Haga clic en "Uncle Wheat" arriba y seleccione "Cuenta pública superior/estrella"
Productos secos de bienestar, entregados lo antes posible.
Encontrar y eliminar posibles errores en el software de desarrollo integrado es una tarea abrumadora.
A menudo se necesita un esfuerzo heroico y herramientas costosas para rastrear la causa raíz de un bloqueo observado, congelamiento u otro comportamiento de tiempo de ejecución no planificado.
En el peor de los casos, la causa raíz corrompe el código o los datos, lo que hace que parezca que el sistema todavía funciona correctamente o al menos por un tiempo.
Los ingenieros a menudo dejan de intentar descubrir la causa de anomalías poco comunes que no son fácilmente reproducibles en el laboratorio, tratándolas como errores de usuario o "problemas técnicos".
Sin embargo, estos fantasmas en la máquina todavía existen. Aquí hay una guía de las causas raíz más comunes de errores difíciles de reproducir. Cada vez que lea el código fuente del firmware, busque los siguientes cinco errores principales. Y sigue las mejores prácticas recomendadas para evitar que te vuelvan a pasar.
Error 1: condiciones de carrera
Una condición de carrera es cualquier situación en la que el resultado combinado de dos o más subprocesos de ejecución (que pueden ser tareas RTOS o main() y un controlador de interrupciones) cambia según el orden exacto de las instrucciones intercaladas. Cada uno se ejecuta en el procesador.
Por ejemplo, suponga que tiene dos subprocesos de ejecución, uno de los cuales incrementa regularmente una variable global (g_counter += 1; ) y el otro la pone a cero por casualidad (g_counter = 0; ). Existe una condición de carrera si el incremento no siempre se puede realizar atómicamente (es decir, dentro de un solo ciclo de instrucción).
Como se muestra en la Figura 1, considere la tarea como un automóvil que se acerca a la misma intersección. Es posible que nunca se produzcan conflictos entre dos actualizaciones de la variable de contador, o que se produzcan con poca frecuencia. Sin embargo, al hacerlo, el contador no se pone a cero en la memoria. Su valor se corrompe al menos hasta el próximo claro. Este efecto podría tener graves consecuencias para el sistema, aunque es posible que no aparezca hasta mucho después de la colisión real.

Práctica recomendada: las condiciones de carrera se pueden evitar al tener que ejecutar secciones críticas de código de forma atómica con un comportamiento restringido preventivo adecuado. Para evitar condiciones de carrera que involucren ISR, al menos una señal de interrupción debe estar deshabilitada durante la duración de otra sección crítica del código.
Para la contención entre tareas de RTOS, la mejor práctica es crear un mutex específico para esa biblioteca compartida, que cada uno debe adquirir antes de ingresar a una sección crítica. Tenga en cuenta que no es una buena idea confiar en las capacidades de una CPU específica para garantizar la atomicidad, ya que esto solo evitará las condiciones de carrera hasta que cambie los compiladores o las CPU.
El tiempo aleatorio de los datos compartidos y la preferencia es el culpable de la condición de carrera. Pero es posible que no siempre ocurran errores, lo que hace que sea increíblemente difícil rastrear el estado racial desde los síntomas observados hasta las causas subyacentes. Por lo tanto, es importante permanecer alerta para proteger todos los objetos compartidos. Cada objeto compartido es un accidente esperando a suceder.
Práctica recomendada: nombrar todos los objetos potencialmente compartidos (incluidas las variables globales, los objetos del montón o los registros periféricos y los punteros a ese objeto) de modo que los riesgos sean obvios para todos los futuros lectores del código; en Netrino Embedded C Coding, los estándares recomiendan el uso de " G_ por esto", prefijo. Encontrar todos los objetos potencialmente compartidos será el primer paso en una revisión del código de condición de carrera.
Error 2: funciones no reentrantes
Técnicamente, el problema de las funciones no reentrantes es un caso especial del problema de la condición de carrera. Y, por razones relacionadas, los errores de tiempo de ejecución causados por funciones no reentrantes a menudo no ocurren de manera reproducible, lo que los hace igualmente difíciles de depurar.
