1. Índice
1.1 Concepto
Un índice es un archivo especial que contiene punteros a todos los registros de la tabla de datos. Puede crear un índice en una o más columnas de la tabla y especificar el tipo de índice. Cada tipo de índice tiene su propia implementación de estructura de datos. (Los detalles específicos se explicarán en el curso principal de la base de datos de seguimiento)
1.2 Función
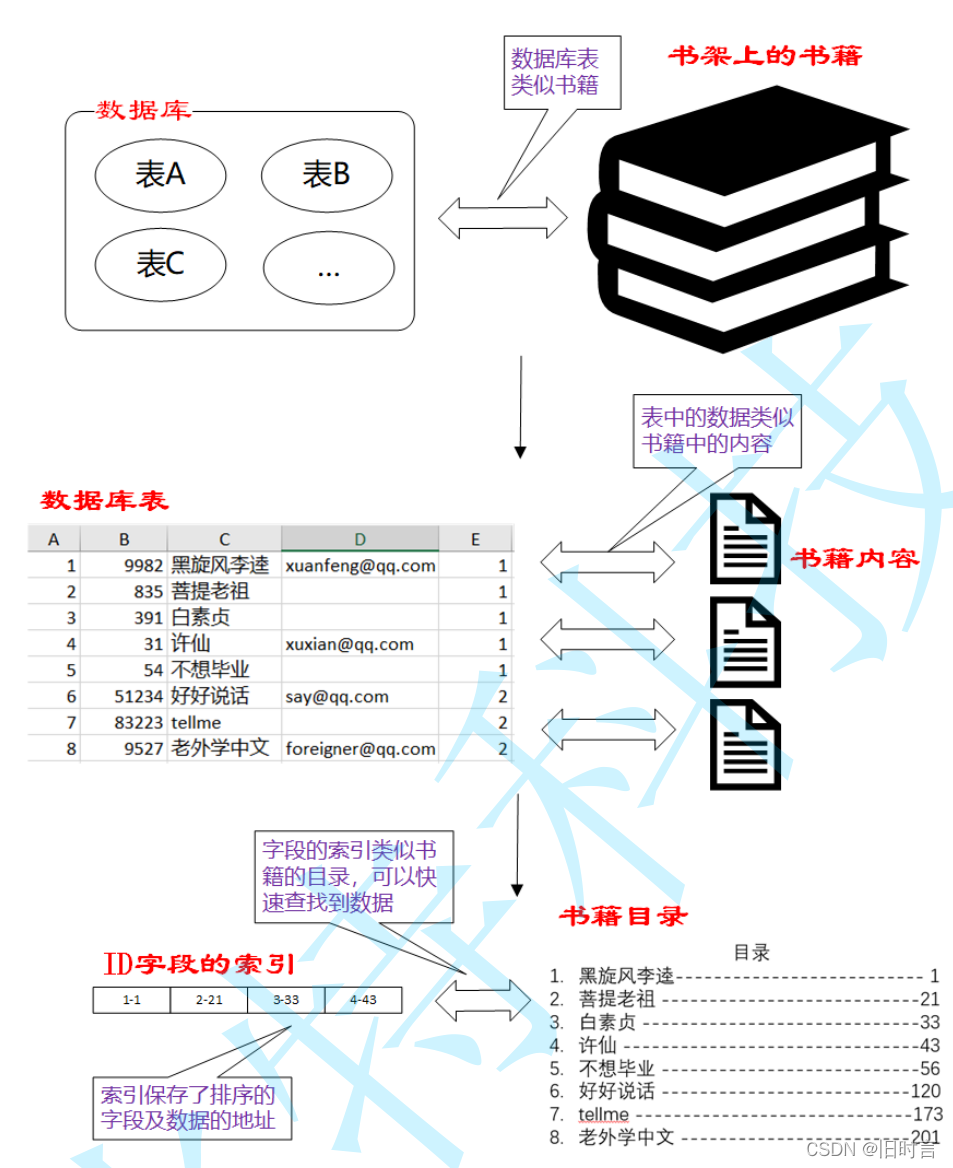
- La relación entre tablas, datos e índices en una base de datos es similar a la relación entre libros en el estante, contenido de libros y catálogos de libros.
