Directorio de artículos
Primero, el marco de pruebas unittest
- unittest es un marco de pruebas unitarias para python, unittest unit testing proporciona soluciones para crear casos de prueba, conjuntos de pruebas y ejecución por lotes. Como marco de pruebas unitarias, unittest también es una prueba ágil para el módulo más pequeño del programa.
- ¿Son unittest y Junit ambas pruebas unitarias? La diferencia es: unittest es una prueba unitaria basada en pruebas funcionales, una prueba funcional basada en la interfaz de usuario, mientras que Junit es un marco de pruebas unitarias de caja blanca.
- Se resolvió la operación repetida de un solo script (importar paquete, obtener el controlador del navegador, cerrar el navegador).
1. Pruebe el firmware
1.1 Configuración()
- Un método para inicializar el entorno antes de ejecutar el script del caso de prueba.
1.2 desmontaje()
- Después de ejecutar el caso de prueba, limpie el entorno.
2. Uso básico de unittest
- Nombre del caso de prueba: test_ .
from selenium import webdriver
import time
import unittest
class TestUnit1(unittest.TestCase):
# 获取浏览器的驱动
def setUp(self):
# 1、self 就是类的引用/实例
# 2、全局变量的定义:self.变量名
self.driver = webdriver.Chrome()
self.driver.maximize_window()
self.url = "https://www.baidu.com/"
self.driver.get(self.url)
time.sleep(3)
# 在百度中搜索信息
# 测试用例的命名: test_
def test_search1(self):
self.driver.find_element_by_id("kw").send_keys("顾一野")
self.driver.find_element_by_id("su").click()
time.sleep(6)
def test_search2(self):
self.driver.find_element_by_id("kw").send_keys("account")
