1. Redis- und MySQL-Datenkonsistenzprojekt mit doppelter Schreibkonsistenz
Solange Sie den Cache verwenden, kann es zu doppeltem Schreiben des Cache und der Datenbank kommen.Solange Sie das doppelte Schreiben verwenden, wird es ein Problem der Datenkonsistenz geben, also wie lösen Sie das Konsistenzproblem?
Doppeltes Schreiben Konsistenz, verschieben Sie zuerst Cache redis oder Datenbank mysql welche?whby?
1.1, Übersicht
Kanal wird hauptsächlich für das Abonnement, den Verbrauch und die Analyse von inkrementellen Protokolldaten in der MySQL-Datenbank verwendet. Es wurde von Alibaba entwickelt und Open Source. Es wurde in der Java-Sprache entwickelt. Der historische Hintergrund ist, dass es in den frühen Tagen von Alibaba Cross- Computerräume aufgrund der Bereitstellung von zwei Computerräumen in Hangzhou und den Vereinigten Staaten.Die Geschäftsanforderungen der Datensynchronisierung werden hauptsächlich durch den Erwerb inkrementeller Änderungen auf der Grundlage von Geschäftsauslösern realisiert. Seit 2010 hat Alibaba nach und nach versucht, das Datenbankprotokoll zu parsen, um inkrementelle Änderungen für die Synchronisation zu erhalten, und daraus das Kanalprojekt abgeleitet;
1.2 Funktion
- Echtzeit-Backup der Datenbank-Spiegeldatenbank
- Indexaufbau und Echtzeitpflege (geteilte heterogene Indizes, invertierte Indizes etc.)
- Business-Cache-Aktualisierung
- Inkrementelle Datenverarbeitung mit Geschäftslogik
1.3, das Prinzip der MySQL-Master-Slave-Replikation

Die MySQL-Master-Slave-Replikation durchläuft die folgenden Schritte:
- Wenn sich die Daten auf dem Masterserver ändern, werden die Änderungen in die binäre Ereignisprotokolldatei geschrieben;
- Der Slave-Server wird das Binärprotokoll auf dem Master-Master-Server innerhalb eines bestimmten Zeitintervalls erkennen, um festzustellen, ob es sich geändert hat.Wenn er feststellt, dass sich das binäre Ereignisprotokoll des Master-Master-Servers geändert hat, startet er einen I/O-Thread Anfordern des binären Master-Ereignisprotokolls;
- Gleichzeitig startet der Master-Master-Server für jeden I/O-Thread einen Dump-Thread (Dump-Thread), um ihm binäre Ereignisprotokolle zu senden;
- Der Slave-Slave-Server speichert das empfangene binäre Ereignisprotokoll in seiner eigenen lokalen Relay-Protokolldatei;
- Der untergeordnete Slave-Server startet den SQL-Thread, um das Binärprotokoll aus dem Relay-Protokoll zu lesen und es lokal wiederzugeben, sodass seine Daten mit denen des Master-Servers konsistent sind 6. Schließlich gehen der E/A-Thread und der SQL-Thread in den Ruhezustand , warten auf das nächste Aufwachen ;
1.4, das Arbeitsprinzip des Kanals
canal simuliert das Interaktionsprotokoll des MySQL-Slaves, gibt vor, MySQL-Slave zu sein, sendet das Dump-Protokoll an den MySQL-Master, der MySQL-Master empfängt die Dump-Anforderung, beginnt, das Binärlog an den Slave (d Byte-Stream)

1.5, konkreter Betrieb
Verteilte Systeme haben nur eine eventuelle Konsistenz, und es ist schwierig, eine starke Konsistenz zu erreichen
- Überprüfen Sie, ob die log_bin-Replikation aktiviert ist
SHOW VARIABLES LIKE 'log_bin'
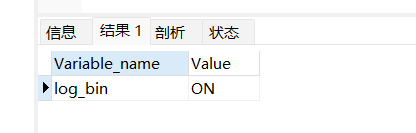
- Ändern Sie die Datenbankkonfiguration my.ini oder my.conf
log-bin=mysql-bin #开启binlog
binlog-format=ROW#选择ROW模式
server_id=1—#配置MySQL replaction需要定义,不要和canal的 slaveld重复
- Zusätzlich zum Aufzeichnen von SQL-Anweisungen zeichnet der ROW-Modus auch die Änderungen jedes Felds auf, was den Änderungsverlauf jeder Datenzeile klar aufzeichnen kann, aber mehr Platz beansprucht.
- Der STATEMENT-Modus zeichnet nur SQL-Anweisungen auf, aber keine Kontextinformationen, was zu Datenverlust während der Datenwiederherstellung führen kann;-
- Der MIX-Modus stellt eine flexiblere Aufzeichnung dar. Theoretisch wird eine Änderung der Tabellenstruktur als Anweisungsmodus aufgezeichnet. Wenn Daten aktualisiert oder gelöscht werden, wechselt es in den Zeilenmodus;