- La función de un índice es similar a la de un catálogo de libros, que se puede utilizar para localizar y recuperar datos rápidamente.
- Los índices son de gran ayuda para mejorar el rendimiento de la base de datos.
1.3 Escenarios de uso


Para considerar la creación de un índice en una columna o columnas de una tabla de base de datos, se deben considerar los siguientes puntos:
- La cantidad de datos es grande y, a menudo, se realizan consultas condicionales en estas columnas.
- Las operaciones de inserción en la tabla de la base de datos y las operaciones de modificación en estas columnas son menos frecuentes.
- Los índices ocupan espacio adicional en el disco
Cuando se cumplan las condiciones anteriores, considere crear índices en estos campos en la tabla para mejorar la eficiencia de las consultas.
Por el contrario, si la columna es consultada incondicionalmente, o cuando se realizan frecuentemente operaciones de inserción y modificación, o cuando el espacio en disco es insuficiente, no se considera la creación de un índice.
1.4 Uso
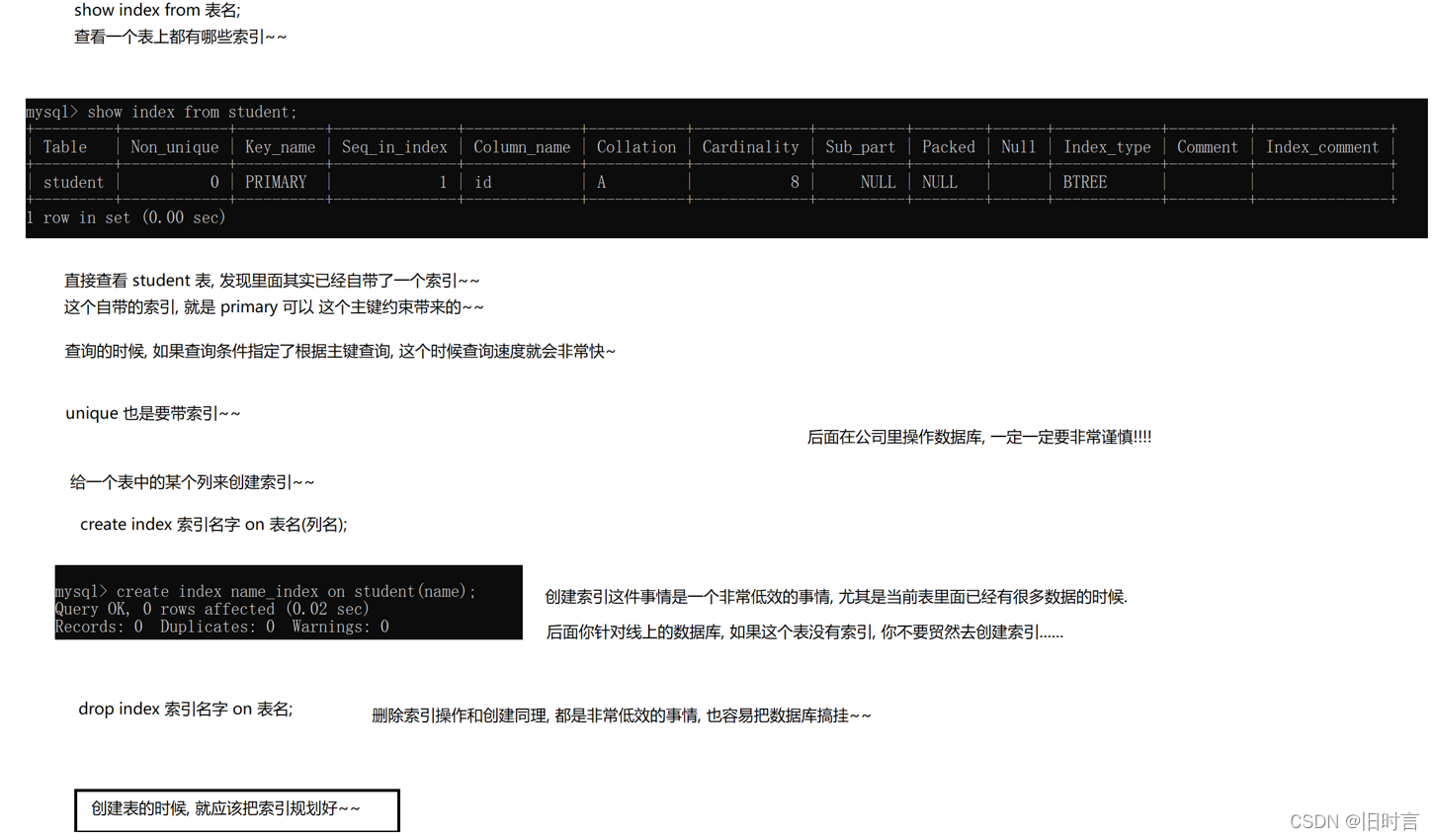

Al crear una restricción de clave principal (PRIMARY KEY), una restricción única (UNIQUE) y una restricción de clave externa (FOREIGN KEY), se crea automáticamente un índice en la columna correspondiente.
- ver índice
show index from 表名;
Caso: Ver el índice existente de la tabla de estudiantes
show index from student;
- crear índice
Para campos que no son claves primarias, restricciones no únicas y claves no foráneas, se pueden crear índices ordinarios
create index 索引名 on 表名(字段名);
Caso: cree un índice para el campo de nombre en la tabla de clase
create index idx_classes_name on classes(name);
- índice de caída
drop index 索引名 on 表名;
Caso: elimine el índice del campo de nombre en la tabla de clases
