb 8 17:14 oom_adj
-r--r--r-- 1 root root 0 Feb 8 17:14 oom_score
lrwxrwxrwx 1 root root 0 Feb 8 17:14 root -> /
-r--r--r-- 1 root root 0 Feb 8 17:14 schedstat
-r-------- 1 root root 0 Feb 8 17:14 smaps
-r--r--r-- 1 root root 0 Feb 8 17:09 stat
-r--r--r-- 1 root root 0 Feb 8 17:14 statm
-r--r--r-- 1 root root 0 Feb 8 17:10 status
dr-xr-xr-x 3 root root 0 Feb 8 17:15 task
-r--r--r-- 1 root root 0 Feb 8 17:14 wchancmdline: el comando completo para iniciar el proceso actual, pero este archivo en el directorio del proceso zombie no contiene información;
[root@rhel5 ~]# more /proc/2674/cmdline
/usr/sbin/saslauthdentorno — una lista de variables de entorno para el proceso actual, separadas entre sí por un carácter NULL; las variables se representan con letras mayúsculas y sus valores se representan con letras minúsculas;
[root@rhel5 ~]# more /proc/2674/environ
TERM=linuxauthdcwd: un enlace simbólico al directorio donde se está ejecutando el proceso actual;
exe: un enlace simbólico al ejecutable (ruta completa) que inició el proceso actual, se puede iniciar una copia del proceso actual a través de /proc/N/exe;
fd: este es un directorio que contiene un descriptor de archivo para cada archivo abierto por el proceso actual, que es un enlace simbólico al archivo real;
[root@rhel5 ~]# ll /proc/2674/fd
total 0
lrwx------ 1 root root 64 Feb 8 17:17 0 -> /dev/null
lrwx------ 1 root root 64 Feb 8 17:17 1 -> /dev/null
lrwx------ 1 root root 64 Feb 8 17:17 2 -> /dev/null
lrwx------ 1 root root 64 Feb 8 17:17 3 -> socket:[7990]
lrwx------ 1 root root 64 Feb 8 17:17 4 -> /var/run/saslauthd/saslauthd.pid
lrwx------ 1 root root 64 Feb 8 17:17 5 -> socket:[7991]
lrwx------ 1 root root 64 Feb 8 17:17 6 -> /var/run/saslauthd/mux.accept
límites: límites flexibles, límites estrictos y unidades de administración para cada recurso restringido utilizado por el proceso actual; este archivo solo puede ser leído por el usuario de UID que realmente inició el proceso actual; (esta característica es compatible con las versiones del kernel posteriores a la 2.6.24) ;
mapas: una lista de regiones asignadas en la memoria y sus permisos de acceso para cada ejecutable y archivo de biblioteca asociado con el proceso actual;
[root@rhel5 ~]# cat /proc/2674/maps
00110000-00239000 r-xp 00000000 08:02 130647 /lib/libcrypto.so.0.9.8e
00239000-0024c000 rwxp 00129000 08:02 130647 /lib/libcrypto.so.0.9.8e
0024c000-00250000 rwxp 0024c000 00:00 0
00250000-00252000 r-xp 00000000 08:02 130462 /lib/libdl-2.5.so
00252000-00253000 r-xp 00001000 08:02 130462 /lib/libdl-2.5.somem — el espacio de memoria ocupado por el proceso actual, utilizado por llamadas al sistema como open, read y lseek, y no puede ser leído por el usuario;
raíz: un enlace simbólico al directorio raíz del proceso actual; en los sistemas Unix y Linux, el comando chroot generalmente se usa para hacer que cada proceso se ejecute en un directorio raíz separado;
stat: información de estado del proceso actual, incluida una columna de datos formateada por el sistema, con poca legibilidad, generalmente utilizada por el comando ps;
statm: información de estado sobre la memoria ocupada por el proceso actual, generalmente expresada en "páginas";
estado: similar a la información proporcionada por stat, pero con una mejor legibilidad, como se muestra a continuación, cada línea representa una información de atributo; consulte la página de manual de proc para obtener más detalles;
[root@rhel5 ~]# more /proc/2674/status
Name: saslauthd
State: S (sleeping)
SleepAVG: 0%
Tgid: 2674
Pid: 2674
PPid: 1
TracerPid: 0
Uid: 0 0 0 0
Gid: 0 0 0 0
FDSize: 32
Groups:
VmPeak: 5576 kB
VmSize: 5572 kB
VmLck: 0 kB
VmHWM: 696 kB
VmRSS: 696 kB
…………tarea: un archivo de directorio que contiene información sobre cada subproceso ejecutado por el proceso actual. El archivo de información relevante para cada subproceso se almacena en un directorio denominado por el número de subproceso (tid), que es similar al contenido de cada subproceso. del directorio de procesos; (esta función es compatible después de la versión 2.6 del kernel).
2. Introducción a los archivos comunes en el directorio /proc
/proc
proc es la abreviatura de proceso. Este archivo de directorio almacena la información relevante del proceso.La información del proceso y el estado del kernel en el sistema se colocan en el proc, que es una carpeta virtual, y la información de datos correspondiente es el estado en la memoria;
/proc/aprox.