self.driver.find_element_by_id("su").click()
time.sleep(6)
# 关闭浏览器
def tearDowm(self):
self.driver.quit()
# 一个入口
if __name__ == "__main__":
unittest.main()
3. Conjunto de pruebas
- Un grupo de casos de prueba formado por la organización de casos de prueba en diferentes archivos.
- Coloque los casos de prueba que deben ejecutarse al mismo tiempo en una suite y ejecútelos al mismo tiempo.
import unittest
from Test import testbaidu1
from Test import testbaidu2
def creatSuit():
# 1、要把不同测试脚本的类中的需要执行的方法放在一个测试套件中
# suit = unittest.TestSuite()
# suit.addTest(testbaidu1.Baidu1("test_hao"))
# suit.addTest(testbaidu2.Baidu2("test_hao"))
# suit.addTest(testbaidu2.Baidu2("test_baidusearch"))
# return suit
# 2、如果需要把一个测试脚本中年所有的测试用例都添加到suit中,怎么做?
# 第一种※:makeSuit
# suit = unittest.TestSuite()
# suit.addTest(unittest.makeSuite(testbaidu1.Baidu1))
# suit.addTest(unittest.makeSuite(testbaidu2.Baidu2))
# return suit
# 第二种:TestLoader
# suit1 = unittest.TestLoader().loadTestsFromTestCase(testbaidu1.Baidu1)
# suit2 = unittest.TestLoader().loadTestsFromTestCase(testbaidu2.Baidu2)
# suit = unittest.TestSuite([suit1, suit2])
# return suit
# 3、可以把一个文件夹下面所有的测试脚本中的测试用例放入测试套件
discover = unittest.defaultTestLoader.discover("../Test", pattern="testbaidu*.py", top_level_dir=None)
return discover
if __name__ == "__main__":
suit = creatSuit()
# verbersity= 0 测试用例成功多少,失败多少, 1 会标注哪个成功/失败, 2 会标注
runner = unittest.TextTestRunner()
runner.run(suit)
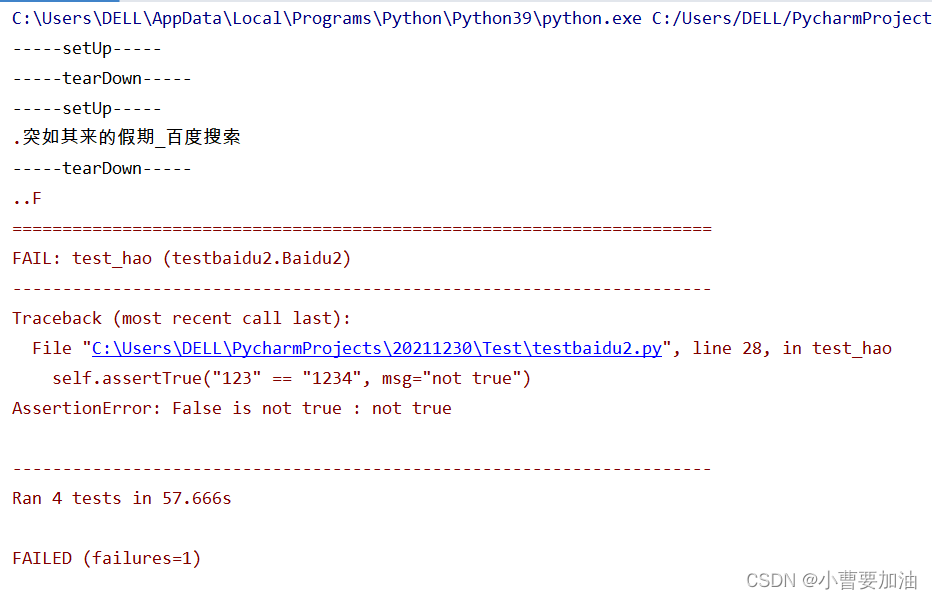
3.1 Orden de ejecución del caso de prueba
