Directorio de artículos
- I. Introducción
- 2. Optimización de alta concurrencia a nivel de base de datos relacional
- 3. Subtabla de subbase de datos Sharding-JDBC
-
- 3.1 Algoritmo incorporado Sharding-JDBC
- 3.2 Algoritmo de módulo
- 3.3 Algoritmo de fragmentación de rango basado en la capacidad de fragmentación
- 3.4 Algoritmo de fragmentación de rango basado en el límite del fragmento
- 3.5 Algoritmo de segmentación de tiempo automático
- 3.6 Sub-base de datos y sub-tabla al mismo tiempo
- Cuarto, el final
I. Introducción
A partir de una alta simultaneidad, este artículo presenta principalmente la subtabla y la subtabla de ShardingJDBC.
El código de este artículo es el siguiente: sharding-jdbc-split sub-database sub-table demo project code
2. Optimización de alta concurrencia a nivel de base de datos relacional
2.1 Problemas de rendimiento causados por datos masivos de MYSQL
De acuerdo con el manual de desarrollo de Ali, si el número de filas en una sola tabla supera los 500 W o la capacidad de datos de una sola tabla supera los 2G, se deben considerar las subtablas horizontales; según el sitio web oficial de MySQL, si el número de columnas en una tabla supera las 1017 columnas, el desarrollador solo debe recordar 1000 columnas, pero se debe considerar la división vertical. Es decir, la cantidad de filas y la capacidad de datos no es suficiente, la tabla se divide horizontalmente, la cantidad de columnas no es suficiente y la tabla se divide verticalmente, de la siguiente manera:

por ejemplo: subtabla horizontal y subbiblioteca horizontal, subtabla vertical (tabla de productos, lista de productos) y subbiblioteca vertical (biblioteca de pedidos, biblioteca de productos, biblioteca de usuarios)
Hay tres cuestiones involucradas en la subtabla de nivel:
El primer problema es determinar la estrategia de fragmentación: hay un problema inevitable con la fragmentación horizontal. Es necesario decidir en qué campo dividir una tabla en varias tablas. Este es el campo de fragmentación. Cómo fragmentar la tabla de destino es la fragmentación. Los esquemas comunes de estrategia de fragmentación incluyen: algoritmo de fragmentación de módulo hash, algoritmo de fragmentación hash consistente (sesgo de anillo hash) y algoritmo de fragmentación de rango.
El segundo problema es determinar la ID distribuida: es necesario personalizar un campo adicional para almacenar la clave principal global única, es decir, la ID distribuida, porque solo se puede garantizar que la clave primaria física de mysql sea única dentro de una tabla. y la partición de tabla horizontal convierte una tabla en Hay varias tablas, y la subtabla horizontal de esta base de datos es transparente para el front-end. El front-end necesita realizar select * from tablename where 主键列= ‘xxx’este tipo de operación, y la columna de identificación ya no puede ser La forma común es agregar una columna adicional a cada tabla de la subtabla horizontal, use el algoritmo uuid o copo de nieve para garantizar la unicidad. Ambos pueden garantizar la unicidad, pero usar el algoritmo de copo de nieve es mejor que uuid, porque uuid no tiene significado y el algoritmo de copo de nieve puede almacenar marcas de tiempo.
El tercer problema es la introducción de dependencias: es necesario hacer que el código Java de back-end opere varias tablas después de la subtabla horizontal como si estuviera operando una tabla, ya sea introduciendo dependencias de Sharding-JDBC en el código del lado del servidor , o independientemente en Linux El principio de instalar el middleware ShardingSphere es el mismo, pero uno se implementa en el nivel de código del lado del servidor y el otro se implementa en el nivel de la base de datos.
2.2 Estrategia de fragmentación
Fragmentación de módulo hash: realice un algoritmo hash en un campo de la tabla para obtener un valor hash, y luego determine en qué fragmento se deben colocar los datos a través de la operación de módulo. Este método es muy adecuado para escenarios de lectura y escritura aleatorios. Puede dispersar aleatoriamente los datos de una tabla grande en varias tablas pequeñas.La premisa es que el algoritmo hash debe estar bien diseñado, es decir, debe estar equilibrado, de la siguiente manera:
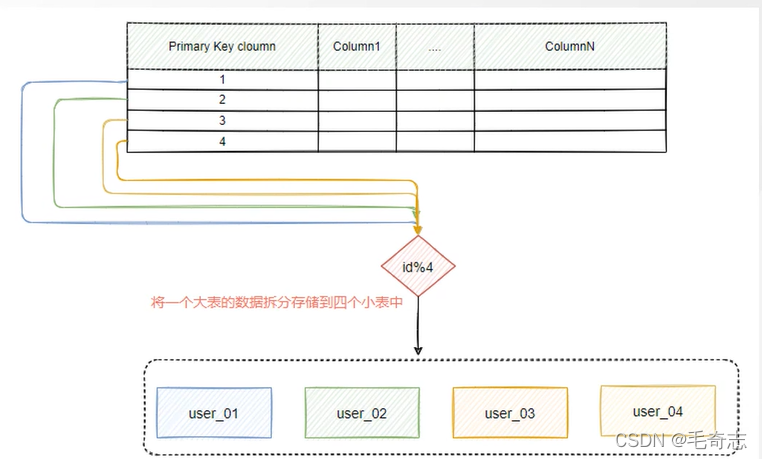
La mayor ventaja de la operación de módulo hash es que es simple. "Hash primero y luego módulo" está bien. La mayor desventaja es que no puede adaptarse a los cambios en las necesidades comerciales. Suponiendo que de acuerdo con el volumen actual y el crecimiento de las tablas de datos, colocamos una mesa grande Se divide en 4 mesas pequeñas, lo que parece satisfacer las necesidades actuales, pero después de un período de funcionamiento, se descubre que cuatro mesas no son suficientes y se deben agregar 4 mesas más para almacenamiento, eso Es decir, se necesitan un total de tablas 8. En este caso, los datos originales deben migrarse en su conjunto, lo cual es muy problemático. Es decir, una vez que la tabla de destino o la base de datos cambien en cantidad, todos los datos deberán migrarse Para reducir el impacto de estos datos a gran escala, se introduce un algoritmo hash consistente, que también es más común en la realidad. desarrollo práctica
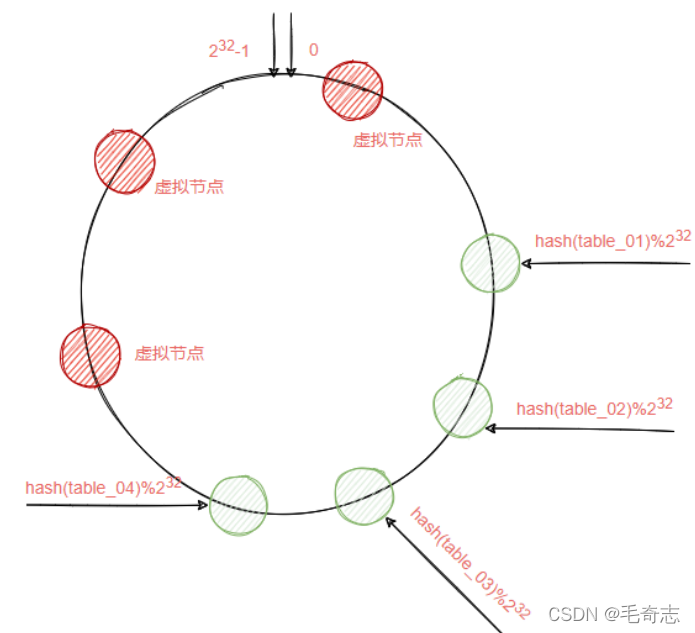
Algoritmo hash coherente: organice todo el espacio de valores hash en un anillo virtual. Por ejemplo, suponga que el espacio de valores de una función hash es 0 ~ 2^ 32 -1, es decir, pasamos el número de 0 ~ 2^ 32 -1 Forme un anillo virtual, el punto directamente encima del anillo representa el 0, el primer punto a la derecha del punto 0 representa el 1, y así sucesivamente, 2, 3, 4, 5, 6... hasta 2^32 -1 , es decir, el primer punto a la izquierda del punto 0 representa 2^32
-1. Llamamos a este anillo compuesto de 2 a los 32 puntos de poder como un anillo hash.