Información de versión de Advanced Power Management (APM) e información de estado relacionada con la batería, generalmente utilizada por el comando apm;
/proc/información del amigo
Archivos de información relevante para diagnosticar problemas de fragmentación de memoria;
/proc/líneacmd
La información de parámetros relevante que se pasa al kernel al inicio, que generalmente se pasa a través de herramientas de gestión de arranque como lilo o grub;
[root@rhel5 ~]# more /proc/cmdline
ro root=/dev/VolGroup00/LogVol00 rhgb quiet/proc/cpuinfo
Un archivo con información sobre el procesador;
/proc/cripto
Una lista de algoritmos criptográficos utilizados por los núcleos instalados en el sistema y detalles de cada algoritmo;
[root@rhel5 ~]# more /proc/crypto
name : crc32c
driver : crc32c-generic
module : kernel
priority : 0
type : digest
blocksize : 32
digestsize : 4
…………/proc/dispositivos
Información sobre todos los dispositivos de bloques y dispositivos de caracteres cargados por el sistema, incluido el número de dispositivo principal y el nombre del grupo de dispositivos (tipo de dispositivo correspondiente al número de dispositivo principal);
[root@rhel5 ~]# more /proc/devices
Character devices:
1 mem
4 /dev/vc/0
4 tty
4 ttyS
…………
Block devices:
1 ramdisk
2 fd
8 sd
…………/proc/diskstats
Lista de estadísticas de E/S de disco para cada dispositivo de disco (las versiones posteriores al kernel 2.5.69 admiten esta función);
/proc/dma
Una lista de información sobre cada canal ISA DMA en uso y registrado;
[root@rhel5 ~]# more /proc/dma
2: floppy
4: cascade/proc/execdominios
Una lista de información sobre los dominios de ejecución admitidos actualmente por el kernel (la "personalidad" única de cada sistema operativo);
[root@rhel5 ~]# more /proc/execdomains
0-0 Linux [kernel]/proc/fb
Archivo de lista de dispositivos de búfer de cuadros, incluido el número de dispositivo y la información del controlador relacionado del dispositivo de búfer de cuadros;
/proc/sistemas de archivos
El archivo de lista de tipos de sistemas de archivos actualmente admitido por el kernel, el sistema de archivos marcado como nodev indica que no se requiere compatibilidad con dispositivos de bloque; por lo general, cuando se monta un dispositivo, si no se especifica el tipo de sistema de archivos, este archivo se utilizará para determinar el sistema de archivos requerido type;
[root@rhel5 ~]# more /proc/filesystems
nodev sysfs
nodev rootfs
nodev proc
iso9660
ext3
…………
…………/proc/interrumpe
Una lista de números de interrupción relacionados con cada IRQ en un sistema de arquitectura X86 o X86_64; cada CPU en una plataforma multiprocesador tiene su propio número de interrupción para cada dispositivo de E/S;
[root@rhel5 ~]# more /proc/interrupts
CPU0
0: 1305421 IO-APIC-edge timer
1: 61 IO-APIC-edge i8042
185: 1068 IO-APIC-level eth0
…………/proc/iomem
La información de mapeo de la memoria (RAM o ROM) en cada dispositivo físico en la memoria del sistema;
[root@rhel5 ~]# more /proc/iomem
00000000-0009f7ff : System RAM
0009f800-0009ffff : reserved
000a0000-000bffff : Video RAM area
000c0000-000c7fff : Video ROM
…………/proc/ioports
Una lista de información del rango de puertos de entrada y salida que está actualmente en uso y se ha registrado para comunicarse con dispositivos físicos; como se muestra a continuación, la primera columna representa el rango de puertos de E/S registrado, seguido de los dispositivos relacionados;
[root@rhel5 ~]# less /proc/ioports
0000-001f : dma1
0020-0021 : pic1
0040-0043 : timer0
0050-0053 : timer1
0060-006f : keyboard
…………/proc/kallsyms
La herramienta de gestión de módulos se utiliza para vincular o enlazar dinámicamente las definiciones de símbolos de los módulos cargables, que genera el kernel (las versiones posteriores al kernel 2.5.71 admiten esta función); por lo general, la cantidad de información en este archivo es bastante grande;
[root@rhel5 ~]# more /proc/kallsyms
c04011f0 T _stext
c04011f0 t run_init_process
c04011f0 T stext
…………/proc/kcore
La memoria física utilizada por el sistema, almacenada en el formato de archivo central ELF (archivo central), cuyo tamaño de archivo es la memoria física utilizada (RAM) más 4 KB; este archivo se utiliza para verificar el estado actual de la estructura de datos del kernel , por lo tanto, generalmente por GBD. Generalmente lo usan las herramientas de depuración, pero no puede usar el comando de vista de archivo para abrir este archivo;
/proc/kmsg
Este archivo se utiliza para guardar la salida de información del núcleo, generalmente utilizado por programas como /sbin/klogd o /bin/dmsg, no intente abrir este archivo con el comando de visualización;
/proc/carga promedio
Guarde los promedios de carga sobre CPU y E / S de disco. Las primeras tres columnas representan los promedios de carga cada 1 segundo, cada 5 segundos y cada 15 segundos, respectivamente, similar a la información relevante generada por el comando uptime; la cuarta columna es Dos valores separados por barras, el primero representa la cantidad de entidades (procesos y subprocesos) que el kernel está programando actualmente, y el último representa la cantidad de entidades de programación del kernel que sobreviven actualmente en el sistema; la quinta columna representa la más reciente archivo antes de ver el PID de un proceso creado por el núcleo;
[root@rhel5 ~]# more /proc/loadavg
0.45 0.12 0.04 4/125 5549
[root@rhel5 ~]# uptime
06:00:54 up 1:06, 3 users, load average: 0.45, 0.12, 0.04
/proc/bloqueos
Guarde información sobre los archivos actualmente bloqueados por el kernel, incluidos los datos de depuración dentro del kernel; cada bloqueo ocupa una fila y tiene un número único; la segunda columna de cada fila en la siguiente información de salida indica el tipo de bloqueo utilizado por el bloqueo actual, POSIX Indica el tipo de bloqueo de archivo actual más nuevo, que es generado por la llamada al sistema lockf. FLOCK es un bloqueo de archivo UNIX tradicional, que es generado por la llamada al sistema flock; la tercera columna también suele estar compuesta de dos tipos. ADVISORY significa que a otros usuarios no se les permite bloquear este archivo, pero se permite Leer, OBLIGATORIO significa que otros usuarios no pueden acceder de ninguna forma durante este período de bloqueo de archivos;