Desafortunadamente, las funciones no reentrantes también son más difíciles de detectar en las revisiones de código que otros tipos de condiciones de carrera.
La figura 2 muestra un escenario típico. Aquí, la entidad de software que se va a adelantar también es una tarea de RTOS. Sin embargo, no operan mediante llamadas directas a objetos compartidos, sino indirectamente mediante llamadas a funciones.
Por ejemplo, suponga que la tarea A llama a una función de protocolo de capa de socket, que llama a una función de protocolo de capa TCP, que llama a una función de protocolo de capa IP, que llama a un controlador Ethernet. Para que el sistema funcione de manera confiable, todas estas funciones deben ser reentrantes.
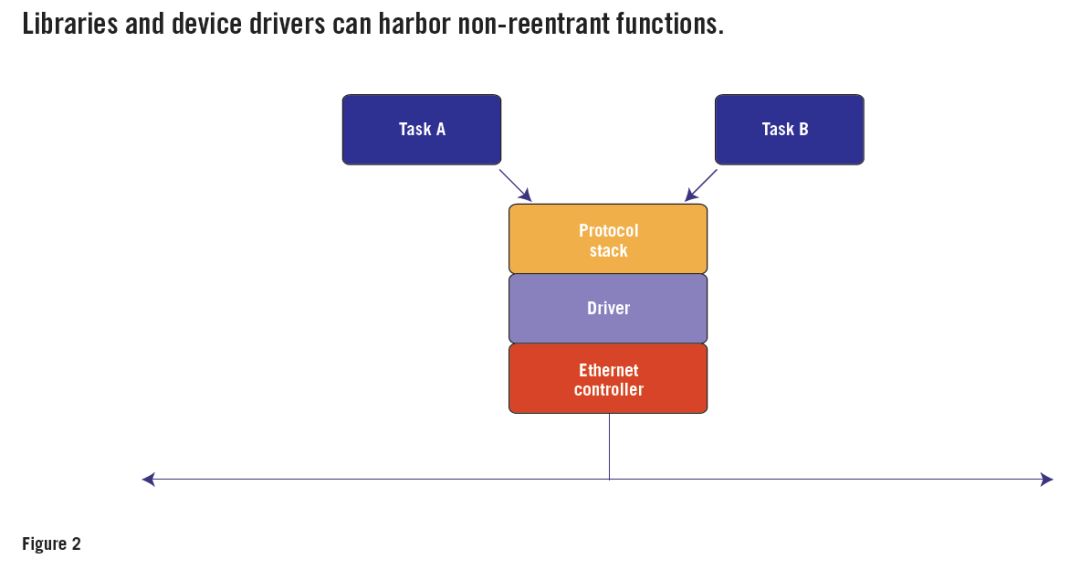
Sin embargo, todas las funciones del controlador de Ethernet operan en los mismos objetos globales en forma de registros del chip controlador de Ethernet. Si se permite la apropiación durante estas operaciones de registro, la tarea B puede apropiarse de la tarea A después de poner en cola el paquete A pero antes de que comience la transmisión.
Luego, la Tarea B llama a una función de capa de socket, que llama a una función de capa TCP, que llama a una función de capa IP, que llama a un controlador Ethernet, y la cola pone en cola y transmite el paquete B. Cuando el control de la CPU vuelva a la tarea A, solicitará la transferencia. Según el diseño del chip controlador de Ethernet, esto podría retransmitir el paquete B o generar un error. El paquete A se pierde y no se envía a la red.
Para poder llamar a las funciones de este controlador Ethernet desde varias tareas RTOS al mismo tiempo, deben volver a entrar. Si cada uno de ellos solo usa variables de pila, no hay nada que hacer.
Por lo tanto, el estilo más común de funciones C es inherentemente reentrante. Sin embargo, los controladores y algunas otras funciones no volverán a entrar a menos que se diseñen cuidadosamente.