- Berechtigung erstellen
//删除canal用户
DROP USER 'canal'@'%';
//创建canal用户
CREATE USER 'canal'@'%' IDENTIFIED BY 'canal';
GRANT ALL PRIVILEGES ON *.* TO 'canal'@'%' IDENTIFIED BY 'canal"';
FLUSH PRIVILEGES;
//查询用户
SELECT* FROM mysql.user;
- Software herunterladen
wget https://github.com/alibaba/canal/releases/download/canal-1.1.5/canal.deployer-1.1.5.tar.gz
-
Die Umgebung wechseln

-
starten Sie den Dienst
-
Client-Code
package com.atguigu.redis.controller;
import com.alibaba.otter.canal.client.CanalConnector;
import com.alibaba.otter.canal.client.CanalConnectors;
import com.alibaba.otter.canal.protocol.CanalEntry;
import com.alibaba.otter.canal.protocol.Message;
import com.alibaba.otter.canal.protocol.CanalEntry.Entry;
import com.alibaba.otter.canal.protocol.CanalEntry.EntryType;
import com.alibaba.otter.canal.protocol.CanalEntry.EventType;
import com.alibaba.otter.canal.protocol.CanalEntry.RowChange;
import com.alibaba.otter.canal.protocol.CanalEntry.RowData;
import com.alibaba.otter.canal.protocol.CanalEntry.Column;
import java.net.InetSocketAddress;
import java.util.List;
public class RedisCanalClientController {
public static final Integer _60SECONDS = 60;
public static void main(String[] args) {
// 创建链接
CanalConnector connector = CanalConnectors.newSingleConnector(new InetSocketAddress("192.168.1.100",
11111), "example", "", "");
int batchSize = 1000;
int emptyCount = 0;
try {
connector.connect();
// connector.subscribe(".*\\..*");
connector.subscribe("redis_demo.t_user");
connector.rollback();
int totalEmptyCount = 10 * _60SECONDS;
while (emptyCount < totalEmptyCount) {
Message message = connector.getWithoutAck(batchSize); // 获取指定数量的数据
long batchId = message.getId();
int size = message.getEntries().size();
if (batchId == -1 || size == 0) {
emptyCount++;
System.out.println("empty count : " + emptyCount);
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
}
} else {
emptyCount = 0;
// System.out.printf("message[batchId=%s,size=%s] \n", batchId, size);
printEntry(message.getEntries());
}
connector.ack(batchId); // 提交确认
// connector.rollback(batchId); // 处理失败, 回滚数据
}
System.out.println("empty too many times, exit");
} finally {
connector.disconnect();
}
}
private static void printEntry(List<Entry> entrys) {
for (Entry entry : entrys) {
if (entry.getEntryType() == EntryType.TRANSACTIONBEGIN || entry.getEntryType() == EntryType.TRANSACTIONEND) {
continue;
}
RowChange rowChage = null;
try {
rowChage = RowChange.parseFrom(entry.getStoreValue());
} catch (Exception e) {
throw new RuntimeException("ERROR ## parser of eromanga-event has an error , data:" + entry.toString(), e);
}
EventType eventType = rowChage.getEventType();
System.out.println(String.format("================> binlog[%s:%s] , name[%s,%s] , eventType : %s",
entry.getHeader().getLogfileName(), entry.getHeader().getLogfileOffset(),
entry.getHeader().getSchemaName(), entry.getHeader().getTableName(), eventType));
for (RowData rowData : rowChage.getRowDatasList()) {
if (eventType == EventType.DELETE) {
printColumn(rowData.getBeforeColumnsList());
} else if (eventType == EventType.INSERT) {
printColumn(rowData.getAfterColumnsList());
} else {
System.out.println("-------> before");
printColumn(rowData.getBeforeColumnsList());
System.out.println("-------> after");
printColumn(rowData.getAfterColumnsList());
}
}
}
}
private static void printColumn(List<Column> columns) {
for (Column column : columns) {
System.out.println(column.getName() + " : " + column.getValue() + " update=" + column.getUpdated());