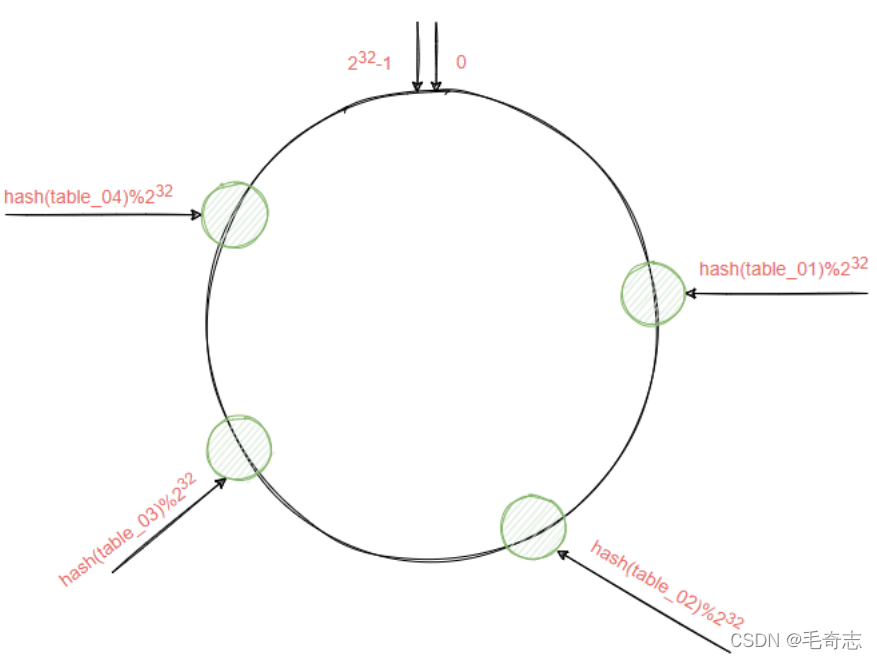
Supongamos ahora que hay cuatro tablas en la tabla horizontal, tabla 1, tabla 2, tabla 3 y tabla 4. En el algoritmo hash coherente, la operación de módulo no se realiza directamente en estas cuatro tablas, sino en 2^32. hash (número de tabla)% 2 ^ 32 El resultado calculado por la fórmula anterior debe ser un número entero entre 0 y 2 ^ 32-1, y luego marque la tabla de destino en la posición correspondiente a este número. Después de que las cuatro tablas sean módulo por hash Caen en una determinada posición del anillo hash, de la siguiente manera:
Al agregar un dato, también se obtiene un valor objetivo tomando la operación de módulo del hash y el anillo hash, y luego, de acuerdo con la posición del anillo hash donde se encuentra el valor objetivo, se busca la tabla objetivo más cercana en el sentido de las agujas del reloj. y los datos se almacenan en la tabla de destino. Por lo tanto, la función del anillo hash también es ayudarnos a determinar en qué tabla se debe insertar un registro y en qué tabla encontrar un registro, de la siguiente manera:
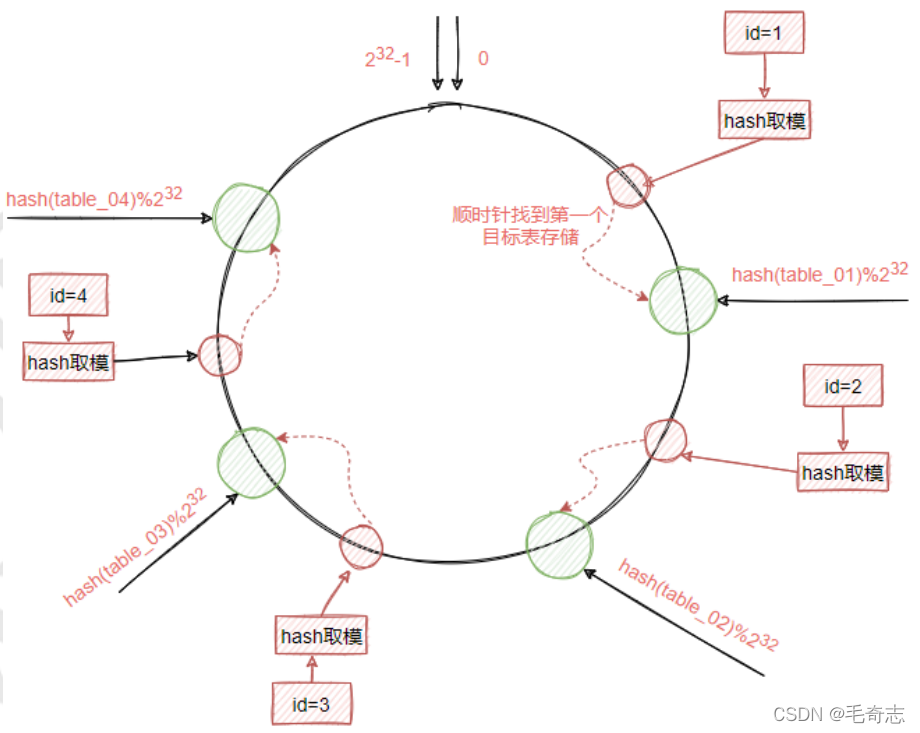
La operación hash coherente no está orientada directamente a la tabla de destino, sino al anillo hash. La ventaja de esto es que cuando es necesario eliminar o agregar una tabla, el impacto en el cambio de datos completo es local, no global. Es decir, insertar y eliminar una tabla solo afectará a esta última tabla. Para agregar una tabla, solo necesita mover algunos datos de la siguiente tabla de la nueva tabla a la nueva tabla; para eliminar una tabla, solo necesita mover los datos de la tabla eliminada a la siguiente tabla.
