1. NameNode的目录结构
-
NameNode在内存中加载了文件系统元数据和block位置的映射关系
-
NameNode会永久性存储文件系统元数据,主要包括
edits、fsimage、seen_txid -
NameNode的目录结构如图所示

-
VERSION: Java属性文件,包含namespaceID(文件系首次格式化使创建)、block池ID、storageType(值为NAME_NODE)等
-
edits:
(1)编辑日志,对文件系统的操作(事务),先记录到edits文件中,同步更新内存的文件系统元数据
(2)inprogress表示这个正在写入的edits文件,其后缀为起始事务id
(3)只带事务id的edits文件,表示存储的事务范围 -
fsimage: 文件系统元数据映像,是文件系统元数据的一个完整的永久性检查点
(1)NameNode发生故障,将磁盘中的fsimage重新加载到内存,以重构元数据的最近状态;再执行edits文件的中的事务,从而恢复最新状态
(2) fsimage存储了文件系统的所有目录和inode信息:对文件来说,包括副本数、修改时间、访问时间、访问许可、block size等;对目录来说:修改时间、访问许可、配置元数据等
-seen_txid: 记录edits中的事务id尾数,故障重启时,会重新执行事务00001 ~ seen_txid
NameNode不负责永久存储block位置映射
- block存储在DataNode中,fsimage不负责记录block的位置映射
- DataNode加入集群后,NameNode会向其索取block列表,以建立block位置映射
- 之后,DataNode也会定期向NameNode报告最新的block位置映射
fsimage的创建过程
- 为了减轻主NameNode的压力,检查点的创建由辅助NameNode完成
- 创建过程如下:
(1)辅助NameNode请求主NameNode停止使用inprogress的edits文件(edits_inprogress_1),主NameNode上卷edits:① 将edits_inprogress_1命名为edits_1-19,② 创建新的inprogress的edits文件(edits_inprogress_20),③ 更新seen_txid,记录事务id的尾数
(2)辅助NameNode通过HTTP GET从主NameNode获取最近的edits_1-19和fsimage文件(fsimage_0)
(3)辅助NameNode将fsimage_0载入内存,逐条执行edits_1-19中事务,产生新的fsimage文件(fsimage_19.ckpt)
(4)fsimage_19.ckpt被发送给主NameNode,先将其保存为临时文件fsimage_19.ckpt
(5)主NameNode将其临时文件fsimage_19.ckpt重命名为fsimage_19

检查点的创建时机
- 受时间间隔参数
dfs.namenode.checkpoint.period和事务数dfs.namenode.checkpoint.txns两个参数配置 - 二者满足其一,则触发检查点的创建,检查是否满足上述配置的频率由
dfs.namenode.checkpoint.check.period控制,默认值为1分钟 - 时间间隔参数,默认值1小时;事务数,默认值100万个
2. DataNode的目录结构
- DataNode的目录结构如图所示
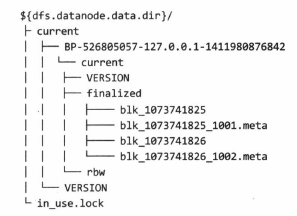
- blk开头的文件: 数据块或数据块的元数据,meta结尾的表示未block的元数据,包含:头部、block的校验和等信息
- BP开头目录名: block池ID作为目录名,如果一个目录中的block超过64个,则创建新的目录
dfs.datanode.dir属性,配置了多个目录,则block会以round-robin的方式写入这些目录中;同时,整个DataNode上的block不会重复
3. 其他操作
Hadoop启动NameNode时,NameNode处于安全模式
- 将fsimage加载到内存、执行edits文件,完成文件系统元数据更新
- DataNode主动向NameNode上报block列表
- NameNode检测到超过99.99%的block满足最小副本级别(默认为1),会在30秒后退出安全模型
- 注意: 启动刚刚格式化的HDFS集群,NameNode不会进入安全模式,因为系统中无任何block
- 注意: 安全模式期间,无法对文件进行写操作:新建、删除、重命名
fsck工具,检查HDFS中block的健康情况
- 过多复制的块: 副本数超过指定副本数的block,管理员无需关注,HDFS会自动删除多余的副本
- 仍需复制的块: 副本数为达到最小副本级别的block,HDFS会自动处理
—— 是副本数,而非最小副本数? - 错误复制的块: block放置违反了副本放置策略的block
- 损坏的块 所有副本均已损坏的block
- 缺失的副本: 无任何副本的block
- 重点关注损坏的块以及缺失的副本
度量和计数器的区别
- 计数器由任务进行采集,面向用户;metric由守护进程采集,面向admin
- 计数器由任务的jvm产生,任务和Application master都会进行汇总;metric独立于接收更新的组件,可以通过jmx输出,由守护进程收集、汇总
4. 添加或移除节点
- 整个Hadoop集群,存在若干DataNode和NodeManager,这两种节点存在添加或移除的情况
- 其添加依靠
include文件指定,移除依靠include文件和exclude文件共同决定
include文件
- 允许连接到NameNode的DataNode由
dfs.hosts属性指定,允许连接到ResourceManager的NodeManager由yarn.resourcemanager.nodes.include-path属性指定 - 这两个属性都存在于include文件中
include文件不同于slaves文件:
- include文件供NameNode和ResourceManager使用,决定哪些节点可以与其相连接
- Hadoop控制脚本使用slaves文件,执行面向整个集群范围的操作,例如重启集群等
exclude文件:
- 不允许连接到NameNode的DataNode节点,由
dfs.hosts.exclue属性指定;不允许连接到ResourceManager的NodeManager由yarn.resourcemanager.nodes.exnclude-path属性指定 - NodeManager节点是否可以连接ResourceManager的判断非常简单:出现在include文件中,未出现在exclude文件中
- DataNode节点是否可以连接NameNode的判断则相对复杂:

节点添加的过程
-
将新节点的网络地址添加到include文件
-
执行命令,将审核过的DataNode更新至NameNode
hdfs dfsadmin -refreshNodes -
执行命令,将审核过的NodeManager更新至ResourceManager
yarn rmadmin -refreshNodes -
更新slaves文件,保证面向集群的操作将覆盖新节点
-
自动新的DataNode或NodeManager
-
确认新的DataNode或NodeManager成功启动:出现在网页中
节点移除的过程

5. 总结
NameNode的内存和磁盘会存储了哪些信息?
- 内存:文件系统元数据、block的位置映射
- 磁盘:永久存储edits和fsimage
辅助NameNode如何创建fsimage(永久性检查点)?
- 主NameNode的roll操作
- 辅助NameNode从主NameNode获取最近的edits和fsimage文件,更新seen_txid
- 辅助NameNode基于fsimage逐条执行edits中的事务,创建fsimage.ckpt文件
- 辅助NameNode将fsimage.ckpt被发送给主NameNode
- 主NameNode将fsimage.ckpt更名为fsimage
NameNode的安全模式
- 启动NameNode,直到
99.99%的block满足最小级别副本的过程 - 期间,对DataNode的写操作都会失败
- 例外:启动一个刚刚格式化的HDFS集群,NameNode不会进入安全模式
fsck工具:
- 能检查:过多副本的块、仍需复制的块、错误复制的块(实质:错误放置的块)、损坏的块(所有副本已损坏)、缺失的副本
- 需要关注:损坏的块、缺失的副本
节点的添加和移除
- include文件和exclude文件,针对DataNode和NodeManager的配置属性
- include文件和slaves文件的却别:前者针对特定守护进程,后者针对集群层面的所有守护进程
- 基于exclude和include文件,如何进行移除DataNode或NodeManager的判断
- 添加或移除文件的过程