drop index idx_classes_name on classes;
1.5 Casos
Prepare la hoja de prueba:
-- 创建用户表
DROP TABLE IF EXISTS test_user;
CREATE TABLE test_user (
id_number INT,
name VARCHAR(20) comment '姓名',
age INT comment '年龄',
create_time timestamp comment '创建日期'
);
Prepare datos de prueba e inserte datos de usuario en lotes (la operación lleva mucho tiempo, alrededor de 1 hora o más):
-- 构建一个8000000条记录的数据
-- 构建的海量表数据需要有差异性,所以使用存储过程来创建, 拷贝下面代码就可以了,暂时不用理解
-- 产生名字
drop function if exists rand_name;
delimiter $$
create function rand_name(n INT, l INT)
returns varchar(255)
begin
declare return_str varchar(255) default '';
declare i int default 0;
while i < n do
if i=0 then
set return_str = rand_string(l);
else
set return_str =concat(return_str,concat(' ', rand_string(l)));
end if;
set i = i + 1;
end while;
return return_str;
end $$
delimiter ;
-- 产生随机字符串
drop function if exists rand_string;
delimiter $$
create function rand_string(n INT)
returns varchar(255)
begin
declare lower_str varchar(100) default
'abcdefghijklmnopqrstuvwxyz';
declare upper_str varchar(100) default
'ABCDEFJHIJKLMNOPQRSTUVWXYZ';
declare return_str varchar(255) default '';
declare i int default 0;
declare tmp int default 5+rand_num(n);
while i < tmp do
if i=0 then
set return_str
=concat(return_str,substring(upper_str,floor(1+rand()*26),1));
else
set return_str
=concat(return_str,substring(lower_str,floor(1+rand()*26),1));
end if;
set i = i + 1;
end while;
return return_str;
end $$
delimiter ;
-- 产生随机数字
drop function if exists rand_num;
delimiter $$
create function rand_num(n int)
returns int(5)
begin
declare i int default 0;
set i = floor(rand()*n);
return i;
end $$
delimiter ;
-- 向用户表批量添加数据
drop procedure if exists insert_user;
delimiter $$