En teoría, cada tabla se puede distribuir uniformemente en todo el anillo hash y, luego, cada registro recién insertado se distribuye uniformemente en cada tabla de la subtabla horizontal, pero la situación real es la siguiente:
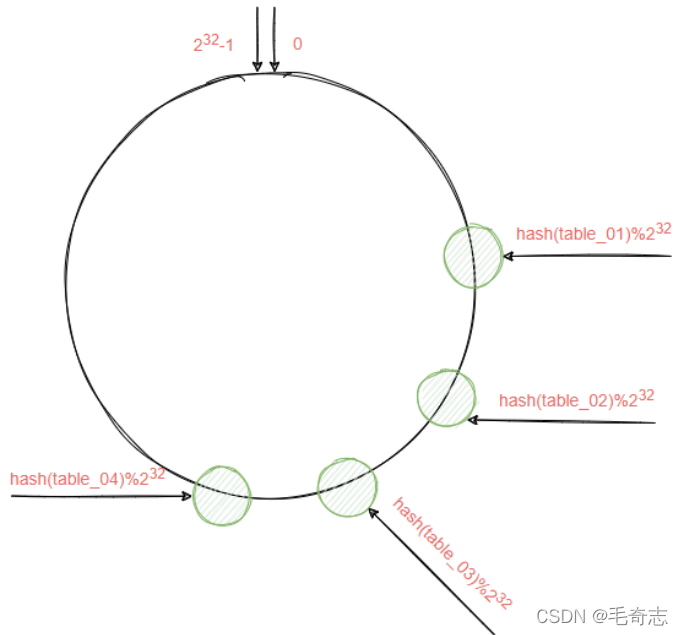
es decir, el anillo hash está sesgado. El problema causado por este fenómeno es que una gran cantidad de datos se guardarán en la misma tabla, lo que resultará en una distribución de datos extremadamente desigual Como se muestra en la figura anterior, una gran cantidad de datos se almacenarán en la tabla table_01.
La solución es copiar cada uno de los cuatro nodos y distribuirlos en el anillo hash. El nodo copiado se denomina nodo virtual. Se pueden virtualizar varios nodos según las necesidades reales. Tenga en cuenta que esto se basa en las necesidades reales, como Puede cree uno para table_02, table_03 y table_04, o puede crear tres para table_02.
Fragmentación de rango: En función de las características comerciales de la tabla de datos, se divide de acuerdo con un cierto rango.Este rango tiene muchos significados, tales como:
① Rango de tiempo, por ejemplo, guardamos una tabla para cada mes según el tiempo de creación de datos. La división basada en el tiempo también se puede utilizar para separar datos calientes y fríos, y cuanto antes se acceda a los datos, se accederá con menos frecuencia.
② Alcance de la región, la región generalmente se refiere a la ubicación geográfica. Por ejemplo, una tabla almacena datos de todo el país. Si la cantidad de datos es grande, se pueden dividir varias tablas según las regiones.
③ Rango de datos, como dividir según el intervalo de datos de un campo.
2.3 Identificación distribuida
Características de la identificación distribuida
① Exclusividad: asegúrese de que la identificación generada sea globalmente única.
② Incremento ordenado: asegúrese de que la identificación generada se incremente de acuerdo con un número determinado para un determinado usuario o empresa.
③ Alta disponibilidad: asegúrese de que las identificaciones se puedan generar correctamente en cualquier momento.
④ Con tiempo: la identificación contiene el tiempo y puede conocer los datos del día de un vistazo
Los esquemas de ID distribuidos son probablemente:
① ID de incremento automático de base de datos (definir tabla global)
② UUID
③ Algoritmo Twitter-Snowflake
2.3.1 Definición de la tabla global
Se crea una tabla de secuencia especialmente en la base de datos, y la ID de incremento automático en la tabla de la base de datos se usa para generar una ID global para los datos de otras empresas. Luego, cada vez que se usa la ID, se puede obtener directamente de esta mesa.
CREATE TABLE `uid_table` ( `id` bigint(20) NOT NULL AUTO_INCREMENT, `business_id` int(11) NOT NULL, PRIMARY KEY (`id`) USING BTREE, UNIQUE (business_type) )
En la aplicación, cada vez que se llama al siguiente código, puede obtener continuamente una identificación incremental.
begin
replace into uid_table (business_id) values(2);
select last_insert_id();
commit;
Entre ellos, replace into es eliminar los mismos datos originales cada vez y agregar uno al mismo tiempo, podemos asegurarnos de obtener una ID de incremento automático cada vez.
Ventajas:
muy simple, utilizando las funciones del sistema de base de datos existente, bajo costo, mantenimiento profesional por DBA.
El número de identificación aumenta de forma monótona y se pueden implementar algunos servicios que tienen requisitos especiales para la identificación.
Desventajas:
Fuerte dependencia de la base de datos, todo el sistema no está disponible cuando la base de datos es anormal, lo cual es un problema fatal. La configuración de la replicación maestro-esclavo puede aumentar la disponibilidad tanto como sea posible
, pero la coherencia de los datos es difícil de garantizar en casos especiales. Las inconsistencias durante la conmutación maestro-esclavo pueden resultar en una numeración repetida.
El cuello de botella de rendimiento de la numeración de ID se limita al rendimiento de lectura y escritura de un solo MySQL.
2.3.2 UUID
El formato de UUID es: xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx 8-4-4-4-12 tiene un total de 36 caracteres, es un
binario de 128 bits convertido a 32 caracteres hexadecimales y luego conectado con 4 - cadena arriba .