- Ordenar por nombre después de test_, 0 ~ 9, A ~ Z, a ~ z. Si la primera letra es la misma, mire la segunda letra y ejecute secuencialmente.
3.2 Ignorar la ejecución de casos de prueba
@unittest.skip("skipping")
4, afirmación
- En el script automatizado para determinar si los resultados reales y los resultados esperados son consistentes.
- Tomando a Baidu como ejemplo, ¿cómo juzgar el éxito de la consulta? El título de una página web es la información de búsqueda, o la aparición de un elemento en la página.
- afirmarEqual(resultado esperado, resultado real, mensaje = "qué generar si el resultado real no coincide con el resultado esperado").
def test_hbaidu(self):
driver = self.driver
url = self.url
driver.get(url)
# self.assertEqual("突如其来的假期_百度搜索", driver.title, msg="实际结果和预期结果不一致" )
self.assertTrue("百度一下,你就知道" == driver.title, msg="不一致!!!")
driver.find_element_by_id("kw").send_keys("突如其来的假期")
driver.find_element_by_id("su").submit()
time.sleep(5)
print(driver.title)
# self.assertEqual(driver.title, "突如其来的假期_百度搜索", msg="实际结果和预期结果不一致" )
time.sleep(6)
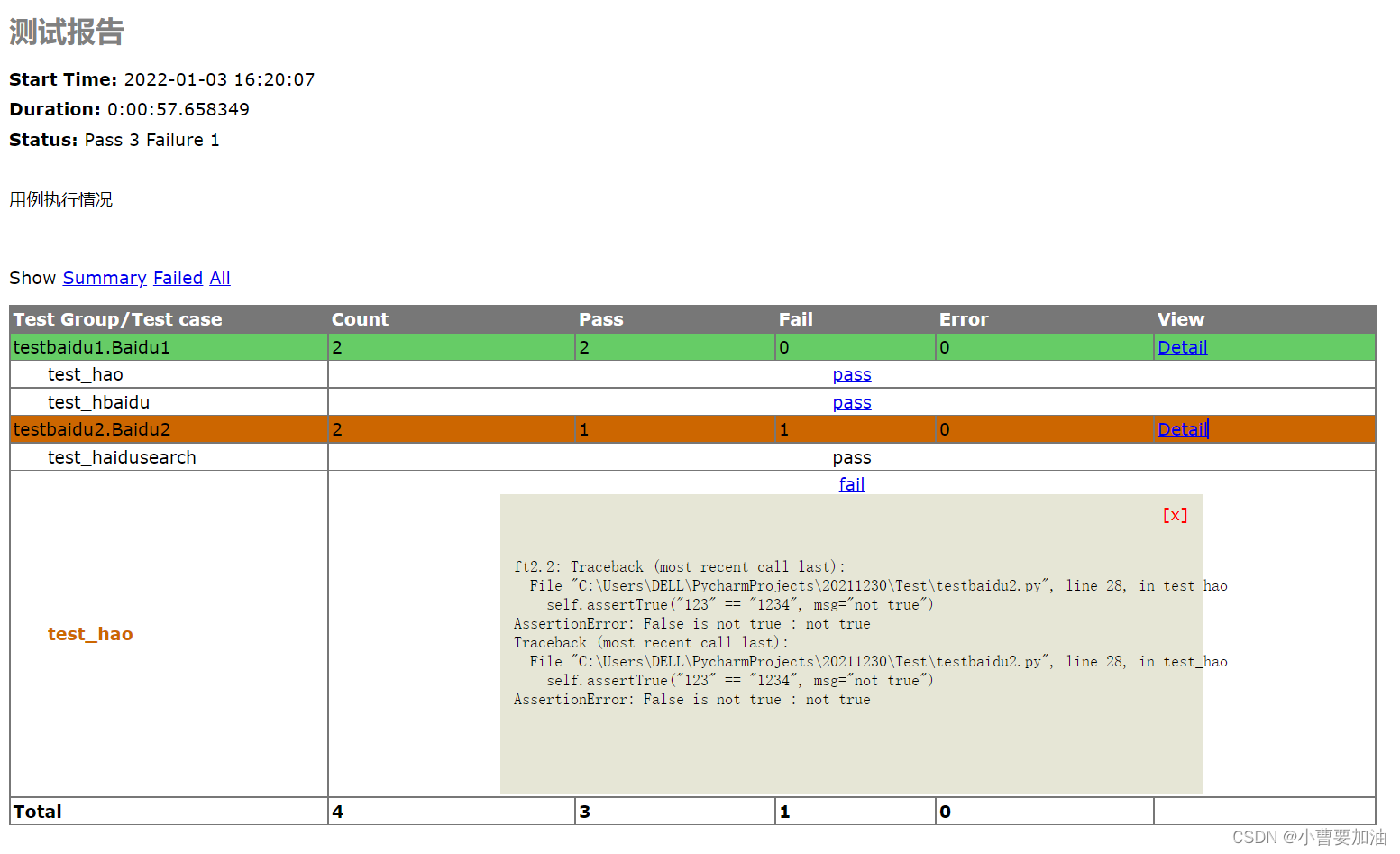
5. Generación de informes HTML
- Cuando hay muchos casos de prueba, es necesario contar los resultados de ejecución de los casos de prueba.
- Los informes HTML y las capturas de pantalla de errores se utilizan para analizar los resultados de la ejecución por lotes de casos de prueba. Las capturas de pantalla de errores pueden ayudarnos a ver la página específica y el estado del error con mayor claridad.