create procedure insert_user(in start int(10),in max_num int(10))
begin
declare i int default 0;
set autocommit = 0;
repeat
set i = i + 1;
insert into test_user values ((start+i) ,rand_name(2,
5),rand_num(120),CURRENT_TIMESTAMP);
until i = max_num
end repeat;
commit;
end $$
delimiter ;
-- 执行存储过程,添加8000000条用户记录
call insert_user(1, 8000000);
Consulta la información del usuario cuyo id_number es 778899:
-- 可以看到耗时4.93秒,这还是在本机一个人来操作,在实际项目中,如果放在公网中,假如同时有1000
个人并发查询,那很可能就死机。
select * from test_user where id_number=556677;

Puede usar la explicación para ver la ejecución de SQL:
explain select * from test_user where id_number=556677;
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: test_user
type: ALL
possible_keys: NULL
key: NULL <== key为null表示没有用到索引
key_len: NULL
ref: NULL
rows: 6
Extra: Using where
1 row in set (0.00 sec)
Para proporcionar velocidad de consulta, cree un índice en el campo id_number:
create index idx_test_user_id_number on test_user(id_number);
Cambie el número de ID para consultar y comparar el tiempo de ejecución:
select * from test_user where id_number=776655;
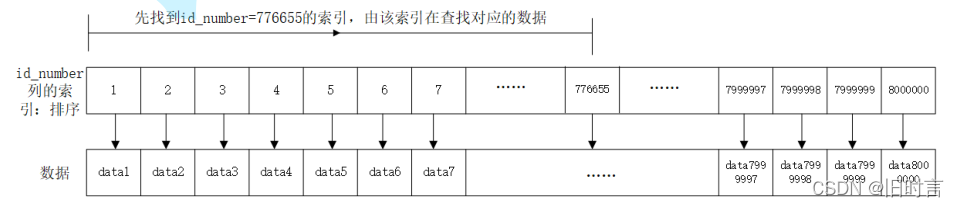
Puede usar la explicación para ver la ejecución de SQL:
explain select * from test_user where id_number=776655;
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: test_user
type: ref
possible_keys: idx_test_user_id_number
key: idx_test_user_id_number <= key用到了idx_test_user_id_number
key_len: NULL
ref: const
rows: 1
Extra: Using where
1 row in set (0.00 sec)
La estructura de datos almacenada por el índice es principalmente el árbol B+ y el método hash. El principio de implementación se explicará en la última parte del principio de la base de datos.
 B-tree:
B-tree:
Los datos de B-tree se almacenan tanto en los nodos hoja como en los nodos no hoja.