[root@rhel5 ~]# more /proc/locks
1: POSIX ADVISORY WRITE 4904 fd:00:4325393 0 EOF
2: POSIX ADVISORY WRITE 4550 fd:00:2066539 0 EOF
3: FLOCK ADVISORY WRITE 4497 fd:00:2066533 0 EOF
/proc/mdstat
Guarde la información de estado actual de varios discos relacionados con RAID. En una máquina que no usa RAID, se muestra de la siguiente manera:
[root@rhel5 ~]# less /proc/mdstat
Personalities :
unused devices: <none>/proc/meminfo
La información sobre la utilización actual de la memoria en el sistema a menudo es utilizada por el comando gratuito; puede usar el comando de vista de archivo para leer directamente este archivo, y su contenido se muestra en dos columnas, la primera es el atributo estadístico y la última es el valor correspondiente;
[root@rhel5 ~]# less /proc/meminfo
MemTotal: 515492 kB
MemFree: 8452 kB
Buffers: 19724 kB
Cached: 376400 kB
SwapCached: 4 kB
…………Compruebe la cantidad de memoria libre:
grep MemFree /proc/meminfo /proc/montajes
Antes de la versión del kernel 2.4.29, el contenido de este archivo son todos los sistemas de archivos actualmente montados por el sistema. En el kernel posterior a la 2.4.19, se introduce el método de usar un espacio de nombres de montaje independiente para cada proceso, y este archivo cambia en consecuencia, se convierte en un enlace simbólico al archivo /proc/self/mounts (una lista de todos los puntos de montaje en el propio espacio de nombres de montaje de cada proceso), /proc/self es un directorio único, que se describirá más adelante;
[root@rhel5 ~]# ll /proc |grep mounts
lrwxrwxrwx 1 root root 11 Feb 8 06:43 mounts -> self/mounts
Como se muestra a continuación, la primera columna indica el dispositivo montado, la segunda columna indica el punto de montaje en el árbol de directorios actual, el tercer punto indica el tipo de sistema de archivos actual y la cuarta columna indica el atributo de montaje (ro o rw) , las columnas quinta y sexta se utilizan para hacer coincidir el atributo de volcado en el archivo /etc/mtab;
[root@rhel5 ~]# more /proc/mounts
rootfs / rootfs rw 0 0
/dev/root / ext3 rw,data=ordered 0 0
/dev /dev tmpfs rw 0 0
/proc /proc proc rw 0 0
/sys /sys sysfs rw 0 0
/proc/bus/usb /proc/bus/usb usbfs rw 0 0
…………/proc/modulos
Una lista de todos los nombres de los módulos actualmente cargados en el kernel, que se puede usar con el comando lsmod o se puede ver directamente; como se muestra a continuación, la primera columna indica el nombre del módulo, la segunda columna indica el espacio de memoria ocupado por el módulo y el la tercera columna indica el módulo Cuántas instancias están cargadas, la cuarta columna indica de qué otros módulos depende este módulo, la quinta columna indica el estado de carga de este módulo (En vivo: ya cargado; Cargando: cargando; Descargando: descargando), sexta columna Indica el desplazamiento de este módulo en la memoria del núcleo;
[root@rhel5 ~]# more /proc/modules
autofs4 24517 2 - Live 0xe09f7000
hidp 23105 2 - Live 0xe0a06000
rfcomm 42457 0 - Live 0xe0ab3000
l2cap 29505 10 hidp,rfcomm, Live 0xe0aaa000
…………
/proc/particiones
Información como el número de dispositivo principal (principal) y el número de dispositivo secundario (menor) de cada partición del dispositivo de bloque, incluida la cantidad de bloques contenidos en cada partición (como se muestra en la tercera columna del resultado a continuación);
[root@rhel5 ~]# more /proc/partitions
major minor #blocks name
8 0 20971520 sda
8 1 104391 sda1
8 2 6907950 sda2
8 3 5630782 sda3
8 4 1 sda4
8 5 3582463 sda5/proc/pci
Una lista de todos los dispositivos PCI y su información de configuración encontrada durante la inicialización del kernel. La información de configuración es principalmente información IRQ relacionada con un dispositivo PCI, que no es muy legible. Puede usar el comando "/sbin/lspci –vb" para obtener más información relacionada comprensible. ; Después del kernel 2.6, este archivo ha sido reemplazado por el directorio /proc/bus/pci y los archivos debajo de él;
/proc/slabinfo
Los objetos que se usan con frecuencia en el kernel (como inode, dentry, etc.) tienen su propio caché, a saber, el grupo de slab, y el archivo /proc/slabinfo enumera la información de slap relacionada con estos objetos; para obtener detalles, consulte el página de manual de slapinfo en la documentación del núcleo;
[root@rhel5 ~]# more /proc/slabinfo
slabinfo - version: 2.1
# name <active_objs> <num_objs> <objsize> <objperslab> <pagesperslab> : tunables <limit> <batchcount> <sharedfactor> : slabdata <ac
tive_slabs> <num_slabs> <sharedavail>
rpc_buffers 8 8 2048 2 1 : tunables 24 12 8 : slabdata 4 4 0
rpc_tasks 8 20 192 20 1 : tunables 120 60 8 : slabdata 1 1 0
rpc_inode_cache 6 9 448 9 1 : tunables 54 27 8 : slabdata 1 1 0
…………
…………
…………/sistema
El archivo de directorio /sys almacena información relacionada con el hardware, y también es una carpeta virtual, no una carpeta en el disco duro real, sino también los datos en la memoria;
Reconocimiento de discos duros recién agregados:
echo "- - -" > /sys/class/scsi_host/hostX/scan #X表示数字,从0开始的/proc/sistema
A diferencia del atributo de "solo lectura" de otros archivos en /proc, la información en este archivo de directorio se puede modificar y las características operativas del kernel se pueden controlar a través de estas configuraciones;
De antemano, puede usar el comando "ls -l" para verificar si un archivo es "escribible". Las operaciones de escritura generalmente se realizan usando un formato similar a "echo DATA > /ruta/a/su/nombre de archivo". Cabe señalar que incluso si se puede escribir en el archivo, generalmente no se puede editar con un editor.