La clave para hacer que una función sea reentrante es suspender la prioridad de todos los accesos a registros periféricos, variables globales, incluidas variables locales estáticas, objetos de almacenamiento dinámico persistentes y regiones de memoria compartida. Esto se puede hacer deshabilitando una o más interrupciones o adquiriendo y liberando un mutex. Los detalles del problema determinan la mejor solución.
Práctica recomendada: cree y oculte un mutex en cada biblioteca o módulo de controlador, que no son inherentemente reentrantes. Haga que la adquisición de este mutex sea un requisito previo para manipular cualquier dato persistente o registros compartidos utilizados en todo el módulo.
Por ejemplo, se puede usar el mismo mutex para evitar condiciones de carrera que involucren registros de controlador de Ethernet y contadores de paquetes globales o locales estáticos. Todas las funciones del módulo que acceden a estos datos deben seguir el protocolo para adquirir el mutex antes de acceder a estos datos.
Tenga en cuenta que las funciones no reentrantes pueden abrirse paso en su base de código como parte de middleware de terceros, código heredado o controladores de dispositivos.
Inquietantemente, una función no reentrante podría incluso ser parte de la biblioteca estándar de C o C++ que viene con el compilador. Si está utilizando el compilador GNU para crear aplicaciones basadas en RTOS, tenga en cuenta que debe utilizar la biblioteca C estándar "newlib" reentrante, no la biblioteca predeterminada.
Error 3: Falta la palabra clave volátil
Si ciertos tipos de variables no están marcados con la palabra clave volátil de C, esto puede generar muchos comportamientos inesperados en los sistemas que solo funcionan correctamente con el optimizador del compilador configurado en un nivel bajo o con el compilador deshabilitado. El calificador volátil se usa durante las declaraciones de variables, donde su propósito es evitar lecturas y escrituras optimizadas de variables.
Por ejemplo, si escribe el código que se muestra en el Listado 1, el optimizador puede dañar la salud del paciente al eliminar la primera línea en un intento de hacer que el programa sea más rápido y más pequeño. Sin embargo, si g_alarm se declara volátil, no se permitirá esta optimización.

Práctica recomendada: se debe utilizar la palabra clave volatile para declarar cada uno:
variables globales a las que accede el ISR y cualquier otra parte del código,
variables globales a las que acceden dos o más tareas RTOS (incluso si se evitan las condiciones de carrera en esos accesos),
un puntero a un registro periférico mapeado en memoria (o conjunto o conjunto de registros), y
Contador de bucle de retardo.
Tenga en cuenta que, además de garantizar que todas las lecturas y escrituras se realicen en una variable determinada, el uso de volatile también restringe al compilador al agregar "puntos de secuencia" adicionales. Se debe realizar un acceso volátil que no sea una lectura o escritura de una variable volátil antes de este acceso.
Error 4: Desbordamiento de pila
Todo programador sabe que el desbordamiento de pila es algo malo. Sin embargo, el impacto de cada desbordamiento de pila es diferente. La naturaleza de la corrupción y el momento de la mala conducta dependen completamente de qué datos o instrucciones se corrompen y cómo se utilizan. Es importante destacar que el período de tiempo entre el desbordamiento de la pila y el momento en que afecta negativamente al sistema depende del tiempo antes de que se use el bit de bloqueo.
Desafortunadamente, Stack Overflow sufre más con los sistemas integrados que con las computadoras de escritorio. Hay varias razones para esto, incluyendo:
(1) Los sistemas integrados generalmente solo ocupan menos RAM;
(2) Por lo general, no hay memoria virtual a la que recurrir (porque no hay disco);
(3) Los diseños de firmware basados en tareas RTOS utilizan múltiples pilas (una para cada tarea), cada una de las cuales debe ser lo suficientemente grande para garantizar que no haya una profundidad de pila única en el peor de los casos;
(4) Los controladores de interrupciones pueden intentar usar estas mismas pilas.