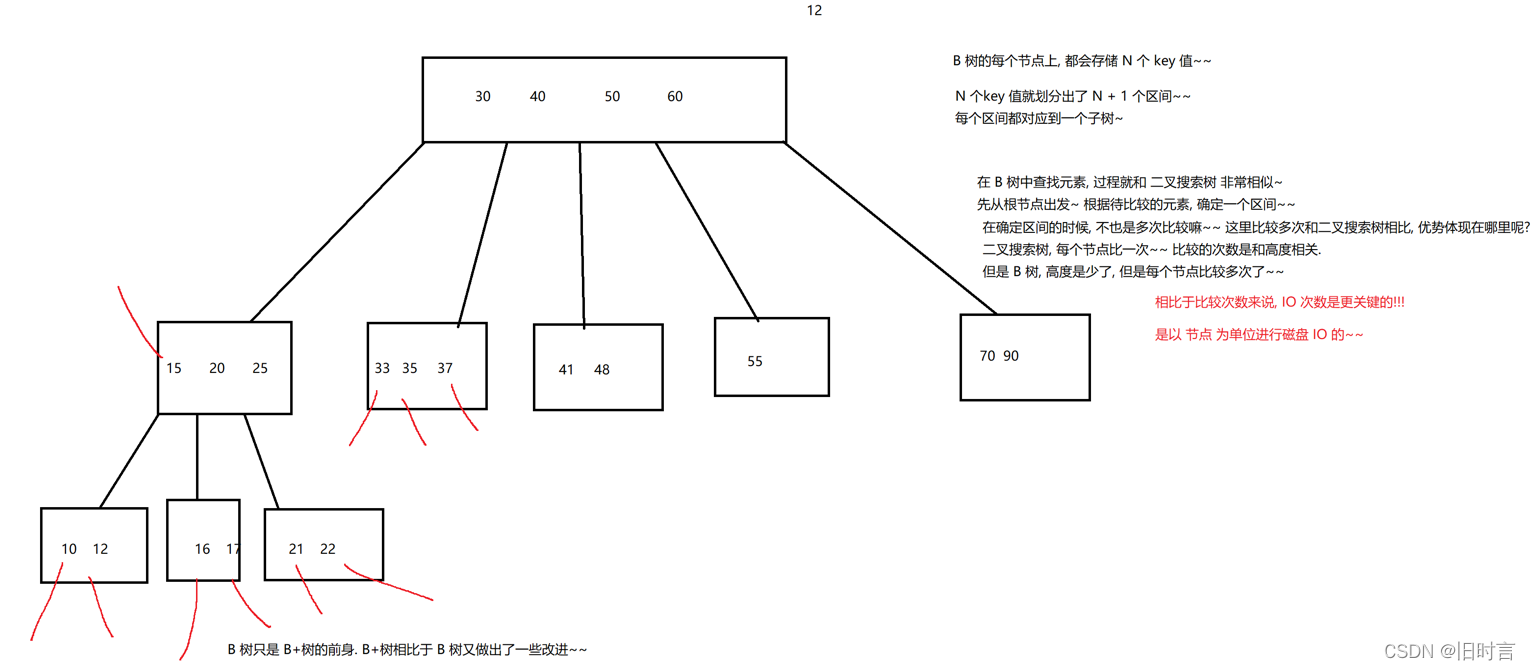 árbol B+:
árbol B+:



2. Asuntos




 Cuando una transacción modifica ciertos datos, otra transacción lee los datos. Por alguna razón, la transacción anterior revoca la modificación de los datos modificados, y los datos modificados están a punto de ser restaurados a su valor original, luego la última transacción lee los datos. es inconsistente con los datos disponibles, lo que se denomina lectura de datos sucios
Cuando una transacción modifica ciertos datos, otra transacción lee los datos. Por alguna razón, la transacción anterior revoca la modificación de los datos modificados, y los datos modificados están a punto de ser restaurados a su valor original, luego la última transacción lee los datos. es inconsistente con los datos disponibles, lo que se denomina lectura de datos sucios