Cinco formas de generar UUID
① UUID basado en tiempo (fecha-hora y dirección MAC): Depende principalmente de la marca de tiempo actual y la dirección mac de la máquina, por lo que
puede garantizar la exclusividad global. (Se usa la dirección Mac, por lo que se exponen la dirección Mac y la hora de generación).
② Para el UUID de seguridad distribuida (fecha y hora e ID de grupo/usuario), los primeros cuatro dígitos de la marca de tiempo de la versión 1 se reemplazan con el POSIX UID o
GID.
③ La versión UUID-MD5 basada en espacio de nombres (hash y espacio de nombres MD5) se obtiene generando un
valor hash MD5 basado en el espacio de nombres/nombre especificado, lo cual no es recomendado por el estándar.
④ UUID (número pseudoaleatorio) basado en números aleatorios: Generado en base a números aleatorios o números pseudoaleatorios.
⑤ Versión UUID-SHA1 basada en el espacio de nombres (hash y espacio de nombres SHA-1): Cambie el algoritmo hash de la versión 3 a SHA1.
En Java, se proporcionan UUID basados en el algoritmo MD5 y UUID basados en números aleatorios.
Ventajas: Generación local, sin consumo de red, generación simple, sin riesgo de alta disponibilidad.
Desventajas:
① No es fácil de almacenar: el UUID es demasiado largo, 16 bytes y 128 bits, generalmente representado por una cadena de 36 longitudes, que no es aplicable en muchos escenarios.
②Información no segura: el algoritmo para generar UUID basado en la dirección MAC puede causar una fuga de la dirección MAC. Esta vulnerabilidad se usó para encontrar
la ubicación del productor del virus Melissa.
③ La eficiencia de la consulta desordenada es baja: dado que el UUID generado es una cadena desordenada e ilegible, su eficiencia de consulta es baja.
④ UUID no es adecuado para la identificación única de la base de datos. Si se usa UUID como clave principal, no aumentará en desorden. Todos saben que la clave principal tiene un
índice, y luego el índice de mysql se realiza a través de b + árbol. Para la inserción de datos UUID, con el fin de optimizar la consulta, se modificará el árbol b+ en la parte inferior del índice. Debido a que los datos UUID están desordenados, cada inserción de datos UUID modificará en gran medida el árbol b+ de la clave principal, lo que afectará seriamente el rendimiento.
2.3.3 Algoritmo de copo de nieve
El algoritmo SnowFlake es un algoritmo de generación de id distribuido de código abierto de Twitter. La idea central es usar un número largo de 64 bits
como identificación única global. La composición del algoritmo del copo de nieve tiene un total de 64 bits, y estos 64 bits se componen de cuatro partes.

La primera parte, 1 bit, se utiliza para representar el bit de signo, y el ID suele ser un número positivo, por lo que este bit de signo suele ser 0.
La segunda parte, que ocupa 41 bits: representa la marca de tiempo, que es la cantidad de milisegundos en la hora del sistema, pero esta marca de tiempo no es la hora actual del sistema
, sino la hora actual de inicio del sistema, que indica el uso de esta ID. esquema de generación El tiempo y la marca de tiempo son para garantizar el orden y la legibilidad, es decir, los desarrolladores pueden adivinar cuándo se generó la identificación de un vistazo. 41 bits pueden representar un número de 2^41 - 1, y el rango de valores que se pueden representar es: 0 a 2^41-1, es decir 41 bits pueden representar un valor de 2^41- 1 milisegundo, que se convierte en una unidad de año (2^ 41-1)/1000 * 60 * 60 * 24*365=69 años, que es un tiempo que puede contener 69 años.
La tercera parte se utiliza para registrar el id de la máquina en funcionamiento, el id contiene 10 bits, lo que significa que este servicio se puede implementar en hasta 2^10 máquinas,
es decir, 1024 máquinas. Los 10 bits se pueden dividir en 2 5 bits. Los primeros 5 bits representan la identificación de la sala de computadoras y los 5 bits representan la identificación de la máquina, lo que significa que se admite un máximo de 2^5 salas de computadoras (32), y cada computadora la sala puede soportar 32 máquinas.
La cuarta parte, que consta de 12 bits, representa una secuencia creciente, utilizada para registrar diferentes id generados en el mismo milisegundo. Si la solicitud la realiza la misma máquina en el mismo milisegundo, se debe usar el número de serie para garantizar la exclusividad, es decir, para garantizar que la ID generada por la misma máquina en el mismo milisegundo sea única. la alta concurrencia de nuestra identificación, que es para garantizar que tenga la misma unicidad de milisegundos de los escenarios concurrentes entrantes. El entero positivo más grande que se puede representar con 12 bits (bit) es 2^12-1=4095, es decir, se pueden usar 4095 números de 0, 1, 2, 3, ... 4094 para representar la generación del misma máquina dentro del mismo intervalo de tiempo (milisegundos) 4095 Números de serie ID. Binario de 12 bits, si todos son 1, entonces el valor final es 4095, es decir, el número más grande que puede almacenar 12 bits es 4095.
3. Subtabla de subbase de datos Sharding-JDBC
3.1 Algoritmo incorporado Sharding-JDBC
Visite el sitio web oficial https://shardingsphere.apache.org/document/current/cn/user-manual/shardingsphere-jdbc/builtin-algorithm/sharding/, que incluye principalmente cuatro
Algoritmo de fragmentación: se usa para separar bases de datos y tablas, el común es tomar módulo
Algoritmo de secuencia distribuida: se usa para generar una identificación global, incluido el uuid y el algoritmo de copo de nieve Algoritmo
de equilibrio de carga: se usa para separar lectura y escritura, seleccione una de varias bibliotecas para escribir Biblioteca para operar
Algoritmo de cifrado: utilizado para cifrar y descifrar




Aquí, la base de datos se dividirá en tablas. Todos los puntos principales son el algoritmo de fragmentación. El algoritmo de secuencia distribuida utiliza directamente el algoritmo de copo de nieve.