El número máximo de subprocesos admitidos por el sistema de consulta:
cat /proc/sys/kernel/threads-maxsubdirectorio /proc/sys/debug
Este directorio suele ser un directorio vacío;
subdirectorio /proc/sys/dev
El directorio que proporciona archivos de información de parámetros para dispositivos especiales en el sistema, y los archivos de información de diferentes dispositivos se almacenan en diferentes subdirectorios, como /proc/sys/dev/cdrom y /proc/sys/dev en la mayoría de los sistemas /raid ( si la función de compatibilidad con raid está habilitada cuando se compila el kernel), que generalmente almacena los archivos de información de parámetros relevantes de cdrom y raid en el sistema;
proceso/estadística
Realiza un seguimiento de varias estadísticas en tiempo real desde la última vez que se inició el sistema; como se muestra a continuación, donde
los ocho valores después de la línea "cpu" representan estadísticas en modo 1/100 (jiffies), modo de usuario de baja prioridad, modo de sistema operativo, modo inactivo, tiempo en modo de espera de E/S, etc.);
la línea "intr" da la información de la interrupción, la primera son todas las interrupciones que han ocurrido desde que se inició el sistema El número de veces; luego cada número corresponde al número de veces que ha ocurrido una interrupción en particular desde que se inició el sistema;
"ctxt" da el número de cambios de contexto de CPU que se han producido desde que se inició el sistema.
"btime" indica el tiempo desde que se inició el sistema, en segundos;
"processes (total_forks) el número de tareas creadas desde que se inició el sistema;
"procs_running": el número de tareas que se están ejecutando actualmente en la cola;
"procs_blocked": el número de tareas actualmente bloqueadas;
[root@rhel5 ~]# more /proc/stat
cpu 2751 26 5771 266413 2555 99 411 0
cpu0 2751 26 5771 266413 2555 99 411 0
intr 2810179 2780489 67 0 3 3 0 5 0 1 0 0 0 1707 0 0 9620 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 5504 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 12781 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
ctxt 427300
btime 1234084100
processes 3491
procs_running 1
procs_blocked 0/proc/intercambios
La partición de intercambio y su información de utilización de espacio en el sistema actual, si hay varias particiones de intercambio, la información de cada partición de intercambio se almacenará en un archivo separado en el directorio /proc/swap, y cuanto menor sea el número de prioridad, mayor la posibilidad de ser utilizado, la siguiente es la información de salida cuando solo hay una partición de intercambio en el sistema del autor;
[root@rhel5 ~]# more /proc/swaps
Filename Type Size Used Priority
/dev/sda8 partition 642560 0 -1
/proc/tiempo de actividad
El tiempo de ejecución desde la última vez que se inició el sistema, como se muestra a continuación, el primer número representa el tiempo de ejecución del sistema y el segundo número representa el tiempo de inactividad del sistema, en segundos;
[root@rhel5 ~]# more /proc/uptime
3809.86 3714.13/proc/versión
El número de versión del kernel que se ejecuta en el sistema actual también mostrará la versión gcc instalada por el sistema en el RHEL5.3 del autor, como se muestra a continuación;
[root@rhel5 ~]# more /proc/version
Linux version 2.6.18-128.el5 ([email protected]) (gcc version 4.1.2 20080704 (Red Hat 4.1.2-44)) #1 SMP Wed Dec 17 11:42:39 EST 2008/proc/vmstat
Varios datos estadísticos de la memoria virtual del sistema actual, la cantidad de información puede ser relativamente grande, que varía de un sistema a otro, y la legibilidad es mejor; el siguiente es un fragmento de la información de salida en la máquina del autor; (El núcleo después 2.6 admite este archivo)
[root@rhel5 ~]# more /proc/vmstat
nr_anon_pages 22270
nr_mapped 8542
nr_file_pages 47706
nr_slab 4720
nr_page_table_pages 897
nr_dirty 21
nr_writeback 0
…………/proc/infozona
La lista de información detallada de la zona de memoria (zona), la cantidad de información es grande, el siguiente es un fragmento de salida:
[root@rhel5 ~]# more /proc/zoneinfo
Node 0, zone DMA
pages free 1208
min 28
low 35
high 42
active 439
inactive 1139
scanned 0 (a: 7 i: 30)
spanned 4096
present 4096
nr_anon_pages 192
nr_mapped 141
nr_file_pages 1385
nr_slab 253
nr_page_table_pages 2
nr_dirty 523
nr_writeback 0
nr_unstable 0
nr_bounce 0
protection: (0, 0, 296, 296)
pagesets
all_unreclaimable: 0
prev_priority: 12
start_pfn: 0
…………3. Crear subnodo de directorio /proc
El mecanismo del módulo del núcleo y el sistema de archivos /proc son características típicas de los sistemas Linux. ¿Puede aprovechar estas funciones para crear los nodos correspondientes en el directorio /proc para archivos especiales, dispositivos, variables públicas, etc.? La respuesta es, por supuesto, sí.
Hay muchas formas en que los módulos del kernel interactúan fuera del espacio del kernel, y el sistema de archivos /proc es una de las formas principales.
Al presentar el sistema de archivos /proc, aquí revisaremos algunos de los conceptos básicos. Un sistema de archivos es la forma en que el sistema operativo organiza los archivos en un disco u otro periférico. Linux admite muchos tipos de sistemas de archivos: minix, ext, ext2, msdos, umsdos, vfat, proc, nfs, iso9660, hpfs, sysv, smb, ncpfs, etc. A diferencia de otros sistemas de archivos, el sistema de archivos /proc es un pseudosistema de archivos. La razón por la que se le llama pseudo sistema de archivos es que no tiene ninguna parte relacionada con el disco, solo existe en la memoria y no ocupa el espacio de la memoria externa. Y tiene muchas similitudes con los sistemas de archivos. Por ejemplo, proporciona una interfaz para acceder a los datos del kernel del sistema en forma de un sistema de archivos y se puede operar con todas las herramientas de archivos comunes. Por ejemplo, podemos ver la información en el archivo proc a través del comando cat, more u otras herramientas de edición de texto. Más importante aún, los usuarios y las aplicaciones pueden obtener información del sistema a través de proc y pueden cambiar algunos parámetros del kernel. Dado que la información del sistema, como los procesos, cambia dinámicamente, cuando un usuario o una aplicación lee un archivo proc, el proc lee dinámicamente la información requerida del kernel del sistema y la envía. El sistema de archivos /proc generalmente se coloca en el directorio /proc.