Para complicar aún más el problema, no existe una prueba exhaustiva para garantizar que una pila en particular sea lo suficientemente grande. Puede probar el sistema en varias condiciones de carga, pero solo durante mucho tiempo. Es posible que las pruebas que solo se ejecutan en "media luna azul" no sean testigos de desbordamientos de pila que solo ocurren en "una luna azul". Bajo restricciones algorítmicas (por ejemplo, sin recurrencia), un análisis de arriba hacia abajo del flujo de control del código puede demostrar que no se produce un desbordamiento de pila. Sin embargo, cada vez que se cambia el código, se debe volver a realizar el análisis de arriba hacia abajo.
Práctica recomendada: al inicio, dibuje patrones de memoria poco probables en toda la pila. (Me gusta usar hexadecimal 23 3D 3D 23, parece una cerca '#==#' en un volcado de memoria ASCII). En tiempo de ejecución, haga que la tarea de administración verifique periódicamente si no hay pintura en el ajuste preestablecido La marca por encima de la marca de agua alta se ha cambiado.
Si encuentra un problema con una pila, registre el error específico en la memoria no volátil (como qué pila y la altura de la inundación) y haga algo seguro para el usuario del producto (como un apagado o reinicio controlado) A puede ocurrir un desbordamiento real. Esta es una buena característica de seguridad adicional para agregar a la tarea de vigilancia.
Error 5: Fragmentación del montón
Los desarrolladores integrados no hacen un buen uso de la asignación de memoria dinámica. Uno de ellos es el problema de la fragmentación del montón.
Todas las estructuras de datos creadas a través de la rutina de biblioteca estándar malloc() de C o la nueva palabra clave de C++ residen en el montón. El montón es un área específica en la RAM con un tamaño máximo predeterminado. Inicialmente, cada asignación en el montón reduce el espacio "libre" restante en la misma cantidad de bytes.
Por ejemplo, el montón en un sistema en particular puede abarcar 10 KB a partir de la dirección 0x20200000. Una asignación de un par de estructuras de datos de 4 KB dejará 2 KB de espacio libre.
El almacenamiento de estructuras de datos que ya no se necesitan se puede devolver al montón llamando a free() o usando la palabra clave delete. En teoría, esto hace que ese espacio de almacenamiento esté disponible para su reutilización durante asignaciones posteriores. Pero el orden de las asignaciones y eliminaciones suele ser al menos pseudoaleatorio, lo que hace que el montón se convierta en un montón de fragmentos más pequeños.
Para ver si la fragmentación podría ser un problema, considere lo que sucedería si la primera de las estructuras de datos de 4 KB anteriores estuviera libre. Ahora el montón consta de un bloque libre de 4 KB y otro bloque libre de 2 KB. No son adyacentes y no se pueden fusionar. Así que nuestro montón se ha dividido. Las asignaciones superiores a 4 KB fallarán a pesar de que el espacio libre total sea de 6 KB.
La fragmentación es similar a la entropía: ambas aumentan con el tiempo. En los sistemas de ejecución prolongada (en otras palabras, la mayoría de los sistemas integrados jamás creados), la fragmentación puede eventualmente causar que algunas solicitudes de asignación fallen. ¿y luego? ¿Cómo debe manejar su firmware las solicitudes de asignación de almacenamiento dinámico fallidas?
Práctica recomendada: evitar el uso del montón por completo es una forma segura de evitar este error. Sin embargo, si la asignación de memoria dinámica es necesaria o conveniente en su sistema, existe otro método para estructurar el almacenamiento dinámico para evitar la fragmentación.
La observación clave es que el problema es causado por solicitudes de tamaño variable. Si todas las solicitudes tienen el mismo tamaño, cualquier bloque libre será tan bueno como cualquier otro bloque, incluso si no se encuentra junto a ningún otro bloque libre. La Figura 3 muestra cómo se implementa el uso de múltiples "montones" (cada uno para solicitudes de asignación de un tamaño específico) como una estructura de datos de "grupo de memoria".