}
}
}
2. Aktualisierungsstrategie für Cache-Double-Write-Konsistenz
2.1 Cache-Doppelschreibkonsistenz
- Wenn Daten in Redis vorhanden sind, müssen sie mit dem Wert in der Datenbank übereinstimmen
- Wenn in redis keine Daten vorhanden sind, sollte der Wert in der Datenbank der neueste Wert sein
Read-Write-Cache: Es wird die synchrone Write-Through-Strategie angewendet Beim Schreiben in den Cache wird auch die Datenbank synchron geschrieben Beim Schreiben in die Datenbank wird auch der Cache synchron geschrieben Die Daten im Cache und in der Datenbank sind konsistent Wenn die Daten konsistent sind, sollte die Strategie des synchronen Durchschreibens übernommen werden.
-
Wann wird synchrones Durchschreiben durchgeführt?
Kleine Daten, ein bestimmter Teil oder eine kleine Gruppe heißer Daten, müssen sofort geändert werden. Sie können den Front-End-Dienst herabstufen, und der Hintergrund wird sofort mit dem direkten Schreiben synchronisiert. -
Wann ist asynchrones verzögertes Schreiben?
- Bei normalen Geschäftsvorgängen wird mysql sofort aktualisiert, und redis kann nach 1 Stunde im Geschäftsbetrieb wirksam werden
- Nachdem eine Ausnahme auftritt, muss die fehlgeschlagene Überzeugung neu gepatcht werden, und die Nachrichten-Middleware wie Kafka oder RabbitMQ muss verwendet werden, um eine Entkopplung zu erreichen und das Neuschreiben erneut zu versuchen.
2.2 Mehrere Update-Strategien für Datenbank- und Cache-Konsistenz
Ziel ist es, die letztendliche Konsistenz der Datenlösung sicherzustellen.
Alle Schreibvorgänge unterliegen der Datenbank , und für Cache-Vorgänge können nur die besten Anstrengungen unternommen werden. Das heißt, wenn die Datenbank erfolgreich geschrieben wurde und das Cache-Update fehlschlägt, werden die nachfolgenden Leseanforderungen, solange die Ablaufzeit erreicht ist, natürlich neue Werte aus der Datenbank lesen und dann den Cache auffüllen, um Konsistenz zu erreichen. Denken Sie daran, die Schreibbibliothek der mysql-Datenbank als Kriterium zu verwenden.
- Auflistungsfehler, Upgrade am frühen Morgen: Singlethreading, solche schweren Datenoperationen sind am besten, kein Multithreading, z. B. wenn die Datenbank und Redis aktualisiert werden müssen und wenn eine große Datenmenge benötigt wird.
2.2.1. Aktualisieren Sie zuerst die Datenbank und dann den Cache
Ausnahme aufgetreten:
- Aktualisieren Sie zuerst den Bestand einer bestimmten Ware in mysql. Der aktuelle Bestand der Ware beträgt 100 und wird auf 99 aktualisiert.
- Aktualisieren Sie zuerst mysql und ändern Sie es erfolgreich auf 99, und aktualisieren Sie dann edis.
- Nehmen wir zu diesem Zeitpunkt an, dass eine Ausnahme auftritt und die Aktualisierung von redis fehlschlägt, was dazu führt, dass das Inventar in mysql 99 und das Inventar in redis 100 beträgt.
- Das obige Vorkommen führt zu inkonsistenten Daten in der Datenbank und im Cache-Redis und zum Lesen von schmutzigen Daten
Aktualisieren Sie zuerst die Datenbank und dann den Cache, aber wenn redis nicht abnormal aktualisiert werden kann, werden die alten schmutzigen Daten immer noch von redis gelesen.
2.2.2, löschen Sie zuerst den Cache und aktualisieren Sie dann die Datenbank
2.2.2.1 Anormale Situation:
-
Thread A löscht zuerst erfolgreich die Daten in redis und aktualisiert dann mysql. Zu diesem Zeitpunkt wird mysql aktualisiert und ist noch nicht fertig (z. B. Netzwerkverzögerung). Zu diesem Zeitpunkt scheint B plötzlich die zwischengespeicherten Daten zu lesen.