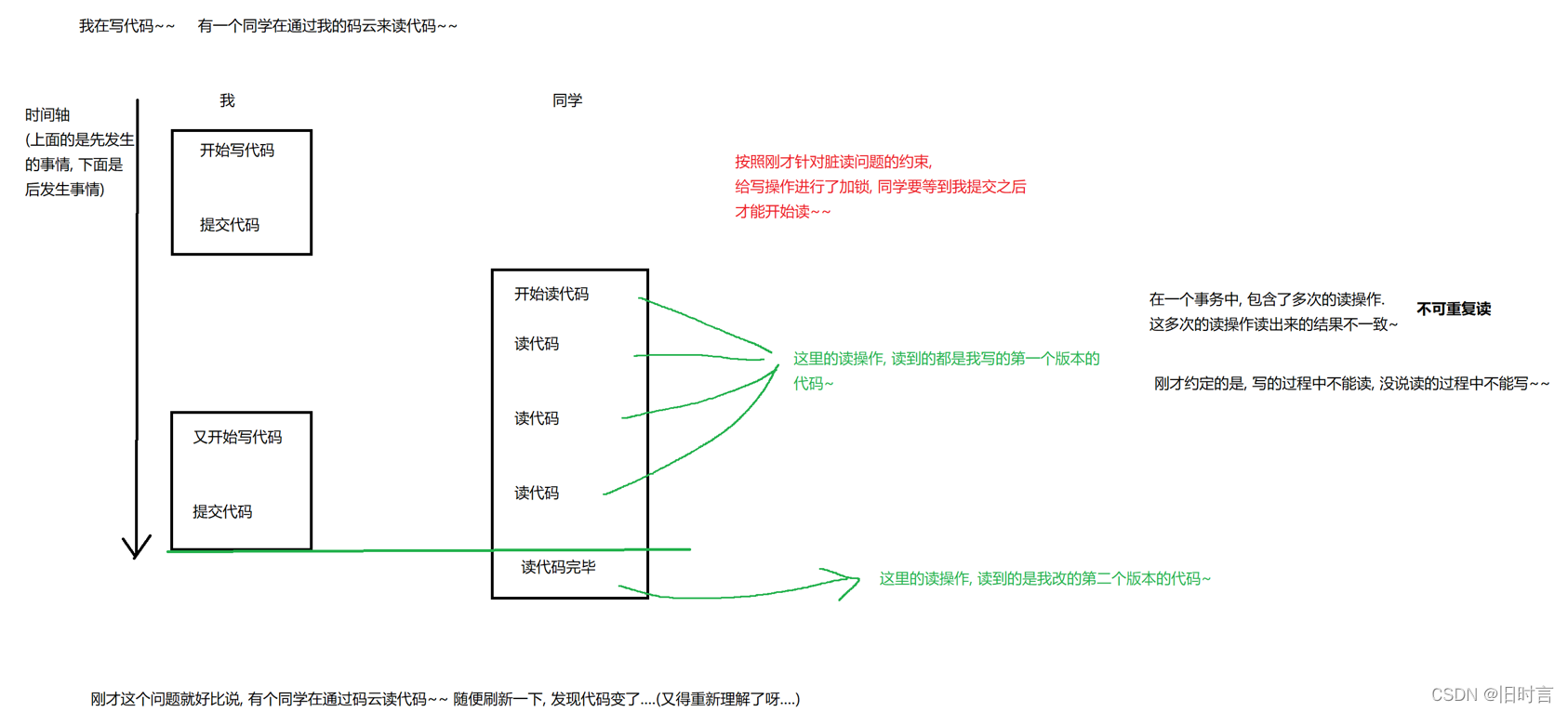
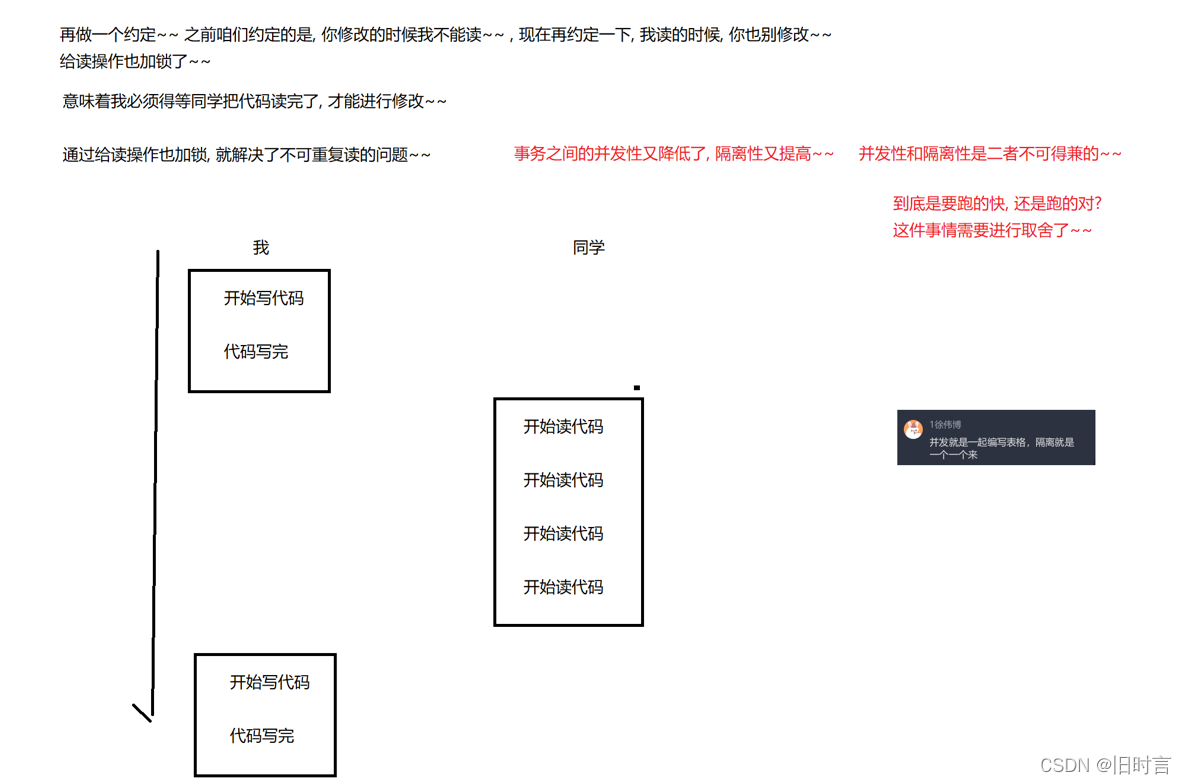
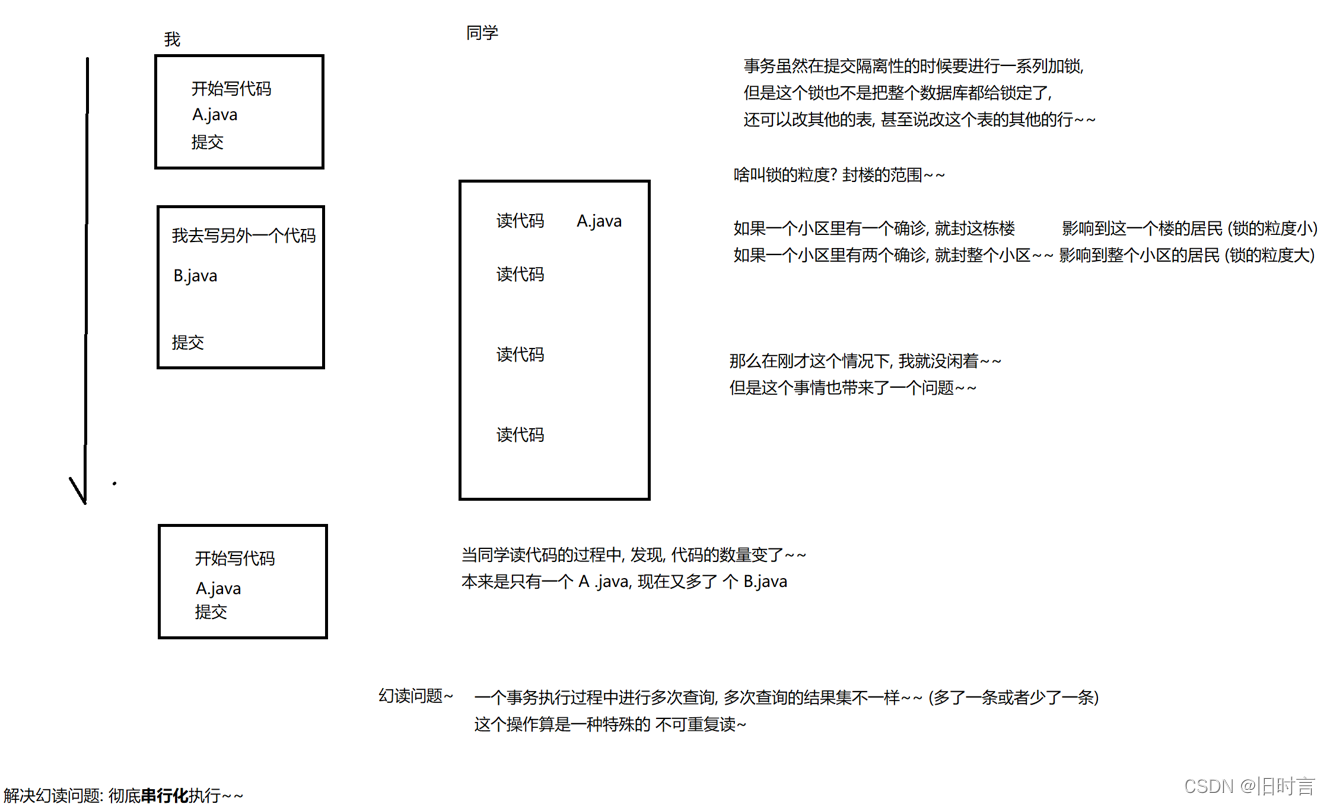



2.1 Por qué usar transacciones
Prepare la hoja de prueba:
drop table if exists accout;
create table accout(
id int primary key auto_increment,
name varchar(20) comment '账户名称',
money decimal(11,2) comment '金额'
);
insert into accout(name, money) values
('阿里巴巴', 5000),
('四十大盗', 1000);
Por ejemplo, los cuarenta ladrones robaron 2000 yuanes de la cuenta de Alibaba.
-- 阿里巴巴账户减少2000
update accout set money=money-2000 where name = '阿里巴巴';
-- 四十大盗账户增加2000
update accout set money=money+2000 where name = '四十大盗';