3.2 Algoritmo de módulo
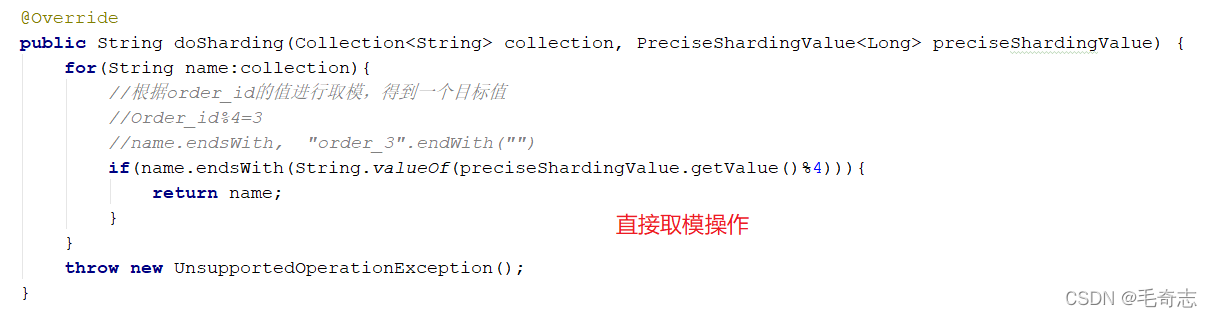
El algoritmo de módulo requiere que implementemos un algoritmo por nosotros mismos y tomemos directamente la operación de módulo, de la siguiente manera:

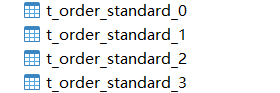
Ejecutar para generar cuatro tablas, de la siguiente manera:
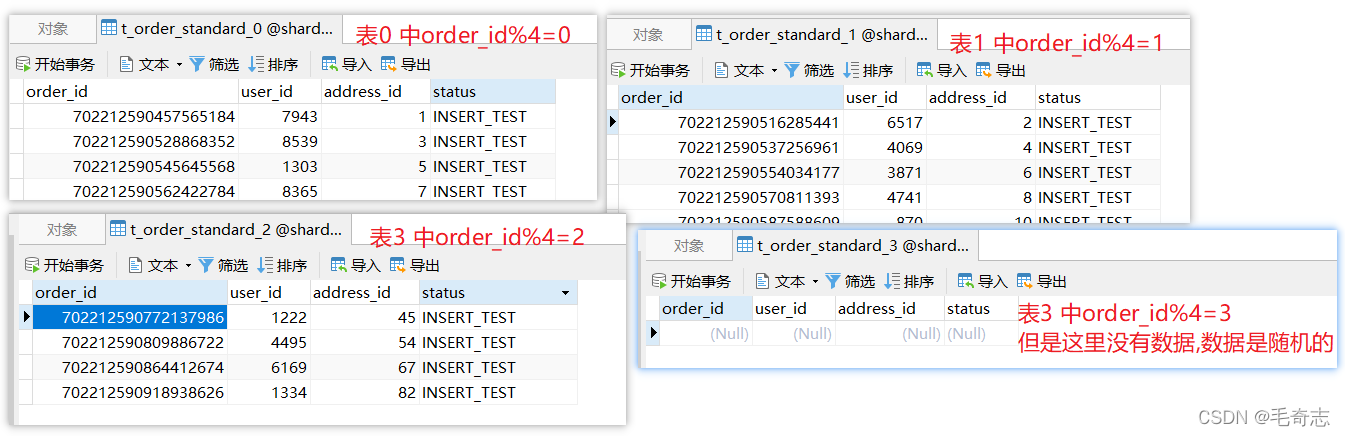
De hecho, también hay un algoritmo de sharding de módulo hash, es decir, localice el método doSharding de la clase HashModShardingAlgorithm, haga el hash primero y luego tome el módulo, de la siguiente manera:

3.3 Algoritmo de fragmentación de rango basado en la capacidad de fragmentación
El algoritmo de fragmentación de rango basado en la capacidad de fragmentos es VOLUME_RANGE, de la siguiente manera:



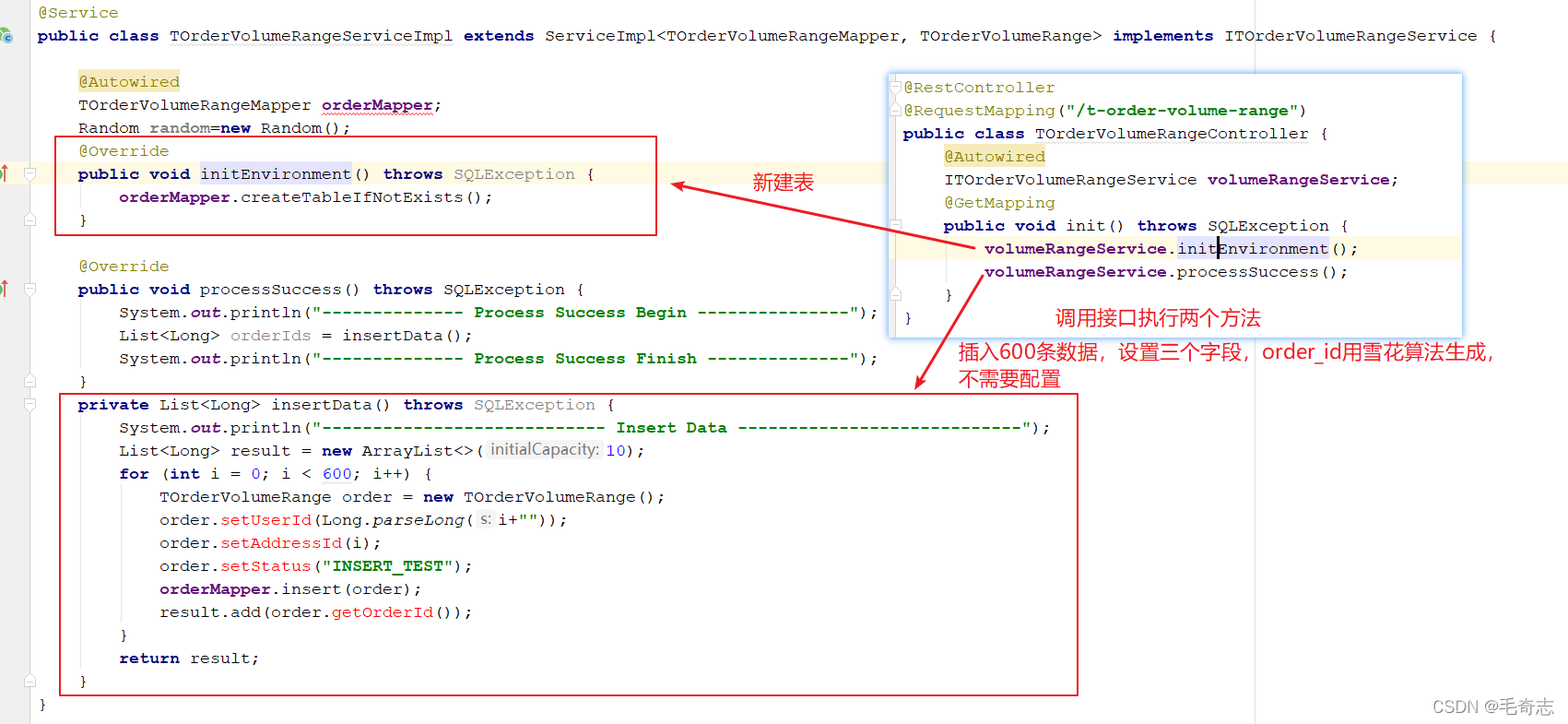
Inserte 600 piezas de datos y divídalas en tablas según el ID de usuario, cada tabla tiene 200 piezas, por lo que después de ejecutar, se generan tres tablas, cada una con 200 piezas de datos

3.4 Algoritmo de fragmentación de rango basado en el límite del fragmento
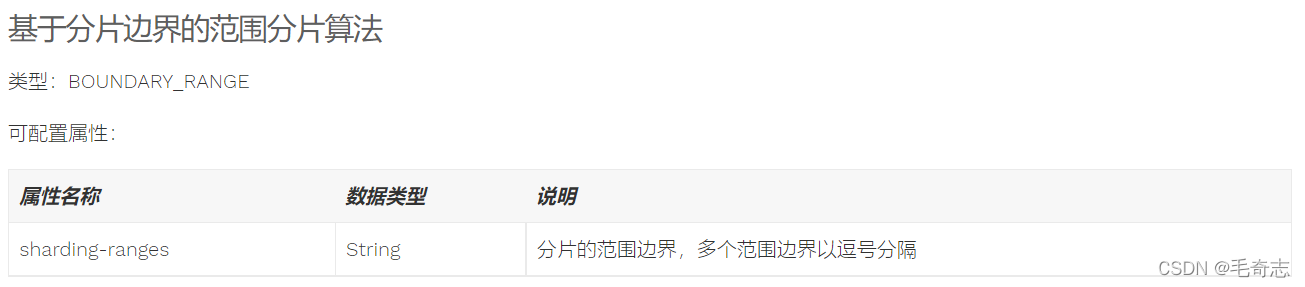
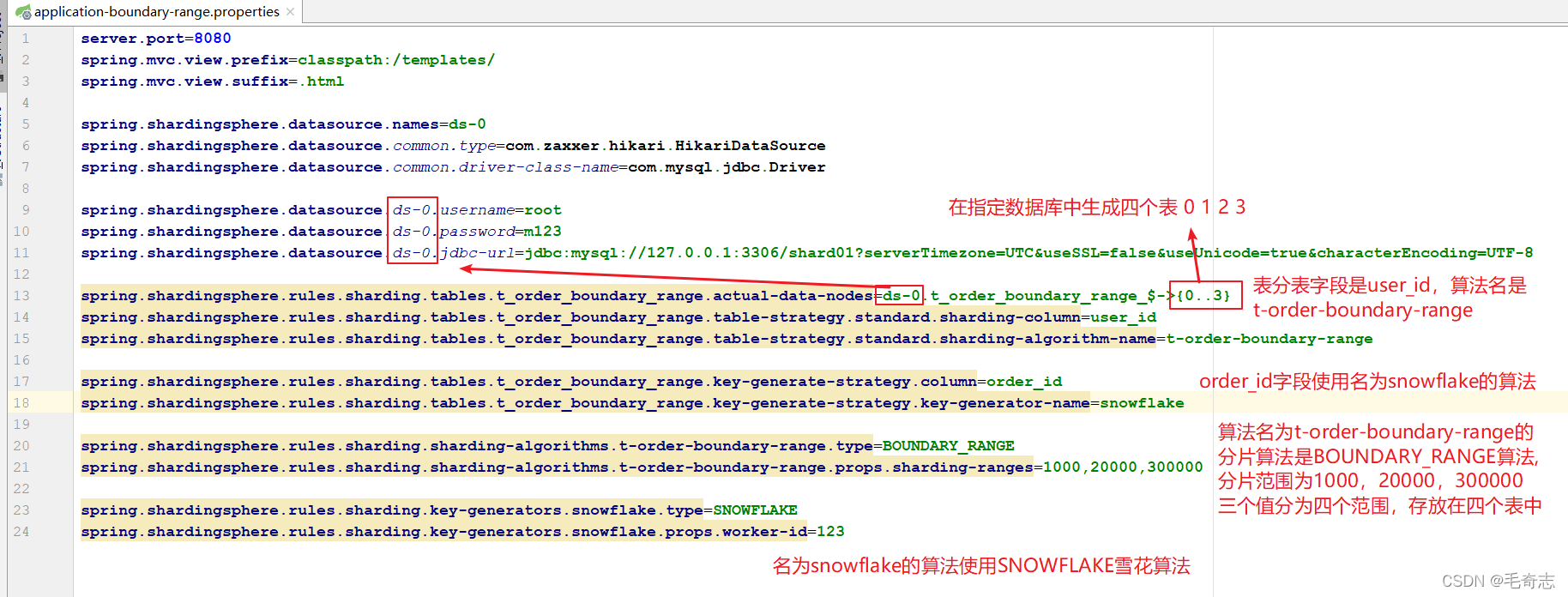