¿Cómo hacer que el sistema de archivos /proc refleje el estado de los módulos del kernel? Echemos un vistazo a este ejemplo un poco más complejo a continuación.
proc_example.c
…………
int init_module()
{
int rv = 0;
/* 创建目录 */
example_dir = proc_mkdir(MODULE_NAME, NULL);
if(example_dir == NULL) {
rv = -ENOMEM;
goto out;
}
example_dir->owner = THIS_MODULE;
/* 快速创建只读文件 jiffies */
jiffies_file = create_proc_read_entry("jiffies", 0444, example_dir,
proc_read_jiffies, NULL);
if(jiffies_file == NULL) {
rv = -ENOMEM;
goto no_jiffies;
}
jiffies_file->owner = THIS_MODULE;
/* 创建规则文件foo 和 bar */
foo_file = create_proc_entry("foo", 0644, example_dir);
if(foo_file == NULL) {
rv = -ENOMEM;
goto no_foo;
}
strcpy(foo_data.name, "foo");
strcpy(foo_data.value, "foo");
foo_file->data = &foo_data;
foo_file->read_proc = proc_read_foobar;
foo_file->write_proc = proc_write_foobar;
foo_file->owner = THIS_MODULE;
bar_file = create_proc_entry("bar", 0644, example_dir);
if(bar_file == NULL) {
rv = -ENOMEM;
goto no_bar;
}
strcpy(bar_data.name, "bar");
strcpy(bar_data.value, "bar");
bar_file->data = &bar_data;
bar_file->read_proc = proc_read_foobar;
bar_file->write_proc = proc_write_foobar;
bar_file->owner = THIS_MODULE;
/* 创建设备文件 tty */
tty_device = proc_mknod("tty", S_IFCHR | 0666, example_dir, MKDEV(5, 0));
if(tty_device == NULL) {
rv = -ENOMEM;
goto no_tty;
}
tty_device->owner = THIS_MODULE;
/* 创建链接文件jiffies_too */
symlink = proc_symlink("jiffies_too", example_dir, "jiffies");
if(symlink == NULL) {
rv = -ENOMEM;
goto no_symlink;
}
symlink->owner = THIS_MODULE;
/* 所有创建都成功 */
printk(KERN_INFO "%s %s initialised\n",
MODULE_NAME, MODULE_VERSION);
return 0;
/*出错处理*/
no_symlink: remove_proc_entry("tty", example_dir);
no_tty: remove_proc_entry("bar", example_dir);
no_bar: remove_proc_entry("foo", example_dir);
no_foo: remove_proc_entry("jiffies", example_dir);
no_jiffies: remove_proc_entry(MODULE_NAME, NULL);
out: return rv;
}
…………
El módulo del kernel proc_example primero crea su propio subdirectorio proc_example en el directorio /proc. Luego, se crean en este directorio tres archivos normales de proceso (foo, bar, jiffies), un archivo de dispositivo (tty) y un enlace de archivo (jiffies_too). Específicamente, foo y bar son dos archivos de lectura y escritura que comparten las funciones proc_read_foobar y proc_write_foobar. jiffies es un archivo de solo lectura que obtiene la hora actual del sistema jiffies. jiffies_too es un enlace simbólico al archivo jiffies.
2. Herramientas de gestión del kernel
1. herramienta de gestión de sysctl
Los parámetros modificados por sysctl son efectivos temporalmente y persistentemente al escribir un archivo de configuración.
#配置文件
/run/sysctl.d/*.conf
/etc/sysctl.d/*.conf
/usr/local/lib/sysctl.d/*.conf
/usr/lib/sysctl.d/*.conf
/lib/sysctl.d/*.conf
/etc/sysctl.conf #主要存放在这里面,一般都在这个配置文件里面编写设置Formato:
A diferencia del formato del archivo, use puntos (.) para separar las rutas. No es necesario escribir /proc/sys, ya que este archivo de configuración corresponde a la gestión de la carpeta /proc/sys.
Parámetros comunes:
-w 临时改变某个指定参数的值
-a 显示所有生效的系统参数
-p 从指定的文件加载系统参数ejemplo:
Prohibir hacer ping a la máquina:
[root@centos8 ~]#cat /etc/sysctl.d/test.conf
net.ipv4.icmp_echo_ignore_all=1
[root@centos8 ~]#sysctl -p /etc/sysctl.d/test.conf
Borrar método de caché:
echo 1|2|3 >/proc/sys/vm/drop_caches2. ulimit limita los recursos del sistema
ulimit limita ciertos recursos del sistema del usuario, incluida la cantidad de archivos que se pueden abrir, el tiempo de CPU que se puede usar, la cantidad total de memoria que se puede usar, etc.
gramática:
ulimit [-acdfHlmnpsStvw] [size] Opciones y parámetros:
-H : hard limit ,严格的设定,必定不能超过这个设定的数值
-S : soft limit ,警告的设定,可以超过这个设定值,但是若超过则有警告讯息
-a : 后面不接任何选项与参数,可列出所有的限制额度
-c : 当某些程序发生错误时,系统可能会将该程序在内存中的信息写成档案,这种档案就被称为核心档案(core file)。
-f : 此 shell 可以建立的最大档案容量(一般可能设定为 2GB)单位为 Kbytes
-d : 程序可使用的最大断裂内存(segment)容量
-l : 可用于锁定 (lock) 的内存量
-m : 设置可以使用的常驻内存的最大值.单位:kbytes
-n : 设置内核可以同时打开的文件描述符的最大值.单位:n
-p : 设置管道缓冲区的最大值.单位:kbytes
-s : 设置堆栈的最大值.单位:kbytes
-v : 设置虚拟内存的最大值.单位:kbytes
-t : 可使用的最大 CPU 时间 (单位为秒)
-u : 单一用户可以使用的最大程序(process)数量 Configuraciones simples generales:
ulimit -SHn 65535 Para hacerlo permanente:
[root@www ~]# vi /etc/security/limits.conf
* soft noproc 65535
* hard noproc 65535
* soft nofile 409600
* hard nofile 409600 ilustrar:
* medios para todos los usuarios
noproc es el número máximo de procesos
nofile es el número máximo de archivos abiertos
Caso:
[root@www ~]# vi /etc/security/limits.conf
# End of file
* soft core unlimit
* hard core unlimit
* soft fsize unlimited
* hard fsize unlimited
* soft data unlimited
* hard data unlimited
* soft nproc 65535
* hard nproc 63535
* soft stack unlimited
* hard stack unlimited
* soft nofile 409600
* hard nofile 409600
gato /etc/security/limits.conf
gato /etc/security/limits.d/90-nproc.conf

La configuración incorrecta de sysctl/ulimit puede hacer que la respuesta del sistema sea muy lenta cuando los indicadores anteriores son muy normales.