Si hay un error de red o la base de datos está caída al ejecutar la primera sentencia SQL anterior, la cuenta de Alibaba se reducirá en 2000, pero la cuenta de Forty Thieves no tendrá la cantidad aumentada.
Solución: use transacciones para controlar, para asegurarse de que las dos sentencias SQL anteriores se ejecuten con éxito o todas las ejecuciones fallen.
2.2 El concepto de transacciones
Una transacción se refiere a un grupo lógico de operaciones, y las unidades que componen este grupo de operaciones tienen éxito o fallan.
En diferentes entornos, puede haber transacciones. Correspondiente en la base de datos, es la transacción de la base de datos.
2.3 Uso
(1) Iniciar transacción: iniciar transacción;
(2) Ejecutar varias sentencias SQL
(3) Revertir o confirmar: revertir/confirmar;
Descripción: revertir significa todos los errores y confirmar significa todos los éxitos.
start transaction;
-- 阿里巴巴账户减少2000
update accout set money=money-2000 where name = '阿里巴巴';
-- 四十大盗账户增加2000
update accout set money=money+2000 where name = '四十大盗';
commit;
Las características y la configuración de las transacciones se explicarán con más detalle en la sección de principios de la base de datos de seguimiento.
3. Resumen del contenido clave
Índice:
(1) Para tablas con alta frecuencia de inserción y eliminación de datos, el índice no es aplicable
(2) Para una columna con alta frecuencia de modificación, esta columna no es aplicable para el índice
(3) Para una columna o columnas con alta frecuencia de consulta , puede crear índices en estas columnas
Transacción:
start transaction;
...
rollback/commit;