5.1 Informe de prueba
import HTMLTestRunner
import os
import sys
import time
import unittest
def createsuite():
discovers = unittest.defaultTestLoader.discover("../Test", pattern="testbaidu*.py", top_level_dir=None)
print(discovers)
return discovers
if __name__=="__main__":
# 文件夹要创建地址,脚本所在的目录,
curpath = sys.path[0]
# c 盘下所有的路径都被打开,相当于一个数组
print(sys.path)
# 只是需要第一个
print(sys.path[0])
# 1,创建文件夹,存放 HTML 报告
if not os.path.exists(curpath+'/resultreport'):
os.makedirs(curpath+'/resultreport')
# 2,文件夹的命名:时间 时分秒,名称绝对不会重复 time.time() 获取时间戳,local转换为当地时间。
# time.strftime() 把本地时间以某一种特定格式展示。
now = time.strftime("%Y-%m-%d-%H %M %S", time.localtime(time.time()))
print(now)
print(time.time())
print(time.localtime(time.time()))
# 文件名
filename = curpath + '/resultreport/'+ now + 'resultreport.html'
# 打开文件,编写内容
with open(filename, 'wb') as fp:
runner = HTMLTestRunner.HTMLTestRunner(stream=fp, title=u"测试报告",
description=u"用例执行情况", verbosity=2)
suite = createsuite()
runner.run(suite)
5.2 Captura de excepciones y capturas de pantalla de errores
- Elementos de BUG: título, número de versión, entorno de prueba, pasos de prueba (datos de prueba), resultados esperados, resultados reales, archivos adjuntos (registros de errores, capturas de pantalla de errores)
- Recurrencia de BUG: Deje que el BUG aparezca nuevamente, para que los desarrolladores puedan localizar el BUG más rápido.
- Se pueden detectar errores y se pueden guardar capturas de pantalla de errores, lo que brinda comodidad a nuestra ubicación de error.
5.2.1 Captura de pantalla de error: get_screenshot_as_file()
def save_errorImage(self, driver,fileName):
# "./" 表示当前路径
if not os.path.exists("./image"):
os.makedirs("./image")
# 错误截图的名称要不一样
now = time.strftime("%Y%m%d-%H%M%S", time.localtime(time.time()))
driver.get_screenshot_as_file("./image/" + now + fileName)
5.2.2 Captura de excepciones
try:
self.assertEqual("肖战_百度搜索", self.driver.title, msg="和预期结果不一致")
except:
self.save_errorImage(self.driver, "error.png")
5.2.3 Código general
from selenium import webdriver
import time
import unittest
import os
class TestUnit1(unittest.TestCase):
# 获取浏览器的驱动
def setUp(self):
# 1、self 就是类的引用/实例
# 2、全局变量的定义:self.变量名
self.driver = webdriver.Chrome()
self.driver.maximize_window()
self.url = "https://www.baidu.com/"
self.driver.get(self.url)
time.sleep(3)
# 在百度中搜索信息
# 测试用例的命名: test_
def test_search1(self):
self.driver.find_element_by_id("kw").send_keys("顾一野")
self.driver.find_element_by_id("su").click()
time.sleep(6)
# 在百度中搜索英文
def test_search2(self):
self.driver.find_element_by_id("kw").send_keys("Lisa")
self.driver.find_element_by_id("su").click()
time.sleep(6)
# 异常捕捉 再传参数时,没有传 self,实例也可以不用传。 在TestCase类下,只有test_ 才执行,其他的只有被调用才执行。
try:
self.assertEqual("肖战_百度搜索", self.driver.title, msg="和预期结果不一致")
except:
self.save_errorImage(self.driver, "error.png")
def save_errorImage(self, driver,fileName):
# "./" 表示当前路径
if not os.path.exists("./image"):
os.makedirs("./image")
# 错误截图的名称要不一样
now = time.strftime("%Y%m%d-%H%M%S", time.localtime(time.time()))
driver.get_screenshot_as_file("./image/" + now + fileName)
# 关闭浏览器
def tearDowm(self):
self.driver.quit()
# 一个入口
if __name__ == "__main__":
unittest.main()
2. Basado en datos
- Por ejemplo, un cuadro de búsqueda, ¿cómo hacer pruebas funcionales?
Por ejemplo, en noticias, ingrese el nombre (chino, inglés), etc., para ver si se busca la información correspondiente. y así. - Caso de prueba automatizado:
- 1. Localice el cuadro de entrada "kw" e ingrese el contenido en el cuadro de entrada.
- 2. Coloque Baidu y haga clic en el botón "su" y haga clic en el botón.