Caso: Para mayor comodidad, configuré todos los parámetros de sysctl/ulimit como redis/elasticsearch/network en el script de inicialización del sistema configure_server.py al mismo tiempo. Como resultado, el parámetro vm.max_map_count que elasticsearch necesita establecer hace que el servidor redis responda lentamente después de una ejecución prolongada.
3, límite de recursos del sistema Linux
Oracle se ejecuta en Linux. Hay ciertos requisitos para las limitaciones de recursos.
límites.conf y sysctl.conf
La instalación de Oracle no puede evitar la configuración de parámetros en estos dos archivos: el archivo sysctl.conf es principalmente para restricciones de recursos en el sistema. El limit.conf principalmente para que los usuarios hagan restricciones de recursos, depende del mecanismo PAM (Módulos de autenticación conectables Módulos de autenticación conectables), la configuración no puede exceder la configuración del sistema operativo.
limites.conf sintaxis:
username|@groupname type resource limitnombredeusuario|@nombre_del_grupo: Configure el nombre de usuario para que sea restringido. Agregue @ antes del nombre del grupo para distinguirlo del nombre de usuario. También puede usar el comodín * para limitar a todos los usuarios.
parámetro:
type:
可以指定 soft,hard 和 -,soft 指的是当前系统生效的设置值。hard 表明系统中所能设定的最大值。soft 的限制不能比har 限制高。用 - 就表明同时设置了 soft 和 hard 的值。
resource:
core - 限制内核文件的大小
date - 最大数据大小
fsize - 最大文件大小
memlock - 最大锁定内存地址空间
nofile - 打开文件的最大数目
rss - 最大持久设置大小
stack - 最大栈大小
cpu - 以分钟为单位的最多 CPU 时间
noproc - 进程的最大数目
as - 地址空间限制
maxlogins - 此用户允许登录的最大数目Configuración de consulta: comando ulimit
Sólo válido para el tty (terminal) actual. El comando ulimit en sí tiene configuraciones blandas y duras. Agregar -H es difícil y agregar -S es suave.
parámetro:
-H 设置硬件资源限制.
-S 设置软件资源限制.
-a 显示当前所有的资源限制.
-c size:设置core文件的最大值.单位:blocks
-d size:设置数据段的最大值.单位:kbytes
-f size:设置创建文件的最大值.单位:blocks
-l size:设置在内存中锁定进程的最大值.单位:kbytes
-m size:设置可以使用的常驻内存的最大值.单位:kbytes
-n size:设置内核可以同时打开的文件描述符的最大值.单位:n
-p size:设置管道缓冲区的最大值.单位:kbytes
-s size:设置堆栈的最大值.单位:kbytes
-t size:设置CPU使用时间的最大上限.单位:seconds
-v size:设置虚拟内存的最大值.单位:kbytesAviso:
ilimitado es un valor especial usado para indicar ilimitado
sistema .c
La mayoría de los parámetros del núcleo se almacenan en el directorio /proc/sys y se pueden cambiar mientras el sistema se está ejecutando, pero fallarán después de reiniciar la máquina. /etc/sysctl.conf es una interfaz que permite cambios en un sistema Linux en ejecución. Contiene algunas opciones avanzadas para la pila TCP/IP y el sistema de memoria virtual. La modificación de los parámetros del kernel tiene efecto de forma permanente. Es decir, existe una relación correspondiente entre los archivos del kernel bajo /proc/sys y las variables en el archivo de configuración sysctl.conf.
Configuración común:
kernel.shmall=4294967296
vm.min_free_kbytes=262144
kernel.sem=4096 524288 4096 128
fs.file-max=6815744
net.ipv4.ip_local_port_range=9000 65500
net.core.rmem_default=262144
net.core.rmem_max=4194304
net.core.wmem_default=262144
net.core.wmem_max=1048576
fs.aio-max-nr=1048576
kernel.shmmni=4096
vm.nr_hugepages=8029ilustrar:
kernel.shmmax:
是核心参数中最重要的参数之一,用于定义单个共享内存段的最大值。设置应该足够大,能在一个共享内存段下容纳下整个的SGA ,设置的过低可能会导致需要创建多个共享内存段,这样可能导致系统性能的下降。至于导致系统下降的主要原因为在实例启动以及ServerProcess创建的时候,多个小的共享内存段可能会导致当时轻微的系统性能的降低(在启动的时候需要去创建多个虚拟地址段,在进程创建的时候要让进程对多个段进行“识别”,会有一些影响),但是其他时候都不会有影响。
官方建议值:
32位Linux系统:可取最大值为4GB(4294967296bytes)-1byte,即4294967295。建议值为多于内存的一半,所以如果是32为系统,一般可取值为4294967295。32位系统对SGA大小有限制,所以SGA肯定可以包含在单个共享内存段中。
64位linux系统:可取的最大值为物理内存值-1byte,建议值为多于物理内存的一半,一般取值大于SGA_MAX_SIZE即可,可以取物理内存-1byte。例如,如果为12GB物理内存,可取12*1024*1024*1024-1=12884901887,SGA肯定会包含在单个共享内存段中。
kernel.shmall:
该参数控制可以使用的共享内存的总页数。Linux共享内存页大小为4KB,共享内存段的大小都是共享内存页大小的整数倍。一个共享内存段的最大大小是16G,那么需要共享内存页数是16GB/4KB=16777216KB /4KB=4194304(页),也就是64Bit系统下16GB物理内存,设置kernel.shmall = 4194304才符合要求(几乎是原来设置2097152的两倍)。这时可以将shmmax参数调整到16G了,同时可以修改SGA_MAX_SIZE和SGA_TARGET为12G(您想设置的SGA最大大小,当然也可以是2G~14G等,还要协调PGA参数及OS等其他内存使用,不能设置太满,比如16G)
kernel.shmmni:
该参数是共享内存段的最大数量。shmmni缺省值4096,一般肯定是够用了。
fs.file-max:
该参数决定了系统中所允许的文件句柄最大数目,文件句柄设置代表linux系统中可以打开的文件的数量。
fs.aio-max-nr:
此参数限制并发未完成的请求,应该设置避免I/O子系统故障。
kernel.sem:
以kernel.sem = 250 32000 100 128为例:
250是参数semmsl的值,表示一个信号量集合中能够包含的信号量最大数目。
32000是参数semmns的值,表示系统内可允许的信号量最大数目。
100是参数semopm的值,表示单个semopm()调用在一个信号量集合上可以执行的操作数量。
128是参数semmni的值,表示系统信号量集合总数。
net.ipv4.ip_local_port_range:
表示应用程序可使用的IPv4端口范围。
net.core.rmem_default:
表示套接字接收缓冲区大小的缺省值。
net.core.rmem_max:
表示套接字接收缓冲区大小的最大值。
net.core.wmem_default:
表示套接字发送缓冲区大小的缺省值。
net.core.wmem_max:表示套接字发送缓冲区大小的最大值。
vm.nr_hugepages=8029 大页数Seis, optimización del kernel de Linux
Método de evaluación del núcleo:
Agregue initcall_debug a los parámetros de inicio para obtener más registros del kernel:
[ 3.750000] calling ov2640_i2c_driver_init+0x0/0x10 @ 1
[ 3.760000] initcall ov2640_i2c_driver_init+0x0/0x10 returned 0 after 544 usecs
[ 3.760000] calling at91sam9x5_video_init+0x0/0x14 @ 1
[ 3.760000] at91sam9x5-video f0030340.lcdheo1: video device registered @ 0xe0d3e340, irq = 24
[ 3.770000] initcall at91sam9x5_video_init+0x0/0x14 returned 0 after 10388 usecs
[ 3.770000] calling gspca_init+0x0/0x18 @ 1
[ 3.770000] gspca_main: v2.14.0 registered
[ 3.770000] initcall gspca_init+0x0/0x18 returned 0 after 3966 usecs
...Alternativamente, puede usar scripts/bootgraph.pl para convertir la información dmesg en una imagen:
$ scripts/bootgraph.pl boot.log > boot.svg
A continuación, encuentre los aspectos que consumen más tiempo y optimícelos.
1. Optimización del compilador
BRAZO contra pulgar2
Compare sistemas y aplicaciones compilados en el conjunto de instrucciones ARM o Thumb2.
ARM: 3,79 MB para rootfs, 227 KB para ffmpeg.
Miniatura 2: 3,10 MB (-18 %), 183 KB (-19 %)。
Rendimiento: el rendimiento de Thumb2 ha mejorado significativamente ligeramente (alrededor de menos del 5%).
Aunque el rendimiento ha mejorado, personalmente sigo eligiendo el conjunto de instrucciones ARM.
Musl contra uClibc
Hay 3 tipos de bibliotecas C para elegir en Buildroot: glibc, musl , uClibc, aquí solo comparamos los últimos 2 tipos de bibliotecas más pequeñas.
musl: 680 KB (directorio stats/lib).
uClibc:570 KB (-16 %)。
uClibc ahorra 110 KB y elegimos uClibc.
2. Optimiza la aplicación
Podemos elegir los componentes funcionales de FFmpeg a través de ./configure.
Además, puede usar los comandos strace y perf para depurar y optimizar el código d interno de FFmpeg.
El resultado después de la optimización:
Sistema de archivos: reducción de 16,11 MB a 3,54 MB (-78 %).
Tiempo de carga y ejecución del programa: 150 ms más corto.
Tiempo de inicio general: 350 ms más corto.
La optimización en el espacio es grande, pero la optimización en el tiempo de inicio es pequeña, porque Linux solo carga las partes necesarias del programa cuando lo ejecuta.
3. Optimizar Init y el sistema de archivos raíz
Ideas:
Utilice bootchartd para analizar el inicio del sistema y recortar los servicios innecesarios.
Combine los scripts de inicio en /etc/init.d/ en uno.
/proc y /sys no están montados.
Corte BusyBox, cuanto más pequeño sea el sistema de archivos, más rápido puede ser el montaje del kernel.
Reemplace el programa Init con nuestra aplicación.
Compile la aplicación estáticamente.
Recorte los archivos que se usan con poca frecuencia y encuentre archivos a los que no se accede durante mucho tiempo:
$ find / -atime -1000 -type fEl resultado después de la optimización:
Sistema de archivos: reducido de 3,54 MB a 2,33 MB (-34 %) después de recortar Busybox.
Tiempo de arranque: básicamente sin cambios, presumiblemente porque el sistema de archivos en sí es lo suficientemente pequeño.
4. Usar initramfs como rootfs
En circunstancias normales, el sistema Linux montará primero initramfs.Init ramfs es pequeño y está ubicado en la memoria, y luego initramfs es responsable de cargar el sistema de archivos raíz.
Cuando recortamos el rootfs de Buildroot muy pequeño, podemos considerar usarlo directamente como initramfs.
¿Cuál es el beneficio de esto?
El initramfs se puede empalmar con el Kernel, y el Bootloader es responsable de cargar el Kernel+initramfs en la memoria, y el kernel ya no necesita acceder al disco.
El kernel ya no necesita funciones relacionadas con el bloque/almacenamiento y el sistema de archivos, el tamaño será más pequeño y el tiempo de carga y el tiempo de inicialización se reducirán.
Tenga en cuenta que la compresión initramfs debe desactivarse (CONFIG_INITRAMFS_COMPRESSION_NONE).