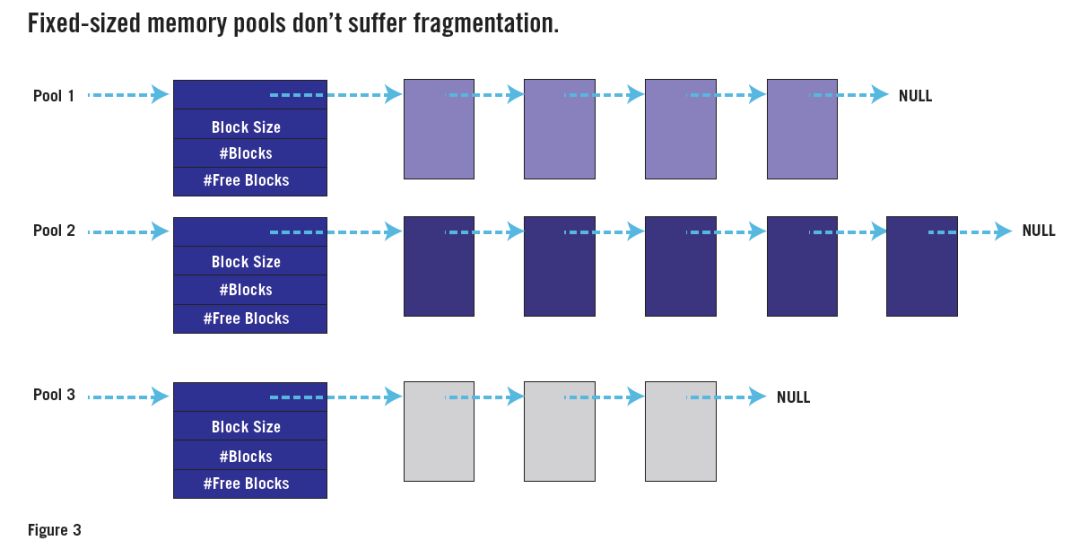
Muchos RTOS tienen API de grupos de memoria de tamaño fijo. Si tiene acceso a uno de ellos, utilícelo en lugar de malloc() y free(). O escriba su propia API de grupo de memoria de tamaño fijo. Solo necesita tres funciones: una para crear un nuevo grupo (M bloques N bytes de tamaño); otra para asignar un bloque (del grupo especificado); un tercio en lugar de free().
La revisión del código sigue siendo una buena práctica,
Se pueden evitar muchos dolores de cabeza de depuración asegurándose primero de que estos errores no existan en el sistema. La mejor manera de hacer esto es que alguien dentro o fuera de la empresa realice una revisión exhaustiva del código. Hacer cumplir la codificación de reglas estándar con las mejores prácticas que describo aquí también debería ayudar. Si sospecha uno de estos errores desagradables en su código existente, probablemente sea más rápido realizar una revisión del código que tratar de rastrear la falla observada hasta la causa raíz.
Fuente:
Artículo original de un bloguero de Huaqing Vision Chengdu Center,
Siga el acuerdo de derechos de autor de CC 4.0 BY-SA, adjunte el enlace de la fuente original y esta declaración para su reimpresión.
https://blog.csdn.net/weixin_44059661/article/details/107839764
Los derechos de autor pertenecen al autor original y son solo para el aprendizaje y la referencia de todos. Si se trata de problemas de derechos de autor, comuníquese conmigo para eliminarlo, gracias ~
-- El fin --
Recomendado en el pasado
¿Cómo hacer un reloj de tubo de imagen retro?
Un proyecto interesante, OLED realiza "3D a simple vista"
¿Ha dominado los puntos de conocimientos básicos incorporados que los novatos suelen pasar por alto?
Ingrese a la fábrica y obtenga una comprensión profunda del proceso de fabricación de chips
El grado de automatización de la fábrica DJI es realmente un poco alto
Haz clic en la tarjeta de presentación para seguirme

Todo lo que pediste se ve bien , lo tomo en serio ya que me gusta