-
Zu diesem Zeitpunkt sind die Daten in Redis leer und Thread B liest sie.Lesen Sie zuerst die Daten in Redis, aber die Daten in Redis wurden von Thread A gelöscht zwei Arten von Problemen.- Der erste ist, dass Thread B den alten Wert von mysql erhalten hat . Thread B stellt fest, dass in redis kein Cache (fehlender Cache) vorhanden ist, und geht sofort zu mysql, um ihn zu lesen. Zu diesem Zeitpunkt wurden die von Thread A zu ändernden Daten in der Datenbank nicht erfolgreich geschrieben, und der alte Wert ist es aus der Datenbank lesen.
- Zweitens schreibt der B-Thread den erhaltenen alten Wert zurück in redis . Thread B kehrt in den Vordergrund zurück, nachdem er die alten Wertdaten erhalten hat, und schreibt sie zurück in redis (die alten Daten, die gerade von Thread A gelöscht wurden, werden sehr wahrscheinlich wieder zurückgeschrieben).

2.2.2.2, die Ursache des Problems
Zwei gleichzeitige Operationen, eine ist die Aktualisierungsoperation und die andere die Abfrageoperation. Der Thread A aktualisiert die Operation. Nach dem Löschen des Caches trifft die Abfrageoperation des B-Threads nicht auf den Cache. Der B-Thread liest zuerst die alten Daten und legt es in den Cache, und dann den A-Thread. Der Aktualisierungsvorgang aktualisiert die Datenbank. Die Daten im Cache sind jedoch immer noch alte Daten, sodass die Daten im Cache schmutzig sind und möglicherweise weiterhin schmutzig sind.
Wenn es sich bei dieser Methode um eine wirklich niedrige Parallelität handelt, wird der alte Wert zurückgeschrieben, und das Problem des Cache-Zusammenbruchs tritt in einer Umgebung mit hoher Parallelität auf.
2.2.2.3 Lösungen
Die verzögerte doppelte Löschstrategie und

die Ruhezeit werden verwendet, um zu simulieren, dass Thread B zuerst Daten aus der Datenbank lesen kann, dann die fehlenden Daten in den Cache schreibt und Thread A sie dann löscht. Daher muss die Ruhezeit von Thread A länger sein als die Zeit, die Thread B benötigt, um Daten zu lesen und sie dann in den Cache zu schreiben. Wenn andere Threads die Daten lesen, stellen sie auf diese Weise fest, dass der Cache fehlt, und lesen daher den neuesten Wert aus der Datenbank. Da dieses Schema das Löschen um einen bestimmten Zeitraum verzögert, nachdem der Cache-Wert zum ersten Mal gelöscht wurde, nennen wir es auch "verzögertes doppeltes Löschen".
2.2.2.3 Nachteile des verzögerten doppelten Löschens
- Wie lange soll diese Löschung ruhen?
Fordern Sie die Schnittstelle mehrmals an, erhalten Sie den Durchschnittswert und addieren Sie eine bestimmte Zeit zum Durchschnittswert - Der Effekt der aktuellen Demonstration ist mysql stand-alone.Was ist, wenn die mysql-Master-Slave-Lese-Schreib-Trennungsarchitektur?
Es ist auch erforderlich, die Schnittstelle mehrmals anzufordern, um den Durchschnittswert zu erhalten, aber es ist notwendig, den Master-Slave zu berechnen Synchronisierungszeit, und addieren Sie eine bestimmte Zeit zum Durchschnittswert hinzu. - Diese synchrone Eliminierungsstrategie reduziert den Durchsatz?
Starten Sie einen Daemon-Thread und löschen Sie ihn asynchron. Das heißt, starten Sie nach dem Aktualisieren der Datenbank einen neuen Thread, um die zwischengespeicherten Daten asynchron zu löschen.