- 3. Determinar el contenido de la búsqueda.
- El método anterior es demasiado complicado y puede utilizar datos para completar casos de prueba que deben ejecutarse varias veces a la vez.
1. Instalación de DDT
- 1. Verifique si ddt está instalado, ingrese pip show ddt en cmd y aparecerá el número de versión, lo que indica que la instalación se realizó correctamente.
- 2. Si no está instalado, ingrese pip install ddt en cmd para instalar.
2. Uso de ddt
- Documentación de referencia: http://ddt.readthedocs.io/en/latest/
- 1. Importar desde ddt import ddt, desempaquetar, datos, file_data e importar sys, csv
- 2. Asegúrese de agregar @ddt antes de la clase
from selenium import webdriver
import time
import unittest
from ddt import ddt, unpack, data, file_data
import sys, csv, os
# 如何读取 TXT 文件中的数据形成数组
def getTxt(file_name):
rows = []
path = sys.path[0]
with open(path + "/" + file_name, 'rt') as f:
readers = csv.reader(f, delimiter=",", quotechar="|")
next(readers, None)
for row in readers:
temprows=[]
for i in row:
temprows.append(i)
rows.append(temprows)
print(rows)
return rows
@ddt
class Search(unittest.TestCase):
def setUp(self):
self.driver = webdriver.Chrome()
self.driver.implicitly_wait(30)
self.url = "https://www.baidu.com/"
self.driver.maximize_window()
self.driver.get(self.url)
time.sleep(6)
@unittest.skip("skipping")
# 1、一次性传一个参数
@data("肖战", "Lisa", "顾一野", "党章")
def test_find1(self, value):
self.driver.find_element_by_id("kw").clear()
self.driver.find_element_by_id("kw").send_keys(value)
self.driver.find_element_by_id("su").click()
time.sleep(5)
@unittest.skip("skipping")
# 2、一次性传两个参数 u:utf-8,防止中文乱码 需要 unpack 来一一对应参数
@data(['Lisa', u"Lisa_百度搜索"], [u'肖战', u"顾一野_百度搜索"])
@unpack
def test_find2(self, value, expected_value):
self.driver.find_element_by_id("kw").clear()
self.driver.find_element_by_id("kw").send_keys(value)
self.driver.find_element_by_id("su").click()
time.sleep(6)
try:
self.assertEqual(expected_value, self.driver.title, msg="与预期结果不一致")
except:
self.save_errorImage(self.driver, "error.png")
time.sleep(5)
@unittest.skip("skipping")
# 3、使用 json 文件(一次传一个数据) ,测试数据在文件里,整洁、保存多
@file_data('test_baidu_data.json')
def test_find3(self, value):
self.driver.find_element_by_id("kw").clear()
self.driver.find_element_by_id("kw").send_keys(value)
self.driver.find_element_by_id("su").click()
time.sleep(5)
# 4、传入一个 txt 文件(可以传多组数据)
@data(*getTxt('test_baidu_data.txt'))
@unpack
def test_find4(self, value, expected_value):
self.driver.find_element_by_id("kw").clear()
self.driver.find_element_by_id("kw").send_keys(value)
self.driver.find_element_by_id("su").click()
time.sleep(5)
# 断言
self.assertEqual(expected_value, self.driver.title, msg="与预期结果不一致")
print(expected_value)
print(self.driver.title)
time.sleep(5)
def save_errorImage(self, driver, fileName):
if not os.path.exists("./image"):
os.makedirs("./image")
now = time.strftime("%Y%m%d-%H%M%S",time.localtime(time.time()))
driver.get_screenshot_as_file("./image/" + now + "-"+ fileName)
# 关闭浏览器
def tearDown(self):
self.driver.quit()
# 一个入口
if __name__ == "__main__":
unittest.main()
test_baidu_data.txt
data
周迅, 周迅_百度搜索
肖战, 肖战_百度搜索
test_baidu_data.json
[
"jolin",
"林俊杰"
]