Ejecute para generar cuatro tablas, que se dividen en tablas según el valor del campo ID de usuario, de la siguiente manera:

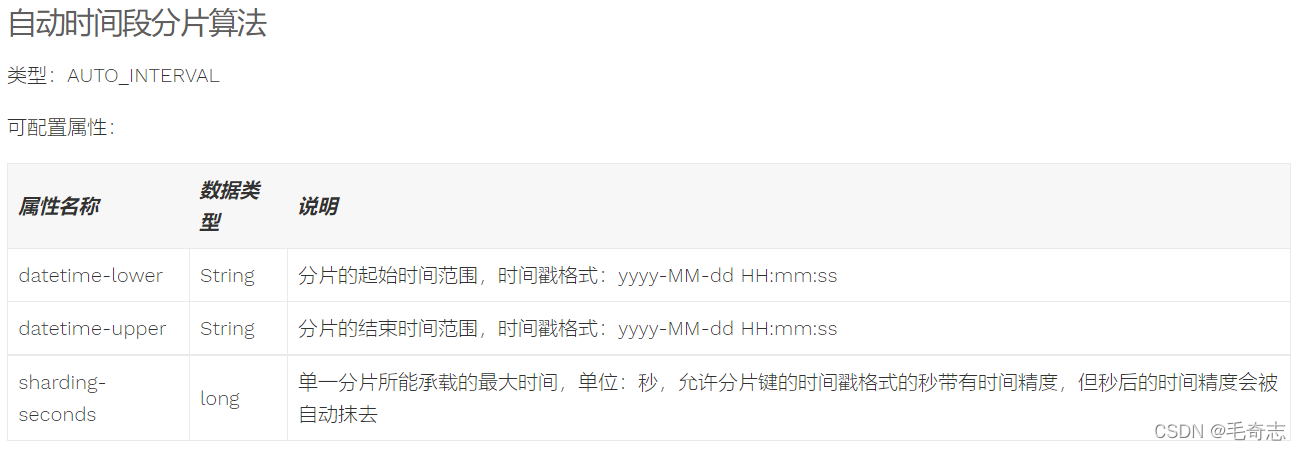
3.5 Algoritmo de segmentación de tiempo automático

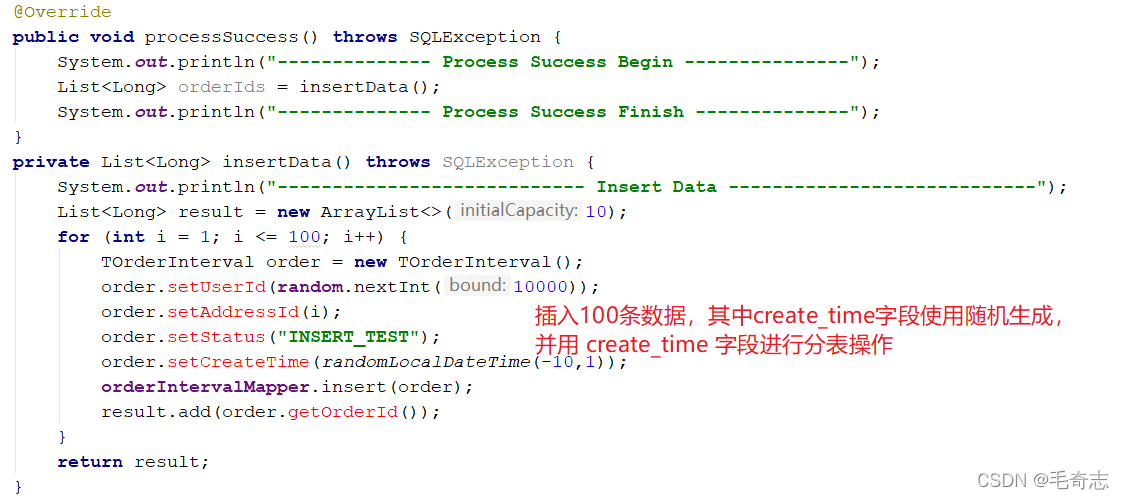
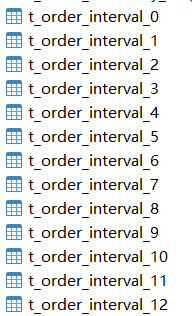
Ejecutar para generar 13 tablas, de la siguiente manera:
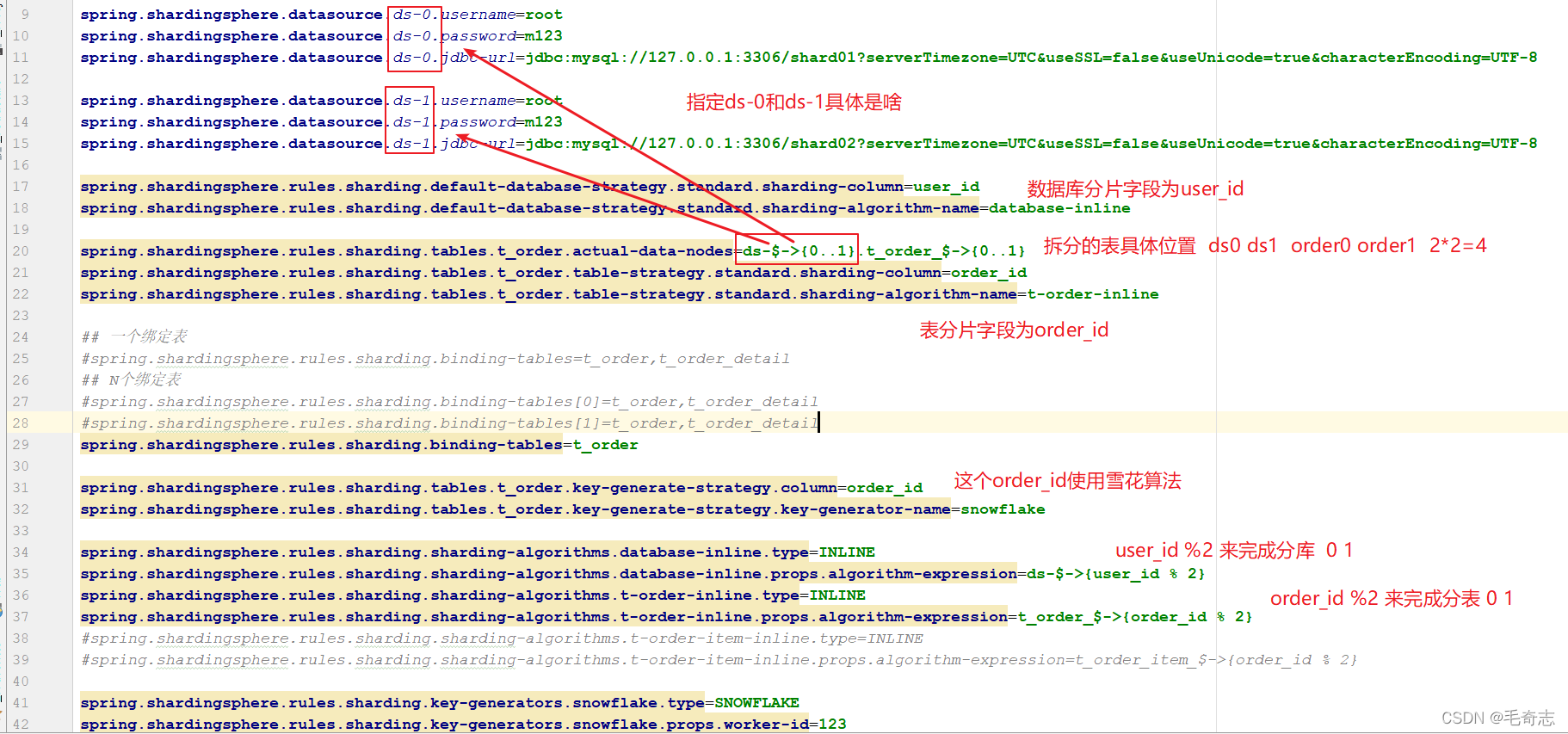
3.6 Sub-base de datos y sub-tabla al mismo tiempo
En lo anterior, solo los datos de una tabla se almacenan en varias tablas en la misma biblioteca. De hecho, podemos almacenar una tabla en varias tablas en varias bibliotecas, de la siguiente manera:
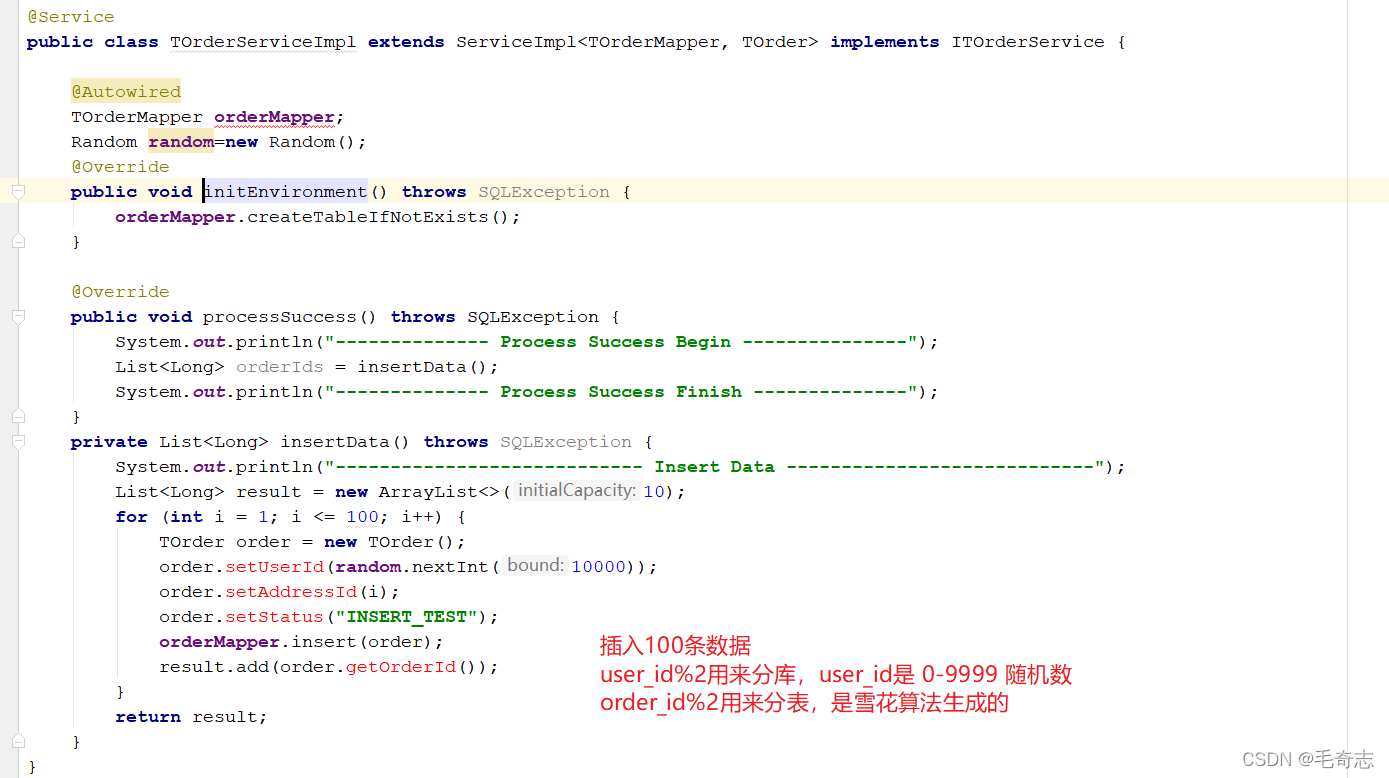

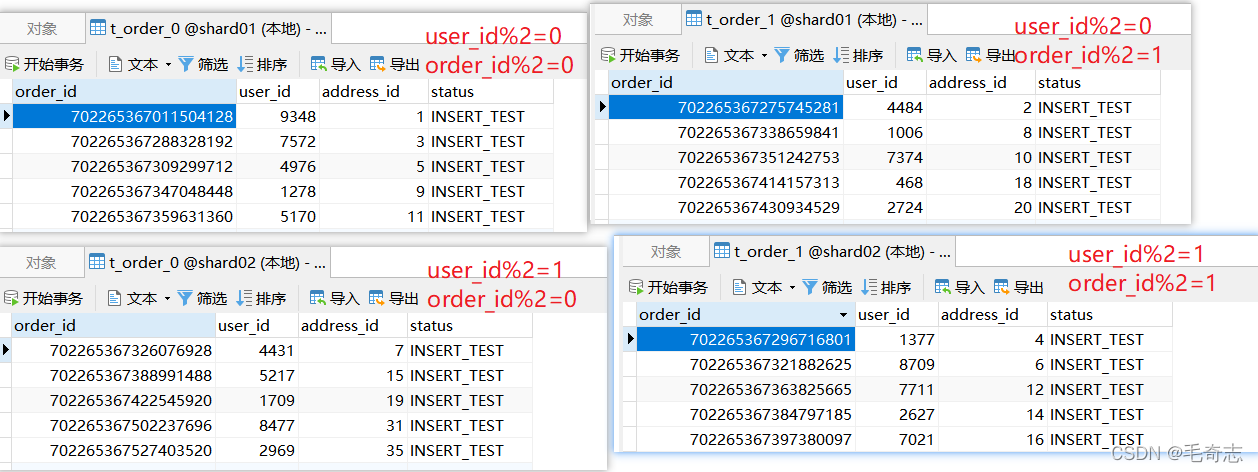
Si la tabla no se divide horizontalmente, los datos están solo en una tabla y la declaración de consulta va al "campo de índice";
después de dividir la tabla horizontalmente, la declaración de consulta va a "campo de fragmento + campo de índice".
Cuarto, el final
A partir de una alta concurrencia, este artículo presenta principalmente la subtabla y la subtabla de ShardingJDBC.El código de este artículo es el siguiente: sharding-jdbc-split sub-database sub-table demo project code
¡Codifique todos los días, progrese todos los días! !