2.2.3. Aktualisieren Sie zuerst die Datenbank und löschen Sie dann den Cache
2.2.3.1 Probleme
Wenn Thread A zuerst den Wert in der Datenbank ändert, wenn die Daten in der Datenbank nicht aktualisiert wurden, liest Thread B zu diesem Zeitpunkt die Daten im Cache, da Thread A die Daten im Cache nicht aktualisiert hat Thread B enthält noch alte Daten.
Aktualisieren Sie zuerst die Datenbank und löschen Sie dann den Cache. Wenn das Löschen des Cache fehlschlägt oder zu spät ist, trifft der Cache zu, wenn die Anforderung erneut auf redis zugreift, und der alte zwischengespeicherte Wert wird gelesen.
2.2.3.2 Lösung:
Der zu löschende zwischengespeicherte Wert oder der zu aktualisierende Datenbankwert kann vorübergehend in der Nachrichtenwarteschlange gespeichert werden (z. B. mit Kafka/RabbitMQ usw.). Wenn das Programm den zwischengespeicherten Wert nicht erfolgreich löschen oder den Datenbankwert aktualisieren kann, kann es diese Werte erneut aus der Nachrichtenwarteschlange lesen und dann erneut löschen oder aktualisieren. Wenn es erfolgreich gelöscht oder aktualisiert werden kann, müssen wir diese Werte aus der Nachrichtenwarteschlange entfernen, um wiederholte Vorgänge zu vermeiden. Zu diesem Zeitpunkt können wir auch sicherstellen, dass die Datenbank und die zwischengespeicherten Daten konsistent sind, andernfalls müssen wir es erneut versuchen. Wenn die Anzahl der Wiederholungen das Limit überschreitet, senden wir bei erfolgreichem Fehlschlag die Fehlermeldung an die Industrie und benachrichtigen das Betriebs- und Wartungspersonal.

Prozess:
- Datenbankdaten aktualisieren
- Die Datenbank schreibt die Vorgangsinformationen in das Binlog-Protokoll
- Das Abonnementprogramm extrahiert die erforderlichen Daten und Schlüssel
- Starten Sie ein weiteres Stück Nicht-Business-Code, um diese Informationen zu erhalten
- Versuch, den Cache-Vorgang zu löschen, und festgestellt, dass das Löschen fehlgeschlagen ist
- Senden Sie diese Informationen an die Nachrichtenwarteschlange
- Rufen Sie die Daten aus der Nachrichtenwarteschlange ab und wiederholen Sie die Operation.
2.2.4, (absolut nicht erlaubt) die Strategie, zuerst den Cache zu aktualisieren und dann die Datenbank zu aktualisieren
2.2.5 Zusammenfassung
In den meisten Geschäftsszenarien verwenden wir Redis als Nur-Lese-Cache.
Wenn die Positionierung ein Nur-Lese-Cache ist, können wir theoretisch zuerst den Cache-Wert löschen und dann die Datenbank aktualisieren oder die Datenbank aktualisieren und dann den Cache löschen, aber es gibt keine perfekte Lösung, das Prinzip, die beiden Übel auszugleichen und zu pflegen Zum geringeren ist mein persönlicher Vorschlag: Es wird bevorzugt, das Schema zu verwenden, zuerst die Datenbank zu aktualisieren und dann den Cache zu löschen. Die Gründe sind wie folgt:
- Wenn Sie zuerst den zwischengespeicherten Wert löschen und dann die Datenbank aktualisieren, kann dies dazu führen, dass aufgrund von Cache-Fehlern Zugriffsanforderungen auf die Datenbank angefordert werden, was die Datenbank unter Druck setzt, ernsthaft zu vollständigem MySQL führt und einen Cache-Zusammenbruch verursacht.
- Wenn die Zeit für das Lesen der Datenbank und das Schreiben des Caches in der Geschäftsanwendung nicht einfach abzuschätzen ist, dann ist die Wartezeit beim verzögerten doppelten Löschen nicht einfach einzustellen.
Wenn wir das Schema verwenden, zuerst die Datenbank zu aktualisieren und dann den Cache zu löschen, müssen wir, wenn die Business-Schicht konsistente Daten lesen muss, vorübergehend gleichzeitige Leseanforderungen auf dem Redis-Cache-Client speichern, wenn wir die Datenbank aktualisieren, und auf die warten Nach dem Löschen des zwischengespeicherten Werts werden die Daten erneut gelesen, um die Datenkonsistenz sicherzustellen.