El resultado después de la optimización:
Incluso con CONFIG_BLOCK y CONFIG_MMC deshabilitados, el tiempo total de arranque sigue siendo 20 ms mayor. Esto puede deberse a que después de ensamblar Kernel + initramfs, el kernel se vuelve mucho más grande y la imagen del kernel debe descomprimirse, lo que aumenta el tiempo de descompresión.
5. Recorta el calco
Deshabilite las funciones relacionadas con Tracers en la piratería del kernel.
Tiempo de inicio: 550ms más corto.
Tamaño del kernel: reducción de 217 KB.
6. Elimina algunas funciones de hardware que no son necesarias
omap8250_platform_driver_init() // (660 ms)
cpsw_driver_init() // (112 ms)
am335x_child_init() // (82 ms)
...7. Bucles preestablecidos por santiamén
En cada arranque, el kernel calibra el valor del ciclo de retardo para la función udelay().
Esto mide el valor de los bucles por santiamén (lpj). Solo necesitamos iniciar el kernel una vez y buscar el valor lpj en el registro:
Calibrating delay loop... 996.14 BogoMIPS (lpj=4980736)Luego complete lpj=4980736 en los parámetros de inicio, puede:
Calibrating delay loop (skipped) preset value.. 996.14 BogoMIPS (lpj=4980736)Aproximadamente 82 ms más corto.
8. Deshabilitar CONFIG_SMP
La inicialización de SMP es lenta. Por lo general, está habilitado en la configuración predeterminada, incluso para una CPU de un solo núcleo.
Si nuestra plataforma es de un solo núcleo, se puede desactivar SMP.
Después del apagado, el núcleo se reduce: -188 KB (-4,6 %) y el tiempo de inicio se reduce en 126 ms.
9. Deshabilitar registro
Agregar silencio a los parámetros de inicio reduce el tiempo de inicio en 577 ms.
Con CONFIG_PRINTK y CONFIG_BUG desactivados, el núcleo se reduce en 118 KB (-5,8 %).
Después de deshabilitar CONFIG_KALLSYMS, el núcleo se reduce en 107 KB (-5,7 %).
En total, el tiempo de inicio se reduce en 767 ms.
10. Habilite CONFIG_EMBEDDED y CONFIG_EXPERT
Esto hace que las llamadas al sistema sean más ágiles y el kernel menos genérico, pero es suficiente para mantener la aplicación en funcionamiento.
El núcleo se reduce en 51 KB.
El tiempo de inicio se reduce en 34 ms.
11. Seleccionar asignadores de memoria SLAB
Por lo general, SLAB, SLOB, SLUB eligen uno de tres.
SLAB: La elección por defecto, la más versátil, la más tradicional y la más fiable.
SLOB: más conciso, menos código, más ahorro de espacio, adecuado para sistemas integrados, después de habilitar, el kernel se reduce en 5 KB, pero el tiempo de inicio aumenta en 1,43 S.
SLUB: Es más adecuado para sistemas grandes.Después de habilitar, el tiempo de inicio aumenta en 2 ms.
Por lo tanto, todavía usamos SLAB.
12. Optimización de la compresión del kernel
Las características de los diferentes métodos de compresión son las siguientes:

Efecto medido:

Parece que gzip y lzo funcionan mejor. El efecto de la prueba debe estar relacionado con el rendimiento de la CPU/disco.
13. Parámetros de compilación del kernel
Habilite CONFIG_CC_OPTIMIZE_FOR_SIZE, esta opción puede reemplazar gcc -O2 con gcc -Os.

Tenga en cuenta que este es solo un resultado de prueba en BeagleBone Black + Linux 5.1, existen diferencias entre las diferentes plataformas.
14. Deshabilite los pseudosistemas de archivos como /proc
Considerar la compatibilidad de la aplicación.
ffmpeg se basa en /proc, por lo que solo se pueden desactivar algunas opciones relacionadas con el proceso: CONFIG_PROC_SYSCTL, CONFIG_PROC_PAGE_MONITOR CONFIG_CONFIGFS_FS, y la hora de inicio no ha cambiado.
cerrar sysfs
15. Empalme DTB
Habilitar CONFIG_ARM_APPENDED_DTB:
$ cat arch/arm/boot/zImage arch/arm/boot/dts/am335x-boneblack-lcd4.dtb > zImage
$ setenv bootcmd 'fatload mmc 0:1 81000000 zImage; bootz 81000000'El tiempo de inicio se reduce en 26 ms.
16. Optimizar el cargador de arranque
Aquí usamos la mejor solución: use el modo Uboot Falcon.
El modo Falcon solo ejecuta la primera etapa de Uboot: SPL, luego omite la Etapa 2 y ejecuta la carga del Kernel.
El tiempo de arranque se reduce en 250 ms.
Resumen de optimización del kernel:
En este punto, la optimización de inicio básicamente se completa y el efecto final es el siguiente:
[0.000000 0.000000]
[0.000785 0.000785] U-Boot SPL 2019.01 (Oct 27 2019 - 08:04:06 +0100)
[0.057822 0.057822] Trying to boot from MMC1
[0.378878 0.321056] fdt_root: FDT_ERR_BADMAGIC
[0.775306 0.396428] Waiting for /dev/video0 to be ready...
[1.966367 1.191061] Starting ffmpeg
...
[2.412284 0.004277] First frame decodedDesde el encendido hasta que la pantalla LCD muestre el primer cuadro de la imagen, el tiempo total es de 2,41 segundos.
Los pasos más efectivos son los siguientes :

Todavía vale la pena optimizar el espacio :
El sistema pasó 1,2 segundos esperando que la cámara USB enumerara, ¿hay alguna forma de acelerarlo aquí?
¿Es posible desactivar tty y el inicio de sesión de terminal?
Finalmente, hay algunos principios a seguir cuando se trata de optimizar el tiempo de inicio :
Por favor, no optimice antes de tiempo.
Comience a optimizar desde algunos puntos con la menor influencia.
Optimización de arriba hacia abajo desde rootfs, kernel, bootloader.